
🚨 Вакансия: Лигалинженер
Ну вот, за последние полгода вижу вторую вакансию лигалинженера, и тоже в классном коллективе. Описание здесь.
Резюме не нужно, пишите сразу их чатботу-рекрутеру.
Крутое FAQ по вакансии — здесь.
По своему опыту скажу, что эта профессия настолько нова, что вы ещё можете своими действиями формировать её образ, ставить смелые эксперименты и не бояться неудач. Будучи просто юристом, так себя вести сложнее, а то и нельзя.
Не упускайте.
Ну вот, за последние полгода вижу вторую вакансию лигалинженера, и тоже в классном коллективе. Описание здесь.
Резюме не нужно, пишите сразу их чатботу-рекрутеру.
Крутое FAQ по вакансии — здесь.
По своему опыту скажу, что эта профессия настолько нова, что вы ещё можете своими действиями формировать её образ, ставить смелые эксперименты и не бояться неудач. Будучи просто юристом, так себя вести сложнее, а то и нельзя.
Не упускайте.
👨🏻🏫 Учим юристов кодить
Итак, этот день настал.
С коллегами по лигалтек-цеху продаём свои знания.
Учим кодить: читать код, понимать код, писать код.
Даём 2 языка программирования и ещё некоторые штуки.
Набираем группу до 16 человек.
(раздувать группу до больших размеров я лично считаю издевательством над образовательным процессом)
Больше инфо на сайте: futurelawschool.net/c4l
〽️ Дам промокод на скидку в 15% человеку, кто:
1) первый(-ая) пришлёт мне в личку вариант названия переменной, который ему/ей больше нравится, из трёх ниженазванных;
2) кратко объяснит свой выбор.
Вот варианты:
A) $tokenToCheck
B) $TokenToCheck
C) $token_to_check
Итак, этот день настал.
С коллегами по лигалтек-цеху продаём свои знания.
Учим кодить: читать код, понимать код, писать код.
Даём 2 языка программирования и ещё некоторые штуки.
Набираем группу до 16 человек.
(раздувать группу до больших размеров я лично считаю издевательством над образовательным процессом)
Больше инфо на сайте: futurelawschool.net/c4l
〽️ Дам промокод на скидку в 15% человеку, кто:
1) первый(-ая) пришлёт мне в личку вариант названия переменной, который ему/ей больше нравится, из трёх ниженазванных;
2) кратко объяснит свой выбор.
Вот варианты:
A) $tokenToCheck
B) $TokenToCheck
C) $token_to_check
futurelawschool.net
FLS | Coding 4 Lawyers
Подготовка юридических инженеров на курсе "Coding 4 Lawyers" на платформе "Future Law School"
📦 Кейсы для будущих техноюристов
Прямо сейчас в Украине знаковое событие: дописывается проект учебной программы курса "Юридические инновации". Это началось ещё в июле. В курсе будет многое, чего доселе не было в украинском юробразовании. Одна из тем - алгоритмы и автоматизация в праве (обожаю их). На ходу подкинул такие идеи для практических занятий.
1⃣ Взяти договір (наприклад, оренди квартири, автомобіля тощо). Подивитися його, подумати, яку мінімальну кількість питань має поставити юрист клієнту, щоб заповнити фактичні дані залежно від предмета договору (істотні умови тощо). Запропонувати оптимальний порядок і формулювання (вигляд) цих питань, а також вимоги до відповідей, з тим, щоб їх міг ставити клієнту автоматизований алгоритм (наприклад, чатбот).
💡 Окрім власне алгоритмізації, студент отримає ще й такий хардскіл, як вміння лаконічно формулювати питання і економити час клієнта.
2⃣ Взяти якийсь сценарій з процесуального кодекса (наприклад, підготовка/подача клопотання про призначення експертизи чи щось більш проблемне на практиці). Проаналізувати його, викласти у вигляді сценарія (опитувальник-чекліст) для чатбота, який допомагає юристу (адвокату) нічого не забути при підготовці і подачі такого документа.
💡 Окрім власне алгоритмізації, студент отримає ще й такі хардскіли, як вміння уважно ставитись до слів у законі, розбивати правові процедури на окремі елементи, "приміряти ці норми на собі" тощо.
Собираюсь ещё развить и углубить. А какие задания поставили бы вы, будь вы преподавателем на таком предмете? Го обсудим в чате или в личке. 🙂 Лучшее попадёт в образовательный раздел лигалтек-энциклопедии.
Прямо сейчас в Украине знаковое событие: дописывается проект учебной программы курса "Юридические инновации". Это началось ещё в июле. В курсе будет многое, чего доселе не было в украинском юробразовании. Одна из тем - алгоритмы и автоматизация в праве (обожаю их). На ходу подкинул такие идеи для практических занятий.
1⃣ Взяти договір (наприклад, оренди квартири, автомобіля тощо). Подивитися його, подумати, яку мінімальну кількість питань має поставити юрист клієнту, щоб заповнити фактичні дані залежно від предмета договору (істотні умови тощо). Запропонувати оптимальний порядок і формулювання (вигляд) цих питань, а також вимоги до відповідей, з тим, щоб їх міг ставити клієнту автоматизований алгоритм (наприклад, чатбот).
💡 Окрім власне алгоритмізації, студент отримає ще й такий хардскіл, як вміння лаконічно формулювати питання і економити час клієнта.
2⃣ Взяти якийсь сценарій з процесуального кодекса (наприклад, підготовка/подача клопотання про призначення експертизи чи щось більш проблемне на практиці). Проаналізувати його, викласти у вигляді сценарія (опитувальник-чекліст) для чатбота, який допомагає юристу (адвокату) нічого не забути при підготовці і подачі такого документа.
💡 Окрім власне алгоритмізації, студент отримає ще й такі хардскіли, як вміння уважно ставитись до слів у законі, розбивати правові процедури на окремі елементи, "приміряти ці норми на собі" тощо.
Собираюсь ещё развить и углубить. А какие задания поставили бы вы, будь вы преподавателем на таком предмете? Го обсудим в чате или в личке. 🙂 Лучшее попадёт в образовательный раздел лигалтек-энциклопедии.
🚡 Гражданский кодекс и ООП
ООП или объектно ориентированное программирование — фундаментальная парадигма в кодинге, о которой должен знать каждый разработчик. Её суть максимально простыми словами: в коде создаём классы (виды "действующих лиц"), описываем их свойства (характеристики) и методы ("активные способности"), наконец создаём объекты (конкретные "действующие лица", принадлежащие к описанному перед этим "виду").
Далее мы можем совершить действие путём называния "действующего лица" и его "способности", например:
myRobotLawyer.read_agreement("договір поставки №244.docx");
Это значит, что объект myRobotLawyer выполнит код из доступного ему метода read_agreement, в который в качестве параметра будет передано название некоего файла "договір поставки №244.docx". Внутри там может быть код, который сделает то, что вам нужно: вытащит текст из docx-файла, найдёт в нём интересующие вас слова и т.д.
📒 Причём здесь гражданский кодекс? А при том, что в процессе диджитализации законодательства Украины к ряду его норм может быть применён именно объектно-ориентированный подход.
Например, если нормы о договоре купли-продажи представить как объект, то у него могут выйти, в частности, такие свойства и методы:
.description — строковая переменная, содержит определение договора из статьи 655;
.possible_object_categories — массив, содержит положения частей 1, 2, 3 статьи 656;
.show_forms — метод, выводит все предусмотренные законом случаи, когда форма договора должна быть письменная + указание на то, что всё остальное допускает устную форму договора;
.check_form — метод, в него нужно передать название предмета договора, чтобы прошла проверка, должна ли быть форма договора письменная (возвращает строку "письмова" или "будь-яка").
Затем так же поступаем и с другими видами договоров. Как думаете, это бред или что-то в этом есть? Стоит копнуть глубже? 🚜
ООП или объектно ориентированное программирование — фундаментальная парадигма в кодинге, о которой должен знать каждый разработчик. Её суть максимально простыми словами: в коде создаём классы (виды "действующих лиц"), описываем их свойства (характеристики) и методы ("активные способности"), наконец создаём объекты (конкретные "действующие лица", принадлежащие к описанному перед этим "виду").
Далее мы можем совершить действие путём называния "действующего лица" и его "способности", например:
myRobotLawyer.read_agreement("договір поставки №244.docx");
Это значит, что объект myRobotLawyer выполнит код из доступного ему метода read_agreement, в который в качестве параметра будет передано название некоего файла "договір поставки №244.docx". Внутри там может быть код, который сделает то, что вам нужно: вытащит текст из docx-файла, найдёт в нём интересующие вас слова и т.д.
📒 Причём здесь гражданский кодекс? А при том, что в процессе диджитализации законодательства Украины к ряду его норм может быть применён именно объектно-ориентированный подход.
Например, если нормы о договоре купли-продажи представить как объект, то у него могут выйти, в частности, такие свойства и методы:
.description — строковая переменная, содержит определение договора из статьи 655;
.possible_object_categories — массив, содержит положения частей 1, 2, 3 статьи 656;
.show_forms — метод, выводит все предусмотренные законом случаи, когда форма договора должна быть письменная + указание на то, что всё остальное допускает устную форму договора;
.check_form — метод, в него нужно передать название предмета договора, чтобы прошла проверка, должна ли быть форма договора письменная (возвращает строку "письмова" или "будь-яка").
Затем так же поступаем и с другими видами договоров. Как думаете, это бред или что-то в этом есть? Стоит копнуть глубже? 🚜
🕶 Кодинг и приватность (чья)?
спойлер: Future Law School расширяется! 🏫
Когда только начинаешь программировать и при этом сразу работаешь над проектом, которым будут пользоваться другие люди, ты уже несёшь ответственность за их приватность. Можно по-разному накосячить, когда собираешь чужие данные.
Например:
1️⃣ Ты собираешь их имейлы и хранишь в незашифрованном виде в базе данных. Или, что ещё хуже, держишь в текстовом файле на сервере, не защищённом от скачивания любым человеком/роботом, который подберёт его адрес.
Где здесь угроза? Твоим юзерам может прийти спам-рассылка.
2️⃣ Кроме предыдущего, ты собираешь ещё пароли, создаваемые твоими юзерами при регистрации, хранишь в незашифрованном виде там же.
Где здесь угроза? Это уже поинтереснее. Теперь благодаря тебе некоторых твоих юзеров могут ещё и взломать.
Есть ещё разные вариации с незащищёнными кукисами, кражей сеанса и множеством других дивных вещей. Поэтому программист (а лигалинженер особенно!), не должен быть нигилистом. 🐗
Не хочешь быть нигилистом? Сегодня запустился телеграм-канал на тему приватности — Privacy HUB.
Каждый будний день у них расписан под контент определённого типа. Знаю, такие челленджы непросты на второй-третий месяц после старта. Будет интересно последить за ними.
Ну и хорошо бы замутить с ними несколько постов на тему приватности в разработке. Замутить?
спойлер: Future Law School расширяется! 🏫
Когда только начинаешь программировать и при этом сразу работаешь над проектом, которым будут пользоваться другие люди, ты уже несёшь ответственность за их приватность. Можно по-разному накосячить, когда собираешь чужие данные.
Например:
1️⃣ Ты собираешь их имейлы и хранишь в незашифрованном виде в базе данных. Или, что ещё хуже, держишь в текстовом файле на сервере, не защищённом от скачивания любым человеком/роботом, который подберёт его адрес.
Где здесь угроза? Твоим юзерам может прийти спам-рассылка.
2️⃣ Кроме предыдущего, ты собираешь ещё пароли, создаваемые твоими юзерами при регистрации, хранишь в незашифрованном виде там же.
Где здесь угроза? Это уже поинтереснее. Теперь благодаря тебе некоторых твоих юзеров могут ещё и взломать.
Есть ещё разные вариации с незащищёнными кукисами, кражей сеанса и множеством других дивных вещей. Поэтому программист (а лигалинженер особенно!), не должен быть нигилистом. 🐗
Не хочешь быть нигилистом? Сегодня запустился телеграм-канал на тему приватности — Privacy HUB.
Каждый будний день у них расписан под контент определённого типа. Знаю, такие челленджы непросты на второй-третий месяц после старта. Будет интересно последить за ними.
Ну и хорошо бы замутить с ними несколько постов на тему приватности в разработке. Замутить?
📗 Теоретический минимум по Computer Science
(Феррейра Фило Владстон)
Мне эту книгу рекомендовали некоторые подписчики канала. Наконец прочёл её! Книга хороша, особенно подход к иллюстрированию материала (некоторые алгоритмы визуализированы пошагово). Рекомендую всем, кто хочет лигалинженерить, но не знает, как подступиться к техническим вопросам.
Привожу список и резюме глав книги в порядке их важности (на мой взгляд) для лигалинженера.
1️⃣ Глава 1 — Основы
🥚 Безусловный мастхев для лигалинженера. Нет логики — нет профессии.
2️⃣ Глава 2 — Вычислительная сложность + Глава 3 — Стратегия
🥚 О том, как посчитать, хватит ли вам времени и памяти, чтобы выполнить чудо-алгоритм, который должен сделать ваш юрбиз богатым. Приёмы постройки чудо-алгоритмов.
3️⃣ Глава 6 — Базы данных
🥚 Как организовать хранение данных таким образом, чтобы сам способ их хранения был полезен и не был вреден.
4️⃣ Глава 4 — Данные
🥚 Об абстракциях и типах данных — гайках и гвоздях программирования.
5️⃣ Глава 5 — Алгоритмы
🥚 Небольшая глава с иллюстрацией нескольких известных алгоритмов.
6️⃣ Глава 8 — Программирование
🥚 Мини-экскурс в любой язык программирования. Знакомство с парадигмами кодинга (кроме ООП).
7️⃣ Глава 7 — Компьютеры
🥚 Понимание компьютера через призму ОЗУ, процессора, компиляции и операционных систем.
Как ни странно, дальше я начал читать "Теоретический минимум по Big Data" (Анналин Ын, Кеннет Су). 🐜
(Феррейра Фило Владстон)
Мне эту книгу рекомендовали некоторые подписчики канала. Наконец прочёл её! Книга хороша, особенно подход к иллюстрированию материала (некоторые алгоритмы визуализированы пошагово). Рекомендую всем, кто хочет лигалинженерить, но не знает, как подступиться к техническим вопросам.
Привожу список и резюме глав книги в порядке их важности (на мой взгляд) для лигалинженера.
1️⃣ Глава 1 — Основы
🥚 Безусловный мастхев для лигалинженера. Нет логики — нет профессии.
2️⃣ Глава 2 — Вычислительная сложность + Глава 3 — Стратегия
🥚 О том, как посчитать, хватит ли вам времени и памяти, чтобы выполнить чудо-алгоритм, который должен сделать ваш юрбиз богатым. Приёмы постройки чудо-алгоритмов.
3️⃣ Глава 6 — Базы данных
🥚 Как организовать хранение данных таким образом, чтобы сам способ их хранения был полезен и не был вреден.
4️⃣ Глава 4 — Данные
🥚 Об абстракциях и типах данных — гайках и гвоздях программирования.
5️⃣ Глава 5 — Алгоритмы
🥚 Небольшая глава с иллюстрацией нескольких известных алгоритмов.
6️⃣ Глава 8 — Программирование
🥚 Мини-экскурс в любой язык программирования. Знакомство с парадигмами кодинга (кроме ООП).
7️⃣ Глава 7 — Компьютеры
🥚 Понимание компьютера через призму ОЗУ, процессора, компиляции и операционных систем.
Как ни странно, дальше я начал читать "Теоретический минимум по Big Data" (Анналин Ын, Кеннет Су). 🐜
📄 "Уверенный пользователь MS Word"
Эта фраза — завсегдатай резюме многих юристов, ищущих работу. Но интересно, сколько из них знают, как технически устроен docx-файл и как это знание может помочь в экстренной ситуации?
Вот что должен знать каждый лигалинженер и желательно знать юристам.
1️⃣ Создайте и назовите docx-файл, например: "тест.docx".
2️⃣ Напишите в нём что-то (например: "робот") и сохраните.
3️⃣ Переименуйте файл в "тест.zip".
4️⃣ Распакуйте этот архив.
5️⃣ Войдите в папку "word", откройте файл "document.xml".
6️⃣ Найдите в нём при помощи Ctrl+F написанные вами слова. Можете увидеть, что его окружает, как устроено всё вокруг.
7️⃣ Удалите несколько тегов (содержимое между символами "<" и ">", включая их) или их кусков, или последние три символа файла ("nt>").
8️⃣ Сохраните файл, заархивируйте всё содержимое назад в zip-архив.
9️⃣ Переименуйте обратно в "тест.docx".
▪️ Попробуйте открыть файл в "Word". Он выдаст ошибку. Теперь вы можете:
1) снова проделать шаги 3—5;
2) вернуть на место все удалённые фрагменты;
3) проделать шаги 8—9.
▪️ Теперь, если вы правильно вернули всё на место, должно открыться без ошибок.
Зачем вот это вот всё?
Иногда документы повреждаются. Этот лайфхак поможет вам получить доступ к уцелевшему содержимому документа при его повреждении, не закачивая его в незнакомые онлайн-сервисы и не рискуя конфиденциальностью данных.
Также это знание полезно, когда вы автоматизируете работу с контентом в .docx-документах, и ваши потребности не закрываются полностью найденными вами библиотеками.
Эта фраза — завсегдатай резюме многих юристов, ищущих работу. Но интересно, сколько из них знают, как технически устроен docx-файл и как это знание может помочь в экстренной ситуации?
Вот что должен знать каждый лигалинженер и желательно знать юристам.
1️⃣ Создайте и назовите docx-файл, например: "тест.docx".
2️⃣ Напишите в нём что-то (например: "робот") и сохраните.
3️⃣ Переименуйте файл в "тест.zip".
4️⃣ Распакуйте этот архив.
5️⃣ Войдите в папку "word", откройте файл "document.xml".
6️⃣ Найдите в нём при помощи Ctrl+F написанные вами слова. Можете увидеть, что его окружает, как устроено всё вокруг.
7️⃣ Удалите несколько тегов (содержимое между символами "<" и ">", включая их) или их кусков, или последние три символа файла ("nt>").
8️⃣ Сохраните файл, заархивируйте всё содержимое назад в zip-архив.
9️⃣ Переименуйте обратно в "тест.docx".
▪️ Попробуйте открыть файл в "Word". Он выдаст ошибку. Теперь вы можете:
1) снова проделать шаги 3—5;
2) вернуть на место все удалённые фрагменты;
3) проделать шаги 8—9.
▪️ Теперь, если вы правильно вернули всё на место, должно открыться без ошибок.
Зачем вот это вот всё?
Иногда документы повреждаются. Этот лайфхак поможет вам получить доступ к уцелевшему содержимому документа при его повреждении, не закачивая его в незнакомые онлайн-сервисы и не рискуя конфиденциальностью данных.
Также это знание полезно, когда вы автоматизируете работу с контентом в .docx-документах, и ваши потребности не закрываются полностью найденными вами библиотеками.
👩🎓 Научиться кодить бесплатно — можно, почему нет?
Давно не рассказывал о своём продвижении в мире кодинга. За последние две недели сделал для себя сразу два открытия, которые хорошо сплелись воедино: Coursera и Notion.
1️⃣ Coursera
Недавно я решил, что PHP и JavaScript — это хорошо, но с моей губозакатывательной сферой интересов (машинное обучение, нейросети и т.д.) язык Python — лучше. Поэтому решил стать более системным парнем и для начала пройти этот бесплатный курс по Python.
На этой платформе есть курсы платные и есть бесплатные. В выбранном мной курсе задания проверяются системой автоматически на серии тестов. Количество баллов за задание получаю исходя из количества тестов, которые моё решение прошло, по 100-бальной системе. Но "зачёт" ставится только за оценку в 100 баллов. Особенное удовольствие доставляет выполнять задания со звёздочкой, которые не обязательны для зачёта учебных недель, но являются самым важным делом в обучении программиста. Пока что нравится. Когда закончу, думаю взять следующий курс по Python и Data Science или Applied Data Science with Python.
2️⃣ Notion
Решил систематизировать свои знания где-то в Интернете. Trello для этого стал тесен, и я попробовал Notion. Оказывается, тут есть фичи и для программистов: можно указывать язык, чтобы сохраняемый вами код приобретал соответствующую разметку синтаксиса. Прикрепляю скриншот.
А вы использовали эти сервисы?
Давно не рассказывал о своём продвижении в мире кодинга. За последние две недели сделал для себя сразу два открытия, которые хорошо сплелись воедино: Coursera и Notion.
1️⃣ Coursera
Недавно я решил, что PHP и JavaScript — это хорошо, но с моей губозакатывательной сферой интересов (машинное обучение, нейросети и т.д.) язык Python — лучше. Поэтому решил стать более системным парнем и для начала пройти этот бесплатный курс по Python.
На этой платформе есть курсы платные и есть бесплатные. В выбранном мной курсе задания проверяются системой автоматически на серии тестов. Количество баллов за задание получаю исходя из количества тестов, которые моё решение прошло, по 100-бальной системе. Но "зачёт" ставится только за оценку в 100 баллов. Особенное удовольствие доставляет выполнять задания со звёздочкой, которые не обязательны для зачёта учебных недель, но являются самым важным делом в обучении программиста. Пока что нравится. Когда закончу, думаю взять следующий курс по Python и Data Science или Applied Data Science with Python.
2️⃣ Notion
Решил систематизировать свои знания где-то в Интернете. Trello для этого стал тесен, и я попробовал Notion. Оказывается, тут есть фичи и для программистов: можно указывать язык, чтобы сохраняемый вами код приобретал соответствующую разметку синтаксиса. Прикрепляю скриншот.
А вы использовали эти сервисы?
{kind=link}
🍳 Состав изучения программирования, да и самого его
После прошлого поста один из подписчиков мне подсказал посмотреть лекции Тимофея Хирьянова по программированию на Python. Решил не откладывать и посмотреть, так как хочу хорошо изучить Python с разных сторон.
Действительно, чувак интересно и понятно расчехляет суть вещей. Досмотрел уже до 6-й лекции, и пока не думаю останавливаться. Кстати, в ней он доступно и детально объясняет суть разных способов сортировки на примере солдат и прапорщиков. Такие "живые" примеры и визуализация очень важны при обучении абстрактным концепциям.
Но что более важно, в первой лекции Тимофей Хирьянов рассказывает, из чего состоит программирование и на чём следует делать акцент при его изучении:
1️⃣ знание синтаксиса языка(-ов) программирования
2️⃣ знание алгоритмов и структур данных
3️⃣ знание прикладных библиотек
4️⃣ практика программирования
5️⃣ дизайн программного обеспечения
6️⃣ групповая работа программистов
Как вы думаете, какие два из этих направлений были отмечены как приоритетные для старта изучения программирования?
После прошлого поста один из подписчиков мне подсказал посмотреть лекции Тимофея Хирьянова по программированию на Python. Решил не откладывать и посмотреть, так как хочу хорошо изучить Python с разных сторон.
Действительно, чувак интересно и понятно расчехляет суть вещей. Досмотрел уже до 6-й лекции, и пока не думаю останавливаться. Кстати, в ней он доступно и детально объясняет суть разных способов сортировки на примере солдат и прапорщиков. Такие "живые" примеры и визуализация очень важны при обучении абстрактным концепциям.
Но что более важно, в первой лекции Тимофей Хирьянов рассказывает, из чего состоит программирование и на чём следует делать акцент при его изучении:
1️⃣ знание синтаксиса языка(-ов) программирования
2️⃣ знание алгоритмов и структур данных
3️⃣ знание прикладных библиотек
4️⃣ практика программирования
5️⃣ дизайн программного обеспечения
6️⃣ групповая работа программистов
Как вы думаете, какие два из этих направлений были отмечены как приоритетные для старта изучения программирования?
🛠 Что такое лигалинженер?
часть 2: чтиво на Медиуме
Маленько увлёкся работой, поэтому постов стало меньше. Сегодня наконец вышли в свет несколько моих подсозревших мыслей о лигалинженерии. Благодаря ей этот канал и появился, когда мой поток сознания превысил объём используемых до того стоков. :)
часть 2: чтиво на Медиуме
Маленько увлёкся работой, поэтому постов стало меньше. Сегодня наконец вышли в свет несколько моих подсозревших мыслей о лигалинженерии. Благодаря ей этот канал и появился, когда мой поток сознания превысил объём используемых до того стоков. :)
Medium
Що таке Legal Engineer?
Для когось це хайп. Для когось — санітар зашкарублого права.
📚 Что общего между Инкотермс и .dll в Windows
Инкотермс позволяет с помощью трёх букв объяснить контрагенту его права и обязанности. Говоришь покупателю "DAP" — и он уже знает, что поставку в место назначения, импортные пошлины и местные налоги оплачивает он.
Ключевое в описании сути Инкотермса — "правила ... обеспечивающие однозначные толкования наиболее широко используемых торговых терминов ... определены заранее в международном признанном документе...".
В разработке есть похожее явление — библиотеки. Когда у вас накапливается некий код, который хорошо выполняет одну и ту же работу, постоянно нужен вам в разных проектах (и к тому же если он уже оформлен при помощи функций или классов), из него можно сделать библиотеку. Это означает, что вы создаёте из этого участка кода минипрограмму, у которой есть свои точки входа, точки выхода, своя логика и своя зона ответственности. Далее вы можете абстрагироваться (отстраниться) от её внутреннего устройства, используя только логику её запуска с передачей нужных параметров.
По сути, фраза "работаем по Инкотермсу 2010 DAP" является похожим запуском "правовой библиотеки" (т.е. свода где-то уже записанных общих юридических правил) и передачей нужных параметров (год редакции, схема работы).
Если это представить как код на языке Python, то может выглядеть как-то так:
import incoterms
newScheme = incoterms.set('2010', 'DAP')
В разных отраслях права есть явления, которые имеют предрасположенность к подобному оформлению, т.е. к заключению в некоторую "капсулу смыслов" с созданием удобного способа взаимодействия с ними. Например, главы гражданского кодекса с разными именованными договорами, составы преступлений, известные фрагменты постановлений ПВСУ и т.д.
Инкотермс позволяет с помощью трёх букв объяснить контрагенту его права и обязанности. Говоришь покупателю "DAP" — и он уже знает, что поставку в место назначения, импортные пошлины и местные налоги оплачивает он.
Ключевое в описании сути Инкотермса — "правила ... обеспечивающие однозначные толкования наиболее широко используемых торговых терминов ... определены заранее в международном признанном документе...".
В разработке есть похожее явление — библиотеки. Когда у вас накапливается некий код, который хорошо выполняет одну и ту же работу, постоянно нужен вам в разных проектах (и к тому же если он уже оформлен при помощи функций или классов), из него можно сделать библиотеку. Это означает, что вы создаёте из этого участка кода минипрограмму, у которой есть свои точки входа, точки выхода, своя логика и своя зона ответственности. Далее вы можете абстрагироваться (отстраниться) от её внутреннего устройства, используя только логику её запуска с передачей нужных параметров.
По сути, фраза "работаем по Инкотермсу 2010 DAP" является похожим запуском "правовой библиотеки" (т.е. свода где-то уже записанных общих юридических правил) и передачей нужных параметров (год редакции, схема работы).
Если это представить как код на языке Python, то может выглядеть как-то так:
import incoterms
newScheme = incoterms.set('2010', 'DAP')
В разных отраслях права есть явления, которые имеют предрасположенность к подобному оформлению, т.е. к заключению в некоторую "капсулу смыслов" с созданием удобного способа взаимодействия с ними. Например, главы гражданского кодекса с разными именованными договорами, составы преступлений, известные фрагменты постановлений ПВСУ и т.д.
🎇 Завет Машиночитаемости Права
На днях вышла книга управляющего партнёра "Симплоер" Антона Вашкевича "Машиночитаемое право: право как электричество".
По сути, это системное изложение тезисов и выводов по ряду аспектов разработки и применения права в машиночитаемой форме.
Оглавление выглядит аппетитно, вот названия некоторых глав и подглав:
▫️ Неэффективность права
▫️ Как автоматизировать право
▫️ Алгоритмизация
▫️ Машинное обучение
▪️ Совместимость права с новым миром
▪️ Подходы к автоматизации права в мире
▪️ Ограничения естественного языка
▪️ Этические вопросы
▪️ Совместимость норм с автоматизацией
И привожу несколько цитат:
📎 "В случае коллизии между машиночитаемыми нормами и нормами, записанными на естественном языке, приоритет должны иметь машиночитаемые. (с. 26)"
📎 "Человек — не самый эффективный исполнитель большинства норм. (с. 34)"
📎 "Самоисполняемость норм блокирует или ограничивает волю людей совершать правонарушения. Но иногда правонарушение оказывается эффективнее соблюдения нормы. (с. 216)"
В общем, кто интересуется проблемами будущего права, книгу стоит прочесть. Местами текст может казаться заумным, но в целом есть доходчивые пояснения и примеры. Особенно меня радуют последние разделы, где идёт мясцо конкретики. 😎
На днях вышла книга управляющего партнёра "Симплоер" Антона Вашкевича "Машиночитаемое право: право как электричество".
По сути, это системное изложение тезисов и выводов по ряду аспектов разработки и применения права в машиночитаемой форме.
Оглавление выглядит аппетитно, вот названия некоторых глав и подглав:
▫️ Неэффективность права
▫️ Как автоматизировать право
▫️ Алгоритмизация
▫️ Машинное обучение
▪️ Совместимость права с новым миром
▪️ Подходы к автоматизации права в мире
▪️ Ограничения естественного языка
▪️ Этические вопросы
▪️ Совместимость норм с автоматизацией
И привожу несколько цитат:
📎 "В случае коллизии между машиночитаемыми нормами и нормами, записанными на естественном языке, приоритет должны иметь машиночитаемые. (с. 26)"
📎 "Человек — не самый эффективный исполнитель большинства норм. (с. 34)"
📎 "Самоисполняемость норм блокирует или ограничивает волю людей совершать правонарушения. Но иногда правонарушение оказывается эффективнее соблюдения нормы. (с. 216)"
В общем, кто интересуется проблемами будущего права, книгу стоит прочесть. Местами текст может казаться заумным, но в целом есть доходчивые пояснения и примеры. Особенно меня радуют последние разделы, где идёт мясцо конкретики. 😎
🧶 Сила данных — в правде
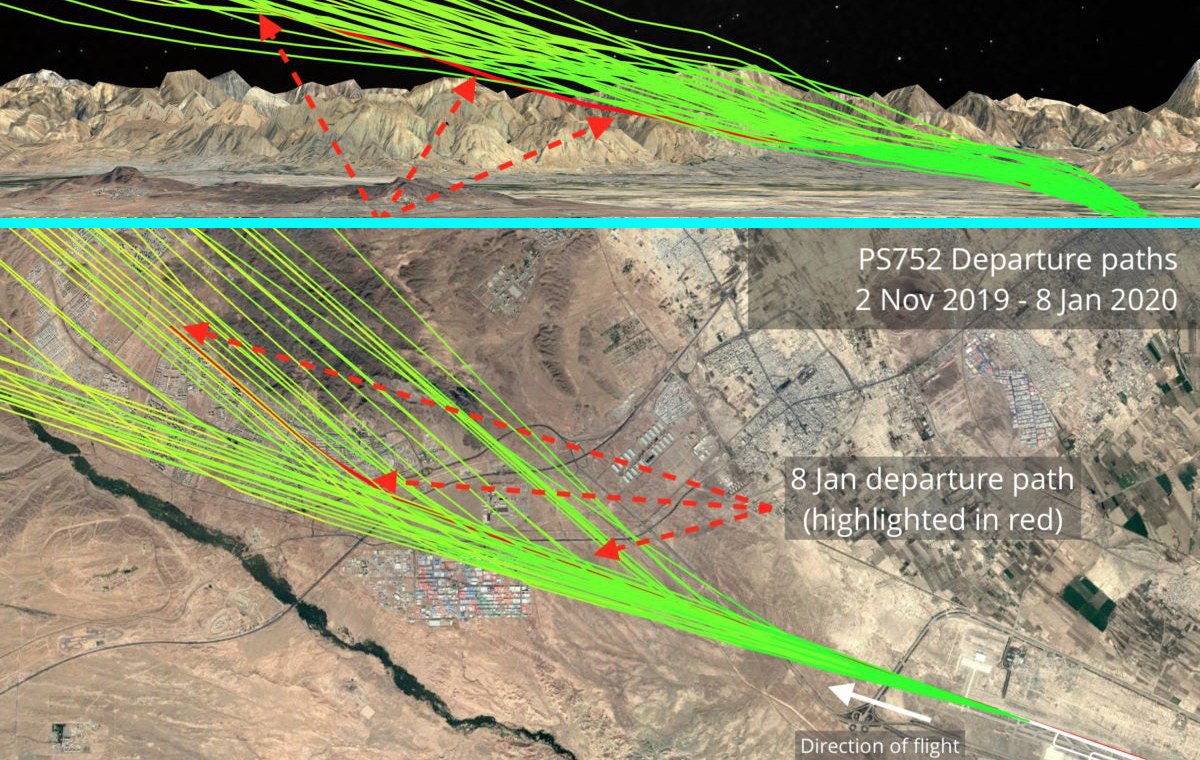
На картинке ниже и в этом видео — драматическая демонстрация ценности больших данных не только в рамках правовой системы отдельного государства, но и в международных отношениях. Видно, что траектория полёта нашего самолёта до момента его сбития не выделялась из множества траекторий предшествующих рейсов. Так "большие данные" становятся мощным противовесом словам "больших людей".
Одна из задач разумной цифровизации государства в том, чтобы не только создавать системы логирования всех значимых событий (регистрационные действия, декларации, реестры уголовных производств и т.д.), но и защищать собранные данные от последующего вмешательства с целью удаления/фальсификации. В условиях, когда данные будут всё больше становиться ключевым доказательством в расследованиях, им нужно обеспечить свой аналог "системы защиты свидетелей".
Но в отличии от человека, который существует в единственном телесном экземпляре, данные можно хешировать, копировать, сохранять их версии, публиковать, транслировать онлайн и при особой нужде блокчейнизировать. Если по-настоящему захотеть, то можно сделать так, чтобы данные было крайне сложно поставить под сомнение.
А если мы хотим строить прозрачное общество, то нужно научиться лелеять данные, но в то же время не бояться делать их открытыми. Максимизация полномочий общества на чтение данных не связана с техническими возможностями по изменению данных. Ведь многие из нас могут зайти на главную страницу Google, но немногие могут редактировать её, верно?
На картинке ниже и в этом видео — драматическая демонстрация ценности больших данных не только в рамках правовой системы отдельного государства, но и в международных отношениях. Видно, что траектория полёта нашего самолёта до момента его сбития не выделялась из множества траекторий предшествующих рейсов. Так "большие данные" становятся мощным противовесом словам "больших людей".
Одна из задач разумной цифровизации государства в том, чтобы не только создавать системы логирования всех значимых событий (регистрационные действия, декларации, реестры уголовных производств и т.д.), но и защищать собранные данные от последующего вмешательства с целью удаления/фальсификации. В условиях, когда данные будут всё больше становиться ключевым доказательством в расследованиях, им нужно обеспечить свой аналог "системы защиты свидетелей".
Но в отличии от человека, который существует в единственном телесном экземпляре, данные можно хешировать, копировать, сохранять их версии, публиковать, транслировать онлайн и при особой нужде блокчейнизировать. Если по-настоящему захотеть, то можно сделать так, чтобы данные было крайне сложно поставить под сомнение.
А если мы хотим строить прозрачное общество, то нужно научиться лелеять данные, но в то же время не бояться делать их открытыми. Максимизация полномочий общества на чтение данных не связана с техническими возможностями по изменению данных. Ведь многие из нас могут зайти на главную страницу Google, но немногие могут редактировать её, верно?
{kind=link}
🐺 ИИ интеллекту волк?
1️⃣ На днях Минцифра объявили о создании экспертного комитета по вопросам развития сферы ИИ в Украине. Приоритеты работы определены хорошие, и это как раз хороший повод запустить серию постов на тему ИИ.
2️⃣ Параллельно, в Минске скоро должно состояться установочное собрание Лаборатории Вычислительного Права, чтобы в дальней перспективе "правовое регулирование и юридические практики в цифровую эпоху обрели ту технологическую поддержку и форму, которая бы соответствовала требованиям настоящего и будущего".
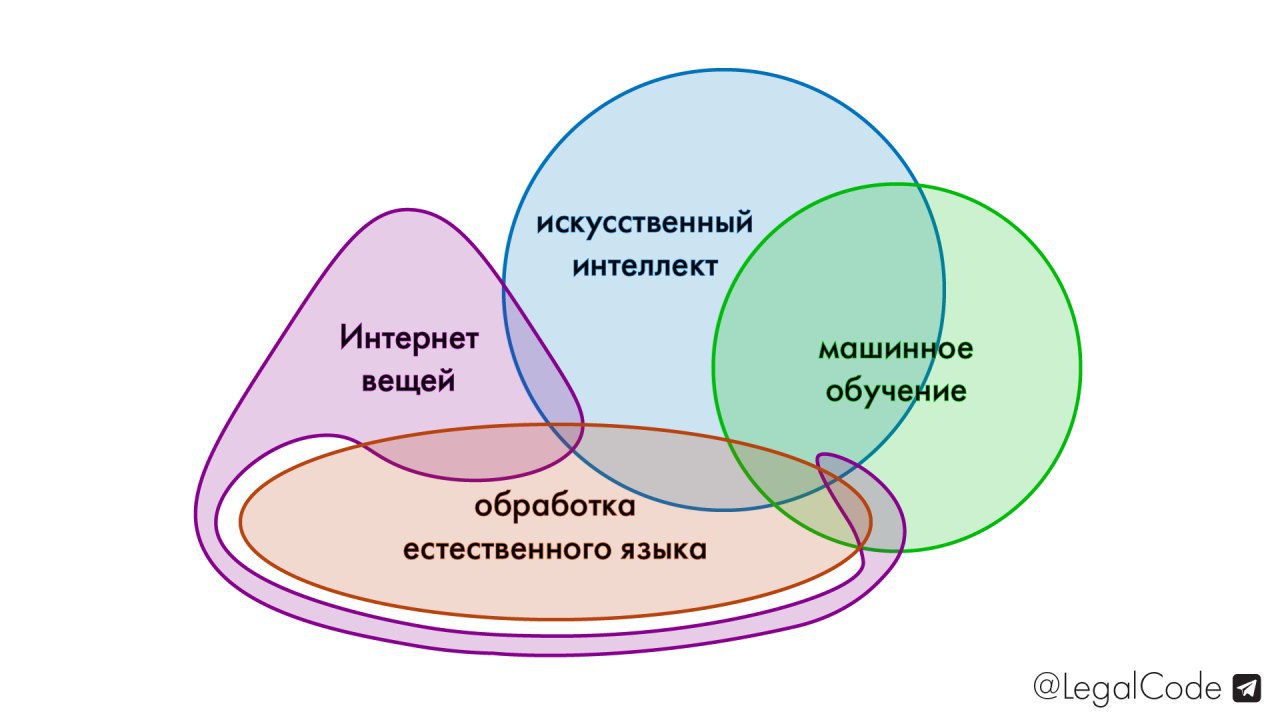
В своих выступлениях я постоянно делаю акцент на том, что термин "искусственный интеллект" (AI) довольно запутанный, часто спорный и пользоваться им следует осторожно (особенно стартаперам на питчах перед инвесторами/фондами). При возможности необходимо озвучивать более конкретные термины: "машинное обучение" (Machine Learning, ML), "обработка естественного языка" (Natural Language Processing, NLP), "Интернет вещей" (Internet of Things, IoT), робототехника (Robotics) и т.д. Эти и другие направления могут как включать элементы "искусственного интеллекта", так и не включать.
Не вдаваясь в пространные рассуждения о философских проблемах термина "ИИ" скажу, что предпочитаю использовать термин "интеллектуализация вычислений/алгоритмов" (ИВ, ИА или ИВ/А), так как это освобождает от необходимости вдаваться в условности, объяснять критерии того, что мы считаем "интеллектом" и доказывать, что наши алгоритмы заслуживают именоваться "интеллектом".
Ниже при помощи кругов Эйлера показываю, как соотносится термин "ИИ" с более конкретными понятиями.
1️⃣ На днях Минцифра объявили о создании экспертного комитета по вопросам развития сферы ИИ в Украине. Приоритеты работы определены хорошие, и это как раз хороший повод запустить серию постов на тему ИИ.
2️⃣ Параллельно, в Минске скоро должно состояться установочное собрание Лаборатории Вычислительного Права, чтобы в дальней перспективе "правовое регулирование и юридические практики в цифровую эпоху обрели ту технологическую поддержку и форму, которая бы соответствовала требованиям настоящего и будущего".
В своих выступлениях я постоянно делаю акцент на том, что термин "искусственный интеллект" (AI) довольно запутанный, часто спорный и пользоваться им следует осторожно (особенно стартаперам на питчах перед инвесторами/фондами). При возможности необходимо озвучивать более конкретные термины: "машинное обучение" (Machine Learning, ML), "обработка естественного языка" (Natural Language Processing, NLP), "Интернет вещей" (Internet of Things, IoT), робототехника (Robotics) и т.д. Эти и другие направления могут как включать элементы "искусственного интеллекта", так и не включать.
Не вдаваясь в пространные рассуждения о философских проблемах термина "ИИ" скажу, что предпочитаю использовать термин "интеллектуализация вычислений/алгоритмов" (ИВ, ИА или ИВ/А), так как это освобождает от необходимости вдаваться в условности, объяснять критерии того, что мы считаем "интеллектом" и доказывать, что наши алгоритмы заслуживают именоваться "интеллектом".
Ниже при помощи кругов Эйлера показываю, как соотносится термин "ИИ" с более конкретными понятиями.
{kind=link}
👓 Из чего состоит машинное обучение
Продолжаем. Машинное обучение (ML) состоит из разных, несхожих направлений. Многие из них объединяет математика, сложные формулы и всё такое. Они уже не первый год влияют на нашу жизнь, сфера их воздействия всё больше выходит за пределы Интернета. Хотелось бы о каждом сделать пост с примерами, как это можно было бы применить в юриспруденции. Но сначала познакомимся с основными.
Например, Педро Домингос в книге "Верховный алгоритм" выделяет пять таких действующих в области машинного обучения научных школ (в хорошем смысле этого слова), именуя их также "племенами":
1️⃣ СИМВОЛИСТЫ 🚠
занятия: использование исходных знаний, "передача готовой экспертизы" компьютеру, определение и обобщение недостающего знания
метод: обратная дедукция
пример: деревья решений, психологические тесты
2️⃣ КОННЕКЦИОНИСТЫ 🧠
занятия: обратная инженерия мозга, нейробиологических механизмов
метод: обратное распространение ошибки (обучение на совершаемых ошибках)
пример: нейросети распознают раковые опухоли
3️⃣ ЭВОЛЮЦИОНИСТЫ 🦕
занятия: симуляция естественного отбора, где неудачные образцы будут "вымирать", а удачные "выживать", размножаться и развиваться дальше, их неудачные потомки — снова "вымирать" и т.д.
метод: генетическое программирование ("рождение" и развитие алгоритмов аки живых существ)
пример: симуляция "пробирки" с соревнующимися микроорганизмами
4️⃣ БАЙЕСОВЦЫ 🧮
занятия: подготовка вероятностного вывода на основе имеющихся и новых поступающих данных
метод: теорема Байеса и ее производные
пример: фильтрация спама в email
5️⃣ АНАЛОГИСТЫ 🖖
занятия: поиск сходств между разными ситуациями + логический вывод других сходств
метод: опорных векторов
пример: рекомендации на основе предпочтений на Нетфликсе и других подобных сервисах
Какое направление интересует вас больше всего?
Продолжаем. Машинное обучение (ML) состоит из разных, несхожих направлений. Многие из них объединяет математика, сложные формулы и всё такое. Они уже не первый год влияют на нашу жизнь, сфера их воздействия всё больше выходит за пределы Интернета. Хотелось бы о каждом сделать пост с примерами, как это можно было бы применить в юриспруденции. Но сначала познакомимся с основными.
Например, Педро Домингос в книге "Верховный алгоритм" выделяет пять таких действующих в области машинного обучения научных школ (в хорошем смысле этого слова), именуя их также "племенами":
1️⃣ СИМВОЛИСТЫ 🚠
занятия: использование исходных знаний, "передача готовой экспертизы" компьютеру, определение и обобщение недостающего знания
метод: обратная дедукция
пример: деревья решений, психологические тесты
2️⃣ КОННЕКЦИОНИСТЫ 🧠
занятия: обратная инженерия мозга, нейробиологических механизмов
метод: обратное распространение ошибки (обучение на совершаемых ошибках)
пример: нейросети распознают раковые опухоли
3️⃣ ЭВОЛЮЦИОНИСТЫ 🦕
занятия: симуляция естественного отбора, где неудачные образцы будут "вымирать", а удачные "выживать", размножаться и развиваться дальше, их неудачные потомки — снова "вымирать" и т.д.
метод: генетическое программирование ("рождение" и развитие алгоритмов аки живых существ)
пример: симуляция "пробирки" с соревнующимися микроорганизмами
4️⃣ БАЙЕСОВЦЫ 🧮
занятия: подготовка вероятностного вывода на основе имеющихся и новых поступающих данных
метод: теорема Байеса и ее производные
пример: фильтрация спама в email
5️⃣ АНАЛОГИСТЫ 🖖
занятия: поиск сходств между разными ситуациями + логический вывод других сходств
метод: опорных векторов
пример: рекомендации на основе предпочтений на Нетфликсе и других подобных сервисах
Какое направление интересует вас больше всего?
🏢 Лигалинженер на службе Холдинга
Давеча агроиндустриальный холдинг МХП разместил лигалинженерскую вакансию, обозначенную терминами "Legal tech specialist" и "специалист по автоматизации".
Среди основных обязанностей как раз есть эти волшебные слова, описывающие сложный лик лигалинженера: "автоматизация", "оптимизация", "создание автоматизированных правовых продуктов и решений", "разработка и поддержка процессов/проектов".
Среди пожеланий внимание привлекают такие:
▫️ опыт работы в "направлении LegaLTech" от трёх лет;
▫️ "опыт участия в проектах по автоматизации / внедрению ПО" (интересно, а участие в хакатонах/невзлетевших стартапах засчитывается?) или "навыки программирования" (интересно, а создание чатботов через pipe.bot засчитывается?);
▫️ уверенное владение Excel, PowerPoint и т.д.
В связи с этим, доктринального исследования требуют вопросы:
0. Настаёт эра лигалинженеров-инхаусов в не-юрбизе?
1. Какую долю заработка (в среднем) такие специалисты смогут откусить автоматизацией у юристов, обслуживающих подобные организации?
2. Они будут забирать работу преимущественно у "внутренних" юристов, юристов-аутсорсеров или у всех сразу?
3. Сколько чеканных монет им за это готовы предложить на старте? Кто сходит на собес, расскажите)
Давеча агроиндустриальный холдинг МХП разместил лигалинженерскую вакансию, обозначенную терминами "Legal tech specialist" и "специалист по автоматизации".
Среди основных обязанностей как раз есть эти волшебные слова, описывающие сложный лик лигалинженера: "автоматизация", "оптимизация", "создание автоматизированных правовых продуктов и решений", "разработка и поддержка процессов/проектов".
Среди пожеланий внимание привлекают такие:
▫️ опыт работы в "направлении LegaLTech" от трёх лет;
▫️ "опыт участия в проектах по автоматизации / внедрению ПО" (интересно, а участие в хакатонах/невзлетевших стартапах засчитывается?) или "навыки программирования" (интересно, а создание чатботов через pipe.bot засчитывается?);
▫️ уверенное владение Excel, PowerPoint и т.д.
В связи с этим, доктринального исследования требуют вопросы:
0. Настаёт эра лигалинженеров-инхаусов в не-юрбизе?
1. Какую долю заработка (в среднем) такие специалисты смогут откусить автоматизацией у юристов, обслуживающих подобные организации?
2. Они будут забирать работу преимущественно у "внутренних" юристов, юристов-аутсорсеров или у всех сразу?
3. Сколько чеканных монет им за это готовы предложить на старте? Кто сходит на собес, расскажите)
🧮 Знакомимся: Теорема Байеса
Что ж, давно здесь не было мяса! Одна из школ машинного обучения — теорема Байеса. Благодаря ей можно делать вероятностные выводы на основе имеющихся данных. То есть можно "предсказывать" (лучше сказать "формировать убеждённость в той или иной степени") как следствия (С), зная о причинах (П), так и причины (П), зная о следствиях (С). Например:
1️⃣ имея много данных о поведении (П) клиента на допросах и типичном влиянии такого поведения на его дальнейший процессуальный статус, адвокат может предполагать, будет ли следователь считать клиента виновным (С);
2️⃣ и наоборот, имея данные о позиции следователя насчёт виноватости (С) клиента, адвокат может предполагать, как клиент себя вёл (П) на допросах.
Но здесь вы должны заметить, что позиция следователя (С) может зависеть не только от того, как вёл (П) себя допрашиваемый. Спектр причин, выливающихся в следствие (обвинить / оставить в покое), может быть довольно широким: П + П + П = С. И теорема Байеса позволяет математически грамотно учитывать сколь угодно большущее количество причин. Главное, чтобы у вас был собран соответствующий набор данных, которым вы доверяете.
📑 Далее вы можете увидеть кусок текста из книги "Верховный алгоритм" Педро Домингоса, в котором я сделал некоторые замены: "врач - адвокат", "пациент - клиент", "грипп - незадекларированные регулярные доходы", "высокая температура - налоговая проверка" и т.д.
🔻🔻🔻
Представьте, что вы адвокат и за последний месяц оказали услугу сотне клиентов. У 14 из них были незадекларированные регулярные доходы (далее НРД), у 20 прошла налоговая проверка, а у 11 — и то и другое.
Условная вероятность налоговой проверки при НРД, таким образом, составляет одиннадцать из четырнадцати, или 11 ⁄ 14. Обусловленность уменьшает размеры рассматриваемой нами вселенной, в данном случае от всех возможных клиентов только до клиентов с НРД.
Во вселенной всех клиентов вероятность налоговой проверки составляет 20 ⁄ 100, а во вселенной клиентов с НРД, — 11 ⁄ 14.
Вероятность того, что у клиента НРД и налоговая проверка, равна доле клиентов с НРД, умноженной на долю клиентов с налоговой проверкой:
P(НРД, НП) = P(НРД) × P(НП | НРД) = 14 ⁄ 100 × 11 ⁄ 14 = 11 ⁄ 100.
Но верно и следующее: P(НРД, НП) = P(НП) × P(НРД | НП).
Таким образом, поскольку и то, и другое равно P(НРД, НП),
то P(НП) × P(НРД | НП) = P(НРД) × P(НП | НРД).
Разделите обе стороны на P(НП), и вы получите
P(НРД | НП) = P(НРД) × P(НП | НРД) / P(НП).
Вот и все! Это теорема Байеса, где незадекларированные регулярные доходы — это причина, а налоговая проверка — следствие.
🔺🔺🔺
Но снова-таки, не стоит забывать, что у налоговых проверок могут быть и другие причины, влияющие на факт их проведения сильнее, чем наличие НРД. Так же, как высокую температуру может вызывать не только грипп. Добавив в формулу математическое представление данных о влиянии и этих причин, вы сделаете ваш вероятностный вывод более точным, обоснованным, реалистичным.
В следующих постах расскажу подробнее, как это работает.
Что ж, давно здесь не было мяса! Одна из школ машинного обучения — теорема Байеса. Благодаря ей можно делать вероятностные выводы на основе имеющихся данных. То есть можно "предсказывать" (лучше сказать "формировать убеждённость в той или иной степени") как следствия (С), зная о причинах (П), так и причины (П), зная о следствиях (С). Например:
1️⃣ имея много данных о поведении (П) клиента на допросах и типичном влиянии такого поведения на его дальнейший процессуальный статус, адвокат может предполагать, будет ли следователь считать клиента виновным (С);
2️⃣ и наоборот, имея данные о позиции следователя насчёт виноватости (С) клиента, адвокат может предполагать, как клиент себя вёл (П) на допросах.
Но здесь вы должны заметить, что позиция следователя (С) может зависеть не только от того, как вёл (П) себя допрашиваемый. Спектр причин, выливающихся в следствие (обвинить / оставить в покое), может быть довольно широким: П + П + П = С. И теорема Байеса позволяет математически грамотно учитывать сколь угодно большущее количество причин. Главное, чтобы у вас был собран соответствующий набор данных, которым вы доверяете.
📑 Далее вы можете увидеть кусок текста из книги "Верховный алгоритм" Педро Домингоса, в котором я сделал некоторые замены: "врач - адвокат", "пациент - клиент", "грипп - незадекларированные регулярные доходы", "высокая температура - налоговая проверка" и т.д.
🔻🔻🔻
Представьте, что вы адвокат и за последний месяц оказали услугу сотне клиентов. У 14 из них были незадекларированные регулярные доходы (далее НРД), у 20 прошла налоговая проверка, а у 11 — и то и другое.
Условная вероятность налоговой проверки при НРД, таким образом, составляет одиннадцать из четырнадцати, или 11 ⁄ 14. Обусловленность уменьшает размеры рассматриваемой нами вселенной, в данном случае от всех возможных клиентов только до клиентов с НРД.
Во вселенной всех клиентов вероятность налоговой проверки составляет 20 ⁄ 100, а во вселенной клиентов с НРД, — 11 ⁄ 14.
Вероятность того, что у клиента НРД и налоговая проверка, равна доле клиентов с НРД, умноженной на долю клиентов с налоговой проверкой:
P(НРД, НП) = P(НРД) × P(НП | НРД) = 14 ⁄ 100 × 11 ⁄ 14 = 11 ⁄ 100.
Но верно и следующее: P(НРД, НП) = P(НП) × P(НРД | НП).
Таким образом, поскольку и то, и другое равно P(НРД, НП),
то P(НП) × P(НРД | НП) = P(НРД) × P(НП | НРД).
Разделите обе стороны на P(НП), и вы получите
P(НРД | НП) = P(НРД) × P(НП | НРД) / P(НП).
Вот и все! Это теорема Байеса, где незадекларированные регулярные доходы — это причина, а налоговая проверка — следствие.
🔺🔺🔺
Но снова-таки, не стоит забывать, что у налоговых проверок могут быть и другие причины, влияющие на факт их проведения сильнее, чем наличие НРД. Так же, как высокую температуру может вызывать не только грипп. Добавив в формулу математическое представление данных о влиянии и этих причин, вы сделаете ваш вероятностный вывод более точным, обоснованным, реалистичным.
В следующих постах расскажу подробнее, как это работает.
🦠 Теорема Байеса и коронавирус
часть 1
Теорема Байеса помогает нивелировать изъян той части нашего мышления, которая связана с оценкой вероятностей. Правильная оценка вероятностей предполагает необходимость быстро посчитать в уме правильные формулы, прежде чем выпалить, авторитетно зевнув, "скорее всего", "маловероятно" и т.д. И вот благодаря тому, что компьютер умеет считать быстро, теорема Байеса расцвела как целое направление машинного обучения. Итак, давайте ещё раз потренируемся считать вероятности на злободневной теме.
Фабула
Предположим, что вы госслужащий в некоем важном органе, который вынужден контактировать с гражданами. Например, вы должны выдавать некие документы, связанные с оформлением факта смерти людей (далее — справки). Во время эпидемии коронавируса количество смертей неизбежно растёт, и в ваш орган должны приходить люди за справками. Как правило, эти люди — родственники либо супруги умерших (далее — близкий человек). Зачастую близкие люди живут вместе. А значит, они почти наверняка тоже будут инфицированы. А значит, если вы работаете в таком месте, реально можете заразиться. А-а-а-а-а!
Задача
Хоть как-то оценить вероятность заражения госслужащего (далее — ВЗГ) в условиях такой эпидемии на первой же встрече с гражданином, пришедшем за справкой об умершем, если известно, что эта смерть — от коронавируса.
Разбор
Обратите внимание: фабула напичкана вероятностными терминами. Перечитайте её, почти в каждом предложении есть такой термин. Давайте попробуем пока что грубо, основываясь на нашем жизненном опыте, присвоить им коэффициенты. Я попробую сделать это исходя из своих представлений, а вы можете подставить свои цифры:
"неизбежно" — 100% или 1
"как правило" — 80% или 0.8
"зачастую" — 71% или 0.71
"почти наверняка" — 93% или 0.93
"реально можете" — 70% или 0.7
Вероятность конечного события (в нашем случае ВЗГ) рассчитывается путём перемножения вероятностей, образующих логическую цепочку событий, которые должны перед ним произойти:
ВЗГ = 1 * 0.8 * 0.71 * 0.93 * 0.7 = 0.369768
Итак, в "рассматриваемой мной вселенной, где принятые мной коэффициенты верны" (эта фраза в кавычках — важный дисклеймер при подобных размышлениях), ВЗГ за первую встречу равна почти 37%.
Много это или мало, решать каждому самостоятельно. :) Но важно помнить, что это вероятность именно нашего сценария, что госслужащего заразит именно тот близкий человек, который жил с умершим и заразился именно от умершего. А на практике этот пришедший человек может быть уже заражен по другой причине. Это значит, что наша формула может стать частью более общей формулы, описывающей полную вероятность заражения, с учётом большего количества факторов.
А какова вероятность пережить две такие встречи, не заразившись? А три встречи? А десять? А что, если выдать служащему костюм химзащиты, сводящий риск к 5%? Рассмотрим в следующем посте.
часть 1
Теорема Байеса помогает нивелировать изъян той части нашего мышления, которая связана с оценкой вероятностей. Правильная оценка вероятностей предполагает необходимость быстро посчитать в уме правильные формулы, прежде чем выпалить, авторитетно зевнув, "скорее всего", "маловероятно" и т.д. И вот благодаря тому, что компьютер умеет считать быстро, теорема Байеса расцвела как целое направление машинного обучения. Итак, давайте ещё раз потренируемся считать вероятности на злободневной теме.
Фабула
Предположим, что вы госслужащий в некоем важном органе, который вынужден контактировать с гражданами. Например, вы должны выдавать некие документы, связанные с оформлением факта смерти людей (далее — справки). Во время эпидемии коронавируса количество смертей неизбежно растёт, и в ваш орган должны приходить люди за справками. Как правило, эти люди — родственники либо супруги умерших (далее — близкий человек). Зачастую близкие люди живут вместе. А значит, они почти наверняка тоже будут инфицированы. А значит, если вы работаете в таком месте, реально можете заразиться. А-а-а-а-а!
Задача
Хоть как-то оценить вероятность заражения госслужащего (далее — ВЗГ) в условиях такой эпидемии на первой же встрече с гражданином, пришедшем за справкой об умершем, если известно, что эта смерть — от коронавируса.
Разбор
Обратите внимание: фабула напичкана вероятностными терминами. Перечитайте её, почти в каждом предложении есть такой термин. Давайте попробуем пока что грубо, основываясь на нашем жизненном опыте, присвоить им коэффициенты. Я попробую сделать это исходя из своих представлений, а вы можете подставить свои цифры:
"неизбежно" — 100% или 1
"как правило" — 80% или 0.8
"зачастую" — 71% или 0.71
"почти наверняка" — 93% или 0.93
"реально можете" — 70% или 0.7
Вероятность конечного события (в нашем случае ВЗГ) рассчитывается путём перемножения вероятностей, образующих логическую цепочку событий, которые должны перед ним произойти:
ВЗГ = 1 * 0.8 * 0.71 * 0.93 * 0.7 = 0.369768
Итак, в "рассматриваемой мной вселенной, где принятые мной коэффициенты верны" (эта фраза в кавычках — важный дисклеймер при подобных размышлениях), ВЗГ за первую встречу равна почти 37%.
Много это или мало, решать каждому самостоятельно. :) Но важно помнить, что это вероятность именно нашего сценария, что госслужащего заразит именно тот близкий человек, который жил с умершим и заразился именно от умершего. А на практике этот пришедший человек может быть уже заражен по другой причине. Это значит, что наша формула может стать частью более общей формулы, описывающей полную вероятность заражения, с учётом большего количества факторов.
А какова вероятность пережить две такие встречи, не заразившись? А три встречи? А десять? А что, если выдать служащему костюм химзащиты, сводящий риск к 5%? Рассмотрим в следующем посте.
🦠 Теорема Байеса и коронавирус
часть 2
В посте выше мы выяснили, что при заданных условиях вероятность заражения госслужащего — 37%.
Как же выяснить вероятность оказаться заражённым по итогам двух таких встреч подряд? В первую очередь в голову может прийти очевидное "умножить 0.37 на 0.37". Но нет. Ведь мы получим 0.1369, т.е. 13%, что являлось бы парадоксом, если бы было ответом на поставленный вопрос. Эти 13% — вероятность заразиться при каждой встрече, т.е. получить вирус от обоих посетителей. Поиск правильного ответа выглядит так:
1) вероятность не заразиться при отдельно взятой встрече:
1 – 0.37 = 0.63, т.е. 63%
2) вероятность два раза подряд не заразиться, т.е. по итогам двух встреч:
0.63 * 0.63 = 0.3969, т.е. 40%
3) вероятность оказаться зараженным по итогам двух встреч:
1 – 0.3969 = 0.6031, т.е. 60%
🧐 А если встреч будет 3, то эта вероятность вырастет до 75%
( 1 – (0.63 * 0.63 * 0.63 ) ).
🧐 А если 10 встреч, то отнимаем от единицы 0.63 в 10-й степени и получаем 0.99015, т.е. 99% риска заразиться.
🧐 А если выдать госслужащим защитные костюмы или создать другие условия, при которых риск заражения на последнем узле нашей цепочки событий уменьшится с 70% до 5%, тогда вероятность заразиться при первой встрече будет равна:
1 * 0.8 * 0.71 * 0.93 * 0.05 = 0,026412 , т.е. менее 3%.
А что если бы эта услуга была цифровизована / предоставлялась онлайн? Тогда бы встречи не было и вероятность заражения таким способом была равна 0%.
Итак, цифровизация, лигалтек и вот это вот всё делают право и государство более … ГИГИЕНИЧНЫМИ. 💎
Далее уже при помощи красавицы-формулы оценим, что будет, если в нашем выдуманном государстве некоторое кол-во служащих после таких встреч поедут сдавать бумажные отчётики в управление. 🙂
часть 2
В посте выше мы выяснили, что при заданных условиях вероятность заражения госслужащего — 37%.
Как же выяснить вероятность оказаться заражённым по итогам двух таких встреч подряд? В первую очередь в голову может прийти очевидное "умножить 0.37 на 0.37". Но нет. Ведь мы получим 0.1369, т.е. 13%, что являлось бы парадоксом, если бы было ответом на поставленный вопрос. Эти 13% — вероятность заразиться при каждой встрече, т.е. получить вирус от обоих посетителей. Поиск правильного ответа выглядит так:
1) вероятность не заразиться при отдельно взятой встрече:
1 – 0.37 = 0.63, т.е. 63%
2) вероятность два раза подряд не заразиться, т.е. по итогам двух встреч:
0.63 * 0.63 = 0.3969, т.е. 40%
3) вероятность оказаться зараженным по итогам двух встреч:
1 – 0.3969 = 0.6031, т.е. 60%
🧐 А если встреч будет 3, то эта вероятность вырастет до 75%
( 1 – (0.63 * 0.63 * 0.63 ) ).
🧐 А если 10 встреч, то отнимаем от единицы 0.63 в 10-й степени и получаем 0.99015, т.е. 99% риска заразиться.
🧐 А если выдать госслужащим защитные костюмы или создать другие условия, при которых риск заражения на последнем узле нашей цепочки событий уменьшится с 70% до 5%, тогда вероятность заразиться при первой встрече будет равна:
1 * 0.8 * 0.71 * 0.93 * 0.05 = 0,026412 , т.е. менее 3%.
А что если бы эта услуга была цифровизована / предоставлялась онлайн? Тогда бы встречи не было и вероятность заражения таким способом была равна 0%.
Итак, цифровизация, лигалтек и вот это вот всё делают право и государство более … ГИГИЕНИЧНЫМИ. 💎
Далее уже при помощи красавицы-формулы оценим, что будет, если в нашем выдуманном государстве некоторое кол-во служащих после таких встреч поедут сдавать бумажные отчётики в управление. 🙂
🦠 Теорема Байеса и коронавирус
часть 3 — дисциплина обновления доверия
Чтобы наконец разобраться, как работает теорема Байеса, представим такое:
▫️ с утра 3 госслужащих — Ашп, Брю и Ван имели незащищённые встречи с посетителями, вероятность заражения при каждой отдельно — 37%
▫️ проведённые встречи: Ашп — 3, Брю — 2, Ван — 1
▫️ в посте выше уже рассчитаны вероятности для таких кейсов: 75, 60 и 37 процентов
▫️ после обеда они повезли отчёты к начальнику Жаку
▫️ Жак принял их по очереди, а также пересёкся с некоторыми дополнительно, образовав таким образом встречи
▫️ встречи Жака: с Ашпом — 1, с Брю — 2, с Ваном — аж 3 (разговорились возле микроволновки и даже в туалете)
▫️ "интенсивность" этих встреч была одинакова, к привезённым документам Жак не прикасался
😡 Стало известно, что Жак заразился в этот день. Других контактов у него не было. Жак заподозрил, что это именно Брю "виноват", ведь на вид был каким-то подуставшим.
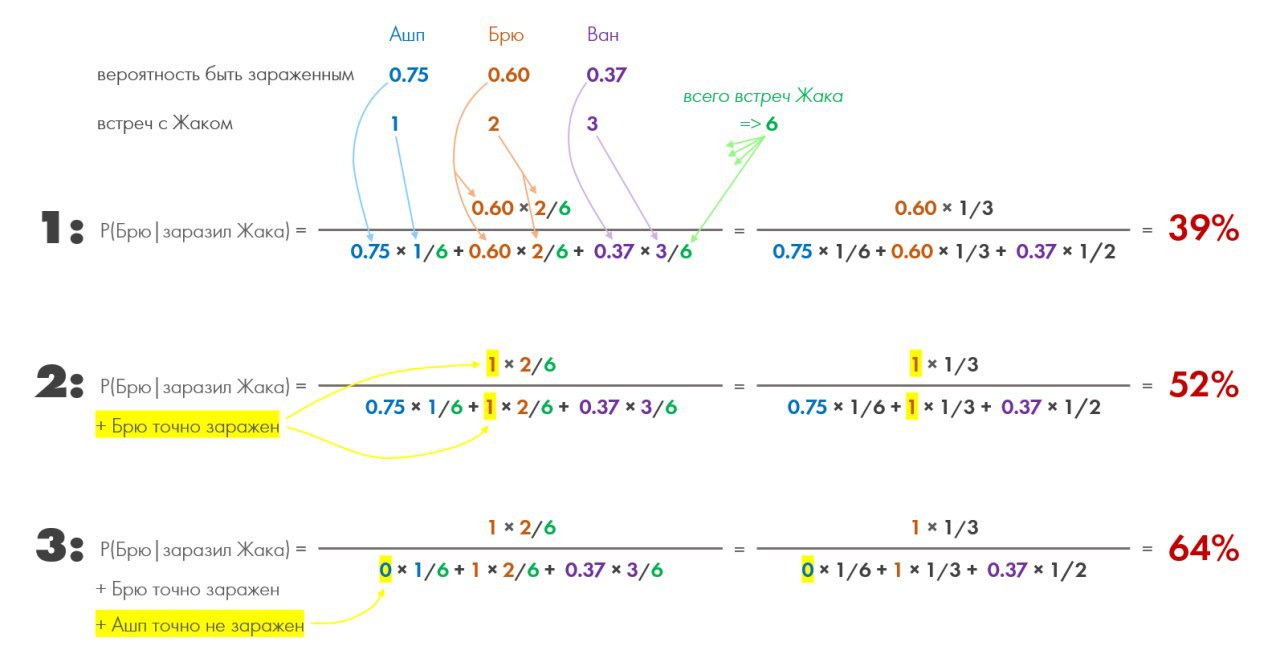
Вопрос 1: Какова вероятность, что Брю заразил Жака?
Вопрос 2: Как изменится этот ответ, если станет известно, что Брю точно уже был заражен?
Вопрос 3: Как изменится ответ на вопрос 2, если станет известно, что Ашп точно ещё не был заражен?
🖼 Все ответы и логику их получения по Байесу постарался вместить на картинку. Ибо это одна из тех тем, которые надо визуализировать, чтобы понять.
💛 Тут при помощи выделения жёлтым показана сила этой формулы: любое изменение связанного фрагмента данных можно быстро наложить и пересчитать, и получим обновлённую общую картину. У нас повысится или понизится уровень доверия к выдвинутой гипотезе. Весьма удобно, когда таких связанных фрагментов очень много и мы загоняем их в компьютер, чтобы он считал всё это безобразие за нас.
P.S. Некоторые рационалисты отмечают, что ничего особенного здесь нет, что это просто дисциплина мышления. Как бы там ни было, на этом построено и пока что не разогнано грязными тряпками целое направление в Machine Learning.
часть 3 — дисциплина обновления доверия
Чтобы наконец разобраться, как работает теорема Байеса, представим такое:
▫️ с утра 3 госслужащих — Ашп, Брю и Ван имели незащищённые встречи с посетителями, вероятность заражения при каждой отдельно — 37%
▫️ проведённые встречи: Ашп — 3, Брю — 2, Ван — 1
▫️ в посте выше уже рассчитаны вероятности для таких кейсов: 75, 60 и 37 процентов
▫️ после обеда они повезли отчёты к начальнику Жаку
▫️ Жак принял их по очереди, а также пересёкся с некоторыми дополнительно, образовав таким образом встречи
▫️ встречи Жака: с Ашпом — 1, с Брю — 2, с Ваном — аж 3 (разговорились возле микроволновки и даже в туалете)
▫️ "интенсивность" этих встреч была одинакова, к привезённым документам Жак не прикасался
😡 Стало известно, что Жак заразился в этот день. Других контактов у него не было. Жак заподозрил, что это именно Брю "виноват", ведь на вид был каким-то подуставшим.
Вопрос 1: Какова вероятность, что Брю заразил Жака?
Вопрос 2: Как изменится этот ответ, если станет известно, что Брю точно уже был заражен?
Вопрос 3: Как изменится ответ на вопрос 2, если станет известно, что Ашп точно ещё не был заражен?
🖼 Все ответы и логику их получения по Байесу постарался вместить на картинку. Ибо это одна из тех тем, которые надо визуализировать, чтобы понять.
💛 Тут при помощи выделения жёлтым показана сила этой формулы: любое изменение связанного фрагмента данных можно быстро наложить и пересчитать, и получим обновлённую общую картину. У нас повысится или понизится уровень доверия к выдвинутой гипотезе. Весьма удобно, когда таких связанных фрагментов очень много и мы загоняем их в компьютер, чтобы он считал всё это безобразие за нас.
P.S. Некоторые рационалисты отмечают, что ничего особенного здесь нет, что это просто дисциплина мышления. Как бы там ни было, на этом построено и пока что не разогнано грязными тряпками целое направление в Machine Learning.
{kind=link}
🐲 Жизнь юриста и теорема Байеса
попрактикуемся?
Давайте применим теорему Байеса теперь к юрпрактике, ведь "эпидемии приходят и уходят, а право вечно".
👩⚖️ Предположим, Аня — крутой адвокат в сфере корпоративного права. Она знает, что согласно открытым данным в государстве 5% зарегистрированных ТОВ (ООО) имеют налоговый долг (их Аня называет "фирмы-долгуны"). Также, проанализировав один лигалтек-сервис, Аня установила, что 40% "фирм-долгунов" имеют адрес массовой регистрации, тогда как для ТОВок без налогового долга это характерно лишь в 16% случаев.
Аня задумалась:
Когда я встречаю фирму с адресом массовой регистрации, то какова вероятность, что эта фирма имеет налоговый долг?
👇 Как думаете?
попрактикуемся?
Давайте применим теорему Байеса теперь к юрпрактике, ведь "эпидемии приходят и уходят, а право вечно".
👩⚖️ Предположим, Аня — крутой адвокат в сфере корпоративного права. Она знает, что согласно открытым данным в государстве 5% зарегистрированных ТОВ (ООО) имеют налоговый долг (их Аня называет "фирмы-долгуны"). Также, проанализировав один лигалтек-сервис, Аня установила, что 40% "фирм-долгунов" имеют адрес массовой регистрации, тогда как для ТОВок без налогового долга это характерно лишь в 16% случаев.
Аня задумалась:
Когда я встречаю фирму с адресом массовой регистрации, то какова вероятность, что эта фирма имеет налоговый долг?
👇 Как думаете?