
🗝 Подсказка к задаче палиндрома
Есть в языках программирования такая штука, как деление с остатком, а то, что мы с его помощью делаем, называется взятие остатка или деление по модулю. Оно выводит либо остаток, который возникает при делении чисел, либо ноль.
🐗 Я условно стал называть это пятым арифметическим действием (вот же неграмотный!), потому что в трёх моих любимых языках программирования (JavaScript, PHP и Python) оно записывается при помощи знака "%":
4 % 2 = 0, потому что 4 / 2 = 2, то есть в остатке ноль,
5 % 2 = 1, потому что 5 / 2 = 2 и в остаток идёт единица.
Зачем выделили под это отдельный знак? Ну, в коде проще записать result = 5 % 2; , чем:
1) result = 5 - 5 / 2 * 2, если деление целых чисел не приводит к получению дробного результата;
2) result = 5 - floor( 5 / 2 ) * 2, если появляется дробный результат, который нужно округлить.
🔎 Зачем это нужно и как это поможет решить задачу палиндрома?
У взятия остатка есть прекрасное свойство, благодаря которому можно легко получить последнюю цифру числа, поделив его с остатком на 10. Например, 245 % 10 = 5, 248 % 10 = 8. То есть это значит, что проблема вычленения нужной цифры — это не проблема.
А ещё деление с остатком на 2 позволяет определить, является число чётным или нечётным:
5 % 2 = 1, 7 % 2 = 1, 131 % 2 = 1, то есть нечётные числа всегда продуцируют единицу;
4 % 2 = 0; 6 % 2 = 0; 132 % 2 = 0, то есть чётные числа всегда продуцируют ноль.
Ещё подсказка: исходите из определения палиндрома и тех его свойств, которые из этого вытекают.
Как успехи с палиндромом?)
🆗 — что-то есть; ⛔️ — не хочу
Есть в языках программирования такая штука, как деление с остатком, а то, что мы с его помощью делаем, называется взятие остатка или деление по модулю. Оно выводит либо остаток, который возникает при делении чисел, либо ноль.
🐗 Я условно стал называть это пятым арифметическим действием (вот же неграмотный!), потому что в трёх моих любимых языках программирования (JavaScript, PHP и Python) оно записывается при помощи знака "%":
4 % 2 = 0, потому что 4 / 2 = 2, то есть в остатке ноль,
5 % 2 = 1, потому что 5 / 2 = 2 и в остаток идёт единица.
Зачем выделили под это отдельный знак? Ну, в коде проще записать result = 5 % 2; , чем:
1) result = 5 - 5 / 2 * 2, если деление целых чисел не приводит к получению дробного результата;
2) result = 5 - floor( 5 / 2 ) * 2, если появляется дробный результат, который нужно округлить.
🔎 Зачем это нужно и как это поможет решить задачу палиндрома?
У взятия остатка есть прекрасное свойство, благодаря которому можно легко получить последнюю цифру числа, поделив его с остатком на 10. Например, 245 % 10 = 5, 248 % 10 = 8. То есть это значит, что проблема вычленения нужной цифры — это не проблема.
А ещё деление с остатком на 2 позволяет определить, является число чётным или нечётным:
5 % 2 = 1, 7 % 2 = 1, 131 % 2 = 1, то есть нечётные числа всегда продуцируют единицу;
4 % 2 = 0; 6 % 2 = 0; 132 % 2 = 0, то есть чётные числа всегда продуцируют ноль.
Ещё подсказка: исходите из определения палиндрома и тех его свойств, которые из этого вытекают.
Как успехи с палиндромом?)
🆗 — что-то есть; ⛔️ — не хочу
💠 Решение задачи с палиндромом
1. Смотрим внимательно дефиниции/свойства, чтобы найти зацепки: палиндром (число) — это число, которое читается одинаково в обоих направлениях, то есть которое будет равно числу, составленному из его цифр задом наперёд. Значит, его последняя цифра равна первой, предпоследняя — второй и т.д. И это правило соблюдается вплоть до центра этого числа, которым может быть одинокая цифра (212, 151, 11011) или же пара цифр (1221, 338833). Итак, мы можем сравнивать поочерёдно первую и последнюю цифры, а затем откидывать их... Но стоп... Кажется, я зашёл слишком далеко. Вернусь в начало.
2. ... читается одинаково в обоих направлениях. Значит, нужно записать его (далее — Старое число) задом наперёд, получив таким образом его зеркальное отражение (далее — Новое число) и сравнить их. Как это сделать? Проговариваю буквально:
0️⃣ буду оперировать Старым и Новым числами;
1️⃣ беру последнюю цифру Старого числа;
2️⃣ прибавляю её к телу Нового числа;
3️⃣ выкидываю её из Старого числа;
🔁 повторяю действия 1️⃣, 2️⃣, 3️⃣, пока в Старом числе не иссякнут цифры;
4️⃣ сравниваю Старое и Новое числа: если они равны, то это палиндром.
3. Вот воплощение этого алгоритма в виде кода на JavaScript:
0️⃣ let numberOldTest = numberOld;
let numberNew = 0; (подготовительная стадия, необходимая для работы)
🔁 while( numberOldTest > 0 ){
1️⃣ digitLast = numberOldTest % 10; (вот к чему относится вчерашняя подсказка)
2️⃣ numberNew = numberNew * 10 + digitLast; (чтобы цифры не суммировались арифметически, нужно повышать разряд числа, умножая основу на 10)
3️⃣ numberOldTest = Math.floor( numberOldTest / 10 ); (тут нужно округлять вниз, чтоб избавиться от дроби)
}
4️⃣ if( numberOld == numberNew ){ alert("это палиндром"); }
Вот и всё. А ведь я на старте чуть не переусложнил решение задачи. Ведь также можно путём математических ухищрений брать первую и последнюю цифры Старого числа и сравнивать их. Затем, если они равны, отбрасывать их (опять-таки, первую сложнее отбросить). И так двигаться до середины числа. И ещё нужно учитывать, что число может состоять как с парного, так и непарного количества цифр. А ещё есть и другие математические способы, просто логика работы и код будут сложнее.
А что получилось у вас? Было ли полезно?
1. Смотрим внимательно дефиниции/свойства, чтобы найти зацепки: палиндром (число) — это число, которое читается одинаково в обоих направлениях, то есть которое будет равно числу, составленному из его цифр задом наперёд. Значит, его последняя цифра равна первой, предпоследняя — второй и т.д. И это правило соблюдается вплоть до центра этого числа, которым может быть одинокая цифра (212, 151, 11011) или же пара цифр (1221, 338833). Итак, мы можем сравнивать поочерёдно первую и последнюю цифры, а затем откидывать их... Но стоп... Кажется, я зашёл слишком далеко. Вернусь в начало.
2. ... читается одинаково в обоих направлениях. Значит, нужно записать его (далее — Старое число) задом наперёд, получив таким образом его зеркальное отражение (далее — Новое число) и сравнить их. Как это сделать? Проговариваю буквально:
0️⃣ буду оперировать Старым и Новым числами;
1️⃣ беру последнюю цифру Старого числа;
2️⃣ прибавляю её к телу Нового числа;
3️⃣ выкидываю её из Старого числа;
🔁 повторяю действия 1️⃣, 2️⃣, 3️⃣, пока в Старом числе не иссякнут цифры;
4️⃣ сравниваю Старое и Новое числа: если они равны, то это палиндром.
3. Вот воплощение этого алгоритма в виде кода на JavaScript:
0️⃣ let numberOldTest = numberOld;
let numberNew = 0; (подготовительная стадия, необходимая для работы)
🔁 while( numberOldTest > 0 ){
1️⃣ digitLast = numberOldTest % 10; (вот к чему относится вчерашняя подсказка)
2️⃣ numberNew = numberNew * 10 + digitLast; (чтобы цифры не суммировались арифметически, нужно повышать разряд числа, умножая основу на 10)
3️⃣ numberOldTest = Math.floor( numberOldTest / 10 ); (тут нужно округлять вниз, чтоб избавиться от дроби)
}
4️⃣ if( numberOld == numberNew ){ alert("это палиндром"); }
Вот и всё. А ведь я на старте чуть не переусложнил решение задачи. Ведь также можно путём математических ухищрений брать первую и последнюю цифры Старого числа и сравнивать их. Затем, если они равны, отбрасывать их (опять-таки, первую сложнее отбросить). И так двигаться до середины числа. И ещё нужно учитывать, что число может состоять как с парного, так и непарного количества цифр. А ещё есть и другие математические способы, просто логика работы и код будут сложнее.
А что получилось у вас? Было ли полезно?
Первый короткий пост на канале: ОПРОС
🏔 Народ, контента много и его ещё можно создавать и создавать, ибо право и программирование — это две очень благодатные нивы, полные загадок и свершений. Перед тем, как самозабвенно упарываться дальше, мне ценно услышать, что вас сейчас интересует больше всего:
1) элементы сугубо кодинга: переменные, классы, циклы, обработка ошибок, виды ошибок, отладчики и прочее;
2) алгоритмизация правовых процессов — примеры, подходы, идеи и прочее;
3) какие-то истории, факапы, личный опыт.
P.S. Очень круто, что всё больше людей начинает комментировать происходящее, причём приводя свои решения в виде кода. Давайте продолжать. 🎉
Пишите в комменты )
#опрос
🏔 Народ, контента много и его ещё можно создавать и создавать, ибо право и программирование — это две очень благодатные нивы, полные загадок и свершений. Перед тем, как самозабвенно упарываться дальше, мне ценно услышать, что вас сейчас интересует больше всего:
1) элементы сугубо кодинга: переменные, классы, циклы, обработка ошибок, виды ошибок, отладчики и прочее;
2) алгоритмизация правовых процессов — примеры, подходы, идеи и прочее;
3) какие-то истории, факапы, личный опыт.
P.S. Очень круто, что всё больше людей начинает комментировать происходящее, причём приводя свои решения в виде кода. Давайте продолжать. 🎉
Пишите в комменты )
#опрос
КАК Я ВОШЁЛ В АЙТИ.
ЧАСТЬ 1. Игрульки и отказ от юридических тасков. 🤓
Спасибо за комментарии! Окей, расскажу сначала немного о своём бэкграунде.
🐣 Если не считать Pascal в лицее и немножко C++ на курсах (где вершиной моего познания стал палиндром и вложенные циклы для решения двумерных задач), то вменяемо программировать я начал в программе для ... создания игр. Это Construct 2, в ней практически не нужно писать код, вместо этого из блоков выстраиваются схемы по типу "событие — действие", "событие — проверка условий — действие" и т.д. То есть изначально я (наверное, как и многие), хотел создавать свои игры, это была реальная мотивация забивать свою голову всякой дичью в виде оптимизации, совместимости, компиляции и прочего. Но до конца я (наверное, как и многие) ни один проект не довёл, у меня там накопилось где-то 15 заготовок. Причём под конец я начал экспериментировать и смешивать жанры, например "тетрис-теннис с элементами RPG в духе World of Warcraft". Кстати, заниматься этим было особенно интересно во время унылых лекций на юрфаке.
🗽 После стажировки в юрфирме Axon Partners в конце 2016-го я обнаглел настолько, что предложил заняться лигалтеком прямо под Новый год, хотя ещё плохо понимал, что это такое (и вообще ещё не было решено, будут ли со мной сотрудничать дальше). И когда решили-таки сотрудничать, самое прикольное то, что первые три лигалтек-проекта я делал в этой программе аж до сентября 2017-го, нагло симулируя с её помощью веб-сайты. Она поддерживала компиляцию в html-файлы, но там были проблемы с вёрсткой, которые я не мог преодолеть, потому что а) не знал HTML и б) кое-что нельзя было преодолеть. Поэтому первые три лигалтек-проекта были уродливы, как не знаю что.
🥀 Итак, благодаря Construct 2 я почти сразу смог отказаться от юридических тасков в Аксоне. Почти сразу, потому что какой-то стрёмный рисёрч успел оставить легалистский шрам в моей душе. И спустя две-три недели Дима Гадомский вручил мне лигалинженерскую рясу, которую я ношу и по сей день. Дальше расскажу о том, какой язык программирования стал моим первым рабочим.
ЧАСТЬ 1. Игрульки и отказ от юридических тасков. 🤓
Спасибо за комментарии! Окей, расскажу сначала немного о своём бэкграунде.
🐣 Если не считать Pascal в лицее и немножко C++ на курсах (где вершиной моего познания стал палиндром и вложенные циклы для решения двумерных задач), то вменяемо программировать я начал в программе для ... создания игр. Это Construct 2, в ней практически не нужно писать код, вместо этого из блоков выстраиваются схемы по типу "событие — действие", "событие — проверка условий — действие" и т.д. То есть изначально я (наверное, как и многие), хотел создавать свои игры, это была реальная мотивация забивать свою голову всякой дичью в виде оптимизации, совместимости, компиляции и прочего. Но до конца я (наверное, как и многие) ни один проект не довёл, у меня там накопилось где-то 15 заготовок. Причём под конец я начал экспериментировать и смешивать жанры, например "тетрис-теннис с элементами RPG в духе World of Warcraft". Кстати, заниматься этим было особенно интересно во время унылых лекций на юрфаке.
🗽 После стажировки в юрфирме Axon Partners в конце 2016-го я обнаглел настолько, что предложил заняться лигалтеком прямо под Новый год, хотя ещё плохо понимал, что это такое (и вообще ещё не было решено, будут ли со мной сотрудничать дальше). И когда решили-таки сотрудничать, самое прикольное то, что первые три лигалтек-проекта я делал в этой программе аж до сентября 2017-го, нагло симулируя с её помощью веб-сайты. Она поддерживала компиляцию в html-файлы, но там были проблемы с вёрсткой, которые я не мог преодолеть, потому что а) не знал HTML и б) кое-что нельзя было преодолеть. Поэтому первые три лигалтек-проекта были уродливы, как не знаю что.
🥀 Итак, благодаря Construct 2 я почти сразу смог отказаться от юридических тасков в Аксоне. Почти сразу, потому что какой-то стрёмный рисёрч успел оставить легалистский шрам в моей душе. И спустя две-три недели Дима Гадомский вручил мне лигалинженерскую рясу, которую я ношу и по сей день. Дальше расскажу о том, какой язык программирования стал моим первым рабочим.
КАК Я ВОШЁЛ В АЙТИ.
ЧАСТЬ 2. Первые три проекта и первый язык программирования. 😎
🗺 1-й проект: им стала интерактивная юридическая карта мира для разных видов бизнеса с фильтрацией по налогам, условиям открытия и поддержания компаний и т.д. Через две недели я принёс прототип в Construct 2, мы начали его наполнять содержимым и экспериментировать. Тут не требовалось никакого сложного программирования, просто распределение данных по группам и их визуальное представление. Но внезапно мы этот проект отложили в сторону, потому что переключились на второй.
🧟♂️ 2-й проект: когда Google объявили, что будут баниться приложения, не имеющие политики приватности, мы сразу же взялись решить эту проблему. За три дня сделали конструктор политик приватности, один из первых вебботов украинского лигалтека — Privacy Policy Bot, он же Франк. Запустили 13 февраля 2017. Он выглядел страшно, в первый день на нём подвисали кнопки, но он работал. Через несколько дней мы выпустили апдейт, в котором вы могли этот же документ получить в фановом виде: он был напикан шутками на английском языке, которые не исключали его юридическое значение. В эти дни я узнал, что такое хостинг и как его настраивать, а также понял, что на первом месте должна быть безотказность софта, а уже затем красивенькие анимации.
🛠 3-й проект: когда подошло время вернуться к 1-му проекту, Дима Гадомский поинтересовался, смогу ли я сделать конструктор таких ботов, как Франк, чтобы и другие юристы могли клепать такие вещи. Я написал в чате, что подумаю. Через 40 минут я сказал, что это возможно. В этот же день началась разработка, растянувшаяся на полгода. Через несколько дней наткнулся на проблему сохранения пользовательских данных на сервере. И вот на форуме Construct 2 нахожу инструкцию о том, как должен выглядеть делающий это скрипт на PHP. Вот так вопрос выбора языка программирования для дальнейшей работы решился сам собой. А к первому проекту мы так и не вернулись.
ЧАСТЬ 2. Первые три проекта и первый язык программирования. 😎
🗺 1-й проект: им стала интерактивная юридическая карта мира для разных видов бизнеса с фильтрацией по налогам, условиям открытия и поддержания компаний и т.д. Через две недели я принёс прототип в Construct 2, мы начали его наполнять содержимым и экспериментировать. Тут не требовалось никакого сложного программирования, просто распределение данных по группам и их визуальное представление. Но внезапно мы этот проект отложили в сторону, потому что переключились на второй.
🧟♂️ 2-й проект: когда Google объявили, что будут баниться приложения, не имеющие политики приватности, мы сразу же взялись решить эту проблему. За три дня сделали конструктор политик приватности, один из первых вебботов украинского лигалтека — Privacy Policy Bot, он же Франк. Запустили 13 февраля 2017. Он выглядел страшно, в первый день на нём подвисали кнопки, но он работал. Через несколько дней мы выпустили апдейт, в котором вы могли этот же документ получить в фановом виде: он был напикан шутками на английском языке, которые не исключали его юридическое значение. В эти дни я узнал, что такое хостинг и как его настраивать, а также понял, что на первом месте должна быть безотказность софта, а уже затем красивенькие анимации.
🛠 3-й проект: когда подошло время вернуться к 1-му проекту, Дима Гадомский поинтересовался, смогу ли я сделать конструктор таких ботов, как Франк, чтобы и другие юристы могли клепать такие вещи. Я написал в чате, что подумаю. Через 40 минут я сказал, что это возможно. В этот же день началась разработка, растянувшаяся на полгода. Через несколько дней наткнулся на проблему сохранения пользовательских данных на сервере. И вот на форуме Construct 2 нахожу инструкцию о том, как должен выглядеть делающий это скрипт на PHP. Вот так вопрос выбора языка программирования для дальнейшей работы решился сам собой. А к первому проекту мы так и не вернулись.
Надёжные способы автоматизировать создание документов
Способ 1. Заполнение шаблонов. 📇
Второй и третий проекты с прошлого поста дали мне знать, что есть два эффективных подхода к подготовке документов при помощи алгоритмов.
Заполнение шаблонов — до боли знакомая ситуация. Допустим, у вас есть готовый шаблон какого-то документа. Чтобы пустить его в дело, достаточно заполнить какие-то индивидуальные данные. Например: шаблоны заявлений в универе; договоры, которые вам подсовывают в банках; акты приёма-передачи результатов услуг и т.д. Чаще всего вписываем туда наименования, контакты, даты, суммы и т.д.
🎮 Автоматизировать такое до неприличия просто:
1. В нужных местах шаблона ставим некие уникальные метки, которые не используются нигде в тексте (например: $name$, $date$, %sumOfMoney%, goodsQuantity).
2. Создаём опросник (можно и в виде чат-бота), где ответами на вопросы являются те данные, которые нам нужно вставить в документ ("Укажите фамилию и инициалы покупателя");
3. Подменяем каждую метку на каждый полученный ответ (таким образом, какой-нибудь "Шпак И.С." заменит собой какую-нибудь метку $nameOfBuyer$);
Чё ещё можно с этим сделать?
🔹 Одна и та же метка может встречаться несколько раз в разных местах документа (например, если наименование контрагента вы хотите разместить в начале и в конце договора).
🔹 Разумеется, между опросником и подменой меток можно втулить ещё алгоритм, который будет производить дополнительные операции над данными: преобразование, дополнение, обрезка и т.д. (например, дробные числа округлять вверх, когда речь идёт о ценах и вы хотите исключить копейки).
🔹 Метку можно заполнить ничем, чтобы она исчезла, если по выбранному юзером сценарию какое-то поле нужно оставить пустым (пустота в этом случае выглядит так: "", '').
🔹 Можно сделать так, что какие-то данные в документе будут формироваться на основе ответов, а не напрямую из них (например, в опроснике юзер выбрал опцию "плачу долларами", и вы добавляете к указанной денежной сумме словесное обозначение долларов).
🌆 Используя такой алгоритм, можно заполнять несколько сотен шаблонов за несколько секунд, если у вас уже есть таблица с нужными данными. Или всё-таки лучше делать это вручную полтора рабочих дня, наслаждаясь спокойствием профессии и слушая город за окном?
А вы когда-нибудь пользовались подобными опросниками?
Или создавали свои?
#шаблон #алгоритмизация #документ
Способ 1. Заполнение шаблонов. 📇
Второй и третий проекты с прошлого поста дали мне знать, что есть два эффективных подхода к подготовке документов при помощи алгоритмов.
Заполнение шаблонов — до боли знакомая ситуация. Допустим, у вас есть готовый шаблон какого-то документа. Чтобы пустить его в дело, достаточно заполнить какие-то индивидуальные данные. Например: шаблоны заявлений в универе; договоры, которые вам подсовывают в банках; акты приёма-передачи результатов услуг и т.д. Чаще всего вписываем туда наименования, контакты, даты, суммы и т.д.
🎮 Автоматизировать такое до неприличия просто:
1. В нужных местах шаблона ставим некие уникальные метки, которые не используются нигде в тексте (например: $name$, $date$, %sumOfMoney%, goodsQuantity).
2. Создаём опросник (можно и в виде чат-бота), где ответами на вопросы являются те данные, которые нам нужно вставить в документ ("Укажите фамилию и инициалы покупателя");
3. Подменяем каждую метку на каждый полученный ответ (таким образом, какой-нибудь "Шпак И.С." заменит собой какую-нибудь метку $nameOfBuyer$);
Чё ещё можно с этим сделать?
🔹 Одна и та же метка может встречаться несколько раз в разных местах документа (например, если наименование контрагента вы хотите разместить в начале и в конце договора).
🔹 Разумеется, между опросником и подменой меток можно втулить ещё алгоритм, который будет производить дополнительные операции над данными: преобразование, дополнение, обрезка и т.д. (например, дробные числа округлять вверх, когда речь идёт о ценах и вы хотите исключить копейки).
🔹 Метку можно заполнить ничем, чтобы она исчезла, если по выбранному юзером сценарию какое-то поле нужно оставить пустым (пустота в этом случае выглядит так: "", '').
🔹 Можно сделать так, что какие-то данные в документе будут формироваться на основе ответов, а не напрямую из них (например, в опроснике юзер выбрал опцию "плачу долларами", и вы добавляете к указанной денежной сумме словесное обозначение долларов).
🌆 Используя такой алгоритм, можно заполнять несколько сотен шаблонов за несколько секунд, если у вас уже есть таблица с нужными данными. Или всё-таки лучше делать это вручную полтора рабочих дня, наслаждаясь спокойствием профессии и слушая город за окном?
А вы когда-нибудь пользовались подобными опросниками?
Или создавали свои?
#шаблон #алгоритмизация #документ
👁 Вычислительное право — выдумка бородачей в свитерах или ...
Вчера прошёл Computational Law & Blockchain Festival наконец и в Киеве, вот видеозапись. Мне очень понравилась презентация Егора Чурилова о вычислительном праве (см. ниже фото одного из слайдов). Кажется, мы сейчас пытаемся перевести наши правовые системы с третьего этапа (дигитализация) на четвёртый (онтологизация/семантизация), хотя в некоторых вопросах ещё застряли и на втором (механизация). В причинах такого пробуксовывания пытались разобраться на последующей панельной дискуссии.
Вот какие микровыводы для себя сделал:
▪️ Digital by default — не шутка, мы всерьёз собираемся двигать общество и право к цифровизации.
▪️ Кибернетики создали разные способы/модели представления человеческого знания (и юридических законов) в цифровом виде, так что у нас даже есть из чего выбирать.
▪️ Но переход не будет резким, привычки менять сложно, поэтому будем расходовать много бумаги ещё некоторое количество лет.
▪️ Технологии можно делать как прозрачными, так и не прозрачными. Но компьютеру всё равно проще логировать свои действия и отчитываться за них, чем судье-человеку, который даже не догадывается, что в послеобеденное время он склонен выносить более мягкие (и даже оправдательные) приговоры (спасибо Егору за классный пример).
▪️ Юристов digital by default и его последствия не вытеснят в один конкретный день, но это не повод его игнорировать. Эта профессия в плане инструментов и образа действий в следующие годы будет меняться значительно быстрее, чем за последние 100 лет. Но лигалхакеры всего мира помогут не потеряться в ворохе технологий и найти себя.
Вчера прошёл Computational Law & Blockchain Festival наконец и в Киеве, вот видеозапись. Мне очень понравилась презентация Егора Чурилова о вычислительном праве (см. ниже фото одного из слайдов). Кажется, мы сейчас пытаемся перевести наши правовые системы с третьего этапа (дигитализация) на четвёртый (онтологизация/семантизация), хотя в некоторых вопросах ещё застряли и на втором (механизация). В причинах такого пробуксовывания пытались разобраться на последующей панельной дискуссии.
Вот какие микровыводы для себя сделал:
▪️ Digital by default — не шутка, мы всерьёз собираемся двигать общество и право к цифровизации.
▪️ Кибернетики создали разные способы/модели представления человеческого знания (и юридических законов) в цифровом виде, так что у нас даже есть из чего выбирать.
▪️ Но переход не будет резким, привычки менять сложно, поэтому будем расходовать много бумаги ещё некоторое количество лет.
▪️ Технологии можно делать как прозрачными, так и не прозрачными. Но компьютеру всё равно проще логировать свои действия и отчитываться за них, чем судье-человеку, который даже не догадывается, что в послеобеденное время он склонен выносить более мягкие (и даже оправдательные) приговоры (спасибо Егору за классный пример).
▪️ Юристов digital by default и его последствия не вытеснят в один конкретный день, но это не повод его игнорировать. Эта профессия в плане инструментов и образа действий в следующие годы будет меняться значительно быстрее, чем за последние 100 лет. Но лигалхакеры всего мира помогут не потеряться в ворохе технологий и найти себя.
{kind=link}
Надёжные способы автоматизировать создание документов
Способ 2. Соединение блоков. 🍢
Выше я рассказал о том, как заполнять шаблоны. Но это весьма тривиальная задача. Нередко структура и содержание документа должны различаться зависимо от ситуации клиента. И тут мы приходим к тому, что документ нужно строить из отдельных блоков, которые должны подставляться зависимо от полученных ответов.
Простая ситуация: задаём 3 вопроса подряд, на каждый из них даётся по 2 ответа, и каждый ответ связан с неким блоком текста, который должен подставиться в документ. У нас в Axon Partners такое было с тем самым Privacy Policy Bot, только там таких вопросов было около двенадцати. И на этой же идее я строил тот самый конструктор ботов, где можно было создать до 15-и вопросов с 4-мя возможными ответами.
🎲 Выходит, потенциально количество вариаций такого документа будет равно произведению сумм ответов по каждому вопросу: 2 х 2 х 2 = 8. И вам как юристу на этапе создания и тестирования такого конструктора необходимо убедиться, что все эти вариации жизнеспособны и не противоречивы: например, что блок из ответа №1 на вопрос №1 совместим с блоком из ответа №2 на вопрос №3 и т.д. Поэтому такое конструирование документа лучше подходит для консультаций, справок и некоторых "блочных" документов по типу несложных политик приватности. Ведь договоры обычно имеют более сложную логику, хотя при некоторой ловкости можно что-то эдакое сотворить и с ними.
И конечно же, при необходимости блок можно сделать пустым.
Способ 2. Соединение блоков. 🍢
Выше я рассказал о том, как заполнять шаблоны. Но это весьма тривиальная задача. Нередко структура и содержание документа должны различаться зависимо от ситуации клиента. И тут мы приходим к тому, что документ нужно строить из отдельных блоков, которые должны подставляться зависимо от полученных ответов.
Простая ситуация: задаём 3 вопроса подряд, на каждый из них даётся по 2 ответа, и каждый ответ связан с неким блоком текста, который должен подставиться в документ. У нас в Axon Partners такое было с тем самым Privacy Policy Bot, только там таких вопросов было около двенадцати. И на этой же идее я строил тот самый конструктор ботов, где можно было создать до 15-и вопросов с 4-мя возможными ответами.
🎲 Выходит, потенциально количество вариаций такого документа будет равно произведению сумм ответов по каждому вопросу: 2 х 2 х 2 = 8. И вам как юристу на этапе создания и тестирования такого конструктора необходимо убедиться, что все эти вариации жизнеспособны и не противоречивы: например, что блок из ответа №1 на вопрос №1 совместим с блоком из ответа №2 на вопрос №3 и т.д. Поэтому такое конструирование документа лучше подходит для консультаций, справок и некоторых "блочных" документов по типу несложных политик приватности. Ведь договоры обычно имеют более сложную логику, хотя при некоторой ловкости можно что-то эдакое сотворить и с ними.
И конечно же, при необходимости блок можно сделать пустым.
{kind=link}
26-й день: запуск чатов! 👁🗨
Друзья, вот нас и стало уже 500! Очень благодарен всем, кто шерит канал. :) Заменяя неудобный интерфейс комментариев, запускаю целых два чата для желающих:
🗯 Common Chat, чтобы обсуждать контент и вообще тематику канала, а именно – более "гуманитарные" и "стратегические" вопросы.
💬 Coder Chat, чтобы обсуждать сугубо кодерские вопросы и, взаимопомогая, забрасывать друг друга кусками кода, осколками конструктивной критики и полезными материалами.
Завтра продолжаю своё повествование. А пока что зацените скриншот альфа версии нашего первого опубликованного лигалтек-продукта в феврале 2017-го. К чему я? Не нужно бояться, что без профессионального дизайнера у вас на старте получится антикрасивый интерфейс. В лигалтеке главное — нутро продукта: его движок, логика и функционал. Считаю, что юрист не обязан ещё и дизайнить. Это можно оставить людям с профессиональным чувством прекрасного. 🎨 Поэтому главное требование к лигалинженерам — хотя бы тексты сделать читабельными.
Друзья, вот нас и стало уже 500! Очень благодарен всем, кто шерит канал. :) Заменяя неудобный интерфейс комментариев, запускаю целых два чата для желающих:
🗯 Common Chat, чтобы обсуждать контент и вообще тематику канала, а именно – более "гуманитарные" и "стратегические" вопросы.
💬 Coder Chat, чтобы обсуждать сугубо кодерские вопросы и, взаимопомогая, забрасывать друг друга кусками кода, осколками конструктивной критики и полезными материалами.
Завтра продолжаю своё повествование. А пока что зацените скриншот альфа версии нашего первого опубликованного лигалтек-продукта в феврале 2017-го. К чему я? Не нужно бояться, что без профессионального дизайнера у вас на старте получится антикрасивый интерфейс. В лигалтеке главное — нутро продукта: его движок, логика и функционал. Считаю, что юрист не обязан ещё и дизайнить. Это можно оставить людям с профессиональным чувством прекрасного. 🎨 Поэтому главное требование к лигалинженерам — хотя бы тексты сделать читабельными.
{kind=link}
Надёжные способы автоматизировать создание документов
Способ 3. Шабменты или фраглоны. 🏈
Разумеется, на практике при создании документов (особенно договоров, актов, заявлений и т.д.) приходится комбинировать способ 1 и способ 2. То есть и данные от юзера напрямую вносить (имена, даты, адреса, номера, суммы и т.д), и какие-то блоки подставлять. Логику процесса я изобразил на картинке ниже.
Обратите внимание, что данные юзера можно вносить как в статичную ("чёрную") часть документа ("желтый" ответ), так и в сами фрагменты ("красный" ответ). Причём порядок действий по такой схеме не имеет значения, хотя с точки зрения оптимизации стоит вносить данные клиента в уже выбранный (используемый) фрагмент.
🧩 То есть на нижнем уровне эти фрагменты ("зелёные") сами становятся шаблонами. В кодинге нередко можно столкнуться с такой многоуровневостью, пошаговостью. Поэтому-то умение мыслить пошагово довольно важно.
Способ 3. Шабменты или фраглоны. 🏈
Разумеется, на практике при создании документов (особенно договоров, актов, заявлений и т.д.) приходится комбинировать способ 1 и способ 2. То есть и данные от юзера напрямую вносить (имена, даты, адреса, номера, суммы и т.д), и какие-то блоки подставлять. Логику процесса я изобразил на картинке ниже.
Обратите внимание, что данные юзера можно вносить как в статичную ("чёрную") часть документа ("желтый" ответ), так и в сами фрагменты ("красный" ответ). Причём порядок действий по такой схеме не имеет значения, хотя с точки зрения оптимизации стоит вносить данные клиента в уже выбранный (используемый) фрагмент.
🧩 То есть на нижнем уровне эти фрагменты ("зелёные") сами становятся шаблонами. В кодинге нередко можно столкнуться с такой многоуровневостью, пошаговостью. Поэтому-то умение мыслить пошагово довольно важно.
{kind=link}
КАК Я ВОШЁЛ В АЙТИ.
ЧАСТЬ 3. Третий проект и закручивание винтов молотком (аспект веры). 🥶
🤖 Как я уже говорил, в конце февраля 2017 я засел за конструктор ботов (не чат-ботов, а тех, которые работают прямо в браузере, я их позднее стал называть веб-ботами). Они должны были работать по вот этому принципу, а сам проект — реализован в виде веб-сайта. На меня свалился не просто пресловутый кодинг ряда процедур, а решение полноценной архитектурной задачи: создание базы данных для юзеров и их ботов, механизма регистрации юзеров, механизма восстановления паролей, разных других механизмов взаимодействия фронтенда и бэкенда в процессе создания, изменения, удаления, запуска и тестирования юзерами их ботов.
👞 Разумеется, осознавать сразу весь этот ворох задач было напряжно (я не сразу понял, с чем связался), поэтому делал маленькие шажки от фиче к фиче. На этом проекте я познал, что такое фуллстак-разработка + ещё дизайном занимался, кнопки всякие рисовал (см. скриншот ниже). Так получилось, что для фронтенда (внешней, доступной юзеру части проекта) я использовал ту самую Construct 2, а для бэкенда — текстовый редактор скриптов в панели управления хостингом сайта.
🔩 В какой-то момент я начал догадываться, что делать такой проект в программе для разработки игр — плохая, очень плохая идея. По скриншоту видно, какими извращениями пришлось заниматься. Но я в неё верил и пытался выжать максимум. К тому же не знал, как выйти на "чистый HTML и JavaScript" и работать "по-взрослому". Что ж, путь в айти бывает и таким.
🗺 Путь в айти: ЧАСТЬ 1, ЧАСТЬ 2
ЧАСТЬ 3. Третий проект и закручивание винтов молотком (аспект веры). 🥶
🤖 Как я уже говорил, в конце февраля 2017 я засел за конструктор ботов (не чат-ботов, а тех, которые работают прямо в браузере, я их позднее стал называть веб-ботами). Они должны были работать по вот этому принципу, а сам проект — реализован в виде веб-сайта. На меня свалился не просто пресловутый кодинг ряда процедур, а решение полноценной архитектурной задачи: создание базы данных для юзеров и их ботов, механизма регистрации юзеров, механизма восстановления паролей, разных других механизмов взаимодействия фронтенда и бэкенда в процессе создания, изменения, удаления, запуска и тестирования юзерами их ботов.
👞 Разумеется, осознавать сразу весь этот ворох задач было напряжно (я не сразу понял, с чем связался), поэтому делал маленькие шажки от фиче к фиче. На этом проекте я познал, что такое фуллстак-разработка + ещё дизайном занимался, кнопки всякие рисовал (см. скриншот ниже). Так получилось, что для фронтенда (внешней, доступной юзеру части проекта) я использовал ту самую Construct 2, а для бэкенда — текстовый редактор скриптов в панели управления хостингом сайта.
🔩 В какой-то момент я начал догадываться, что делать такой проект в программе для разработки игр — плохая, очень плохая идея. По скриншоту видно, какими извращениями пришлось заниматься. Но я в неё верил и пытался выжать максимум. К тому же не знал, как выйти на "чистый HTML и JavaScript" и работать "по-взрослому". Что ж, путь в айти бывает и таким.
🗺 Путь в айти: ЧАСТЬ 1, ЧАСТЬ 2
{kind=link}
Надёжные способы автоматизировать создание документов
Способ 4. Оценка комбинаций. 🌗
Описанные ранее способ 1, способ 2 и способ 3 — довольно просты, ведь в их основе гипотеза о том, что каждый ответ на каждый вопрос — "самостоятельная фигура", то есть влияет самостоятельно и напрямую на некоторый участок в документе. Но иногда бывает и так, что нужно "связать" два идущих один за другим вопроса, оценить ответы на них в совокупности. Например, когда речь идёт об оценке рисков (и мы делаем документ-консультацию по рискам), нужно видеть ситуацию клиента более масштабно и целостно.
🧮 Тогда приходится оценивать все возможные комбинации этих ответов. Если на первый вопрос 2 ответа, а на второй — 3, тогда комбинаций будет 2 х 3 = 6. "Карту" этих комбинаций на стадии прототипирования можно строить в виде таблицы. А соответствующий участок кода может выглядеть так, как изображено на картинке.
🥭 Кстати, в ходе своей работы в Аксоне над проектом Memelex мне пришлось научиться рисовать в Adobe Illustrator, чтобы не напрягать дизайнеров по мелочам. Теперь пользуюсь этим и здесь. Правда, нужно научиться ещё цвета подбирать. :)
Способ 4. Оценка комбинаций. 🌗
Описанные ранее способ 1, способ 2 и способ 3 — довольно просты, ведь в их основе гипотеза о том, что каждый ответ на каждый вопрос — "самостоятельная фигура", то есть влияет самостоятельно и напрямую на некоторый участок в документе. Но иногда бывает и так, что нужно "связать" два идущих один за другим вопроса, оценить ответы на них в совокупности. Например, когда речь идёт об оценке рисков (и мы делаем документ-консультацию по рискам), нужно видеть ситуацию клиента более масштабно и целостно.
🧮 Тогда приходится оценивать все возможные комбинации этих ответов. Если на первый вопрос 2 ответа, а на второй — 3, тогда комбинаций будет 2 х 3 = 6. "Карту" этих комбинаций на стадии прототипирования можно строить в виде таблицы. А соответствующий участок кода может выглядеть так, как изображено на картинке.
🥭 Кстати, в ходе своей работы в Аксоне над проектом Memelex мне пришлось научиться рисовать в Adobe Illustrator, чтобы не напрягать дизайнеров по мелочам. Теперь пользуюсь этим и здесь. Правда, нужно научиться ещё цвета подбирать. :)
{kind=link}
🧗♂️ Личный ТОП 5 источников обучения кодерству, которые сформировали меня:
🛷 5. Инструкции/мануалы по созданию несложных игр в программе Construct 2 и сам опыт взаимодействия с ней. Научился структурировать происходящее по ту сторону монитора, ставить цели, прокладывать пути и т.д.
🚴♂️ 4. Курсы программирования, на которые я пошёл в конце 2016-го и откуда ушёл где-то через два месяца. На них я научился думать над построением алгоритмов. Как пример я уже приводил задачу с палиндромом. На самом деле, там можно было взять гораздо больше, но решил дальше идти сам. Обобщённо: я не хотел учиться собирать Феррари, когда мне нужно было сделать электрочайник.
🥉 3. Также восполнить пробел в основах мне помогло приложение SoloLearn. В нём я прошёл курсы по HTML, CSS, JS, PHP, SQL, Python и jQuery. Ничего особо выдающегося в этом нет, просто основы синтаксиса всех этих технологий. Но у этого приложения есть своё коммьюнити по всему миру, всякие обсуждения, даже челленджи. К каждому обучающему заданию/вопросу прилагается своё обсуждение в комментах.
🥈 2. Далее идут некоторые книги, которые я очень выборочно и точечно изучал. В них информация обычно структурирована, подаётся в едином стиле, с нарастающей глубиной. Свою первую нейросеть я сделал именно благодаря книге. Это не тот жанр литературы, который нужно читать обязательно от корки до корки, хотя и здесь есть книги, которые этого заслуживают. Планирую скоро закупиться некоторыми.
🥇 1. Больше всего я самообучился, просто гугля вопросы и попадая на такие ресурсы, как stackovefrlow, w3schools и иногда даже форумы не первой свежести. Сюда же можно отнести мануалы типа php.net.
Расскажите в чате, какова ваша версия такого топа? От чего больше профита получили вы?
🛷 5. Инструкции/мануалы по созданию несложных игр в программе Construct 2 и сам опыт взаимодействия с ней. Научился структурировать происходящее по ту сторону монитора, ставить цели, прокладывать пути и т.д.
🚴♂️ 4. Курсы программирования, на которые я пошёл в конце 2016-го и откуда ушёл где-то через два месяца. На них я научился думать над построением алгоритмов. Как пример я уже приводил задачу с палиндромом. На самом деле, там можно было взять гораздо больше, но решил дальше идти сам. Обобщённо: я не хотел учиться собирать Феррари, когда мне нужно было сделать электрочайник.
🥉 3. Также восполнить пробел в основах мне помогло приложение SoloLearn. В нём я прошёл курсы по HTML, CSS, JS, PHP, SQL, Python и jQuery. Ничего особо выдающегося в этом нет, просто основы синтаксиса всех этих технологий. Но у этого приложения есть своё коммьюнити по всему миру, всякие обсуждения, даже челленджи. К каждому обучающему заданию/вопросу прилагается своё обсуждение в комментах.
🥈 2. Далее идут некоторые книги, которые я очень выборочно и точечно изучал. В них информация обычно структурирована, подаётся в едином стиле, с нарастающей глубиной. Свою первую нейросеть я сделал именно благодаря книге. Это не тот жанр литературы, который нужно читать обязательно от корки до корки, хотя и здесь есть книги, которые этого заслуживают. Планирую скоро закупиться некоторыми.
🥇 1. Больше всего я самообучился, просто гугля вопросы и попадая на такие ресурсы, как stackovefrlow, w3schools и иногда даже форумы не первой свежести. Сюда же можно отнести мануалы типа php.net.
Расскажите в чате, какова ваша версия такого топа? От чего больше профита получили вы?
Надёжные способы автоматизировать создание документов
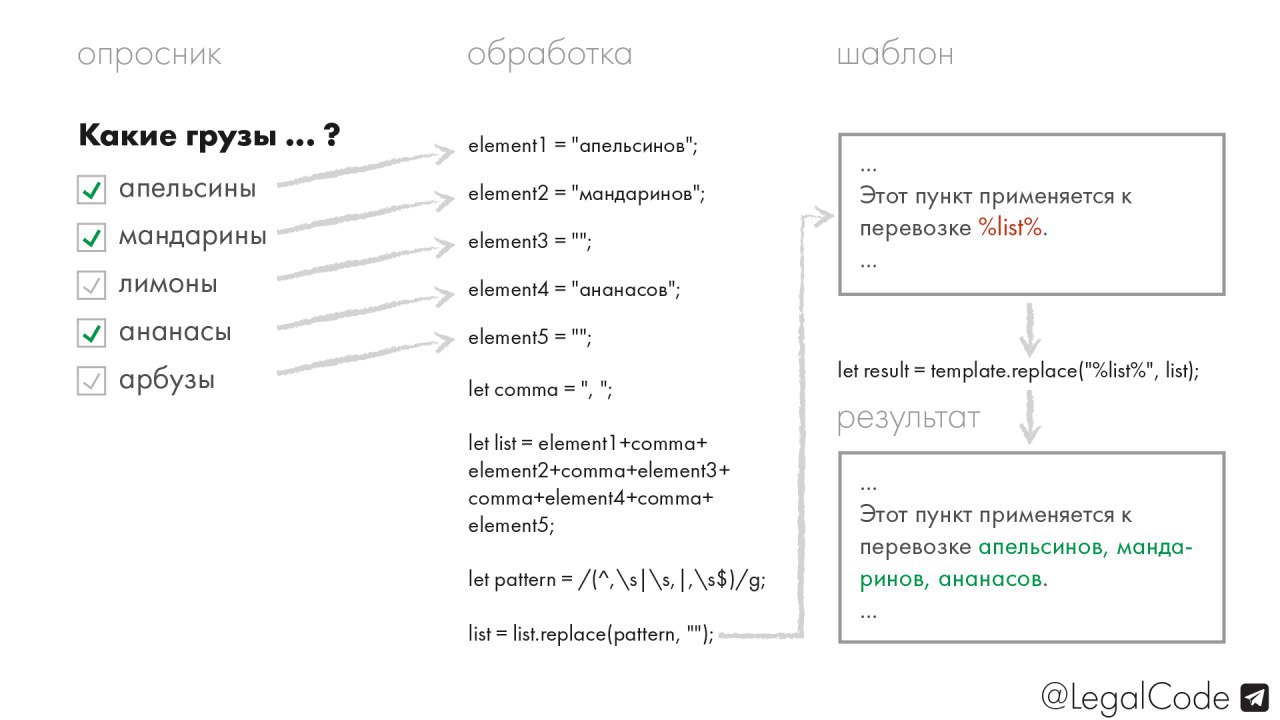
Приём "построение перечня из перечня". ✅
Бывает так, что при опросе юзера/клиента нужно допускать выбор нескольких опций одновременно. Веб-разработчики знают, что для этого обычно используються "чекбоксы" (checkboxes). При создании юридических документов это может понадобиться, когда формируются перечни/списки, например: перечень товаров, услуг или работ, которые должны поставляться по договору.
Как выглядит логика алгоритма, делающего переход от натыканных клиентом галочек к конечному списку в документе, я изобразил на картинке. И понятное дело, падежи (и вообще слова) на чекбоксах и в конечном списке могут не совпадать, всё зависит от ваших нужд.
Вам приходилось кодить похожие вещи? Можем обсудить в чате.
Приём "построение перечня из перечня". ✅
Бывает так, что при опросе юзера/клиента нужно допускать выбор нескольких опций одновременно. Веб-разработчики знают, что для этого обычно используються "чекбоксы" (checkboxes). При создании юридических документов это может понадобиться, когда формируются перечни/списки, например: перечень товаров, услуг или работ, которые должны поставляться по договору.
Как выглядит логика алгоритма, делающего переход от натыканных клиентом галочек к конечному списку в документе, я изобразил на картинке. И понятное дело, падежи (и вообще слова) на чекбоксах и в конечном списке могут не совпадать, всё зависит от ваших нужд.
Вам приходилось кодить похожие вещи? Можем обсудить в чате.
{kind=link}
КАК Я ВОШЁЛ В АЙТИ.
ЧАСТЬ 4. Знакомство с HTML/CSS/JavaScript и боль. 🦷
Где-то на четвёртом месяце работы над конструктором ботов я понял, что параллельно нужно начать изучение HTML, CSS и JavaScript, чтобы больше не делать такую дичь. Его уже, так и быть, заканчивал в Construct 2, но новые проекты твёрдо решил пилить "по-взрослому".
Уже плохо помню, с чего начал изучать, это всё как-то в кучу свалилось. Меня кормил гугл: я там находил и общую документацию, и всякие форумы, и статьи на Хабре. Философию работы HTML с его padding-ами и margin-ами я закусывал стилизацией CSS, пытаясь управлять всем этим при помощи JavaScript-а. Голова взрывалась, учился методом проб и ошибок, причём на одну пробу приходилось две ошибки. Сразу попал на какой-то источник, который подсадил меня на иглу jQuery, с которой я не слажу до сих пор.
Для непосвящённых: jQuery — это такая штука, которую подключаешь у себя на сайте, и кодить на JavaScript становится проще. Например, нужно в элемент с id=myText1 вписать текст "hello":
😳 код без jQuery, т.е. на "чистом" JavaScript:
var el = document.getElementById("myText1");
el.innerHTML = "hello";
😌 Этот же код с jQuery:
$("#myText1").html("hello");
Но более-менее освоив этот букет, я с тех пор смог создавать фулл-стак проекты, то есть выполнять "в одно рыло" полный цикл разработки веб-сайта, начиная с управления его внешним видом и заканчивая самой отдалённой базой данных. Первой апробацией стал сайт-энциклопедия по украинскому лигалтеку в августе 2017. Недавно я основательно переделал его некоторые разделы, а другие прикрыл, ведь сделано было ужасно. Правда, я до сих пор так и не полюбил "верстать" сайты, то есть настраивать их внешний вид, интерфейс и т.д. Мне больше по душе писать алгоритмы на бэкенде, вплоть до нейросетей.
🗺 Путь в айти: ЧАСТЬ 1, ЧАСТЬ 2, ЧАСТЬ 3
ЧАСТЬ 4. Знакомство с HTML/CSS/JavaScript и боль. 🦷
Где-то на четвёртом месяце работы над конструктором ботов я понял, что параллельно нужно начать изучение HTML, CSS и JavaScript, чтобы больше не делать такую дичь. Его уже, так и быть, заканчивал в Construct 2, но новые проекты твёрдо решил пилить "по-взрослому".
Уже плохо помню, с чего начал изучать, это всё как-то в кучу свалилось. Меня кормил гугл: я там находил и общую документацию, и всякие форумы, и статьи на Хабре. Философию работы HTML с его padding-ами и margin-ами я закусывал стилизацией CSS, пытаясь управлять всем этим при помощи JavaScript-а. Голова взрывалась, учился методом проб и ошибок, причём на одну пробу приходилось две ошибки. Сразу попал на какой-то источник, который подсадил меня на иглу jQuery, с которой я не слажу до сих пор.
Для непосвящённых: jQuery — это такая штука, которую подключаешь у себя на сайте, и кодить на JavaScript становится проще. Например, нужно в элемент с id=myText1 вписать текст "hello":
😳 код без jQuery, т.е. на "чистом" JavaScript:
var el = document.getElementById("myText1");
el.innerHTML = "hello";
😌 Этот же код с jQuery:
$("#myText1").html("hello");
Но более-менее освоив этот букет, я с тех пор смог создавать фулл-стак проекты, то есть выполнять "в одно рыло" полный цикл разработки веб-сайта, начиная с управления его внешним видом и заканчивая самой отдалённой базой данных. Первой апробацией стал сайт-энциклопедия по украинскому лигалтеку в августе 2017. Недавно я основательно переделал его некоторые разделы, а другие прикрыл, ведь сделано было ужасно. Правда, я до сих пор так и не полюбил "верстать" сайты, то есть настраивать их внешний вид, интерфейс и т.д. Мне больше по душе писать алгоритмы на бэкенде, вплоть до нейросетей.
🗺 Путь в айти: ЧАСТЬ 1, ЧАСТЬ 2, ЧАСТЬ 3
🚥 Какими словами описывать свои разработки/алгоритмы
Как я уже писал раньше, алгоритмы своих разработок перед созданием важно грамотно описывать словами. Но это нужно не только для продуктивного самокопания, а и чтобы подключать к работе коллег, наёмников, инвесторов и прочих товарищей. Но описывать можно по-разному и с разным выхлопом. Чтобы объяснить это, я для своих презентаций соорудил "принцип светофора" (см. картинку), согласно которому разговоры о неначатых или недоделанных разработках/продуктах/алгоритмах нужно классифицировать на такие виды.
🅾️ Красные слова — ими описываете ваши глобальные цели и мечты, к которым вас ваша разработка должна приблизить. Эти слова лучше держать при себе. Разве что из них потом можно вывести какой-нибудь слоган в маркетинговых целях, для релиза или "ранних продаж". Эти слова не описывают сам алгоритм, лишь его глобальные последствия, ожидаемый эффект, миссию. Поэтому они нам как разработчикам не особо интересны (разве что для воодушевления, куда же без него в бессонные ночи).
📳 Жёлтые слова — они лаконично описывают общую логику, бизнес-логику работы вашего продукта. Они уже интересны вашим потенциальным инвесторам, но всё ещё недостаточно конкретны для кодеров, так как под одно такое описание можно сообразить несколько разных подходов к технической реализации.
✅ Зелёные слова — здесь уже каждая фраза должна давать чёткое понимание того, что кодер должен сделать. Каждая такая фраза является "аватарой", заголовком для некоторого количества строк кода, примерно от десятка до сотни. По сути, из этих слов пишутся технические задания кодерам. Этими словами должны уметь разговаривать лигалинженеры (кстати, о лигалинженерах скоро поговорим отдельно).
Так что стараюсь выбивать из себя дурь и сразу говорить жёлтыми словами, а перед этим думать наперёд зелёными. Хотя во время брейншторминга люди думают всеми словами подряд, ведь хорошая идея может быть высказана и в общей абстрактной форме. Затем её нужно грамотно сузить и превратить в техническую задачу.
Как я уже писал раньше, алгоритмы своих разработок перед созданием важно грамотно описывать словами. Но это нужно не только для продуктивного самокопания, а и чтобы подключать к работе коллег, наёмников, инвесторов и прочих товарищей. Но описывать можно по-разному и с разным выхлопом. Чтобы объяснить это, я для своих презентаций соорудил "принцип светофора" (см. картинку), согласно которому разговоры о неначатых или недоделанных разработках/продуктах/алгоритмах нужно классифицировать на такие виды.
🅾️ Красные слова — ими описываете ваши глобальные цели и мечты, к которым вас ваша разработка должна приблизить. Эти слова лучше держать при себе. Разве что из них потом можно вывести какой-нибудь слоган в маркетинговых целях, для релиза или "ранних продаж". Эти слова не описывают сам алгоритм, лишь его глобальные последствия, ожидаемый эффект, миссию. Поэтому они нам как разработчикам не особо интересны (разве что для воодушевления, куда же без него в бессонные ночи).
📳 Жёлтые слова — они лаконично описывают общую логику, бизнес-логику работы вашего продукта. Они уже интересны вашим потенциальным инвесторам, но всё ещё недостаточно конкретны для кодеров, так как под одно такое описание можно сообразить несколько разных подходов к технической реализации.
✅ Зелёные слова — здесь уже каждая фраза должна давать чёткое понимание того, что кодер должен сделать. Каждая такая фраза является "аватарой", заголовком для некоторого количества строк кода, примерно от десятка до сотни. По сути, из этих слов пишутся технические задания кодерам. Этими словами должны уметь разговаривать лигалинженеры (кстати, о лигалинженерах скоро поговорим отдельно).
Так что стараюсь выбивать из себя дурь и сразу говорить жёлтыми словами, а перед этим думать наперёд зелёными. Хотя во время брейншторминга люди думают всеми словами подряд, ведь хорошая идея может быть высказана и в общей абстрактной форме. Затем её нужно грамотно сузить и превратить в техническую задачу.
{kind=link}
О (не)автоматизации дьюдилов 🤬
Пост на тему боли. Есть такая разновидность юридической услуги — "дьюдил" (due diligence), известная также как юридический аудит. Это когда ты изучаешь ряд документов клиента (например, 300 договоров на разработку ПО за последние два года) на предмет разных рисков. Вот мне друзья вчера скинули фотку этого действа (см. ниже).
👔 Если ты юрист, то для тебя обычный юридический дьюдил в наших реалиях означает:
1) клиент присылает сканы документов;
2) клиент присылает фотки документов (качество оных весьма вариативно);
3) идёшь к клиенту и фоткаешь/сканируешь эти документы, потом работаешь с фотками/сканами;
4) идёшь к клиенту и дьюдилишь у него, ведь документы секретны, их нельзя фоткать/сканить и тем более пересылать в сети.
🔌 Если сильно повезёт, что-то достанется в электронной форме. Кстати, кому на дьюдил доставались оцифрованные pdf/docx (с возможностью поиска по тексту) или же изначально электронные документы, напишите пжлст в чате.
🕰 К чему это я? А к тому, что дьюдил — это идеальный кандидат на автоматизацию, за счёт которой можно сберечь десятки и сотни рабочих часов в год. Зная закономерности построения юридических текстов и имея опыт в запрашиваемой отрасли (например, интеллектуальная собственность), юрист может соорудить для себя дьюдил-алгоритм, который за несколько секунд "просмотрит" сотни документов и найдёт много чего, что человек мог бы пропустить. Но для этого прежде всего нужно иметь эти документы в цифровом виде. Поэтому реалии, согласно которым тонны документов нужно держать в бумаге, отодвигают нас от многих благ автоматизации.
#дьюдил #duediligence #автоматизация
Пост на тему боли. Есть такая разновидность юридической услуги — "дьюдил" (due diligence), известная также как юридический аудит. Это когда ты изучаешь ряд документов клиента (например, 300 договоров на разработку ПО за последние два года) на предмет разных рисков. Вот мне друзья вчера скинули фотку этого действа (см. ниже).
👔 Если ты юрист, то для тебя обычный юридический дьюдил в наших реалиях означает:
1) клиент присылает сканы документов;
2) клиент присылает фотки документов (качество оных весьма вариативно);
3) идёшь к клиенту и фоткаешь/сканируешь эти документы, потом работаешь с фотками/сканами;
4) идёшь к клиенту и дьюдилишь у него, ведь документы секретны, их нельзя фоткать/сканить и тем более пересылать в сети.
🔌 Если сильно повезёт, что-то достанется в электронной форме. Кстати, кому на дьюдил доставались оцифрованные pdf/docx (с возможностью поиска по тексту) или же изначально электронные документы, напишите пжлст в чате.
🕰 К чему это я? А к тому, что дьюдил — это идеальный кандидат на автоматизацию, за счёт которой можно сберечь десятки и сотни рабочих часов в год. Зная закономерности построения юридических текстов и имея опыт в запрашиваемой отрасли (например, интеллектуальная собственность), юрист может соорудить для себя дьюдил-алгоритм, который за несколько секунд "просмотрит" сотни документов и найдёт много чего, что человек мог бы пропустить. Но для этого прежде всего нужно иметь эти документы в цифровом виде. Поэтому реалии, согласно которым тонны документов нужно держать в бумаге, отодвигают нас от многих благ автоматизации.
#дьюдил #duediligence #автоматизация
{kind=link}
оптимизация/рефакторинг и правосудие будущего
☔️ часть 1 — пролог
💧 Есть в кодинге такая штука, как оптимизация кода. Она нужна, чтобы ускорять его выполнение, что очень важно в высоконагруженных крупных проектах. Оптимизация состоит в максимально возможном упрощении кода для выполнения машиной, что обычно приводит к:
1) усложнению восприятия этого кода его же автором;
2) крайне сложному восприятию и долгому разбору этого кода посторонними людьми.
💦 Своеобразным "антонимом" оптимизации называют рефакторинг. Это процесс "переписывания" кода для максимизации комфорта понимания этого кода человеком и взаимодействия с ним. Это обычно приводит к тому, что такой код дольше выполняется компьютером.
Разберём оптимизацию на примере:
В нашем интерфейсе некая полоска должна начать зеленеть, когда её длина больше 50% от максимально возможной. Чем длиннее она, тем более насыщенной должна быть. Например, чем больше запланированных налогов и сборов уплатил предприниматель, тем длиннее эта полоска, а значит и более зелёного цвета. Итак, нам нужно создать алгоритм, "извлекающий" интенсивность цвета из процента длины полоски.
Кодим (в конце строчки после "//" показываю наше текущее значение):
// пусть в переменную percent к нам попало значение 68:
let percent = taxPercentQuantity; //68
// отнять от значения процента половину полоски, чтобы понять, сколько процентов "заходит" на её вторую половину:
let x = percent-50; //18
// умножить на два, чтобы получить процентное отношение значения к этой половине длины полоски:
x = x * 2; //36
// умножить на один процент от значения 255, чтобы получить RGB-параметр нужного количества зелёного цвета:
x = x * 255/100; //91.8
// округлить финальное значение:
let result = Math.round(x); //92
// подставить это значение в параметр количества зелёного цвета нашей полоски:
$("#line").css("background-color", "rgb(0, "+result+", 0, 1)");
В итоге мы получили понятный, пошагово расписанный код. А теперь начинаем постепенно оптимизировать (сжимать) его, насколько можем:
1. let x = (percent-50) * 2 * 2.55; result = Math.round(x);
2. let x = (percent-50) * 5.1; result = Math.round(x);
3. let result = Math.round( (percent-50) * 5.1 );
☔️ В итоге мы четыре строки сжали в одну, попутно произведя математические преобразования, которые ничуть не меняют наш результат. Но они меняют кое-что другое в нашей голове. Следующим постом я объясню, как это может повлиять на философию правосудия будущего.
☔️ часть 1 — пролог
💧 Есть в кодинге такая штука, как оптимизация кода. Она нужна, чтобы ускорять его выполнение, что очень важно в высоконагруженных крупных проектах. Оптимизация состоит в максимально возможном упрощении кода для выполнения машиной, что обычно приводит к:
1) усложнению восприятия этого кода его же автором;
2) крайне сложному восприятию и долгому разбору этого кода посторонними людьми.
💦 Своеобразным "антонимом" оптимизации называют рефакторинг. Это процесс "переписывания" кода для максимизации комфорта понимания этого кода человеком и взаимодействия с ним. Это обычно приводит к тому, что такой код дольше выполняется компьютером.
Разберём оптимизацию на примере:
В нашем интерфейсе некая полоска должна начать зеленеть, когда её длина больше 50% от максимально возможной. Чем длиннее она, тем более насыщенной должна быть. Например, чем больше запланированных налогов и сборов уплатил предприниматель, тем длиннее эта полоска, а значит и более зелёного цвета. Итак, нам нужно создать алгоритм, "извлекающий" интенсивность цвета из процента длины полоски.
Кодим (в конце строчки после "//" показываю наше текущее значение):
// пусть в переменную percent к нам попало значение 68:
let percent = taxPercentQuantity; //68
// отнять от значения процента половину полоски, чтобы понять, сколько процентов "заходит" на её вторую половину:
let x = percent-50; //18
// умножить на два, чтобы получить процентное отношение значения к этой половине длины полоски:
x = x * 2; //36
// умножить на один процент от значения 255, чтобы получить RGB-параметр нужного количества зелёного цвета:
x = x * 255/100; //91.8
// округлить финальное значение:
let result = Math.round(x); //92
// подставить это значение в параметр количества зелёного цвета нашей полоски:
$("#line").css("background-color", "rgb(0, "+result+", 0, 1)");
В итоге мы получили понятный, пошагово расписанный код. А теперь начинаем постепенно оптимизировать (сжимать) его, насколько можем:
1. let x = (percent-50) * 2 * 2.55; result = Math.round(x);
2. let x = (percent-50) * 5.1; result = Math.round(x);
3. let result = Math.round( (percent-50) * 5.1 );
☔️ В итоге мы четыре строки сжали в одну, попутно произведя математические преобразования, которые ничуть не меняют наш результат. Но они меняют кое-что другое в нашей голове. Следующим постом я объясню, как это может повлиять на философию правосудия будущего.
оптимизация/рефакторинг и правосудие будущего
🌫 часть 2 — зашифрованное правосудие
В предыдущем посте мы пришли к тому, что сжали код практически в четыре раза без потери функциональности и результата. Но изменилось представление некого знания о сути алгоритма, заложенного нами в этот код. До оптимизации формула этого знания выглядела так:
💦 y = округлить( ( x - 50 ) * 2 * 255 / 100 )
После оптимизации стала выглядеть так:
💧 y = округлить( ( x - 50 ) * 5.1 )
Если мы затем опубликуем этот код как библиотеку (например, выложим на гитхабе) и не поясним эту строку комментариями, то не все поймут, что означает число 5.1, откуда оно взялось. Это число 5.1 станет, по сути, зашифрованным цифровым знанием. Постороннему человеку придётся реконструировать наше изначальное мышление, пройти наш путь заново, чтобы понять и воссоздать логику этого алгоритма (здравствуй, рефакторинг).
Итак, причём здесь правосудие? А при том, что оптимизация больших вычислительных систем, в основе которых лежит математика и логика и которые разрабатываются с целью автоматизировать принятие правовых решений, может привести к тому, что правосудие будет выглядеть примерно так:
y = ( x * 2.45 ) + ( z * 0.2 ) - 1200
... и даже так:
y = 1.0 / ( 1.0 + exp( -( 0.525 * 1.0 / ( 1.0 + exp( -x ) ) ) ) ) + 0.2
То есть суть и логика диджитализированного правосудия вдруг окажется скрыта за оптимизированными логическими и математическими преобразованиями. Хорошо ли это? Отвечу так: это вовсе неплохо, если разработчики будут:
1️⃣ тщательно документировать свой код, поясняя происхождение всех вводных данных и факт применения математических констант и традиционных формул;
2️⃣ в случае оптимизации кода, которая ведёт к "сжатию правового знания", тщательно документировать те параметры, которые явно использовались до оптимизации и во что они "сжались" в ходе таковой;
3️⃣ в идеале — делать две версии кода: оптимизированную и "полную", по которой можно будет исследовать логику работы системы в случае необходимости (например, при успешном обжаловании такого диджитализированного решения).
📙 Недавно на канале "Future Law School" упоминалась книга Педро Домингоса "Верховный алгоритм ... ". Прочёл её в прошлом году, в ней действительно в доступной форме изложена тема алгоритмизации в машинном обучении, показаны некоторые математические формулы, которые используются далеко не в математических целях.
🌫 часть 2 — зашифрованное правосудие
В предыдущем посте мы пришли к тому, что сжали код практически в четыре раза без потери функциональности и результата. Но изменилось представление некого знания о сути алгоритма, заложенного нами в этот код. До оптимизации формула этого знания выглядела так:
💦 y = округлить( ( x - 50 ) * 2 * 255 / 100 )
После оптимизации стала выглядеть так:
💧 y = округлить( ( x - 50 ) * 5.1 )
Если мы затем опубликуем этот код как библиотеку (например, выложим на гитхабе) и не поясним эту строку комментариями, то не все поймут, что означает число 5.1, откуда оно взялось. Это число 5.1 станет, по сути, зашифрованным цифровым знанием. Постороннему человеку придётся реконструировать наше изначальное мышление, пройти наш путь заново, чтобы понять и воссоздать логику этого алгоритма (здравствуй, рефакторинг).
Итак, причём здесь правосудие? А при том, что оптимизация больших вычислительных систем, в основе которых лежит математика и логика и которые разрабатываются с целью автоматизировать принятие правовых решений, может привести к тому, что правосудие будет выглядеть примерно так:
y = ( x * 2.45 ) + ( z * 0.2 ) - 1200
... и даже так:
y = 1.0 / ( 1.0 + exp( -( 0.525 * 1.0 / ( 1.0 + exp( -x ) ) ) ) ) + 0.2
То есть суть и логика диджитализированного правосудия вдруг окажется скрыта за оптимизированными логическими и математическими преобразованиями. Хорошо ли это? Отвечу так: это вовсе неплохо, если разработчики будут:
1️⃣ тщательно документировать свой код, поясняя происхождение всех вводных данных и факт применения математических констант и традиционных формул;
2️⃣ в случае оптимизации кода, которая ведёт к "сжатию правового знания", тщательно документировать те параметры, которые явно использовались до оптимизации и во что они "сжались" в ходе таковой;
3️⃣ в идеале — делать две версии кода: оптимизированную и "полную", по которой можно будет исследовать логику работы системы в случае необходимости (например, при успешном обжаловании такого диджитализированного решения).
📙 Недавно на канале "Future Law School" упоминалась книга Педро Домингоса "Верховный алгоритм ... ". Прочёл её в прошлом году, в ней действительно в доступной форме изложена тема алгоритмизации в машинном обучении, показаны некоторые математические формулы, которые используются далеко не в математических целях.
оптимизация/рефакторинг и правосудие будущего
🌧 часть 3 — безупречная отчётность компьютера
Предыдущий пост мог нагнать пессимизма в размышления о диджитализации правосудия. Дескать, алгоритмы всё равно будут непонятными и непрозрачными, невзирая на тщательно задокументированный код, ведь конечный пользователь не обязан разбираться в коде, чтобы понять правомерность цифрового решения. На самом деле, для обеспечения понятности работы программ существует логирование (запись, фиксация) "производимых действий", "принимаемых решений", а для обеспечения их прозрачности — вывод всех логов конечным пользователям.
Что такое логирование и логи?
Привожу пример из юридической практики.
🖨 Стажеру Сергею в гипотетической юридической фирме "Аспера" поручили отсканировать 50 договоров, попутно проверяя наличие подписей. В ходе сканирования Сергей установил, что в договорах № 12, 17, 32 и 45 отсутствуют нужные подписи. Рядом со сканером лежал листок, куда Сергей записывал номера этих договоров. Эти записи = логи, листок = лог-файл, а процесс записи = логирование. Благодаря "лог-файлу" Сергея старшему юристу не придётся вручную перелопачивать все 50 договоров.
🦅 Логи можно применять везде, где есть возможность записи в файл или в базу данных. Насколько мне известно по моей практике, между любыми двумя строчками/инструкциями кода можно впихнуть команду на логирование текущего состояния системы (разумеется, просто так это делать не нужно). Логировать можно даже стадии отработки узлов нейросетей, чтобы искать изъяны в их логике, а ведь они считаются довольно закрытыми системами.
🔬 Так что при грамотной архитектуре и логировании диджитализированное правосудие не будет котом в мешке или котом Шредингера. Да и вообще котом. В отличие от человека, который в послеобеденное время может (не отдавая ни себе, ни обществу отчёт) выносить более мягкие решения. Который может путать слова, цифры, эмоционально поддаваться на присутствие толпы за окном и ретранслировать в судебное решение многие другие иррациональные факторы.
🌧 часть 3 — безупречная отчётность компьютера
Предыдущий пост мог нагнать пессимизма в размышления о диджитализации правосудия. Дескать, алгоритмы всё равно будут непонятными и непрозрачными, невзирая на тщательно задокументированный код, ведь конечный пользователь не обязан разбираться в коде, чтобы понять правомерность цифрового решения. На самом деле, для обеспечения понятности работы программ существует логирование (запись, фиксация) "производимых действий", "принимаемых решений", а для обеспечения их прозрачности — вывод всех логов конечным пользователям.
Что такое логирование и логи?
Привожу пример из юридической практики.
🖨 Стажеру Сергею в гипотетической юридической фирме "Аспера" поручили отсканировать 50 договоров, попутно проверяя наличие подписей. В ходе сканирования Сергей установил, что в договорах № 12, 17, 32 и 45 отсутствуют нужные подписи. Рядом со сканером лежал листок, куда Сергей записывал номера этих договоров. Эти записи = логи, листок = лог-файл, а процесс записи = логирование. Благодаря "лог-файлу" Сергея старшему юристу не придётся вручную перелопачивать все 50 договоров.
🦅 Логи можно применять везде, где есть возможность записи в файл или в базу данных. Насколько мне известно по моей практике, между любыми двумя строчками/инструкциями кода можно впихнуть команду на логирование текущего состояния системы (разумеется, просто так это делать не нужно). Логировать можно даже стадии отработки узлов нейросетей, чтобы искать изъяны в их логике, а ведь они считаются довольно закрытыми системами.
🔬 Так что при грамотной архитектуре и логировании диджитализированное правосудие не будет котом в мешке или котом Шредингера. Да и вообще котом. В отличие от человека, который в послеобеденное время может (не отдавая ни себе, ни обществу отчёт) выносить более мягкие решения. Который может путать слова, цифры, эмоционально поддаваться на присутствие толпы за окном и ретранслировать в судебное решение многие другие иррациональные факторы.
Ⓜ️ Математику в каждый мозг по самое ЗНО
На прошлой неделе прогремела новость о том, что ЗНО по математике станет обязательным с 2021 года в Украине. К тому же, оно будет иметь два уровня сложности (на выбор).
Зачем? Перевожу цитату министра с источника: "Базовые навыки по математике необходимы каждому человеку — она развивает логическое и абстрактное мышление. А это навыки, которые нужны всем людям, и всё больше стран делают внешний экзамен по математике обязательным для всех детей после завершения школы". Также математика, наряду с английским языком, названа "чрезвычайно важной для человека, который хочет быть конкурентным в современном мире".
С одной стороны, это круто, одобряю. Но почему-то не даёт покоя одна мысль. Ведь кроме этого, знания биологии собственного тела важны для человека, который хочет оставаться жизнеспособным. И физика — тоже как бы наука о законах, которые действуют повсюду. И как раз задача школы — расчехлить новоиспечённого человека в минимальном наборе самых важных знаний, наработанных цивилизацией.
💻 Поэтому давайте к 2026-му году топить за ЗНО по кодингу. А к 2031-му — по экологии, как раз будет горячо.
#новости #news #математика
На прошлой неделе прогремела новость о том, что ЗНО по математике станет обязательным с 2021 года в Украине. К тому же, оно будет иметь два уровня сложности (на выбор).
Зачем? Перевожу цитату министра с источника: "Базовые навыки по математике необходимы каждому человеку — она развивает логическое и абстрактное мышление. А это навыки, которые нужны всем людям, и всё больше стран делают внешний экзамен по математике обязательным для всех детей после завершения школы". Также математика, наряду с английским языком, названа "чрезвычайно важной для человека, который хочет быть конкурентным в современном мире".
С одной стороны, это круто, одобряю. Но почему-то не даёт покоя одна мысль. Ведь кроме этого, знания биологии собственного тела важны для человека, который хочет оставаться жизнеспособным. И физика — тоже как бы наука о законах, которые действуют повсюду. И как раз задача школы — расчехлить новоиспечённого человека в минимальном наборе самых важных знаний, наработанных цивилизацией.
💻 Поэтому давайте к 2026-му году топить за ЗНО по кодингу. А к 2031-му — по экологии, как раз будет горячо.
#новости #news #математика
{kind=link}