
Что делать с несбалансированным набором данных?
Несбалансированный набор данных приводит к тому, что обычные показатели классификации, такие как точность, не работают. Есть несколько способов справиться с несбалансированным набором данных:
1, выберите различные метрики для оценки модели в зависимости от проблемы: оценка F, отзыв, точность и т. Д.
2, исключить некоторые наблюдения из большего набора: уменьшить выборку большего набора путем случайного отбрасывания некоторых данных из этого набора.
3, увеличьте количество наблюдений для меньшего набора: увеличьте выборку меньшего набора либо путем создания нескольких копий точек данных в меньшем наборе (может привести к переобучению модели), либо с помощью создания синтетических данных, таких как SMOTE, где мы используйте существующие данные в меньшем наборе, чтобы создать новые точки данных, которые выглядят как существующие.
Несбалансированный набор данных приводит к тому, что обычные показатели классификации, такие как точность, не работают. Есть несколько способов справиться с несбалансированным набором данных:
1, выберите различные метрики для оценки модели в зависимости от проблемы: оценка F, отзыв, точность и т. Д.
2, исключить некоторые наблюдения из большего набора: уменьшить выборку большего набора путем случайного отбрасывания некоторых данных из этого набора.
3, увеличьте количество наблюдений для меньшего набора: увеличьте выборку меньшего набора либо путем создания нескольких копий точек данных в меньшем наборе (может привести к переобучению модели), либо с помощью создания синтетических данных, таких как SMOTE, где мы используйте существующие данные в меньшем наборе, чтобы создать новые точки данных, которые выглядят как существующие.
Что делать с отсутствующими данными?
Ответ сильно зависит от конкретных сценариев, но вот несколько вариантов:
1, удалите недостающие строки / столбцы, если размер набора данных существенно не уменьшится, если их фильтрация не приведет к смещению выборки.
2, используйте среднее значение / медиана / режим для замены отсутствующего значения: это может быть проблематичным, поскольку оно уменьшает дисперсию функции и игнорирует корреляцию между этой функцией и другими функциями.
3, спрогнозируйте значение, построив интерполятор или предсказав их на основе других функций.
4, используйте пропущенное значение как отдельную функцию: возможно, некоторые значения отсутствуют по определенным причинам, которые могут быть полезны для анализа данных.
Ответ сильно зависит от конкретных сценариев, но вот несколько вариантов:
1, удалите недостающие строки / столбцы, если размер набора данных существенно не уменьшится, если их фильтрация не приведет к смещению выборки.
2, используйте среднее значение / медиана / режим для замены отсутствующего значения: это может быть проблематичным, поскольку оно уменьшает дисперсию функции и игнорирует корреляцию между этой функцией и другими функциями.
3, спрогнозируйте значение, построив интерполятор или предсказав их на основе других функций.
4, используйте пропущенное значение как отдельную функцию: возможно, некоторые значения отсутствуют по определенным причинам, которые могут быть полезны для анализа данных.
Что такое нормализация данных и почему?
Нормализация (или масштабирование) данных позволяет всем непрерывным функциям иметь более согласованный диапазон значений. Для каждой функции мы вычитаем ее среднее значение и делим на стандартную ошибку или диапазон. Цель состоит в том, чтобы все непрерывные объекты находились в одном масштабе. Нормализация данных полезна как минимум в трех случаях:
1, для алгоритмов, использующих евклидово расстояние: Kmeans, KNN: разные масштабы искажают расчет расстояния.
2, для алгоритмов, которые оптимизируются с помощью градиентного спуска: функции в разных масштабах затрудняют сходимость градиентного спуска.
3, для уменьшения размерности (PCA): находит комбинации функций, которые имеют наибольшую дисперсию
Нормализация (или масштабирование) данных позволяет всем непрерывным функциям иметь более согласованный диапазон значений. Для каждой функции мы вычитаем ее среднее значение и делим на стандартную ошибку или диапазон. Цель состоит в том, чтобы все непрерывные объекты находились в одном масштабе. Нормализация данных полезна как минимум в трех случаях:
1, для алгоритмов, использующих евклидово расстояние: Kmeans, KNN: разные масштабы искажают расчет расстояния.
2, для алгоритмов, которые оптимизируются с помощью градиентного спуска: функции в разных масштабах затрудняют сходимость градиентного спуска.
3, для уменьшения размерности (PCA): находит комбинации функций, которые имеют наибольшую дисперсию
👍2🥰2
Какой метод перекрестной проверки следует использовать для набора данных временных рядов?
Методы перекрестной проверки по умолчанию перемешивают данные перед их разделением на разные группы, что нежелательно для анализа временных рядов. Порядок данных временных рядов имеет значение, и мы не хотим обучаться на будущих данных и тестировать на прошлых данных. Вместо этого нам нужно сохранять порядок и тренироваться только на прошлом.
Есть два метода: «скользящее окно» и «прямая цепочка». Во-первых, мы сохраняем порядок наших данных и разрезаем их на разные сгибы. В скользящем окне мы тренируемся на сгибе 1 и тестируем на сгибе 2. Затем мы тренируемся на сгибе 2 и тестируем на сгибе 3. Мы закончим, пока не проверим последний сгиб. В прямой цепочке мы тренируемся на сгибе 1, тестируем на сгибе 2. Затем мы тренируемся на сгибе 1 + 2, тестируем на сгибе 3. Затем тренируемся на сгибе 1 + 2 + 3, тестируем на сгибе 4. Мы остановимся, пока не будем проверить последнюю складку.
@machinelearning_interview
Методы перекрестной проверки по умолчанию перемешивают данные перед их разделением на разные группы, что нежелательно для анализа временных рядов. Порядок данных временных рядов имеет значение, и мы не хотим обучаться на будущих данных и тестировать на прошлых данных. Вместо этого нам нужно сохранять порядок и тренироваться только на прошлом.
Есть два метода: «скользящее окно» и «прямая цепочка». Во-первых, мы сохраняем порядок наших данных и разрезаем их на разные сгибы. В скользящем окне мы тренируемся на сгибе 1 и тестируем на сгибе 2. Затем мы тренируемся на сгибе 2 и тестируем на сгибе 3. Мы закончим, пока не проверим последний сгиб. В прямой цепочке мы тренируемся на сгибе 1, тестируем на сгибе 2. Затем мы тренируемся на сгибе 1 + 2, тестируем на сгибе 3. Затем тренируемся на сгибе 1 + 2 + 3, тестируем на сгибе 4. Мы остановимся, пока не будем проверить последнюю складку.
@machinelearning_interview
👍4
Что такое упаковка и повышение? Почему мы их используем?
Бэггинг - это параллельная тренировка моделей ансамбля. У нас есть набор идентичных моделей обучения со случайно выбранными подвыборками (с заменой) и функциями. Окончательный прогноз объединяет прогнозы всех моделей. Для задач классификации требуется большинство голосов. В то время как для задач регрессии требуется среднее значение всех прогнозов модели. Бэггинг обычно используется для борьбы с переобучением, и Random Forest - отличный тому пример.
Boosting - это вертикальное обучение моделей. Требуется серия моделей, каждая из которых повторяет результат предыдущей. Он обучен на данных, повторно взвешенных, чтобы сосредоточиться на данных, которые предыдущие модели ошибались. Окончательные прогнозы затем объединяются в средневзвешенное значение в конце. Повышение - это техника, которая борется с недостаточной подгонкой, и деревья принятия решений с градиентным усилением - отличный тому пример.
@machinelearning_interview
Бэггинг - это параллельная тренировка моделей ансамбля. У нас есть набор идентичных моделей обучения со случайно выбранными подвыборками (с заменой) и функциями. Окончательный прогноз объединяет прогнозы всех моделей. Для задач классификации требуется большинство голосов. В то время как для задач регрессии требуется среднее значение всех прогнозов модели. Бэггинг обычно используется для борьбы с переобучением, и Random Forest - отличный тому пример.
Boosting - это вертикальное обучение моделей. Требуется серия моделей, каждая из которых повторяет результат предыдущей. Он обучен на данных, повторно взвешенных, чтобы сосредоточиться на данных, которые предыдущие модели ошибались. Окончательные прогнозы затем объединяются в средневзвешенное значение в конце. Повышение - это техника, которая борется с недостаточной подгонкой, и деревья принятия решений с градиентным усилением - отличный тому пример.
@machinelearning_interview
👎6❤1
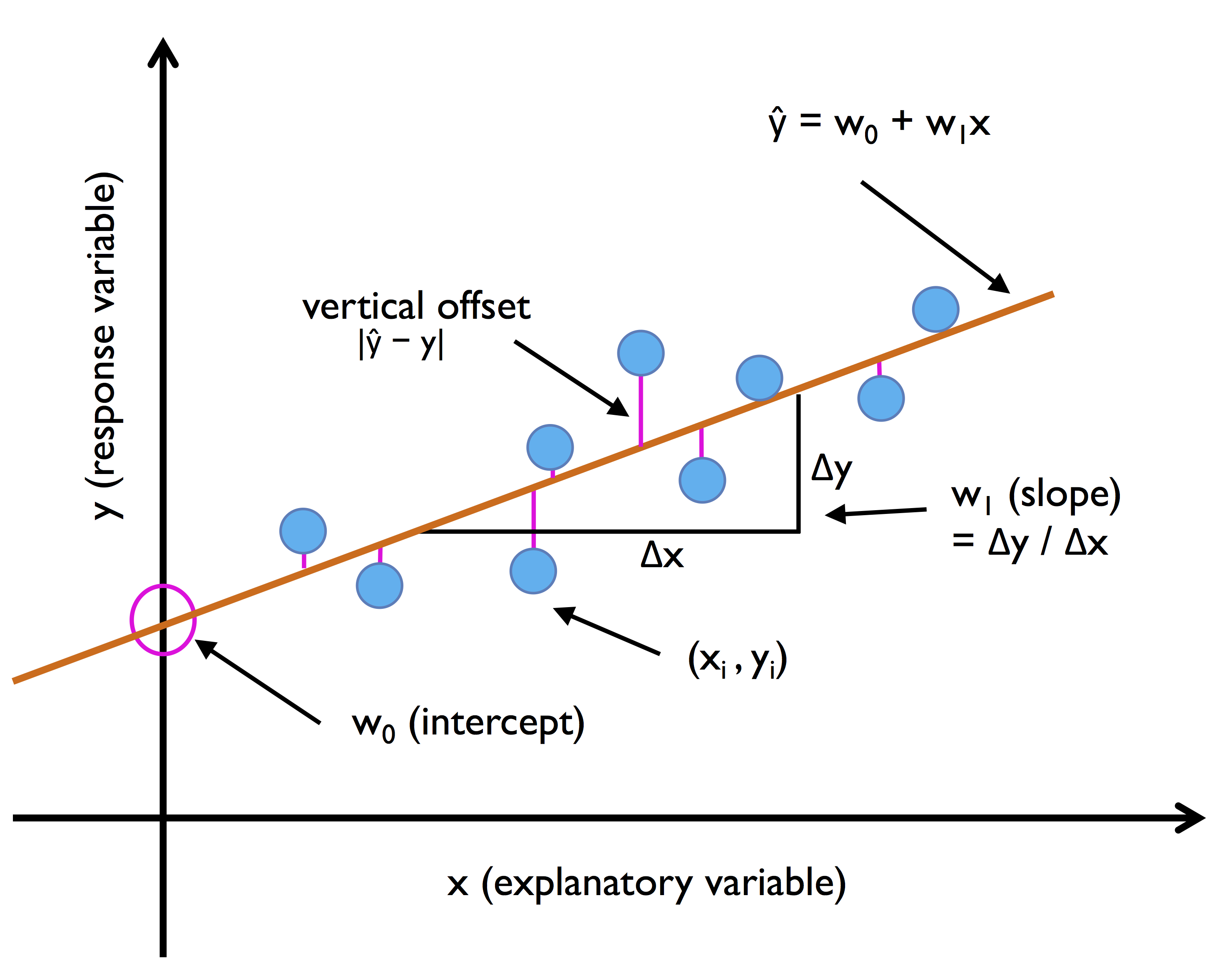
Как оценивать модели линейной регрессии?
Есть несколько способов оценить модели линейной регрессии. Для оценки модели мы можем использовать такие показатели, как средняя абсолютная ошибка (MAE), среднеквадратичная ошибка (MSE), среднеквадратичная ошибка (RMSE). Обратите внимание: если вы не хотите, чтобы выбросы влияли на производительность вашей модели, вам следует использовать MAE, а не MSE. В дополнение к этим показателям мы также можем использовать R-квадрат или скорректированный R-квадрат (R2). R-Squared - это мера, которая сравнивает модель, которую вы построили, с базовой моделью, где базовая модель все время предсказывает среднее значение y.
Если ваша модель хуже, чем базовая модель, R-Squared может быть меньше нуля. Скорректированный R-Squared корректирует R-Squared в зависимости от того, сколько функций ваша модель использовала для прогнозирования. Если увеличение одной функции не улучшает производительность модели, чем ожидалось, скорректированный R-Squared будет уменьшаться.
Обратите внимание, что MAE и MSE трудно интерпретировать без контекста, потому что они зависят от масштаба данных. Однако, поскольку R-Squared имеет фиксированный диапазон, значение, близкое к 1, всегда означает, что модель достаточно хорошо соответствует данным.
@machinelearning_interview
Есть несколько способов оценить модели линейной регрессии. Для оценки модели мы можем использовать такие показатели, как средняя абсолютная ошибка (MAE), среднеквадратичная ошибка (MSE), среднеквадратичная ошибка (RMSE). Обратите внимание: если вы не хотите, чтобы выбросы влияли на производительность вашей модели, вам следует использовать MAE, а не MSE. В дополнение к этим показателям мы также можем использовать R-квадрат или скорректированный R-квадрат (R2). R-Squared - это мера, которая сравнивает модель, которую вы построили, с базовой моделью, где базовая модель все время предсказывает среднее значение y.
Если ваша модель хуже, чем базовая модель, R-Squared может быть меньше нуля. Скорректированный R-Squared корректирует R-Squared в зависимости от того, сколько функций ваша модель использовала для прогнозирования. Если увеличение одной функции не улучшает производительность модели, чем ожидалось, скорректированный R-Squared будет уменьшаться.
Обратите внимание, что MAE и MSE трудно интерпретировать без контекста, потому что они зависят от масштаба данных. Однако, поскольку R-Squared имеет фиксированный диапазон, значение, близкое к 1, всегда означает, что модель достаточно хорошо соответствует данным.
@machinelearning_interview
{kind=link}
👍4🥰1
Как оценивать регрессионные модели и как оценивать модели классификации? (также укажите эффективность)
Чтобы оценить модель, нам необходимо оценить ее технические и практические характеристики. С технической точки зрения, в зависимости от сценариев, мы используем MSE, MAE, RMSE и т. Д. Для оценки регрессионных моделей и используем точность, отзыв, прецизионность, оценку F, AUC для оценки моделей классификации. У меня есть статья, в которой описывается выбор метрик для оценки моделей классификации:
С практической стороны нам нужно оценить, готова ли модель к развертыванию и использованию бизнес-метрик в этом случае. Если мы улучшаем старую модель, мы можем просто сравнить метрики методов между старой моделью и новой моделью, чтобы увидеть, имеет ли новая модель лучшую производительность. Если это лучшая модель, которую вы строите, вам необходимо определить «хорошую производительность» с помощью бизнес-показателей. Например, сколько будет потерь, если мы будем следовать неверным прогнозам модели, и это сильно зависит от бизнес-сценариев. Если отправка рекламы обходится дешево, то модель все равно имеет низкую точность. Однако, если отправка рекламы стоит дорого, нам нужна более высокая точность.
@machinelearning_interview
Чтобы оценить модель, нам необходимо оценить ее технические и практические характеристики. С технической точки зрения, в зависимости от сценариев, мы используем MSE, MAE, RMSE и т. Д. Для оценки регрессионных моделей и используем точность, отзыв, прецизионность, оценку F, AUC для оценки моделей классификации. У меня есть статья, в которой описывается выбор метрик для оценки моделей классификации:
С практической стороны нам нужно оценить, готова ли модель к развертыванию и использованию бизнес-метрик в этом случае. Если мы улучшаем старую модель, мы можем просто сравнить метрики методов между старой моделью и новой моделью, чтобы увидеть, имеет ли новая модель лучшую производительность. Если это лучшая модель, которую вы строите, вам необходимо определить «хорошую производительность» с помощью бизнес-показателей. Например, сколько будет потерь, если мы будем следовать неверным прогнозам модели, и это сильно зависит от бизнес-сценариев. Если отправка рекламы обходится дешево, то модель все равно имеет низкую точность. Однако, если отправка рекламы стоит дорого, нам нужна более высокая точность.
@machinelearning_interview
{kind=link}
🔥5
Какой метод перекрёстной проверки вы бы использовали для набора данных временных рядов?
Нормальная k-кратная процедура перекрёстной проверки может быть проблематичной для временных рядов.
Наиболее результативный подход для временных рядов — это прямая цепочка, где процедура выглядит примерно так:
сгиб 1: тренировка [1], тест [2];
сгиб 2: тренировка [1 2], тест [3];
сгиб 3: тренировка [1 2 3], тест [4];
сгиб 4: тренировка [1 2 3 4], тест [5];
сгиб 5: тренировка [1 2 3 4 5], тест [6].
Это более точно показывает ситуацию, где можно моделировать прошлые данные и прогнозировать прогнозные данные.
@machinelearning_interview
Нормальная k-кратная процедура перекрёстной проверки может быть проблематичной для временных рядов.
Наиболее результативный подход для временных рядов — это прямая цепочка, где процедура выглядит примерно так:
сгиб 1: тренировка [1], тест [2];
сгиб 2: тренировка [1 2], тест [3];
сгиб 3: тренировка [1 2 3], тест [4];
сгиб 4: тренировка [1 2 3 4], тест [5];
сгиб 5: тренировка [1 2 3 4 5], тест [6].
Это более точно показывает ситуацию, где можно моделировать прошлые данные и прогнозировать прогнозные данные.
@machinelearning_interview
{kind=link}
👍7
"Что такое мешающий фактор?"
Это посторонние факторы статистической модели, которые прямо или обратно пропорционально коррелируют как с зависимой, так и с независимой переменной. Оценка не учитывает мешающий фактор, зато сама профессия Data Scientist предусматривает его изучение.
@machinelearning_interview
Это посторонние факторы статистической модели, которые прямо или обратно пропорционально коррелируют как с зависимой, так и с независимой переменной. Оценка не учитывает мешающий фактор, зато сама профессия Data Scientist предусматривает его изучение.
@machinelearning_interview
👍5
#вопросы_с_собеседований
Что такое Random Forest?
Random Forest, или случайный лес, — это один из немногих универсальных алгоритмов обучения, который способен выполнять задачи классификации, регрессии и кластеризации.
Случайный лес состоит из большого количества отдельных деревьев решений, которые по сути являются ансамблем методов. Каждое дерево в случайном лесу возвращает прогноз класса, и класс с наибольшим количеством голосов становится прогнозом леса.
Что такое Random Forest?
Random Forest, или случайный лес, — это один из немногих универсальных алгоритмов обучения, который способен выполнять задачи классификации, регрессии и кластеризации.
Случайный лес состоит из большого количества отдельных деревьев решений, которые по сути являются ансамблем методов. Каждое дерево в случайном лесу возвращает прогноз класса, и класс с наибольшим количеством голосов становится прогнозом леса.
👍9❤1
РАССКАЖИТЕ МНЕ О ТОМ, ДЛЯ ЧЕГО БЫЛ СОЗДАН ЭТОТ НАБОР ДАННЫХ В РАМКАХ АНАЛИТИЧЕСКОГО ПРОЦЕССА.
Esquivel любит этот вопрос, потому что он заставляет кандидатов задуматься о недостатках данных - важной части набора навыков. Говорит Эскивель: «Легко указать и понять, что измеримые структурные атрибуты данных, с которыми мы работаем, часто коррелируют с высокими показателями производительности модели. Однако гораздо менее интуитивно понятно объяснять, как социальный и культурный контекст, в котором был создан набор данных, может привести к моделям, которые воспроизводят предубеждения или полагаются на выводы, исключительные для этого контекста, что приводит к циклам отрицательной обратной связи, неправильному взвешиванию выборки и оценке , а также неожиданные или даже недействительные результаты при применении к другому или большему контексту ».
@machinelearning_interview
Esquivel любит этот вопрос, потому что он заставляет кандидатов задуматься о недостатках данных - важной части набора навыков. Говорит Эскивель: «Легко указать и понять, что измеримые структурные атрибуты данных, с которыми мы работаем, часто коррелируют с высокими показателями производительности модели. Однако гораздо менее интуитивно понятно объяснять, как социальный и культурный контекст, в котором был создан набор данных, может привести к моделям, которые воспроизводят предубеждения или полагаются на выводы, исключительные для этого контекста, что приводит к циклам отрицательной обратной связи, неправильному взвешиванию выборки и оценке , а также неожиданные или даже недействительные результаты при применении к другому или большему контексту ».
@machinelearning_interview
👍5
Как интерпретировать регуляризацию L2 с байесовской точки зрения?
Где p (β | y, X) - апостериорное распределение, p (β) - априорное распределение, а p (y | X, β) - функция правдоподобия. Когда игнорируется априорное распределение и максимизируется только функция правдоподобия для оценки β, у нас нет никакой регуляризации. Имея предположения о предварительном распределении, мы добавляем регуляризацию, что означает, что мы накладываем некоторые ограничения на то, какое значение β может быть выбрано для этой модели. Для L2-регуляризации мы добавляем предположение, что β следует нормальному распределению со средним значением, равным нулю.
Для получения дополнительной информации о байесовской статистике вы можете прочитать следующую статью
@machinelearning_interview
Где p (β | y, X) - апостериорное распределение, p (β) - априорное распределение, а p (y | X, β) - функция правдоподобия. Когда игнорируется априорное распределение и максимизируется только функция правдоподобия для оценки β, у нас нет никакой регуляризации. Имея предположения о предварительном распределении, мы добавляем регуляризацию, что означает, что мы накладываем некоторые ограничения на то, какое значение β может быть выбрано для этой модели. Для L2-регуляризации мы добавляем предположение, что β следует нормальному распределению со средним значением, равным нулю.
Для получения дополнительной информации о байесовской статистике вы можете прочитать следующую статью
@machinelearning_interview
❤5👎1
ОЖИДАЙТЕ ТЕХНИЧЕСКИЕ ВОПРОСЫ ПО ФРЕЙМВОРКАМ И МОДЕЛЯМ МАШИННОГО ОБУЧЕНИЯ, А ТАКЖЕ НЕКОТОРЫЕ КОНЦЕПТУАЛЬНЫЕ ВОПРОСЫ.
Вам следует «убрать свои фреймворки и распространенные модели машинного обучения, например PCA, регрессию и кластеризацию». Вы также должны быть в состоянии «продемонстрировать понимание общих стеков машинного обучения у облачных провайдеров (AWS, Azure или GCloud), например, с помощью AWS - S3 buckets или RDS + lambda + AWS ML и т. д.»
Или воспользуйтесь этим советом Аллена Лу, бывшего стажера по машинному обучению в Google, который в недавнем посте на Quora изложил вопросы собеседования при приеме на работу по машинному обучению, которые он решал, чтобы получить стажировку: «Общие вопросы будут сосредоточены на основных темах машинного обучения, таких как логистическая регрессия, SVM, наивный байесовский метод и т. д. Вас также, вероятно, спросят об основных принципах нейронных сетей, таких как полносвязные уровни, функции активации и плюсы / минусы глубокое обучение (больше скрытых слоев)».
Однако Google не остановился на технических вопросах. (Зачем им?) Как и в вопросах, связанных с принятием решений, которые мы упоминали ранее, Google также любит немного концептуально. Лу говорит: «вы можете ожидать некоторых концептуальных вопросов, таких как смещения и дисперсии, различные функции потерь, переоснащение / регуляризация и т. д.»
Итог: опять же, технические вопросы собеседования будут разными, но лучший способ подготовиться к ним - это просмотреть все основные темы машинного обучения, которые вы изучили, чтобы вы чувствовали себя комфортно, говоря о них.
@machinelearning_interview
Вам следует «убрать свои фреймворки и распространенные модели машинного обучения, например PCA, регрессию и кластеризацию». Вы также должны быть в состоянии «продемонстрировать понимание общих стеков машинного обучения у облачных провайдеров (AWS, Azure или GCloud), например, с помощью AWS - S3 buckets или RDS + lambda + AWS ML и т. д.»
Или воспользуйтесь этим советом Аллена Лу, бывшего стажера по машинному обучению в Google, который в недавнем посте на Quora изложил вопросы собеседования при приеме на работу по машинному обучению, которые он решал, чтобы получить стажировку: «Общие вопросы будут сосредоточены на основных темах машинного обучения, таких как логистическая регрессия, SVM, наивный байесовский метод и т. д. Вас также, вероятно, спросят об основных принципах нейронных сетей, таких как полносвязные уровни, функции активации и плюсы / минусы глубокое обучение (больше скрытых слоев)».
Однако Google не остановился на технических вопросах. (Зачем им?) Как и в вопросах, связанных с принятием решений, которые мы упоминали ранее, Google также любит немного концептуально. Лу говорит: «вы можете ожидать некоторых концептуальных вопросов, таких как смещения и дисперсии, различные функции потерь, переоснащение / регуляризация и т. д.»
Итог: опять же, технические вопросы собеседования будут разными, но лучший способ подготовиться к ним - это просмотреть все основные темы машинного обучения, которые вы изучили, чтобы вы чувствовали себя комфортно, говоря о них.
@machinelearning_interview
❤3👍1
Объясните, что такое регуляризация и почему она полезна
Регуляризация в машинном обучении — метод добавления дополнительных ограничений к условию для того, чтобы предотвратить переобучение системы или решить некорректно поставленную задачу. Часто это ограничение представляет собой штраф за излишнюю сложность модели.
Прогнозы модели должны затем минимизировать функцию потерь, вычисленную на регуляризованном обучающем наборе.
Статья
@machinelearning_interview
Регуляризация в машинном обучении — метод добавления дополнительных ограничений к условию для того, чтобы предотвратить переобучение системы или решить некорректно поставленную задачу. Часто это ограничение представляет собой штраф за излишнюю сложность модели.
Прогнозы модели должны затем минимизировать функцию потерь, вычисленную на регуляризованном обучающем наборе.
Статья
@machinelearning_interview
👍3
КАК ВЫ ОБЩАЕТЕСЬ КАК С ТЕХНИЧЕСКОЙ, ТАК И С НЕТЕХНИЧЕСКОЙ АУДИТОРИЕЙ?
Серхио Моралес Эскивель, специалист по анализу данных из компании Growth Acceleration Partners (GAP), задает вопросы о стиле общения каждый раз, когда он берет на себя собеседование на роль машинного обучения. Зачем? «Я ищу не только кандидатов, которые хотят поделиться своими знаниями и взаимодействовать с другими в рамках нашей аналитической практики, но также тех, кто ценит роль прозрачности и прямого общения в решении проблем, обсуждении альтернативных решений и представлении результатов и идей коллегам. и другие заинтересованные стороны », - говорит Эскивель. «Активное распространение нашего процесса ... может привести нас к мысли, к которой мы бы не пришли в одиночку».
Итог: если вы не можете донести свою работу до людей за пределами вашей команды, вы должны начать работать над этим прямо сейчас. И в процессе собеседования, убедитесь, что вы четко сформулировать, каким образом вы бы общаться внутри и снаружи (в том числе, как они отличаются).
@machinelearning_interview
Серхио Моралес Эскивель, специалист по анализу данных из компании Growth Acceleration Partners (GAP), задает вопросы о стиле общения каждый раз, когда он берет на себя собеседование на роль машинного обучения. Зачем? «Я ищу не только кандидатов, которые хотят поделиться своими знаниями и взаимодействовать с другими в рамках нашей аналитической практики, но также тех, кто ценит роль прозрачности и прямого общения в решении проблем, обсуждении альтернативных решений и представлении результатов и идей коллегам. и другие заинтересованные стороны », - говорит Эскивель. «Активное распространение нашего процесса ... может привести нас к мысли, к которой мы бы не пришли в одиночку».
Итог: если вы не можете донести свою работу до людей за пределами вашей команды, вы должны начать работать над этим прямо сейчас. И в процессе собеседования, убедитесь, что вы четко сформулировать, каким образом вы бы общаться внутри и снаружи (в том числе, как они отличаются).
@machinelearning_interview
👍3🤔1
ПОЧЕМУ ВЫ ИСПОЛЬЗУЕТЕ ЭТОТ АЛГОРИТМ?
Сьюзан Шу Чанг, специалист по обработке данных из Bell, говорит, что по мере прохождения процесса вам следует ожидать таких вопросов: «Почему?». «Я [обычно задаю это] в ответ на то, что кандидат мог упомянуть в качестве ответа в тематическом исследовании науки о данных. Им нужно обосновать это [и показать], что они знают все за и против, а не просто предлагают это, потому что это звучит круто».
Итог: есть много вариантов подхода к проблеме - вам нужно показать, что вы можете критически относиться к той, которую решите использовать.
@machinelearning_interview
Сьюзан Шу Чанг, специалист по обработке данных из Bell, говорит, что по мере прохождения процесса вам следует ожидать таких вопросов: «Почему?». «Я [обычно задаю это] в ответ на то, что кандидат мог упомянуть в качестве ответа в тематическом исследовании науки о данных. Им нужно обосновать это [и показать], что они знают все за и против, а не просто предлагают это, потому что это звучит круто».
Итог: есть много вариантов подхода к проблеме - вам нужно показать, что вы можете критически относиться к той, которую решите использовать.
@machinelearning_interview
👍5
Forwarded from Анализ данных (Data analysis)
3️⃣ распространенные ошибки при поиске работы в области науки о данных в 2022 году
Читать
@data_analysis_ml
Читать
@data_analysis_ml
Telegraph
3 распространенные ошибки при поиске работы в области науки о данных в 2022 году
Ищете работу в области науки о данных и замечаете, что ваши усилия не приносят результатов? Не исключено, что вы практически все делаете правильно, но допускаете одну оплошность, которая не оставляет ни единого шанса на получение работы. Какие распространенные…
👍9
#тест
От чего НЕ зависит величина статистической мощности?
От чего НЕ зависит величина статистической мощности?
Anonymous Quiz
12%
размер выборки для подтверждения статистической гипотезы
21%
величина эффекта (разности между сравниваемыми средними)
44%
матожидание случайной величины
23%
величина уровня значимости
👍9
КАК БЫ ВЫ ПОДОШЛИ К ПОНИМАНИЮ ТОГО, КАКИЕ ОШИБКИ ДОПУСКАЕТ АЛГОРИТМ?
Этот вопрос касается демонстрации ваших навыков решения проблем, помимо выявления ошибки в первую очередь, поэтому сосредоточьте внимание на действенных шагах. Он исходит от Джейсона Дэвиса, генерального директора и соучредителя Simon Data, поставщика платформы данных о клиентах (CDP). Вот почему это нравится Дэвису: «Я хочу видеть, что они думают о проблеме с разных сторон. В Simon Data ключевой частью нашего предложения является партнерство с нашими клиентскими брендами, которое помогает им решать сложные бизнес-задачи. Нам нужен кандидат, который рассмотрит, плохи ли данные или есть ли в алгоритме какие-либо непредвиденные предубеждения, которые мы можем устранить, но правильный кандидат также подумает, не ограничиваясь технической проблемой, и спросит, правильно ли мы моделируем бизнес. проблема для конкретного клиента ».
Итог: для подобных вопросов сосредоточьтесь на действии, например, на том, какие дальнейшие шаги вы предпримете для решения проблем, и вы не сойдете с пути.
@machinelearning_interview
Этот вопрос касается демонстрации ваших навыков решения проблем, помимо выявления ошибки в первую очередь, поэтому сосредоточьте внимание на действенных шагах. Он исходит от Джейсона Дэвиса, генерального директора и соучредителя Simon Data, поставщика платформы данных о клиентах (CDP). Вот почему это нравится Дэвису: «Я хочу видеть, что они думают о проблеме с разных сторон. В Simon Data ключевой частью нашего предложения является партнерство с нашими клиентскими брендами, которое помогает им решать сложные бизнес-задачи. Нам нужен кандидат, который рассмотрит, плохи ли данные или есть ли в алгоритме какие-либо непредвиденные предубеждения, которые мы можем устранить, но правильный кандидат также подумает, не ограничиваясь технической проблемой, и спросит, правильно ли мы моделируем бизнес. проблема для конкретного клиента ».
Итог: для подобных вопросов сосредоточьтесь на действии, например, на том, какие дальнейшие шаги вы предпримете для решения проблем, и вы не сойдете с пути.
@machinelearning_interview
👍5
КАКИЕ СПЕЦИАЛИСТЫ ПО ДАННЫМ ИЛИ СТАРТАПЫ, ОСНОВАННЫЕ НА НАУКЕ О ДАННЫХ, ВАМ БОЛЬШЕ ВСЕГО НРАВЯТСЯ И ПОЧЕМУ?
Даже если вы начинаете заниматься машинным обучением, вы должны быть в курсе тенденций и громких имен в отрасли. Этот вопрос определяет, насколько вы погружены в [науку о данных, машинное обучение, чем бы вы ни занимались], так что как лучше подготовиться? Имейте наготове несколько имен (вроде ваших любимых влиятельных лиц).
@machinelearning_interview
Даже если вы начинаете заниматься машинным обучением, вы должны быть в курсе тенденций и громких имен в отрасли. Этот вопрос определяет, насколько вы погружены в [науку о данных, машинное обучение, чем бы вы ни занимались], так что как лучше подготовиться? Имейте наготове несколько имен (вроде ваших любимых влиятельных лиц).
@machinelearning_interview
👍5