
Надёжные способы автоматизировать создание документов
Способ 2. Соединение блоков. 🍢
Выше я рассказал о том, как заполнять шаблоны. Но это весьма тривиальная задача. Нередко структура и содержание документа должны различаться зависимо от ситуации клиента. И тут мы приходим к тому, что документ нужно строить из отдельных блоков, которые должны подставляться зависимо от полученных ответов.
Простая ситуация: задаём 3 вопроса подряд, на каждый из них даётся по 2 ответа, и каждый ответ связан с неким блоком текста, который должен подставиться в документ. У нас в Axon Partners такое было с тем самым Privacy Policy Bot, только там таких вопросов было около двенадцати. И на этой же идее я строил тот самый конструктор ботов, где можно было создать до 15-и вопросов с 4-мя возможными ответами.
🎲 Выходит, потенциально количество вариаций такого документа будет равно произведению сумм ответов по каждому вопросу: 2 х 2 х 2 = 8. И вам как юристу на этапе создания и тестирования такого конструктора необходимо убедиться, что все эти вариации жизнеспособны и не противоречивы: например, что блок из ответа №1 на вопрос №1 совместим с блоком из ответа №2 на вопрос №3 и т.д. Поэтому такое конструирование документа лучше подходит для консультаций, справок и некоторых "блочных" документов по типу несложных политик приватности. Ведь договоры обычно имеют более сложную логику, хотя при некоторой ловкости можно что-то эдакое сотворить и с ними.
И конечно же, при необходимости блок можно сделать пустым.
Способ 2. Соединение блоков. 🍢
Выше я рассказал о том, как заполнять шаблоны. Но это весьма тривиальная задача. Нередко структура и содержание документа должны различаться зависимо от ситуации клиента. И тут мы приходим к тому, что документ нужно строить из отдельных блоков, которые должны подставляться зависимо от полученных ответов.
Простая ситуация: задаём 3 вопроса подряд, на каждый из них даётся по 2 ответа, и каждый ответ связан с неким блоком текста, который должен подставиться в документ. У нас в Axon Partners такое было с тем самым Privacy Policy Bot, только там таких вопросов было около двенадцати. И на этой же идее я строил тот самый конструктор ботов, где можно было создать до 15-и вопросов с 4-мя возможными ответами.
🎲 Выходит, потенциально количество вариаций такого документа будет равно произведению сумм ответов по каждому вопросу: 2 х 2 х 2 = 8. И вам как юристу на этапе создания и тестирования такого конструктора необходимо убедиться, что все эти вариации жизнеспособны и не противоречивы: например, что блок из ответа №1 на вопрос №1 совместим с блоком из ответа №2 на вопрос №3 и т.д. Поэтому такое конструирование документа лучше подходит для консультаций, справок и некоторых "блочных" документов по типу несложных политик приватности. Ведь договоры обычно имеют более сложную логику, хотя при некоторой ловкости можно что-то эдакое сотворить и с ними.
И конечно же, при необходимости блок можно сделать пустым.
{kind=link}
26-й день: запуск чатов! 👁🗨
Друзья, вот нас и стало уже 500! Очень благодарен всем, кто шерит канал. :) Заменяя неудобный интерфейс комментариев, запускаю целых два чата для желающих:
🗯 Common Chat, чтобы обсуждать контент и вообще тематику канала, а именно – более "гуманитарные" и "стратегические" вопросы.
💬 Coder Chat, чтобы обсуждать сугубо кодерские вопросы и, взаимопомогая, забрасывать друг друга кусками кода, осколками конструктивной критики и полезными материалами.
Завтра продолжаю своё повествование. А пока что зацените скриншот альфа версии нашего первого опубликованного лигалтек-продукта в феврале 2017-го. К чему я? Не нужно бояться, что без профессионального дизайнера у вас на старте получится антикрасивый интерфейс. В лигалтеке главное — нутро продукта: его движок, логика и функционал. Считаю, что юрист не обязан ещё и дизайнить. Это можно оставить людям с профессиональным чувством прекрасного. 🎨 Поэтому главное требование к лигалинженерам — хотя бы тексты сделать читабельными.
Друзья, вот нас и стало уже 500! Очень благодарен всем, кто шерит канал. :) Заменяя неудобный интерфейс комментариев, запускаю целых два чата для желающих:
🗯 Common Chat, чтобы обсуждать контент и вообще тематику канала, а именно – более "гуманитарные" и "стратегические" вопросы.
💬 Coder Chat, чтобы обсуждать сугубо кодерские вопросы и, взаимопомогая, забрасывать друг друга кусками кода, осколками конструктивной критики и полезными материалами.
Завтра продолжаю своё повествование. А пока что зацените скриншот альфа версии нашего первого опубликованного лигалтек-продукта в феврале 2017-го. К чему я? Не нужно бояться, что без профессионального дизайнера у вас на старте получится антикрасивый интерфейс. В лигалтеке главное — нутро продукта: его движок, логика и функционал. Считаю, что юрист не обязан ещё и дизайнить. Это можно оставить людям с профессиональным чувством прекрасного. 🎨 Поэтому главное требование к лигалинженерам — хотя бы тексты сделать читабельными.
{kind=link}
Надёжные способы автоматизировать создание документов
Способ 3. Шабменты или фраглоны. 🏈
Разумеется, на практике при создании документов (особенно договоров, актов, заявлений и т.д.) приходится комбинировать способ 1 и способ 2. То есть и данные от юзера напрямую вносить (имена, даты, адреса, номера, суммы и т.д), и какие-то блоки подставлять. Логику процесса я изобразил на картинке ниже.
Обратите внимание, что данные юзера можно вносить как в статичную ("чёрную") часть документа ("желтый" ответ), так и в сами фрагменты ("красный" ответ). Причём порядок действий по такой схеме не имеет значения, хотя с точки зрения оптимизации стоит вносить данные клиента в уже выбранный (используемый) фрагмент.
🧩 То есть на нижнем уровне эти фрагменты ("зелёные") сами становятся шаблонами. В кодинге нередко можно столкнуться с такой многоуровневостью, пошаговостью. Поэтому-то умение мыслить пошагово довольно важно.
Способ 3. Шабменты или фраглоны. 🏈
Разумеется, на практике при создании документов (особенно договоров, актов, заявлений и т.д.) приходится комбинировать способ 1 и способ 2. То есть и данные от юзера напрямую вносить (имена, даты, адреса, номера, суммы и т.д), и какие-то блоки подставлять. Логику процесса я изобразил на картинке ниже.
Обратите внимание, что данные юзера можно вносить как в статичную ("чёрную") часть документа ("желтый" ответ), так и в сами фрагменты ("красный" ответ). Причём порядок действий по такой схеме не имеет значения, хотя с точки зрения оптимизации стоит вносить данные клиента в уже выбранный (используемый) фрагмент.
🧩 То есть на нижнем уровне эти фрагменты ("зелёные") сами становятся шаблонами. В кодинге нередко можно столкнуться с такой многоуровневостью, пошаговостью. Поэтому-то умение мыслить пошагово довольно важно.
{kind=link}
КАК Я ВОШЁЛ В АЙТИ.
ЧАСТЬ 3. Третий проект и закручивание винтов молотком (аспект веры). 🥶
🤖 Как я уже говорил, в конце февраля 2017 я засел за конструктор ботов (не чат-ботов, а тех, которые работают прямо в браузере, я их позднее стал называть веб-ботами). Они должны были работать по вот этому принципу, а сам проект — реализован в виде веб-сайта. На меня свалился не просто пресловутый кодинг ряда процедур, а решение полноценной архитектурной задачи: создание базы данных для юзеров и их ботов, механизма регистрации юзеров, механизма восстановления паролей, разных других механизмов взаимодействия фронтенда и бэкенда в процессе создания, изменения, удаления, запуска и тестирования юзерами их ботов.
👞 Разумеется, осознавать сразу весь этот ворох задач было напряжно (я не сразу понял, с чем связался), поэтому делал маленькие шажки от фиче к фиче. На этом проекте я познал, что такое фуллстак-разработка + ещё дизайном занимался, кнопки всякие рисовал (см. скриншот ниже). Так получилось, что для фронтенда (внешней, доступной юзеру части проекта) я использовал ту самую Construct 2, а для бэкенда — текстовый редактор скриптов в панели управления хостингом сайта.
🔩 В какой-то момент я начал догадываться, что делать такой проект в программе для разработки игр — плохая, очень плохая идея. По скриншоту видно, какими извращениями пришлось заниматься. Но я в неё верил и пытался выжать максимум. К тому же не знал, как выйти на "чистый HTML и JavaScript" и работать "по-взрослому". Что ж, путь в айти бывает и таким.
🗺 Путь в айти: ЧАСТЬ 1, ЧАСТЬ 2
ЧАСТЬ 3. Третий проект и закручивание винтов молотком (аспект веры). 🥶
🤖 Как я уже говорил, в конце февраля 2017 я засел за конструктор ботов (не чат-ботов, а тех, которые работают прямо в браузере, я их позднее стал называть веб-ботами). Они должны были работать по вот этому принципу, а сам проект — реализован в виде веб-сайта. На меня свалился не просто пресловутый кодинг ряда процедур, а решение полноценной архитектурной задачи: создание базы данных для юзеров и их ботов, механизма регистрации юзеров, механизма восстановления паролей, разных других механизмов взаимодействия фронтенда и бэкенда в процессе создания, изменения, удаления, запуска и тестирования юзерами их ботов.
👞 Разумеется, осознавать сразу весь этот ворох задач было напряжно (я не сразу понял, с чем связался), поэтому делал маленькие шажки от фиче к фиче. На этом проекте я познал, что такое фуллстак-разработка + ещё дизайном занимался, кнопки всякие рисовал (см. скриншот ниже). Так получилось, что для фронтенда (внешней, доступной юзеру части проекта) я использовал ту самую Construct 2, а для бэкенда — текстовый редактор скриптов в панели управления хостингом сайта.
🔩 В какой-то момент я начал догадываться, что делать такой проект в программе для разработки игр — плохая, очень плохая идея. По скриншоту видно, какими извращениями пришлось заниматься. Но я в неё верил и пытался выжать максимум. К тому же не знал, как выйти на "чистый HTML и JavaScript" и работать "по-взрослому". Что ж, путь в айти бывает и таким.
🗺 Путь в айти: ЧАСТЬ 1, ЧАСТЬ 2
{kind=link}
Надёжные способы автоматизировать создание документов
Способ 4. Оценка комбинаций. 🌗
Описанные ранее способ 1, способ 2 и способ 3 — довольно просты, ведь в их основе гипотеза о том, что каждый ответ на каждый вопрос — "самостоятельная фигура", то есть влияет самостоятельно и напрямую на некоторый участок в документе. Но иногда бывает и так, что нужно "связать" два идущих один за другим вопроса, оценить ответы на них в совокупности. Например, когда речь идёт об оценке рисков (и мы делаем документ-консультацию по рискам), нужно видеть ситуацию клиента более масштабно и целостно.
🧮 Тогда приходится оценивать все возможные комбинации этих ответов. Если на первый вопрос 2 ответа, а на второй — 3, тогда комбинаций будет 2 х 3 = 6. "Карту" этих комбинаций на стадии прототипирования можно строить в виде таблицы. А соответствующий участок кода может выглядеть так, как изображено на картинке.
🥭 Кстати, в ходе своей работы в Аксоне над проектом Memelex мне пришлось научиться рисовать в Adobe Illustrator, чтобы не напрягать дизайнеров по мелочам. Теперь пользуюсь этим и здесь. Правда, нужно научиться ещё цвета подбирать. :)
Способ 4. Оценка комбинаций. 🌗
Описанные ранее способ 1, способ 2 и способ 3 — довольно просты, ведь в их основе гипотеза о том, что каждый ответ на каждый вопрос — "самостоятельная фигура", то есть влияет самостоятельно и напрямую на некоторый участок в документе. Но иногда бывает и так, что нужно "связать" два идущих один за другим вопроса, оценить ответы на них в совокупности. Например, когда речь идёт об оценке рисков (и мы делаем документ-консультацию по рискам), нужно видеть ситуацию клиента более масштабно и целостно.
🧮 Тогда приходится оценивать все возможные комбинации этих ответов. Если на первый вопрос 2 ответа, а на второй — 3, тогда комбинаций будет 2 х 3 = 6. "Карту" этих комбинаций на стадии прототипирования можно строить в виде таблицы. А соответствующий участок кода может выглядеть так, как изображено на картинке.
🥭 Кстати, в ходе своей работы в Аксоне над проектом Memelex мне пришлось научиться рисовать в Adobe Illustrator, чтобы не напрягать дизайнеров по мелочам. Теперь пользуюсь этим и здесь. Правда, нужно научиться ещё цвета подбирать. :)
{kind=link}
🧗♂️ Личный ТОП 5 источников обучения кодерству, которые сформировали меня:
🛷 5. Инструкции/мануалы по созданию несложных игр в программе Construct 2 и сам опыт взаимодействия с ней. Научился структурировать происходящее по ту сторону монитора, ставить цели, прокладывать пути и т.д.
🚴♂️ 4. Курсы программирования, на которые я пошёл в конце 2016-го и откуда ушёл где-то через два месяца. На них я научился думать над построением алгоритмов. Как пример я уже приводил задачу с палиндромом. На самом деле, там можно было взять гораздо больше, но решил дальше идти сам. Обобщённо: я не хотел учиться собирать Феррари, когда мне нужно было сделать электрочайник.
🥉 3. Также восполнить пробел в основах мне помогло приложение SoloLearn. В нём я прошёл курсы по HTML, CSS, JS, PHP, SQL, Python и jQuery. Ничего особо выдающегося в этом нет, просто основы синтаксиса всех этих технологий. Но у этого приложения есть своё коммьюнити по всему миру, всякие обсуждения, даже челленджи. К каждому обучающему заданию/вопросу прилагается своё обсуждение в комментах.
🥈 2. Далее идут некоторые книги, которые я очень выборочно и точечно изучал. В них информация обычно структурирована, подаётся в едином стиле, с нарастающей глубиной. Свою первую нейросеть я сделал именно благодаря книге. Это не тот жанр литературы, который нужно читать обязательно от корки до корки, хотя и здесь есть книги, которые этого заслуживают. Планирую скоро закупиться некоторыми.
🥇 1. Больше всего я самообучился, просто гугля вопросы и попадая на такие ресурсы, как stackovefrlow, w3schools и иногда даже форумы не первой свежести. Сюда же можно отнести мануалы типа php.net.
Расскажите в чате, какова ваша версия такого топа? От чего больше профита получили вы?
🛷 5. Инструкции/мануалы по созданию несложных игр в программе Construct 2 и сам опыт взаимодействия с ней. Научился структурировать происходящее по ту сторону монитора, ставить цели, прокладывать пути и т.д.
🚴♂️ 4. Курсы программирования, на которые я пошёл в конце 2016-го и откуда ушёл где-то через два месяца. На них я научился думать над построением алгоритмов. Как пример я уже приводил задачу с палиндромом. На самом деле, там можно было взять гораздо больше, но решил дальше идти сам. Обобщённо: я не хотел учиться собирать Феррари, когда мне нужно было сделать электрочайник.
🥉 3. Также восполнить пробел в основах мне помогло приложение SoloLearn. В нём я прошёл курсы по HTML, CSS, JS, PHP, SQL, Python и jQuery. Ничего особо выдающегося в этом нет, просто основы синтаксиса всех этих технологий. Но у этого приложения есть своё коммьюнити по всему миру, всякие обсуждения, даже челленджи. К каждому обучающему заданию/вопросу прилагается своё обсуждение в комментах.
🥈 2. Далее идут некоторые книги, которые я очень выборочно и точечно изучал. В них информация обычно структурирована, подаётся в едином стиле, с нарастающей глубиной. Свою первую нейросеть я сделал именно благодаря книге. Это не тот жанр литературы, который нужно читать обязательно от корки до корки, хотя и здесь есть книги, которые этого заслуживают. Планирую скоро закупиться некоторыми.
🥇 1. Больше всего я самообучился, просто гугля вопросы и попадая на такие ресурсы, как stackovefrlow, w3schools и иногда даже форумы не первой свежести. Сюда же можно отнести мануалы типа php.net.
Расскажите в чате, какова ваша версия такого топа? От чего больше профита получили вы?
Надёжные способы автоматизировать создание документов
Приём "построение перечня из перечня". ✅
Бывает так, что при опросе юзера/клиента нужно допускать выбор нескольких опций одновременно. Веб-разработчики знают, что для этого обычно используються "чекбоксы" (checkboxes). При создании юридических документов это может понадобиться, когда формируются перечни/списки, например: перечень товаров, услуг или работ, которые должны поставляться по договору.
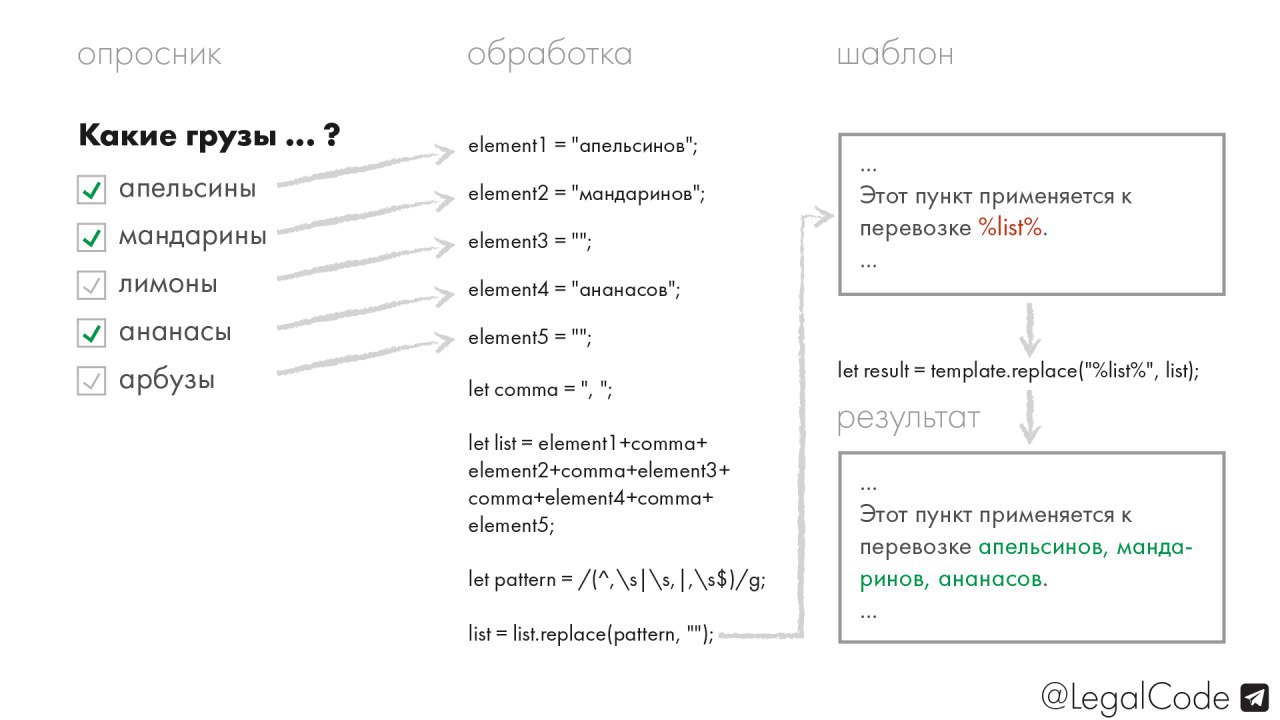
Как выглядит логика алгоритма, делающего переход от натыканных клиентом галочек к конечному списку в документе, я изобразил на картинке. И понятное дело, падежи (и вообще слова) на чекбоксах и в конечном списке могут не совпадать, всё зависит от ваших нужд.
Вам приходилось кодить похожие вещи? Можем обсудить в чате.
Приём "построение перечня из перечня". ✅
Бывает так, что при опросе юзера/клиента нужно допускать выбор нескольких опций одновременно. Веб-разработчики знают, что для этого обычно используються "чекбоксы" (checkboxes). При создании юридических документов это может понадобиться, когда формируются перечни/списки, например: перечень товаров, услуг или работ, которые должны поставляться по договору.
Как выглядит логика алгоритма, делающего переход от натыканных клиентом галочек к конечному списку в документе, я изобразил на картинке. И понятное дело, падежи (и вообще слова) на чекбоксах и в конечном списке могут не совпадать, всё зависит от ваших нужд.
Вам приходилось кодить похожие вещи? Можем обсудить в чате.
{kind=link}
КАК Я ВОШЁЛ В АЙТИ.
ЧАСТЬ 4. Знакомство с HTML/CSS/JavaScript и боль. 🦷
Где-то на четвёртом месяце работы над конструктором ботов я понял, что параллельно нужно начать изучение HTML, CSS и JavaScript, чтобы больше не делать такую дичь. Его уже, так и быть, заканчивал в Construct 2, но новые проекты твёрдо решил пилить "по-взрослому".
Уже плохо помню, с чего начал изучать, это всё как-то в кучу свалилось. Меня кормил гугл: я там находил и общую документацию, и всякие форумы, и статьи на Хабре. Философию работы HTML с его padding-ами и margin-ами я закусывал стилизацией CSS, пытаясь управлять всем этим при помощи JavaScript-а. Голова взрывалась, учился методом проб и ошибок, причём на одну пробу приходилось две ошибки. Сразу попал на какой-то источник, который подсадил меня на иглу jQuery, с которой я не слажу до сих пор.
Для непосвящённых: jQuery — это такая штука, которую подключаешь у себя на сайте, и кодить на JavaScript становится проще. Например, нужно в элемент с id=myText1 вписать текст "hello":
😳 код без jQuery, т.е. на "чистом" JavaScript:
var el = document.getElementById("myText1");
el.innerHTML = "hello";
😌 Этот же код с jQuery:
$("#myText1").html("hello");
Но более-менее освоив этот букет, я с тех пор смог создавать фулл-стак проекты, то есть выполнять "в одно рыло" полный цикл разработки веб-сайта, начиная с управления его внешним видом и заканчивая самой отдалённой базой данных. Первой апробацией стал сайт-энциклопедия по украинскому лигалтеку в августе 2017. Недавно я основательно переделал его некоторые разделы, а другие прикрыл, ведь сделано было ужасно. Правда, я до сих пор так и не полюбил "верстать" сайты, то есть настраивать их внешний вид, интерфейс и т.д. Мне больше по душе писать алгоритмы на бэкенде, вплоть до нейросетей.
🗺 Путь в айти: ЧАСТЬ 1, ЧАСТЬ 2, ЧАСТЬ 3
ЧАСТЬ 4. Знакомство с HTML/CSS/JavaScript и боль. 🦷
Где-то на четвёртом месяце работы над конструктором ботов я понял, что параллельно нужно начать изучение HTML, CSS и JavaScript, чтобы больше не делать такую дичь. Его уже, так и быть, заканчивал в Construct 2, но новые проекты твёрдо решил пилить "по-взрослому".
Уже плохо помню, с чего начал изучать, это всё как-то в кучу свалилось. Меня кормил гугл: я там находил и общую документацию, и всякие форумы, и статьи на Хабре. Философию работы HTML с его padding-ами и margin-ами я закусывал стилизацией CSS, пытаясь управлять всем этим при помощи JavaScript-а. Голова взрывалась, учился методом проб и ошибок, причём на одну пробу приходилось две ошибки. Сразу попал на какой-то источник, который подсадил меня на иглу jQuery, с которой я не слажу до сих пор.
Для непосвящённых: jQuery — это такая штука, которую подключаешь у себя на сайте, и кодить на JavaScript становится проще. Например, нужно в элемент с id=myText1 вписать текст "hello":
😳 код без jQuery, т.е. на "чистом" JavaScript:
var el = document.getElementById("myText1");
el.innerHTML = "hello";
😌 Этот же код с jQuery:
$("#myText1").html("hello");
Но более-менее освоив этот букет, я с тех пор смог создавать фулл-стак проекты, то есть выполнять "в одно рыло" полный цикл разработки веб-сайта, начиная с управления его внешним видом и заканчивая самой отдалённой базой данных. Первой апробацией стал сайт-энциклопедия по украинскому лигалтеку в августе 2017. Недавно я основательно переделал его некоторые разделы, а другие прикрыл, ведь сделано было ужасно. Правда, я до сих пор так и не полюбил "верстать" сайты, то есть настраивать их внешний вид, интерфейс и т.д. Мне больше по душе писать алгоритмы на бэкенде, вплоть до нейросетей.
🗺 Путь в айти: ЧАСТЬ 1, ЧАСТЬ 2, ЧАСТЬ 3
🚥 Какими словами описывать свои разработки/алгоритмы
Как я уже писал раньше, алгоритмы своих разработок перед созданием важно грамотно описывать словами. Но это нужно не только для продуктивного самокопания, а и чтобы подключать к работе коллег, наёмников, инвесторов и прочих товарищей. Но описывать можно по-разному и с разным выхлопом. Чтобы объяснить это, я для своих презентаций соорудил "принцип светофора" (см. картинку), согласно которому разговоры о неначатых или недоделанных разработках/продуктах/алгоритмах нужно классифицировать на такие виды.
🅾️ Красные слова — ими описываете ваши глобальные цели и мечты, к которым вас ваша разработка должна приблизить. Эти слова лучше держать при себе. Разве что из них потом можно вывести какой-нибудь слоган в маркетинговых целях, для релиза или "ранних продаж". Эти слова не описывают сам алгоритм, лишь его глобальные последствия, ожидаемый эффект, миссию. Поэтому они нам как разработчикам не особо интересны (разве что для воодушевления, куда же без него в бессонные ночи).
📳 Жёлтые слова — они лаконично описывают общую логику, бизнес-логику работы вашего продукта. Они уже интересны вашим потенциальным инвесторам, но всё ещё недостаточно конкретны для кодеров, так как под одно такое описание можно сообразить несколько разных подходов к технической реализации.
✅ Зелёные слова — здесь уже каждая фраза должна давать чёткое понимание того, что кодер должен сделать. Каждая такая фраза является "аватарой", заголовком для некоторого количества строк кода, примерно от десятка до сотни. По сути, из этих слов пишутся технические задания кодерам. Этими словами должны уметь разговаривать лигалинженеры (кстати, о лигалинженерах скоро поговорим отдельно).
Так что стараюсь выбивать из себя дурь и сразу говорить жёлтыми словами, а перед этим думать наперёд зелёными. Хотя во время брейншторминга люди думают всеми словами подряд, ведь хорошая идея может быть высказана и в общей абстрактной форме. Затем её нужно грамотно сузить и превратить в техническую задачу.
Как я уже писал раньше, алгоритмы своих разработок перед созданием важно грамотно описывать словами. Но это нужно не только для продуктивного самокопания, а и чтобы подключать к работе коллег, наёмников, инвесторов и прочих товарищей. Но описывать можно по-разному и с разным выхлопом. Чтобы объяснить это, я для своих презентаций соорудил "принцип светофора" (см. картинку), согласно которому разговоры о неначатых или недоделанных разработках/продуктах/алгоритмах нужно классифицировать на такие виды.
🅾️ Красные слова — ими описываете ваши глобальные цели и мечты, к которым вас ваша разработка должна приблизить. Эти слова лучше держать при себе. Разве что из них потом можно вывести какой-нибудь слоган в маркетинговых целях, для релиза или "ранних продаж". Эти слова не описывают сам алгоритм, лишь его глобальные последствия, ожидаемый эффект, миссию. Поэтому они нам как разработчикам не особо интересны (разве что для воодушевления, куда же без него в бессонные ночи).
📳 Жёлтые слова — они лаконично описывают общую логику, бизнес-логику работы вашего продукта. Они уже интересны вашим потенциальным инвесторам, но всё ещё недостаточно конкретны для кодеров, так как под одно такое описание можно сообразить несколько разных подходов к технической реализации.
✅ Зелёные слова — здесь уже каждая фраза должна давать чёткое понимание того, что кодер должен сделать. Каждая такая фраза является "аватарой", заголовком для некоторого количества строк кода, примерно от десятка до сотни. По сути, из этих слов пишутся технические задания кодерам. Этими словами должны уметь разговаривать лигалинженеры (кстати, о лигалинженерах скоро поговорим отдельно).
Так что стараюсь выбивать из себя дурь и сразу говорить жёлтыми словами, а перед этим думать наперёд зелёными. Хотя во время брейншторминга люди думают всеми словами подряд, ведь хорошая идея может быть высказана и в общей абстрактной форме. Затем её нужно грамотно сузить и превратить в техническую задачу.
{kind=link}
О (не)автоматизации дьюдилов 🤬
Пост на тему боли. Есть такая разновидность юридической услуги — "дьюдил" (due diligence), известная также как юридический аудит. Это когда ты изучаешь ряд документов клиента (например, 300 договоров на разработку ПО за последние два года) на предмет разных рисков. Вот мне друзья вчера скинули фотку этого действа (см. ниже).
👔 Если ты юрист, то для тебя обычный юридический дьюдил в наших реалиях означает:
1) клиент присылает сканы документов;
2) клиент присылает фотки документов (качество оных весьма вариативно);
3) идёшь к клиенту и фоткаешь/сканируешь эти документы, потом работаешь с фотками/сканами;
4) идёшь к клиенту и дьюдилишь у него, ведь документы секретны, их нельзя фоткать/сканить и тем более пересылать в сети.
🔌 Если сильно повезёт, что-то достанется в электронной форме. Кстати, кому на дьюдил доставались оцифрованные pdf/docx (с возможностью поиска по тексту) или же изначально электронные документы, напишите пжлст в чате.
🕰 К чему это я? А к тому, что дьюдил — это идеальный кандидат на автоматизацию, за счёт которой можно сберечь десятки и сотни рабочих часов в год. Зная закономерности построения юридических текстов и имея опыт в запрашиваемой отрасли (например, интеллектуальная собственность), юрист может соорудить для себя дьюдил-алгоритм, который за несколько секунд "просмотрит" сотни документов и найдёт много чего, что человек мог бы пропустить. Но для этого прежде всего нужно иметь эти документы в цифровом виде. Поэтому реалии, согласно которым тонны документов нужно держать в бумаге, отодвигают нас от многих благ автоматизации.
#дьюдил #duediligence #автоматизация
Пост на тему боли. Есть такая разновидность юридической услуги — "дьюдил" (due diligence), известная также как юридический аудит. Это когда ты изучаешь ряд документов клиента (например, 300 договоров на разработку ПО за последние два года) на предмет разных рисков. Вот мне друзья вчера скинули фотку этого действа (см. ниже).
👔 Если ты юрист, то для тебя обычный юридический дьюдил в наших реалиях означает:
1) клиент присылает сканы документов;
2) клиент присылает фотки документов (качество оных весьма вариативно);
3) идёшь к клиенту и фоткаешь/сканируешь эти документы, потом работаешь с фотками/сканами;
4) идёшь к клиенту и дьюдилишь у него, ведь документы секретны, их нельзя фоткать/сканить и тем более пересылать в сети.
🔌 Если сильно повезёт, что-то достанется в электронной форме. Кстати, кому на дьюдил доставались оцифрованные pdf/docx (с возможностью поиска по тексту) или же изначально электронные документы, напишите пжлст в чате.
🕰 К чему это я? А к тому, что дьюдил — это идеальный кандидат на автоматизацию, за счёт которой можно сберечь десятки и сотни рабочих часов в год. Зная закономерности построения юридических текстов и имея опыт в запрашиваемой отрасли (например, интеллектуальная собственность), юрист может соорудить для себя дьюдил-алгоритм, который за несколько секунд "просмотрит" сотни документов и найдёт много чего, что человек мог бы пропустить. Но для этого прежде всего нужно иметь эти документы в цифровом виде. Поэтому реалии, согласно которым тонны документов нужно держать в бумаге, отодвигают нас от многих благ автоматизации.
#дьюдил #duediligence #автоматизация
{kind=link}
оптимизация/рефакторинг и правосудие будущего
☔️ часть 1 — пролог
💧 Есть в кодинге такая штука, как оптимизация кода. Она нужна, чтобы ускорять его выполнение, что очень важно в высоконагруженных крупных проектах. Оптимизация состоит в максимально возможном упрощении кода для выполнения машиной, что обычно приводит к:
1) усложнению восприятия этого кода его же автором;
2) крайне сложному восприятию и долгому разбору этого кода посторонними людьми.
💦 Своеобразным "антонимом" оптимизации называют рефакторинг. Это процесс "переписывания" кода для максимизации комфорта понимания этого кода человеком и взаимодействия с ним. Это обычно приводит к тому, что такой код дольше выполняется компьютером.
Разберём оптимизацию на примере:
В нашем интерфейсе некая полоска должна начать зеленеть, когда её длина больше 50% от максимально возможной. Чем длиннее она, тем более насыщенной должна быть. Например, чем больше запланированных налогов и сборов уплатил предприниматель, тем длиннее эта полоска, а значит и более зелёного цвета. Итак, нам нужно создать алгоритм, "извлекающий" интенсивность цвета из процента длины полоски.
Кодим (в конце строчки после "//" показываю наше текущее значение):
// пусть в переменную percent к нам попало значение 68:
let percent = taxPercentQuantity; //68
// отнять от значения процента половину полоски, чтобы понять, сколько процентов "заходит" на её вторую половину:
let x = percent-50; //18
// умножить на два, чтобы получить процентное отношение значения к этой половине длины полоски:
x = x * 2; //36
// умножить на один процент от значения 255, чтобы получить RGB-параметр нужного количества зелёного цвета:
x = x * 255/100; //91.8
// округлить финальное значение:
let result = Math.round(x); //92
// подставить это значение в параметр количества зелёного цвета нашей полоски:
$("#line").css("background-color", "rgb(0, "+result+", 0, 1)");
В итоге мы получили понятный, пошагово расписанный код. А теперь начинаем постепенно оптимизировать (сжимать) его, насколько можем:
1. let x = (percent-50) * 2 * 2.55; result = Math.round(x);
2. let x = (percent-50) * 5.1; result = Math.round(x);
3. let result = Math.round( (percent-50) * 5.1 );
☔️ В итоге мы четыре строки сжали в одну, попутно произведя математические преобразования, которые ничуть не меняют наш результат. Но они меняют кое-что другое в нашей голове. Следующим постом я объясню, как это может повлиять на философию правосудия будущего.
☔️ часть 1 — пролог
💧 Есть в кодинге такая штука, как оптимизация кода. Она нужна, чтобы ускорять его выполнение, что очень важно в высоконагруженных крупных проектах. Оптимизация состоит в максимально возможном упрощении кода для выполнения машиной, что обычно приводит к:
1) усложнению восприятия этого кода его же автором;
2) крайне сложному восприятию и долгому разбору этого кода посторонними людьми.
💦 Своеобразным "антонимом" оптимизации называют рефакторинг. Это процесс "переписывания" кода для максимизации комфорта понимания этого кода человеком и взаимодействия с ним. Это обычно приводит к тому, что такой код дольше выполняется компьютером.
Разберём оптимизацию на примере:
В нашем интерфейсе некая полоска должна начать зеленеть, когда её длина больше 50% от максимально возможной. Чем длиннее она, тем более насыщенной должна быть. Например, чем больше запланированных налогов и сборов уплатил предприниматель, тем длиннее эта полоска, а значит и более зелёного цвета. Итак, нам нужно создать алгоритм, "извлекающий" интенсивность цвета из процента длины полоски.
Кодим (в конце строчки после "//" показываю наше текущее значение):
// пусть в переменную percent к нам попало значение 68:
let percent = taxPercentQuantity; //68
// отнять от значения процента половину полоски, чтобы понять, сколько процентов "заходит" на её вторую половину:
let x = percent-50; //18
// умножить на два, чтобы получить процентное отношение значения к этой половине длины полоски:
x = x * 2; //36
// умножить на один процент от значения 255, чтобы получить RGB-параметр нужного количества зелёного цвета:
x = x * 255/100; //91.8
// округлить финальное значение:
let result = Math.round(x); //92
// подставить это значение в параметр количества зелёного цвета нашей полоски:
$("#line").css("background-color", "rgb(0, "+result+", 0, 1)");
В итоге мы получили понятный, пошагово расписанный код. А теперь начинаем постепенно оптимизировать (сжимать) его, насколько можем:
1. let x = (percent-50) * 2 * 2.55; result = Math.round(x);
2. let x = (percent-50) * 5.1; result = Math.round(x);
3. let result = Math.round( (percent-50) * 5.1 );
☔️ В итоге мы четыре строки сжали в одну, попутно произведя математические преобразования, которые ничуть не меняют наш результат. Но они меняют кое-что другое в нашей голове. Следующим постом я объясню, как это может повлиять на философию правосудия будущего.
оптимизация/рефакторинг и правосудие будущего
🌫 часть 2 — зашифрованное правосудие
В предыдущем посте мы пришли к тому, что сжали код практически в четыре раза без потери функциональности и результата. Но изменилось представление некого знания о сути алгоритма, заложенного нами в этот код. До оптимизации формула этого знания выглядела так:
💦 y = округлить( ( x - 50 ) * 2 * 255 / 100 )
После оптимизации стала выглядеть так:
💧 y = округлить( ( x - 50 ) * 5.1 )
Если мы затем опубликуем этот код как библиотеку (например, выложим на гитхабе) и не поясним эту строку комментариями, то не все поймут, что означает число 5.1, откуда оно взялось. Это число 5.1 станет, по сути, зашифрованным цифровым знанием. Постороннему человеку придётся реконструировать наше изначальное мышление, пройти наш путь заново, чтобы понять и воссоздать логику этого алгоритма (здравствуй, рефакторинг).
Итак, причём здесь правосудие? А при том, что оптимизация больших вычислительных систем, в основе которых лежит математика и логика и которые разрабатываются с целью автоматизировать принятие правовых решений, может привести к тому, что правосудие будет выглядеть примерно так:
y = ( x * 2.45 ) + ( z * 0.2 ) - 1200
... и даже так:
y = 1.0 / ( 1.0 + exp( -( 0.525 * 1.0 / ( 1.0 + exp( -x ) ) ) ) ) + 0.2
То есть суть и логика диджитализированного правосудия вдруг окажется скрыта за оптимизированными логическими и математическими преобразованиями. Хорошо ли это? Отвечу так: это вовсе неплохо, если разработчики будут:
1️⃣ тщательно документировать свой код, поясняя происхождение всех вводных данных и факт применения математических констант и традиционных формул;
2️⃣ в случае оптимизации кода, которая ведёт к "сжатию правового знания", тщательно документировать те параметры, которые явно использовались до оптимизации и во что они "сжались" в ходе таковой;
3️⃣ в идеале — делать две версии кода: оптимизированную и "полную", по которой можно будет исследовать логику работы системы в случае необходимости (например, при успешном обжаловании такого диджитализированного решения).
📙 Недавно на канале "Future Law School" упоминалась книга Педро Домингоса "Верховный алгоритм ... ". Прочёл её в прошлом году, в ней действительно в доступной форме изложена тема алгоритмизации в машинном обучении, показаны некоторые математические формулы, которые используются далеко не в математических целях.
🌫 часть 2 — зашифрованное правосудие
В предыдущем посте мы пришли к тому, что сжали код практически в четыре раза без потери функциональности и результата. Но изменилось представление некого знания о сути алгоритма, заложенного нами в этот код. До оптимизации формула этого знания выглядела так:
💦 y = округлить( ( x - 50 ) * 2 * 255 / 100 )
После оптимизации стала выглядеть так:
💧 y = округлить( ( x - 50 ) * 5.1 )
Если мы затем опубликуем этот код как библиотеку (например, выложим на гитхабе) и не поясним эту строку комментариями, то не все поймут, что означает число 5.1, откуда оно взялось. Это число 5.1 станет, по сути, зашифрованным цифровым знанием. Постороннему человеку придётся реконструировать наше изначальное мышление, пройти наш путь заново, чтобы понять и воссоздать логику этого алгоритма (здравствуй, рефакторинг).
Итак, причём здесь правосудие? А при том, что оптимизация больших вычислительных систем, в основе которых лежит математика и логика и которые разрабатываются с целью автоматизировать принятие правовых решений, может привести к тому, что правосудие будет выглядеть примерно так:
y = ( x * 2.45 ) + ( z * 0.2 ) - 1200
... и даже так:
y = 1.0 / ( 1.0 + exp( -( 0.525 * 1.0 / ( 1.0 + exp( -x ) ) ) ) ) + 0.2
То есть суть и логика диджитализированного правосудия вдруг окажется скрыта за оптимизированными логическими и математическими преобразованиями. Хорошо ли это? Отвечу так: это вовсе неплохо, если разработчики будут:
1️⃣ тщательно документировать свой код, поясняя происхождение всех вводных данных и факт применения математических констант и традиционных формул;
2️⃣ в случае оптимизации кода, которая ведёт к "сжатию правового знания", тщательно документировать те параметры, которые явно использовались до оптимизации и во что они "сжались" в ходе таковой;
3️⃣ в идеале — делать две версии кода: оптимизированную и "полную", по которой можно будет исследовать логику работы системы в случае необходимости (например, при успешном обжаловании такого диджитализированного решения).
📙 Недавно на канале "Future Law School" упоминалась книга Педро Домингоса "Верховный алгоритм ... ". Прочёл её в прошлом году, в ней действительно в доступной форме изложена тема алгоритмизации в машинном обучении, показаны некоторые математические формулы, которые используются далеко не в математических целях.
оптимизация/рефакторинг и правосудие будущего
🌧 часть 3 — безупречная отчётность компьютера
Предыдущий пост мог нагнать пессимизма в размышления о диджитализации правосудия. Дескать, алгоритмы всё равно будут непонятными и непрозрачными, невзирая на тщательно задокументированный код, ведь конечный пользователь не обязан разбираться в коде, чтобы понять правомерность цифрового решения. На самом деле, для обеспечения понятности работы программ существует логирование (запись, фиксация) "производимых действий", "принимаемых решений", а для обеспечения их прозрачности — вывод всех логов конечным пользователям.
Что такое логирование и логи?
Привожу пример из юридической практики.
🖨 Стажеру Сергею в гипотетической юридической фирме "Аспера" поручили отсканировать 50 договоров, попутно проверяя наличие подписей. В ходе сканирования Сергей установил, что в договорах № 12, 17, 32 и 45 отсутствуют нужные подписи. Рядом со сканером лежал листок, куда Сергей записывал номера этих договоров. Эти записи = логи, листок = лог-файл, а процесс записи = логирование. Благодаря "лог-файлу" Сергея старшему юристу не придётся вручную перелопачивать все 50 договоров.
🦅 Логи можно применять везде, где есть возможность записи в файл или в базу данных. Насколько мне известно по моей практике, между любыми двумя строчками/инструкциями кода можно впихнуть команду на логирование текущего состояния системы (разумеется, просто так это делать не нужно). Логировать можно даже стадии отработки узлов нейросетей, чтобы искать изъяны в их логике, а ведь они считаются довольно закрытыми системами.
🔬 Так что при грамотной архитектуре и логировании диджитализированное правосудие не будет котом в мешке или котом Шредингера. Да и вообще котом. В отличие от человека, который в послеобеденное время может (не отдавая ни себе, ни обществу отчёт) выносить более мягкие решения. Который может путать слова, цифры, эмоционально поддаваться на присутствие толпы за окном и ретранслировать в судебное решение многие другие иррациональные факторы.
🌧 часть 3 — безупречная отчётность компьютера
Предыдущий пост мог нагнать пессимизма в размышления о диджитализации правосудия. Дескать, алгоритмы всё равно будут непонятными и непрозрачными, невзирая на тщательно задокументированный код, ведь конечный пользователь не обязан разбираться в коде, чтобы понять правомерность цифрового решения. На самом деле, для обеспечения понятности работы программ существует логирование (запись, фиксация) "производимых действий", "принимаемых решений", а для обеспечения их прозрачности — вывод всех логов конечным пользователям.
Что такое логирование и логи?
Привожу пример из юридической практики.
🖨 Стажеру Сергею в гипотетической юридической фирме "Аспера" поручили отсканировать 50 договоров, попутно проверяя наличие подписей. В ходе сканирования Сергей установил, что в договорах № 12, 17, 32 и 45 отсутствуют нужные подписи. Рядом со сканером лежал листок, куда Сергей записывал номера этих договоров. Эти записи = логи, листок = лог-файл, а процесс записи = логирование. Благодаря "лог-файлу" Сергея старшему юристу не придётся вручную перелопачивать все 50 договоров.
🦅 Логи можно применять везде, где есть возможность записи в файл или в базу данных. Насколько мне известно по моей практике, между любыми двумя строчками/инструкциями кода можно впихнуть команду на логирование текущего состояния системы (разумеется, просто так это делать не нужно). Логировать можно даже стадии отработки узлов нейросетей, чтобы искать изъяны в их логике, а ведь они считаются довольно закрытыми системами.
🔬 Так что при грамотной архитектуре и логировании диджитализированное правосудие не будет котом в мешке или котом Шредингера. Да и вообще котом. В отличие от человека, который в послеобеденное время может (не отдавая ни себе, ни обществу отчёт) выносить более мягкие решения. Который может путать слова, цифры, эмоционально поддаваться на присутствие толпы за окном и ретранслировать в судебное решение многие другие иррациональные факторы.
Ⓜ️ Математику в каждый мозг по самое ЗНО
На прошлой неделе прогремела новость о том, что ЗНО по математике станет обязательным с 2021 года в Украине. К тому же, оно будет иметь два уровня сложности (на выбор).
Зачем? Перевожу цитату министра с источника: "Базовые навыки по математике необходимы каждому человеку — она развивает логическое и абстрактное мышление. А это навыки, которые нужны всем людям, и всё больше стран делают внешний экзамен по математике обязательным для всех детей после завершения школы". Также математика, наряду с английским языком, названа "чрезвычайно важной для человека, который хочет быть конкурентным в современном мире".
С одной стороны, это круто, одобряю. Но почему-то не даёт покоя одна мысль. Ведь кроме этого, знания биологии собственного тела важны для человека, который хочет оставаться жизнеспособным. И физика — тоже как бы наука о законах, которые действуют повсюду. И как раз задача школы — расчехлить новоиспечённого человека в минимальном наборе самых важных знаний, наработанных цивилизацией.
💻 Поэтому давайте к 2026-му году топить за ЗНО по кодингу. А к 2031-му — по экологии, как раз будет горячо.
#новости #news #математика
На прошлой неделе прогремела новость о том, что ЗНО по математике станет обязательным с 2021 года в Украине. К тому же, оно будет иметь два уровня сложности (на выбор).
Зачем? Перевожу цитату министра с источника: "Базовые навыки по математике необходимы каждому человеку — она развивает логическое и абстрактное мышление. А это навыки, которые нужны всем людям, и всё больше стран делают внешний экзамен по математике обязательным для всех детей после завершения школы". Также математика, наряду с английским языком, названа "чрезвычайно важной для человека, который хочет быть конкурентным в современном мире".
С одной стороны, это круто, одобряю. Но почему-то не даёт покоя одна мысль. Ведь кроме этого, знания биологии собственного тела важны для человека, который хочет оставаться жизнеспособным. И физика — тоже как бы наука о законах, которые действуют повсюду. И как раз задача школы — расчехлить новоиспечённого человека в минимальном наборе самых важных знаний, наработанных цивилизацией.
💻 Поэтому давайте к 2026-му году топить за ЗНО по кодингу. А к 2031-му — по экологии, как раз будет горячо.
#новости #news #математика
{kind=link}
🐟 О канале: веб-навигатор и посольство в Facebook
1. Каналу уже два месяца, а правила тегирования постов до сих пор не продуманы да и вообще тегирование я запорол изначально. Но взамен сделал веб-навигатор по постам канала, который буду обновлять раз в неделю. Здесь можно сразу увидеть, какие темы раскрыты и перейти в любой нужный пост. Да и если с каналом что-то случится, на этой странице будут дальнейшие координаты.
2. Также я открыл посольство в Facebook. Контент туда дублироваться не будет, максимум анонсы. Экспансия киберпространства продолжается. 😊
1. Каналу уже два месяца, а правила тегирования постов до сих пор не продуманы да и вообще тегирование я запорол изначально. Но взамен сделал веб-навигатор по постам канала, который буду обновлять раз в неделю. Здесь можно сразу увидеть, какие темы раскрыты и перейти в любой нужный пост. Да и если с каналом что-то случится, на этой странице будут дальнейшие координаты.
2. Также я открыл посольство в Facebook. Контент туда дублироваться не будет, максимум анонсы. Экспансия киберпространства продолжается. 😊
{kind=link}
👁 Держава прозревает: машиночитабельные уставы
На этой неделе мы стали свидетелями знакового события: правительство Украины утвердило машиночитабельный модельный устав. Я узнал об этом из статьи Никиты Подгайного. Денис Иванов объяснил глобальное значение этого события. А я по привычке хочу пройтись по некоторым техвопросам.
1️⃣ Как это будет/может выглядеть?
На картинках в тексте Никиты изображен JSON. Я о нём здесь ещё не писал, поэтому простыми словами: JSON — это один из популярных способов объединять и структурировать данные, чтобы они были "понятны" компьютеру и в то же время удобно воспринимались человеком. Но пока неизвестно, будет ли этот сервис генерировать именно JSON-ы. Может, цифровой код действительно окажется "цифровым" кодом. Тогда получится, что однажды в 2020-м году будет заключена сделка между ТОВ с модельным уставом редакции 112131213 и ТОВ с модельным уставом редакции 121112212.
2️⃣ Может ли быть несколько модельных уставов в одном государстве?
Конечно. "Модельный" не значит "единственный". В этом случае "модель" скорее означает "версия". А для того, чтобы идентифицировать модель, не обязательно изучать экземпляр устава побуквенно, для этого как раз и будет цифровой код (аки номер версии). Ведь проще сказать "у меня Audi A7 2.8 FSI", чем описывать мощность двигателя, тип трансмисии и ряд других параметров.
3️⃣ Что дальше?
Это можно применить не только к уставам юрлиц. Через это можно пропустить огромное количество документов. И дело не только в шаблонизации как упрощении процедуры создания документа. Можно прийти к тому, чтобы не плодить сотни одинаковых документов (где отличается зачастую только дата и имена), а вместо этого формировать указатели на них, например: приказ_об_увольнении(142, "Гусачок Григорий Семёнович", "06.05.2019" ... ). Видите, выглядит как функция, в которую первым параметром передаём цифровой код, а дальше перечисляем нужные фактические данные, которые должны попасть в этот документ (имя увольняемого, дата увольнения и т.д.). Таким образом, сотню "приказов об увольнении" можно будет записать в столбик на нескольких А4.
Видите, чтобы сделать общество счастливее, не обязательно упарываться в блокчейн и нейросети. Less is more. Будем внимательно следить за диджитализацией этого вопроса.
На этой неделе мы стали свидетелями знакового события: правительство Украины утвердило машиночитабельный модельный устав. Я узнал об этом из статьи Никиты Подгайного. Денис Иванов объяснил глобальное значение этого события. А я по привычке хочу пройтись по некоторым техвопросам.
1️⃣ Как это будет/может выглядеть?
На картинках в тексте Никиты изображен JSON. Я о нём здесь ещё не писал, поэтому простыми словами: JSON — это один из популярных способов объединять и структурировать данные, чтобы они были "понятны" компьютеру и в то же время удобно воспринимались человеком. Но пока неизвестно, будет ли этот сервис генерировать именно JSON-ы. Может, цифровой код действительно окажется "цифровым" кодом. Тогда получится, что однажды в 2020-м году будет заключена сделка между ТОВ с модельным уставом редакции 112131213 и ТОВ с модельным уставом редакции 121112212.
2️⃣ Может ли быть несколько модельных уставов в одном государстве?
Конечно. "Модельный" не значит "единственный". В этом случае "модель" скорее означает "версия". А для того, чтобы идентифицировать модель, не обязательно изучать экземпляр устава побуквенно, для этого как раз и будет цифровой код (аки номер версии). Ведь проще сказать "у меня Audi A7 2.8 FSI", чем описывать мощность двигателя, тип трансмисии и ряд других параметров.
3️⃣ Что дальше?
Это можно применить не только к уставам юрлиц. Через это можно пропустить огромное количество документов. И дело не только в шаблонизации как упрощении процедуры создания документа. Можно прийти к тому, чтобы не плодить сотни одинаковых документов (где отличается зачастую только дата и имена), а вместо этого формировать указатели на них, например: приказ_об_увольнении(142, "Гусачок Григорий Семёнович", "06.05.2019" ... ). Видите, выглядит как функция, в которую первым параметром передаём цифровой код, а дальше перечисляем нужные фактические данные, которые должны попасть в этот документ (имя увольняемого, дата увольнения и т.д.). Таким образом, сотню "приказов об увольнении" можно будет записать в столбик на нескольких А4.
Видите, чтобы сделать общество счастливее, не обязательно упарываться в блокчейн и нейросети. Less is more. Будем внимательно следить за диджитализацией этого вопроса.
ТОП-50 юрбиза + ненапряжный кодинг = 🍑
Только что в рамках Общества Мёртвых Юристов мы запустили первый веб-проект. Типа тайное делаем явным, а запутанное — подсчитанным. Как оказалось, есть у "высшей лиги" нашего юрбиза свои причуды. Уверен: рейтинг, основанный на данных, будет более объективным, нежели закулисные поделки.
⚙️ Технически он не был сложным, понадобилось всего лишь:
1) данные из Excel перенести в базу данных MySQL;
2) выводить данные на веб-интерфейс, умножать, сравнивать, высчитывать проценты;
3) упорядочивать данные и скармливать их библиотеке Chart.js согласно документации;
4) немного покреативить с визуализацией "корпоративного ландшафта" юрбиза;
5) прислушиваться к толковому дизайнеру и вносить правки.
У меня это заняло три-четыре недели размеренного кодинга. Но как написал Дима, работа шла "несколько сраных месяцев" (по ходу, данные собирали, а меня подключили в конце). На выходе имеем амбициозный журналистский проект с почти BigData-основой. Дальше — больше.
Как оно вам?
Только что в рамках Общества Мёртвых Юристов мы запустили первый веб-проект. Типа тайное делаем явным, а запутанное — подсчитанным. Как оказалось, есть у "высшей лиги" нашего юрбиза свои причуды. Уверен: рейтинг, основанный на данных, будет более объективным, нежели закулисные поделки.
⚙️ Технически он не был сложным, понадобилось всего лишь:
1) данные из Excel перенести в базу данных MySQL;
2) выводить данные на веб-интерфейс, умножать, сравнивать, высчитывать проценты;
3) упорядочивать данные и скармливать их библиотеке Chart.js согласно документации;
4) немного покреативить с визуализацией "корпоративного ландшафта" юрбиза;
5) прислушиваться к толковому дизайнеру и вносить правки.
У меня это заняло три-четыре недели размеренного кодинга. Но как написал Дима, работа шла "несколько сраных месяцев" (по ходу, данные собирали, а меня подключили в конце). На выходе имеем амбициозный журналистский проект с почти BigData-основой. Дальше — больше.
Как оно вам?
{kind=link}
КАК Я ВОШЁЛ В АЙТИ.
ЧАСТЬ 5. Закрытие первого крупного проекта. И второго. 📉
В прошлом рассказе я подошёл к сентябрю 2017 года. Примерно 5 числа состоялся релиз того самого конструктора ботов-генераторов документов. Появились юзеры-первопроходцы. И вместе с ними — вполне заслуженные жалобы на интерфейс, юзабилити и т.д. Но тем не менее, у кого-то получилось этим пользоваться. Поэтому мы в рамках серии аксоновских фриколоерингов даже проводили конкурс на создание наилучшего бота на этой платформе. Во Львове вручили приз победителю.
Но через некоторое время мы этот сервис закрыли. Почему? Параллельно к небу воспарила платформа ботоделов-майндмепистов, на которой можно создавать нелинейных чат-ботов без кодинга. И в таких условиях держаться за проект, который технически и морально позади нормального WYSIWYG решения я не видел смысла.
🧟♂️=>🦸♂️ Этой же осенью, пользуясь новообретёнными знаниями JavaScript, HTML и CSS, я переделал нашего веб-бота Франка (который делал политики приватности). Получилось красиво, но показать уже не могу, так как этот проект мы тоже закрыли. Почему? Началась эра GDPR, с вопросами приватности всё стало чуточку сложнее, и мы как эту услугу стали предоставлять довольно щепетильно и с индивидуальным подходом, который непросто алгоритмизировать.
Параллельно у нас в компании обострялся вопрос с организацией собственной юридической базы знаний, это был прямой вызов мне, поэтому я всё больше думал уже об этом.
🗺 Путь в айти: ч.1, ч.2, ч.3, ч.4
ЧАСТЬ 5. Закрытие первого крупного проекта. И второго. 📉
В прошлом рассказе я подошёл к сентябрю 2017 года. Примерно 5 числа состоялся релиз того самого конструктора ботов-генераторов документов. Появились юзеры-первопроходцы. И вместе с ними — вполне заслуженные жалобы на интерфейс, юзабилити и т.д. Но тем не менее, у кого-то получилось этим пользоваться. Поэтому мы в рамках серии аксоновских фриколоерингов даже проводили конкурс на создание наилучшего бота на этой платформе. Во Львове вручили приз победителю.
Но через некоторое время мы этот сервис закрыли. Почему? Параллельно к небу воспарила платформа ботоделов-майндмепистов, на которой можно создавать нелинейных чат-ботов без кодинга. И в таких условиях держаться за проект, который технически и морально позади нормального WYSIWYG решения я не видел смысла.
🧟♂️=>🦸♂️ Этой же осенью, пользуясь новообретёнными знаниями JavaScript, HTML и CSS, я переделал нашего веб-бота Франка (который делал политики приватности). Получилось красиво, но показать уже не могу, так как этот проект мы тоже закрыли. Почему? Началась эра GDPR, с вопросами приватности всё стало чуточку сложнее, и мы как эту услугу стали предоставлять довольно щепетильно и с индивидуальным подходом, который непросто алгоритмизировать.
Параллельно у нас в компании обострялся вопрос с организацией собственной юридической базы знаний, это был прямой вызов мне, поэтому я всё больше думал уже об этом.
🗺 Путь в айти: ч.1, ч.2, ч.3, ч.4
⛓ Почему не нужно бояться КЭП, то есть ЭЦП
Сталкиваюсь с тем, что многие люди, включая студентов юрфака, незнакомы с ЭЦП — электронной цифровой подписью (с недавних пор юридически правильно говорить КЭП — квалифицированная электронная подпись). А ведь она обретает всё большую роль в диджитализации права и государства. Например, только с КЭП можно попасть в электронный кабинет налогоплательщика, электронный суд и некоторые другие лигалтек-решения государства.
🚟 В канале о юрне вышел хороший пост об этом инструменте, а я хотел бы прояснить его техническую философию.
На первый взгляд, КЭП — файлик непонятного формата (например, .dat или .jks) на флешке, который был "сделан" в налоговой, скачан в "Приват24" или получен другим способом. Но это не так. Подпись — не сам файлик. Почему это круче, чем подпись ручкой на бумаге?
🖊 Когда вы подписываете документ (а точнее, лист бумаги) ручкой, то подписью становится горстка чернил, попавших на лист. И вы этой подписью в лучшем случае подтверждаете лишь факт того, что вы её поставили в этом конкретном участке листа. Ни за что другое ни вы, ни эта подпись не можете ручаться. Ведь эта подпись не взаимодействует с информацией на документе; факт постановки вами этой подписи не препятствует дальнейшему изменению/появлению данных на этом листе. Такая подпись — это лишь безвольное молчаливое свидетельство того, что когда-то кем-то она была здесь поставлена.
🧮 Процесс подписания документа КЭП намного более глубок и интеллектуален, нежели дублирование наскальной живописи с первых страниц наших паспортов. При таком подписании происходит некоторая магия, благодаря которой:
1. Подтверждается, что это именно ваша подпись.
2. Фиксируется момент времени подписания.
3. Фиксируется содержимое документа, который вы подписали. Если после подписания кто-то изменит документ, то это сразу же выяснится при проверке подписи. Интересно, почему? Можете читать дальше.
КЭП придумали не на пустом месте, она связана с хешированием. Не вдаваясь в пространные многословные определения, объясняю на упрощённом примере:
содержимое документа: "Я должен вернуть Грише 200 долларов."
хеш этого содержимого: n3ioG2n5b0PflsBt38
подписываю КЭП этот хеш: oN38gDTr3743Qn3Nfwj492nd
Гриша меняет содержание документа: "Я должен вернуть Грише 2000 долларов."
хеш этого содержимого уже другой: u11Rjkn05njkdnklPy
соответственно, моя подпись должна была бы выглядеть иначе: aA84kBrd09h3ifdSdG30ud772jsF
При проверке это сразу выяснится, и я заподозрю неладное.
На практике эти процессы более сложные и надёжные. Главное не хранить КЭП-файл и пароль от него где попало. 🙂
Сталкиваюсь с тем, что многие люди, включая студентов юрфака, незнакомы с ЭЦП — электронной цифровой подписью (с недавних пор юридически правильно говорить КЭП — квалифицированная электронная подпись). А ведь она обретает всё большую роль в диджитализации права и государства. Например, только с КЭП можно попасть в электронный кабинет налогоплательщика, электронный суд и некоторые другие лигалтек-решения государства.
🚟 В канале о юрне вышел хороший пост об этом инструменте, а я хотел бы прояснить его техническую философию.
На первый взгляд, КЭП — файлик непонятного формата (например, .dat или .jks) на флешке, который был "сделан" в налоговой, скачан в "Приват24" или получен другим способом. Но это не так. Подпись — не сам файлик. Почему это круче, чем подпись ручкой на бумаге?
🖊 Когда вы подписываете документ (а точнее, лист бумаги) ручкой, то подписью становится горстка чернил, попавших на лист. И вы этой подписью в лучшем случае подтверждаете лишь факт того, что вы её поставили в этом конкретном участке листа. Ни за что другое ни вы, ни эта подпись не можете ручаться. Ведь эта подпись не взаимодействует с информацией на документе; факт постановки вами этой подписи не препятствует дальнейшему изменению/появлению данных на этом листе. Такая подпись — это лишь безвольное молчаливое свидетельство того, что когда-то кем-то она была здесь поставлена.
🧮 Процесс подписания документа КЭП намного более глубок и интеллектуален, нежели дублирование наскальной живописи с первых страниц наших паспортов. При таком подписании происходит некоторая магия, благодаря которой:
1. Подтверждается, что это именно ваша подпись.
2. Фиксируется момент времени подписания.
3. Фиксируется содержимое документа, который вы подписали. Если после подписания кто-то изменит документ, то это сразу же выяснится при проверке подписи. Интересно, почему? Можете читать дальше.
КЭП придумали не на пустом месте, она связана с хешированием. Не вдаваясь в пространные многословные определения, объясняю на упрощённом примере:
содержимое документа: "Я должен вернуть Грише 200 долларов."
хеш этого содержимого: n3ioG2n5b0PflsBt38
подписываю КЭП этот хеш: oN38gDTr3743Qn3Nfwj492nd
Гриша меняет содержание документа: "Я должен вернуть Грише 2000 долларов."
хеш этого содержимого уже другой: u11Rjkn05njkdnklPy
соответственно, моя подпись должна была бы выглядеть иначе: aA84kBrd09h3ifdSdG30ud772jsF
При проверке это сразу выяснится, и я заподозрю неладное.
На практике эти процессы более сложные и надёжные. Главное не хранить КЭП-файл и пароль от него где попало. 🙂
Telegram
Юрня, дно і нелогічність
Якщо ви підписали договір ЕЦП (КЕП), то друкувати чи зберігати його у паперовому вигляді непотрібно 👌
Для тих, хто не знає, що таке електронний цифровий підпис чи кваліфікований електронний підпис, ось тут є інтро. Як прочитаєте, повертайтесь.
Отже:
1.…
Для тих, хто не знає, що таке електронний цифровий підпис чи кваліфікований електронний підпис, ось тут є інтро. Як прочитаєте, повертайтесь.
Отже:
1.…
🍯 Как юристу заработать на автоматизации
часть 1 — формируем картину настоящего и будущего
Disclaimer: Нижеследующие размышления не связаны с моей практикой, все совпадения случайны. Поехали.
Гипотетически представим ваш расклад до автоматизации:
▪️ вы многопрофильный юрист и у вас есть один вид задач, механизм выполнения которых вы отточили — создание несложных документов;
▪️ клиент даёт данные, а вы: в зависимости от сочетания двух обстоятельств, указанных в этих же данных, выбираете 1 из 5 возможных шаблонов, вносите в него эти данные и отправляете клиенту;
▪️ за 1 такой документ вы получаете 8 долларов (~ 208 гривен);
▪️ таких документов в день в среднем 2, каждый занимает по 25 минут времени (21 на создание, 4 на вычитку);
▪️ итак, в день вы тратите 50 минут, зарабатывая 16 долларов; иначе говоря, трата времени и сил на эту задачу приносит вам 1 доллар примерно каждые 3 минуты.
Представим ваш расклад после автоматизации:
▫️ имея представление о технологиях, вы прикинули, что, щёлкая по кнопочкам интерфейса, вы будете создавать такой документ не за 25 минут, а в среднем за 6 минут (2 на создание, 4 на вычитку);
▫️ вы понимаете, что на эту же задачу будет уходить почти в 4 раза меньше времени;
▫️ итак, в день вы будете тратить в среднем 12 минут, зарабатывая те же 16 долларов; иначе говоря, теперь каждые 45 секунд приносят вам 1 доллар;
▫️ но при этом больше таких документов в "сэкономленные" 38 минут ( 50 - 12 = 38 ) вы всунуть не сможете, ибо эти заказы не стоят у вас в очереди, а появляются в среднем дважды в день.
🤔 Выглядит приятно. Но теперь нужно прикинуть, сколько времени и средств вы потратите на перекидывание этого моста из настоящего в будущее — разработку продукта (интерфейса с кнопочками). Нутро подсказывает вам (и весьма правильно), что тут одним интерфейсом не обойтись, ведь вам нужно, чтобы генерировались готовые файлы в формате .docx, которые вы затем будете 4 минуты вычитывать. Вы дорожите своей репутацией и не будете отсылать клиенту невычитанный документ, а вычитывать быстрее у вас не получается.
😳 И, когда продукт будет готов, вы допускаете, что иногда могут вылезать какие-то неприятности и неучтённые на этапе разработки нюансы, которые поначалу будут усложнять подготовку отдельных документов. Если это будет часто, вы можете нервничать и даже иногда делать работу "с нуля по старинке". В итоге можете даже пожалеть о таком "инноваторстве", вернуться в прошлое и сжечь мост.
Поэтому, чтобы не сжигались мосты, в следующем посте продолжу размышления и подсчёты.
#автоматизация #заработок #деньги
часть 1 — формируем картину настоящего и будущего
Disclaimer: Нижеследующие размышления не связаны с моей практикой, все совпадения случайны. Поехали.
Гипотетически представим ваш расклад до автоматизации:
▪️ вы многопрофильный юрист и у вас есть один вид задач, механизм выполнения которых вы отточили — создание несложных документов;
▪️ клиент даёт данные, а вы: в зависимости от сочетания двух обстоятельств, указанных в этих же данных, выбираете 1 из 5 возможных шаблонов, вносите в него эти данные и отправляете клиенту;
▪️ за 1 такой документ вы получаете 8 долларов (~ 208 гривен);
▪️ таких документов в день в среднем 2, каждый занимает по 25 минут времени (21 на создание, 4 на вычитку);
▪️ итак, в день вы тратите 50 минут, зарабатывая 16 долларов; иначе говоря, трата времени и сил на эту задачу приносит вам 1 доллар примерно каждые 3 минуты.
Представим ваш расклад после автоматизации:
▫️ имея представление о технологиях, вы прикинули, что, щёлкая по кнопочкам интерфейса, вы будете создавать такой документ не за 25 минут, а в среднем за 6 минут (2 на создание, 4 на вычитку);
▫️ вы понимаете, что на эту же задачу будет уходить почти в 4 раза меньше времени;
▫️ итак, в день вы будете тратить в среднем 12 минут, зарабатывая те же 16 долларов; иначе говоря, теперь каждые 45 секунд приносят вам 1 доллар;
▫️ но при этом больше таких документов в "сэкономленные" 38 минут ( 50 - 12 = 38 ) вы всунуть не сможете, ибо эти заказы не стоят у вас в очереди, а появляются в среднем дважды в день.
🤔 Выглядит приятно. Но теперь нужно прикинуть, сколько времени и средств вы потратите на перекидывание этого моста из настоящего в будущее — разработку продукта (интерфейса с кнопочками). Нутро подсказывает вам (и весьма правильно), что тут одним интерфейсом не обойтись, ведь вам нужно, чтобы генерировались готовые файлы в формате .docx, которые вы затем будете 4 минуты вычитывать. Вы дорожите своей репутацией и не будете отсылать клиенту невычитанный документ, а вычитывать быстрее у вас не получается.
😳 И, когда продукт будет готов, вы допускаете, что иногда могут вылезать какие-то неприятности и неучтённые на этапе разработки нюансы, которые поначалу будут усложнять подготовку отдельных документов. Если это будет часто, вы можете нервничать и даже иногда делать работу "с нуля по старинке". В итоге можете даже пожалеть о таком "инноваторстве", вернуться в прошлое и сжечь мост.
Поэтому, чтобы не сжигались мосты, в следующем посте продолжу размышления и подсчёты.
#автоматизация #заработок #деньги