
"Код, который пишется человеком, будет содержать человеческие ошибки."
👄 Например, делаете вы автоматический "цензор матов" (известен в народе как матфильтр) для своего проекта, где юзеры могут размещать свои тексты. И хотите литературное слово "суки" во всех падежах заменять на **** (для соблюдения неких приличий). Вот вам сразу три проблемы в этом благородном занятии.
1️⃣ По умолчанию заменяться будут не только обозначения собачек, но и веток:
"На торчащие снизу суки деревьев коммунальные службы должны обращать особое внимание".
Чтобы заставить компьютер перед бездумной заменой хотя бы с 80-процентной вероятностью определить заложенный автором смысл этого слова, нужно уже подключать более сложные алгоритмы — по сути NLP, и это отдельная тема.
2️⃣ Есть нюанс, когда вам нужно заставить алгоритм не заменять это буквосочетание в словах "сукалки" и "барсуки", но при этом заменять в ",суки", ".суки" без потери соответствующего знака. Это уже вопрос к регулярным выражениям, тоже отдельная тема.
3️⃣ Когда вы замените все формы этого слова (или, что ещё хуже, куски других слов) на ****, вы не сможете с полученным текстом проделать аналогичную операцию в обратном направлении, т.е. восстановить содержание. Это похоже на идею энтропии: смешав кетчуп и майонез, вы не сможете их разделить. Поэтому нужно позаботиться о том, чтобы сохранить в базе данных отдельно изначальную версию присланного текста и отдельно "очищенную".
🗣 На самом деле, тема NLP и регулярных выражений гораздо более связана с инновациями в праве, нежели в приведённом примере. Например, в работе с текстами судебных решений, на чём съел не одну собаку лигалтек-проект "Суд на долоні".
👄 Например, делаете вы автоматический "цензор матов" (известен в народе как матфильтр) для своего проекта, где юзеры могут размещать свои тексты. И хотите литературное слово "суки" во всех падежах заменять на **** (для соблюдения неких приличий). Вот вам сразу три проблемы в этом благородном занятии.
1️⃣ По умолчанию заменяться будут не только обозначения собачек, но и веток:
"На торчащие снизу суки деревьев коммунальные службы должны обращать особое внимание".
Чтобы заставить компьютер перед бездумной заменой хотя бы с 80-процентной вероятностью определить заложенный автором смысл этого слова, нужно уже подключать более сложные алгоритмы — по сути NLP, и это отдельная тема.
2️⃣ Есть нюанс, когда вам нужно заставить алгоритм не заменять это буквосочетание в словах "сукалки" и "барсуки", но при этом заменять в ",суки", ".суки" без потери соответствующего знака. Это уже вопрос к регулярным выражениям, тоже отдельная тема.
3️⃣ Когда вы замените все формы этого слова (или, что ещё хуже, куски других слов) на ****, вы не сможете с полученным текстом проделать аналогичную операцию в обратном направлении, т.е. восстановить содержание. Это похоже на идею энтропии: смешав кетчуп и майонез, вы не сможете их разделить. Поэтому нужно позаботиться о том, чтобы сохранить в базе данных отдельно изначальную версию присланного текста и отдельно "очищенную".
🗣 На самом деле, тема NLP и регулярных выражений гораздо более связана с инновациями в праве, нежели в приведённом примере. Например, в работе с текстами судебных решений, на чём съел не одну собаку лигалтек-проект "Суд на долоні".
🛠 Что такое лигалинженер?
часть 1 — постановка вопроса и LISS 2019
⌨️ Фокус этого канала всё так же — программирование для юристов. Большая часть постов должна быть посвящена кодингу, всяким техническим приёмам, концепциям, визуализациям алгоритмов в разрезе права. И вот я уже который месяц думаю, достаточно ли этого, чтобы стать лигалинженером?
⛰ В пятницу закончилась замечательная недельная Legal Innovations Summer School. Скоро опубликую свою рефлексию на Медиуме. Сейчас же можно глянуть пост Дениса Иванова, обзор Минюста и статью Loyer.
🏛 Это событие более чем косвенно связано с обучением лигалинженеров. Только представьте, что где-то в 2020-е годы на бакалаврате вашего ВУЗа будет дисциплина примерно с такими темами:
🔹 диджитализация права: практика и перспективы;
🔹 дизайн-мышление юриста;
🔹 чатботы в работе юриста: как создать и применить;
🔹 блокчейн в праве;
🔹 фандрейзинг и монетизация лигалтек-продуктов;
🔹 возможности нейросетей и теоремы Байеса в решении правовых задач;
🔹 предиктивная аналитика;
и т.д.
🛶 Ну прям идеальное начало для входа в эту нишевую профессию! Но станут ли выпускники такого бакалаврата лигалинженерами автоматически? Для начала нужно разобраться с этим термином. Поэтому хочу узнать ваше мнение:
▪️ может ли лигалинженер не уметь кодить вовсе?
▪️ как следует понимать частицу "-инженер" в этом термине? Как умение различать sql, js, py, css и применять хоть что-то из этого? Или как умение выстраивать работу фирмы/госоргана с CRM и чатботами? Или и то, и то?
Го обсуждать.
часть 1 — постановка вопроса и LISS 2019
⌨️ Фокус этого канала всё так же — программирование для юристов. Большая часть постов должна быть посвящена кодингу, всяким техническим приёмам, концепциям, визуализациям алгоритмов в разрезе права. И вот я уже который месяц думаю, достаточно ли этого, чтобы стать лигалинженером?
⛰ В пятницу закончилась замечательная недельная Legal Innovations Summer School. Скоро опубликую свою рефлексию на Медиуме. Сейчас же можно глянуть пост Дениса Иванова, обзор Минюста и статью Loyer.
🏛 Это событие более чем косвенно связано с обучением лигалинженеров. Только представьте, что где-то в 2020-е годы на бакалаврате вашего ВУЗа будет дисциплина примерно с такими темами:
🔹 диджитализация права: практика и перспективы;
🔹 дизайн-мышление юриста;
🔹 чатботы в работе юриста: как создать и применить;
🔹 блокчейн в праве;
🔹 фандрейзинг и монетизация лигалтек-продуктов;
🔹 возможности нейросетей и теоремы Байеса в решении правовых задач;
🔹 предиктивная аналитика;
и т.д.
🛶 Ну прям идеальное начало для входа в эту нишевую профессию! Но станут ли выпускники такого бакалаврата лигалинженерами автоматически? Для начала нужно разобраться с этим термином. Поэтому хочу узнать ваше мнение:
▪️ может ли лигалинженер не уметь кодить вовсе?
▪️ как следует понимать частицу "-инженер" в этом термине? Как умение различать sql, js, py, css и применять хоть что-то из этого? Или как умение выстраивать работу фирмы/госоргана с CRM и чатботами? Или и то, и то?
Го обсуждать.
Робот, как подать иск в хозяйственный суд?
🌠 Иногда кодинг представляется несколько романтизированно: ведь ты можешь создавать самостоятельные мирки, живущие по придуманным тобой законам. И, поддаваясь азарту, начинаешь мечтать о создании чего-то великого. Ну или хотя бы некоего виртуального помощника, распознающего твои вопросы и дающего релевантные ответы.
🏛 Например, задаёшь ты ему вопрос "Как подать иск в хозяйственный суд?", а он, не зная ответ напрямую, выдаёт структурированный ответ на базе соответствующих статей процессуального кодекса.
🛤 Однако, когда хочешь перейти от мечт к действию, задаёшься холодными вопросами "как это работает?", "с чего начать?". Ок, сделаем эскиз логики происходящего с человеческой точки зрения. В нашем мозгу это происходит очень быстро, а при алгоритмизации нужно уметь выделять и выстраивать стадии, где результат первой стадии становится отправной точкой (а иногда и ресурсами) для следующей и т.д.
1️⃣ Начинаем с того, чтобы детектировать сам вопрос (см. жёлтые стрелки на картинке). Можем презюмировать, что в конце вопроса стоит "?". Конечно, бывает всякое, но мы пока что тяжёлые случаи опустим.
2️⃣ Далее нужно установить тип вопроса ("как", "что", "где", "когда", "истинно ли" и т.д.), т.е. какой род данных вопрошающий хочет получить ("способ", "объект", "место", "время", "да/нет" и т.д.). (см. жёлтые стрелки на картинке)
3️⃣ Теперь нужно установить наличие и характер данных в самом вопросе. То есть тупо распознать слова. В нашем случае это "подать", "иск", "в", "хозяйственный", "суд".
4️⃣ Ищем связи между словами, выявляя термины и отношения между ними. Здесь должно стать ясно, что:
🔸 "подать иск" — это целостное действие (правовой термин),
🔸 "хозяйственный суд" — целостное явление (правовой термин),
🔸 "в" связывает действие с явлением (образуя правовую ситуацию).
На этой стадии нужно исходить из типа языка. Например, украинский и русский — это синтетические языки, а английский — преимущественно аналитический. Работа с ними строится по-разному. Хотя на картинке видно, что конечная цель вполне достижима для обоих типов.
5️⃣ Теперь идём к общего к частному. Если презюмируем, что ответ на вопрос должен браться из законодательства, ищем там. "хозяйственный суд" + "иск" должны вывести нас (например, чисто контекстуально) на конкретный кодекс (для начала берём его как наиболее "сильный" и обширный источник), действие "подать иск" — на его конкретные главы, а тип вопроса вместе с выявленной нами правовой ситуацией позволяет сфокусироваться на двух нужных статьях (для полноты ответа можно задействовать и статью 170). Градус сложности происходящего тут резко возрастает, ведь компьютер должен, по сути, сопоставить смыслы в вопросе и в тексте закона, выявить соотвествие между ними. Если текст закона не был предварительно размечен, то тут начинается грязное NLP. И здесь теоретически можно испытать несколько алгоритмов машинного обучения, с разными особенностями. Но вам придётся решить, будет компьютер мыслить категориями вероятностей (например, при помощи нейросетей или теоремы Байеса) или же будет ездить по дедуктивным рельсам, упираясь в тупики лингвистической неопределённости.
6️⃣ Далее начинается ещё более утончённая процедура, которая не уместится в этот пост. Ведь мы хотим получить не просто текст статей, а структурированный ответ, не так ли?
Продолжать эту тему? 🧐
🌠 Иногда кодинг представляется несколько романтизированно: ведь ты можешь создавать самостоятельные мирки, живущие по придуманным тобой законам. И, поддаваясь азарту, начинаешь мечтать о создании чего-то великого. Ну или хотя бы некоего виртуального помощника, распознающего твои вопросы и дающего релевантные ответы.
🏛 Например, задаёшь ты ему вопрос "Как подать иск в хозяйственный суд?", а он, не зная ответ напрямую, выдаёт структурированный ответ на базе соответствующих статей процессуального кодекса.
🛤 Однако, когда хочешь перейти от мечт к действию, задаёшься холодными вопросами "как это работает?", "с чего начать?". Ок, сделаем эскиз логики происходящего с человеческой точки зрения. В нашем мозгу это происходит очень быстро, а при алгоритмизации нужно уметь выделять и выстраивать стадии, где результат первой стадии становится отправной точкой (а иногда и ресурсами) для следующей и т.д.
1️⃣ Начинаем с того, чтобы детектировать сам вопрос (см. жёлтые стрелки на картинке). Можем презюмировать, что в конце вопроса стоит "?". Конечно, бывает всякое, но мы пока что тяжёлые случаи опустим.
2️⃣ Далее нужно установить тип вопроса ("как", "что", "где", "когда", "истинно ли" и т.д.), т.е. какой род данных вопрошающий хочет получить ("способ", "объект", "место", "время", "да/нет" и т.д.). (см. жёлтые стрелки на картинке)
3️⃣ Теперь нужно установить наличие и характер данных в самом вопросе. То есть тупо распознать слова. В нашем случае это "подать", "иск", "в", "хозяйственный", "суд".
4️⃣ Ищем связи между словами, выявляя термины и отношения между ними. Здесь должно стать ясно, что:
🔸 "подать иск" — это целостное действие (правовой термин),
🔸 "хозяйственный суд" — целостное явление (правовой термин),
🔸 "в" связывает действие с явлением (образуя правовую ситуацию).
На этой стадии нужно исходить из типа языка. Например, украинский и русский — это синтетические языки, а английский — преимущественно аналитический. Работа с ними строится по-разному. Хотя на картинке видно, что конечная цель вполне достижима для обоих типов.
5️⃣ Теперь идём к общего к частному. Если презюмируем, что ответ на вопрос должен браться из законодательства, ищем там. "хозяйственный суд" + "иск" должны вывести нас (например, чисто контекстуально) на конкретный кодекс (для начала берём его как наиболее "сильный" и обширный источник), действие "подать иск" — на его конкретные главы, а тип вопроса вместе с выявленной нами правовой ситуацией позволяет сфокусироваться на двух нужных статьях (для полноты ответа можно задействовать и статью 170). Градус сложности происходящего тут резко возрастает, ведь компьютер должен, по сути, сопоставить смыслы в вопросе и в тексте закона, выявить соотвествие между ними. Если текст закона не был предварительно размечен, то тут начинается грязное NLP. И здесь теоретически можно испытать несколько алгоритмов машинного обучения, с разными особенностями. Но вам придётся решить, будет компьютер мыслить категориями вероятностей (например, при помощи нейросетей или теоремы Байеса) или же будет ездить по дедуктивным рельсам, упираясь в тупики лингвистической неопределённости.
6️⃣ Далее начинается ещё более утончённая процедура, которая не уместится в этот пост. Ведь мы хотим получить не просто текст статей, а структурированный ответ, не так ли?
Продолжать эту тему? 🧐
{kind=link}
🖇 Машиночтение немашиночитабельного закона
часть 2: наша первая гипотеза
Итак, давайте подумаем: чему нужно научить робота, чтобы он на поставленный вопрос готовил структурированный, не перегруженный лишней информацией ответ из статей закона?
Не погружаясь в теорию и опыт компьютерной лингвистики (мы же хотим научиться алгоритмизировать, а не брать готовые решения?), предположим следующее:
🔹 Нужно выделять в тексте предложения (sentences) и оценивать их. В законодательстве предложение часто содержит некоторую идею (ситуацию, правоотношение, право, обязанность и т.д.), и выше среднего вероятность, что следующее предложение будет содержать уже другую идею. Робот должен оценивать каждое предложение отдельно. И не выдавать те предложения, которые "не подходят".
🔹 В каждом предложении нужно найти слова (и их производные формы), которые присутствуют в поставленном вопросе. Например, для нашего вопроса "як подати позов до господарського суду" это будут такие формы:
▫️ подати, подавати (можно добавить ещё подав [позивач], подала [особа]);
▫️ подання, поданню, поданням, поданні;
▫️ позов, позову, позовом, позові;
▫️ суд, суду, судом, суді.
Для полноты анализа можно ещё докинуть это:
▫️ позовний, позовного, позовному, позовним + позовна, позовної, позовній, позовну, позовною + позовне;
🔹 Что касается слова "господарський", то искать его здесь не надо (если мы уже находимся в нужном процессуальном кодексе). То есть на более ранней стадии нужно было заключить, что это слово является определяющим для выбора закона, но не выбора норм в нём. Служебные слова "як" и "до" мы пока тоже опустим.
Ну а дальше можно действовать по-разному. Простенький подход, который первый пришёл в голову — тупо подсчитать найденные слова/корни в предложениях, и выбрать предложения, где находок больше.
Сработает ли это? 🧐
1. Это наша гипотеза (предположение, надежда, ожидание и т.д.).
2. Значит, её нужно проверить.
3. Значит, напишем алгоритм, который поможет её проверить (ну или хотя бы оценить конкретно в этом кейсе).
Кодинг мне нравится тем, что любую дурную мысль, если она поддаётся логическому изложению, можно проверить на практике и даже извлечь из неё пользу.
Оставайтесь с нами. 🎷
часть 2: наша первая гипотеза
Итак, давайте подумаем: чему нужно научить робота, чтобы он на поставленный вопрос готовил структурированный, не перегруженный лишней информацией ответ из статей закона?
Не погружаясь в теорию и опыт компьютерной лингвистики (мы же хотим научиться алгоритмизировать, а не брать готовые решения?), предположим следующее:
🔹 Нужно выделять в тексте предложения (sentences) и оценивать их. В законодательстве предложение часто содержит некоторую идею (ситуацию, правоотношение, право, обязанность и т.д.), и выше среднего вероятность, что следующее предложение будет содержать уже другую идею. Робот должен оценивать каждое предложение отдельно. И не выдавать те предложения, которые "не подходят".
🔹 В каждом предложении нужно найти слова (и их производные формы), которые присутствуют в поставленном вопросе. Например, для нашего вопроса "як подати позов до господарського суду" это будут такие формы:
▫️ подати, подавати (можно добавить ещё подав [позивач], подала [особа]);
▫️ подання, поданню, поданням, поданні;
▫️ позов, позову, позовом, позові;
▫️ суд, суду, судом, суді.
Для полноты анализа можно ещё докинуть это:
▫️ позовний, позовного, позовному, позовним + позовна, позовної, позовній, позовну, позовною + позовне;
🔹 Что касается слова "господарський", то искать его здесь не надо (если мы уже находимся в нужном процессуальном кодексе). То есть на более ранней стадии нужно было заключить, что это слово является определяющим для выбора закона, но не выбора норм в нём. Служебные слова "як" и "до" мы пока тоже опустим.
Ну а дальше можно действовать по-разному. Простенький подход, который первый пришёл в голову — тупо подсчитать найденные слова/корни в предложениях, и выбрать предложения, где находок больше.
Сработает ли это? 🧐
1. Это наша гипотеза (предположение, надежда, ожидание и т.д.).
2. Значит, её нужно проверить.
3. Значит, напишем алгоритм, который поможет её проверить (ну или хотя бы оценить конкретно в этом кейсе).
Кодинг мне нравится тем, что любую дурную мысль, если она поддаётся логическому изложению, можно проверить на практике и даже извлечь из неё пользу.
Оставайтесь с нами. 🎷
🖇 Машиночтение немашиночитабельного закона
часть 3: проверка первой гипотезы
🎯 Итак, я начал проверять гипотезу на практике. Сначала предельно уточнил её, что важно технически:
"Ожидается, что ответом на поставленный вопрос будет предложение, которое содержит как минимум по одному слову, принадлежащему каждой из трёх групп слов, состоящих из неслужебных слов в поставленном вопросе и некоторых производных от них (далее — ключевые слова)".
🍽 Далее готовлю алгоритм:
1. Скопировал текст кодекса в переменную.
2. Сделал три массива для каждого из ключевых слов вопроса. Это нужно, чтобы удостовериться, что в найденном предложении есть как минимум по одному слову из каждой "словесной группы". Дополнительно добавил форму "подається", так как в этом состоянии глаголы часто используются в текстах законов.
3. Для определения "границы предложения" использую регулярку /(?<=\D)\./. То есть наш робот будет считать, что точка стоит в конце предложения, если перед ней находятся "нецифры". Это грубое допущение, но для наших целей пока сойдёт. ?<= — это квантификатор, о них надо будет рассказать отдельно.
4. Для поиска ключевых слов использую паттерн регулярки '(?<![а-яіїє])'+текущее слово+'(?![а-яіїє])'.
🎳 Наметим KPI для алгоритма:
1. обязательно (на мой взгляд) должен найти предложения из ч. 1 ст. 171, ч. 1 ст. 172, ч. 2, 3 ст. 162, ч. 1, 2 ст. 164 ХПК Украины;
2. допускаются находки других предложений по теме, например из ч. 1 ст. 173, ч. 3, 5 ст. 164;
3. не должно найти ничего лишнего.
Алгоритм нашёл 46 предложений, которые удовлетворяют требованиям гипотезы.
🔬 Оценим по нашему KPI:
1.1. алгоритм нашёл:
ч. 2 ст. 162 (№28 в списке находок), ч. 3 ст. 162 (№ 29), ч. 1 ст. 171 (№ 30)
1.2. алгоритм не нашёл:
ч. 1 ст. 172, ч. 1, 2 ст. 164.
2. дополнительных полезных находок нет.
3. алгоритм нашёл много лишнего, а именно 43 предложения.
🧪 Делаем вывод. Эта гипотеза:
1) недостаточно точна, ведь алгоритм нашёл примерно половину из искомого;
2) поверхностна, ведь намеченный "критерий ответоспособности" слабо соотносится со смыслом искомого.
🙂 Для тех, кто дочитал сюда: протестировать прототип можно ЗДЕСЬ.
🤷♂️ Примерно так и выглядят некоторые лигалтек-эксперименты. Имею некоторые идеи, как эту гипотезу улучшить. А что думаете вы? Продолжать эту тему?
часть 3: проверка первой гипотезы
🎯 Итак, я начал проверять гипотезу на практике. Сначала предельно уточнил её, что важно технически:
"Ожидается, что ответом на поставленный вопрос будет предложение, которое содержит как минимум по одному слову, принадлежащему каждой из трёх групп слов, состоящих из неслужебных слов в поставленном вопросе и некоторых производных от них (далее — ключевые слова)".
🍽 Далее готовлю алгоритм:
1. Скопировал текст кодекса в переменную.
2. Сделал три массива для каждого из ключевых слов вопроса. Это нужно, чтобы удостовериться, что в найденном предложении есть как минимум по одному слову из каждой "словесной группы". Дополнительно добавил форму "подається", так как в этом состоянии глаголы часто используются в текстах законов.
3. Для определения "границы предложения" использую регулярку /(?<=\D)\./. То есть наш робот будет считать, что точка стоит в конце предложения, если перед ней находятся "нецифры". Это грубое допущение, но для наших целей пока сойдёт. ?<= — это квантификатор, о них надо будет рассказать отдельно.
4. Для поиска ключевых слов использую паттерн регулярки '(?<![а-яіїє])'+текущее слово+'(?![а-яіїє])'.
🎳 Наметим KPI для алгоритма:
1. обязательно (на мой взгляд) должен найти предложения из ч. 1 ст. 171, ч. 1 ст. 172, ч. 2, 3 ст. 162, ч. 1, 2 ст. 164 ХПК Украины;
2. допускаются находки других предложений по теме, например из ч. 1 ст. 173, ч. 3, 5 ст. 164;
3. не должно найти ничего лишнего.
Алгоритм нашёл 46 предложений, которые удовлетворяют требованиям гипотезы.
🔬 Оценим по нашему KPI:
1.1. алгоритм нашёл:
ч. 2 ст. 162 (№28 в списке находок), ч. 3 ст. 162 (№ 29), ч. 1 ст. 171 (№ 30)
1.2. алгоритм не нашёл:
ч. 1 ст. 172, ч. 1, 2 ст. 164.
2. дополнительных полезных находок нет.
3. алгоритм нашёл много лишнего, а именно 43 предложения.
🧪 Делаем вывод. Эта гипотеза:
1) недостаточно точна, ведь алгоритм нашёл примерно половину из искомого;
2) поверхностна, ведь намеченный "критерий ответоспособности" слабо соотносится со смыслом искомого.
🙂 Для тех, кто дочитал сюда: протестировать прототип можно ЗДЕСЬ.
🤷♂️ Примерно так и выглядят некоторые лигалтек-эксперименты. Имею некоторые идеи, как эту гипотезу улучшить. А что думаете вы? Продолжать эту тему?
✂️ Зачем юристам регулярки?
На тему регулярок здесь ещё не было постов, только упоминания: №1, №2. И перед тем, как продолжить нашу тему, хочу остановиться на них подробнее.
🏛 Представьте, что вам нужно просмотреть в кодексе все предложения со словом "суд", но при этом вас не интересуют такие слова, как "судебный", "досудебный" и т.д. Что бы мы сделали, используя стандартный Ctrl+F?
Первое, что приходит в голову — искать по каждому падежу отдельно, но с нюансами:
1) именительный и винительный — "суд " (с пробелом, чтобы избежать "судебный" и "досудебный");
2) родительный — "суда";
3) дательный — "суду";
4) творительный — "судом";
5) предложный — "суде " (с пробелом, чтобы избежать "судебный" и "досудебный").
🎢 То есть 5 раз мы меняем слово и проходим по всему тексту. А затем осознаём, что слово "суд" и "суде" могут также находиться не только перед пробелом, а и перед точкой (.), запятой (,), точкой с запятой (;) и двоеточием (:). И вместо 5 прохождений получаем 13: наши 5 + "суд.", "суд,", "суд;", "суд:" + "суде.", "суде,", "суде;", "суде:".
Гемор? Гемор. И вот тут появляются регулярки.
Вот как сделать то же самое всего за один раз:
✂️ /((суд|суде)(\s|\.|,|;|:)|суда|суду|судом)/gi
Или даже так:
✂️ /(?<![а-яєіїґ])суд(|а|у|ом|е)(?![а-яєіїґ])/gi
Вторая регулярка круче тем, что не пропустит слово "судомы". Но она может работать не во всех браузерах. Однако можно и первую допилить для этого.
📕 Сделал для вас такой справочник на базе слова "суд":
https://legaltech.org.ua/legalcode/regexp
На тему регулярок здесь ещё не было постов, только упоминания: №1, №2. И перед тем, как продолжить нашу тему, хочу остановиться на них подробнее.
🏛 Представьте, что вам нужно просмотреть в кодексе все предложения со словом "суд", но при этом вас не интересуют такие слова, как "судебный", "досудебный" и т.д. Что бы мы сделали, используя стандартный Ctrl+F?
Первое, что приходит в голову — искать по каждому падежу отдельно, но с нюансами:
1) именительный и винительный — "суд " (с пробелом, чтобы избежать "судебный" и "досудебный");
2) родительный — "суда";
3) дательный — "суду";
4) творительный — "судом";
5) предложный — "суде " (с пробелом, чтобы избежать "судебный" и "досудебный").
🎢 То есть 5 раз мы меняем слово и проходим по всему тексту. А затем осознаём, что слово "суд" и "суде" могут также находиться не только перед пробелом, а и перед точкой (.), запятой (,), точкой с запятой (;) и двоеточием (:). И вместо 5 прохождений получаем 13: наши 5 + "суд.", "суд,", "суд;", "суд:" + "суде.", "суде,", "суде;", "суде:".
Гемор? Гемор. И вот тут появляются регулярки.
Вот как сделать то же самое всего за один раз:
✂️ /((суд|суде)(\s|\.|,|;|:)|суда|суду|судом)/gi
Или даже так:
✂️ /(?<![а-яєіїґ])суд(|а|у|ом|е)(?![а-яєіїґ])/gi
Вторая регулярка круче тем, что не пропустит слово "судомы". Но она может работать не во всех браузерах. Однако можно и первую допилить для этого.
📕 Сделал для вас такой справочник на базе слова "суд":
https://legaltech.org.ua/legalcode/regexp
{kind=link}
🖇 Машиночтение немашиночитабельного закона
часть 4: углубление гипотезы и проверка
Как можно развить гипотезу и улучшить лежащее в её основе решение? Надо рассмотреть, чем же отличаются "подходящие" и "неподходящие" предложения, а именно — за какое отличие между ними можно зацепиться технически. И оно есть: в "подходящих" предложениях ключевые слова расположены взаимно ближе.
🏃♂️ Введём условный термин – "расстояние".
В предложении "Суд работает до обеда":
1) слово "суд" находится на расстоянии 1 до слова "работает", на расстоянии 3 до слова "обеда";
2) и наоборот, слово "обеда" находится на расстоянии 3 до слова "суд".
Итак, я выдвигаю новую гипотезу:
Предложение, возможно, подходит тогда, когда ключевые слова находятся на расстоянии не более 5 друг от друга (далее — max_distance).
Проверяем. Для этого я усовершенствовал прототип, добавив блок кода с такой логикой:
1) взять предложение, в котором есть все 3 ключевые слова (напомню, в прошлый раз этих предложений вышло 46);
2) убрать из него знаки препинания и превратить его в массив слов, используя метод .split(" ");
3) пройтись циклом по массиву и зафиксировать позиции, на которых находятся ключевые слова данного предложения;
4) вычислить расстояния между всеми словами (а именно между 1-м и 2-м, 2-м и 3-м, 1-м и 3-м), отрицательные значения фиксим функцией Math.abs();
5) если все три расстояния меньше нашей константы max_distance, тогда это предложение выводим в список результатов.
Результатов вышло 4. Среди них был только один однозначно желанный. Но среди трёх других были нормы насчёт обеспечения иска ("забезпечення позову"), что близко к тематике поставленного вопроса.
Увеличил max_distance с 5 до 7. Результатов стало 9, и среди них появился второй однозначно желанный. Остальные также касаются обеспечения иска.
Неидеально, но уже ощутимо лучше. Вот прототип.
часть 4: углубление гипотезы и проверка
Как можно развить гипотезу и улучшить лежащее в её основе решение? Надо рассмотреть, чем же отличаются "подходящие" и "неподходящие" предложения, а именно — за какое отличие между ними можно зацепиться технически. И оно есть: в "подходящих" предложениях ключевые слова расположены взаимно ближе.
🏃♂️ Введём условный термин – "расстояние".
В предложении "Суд работает до обеда":
1) слово "суд" находится на расстоянии 1 до слова "работает", на расстоянии 3 до слова "обеда";
2) и наоборот, слово "обеда" находится на расстоянии 3 до слова "суд".
Итак, я выдвигаю новую гипотезу:
Предложение, возможно, подходит тогда, когда ключевые слова находятся на расстоянии не более 5 друг от друга (далее — max_distance).
Проверяем. Для этого я усовершенствовал прототип, добавив блок кода с такой логикой:
1) взять предложение, в котором есть все 3 ключевые слова (напомню, в прошлый раз этих предложений вышло 46);
2) убрать из него знаки препинания и превратить его в массив слов, используя метод .split(" ");
3) пройтись циклом по массиву и зафиксировать позиции, на которых находятся ключевые слова данного предложения;
4) вычислить расстояния между всеми словами (а именно между 1-м и 2-м, 2-м и 3-м, 1-м и 3-м), отрицательные значения фиксим функцией Math.abs();
5) если все три расстояния меньше нашей константы max_distance, тогда это предложение выводим в список результатов.
Результатов вышло 4. Среди них был только один однозначно желанный. Но среди трёх других были нормы насчёт обеспечения иска ("забезпечення позову"), что близко к тематике поставленного вопроса.
Увеличил max_distance с 5 до 7. Результатов стало 9, и среди них появился второй однозначно желанный. Остальные также касаются обеспечения иска.
Неидеально, но уже ощутимо лучше. Вот прототип.
{kind=link}
🖇 Машиночтение немашиночитабельного закона
часть 5: проверка гипотезы на другом кейсе
Чтобы более полно оценить наш алгоритм/гипотезу, надо задать другие вопросы. То есть тестировать нужно на материале, который не участвовал в разработке. Итак, поехали.
1️⃣ Вопрос "Що таке судовий збір?" — тут из неслужебных слов ненаписанная мной часть программы должна выделить два массива:
1) "збір", "збору", "збором", "зборі";
2) "судовий", "судового", "судовому", "судовим".
Итог — 32 находки, во всех фигурирует термин "судовий збір". По сути, нашло всё подряд, без приоритезации.
2️⃣ Перенесёмся теперь в уголовный кодекс, зададим вопрос "Розкажи про службове становище". Тут из неслужебных слов ненаписанная мной часть программы должна выделить два массива:
1) "службове", "службового", "службовому", "службовим";
2) "становище", "становища", "становищу", "становищем", "становищі".
Итог — 26 находок. Аналогично, всё подряд.
🤷♂️ По сути, мы получили удобный аналог спаму "Ctrl+F" по всем падежам. И здесь нет "сознательного" подхода к логике вопроса. Это требует дополнительных усилий. Например, когда вопрос содержит структуры "что такое XYZ ?" или "как следует понимать XYZ ?", то нужно выводить не просто предложения, содержащие вариации XYZ. А в первую очередь те предложения, которые содержат дефиницию или в которых иным образом описываются признаки XYZ.
Как это сделать? Ну, например, в первую очередь ориентироваться на предложения, где XYZ стоит в именительном падеже в начале предложения или в начале строки большого предложения-перечня (как это бывает в законах). Но а если юзер задаст вопрос, где неправильно употребит правовой термин? Например, вместо "судебный сбор" напишет "судебная дань"? Будет ноль результатов. Так что эту модель можно дорабатывать и дорабатывать.
💡 Думаю, у вас появилось представление, как своими руками можно экспериментировать (говнокодить) с "правовой лингвистикой". Сделаю ещё один пост о ней и наконец "сменю пластинку". 🙂
часть 5: проверка гипотезы на другом кейсе
Чтобы более полно оценить наш алгоритм/гипотезу, надо задать другие вопросы. То есть тестировать нужно на материале, который не участвовал в разработке. Итак, поехали.
1️⃣ Вопрос "Що таке судовий збір?" — тут из неслужебных слов ненаписанная мной часть программы должна выделить два массива:
1) "збір", "збору", "збором", "зборі";
2) "судовий", "судового", "судовому", "судовим".
Итог — 32 находки, во всех фигурирует термин "судовий збір". По сути, нашло всё подряд, без приоритезации.
2️⃣ Перенесёмся теперь в уголовный кодекс, зададим вопрос "Розкажи про службове становище". Тут из неслужебных слов ненаписанная мной часть программы должна выделить два массива:
1) "службове", "службового", "службовому", "службовим";
2) "становище", "становища", "становищу", "становищем", "становищі".
Итог — 26 находок. Аналогично, всё подряд.
🤷♂️ По сути, мы получили удобный аналог спаму "Ctrl+F" по всем падежам. И здесь нет "сознательного" подхода к логике вопроса. Это требует дополнительных усилий. Например, когда вопрос содержит структуры "что такое XYZ ?" или "как следует понимать XYZ ?", то нужно выводить не просто предложения, содержащие вариации XYZ. А в первую очередь те предложения, которые содержат дефиницию или в которых иным образом описываются признаки XYZ.
Как это сделать? Ну, например, в первую очередь ориентироваться на предложения, где XYZ стоит в именительном падеже в начале предложения или в начале строки большого предложения-перечня (как это бывает в законах). Но а если юзер задаст вопрос, где неправильно употребит правовой термин? Например, вместо "судебный сбор" напишет "судебная дань"? Будет ноль результатов. Так что эту модель можно дорабатывать и дорабатывать.
💡 Думаю, у вас появилось представление, как своими руками можно экспериментировать (говнокодить) с "правовой лингвистикой". Сделаю ещё один пост о ней и наконец "сменю пластинку". 🙂
🖇 Машиночтение немашиночитабельного закона
часть 6: трюк нечтения закона
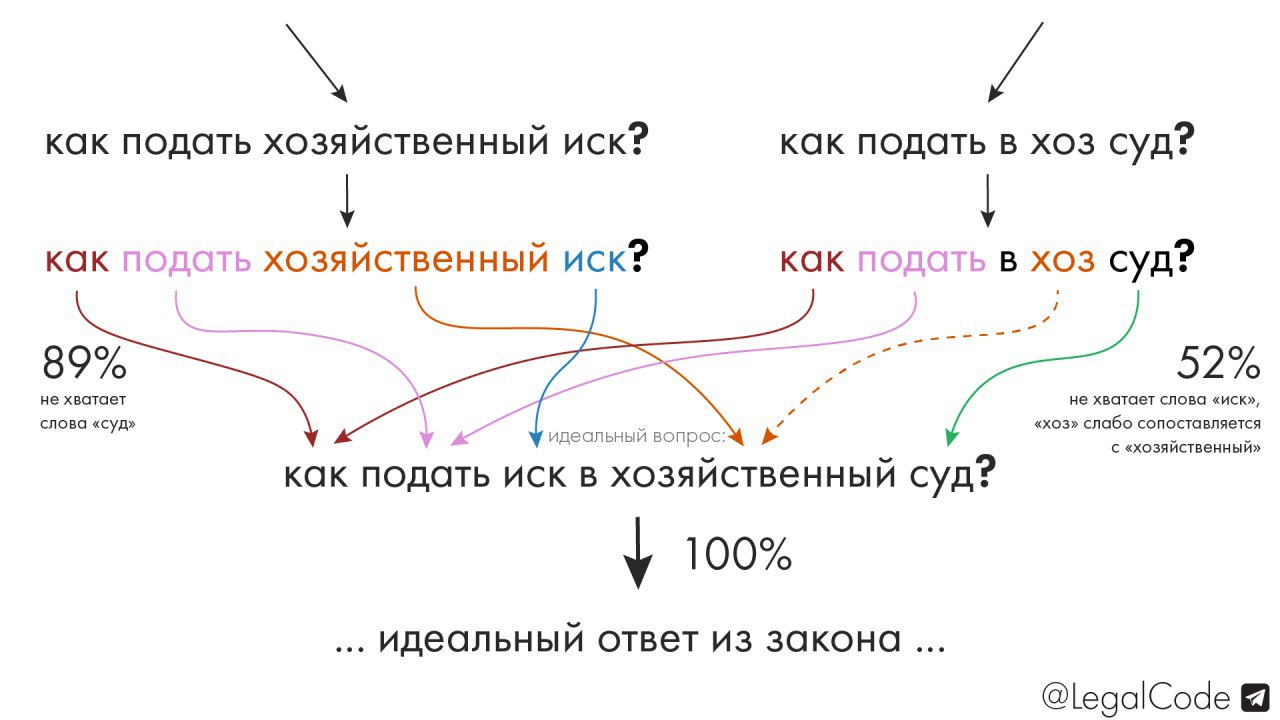
Пять предыдущих постов связаны с попытками, не сильно напрягаясь, сопоставить лексикон вопроса с лексиконом закона, чтобы выдать нормы, более-менее годящиеся в качестве ответа. Но при постройке подобной "экспертной" системы можно также прибегнуть к одной хитрости.
1️⃣ Вручную "размечаем" кодекс, связывая часто задаваемые вопросы с его текстом.
2️⃣ Таким образом, у нас появляется, условно, 200 идеально построенных вопросов, и у каждого есть свой идеально подходящий ответ.
3️⃣ Вопросы, которые приходят от юзера, сопоставляем не с текстом кодекса, а с нашими "идеальными" вопросами. Ведь гораздо проще эффективно сравнить два вопроса, чем вопрос с законом. Можно высчитывать некий "индекс соответствия", в процентах.
Подробнее моя мысль — на картинке.
Прототип делать не стал, у них мало просмотров 🙂.
часть 6: трюк нечтения закона
Пять предыдущих постов связаны с попытками, не сильно напрягаясь, сопоставить лексикон вопроса с лексиконом закона, чтобы выдать нормы, более-менее годящиеся в качестве ответа. Но при постройке подобной "экспертной" системы можно также прибегнуть к одной хитрости.
1️⃣ Вручную "размечаем" кодекс, связывая часто задаваемые вопросы с его текстом.
2️⃣ Таким образом, у нас появляется, условно, 200 идеально построенных вопросов, и у каждого есть свой идеально подходящий ответ.
3️⃣ Вопросы, которые приходят от юзера, сопоставляем не с текстом кодекса, а с нашими "идеальными" вопросами. Ведь гораздо проще эффективно сравнить два вопроса, чем вопрос с законом. Можно высчитывать некий "индекс соответствия", в процентах.
Подробнее моя мысль — на картинке.
Прототип делать не стал, у них мало просмотров 🙂.
{kind=link}
🦆 DRY: почему код похож на договор, а договор — на код
Представьте, что вы пишете договор и, подобно градостроителю, считаете, что чем больше, тем лучше. В какой-то момент может дойти даже до того, что что сроки поставки товара будут предусмотрены аж в двух местах. Потом ваш договор попадает к кому-то ещё (или к вам же, но спустя полгода). Вы или ваша жертва меняете срок только в одном месте, не вычитываете договор полностью, и в нём появляется противоречие, которое на практике может вылиться во всякое. В кодинге происходит то же самое, только можно получить катастрофические ошибки и уязвимости.
🦠 Это и есть нарушение принципа DRY — don’t repeat yourself.
Классическая формула: "Каждая часть знания должна иметь единственное, непротиворечивое и авторитетное представление в рамках системы".
Вот несколько его тезисов, которые подходят как для программирования, так и для юриспруденции (от маленьких договорчиков до крупнейших кодексов):
🔹 Нужно делить систему на управляемые по отдельности части (код на функции/методы, договор на автономные пункты, закон на отдельные статьи/разделы).
🔹 Делить можно до тех пор, пока отдельная часть не будет отвечать за отдельное действие (в коде отдельная функция/метод для конкретного действия, в законе отдельная статья или норма для конкретного вопроса).
🔹 Каждая отдельная часть должна описывать некий смысл (часть информации) достаточно "авторитетно", чтобы не приходилось продолжать её описание где-то за его пределами. То есть не стоит бросать огрызок дефиниции в начале закона/договора, чтобы заканчивать её где-то в Особой части.
🔹 Каждый смысл (часть информации) должен встречаться лишь один раз! Если нужно использовать какую-то идею по-разному, то стоит в одном месте прописать её таким образом, чтобы допустить использование нужной степени разности. В кодинге это достигается путём передачи параметров в функцию (см. пример на картинке). В законодательстве — учимся мыслить системно, править косяки прошлого и не повторяться. В договоре — ну камон, длина — не признак мастерства. В канале Юрня... вам это докажут.
Вдохновение черпал здесь.
Представьте, что вы пишете договор и, подобно градостроителю, считаете, что чем больше, тем лучше. В какой-то момент может дойти даже до того, что что сроки поставки товара будут предусмотрены аж в двух местах. Потом ваш договор попадает к кому-то ещё (или к вам же, но спустя полгода). Вы или ваша жертва меняете срок только в одном месте, не вычитываете договор полностью, и в нём появляется противоречие, которое на практике может вылиться во всякое. В кодинге происходит то же самое, только можно получить катастрофические ошибки и уязвимости.
🦠 Это и есть нарушение принципа DRY — don’t repeat yourself.
Классическая формула: "Каждая часть знания должна иметь единственное, непротиворечивое и авторитетное представление в рамках системы".
Вот несколько его тезисов, которые подходят как для программирования, так и для юриспруденции (от маленьких договорчиков до крупнейших кодексов):
🔹 Нужно делить систему на управляемые по отдельности части (код на функции/методы, договор на автономные пункты, закон на отдельные статьи/разделы).
🔹 Делить можно до тех пор, пока отдельная часть не будет отвечать за отдельное действие (в коде отдельная функция/метод для конкретного действия, в законе отдельная статья или норма для конкретного вопроса).
🔹 Каждая отдельная часть должна описывать некий смысл (часть информации) достаточно "авторитетно", чтобы не приходилось продолжать её описание где-то за его пределами. То есть не стоит бросать огрызок дефиниции в начале закона/договора, чтобы заканчивать её где-то в Особой части.
🔹 Каждый смысл (часть информации) должен встречаться лишь один раз! Если нужно использовать какую-то идею по-разному, то стоит в одном месте прописать её таким образом, чтобы допустить использование нужной степени разности. В кодинге это достигается путём передачи параметров в функцию (см. пример на картинке). В законодательстве — учимся мыслить системно, править косяки прошлого и не повторяться. В договоре — ну камон, длина — не признак мастерства. В канале Юрня... вам это докажут.
Вдохновение черпал здесь.
{kind=link}
💋 KISS: принцип простоты в праве и кодинге
Представьте, что пишете закон или большой договор. Возможно, у вас есть опыт написания научных работ с универских годов. И, помня всё это торжество мыследействия, вы и здесь хотите подойти фундаментально, доктринально. Построить сложную систему, словно собор, со множеством перегородок и форм. Но при этом надо помнить о простоте.
⛏ Простое проще понять.
⛏ С простым проще работать.
⛏ Простое хорошо работает.
⛏ Простое не противоречит самому себе.
⛏ Простое надёжно.
Вариаций расшифровки принципа KISS несколько, мне наиболее нравится эта:
"keep it short and simple".
Но в законах с простотой есть нюансы: иногда слишком простые/короткие слова/формулировки могут усложнить правоприменение. И в договорах от недосказанности, чрезмерных упрощений могут возникнуть проблемы. Приходится балансировать. Одно из проявлений искажения баланса — небезыствестная в наших кругах юрня.
В кодинге же проще понять суть полезной простоты.
Код императивен.
Выполняется каждая написанная строчка.
Должно быть написано то, что ведёт к цели, и не более.
Глобальная задача должна быть разбита на легко осознаваемые подзадачи.
Подзадача хорошо осознаваема, если её можно описать предложением до 7-10 слов. Например: "очищаю переменную от двойных пробелов", "записываю действие юзера в лог-файл".
Должны быть задействованы те инструменты, которых достаточно для выполнения задачи. Не нужно убивать муху гранатой.
Пример:
Если вам нужно записать в переменную "да" или "нет", то лучше взять булевый тип (true/false), чем писать в строковой переменной "yes" или "no". И уж тем более, не использовать для этого отдельный массив ("мерзость какая", — подумают сейчас некоторые подписчики).
Но с принципом простоты не всё так просто, поэтому будет ещё пост.
Представьте, что пишете закон или большой договор. Возможно, у вас есть опыт написания научных работ с универских годов. И, помня всё это торжество мыследействия, вы и здесь хотите подойти фундаментально, доктринально. Построить сложную систему, словно собор, со множеством перегородок и форм. Но при этом надо помнить о простоте.
⛏ Простое проще понять.
⛏ С простым проще работать.
⛏ Простое хорошо работает.
⛏ Простое не противоречит самому себе.
⛏ Простое надёжно.
Вариаций расшифровки принципа KISS несколько, мне наиболее нравится эта:
"keep it short and simple".
Но в законах с простотой есть нюансы: иногда слишком простые/короткие слова/формулировки могут усложнить правоприменение. И в договорах от недосказанности, чрезмерных упрощений могут возникнуть проблемы. Приходится балансировать. Одно из проявлений искажения баланса — небезыствестная в наших кругах юрня.
В кодинге же проще понять суть полезной простоты.
Код императивен.
Выполняется каждая написанная строчка.
Должно быть написано то, что ведёт к цели, и не более.
Глобальная задача должна быть разбита на легко осознаваемые подзадачи.
Подзадача хорошо осознаваема, если её можно описать предложением до 7-10 слов. Например: "очищаю переменную от двойных пробелов", "записываю действие юзера в лог-файл".
Должны быть задействованы те инструменты, которых достаточно для выполнения задачи. Не нужно убивать муху гранатой.
Пример:
Если вам нужно записать в переменную "да" или "нет", то лучше взять булевый тип (true/false), чем писать в строковой переменной "yes" или "no". И уж тем более, не использовать для этого отдельный массив ("мерзость какая", — подумают сейчас некоторые подписчики).
Но с принципом простоты не всё так просто, поэтому будет ещё пост.
🚨 Вакансия: Лигалинженер
Ну вот, за последние полгода вижу вторую вакансию лигалинженера, и тоже в классном коллективе. Описание здесь.
Резюме не нужно, пишите сразу их чатботу-рекрутеру.
Крутое FAQ по вакансии — здесь.
По своему опыту скажу, что эта профессия настолько нова, что вы ещё можете своими действиями формировать её образ, ставить смелые эксперименты и не бояться неудач. Будучи просто юристом, так себя вести сложнее, а то и нельзя.
Не упускайте.
Ну вот, за последние полгода вижу вторую вакансию лигалинженера, и тоже в классном коллективе. Описание здесь.
Резюме не нужно, пишите сразу их чатботу-рекрутеру.
Крутое FAQ по вакансии — здесь.
По своему опыту скажу, что эта профессия настолько нова, что вы ещё можете своими действиями формировать её образ, ставить смелые эксперименты и не бояться неудач. Будучи просто юристом, так себя вести сложнее, а то и нельзя.
Не упускайте.
👨🏻🏫 Учим юристов кодить
Итак, этот день настал.
С коллегами по лигалтек-цеху продаём свои знания.
Учим кодить: читать код, понимать код, писать код.
Даём 2 языка программирования и ещё некоторые штуки.
Набираем группу до 16 человек.
(раздувать группу до больших размеров я лично считаю издевательством над образовательным процессом)
Больше инфо на сайте: futurelawschool.net/c4l
〽️ Дам промокод на скидку в 15% человеку, кто:
1) первый(-ая) пришлёт мне в личку вариант названия переменной, который ему/ей больше нравится, из трёх ниженазванных;
2) кратко объяснит свой выбор.
Вот варианты:
A) $tokenToCheck
B) $TokenToCheck
C) $token_to_check
Итак, этот день настал.
С коллегами по лигалтек-цеху продаём свои знания.
Учим кодить: читать код, понимать код, писать код.
Даём 2 языка программирования и ещё некоторые штуки.
Набираем группу до 16 человек.
(раздувать группу до больших размеров я лично считаю издевательством над образовательным процессом)
Больше инфо на сайте: futurelawschool.net/c4l
〽️ Дам промокод на скидку в 15% человеку, кто:
1) первый(-ая) пришлёт мне в личку вариант названия переменной, который ему/ей больше нравится, из трёх ниженазванных;
2) кратко объяснит свой выбор.
Вот варианты:
A) $tokenToCheck
B) $TokenToCheck
C) $token_to_check
📦 Кейсы для будущих техноюристов
Прямо сейчас в Украине знаковое событие: дописывается проект учебной программы курса "Юридические инновации". Это началось ещё в июле. В курсе будет многое, чего доселе не было в украинском юробразовании. Одна из тем - алгоритмы и автоматизация в праве (обожаю их). На ходу подкинул такие идеи для практических занятий.
1⃣ Взяти договір (наприклад, оренди квартири, автомобіля тощо). Подивитися його, подумати, яку мінімальну кількість питань має поставити юрист клієнту, щоб заповнити фактичні дані залежно від предмета договору (істотні умови тощо). Запропонувати оптимальний порядок і формулювання (вигляд) цих питань, а також вимоги до відповідей, з тим, щоб їх міг ставити клієнту автоматизований алгоритм (наприклад, чатбот).
💡 Окрім власне алгоритмізації, студент отримає ще й такий хардскіл, як вміння лаконічно формулювати питання і економити час клієнта.
2⃣ Взяти якийсь сценарій з процесуального кодекса (наприклад, підготовка/подача клопотання про призначення експертизи чи щось більш проблемне на практиці). Проаналізувати його, викласти у вигляді сценарія (опитувальник-чекліст) для чатбота, який допомагає юристу (адвокату) нічого не забути при підготовці і подачі такого документа.
💡 Окрім власне алгоритмізації, студент отримає ще й такі хардскіли, як вміння уважно ставитись до слів у законі, розбивати правові процедури на окремі елементи, "приміряти ці норми на собі" тощо.
Собираюсь ещё развить и углубить. А какие задания поставили бы вы, будь вы преподавателем на таком предмете? Го обсудим в чате или в личке. 🙂 Лучшее попадёт в образовательный раздел лигалтек-энциклопедии.
Прямо сейчас в Украине знаковое событие: дописывается проект учебной программы курса "Юридические инновации". Это началось ещё в июле. В курсе будет многое, чего доселе не было в украинском юробразовании. Одна из тем - алгоритмы и автоматизация в праве (обожаю их). На ходу подкинул такие идеи для практических занятий.
1⃣ Взяти договір (наприклад, оренди квартири, автомобіля тощо). Подивитися його, подумати, яку мінімальну кількість питань має поставити юрист клієнту, щоб заповнити фактичні дані залежно від предмета договору (істотні умови тощо). Запропонувати оптимальний порядок і формулювання (вигляд) цих питань, а також вимоги до відповідей, з тим, щоб їх міг ставити клієнту автоматизований алгоритм (наприклад, чатбот).
💡 Окрім власне алгоритмізації, студент отримає ще й такий хардскіл, як вміння лаконічно формулювати питання і економити час клієнта.
2⃣ Взяти якийсь сценарій з процесуального кодекса (наприклад, підготовка/подача клопотання про призначення експертизи чи щось більш проблемне на практиці). Проаналізувати його, викласти у вигляді сценарія (опитувальник-чекліст) для чатбота, який допомагає юристу (адвокату) нічого не забути при підготовці і подачі такого документа.
💡 Окрім власне алгоритмізації, студент отримає ще й такі хардскіли, як вміння уважно ставитись до слів у законі, розбивати правові процедури на окремі елементи, "приміряти ці норми на собі" тощо.
Собираюсь ещё развить и углубить. А какие задания поставили бы вы, будь вы преподавателем на таком предмете? Го обсудим в чате или в личке. 🙂 Лучшее попадёт в образовательный раздел лигалтек-энциклопедии.
🚡 Гражданский кодекс и ООП
ООП или объектно ориентированное программирование — фундаментальная парадигма в кодинге, о которой должен знать каждый разработчик. Её суть максимально простыми словами: в коде создаём классы (виды "действующих лиц"), описываем их свойства (характеристики) и методы ("активные способности"), наконец создаём объекты (конкретные "действующие лица", принадлежащие к описанному перед этим "виду").
Далее мы можем совершить действие путём называния "действующего лица" и его "способности", например:
myRobotLawyer.read_agreement("договір поставки №244.docx");
Это значит, что объект myRobotLawyer выполнит код из доступного ему метода read_agreement, в который в качестве параметра будет передано название некоего файла "договір поставки №244.docx". Внутри там может быть код, который сделает то, что вам нужно: вытащит текст из docx-файла, найдёт в нём интересующие вас слова и т.д.
📒 Причём здесь гражданский кодекс? А при том, что в процессе диджитализации законодательства Украины к ряду его норм может быть применён именно объектно-ориентированный подход.
Например, если нормы о договоре купли-продажи представить как объект, то у него могут выйти, в частности, такие свойства и методы:
.description — строковая переменная, содержит определение договора из статьи 655;
.possible_object_categories — массив, содержит положения частей 1, 2, 3 статьи 656;
.show_forms — метод, выводит все предусмотренные законом случаи, когда форма договора должна быть письменная + указание на то, что всё остальное допускает устную форму договора;
.check_form — метод, в него нужно передать название предмета договора, чтобы прошла проверка, должна ли быть форма договора письменная (возвращает строку "письмова" или "будь-яка").
Затем так же поступаем и с другими видами договоров. Как думаете, это бред или что-то в этом есть? Стоит копнуть глубже? 🚜
ООП или объектно ориентированное программирование — фундаментальная парадигма в кодинге, о которой должен знать каждый разработчик. Её суть максимально простыми словами: в коде создаём классы (виды "действующих лиц"), описываем их свойства (характеристики) и методы ("активные способности"), наконец создаём объекты (конкретные "действующие лица", принадлежащие к описанному перед этим "виду").
Далее мы можем совершить действие путём называния "действующего лица" и его "способности", например:
myRobotLawyer.read_agreement("договір поставки №244.docx");
Это значит, что объект myRobotLawyer выполнит код из доступного ему метода read_agreement, в который в качестве параметра будет передано название некоего файла "договір поставки №244.docx". Внутри там может быть код, который сделает то, что вам нужно: вытащит текст из docx-файла, найдёт в нём интересующие вас слова и т.д.
📒 Причём здесь гражданский кодекс? А при том, что в процессе диджитализации законодательства Украины к ряду его норм может быть применён именно объектно-ориентированный подход.
Например, если нормы о договоре купли-продажи представить как объект, то у него могут выйти, в частности, такие свойства и методы:
.description — строковая переменная, содержит определение договора из статьи 655;
.possible_object_categories — массив, содержит положения частей 1, 2, 3 статьи 656;
.show_forms — метод, выводит все предусмотренные законом случаи, когда форма договора должна быть письменная + указание на то, что всё остальное допускает устную форму договора;
.check_form — метод, в него нужно передать название предмета договора, чтобы прошла проверка, должна ли быть форма договора письменная (возвращает строку "письмова" или "будь-яка").
Затем так же поступаем и с другими видами договоров. Как думаете, это бред или что-то в этом есть? Стоит копнуть глубже? 🚜
🕶 Кодинг и приватность (чья)?
спойлер: Future Law School расширяется! 🏫
Когда только начинаешь программировать и при этом сразу работаешь над проектом, которым будут пользоваться другие люди, ты уже несёшь ответственность за их приватность. Можно по-разному накосячить, когда собираешь чужие данные.
Например:
1️⃣ Ты собираешь их имейлы и хранишь в незашифрованном виде в базе данных. Или, что ещё хуже, держишь в текстовом файле на сервере, не защищённом от скачивания любым человеком/роботом, который подберёт его адрес.
Где здесь угроза? Твоим юзерам может прийти спам-рассылка.
2️⃣ Кроме предыдущего, ты собираешь ещё пароли, создаваемые твоими юзерами при регистрации, хранишь в незашифрованном виде там же.
Где здесь угроза? Это уже поинтереснее. Теперь благодаря тебе некоторых твоих юзеров могут ещё и взломать.
Есть ещё разные вариации с незащищёнными кукисами, кражей сеанса и множеством других дивных вещей. Поэтому программист (а лигалинженер особенно!), не должен быть нигилистом. 🐗
Не хочешь быть нигилистом? Сегодня запустился телеграм-канал на тему приватности — Privacy HUB.
Каждый будний день у них расписан под контент определённого типа. Знаю, такие челленджы непросты на второй-третий месяц после старта. Будет интересно последить за ними.
Ну и хорошо бы замутить с ними несколько постов на тему приватности в разработке. Замутить?
спойлер: Future Law School расширяется! 🏫
Когда только начинаешь программировать и при этом сразу работаешь над проектом, которым будут пользоваться другие люди, ты уже несёшь ответственность за их приватность. Можно по-разному накосячить, когда собираешь чужие данные.
Например:
1️⃣ Ты собираешь их имейлы и хранишь в незашифрованном виде в базе данных. Или, что ещё хуже, держишь в текстовом файле на сервере, не защищённом от скачивания любым человеком/роботом, который подберёт его адрес.
Где здесь угроза? Твоим юзерам может прийти спам-рассылка.
2️⃣ Кроме предыдущего, ты собираешь ещё пароли, создаваемые твоими юзерами при регистрации, хранишь в незашифрованном виде там же.
Где здесь угроза? Это уже поинтереснее. Теперь благодаря тебе некоторых твоих юзеров могут ещё и взломать.
Есть ещё разные вариации с незащищёнными кукисами, кражей сеанса и множеством других дивных вещей. Поэтому программист (а лигалинженер особенно!), не должен быть нигилистом. 🐗
Не хочешь быть нигилистом? Сегодня запустился телеграм-канал на тему приватности — Privacy HUB.
Каждый будний день у них расписан под контент определённого типа. Знаю, такие челленджы непросты на второй-третий месяц после старта. Будет интересно последить за ними.
Ну и хорошо бы замутить с ними несколько постов на тему приватности в разработке. Замутить?
📗 Теоретический минимум по Computer Science
(Феррейра Фило Владстон)
Мне эту книгу рекомендовали некоторые подписчики канала. Наконец прочёл её! Книга хороша, особенно подход к иллюстрированию материала (некоторые алгоритмы визуализированы пошагово). Рекомендую всем, кто хочет лигалинженерить, но не знает, как подступиться к техническим вопросам.
Привожу список и резюме глав книги в порядке их важности (на мой взгляд) для лигалинженера.
1️⃣ Глава 1 — Основы
🥚 Безусловный мастхев для лигалинженера. Нет логики — нет профессии.
2️⃣ Глава 2 — Вычислительная сложность + Глава 3 — Стратегия
🥚 О том, как посчитать, хватит ли вам времени и памяти, чтобы выполнить чудо-алгоритм, который должен сделать ваш юрбиз богатым. Приёмы постройки чудо-алгоритмов.
3️⃣ Глава 6 — Базы данных
🥚 Как организовать хранение данных таким образом, чтобы сам способ их хранения был полезен и не был вреден.
4️⃣ Глава 4 — Данные
🥚 Об абстракциях и типах данных — гайках и гвоздях программирования.
5️⃣ Глава 5 — Алгоритмы
🥚 Небольшая глава с иллюстрацией нескольких известных алгоритмов.
6️⃣ Глава 8 — Программирование
🥚 Мини-экскурс в любой язык программирования. Знакомство с парадигмами кодинга (кроме ООП).
7️⃣ Глава 7 — Компьютеры
🥚 Понимание компьютера через призму ОЗУ, процессора, компиляции и операционных систем.
Как ни странно, дальше я начал читать "Теоретический минимум по Big Data" (Анналин Ын, Кеннет Су). 🐜
(Феррейра Фило Владстон)
Мне эту книгу рекомендовали некоторые подписчики канала. Наконец прочёл её! Книга хороша, особенно подход к иллюстрированию материала (некоторые алгоритмы визуализированы пошагово). Рекомендую всем, кто хочет лигалинженерить, но не знает, как подступиться к техническим вопросам.
Привожу список и резюме глав книги в порядке их важности (на мой взгляд) для лигалинженера.
1️⃣ Глава 1 — Основы
🥚 Безусловный мастхев для лигалинженера. Нет логики — нет профессии.
2️⃣ Глава 2 — Вычислительная сложность + Глава 3 — Стратегия
🥚 О том, как посчитать, хватит ли вам времени и памяти, чтобы выполнить чудо-алгоритм, который должен сделать ваш юрбиз богатым. Приёмы постройки чудо-алгоритмов.
3️⃣ Глава 6 — Базы данных
🥚 Как организовать хранение данных таким образом, чтобы сам способ их хранения был полезен и не был вреден.
4️⃣ Глава 4 — Данные
🥚 Об абстракциях и типах данных — гайках и гвоздях программирования.
5️⃣ Глава 5 — Алгоритмы
🥚 Небольшая глава с иллюстрацией нескольких известных алгоритмов.
6️⃣ Глава 8 — Программирование
🥚 Мини-экскурс в любой язык программирования. Знакомство с парадигмами кодинга (кроме ООП).
7️⃣ Глава 7 — Компьютеры
🥚 Понимание компьютера через призму ОЗУ, процессора, компиляции и операционных систем.
Как ни странно, дальше я начал читать "Теоретический минимум по Big Data" (Анналин Ын, Кеннет Су). 🐜
📄 "Уверенный пользователь MS Word"
Эта фраза — завсегдатай резюме многих юристов, ищущих работу. Но интересно, сколько из них знают, как технически устроен docx-файл и как это знание может помочь в экстренной ситуации?
Вот что должен знать каждый лигалинженер и желательно знать юристам.
1️⃣ Создайте и назовите docx-файл, например: "тест.docx".
2️⃣ Напишите в нём что-то (например: "робот") и сохраните.
3️⃣ Переименуйте файл в "тест.zip".
4️⃣ Распакуйте этот архив.
5️⃣ Войдите в папку "word", откройте файл "document.xml".
6️⃣ Найдите в нём при помощи Ctrl+F написанные вами слова. Можете увидеть, что его окружает, как устроено всё вокруг.
7️⃣ Удалите несколько тегов (содержимое между символами "<" и ">", включая их) или их кусков, или последние три символа файла ("nt>").
8️⃣ Сохраните файл, заархивируйте всё содержимое назад в zip-архив.
9️⃣ Переименуйте обратно в "тест.docx".
▪️ Попробуйте открыть файл в "Word". Он выдаст ошибку. Теперь вы можете:
1) снова проделать шаги 3—5;
2) вернуть на место все удалённые фрагменты;
3) проделать шаги 8—9.
▪️ Теперь, если вы правильно вернули всё на место, должно открыться без ошибок.
Зачем вот это вот всё?
Иногда документы повреждаются. Этот лайфхак поможет вам получить доступ к уцелевшему содержимому документа при его повреждении, не закачивая его в незнакомые онлайн-сервисы и не рискуя конфиденциальностью данных.
Также это знание полезно, когда вы автоматизируете работу с контентом в .docx-документах, и ваши потребности не закрываются полностью найденными вами библиотеками.
Эта фраза — завсегдатай резюме многих юристов, ищущих работу. Но интересно, сколько из них знают, как технически устроен docx-файл и как это знание может помочь в экстренной ситуации?
Вот что должен знать каждый лигалинженер и желательно знать юристам.
1️⃣ Создайте и назовите docx-файл, например: "тест.docx".
2️⃣ Напишите в нём что-то (например: "робот") и сохраните.
3️⃣ Переименуйте файл в "тест.zip".
4️⃣ Распакуйте этот архив.
5️⃣ Войдите в папку "word", откройте файл "document.xml".
6️⃣ Найдите в нём при помощи Ctrl+F написанные вами слова. Можете увидеть, что его окружает, как устроено всё вокруг.
7️⃣ Удалите несколько тегов (содержимое между символами "<" и ">", включая их) или их кусков, или последние три символа файла ("nt>").
8️⃣ Сохраните файл, заархивируйте всё содержимое назад в zip-архив.
9️⃣ Переименуйте обратно в "тест.docx".
▪️ Попробуйте открыть файл в "Word". Он выдаст ошибку. Теперь вы можете:
1) снова проделать шаги 3—5;
2) вернуть на место все удалённые фрагменты;
3) проделать шаги 8—9.
▪️ Теперь, если вы правильно вернули всё на место, должно открыться без ошибок.
Зачем вот это вот всё?
Иногда документы повреждаются. Этот лайфхак поможет вам получить доступ к уцелевшему содержимому документа при его повреждении, не закачивая его в незнакомые онлайн-сервисы и не рискуя конфиденциальностью данных.
Также это знание полезно, когда вы автоматизируете работу с контентом в .docx-документах, и ваши потребности не закрываются полностью найденными вами библиотеками.
👩🎓 Научиться кодить бесплатно — можно, почему нет?
Давно не рассказывал о своём продвижении в мире кодинга. За последние две недели сделал для себя сразу два открытия, которые хорошо сплелись воедино: Coursera и Notion.
1️⃣ Coursera
Недавно я решил, что PHP и JavaScript — это хорошо, но с моей губозакатывательной сферой интересов (машинное обучение, нейросети и т.д.) язык Python — лучше. Поэтому решил стать более системным парнем и для начала пройти этот бесплатный курс по Python.
На этой платформе есть курсы платные и есть бесплатные. В выбранном мной курсе задания проверяются системой автоматически на серии тестов. Количество баллов за задание получаю исходя из количества тестов, которые моё решение прошло, по 100-бальной системе. Но "зачёт" ставится только за оценку в 100 баллов. Особенное удовольствие доставляет выполнять задания со звёздочкой, которые не обязательны для зачёта учебных недель, но являются самым важным делом в обучении программиста. Пока что нравится. Когда закончу, думаю взять следующий курс по Python и Data Science или Applied Data Science with Python.
2️⃣ Notion
Решил систематизировать свои знания где-то в Интернете. Trello для этого стал тесен, и я попробовал Notion. Оказывается, тут есть фичи и для программистов: можно указывать язык, чтобы сохраняемый вами код приобретал соответствующую разметку синтаксиса. Прикрепляю скриншот.
А вы использовали эти сервисы?
Давно не рассказывал о своём продвижении в мире кодинга. За последние две недели сделал для себя сразу два открытия, которые хорошо сплелись воедино: Coursera и Notion.
1️⃣ Coursera
Недавно я решил, что PHP и JavaScript — это хорошо, но с моей губозакатывательной сферой интересов (машинное обучение, нейросети и т.д.) язык Python — лучше. Поэтому решил стать более системным парнем и для начала пройти этот бесплатный курс по Python.
На этой платформе есть курсы платные и есть бесплатные. В выбранном мной курсе задания проверяются системой автоматически на серии тестов. Количество баллов за задание получаю исходя из количества тестов, которые моё решение прошло, по 100-бальной системе. Но "зачёт" ставится только за оценку в 100 баллов. Особенное удовольствие доставляет выполнять задания со звёздочкой, которые не обязательны для зачёта учебных недель, но являются самым важным делом в обучении программиста. Пока что нравится. Когда закончу, думаю взять следующий курс по Python и Data Science или Applied Data Science with Python.
2️⃣ Notion
Решил систематизировать свои знания где-то в Интернете. Trello для этого стал тесен, и я попробовал Notion. Оказывается, тут есть фичи и для программистов: можно указывать язык, чтобы сохраняемый вами код приобретал соответствующую разметку синтаксиса. Прикрепляю скриншот.
А вы использовали эти сервисы?
{kind=link}
🍳 Состав изучения программирования, да и самого его
После прошлого поста один из подписчиков мне подсказал посмотреть лекции Тимофея Хирьянова по программированию на Python. Решил не откладывать и посмотреть, так как хочу хорошо изучить Python с разных сторон.
Действительно, чувак интересно и понятно расчехляет суть вещей. Досмотрел уже до 6-й лекции, и пока не думаю останавливаться. Кстати, в ней он доступно и детально объясняет суть разных способов сортировки на примере солдат и прапорщиков. Такие "живые" примеры и визуализация очень важны при обучении абстрактным концепциям.
Но что более важно, в первой лекции Тимофей Хирьянов рассказывает, из чего состоит программирование и на чём следует делать акцент при его изучении:
1️⃣ знание синтаксиса языка(-ов) программирования
2️⃣ знание алгоритмов и структур данных
3️⃣ знание прикладных библиотек
4️⃣ практика программирования
5️⃣ дизайн программного обеспечения
6️⃣ групповая работа программистов
Как вы думаете, какие два из этих направлений были отмечены как приоритетные для старта изучения программирования?
После прошлого поста один из подписчиков мне подсказал посмотреть лекции Тимофея Хирьянова по программированию на Python. Решил не откладывать и посмотреть, так как хочу хорошо изучить Python с разных сторон.
Действительно, чувак интересно и понятно расчехляет суть вещей. Досмотрел уже до 6-й лекции, и пока не думаю останавливаться. Кстати, в ней он доступно и детально объясняет суть разных способов сортировки на примере солдат и прапорщиков. Такие "живые" примеры и визуализация очень важны при обучении абстрактным концепциям.
Но что более важно, в первой лекции Тимофей Хирьянов рассказывает, из чего состоит программирование и на чём следует делать акцент при его изучении:
1️⃣ знание синтаксиса языка(-ов) программирования
2️⃣ знание алгоритмов и структур данных
3️⃣ знание прикладных библиотек
4️⃣ практика программирования
5️⃣ дизайн программного обеспечения
6️⃣ групповая работа программистов
Как вы думаете, какие два из этих направлений были отмечены как приоритетные для старта изучения программирования?
🛠 Что такое лигалинженер?
часть 2: чтиво на Медиуме
Маленько увлёкся работой, поэтому постов стало меньше. Сегодня наконец вышли в свет несколько моих подсозревших мыслей о лигалинженерии. Благодаря ей этот канал и появился, когда мой поток сознания превысил объём используемых до того стоков. :)
часть 2: чтиво на Медиуме
Маленько увлёкся работой, поэтому постов стало меньше. Сегодня наконец вышли в свет несколько моих подсозревших мыслей о лигалинженерии. Благодаря ей этот канал и появился, когда мой поток сознания превысил объём используемых до того стоков. :)
Medium
Що таке Legal Engineer?
Для когось це хайп. Для когось — санітар зашкарублого права.