
Генерация ID в распределённой системе, часть 2: базы данных
Коротенькое дополнение к предыдущему посту
Каждая вторая статья про id пишет, что генерация через БД подойдёт только пет-проектам или MVP. И для нормальной работы нужен кластер сервисов, чья единственная задача — выдавать другим сервисам id. Отдельный кластер специальных сервисов, не меньше!!1
На большинстве моих проектов ID сущностей создавались через саму БД, и всё было хорошо. В посте покажу несложный приём, который часто используется.
Начнём сначала. Когда в строке с ID пишется строка
Что не так: чтобы id не повторялись, запросы должны проходить через один экземпляр БД. Если сущности создаются часто и объём данных растёт, то такой подход усложняет масштабируемость. Непонятно, как добавить ещё один экземпляр БД
Но если данных не очень много, то вариант отличный.
Следующий шаг: вся последовательность равномерно делится между экземплярами БД.
Например, для 3 экземпляров БД (шардов) шаг будет равен трём и формируются такие id:
▫️ В первом шарде: 1, 4, 7, 10, …
▫️ Во втором: 2, 5, 8, 11, …
▫️ В третьем: 3, 6, 9, 12, …
Скрипт для второго шарда выглядит так:
✅ Несложно мигрировать с первого варианта на второй
😐 Не все БД поддерживают инкремент с шагом
😐 Для каждого экземпляра БД нужен свой скрипт
😐 Менять количество экземпляров БД — очень волнительный процесс
Разумеется, подход с разделением ID не подходит для всех ситуаций. Но этот приём знают не все, поэтому он заслужил отдельный пост:)
Коротенькое дополнение к предыдущему посту
Каждая вторая статья про id пишет, что генерация через БД подойдёт только пет-проектам или MVP. И для нормальной работы нужен кластер сервисов, чья единственная задача — выдавать другим сервисам id. Отдельный кластер специальных сервисов, не меньше!!1
На большинстве моих проектов ID сущностей создавались через саму БД, и всё было хорошо. В посте покажу несложный приём, который часто используется.
Начнём сначала. Когда в строке с ID пишется строка
ID SERIAL PRIMARY KEYвнутри БД создаётся счётчик, который увеличивается при каждой вставке
Что не так: чтобы id не повторялись, запросы должны проходить через один экземпляр БД. Если сущности создаются часто и объём данных растёт, то такой подход усложняет масштабируемость. Непонятно, как добавить ещё один экземпляр БД
Но если данных не очень много, то вариант отличный.
Следующий шаг: вся последовательность равномерно делится между экземплярами БД.
Например, для 3 экземпляров БД (шардов) шаг будет равен трём и формируются такие id:
▫️ В первом шарде: 1, 4, 7, 10, …
▫️ Во втором: 2, 5, 8, 11, …
▫️ В третьем: 3, 6, 9, 12, …
Скрипт для второго шарда выглядит так:
CREATE SEQUENCE userIdGen INCREMENT BY 3 START WITH 2;✅ Нагрузка на БД ниже по сравнению с первым вариантом
✅ Несложно мигрировать с первого варианта на второй
😐 Не все БД поддерживают инкремент с шагом
😐 Для каждого экземпляра БД нужен свой скрипт
😐 Менять количество экземпляров БД — очень волнительный процесс
Разумеется, подход с разделением ID не подходит для всех ситуаций. Но этот приём знают не все, поэтому он заслужил отдельный пост:)
{kind=link}
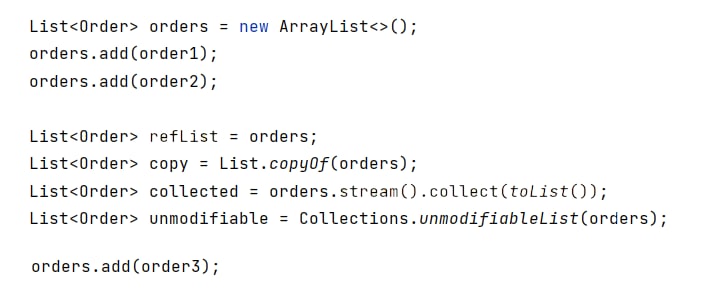
В каком списке будет три элемента после выполнения кода выше?
Anonymous Poll
15%
Ни в одном
74%
refList
8%
copy
7%
collected
15%
unmodifiable
Как скопировать коллекцию?
Вопрос хоть и звучит просто, но однозначно ответить на него нельзя. У внимательного разработчика сразу возникнут вопросы по ТЗ:
🤔 Как связаны исходник и копия? Если исходная коллекция поменяется, отразится ли это на копии?
🤔 Нужна изменяемая или неизменяемая копия?
Для любой комбинации ответов у джавы есть решение:
1️⃣ Изменяемый прокси
Прокси означает, что новый объект работает с теми же ссылками, что и старый.
Изменяемый — что манипуляции с новым списком разрешены и приведут к изменениям в исходнике.
Реализация простейшая:
Теперь перейдём к группе "копии" (collectedList и copy). Сейчас объясню, чем они отличаются от предыдущих вариантов
Каждый список — это набор ссылок. Исходный лист можно представить так:
▫️ ref1 → Order1
▫️ ref2 → Order2
▫️ list → структура данных, которая работает со ссылками ref1 и ref2
В прокси вариантах мы работаем с тем же list и с тем же набором [ref1, ref2].
В команде "копий" создаётся новый набор ссылок на те же объекты:
▫️ ref3 → Order1
▫️ ref4 → Order2
"Копии" работают с другим набором ссылок: [ref3, ref4]. Изменение исходного набора никак не влияет на набор ссылок в "копиях".
Ну и реализации:
3️⃣ Изменяемая копия
❗️Важно: речь идёт только о ссылках и наборах ссылок. Объекты Order не копируются и остаются теми же. Если у объекта [order:1] id изменится на 100, то во всех списках будет [order:100]
Для удобства свела все варианты в табличку:
Вопрос хоть и звучит просто, но однозначно ответить на него нельзя. У внимательного разработчика сразу возникнут вопросы по ТЗ:
🤔 Как связаны исходник и копия? Если исходная коллекция поменяется, отразится ли это на копии?
🤔 Нужна изменяемая или неизменяемая копия?
Для любой комбинации ответов у джавы есть решение:
1️⃣ Изменяемый прокси
Прокси означает, что новый объект работает с теми же ссылками, что и старый.
Изменяемый — что манипуляции с новым списком разрешены и приведут к изменениям в исходнике.
Реализация простейшая:
refList = list2️⃣ Неизменяемый прокси
ummodifiable = Collections.unmodifiableList(list)Методы
add, remove и replace у нового списка выбрасывают исключение. Менять исходную коллекцию никто не запрещает. Все изменения отобразятся во всех прокси.Теперь перейдём к группе "копии" (collectedList и copy). Сейчас объясню, чем они отличаются от предыдущих вариантов
Каждый список — это набор ссылок. Исходный лист можно представить так:
▫️ ref1 → Order1
▫️ ref2 → Order2
▫️ list → структура данных, которая работает со ссылками ref1 и ref2
В прокси вариантах мы работаем с тем же list и с тем же набором [ref1, ref2].
В команде "копий" создаётся новый набор ссылок на те же объекты:
▫️ ref3 → Order1
▫️ ref4 → Order2
"Копии" работают с другим набором ссылок: [ref3, ref4]. Изменение исходного набора никак не влияет на набор ссылок в "копиях".
Ну и реализации:
3️⃣ Изменяемая копия
collectedList = list.stream().collect(toList())4️⃣ Неизменяемая копия
copy = List.copyOf(list)Правильный ответ на вопрос перед постом: refList, ummodifiable
❗️Важно: речь идёт только о ссылках и наборах ссылок. Объекты Order не копируются и остаются теми же. Если у объекта [order:1] id изменится на 100, то во всех списках будет [order:100]
Для удобства свела все варианты в табличку:
{kind=link}
Зарплаты в Европе
Нашла недавно отчёт компании talent.io про зарплаты разработчиков в Европе. Статистика собрана на основе 100 тысяч офферов, и выглядит правдоподобно. Сам доклад называется Tech Salary Report 2022, его можно взять тут в обмен на почту.
Расскажу самое важное.
Специализация
Java — не самый популярный язык для бэкенда, по частоте вакансий с ним соперничают JS (Node.js) и Python (Django). Ещё очень популярен Go, а во Франции в спину дышит PHP (Symphony).
Вакансий на бэкенд и фуллстэк примерно поровну. Специализация на уровень зарплаты влияет мало: frontend, backend, mobile и fullstack разработчики зарабатывают почти одинаково.
Зарплаты
В табличке показаны средние по городам. Сверху — годы опыта, в ячейках — зп в тысячах евро за год. Указаны до вычета налогов, так что смело отбрасывайте 20-50%
Фрилансеры
Средняя дневная ставка бэкендера с опытом 3-6 лет — €480, с опытом больше 7 лет — €590.
Удалёнка
9% компаний требуют обязательного присутствия в офисе. 14% практикуют full remote, остальные работают в гибридном режиме.
Сотрудники часто разбросаны по всей Европе. Например, 58% сотрудников-удалёнщиков в Берлине живут не в Германии.
Франция
идёт отдельным пунктом, потому что статистика сильно отличается от других стран
▫️ Вакансий с Full-stack в 2.5 раза больше, чем просто на бэкенд
▫️ Очень большой спрос на DevOps
▫️ Французы любят работать с французами даже в условиях удалёнки. 84% сотрудников живут во Франции.
Нашла недавно отчёт компании talent.io про зарплаты разработчиков в Европе. Статистика собрана на основе 100 тысяч офферов, и выглядит правдоподобно. Сам доклад называется Tech Salary Report 2022, его можно взять тут в обмен на почту.
Расскажу самое важное.
Специализация
Java — не самый популярный язык для бэкенда, по частоте вакансий с ним соперничают JS (Node.js) и Python (Django). Ещё очень популярен Go, а во Франции в спину дышит PHP (Symphony).
Вакансий на бэкенд и фуллстэк примерно поровну. Специализация на уровень зарплаты влияет мало: frontend, backend, mobile и fullstack разработчики зарабатывают почти одинаково.
Зарплаты
В табличке показаны средние по городам. Сверху — годы опыта, в ячейках — зп в тысячах евро за год. Указаны до вычета налогов, так что смело отбрасывайте 20-50%
|0-1|2-3|4-6|7+
Paris |40 |45 |50 |58
Berlin |50 |55 |63 |69
London |41 |58 |70 |76
Amsterdam|40 |45 |55 |64
Brussels |36 |40 |49 |59
Munich |48 |58 |62 |70
Hamburg |45 |55 |60 |70
Lille |33 |35 |42 |45
Lyon |35 |39 |43 |47
Bordeaux |34 |40 |43 |52
Toulouse |35 |37 |41 |45
(великолепная ascii-табличка заслужила огонёк!)Фрилансеры
Средняя дневная ставка бэкендера с опытом 3-6 лет — €480, с опытом больше 7 лет — €590.
Удалёнка
9% компаний требуют обязательного присутствия в офисе. 14% практикуют full remote, остальные работают в гибридном режиме.
Сотрудники часто разбросаны по всей Европе. Например, 58% сотрудников-удалёнщиков в Берлине живут не в Германии.
Франция
идёт отдельным пунктом, потому что статистика сильно отличается от других стран
▫️ Вакансий с Full-stack в 2.5 раза больше, чем просто на бэкенд
▫️ Очень большой спрос на DevOps
▫️ Французы любят работать с французами даже в условиях удалёнки. 84% сотрудников живут во Франции.
{kind=link}
Связывание методов и бездумный копипаст
Вопрос выше связан с темой связывания методов. Начну с неё, а потом немного поворчу на интернет.
Итак, связывание бывает:
▫️ Позднее (динамическое) — решение, какой метод вызвать, принимается во время работы программы
▫️ Раннее (статическое) — решение принимается на этапе компиляции. В рантайме нет лишних движений, и скорость вызова таких методов чуть выше
Для статических методов работает (сюрприз) статическое связывание. Статические методы в классах
Поэтому правильный ответ в опросе выше — "Parent". Метод определяется во время компиляции по типу указателя.
❓ Что из этого можно вынести?
Если посмотреть на
Поэтому best practice — вызывать статические методы, обращаясь к классу:
Вопрос про связывание часто входит в списки java interview questions, но почти все статьи содержат неверную информацию. Пишут, что
▪️ Статическое связывание используют
▪️ Динамическое — методы интерфейсов и перегруженные методы
Кажется логичным, но давайте проверим. Для разных типов связывания используется разные инструкции байткода. Посмотреть их можно через консоль
Нас интересуют инструкции invoke*. Немного поиграв с кодом можно увидеть, что для public, protected, private и final методов используется
Сразу возникает вопрос:
❓ Почему для private и final методов используется динамическое связывание? Ведь метод точно не переопределяется и это известно во время компиляции
Для final ответ кроется в спецификации java, пункт 13.4.17. Суть такая: final метод может однажды перестать быть final, и кто-то может его переопределить. Когда класс, который переопределил метод, будет взаимодействовать со старым байткодом, ничего не должно сломаться.
Правила работы с private методами описаны в спецификации JVM, пункт 5.4.6. Причина использования
❓ Зачем это знать?
Для написания кода это абсолютно не важно. Но это яркий пример некорректной информации, которая бездумно копируется в джуниорские опросники👎
А вот на курсе многопоточки мы постоянно лазаем по исходникам java.util.concurrent, поэтому инфа абсолютно живая и актуальная. Минутка рекламы, но почему бы и нет:) Присоединяйтесь: https://fillthegaps.ru/mt6
Вопрос выше связан с темой связывания методов. Начну с неё, а потом немного поворчу на интернет.
Итак, связывание бывает:
▫️ Позднее (динамическое) — решение, какой метод вызвать, принимается во время работы программы
▫️ Раннее (статическое) — решение принимается на этапе компиляции. В рантайме нет лишних движений, и скорость вызова таких методов чуть выше
Для статических методов работает (сюрприз) статическое связывание. Статические методы в классах
Parent и Child не переопределяют друг друга и относятся к разным классам. Над методом в классе Child нельзя поставить Override и вызвать внутри super.getName();Поэтому правильный ответ в опросе выше — "Parent". Метод определяется во время компиляции по типу указателя.
❓ Что из этого можно вынести?
Если посмотреть на
getName, то непонятно, статический он или обычный, учитывается тип экземпляра или нет. Это затрудняет чтение кода и считается плохой практикой. Настолько плохой, что Intellij IDEA даже не показывает статические методы в выпадающем списке для объекта. Поэтому best practice — вызывать статические методы, обращаясь к классу:
Parent.getName()Теперь о грустном.
Вопрос про связывание часто входит в списки java interview questions, но почти все статьи содержат неверную информацию. Пишут, что
▪️ Статическое связывание используют
private, final, static методы и конструкторы▪️ Динамическое — методы интерфейсов и перегруженные методы
Кажется логичным, но давайте проверим. Для разных типов связывания используется разные инструкции байткода. Посмотреть их можно через консоль
javap -c -v LovelyService.classили в IDEA: View → Show Bytecode
Нас интересуют инструкции invoke*. Немного поиграв с кодом можно увидеть, что для public, protected, private и final методов используется
invokevirtual — динамическая типизация. Статические методы используют инструкцию invokestatic. Сразу возникает вопрос:
❓ Почему для private и final методов используется динамическое связывание? Ведь метод точно не переопределяется и это известно во время компиляции
Для final ответ кроется в спецификации java, пункт 13.4.17. Суть такая: final метод может однажды перестать быть final, и кто-то может его переопределить. Когда класс, который переопределил метод, будет взаимодействовать со старым байткодом, ничего не должно сломаться.
Правила работы с private методами описаны в спецификации JVM, пункт 5.4.6. Причина использования
invokevirtual не указана, но подозреваю, что ситуация как у final❓ Зачем это знать?
Для написания кода это абсолютно не важно. Но это яркий пример некорректной информации, которая бездумно копируется в джуниорские опросники👎
А вот на курсе многопоточки мы постоянно лазаем по исходникам java.util.concurrent, поэтому инфа абсолютно живая и актуальная. Минутка рекламы, но почему бы и нет:) Присоединяйтесь: https://fillthegaps.ru/mt6
Как потоки в java соотносятся с потоками операционной системы?
Anonymous Poll
50%
1:1 (1 экземпляр Thread → 1 поток ОС)
6%
1:N (1 экземпляр Thread → N потоков ОС)
24%
N:1 (N экземпляров Thread → 1 поток ОС)
20%
N:M (N экземпляров Thread → M потоков ОС)
А какое соотношение потоков с потоками ОС в python?
Anonymous Poll
37%
1:1 (1 экземпляр Thread → 1 поток ОС)
11%
1:N (1 экземпляр Thread → N потоков ОС)
35%
N:1 (N экземпляров Thread → 1 поток ОС)
16%
N:M (N экземпляров Thread → M потоков ОС)
Как устроена многопоточность в разных языках
В этом посте упрощённо опишу, как происходит работа с потоками в разных языках. Для сравнения возьму 4 популярных в Европе бэкенд языка — Python, JavaScript, Java и Go.
Начнём с основ.
Любой бэк работает на каком-то железе. Основная цель при разработке — задействовать ресурсы процессора на максимум. Если у процессора 8 ядер, то одновременно могут выполняться 8 задач. Как это достигается:
Python и JavaScript
В этих языках в каждый момент времени выполняется только одна задача. В этом смысле языки можно назвать однопоточными.
Когда задача запускается "в другом потоке", она логически изолируется от текущей. Например, запрос 1 выполняется в потоке Т1, запрос 2 — в потоке Т2. У каждого запроса теперь своя область видимости и локальные переменные.
Эти логические потоки попеременно получают доступ к одному потоку ОС, а значит и к одному ядру.
Один экземпляр сервиса нагружает только одно ядро процессора. Чтобы задействовать 8 ядер, запускают 8 экземпляров сервиса + балансировщик
Плюсы:
✔️ Нет многопоточных проблем
✔️ Код получается линейный, его легко тестировать и дебажить
Минусы:
🙁 Нет общей памяти между сервисами. Для обмена и накопления данных активно используются кэши, месседж брокеры и БД
🙁 Как следствие — чуть более сложная инфраструктура
Java
Потоки в джаве соотносятся с потоками ОС в отношении 1 к 1, поэтому в каждый момент времени может идти работа над 8 задачами (если ядер 8).
Плюсы:
✔️ Один сервис вместо 8 — не нужен дополнительный балансировщик
✔️Общая память между потоками — можно переиспользовать данные и компоненты
✔️ Больше вариантов работы — на выбор даётся классический (thread-per-request) и реактивный стиль. А скоро добавятся виртуальные потоки 🥳
✔️ Шикарная библиотека java.util.concurrent с инструментами на любой вкус
Минусы:
🙁 Код становится сложнее
🙁 Сложно тестировать и дебажить
🙁 Многопоточные сложности: гонки, дедлоки, проблемы с видимостью и атомарностью
🙁 Сложно добиться оптимальной загрузки процессора. Для разных задач нужно подбирать разные параметры и решения
Go
Потоки в go (горутины) соотносятся с потоками ОС как многие ко многим. Сервису нужно гораздо меньше потоков ОС, чем в java.
Благодаря особенностям реализации горутины показывают лучшую производительность в сервисах с большим количеством блокирующих вызовов. В итоге получается отличный микс классической и реактивной архитектуры.
Плюсы:
✔️ Многопоточный код в некоторых случаях проще, чем в джаве
✔️ Один сервис и общая память между потоками
✔️ Отличная работа с блокирующими вызовами
Минусы:
🙁 Всё ещё актуальны многопоточные сложности из пункта про джаву
Это очень базовое описание механизмов работы с потоками. Работающий бэк можно написать на любом языке выше. В тех же Node.js и Django давно есть модули, облегчающие работу с несколькими экземплярами и передачей данных. Но в джаве модель работы с потоками самая сложная и разнообразная.
И правильный ответ на вопрос перед постом: для java соотношение 1:1, для python — N:1
В этом посте упрощённо опишу, как происходит работа с потоками в разных языках. Для сравнения возьму 4 популярных в Европе бэкенд языка — Python, JavaScript, Java и Go.
Начнём с основ.
Любой бэк работает на каком-то железе. Основная цель при разработке — задействовать ресурсы процессора на максимум. Если у процессора 8 ядер, то одновременно могут выполняться 8 задач. Как это достигается:
Python и JavaScript
В этих языках в каждый момент времени выполняется только одна задача. В этом смысле языки можно назвать однопоточными.
Когда задача запускается "в другом потоке", она логически изолируется от текущей. Например, запрос 1 выполняется в потоке Т1, запрос 2 — в потоке Т2. У каждого запроса теперь своя область видимости и локальные переменные.
Эти логические потоки попеременно получают доступ к одному потоку ОС, а значит и к одному ядру.
Один экземпляр сервиса нагружает только одно ядро процессора. Чтобы задействовать 8 ядер, запускают 8 экземпляров сервиса + балансировщик
Плюсы:
✔️ Нет многопоточных проблем
✔️ Код получается линейный, его легко тестировать и дебажить
Минусы:
🙁 Нет общей памяти между сервисами. Для обмена и накопления данных активно используются кэши, месседж брокеры и БД
🙁 Как следствие — чуть более сложная инфраструктура
Java
Потоки в джаве соотносятся с потоками ОС в отношении 1 к 1, поэтому в каждый момент времени может идти работа над 8 задачами (если ядер 8).
Плюсы:
✔️ Один сервис вместо 8 — не нужен дополнительный балансировщик
✔️Общая память между потоками — можно переиспользовать данные и компоненты
✔️ Больше вариантов работы — на выбор даётся классический (thread-per-request) и реактивный стиль. А скоро добавятся виртуальные потоки 🥳
✔️ Шикарная библиотека java.util.concurrent с инструментами на любой вкус
Минусы:
🙁 Код становится сложнее
🙁 Сложно тестировать и дебажить
🙁 Многопоточные сложности: гонки, дедлоки, проблемы с видимостью и атомарностью
🙁 Сложно добиться оптимальной загрузки процессора. Для разных задач нужно подбирать разные параметры и решения
Go
Потоки в go (горутины) соотносятся с потоками ОС как многие ко многим. Сервису нужно гораздо меньше потоков ОС, чем в java.
Благодаря особенностям реализации горутины показывают лучшую производительность в сервисах с большим количеством блокирующих вызовов. В итоге получается отличный микс классической и реактивной архитектуры.
Плюсы:
✔️ Многопоточный код в некоторых случаях проще, чем в джаве
✔️ Один сервис и общая память между потоками
✔️ Отличная работа с блокирующими вызовами
Минусы:
🙁 Всё ещё актуальны многопоточные сложности из пункта про джаву
Это очень базовое описание механизмов работы с потоками. Работающий бэк можно написать на любом языке выше. В тех же Node.js и Django давно есть модули, облегчающие работу с несколькими экземплярами и передачей данных. Но в джаве модель работы с потоками самая сложная и разнообразная.
И правильный ответ на вопрос перед постом: для java соотношение 1:1, для python — N:1
Синтаксис Go, часть 1: полезные штуки, которых нет в Java
Некоторое время назад я начала изучать Go. Мотивация очень простая:
🔸 Популярность. Go занимает 4 место в Европе среди языков бэкенда. У Озона, Ламоды, ВК, Авито и других больших ребят есть сервисы на Go
🔸 Интерес. От языка, созданного гуглом, жду интересных идей и подходов к старым проблемам
🔸 А вдруг го лучше джавы? Может новые микросервисы писать на Go? Вдруг пора менять стэк и заводить канал Go: fill the gaps? Хочется разобраться и составить мнение на этот счёт
Первый шаг в изучении языка — синтаксис и стандартные библиотеки. Я человек простой, и тоже иду по этому пути.
Для большинства конструкций в Go можно легко найти аналоги в java. В этом посте я рассказажу об особенностях го, у которых НЕТ прямых аналогов в джаве.
Если бы я писала пост летом, то первым пунктом стали бы горутины, киллер-фича Go. В java 19 вышли виртуальные потоки, которые на первый взгляд похожи на горутины. В нюансах я когда-нибудь разберусь, а сейчас расскажу, чего в джаве точно нет:
1️⃣ Можно вернуть несколько значений из функции
Вернуть два значения — сверхпопулярный кейс, во многих java проектах для этих целей используют Map.Entry или создают класс Pair.
До сих пор не понимаю, почему в джаве нельзя вернуть пару. Технически это не должно быть сложно, можно сделать что-то среднее между дженериками и LambdaMetaFactory. Или добавить класс Pair в стандартную библиотеку.
2️⃣ Нет наследования
Только интерфейсы и композиция. Никаких проблем с абстрактными классами и сложными иерархиями. Одобряю👌
3️⃣ Объект можно передать по ссылке и по значению
В java всё однозначно:
▪️
▪️
В Go вариантов больше:
▫️
▫️
▫️
▫️
4️⃣ Оператор select
для получения самого быстрого результата от асинхронных задач.
Как это выглядит: допустим, мы отправили три задачи в асинхронное исполнение. Пишем:
Самый близкий java аналог — конструкция
За кадром осталось много конструкций, которые выглядят по-другому, но я пока не поняла, чем они лучше аналогов в java. Возможно, когда перейду к изучению лучших практик, плюсы станут более весомыми. А может и нет:)
Но не всё так радужно, и в следующем посте опишу особенности Go, которые мне НЕ понравились😈
Некоторое время назад я начала изучать Go. Мотивация очень простая:
🔸 Популярность. Go занимает 4 место в Европе среди языков бэкенда. У Озона, Ламоды, ВК, Авито и других больших ребят есть сервисы на Go
🔸 Интерес. От языка, созданного гуглом, жду интересных идей и подходов к старым проблемам
🔸 А вдруг го лучше джавы? Может новые микросервисы писать на Go? Вдруг пора менять стэк и заводить канал Go: fill the gaps? Хочется разобраться и составить мнение на этот счёт
Первый шаг в изучении языка — синтаксис и стандартные библиотеки. Я человек простой, и тоже иду по этому пути.
Для большинства конструкций в Go можно легко найти аналоги в java. В этом посте я рассказажу об особенностях го, у которых НЕТ прямых аналогов в джаве.
Если бы я писала пост летом, то первым пунктом стали бы горутины, киллер-фича Go. В java 19 вышли виртуальные потоки, которые на первый взгляд похожи на горутины. В нюансах я когда-нибудь разберусь, а сейчас расскажу, чего в джаве точно нет:
1️⃣ Можно вернуть несколько значений из функции
name, count := processUser(user)Подобные штуки доступны и в других языках, например, в Python.
Вернуть два значения — сверхпопулярный кейс, во многих java проектах для этих целей используют Map.Entry или создают класс Pair.
До сих пор не понимаю, почему в джаве нельзя вернуть пару. Технически это не должно быть сложно, можно сделать что-то среднее между дженериками и LambdaMetaFactory. Или добавить класс Pair в стандартную библиотеку.
2️⃣ Нет наследования
Только интерфейсы и композиция. Никаких проблем с абстрактными классами и сложными иерархиями. Одобряю👌
3️⃣ Объект можно передать по ссылке и по значению
В java всё однозначно:
▪️
void m(int value) — примитив копируется и манипуляции с value не отразятся на переданной переменной▪️
void m(User user) — ссылка копируется, но указывает на тот же объектВ Go вариантов больше:
▫️
func m(value int) — примитив копируется как в джаве ▫️
func m(value *int) — передаём ссылку на примитив, внутри метода ей можно присвоить другое значение▫️
func m(value User) — в метод передаётся полная копия объекта▫️
func m(value *User) — передаём исходную ссылку на объект. Её можно переприсвоить новому объекту, и сам объект, конечно, можно менять4️⃣ Оператор select
для получения самого быстрого результата от асинхронных задач.
Как это выглядит: допустим, мы отправили три задачи в асинхронное исполнение. Пишем:
select {
результат задачи 1: код А
результат задачи 2: код Б
результат задачи 3: код Ц
}
Какая задача первой вернёт результат, такой код и выполнится. При этом нам сразу доступен результат завершённой задачи.Самый близкий java аналог — конструкция
CompletableFuture.anyOf(задача1, задача2, задача3).thenRun(код)Код в
thenRun выполнится, когда одна из задач завершится. Затем нужно пройтись по всем объектам CompletableFuture, чтобы выяснить, какая именно задача завершилась, и забрать у неё результат. В go эту задачу выполнить гораздо проще.За кадром осталось много конструкций, которые выглядят по-другому, но я пока не поняла, чем они лучше аналогов в java. Возможно, когда перейду к изучению лучших практик, плюсы станут более весомыми. А может и нет:)
Но не всё так радужно, и в следующем посте опишу особенности Go, которые мне НЕ понравились😈
Синтаксис Go, часть 2: неудачные моменты
В изучении нового языка, фреймворка или библиотеки очень важны анализ и сравнение. В чём разница подходов, где какие плюсы и минусы, что для каких кейсов подойдёт. Если планируете расти дальше сеньора, то такие навыки пригодятся.
В этом посте опишу 3 особенности Go. Их сложно отнести к достоинствам, но они помогают по-новому оценить привычные java конструкции
1️⃣ Неудобная работа с ошибками
Как и в java, в go ошибки делятся на две категории:
🔹
Многие методы возвращают пару результат-ошибка:
❌ Если метод возвращает разные ошибки, то разработчику нужно самому найти в исходном коде возможные варианты и написать что-то вроде “если ошибка типа А, то … , если типа Б, то …”
❌ Большинство ошибок в стандартной библиотеке — обычный error с текстом. Обрабатывать в таком виде очень неудобно
❌ Компилятор не требует обработки ошибок
🔹
Аналог RuntimeException, паника поднимается по стеку вызовов, пока не встретит обработчик. Если не встретит, программа завершается.
Что не нравится:
❌ Большинство паник содержат просто строчку с текстом
❌ Обработчики ловят всё подряд
Эти недостатки вижу не только я. Для Go версии 2 (сейчас 1.19) идут активные обсуждения, как сделать работу с ошибками лучше.
2️⃣ Оригинальное форматирование
В большинстве языков для перевода даты в строку и обратно используются шаблоны типа yyyy-MM-dd
Go выбрал другой путь. Задать формат — значит написать, как выглядит в этом представлении 2 января 2006 года, время 15:04:05.
Пример: чтобы отформатировать переменную dateTime в виде "сначала время через двоеточие, потом дата через дефис" пишем
Какие преимущества у такого оригинального форматирования? Абсолютно никаких.
К счастью, есть сторонние библиотеки, работающие с привычным yyyy-MM-dd
3️⃣ Неудобная работа с наборами элементов
Коллекции в java — прекрасные абстракции для обработки данных. Например, ArrayList — коллекция, в основе которой лежит массив с конечной длиной. ArrayList скрывает часть сложности — если нужно добавить элемент в середину, то все манипуляции с массивом ArrayList берёт на себя.
А с появлением Stream API работать с данными — сплошное удовольствие🥰
В Go абстракция над массивом называется slice (срез), у неё есть буфер и довольно специфичное поведение.
(если вы заинтригованы, рекомендую этот текст и это видео)
Целевые кейсы по работе с данными в Go скорее всего отличаются от джавовских. Поэтому и набор методов другой. Например, в стандартной библиотеке нет метода contains. Если надо — пиши сам:
Абстракции в Go, кажется, хорошо подходят для оконных функций (посчитать среднее за 5 минут, максимальное за час) или случаев, когда исходные данные не меняются.
Но для энтерпрайзных ситуаций это выглядит сложно, неудобно и ненадёжно.
❓ Что дальше?
Для меня в обучении интересно не только прокачать hard skills, но и набраться новых идей. Даже простое изучение синтаксиса привело к каким-то мыслям, так что продолжу разбираться с Go. В планах изучить основные библиотеки, паттерны и лучшие практики. Посмотреть на внутрянку, бенчмарки, изучить продакшн кейсы.
Об этом писать не буду, канал всё-таки про джаву. Но если встречу что-нибудь интересное, чего нет в java инфополе, то обязательно поделюсь:)
В изучении нового языка, фреймворка или библиотеки очень важны анализ и сравнение. В чём разница подходов, где какие плюсы и минусы, что для каких кейсов подойдёт. Если планируете расти дальше сеньора, то такие навыки пригодятся.
В этом посте опишу 3 особенности Go. Их сложно отнести к достоинствам, но они помогают по-новому оценить привычные java конструкции
1️⃣ Неудобная работа с ошибками
Как и в java, в go ошибки делятся на две категории:
🔹
error — ожидаемые ошибки, с которыми можно справиться. Например, файл не найден или у даты неверный форматМногие методы возвращают пару результат-ошибка:
result, err := process()Сразу после вызова метода проверяем, всё ли ок:
if err != nil { обработка ошибки }
Что не нравится:❌ Если метод возвращает разные ошибки, то разработчику нужно самому найти в исходном коде возможные варианты и написать что-то вроде “если ошибка типа А, то … , если типа Б, то …”
❌ Большинство ошибок в стандартной библиотеке — обычный error с текстом. Обрабатывать в таком виде очень неудобно
❌ Компилятор не требует обработки ошибок
🔹
panic — непоправимые ошибки, например, выход на пределы массива. Аналог RuntimeException, паника поднимается по стеку вызовов, пока не встретит обработчик. Если не встретит, программа завершается.
Что не нравится:
❌ Большинство паник содержат просто строчку с текстом
❌ Обработчики ловят всё подряд
Эти недостатки вижу не только я. Для Go версии 2 (сейчас 1.19) идут активные обсуждения, как сделать работу с ошибками лучше.
2️⃣ Оригинальное форматирование
В большинстве языков для перевода даты в строку и обратно используются шаблоны типа yyyy-MM-dd
Go выбрал другой путь. Задать формат — значит написать, как выглядит в этом представлении 2 января 2006 года, время 15:04:05.
Пример: чтобы отформатировать переменную dateTime в виде "сначала время через двоеточие, потом дата через дефис" пишем
currentTime.Format("15:04:05 02-01-2006"))
Почему такая дата? Потому что в американском формате это 01.02 03:04:05 06 -07 (месяц, число, время, год, часовой пояс)Какие преимущества у такого оригинального форматирования? Абсолютно никаких.
К счастью, есть сторонние библиотеки, работающие с привычным yyyy-MM-dd
3️⃣ Неудобная работа с наборами элементов
Коллекции в java — прекрасные абстракции для обработки данных. Например, ArrayList — коллекция, в основе которой лежит массив с конечной длиной. ArrayList скрывает часть сложности — если нужно добавить элемент в середину, то все манипуляции с массивом ArrayList берёт на себя.
А с появлением Stream API работать с данными — сплошное удовольствие🥰
В Go абстракция над массивом называется slice (срез), у неё есть буфер и довольно специфичное поведение.
(если вы заинтригованы, рекомендую этот текст и это видео)
Целевые кейсы по работе с данными в Go скорее всего отличаются от джавовских. Поэтому и набор методов другой. Например, в стандартной библиотеке нет метода contains. Если надо — пиши сам:
for _, a := range s {
if a == e { return true }
}
putIfAbsent, indexOf, isEmpty, метод вставки в начало/середину — всего этого нет. Абстракции в Go, кажется, хорошо подходят для оконных функций (посчитать среднее за 5 минут, максимальное за час) или случаев, когда исходные данные не меняются.
Но для энтерпрайзных ситуаций это выглядит сложно, неудобно и ненадёжно.
❓ Что дальше?
Для меня в обучении интересно не только прокачать hard skills, но и набраться новых идей. Даже простое изучение синтаксиса привело к каким-то мыслям, так что продолжу разбираться с Go. В планах изучить основные библиотеки, паттерны и лучшие практики. Посмотреть на внутрянку, бенчмарки, изучить продакшн кейсы.
Об этом писать не буду, канал всё-таки про джаву. Но если встречу что-нибудь интересное, чего нет в java инфополе, то обязательно поделюсь:)
Асинхронность, параллельность, многопоточность
Опишу простыми словами разницу между этими и близкими терминами.
Многоядерный
Относится к процессору. У процессора 4-16 ядер, каждое работает независимо от других. Если ядер 8, то в каждый момент процессор работает над 8 задачами.
Во многих процессорах есть технология hyper-threading, когда на 1 ядре выполняются 2 задачи. Тогда на 8 ядрах могут одновременно выполняться 16 задач.
Многопоточный
Относится к языку программирования. Это возможность изолировать задачи в разных потоках. У каждого потока свои локальные переменные, область видимости и исполняемый код. Очень удобно:)
Если у процессора 8 ядер, в java приложении в каждый момент выполняются не больше 8 потоков (= не больше 8 задач). В других языках дело обстоит по-другому, подробнее в этом посте.
Многопоточность — свойство языка, но в жизни часто упоминают "многопоточный код". Это код, в котором задачи из разных потоков взаимодействуют между собой. Например, запросы увеличивают общую переменную — счётчик запросов. Или задача делится на подзадачи, и они выполняются в разных потоках.
Когда в вакансии пишут про знания многопоточки, то имеют в виду мастерское владение java.util.concurrent, знание возможных многопоточных проблем и лучших практик.
Concurrency
Относится к системе в целом. Система называется concurrent, если в ней выполняются несколько задач и актуальны проблемы:
🔹 как поделить системные ресурсы между задачами
🔹 как координировать задачи между собой
🔹 как корректно работать с общими ресурсами
🔹 как сделать так, чтобы ничего не сломалось при увеличении нагрузки
В наши дни сложно найти что-то НЕ concurrent, все веб-сервисы попадают в эту категорию. На практике под concurrent кодом подразумевается, что проблемы выше решает не только фреймворк, но и разработчик.
Параллельный
Относится к задачам. Параллельно = одновременно. Процессор с 8 ядрами выполняет в каждый момент времени 8 задач = процессор параллельно выполняет 8 задач.
В жизни термин употребляется не так строго.
Допустим, нужно обработать 10 млн элементов. Если делать это последовательно, то будет работать одно ядро процессора, а остальные 7 (если ядер 8) — простаивать.
При параллельной обработке задача разбивается на 10 частей по 1 млн, и каждая подзадача отправляется в отдельный поток. Вычислениями занимаются больше ядер, и общий результат посчитается быстрее.
Значит ли это, что все 10 задач выполняются одновременно?
Нет. Если у процессора 8 ядер, то в один момент выполняется максимум 8 задач. Но подобную схему всё равно называют параллельной обработкой
Асинхронный
Относится к общению между потоками, классами или сервисами.
Синхронный означает, что участник 1 останавливает свою работу и ждёт результата от участника 2:
▫️ поток отправил запрос в БД и ждёт ответ
▫️ сервис отправил HTTP-запрос в другой сервис и ждёт ответ
▫️ поток отправил задачу в executor и ждёт результат через join
Часто используют слово "блокирующий" как синоним синхронного запроса
Асинхронный — когда участник 1 отправил запрос и НЕ ждёт ответ. Результат либо не нужен, либо участник 2 сам инициирует общение, когда результат готов:
▫️ поток отправил задачу в executor и не вызывает у задачи join
▫️ сервис отправляет сообщение в месседж брокер
Многие инструменты выглядят как синхронные, но под капотом работают асинхронно. Например, метод sendAsync в HttpCLient или реактивные драйвера БД.
🎁 Бонус — чтобы понять, что могут спросить на собесах, воспользуйтесь формулой:
Может ли (термин 1) быть/не быть (термин 2)?
Например,
❓ Возможна ли многопоточная программа без параллельности?да
❓ А параллельная без многопоточности? нет
❓ Может ли однопоточная программа быть асинхронной? да
❓ Возможны ли многопоточные проблемы в программе, запущенной на одноядерном процессоре? да
Опишу простыми словами разницу между этими и близкими терминами.
Многоядерный
Относится к процессору. У процессора 4-16 ядер, каждое работает независимо от других. Если ядер 8, то в каждый момент процессор работает над 8 задачами.
Во многих процессорах есть технология hyper-threading, когда на 1 ядре выполняются 2 задачи. Тогда на 8 ядрах могут одновременно выполняться 16 задач.
Многопоточный
Относится к языку программирования. Это возможность изолировать задачи в разных потоках. У каждого потока свои локальные переменные, область видимости и исполняемый код. Очень удобно:)
Если у процессора 8 ядер, в java приложении в каждый момент выполняются не больше 8 потоков (= не больше 8 задач). В других языках дело обстоит по-другому, подробнее в этом посте.
Многопоточность — свойство языка, но в жизни часто упоминают "многопоточный код". Это код, в котором задачи из разных потоков взаимодействуют между собой. Например, запросы увеличивают общую переменную — счётчик запросов. Или задача делится на подзадачи, и они выполняются в разных потоках.
Когда в вакансии пишут про знания многопоточки, то имеют в виду мастерское владение java.util.concurrent, знание возможных многопоточных проблем и лучших практик.
Concurrency
Относится к системе в целом. Система называется concurrent, если в ней выполняются несколько задач и актуальны проблемы:
🔹 как поделить системные ресурсы между задачами
🔹 как координировать задачи между собой
🔹 как корректно работать с общими ресурсами
🔹 как сделать так, чтобы ничего не сломалось при увеличении нагрузки
В наши дни сложно найти что-то НЕ concurrent, все веб-сервисы попадают в эту категорию. На практике под concurrent кодом подразумевается, что проблемы выше решает не только фреймворк, но и разработчик.
Параллельный
Относится к задачам. Параллельно = одновременно. Процессор с 8 ядрами выполняет в каждый момент времени 8 задач = процессор параллельно выполняет 8 задач.
В жизни термин употребляется не так строго.
Допустим, нужно обработать 10 млн элементов. Если делать это последовательно, то будет работать одно ядро процессора, а остальные 7 (если ядер 8) — простаивать.
При параллельной обработке задача разбивается на 10 частей по 1 млн, и каждая подзадача отправляется в отдельный поток. Вычислениями занимаются больше ядер, и общий результат посчитается быстрее.
Значит ли это, что все 10 задач выполняются одновременно?
Нет. Если у процессора 8 ядер, то в один момент выполняется максимум 8 задач. Но подобную схему всё равно называют параллельной обработкой
Асинхронный
Относится к общению между потоками, классами или сервисами.
Синхронный означает, что участник 1 останавливает свою работу и ждёт результата от участника 2:
▫️ поток отправил запрос в БД и ждёт ответ
▫️ сервис отправил HTTP-запрос в другой сервис и ждёт ответ
▫️ поток отправил задачу в executor и ждёт результат через join
Часто используют слово "блокирующий" как синоним синхронного запроса
Асинхронный — когда участник 1 отправил запрос и НЕ ждёт ответ. Результат либо не нужен, либо участник 2 сам инициирует общение, когда результат готов:
▫️ поток отправил задачу в executor и не вызывает у задачи join
▫️ сервис отправляет сообщение в месседж брокер
Многие инструменты выглядят как синхронные, но под капотом работают асинхронно. Например, метод sendAsync в HttpCLient или реактивные драйвера БД.
🎁 Бонус — чтобы понять, что могут спросить на собесах, воспользуйтесь формулой:
Может ли (термин 1) быть/не быть (термин 2)?
Например,
❓ Возможна ли многопоточная программа без параллельности?
{kind=link}
Что напечатается в консоли после выполнения кода выше?
Anonymous Poll
68%
true true
22%
true false
7%
false true
3%
false false
Boxing и unboxing
В java 2 типа сущностей — примитивы и ссылочные типы. К первой группе относятся int, long, boolean и остальные типы с маленькой буквы. В таких переменных хранится само значение. Набор действий с примитивами ограничен, зато вычисления происходят с космической скоростью.
К ссылочным типам относится всё остальное: объекты, массивы, интерфейсы и тд. Такие переменные хранят указатель на участок памяти, где находится объект. Объекты занимают больше места, чем примитивы, зато функционал гораздо шире.
Работать с коллекциями приятнее, чем с массивами, поэтому в джава сделаликостыль workaround для примитивных типов — классы-обёртки (Integer, Long, …) и боксинг/анбоксинг.
В целом это удобно, но появляются проблемы:
❌ Неосознанный boxing/unboxing и лишняя трата памяти и времени
❌ NPE в неожиданных местах
❌ Неоднозначная работа с ==
❌ Трудности по работе с массивами
Что происходит в коде выше?
Сигнатура метода asList выглядит так:
Во второй части ситуация менее однозначная. Для массивов и коллекций не работает автоматическое приведение типов и боксинг/анбоксинг:
❌ List<Child> не приводится автоматически к List<Parent>
❌ Массив int не приводится автоматически к массиву Integer
В метод уже приходит ссылка — ссылка на массив примитивов. JVM всё устраивает, и она создаёт List из ссылок на массив.
Получится
⭐️ Заметка 1: немного смуты здесь вносит var. Если писать целиком
⭐️ Заметка 2: сигнатура contains выглядит так:
❓ Как получить нормальный список из массива примитивов?
В java 2 типа сущностей — примитивы и ссылочные типы. К первой группе относятся int, long, boolean и остальные типы с маленькой буквы. В таких переменных хранится само значение. Набор действий с примитивами ограничен, зато вычисления происходят с космической скоростью.
К ссылочным типам относится всё остальное: объекты, массивы, интерфейсы и тд. Такие переменные хранят указатель на участок памяти, где находится объект. Объекты занимают больше места, чем примитивы, зато функционал гораздо шире.
Работать с коллекциями приятнее, чем с массивами, поэтому в джава сделали
В целом это удобно, но появляются проблемы:
❌ Неосознанный boxing/unboxing и лишняя трата памяти и времени
❌ NPE в неожиданных местах
❌ Неоднозначная работа с ==
❌ Трудности по работе с массивами
Что происходит в коде выше?
Сигнатура метода asList выглядит так:
List<T> asList(T… a)Метод ждёт на вход объекты ссылочных типов. В случае stringArr всё ок, передаются 4 ссылки на объект String, и создаётся список с 4 элементами.
Во второй части ситуация менее однозначная. Для массивов и коллекций не работает автоматическое приведение типов и боксинг/анбоксинг:
❌ List<Child> не приводится автоматически к List<Parent>
❌ Массив int не приводится автоматически к массиву Integer
В метод уже приходит ссылка — ссылка на массив примитивов. JVM всё устраивает, и она создаёт List из ссылок на массив.
Получится
List<int[]>, в котором будет один элемент — ссылка на {1,2,3}. Массив с числом не сравнить, поэтому ответ на вопрос перед постом: true false⭐️ Заметка 1: немного смуты здесь вносит var. Если писать целиком
List<Integer> res = Arrays.asList(intArray)то компилятор сразу укажет на несоответствие типов
⭐️ Заметка 2: сигнатура contains выглядит так:
boolean contains(Object o)Метод примет что угодно — строку, примитив (здесь выполнится боксинг) или экземпляр StringBuilder. Поэтому ошибок компиляции нет
❓ Как получить нормальный список из массива примитивов?
var intList = Arrays.stream(intArray).boxed().collect(toList());Закончу на оптимистичной ноте. В рамках Project Valhalla в JVM добавят три новых типа данных: value objects, primitive classes, specialized generics. В двух словах об этом не рассказать, но есть шанс, что через 10 лет код выше будет работать, как ожидается🤭
{kind=link}
Что выведется в консоль в результате работы программы?
Anonymous Poll
1%
0
8%
5
36%
10
4%
Ошибка компиляции в точке А
52%
Ошибка компиляции в точке Б
Что такое effectively final и что с ним делать
Начну с правильного ответа на вопрос выше. В точке Б мы получим предупреждение компилятора: local variables referenced from a lambda expression must be final or effectively final
В этом посте обсудим, что означает effectively final, о чём молчит спецификация и как менять переменные внутри лямбд.
Про модификатор final всё понятно — он запрещает изменение переменной
Чтобы компилятор не ругался, надо выполнить два условия:
1️⃣ Локальная переменная однозначно определена до начала лямбда-выражения
Так не скомпилируется:
JLS 15.27.2 говорит, что ограничение помогает избежать многопоточных проблем: The restriction to effectively final variables prohibits access to dynamically-changing local variables, whose capture would likely introduce concurrency problems
С первого взгляда звучит разумно. Основное применение лямбд — в рамках Stream API. В Stream API есть опция parallel(), которая запускает выполнение в разных потоках. Там и возникнут concurrency problems.
Но я не принимаю это объяснение, потому что:
🤔 С каких пор компилятор волнуют многопоточные проблемы? Вся многопоточка отдана под контроль разработчика с начала времён
🤔 Если локальная переменная станет полем класса, то компилятор перестанет ругаться. При этом вероятность concurrency problems увеличится в разы
Моя гипотеза: требование final/effectively final связано с особенностями реализации лямбд и ограничением модели памяти. Это технические сложности в JVM и ничего больше. Отсутствие многопоточных проблем, о которых говорится в JLS, это всего лишь следствие, а не причина.
❓ Как же менять переменные внутри лямбд?
1️⃣ Сделать переменную полем класса:
2️⃣ Использовать Atomic обёртку
Для примитивов:
Начну с правильного ответа на вопрос выше. В точке Б мы получим предупреждение компилятора: local variables referenced from a lambda expression must be final or effectively final
В этом посте обсудим, что означает effectively final, о чём молчит спецификация и как менять переменные внутри лямбд.
Про модификатор final всё понятно — он запрещает изменение переменной
final int count = 100;
count всегда будет равен 100. Каждый, кто напишет count = 200;будет осуждён компилятором. Для ссылок схема такая же:
final User admin = User.createAdmin();Ссылка
admin всегда будет указывать на объект User с параметрами админа. Никто не может её переприсвоить:❌ admin = new User(…)Effectively final называется переменная, значение которой не меняется после инициализации. По сути это тот же final, но без ключевого слова.
Чтобы компилятор не ругался, надо выполнить два условия:
1️⃣ Локальная переменная однозначно определена до начала лямбда-выражения
Так не скомпилируется:
int x;Вот так норм:
if (…) х = 10
int x;2️⃣ Переменная не меняется внутри лямбды и после неё
if (…) х = 10; else х = 15;
int х = 10;❓ Зачем нужно такое ограничение?
…лямбда…
❌ х = 15
User user = …
…лямбда…
❌ user = userRepository.findByName(…)
✅ user.setTIN(…)
JLS 15.27.2 говорит, что ограничение помогает избежать многопоточных проблем: The restriction to effectively final variables prohibits access to dynamically-changing local variables, whose capture would likely introduce concurrency problems
С первого взгляда звучит разумно. Основное применение лямбд — в рамках Stream API. В Stream API есть опция parallel(), которая запускает выполнение в разных потоках. Там и возникнут concurrency problems.
Но я не принимаю это объяснение, потому что:
🤔 С каких пор компилятор волнуют многопоточные проблемы? Вся многопоточка отдана под контроль разработчика с начала времён
🤔 Если локальная переменная станет полем класса, то компилятор перестанет ругаться. При этом вероятность concurrency problems увеличится в разы
Моя гипотеза: требование final/effectively final связано с особенностями реализации лямбд и ограничением модели памяти. Это технические сложности в JVM и ничего больше. Отсутствие многопоточных проблем, о которых говорится в JLS, это всего лишь следствие, а не причина.
❓ Как же менять переменные внутри лямбд?
1️⃣ Сделать переменную полем класса:
int count;Не лучший вариант, переменная доступна теперь другим потокам. Concurrency problems!
public void m() {
list.forEach(v -> count++);
}
2️⃣ Использовать Atomic обёртку
Для примитивов:
AtomicInteger count = new AtomicInteger(0);Для ссылок:
list.forEach(v -> count.incrementAndGet())
AtomicReference<User> user = new AtomicReference<>();3️⃣ Использовать массив с одним элементом
…map(i -> user.set(…))
int[] res = new int[] {0};
list.forEach(v -> res[0]++);
Популярный вариант, который подходит и для примитивов, и для ссылок. Но мне больше нравится вариант с Atomic:)