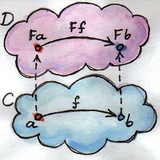
Задача (де)сериализации структур в json решается тремя способами:
1. Проанализировать поля в рантайме с помощью рефлексии;
2. "Заранее" статически проанализировать структуры и нагенерировать для них кодеки;
3. Переложить все поля класса в json и обратно руками :)
В Scala по первому пути идёт, например, старая библиотека json4s. Но рантайм-рефлексия работает в несколько раз медленнее заранее сгенерированного кода, а сериализация частенько становится узким местом высоконагруженных приложений. Поэтому сообщество сместилось в сторону второго подхода, который реализует библиотека circe.
Паттерн у генерации всяческих сериализаторов на Scala примерно одинаковый: объявляется тайпкласс с дефолтными инстансами для примитивов (String, Int, Boolean, etc...) и пользовательскими инстансами для своих типов. Для кейс-классов макросом (или встроенной деривацией в Scala 3) выводятся составные инстансы, в которых поля структуры сопоставляются полю в json и конвертируются кодеком для типа поля.
Результирующий код в рантайме ведёт себя так же быстро как перекладывание руками, но при этом кодек не нужно писать и поддерживать самостоятельно.
А вспомнил я об этом, потому что наткнулся на библиотеку ffjson, которая решает те же проблемы в голанге. Стандартный пакет использует рантайм-рефлексию, поэтому ffjson его обгоняет. Только вместо макросов там кодеки просто кодогенерируются перед сборкой проекта. Языки разные, а проблемы у всех одинаковые :)
1. Проанализировать поля в рантайме с помощью рефлексии;
2. "Заранее" статически проанализировать структуры и нагенерировать для них кодеки;
3. Переложить все поля класса в json и обратно руками :)
В Scala по первому пути идёт, например, старая библиотека json4s. Но рантайм-рефлексия работает в несколько раз медленнее заранее сгенерированного кода, а сериализация частенько становится узким местом высоконагруженных приложений. Поэтому сообщество сместилось в сторону второго подхода, который реализует библиотека circe.
Паттерн у генерации всяческих сериализаторов на Scala примерно одинаковый: объявляется тайпкласс с дефолтными инстансами для примитивов (String, Int, Boolean, etc...) и пользовательскими инстансами для своих типов. Для кейс-классов макросом (или встроенной деривацией в Scala 3) выводятся составные инстансы, в которых поля структуры сопоставляются полю в json и конвертируются кодеком для типа поля.
trait Encoder[T] {
def encode(obj: T): Json
}
implicit val stringEncoder: Encoder[String] =
(str: String) => Json.fromString(str)
@JsonCodec case class Sample(stringValue: String)Результирующий код в рантайме ведёт себя так же быстро как перекладывание руками, но при этом кодек не нужно писать и поддерживать самостоятельно.
А вспомнил я об этом, потому что наткнулся на библиотеку ffjson, которая решает те же проблемы в голанге. Стандартный пакет использует рантайм-рефлексию, поэтому ffjson его обгоняет. Только вместо макросов там кодеки просто кодогенерируются перед сборкой проекта. Языки разные, а проблемы у всех одинаковые :)
Поигрался с match types в Scala 3. Сильно хотел использовать их для определения зависимости возвращаемого типа функции от типа аргумента, но не прокатило. Не понравилось, что матчинг при использовании типа происходит в рантайме, поэтому можно словить исключение
Полный пример в Scastie. Для переменной
Второе следствие матчинга в рантайме — потеря ленивости аргументов:
Полный пример в Scastie.
Пока не понимаю, является ли матчинг в рантайме следствием фундаментальных ограничений языка. Но вообще хотелось бы иметь возможность без костылей сделать зависимую типизацию для своей функции, просто разматчив тип аргумента.
Появление summonFrom и transparent inline позволяет накостылить нечто подобное чуть менее вербозно, чем в Scala 2, но всё равно не интуитивно.
Пример на Scala 2: https://github.com/zio/zio/issues/5241
Он же на Scala 3: https://scastie.scala-lang.org/EwfBu7rcTwi6UQ11VYMwEQ
Несмотря на то, что эта штука работает, выглядит она не как нативная языковая
конструкция, а как насилие над компилятором.
MatchError:type Invert[T] = T match
case String => Int
case Int => String
def invert[T](t: T): Invert[T] =
t match
case s: String => s.length
case i: Int => i.toString
val test = invert(false) // упадёт в рантайме
Полный пример в Scastie. Для переменной
test компилятор выводит тип Invert[Boolean], но не проверяет, есть ли такая ветка в определении типа. В итоге код компилируется, но падает при запуске.Второе следствие матчинга в рантайме — потеря ленивости аргументов:
type Eval[T] = T match
case Any => "do nothing"
def eval[T](t: => T): Eval[T] =
t match
case _: Any => "do nothing"
val a = eval {
println("oooops")
42
}
Полный пример в Scastie.
Пока не понимаю, является ли матчинг в рантайме следствием фундаментальных ограничений языка. Но вообще хотелось бы иметь возможность без костылей сделать зависимую типизацию для своей функции, просто разматчив тип аргумента.
Появление summonFrom и transparent inline позволяет накостылить нечто подобное чуть менее вербозно, чем в Scala 2, но всё равно не интуитивно.
Пример на Scala 2: https://github.com/zio/zio/issues/5241
Он же на Scala 3: https://scastie.scala-lang.org/EwfBu7rcTwi6UQ11VYMwEQ
Несмотря на то, что эта штука работает, выглядит она не как нативная языковая
конструкция, а как насилие над компилятором.
Lil Functor
Поигрался с match types в Scala 3. Сильно хотел использовать их для определения зависимости возвращаемого типа функции от типа аргумента, но не прокатило. Не понравилось, что матчинг при использовании типа происходит в рантайме, поэтому можно словить исключение…
Добрый человек в комментах подсказал, что первая проблема решается флагом
-Ycheck-all-patmat. Очень странно, что он не включен по дефолту.Напоминаю, что Яндекс.Вертикали нанимают скалистов!
Мы делаем три площадки объявлений: auto.ru, Я.Недвижимость и Я.Объявления. Подробный рассказ о RSU, техническом стеке и стульях Herman Miller можно прочитать в вакансии: https://telegra.ph/Vakansiya-behkend-razrabotchika-na-Scala-03-04
Со своей колокольни могу добавить, что вам особенно нужно в Вертикали, если:
– вы планируете переход из разработки в управление. В этом случае у вас будет синергия с постоянной потребностью лидов разработки в Вертикалях;
– вы вэлью-челик с интересом к продукту и сильной технической базой. Вам будет комфортно и не скучно работать в продуктовых командах;
– вы хотите перейти из джавы в скалу. У нас есть опыт адаптации джавистов, а размер компании обеспечит плавный переход;
– вы работаете в стартапе и хотите попробовать бигтех на вкус. Вертикали достаточно небольшой юнит по меркам Яндекса, поэтому шока от перехода в корпорацию почти не будет. А вот все плюшки — будут.
Резюме и вопросы присылайте в лс -> @poslegm
И самое главное: нельзя. игнорировать. тотал.
Мы делаем три площадки объявлений: auto.ru, Я.Недвижимость и Я.Объявления. Подробный рассказ о RSU, техническом стеке и стульях Herman Miller можно прочитать в вакансии: https://telegra.ph/Vakansiya-behkend-razrabotchika-na-Scala-03-04
Со своей колокольни могу добавить, что вам особенно нужно в Вертикали, если:
– вы планируете переход из разработки в управление. В этом случае у вас будет синергия с постоянной потребностью лидов разработки в Вертикалях;
– вы вэлью-челик с интересом к продукту и сильной технической базой. Вам будет комфортно и не скучно работать в продуктовых командах;
– вы хотите перейти из джавы в скалу. У нас есть опыт адаптации джавистов, а размер компании обеспечит плавный переход;
– вы работаете в стартапе и хотите попробовать бигтех на вкус. Вертикали достаточно небольшой юнит по меркам Яндекса, поэтому шока от перехода в корпорацию почти не будет. А вот все плюшки — будут.
Резюме и вопросы присылайте в лс -> @poslegm
И самое главное: нельзя. игнорировать. тотал.
Нашёл библиотечку OCDQuery с генерацией запросов на doobie по пользовательским моделям данных. Сама библиотека выглядит заброшенной, а вот в документации лежит сокровище — понятное описание проблематики и реализации паттерна Higher Kinded Data для моделей сущностей из БД.
https://scalalandio.github.io/ocdquery/#Initialidea
Проблема: часть колонок заполняются БД по заданным правилам (автоинкремент id, например). Соответственно, они присутствуют в модели, которая из базы читается, но бесполезны в той, которая в базу пишется. Ещё при накатывании миграций нужны не значения полей, а названия соответствующих колонок.
Можно решать это отдельными моделями на каждый вариант использования, можно накостылить
Описываем кейс-класс, поля которого лежат в контейнерах, тип которых задаётся при создании. Под каждый способ использования модели задаётся комбинация контейнеров.
Количество тайп-параметров и их комбинаций можно делать любое в зависимости от сценариев использования данных. Главное не получить комбинаторный взрыв :)
https://scalalandio.github.io/ocdquery/#Initialidea
Проблема: часть колонок заполняются БД по заданным правилам (автоинкремент id, например). Соответственно, они присутствуют в модели, которая из базы читается, но бесполезны в той, которая в базу пишется. Ещё при накатывании миграций нужны не значения полей, а названия соответствующих колонок.
Можно решать это отдельными моделями на каждый вариант использования, можно накостылить
null/Option на все колонки. А можно применить HKD.Описываем кейс-класс, поля которого лежат в контейнерах, тип которых задаётся при создании. Под каждый способ использования модели задаётся комбинация контейнеров.
case class ColumnName(name: String)
type Id[A] = A // когда поле обязательно присутствует
type UnitF[A] = Unit // когда поле будет создано базой
type ColumnNameF[A] = ColumnName // для миграций
// F для пользовательских полей
// С для полей, управляемых базой
case class User[F[_], C[_]](id: C[String], name: F[String])
type UserSelect = User[Id, Id] // все поля будут присутствовать в модели
type UserInsert = User[Id, UnitF] // поля, управляемые базой, будут заполнены Unit
type UserColumns = User[ColumnNameF, ColumnNameF] // вместо всех полей будут экземпляры ColumnNames
Количество тайп-параметров и их комбинаций можно делать любое в зависимости от сценариев использования данных. Главное не получить комбинаторный взрыв :)
Не сразу заметно, но в документации третьей скалы работает аналог Hoogle. Hoogle — это поисковый движок по библиотекам на Haskell, умеющий искать по сигнатуре функции. В документации Scala 3 тоже можно нажать на лупу и ввести, например,
Поиск сделан на библиотеке Inquire. Как подключить её в свой скаладок, не понятно. Ещё в Hoogle проиндексированы все хаскельные библиотеки, а Inquire умеет искать только по текущей.
Пока выглядит скорее как игрушка, но вот если бы в IDEA или Metals появилось аналогичное решение с поиском по сигнатурам в проекте и его зависимостях, было бы прямо круто.
Option[A] => A => Boolean: поиск найдёт функцию contains. Правда, далеко не на первом месте.Поиск сделан на библиотеке Inquire. Как подключить её в свой скаладок, не понятно. Ещё в Hoogle проиндексированы все хаскельные библиотеки, а Inquire умеет искать только по текущей.
Пока выглядит скорее как игрушка, но вот если бы в IDEA или Metals появилось аналогичное решение с поиском по сигнатурам в проекте и его зависимостях, было бы прямо круто.
От чтения тайпскриптовых ФП-библиотек (раз, два) складывается впечатление, что они проходят тот же этап, что и скалисты несколько лет назад, когда тащили всё подряд из хаскеля. Только в тайпскрипте это выглядит как будто бы ещё хуже: один только заменитель do-нотации чего стоит. В исходниках ещё много вещей, которые интересны своей изобретательностью в обходе ограничений компилятора, но болезнены в использовании.
Похоже, что "переводы" хаскеля — это проклятие всех языков с развитой системой типов, а идиоматичный инструментарий для ФП появляется только спустя годы экспериментов.
Система типов в TS при этом передовая для промышленного языка: условные типы, типы-литералы даже с поддержкой шаблонов, flow typing, пересечения и объединения типов. Часть этих фич только появилась в Scala 3, а в тайпскрипте существует уже несколько лет. Возможно, тайплевельные истории там не летят из-за интеропа с JS, который гораздо более неприятный, чем интероп с джавой в Scala-мире.
Похоже, что "переводы" хаскеля — это проклятие всех языков с развитой системой типов, а идиоматичный инструментарий для ФП появляется только спустя годы экспериментов.
Система типов в TS при этом передовая для промышленного языка: условные типы, типы-литералы даже с поддержкой шаблонов, flow typing, пересечения и объединения типов. Часть этих фич только появилась в Scala 3, а в тайпскрипте существует уже несколько лет. Возможно, тайплевельные истории там не летят из-за интеропа с JS, который гораздо более неприятный, чем интероп с джавой в Scala-мире.
Есть один супер-интересный канал с разбором пейперов по распределённым системам, на котором несправедливо мало подписчиков.
Всем советую подписаться, там о больших и сложных вещах понятным языком рассказывают. Сегодня вот вышел пост о FoundationDB.
https://t.me/shark_in_it
Всем советую подписаться, там о больших и сложных вещах понятным языком рассказывают. Сегодня вот вышел пост о FoundationDB.
https://t.me/shark_in_it
Telegram
Акула (в) IT
FoundationDB: A Distributed Unbundled Transactional Key Value Store
#shark_whitepaper
Пока я пытаюсь осилить ARIES, немного ненапряжного и очень свежего case-study от июня 2021 года. Работа про распределенное KV хранилище FoundationDB. Всех авторов перечислять…
#shark_whitepaper
Пока я пытаюсь осилить ARIES, немного ненапряжного и очень свежего case-study от июня 2021 года. Работа про распределенное KV хранилище FoundationDB. Всех авторов перечислять…
Удобнейший плагин для релизов артефактов в Maven Central sbt-ci-release переехал в организацию sbt на гитхабе и похоже стал официально рекомендованным способом автоматизации релизов.
Это здорово, потому что релизить что-то в Maven Central — долгий и болезненный процесс, а с этим плагином всё как-то само происходит.
Это здорово, потому что релизить что-то в Maven Central — долгий и болезненный процесс, а с этим плагином всё как-то само происходит.
Канал перевалил за 1000 подписчиков, очень радостное для меня число! Пока вы не успели отписаться, сделаю стандартный телеграм-пост с каналами об ИТ, которые я читаю.
* @oleg_log, @oleg_fov — Олег пишет об индустрии. Удивляюсь его продуктивности и читаю, чтобы держать руку на пульсе;
* @bigflatmappa — канал контрибутора ФП-библиотек с историями о том, что он туда контрибутит. Стоит подписаться, чтобы проникнуться духом 10х программирования;
* @yourcybergrandpa — дед ворчит на облака;
* @architect_says — дед ворчит на Agile;
* @nikitonsky_pub — Никита Прокопов ворчит на всё вокруг;
* @nosingularity — о базах данных и инструментарии для них;
* @dereference_pointer_there — личный блог без чётко очерченной тематики (но частенько про Rust);
* @pmdaily — о продуктовой разработке и взаимоотношениях программиста с бизнесом;
* @scala_channel_ru — важные новости и анонсы из мира Scala;
* @daily_ponv — в основном ссылки на сложные пейперы;
* @shark_in_it — резюме пейперов о распределённых системах и базах данных;
* @scalabin — Антон давно ничего не писал, но если вдруг напишет — точно будет интересно;
* @consensus_io — о распределённых системах.
И конечно же чаты самого дружелюбного в мире сообщества, в котором высококвалифицированные специалисты помогают всем желающим стать 10x скалистом:
@scala_ru, @scala_learn, @scala_jobs, @ru_zio, @akka_ru
* @oleg_log, @oleg_fov — Олег пишет об индустрии. Удивляюсь его продуктивности и читаю, чтобы держать руку на пульсе;
* @bigflatmappa — канал контрибутора ФП-библиотек с историями о том, что он туда контрибутит. Стоит подписаться, чтобы проникнуться духом 10х программирования;
* @yourcybergrandpa — дед ворчит на облака;
* @architect_says — дед ворчит на Agile;
* @nikitonsky_pub — Никита Прокопов ворчит на всё вокруг;
* @nosingularity — о базах данных и инструментарии для них;
* @dereference_pointer_there — личный блог без чётко очерченной тематики (но частенько про Rust);
* @pmdaily — о продуктовой разработке и взаимоотношениях программиста с бизнесом;
* @scala_channel_ru — важные новости и анонсы из мира Scala;
* @daily_ponv — в основном ссылки на сложные пейперы;
* @shark_in_it — резюме пейперов о распределённых системах и базах данных;
* @scalabin — Антон давно ничего не писал, но если вдруг напишет — точно будет интересно;
* @consensus_io — о распределённых системах.
И конечно же чаты самого дружелюбного в мире сообщества, в котором высококвалифицированные специалисты помогают всем желающим стать 10x скалистом:
@scala_ru, @scala_learn, @scala_jobs, @ru_zio, @akka_ru
Посмотрел на Ruby Russia кейноут создателя языка. Там он всерёз говорит об оптимизации языка под микробенчмарки, потому что программисты слишком серьёзно к ним относятся, и выбирают языки, которые обгоняют Ruby. То есть буквально не из-за того, что ускорение рантайма принесёт какую-то ценность, а ради увеличения привлекательности языка. Дальше рассказывал про целый роадмап повышения перфоманса Ruby: многоуровневый JIT, гранты контрибуторам за микрооптимизации. И всё это под соусом того, что «медлительность» вредит маркетингу.
И вот не понимаю: программисты действительно столько внимания уделяют синтетическим бенчмаркам? Почему?
Конечно, есть критичные к перфомансу области разработки, но они уже заняты специфичными языками: Rust, C++. На Ruby пишутся в основном веб-бэкенды, а в них, чтобы упереться в производительность *языка*, надо особо постараться. Если в сервисе что-то тормозит, то почти всегда накосячил программист, а не рантайм. На своей практике припоминаю только два случая, когда тормоза на высоких нагрузках можно было с натяжкой списать на проблемы платформы. Оба связаны с (де-)сериализацией, что характерно :). Но и они решились не переписыванием со скалы на раст, а просто заменой библиотеки и небольшими оптимизациями кода.
А что до синтетических бенчмарков: в самом популярном сравнении HTTP серверов akka-http стабильно болтается около 190-го места. При этом в проде работает нормально и кушать не просит. Если что-то и тормозит, то в коде приложения, а не фреймворка. Современное состояние индустрии таково, что фреймворк со дна бенчмарков может держать внушительную нагрузку! И это не говоря о дешёвом железе.
Поэтому в моих глазах топ причин плохого перфоманса выглядит так:
1. баг в коде;
2. ошибка конфигурации;
3. ошибка дизайна системы;
4. ... программист обосрался где-то ещё ...
5. медленный рантайм языка.
Или в руби всё настолько плохо с производительностью, что даже скала по сравнению с ней летает? Или программистам комфортно списывать свои оплошности на «медленный язык»?
И вот не понимаю: программисты действительно столько внимания уделяют синтетическим бенчмаркам? Почему?
Конечно, есть критичные к перфомансу области разработки, но они уже заняты специфичными языками: Rust, C++. На Ruby пишутся в основном веб-бэкенды, а в них, чтобы упереться в производительность *языка*, надо особо постараться. Если в сервисе что-то тормозит, то почти всегда накосячил программист, а не рантайм. На своей практике припоминаю только два случая, когда тормоза на высоких нагрузках можно было с натяжкой списать на проблемы платформы. Оба связаны с (де-)сериализацией, что характерно :). Но и они решились не переписыванием со скалы на раст, а просто заменой библиотеки и небольшими оптимизациями кода.
А что до синтетических бенчмарков: в самом популярном сравнении HTTP серверов akka-http стабильно болтается около 190-го места. При этом в проде работает нормально и кушать не просит. Если что-то и тормозит, то в коде приложения, а не фреймворка. Современное состояние индустрии таково, что фреймворк со дна бенчмарков может держать внушительную нагрузку! И это не говоря о дешёвом железе.
Поэтому в моих глазах топ причин плохого перфоманса выглядит так:
1. баг в коде;
2. ошибка конфигурации;
3. ошибка дизайна системы;
4. ... программист обосрался где-то ещё ...
5. медленный рантайм языка.
Или в руби всё настолько плохо с производительностью, что даже скала по сравнению с ней летает? Или программистам комфортно списывать свои оплошности на «медленный язык»?
Длинный блогпост с подробным объяснением тайп констрейнтов в скале. От паттернов использования до собственной реализации.
Как работают эти магические
https://blog.bruchez.name/posts/generalized-type-constraints-in-scala/
Как работают эти магические
<:<, =:=, и почему недостаточно обычных тайп баундов. Для меня при изучении скалы это долгое время был один из самых непонятных вопросов.https://blog.bruchez.name/posts/generalized-type-constraints-in-scala/
Erik’s Ponderings
Generalized type constraints in Scala (without a PhD)
Introduction
Forwarded from PONV Daily (Igal Tabachnik)
Габриель Вольпе пишет новую книгу про функциональную архитектуру на Скала 3 https://twitter.com/volpegabriel87/status/1448241688342892545
Ещё полгода назад в sbt появилась возможность прописывать схему версионирования зависимостей. Это помогает системе сборке сигнализировать о бинарной несовместимости зная правила версионирования конкретной библиотеки, то есть с меньшим количеством ложных срабатываний. Подробнее об этом написано здесь.
Для меня стало открытием, что версионирование библиотек в скала-экосистеме — это вовсе не кривой semver, а другие схемы со своей формализацией. Так, стандартная библиотека версионируется по PVP:
А другие библиотеки, например, проекты Typelevel, используют early-semver. В нём первая цифра увеличивается только при изменениях, ломающих бинарную совместимость. Если же major=0, то бинарную совместимость можно ломать при каждом минорном релизе. Собственно поэтому версия circe до сих пор начинается с нуля :) И рекомендацией для библиотек является как раз использование early-semver.
Для меня стало открытием, что версионирование библиотек в скала-экосистеме — это вовсе не кривой semver, а другие схемы со своей формализацией. Так, стандартная библиотека версионируется по PVP:
epoch.major.minor. В отличие от semver в нём не надо увеличивать первую цифру при каждом ломающем изменении: её можно инкрементить на усмотрение автора о важности обновления.А другие библиотеки, например, проекты Typelevel, используют early-semver. В нём первая цифра увеличивается только при изменениях, ломающих бинарную совместимость. Если же major=0, то бинарную совместимость можно ломать при каждом минорном релизе. Собственно поэтому версия circe до сих пор начинается с нуля :) И рекомендацией для библиотек является как раз использование early-semver.
В DI-фреймворке под названием ZIO можно автовайрить зависимости с помощью zio-magic, который ещё и встроят в версию 2.0. Код выглядит примерно так:
А дальше макрос на этапе компиляции выстроит граф зависимостей по входящим типам слоёв. Но частенько в приложении бывают классы, принимающие зависимости одного и того же типа. Допустим, grpc-клиенты к микросервисам
Но мне это не нравится, потому что приходится внедрять куски ручного построения графа зависимостей в плоский список слоёв.
Так как вайринг происходит во время компиляции, различать зависимости нужно на уровне типов. Сразу пришла идея использовать тайп-теги: пометить слой зависимости каким-то тегом, и такой же тип затребовать в слое-получателе. Собственно, после некоторого пердолинга с компилятором было написано такое вот поделие: https://gist.github.com/poslegm/f252994a15453457e64d6498249928f3.
И с ним можно писать уже так:
К сожалению не получилось придумать реализацию
Зато теперь все зависимости укладываются в один плоский список, а zio-magic ругнётся, если не будет протегированной зависимости к какому-то слою.
ZLayer.fromMagic[Env](
UsersRepository.live,
ClientsRepository.live,
RegistrationService.live
)
А дальше макрос на этапе компиляции выстроит граф зависимостей по входящим типам слоёв. Но частенько в приложении бывают классы, принимающие зависимости одного и того же типа. Допустим, grpc-клиенты к микросервисам
BillingClient и NotificatorClient принимают в зависимости GrpcConfig. Содержимое этих конфигов очевидно разное, но на уровне типов этого не видно, поэтому нельзя понять, какой экземляр конфига к кому относится. Можно решить это ручным вайрингом:ZLayer.fromMagic[Env](
Grpc.live,
Config.loadLayer[GrpcConfig]("billing") ++ ZLayer.environment[Has[Grpc]] >>> BillingClient.live,
Config.loadLayer[GrpcConfig]("notificator") ++ ZLayer.environment[Has[Grpc]] >>> NotificatorClient.live
)
Но мне это не нравится, потому что приходится внедрять куски ручного построения графа зависимостей в плоский список слоёв.
Так как вайринг происходит во время компиляции, различать зависимости нужно на уровне типов. Сразу пришла идея использовать тайп-теги: пометить слой зависимости каким-то тегом, и такой же тип затребовать в слое-получателе. Собственно, после некоторого пердолинга с компилятором было написано такое вот поделие: https://gist.github.com/poslegm/f252994a15453457e64d6498249928f3.
И с ним можно писать уже так:
ZLayer.fromMagic[Env](
Grpc.live,
Config.loadLayer[GrpcConfig]("billing").tagged[BillingClient.Service],
Config.loadLayer[GrpcConfig]("notificator").tagged[NotificatorClient.Service],
BillingClient.live.requireTagged[GrpcConfig, BillingClient.Service, Has[Grpc]],
NotificatorClient.live.requireTagged[GrpcConfig, NotificatorClient.Service, Has[Grpc]]
)
К сожалению не получилось придумать реализацию
requireTagged, в которой не надо явно указывать компилятору тип "остатка" требуемых слоёв, кроме протегированного.Зато теперь все зависимости укладываются в один плоский список, а zio-magic ругнётся, если не будет протегированной зависимости к какому-то слою.
Совсем недавно скала-сообщество бурлило из-за внезапно обнаруженного отсутствия forward compatibility в Scala 3. Штука и правда неприятная, но, на мой взгляд, скалисты излишне всё драматизировали. На то они и скалисты!
Подробно о проблеме можно почитать тут.
А пару часов назад на форуме разработчиков языка появился план по исправлению этого неудобства — https://contributors.scala-lang.org/t/improving-scala-3-forward-compatibility/5298
TL;DR: будет `-target`, как в джаве.
Подробно о проблеме можно почитать тут.
А пару часов назад на форуме разработчиков языка появился план по исправлению этого неудобства — https://contributors.scala-lang.org/t/improving-scala-3-forward-compatibility/5298
TL;DR: будет `-target`, как в джаве.
Адам Фрейзер (кор-контрибутор ZIO) сделал доклад с очередным набросом на скалу-как-хаскель, дескать, теорию категорий надо знать. Мне понятно, почему Ziverge атакует «академическое» ФП с точки зрения маркетинга своей экосистемы. В этом ключе разумно давить на неофитов стереотипом о сложной математике, без которой в библиотеках конкурента не разобраться.
Но только на практике я программировал в функциональном стиле на Scala до появления ZIO, не зная при этом теорию категорий. Не горжусь своим невежеством в этом вопросе, но вэлью делать оно не мешает. Для программиста все эти монады, стрелки Клейсли и контравариантные функторы в коде быстро превращаются в паттерны со странными названиями. И их изучение мало отличается от изучения синглтонов, визиторов и абстрактных фабрик.
Tagless Final на скале мне неудобен скорее из-за упора на ад-хок полиморфизм, который заставляет учить слишком много тайпклассов. Правда для этого нужна хорошая память, а не математический аппарат :)
Но только на практике я программировал в функциональном стиле на Scala до появления ZIO, не зная при этом теорию категорий. Не горжусь своим невежеством в этом вопросе, но вэлью делать оно не мешает. Для программиста все эти монады, стрелки Клейсли и контравариантные функторы в коде быстро превращаются в паттерны со странными названиями. И их изучение мало отличается от изучения синглтонов, визиторов и абстрактных фабрик.
Tagless Final на скале мне неудобен скорее из-за упора на ад-хок полиморфизм, который заставляет учить слишком много тайпклассов. Правда для этого нужна хорошая память, а не математический аппарат :)
Новая микро-драма в Scala-сообществе: Роб Норрис, мейнтенер библиотеки для работы с SQL doobie, удалил интеграцию с другой библиотекой для SQL quill, потому что та вошла под крыло компании Ziverge, с которой у Норриса личный конфликт.
Поддерживать интеграции нескольких независимых библиотек в общем случае большая нагрузка на мейнтейнеров из-за необходимости «дружить» API, изменяющиеся без согласования друг с другом. То, что такая интеграция находилась непосредственно в doobie, а не поддерживалась в виде опосредованной библиотеки, накладывало определённую нагрузку и риски на мейнтейнеров. Поэтому, на мой взгляд, они в праве отказываться от поддержки таких решений по уйме причин: расхождения API, сложность работы с зависимостями, нехватка личного времени и т.д.
Но Норрис решил в один момент разбомбить Воронеж, то есть конечных пользователей, использующих эту интеграцию в проде. Что можно было сделать лучше?
1. Вынести интеграцию в отдельный репозиторий на гитхабе, сохранив неймспейс и название джарника. Если не хочется делать это самостоятельно, поставить issue на авторов quill с обозначенными сроками отказа от поддержки.
2. Задепрекейтить код интеграции, обозначив версию, в которой он будет удалён.
3. Изначально держать коннекторы в отдельных репозиториях и версионировать их независимо от основной библиотеки. В этом плане ZIO более дальновидно.
Собственно, сообщество подсуетилось и спасло эти аж ~200 строк кода интеграции. Которые, впрочем, можно и в свой проект скопипастить.
К слову, ценность этой интеграции для меня под вопросом. Писать код на DSL квилла и запускать на транзакторе из doobie не особо здорово, потому что doobie гвоздями прибит к jdbc. Хотелось бы наоборот, писать plain SQL в духе doobie и запускать их на асинхронном драйвере к постгре или другой базе, которые как раз поддерживаются в quill.
Эмоциональный выпад Норриса был замечен в высоких кабинетах Лозанны, и профессор Одерски лично отметил поведение деструктивным. В ответ на форуме контрибуторов Scala была созданна тема, в которой сообщество было обвинено в токсичности к меньшинствам, а Одерски чуть ли не в причастности к убийствам. Но об SQL и поддержке библиотек там ни слова, поэтому читать стоит только если очень хочется насладиться дивным новым миром.
Поддерживать интеграции нескольких независимых библиотек в общем случае большая нагрузка на мейнтейнеров из-за необходимости «дружить» API, изменяющиеся без согласования друг с другом. То, что такая интеграция находилась непосредственно в doobie, а не поддерживалась в виде опосредованной библиотеки, накладывало определённую нагрузку и риски на мейнтейнеров. Поэтому, на мой взгляд, они в праве отказываться от поддержки таких решений по уйме причин: расхождения API, сложность работы с зависимостями, нехватка личного времени и т.д.
Но Норрис решил в один момент разбомбить Воронеж, то есть конечных пользователей, использующих эту интеграцию в проде. Что можно было сделать лучше?
1. Вынести интеграцию в отдельный репозиторий на гитхабе, сохранив неймспейс и название джарника. Если не хочется делать это самостоятельно, поставить issue на авторов quill с обозначенными сроками отказа от поддержки.
2. Задепрекейтить код интеграции, обозначив версию, в которой он будет удалён.
3. Изначально держать коннекторы в отдельных репозиториях и версионировать их независимо от основной библиотеки. В этом плане ZIO более дальновидно.
Собственно, сообщество подсуетилось и спасло эти аж ~200 строк кода интеграции. Которые, впрочем, можно и в свой проект скопипастить.
К слову, ценность этой интеграции для меня под вопросом. Писать код на DSL квилла и запускать на транзакторе из doobie не особо здорово, потому что doobie гвоздями прибит к jdbc. Хотелось бы наоборот, писать plain SQL в духе doobie и запускать их на асинхронном драйвере к постгре или другой базе, которые как раз поддерживаются в quill.
Эмоциональный выпад Норриса был замечен в высоких кабинетах Лозанны, и профессор Одерски лично отметил поведение деструктивным. В ответ на форуме контрибуторов Scala была созданна тема, в которой сообщество было обвинено в токсичности к меньшинствам, а Одерски чуть ли не в причастности к убийствам. Но об SQL и поддержке библиотек там ни слова, поэтому читать стоит только если очень хочется насладиться дивным новым миром.
Вот и пригодилась компиляция Scala → JavaScript. Только не для фронтенда.
Daniel Spiewak в концепте serverless-фреймворка предлагает компилировать код на Scala в JS, чтобы запускать его на движке V8. Таким образом получится избежать проблемы холодного старта JVM для короткоживущих функций. V8 не надо прогревать, а код для него можно писать всё на той же Scala. Не зря ведь scala.js делали и библиотеки под него кроссбилдили!
Понятно, что scala-native слишком далека от готовности к проду, но интересно, почему решили не использовать Native Image в GraalVM. Решение с js в любом случае оригинальное и может быть из него что-то вырастет.
Сам концепт: https://gist.github.com/djspiewak/37a4ea0d7a5237144ec8b56a76ed080d
Прототип библиотеки: https://github.com/typelevel/feral
Daniel Spiewak в концепте serverless-фреймворка предлагает компилировать код на Scala в JS, чтобы запускать его на движке V8. Таким образом получится избежать проблемы холодного старта JVM для короткоживущих функций. V8 не надо прогревать, а код для него можно писать всё на той же Scala. Не зря ведь scala.js делали и библиотеки под него кроссбилдили!
Понятно, что scala-native слишком далека от готовности к проду, но интересно, почему решили не использовать Native Image в GraalVM. Решение с js в любом случае оригинальное и может быть из него что-то вырастет.
Сам концепт: https://gist.github.com/djspiewak/37a4ea0d7a5237144ec8b56a76ed080d
Прототип библиотеки: https://github.com/typelevel/feral
Текстовая версия недавнего доклада Li Haoyi (автора книги Hands On Scala и множества библиотек и инструментов) о применении Scala в DataBricks. Наконец-то нормальная саццесс-стори вместо набивших оскомину драм в сообществе. Там и про управление зависимостями, и про сборку с CI, и про скрипты на библиотеках самого Li.
https://databricks.com/blog/2021/12/03/scala-at-scale-at-databricks.html
we have been able to scale our Scala-using engineering teams without issue and reap the benefits of using Scala as a lingua franca across the organization
https://databricks.com/blog/2021/12/03/scala-at-scale-at-databricks.html
we have been able to scale our Scala-using engineering teams without issue and reap the benefits of using Scala as a lingua franca across the organization
Дорогие подписчики, поздравляю с новым годом!
Желаю вам в 2022 карьерных достижений, академических изысканий и жадного ума 🚀
Желаю вам в 2022 карьерных достижений, академических изысканий и жадного ума 🚀