
Java 20: новый костыль в HashMap
На вопрос выше логично ответить
Итак, что происходит внутри HashMap?
Ячейки хэш-таблицы (или бакеты) хранятся в переменной
При вызове
Кажется, что всё в порядке, но мы забыли про ребалансировку😒
HashMap хорошо работает, когда в каждом бакете 0 или 1 элемент. Тогда скорость поиска и добавления будет той самой О(1).
Когда элементов становится больше, растёт шанс, что в один бакет попадёт несколько элементов. Поэтому в определённый момент HashMap удваивает количество бакетов и перераспределяет элементы. За момент, когда пора начать эту операцию, отвечает поле
Его первое значение считается как [планируемое число элементов * 0.75], т.е когда HashMap заполнен на 3/4. При удвоении числа бакетов threshold тоже удваивается.
И смотрите, что получается:
🔹 Мы хотим добавить в мэп 1000 элементов и вызываем конструктор с подходящим параметром initialCapacity:
🔹 Рассчитывается threshold: 1024*0,75 = 768
🔹 Добавляется 768 элементов
🔹 Приходит 769 элемент, начинается ребалансировка:
▫️ количество бакетов удваивается, теперь их 2048
▫️ текущие элементы распределяются между ними
▫️ новый threshold удваивается, теперь это 1538
Что получилось: мы пообещали добавить в HashMap 1000 элементов. Сдержали обещание, но перестройка мэп всё равно произошла.
Чтобы HashMap работал оптимально, нужно учесть ребалансировку и передать в конструктор, например, 1500. Надо знать детали реализации, чтобы получить то, что хотим.
И это образцовое нарушение инкапсуляции🤌
В java 20 в HashMap добавили костыльный метод, который исправляет ситуацию:
Почему это костыль? Потому что исходная проблема не решается. Жизнь пользователя не становится легче, ему нужно запомнить "чтобы задать размер мэп — не пользуйся конструктором, пользуйся специальным методом".
Хороший API — понятный, удобный и дружелюбный. Пользователю легко выбрать нужный метод, все параметры хорошо описаны в документации. Когнитивная нагрузка при использовании минимальна, нет подводных камней и обходных путей. Для собеседований сложно придумать вопрос с подвохом🙂
Важные заметки:
🔸 В JDK много образцового кода, и я рекомендую изучать исходники как можно чаще. HashMap — неприятное исключение
🔸 В ConcurrentHashMap всё хорошо.
На вопрос выше логично ответить
new HashMap<>(1000). Сначала расскажу, почему этот ответ не походит. Потом наглядно покажу нарушение инкапсуляции, и что за костыль добавили в Java 20.Итак, что происходит внутри HashMap?
Ячейки хэш-таблицы (или бакеты) хранятся в переменной
Node[] table как простой массив.При вызове
new HashMap() без параметров создаётся 16 бакетов. Если передать параметр с размером, то берётся ближайшая степень двойки. new HashMap(1000) создаёт массив из 1024 элементов.Кажется, что всё в порядке, но мы забыли про ребалансировку😒
HashMap хорошо работает, когда в каждом бакете 0 или 1 элемент. Тогда скорость поиска и добавления будет той самой О(1).
Когда элементов становится больше, растёт шанс, что в один бакет попадёт несколько элементов. Поэтому в определённый момент HashMap удваивает количество бакетов и перераспределяет элементы. За момент, когда пора начать эту операцию, отвечает поле
threshold.Его первое значение считается как [планируемое число элементов * 0.75], т.е когда HashMap заполнен на 3/4. При удвоении числа бакетов threshold тоже удваивается.
И смотрите, что получается:
🔹 Мы хотим добавить в мэп 1000 элементов и вызываем конструктор с подходящим параметром initialCapacity:
new HashMap(1000);
🔹 Создаётся 1024 бакета (ближайшая степень двойки)🔹 Рассчитывается threshold: 1024*0,75 = 768
🔹 Добавляется 768 элементов
🔹 Приходит 769 элемент, начинается ребалансировка:
▫️ количество бакетов удваивается, теперь их 2048
▫️ текущие элементы распределяются между ними
▫️ новый threshold удваивается, теперь это 1538
Что получилось: мы пообещали добавить в HashMap 1000 элементов. Сдержали обещание, но перестройка мэп всё равно произошла.
Чтобы HashMap работал оптимально, нужно учесть ребалансировку и передать в конструктор, например, 1500. Надо знать детали реализации, чтобы получить то, что хотим.
И это образцовое нарушение инкапсуляции🤌
В java 20 в HashMap добавили костыльный метод, который исправляет ситуацию:
HashMap.newHashMap(1000);
Внутри произойдёт вычисление 1000 / 0.75 = 1334, в итоге создаётся 2048 бакетов.Почему это костыль? Потому что исходная проблема не решается. Жизнь пользователя не становится легче, ему нужно запомнить "чтобы задать размер мэп — не пользуйся конструктором, пользуйся специальным методом".
Хороший API — понятный, удобный и дружелюбный. Пользователю легко выбрать нужный метод, все параметры хорошо описаны в документации. Когнитивная нагрузка при использовании минимальна, нет подводных камней и обходных путей. Для собеседований сложно придумать вопрос с подвохом🙂
Важные заметки:
🔸 В JDK много образцового кода, и я рекомендую изучать исходники как можно чаще. HashMap — неприятное исключение
🔸 В ConcurrentHashMap всё хорошо.
new ConcurrentHashMap(1000) сразу создаёт 2048 бакетов и не занимается лишними балансировкамиJUnit: самое важное
Информация ниже не новая, но очень важная. Так что грех не повторить:)
Ниже особенности и фичи JUnit, которые полезно знать большинству разработчиков. Если что-то заинтересовало и непонятно — поможет JUnit 5 User Guide
1️⃣ Жизненный цикл теста
Каждый тест — это метод с аннотацией
Через аннотацию
Чтобы выполнить что-то до или после выполнения теста, используются методы с аннотациями:
Благодаря этому тесты выполняются независимо.
Этим JUnit отличается от TestNG, где создаётся один экземпляр класса на все тестовые методы. Если хочется как в TestNG, добавьте над классом аннотацию
Сердце каждого теста - методы с приставкой assert*:
3️⃣ Группировка тестов
Аннотация
Можно указывать тэги в системе сборки и при запуске тестов из IDE.
4️⃣ Отключение тестов
Аннотация
▫️ операционной системы
Помогают запустить один тест с разными аргументами. Выглядит так:
Вместо готового списка можно брать значения
🔸 из CSV файла
▫️ Через ассерт
▫️ Hamсrest, AssertJ — расширенные библиотеки методов-ассертов
▫️ Mockito для заглушек. Добавляете библиотеку в pom.xml или build.gradle, а в тест - аннотацию
▫️ Java Faker — генератор данных для тестов
Ещё я когда-то писала 2 хороших поста на тему, чем отличается JUnit 4 от Unit 5. Если вас удивляет, почему там разные аннотации и почему версии не совместимы друг с другом, то почитайте:)
Информация ниже не новая, но очень важная. Так что грех не повторить:)
Ниже особенности и фичи JUnit, которые полезно знать большинству разработчиков. Если что-то заинтересовало и непонятно — поможет JUnit 5 User Guide
1️⃣ Жизненный цикл теста
Каждый тест — это метод с аннотацией
@Test.Через аннотацию
@DisplayName задаётся симпатичное имя теста в отчёте.Чтобы выполнить что-то до или после выполнения теста, используются методы с аннотациями:
▫️ @Before, @BeforeAllJUnit создаёт новый экземпляр класса на каждый тестовый метод. Класс
▫️ @After, @AfterAll
ServiceTest с пятью методами @Test во время запуска превратится в 5 экземпляров класса ServiceTest.Благодаря этому тесты выполняются независимо.
Этим JUnit отличается от TestNG, где создаётся один экземпляр класса на все тестовые методы. Если хочется как в TestNG, добавьте над классом аннотацию
@TestInstance(Lifecycle.PER_CLASS)
2️⃣ ПроверкиСердце каждого теста - методы с приставкой assert*:
🔸 assertTrueВ самом JUnit мало методов, более удобные ассерты есть в библиотеках Hamсrest и AssertJ. AssertJ, на мой взгляд, более читабельный, но Hamсrest используется чаще.
🔸 assertEquals
🔸 assertInstanceOf
3️⃣ Группировка тестов
Аннотация
@Tag("groupName") объединяет тесты в группы. Работает и для одного теста, и для класса.Можно указывать тэги в системе сборки и при запуске тестов из IDE.
4️⃣ Отключение тестов
Аннотация
@Disabled. Есть продвинутые варианты, можно отключить тесты для▫️ операционной системы
@DisabledOnOs(WINDOWS)▫️ версии java
@DisabledOnJre(JAVA_9)▫️ системных переменных:
@DisabledForJreRange(min = JAVA_9)
@DisabledIfSystemProperty(named = "ci-server", matches = "true")5️⃣ Параметризированные тесты
@DisabledIfEnvironmentVariable(named = "ENV", matches = ".*development.*")
Помогают запустить один тест с разными аргументами. Выглядит так:
@ParameterizedTestТакой тест запустится дважды - с аргументом 100 и -14.
@ValueSource(ints={100,-14})
public void test(int input) {}
Вместо готового списка можно брать значения
🔸 из CSV файла
@CsvSource
🔸 из метода @MethodSource
6️⃣ Проверка таймаута▫️ Через ассерт
assertTimeout(ofMinutes(2), ()->{});
▫️ Через аннотацию@Timeout(value=42,unit=SECONDS)7️⃣ Полезные библиотеки
▫️ Hamсrest, AssertJ — расширенные библиотеки методов-ассертов
▫️ Mockito для заглушек. Добавляете библиотеку в pom.xml или build.gradle, а в тест - аннотацию
@ExtendWith(MockitoExtension.class)
▫️ Testcontainers для запуска внешних компонентов в докере. Добавляем библиотеку, аннотацию @Testcontainers над классом и @Container над компонентом▫️ Java Faker — генератор данных для тестов
Ещё я когда-то писала 2 хороших поста на тему, чем отличается JUnit 4 от Unit 5. Если вас удивляет, почему там разные аннотации и почему версии не совместимы друг с другом, то почитайте:)
Брейкпойнты в Intellij IDEA
Когда я была джуниором-мидлом, проводила в дебаге 80% рабочего времени. Скучаю по временам, когда можно спокойно работать с кодом целый день. Не копаться в гигантских логах, не ходить на митинги по полдня, не делать код-ревью всей команды.
Если вам доступно удовольствие писать код — цените его:)
Большинство разработчиков пользуются только базовым дебагом в IDEA: щёлкнуть рядом с номером строки, чтобы добавить или удалить брейкпойнт. Чтобы отладка стала быстрой и приятной, есть 4 классные фичи:
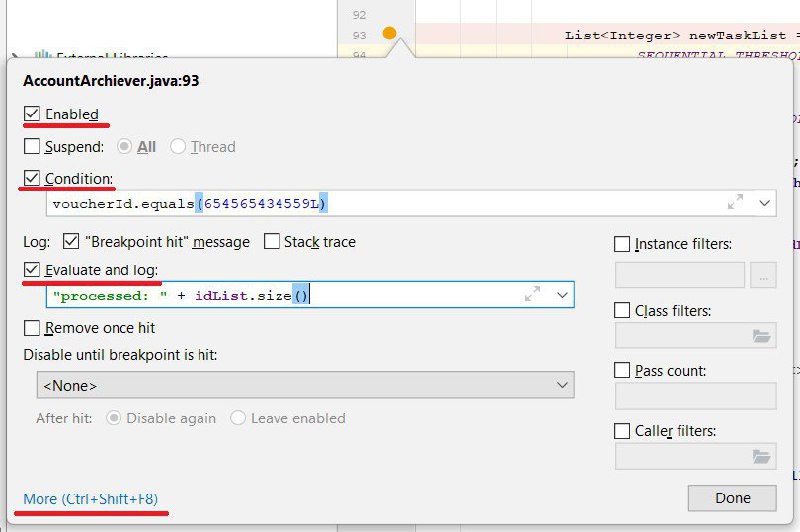
1️⃣ Условия остановки
Если метод часто вызывается, или брейкпойнт стоит в цикле, не тратьте время на ожидание нужных значений:
🔹Правый щелчок по брейкпойнту
🔹Добавить в Condition условие остановки — можно использовать все доступные переменные, объекты и методы
2️⃣ Изменение параметров в динамике
Чтобы посмотреть, как меняются переменные, их обычно выводят в консоль через System.out.println. Более продвинутый вариант:
🔸Зажать Shift и добавить брейкпойнт
🔸Щёлкнуть галочку
Отладчик не будет останавливать выполнение, а запишет в консоль значение выражения.
Незаменимая фича для отладки многопоточных приложений, кода сторонних библиотек и удалённого дебага!
3️⃣ Отключение брейкпойнта
Ненужный брейкпойнт можно не удалять, а отключить:
▪️Щёлкнуть колёсиком по брейкпойнту
ИЛИ
▪️Правый щёлчок по брейкпойнту → снять галочку с Enabled
4️⃣ Массовое удаление
Когда в проекте много брейкпойнтов, IDE при дебаге немного тормозит. Чтобы удалить ненужные, откройте полный список:
▫️Правый клик по любому брейкпойнту
▫️Ссылка
▫️Удаляем ненужные
В этом окне ещё есть фильтры для выборочной остановки, но удобнее пользоваться условиями из первого пункта.
Когда я была джуниором-мидлом, проводила в дебаге 80% рабочего времени. Скучаю по временам, когда можно спокойно работать с кодом целый день. Не копаться в гигантских логах, не ходить на митинги по полдня, не делать код-ревью всей команды.
Если вам доступно удовольствие писать код — цените его:)
Большинство разработчиков пользуются только базовым дебагом в IDEA: щёлкнуть рядом с номером строки, чтобы добавить или удалить брейкпойнт. Чтобы отладка стала быстрой и приятной, есть 4 классные фичи:
1️⃣ Условия остановки
Если метод часто вызывается, или брейкпойнт стоит в цикле, не тратьте время на ожидание нужных значений:
🔹Правый щелчок по брейкпойнту
🔹Добавить в Condition условие остановки — можно использовать все доступные переменные, объекты и методы
2️⃣ Изменение параметров в динамике
Чтобы посмотреть, как меняются переменные, их обычно выводят в консоль через System.out.println. Более продвинутый вариант:
🔸Зажать Shift и добавить брейкпойнт
🔸Щёлкнуть галочку
Evaluate and log
🔸Вписать нужное выражениеОтладчик не будет останавливать выполнение, а запишет в консоль значение выражения.
Незаменимая фича для отладки многопоточных приложений, кода сторонних библиотек и удалённого дебага!
3️⃣ Отключение брейкпойнта
Ненужный брейкпойнт можно не удалять, а отключить:
▪️Щёлкнуть колёсиком по брейкпойнту
ИЛИ
▪️Правый щёлчок по брейкпойнту → снять галочку с Enabled
4️⃣ Массовое удаление
Когда в проекте много брейкпойнтов, IDE при дебаге немного тормозит. Чтобы удалить ненужные, откройте полный список:
▫️Правый клик по любому брейкпойнту
▫️Ссылка
More
▫️Слева видим список брейкпойнтов▫️Удаляем ненужные
В этом окне ещё есть фильтры для выборочной остановки, но удобнее пользоваться условиями из первого пункта.
{kind=link}
Java 21: String templates
Сегодня вышла java 20🥳
А в сентябре выходит java 21 (LTS) с интересной превью фичей — String templates. Про неё и расскажу в этом посте.
Есть две стратегии работы со строками:
🔸 Конкатенация — собираем строку по частям:
🔸 Интерполяция — замена переменных внутри шаблона:
В начале строки нужно добавить
❓ Зачем нужен префикс STR? Почему нельзя просто добавить новый функционал в строки?
Здесь 2 причины:
1️⃣ Для обратной совместимости
На джаве написано много кода, и наверняка какие-то строки содержат блоки \{}. Будет обидно, если этот код перестанет компилироваться. Поэтому строки для интерполяции нужно явно обозначить
2️⃣ Может быть не только STR😱
Здесь открывается портал в другой мир. По задумке авторов темплейты могут подставлять переменные, валидировать данные и делать преобразования. Например, так:
Но рано радоваться🙂 Из коробки этого не будет, только набор классов для кастомизации. Будем надеяться, что авторы библиотек возьмут фичу на вооружение.
❓ Как это работает? Выглядит как магия!
В JDK появится статическое поле StringProcessor STR, а строка
во время компиляции превратится в
Cинтаксический сахарок и никакого волшебства✨
Сегодня вышла java 20🥳
А в сентябре выходит java 21 (LTS) с интересной превью фичей — String templates. Про неё и расскажу в этом посте.
Есть две стратегии работы со строками:
🔸 Конкатенация — собираем строку по частям:
String str = "Hello, " + name + "!";Сюда же относится StringBuilder, метод concat и тд.
🔸 Интерполяция — замена переменных внутри шаблона:
String name = "Jake";В чистом виде в java такого нет. В Formatter и MessageFormat вместо переменных какие-то %s и %d, а переменные стоят отдельно:
String str = "Hello, ${name}!";
String.format("%d plus %d equals %d", x, y, x + y);
Для сравнения, как это выглядит в Kotlin:"$x plus $y equals ${x + y}"
Так вот, в java 21 появится интерполяция!В начале строки нужно добавить
STR., а переменные поместить в \{}
int x = 10, y = 20;Хорошо работает вместе с текстовыми блоками (многострочные строки в тройных кавычках):
String str = STR."\{x} + \{y} = \{x + y}";
// "10 + 20 = 30"
String name = "Joan";Внутри можно вызывать методы и писать блоки кода:
String phone = "555-123";
String json = STR."""
{
"name": "\{name}",
"phone":"\{phone}",
}
""";
String time = STR."The time is \{
DateTimeFormatter
.ofPattern("HH:mm:ss")
.format(LocalTime.now())
} right now";
//"The time is 09:01:45 right now"
Читаемость текста снижается, но если очень хочется — почему нет.❓ Зачем нужен префикс STR? Почему нельзя просто добавить новый функционал в строки?
Здесь 2 причины:
1️⃣ Для обратной совместимости
На джаве написано много кода, и наверняка какие-то строки содержат блоки \{}. Будет обидно, если этот код перестанет компилироваться. Поэтому строки для интерполяции нужно явно обозначить
2️⃣ Может быть не только STR😱
Здесь открывается портал в другой мир. По задумке авторов темплейты могут подставлять переменные, валидировать данные и делать преобразования. Например, так:
JSONObject json = JSON."{ id: \{id}}";
или даже так:ResultSet rs = DB."SELECT * FROM Person WHERE name = \{name}";
Для запросов в БД это, наверное, слишком, а вот для работы с JSON выглядит очень удобно.Но рано радоваться🙂 Из коробки этого не будет, только набор классов для кастомизации. Будем надеяться, что авторы библиотек возьмут фичу на вооружение.
❓ Как это работает? Выглядит как магия!
В JDK появится статическое поле StringProcessor STR, а строка
String str = STR."\{name}!"; во время компиляции превратится в
StringTemplate template = new StringTemplate(паттерн, параметры);
String str = STR.process(template);Cинтаксический сахарок и никакого волшебства✨
{kind=link}
Best practice: имена методов в ООП и функциональном подходе
В идеальном мире не нужно читать документацию и изучать внутрянку класса, чтобы правильно с ним работать. В этом посте расскажу best practice, о котором мало говорят, но который здорово повышает дружелюбность API.
Начнём с вопроса перед постом. Если не искать подвох, то в sum мы ждём 0+10+20=30.
Но подвох, разумеется, есть.
Давным-давно основной парадигмой разработки было ООП. Вся работа строилась на изменении объектов, и этот подход отражался в названиях методов:
Исключения встречались редко, их нужно было просто запомнить. С юных лет все знают, что String — неизменяемый, и просто вызвать метод недостаточно:
▫️ меняется текущий объект, и надо просто вызвать метод
или
▫️ создаётся новый объект, который надо куда-то присвоить
Для такого случая есть best practice:
✅ Когда метод меняет внутреннее состояние объекта, имя метода начинается с глагола
✅ Методы НЕизменяемых объектов используют другие конструкции
Простой пример. Чтобы изменить внутренние поля, используем метод
🔸 Причастия:
🔸 Предлоги и союзы:
🔸 Существительное в чистом виде:
❗️ Исключение: если класс использует Fluent API, обычно используются глаголы:
В идеальном мире не нужно читать документацию и изучать внутрянку класса, чтобы правильно с ним работать. В этом посте расскажу best practice, о котором мало говорят, но который здорово повышает дружелюбность API.
Начнём с вопроса перед постом. Если не искать подвох, то в sum мы ждём 0+10+20=30.
Но подвох, разумеется, есть.
BigInteger — неизменяемый класс. sum.add(10) создаёт новый объект, а исходная переменная не меняется. В итоге ни один add не влияет на sum. В консоль напечатается 0.Давным-давно основной парадигмой разработки было ООП. Вся работа строилась на изменении объектов, и этот подход отражался в названиях методов:
sum.add(4), user.setName("Alisa").Исключения встречались редко, их нужно было просто запомнить. С юных лет все знают, что String — неизменяемый, и просто вызвать метод недостаточно:
String str = " Java ";Последние годы растёт тренд на неизменяемость. При вызове метода должно быть понятно:
❌ str.trim();
✅ str = str.trim();
▫️ меняется текущий объект, и надо просто вызвать метод
или
▫️ создаётся новый объект, который надо куда-то присвоить
Для такого случая есть best practice:
✅ Когда метод меняет внутреннее состояние объекта, имя метода начинается с глагола
✅ Методы НЕизменяемых объектов используют другие конструкции
Простой пример. Чтобы изменить внутренние поля, используем метод
set*:order.setDeliveryDate(…);Создать новый объект на основе текущего — метод
with*:order = order.withDeliveryDate(…);Для более сложных операций нужно включить креативность. Здесь помогут:
🔸 Причастия:
order.cancel(); // изменить текущий объектOrder o = order.cancelled(); // создать новый🔸 Предлоги и союзы:
String s = str.toLowerCase();// вместо addDays
LocalDate l = now().plusDays(12);
🔸 Существительное в чистом виде:
String sub = str.substring(1);Цель здесь одна — показать, что текущий объект не меняется
❗️ Исключение: если класс использует Fluent API, обычно используются глаголы:
Optional opt = …Итого: с изменяемыми и неизменяемыми объектами работа идёт по-разному. Имена методов подсказывают, как правильно пользоваться классом. Хорошей практикой считается использовать глаголы для изменяемых объектов, и что-то другое для неизменяемых☀️
opt.map(…).filter(…)
Чем отличаются опции JVM, которые начинаются на -X, от опций, которые начинаются на -XX?
Anonymous Poll
6%
У -Х приоритет над -ХХ
6%
У -ХХ приоритет над -Х
13%
-Х работают на всех операционных системах, -ХХ специфичны для отдельных ОС и архитектур
15%
-ХХ могут быть удалены в будущем, -Х вряд ли
37%
-Х задаёт параметры JVM на старте, -ХХ определяет процесс работы
23%
Ничем, -X и -XX равнозначны
VM Options
— это параметры, которые указываются при запуске JVM. В этом посте расскажу, чем они отличаются, и как безопасно перейти на новую версию java. В конце будет список самых популярных (и полезных) опций.
Все JVM опции делятся на три группы:
⚙️ Стандартные
Пишутся через минус и поддерживаются всеми JVM.
Пример:
Начинаются на -Х и определяют базовые свойства JVM. Могут не работать во всех JVM, но если поддерживаются, то вряд ли удалятся.
Пример:
Начинаются на -ХХ и касаются внутренних механизмов JVM. Не поддерживаются всеми JVM, часто меняются и удаляются.
Пример:
Цикл отключения опций не совсем стандартный. В обычном коде что-то помечается Deprecated, и спустя время удаляется. VM Options используют более длинный цикл:
🔸 Deprecate: функционал работает, при запуске появляется warning
🔸 Obsolete: функция не выполняется, JVM пишет предупреждения
🔸 Expired: JVM не запускается
Многие опции очень нестабильны и часто меняются. Чтобы безопасно обновить версию java, нужно проверить набор опций через JaCoLine . Он подсветит устаревшие или уже бесполезные опции.
Полезные опции для java 11
(да, недавно вышла java 20, но самая популярная версия всё ещё 11)
1️⃣ Память
▫️ Начальный размер хипа:
▫️ Максимальный размер хипа:
▫️ Serial GC:
▫️ ZGC:
⚙️ Нестандартные:
— это параметры, которые указываются при запуске JVM. В этом посте расскажу, чем они отличаются, и как безопасно перейти на новую версию java. В конце будет список самых популярных (и полезных) опций.
Все JVM опции делятся на три группы:
⚙️ Стандартные
Пишутся через минус и поддерживаются всеми JVM.
Пример:
-classpath, -server, -version
⚙️ НестандартныеНачинаются на -Х и определяют базовые свойства JVM. Могут не работать во всех JVM, но если поддерживаются, то вряд ли удалятся.
Пример:
-Xmx, -Xms
⚙️ ПродвинутыеНачинаются на -ХХ и касаются внутренних механизмов JVM. Не поддерживаются всеми JVM, часто меняются и удаляются.
Пример:
-XX:MaxGCPauseMillis=500
Некоторые продвинутые опции требуют дополнительных флажков. Для экспериментальных фич обязателен -XX:+UnlockExperimentalVMOptions. Многие фичи диагностики не заработают без -XX:+UnlockDiagnosticVMOptions
Количество опций часто меняется. В 11 версии OpenJDK 1504 опции, а в 17 на 200 опций меньше.Цикл отключения опций не совсем стандартный. В обычном коде что-то помечается Deprecated, и спустя время удаляется. VM Options используют более длинный цикл:
🔸 Deprecate: функционал работает, при запуске появляется warning
🔸 Obsolete: функция не выполняется, JVM пишет предупреждения
🔸 Expired: JVM не запускается
Многие опции очень нестабильны и часто меняются. Чтобы безопасно обновить версию java, нужно проверить набор опций через JaCoLine . Он подсветит устаревшие или уже бесполезные опции.
Полезные опции для java 11
(да, недавно вышла java 20, но самая популярная версия всё ещё 11)
1️⃣ Память
▫️ Начальный размер хипа:
-Xms256m в абсолютных значениях, -XX:InitialRAMPercentage=60 - в процентах от RAM▫️ Максимальный размер хипа:
-Xmx8g или -XX:MaxRAMPercentage=60
▫️ Снять heap dump при переполнении памяти: -XX:+HeapDumpOnOutOfMemoryError. Адрес выходного файла задаётся в -XX:HeapDumpPath
2️⃣ Сборщик мусора▫️ Serial GC:
-XX:+UseSerialGC
▫️ Parallel GC: -XX:+UseParalllGC
▫️ CMS: -XX:+UseConcMarkSweepGC
▫️ G1: -XX:+UseG1GC (вариант по умолчанию)▫️ ZGC:
-XX:+UnlockExperimentalVMOptions -XX:+UseZGC
▫️ Shenandoah: -XX:+UnlockExperimentalVMOptions -XX:+UseShenandoahGC
Вывести статистику сборщика при завершении работы: -XX:+UnlockDiagnosticVMOptions ‑XX:NativeMemoryTracking=summary ‑XX:+PrintNMTStatistics
Базовое логгирование коллектора: -Xlog:gc
Максимально информативное: -Xlog:gc*
3️⃣ Посмотреть все доступные опции⚙️ Нестандартные:
java -X
⚙️ Продвинутые: java -XX:+UnlockDiagnosticVMOptions -XX:+UnlockExperimentalVMOptions -XX:+PrintFlagsFinalHashMap и принципы SOLID
На большинстве собесов спрашивают одно и то же. Как работает HashMap, принципы ООП и SOLID, разница абстрактного класса и интерфейса, жизненный цикл бина.
Когда я была junior/middle, 80% вопросов повторялись на каждом собеседовании. И вопросы возникали уже у меня:
🤔 Как интервьюеры поймут, что я топчик, если спрашивают такую банальщину?
🤔 Почему в вакансии целая страница требований и технологий, но мы ничего из этого не обсуждаем?
🤔 Может на проекте всё очень плохо, а код написан на java 6?
И только когда я начала собеседовать людей, то поняла, зачем это всё.
Всё дело в специфике найма джуниоров и мидлов.
На каждом проекте свой стэк, задачи и особенности. С рынка вряд ли придёт человек, который с ходу вольётся в проект, зная все нюансы технологий. В любом случае он будет немного доучиваться.
Поэтому важно, чтобы человек имел крепкий фундамент и был приятным в общении на технические темы. И стандартные вопросы подходят для этого великолепно:
1️⃣ Это база🤌
Желание обсудить саги и агрегаты это здорово, но большую часть времени разработчик проводит с кодом. Stream API, коммиты, структуры данных — в этом не должно быть пробелов.
В далёкие времена на собесах обсуждали только теорию и давали тесты с безумным синтаксисом и пропущенными скобками. Это довольно бесполезно, но всё ещё встречается.
Сегодня собесы больше ориентируются на практику. Бывает, что кандидат лихо объясняет synchronization order, но не видит ошибок в простом многопоточном коде. Не смущайтесь лёгких заданий, они не так просты, как кажутся:)
Время собеседования очень ограничено. Выделенные 30-60 минут лучше потратить на базу. Если с ней всё хорошо — остальное приложится
2️⃣ Легко сравнить кандидатов между собой
Если 10 человек расскажут устройство HashMap, получится 10 разных ответов.
Первый кандидат расскажет так, что ничего не понятно. Второй закопается в объяснении работы хэша и свернёт с темы. Третий оттараторит заученный текст и не поймёт дополнительный вопрос. Из четвёртого придётся тащить каждое предложение.
Поэтому часто стандартных вопросов достаточно, чтобы понять, насколько приятно общаться с человеком и как глубоко он понимает базу. Умничку видно сразу🙂
❓ Если спрашивают банальщину — значит проект скучный?
Для младших грейдов вопросы могут вообще не коррелировать с будущими задачами. И наоборот — алгоритмы и system design не означают, что будущая работа будет интересной и разнообразной
❓ Как выделиться среди других кандидатов, если задают только общие вопросы?
Если вас позвали на собес, значит вы уже прошли жёсткие фильтры, и резюме оставило приятное впечатление. Ваша задача — его закрепить
Если интервьюер чем-то заинтересуется в вашем опыте, он обязательно спросит:)
❗️ Я отвечал на всё правильно, но оффер не прислали!
Причина может быть вообще не в вас. Может пришёл кандидат с более релевантным опытом, или бюджет перераспределили на другие цели.
Найм — очень субъективный процесс. Интервьюер всегда найдёт, к чему прицепится, если у вас фамилия, как у его бывшей жены. И наоборот, если с первых минут установился контакт, даже небольшие ошибки не испортят впечатления.
На большинстве собесов спрашивают одно и то же. Как работает HashMap, принципы ООП и SOLID, разница абстрактного класса и интерфейса, жизненный цикл бина.
Когда я была junior/middle, 80% вопросов повторялись на каждом собеседовании. И вопросы возникали уже у меня:
🤔 Как интервьюеры поймут, что я топчик, если спрашивают такую банальщину?
🤔 Почему в вакансии целая страница требований и технологий, но мы ничего из этого не обсуждаем?
🤔 Может на проекте всё очень плохо, а код написан на java 6?
И только когда я начала собеседовать людей, то поняла, зачем это всё.
Всё дело в специфике найма джуниоров и мидлов.
На каждом проекте свой стэк, задачи и особенности. С рынка вряд ли придёт человек, который с ходу вольётся в проект, зная все нюансы технологий. В любом случае он будет немного доучиваться.
Поэтому важно, чтобы человек имел крепкий фундамент и был приятным в общении на технические темы. И стандартные вопросы подходят для этого великолепно:
1️⃣ Это база🤌
Желание обсудить саги и агрегаты это здорово, но большую часть времени разработчик проводит с кодом. Stream API, коммиты, структуры данных — в этом не должно быть пробелов.
В далёкие времена на собесах обсуждали только теорию и давали тесты с безумным синтаксисом и пропущенными скобками. Это довольно бесполезно, но всё ещё встречается.
Сегодня собесы больше ориентируются на практику. Бывает, что кандидат лихо объясняет synchronization order, но не видит ошибок в простом многопоточном коде. Не смущайтесь лёгких заданий, они не так просты, как кажутся:)
Время собеседования очень ограничено. Выделенные 30-60 минут лучше потратить на базу. Если с ней всё хорошо — остальное приложится
2️⃣ Легко сравнить кандидатов между собой
Если 10 человек расскажут устройство HashMap, получится 10 разных ответов.
Первый кандидат расскажет так, что ничего не понятно. Второй закопается в объяснении работы хэша и свернёт с темы. Третий оттараторит заученный текст и не поймёт дополнительный вопрос. Из четвёртого придётся тащить каждое предложение.
Поэтому часто стандартных вопросов достаточно, чтобы понять, насколько приятно общаться с человеком и как глубоко он понимает базу. Умничку видно сразу🙂
❓ Если спрашивают банальщину — значит проект скучный?
Для младших грейдов вопросы могут вообще не коррелировать с будущими задачами. И наоборот — алгоритмы и system design не означают, что будущая работа будет интересной и разнообразной
❓ Как выделиться среди других кандидатов, если задают только общие вопросы?
Если вас позвали на собес, значит вы уже прошли жёсткие фильтры, и резюме оставило приятное впечатление. Ваша задача — его закрепить
Если интервьюер чем-то заинтересуется в вашем опыте, он обязательно спросит:)
❗️ Я отвечал на всё правильно, но оффер не прислали!
Причина может быть вообще не в вас. Может пришёл кандидат с более релевантным опытом, или бюджет перераспределили на другие цели.
Найм — очень субъективный процесс. Интервьюер всегда найдёт, к чему прицепится, если у вас фамилия, как у его бывшей жены. И наоборот, если с первых минут установился контакт, даже небольшие ошибки не испортят впечатления.
Intellij IDEA: комментарии TODO
Часто встречаются ситуации, когда нужно запомнить место в коде:
⭐️ Внести изменения по задаче, но чуть позже
⭐️ Отметить непокрытый тестами код
⭐️ Обсудить метод с коллегой
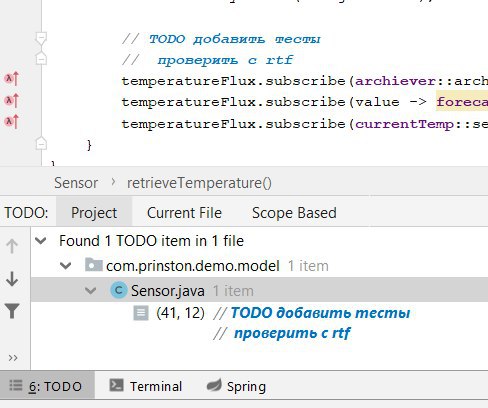
Для таких случаев в IDEA есть специальный тип комментариев. Он начинается со слов
Если списка нет, ищите его через View → Tool Windows → TODO
Помимо стандартных
Очень удобно использовать TODO для текущих задач, чтобы ничего не забыть. Чтобы отметить код, который исправит кто-то другой, не забудьте закинуть соответствующую задачу в бэклог:)
Часто встречаются ситуации, когда нужно запомнить место в коде:
⭐️ Внести изменения по задаче, но чуть позже
⭐️ Отметить непокрытый тестами код
⭐️ Обсудить метод с коллегой
Для таких случаев в IDEA есть специальный тип комментариев. Он начинается со слов
TODO и выглядит так:// TODO добавить тестыВсе такие комментарии можно посмотреть в окне TODO внизу экрана. Через него же можно перейти в нужное место кода в один клик.
Если списка нет, ищите его через View → Tool Windows → TODO
Помимо стандартных
TODO и FIXME можно добавить свои метки, например, OPTIMIZE, ASK, TEST. Сделать это можно в File → Settings → Editor → TODOОчень удобно использовать TODO для текущих задач, чтобы ничего не забыть. Чтобы отметить код, который исправит кто-то другой, не забудьте закинуть соответствующую задачу в бэклог:)
{kind=link}
Структура проекта и качество кода, часть 1
Структура проекта — это то, как мы раскладываем классы по папочкам. Хорошая структура помогает не только ориентироваться в проекте, но и писать более качественный код.
Сейчас покажу, как это работает.
Разделение по слоям
Начнём с структуры, которая встречается в большинстве туториалов и пет-проектах начинающих:
📂 controller
— UserController, TicketController
📂 service
— UserService, TicketService
📂 repository
— UserRepository, TicketRepository
Чтобы классы могли использовать друг друга, все классы и методы должны быть
В такой структуре естественным путём повышается связность. Если в
Всё связано со всем. Поменяешь в одном месте — сломается в другом. В пет-проекте с этим можно справиться, но для коммерческих проектов такая структура не подходит
Разделение по функциям
Складываем в один пекедж всё, связанное с какой-то сущностью. Оставляем 1-2 класса с модификатором
📂 user
— UserController, UserService, UserRepository
📂 ticket
— TicketController, TicketService, TicketRepository
📂 export
— ExportService, ExcelFormatter
Дефолтный модификатор ограничивает доступ между пэкеджами. Если
✅ Связность классов снижается, упрощается поддержка и тестирование
😐 Каждый класс решает не бизнес-задачу, а инфраструктурную.
😐 Высокая связность между бизнес-кейсами. Появляются десятки универсальных методов, которые "переиспользуются" в бизнес-сценариях. Например, создание и редактирование пользователя часто делают через один метод. Меняем одно — неизбежно задеваем похожие сценарии.
Разделение по бизнес-кейсам
Складываем в один пекедж все классы, связанные с бизнес-процессом. Большинство классов стоит с
📂 newUser
— NewUserController, NewUserService, UserRepository
📂 buyTicket
— BuyTicketController, BuyTicketService, TicketRepository
📂 refundTicket — …
📂 export — …
Количество классов увеличивается, но они становятся меньше и более изолированными. Связность между бизнес-сценариями максимально снижается.
Итого: чёткая структура проекта и модификаторы доступа снижают связность между компонентами на уровне компиляции.
Однако очень мало проектов используют эту практику. Не потому что разработчики плохие, а потому что на большинстве проектов этот подход не сработает. Почему так получается и кто виноват — расскажу в следующем посте:)
Структура проекта — это то, как мы раскладываем классы по папочкам. Хорошая структура помогает не только ориентироваться в проекте, но и писать более качественный код.
Сейчас покажу, как это работает.
Разделение по слоям
Начнём с структуры, которая встречается в большинстве туториалов и пет-проектах начинающих:
📂 controller
— UserController, TicketController
📂 service
— UserService, TicketService
📂 repository
— UserRepository, TicketRepository
Чтобы классы могли использовать друг друга, все классы и методы должны быть
public. В такой структуре естественным путём повышается связность. Если в
UserService хочется узнать номер билета, то самое простое — добавить TicketRepository и вызвать нужный метод. Всё связано со всем. Поменяешь в одном месте — сломается в другом. В пет-проекте с этим можно справиться, но для коммерческих проектов такая структура не подходит
Разделение по функциям
Складываем в один пекедж всё, связанное с какой-то сущностью. Оставляем 1-2 класса с модификатором
public, остальным даём дефолтный модификатор доступа: 📂 user
— UserController, UserService, UserRepository
📂 ticket
— TicketController, TicketService, TicketRepository
📂 export
— ExportService, ExcelFormatter
Дефолтный модификатор ограничивает доступ между пэкеджами. Если
UserService хочет сформировать отчёт по пользователям, он вынужден идти через ExportService, потому что ExcelFormatter ему не виден.✅ Связность классов снижается, упрощается поддержка и тестирование
😐 Каждый класс решает не бизнес-задачу, а инфраструктурную.
UserRepository — точка доступа к таблице users. UserService — класс по работе с классом User. Классы становятся огромными😐 Высокая связность между бизнес-кейсами. Появляются десятки универсальных методов, которые "переиспользуются" в бизнес-сценариях. Например, создание и редактирование пользователя часто делают через один метод. Меняем одно — неизбежно задеваем похожие сценарии.
Разделение по бизнес-кейсам
Складываем в один пекедж все классы, связанные с бизнес-процессом. Большинство классов стоит с
default модификатором и недоступна за пределами пэкеджа: 📂 newUser
— NewUserController, NewUserService, UserRepository
📂 buyTicket
— BuyTicketController, BuyTicketService, TicketRepository
📂 refundTicket — …
📂 export — …
Количество классов увеличивается, но они становятся меньше и более изолированными. Связность между бизнес-сценариями максимально снижается.
Итого: чёткая структура проекта и модификаторы доступа снижают связность между компонентами на уровне компиляции.
Однако очень мало проектов используют эту практику. Не потому что разработчики плохие, а потому что на большинстве проектов этот подход не сработает. Почему так получается и кто виноват — расскажу в следующем посте:)
Структура проекта и качество кода, часть 2
В прошлом посте мы рассмотрели основные структуры, по которым делаются проекты. Структура помогает легко ориентироваться в коде, плюс снижает связность между компонентами за счёт модификаторов доступа.
Просто так использовать
Но кое-что разрушает эту прекрасную картину: ✨фреймворки✨
Чтобы Spring мог сотворить волшебство, приходится немного жертвовать изоляцией. Начиная с public репозиториев и заканчивая одним контекстом на всё приложение.
При использовании спринга (или других фреймворков) связность между компонентами меньше ограничивается и с течением времени растёт.
Но выход есть!
Поделить функциональность не на пэкеджи, а на Maven/Gradle модули:
📂 registration
— 📂 src
— Controller, Service, Repository
— 📂 test
pom.xml
📂 export
⚠️ Обратите внимание, каждый модуль — просто набор классов и тестов, а не отдельный микросервис!
Связность при таком подходе снижается ещё больше:
✅ У каждого модуля свой набор зависимостей
✅ Нет общего контекста
Можно, наверное, поделить приложение на java модули, но модули Maven/Gradle встречаются гораздо чаще.
Совсем большие проекты идут ещё дальше. В Hexagonal/Clean/Onion/… architecture каждый бизнес-сценарий делится на модули бизнес-правил, адаптеров, инфраструктуры и тд.
✅ Минимальная связность, ультра простое тестирование
😐 Количество модулей, классов и интерфейсов увеличивается в разы
😐 Легко скатиться в карго-культ, нужен опыт для правильной реализации
Резюме
Spring — классный фреймворк, и здорово облегчает рутинные задачи. Но у него есть тёмная сторона — благодаря общему контексту связность кода неизбежно повышается. Чтобы проект не превратился в болото, в первую очередь нужен высокий профессиональный уровень всей команды.
Если приложение большое, имеет смысл поделить его на отдельные модули. У каждого бизнес-процесса будет свой контекст и набор зависимостей. Поддерживать такую структуру будет гораздо проще👍
В прошлом посте мы рассмотрели основные структуры, по которым делаются проекты. Структура помогает легко ориентироваться в коде, плюс снижает связность между компонентами за счёт модификаторов доступа.
Просто так использовать
default класс из другого пэкеджа (то есть повысить связность) не получится, код не скомпилируется. Либо придётся менять модификатор доступа, что точно будет заметно на ревью.Но кое-что разрушает эту прекрасную картину: ✨фреймворки✨
Чтобы Spring мог сотворить волшебство, приходится немного жертвовать изоляцией. Начиная с public репозиториев и заканчивая одним контекстом на всё приложение.
При использовании спринга (или других фреймворков) связность между компонентами меньше ограничивается и с течением времени растёт.
Но выход есть!
Поделить функциональность не на пэкеджи, а на Maven/Gradle модули:
📂 registration
— 📂 src
— Controller, Service, Repository
— 📂 test
pom.xml
📂 export
⚠️ Обратите внимание, каждый модуль — просто набор классов и тестов, а не отдельный микросервис!
Связность при таком подходе снижается ещё больше:
✅ У каждого модуля свой набор зависимостей
✅ Нет общего контекста
Можно, наверное, поделить приложение на java модули, но модули Maven/Gradle встречаются гораздо чаще.
Совсем большие проекты идут ещё дальше. В Hexagonal/Clean/Onion/… architecture каждый бизнес-сценарий делится на модули бизнес-правил, адаптеров, инфраструктуры и тд.
✅ Минимальная связность, ультра простое тестирование
😐 Количество модулей, классов и интерфейсов увеличивается в разы
😐 Легко скатиться в карго-культ, нужен опыт для правильной реализации
Резюме
Spring — классный фреймворк, и здорово облегчает рутинные задачи. Но у него есть тёмная сторона — благодаря общему контексту связность кода неизбежно повышается. Чтобы проект не превратился в болото, в первую очередь нужен высокий профессиональный уровень всей команды.
Если приложение большое, имеет смысл поделить его на отдельные модули. У каждого бизнес-процесса будет свой контекст и набор зависимостей. Поддерживать такую структуру будет гораздо проще👍
Анонс курса по многопоточке
Старт: 5 июня
Длительность: 9 недель
Кто давно ждал и уже готов → http://fillthegaps.ru/mt
Теперь подробнее. У курса две основные задачи:
✅ Научиться писать хороший многопоточный код
Разберём типовые энтерпрайзные задачи, огромное количество кейсов, лучших практик и возможных ошибок. Сравним производительность разных решений для разных ситуаций
✅ Подготовимся к собеседованиям, где требуется concurrency. Обсудим стандартные и нестандартные вопросы, порешаем тестовые задания
Что говорят ученики:
👨🦱 “Курс понравился тем, что он "от разработчиков разработчикам": примеры реальных библиотек для разбора, приближенные к реальным задачи для кодинга”
👨🦱 ”Курс очень интенсивный, охватывает не только многопоточку, но и смежные темы, учит разным лайфхакам полезным для практического использования, обращает внимание на темы, которые легко или упустить, изучая тему самостоятельно, или вообще можно никогда не узнать без курса”
👨🦱 ”Есть очень много свежей информации, которую сконцентрировано в едином источнике не получить”
👨🦱 “Это не с нуля совсем курс, и больше про правду разработки, разбавленную вопросами с собесов, а не про чистые знания.”
Отзывы целиком можно почитать тут
Для какого уровня курс?
Middle и выше
✔️ Есть рассрочка на 3 и 6 месяцев
✔️ Принимаются карты любых банков
✔️ Курс можно оплатить за счёт компании
Аналогов у курса нет. Вообще:)
С каждым потоком программа становится лучше, задания интереснее, а учёба приятнее. Если хотите разобраться с многопоточкой, и вам близок мой стиль изложения — записывайтесь, будет очень полезно!
http://fillthegaps.ru/mt
Старт: 5 июня
Длительность: 9 недель
Кто давно ждал и уже готов → http://fillthegaps.ru/mt
Теперь подробнее. У курса две основные задачи:
✅ Научиться писать хороший многопоточный код
Разберём типовые энтерпрайзные задачи, огромное количество кейсов, лучших практик и возможных ошибок. Сравним производительность разных решений для разных ситуаций
✅ Подготовимся к собеседованиям, где требуется concurrency. Обсудим стандартные и нестандартные вопросы, порешаем тестовые задания
Что говорят ученики:
👨🦱 “Курс понравился тем, что он "от разработчиков разработчикам": примеры реальных библиотек для разбора, приближенные к реальным задачи для кодинга”
👨🦱 ”Курс очень интенсивный, охватывает не только многопоточку, но и смежные темы, учит разным лайфхакам полезным для практического использования, обращает внимание на темы, которые легко или упустить, изучая тему самостоятельно, или вообще можно никогда не узнать без курса”
👨🦱 ”Есть очень много свежей информации, которую сконцентрировано в едином источнике не получить”
👨🦱 “Это не с нуля совсем курс, и больше про правду разработки, разбавленную вопросами с собесов, а не про чистые знания.”
Отзывы целиком можно почитать тут
Для какого уровня курс?
Middle и выше
✔️ Есть рассрочка на 3 и 6 месяцев
✔️ Принимаются карты любых банков
✔️ Курс можно оплатить за счёт компании
Аналогов у курса нет. Вообще:)
С каждым потоком программа становится лучше, задания интереснее, а учёба приятнее. Если хотите разобраться с многопоточкой, и вам близок мой стиль изложения — записывайтесь, будет очень полезно!
http://fillthegaps.ru/mt
Что изменилось в этом потоке?
Курс — мой любимый пет-проект, который я развиваю уже третий год.
Казалось бы, уже 7 потоков прошло. Всем всё нравится — половину мест с обратной связью уже разобрали, отзывы отличные. Что ещё улучшать? А вот есть что:)
✅ Практические задания
Практика — самая сильная часть курса. Теория осталась плюс-минус такой же с 2021 года, а практическая часть постоянно развивается. Тесты, написание кода, анализ реального кода, лабораторные работы — только так появляется уверенность при работе с многопоточкой.
Для этого потока добавила пару классных примеров из Spring core на разбор, отшлифовала формулировки тестов, написала несколько гайдов для самопроверки для тарифа без обратной связи
✅ Предобучение
До прохождения курса многие вообще не трогали многопоточку. И для некоторых учеников нагрузка оказывается очень серьёзной.
Чтобы чуть снизить уровень стресса, учёба теперь делится на два шага:
1. Предобучение — в спокойном темпе изучить основы и потренироваться на простых примерах
2. Основной курс — закрепить основы и углубиться в детали
В итоге
▫️ Новички чуть больше работают с базой и основной курс зайдёт легче (я надеюсь)
▫️ Опытные ребята пропускают предобучение и не тратят время на лёгкие задачки
Подготовительный этап совсем небольшой, поэтому решила сделать его открытым. Если хотите подтянуть основы многопоточности — welcome
✅ Налоговый вычет
Если вы платите налоги в России, то в следующем году можно подать заявление в налоговую и вернуть 13% стоимости курса!!!
Ученики февральского потока тоже могут оформить вычет! Как это сделать и какие документы нужны — написала на сайте в разделе "популярные вопросы".
https://fillthegaps.ru/mt
Курс — мой любимый пет-проект, который я развиваю уже третий год.
Казалось бы, уже 7 потоков прошло. Всем всё нравится — половину мест с обратной связью уже разобрали, отзывы отличные. Что ещё улучшать? А вот есть что:)
✅ Практические задания
Практика — самая сильная часть курса. Теория осталась плюс-минус такой же с 2021 года, а практическая часть постоянно развивается. Тесты, написание кода, анализ реального кода, лабораторные работы — только так появляется уверенность при работе с многопоточкой.
Для этого потока добавила пару классных примеров из Spring core на разбор, отшлифовала формулировки тестов, написала несколько гайдов для самопроверки для тарифа без обратной связи
✅ Предобучение
До прохождения курса многие вообще не трогали многопоточку. И для некоторых учеников нагрузка оказывается очень серьёзной.
Чтобы чуть снизить уровень стресса, учёба теперь делится на два шага:
1. Предобучение — в спокойном темпе изучить основы и потренироваться на простых примерах
2. Основной курс — закрепить основы и углубиться в детали
В итоге
▫️ Новички чуть больше работают с базой и основной курс зайдёт легче (я надеюсь)
▫️ Опытные ребята пропускают предобучение и не тратят время на лёгкие задачки
Подготовительный этап совсем небольшой, поэтому решила сделать его открытым. Если хотите подтянуть основы многопоточности — welcome
✅ Налоговый вычет
Если вы платите налоги в России, то в следующем году можно подать заявление в налоговую и вернуть 13% стоимости курса!!!
Ученики февральского потока тоже могут оформить вычет! Как это сделать и какие документы нужны — написала на сайте в разделе "популярные вопросы".
https://fillthegaps.ru/mt
Последний день для ранних пташек
Сегодня последний день, когда можно вписаться на курс как early bird🦅
Курс строится вокруг java.util.concurrent — боевой лошадки каждого нагруженного сервиса. В деталях изучим все классы, концепты и практическое применение. Разберём огромное количество кейсов, лучших практик и возможных ошибок.
Ну и по мелочи — разберёмся с тестированием многопоточки, сравним разные подходы (реактивщина, Project Loom, корутины), подготовимся к собеседованиям. Всё шаг за шагом и с картинками:)
👨🦱 “Курс великолепный, не пожалел ни одного рубля, что потратил. Это уникальный курс в своем сегменте, особенно на русском рынке. Всем советую, на курсе вы найдете все ответы на интересующие вас вопросы. Более того из курса вы сможете узнать то, что просто нет в открытом доступе нигде, исключительно авторские наработки. Однозначно советую всем бэкэнд разработчикам, даже если вы не особо используете многопточку - это очень поможет вам в понимании многопоточного кода фреймворков и вообще сильно улучшит ваш кругозор. Советую брать с обратной связью - сильно увеличивает пользу от курса.”
Старт: 5 июня
Длительность: 9 недель
✅ Оплата за счёт компании
✅ Рассрочка на 3 или 6 месяцев
✅ Налоговый вычет 13%
Завтра цена вырастет, присоединяйтесь сегодня!
http://fillthegaps.ru/mt
Сегодня последний день, когда можно вписаться на курс как early bird🦅
Курс строится вокруг java.util.concurrent — боевой лошадки каждого нагруженного сервиса. В деталях изучим все классы, концепты и практическое применение. Разберём огромное количество кейсов, лучших практик и возможных ошибок.
Ну и по мелочи — разберёмся с тестированием многопоточки, сравним разные подходы (реактивщина, Project Loom, корутины), подготовимся к собеседованиям. Всё шаг за шагом и с картинками:)
👨🦱 “Курс великолепный, не пожалел ни одного рубля, что потратил. Это уникальный курс в своем сегменте, особенно на русском рынке. Всем советую, на курсе вы найдете все ответы на интересующие вас вопросы. Более того из курса вы сможете узнать то, что просто нет в открытом доступе нигде, исключительно авторские наработки. Однозначно советую всем бэкэнд разработчикам, даже если вы не особо используете многопточку - это очень поможет вам в понимании многопоточного кода фреймворков и вообще сильно улучшит ваш кругозор. Советую брать с обратной связью - сильно увеличивает пользу от курса.”
Старт: 5 июня
Длительность: 9 недель
✅ Оплата за счёт компании
✅ Рассрочка на 3 или 6 месяцев
✅ Налоговый вычет 13%
Завтра цена вырастет, присоединяйтесь сегодня!
http://fillthegaps.ru/mt
{kind=link}
Конструкция <E extends Enum<E>> в определении Enum нужна чтобы
Anonymous Poll
9%
Запретить наследование от сгенерированного класса
12%
Разработчик не мог создать наследника Enum
35%
Ограничить использование дженериков внутри enum
16%
Предотвратить рекурсивное наследование классов
27%
Не допустить сравнения разных enum между собой
Self-referential generic, часть 1
Кто участвовал в декабрьском адвенте, точно помнит, что
В определении класса
Чтобы понять, какая проблема решается, представим, что этой конструкции нет. И определение енама выглядит так:
Есть более важный момент. Пользователь может спокойно сравнить животное и конвертер, ошибка возникнет только в рантайме. Это выглядит странно, ведь enum Animal и enum Converter никак не связаны между собой.
Здесь дженерик выходит на сцену:
✅ При компиляции происходит проверка типов:
Self-referential generic позволяет использовать дочерний тип в интерфейсах и методах родителя. Для некоторых кейсов этот приём здорово упрощает код и снижает количество ошибок. В следующем посте покажу ещё один пример использования.
Ответ на вопрос перед постом: self-referential generic помогает ограничить сравнение разных enum между собой.
Кто участвовал в декабрьском адвенте, точно помнит, что
еnum компилируется в наследник класса Enum:public enum Animal {WOLF, TIGER}
↓public class Animal extends Enum {
public static final Animal WOLF;
public static final Animal TIGER;
}
Подробнее об этом и енамах в целом можно почитать тут — раз, два и три.В определении класса
Enum используется конструкция, которая называется self-referential generic (или self-bound type, или recursive generic):EnumᐸE extends EnumᐸEᐳᐳВ этом посте расскажу, что это такое и зачем нужно.
Чтобы понять, какая проблема решается, представим, что этой конструкции нет. И определение енама выглядит так:
public abstract class MyEnum implements ComparableᐸMyEnumᐳПользователь определяет enum Animal и enum Converter. Компилятор превращает это в классы
Animal extends MyEnumКаждый класс должен реализовать интерфейс
Converter extends MyEnum
ComparableᐸMyEnumᐳ и метод compareTo. Чтобы не сравнивать животных и конвертеры, придётся использовать instanceof: public final int compareTo(MyEnum o) {
if (o instanceOf Animal other) {
// сравниваем зверюшек
// return ...
}
throw IllegalArgumentException();
}
В самом instanceOf нет ничего плохого. Тем более этот код генерируется при компиляции и остаётся за кадром.Есть более важный момент. Пользователь может спокойно сравнить животное и конвертер, ошибка возникнет только в рантайме. Это выглядит странно, ведь enum Animal и enum Converter никак не связаны между собой.
Здесь дженерик выходит на сцену:
public abstract class EnumᐸE extends EnumᐸEᐳᐳ implements ComparableᐸEᐳ🔸 Добавляем параметр E, совместимый с классом
Enum
🔸 Используем E в интерфейсе Comparable
🔸 Компилируем enum Animal вpublic class Animal extends EnumᐸAnimalᐳ🔸 Теперь
Comparable использует тип Animal, и метод compareTo станет таким:public int compareTo(Animal o)✅ Убрали
instanceOf, код стал меньше и быстрее✅ При компиляции происходит проверка типов:
Animal zebra = Animal.ZEBRA;❌
Converter csv = Converter.CSV;
zebra.compareTo(csv); // не скомпилируется!Self-referential generic позволяет использовать дочерний тип в интерфейсах и методах родителя. Для некоторых кейсов этот приём здорово упрощает код и снижает количество ошибок. В следующем посте покажу ещё один пример использования.
Ответ на вопрос перед постом: self-referential generic помогает ограничить сравнение разных enum между собой.
Self-referential generic, часть 2
В прошлом посте мы выяснили, зачем self-referential generic нужен в
Дано: класс Delivery с информацией о доставке. Метод cancelled делает заказ недействительным. У класса есть наследник FastDelivery, в котором дополнительно хранится ID курьера:
🔸 Добавляем параметр в родителя
🔹 Метод create и его переопределение позволяют использовать поля, доступные в наследнике и вернуть нужный объект
🔹 Self-referential generic помогает вернуть нужный тип в методе cancelled
Готовый код доступен здесь
Резюме
Рассмотрите использование self-referential generic, когда
▫️ У вас есть иерархия
▫️ Родительский тип упоминается в аргументах или возвращаемом значении
Дополнительная типизация снизит количество кода, вытащит ошибки на этап компиляции и для некоторых случаев окажется очень изящным решением✨
В прошлом посте мы выяснили, зачем self-referential generic нужен в
Enum: для использования дочернего типа при реализации интерфейса родителя. Это довольно экзотичный кейс. Сегодня покажу более практичный пример, как дженерики облегчили работу с иерархией и неизменяемыми переменными.Дано: класс Delivery с информацией о доставке. Метод cancelled делает заказ недействительным. У класса есть наследник FastDelivery, в котором дополнительно хранится ID курьера:
class Delivery {
final long id;
final boolean isActive;
public Delivery(long id, boolean isActive) {…}
public Delivery cancelled() {
return new Delivery(this.id, false);
}
}
class FastDelivery extends Delivery {
private final long courierId;
public FastDelivery(…) {…}
public long getCourierId() {
return courierId;
}
}
Проблема: метод cancelled возвращает объект типа Delivery, и мы теряем информацию о курьере:FastDelivery fast = new FastDelivery(…);В такой ситуации помогут self-referential generic и небольшой обходной манёвр:
Delivery cancelled = fast.cancelled();
❌ long id = fast.getCourierId();
🔸 Добавляем параметр в родителя
public class DeliveryᐸT extends DeliveryᐸTᐳᐳ🔸 Создаём метод create, который возвращает нужный экземпляр
protected T create(long id, boolean isActive) {
return (T) new Delivery(id, isActive);
}
🔸 Используем этот метод в cancelledpublic T cancelled() {
return create(this.id, false);
}
🔸 Определяем параметр в наследникеpublic class FastDelivery extends DeliveryᐸFastDeliveryᐳ🔸 Переопределяем метод create в наследнике
protected FastDelivery create(long id, boolean isActive) {
return new FastDelivery(this.id, this.isActive, courierId);
}
Всё! Теперь информация не теряется:FastDelivery fast = new FastDelivery(…);Здесь используется комбо двух приёмов:
FastDelivery cancelled = fast.cancelled();
✅ long id = cancelled.getCourierId();
🔹 Метод create и его переопределение позволяют использовать поля, доступные в наследнике и вернуть нужный объект
🔹 Self-referential generic помогает вернуть нужный тип в методе cancelled
Готовый код доступен здесь
Резюме
Рассмотрите использование self-referential generic, когда
▫️ У вас есть иерархия
▫️ Родительский тип упоминается в аргументах или возвращаемом значении
Дополнительная типизация снизит количество кода, вытащит ошибки на этап компиляции и для некоторых случаев окажется очень изящным решением✨