
🎇 Завет Машиночитаемости Права
На днях вышла книга управляющего партнёра "Симплоер" Антона Вашкевича "Машиночитаемое право: право как электричество".
По сути, это системное изложение тезисов и выводов по ряду аспектов разработки и применения права в машиночитаемой форме.
Оглавление выглядит аппетитно, вот названия некоторых глав и подглав:
▫️ Неэффективность права
▫️ Как автоматизировать право
▫️ Алгоритмизация
▫️ Машинное обучение
▪️ Совместимость права с новым миром
▪️ Подходы к автоматизации права в мире
▪️ Ограничения естественного языка
▪️ Этические вопросы
▪️ Совместимость норм с автоматизацией
И привожу несколько цитат:
📎 "В случае коллизии между машиночитаемыми нормами и нормами, записанными на естественном языке, приоритет должны иметь машиночитаемые. (с. 26)"
📎 "Человек — не самый эффективный исполнитель большинства норм. (с. 34)"
📎 "Самоисполняемость норм блокирует или ограничивает волю людей совершать правонарушения. Но иногда правонарушение оказывается эффективнее соблюдения нормы. (с. 216)"
В общем, кто интересуется проблемами будущего права, книгу стоит прочесть. Местами текст может казаться заумным, но в целом есть доходчивые пояснения и примеры. Особенно меня радуют последние разделы, где идёт мясцо конкретики. 😎
На днях вышла книга управляющего партнёра "Симплоер" Антона Вашкевича "Машиночитаемое право: право как электричество".
По сути, это системное изложение тезисов и выводов по ряду аспектов разработки и применения права в машиночитаемой форме.
Оглавление выглядит аппетитно, вот названия некоторых глав и подглав:
▫️ Неэффективность права
▫️ Как автоматизировать право
▫️ Алгоритмизация
▫️ Машинное обучение
▪️ Совместимость права с новым миром
▪️ Подходы к автоматизации права в мире
▪️ Ограничения естественного языка
▪️ Этические вопросы
▪️ Совместимость норм с автоматизацией
И привожу несколько цитат:
📎 "В случае коллизии между машиночитаемыми нормами и нормами, записанными на естественном языке, приоритет должны иметь машиночитаемые. (с. 26)"
📎 "Человек — не самый эффективный исполнитель большинства норм. (с. 34)"
📎 "Самоисполняемость норм блокирует или ограничивает волю людей совершать правонарушения. Но иногда правонарушение оказывается эффективнее соблюдения нормы. (с. 216)"
В общем, кто интересуется проблемами будущего права, книгу стоит прочесть. Местами текст может казаться заумным, но в целом есть доходчивые пояснения и примеры. Особенно меня радуют последние разделы, где идёт мясцо конкретики. 😎
🧶 Сила данных — в правде
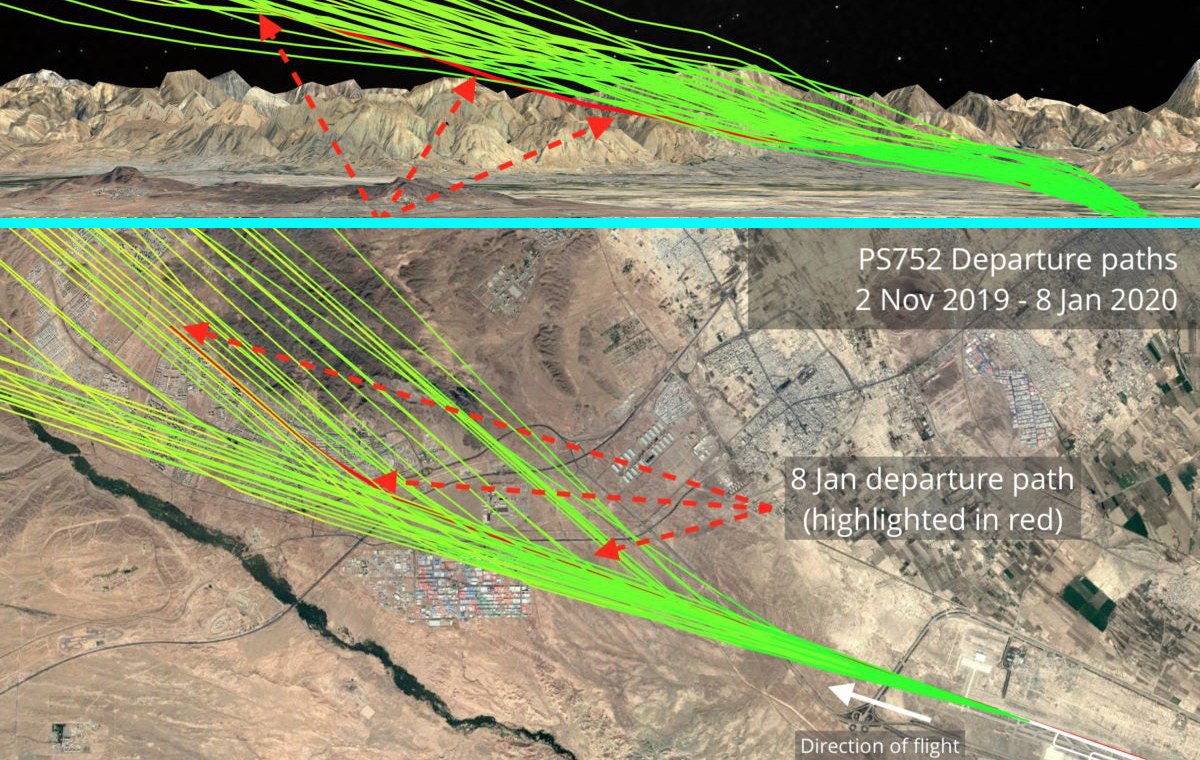
На картинке ниже и в этом видео — драматическая демонстрация ценности больших данных не только в рамках правовой системы отдельного государства, но и в международных отношениях. Видно, что траектория полёта нашего самолёта до момента его сбития не выделялась из множества траекторий предшествующих рейсов. Так "большие данные" становятся мощным противовесом словам "больших людей".
Одна из задач разумной цифровизации государства в том, чтобы не только создавать системы логирования всех значимых событий (регистрационные действия, декларации, реестры уголовных производств и т.д.), но и защищать собранные данные от последующего вмешательства с целью удаления/фальсификации. В условиях, когда данные будут всё больше становиться ключевым доказательством в расследованиях, им нужно обеспечить свой аналог "системы защиты свидетелей".
Но в отличии от человека, который существует в единственном телесном экземпляре, данные можно хешировать, копировать, сохранять их версии, публиковать, транслировать онлайн и при особой нужде блокчейнизировать. Если по-настоящему захотеть, то можно сделать так, чтобы данные было крайне сложно поставить под сомнение.
А если мы хотим строить прозрачное общество, то нужно научиться лелеять данные, но в то же время не бояться делать их открытыми. Максимизация полномочий общества на чтение данных не связана с техническими возможностями по изменению данных. Ведь многие из нас могут зайти на главную страницу Google, но немногие могут редактировать её, верно?
На картинке ниже и в этом видео — драматическая демонстрация ценности больших данных не только в рамках правовой системы отдельного государства, но и в международных отношениях. Видно, что траектория полёта нашего самолёта до момента его сбития не выделялась из множества траекторий предшествующих рейсов. Так "большие данные" становятся мощным противовесом словам "больших людей".
Одна из задач разумной цифровизации государства в том, чтобы не только создавать системы логирования всех значимых событий (регистрационные действия, декларации, реестры уголовных производств и т.д.), но и защищать собранные данные от последующего вмешательства с целью удаления/фальсификации. В условиях, когда данные будут всё больше становиться ключевым доказательством в расследованиях, им нужно обеспечить свой аналог "системы защиты свидетелей".
Но в отличии от человека, который существует в единственном телесном экземпляре, данные можно хешировать, копировать, сохранять их версии, публиковать, транслировать онлайн и при особой нужде блокчейнизировать. Если по-настоящему захотеть, то можно сделать так, чтобы данные было крайне сложно поставить под сомнение.
А если мы хотим строить прозрачное общество, то нужно научиться лелеять данные, но в то же время не бояться делать их открытыми. Максимизация полномочий общества на чтение данных не связана с техническими возможностями по изменению данных. Ведь многие из нас могут зайти на главную страницу Google, но немногие могут редактировать её, верно?
{kind=link}
🐺 ИИ интеллекту волк?
1️⃣ На днях Минцифра объявили о создании экспертного комитета по вопросам развития сферы ИИ в Украине. Приоритеты работы определены хорошие, и это как раз хороший повод запустить серию постов на тему ИИ.
2️⃣ Параллельно, в Минске скоро должно состояться установочное собрание Лаборатории Вычислительного Права, чтобы в дальней перспективе "правовое регулирование и юридические практики в цифровую эпоху обрели ту технологическую поддержку и форму, которая бы соответствовала требованиям настоящего и будущего".
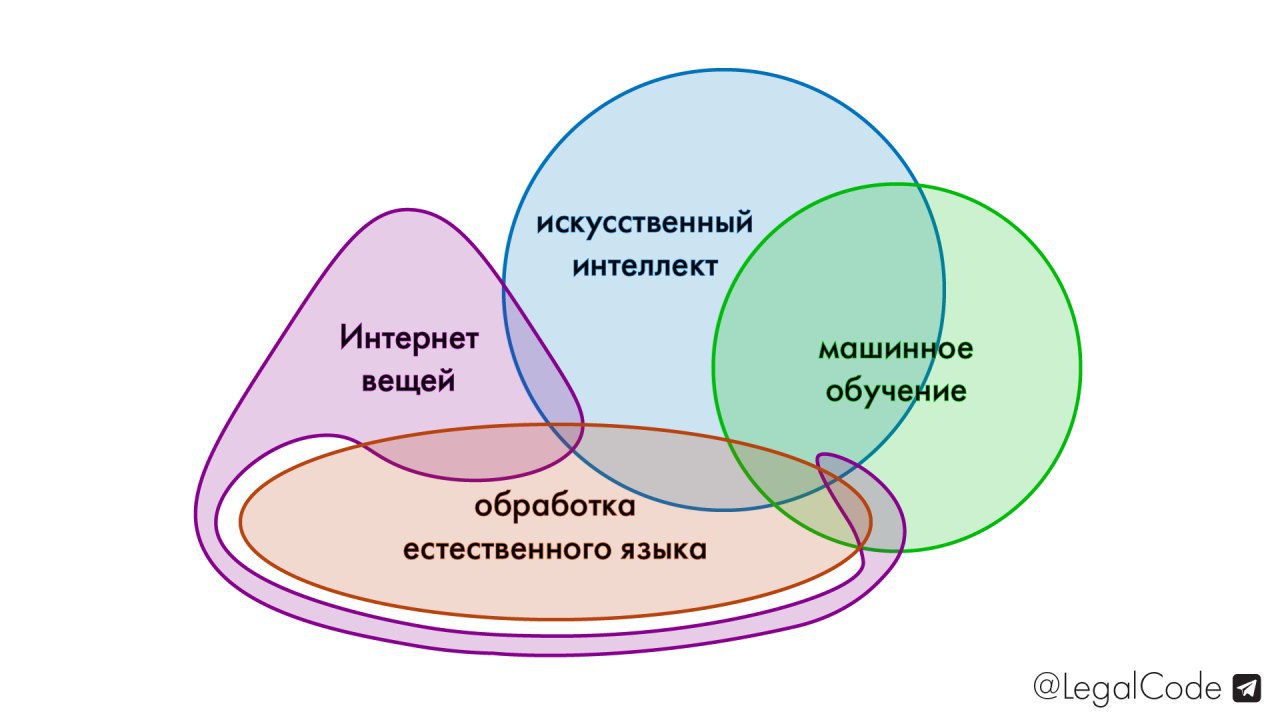
В своих выступлениях я постоянно делаю акцент на том, что термин "искусственный интеллект" (AI) довольно запутанный, часто спорный и пользоваться им следует осторожно (особенно стартаперам на питчах перед инвесторами/фондами). При возможности необходимо озвучивать более конкретные термины: "машинное обучение" (Machine Learning, ML), "обработка естественного языка" (Natural Language Processing, NLP), "Интернет вещей" (Internet of Things, IoT), робототехника (Robotics) и т.д. Эти и другие направления могут как включать элементы "искусственного интеллекта", так и не включать.
Не вдаваясь в пространные рассуждения о философских проблемах термина "ИИ" скажу, что предпочитаю использовать термин "интеллектуализация вычислений/алгоритмов" (ИВ, ИА или ИВ/А), так как это освобождает от необходимости вдаваться в условности, объяснять критерии того, что мы считаем "интеллектом" и доказывать, что наши алгоритмы заслуживают именоваться "интеллектом".
Ниже при помощи кругов Эйлера показываю, как соотносится термин "ИИ" с более конкретными понятиями.
1️⃣ На днях Минцифра объявили о создании экспертного комитета по вопросам развития сферы ИИ в Украине. Приоритеты работы определены хорошие, и это как раз хороший повод запустить серию постов на тему ИИ.
2️⃣ Параллельно, в Минске скоро должно состояться установочное собрание Лаборатории Вычислительного Права, чтобы в дальней перспективе "правовое регулирование и юридические практики в цифровую эпоху обрели ту технологическую поддержку и форму, которая бы соответствовала требованиям настоящего и будущего".
В своих выступлениях я постоянно делаю акцент на том, что термин "искусственный интеллект" (AI) довольно запутанный, часто спорный и пользоваться им следует осторожно (особенно стартаперам на питчах перед инвесторами/фондами). При возможности необходимо озвучивать более конкретные термины: "машинное обучение" (Machine Learning, ML), "обработка естественного языка" (Natural Language Processing, NLP), "Интернет вещей" (Internet of Things, IoT), робототехника (Robotics) и т.д. Эти и другие направления могут как включать элементы "искусственного интеллекта", так и не включать.
Не вдаваясь в пространные рассуждения о философских проблемах термина "ИИ" скажу, что предпочитаю использовать термин "интеллектуализация вычислений/алгоритмов" (ИВ, ИА или ИВ/А), так как это освобождает от необходимости вдаваться в условности, объяснять критерии того, что мы считаем "интеллектом" и доказывать, что наши алгоритмы заслуживают именоваться "интеллектом".
Ниже при помощи кругов Эйлера показываю, как соотносится термин "ИИ" с более конкретными понятиями.
{kind=link}
👓 Из чего состоит машинное обучение
Продолжаем. Машинное обучение (ML) состоит из разных, несхожих направлений. Многие из них объединяет математика, сложные формулы и всё такое. Они уже не первый год влияют на нашу жизнь, сфера их воздействия всё больше выходит за пределы Интернета. Хотелось бы о каждом сделать пост с примерами, как это можно было бы применить в юриспруденции. Но сначала познакомимся с основными.
Например, Педро Домингос в книге "Верховный алгоритм" выделяет пять таких действующих в области машинного обучения научных школ (в хорошем смысле этого слова), именуя их также "племенами":
1️⃣ СИМВОЛИСТЫ 🚠
занятия: использование исходных знаний, "передача готовой экспертизы" компьютеру, определение и обобщение недостающего знания
метод: обратная дедукция
пример: деревья решений, психологические тесты
2️⃣ КОННЕКЦИОНИСТЫ 🧠
занятия: обратная инженерия мозга, нейробиологических механизмов
метод: обратное распространение ошибки (обучение на совершаемых ошибках)
пример: нейросети распознают раковые опухоли
3️⃣ ЭВОЛЮЦИОНИСТЫ 🦕
занятия: симуляция естественного отбора, где неудачные образцы будут "вымирать", а удачные "выживать", размножаться и развиваться дальше, их неудачные потомки — снова "вымирать" и т.д.
метод: генетическое программирование ("рождение" и развитие алгоритмов аки живых существ)
пример: симуляция "пробирки" с соревнующимися микроорганизмами
4️⃣ БАЙЕСОВЦЫ 🧮
занятия: подготовка вероятностного вывода на основе имеющихся и новых поступающих данных
метод: теорема Байеса и ее производные
пример: фильтрация спама в email
5️⃣ АНАЛОГИСТЫ 🖖
занятия: поиск сходств между разными ситуациями + логический вывод других сходств
метод: опорных векторов
пример: рекомендации на основе предпочтений на Нетфликсе и других подобных сервисах
Какое направление интересует вас больше всего?
Продолжаем. Машинное обучение (ML) состоит из разных, несхожих направлений. Многие из них объединяет математика, сложные формулы и всё такое. Они уже не первый год влияют на нашу жизнь, сфера их воздействия всё больше выходит за пределы Интернета. Хотелось бы о каждом сделать пост с примерами, как это можно было бы применить в юриспруденции. Но сначала познакомимся с основными.
Например, Педро Домингос в книге "Верховный алгоритм" выделяет пять таких действующих в области машинного обучения научных школ (в хорошем смысле этого слова), именуя их также "племенами":
1️⃣ СИМВОЛИСТЫ 🚠
занятия: использование исходных знаний, "передача готовой экспертизы" компьютеру, определение и обобщение недостающего знания
метод: обратная дедукция
пример: деревья решений, психологические тесты
2️⃣ КОННЕКЦИОНИСТЫ 🧠
занятия: обратная инженерия мозга, нейробиологических механизмов
метод: обратное распространение ошибки (обучение на совершаемых ошибках)
пример: нейросети распознают раковые опухоли
3️⃣ ЭВОЛЮЦИОНИСТЫ 🦕
занятия: симуляция естественного отбора, где неудачные образцы будут "вымирать", а удачные "выживать", размножаться и развиваться дальше, их неудачные потомки — снова "вымирать" и т.д.
метод: генетическое программирование ("рождение" и развитие алгоритмов аки живых существ)
пример: симуляция "пробирки" с соревнующимися микроорганизмами
4️⃣ БАЙЕСОВЦЫ 🧮
занятия: подготовка вероятностного вывода на основе имеющихся и новых поступающих данных
метод: теорема Байеса и ее производные
пример: фильтрация спама в email
5️⃣ АНАЛОГИСТЫ 🖖
занятия: поиск сходств между разными ситуациями + логический вывод других сходств
метод: опорных векторов
пример: рекомендации на основе предпочтений на Нетфликсе и других подобных сервисах
Какое направление интересует вас больше всего?
🏢 Лигалинженер на службе Холдинга
Давеча агроиндустриальный холдинг МХП разместил лигалинженерскую вакансию, обозначенную терминами "Legal tech specialist" и "специалист по автоматизации".
Среди основных обязанностей как раз есть эти волшебные слова, описывающие сложный лик лигалинженера: "автоматизация", "оптимизация", "создание автоматизированных правовых продуктов и решений", "разработка и поддержка процессов/проектов".
Среди пожеланий внимание привлекают такие:
▫️ опыт работы в "направлении LegaLTech" от трёх лет;
▫️ "опыт участия в проектах по автоматизации / внедрению ПО" (интересно, а участие в хакатонах/невзлетевших стартапах засчитывается?) или "навыки программирования" (интересно, а создание чатботов через pipe.bot засчитывается?);
▫️ уверенное владение Excel, PowerPoint и т.д.
В связи с этим, доктринального исследования требуют вопросы:
0. Настаёт эра лигалинженеров-инхаусов в не-юрбизе?
1. Какую долю заработка (в среднем) такие специалисты смогут откусить автоматизацией у юристов, обслуживающих подобные организации?
2. Они будут забирать работу преимущественно у "внутренних" юристов, юристов-аутсорсеров или у всех сразу?
3. Сколько чеканных монет им за это готовы предложить на старте? Кто сходит на собес, расскажите)
Давеча агроиндустриальный холдинг МХП разместил лигалинженерскую вакансию, обозначенную терминами "Legal tech specialist" и "специалист по автоматизации".
Среди основных обязанностей как раз есть эти волшебные слова, описывающие сложный лик лигалинженера: "автоматизация", "оптимизация", "создание автоматизированных правовых продуктов и решений", "разработка и поддержка процессов/проектов".
Среди пожеланий внимание привлекают такие:
▫️ опыт работы в "направлении LegaLTech" от трёх лет;
▫️ "опыт участия в проектах по автоматизации / внедрению ПО" (интересно, а участие в хакатонах/невзлетевших стартапах засчитывается?) или "навыки программирования" (интересно, а создание чатботов через pipe.bot засчитывается?);
▫️ уверенное владение Excel, PowerPoint и т.д.
В связи с этим, доктринального исследования требуют вопросы:
0. Настаёт эра лигалинженеров-инхаусов в не-юрбизе?
1. Какую долю заработка (в среднем) такие специалисты смогут откусить автоматизацией у юристов, обслуживающих подобные организации?
2. Они будут забирать работу преимущественно у "внутренних" юристов, юристов-аутсорсеров или у всех сразу?
3. Сколько чеканных монет им за это готовы предложить на старте? Кто сходит на собес, расскажите)
🧮 Знакомимся: Теорема Байеса
Что ж, давно здесь не было мяса! Одна из школ машинного обучения — теорема Байеса. Благодаря ей можно делать вероятностные выводы на основе имеющихся данных. То есть можно "предсказывать" (лучше сказать "формировать убеждённость в той или иной степени") как следствия (С), зная о причинах (П), так и причины (П), зная о следствиях (С). Например:
1️⃣ имея много данных о поведении (П) клиента на допросах и типичном влиянии такого поведения на его дальнейший процессуальный статус, адвокат может предполагать, будет ли следователь считать клиента виновным (С);
2️⃣ и наоборот, имея данные о позиции следователя насчёт виноватости (С) клиента, адвокат может предполагать, как клиент себя вёл (П) на допросах.
Но здесь вы должны заметить, что позиция следователя (С) может зависеть не только от того, как вёл (П) себя допрашиваемый. Спектр причин, выливающихся в следствие (обвинить / оставить в покое), может быть довольно широким: П + П + П = С. И теорема Байеса позволяет математически грамотно учитывать сколь угодно большущее количество причин. Главное, чтобы у вас был собран соответствующий набор данных, которым вы доверяете.
📑 Далее вы можете увидеть кусок текста из книги "Верховный алгоритм" Педро Домингоса, в котором я сделал некоторые замены: "врач - адвокат", "пациент - клиент", "грипп - незадекларированные регулярные доходы", "высокая температура - налоговая проверка" и т.д.
🔻🔻🔻
Представьте, что вы адвокат и за последний месяц оказали услугу сотне клиентов. У 14 из них были незадекларированные регулярные доходы (далее НРД), у 20 прошла налоговая проверка, а у 11 — и то и другое.
Условная вероятность налоговой проверки при НРД, таким образом, составляет одиннадцать из четырнадцати, или 11 ⁄ 14. Обусловленность уменьшает размеры рассматриваемой нами вселенной, в данном случае от всех возможных клиентов только до клиентов с НРД.
Во вселенной всех клиентов вероятность налоговой проверки составляет 20 ⁄ 100, а во вселенной клиентов с НРД, — 11 ⁄ 14.
Вероятность того, что у клиента НРД и налоговая проверка, равна доле клиентов с НРД, умноженной на долю клиентов с налоговой проверкой:
P(НРД, НП) = P(НРД) × P(НП | НРД) = 14 ⁄ 100 × 11 ⁄ 14 = 11 ⁄ 100.
Но верно и следующее: P(НРД, НП) = P(НП) × P(НРД | НП).
Таким образом, поскольку и то, и другое равно P(НРД, НП),
то P(НП) × P(НРД | НП) = P(НРД) × P(НП | НРД).
Разделите обе стороны на P(НП), и вы получите
P(НРД | НП) = P(НРД) × P(НП | НРД) / P(НП).
Вот и все! Это теорема Байеса, где незадекларированные регулярные доходы — это причина, а налоговая проверка — следствие.
🔺🔺🔺
Но снова-таки, не стоит забывать, что у налоговых проверок могут быть и другие причины, влияющие на факт их проведения сильнее, чем наличие НРД. Так же, как высокую температуру может вызывать не только грипп. Добавив в формулу математическое представление данных о влиянии и этих причин, вы сделаете ваш вероятностный вывод более точным, обоснованным, реалистичным.
В следующих постах расскажу подробнее, как это работает.
Что ж, давно здесь не было мяса! Одна из школ машинного обучения — теорема Байеса. Благодаря ей можно делать вероятностные выводы на основе имеющихся данных. То есть можно "предсказывать" (лучше сказать "формировать убеждённость в той или иной степени") как следствия (С), зная о причинах (П), так и причины (П), зная о следствиях (С). Например:
1️⃣ имея много данных о поведении (П) клиента на допросах и типичном влиянии такого поведения на его дальнейший процессуальный статус, адвокат может предполагать, будет ли следователь считать клиента виновным (С);
2️⃣ и наоборот, имея данные о позиции следователя насчёт виноватости (С) клиента, адвокат может предполагать, как клиент себя вёл (П) на допросах.
Но здесь вы должны заметить, что позиция следователя (С) может зависеть не только от того, как вёл (П) себя допрашиваемый. Спектр причин, выливающихся в следствие (обвинить / оставить в покое), может быть довольно широким: П + П + П = С. И теорема Байеса позволяет математически грамотно учитывать сколь угодно большущее количество причин. Главное, чтобы у вас был собран соответствующий набор данных, которым вы доверяете.
📑 Далее вы можете увидеть кусок текста из книги "Верховный алгоритм" Педро Домингоса, в котором я сделал некоторые замены: "врач - адвокат", "пациент - клиент", "грипп - незадекларированные регулярные доходы", "высокая температура - налоговая проверка" и т.д.
🔻🔻🔻
Представьте, что вы адвокат и за последний месяц оказали услугу сотне клиентов. У 14 из них были незадекларированные регулярные доходы (далее НРД), у 20 прошла налоговая проверка, а у 11 — и то и другое.
Условная вероятность налоговой проверки при НРД, таким образом, составляет одиннадцать из четырнадцати, или 11 ⁄ 14. Обусловленность уменьшает размеры рассматриваемой нами вселенной, в данном случае от всех возможных клиентов только до клиентов с НРД.
Во вселенной всех клиентов вероятность налоговой проверки составляет 20 ⁄ 100, а во вселенной клиентов с НРД, — 11 ⁄ 14.
Вероятность того, что у клиента НРД и налоговая проверка, равна доле клиентов с НРД, умноженной на долю клиентов с налоговой проверкой:
P(НРД, НП) = P(НРД) × P(НП | НРД) = 14 ⁄ 100 × 11 ⁄ 14 = 11 ⁄ 100.
Но верно и следующее: P(НРД, НП) = P(НП) × P(НРД | НП).
Таким образом, поскольку и то, и другое равно P(НРД, НП),
то P(НП) × P(НРД | НП) = P(НРД) × P(НП | НРД).
Разделите обе стороны на P(НП), и вы получите
P(НРД | НП) = P(НРД) × P(НП | НРД) / P(НП).
Вот и все! Это теорема Байеса, где незадекларированные регулярные доходы — это причина, а налоговая проверка — следствие.
🔺🔺🔺
Но снова-таки, не стоит забывать, что у налоговых проверок могут быть и другие причины, влияющие на факт их проведения сильнее, чем наличие НРД. Так же, как высокую температуру может вызывать не только грипп. Добавив в формулу математическое представление данных о влиянии и этих причин, вы сделаете ваш вероятностный вывод более точным, обоснованным, реалистичным.
В следующих постах расскажу подробнее, как это работает.
🦠 Теорема Байеса и коронавирус
часть 1
Теорема Байеса помогает нивелировать изъян той части нашего мышления, которая связана с оценкой вероятностей. Правильная оценка вероятностей предполагает необходимость быстро посчитать в уме правильные формулы, прежде чем выпалить, авторитетно зевнув, "скорее всего", "маловероятно" и т.д. И вот благодаря тому, что компьютер умеет считать быстро, теорема Байеса расцвела как целое направление машинного обучения. Итак, давайте ещё раз потренируемся считать вероятности на злободневной теме.
Фабула
Предположим, что вы госслужащий в некоем важном органе, который вынужден контактировать с гражданами. Например, вы должны выдавать некие документы, связанные с оформлением факта смерти людей (далее — справки). Во время эпидемии коронавируса количество смертей неизбежно растёт, и в ваш орган должны приходить люди за справками. Как правило, эти люди — родственники либо супруги умерших (далее — близкий человек). Зачастую близкие люди живут вместе. А значит, они почти наверняка тоже будут инфицированы. А значит, если вы работаете в таком месте, реально можете заразиться. А-а-а-а-а!
Задача
Хоть как-то оценить вероятность заражения госслужащего (далее — ВЗГ) в условиях такой эпидемии на первой же встрече с гражданином, пришедшем за справкой об умершем, если известно, что эта смерть — от коронавируса.
Разбор
Обратите внимание: фабула напичкана вероятностными терминами. Перечитайте её, почти в каждом предложении есть такой термин. Давайте попробуем пока что грубо, основываясь на нашем жизненном опыте, присвоить им коэффициенты. Я попробую сделать это исходя из своих представлений, а вы можете подставить свои цифры:
"неизбежно" — 100% или 1
"как правило" — 80% или 0.8
"зачастую" — 71% или 0.71
"почти наверняка" — 93% или 0.93
"реально можете" — 70% или 0.7
Вероятность конечного события (в нашем случае ВЗГ) рассчитывается путём перемножения вероятностей, образующих логическую цепочку событий, которые должны перед ним произойти:
ВЗГ = 1 * 0.8 * 0.71 * 0.93 * 0.7 = 0.369768
Итак, в "рассматриваемой мной вселенной, где принятые мной коэффициенты верны" (эта фраза в кавычках — важный дисклеймер при подобных размышлениях), ВЗГ за первую встречу равна почти 37%.
Много это или мало, решать каждому самостоятельно. :) Но важно помнить, что это вероятность именно нашего сценария, что госслужащего заразит именно тот близкий человек, который жил с умершим и заразился именно от умершего. А на практике этот пришедший человек может быть уже заражен по другой причине. Это значит, что наша формула может стать частью более общей формулы, описывающей полную вероятность заражения, с учётом большего количества факторов.
А какова вероятность пережить две такие встречи, не заразившись? А три встречи? А десять? А что, если выдать служащему костюм химзащиты, сводящий риск к 5%? Рассмотрим в следующем посте.
часть 1
Теорема Байеса помогает нивелировать изъян той части нашего мышления, которая связана с оценкой вероятностей. Правильная оценка вероятностей предполагает необходимость быстро посчитать в уме правильные формулы, прежде чем выпалить, авторитетно зевнув, "скорее всего", "маловероятно" и т.д. И вот благодаря тому, что компьютер умеет считать быстро, теорема Байеса расцвела как целое направление машинного обучения. Итак, давайте ещё раз потренируемся считать вероятности на злободневной теме.
Фабула
Предположим, что вы госслужащий в некоем важном органе, который вынужден контактировать с гражданами. Например, вы должны выдавать некие документы, связанные с оформлением факта смерти людей (далее — справки). Во время эпидемии коронавируса количество смертей неизбежно растёт, и в ваш орган должны приходить люди за справками. Как правило, эти люди — родственники либо супруги умерших (далее — близкий человек). Зачастую близкие люди живут вместе. А значит, они почти наверняка тоже будут инфицированы. А значит, если вы работаете в таком месте, реально можете заразиться. А-а-а-а-а!
Задача
Хоть как-то оценить вероятность заражения госслужащего (далее — ВЗГ) в условиях такой эпидемии на первой же встрече с гражданином, пришедшем за справкой об умершем, если известно, что эта смерть — от коронавируса.
Разбор
Обратите внимание: фабула напичкана вероятностными терминами. Перечитайте её, почти в каждом предложении есть такой термин. Давайте попробуем пока что грубо, основываясь на нашем жизненном опыте, присвоить им коэффициенты. Я попробую сделать это исходя из своих представлений, а вы можете подставить свои цифры:
"неизбежно" — 100% или 1
"как правило" — 80% или 0.8
"зачастую" — 71% или 0.71
"почти наверняка" — 93% или 0.93
"реально можете" — 70% или 0.7
Вероятность конечного события (в нашем случае ВЗГ) рассчитывается путём перемножения вероятностей, образующих логическую цепочку событий, которые должны перед ним произойти:
ВЗГ = 1 * 0.8 * 0.71 * 0.93 * 0.7 = 0.369768
Итак, в "рассматриваемой мной вселенной, где принятые мной коэффициенты верны" (эта фраза в кавычках — важный дисклеймер при подобных размышлениях), ВЗГ за первую встречу равна почти 37%.
Много это или мало, решать каждому самостоятельно. :) Но важно помнить, что это вероятность именно нашего сценария, что госслужащего заразит именно тот близкий человек, который жил с умершим и заразился именно от умершего. А на практике этот пришедший человек может быть уже заражен по другой причине. Это значит, что наша формула может стать частью более общей формулы, описывающей полную вероятность заражения, с учётом большего количества факторов.
А какова вероятность пережить две такие встречи, не заразившись? А три встречи? А десять? А что, если выдать служащему костюм химзащиты, сводящий риск к 5%? Рассмотрим в следующем посте.
🦠 Теорема Байеса и коронавирус
часть 2
В посте выше мы выяснили, что при заданных условиях вероятность заражения госслужащего — 37%.
Как же выяснить вероятность оказаться заражённым по итогам двух таких встреч подряд? В первую очередь в голову может прийти очевидное "умножить 0.37 на 0.37". Но нет. Ведь мы получим 0.1369, т.е. 13%, что являлось бы парадоксом, если бы было ответом на поставленный вопрос. Эти 13% — вероятность заразиться при каждой встрече, т.е. получить вирус от обоих посетителей. Поиск правильного ответа выглядит так:
1) вероятность не заразиться при отдельно взятой встрече:
1 – 0.37 = 0.63, т.е. 63%
2) вероятность два раза подряд не заразиться, т.е. по итогам двух встреч:
0.63 * 0.63 = 0.3969, т.е. 40%
3) вероятность оказаться зараженным по итогам двух встреч:
1 – 0.3969 = 0.6031, т.е. 60%
🧐 А если встреч будет 3, то эта вероятность вырастет до 75%
( 1 – (0.63 * 0.63 * 0.63 ) ).
🧐 А если 10 встреч, то отнимаем от единицы 0.63 в 10-й степени и получаем 0.99015, т.е. 99% риска заразиться.
🧐 А если выдать госслужащим защитные костюмы или создать другие условия, при которых риск заражения на последнем узле нашей цепочки событий уменьшится с 70% до 5%, тогда вероятность заразиться при первой встрече будет равна:
1 * 0.8 * 0.71 * 0.93 * 0.05 = 0,026412 , т.е. менее 3%.
А что если бы эта услуга была цифровизована / предоставлялась онлайн? Тогда бы встречи не было и вероятность заражения таким способом была равна 0%.
Итак, цифровизация, лигалтек и вот это вот всё делают право и государство более … ГИГИЕНИЧНЫМИ. 💎
Далее уже при помощи красавицы-формулы оценим, что будет, если в нашем выдуманном государстве некоторое кол-во служащих после таких встреч поедут сдавать бумажные отчётики в управление. 🙂
часть 2
В посте выше мы выяснили, что при заданных условиях вероятность заражения госслужащего — 37%.
Как же выяснить вероятность оказаться заражённым по итогам двух таких встреч подряд? В первую очередь в голову может прийти очевидное "умножить 0.37 на 0.37". Но нет. Ведь мы получим 0.1369, т.е. 13%, что являлось бы парадоксом, если бы было ответом на поставленный вопрос. Эти 13% — вероятность заразиться при каждой встрече, т.е. получить вирус от обоих посетителей. Поиск правильного ответа выглядит так:
1) вероятность не заразиться при отдельно взятой встрече:
1 – 0.37 = 0.63, т.е. 63%
2) вероятность два раза подряд не заразиться, т.е. по итогам двух встреч:
0.63 * 0.63 = 0.3969, т.е. 40%
3) вероятность оказаться зараженным по итогам двух встреч:
1 – 0.3969 = 0.6031, т.е. 60%
🧐 А если встреч будет 3, то эта вероятность вырастет до 75%
( 1 – (0.63 * 0.63 * 0.63 ) ).
🧐 А если 10 встреч, то отнимаем от единицы 0.63 в 10-й степени и получаем 0.99015, т.е. 99% риска заразиться.
🧐 А если выдать госслужащим защитные костюмы или создать другие условия, при которых риск заражения на последнем узле нашей цепочки событий уменьшится с 70% до 5%, тогда вероятность заразиться при первой встрече будет равна:
1 * 0.8 * 0.71 * 0.93 * 0.05 = 0,026412 , т.е. менее 3%.
А что если бы эта услуга была цифровизована / предоставлялась онлайн? Тогда бы встречи не было и вероятность заражения таким способом была равна 0%.
Итак, цифровизация, лигалтек и вот это вот всё делают право и государство более … ГИГИЕНИЧНЫМИ. 💎
Далее уже при помощи красавицы-формулы оценим, что будет, если в нашем выдуманном государстве некоторое кол-во служащих после таких встреч поедут сдавать бумажные отчётики в управление. 🙂
🦠 Теорема Байеса и коронавирус
часть 3 — дисциплина обновления доверия
Чтобы наконец разобраться, как работает теорема Байеса, представим такое:
▫️ с утра 3 госслужащих — Ашп, Брю и Ван имели незащищённые встречи с посетителями, вероятность заражения при каждой отдельно — 37%
▫️ проведённые встречи: Ашп — 3, Брю — 2, Ван — 1
▫️ в посте выше уже рассчитаны вероятности для таких кейсов: 75, 60 и 37 процентов
▫️ после обеда они повезли отчёты к начальнику Жаку
▫️ Жак принял их по очереди, а также пересёкся с некоторыми дополнительно, образовав таким образом встречи
▫️ встречи Жака: с Ашпом — 1, с Брю — 2, с Ваном — аж 3 (разговорились возле микроволновки и даже в туалете)
▫️ "интенсивность" этих встреч была одинакова, к привезённым документам Жак не прикасался
😡 Стало известно, что Жак заразился в этот день. Других контактов у него не было. Жак заподозрил, что это именно Брю "виноват", ведь на вид был каким-то подуставшим.
Вопрос 1: Какова вероятность, что Брю заразил Жака?
Вопрос 2: Как изменится этот ответ, если станет известно, что Брю точно уже был заражен?
Вопрос 3: Как изменится ответ на вопрос 2, если станет известно, что Ашп точно ещё не был заражен?
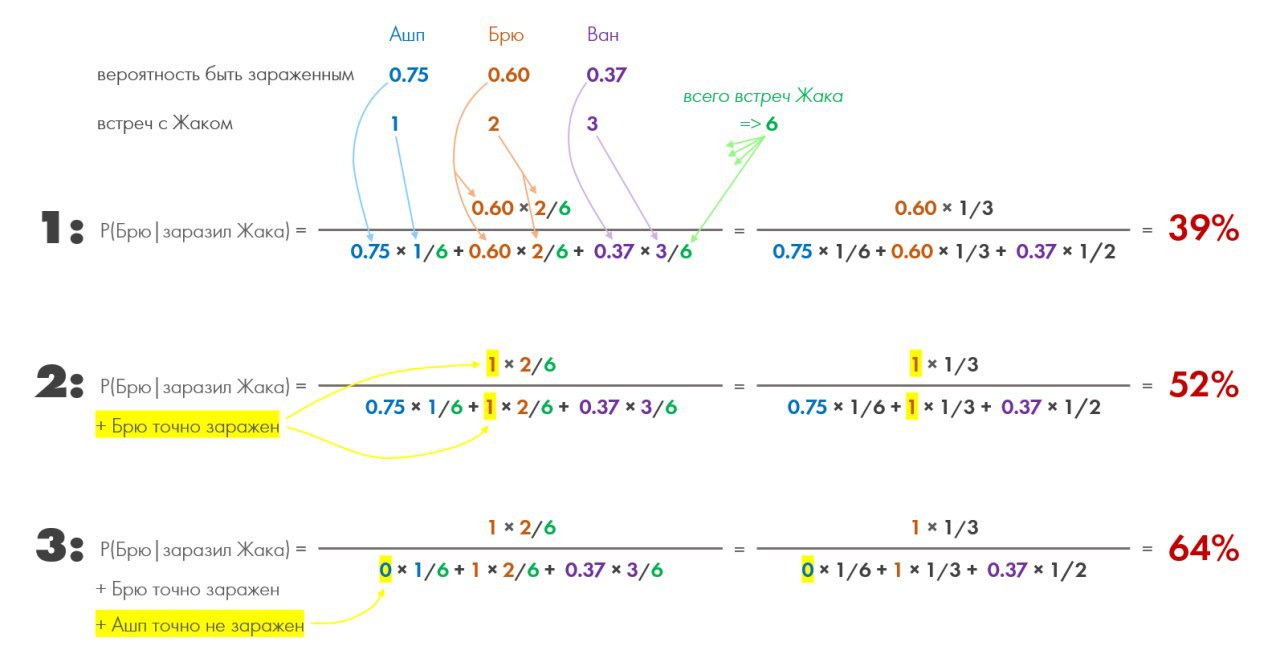
🖼 Все ответы и логику их получения по Байесу постарался вместить на картинку. Ибо это одна из тех тем, которые надо визуализировать, чтобы понять.
💛 Тут при помощи выделения жёлтым показана сила этой формулы: любое изменение связанного фрагмента данных можно быстро наложить и пересчитать, и получим обновлённую общую картину. У нас повысится или понизится уровень доверия к выдвинутой гипотезе. Весьма удобно, когда таких связанных фрагментов очень много и мы загоняем их в компьютер, чтобы он считал всё это безобразие за нас.
P.S. Некоторые рационалисты отмечают, что ничего особенного здесь нет, что это просто дисциплина мышления. Как бы там ни было, на этом построено и пока что не разогнано грязными тряпками целое направление в Machine Learning.
часть 3 — дисциплина обновления доверия
Чтобы наконец разобраться, как работает теорема Байеса, представим такое:
▫️ с утра 3 госслужащих — Ашп, Брю и Ван имели незащищённые встречи с посетителями, вероятность заражения при каждой отдельно — 37%
▫️ проведённые встречи: Ашп — 3, Брю — 2, Ван — 1
▫️ в посте выше уже рассчитаны вероятности для таких кейсов: 75, 60 и 37 процентов
▫️ после обеда они повезли отчёты к начальнику Жаку
▫️ Жак принял их по очереди, а также пересёкся с некоторыми дополнительно, образовав таким образом встречи
▫️ встречи Жака: с Ашпом — 1, с Брю — 2, с Ваном — аж 3 (разговорились возле микроволновки и даже в туалете)
▫️ "интенсивность" этих встреч была одинакова, к привезённым документам Жак не прикасался
😡 Стало известно, что Жак заразился в этот день. Других контактов у него не было. Жак заподозрил, что это именно Брю "виноват", ведь на вид был каким-то подуставшим.
Вопрос 1: Какова вероятность, что Брю заразил Жака?
Вопрос 2: Как изменится этот ответ, если станет известно, что Брю точно уже был заражен?
Вопрос 3: Как изменится ответ на вопрос 2, если станет известно, что Ашп точно ещё не был заражен?
🖼 Все ответы и логику их получения по Байесу постарался вместить на картинку. Ибо это одна из тех тем, которые надо визуализировать, чтобы понять.
💛 Тут при помощи выделения жёлтым показана сила этой формулы: любое изменение связанного фрагмента данных можно быстро наложить и пересчитать, и получим обновлённую общую картину. У нас повысится или понизится уровень доверия к выдвинутой гипотезе. Весьма удобно, когда таких связанных фрагментов очень много и мы загоняем их в компьютер, чтобы он считал всё это безобразие за нас.
P.S. Некоторые рационалисты отмечают, что ничего особенного здесь нет, что это просто дисциплина мышления. Как бы там ни было, на этом построено и пока что не разогнано грязными тряпками целое направление в Machine Learning.
{kind=link}
🐲 Жизнь юриста и теорема Байеса
попрактикуемся?
Давайте применим теорему Байеса теперь к юрпрактике, ведь "эпидемии приходят и уходят, а право вечно".
👩⚖️ Предположим, Аня — крутой адвокат в сфере корпоративного права. Она знает, что согласно открытым данным в государстве 5% зарегистрированных ТОВ (ООО) имеют налоговый долг (их Аня называет "фирмы-долгуны"). Также, проанализировав один лигалтек-сервис, Аня установила, что 40% "фирм-долгунов" имеют адрес массовой регистрации, тогда как для ТОВок без налогового долга это характерно лишь в 16% случаев.
Аня задумалась:
Когда я встречаю фирму с адресом массовой регистрации, то какова вероятность, что эта фирма имеет налоговый долг?
👇 Как думаете?
попрактикуемся?
Давайте применим теорему Байеса теперь к юрпрактике, ведь "эпидемии приходят и уходят, а право вечно".
👩⚖️ Предположим, Аня — крутой адвокат в сфере корпоративного права. Она знает, что согласно открытым данным в государстве 5% зарегистрированных ТОВ (ООО) имеют налоговый долг (их Аня называет "фирмы-долгуны"). Также, проанализировав один лигалтек-сервис, Аня установила, что 40% "фирм-долгунов" имеют адрес массовой регистрации, тогда как для ТОВок без налогового долга это характерно лишь в 16% случаев.
Аня задумалась:
Когда я встречаю фирму с адресом массовой регистрации, то какова вероятность, что эта фирма имеет налоговый долг?
👇 Как думаете?
Такая вероятность равна:
Anonymous Quiz
20%
38%, если посчитать!
25%
12%, само собой!
13%
62%, таков удельный вес выборки.
19%
3%, это же очевидно!
23%
40%, ответ уже в условии.
🧮 Заканчиваем с постами о Байесе
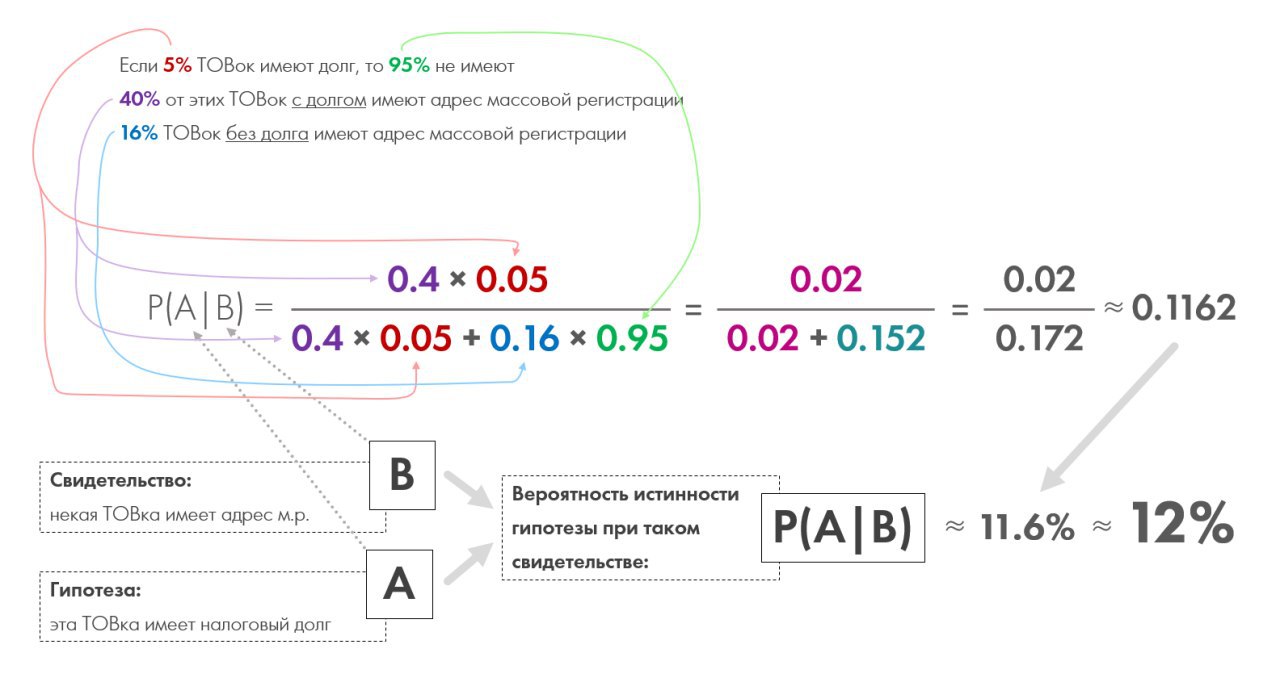
Ответ на предыдущую задачу на картинке. Всего лишь 12%.
Как видите, "бытовой" подход к подобного рода вопросам, ответы "навскидку", "полагаясь на жизненный опыт" нередко приводят к ошибкам. А каждый ли юрист может позволить себе часто ошибаться, независимо от того, признаёт ли он за собой такое право или нет? 🙂
Поэтому если вы будете для клиентов делать анализ каких-нибудь рисков, угроз и у вас будет доступ к подходящей статистике, то грех не воспользоваться этим подходом. Также на эту тему ещё есть замечательная формула Бернулли, но больше не буду грузить на эту тему.
Скажу только, что довольно похожа на эту задачу ситуация, когда вы узнаёте, что у человека Х высокая температура (далее — ВТ). ВТ является следствием многих разных причин (частая реакция организма на многие возбудители), поэтому гипотеза о том, что встреченный сейчас человек с ВТ с ВЫСОКОЙ вероятностью болен Сами-Знаете-Чем — это скорее амбициозное заявление. Не забывайте о Байесе. 🙂
А как вы считаете, нужно ли юристам более углублённо изучать теорию вероятностей, статистику?
Ответ на предыдущую задачу на картинке. Всего лишь 12%.
Как видите, "бытовой" подход к подобного рода вопросам, ответы "навскидку", "полагаясь на жизненный опыт" нередко приводят к ошибкам. А каждый ли юрист может позволить себе часто ошибаться, независимо от того, признаёт ли он за собой такое право или нет? 🙂
Поэтому если вы будете для клиентов делать анализ каких-нибудь рисков, угроз и у вас будет доступ к подходящей статистике, то грех не воспользоваться этим подходом. Также на эту тему ещё есть замечательная формула Бернулли, но больше не буду грузить на эту тему.
Скажу только, что довольно похожа на эту задачу ситуация, когда вы узнаёте, что у человека Х высокая температура (далее — ВТ). ВТ является следствием многих разных причин (частая реакция организма на многие возбудители), поэтому гипотеза о том, что встреченный сейчас человек с ВТ с ВЫСОКОЙ вероятностью болен Сами-Знаете-Чем — это скорее амбициозное заявление. Не забывайте о Байесе. 🙂
А как вы считаете, нужно ли юристам более углублённо изучать теорию вероятностей, статистику?
{kind=link}
👨👩👧👦 Как контроль версий сделает вас лучше
Первоначальная цель этого канала — обучение юристов программированию (затем я начал затрагивать и другие темы, с которыми работал). Поэтому дам совет для начинающих кодеров, как одним инструментом решить две насущные проблемы.
🐛 Проблема №1. Нужно отслеживать свой прогресс. Хороший способ делать это — смотреть на свой прошлый код, видеть его недостатки, улучшать его. Отдавать себе отчёт, где и почему код был неэффективным, плохо читающимся. Понимать, где и в чём я вырос(-ла) за месяц, год, два. Но как его хранить? Плодить файлы, наподобие как с договорами в формате .docx, называя их "scriptanalysis2020-05-18 v1.docx", "scriptanalysis2020-05-18 v2.docx" ?
🐛 Проблема №2. Когда кодишь уже несколько месяцев, начинаешь замечать, что есть повторяющиеся куски кода, которые кочуют из проекта в проект. Бывает, делая 9-й проект, вспоминаешь, что сюда надо бы вставить функцию из 4-го проекта, а сюда — те прекрасные три строчки из 6-го проекта. И если не помнишь наизусть, приходится лезть в 4-й и 6-й проект за этими штуками.
Обе проблемы можно решить при помощи репозиториев и систем контроля версий. Например, я использую тот самый Github. На Гитхабе можно завести приватный репозиторий, насоздавать в нём файлов и наполнить их вашим кодом. Теперь проблема №2 решена: у вас есть некое общее место, откуда вы с лёгкостью достанете нужный универсальный код. А если вы будете регулярно обновлять ваши файлы, делая в них коммиты с обновлённым кодом, то затем, используя кнопку "History", вы будете видеть, как менялся файл от коммита к коммиту, т.е. как двигался ваш прогресс (проблема №1).
P.S. Конечно, это не является страховкой от того, что из проекта в проект будет кочевать плохой код, если такая плохизна вовремя не осознана. 🙂
На скрине Гитхаб показывает, как коммит изменил содержание файла:
Первоначальная цель этого канала — обучение юристов программированию (затем я начал затрагивать и другие темы, с которыми работал). Поэтому дам совет для начинающих кодеров, как одним инструментом решить две насущные проблемы.
🐛 Проблема №1. Нужно отслеживать свой прогресс. Хороший способ делать это — смотреть на свой прошлый код, видеть его недостатки, улучшать его. Отдавать себе отчёт, где и почему код был неэффективным, плохо читающимся. Понимать, где и в чём я вырос(-ла) за месяц, год, два. Но как его хранить? Плодить файлы, наподобие как с договорами в формате .docx, называя их "scriptanalysis2020-05-18 v1.docx", "scriptanalysis2020-05-18 v2.docx" ?
🐛 Проблема №2. Когда кодишь уже несколько месяцев, начинаешь замечать, что есть повторяющиеся куски кода, которые кочуют из проекта в проект. Бывает, делая 9-й проект, вспоминаешь, что сюда надо бы вставить функцию из 4-го проекта, а сюда — те прекрасные три строчки из 6-го проекта. И если не помнишь наизусть, приходится лезть в 4-й и 6-й проект за этими штуками.
Обе проблемы можно решить при помощи репозиториев и систем контроля версий. Например, я использую тот самый Github. На Гитхабе можно завести приватный репозиторий, насоздавать в нём файлов и наполнить их вашим кодом. Теперь проблема №2 решена: у вас есть некое общее место, откуда вы с лёгкостью достанете нужный универсальный код. А если вы будете регулярно обновлять ваши файлы, делая в них коммиты с обновлённым кодом, то затем, используя кнопку "History", вы будете видеть, как менялся файл от коммита к коммиту, т.е. как двигался ваш прогресс (проблема №1).
P.S. Конечно, это не является страховкой от того, что из проекта в проект будет кочевать плохой код, если такая плохизна вовремя не осознана. 🙂
На скрине Гитхаб показывает, как коммит изменил содержание файла:
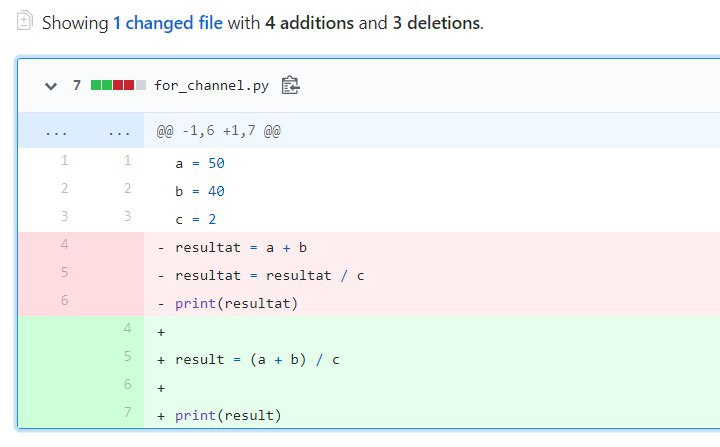{kind=link}
🎨 Программируйте и рисуйте
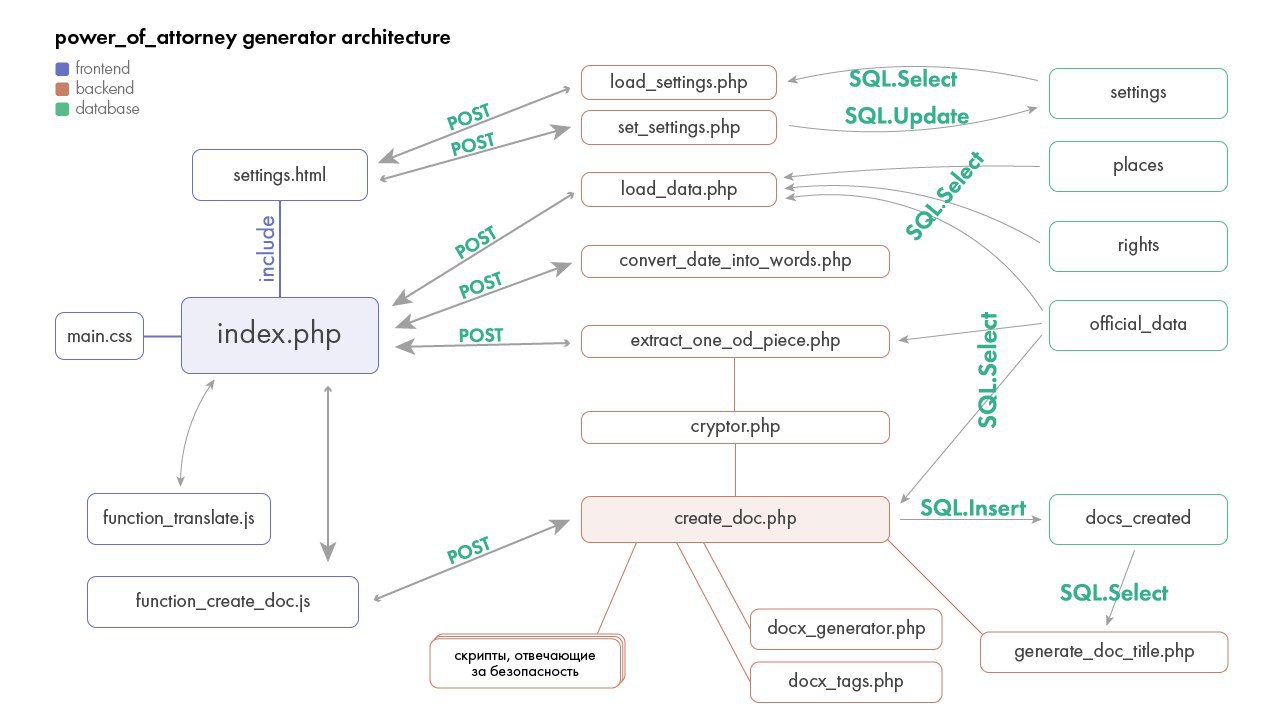
Недавно сделал для юристов веб-конструктор доверенностей. Это тривиальный проект с точки зрения размахов современной лигалтек-индустрии. Но если смотреть на него с технической стороны, то он уже требует построения полноценной архитектуры из файлов, скриптов и таблиц базы данных. Стек технологий в этом случае описывается уже минимум пятью словами: HTML, CSS, JavaScript, PHP и MySQL.
И тут без визуального планирования, которое должно плавно перетечь в документирование, не обойтись. Ведь не то что через полгода, а даже если через месяц вас попросят внести какие-нибудь правки в подобный проект, то без документации или хотя бы внятной схемы это может занять добрых пятьдесят минут вместо двадцати. А если это будет другой чел, то он за это может заплатить полутора часами и головной болью.
Поэтому стоит визуально планировать и документировать такую работу, ведь сразу будет видно:
▫️ "точки входа" с фронтенда на бэкенд,
▫️ по каким "тропкам" бегут данные,
▫️ какие зависимости есть в проекте и т.д.
А ещё это просто красиво. 🧑🎨
Сначала это удобно делать на бумаге (я всегда с неё начинаю новые проекты), затем на компе. По привычке продолжаю в Illustrator. В этот раз получилось как-то так:
Недавно сделал для юристов веб-конструктор доверенностей. Это тривиальный проект с точки зрения размахов современной лигалтек-индустрии. Но если смотреть на него с технической стороны, то он уже требует построения полноценной архитектуры из файлов, скриптов и таблиц базы данных. Стек технологий в этом случае описывается уже минимум пятью словами: HTML, CSS, JavaScript, PHP и MySQL.
И тут без визуального планирования, которое должно плавно перетечь в документирование, не обойтись. Ведь не то что через полгода, а даже если через месяц вас попросят внести какие-нибудь правки в подобный проект, то без документации или хотя бы внятной схемы это может занять добрых пятьдесят минут вместо двадцати. А если это будет другой чел, то он за это может заплатить полутора часами и головной болью.
Поэтому стоит визуально планировать и документировать такую работу, ведь сразу будет видно:
▫️ "точки входа" с фронтенда на бэкенд,
▫️ по каким "тропкам" бегут данные,
▫️ какие зависимости есть в проекте и т.д.
А ещё это просто красиво. 🧑🎨
Сначала это удобно делать на бумаге (я всегда с неё начинаю новые проекты), затем на компе. По привычке продолжаю в Illustrator. В этот раз получилось как-то так:
{kind=link}
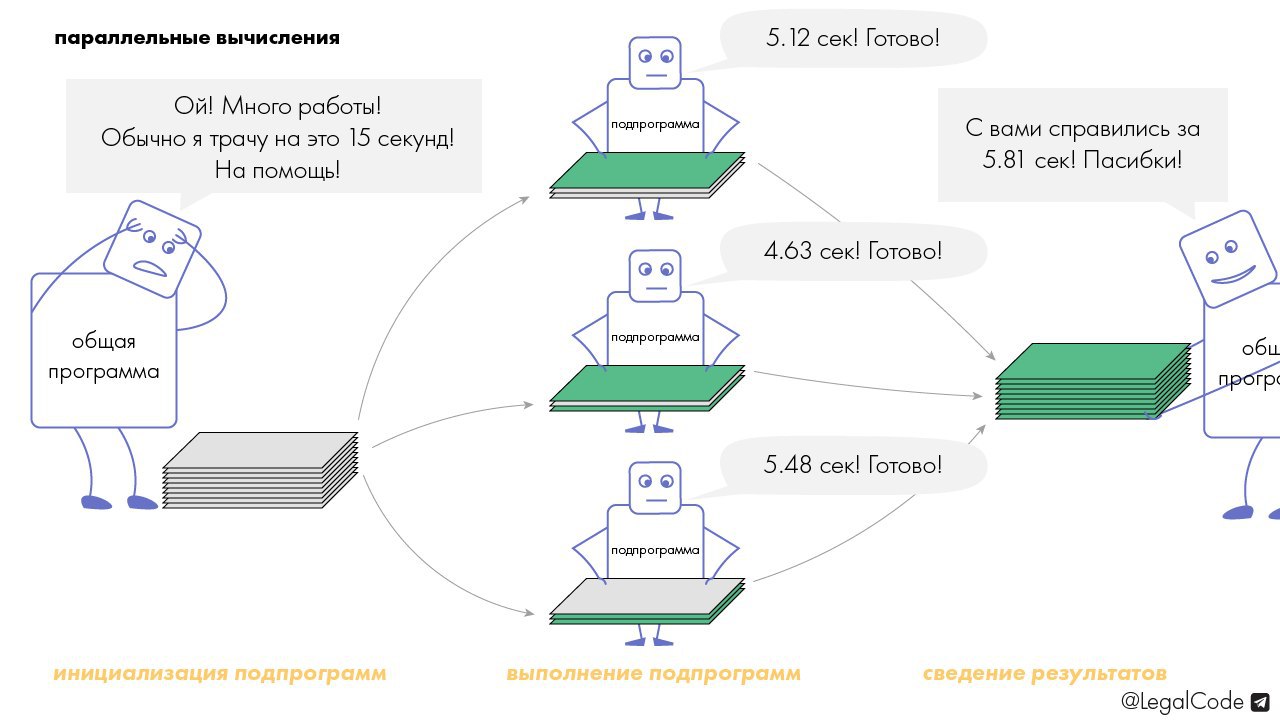
🎛 Работаем параллельно
Представьте, что юридическая фирма "Альбус и партнёры" через 25 минут должна отдать 1000 листов материалов иска курьеру, но ещё не проставлены обязательные печати на каждом листе.
Чтобы проставить печать на одном листе и перейти к следующему, нужно потратить в среднем 2 секунды. Итак, у одного человека эта благородная задача займёт: 1000 * 2 / 60 = 33 минуты. То есть он не успеет это сделать в срок, если, конечно, не будет пропечатывать каждый лист за полторы секунды.
🐾 Но если у фирмы есть хотя бы 2 таких печати и 2 человека, то можно успеть. Ведь нет разницы, в каком порядке пропечатываются листы: 1000-му листу всё равно, пропечатан он после 999-го или нет. А значит, все листы можно поделить на 2 пачки, дать 2-м людям и вооружить 2-мя печатями. Они сделают эту работу параллельно за 1000 * 2 / 60 / 2 = 16 минут 40 секунд, в два "потока" ("подпрограммы"), и в конце лишь останется соединить назад эти две пачки, что займёт, скажем, до 10 секунд.
Что мы видим? Результат тот же, а времени потрачено меньше. В этом идея параллельных вычислений и в программировании.
⚡️ Важное условие: порядок (последовательность) выполнения работы не должен влиять на конечный результат.
🔦 Например, подобное разделение программы на подпрограммы я реализовал в нашей юридической поисковой системе при полнотекстовом поиске. Когда она видит, что запросу соответствует более 8 источников, она начинает плодить подпрограммы в некоем кол-ве x, которое зависит от кол-ва источников, но не более 16. Сервер выполняет их одновременно, по готовности результаты их работы возвращаются в "материнскую" программу. Прирост скорости такого поиска составляет в среднем 215%.
Ну и, как всегда, держите визуализацию:
Представьте, что юридическая фирма "Альбус и партнёры" через 25 минут должна отдать 1000 листов материалов иска курьеру, но ещё не проставлены обязательные печати на каждом листе.
Чтобы проставить печать на одном листе и перейти к следующему, нужно потратить в среднем 2 секунды. Итак, у одного человека эта благородная задача займёт: 1000 * 2 / 60 = 33 минуты. То есть он не успеет это сделать в срок, если, конечно, не будет пропечатывать каждый лист за полторы секунды.
🐾 Но если у фирмы есть хотя бы 2 таких печати и 2 человека, то можно успеть. Ведь нет разницы, в каком порядке пропечатываются листы: 1000-му листу всё равно, пропечатан он после 999-го или нет. А значит, все листы можно поделить на 2 пачки, дать 2-м людям и вооружить 2-мя печатями. Они сделают эту работу параллельно за 1000 * 2 / 60 / 2 = 16 минут 40 секунд, в два "потока" ("подпрограммы"), и в конце лишь останется соединить назад эти две пачки, что займёт, скажем, до 10 секунд.
Что мы видим? Результат тот же, а времени потрачено меньше. В этом идея параллельных вычислений и в программировании.
⚡️ Важное условие: порядок (последовательность) выполнения работы не должен влиять на конечный результат.
🔦 Например, подобное разделение программы на подпрограммы я реализовал в нашей юридической поисковой системе при полнотекстовом поиске. Когда она видит, что запросу соответствует более 8 источников, она начинает плодить подпрограммы в некоем кол-ве x, которое зависит от кол-ва источников, но не более 16. Сервер выполняет их одновременно, по готовности результаты их работы возвращаются в "материнскую" программу. Прирост скорости такого поиска составляет в среднем 215%.
Ну и, как всегда, держите визуализацию:
{kind=link}
🐗 Перешёл в IT
недоспойлер: в продуктовую компанию (о термине), больше пока сказать не могу
Каюсь, давно не писал посты сюда. Всё это время искал работу в IT, параллельно лихорадочно повышая квалификацию. Спустя 6 недель поисков удалось найти. Позади осталось около 10 отказов, из них 1 проваленный скрининг по телефону и 2 проваленных тестовых задания. Также 7 заявок остались без ответа. Но благодаря всему этому я узнал, насколько был некомпетентен всё это время. Например:
💀 Все созданные мной продукты не соответствуют ни одному паттерну проектирования. А зря. Это ппц важная штука.
💀 ООП на практике применял очень редко, а зря (да-да, овладел искусством процедурного и функционального стилей).
💀 Не работал с Линуксом и консолью, не знал даже базовых команд, а зря. Но на новой работе с первых же минут пришлось освоить, а спустя три дня осознал, насколько это нужно и полезно.
💀 Не работал с фреймворками для своего основного языка программирования (PHP). Очень зря. Этот пункт не позволил даже просто податься на массу аппетитных вакансий (именно джуновских). Часто требуется хотя бы полгода-год опыта с тем или иным фреймворком. Видел даже вакансию от крутого проекта из нашей лигалтек-экосистемы "Legal Nodes", там нужен был опыт с фреймворком.
Поэтому, уважаемые свитчеры, кто хочет перейти на сторону IT как программист, советую сначала поизучать вакансии, выписать из них кучу незнакомых слов, которые пишут работодатели, и разбираться, разбираться, разбираться. Готовиться к любому контакту с работодателем как к смеси экзамена и турнира на вылет. Да вообще советов ещё уйму можно дать, и их в Интернете пруд пруди. Кстати, тут скоро будет занятный ивент на тему свитчерства по маршруту "право - IT", меня с моим диагнозом туда тоже взяли. 🤕
P.S. Канал будет жить, вас не брошу. Он не для рекламы, а ради торжества нашей юной лигалинженерской отрасли. Скоро возобновлю поставку постов.
недоспойлер: в продуктовую компанию (о термине), больше пока сказать не могу
Каюсь, давно не писал посты сюда. Всё это время искал работу в IT, параллельно лихорадочно повышая квалификацию. Спустя 6 недель поисков удалось найти. Позади осталось около 10 отказов, из них 1 проваленный скрининг по телефону и 2 проваленных тестовых задания. Также 7 заявок остались без ответа. Но благодаря всему этому я узнал, насколько был некомпетентен всё это время. Например:
💀 Все созданные мной продукты не соответствуют ни одному паттерну проектирования. А зря. Это ппц важная штука.
💀 ООП на практике применял очень редко, а зря (да-да, овладел искусством процедурного и функционального стилей).
💀 Не работал с Линуксом и консолью, не знал даже базовых команд, а зря. Но на новой работе с первых же минут пришлось освоить, а спустя три дня осознал, насколько это нужно и полезно.
💀 Не работал с фреймворками для своего основного языка программирования (PHP). Очень зря. Этот пункт не позволил даже просто податься на массу аппетитных вакансий (именно джуновских). Часто требуется хотя бы полгода-год опыта с тем или иным фреймворком. Видел даже вакансию от крутого проекта из нашей лигалтек-экосистемы "Legal Nodes", там нужен был опыт с фреймворком.
Поэтому, уважаемые свитчеры, кто хочет перейти на сторону IT как программист, советую сначала поизучать вакансии, выписать из них кучу незнакомых слов, которые пишут работодатели, и разбираться, разбираться, разбираться. Готовиться к любому контакту с работодателем как к смеси экзамена и турнира на вылет. Да вообще советов ещё уйму можно дать, и их в Интернете пруд пруди. Кстати, тут скоро будет занятный ивент на тему свитчерства по маршруту "право - IT", меня с моим диагнозом туда тоже взяли. 🤕
P.S. Канал будет жить, вас не брошу. Он не для рекламы, а ради торжества нашей юной лигалинженерской отрасли. Скоро возобновлю поставку постов.
🎡 Паттерны в кодинге и праве
В разработке часто встречаются повторяющиеся из десятилетия в десятилетие ситуации:
▫️ обработка заказов с разными дополнениями (чай с сахаром, кофе с двойными сливками);
▫️ управление игровыми персонажами и их динамично меняющимся поведением (разные баффы и дебаффы на разных персах в Дотке);
▫️ мониторинг изменений состояния некоего элемента со стороны разных субъектов;
и т.д.
Для грамотного программирования этих механизмов применяются разные паттерны. Паттерн — это устоявшаяся схема связывания между собой программных сущностей, при которой система получит определённые преимущества и недостатки. Задача паттерна — сделать хорошо и не сделать плохо. Ключевое проявление хорошести — "гибкость системы", то есть насколько удобно, легко и быстро можно будет вносить в неё изменения с минимальным риском что-нибудь сломать. Короче, правильно выбранный паттерн — сэкономленный бабос и нервы заказчика.
⚙️ В кодинге есть куча паттернов. Вот недавно решил освоить несколько из них и наткнулся на крутой сайт, где есть и объяснения, и хорошие примеры. Также о паттернах написана легко читающаяся книга с картинками (да почти с комиксами!). По этим источникам внимательно изучаю и отрабатываю на практике паттерны, перед тем как лепить их в резюме.
⚖️ В праве тоже есть паттерны. Например, паттерны структурирования закона, судебного решения и договора различны. Если закон и договор ещё как-то можно сделать похожими по структуре, то судебные решения ярко от них отличаются. Но в то же время, для них одновременно характерен такой функциональный паттерн, как использование ссылки на положения, которые уже прозвучали:
1️⃣ (далі по тексту - Виконавець) — см. во многих договорах
2️⃣ (далі - Реєстр) — см в ч. 1 ст. 16 этого закона
3️⃣ (0.3, 0.5 і 1 грам, - далі «доза») — см. в этом решении
Следование паттернам, их правильное применение и в программировании, и в праве позволяет:
🔹 добиться быстрого обмена информацией между программистами / между юристами;
🔹 добиться быстрого восприятия происходящего в коде, договоре, судебном решении и т.д. человеком, который видит этот код/документ впервые;
🔹 создать эффективный код/документ, с которыми легко и приятно работать, вносить изменения без большого риска заложить баги.
⚠️ Важно: следует отличать паттерны проектирования (Strategy, Decorator, Adapter и т.д.) от принципов разработки (DRY, KISS, YAGNI, SOLID). Кстати, я уже писал ранее о принципах DRY и KISS.
В разработке часто встречаются повторяющиеся из десятилетия в десятилетие ситуации:
▫️ обработка заказов с разными дополнениями (чай с сахаром, кофе с двойными сливками);
▫️ управление игровыми персонажами и их динамично меняющимся поведением (разные баффы и дебаффы на разных персах в Дотке);
▫️ мониторинг изменений состояния некоего элемента со стороны разных субъектов;
и т.д.
Для грамотного программирования этих механизмов применяются разные паттерны. Паттерн — это устоявшаяся схема связывания между собой программных сущностей, при которой система получит определённые преимущества и недостатки. Задача паттерна — сделать хорошо и не сделать плохо. Ключевое проявление хорошести — "гибкость системы", то есть насколько удобно, легко и быстро можно будет вносить в неё изменения с минимальным риском что-нибудь сломать. Короче, правильно выбранный паттерн — сэкономленный бабос и нервы заказчика.
⚙️ В кодинге есть куча паттернов. Вот недавно решил освоить несколько из них и наткнулся на крутой сайт, где есть и объяснения, и хорошие примеры. Также о паттернах написана легко читающаяся книга с картинками (да почти с комиксами!). По этим источникам внимательно изучаю и отрабатываю на практике паттерны, перед тем как лепить их в резюме.
⚖️ В праве тоже есть паттерны. Например, паттерны структурирования закона, судебного решения и договора различны. Если закон и договор ещё как-то можно сделать похожими по структуре, то судебные решения ярко от них отличаются. Но в то же время, для них одновременно характерен такой функциональный паттерн, как использование ссылки на положения, которые уже прозвучали:
1️⃣ (далі по тексту - Виконавець) — см. во многих договорах
2️⃣ (далі - Реєстр) — см в ч. 1 ст. 16 этого закона
3️⃣ (0.3, 0.5 і 1 грам, - далі «доза») — см. в этом решении
Следование паттернам, их правильное применение и в программировании, и в праве позволяет:
🔹 добиться быстрого обмена информацией между программистами / между юристами;
🔹 добиться быстрого восприятия происходящего в коде, договоре, судебном решении и т.д. человеком, который видит этот код/документ впервые;
🔹 создать эффективный код/документ, с которыми легко и приятно работать, вносить изменения без большого риска заложить баги.
⚠️ Важно: следует отличать паттерны проектирования (Strategy, Decorator, Adapter и т.д.) от принципов разработки (DRY, KISS, YAGNI, SOLID). Кстати, я уже писал ранее о принципах DRY и KISS.
🎼 BPMN — разложи свой бизнес-процесс по нотам
Обнаружил ещё одну замечательную точку приложения усилий лигалинженера (и не только) — создание и обслуживание схем на языке моделирования бизнес-процессов BPMN при автоматизации чего-либо. Это такие схемы, где в большей мере человекочитаемым языком можно показать логику взаимодействий нескольких слоёв многоуровневой системы. Система может состоять из человеков, софта и чего угодно. Расписать можно как абстрактно, так и конкретно, отмечая каждое действие, особенно в точках взаимодействий слоёв.
На подобной схеме ниже изобразил, что происходит, когда я, используя телеграм-бота, отправляю информацию на бэкенд своего веб-сервера, чтобы сохранить её в базе данных. Использовал этот онлайн-сервис. Есть и куча других.
Такие схемы помогают удобно передавать знания об устройстве и работе системы, а также видеть, сколько раз в общий поток вклинивается тот или иной слой. Например, чётко видно, что человек (я) на своём слое лишь пишет и отправляет сообщение, а затем (не успев даже моргнуть) увидит уже отчёт о результате. Пока человек ждёт, "под капотом" произойдёт куча того, что иногда называют "магией", хотя на самом деле это предельно конкретные вещи.
Беру инструмент на вооружение и вам рекомендую. У меня ппц сколько систем создано, которые неплохо бы таким образом задокументировать. 🤓
Правда, напоминает нотный стан?
Обнаружил ещё одну замечательную точку приложения усилий лигалинженера (и не только) — создание и обслуживание схем на языке моделирования бизнес-процессов BPMN при автоматизации чего-либо. Это такие схемы, где в большей мере человекочитаемым языком можно показать логику взаимодействий нескольких слоёв многоуровневой системы. Система может состоять из человеков, софта и чего угодно. Расписать можно как абстрактно, так и конкретно, отмечая каждое действие, особенно в точках взаимодействий слоёв.
На подобной схеме ниже изобразил, что происходит, когда я, используя телеграм-бота, отправляю информацию на бэкенд своего веб-сервера, чтобы сохранить её в базе данных. Использовал этот онлайн-сервис. Есть и куча других.
Такие схемы помогают удобно передавать знания об устройстве и работе системы, а также видеть, сколько раз в общий поток вклинивается тот или иной слой. Например, чётко видно, что человек (я) на своём слое лишь пишет и отправляет сообщение, а затем (не успев даже моргнуть) увидит уже отчёт о результате. Пока человек ждёт, "под капотом" произойдёт куча того, что иногда называют "магией", хотя на самом деле это предельно конкретные вещи.
Беру инструмент на вооружение и вам рекомендую. У меня ппц сколько систем создано, которые неплохо бы таким образом задокументировать. 🤓
Правда, напоминает нотный стан?
{kind=link}
🚔 Лигалтек и Государство
Завтра начинается третий месяц, как я работаю в Минцифре. За это время успел сделать для себя массу выводов. Один из них: работа над инновациями, их внедрением и распространением — это кропотливый ежедневный труд, от которого нельзя ожидать сиюминутного выхлопа. Этим диджитальным культурам, которые сеем сегодня, нужно время, чтобы укорениться и взойти.
В первые годы своих лигалинженерских исканий я думал, что все наши проблемы должен решить код. Но вот некоторый код уже появился и продолжает появляться в рамках развития государственных сервисов. И теперь пришло время работы с людьми. Поведение людей сложнее, чем поведение кода. С ними приходится спорить, убеждать, уметь смотреть на мир с их стороны. Цифровые технологии, государственные API, открытые данные сами себя не внедрят. Внедрение идёт через принятие и желание, взаимодействие и соглашения.
И понял я, что нам в государственном лигалтеке сейчас нужен в первую очередь не ИИ, а нужно:
▪️ чтобы государственный реестр не ложился от нескольких десятков прилетевших одновременно запросов, а был безотказен, как сапёрная лопатка;
▪️ чтобы человек не унижался 5-10-15 рабочих дней в попытках получить справку о том, что он не лось, а получил её в 2 клика;
▪️ и так далее.
Проще говоря, нам нужна сначала безотказность if-else, над которым мы, бывает, посмеиваемся. А ИИ в праве... ИИ подождёт. Надо сначала показать и доказать людям правильное лицо технологий: скорость, глобальность, удобство, простоту. А не объяснять, что нейросеть переобучилась или застряла в локальном минимуме и поэтому отказала в пенсии 100-летнему человеку.
Завтра начинается третий месяц, как я работаю в Минцифре. За это время успел сделать для себя массу выводов. Один из них: работа над инновациями, их внедрением и распространением — это кропотливый ежедневный труд, от которого нельзя ожидать сиюминутного выхлопа. Этим диджитальным культурам, которые сеем сегодня, нужно время, чтобы укорениться и взойти.
В первые годы своих лигалинженерских исканий я думал, что все наши проблемы должен решить код. Но вот некоторый код уже появился и продолжает появляться в рамках развития государственных сервисов. И теперь пришло время работы с людьми. Поведение людей сложнее, чем поведение кода. С ними приходится спорить, убеждать, уметь смотреть на мир с их стороны. Цифровые технологии, государственные API, открытые данные сами себя не внедрят. Внедрение идёт через принятие и желание, взаимодействие и соглашения.
И понял я, что нам в государственном лигалтеке сейчас нужен в первую очередь не ИИ, а нужно:
▪️ чтобы государственный реестр не ложился от нескольких десятков прилетевших одновременно запросов, а был безотказен, как сапёрная лопатка;
▪️ чтобы человек не унижался 5-10-15 рабочих дней в попытках получить справку о том, что он не лось, а получил её в 2 клика;
▪️ и так далее.
Проще говоря, нам нужна сначала безотказность if-else, над которым мы, бывает, посмеиваемся. А ИИ в праве... ИИ подождёт. Надо сначала показать и доказать людям правильное лицо технологий: скорость, глобальность, удобство, простоту. А не объяснять, что нейросеть переобучилась или застряла в локальном минимуме и поэтому отказала в пенсии 100-летнему человеку.
{kind=link}