
Списки, часть 2: что и когда использовать
В большинстве статей пишут, что LinkedList подходит для частой вставки или удаления элементов. На JavaRush также упоминают обход списка с периодической вставкой.
В теории всё так, но обычно в энтерпрайзе менее изысканные задачи:
🔸 Заполнить список
🔸 Отсортировать (встроенной функцией, конечно)
🔸 Обойти все элементы
🔸 Сделать что-нибудь с помощью Stream API
Для этих сценариев я сделала бенчмарки. У Stream API выделила 4 случая:
▫️ Простой однопоточный: stream→filter→collect
▫️ Сложный однопоточный: stream→map→filter→map→filter→collect
▫️ Простой с опцией parallel()
▫️ Сложный с опцией parallel()
Начнём с заполнения списка.
В прошлом посте выяснили, что до 100к элементов между списками почти нет разницы. ArrayList тратит много времени на копирование, а LinkedList — на создание обёрток и соединение ссылок.
Если количество элементов известно заранее, его можно указать в конструкторе:
Также ArrayList однозначно победил в номинациях:
🔹 Сортировка
🔹 Обход через цикл for
🔹 Простые Stream API
🔹 Любые Stream API с опцией parallel()
В сложных однопоточных Stream API большая часть вычислений идёт на что-то полезное, и влияние оверхеда снижается. Ожидаемо:)
Ещё факты против LinkedList:
🔸 Большинство классов JDK используют ArrayList для внутренних задач
🔸 Joshua Bloch (автор класса и книжки Effective Java) в 2015 написал твит:
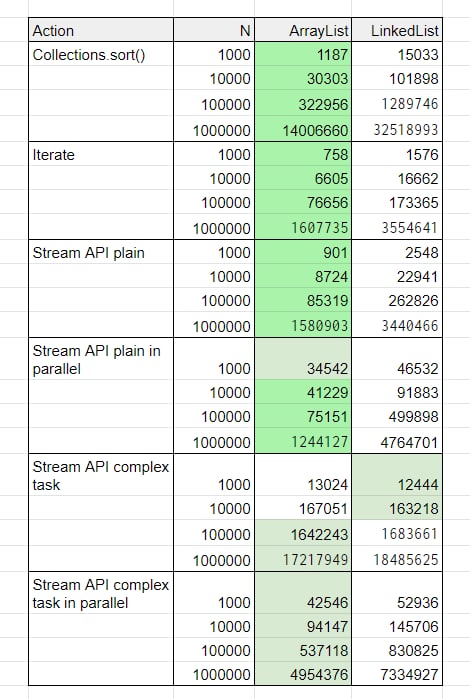
На картинке часть моих бенчмарков. N — количество элементов в списке. Зелёный цвет обозначает победителя в категории. Ярко-зелёный — разница значений более 50%.
❗️Результаты на разных железках могут отличаться ❗️
В большинстве статей пишут, что LinkedList подходит для частой вставки или удаления элементов. На JavaRush также упоминают обход списка с периодической вставкой.
В теории всё так, но обычно в энтерпрайзе менее изысканные задачи:
🔸 Заполнить список
🔸 Отсортировать (встроенной функцией, конечно)
🔸 Обойти все элементы
🔸 Сделать что-нибудь с помощью Stream API
Для этих сценариев я сделала бенчмарки. У Stream API выделила 4 случая:
▫️ Простой однопоточный: stream→filter→collect
▫️ Сложный однопоточный: stream→map→filter→map→filter→collect
▫️ Простой с опцией parallel()
▫️ Сложный с опцией parallel()
Начнём с заполнения списка.
В прошлом посте выяснили, что до 100к элементов между списками почти нет разницы. ArrayList тратит много времени на копирование, а LinkedList — на создание обёрток и соединение ссылок.
Если количество элементов известно заранее, его можно указать в конструкторе:
List list = new ArrayList(25);Без лишнего копирования и переносов разница в скорости становится ошеломительной — список заполняется на 20-80% быстрее!
Также ArrayList однозначно победил в номинациях:
🔹 Сортировка
🔹 Обход через цикл for
🔹 Простые Stream API
🔹 Любые Stream API с опцией parallel()
В сложных однопоточных Stream API большая часть вычислений идёт на что-то полезное, и влияние оверхеда снижается. Ожидаемо:)
Ещё факты против LinkedList:
🔸 Большинство классов JDK используют ArrayList для внутренних задач
🔸 Joshua Bloch (автор класса и книжки Effective Java) в 2015 написал твит:
"Does anyone actually use LinkedList? I wrote it, and I never use it."Но аналоги LinkedList иногда встречаются. В Scala для неизменяемого списка за основу взят именно двусвязный. Возможно, это лучше для каких-то сценариев, но пока не знаю для каких.
На картинке часть моих бенчмарков. N — количество элементов в списке. Зелёный цвет обозначает победителя в категории. Ярко-зелёный — разница значений более 50%.
❗️Результаты на разных железках могут отличаться ❗️
{kind=link}
Небольшой апдейт: в scala список односвязный
Спасибо неравнодушным подписчикам!
Спасибо неравнодушным подписчикам!
Что такое идемпотентность?
Anonymous Poll
10%
Отсутствие сайд-эффектов при вызове метода
18%
Однократный side effect при многократном вызове метода
5%
Отсутствие исключений при повторном вызове с теми же параметрами
59%
Одно и то же возвращаемое значение при одинаковых входных данных
8%
Что-то с мужчинами после 50
Идемпотентность
Идемпотентная операция — операция, которая при многократном вызове оставляет систему в одном и том же состоянии. Это значит, что:
🔸 Возвращаемый результат один и тот же
🔸 Сайд эффекты не накапливаются
Неважно сколько раз вызван метод — эффект будет одинаковый. Что может быть сайд-эффектом: запись в БД, обновление статистики, запись в файл, изменение общих переменных.
Примеры идемпотентных операций:
✅ Удалить элемент с id=50
(10 вызовов → 1 удаление)
❌ Удалить элемент максимального размера
(10 вызовов → 10 удалённых элементов)
✅ Прочитать число из БД, умножить результат на 2 и вернуть пользователю
❌ Прочитать число из БД и обновить статистику запросов
В чём смысл?
Идемпотентные операции повышают устойчивость системы.
Допустим, мы отправили запрос на сервер, и соединение пропало. Спустя 3 секунды восстановилось. Возникает дилемма:
🤔 Отправить запрос ещё раз? Но вдруг он уже был обработан…
🤔 Может не отправлять? А если предыдущий пропал…
Запрос либо дублируется, либо теряется. Для идемпотентного запроса такой проблемы нет, можно спокойно отправить его ещё раз.
На собеседованиях вопрос идемпотентности обычно обсуждают со стороны HTTP вызовов. Нужно сказать, что
Но жизнь чуть сложнее.
🔹 Во-первых, идемпотентность зависит от бизнес-логики, а не от выбранного метода
Здесь самое сложное — держать под контролем сайд эффекты. Возьмём как пример увеличение счётчика в БД:
Добавить в таблицу (и сущность) поле version. Клиент передаёт номер текущей версии при обновлении. Запрос получается такой:
Клиент генерирует ID и добавляет его в хэдер HTTP запроса:
Процесс фильтрации дубликатов называется дедупликацией.
❓ Выглядит как лишняя сложность, нужна ли вообще идемпотентность?
Исходная проблема — что делать с только что отправленными запросами при потере связи. Идемпотентность и повторная отправка — рабочий способ, но не единственный. О другом расскажу в следующем посте.
Идемпотентная операция — операция, которая при многократном вызове оставляет систему в одном и том же состоянии. Это значит, что:
🔸 Возвращаемый результат один и тот же
🔸 Сайд эффекты не накапливаются
Неважно сколько раз вызван метод — эффект будет одинаковый. Что может быть сайд-эффектом: запись в БД, обновление статистики, запись в файл, изменение общих переменных.
Примеры идемпотентных операций:
✅ Удалить элемент с id=50
(10 вызовов → 1 удаление)
❌ Удалить элемент максимального размера
(10 вызовов → 10 удалённых элементов)
✅ Прочитать число из БД, умножить результат на 2 и вернуть пользователю
❌ Прочитать число из БД и обновить статистику запросов
В чём смысл?
Идемпотентные операции повышают устойчивость системы.
Допустим, мы отправили запрос на сервер, и соединение пропало. Спустя 3 секунды восстановилось. Возникает дилемма:
🤔 Отправить запрос ещё раз? Но вдруг он уже был обработан…
🤔 Может не отправлять? А если предыдущий пропал…
Запрос либо дублируется, либо теряется. Для идемпотентного запроса такой проблемы нет, можно спокойно отправить его ещё раз.
На собеседованиях вопрос идемпотентности обычно обсуждают со стороны HTTP вызовов. Нужно сказать, что
GET, PUT and DELETE идемпотентные, а POST — нет.Но жизнь чуть сложнее.
🔹 Во-первых, идемпотентность зависит от бизнес-логики, а не от выбранного метода
Здесь самое сложное — держать под контролем сайд эффекты. Возьмём как пример увеличение счётчика в БД:
UPDATE t SET value=value+1Как сделать его идемпотентным?
Добавить в таблицу (и сущность) поле version. Клиент передаёт номер текущей версии при обновлении. Запрос получается такой:
UPDATE t SET value=value+1, version=version+1 WHERE version=88🔹 Во-вторых, POST запросы можно сделать идемпотентными. Например так:
Клиент генерирует ID и добавляет его в хэдер HTTP запроса:
Idempotency-Key: 4872934Сервис хранит у себя список ID недавних запросов. Если операции с таким ID ещё не было, сервис начнет выполнение.
Процесс фильтрации дубликатов называется дедупликацией.
❓ Выглядит как лишняя сложность, нужна ли вообще идемпотентность?
Исходная проблема — что делать с только что отправленными запросами при потере связи. Идемпотентность и повторная отправка — рабочий способ, но не единственный. О другом расскажу в следующем посте.
Гарантии доставки
Вспомним проблему из прошлого поста.
Мы отправили запрос, соединение тут же пропало и восстановилось через 3 секунды. Что делать с запросом?
Если запрос идемпотентный, спокойно повторяем отправку.
❓А если нет?
Тогда выбираем одну из трёх стратегий: at least once, at most once или exactly once.
Вообще эти термины используются для месседж брокеров и доставки сообщений, но те же принципы верны для HTTP запросов и любого взаимодействия.
В чём суть:
1️⃣ At most once
Получатель не хочет разбираться с дубликатами, и потеря сообщений это ок. Поэтому повторно ничего не отправляем.
2️⃣ At least once
В процесс общения добавляется 1 шаг — уведомление о получении. Отправитель повторяет запрос, пока не получит уведомление.
✅ Сообщение точно будет доставлено
❌ Может быть доставлено несколько раз
3️⃣ Exactly once
Идеальный вариант: когда дубликаты не нужны, и потеря сообщений неприемлема.
Общая схема простая. У каждого сообщения есть ID. Получатель ведёт список полученных ID и для каждого сообщения
▫️ Отправляет уведомление о получении
▫️ Проверяет, не приходило ли такое сообщение раньше. Если да — отбрасывает его, если нет — обрабатывает
Выглядит легко, но в распределённых системах задача усложняется. Что угодно может отвалиться, данные нужно реплицировать, адреса постоянно меняются и тд. В Kafka гарантия exactly once появилась только в 2017 году, и документ с дизайном занимает 67 страниц.
❓ Что делать с этим знанием?
Узнать, какая стратегия используется на вашем проекте, и есть ли дополнительные требования к коду. Для разработчика этого достаточно, обычно все заботы о гарантиях берут на себя архитекторы🤓
❓ Что почитать о сложностях exactly-once в распределённых системах?
▫️ Семантика exactly-once в Apache Kafka
▫️ Подробный разбор проблем на примере очереди Amazon (англ)
▫️ Сборник статей про exactly-once (англ)
Вспомним проблему из прошлого поста.
Мы отправили запрос, соединение тут же пропало и восстановилось через 3 секунды. Что делать с запросом?
Если запрос идемпотентный, спокойно повторяем отправку.
❓А если нет?
Тогда выбираем одну из трёх стратегий: at least once, at most once или exactly once.
Вообще эти термины используются для месседж брокеров и доставки сообщений, но те же принципы верны для HTTP запросов и любого взаимодействия.
В чём суть:
1️⃣ At most once
Получатель не хочет разбираться с дубликатами, и потеря сообщений это ок. Поэтому повторно ничего не отправляем.
2️⃣ At least once
В процесс общения добавляется 1 шаг — уведомление о получении. Отправитель повторяет запрос, пока не получит уведомление.
✅ Сообщение точно будет доставлено
❌ Может быть доставлено несколько раз
3️⃣ Exactly once
Идеальный вариант: когда дубликаты не нужны, и потеря сообщений неприемлема.
Общая схема простая. У каждого сообщения есть ID. Получатель ведёт список полученных ID и для каждого сообщения
▫️ Отправляет уведомление о получении
▫️ Проверяет, не приходило ли такое сообщение раньше. Если да — отбрасывает его, если нет — обрабатывает
Выглядит легко, но в распределённых системах задача усложняется. Что угодно может отвалиться, данные нужно реплицировать, адреса постоянно меняются и тд. В Kafka гарантия exactly once появилась только в 2017 году, и документ с дизайном занимает 67 страниц.
❓ Что делать с этим знанием?
Узнать, какая стратегия используется на вашем проекте, и есть ли дополнительные требования к коду. Для разработчика этого достаточно, обычно все заботы о гарантиях берут на себя архитекторы🤓
❓ Что почитать о сложностях exactly-once в распределённых системах?
▫️ Семантика exactly-once в Apache Kafka
▫️ Подробный разбор проблем на примере очереди Amazon (англ)
▫️ Сборник статей про exactly-once (англ)
Как вы связываете компоненты в рабочем проекте? Где ставите Autowired?
Anonymous Poll
74%
Через конструктор
9%
Через сеттеры
28%
Ставим Autowired просто над полями
Spring: где ставить Autowired
Аннотацию Autowired можно ставить над конструктором, сеттером и просто над полем.
Есть популярная рекомендация, что через конструктор — самое правильное. На эту тему написаны сотни(!) статей и ответов на StackOverflow. Даже Intellij IDEA подсказывает, что "Field injection is not recommended"
В большинстве моих проектов Autowired ставили над полем, потому что так короче. В этом посте разберёмся, откуда взялась эта рекомендация, и насколько она актуальна.
❓ В чём разница между способами с точки зрения Spring?
Только в порядке установки для каждого бина:
▫️ Циклические зависимости возможны везде
▫️ Прокси создаются корректно
▫️ Отсутствующие зависимости обнаруживаются при компиляции или на старте приложения
❓ Откуда взялась эта рекомендация?
Большинство авторов ссылаются на документацию. В разделе Dependency Injection указаны только два способа — конструктор и сеттер. Они универсальны и для XML конфигурации, и для аннотаций.
В этом же разделе стоит рекомендация — использовать конструктор для обязательных и final полей, сеттер — для необязательных.
Autowired над полями относится только к annotation-based конфигурации, поэтому находится в другом разделе. В документации нет ни единого упоминания, что Autowired над полями — это грех и хуже конструкторов и сеттеров.
Рассмотрим основные аргументы против Autowired над полем:
😱 Слишком просто добавлять новые зависимости. Класс легко может потерять единственную ответственность. А когда в конструкторе 10 параметров, это сразу заметно
💁 Единственная ответственность Autowired — внедрить зависимость. Следить за дизайном — задача программиста
😱 Зависимость от DI-контейнера. Класс с аннотациями нельзя использовать за пределами проекта
💁 Ни разу не было такой потребности
😱 Полям нельзя добавить final
💁 Жаль, конечно, но мало кто в рантайме заменяет сервисы и репозитории
😱 Autowired поля проставляются через Reflection
💁 Если вам важно, что делает фреймворк под капотом, посмотрите на класс Constructor Resolver, там рефлекшена в 10 раз больше
😱 Непонятно, какие зависимости обязательные, а какие нет
💁 По умолчанию все Autowired зависимости обязательные. Если что-то необязательно, то можно поставить флажок (required=false)
😱 Непонятно, как тестировать такие классы без поднятия контекста
💁 10 лет назад было действительно никак. Сейчас юнит-тесты легко писать с помощью Mockito аннотаций @InjectMocks и @MockBean
Итого
Autowired над полями — самый лаконичный способ внедрить зависимость. Я не нашла ни одного весомого аргумента против. Для типичного энтерпрайз приложения этот способ идеально подходит.
Лучшие практики и рекомендации формируются в своём контексте. Когда контекст меняется, практика может стать неактуальной. И это норм🙂
Аннотацию Autowired можно ставить над конструктором, сеттером и просто над полем.
Есть популярная рекомендация, что через конструктор — самое правильное. На эту тему написаны сотни(!) статей и ответов на StackOverflow. Даже Intellij IDEA подсказывает, что "Field injection is not recommended"
В большинстве моих проектов Autowired ставили над полем, потому что так короче. В этом посте разберёмся, откуда взялась эта рекомендация, и насколько она актуальна.
❓ В чём разница между способами с точки зрения Spring?
Только в порядке установки для каждого бина:
Конструктор→поля→сеттерыВ остальном механизмы спринга работают одинаково:
▫️ Циклические зависимости возможны везде
▫️ Прокси создаются корректно
▫️ Отсутствующие зависимости обнаруживаются при компиляции или на старте приложения
❓ Откуда взялась эта рекомендация?
Большинство авторов ссылаются на документацию. В разделе Dependency Injection указаны только два способа — конструктор и сеттер. Они универсальны и для XML конфигурации, и для аннотаций.
В этом же разделе стоит рекомендация — использовать конструктор для обязательных и final полей, сеттер — для необязательных.
Autowired над полями относится только к annotation-based конфигурации, поэтому находится в другом разделе. В документации нет ни единого упоминания, что Autowired над полями — это грех и хуже конструкторов и сеттеров.
Рассмотрим основные аргументы против Autowired над полем:
😱 Слишком просто добавлять новые зависимости. Класс легко может потерять единственную ответственность. А когда в конструкторе 10 параметров, это сразу заметно
💁 Единственная ответственность Autowired — внедрить зависимость. Следить за дизайном — задача программиста
😱 Зависимость от DI-контейнера. Класс с аннотациями нельзя использовать за пределами проекта
💁 Ни разу не было такой потребности
😱 Полям нельзя добавить final
💁 Жаль, конечно, но мало кто в рантайме заменяет сервисы и репозитории
😱 Autowired поля проставляются через Reflection
💁 Если вам важно, что делает фреймворк под капотом, посмотрите на класс Constructor Resolver, там рефлекшена в 10 раз больше
😱 Непонятно, какие зависимости обязательные, а какие нет
💁 По умолчанию все Autowired зависимости обязательные. Если что-то необязательно, то можно поставить флажок (required=false)
😱 Непонятно, как тестировать такие классы без поднятия контекста
💁 10 лет назад было действительно никак. Сейчас юнит-тесты легко писать с помощью Mockito аннотаций @InjectMocks и @MockBean
Итого
Autowired над полями — самый лаконичный способ внедрить зависимость. Я не нашла ни одного весомого аргумента против. Для типичного энтерпрайз приложения этот способ идеально подходит.
Лучшие практики и рекомендации формируются в своём контексте. Когда контекст меняется, практика может стать неактуальной. И это норм🙂
Postman: полезные фичи
Главная задача Postman — отправлять запросы в веб-сервисы через красивый интерфейс.
В этом посте я расскажу о других фичах Postman, которые облегчают жизнь строителям энтерпрайза. Может вам что-то пригодится🙂
1️⃣ Сохранять запросы в коллекции
Удобно группировать запросы по сервисам или фичам.
Рекомендую давать запросам осмысленные названия. Чтобы задать имя, нажмите на многоточие справа от запроса → Rename
2️⃣ Сформировать curl
cUrl — это консольная команда, которая отправляет запросы. Писать её иногда утомительно, и Postman может здесь помочь.
Справа от кнопки Send есть кнопка </>. Выбираете cURL и копируете запрос.
3️⃣ Переменные в запросах и входных параметрах
Выглядит это так:
Переменные задаются на вкладке Environments:
▫️ Глобальные переменные доступны всем
▫️ Environment — наборы переменных, которые переключаются в выпадающем списке справа от запроса. Удобно сделать наборы для локальных вызовов, удалённого и тестового стенда.
Чтобы использовать переменную, запишите её в двойные скобочки
Начните набирать {{ и найдите в списке переменные random*
Их гигантское количество — рандомные числа, даты, страны, цвета, емейлы, банковские счета и даже биткойн-кошельки
5️⃣ Отправлять WebSocket и gRPS запросы
Пока в стадии бета, но я этим фичам очень рада🥰
Как найти: в левом верхнем углу под иконкой Postman находится имя вокспейса. Рядом с ним две кнопки — New и Import. Жмёте на New, выбираете нужный протокол
6️⃣ Добавить набор хэдеров во все запросы коллекции
Это делается с помощью скриптов.
Щёлкаете на коллекцию, переходите на вкладку pre-request Script, там пишете JS скрипт. Это несложно, там есть автозаполнение🙂 Для хедеров код выглядит так:
Больше подробностей — в документации
PS Убрала кнопку с сердечком, ставьте реакции, пожалуйста:) Так я буду понимать, какие темы нравятся, а какие не очень
Главная задача Postman — отправлять запросы в веб-сервисы через красивый интерфейс.
В этом посте я расскажу о других фичах Postman, которые облегчают жизнь строителям энтерпрайза. Может вам что-то пригодится🙂
1️⃣ Сохранять запросы в коллекции
Удобно группировать запросы по сервисам или фичам.
Рекомендую давать запросам осмысленные названия. Чтобы задать имя, нажмите на многоточие справа от запроса → Rename
2️⃣ Сформировать curl
cUrl — это консольная команда, которая отправляет запросы. Писать её иногда утомительно, и Postman может здесь помочь.
Справа от кнопки Send есть кнопка </>. Выбираете cURL и копируете запрос.
3️⃣ Переменные в запросах и входных параметрах
Выглядит это так:
http://{{host}}:8080/book/12
Очень удобно определить переменные хоста и данные авторизации. Тогда их можно не прописывать в каждом запросе и быстро менять.Переменные задаются на вкладке Environments:
▫️ Глобальные переменные доступны всем
▫️ Environment — наборы переменных, которые переключаются в выпадающем списке справа от запроса. Удобно сделать наборы для локальных вызовов, удалённого и тестового стенда.
Чтобы использовать переменную, запишите её в двойные скобочки
{{host}}
4️⃣ Добавлять рандом в запросы и входные параметрыНачните набирать {{ и найдите в списке переменные random*
Их гигантское количество — рандомные числа, даты, страны, цвета, емейлы, банковские счета и даже биткойн-кошельки
5️⃣ Отправлять WebSocket и gRPS запросы
Пока в стадии бета, но я этим фичам очень рада🥰
Как найти: в левом верхнем углу под иконкой Postman находится имя вокспейса. Рядом с ним две кнопки — New и Import. Жмёте на New, выбираете нужный протокол
6️⃣ Добавить набор хэдеров во все запросы коллекции
Это делается с помощью скриптов.
Щёлкаете на коллекцию, переходите на вкладку pre-request Script, там пишете JS скрипт. Это несложно, там есть автозаполнение🙂 Для хедеров код выглядит так:
pm.request.addHeader({key:'Header1',value:'value2'});
Если вам нужна особенная генерация входных параметров, это тоже легко сделать через скрипты.Больше подробностей — в документации
PS Убрала кнопку с сердечком, ставьте реакции, пожалуйста:) Так я буду понимать, какие темы нравятся, а какие не очень
String и неточный нейминг
Сегодня пост короткий, но полезный:
▪️ Увидите на простом примере, как важны имена методов
▪️ Узнаете, как оптимизировать работу со строками
Возьмём простую задачу — поменять в строке все буквы А на B. Идея подскажет три метода:
▫️ replace
▫️ replaceFirst
▫️ replaceAll
Что говорит здравый смысл? replaceFirst поменяет первую найденную букву, replace — непонятно, но вот replaceAll точно подходит, берём!
Посмотрим реализацию методов в java 11:
Также работает через RegEx, но заменяет только первое вхождение.
(в java 8 внутри replace тоже используются регулярки, и разница между replace и replaceAll очень туманна)
Что отсюда следует:
1️⃣ Переходите на java 11
2️⃣ Если вам не нужен функционал регулярок, используйте replace. Методы с Pattern.compile работают очень долго!
3️⃣ Давайте методам осмысленные имена. Должно быть понятно, что метод делает, и чем отличается от других. Автор методов replace* об этом не подумал, и теперь сотни проектов выбирают неподходящий вариант
❓ Есть ли разница между replace("a", "b") и replace('a', 'b')?
У replace два перегруженных варианта — для одиночных символов и для строк. В java 8 быстрее работает метод для символов, в java 11 между ними почти нет разницы
❓ Как удалить символы из строки?
В стандартной библиотеке нет метода remove. В java 11 для этой задачи подойдёт replace. В java 8 для критичных мест лучше взять StringUtils.remove из библиотеки Apache Commons Lang
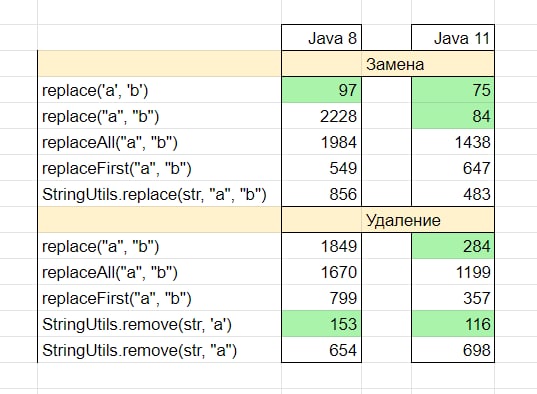
Ниже — бенчмарки для разных джав и время в наносекундах. Результаты на разных железках могут отличаться!
Сегодня пост короткий, но полезный:
▪️ Увидите на простом примере, как важны имена методов
▪️ Узнаете, как оптимизировать работу со строками
Возьмём простую задачу — поменять в строке все буквы А на B. Идея подскажет три метода:
▫️ replace
▫️ replaceFirst
▫️ replaceAll
Что говорит здравый смысл? replaceFirst поменяет первую найденную букву, replace — непонятно, но вот replaceAll точно подходит, берём!
Посмотрим реализацию методов в java 11:
🔸 replace("A", "B")
Проверяет, что в строке вообще есть буквы А. Если да, создаётся новый массив символов и копируются значения исходной строки с заменой всех A на B🔸 replaceAll("A", "B")
Раскрывается в обработчик регулярных выражений:Pattern.compile("A").matcher(this).replaceAll("B")
🔸 replaceFirst("A", "B")Также работает через RegEx, но заменяет только первое вхождение.
(в java 8 внутри replace тоже используются регулярки, и разница между replace и replaceAll очень туманна)
Что отсюда следует:
1️⃣ Переходите на java 11
2️⃣ Если вам не нужен функционал регулярок, используйте replace. Методы с Pattern.compile работают очень долго!
3️⃣ Давайте методам осмысленные имена. Должно быть понятно, что метод делает, и чем отличается от других. Автор методов replace* об этом не подумал, и теперь сотни проектов выбирают неподходящий вариант
❓ Есть ли разница между replace("a", "b") и replace('a', 'b')?
У replace два перегруженных варианта — для одиночных символов и для строк. В java 8 быстрее работает метод для символов, в java 11 между ними почти нет разницы
❓ Как удалить символы из строки?
В стандартной библиотеке нет метода remove. В java 11 для этой задачи подойдёт replace. В java 8 для критичных мест лучше взять StringUtils.remove из библиотеки Apache Commons Lang
Ниже — бенчмарки для разных джав и время в наносекундах. Результаты на разных железках могут отличаться!
{kind=link}
Задачи на сообразительность
Иногда на собеседованиях дают "задачку на сообразительность". Перевернуть строку, поделить торт на части, бросить шар из окна и так далее.
Когда я была джуниором, то не любила такие задачи. От волнения мыслительные способности опускались на уровень обезьянки. Я могла минуту смотреть на задачу с абсолютной пустотой в голове.
У сеньоров тоже бывает ступор. Человек несколько лет заботился о микросервисах, проводил сложные интеграции и вникал в запутанные бизнес-требования. Задачи вроде "сколько шариков вытащить из ящика" для него крайне непривычны.
Что мне помогало: решить перед собеседованием несколько подобных задач. Тогда на самом собесе мозг включается быстрее.
Ниже — плейлист для практики
🎵 Программистские
▫️ Развернуть строку: abc → cba
▫️ Развернуть число: 123 → 321
▫️ Для массива чисел и заданного числа найти пары элементов, которые в сумме равны этому числу
Пример: массив [5,7,8,2,12,30,10,16], требуемая сумма — 15
Ответ: 5 и 10, 7 и 8
▫️ Найти в массиве числа, у которых нет дубликата в этом же массиве: [1,2,3,1,2] → 3
▫️ Проверить, является ли строка палиндромом (читается одинаково слева направо и справа налево)
▫️ Проверить, является ли число палиндромом
▫️ Проверить, являются ли строки анаграммами (состоят из одних и тех же букв)
▫️ Проверить, является ли числа анаграммами
▫️ Вывести слова в строке в обратном порядке
▫️ Реализовать игру FizzBuzz. Написать алгоритм, который выводит числа от 1 до N. Если число делится на 3 — выводить fizz, если на 5 — buzz, если на 3 и 5 — fizz buzz
▫️ Посчитать статистику символов в строке
java → j:1, a:2, v:1
▫️ Найти наибольший общий делитель двух чисел
▫️ Написать конвертер систем счисления: обычных чисел в римские, десятеричную систему в двоичную, 8- и 16-ричную
Больше задач ищите на LeetCode, уровень Easy и Medium. Учить решения бесполезно, так как у задач много вариаций🙂
🎵 Предметные
▪️ В ящике 100 белых и 100 черных шаров. Сколько шаров нужно вытащить, чтобы среди них было 2 одноцветных?
▪️ Есть 15 одинаковых с виду шариков, но один чуть тяжелее других. Сколько нужно взвешиваний, чтобы найти этот шар?
▪️ Как из полного сосуда ёмкостью в 12л отлить половину, пользуясь двумя пустыми сосудами ёмкостью в 8л и 5л?
▪️ Есть 8 батареек, 4 из них рабочие. Фонарику нужно 2 батарейки. Сколько пар нужно протестировать, чтобы найти рабочую?
Задачки такого типа классно решать в компании или вместе с детьми🙂 Ссылка на 50 других задач
Иногда на собеседованиях дают "задачку на сообразительность". Перевернуть строку, поделить торт на части, бросить шар из окна и так далее.
Когда я была джуниором, то не любила такие задачи. От волнения мыслительные способности опускались на уровень обезьянки. Я могла минуту смотреть на задачу с абсолютной пустотой в голове.
У сеньоров тоже бывает ступор. Человек несколько лет заботился о микросервисах, проводил сложные интеграции и вникал в запутанные бизнес-требования. Задачи вроде "сколько шариков вытащить из ящика" для него крайне непривычны.
Что мне помогало: решить перед собеседованием несколько подобных задач. Тогда на самом собесе мозг включается быстрее.
Ниже — плейлист для практики
🎵 Программистские
▫️ Развернуть строку: abc → cba
▫️ Развернуть число: 123 → 321
▫️ Для массива чисел и заданного числа найти пары элементов, которые в сумме равны этому числу
Пример: массив [5,7,8,2,12,30,10,16], требуемая сумма — 15
Ответ: 5 и 10, 7 и 8
▫️ Найти в массиве числа, у которых нет дубликата в этом же массиве: [1,2,3,1,2] → 3
▫️ Проверить, является ли строка палиндромом (читается одинаково слева направо и справа налево)
▫️ Проверить, является ли число палиндромом
▫️ Проверить, являются ли строки анаграммами (состоят из одних и тех же букв)
▫️ Проверить, является ли числа анаграммами
▫️ Вывести слова в строке в обратном порядке
▫️ Реализовать игру FizzBuzz. Написать алгоритм, который выводит числа от 1 до N. Если число делится на 3 — выводить fizz, если на 5 — buzz, если на 3 и 5 — fizz buzz
▫️ Посчитать статистику символов в строке
java → j:1, a:2, v:1
▫️ Найти наибольший общий делитель двух чисел
▫️ Написать конвертер систем счисления: обычных чисел в римские, десятеричную систему в двоичную, 8- и 16-ричную
Больше задач ищите на LeetCode, уровень Easy и Medium. Учить решения бесполезно, так как у задач много вариаций🙂
🎵 Предметные
▪️ В ящике 100 белых и 100 черных шаров. Сколько шаров нужно вытащить, чтобы среди них было 2 одноцветных?
▪️ Есть 15 одинаковых с виду шариков, но один чуть тяжелее других. Сколько нужно взвешиваний, чтобы найти этот шар?
▪️ Как из полного сосуда ёмкостью в 12л отлить половину, пользуясь двумя пустыми сосудами ёмкостью в 8л и 5л?
▪️ Есть 8 батареек, 4 из них рабочие. Фонарику нужно 2 батарейки. Сколько пар нужно протестировать, чтобы найти рабочую?
Задачки такого типа классно решать в компании или вместе с детьми🙂 Ссылка на 50 других задач
Вопрос 1: в чём разница checked и unchecked исключений?
Anonymous Poll
11%
checked можно ловить в блоке try-catch, unchecked — нельзя
3%
checked ожидаются JVM, поэтому затраты на поддержку ниже
81%
Обработка checked исключений обязательна и проверяется во время компиляции
5%
checked исключения показывают ошибки бизнес-логики, unchecked — плохо написанный код
Вопрос 2: рассмотрим простое веб-приложение на Spring. В запросах часто передается ID пользователей. Если ID некорректный, бросается UserNotFoundException. Как его реализовать?
Anonymous Poll
8%
class UserNotFoundException extends Throwable
1%
class UserNotFoundException extends Error
31%
class UserNotFoundException extends Exception
60%
class UserNotFoundException extends RuntimeException
Исключения: сhecked или unchecked?
Сегодня пост о разнице между типами исключений и о том, какой тип выбрать для ошибок бизнес-логики.
Основы
🔸Checked исключения — наследники класса Exception:
🔸Unchecked исключения — наследники класса RuntimeException:
Оба типа можно поймать в блоке try-catch. Единственная техническая разница между checked и unchecked — обязательная обработка checked исключений. На уровне JVM разницы нет — производительность обоих типов одинакова.
За что отвечают стандартные исключения JDK
▫️ checked говорят об ошибках с "внешними" причинами: файл не найден, поток прервали, сокет закрыт, указанный класс не найден. Исключения показывают возможные проблемы, которые в будущем могут повториться
▫️ unchecked указывают на ошибки в коде: передали null вместо объекта, пришёл некорректный аргумент, нельзя привести объект к указанному типу. Исправляются при обнаружении, и в будущем такая ошибка не ожидается
Ошибки бизнес-логики
Не найден пользователь, не хватает прав, превышен лимит снятия денег со счёта. Какие это исключения: checked или unchecked?
В старых статьях по java и на многих курсах ответ однозначен. Исключения должны быть checked, чтобы ошибка не дошла до пользователя.
На JavaRush и в других статьях пишут, что checked исключения никто не использует, потому что это неудобно.
Кто же прав?
Исключения бизнес-логики — ожидаемые события, которые нужно обработать. Пользователь должен увидеть не стектрейс, а красивое сообщение💅
Многие фреймворки облегчают работу с исключениями. Если в Spring задать обработчик для UserNotFoundException, то туда попадут UserNotFoundException из любой части сервиса. Spring в любом случае их поймает, поэтому исключения бизнес-логики делают unchecked. Код получается гораздо чище.
По этой же причине checked иногда переводят в unchecked:
▫️ Если приложение написано на чистой java, то исключения бизнес-логики будут скорее всего checked
▫️ Если приложение использует фреймворк, который перехватывает исключения, их можно сделать unchecked
Правильные ответы на вопросы перед постом:
⭐️Вопрос 1: обработка checked исключений обязательна и проверяется на этапе компиляции
⭐️Вопрос 2: на практике чаще встречается
Сегодня пост о разнице между типами исключений и о том, какой тип выбрать для ошибок бизнес-логики.
Основы
🔸Checked исключения — наследники класса Exception:
class IOException extends Exception
Явно указываются в определении метода:void write(int c) throws IOException
Код с обработкой исключения обязателен, иначе программа не скомпилируется🔸Unchecked исключения — наследники класса RuntimeException:
class NullPointerException extends RuntimeException
О них не пишут в сигнатуре методов и редко ловят в блоке try-catch. Компилятор не предупредит о возможных ошибках, но иногда о них предупреждает IDE.Оба типа можно поймать в блоке try-catch. Единственная техническая разница между checked и unchecked — обязательная обработка checked исключений. На уровне JVM разницы нет — производительность обоих типов одинакова.
За что отвечают стандартные исключения JDK
▫️ checked говорят об ошибках с "внешними" причинами: файл не найден, поток прервали, сокет закрыт, указанный класс не найден. Исключения показывают возможные проблемы, которые в будущем могут повториться
▫️ unchecked указывают на ошибки в коде: передали null вместо объекта, пришёл некорректный аргумент, нельзя привести объект к указанному типу. Исправляются при обнаружении, и в будущем такая ошибка не ожидается
Ошибки бизнес-логики
Не найден пользователь, не хватает прав, превышен лимит снятия денег со счёта. Какие это исключения: checked или unchecked?
В старых статьях по java и на многих курсах ответ однозначен. Исключения должны быть checked, чтобы ошибка не дошла до пользователя.
На JavaRush и в других статьях пишут, что checked исключения никто не использует, потому что это неудобно.
Кто же прав?
Исключения бизнес-логики — ожидаемые события, которые нужно обработать. Пользователь должен увидеть не стектрейс, а красивое сообщение💅
Многие фреймворки облегчают работу с исключениями. Если в Spring задать обработчик для UserNotFoundException, то туда попадут UserNotFoundException из любой части сервиса. Spring в любом случае их поймает, поэтому исключения бизнес-логики делают unchecked. Код получается гораздо чище.
По этой же причине checked иногда переводят в unchecked:
catch (SQLException e)
{ throw new IllegalStateException(e); }
Резюме▫️ Если приложение написано на чистой java, то исключения бизнес-логики будут скорее всего checked
▫️ Если приложение использует фреймворк, который перехватывает исключения, их можно сделать unchecked
Правильные ответы на вопросы перед постом:
⭐️Вопрос 1: обработка checked исключений обязательна и проверяется на этапе компиляции
⭐️Вопрос 2: на практике чаще встречается
extends RuntimeException
но вариант extends Exception тоже ок{kind=link}
{kind=link}
BigDecimal
В этом посте обсудим, зачем нужен этот класс и как не ошибиться при использовании.
Ответ на первый вопрос перед постом — false. Сумма 0.1 и 0.2 равна 0.30000000000000004.
Запустим тот же пример на Python 2.7:
Oracle подробно объясняет этот феномен на 80 страницах. Главная проблема в том, как десятичная часть хранится в двоичном формате.
Целые числа записываются через степень двойки однозначно:
С 0.2 похожая ситуация, поэтому результат получается искажённым.
Python 2.7 использует для вычислений ту же систему, но показывает меньше знаков после запятой. Поэтому ответ выглядит нормально. Python 3 выводит больше знаков и результат похож на результат java:
Если хранить целую и дробную часть одинаково, то для вычислений не нужно дополнительных преобразований. Результат считается быстро, а уровень погрешности на практике низкий. В нашем примере ошибка на 16 разрядов ниже основного значения, в большинстве случаев это ок.
Для точных вычислений используются три основных метода:
🔸Ограниченная точность (limited-precision decimal)
🔸Символьная логика (symbolic calculations)
🔸Длинная арифметика (arbitrary-precision decimal)
BigDecimal использует последний подход. Число 12.345 хранится как пара:
▫️целое значение: 12345
▫️количество десятичных знаков: 3
За счёт этого BigDecimal хранит числа без потери точности. Целая часть хранится либо в переменной int, либо в массиве. Размер числа ограничен только количеством доступной памяти.
Из минусов:
❌ Медленные вычисления
❌ Большой расход памяти
❌ Много промежуточных объектов
❌ Менее выразительный код
Теперь ответ на второй вопрос перед постом:
объекты
В конструктор
0.20000000000000001110223...
Поэтому объект BigDecimal будет хранить это число, а не 0.2
Это самая частая ошибка при работе с BigDecimal. Для чисел с запятой надёжнее передавать в конструктор строку.
В этом посте обсудим, зачем нужен этот класс и как не ошибиться при использовании.
Ответ на первый вопрос перед постом — false. Сумма 0.1 и 0.2 равна 0.30000000000000004.
Запустим тот же пример на Python 2.7:
print(0.1 + 0.2)Почему python справился с примером, а java — нет? Как писать на java высоконагруженные приложения, если она не может сложить 0.1 и 0.2?😒
0.3
Oracle подробно объясняет этот феномен на 80 страницах. Главная проблема в том, как десятичная часть хранится в двоичном формате.
Целые числа записываются через степень двойки однозначно:
9 = 8 + 1 = 2^3 + 2^0 → 1001Десятичная часть выражается через отрицательную степень двойки. Иногда получается нормально:
0.5 = 2^(-1) → 0.1Иногда не очень:
0.1 = 2^(-4) + 2^(-5) + 2^(-8) + … →Если перевести это обратно в десятичную форму, видно, что хранится там совсем не 0.1, а 0.100000001490116119384765625
0.00111101110011001100110011001
С 0.2 похожая ситуация, поэтому результат получается искажённым.
Python 2.7 использует для вычислений ту же систему, но показывает меньше знаков после запятой. Поэтому ответ выглядит нормально. Python 3 выводит больше знаков и результат похож на результат java:
print(0.1 + 0.2)❓Зачем использовать такую неточную систему?
0.30000000000000004
Если хранить целую и дробную часть одинаково, то для вычислений не нужно дополнительных преобразований. Результат считается быстро, а уровень погрешности на практике низкий. В нашем примере ошибка на 16 разрядов ниже основного значения, в большинстве случаев это ок.
Для точных вычислений используются три основных метода:
🔸Ограниченная точность (limited-precision decimal)
🔸Символьная логика (symbolic calculations)
🔸Длинная арифметика (arbitrary-precision decimal)
BigDecimal использует последний подход. Число 12.345 хранится как пара:
▫️целое значение: 12345
▫️количество десятичных знаков: 3
За счёт этого BigDecimal хранит числа без потери точности. Целая часть хранится либо в переменной int, либо в массиве. Размер числа ограничен только количеством доступной памяти.
Из минусов:
❌ Медленные вычисления
❌ Большой расход памяти
❌ Много промежуточных объектов
❌ Менее выразительный код
Теперь ответ на второй вопрос перед постом:
объекты
BigDecimal(0.2) и BigDecimal("0.2") НЕ равны.В конструктор
BigDecimal(0.2)передаётся примитив double, в котором вместо 0.2 лежит
0.20000000000000001110223...
Поэтому объект BigDecimal будет хранить это число, а не 0.2
Это самая частая ошибка при работе с BigDecimal. Для чисел с запятой надёжнее передавать в конструктор строку.
Статистика вакансий HeadHunter (Мск+Спб)
Проанализировала 1120 вакансий java разработчиков на HH с точки зрения зарплат и основных технологий.
👶 Junior
Вакансий: 39 или 3% от общего количества
Половина вакансий в категории "без опыта", половина требует опыт "от года до трёх".
Зарплата указана в 36% случаев, диапазон 15-110к
Что используется:
▫️ Реляционные БД: Postgres, Oracle, общение с ними через Hibernate и JPA
▫️ Spring: MVC, Boot
▫️ Системы сборки: maven/gradle примерно поровну
▫️ git
▫️ Devops-штуки: docker, Openshift, Jenkins, Ansible
▫️ Kafka
▫️ В каждой третьей вакансии упоминается фронтэнд: JS/React/CSS
▫️ В каждой пятой — Kotlin
👩💻Middle (от года до трёх лет)
Вакансий: 382 или 34% от общего количества
Здесь самые секретные зарплаты — конкретные цифры указаны только в 27% вакансий, диапазон 32-400к
Что используется:
▫️ Реляционные БД: Postgres, Oracle, общение через Hibernate
▫️ Spring: Boot, Cloud, Data
▫️ Devops: docker, Kubernetes, Openshift, Linux, Jenkins
▫️ Системы сборки: maven встречается в 2 раза чаще gradle
▫️ Kafka
▫️ Kotlin в 15% вакансий
🧙Senior (3-6 лет опыта)
Вакансий: 648 или 58% от общего количества
Зарплаты указаны в 45% случаев, диапазон 120-700к
Что используется:
▫️ Реляционные БД: Postgre, Oracle
▫️ NoSQL: Redis
▫️ Spring: Boot, Data, Security, Cloud
▫️ Devops: docker, Kubernetes, Openshift, Linux, Jenkins)
▫️ Kafka
▫️ Kotlin в каждом пятом проекте
⭐️ Stars (6+ лет)
Вакансий: 51 или 4% от общего количества
Зарплата указана в 71% случаев, диапазон 160-1050к
Много вакансий на английском, что накладывает свой отпечаток🙂 Кандидат должен быть strong and passionate, ловить opportunity и отвечать за evolution. Упор на soft skills, много обязанностей по менторингу, архитектуре и общению с бизнесом. Каждая пятая вакансия упоминает релокацию.
Из технического:
▫️ В реляционных БД доминирует Postgre
▫️ NoSQL — Redis, MongoDB
▫️ Брокеры: Kafka и RabbitMQ
▫️ Docker, Kubernetes
▫️ Spring
▫️ Kotlin — 27% вакансий
Общее впечатление — вакансий стало раза в полтора больше, чем год назад. Технологии в вакансиях стали скучнее — редко упоминается AWS и GCP, список NoSQL заметно похудел. Зато Kotlin и Gradle набирают обороты.
Годы идут, но самый популярный стек остаётся тем же: Spring + Postgre + Kafka (+ иногда Redis)
Проанализировала 1120 вакансий java разработчиков на HH с точки зрения зарплат и основных технологий.
👶 Junior
Вакансий: 39 или 3% от общего количества
Половина вакансий в категории "без опыта", половина требует опыт "от года до трёх".
Зарплата указана в 36% случаев, диапазон 15-110к
Что используется:
▫️ Реляционные БД: Postgres, Oracle, общение с ними через Hibernate и JPA
▫️ Spring: MVC, Boot
▫️ Системы сборки: maven/gradle примерно поровну
▫️ git
▫️ Devops-штуки: docker, Openshift, Jenkins, Ansible
▫️ Kafka
▫️ В каждой третьей вакансии упоминается фронтэнд: JS/React/CSS
▫️ В каждой пятой — Kotlin
👩💻Middle (от года до трёх лет)
Вакансий: 382 или 34% от общего количества
Здесь самые секретные зарплаты — конкретные цифры указаны только в 27% вакансий, диапазон 32-400к
Что используется:
▫️ Реляционные БД: Postgres, Oracle, общение через Hibernate
▫️ Spring: Boot, Cloud, Data
▫️ Devops: docker, Kubernetes, Openshift, Linux, Jenkins
▫️ Системы сборки: maven встречается в 2 раза чаще gradle
▫️ Kafka
▫️ Kotlin в 15% вакансий
🧙Senior (3-6 лет опыта)
Вакансий: 648 или 58% от общего количества
Зарплаты указаны в 45% случаев, диапазон 120-700к
Что используется:
▫️ Реляционные БД: Postgre, Oracle
▫️ NoSQL: Redis
▫️ Spring: Boot, Data, Security, Cloud
▫️ Devops: docker, Kubernetes, Openshift, Linux, Jenkins)
▫️ Kafka
▫️ Kotlin в каждом пятом проекте
⭐️ Stars (6+ лет)
Вакансий: 51 или 4% от общего количества
Зарплата указана в 71% случаев, диапазон 160-1050к
Много вакансий на английском, что накладывает свой отпечаток🙂 Кандидат должен быть strong and passionate, ловить opportunity и отвечать за evolution. Упор на soft skills, много обязанностей по менторингу, архитектуре и общению с бизнесом. Каждая пятая вакансия упоминает релокацию.
Из технического:
▫️ В реляционных БД доминирует Postgre
▫️ NoSQL — Redis, MongoDB
▫️ Брокеры: Kafka и RabbitMQ
▫️ Docker, Kubernetes
▫️ Spring
▫️ Kotlin — 27% вакансий
Общее впечатление — вакансий стало раза в полтора больше, чем год назад. Технологии в вакансиях стали скучнее — редко упоминается AWS и GCP, список NoSQL заметно похудел. Зато Kotlin и Gradle набирают обороты.
Годы идут, но самый популярный стек остаётся тем же: Spring + Postgre + Kafka (+ иногда Redis)
Где пригодится интерфейс Supplier
Функциональные интерфейсы появились в java 8 и помогают писать код в функциональном стиле:
🔸 Function преобразует элемент в новое значение:
Популярные версии:
1️⃣ Кастомизация экземпляра. Передаём другой Supplier — возвращается другой экземпляр.
Для этой задачи проще указать интерфейс в параметрах
2️⃣ Реализация фабрики
Вариант из Effective Java, item 5. Источник авторитетный, но исходная цель Supplier здесь ускользает.
Во-первых, зачем передавать в параметры метода фабрику? Почему бы не создать экземпляр ранее и передать его?
Во-вторых, цель фабричного метода — упростить создание сложных объектов или отдавать разные объекты в зависимости от параметров. Supplier не содержит параметров и слабо подходит под эту задачу.
Цель Supplier — ленивая инициализация. Объект создаётся, когда он нужен, либо не создаётся вообще.
Игрушечный пример:
Другой пример — метод Optional orElseGet(Supplier supplier). Новый объект создаётся только, если Optional пуст.
Supplier участвует в сдвиге java в сторону функциональности. Function, Predicate и Concumer организуют функции высшего порядка, а Supplier — ленивые вычисления. Полезно в двух случаях:
✅ Когда объект может не пригодиться внутри метода
✅ Инициализировать объект нужно в момент вызова, не раньше. Например, у объекта в конструкторе есть LocalTime.now()
Функциональные интерфейсы появились в java 8 и помогают писать код в функциональном стиле:
🔸 Function преобразует элемент в новое значение:
stream().map(x → x.toString())🔸 Через Predicate передаётся условие фильтрации:
stream.filter(x → x > 5)🔸 Consumer используется в Stream API и библиотечных классах как терминальная операция:
list.forEach(e → System.out::println)🔸 Supplier ничего не принимает, но возвращает значение:
Stream.generate(() -> LocalTime.now())Function, Predicate и Concumer активно используются за пределами Stream API, а вот что делать с Supplier — не всем понятно. Зачем определять метод
void m(Supplier<List> list)вместо
void m(List list) ?Популярные версии:
1️⃣ Кастомизация экземпляра. Передаём другой Supplier — возвращается другой экземпляр.
Для этой задачи проще указать интерфейс в параметрах
2️⃣ Реализация фабрики
Вариант из Effective Java, item 5. Источник авторитетный, но исходная цель Supplier здесь ускользает.
Во-первых, зачем передавать в параметры метода фабрику? Почему бы не создать экземпляр ранее и передать его?
Во-вторых, цель фабричного метода — упростить создание сложных объектов или отдавать разные объекты в зависимости от параметров. Supplier не содержит параметров и слабо подходит под эту задачу.
Цель Supplier — ленивая инициализация. Объект создаётся, когда он нужен, либо не создаётся вообще.
Игрушечный пример:
public Connection init(Supplier<Connection> connSupplier) {
// взять коннекшн из пула
return connSupplier.get();
}
Если выполнение не дойдёт до connSupplier, новый объект создан не будет. В варианте public Connection init(Connection conn)для вызова метода нужно передать УЖЕ готовый экземпляр.
Другой пример — метод Optional orElseGet(Supplier supplier). Новый объект создаётся только, если Optional пуст.
Supplier участвует в сдвиге java в сторону функциональности. Function, Predicate и Concumer организуют функции высшего порядка, а Supplier — ленивые вычисления. Полезно в двух случаях:
✅ Когда объект может не пригодиться внутри метода
✅ Инициализировать объект нужно в момент вызова, не раньше. Например, у объекта в конструкторе есть LocalTime.now()