
10% — это наши знания,
40% — наше мышление,
50% — это наше окружение.
Недостаточно изучить SEO.
Хорошие решения приходят через опыт, а опыт приходит через плохие решения.
Выбирайте свое окружение с умом.
Окружите себя правильными людьми.
@MikeBlazerX
40% — наше мышление,
50% — это наше окружение.
Недостаточно изучить SEO.
Хорошие решения приходят через опыт, а опыт приходит через плохие решения.
Выбирайте свое окружение с умом.
Окружите себя правильными людьми.
@MikeBlazerX
Всем приятно провести день в воде. Вода влажная, и ее можно пить, используя [купить фильтры для воды]. Вот ссылка из [Википедии] о молоке, чтобы эта статья выглядела естественно.
Оригинал
@MikeBlazerX
Оригинал
@MikeBlazerX
Просматривая некоторые проиндексированные страницы клиента, Оливер Мейсон заметил, что основной контент не всегда присутствует в отрендеренном DOM, возвращаемом инструментом инспекции URL.
Хотя в Google Search Console можно получить информацию о файлах, которые Гугл не загрузил (только для проиндексированных страниц), мы все же можем сделать обоснованный вывод, что отсутствие основного содержимого, скорее всего, является основной причиной того, что представленные URL были просканированы, но не проиндексированы
Большинство SEO-специалистов знакомы с отключением JavaScript, чтобы посмотреть, как будет выглядеть страница без него.
Еще вы наверное слышали о том, что у Гугла есть бюджет на рендеринг и Гугл в процессе рендеринга не всегда скачивает все шрифты и джаваскрипт файлы используемые на страницах.
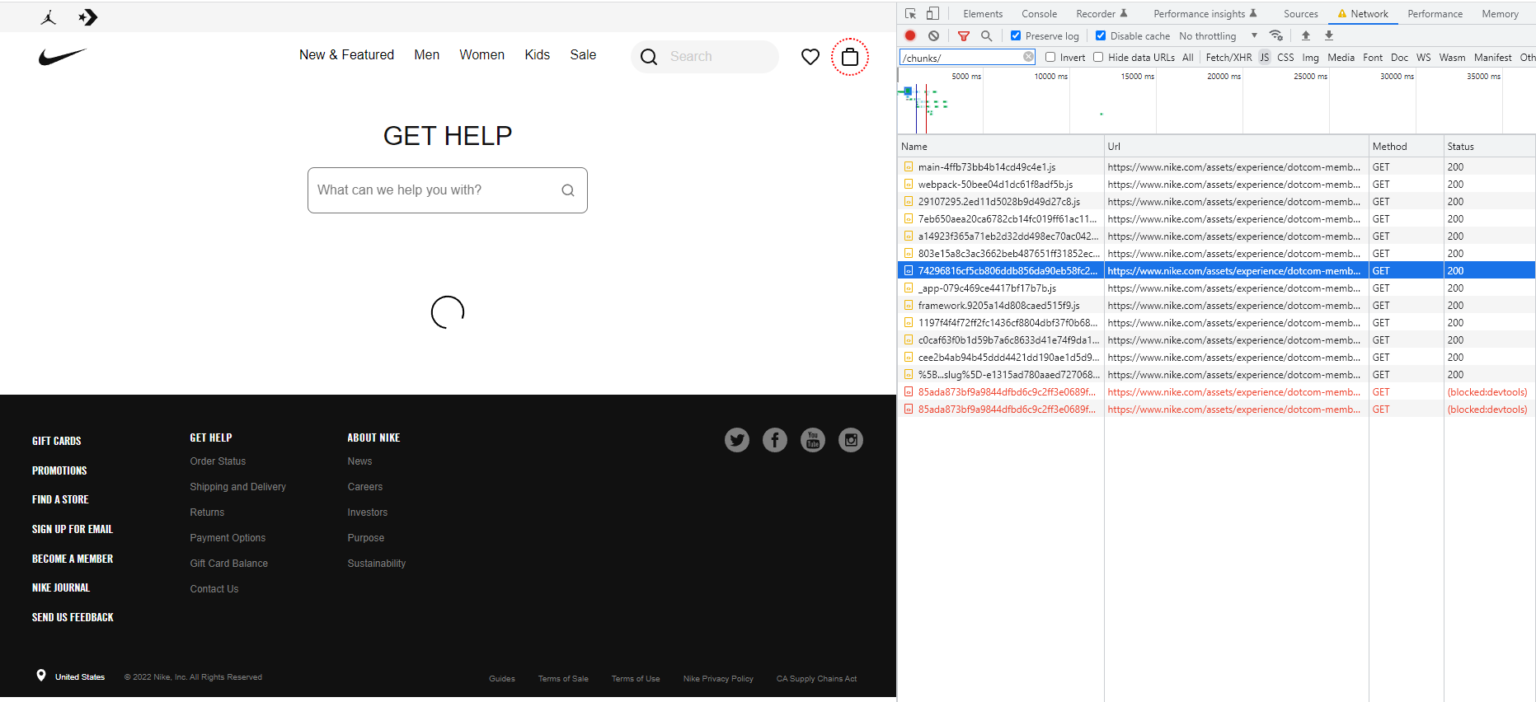
На примере страницы nike.com/help/a/shipping-delivery Оливер показал, как отключение всего одного JS файла сделает отображение основного контента на странице НЕВОЗМОЖНЫМ.
Теперь представьте, как Гугл экономя ресурсы может решить не скачивать этот JS файл...
У Найка есть 1 файл, без которого ничего не работает, а на сайте клиента Оливера таких "блокировщиков" - 25!
Пример Nike иллюстрирует, что существуют сценарии, в которых мы не просто просим Google выполнить некоторые JS, чтобы добраться до основного контента, но требуем, чтобы они загрузили и выполнили 25, 50, 100+ отдельных скриптов, чтобы увидеть основной контент на одном URL.
Рассчитывать на то, что Гугл это сделают, очень оптимистично.
Более подробно обо всем этом Оливер рассказывает в статье, там также узнаете, как пользоваться фичей "Request Blocking" в Chrome Dev Tools.
@MikeBlazerX
Хотя в Google Search Console можно получить информацию о файлах, которые Гугл не загрузил (только для проиндексированных страниц), мы все же можем сделать обоснованный вывод, что отсутствие основного содержимого, скорее всего, является основной причиной того, что представленные URL были просканированы, но не проиндексированы
Большинство SEO-специалистов знакомы с отключением JavaScript, чтобы посмотреть, как будет выглядеть страница без него.
Еще вы наверное слышали о том, что у Гугла есть бюджет на рендеринг и Гугл в процессе рендеринга не всегда скачивает все шрифты и джаваскрипт файлы используемые на страницах.
На примере страницы nike.com/help/a/shipping-delivery Оливер показал, как отключение всего одного JS файла сделает отображение основного контента на странице НЕВОЗМОЖНЫМ.
Теперь представьте, как Гугл экономя ресурсы может решить не скачивать этот JS файл...
У Найка есть 1 файл, без которого ничего не работает, а на сайте клиента Оливера таких "блокировщиков" - 25!
Пример Nike иллюстрирует, что существуют сценарии, в которых мы не просто просим Google выполнить некоторые JS, чтобы добраться до основного контента, но требуем, чтобы они загрузили и выполнили 25, 50, 100+ отдельных скриптов, чтобы увидеть основной контент на одном URL.
Рассчитывать на то, что Гугл это сделают, очень оптимистично.
Более подробно обо всем этом Оливер рассказывает в статье, там также узнаете, как пользоваться фичей "Request Blocking" в Chrome Dev Tools.
@MikeBlazerX
{kind=link}
Кейс, как AI контент был наказан HCU апдейтом Гугла
Обнаружить низкокачественный контент ИИ на самом деле не так уж сложно.
Такие инструменты, как GLTR или детектор результата от Huggingface, быстро находят ИИ-контент, основываясь на предсказуемости слов в тексте.
В своей статье Кевин Индиг сравнивает контент сайта, который был наказан обновлением полезного контента Google, с контентом на ту же тему из Википедии.
Даже простые бесплатные инструменты показывают более низкую предсказуемость слов (красный + фиолетовый цвета в скриншотах) в контенте Википедии.
Меньше предсказуемость = больше вероятность того, что это человек.
Google, вероятно, использует гораздо более сложные системы для предсказания слов (возможно, сущностей) и обнаружения ИИ-контента.
Если ваш контент, созданный ИИ, не проходит тест бесплатного инструмента, Google это уже засек.
@MikeBlazerX
Обнаружить низкокачественный контент ИИ на самом деле не так уж сложно.
Такие инструменты, как GLTR или детектор результата от Huggingface, быстро находят ИИ-контент, основываясь на предсказуемости слов в тексте.
В своей статье Кевин Индиг сравнивает контент сайта, который был наказан обновлением полезного контента Google, с контентом на ту же тему из Википедии.
Даже простые бесплатные инструменты показывают более низкую предсказуемость слов (красный + фиолетовый цвета в скриншотах) в контенте Википедии.
Меньше предсказуемость = больше вероятность того, что это человек.
Google, вероятно, использует гораздо более сложные системы для предсказания слов (возможно, сущностей) и обнаружения ИИ-контента.
Если ваш контент, созданный ИИ, не проходит тест бесплатного инструмента, Google это уже засек.
@MikeBlazerX
Шаблоны ТЗ для написания текстов на английском языке
Любой сеошник/контентщик нуждается в хороших текстах и беситься от составления ТЗ под копирайт.
По этой ссылке вы найдете кладезь бесплатных шаблонов ТЗ от:
— Portent
— Avo
— Writing Studio
— Content Harmony
— Convince & Convert
— Brafton
— Content Folks
— Orbit Media
— Zapier
— Daniel Chung
— Smart Blogger
— Jake Sheridan
— Kameron Jenkin
Экономьте свое время!
@MikeBlazerX
Любой сеошник/контентщик нуждается в хороших текстах и беситься от составления ТЗ под копирайт.
По этой ссылке вы найдете кладезь бесплатных шаблонов ТЗ от:
— Portent
— Avo
— Writing Studio
— Content Harmony
— Convince & Convert
— Brafton
— Content Folks
— Orbit Media
— Zapier
— Daniel Chung
— Smart Blogger
— Jake Sheridan
— Kameron Jenkin
Экономьте свое время!
@MikeBlazerX
Google Photos запустили новый алгоритм компрессии фотографий и этим испоганили людям их библиотеки с фотками датированными с 2002 г.
Почему не протестировали это по полной программе?
Надо надеяться, что хотя бы бекапы сделали прежде чем такое творить.
Подробнее об этом тут
@MikeBlazerX
Почему не протестировали это по полной программе?
Надо надеяться, что хотя бы бекапы сделали прежде чем такое творить.
Подробнее об этом тут
@MikeBlazerX
Whisper - новая модель преобразования речи в текст от OpenAI
1. Лучшие английские транскрипции в своем классе!
Whisper может достичь надежности и точности распознавания английской речи на уровне человека.
Обученная на 680 тыс. часов многоязычных данных, собранных из Интернета, эта модель устойчива к акцентам, фоновому шуму и техническому языку.
2. Многоязычные транскрипции
Новая модель способна транскрибировать текст на нескольких языках, а также переводить с этих языков на английский.
3. Открытый исходный код
OpenAI сделал модели транскрипции открытыми, что послужит основой для создания полезных приложений и дальнейших исследований в области надежной обработки речи.
Модель "Шепот" (whisper) доступна в пяти различных вариантах:
- крошечный (39 М)
- базовый (74 М)
- малый (244 М)
- средний (769 M)
- большой (1550 M)
Посмотрите карточку Whisper здесь: github.com/openai/whisper/blob/main/model-card.md
Чтобы понять, как работает модель рекомендую прочитать научную статью "Robust Speech Recognition via Large-Scale Weak Supervision".
--
В видео, которым поделился Дэнни Ричман слышно и видно, как очень сильный акцент (для многих даже непонятный) без проблем преобразуется в текст.
Уже представляю, как некоторые начинают думать о том, как генерить текстовый контент с видео и подкастов при помощи Виспера...
Какие применения этому вы видите?
@MikeBlazerX
1. Лучшие английские транскрипции в своем классе!
Whisper может достичь надежности и точности распознавания английской речи на уровне человека.
Обученная на 680 тыс. часов многоязычных данных, собранных из Интернета, эта модель устойчива к акцентам, фоновому шуму и техническому языку.
2. Многоязычные транскрипции
Новая модель способна транскрибировать текст на нескольких языках, а также переводить с этих языков на английский.
3. Открытый исходный код
OpenAI сделал модели транскрипции открытыми, что послужит основой для создания полезных приложений и дальнейших исследований в области надежной обработки речи.
Модель "Шепот" (whisper) доступна в пяти различных вариантах:
- крошечный (39 М)
- базовый (74 М)
- малый (244 М)
- средний (769 M)
- большой (1550 M)
Посмотрите карточку Whisper здесь: github.com/openai/whisper/blob/main/model-card.md
Чтобы понять, как работает модель рекомендую прочитать научную статью "Robust Speech Recognition via Large-Scale Weak Supervision".
--
В видео, которым поделился Дэнни Ричман слышно и видно, как очень сильный акцент (для многих даже непонятный) без проблем преобразуется в текст.
Уже представляю, как некоторые начинают думать о том, как генерить текстовый контент с видео и подкастов при помощи Виспера...
Какие применения этому вы видите?
@MikeBlazerX
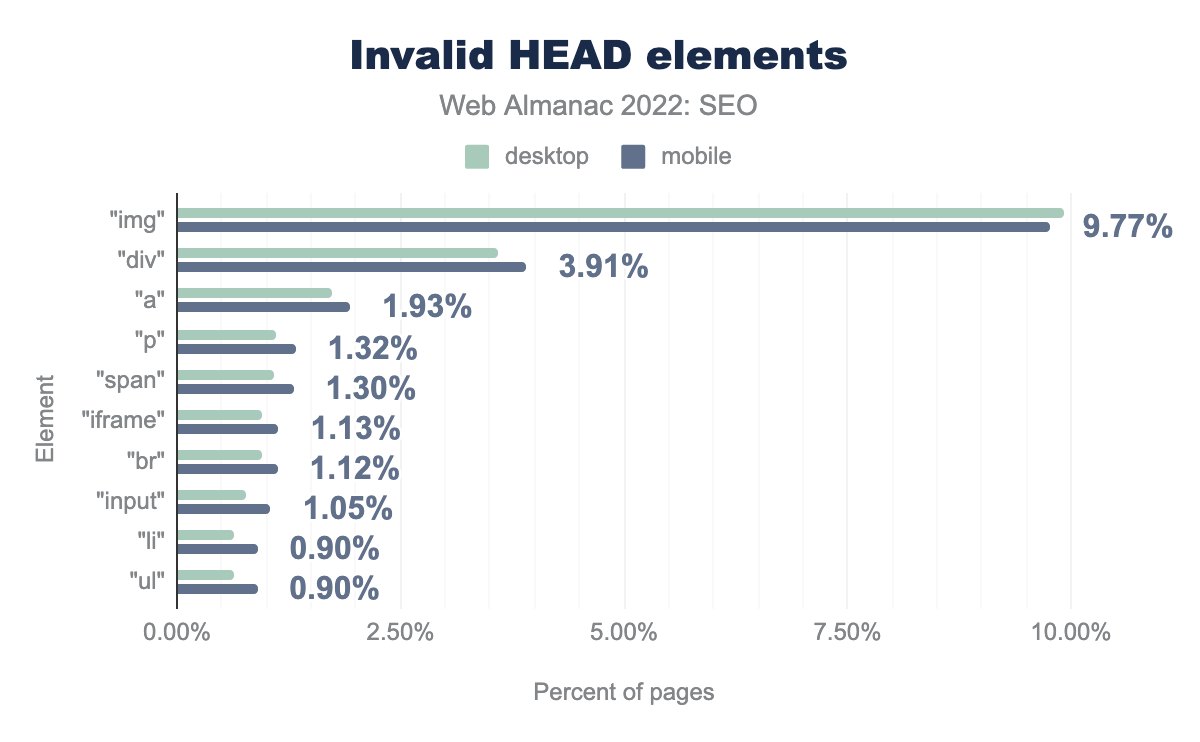
ВЕБ-АЛЬМАНАХ 2022 - ежегодный отчет HTTP Archive о состоянии интернета
Веб-альманах - это всеобъемлющий отчет о состоянии интернета, подкрепленный реальными данными и доверием веб-экспертов.
Проверено веб сайтов - 8.36М
Обработано данных 43.88 Тб
Издание 2022 года состоит из 22 глав, охватывающих аспекты содержания страниц, пользовательского опыта, публикации и распространения.
В главе по SEO были охвачены такие основные категории:
— Crawlability & indexability
— Canonical tags
— Page experience
— On page
— Structured Data
— Links
— AMP
Результаты 2022 года они сравнили с данными 2021 года, а в некоторых случаях и 2020 года.
Спешите ознакомиться с инсайтами: almanac.httparchive.org/en/2022/seo
@MikeBlazerX
Веб-альманах - это всеобъемлющий отчет о состоянии интернета, подкрепленный реальными данными и доверием веб-экспертов.
Проверено веб сайтов - 8.36М
Обработано данных 43.88 Тб
Издание 2022 года состоит из 22 глав, охватывающих аспекты содержания страниц, пользовательского опыта, публикации и распространения.
В главе по SEO были охвачены такие основные категории:
— Crawlability & indexability
— Canonical tags
— Page experience
— On page
— Structured Data
— Links
— AMP
Результаты 2022 года они сравнили с данными 2021 года, а в некоторых случаях и 2020 года.
Спешите ознакомиться с инсайтами: almanac.httparchive.org/en/2022/seo
@MikeBlazerX
{kind=link}
JR Oakes спросил у Джона Мюллера о том, может ли удаления отчета по международному таргетингу в Гугл консоли указывать на то, что Google больше не нуждается в сигналах hreflang для группировки контента?
И, возможно, в конечном итоге хрефленг может быть заменен другой, более простой конструкцией как например
Мюллер ответил, что это изменение ни на что не указывает, это просто изменение, которое есть и далее еще написал несколько твитов в тред:
Люди копируют и вставляют атрибут
Я знаю, мы могли бы включить мета-тег с хэшем содержимого основного языка в sha256 base64, чтобы упростить связь между страницами:
<meta name="canonical" data-content="30401a1d401b60ff48923929ca4e0e85d7d7640b397863b95fd418838e248972">
... с требованием, чтобы страница никогда не меняла свой HTML. 😱
--
Шутник Мюллер, ай шутник.
@MikeBlazerX
И, возможно, в конечном итоге хрефленг может быть заменен другой, более простой конструкцией как например
<html lang="">?Мюллер ответил, что это изменение ни на что не указывает, это просто изменение, которое есть и далее еще написал несколько твитов в тред:
Люди копируют и вставляют атрибут
lang из шаблонов, поэтому везде просто английский, это кажется особенно плохим вариантом для использования lang в качестве сигнала.Я знаю, мы могли бы включить мета-тег с хэшем содержимого основного языка в sha256 base64, чтобы упростить связь между страницами:
--
Шутник Мюллер, ай шутник.
@MikeBlazerX
Джейк Томас поместил 1000 результатов поиска на YouTube в базу данных.
Он обнаружил несколько удивительных тенденций, которые могут помочь вам улучшить SEO на YouTube.
Джейк выполнил 200 поисковых запросов и записал названия 5 лучших результатов по каждому из них.
50% запросов были "how to __".
28% запросов были "best __".
Вот наиболее распространенные триггеры кликов в заголовках, которые ранжируются в поиске:
— Текущий год
— Список
— Слово "beginner"
— Авторитет
— Временные рамки
"2022" был самым распространенным словом в этой базе данных.
45% названий, ранжированных для "Best __", имеют текущий год.
3.4% заголовков содержат эмодзи😲.
Среднее количество символов в заголовке составило 52.5.
19% заголовков заканчиваются скобками, и в основном они включают текущий год или ключевые слова в скобках.
Для поисковых запросов "How to __" 2.5% заголовков, занявших первое место, были вопросами.
Для поиска "Best __" 4.2% заголовков были вопросами.
Для поисковых запросов "X vs. Y" 31% заголовков заканчивались вопросом.
В ~1% этих заголовков содержится негатив (страх, предупреждение, сожаление, ошибки и т.д.).
Для сравнения, в базе данных вирусных видеороликов Джейка, 40% заголовков содержат негатив.
Конечно, это может быть связано с тем, как он сформулировал поиск, но интересно отметить.
Слово "fast" встречалось в 6.7% заголовков, что более чем в два раза чаще, чем слово "easy" (3.1%).
Удивляет, что, согласно этому неофициальному исследованию, люди предпочитают "скорость", а не "легкость".
9% заголовков содержали двоеточие.
Если вы думаете написать заголовок типа "Business Credit Cards: Best Business Credit Cards in 2022", Джейк советует лучше убрать часть "Business Credit Cards:".
5.3% ЗАГОЛОВКОВ БЫЛИ НАПИСАНЫ ЗАГЛАВНЫМИ БУКВАМИ.
Написание заголовков заглавными буквами делает их более трудными для чтения, чем использование обычной капитализации.
Только 4.1% заголовков содержали слово "I" (я).
@MikeBlazerX
Он обнаружил несколько удивительных тенденций, которые могут помочь вам улучшить SEO на YouTube.
Джейк выполнил 200 поисковых запросов и записал названия 5 лучших результатов по каждому из них.
50% запросов были "how to __".
28% запросов были "best __".
Вот наиболее распространенные триггеры кликов в заголовках, которые ранжируются в поиске:
— Текущий год
— Список
— Слово "beginner"
— Авторитет
— Временные рамки
"2022" был самым распространенным словом в этой базе данных.
45% названий, ранжированных для "Best __", имеют текущий год.
3.4% заголовков содержат эмодзи😲.
Среднее количество символов в заголовке составило 52.5.
19% заголовков заканчиваются скобками, и в основном они включают текущий год или ключевые слова в скобках.
Для поисковых запросов "How to __" 2.5% заголовков, занявших первое место, были вопросами.
Для поиска "Best __" 4.2% заголовков были вопросами.
Для поисковых запросов "X vs. Y" 31% заголовков заканчивались вопросом.
В ~1% этих заголовков содержится негатив (страх, предупреждение, сожаление, ошибки и т.д.).
Для сравнения, в базе данных вирусных видеороликов Джейка, 40% заголовков содержат негатив.
Конечно, это может быть связано с тем, как он сформулировал поиск, но интересно отметить.
Слово "fast" встречалось в 6.7% заголовков, что более чем в два раза чаще, чем слово "easy" (3.1%).
Удивляет, что, согласно этому неофициальному исследованию, люди предпочитают "скорость", а не "легкость".
9% заголовков содержали двоеточие.
Если вы думаете написать заголовок типа "Business Credit Cards: Best Business Credit Cards in 2022", Джейк советует лучше убрать часть "Business Credit Cards:".
5.3% ЗАГОЛОВКОВ БЫЛИ НАПИСАНЫ ЗАГЛАВНЫМИ БУКВАМИ.
Написание заголовков заглавными буквами делает их более трудными для чтения, чем использование обычной капитализации.
Только 4.1% заголовков содержали слово "I" (я).
@MikeBlazerX
56% SEO-специалистов заявили, что на создание одной ссылки уходит от 1 до 5 часов...
И что с того, что у вашего конкурента на 10 000 ссылок больше, чем у вас... это 30 000 часов только на то, чтобы догнать его.
При цене $100 в час, это $3 миллиона баксов, чтобы просто догнать конкурента.
@MikeBlazerX
И что с того, что у вашего конкурента на 10 000 ссылок больше, чем у вас... это 30 000 часов только на то, чтобы догнать его.
При цене $100 в час, это $3 миллиона баксов, чтобы просто догнать конкурента.
@MikeBlazerX
Как автоматически удалять карты сайта в массовом порядке в Google Search Console
К сожалению, пользовательский интерфейс в GSC не поддерживает массового удаления карт сайта.
Все, что вам нужно сделать в этом случае, это собрать список карт сайта.
Просто скопируйте таблицу из 1000 сайтмапов (максимальное ограничение) из GSC или можете их спарсить с помощью расширения для Хром браузера (например, используя web scraper).
Затем используйте функцию
Просто откройте любой отдельный сайтмап в GSC и скопируйте URL. Он будет выглядеть так:
https://search.google.com/search-console/sitemaps/info-drilldown?resource_id=sc-domai[...].com&sitemap=http:%2F%2Fwww.xyz.com%2Fsitemap-abc.xml
Установите расширение Axiom для Chrome, которое позволяет выполнять задачи с помощью автоматизации браузера без написания кода.
Это видео поможет разобраться во всем процессе.
Вот аксиома, которую вам нужно будет импортировать в расширение chrome для выполнения этой автоматизации:
https://drive.google.com/file/d/1X3FKwx3_3eeHXISlUOazy4z2z9VN_Ikl/view
Как импортировать аксиому можно узнать в видео.
В двух словах, Axiom делает следующее:
— Открывает по очереди каждый URL-адрес карты сайта.
— Нажимает на значок меню с тремя точками справа. Затем выбирает опцию удаления карты сайта.
— Нажимает на кнопку "Удалить". Ждет 10 секунд, пока GSC обработает удаление.
Каждый пользователь получает 30 минут бесплатного времени работы в новом облачном сервисе Axiom и этого достаточно, чтобы удалить более 1500 сайтмапов.
Весь процесс на английском описан тут.
Это можно сделать также и через GSC API, но придется немного поиграться с кодом.
@MikeBlazerX
К сожалению, пользовательский интерфейс в GSC не поддерживает массового удаления карт сайта.
Все, что вам нужно сделать в этом случае, это собрать список карт сайта.
Просто скопируйте таблицу из 1000 сайтмапов (максимальное ограничение) из GSC или можете их спарсить с помощью расширения для Хром браузера (например, используя web scraper).
Затем используйте функцию
CONCAT() (в Экселе или Гугл таблицах) для создания конечных URL-адресов, которые показывают детали карты сайта в GSC.Просто откройте любой отдельный сайтмап в GSC и скопируйте URL. Он будет выглядеть так:
https://search.google.com/search-console/sitemaps/info-drilldown?resource_id=sc-domai[...].com&sitemap=http:%2F%2Fwww.xyz.com%2Fsitemap-abc.xml
Установите расширение Axiom для Chrome, которое позволяет выполнять задачи с помощью автоматизации браузера без написания кода.
Это видео поможет разобраться во всем процессе.
Вот аксиома, которую вам нужно будет импортировать в расширение chrome для выполнения этой автоматизации:
https://drive.google.com/file/d/1X3FKwx3_3eeHXISlUOazy4z2z9VN_Ikl/view
Как импортировать аксиому можно узнать в видео.
В двух словах, Axiom делает следующее:
— Открывает по очереди каждый URL-адрес карты сайта.
— Нажимает на значок меню с тремя точками справа. Затем выбирает опцию удаления карты сайта.
— Нажимает на кнопку "Удалить". Ждет 10 секунд, пока GSC обработает удаление.
Каждый пользователь получает 30 минут бесплатного времени работы в новом облачном сервисе Axiom и этого достаточно, чтобы удалить более 1500 сайтмапов.
Весь процесс на английском описан тут.
Это можно сделать также и через GSC API, но придется немного поиграться с кодом.
@MikeBlazerX
{kind=link}
Марк Престон провел много исследований, касающихся уровня заработной платы SEO-специалистов, и пришел к выводу, что...
Вы стоите столько, сколько кто-то готов за вас заплатить.
Это касается агентств, штатных сотрудников и фрилансеров.
Рынок, конечно, не устанавливает того, какова ваша стоимость...
Только вы сами можете определить это.
Проблема в том, что...
Большинство людей в отрасли просто не понимают, как оценить себя, поэтому они используют такие вещи, как средние показатели по отрасли, основанные на должностях, в качестве ориентира.
Ряд сеошников с этим не согласились, приводили свои аргументы и мысли.
Марк им ответил так:
Вы готовы заплатить $0,50 за бутылку воды в супермаркете, $2 в спортзале и $3 в кинотеатре.
Одна и та же бутылка воды. Единственное, что изменило ее ценность/стоимость, - это обстоятельства.
Тот же сеошник будет стоить больше в зависимости от ценности, которую он предоставляет компании.
@MikeBlazerX
Вы стоите столько, сколько кто-то готов за вас заплатить.
Это касается агентств, штатных сотрудников и фрилансеров.
Рынок, конечно, не устанавливает того, какова ваша стоимость...
Только вы сами можете определить это.
Проблема в том, что...
Большинство людей в отрасли просто не понимают, как оценить себя, поэтому они используют такие вещи, как средние показатели по отрасли, основанные на должностях, в качестве ориентира.
Ряд сеошников с этим не согласились, приводили свои аргументы и мысли.
Марк им ответил так:
Вы готовы заплатить $0,50 за бутылку воды в супермаркете, $2 в спортзале и $3 в кинотеатре.
Одна и та же бутылка воды. Единственное, что изменило ее ценность/стоимость, - это обстоятельства.
Тот же сеошник будет стоить больше в зависимости от ценности, которую он предоставляет компании.
@MikeBlazerX
Еще одна из причин, почему RSS не мертв
За последние 30 дней Googlebot посетил RSS Feed новостей сайта Джона Хеншоу более 2 тысяч раз.
По ходу, что это гораздо лучше, чем использование сайтмапов XML в GSC.
В документации Гугла также есть такая строка:
"Если на вашем сайте нет RSS или Atom фида, Google автоматически сгенерирует фид для всего вашего домена на основе нашего представления о вашем сайте."
В добавок, Джон Мюллер написал, что RSS 100% не умер, и призвал кормить фидами ботов Гугла.
@MikeBlazerX
За последние 30 дней Googlebot посетил RSS Feed новостей сайта Джона Хеншоу более 2 тысяч раз.
По ходу, что это гораздо лучше, чем использование сайтмапов XML в GSC.
В документации Гугла также есть такая строка:
"Если на вашем сайте нет RSS или Atom фида, Google автоматически сгенерирует фид для всего вашего домена на основе нашего представления о вашем сайте."
В добавок, Джон Мюллер написал, что RSS 100% не умер, и призвал кормить фидами ботов Гугла.
@MikeBlazerX
suggestmachine.com — это просто сумасшедший SEO инструмент для генережки огромного списка длиннохвостых запросов ...
И он 100% бесплатный!
Введите до 10 посевных ключевиков и получите массу отличных длиннохвостых ключей.
@MikeBlazerX
И он 100% бесплатный!
Введите до 10 посевных ключевиков и получите массу отличных длиннохвостых ключей.
@MikeBlazerX
Знали ли вы, что раздувание количества просмотров страниц в ГА происходит из-за людей, которые держат вкладки браузера открытыми? 🤯
Инсайт от Дана ДиТомазо
@MikeBlazerX
Инсайт от Дана ДиТомазо
@MikeBlazerX
Сбор данных Google Suggestions API для SEO-инсайтов с помощью Python
Google Suggestions API - это недооцененный, но мощный API, позволяющий понять тенденции того, что ищут люди.
К тому же, к нему не нужны никакие ключи, ни OAuth, и у него мало параметров для настройки.
Нет даже официальной документации. Создается впечатление, что Google забыл об этом проекте.
Предлагаю покопаться в этом вместе с Грегом Бернхардтом, пока этот АПИ не отключили!
Вот коллаб для быстрого запуска:
colab.research.google.com/drive/18Nta_IO3pi-iu5eYxgGIfjjZ63PIJuKV
Все детали тут.
@MikeBlazerX
Google Suggestions API - это недооцененный, но мощный API, позволяющий понять тенденции того, что ищут люди.
К тому же, к нему не нужны никакие ключи, ни OAuth, и у него мало параметров для настройки.
Нет даже официальной документации. Создается впечатление, что Google забыл об этом проекте.
Предлагаю покопаться в этом вместе с Грегом Бернхардтом, пока этот АПИ не отключили!
Вот коллаб для быстрого запуска:
colab.research.google.com/drive/18Nta_IO3pi-iu5eYxgGIfjjZ63PIJuKV
Все детали тут.
@MikeBlazerX
Идея от Алекса Васева: сайт в нише моды, который фокусируется на комбинациях одежды.
Эта ниша имеет высокий потенциал трафика:
— Количество ключевых слов: 137,885
— Общий объем: 1.7M
Примеры тем помогут вам лучше понять суть проекта:
— Как носить платье с ковбойскими сапогами
— Какую обувь носить с джинсами
— Что носить с брюками мятно-зеленого цвета
— Какие цвета сочетаются с зеленой одеждой
— Корсетные топы большого размера для ношения с джинсами
Некоторые из категорий, которые можно создать на сайте:
— Головные уборы
— Верхняя одежда
— Нижняя одежда
— Обувь
— Сочетания цветов
Нацельтесь сначала на ключевые слова с низкой конкуренцией в разных кластерах.
Потенциал трафика только от низкоконкурентных ключевых слов - высок.
Алекс использовал эти первичные ключевые слова для составления списка идей по темам:
wear with *
what color * to wear with *
Чтобы разбить контент на кластеры, добавьте к начальному ключевому слову следующие модификаторы:
wear with jeans
what color shoes to wear with
И так далее...
Используя эти тематические идеи, вы не ограничены только органическим трафиком из поисковых систем. Вы можете получить тонну вовлеченности на самых популярных платформах социальных сетей.
Это видео на TikTok было просмотрено более 900 тысяч раз:
tiktok.com/@beingjulia/video/7085098426261687557
@MikeBlazerX
Эта ниша имеет высокий потенциал трафика:
— Количество ключевых слов: 137,885
— Общий объем: 1.7M
Примеры тем помогут вам лучше понять суть проекта:
— Как носить платье с ковбойскими сапогами
— Какую обувь носить с джинсами
— Что носить с брюками мятно-зеленого цвета
— Какие цвета сочетаются с зеленой одеждой
— Корсетные топы большого размера для ношения с джинсами
Некоторые из категорий, которые можно создать на сайте:
— Головные уборы
— Верхняя одежда
— Нижняя одежда
— Обувь
— Сочетания цветов
Нацельтесь сначала на ключевые слова с низкой конкуренцией в разных кластерах.
Потенциал трафика только от низкоконкурентных ключевых слов - высок.
Алекс использовал эти первичные ключевые слова для составления списка идей по темам:
wear with *
what color * to wear with *
Чтобы разбить контент на кластеры, добавьте к начальному ключевому слову следующие модификаторы:
wear with jeans
what color shoes to wear with
И так далее...
Используя эти тематические идеи, вы не ограничены только органическим трафиком из поисковых систем. Вы можете получить тонну вовлеченности на самых популярных платформах социальных сетей.
Это видео на TikTok было просмотрено более 900 тысяч раз:
tiktok.com/@beingjulia/video/7085098426261687557
@MikeBlazerX
{kind=link}
Саймон Кокс открыл таблицу Google с аудитом, который он проводил 18 месяцев назад, и получил предупреждение по электронной почте от Google!
"Этот файл нарушает условия использования Google Drive"
Интересно, что вызвало это, ведь ни один из URL-адресов в таблице не является подозрительным.
Может быть, дело в количестве URL-адресов в таблице?
Это может быть проблемой для технических SEO-аудитов!
Потом в верхней части листа Google появляется эта полоса (со скриншота).
Саймон запросил пересмотр.
В нем есть вкладка со всеми доменами, которые Саймон смог найти, связанными с сайтом в прошлом, некоторые были экспайренны - интересно, не был ли один из них отмечен как опасный.
При дальнейшем расследовании домен, который в списке был указан как экспайренный, был восстановлен и теперь редиректит на новый сайт - так что, вероятно, дело не в этом!
И это не WP-сайт, так что вероятность взлома меньше.
--
В общем, имейте в виду, что все, что храниться в Гугл Драйве может однажды стать недоступным...
@MikeBlazerX
"Этот файл нарушает условия использования Google Drive"
Интересно, что вызвало это, ведь ни один из URL-адресов в таблице не является подозрительным.
Может быть, дело в количестве URL-адресов в таблице?
Это может быть проблемой для технических SEO-аудитов!
Потом в верхней части листа Google появляется эта полоса (со скриншота).
Саймон запросил пересмотр.
В нем есть вкладка со всеми доменами, которые Саймон смог найти, связанными с сайтом в прошлом, некоторые были экспайренны - интересно, не был ли один из них отмечен как опасный.
При дальнейшем расследовании домен, который в списке был указан как экспайренный, был восстановлен и теперь редиректит на новый сайт - так что, вероятно, дело не в этом!
И это не WP-сайт, так что вероятность взлома меньше.
--
В общем, имейте в виду, что все, что храниться в Гугл Драйве может однажды стать недоступным...
@MikeBlazerX