
Удаление пробелов вокруг переменной в bash
Очень часто помогает при арифметических операциях, когда парсишь откуда-то значения и до или после нужного значения затесался пробел или ещё какой-то иной непечатаемый символ - через tr можно всё выпилить.
echo "a " | tr -d [[:space:]]
Очень часто помогает при арифметических операциях, когда парсишь откуда-то значения и до или после нужного значения затесался пробел или ещё какой-то иной непечатаемый символ - через tr можно всё выпилить.
Вывод всех значений JSON-массива в виде key-value:
jq -r '.[] | to_entries
[
{
"key": "id",
"value": 110
},
{
"key": "name",
"value": "frc_runner"
},
{
"key": "username",
"value": "frc_runner"
}
]
Forwarded from ServerAdmin.ru
Решил поделиться с вами, а заодно и разобрать работу одной консольной команды в linux, которая позволяет быстро посмотреть, кто занимает оперативную память на сервере. Сразу предупреждаю, что тема с памятью в linux очень замороченная. Ее нельзя просто взять, посмотреть и все понять :)
Если захотите разобраться в этом вопросе, то гуглите "linux memory rss virt" и читайте, разбирайтесь, проверяйте. Я буду подсчитывать использование rss памяти. Для этого предлагаю следующий скрипт, который можно запустить в bash консоли:
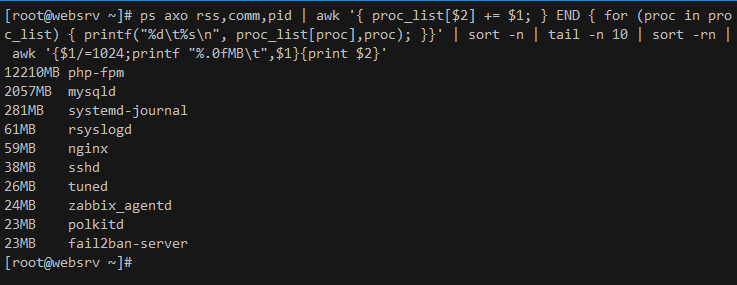
ps axo rss,comm,pid | awk '{ proc_list[$2] += $1; } END { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 10 | sort -rn | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}'
Разбираем, что он делает:
1️⃣ ps axo rss,comm,pid - выводит список всех процессов, указывая pid, само название процесса и потребление памяти rss. Если у вас работает, к примеру, php-fpm, то у него может быть сотни процессов, так что сама по себе эта команда малоинформативна, так как генерирует огромный список. Начинаем его обрабатывать.
2️⃣ awk '{ proc_list[$2] += $1; } END - в данном случае $2 это второй столбец (название процесса) списка, полученного из первой команды, $1 (rss) - первый. Таким образом мы создаем словарь из названий процессов и в этом словаре сразу же суммируем rss всех процессов с одним и тем же именем. То есть записываем примерно следующее:
proc_list = ( [php-fpm]=51224, [mysql]=31441 ) и т.д.
3️⃣ { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' - заключительная часть обработки в awk, которая в цикле перебирает все названия процессов в словаре и выводит их по одному в каждой строке. В данном случае proc_list[proc] будет выводить rss процесса, proc - его название, конструкция "%d\t%s\n" определяет формат вывода: %d - десятичное число, \t - табуляция, %s - строка, \n - переход на новую строку.
4️⃣ | sort -n | tail -n 10 | sort -rn - это самая простая часть. Тут мы сначала сортируем предыдущий список по первому столбцу (rss) от меньшего к большему, потом оставляем только 10 последних значений (можете изменить, если вам надо больше), и делаем обратную сортировку, от большего к меньшему.
5️⃣ | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}' - здесь мы просто причесываем вывод, деля rss на 1024, чтобы перевести в мегабайты и их же дописываем в конце. %.0f - округление до целого, \t - добавляет табуляцию. Можете это убрать, если вам не нужно.
Надеюсь после этого разбора магия bash вам покажется чуть более понятной. Такие однострочные конструкции трудно сходу воспринять и понять, если нет нормального опыта программирования на bash.
Я не сказать, что хорошо на нем программирую. Более того, даже этот скрипт я придумал не сам. Увидел когда-то и сохранил. Он достаточно известный и хорошо гуглится. Но вот разбора с описанием не найти. Восполняю пробел.
Сохрани на память. Частенько бывает нужен, если работаешь в консоли.
Если захотите разобраться в этом вопросе, то гуглите "linux memory rss virt" и читайте, разбирайтесь, проверяйте. Я буду подсчитывать использование rss памяти. Для этого предлагаю следующий скрипт, который можно запустить в bash консоли:
ps axo rss,comm,pid | awk '{ proc_list[$2] += $1; } END { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 10 | sort -rn | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}'
Разбираем, что он делает:
1️⃣ ps axo rss,comm,pid - выводит список всех процессов, указывая pid, само название процесса и потребление памяти rss. Если у вас работает, к примеру, php-fpm, то у него может быть сотни процессов, так что сама по себе эта команда малоинформативна, так как генерирует огромный список. Начинаем его обрабатывать.
2️⃣ awk '{ proc_list[$2] += $1; } END - в данном случае $2 это второй столбец (название процесса) списка, полученного из первой команды, $1 (rss) - первый. Таким образом мы создаем словарь из названий процессов и в этом словаре сразу же суммируем rss всех процессов с одним и тем же именем. То есть записываем примерно следующее:
proc_list = ( [php-fpm]=51224, [mysql]=31441 ) и т.д.
3️⃣ { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' - заключительная часть обработки в awk, которая в цикле перебирает все названия процессов в словаре и выводит их по одному в каждой строке. В данном случае proc_list[proc] будет выводить rss процесса, proc - его название, конструкция "%d\t%s\n" определяет формат вывода: %d - десятичное число, \t - табуляция, %s - строка, \n - переход на новую строку.
4️⃣ | sort -n | tail -n 10 | sort -rn - это самая простая часть. Тут мы сначала сортируем предыдущий список по первому столбцу (rss) от меньшего к большему, потом оставляем только 10 последних значений (можете изменить, если вам надо больше), и делаем обратную сортировку, от большего к меньшему.
5️⃣ | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}' - здесь мы просто причесываем вывод, деля rss на 1024, чтобы перевести в мегабайты и их же дописываем в конце. %.0f - округление до целого, \t - добавляет табуляцию. Можете это убрать, если вам не нужно.
Надеюсь после этого разбора магия bash вам покажется чуть более понятной. Такие однострочные конструкции трудно сходу воспринять и понять, если нет нормального опыта программирования на bash.
Я не сказать, что хорошо на нем программирую. Более того, даже этот скрипт я придумал не сам. Увидел когда-то и сохранил. Он достаточно известный и хорошо гуглится. Но вот разбора с описанием не найти. Восполняю пробел.
Сохрани на память. Частенько бывает нужен, если работаешь в консоли.
{kind=link}
Простая команда по созданию временных файлов или папок с динамическим наименованием. Может пригодиться вместо ручного создания файлов. Поддерживает также шаблоны, по которому генерируется имя.
Например, создание директории /tmp/ci-XXXXXX:
#bash
Например, создание директории /tmp/ci-XXXXXX:
mktemp -d -t ci-XXXXXX
/tmp/ci-itSU8p
#bash
IT lux
Удаление пробелов вокруг переменной в bash echo "a " | tr -d [[:space:]] Очень часто помогает при арифметических операциях, когда парсишь откуда-то значения и до или после нужного значения затесался пробел или ещё какой-то иной непечатаемый символ - через…
При редактировании YAML-файлов через Vim для удобства можно добавить следующий конфиг в vimrc. Теперь при редактировании файлов с расширением yaml|yml будут использоваться 2 пробельных отступа вместо табов + удобный перенос строк. Но лично мне удобнее писать YAML в GUI-редакторе, а Vim скорее для быстрых правок на самом сервере.
syntax on#vim
filetype plugin indent on
autocmd FileType yaml setlocal ts=2 sts=2 sw=2 expandtab
set is hlsearch ai ic scs
nnoremap <esc><esc> :nohls<cr>
На vc.ru прочитал интересную статью, где автор пишет, почему он не хочет регистрироваться в клабхаус. Честно сказать, я про эту соц. сеть слышал лишь отдаленно, но суть не в ней.
Мне очень понравилось, как автор высказал мысли о потреблении контента, когда весь день человека сводится к тому, чтобы постоянно получать информацию, а не воспроизводить. И действительно, я иногда ощущаю это на себе. Например, когда сидел вечером и читал эту статью вместо решения задач, которых у меня много.
На самом деле есть такая проблема, касающаяся потребления. Например, мне нужно написать playbook на ansible. Я беру кучу учебников, видосов и пытаюсь изучить базис - теория, мат. часть, лучшие практики. И, как правило, это все в документации. Я прыгаю от ссылки к ссылке, выписываю кучу всего, что касается правильного написания и в итоге понимаю, что сижу и трачу время на то, что мне возможно не понадобится вообще или в ближайшее время. Да, получать знания полезно, но без применения на практике пользы в них не так много, и спроси меня через неделю о том, что я прочитал, то наверняка ответить будет уже сложнее.
Это я всё к тому, что вместо постоянного раскуривания документации и прочих источников, нужно просто брать и делать уже хоть что-то, и по ходу дела уже разбираться с возникающими проблемами. Как результат - на выходе будет минимально рабочий продукт, результат труда, который можно оценить и получить удовлетворение от проделанной работы. Казалось бы - всё вышесказанное очевидная вещь, но на практике не у всех получается просто брать и делать, не зарывшись в обширную документацию.
На своём личном опыте стараюсь не зарываться в кучу контента (в основном каналы в тг, отдельные сайты\блоги и ютуб), коего во всяких лентах новостей у меня достаточно много. Везде, где можно, оформлены подписки и в неделю выделяю какое-то специальное время, в которое проверяю по возможности все источники, а в рабочее время по будням стараюсь не отвлекаться от рабочих задач.
P.S. В кач-ве исключения в ситуации постоянного потребления информация без её практического применения мне видится должность руководителя (менеджера) над техническими специалистами, который должен понимать хотя бы какую-то теорию - для таких людей допустимо просто знать какой-то материал для понимания. Но и то, сама по себе информация не несёт смысла, человек так или иначе должен с ней как-то работать и взаимодействовать.
#offtop
Мне очень понравилось, как автор высказал мысли о потреблении контента, когда весь день человека сводится к тому, чтобы постоянно получать информацию, а не воспроизводить. И действительно, я иногда ощущаю это на себе. Например, когда сидел вечером и читал эту статью вместо решения задач, которых у меня много.
На самом деле есть такая проблема, касающаяся потребления. Например, мне нужно написать playbook на ansible. Я беру кучу учебников, видосов и пытаюсь изучить базис - теория, мат. часть, лучшие практики. И, как правило, это все в документации. Я прыгаю от ссылки к ссылке, выписываю кучу всего, что касается правильного написания и в итоге понимаю, что сижу и трачу время на то, что мне возможно не понадобится вообще или в ближайшее время. Да, получать знания полезно, но без применения на практике пользы в них не так много, и спроси меня через неделю о том, что я прочитал, то наверняка ответить будет уже сложнее.
Это я всё к тому, что вместо постоянного раскуривания документации и прочих источников, нужно просто брать и делать уже хоть что-то, и по ходу дела уже разбираться с возникающими проблемами. Как результат - на выходе будет минимально рабочий продукт, результат труда, который можно оценить и получить удовлетворение от проделанной работы. Казалось бы - всё вышесказанное очевидная вещь, но на практике не у всех получается просто брать и делать, не зарывшись в обширную документацию.
На своём личном опыте стараюсь не зарываться в кучу контента (в основном каналы в тг, отдельные сайты\блоги и ютуб), коего во всяких лентах новостей у меня достаточно много. Везде, где можно, оформлены подписки и в неделю выделяю какое-то специальное время, в которое проверяю по возможности все источники, а в рабочее время по будням стараюсь не отвлекаться от рабочих задач.
P.S. В кач-ве исключения в ситуации постоянного потребления информация без её практического применения мне видится должность руководителя (менеджера) над техническими специалистами, который должен понимать хотя бы какую-то теорию - для таких людей допустимо просто знать какой-то материал для понимания. Но и то, сама по себе информация не несёт смысла, человек так или иначе должен с ней как-то работать и взаимодействовать.
#offtop
Упоминание gixy (софтина для анализа конфига Nginx) уже встречалось во многих тематических каналах по администрированию, но я просто оставлю ссылку на его у себя, чтобы не забыть.
#nginx
#nginx
GitHub
GitHub - yandex/gixy: Nginx configuration static analyzer
Nginx configuration static analyzer. Contribute to yandex/gixy development by creating an account on GitHub.
Написал очередную статью по настройке http-auth в Nginx через Active Directory.
Вообще интересные решения у Nginx засчёт наличия модулей, можно гибко настраивать даже opensource версию, не говоря про Nginx Plus и его огромный функционал. Ну, и конечно же хвала всем энтузиастам, которые пилят модули и выкладывают их в свободный доступ.
#Nginx #Samba #AD
Вообще интересные решения у Nginx засчёт наличия модулей, можно гибко настраивать даже opensource версию, не говоря про Nginx Plus и его огромный функционал. Ну, и конечно же хвала всем энтузиастам, которые пилят модули и выкладывают их в свободный доступ.
#Nginx #Samba #AD
Удобная функция в curl, позволяющая разрезолвить домен в указанный адрес для нужного порта, добавляя этот адрес в DNS-кеш. Бывает полезно для более точных проверок, когда старые DNS-записи жестко кешируют браузеры или сама ОС.
curl -L -v --resolve 'it-lux.ru:80:87.236.16.179' --resolve 'it-lux.ru:443:87.236.16.179' it-lux.ru#curl
Столкнулся с проблемой, когда при обращении на адрес вида domain.ru/admin///////// и добавлении n-ого количества слешей в request_uri, слеши либо мешают корректной работе сайта, либо просто остаются в адресе - выглядит это не очень.
По идее проблема должна решаться на стороне Nginx директивой merge_slashes в значении on (которое по дефолту, судя по доке), но в моём случае это не сработало даже при явном указании директивы в нужном контексте.
Поэтому воспользовался простым регулярным выражением, которое делает замену всех множественных слешей:
#nginx
По идее проблема должна решаться на стороне Nginx директивой merge_slashes в значении on (которое по дефолту, судя по доке), но в моём случае это не сработало даже при явном указании директивы в нужном контексте.
Поэтому воспользовался простым регулярным выражением, которое делает замену всех множественных слешей:
location ~* // {
rewrite ^(.*?)//+(.*)$ $1/$2 permanent;
}
Есть ещё не совсем кошерный, но вполне рабочий вариант, когда осуществляется 301 редирект на uri, в котором Nginx уже произвёл очистку мусорных слешей:if ($request_uri ~ ^[^?]*//) {
rewrite ^ $uri permanent;
}
P.S. На многих сайтах такое поведение не обрабатывается и слеши из урла не убираются. Хотя на google.com////, например, настроена обработка.#nginx
Удаление промежуточных образов. Иногда при сборке контейнеров возникают слои, не связанные тэгами с имеющимися образами. Пример таких образов, где указано <none>:
Они занимают место и могут быть удалены одной командой:
#docker
docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx 1.19.6-alpine-2.0 f734e67211d1 4 days ago 133MB
nginx 1.19.10 62d49f9bab67 6 days ago 133MB
<none> <none> dde3e316aea4 2 months ago 133MB
httpd 2.4.6-centos-2.0 4df283c914ea 2 months ago 1.06GB
<none> <none> a79f5bf21224 2 months ago 278MB
init release-24-2-1 396e5b5e45df 2 months ago 175MB
init release-24-2 7e38634a62b1 2 months ago 175MB
<none> <none> 9cbc8cbbc5e4 2 months ago 1.06GB
Они занимают место и могут быть удалены одной командой:
docker rmi $(docker images --filter "dangling=true" -q --no-trunc)
#docker
Привык админить серверы на centos, а тут добрался до Debian 10. После установки поставил ntpd для синхронизации времени, но в timedatectl строчка "System clock synchronized" говорила о том, что время не синхронизируется, хотя ntpd запущен. Проблема оказалась в имеющемся из коробки сервисе, который мешает работе ntpd. На Red Hat based ОС данный пакет не включен в состав systemd, а в Debian же наоборот. Поэтому я его просто отключил:
После чего синхронизация времени успешно выполнилась:
#linux #debian #ntp
systemctl disable systemd-timesyncd --now
После чего синхронизация времени успешно выполнилась:
timedatectl
Local time: Wed 2021-04-21 14:33:26 MSK
Universal time: Wed 2021-04-21 11:33:26 UTC
RTC time: Wed 2021-04-21 11:33:27
Time zone: Europe/Moscow (MSK, +0300)
System clock synchronized: yes
NTP service: inactive
RTC in local TZ: no
#linux #debian #ntp
Столкнулся с интересной ситуацией: на одном из проектов на kubernetes проводился аудит ИБ, и от них пришли претензии, что в публичке фигурирует сертификат Kubernetes Ingress Controller fake certificate и они потребовали объяснений. Поначалу подумал, что какую-то дырку нарыли безопасники, но потом понял, что не всё так однозначно.
Я догадался, что ИБ проводили проверку цепочки сертификатов, а потому воспользовался авторитетным ресурсом ssllabs, и да, по окончании проверки там я также увидел fake cert от кубера. Причина, почему этот сертификат фигурирует, одна - при обращении по протоколу HTTP к запрашиваемому ресурсу обычно используется расширение для TLS - Server Name Indication для установления имени до выполнения хендшейка. И с этим всё было ок, а вот ещё на ssllabs выполняется вторая проверка с пустым SNI, т.е. по IP-адресу с использованием https протокола. И в таком случае Nginx Ingress Controller выполняет стандартную процедуру - отдает свой фейковый серт, т.к. запрос попал в дефолтный location. Для пущей убедительности пришлось обратиться к RFC, указав, что это проблемы клиента, а ответ с помощью самоподписанного сертификата - это не уязвимость сама по себе.
Но ИБ этого показалось мало и было требование выпилить fake cert, чтобы он нигде не фигурировал. В итоге варианта оказалось два:
1) настроить в манифесте Ingress Controller ключ --default-ssl-certificate, указав в нём серт по умолчанию. Например, для своего основного домена.
2) настроить игнорирование невалидных запросов без SNI, отдавая 444 код, например. Но реализовать так просто это не получится, т.к. требуются правки на уровне кода в Ingress Controller, о чём написано в issue
UPD. С выходом Nginx 1.20 появилась директива ssl_reject_handshake on, которая будет по умолчанию отсекать запросы с неизвестными именами хостнеймов в поле SNI.
#offtop #nginx_ingress_controller
Я догадался, что ИБ проводили проверку цепочки сертификатов, а потому воспользовался авторитетным ресурсом ssllabs, и да, по окончании проверки там я также увидел fake cert от кубера. Причина, почему этот сертификат фигурирует, одна - при обращении по протоколу HTTP к запрашиваемому ресурсу обычно используется расширение для TLS - Server Name Indication для установления имени до выполнения хендшейка. И с этим всё было ок, а вот ещё на ssllabs выполняется вторая проверка с пустым SNI, т.е. по IP-адресу с использованием https протокола. И в таком случае Nginx Ingress Controller выполняет стандартную процедуру - отдает свой фейковый серт, т.к. запрос попал в дефолтный location. Для пущей убедительности пришлось обратиться к RFC, указав, что это проблемы клиента, а ответ с помощью самоподписанного сертификата - это не уязвимость сама по себе.
Но ИБ этого показалось мало и было требование выпилить fake cert, чтобы он нигде не фигурировал. В итоге варианта оказалось два:
1) настроить в манифесте Ingress Controller ключ --default-ssl-certificate, указав в нём серт по умолчанию. Например, для своего основного домена.
2) настроить игнорирование невалидных запросов без SNI, отдавая 444 код, например. Но реализовать так просто это не получится, т.к. требуются правки на уровне кода в Ingress Controller, о чём написано в issue
UPD. С выходом Nginx 1.20 появилась директива ssl_reject_handshake on, которая будет по умолчанию отсекать запросы с неизвестными именами хостнеймов в поле SNI.
#offtop #nginx_ingress_controller