
Геймификация. Тетрис и паттерны взаимодействия
Пару лет назад я писал в блоге о своем эксперименте с Тетрисом в ВК. Оказывается, тетрис это крайне хороший пример-артефакт, чтобы показать как изменяются и эволюционируют паттерны поведения при взаимодействии с устройством.
https://www.i-programmer.info/news/144-graphics-and-games/15597-the-power-of-tetris-to-improve-human-performance.html
В 2018 году, игрок на кубке тетриса Джозеф Сэли, которому тогда было 16 лет и который был новичком в игре, использовал технику "гипертаппинг", которая должна была доминировать в соревновательной игре. Вместо того, чтобы ставить фигуры на место, удерживая левую или правую кнопку на ретро-крестовине, этот метод игры, разработанный Кодзи Нисио, требует от игроков быстрого нажатия на крестовину с правильными интервалами, чтобы перемещайте фигуры тетриса в разные стороны, не теряя скорости. Поскольку для эффективности требуется более 10 нажатий кнопок в секунду, это более рискованный и требовательный стиль игры, а также сложный в освоении.
Hypertapping уже идет на убыль. Теперь есть более новая и еще более быстрая техника игры в Tetris, перекатывание, которое включает в себя удары пальцами по задней части контроллера NES, нажимая на кнопки на другой стороне. Игрок бьет по контроллеру сзади!
https://www.youtube.com/watch?v=n-BZ5-Q48lE&feature=emb_title
Это, конечно, похоже на прикол, но этот прикол хорошо демонстрирует как сильно могут изменятся привычные способы взаимодействия с интерфейсами по прошествии времени. Очень большое число инноваций на уровне интерфейса сейчас нам,кажется, до сих пор неизвестно потому что прошло слишком мало времени.
Пару лет назад я писал в блоге о своем эксперименте с Тетрисом в ВК. Оказывается, тетрис это крайне хороший пример-артефакт, чтобы показать как изменяются и эволюционируют паттерны поведения при взаимодействии с устройством.
https://www.i-programmer.info/news/144-graphics-and-games/15597-the-power-of-tetris-to-improve-human-performance.html
В 2018 году, игрок на кубке тетриса Джозеф Сэли, которому тогда было 16 лет и который был новичком в игре, использовал технику "гипертаппинг", которая должна была доминировать в соревновательной игре. Вместо того, чтобы ставить фигуры на место, удерживая левую или правую кнопку на ретро-крестовине, этот метод игры, разработанный Кодзи Нисио, требует от игроков быстрого нажатия на крестовину с правильными интервалами, чтобы перемещайте фигуры тетриса в разные стороны, не теряя скорости. Поскольку для эффективности требуется более 10 нажатий кнопок в секунду, это более рискованный и требовательный стиль игры, а также сложный в освоении.
Hypertapping уже идет на убыль. Теперь есть более новая и еще более быстрая техника игры в Tetris, перекатывание, которое включает в себя удары пальцами по задней части контроллера NES, нажимая на кнопки на другой стороне. Игрок бьет по контроллеру сзади!
https://www.youtube.com/watch?v=n-BZ5-Q48lE&feature=emb_title
Это, конечно, похоже на прикол, но этот прикол хорошо демонстрирует как сильно могут изменятся привычные способы взаимодействия с интерфейсами по прошествии времени. Очень большое число инноваций на уровне интерфейса сейчас нам,кажется, до сих пор неизвестно потому что прошло слишком мало времени.
Рубрика «Много полезного» о взаимодействиях за последнюю неделю
Поведенческая изменчивость для теста Тьюринга
Человеческая поведенческая изменчивость стирает различие между человеком и машиной в невербальном тесте Тьюринга. Группа исследователей тестировала поведение роботов на удаленном управлении оператором и программой. Разницу между поведением робота респонденты не нашли. Общая концепция «теста Тьюринга» может быть использована в качестве основы для разработки экспериментальных исследований, направленных на оценку того, какие поведенческие особенности должны быть реализованы на искусственном агенте, чтобы сделать возможным или невозможным для человека-наблюдателя отличить компьютерную программу от человека.
Ну и вот: понимание кто сейчас управляет машиной - робот или человек - в случае предсказаний “машина” стремилось к истине в более 50 процентов случаев. Кажется, что разброс несколько сложнее, но скорее интересна сама дискуссия о поведенческом варианте теста Тьюринга. С другой стороны, участники смогли угадать, когда человек контролировал ситуацию более чем в 50% случаев, что, по словам авторов, свидетельствует о том, что люди чувствительны к тонким изменениям в человеческом поведении. Маскарад роботов не за горами.
https://www.science.org/doi/10.1126/scirobotics.abo1241
https://www.inverse.com/innovation/turing-test
Жесты в VR
Академия голограмм WIMI в Гонк Конге (http://hologramsociety.wimiar.com/en/ ) написала новую техническую статью, описывающую технологию взаимодействия жестов человека и компьютера на основе зрения в виртуальной реальности. Документ больше похож на манифест с перечислением методов для распознавания движения в виртуальной среде, но тут надо смотреть на все перечисленных методы
Распознавание рук и сегментация
Распознавание шейпов и форм руки
Цвет кожи рук распознавание
Детекторы движения
Шаблоны основных действий при взаимодействии
Скрытые марковские модели Для распознавания жестов скрытые марковские модели больше подходят для непрерывного распознавания жестов, особенно для сложных жестов, связанных с контекстом.
Из интересного: использование цветовых обозначений в VR для распознавания предметов. Ну те разрисовать фаланги пальцев в VR в разные цвета для контроля над жестами - примитивный, но хороший ход, учитывая ограниченность жестов в культурах людей. https://www.globenewswire.com/en/news-release/2022/07/18/2481055/0/en/WIMI-Hologram-Academy-Vision-based-Human-Computer-Gesture-Interaction-Technology-in-Virtual-Reality.html
Эта же академия два дня назад выпустила статью про мониторинг работы роботов в вирутальной среде: https://www.streetinsider.com/Globe+Newswire/WIMI+Hologram+Academy%3A+Virtual+Reality-based+Intelligent+Monitoring+System+for+Robots+working+Conditions/20366044.html
Шар или Co-Orb
Университет Карнеги показал учебный проект студентов: шар, который принимает сообщения из рабочих чатов и выводит на мигающий шар. Co-Orb использует обработку естественного языка для выделения в сообщениях таких ключевых слов, как «спасибо», «благодарю». Затем он запрашивает отправителя и спрашивает, не хотят ли они отправить благодарность Co-Orb своего коллеги. Сообщение отправляется на лампу получателя, которая загорается персонализированными смайликами и именем отправителя. Затем получатель может коснуться Co-Orb, чтобы услышать сообщение, прочитанное вслух.
https://www.cmu.edu/news/stories/archives/2022/july/co-orb.html
Скажи «Спасибо» за работу, как кажется, хорошее решение для того, чтобы повысить удовлетворенность сотрудников, но обычно такое хорошо работало в интранетах или мобильных рабочих местах.
https://www.youtube.com/watch?v=x1iq6UMzmRo&feature=emb_imp_woyt
Поведенческая изменчивость для теста Тьюринга
Человеческая поведенческая изменчивость стирает различие между человеком и машиной в невербальном тесте Тьюринга. Группа исследователей тестировала поведение роботов на удаленном управлении оператором и программой. Разницу между поведением робота респонденты не нашли. Общая концепция «теста Тьюринга» может быть использована в качестве основы для разработки экспериментальных исследований, направленных на оценку того, какие поведенческие особенности должны быть реализованы на искусственном агенте, чтобы сделать возможным или невозможным для человека-наблюдателя отличить компьютерную программу от человека.
Ну и вот: понимание кто сейчас управляет машиной - робот или человек - в случае предсказаний “машина” стремилось к истине в более 50 процентов случаев. Кажется, что разброс несколько сложнее, но скорее интересна сама дискуссия о поведенческом варианте теста Тьюринга. С другой стороны, участники смогли угадать, когда человек контролировал ситуацию более чем в 50% случаев, что, по словам авторов, свидетельствует о том, что люди чувствительны к тонким изменениям в человеческом поведении. Маскарад роботов не за горами.
https://www.science.org/doi/10.1126/scirobotics.abo1241
https://www.inverse.com/innovation/turing-test
Жесты в VR
Академия голограмм WIMI в Гонк Конге (http://hologramsociety.wimiar.com/en/ ) написала новую техническую статью, описывающую технологию взаимодействия жестов человека и компьютера на основе зрения в виртуальной реальности. Документ больше похож на манифест с перечислением методов для распознавания движения в виртуальной среде, но тут надо смотреть на все перечисленных методы
Распознавание рук и сегментация
Распознавание шейпов и форм руки
Цвет кожи рук распознавание
Детекторы движения
Шаблоны основных действий при взаимодействии
Скрытые марковские модели Для распознавания жестов скрытые марковские модели больше подходят для непрерывного распознавания жестов, особенно для сложных жестов, связанных с контекстом.
Из интересного: использование цветовых обозначений в VR для распознавания предметов. Ну те разрисовать фаланги пальцев в VR в разные цвета для контроля над жестами - примитивный, но хороший ход, учитывая ограниченность жестов в культурах людей. https://www.globenewswire.com/en/news-release/2022/07/18/2481055/0/en/WIMI-Hologram-Academy-Vision-based-Human-Computer-Gesture-Interaction-Technology-in-Virtual-Reality.html
Эта же академия два дня назад выпустила статью про мониторинг работы роботов в вирутальной среде: https://www.streetinsider.com/Globe+Newswire/WIMI+Hologram+Academy%3A+Virtual+Reality-based+Intelligent+Monitoring+System+for+Robots+working+Conditions/20366044.html
Шар или Co-Orb
Университет Карнеги показал учебный проект студентов: шар, который принимает сообщения из рабочих чатов и выводит на мигающий шар. Co-Orb использует обработку естественного языка для выделения в сообщениях таких ключевых слов, как «спасибо», «благодарю». Затем он запрашивает отправителя и спрашивает, не хотят ли они отправить благодарность Co-Orb своего коллеги. Сообщение отправляется на лампу получателя, которая загорается персонализированными смайликами и именем отправителя. Затем получатель может коснуться Co-Orb, чтобы услышать сообщение, прочитанное вслух.
https://www.cmu.edu/news/stories/archives/2022/july/co-orb.html
Скажи «Спасибо» за работу, как кажется, хорошее решение для того, чтобы повысить удовлетворенность сотрудников, но обычно такое хорошо работало в интранетах или мобильных рабочих местах.
https://www.youtube.com/watch?v=x1iq6UMzmRo&feature=emb_imp_woyt
👍1
Словарь юного HCI. Keystroke dynamics
Поведенческая биометрическая метрика Keystroke Dynamics использует манеру и ритм, в котором человек набирает символы на клавиатуре. Такой клавиатурный почерк относится к динамическим (поведенческим) биометрическим характеристикам, описывающим подсознательные действия, привычные для пользователя: он характеризует динамику ввода парольной фразы.
Стандартная клавиатура позволяет измерить следующие временные характеристики: время удержания клавиши нажатой и интервал времени между нажатиями клавиш. А также некоторые другие параметры: общее время набора парольной фразы, частота возникновения ошибок при наборе, факт использования дополнительных клавиш (использование числовой клавиатуры), особенности ввода заглавных букв (использование клавиши Shift или Caps Lock) и т. д.
Итак, мы знаем ритм набора, время потраченное на набор, специфику вводу заглавных и строчных. У большинства людей есть определенные буквы, на поиск которых у них уходит больше времени, чем их среднее время поиска по другим буквам. Правши могут быть быстрее при нажатии клавиш пальцами правой руки. Указательные пальцы могут быть значительно более быстрыми, чем другие пальцы. Кроме того, последовательности букв могут иметь характерные для человека свойства. Распространенные «ошибки» также могут быть весьма характерными для конкретного человека. Все это позволяет еще и авторизовать личность юзера.
Более того, у разных клавиатур разная эргономика… это означает, что кого-то можно поймать, если обратить внимание на эргономику необычной клавы авторизации. К сожалению, очевидна нестабильность такой метрики — разное время суток, усталость, болезнь влияют на биометрические показатели ввода паролей.
Поведенческая биометрическая метрика Keystroke Dynamics использует манеру и ритм, в котором человек набирает символы на клавиатуре. Такой клавиатурный почерк относится к динамическим (поведенческим) биометрическим характеристикам, описывающим подсознательные действия, привычные для пользователя: он характеризует динамику ввода парольной фразы.
Стандартная клавиатура позволяет измерить следующие временные характеристики: время удержания клавиши нажатой и интервал времени между нажатиями клавиш. А также некоторые другие параметры: общее время набора парольной фразы, частота возникновения ошибок при наборе, факт использования дополнительных клавиш (использование числовой клавиатуры), особенности ввода заглавных букв (использование клавиши Shift или Caps Lock) и т. д.
Итак, мы знаем ритм набора, время потраченное на набор, специфику вводу заглавных и строчных. У большинства людей есть определенные буквы, на поиск которых у них уходит больше времени, чем их среднее время поиска по другим буквам. Правши могут быть быстрее при нажатии клавиш пальцами правой руки. Указательные пальцы могут быть значительно более быстрыми, чем другие пальцы. Кроме того, последовательности букв могут иметь характерные для человека свойства. Распространенные «ошибки» также могут быть весьма характерными для конкретного человека. Все это позволяет еще и авторизовать личность юзера.
Более того, у разных клавиатур разная эргономика… это означает, что кого-то можно поймать, если обратить внимание на эргономику необычной клавы авторизации. К сожалению, очевидна нестабильность такой метрики — разное время суток, усталость, болезнь влияют на биометрические показатели ввода паролей.
Социология ИИ
Да, действительно, на английском существует популярный жанр социологии алгоритмов в современной Академии, но поговорим сегодня о книжке, которую я скачал с сайта ВЦИОМ (некоторые книжки на сайте ВЦИОМ даже я немного подготовил и низачто не догадаетесь где).
От искусственного интеллекта к искусственной социальности. Новые исследовательские проблемы современной социальной аналитики
Это классический пример сборника статей скучных и старых авторов на тему социальности - советские шестидесятники рассуждают о айти на деньги грантов РНФ и РГНФ. Удручающее зрелище: интервью с эйчарами айти-компаний, переводные книги о теории ИИ, обороты в духе «понятие, теория и обогащение ИИ». Отсылки к Никласу Луману в 2022 году, кое-где цитируется социология интеллектуалов Рэдмонда Коллинза. User research? HCI?
В общем за этот чудесный образчик чучел интеллектуалов я отдал 150 рублей онлайн, так что не жалко. Показательно, что такое карго социальных ученых оплачивается из кармана государства, пусть даже подход кураторов в духе Кириенко можно назвать куда более сциентистким.
Да, действительно, на английском существует популярный жанр социологии алгоритмов в современной Академии, но поговорим сегодня о книжке, которую я скачал с сайта ВЦИОМ (некоторые книжки на сайте ВЦИОМ даже я немного подготовил и низачто не догадаетесь где).
От искусственного интеллекта к искусственной социальности. Новые исследовательские проблемы современной социальной аналитики
Это классический пример сборника статей скучных и старых авторов на тему социальности - советские шестидесятники рассуждают о айти на деньги грантов РНФ и РГНФ. Удручающее зрелище: интервью с эйчарами айти-компаний, переводные книги о теории ИИ, обороты в духе «понятие, теория и обогащение ИИ». Отсылки к Никласу Луману в 2022 году, кое-где цитируется социология интеллектуалов Рэдмонда Коллинза. User research? HCI?
В общем за этот чудесный образчик чучел интеллектуалов я отдал 150 рублей онлайн, так что не жалко. Показательно, что такое карго социальных ученых оплачивается из кармана государства, пусть даже подход кураторов в духе Кириенко можно назвать куда более сциентистким.
Rezaev_A_V_Novye_issledovaniya_II.pdf
1.2 MB
От искусственного интеллекта к искусственной социальности: новые исследовательские проблемы современной социальной аналитики
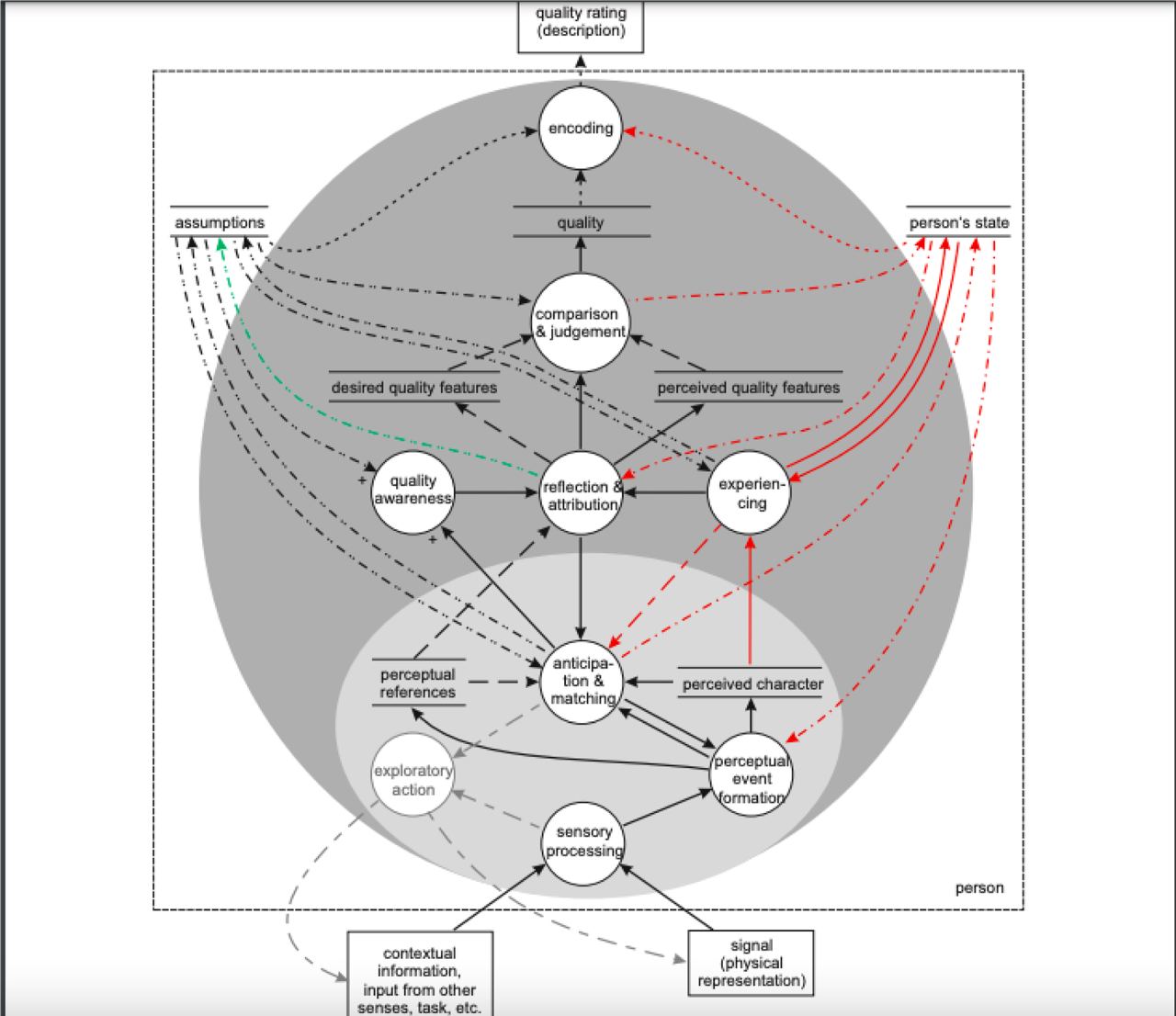
Продолжаю ковырять метрику Quality of experience из телекома.
Это некоторый аналог UX, который касается а) игр б) видеосмотрения в) телефонии. Попробуем дать определение из книжек:
Quality of Experience (QoE) — это степень удовольствия или раздражения человека, чье переживание связано с приложением, службой или системой. Это результат оценки человеком выполнения его или ее ожиданий и потребности в отношении полезности и/или удовольствия в свете контекста, личности и текущего положения дел.
Основой QoE является восприятие. Современная концепция обработки нейронных сигналов во время восприятия происходит в несколько этапов, итеративно. Процесс восприятия начинается с воздействие соответствующих раздражителей на один или несколько органов чувств человека. Сенсорный орган (органы), физические представления стимулов преобразуются в нейронные представления, включающие характеристические электрические сигналы. Это представление передается в мозг через нейронные для дальнейшей обработки. при передаче в соответствующую область мозга эти представления трансформируются от первоначальных стимулов к более абстрактным, символическим представлениям. Следует отметить, что контекстуальная и/или связанная с заданием информация, предоставляемая лицам, обрабатываются через их органы чувств и последующую нейронную обработку, возможно, в других модальностях. Такая информация либо непосредственно влияет на процесс восприятия, или делает это с помощью информации, доступной с точки зрения концепций более высокого уровня.
Еще на весь процесс восприятия есть своеобразные дупликаты в виде памяти: сенсорная память: это периферическая память, которая хранит репрезентации сенсорных стимулов в течение коротких промежутков времени от 150 мс до 2 с, чтобы их можно было извлечь с помощью более высоких уровней. Рабочая краткосрочная память и долговременная память - ну тут все ясно. Тот или иной стимул может воздействовать на память и влиять на дальнейшую обработку сигнала.
Ок, на схеме достаточно любопытны еще и красные линии - это изменение качества восприятия с учетом сигнала, которое влияет на пользователя. Я имею ввиду поворот головы на звук, движение глаз на вспышки цвета. Эти повороты в свою очередь влияют на оценки восприятия.
Картинка по Quality and Quality of Experience Alexander Raake and Sebastian Egger
Это некоторый аналог UX, который касается а) игр б) видеосмотрения в) телефонии. Попробуем дать определение из книжек:
Quality of Experience (QoE) — это степень удовольствия или раздражения человека, чье переживание связано с приложением, службой или системой. Это результат оценки человеком выполнения его или ее ожиданий и потребности в отношении полезности и/или удовольствия в свете контекста, личности и текущего положения дел.
Основой QoE является восприятие. Современная концепция обработки нейронных сигналов во время восприятия происходит в несколько этапов, итеративно. Процесс восприятия начинается с воздействие соответствующих раздражителей на один или несколько органов чувств человека. Сенсорный орган (органы), физические представления стимулов преобразуются в нейронные представления, включающие характеристические электрические сигналы. Это представление передается в мозг через нейронные для дальнейшей обработки. при передаче в соответствующую область мозга эти представления трансформируются от первоначальных стимулов к более абстрактным, символическим представлениям. Следует отметить, что контекстуальная и/или связанная с заданием информация, предоставляемая лицам, обрабатываются через их органы чувств и последующую нейронную обработку, возможно, в других модальностях. Такая информация либо непосредственно влияет на процесс восприятия, или делает это с помощью информации, доступной с точки зрения концепций более высокого уровня.
Еще на весь процесс восприятия есть своеобразные дупликаты в виде памяти: сенсорная память: это периферическая память, которая хранит репрезентации сенсорных стимулов в течение коротких промежутков времени от 150 мс до 2 с, чтобы их можно было извлечь с помощью более высоких уровней. Рабочая краткосрочная память и долговременная память - ну тут все ясно. Тот или иной стимул может воздействовать на память и влиять на дальнейшую обработку сигнала.
Ок, на схеме достаточно любопытны еще и красные линии - это изменение качества восприятия с учетом сигнала, которое влияет на пользователя. Я имею ввиду поворот головы на звук, движение глаз на вспышки цвета. Эти повороты в свою очередь влияют на оценки восприятия.
Картинка по Quality and Quality of Experience Alexander Raake and Sebastian Egger
{kind=link}
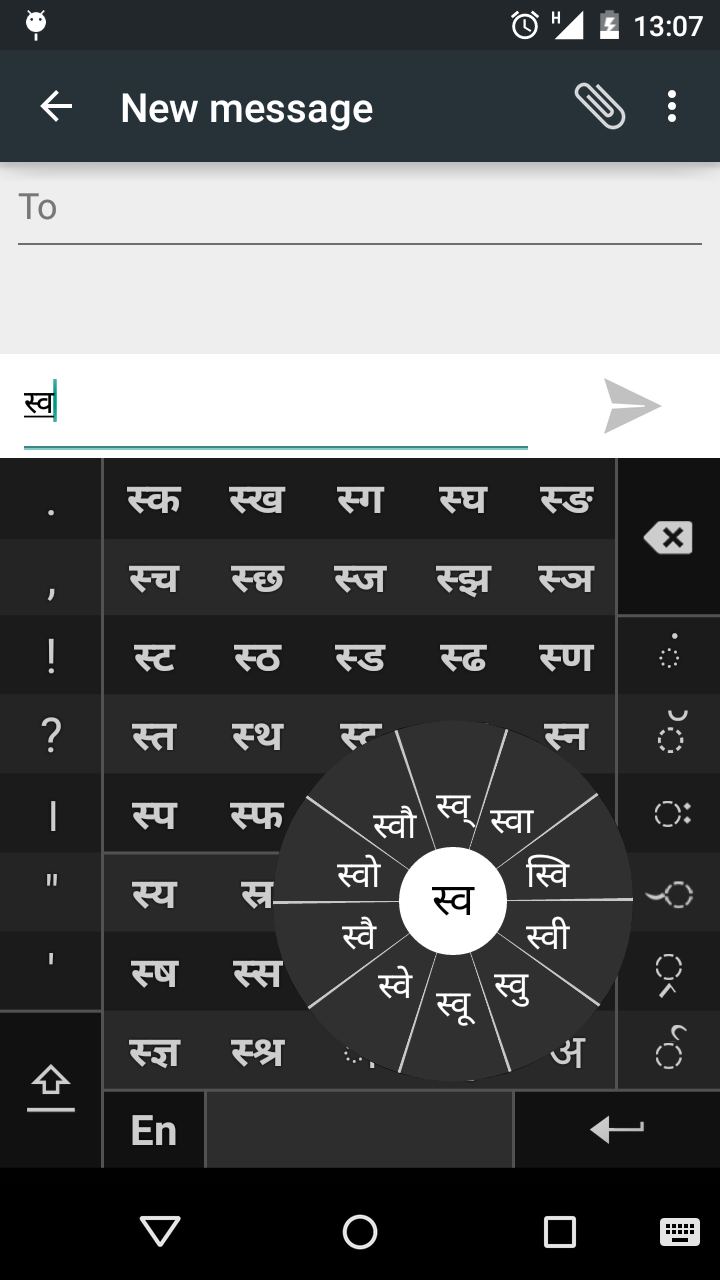
Странные интерфейсы
Swarachakra - это приложение с корнями в индустриальном дизайне Индии: 28 одних только государственных языков и тот факт, несмотря на то, что проникновение смартфонов в Индии растет, ввод текста в индийских алфавитах уже много лет остается проблемой. Согласно Обследованию развития человеческого потенциала в Индии за 2005 год, опрошенные домохозяйства сообщили, что 72 процента мужчин не говорят по-английски.
Несовпадение деванагари и латиницы привели к альтернативным разработкам клавиатур и виртуальных клавиатур на мобильных устройствах. Соответственно колесо с дополнительными символами появляется при долгом нажатии предоставляя допсимволы и символы других национальных языков Индии при необходимости (перейти с хинду на тамильский условно)
https://play.google.com/store/apps/details?id=iit.android.swarachakra
Скачиваний не очень много, но разработчики поддерживают колесо сразу на нескольких языках и это госпроект по развитию цифровой грамотности
Swarachakra - это приложение с корнями в индустриальном дизайне Индии: 28 одних только государственных языков и тот факт, несмотря на то, что проникновение смартфонов в Индии растет, ввод текста в индийских алфавитах уже много лет остается проблемой. Согласно Обследованию развития человеческого потенциала в Индии за 2005 год, опрошенные домохозяйства сообщили, что 72 процента мужчин не говорят по-английски.
Несовпадение деванагари и латиницы привели к альтернативным разработкам клавиатур и виртуальных клавиатур на мобильных устройствах. Соответственно колесо с дополнительными символами появляется при долгом нажатии предоставляя допсимволы и символы других национальных языков Индии при необходимости (перейти с хинду на тамильский условно)
https://play.google.com/store/apps/details?id=iit.android.swarachakra
Скачиваний не очень много, но разработчики поддерживают колесо сразу на нескольких языках и это госпроект по развитию цифровой грамотности
{kind=link}
❤4👍1🔥1
Исследования промышленного дизайна в Индии.
В прошлом посте была ссылка на отделы Industrial Design Center в Индии: как я понимаю, Индия страна с бурно развивающимися технологиями и еще более сложными проблемами, которые она пытается решить.Центр промышленного дизайна был создан в 1969 году правительством Индии под эгидой Индийского технологического института в Бомбее: речь шла о создании самых горящих вещей, которые требовали промышленного дизана. Что сейчас? На сайте достаточно интересный набор http://www.idc.iitb.ac.in
Тут интересный ориентализм:
Dig Folk Tales initiative: инициатива по оцифровке сказок и преданий народов Индии в цифровом виде: поиск ресурсов, анализ и визуализация контента на различных носителях и обеспечение его свободного доступа для всех. Например, проводится исследование сказителей одного из крупных народов Индии http://www.idc.iitb.ac.in/resources/dt-july-2009/kaavad.pdf
Исследование бамбука: Бамбук, как самая быстрорастущая биомасса, является экологически чистым и перспективным материалом для дизайнеров. Эта исследовательская группа работает над изучением вариантов креативного дизайна с использованием бамбука.
Из смешного: есть https://www.researchgate.net/publication/277893043_Simulating_the_Appearance_of_Painted_and_Digital_Display_Type_on_Shop_Signs_in_India
В статье речь идет о визуальных сигналах небольших магазинов на улицах Индии и, кажется, о влиянии на юзера. Картинки интереснее
Есть и просто госзаказ от правительства Индии, например, новый дизайн почтового ящика для национальной почтовой службы. http://www.idc.iitb.ac.in/resources/dt-jan-2009/New%20Post%20Box%20Design.pdf
В прошлом посте была ссылка на отделы Industrial Design Center в Индии: как я понимаю, Индия страна с бурно развивающимися технологиями и еще более сложными проблемами, которые она пытается решить.Центр промышленного дизайна был создан в 1969 году правительством Индии под эгидой Индийского технологического института в Бомбее: речь шла о создании самых горящих вещей, которые требовали промышленного дизана. Что сейчас? На сайте достаточно интересный набор http://www.idc.iitb.ac.in
Тут интересный ориентализм:
Dig Folk Tales initiative: инициатива по оцифровке сказок и преданий народов Индии в цифровом виде: поиск ресурсов, анализ и визуализация контента на различных носителях и обеспечение его свободного доступа для всех. Например, проводится исследование сказителей одного из крупных народов Индии http://www.idc.iitb.ac.in/resources/dt-july-2009/kaavad.pdf
Исследование бамбука: Бамбук, как самая быстрорастущая биомасса, является экологически чистым и перспективным материалом для дизайнеров. Эта исследовательская группа работает над изучением вариантов креативного дизайна с использованием бамбука.
Из смешного: есть https://www.researchgate.net/publication/277893043_Simulating_the_Appearance_of_Painted_and_Digital_Display_Type_on_Shop_Signs_in_India
В статье речь идет о визуальных сигналах небольших магазинов на улицах Индии и, кажется, о влиянии на юзера. Картинки интереснее
Есть и просто госзаказ от правительства Индии, например, новый дизайн почтового ящика для национальной почтовой службы. http://www.idc.iitb.ac.in/resources/dt-jan-2009/New%20Post%20Box%20Design.pdf
👍4
Алгоритмоцентрический дизайн. UX для дата-сцайнтистов
Вообще в мире растет направление работы с дизайном, ориентированным на работу с данными и аналитикой этих данных. Брайан О’Нил — основатель Designing for Analytics из США и он еще ведет подкаст «Испытание данных». Он помогает руководителям продуктов и специалистам по стратегии данных внедрять инновации, применяя дизайн, ориентированный на человека, к науке о данных и аналитике. Много его манифестов на видео https://www.youtube.com/watch?v=VjfxUBIXW5w&ab_channel=RiskGroupLLC
https://designingforanalytics.com/
Действительно, хороший дизайн и UX хорошо сказывается на понимание дашбордов и данных, которыми оперируют в аналитическом мире. Тут действительно есть несколько интересных мыслей, например, отчет от VentureBeat AI который гордо рапортует, что большинство проектов ДС - 87 процентов не доходит до запуска.
https://venturebeat.com/ai/why-do-87-of-data-science-projects-never-make-it-into-production/
Одна из причин - действительно неадаптированность данных к продуктам. Есть тенденция в корпорациях доводить сырые данные до пометки «Это продукт». На моей памяти один отдел очень крупного ритейлера в РФ назвал продуктом формулу уценки товара - ну те динамически рассчитываемую скидки на хрючево в эксельке и САПе.
Так вот, Брайан рассылает шпаргалки для продактов дата-продуктов в которых достаточно любопытно рекомендует очевидные вещи, типа всегда показывать на дашборде данные для сравнения с чем-то, ответы на вопросы «достаточно ли этого изменения в метриках» для чего-то, может быть выводить на дашборды данные конкурентов опять таки для сравнения.
Ну еще какие-то базовые вещи есть в духе 1) «урежем» данные дашбордов как излишние, 2) нарисуйте карту стейкхолдеров для того, чтобы избежать конфликтов внимания разных ролей на дашборде, 3) показывайте вовремя изменения метрик(очень часто забывают выводить какие-то несвязанные метрики на доски, например, метрики маркетинга на доску для продукта).
Вроде все очевидно, но всегда полезно хорошее повторить. Шпаргалка следующим постом
Наиболее ценной мне кажется вот эта мысль: Many engineering and technical companies are afraid to make estimates and predictions, because they often intimately know the flaws and gaps in the algorithm or the analytics. In reality, most users would probably trade a reduced-accuracy, software-generated recommendation over a tool that requires them to do all of their own data analysis from scratch.
Никогда не следует боятся делать выводы за юзера при создании дашборда, даже если наш алгоритм несовершенен. В этом что-то есть.
Вообще в мире растет направление работы с дизайном, ориентированным на работу с данными и аналитикой этих данных. Брайан О’Нил — основатель Designing for Analytics из США и он еще ведет подкаст «Испытание данных». Он помогает руководителям продуктов и специалистам по стратегии данных внедрять инновации, применяя дизайн, ориентированный на человека, к науке о данных и аналитике. Много его манифестов на видео https://www.youtube.com/watch?v=VjfxUBIXW5w&ab_channel=RiskGroupLLC
https://designingforanalytics.com/
Действительно, хороший дизайн и UX хорошо сказывается на понимание дашбордов и данных, которыми оперируют в аналитическом мире. Тут действительно есть несколько интересных мыслей, например, отчет от VentureBeat AI который гордо рапортует, что большинство проектов ДС - 87 процентов не доходит до запуска.
https://venturebeat.com/ai/why-do-87-of-data-science-projects-never-make-it-into-production/
Одна из причин - действительно неадаптированность данных к продуктам. Есть тенденция в корпорациях доводить сырые данные до пометки «Это продукт». На моей памяти один отдел очень крупного ритейлера в РФ назвал продуктом формулу уценки товара - ну те динамически рассчитываемую скидки на хрючево в эксельке и САПе.
Так вот, Брайан рассылает шпаргалки для продактов дата-продуктов в которых достаточно любопытно рекомендует очевидные вещи, типа всегда показывать на дашборде данные для сравнения с чем-то, ответы на вопросы «достаточно ли этого изменения в метриках» для чего-то, может быть выводить на дашборды данные конкурентов опять таки для сравнения.
Ну еще какие-то базовые вещи есть в духе 1) «урежем» данные дашбордов как излишние, 2) нарисуйте карту стейкхолдеров для того, чтобы избежать конфликтов внимания разных ролей на дашборде, 3) показывайте вовремя изменения метрик(очень часто забывают выводить какие-то несвязанные метрики на доски, например, метрики маркетинга на доску для продукта).
Вроде все очевидно, но всегда полезно хорошее повторить. Шпаргалка следующим постом
Наиболее ценной мне кажется вот эта мысль: Many engineering and technical companies are afraid to make estimates and predictions, because they often intimately know the flaws and gaps in the algorithm or the analytics. In reality, most users would probably trade a reduced-accuracy, software-generated recommendation over a tool that requires them to do all of their own data analysis from scratch.
Никогда не следует боятся делать выводы за юзера при создании дашборда, даже если наш алгоритм несовершенен. В этом что-то есть.
YouTube
Human Centric Algorithmic Design for Data Analytics
Risk Group discusses Human Centric Algorithmic Design for Data Analytics with Brian O’Neal, Founder of Designing for Analytics and Host of Experiencing Data Podcast based in the United States.
❤5
Designing-for-Analytics-Self-Assessment-Guide.pdf
138.9 KB
Передай другу дата-сцайнтисту, эта листовка - пропуск на дизайнерскую линию фронта
👍2
Как хороший дизайн помогает хорошим алгоритмам?
В статье Seeing Like an Algorithm бывший продакт видео Меты и Амазона Eugene Wei раскрывает некоторые очевидные неочевидности. Источник публичный, поэтому я думаю, что многим новичкам на канале будет небезынтересно почитать о таком подходе, который предполагает алгоритмоцентризм в UX.
Итак, в https://www.eugenewei.com/blog/2020/9/18/seeing-like-an-algorithm поднимается вопрос - как при помощи дизайна достигнуть максимальной отдачи от алгоритмов машинного обучения при разработке приложений и сервисов?
Изначально для TikTok (или Douyin, его китайского предка), которому нужен был алгоритм, способный рекомендовать зрителям короткие видеоролики, не было массивного общедоступного обучающего набора данных. Где вы можете найти короткие видеоролики с мемами, детьми, танцующими и поющими липсинки, домашними животными, инфлюенсерами, продвигающими бренды, солдатами, бегущими через полосу препятствий, детьми? Даже если бы у вас были такие видео, где бы вы могли найти сопоставимые данные о том, как пользователи относится к таким видео?
В уникальной задаче о курице и яйце те самые типы видео, на которых должен обучаться алгоритм TikTok, было невозможно создать без инструментов и фильтров приложения для камеры, лицензированных музыкальных клипов и музыки. В этом и заключается магия дизайна TikTok: это замкнутый цикл обратной связи, который вдохновляет и позволяет создавать и просматривать видео, на которых можно обучать его алгоритм. Чтобы его алгоритм стал таким же эффективным, TikTok стал собственным источником обучающих данных.
Если раньше дизайнеры и теоретики предполагали, что мы должны максимально удалять трение между приложением и юзером, то теперь мы все больше думает не в русле эргономики, а гедономики, способа получить фан и удовольствие. Важно при этом, что такой фан и удовольствие сами по себе могут требовать нетривиальных усилий и труда.
Что если ключ к лучшему обслуживанию ваших пользователей во многом зависит от обучения алгоритма машинного обучения? Что, если этому алгоритму машинного обучения нужен массивный набор обучающих данных? Когда машинное обучение находится на подъеме в мире — это становится все более важной задачей проектирования.
Вы смотрите видео, у вас мало интерфейса - в этот же момент какой-то человек из операционной группы TikTok уже просмотрел видео и добавил множество соответствующих тегов или ярлыков. Алгоритм видит только ваше поведение и ярлыки.
Все просто, но сравните то, что видит алгоритм TikTok FYP, с тем, что видит сопоставимый алгоритм рекомендаций в большинстве других каналов социальных сетей: социальные графы, «Возможно Вы знакомы», всякий мусор типа подарочков, стикеров, способов монетизации развлекательных порталов, данные портлетов. Бесконечные ленты — это апофеоз дизайна, ориентированного на юзера, минимальное усилие и при этом навигация при необходимости с кучей настроек.
ТикТок предлагает работать, чтобы им пользоватся — его надо листать пальцем и с усилием!
Другим примером может быть кнопка «Дизлайка» в условном реддите, которая тоже требует усилий, но при это тренирует алгоритм рекомендаций. Также и твиттер - с его блокировками юзеров и блокировкой слов в твитах для ручной настройки алгоритма.
В статье Seeing Like an Algorithm бывший продакт видео Меты и Амазона Eugene Wei раскрывает некоторые очевидные неочевидности. Источник публичный, поэтому я думаю, что многим новичкам на канале будет небезынтересно почитать о таком подходе, который предполагает алгоритмоцентризм в UX.
Итак, в https://www.eugenewei.com/blog/2020/9/18/seeing-like-an-algorithm поднимается вопрос - как при помощи дизайна достигнуть максимальной отдачи от алгоритмов машинного обучения при разработке приложений и сервисов?
Изначально для TikTok (или Douyin, его китайского предка), которому нужен был алгоритм, способный рекомендовать зрителям короткие видеоролики, не было массивного общедоступного обучающего набора данных. Где вы можете найти короткие видеоролики с мемами, детьми, танцующими и поющими липсинки, домашними животными, инфлюенсерами, продвигающими бренды, солдатами, бегущими через полосу препятствий, детьми? Даже если бы у вас были такие видео, где бы вы могли найти сопоставимые данные о том, как пользователи относится к таким видео?
В уникальной задаче о курице и яйце те самые типы видео, на которых должен обучаться алгоритм TikTok, было невозможно создать без инструментов и фильтров приложения для камеры, лицензированных музыкальных клипов и музыки. В этом и заключается магия дизайна TikTok: это замкнутый цикл обратной связи, который вдохновляет и позволяет создавать и просматривать видео, на которых можно обучать его алгоритм. Чтобы его алгоритм стал таким же эффективным, TikTok стал собственным источником обучающих данных.
Если раньше дизайнеры и теоретики предполагали, что мы должны максимально удалять трение между приложением и юзером, то теперь мы все больше думает не в русле эргономики, а гедономики, способа получить фан и удовольствие. Важно при этом, что такой фан и удовольствие сами по себе могут требовать нетривиальных усилий и труда.
Что если ключ к лучшему обслуживанию ваших пользователей во многом зависит от обучения алгоритма машинного обучения? Что, если этому алгоритму машинного обучения нужен массивный набор обучающих данных? Когда машинное обучение находится на подъеме в мире — это становится все более важной задачей проектирования.
Вы смотрите видео, у вас мало интерфейса - в этот же момент какой-то человек из операционной группы TikTok уже просмотрел видео и добавил множество соответствующих тегов или ярлыков. Алгоритм видит только ваше поведение и ярлыки.
Все просто, но сравните то, что видит алгоритм TikTok FYP, с тем, что видит сопоставимый алгоритм рекомендаций в большинстве других каналов социальных сетей: социальные графы, «Возможно Вы знакомы», всякий мусор типа подарочков, стикеров, способов монетизации развлекательных порталов, данные портлетов. Бесконечные ленты — это апофеоз дизайна, ориентированного на юзера, минимальное усилие и при этом навигация при необходимости с кучей настроек.
ТикТок предлагает работать, чтобы им пользоватся — его надо листать пальцем и с усилием!
Другим примером может быть кнопка «Дизлайка» в условном реддите, которая тоже требует усилий, но при это тренирует алгоритм рекомендаций. Также и твиттер - с его блокировками юзеров и блокировкой слов в твитах для ручной настройки алгоритма.
Remains of the Day
Seeing Like an Algorithm — Remains of the Day
❤4👍2
История интерфейсов
Графический интерфейс компьютера Apple Lisa, одного из самых первых проектов Apple: существуют разные легенды о названии, что, мол, дескать в честь дочери Стива Джобса.
Интересно другое: это был самый первый случай локализации интерфейса и целого пакета офисных программ для разных задач. В пакет входили LisaWrite, LisaDraw, LisaGraph, LisaCalc, LisaProject, LisaList. Ничего не напоминает? По ряду причин проект скорее провалился и был подзабыт(выход макинтошей, коньюнктура рынка, перестановки в компании)
Есть отдельное мемное рекламное промо-видео «На компьютере можно делать презентации? Инкрезибл!» https://www.youtube.com/watch?v=wbO-vY9tbNY
Посмотрите уж, не откажите себе в удовольствии.
Графический интерфейс компьютера Apple Lisa, одного из самых первых проектов Apple: существуют разные легенды о названии, что, мол, дескать в честь дочери Стива Джобса.
Интересно другое: это был самый первый случай локализации интерфейса и целого пакета офисных программ для разных задач. В пакет входили LisaWrite, LisaDraw, LisaGraph, LisaCalc, LisaProject, LisaList. Ничего не напоминает? По ряду причин проект скорее провалился и был подзабыт(выход макинтошей, коньюнктура рынка, перестановки в компании)
Есть отдельное мемное рекламное промо-видео «На компьютере можно делать презентации? Инкрезибл!» https://www.youtube.com/watch?v=wbO-vY9tbNY
Посмотрите уж, не откажите себе в удовольствии.
🔥3👍1
Взаимодействие «Животное-машина». Свежее с Гардиан
Некоммерческая группа Earth Species Project (ESP) выступает со смелыми амбициями: расшифровать нечеловеческое общение с помощью формы искусственного интеллекта (ИИ), называемой машинным обучением, и сделать все общедоступные ноу-хау, тем самым углубляя наши связи с другими живыми существами и помогая их защищать. Что может породить Google Translate для царства животных?
https://www.earthspecies.org/
Все это, конечно, очень хорошо, но мы раньше многократно писали об интерфейсах и переводчиках для доместицированных животных, которые будут расширять присутствие умных колонок в семьях - являесь по сути единственным переводчиком для пушистого члена семьи. Отрадно, что тема ACI - animal computer interaction - перестает быть частью исключительно умных книжек (например, конференция https://dl.acm.org/conference/aci/proceedings )и попадает в СМИ
https://www.theguardian.com/science/2022/jul/31/can-artificial-intelligence-really-help-us-talk-to-the-animals
Понятно, что концептуально, это не будет настоящим языком и настоящим переводчиком, но скорее медиатором между символическим “языком” - первой сигнальной системой по Павлову и некоторыми кусками информации, которые будут даваться по случаю пользователю-человеку.
Я тут люблю вспоминать книгу про взаимодействие человека и собаки, которое включает в себя полный цикл когнитивной оценки и исполнения, в котором собака является целью, действует, наблюдает. Дрессировка собаки и познание также играют важную роль в этой истории. Авторы исследования Canine-Centered Computing предлагают по новому взглянуть на тренд и растущую роль животных в HCI. С одной стороны, нам предлагают адаптированную версию фреймворка Нормана из «Дизайна привычных вещей», но уже про животных. С другой стороны, тут есть и попытка проектирования опросников с целью объяснения коллаборации и совместной работы человека и собаки при взаимодействии с технологиями (например, сценарий поиска бомб): ведь надо настроить сенсорные панели и прочие инструменты для того, чтобы собирать данные с собаки.
Есть соответствующие главы о дрессировке, этике исследований и перспективах развития Canine–Centered Interactions and Interfaces.
Некоммерческая группа Earth Species Project (ESP) выступает со смелыми амбициями: расшифровать нечеловеческое общение с помощью формы искусственного интеллекта (ИИ), называемой машинным обучением, и сделать все общедоступные ноу-хау, тем самым углубляя наши связи с другими живыми существами и помогая их защищать. Что может породить Google Translate для царства животных?
https://www.earthspecies.org/
Все это, конечно, очень хорошо, но мы раньше многократно писали об интерфейсах и переводчиках для доместицированных животных, которые будут расширять присутствие умных колонок в семьях - являесь по сути единственным переводчиком для пушистого члена семьи. Отрадно, что тема ACI - animal computer interaction - перестает быть частью исключительно умных книжек (например, конференция https://dl.acm.org/conference/aci/proceedings )и попадает в СМИ
https://www.theguardian.com/science/2022/jul/31/can-artificial-intelligence-really-help-us-talk-to-the-animals
Понятно, что концептуально, это не будет настоящим языком и настоящим переводчиком, но скорее медиатором между символическим “языком” - первой сигнальной системой по Павлову и некоторыми кусками информации, которые будут даваться по случаю пользователю-человеку.
Я тут люблю вспоминать книгу про взаимодействие человека и собаки, которое включает в себя полный цикл когнитивной оценки и исполнения, в котором собака является целью, действует, наблюдает. Дрессировка собаки и познание также играют важную роль в этой истории. Авторы исследования Canine-Centered Computing предлагают по новому взглянуть на тренд и растущую роль животных в HCI. С одной стороны, нам предлагают адаптированную версию фреймворка Нормана из «Дизайна привычных вещей», но уже про животных. С другой стороны, тут есть и попытка проектирования опросников с целью объяснения коллаборации и совместной работы человека и собаки при взаимодействии с технологиями (например, сценарий поиска бомб): ведь надо настроить сенсорные панели и прочие инструменты для того, чтобы собирать данные с собаки.
Есть соответствующие главы о дрессировке, этике исследований и перспективах развития Canine–Centered Interactions and Interfaces.
🔥3❤1🥰1
UX и дата-сцайнс и дата-продукты.
Скачал несколько книг, начиная с классического Эдварда Тафти (основатель информационной архитектуры), который еще жив и пишет настоящие палимпсесты из слоев иллюстраций и диаграмм, и заканчивая модной девушкой Джорджией Лупи из Facebook, которая написала книгу «Dear Data» в стилистике пастельных феминистических рисунков карандашом.
Выглядят они, конечно, круто, но сколько помню знакомых дата-инженеров и членов команд дата-продуктов — не поймут. Зато нашел https://datavizproject.com/ проект с визардами, где можно подобрать визуализацию и диаграмму по типу паттерна в эксельке и удобренную примерами использования такой визуализации. Наверное, для чуваков, которые умеют работать с визуальными данными это не проблема. Такой же каталог есть и тут https://datavizcatalogue.com/index.html
В старой статье на UX matters достаточно занятный обзор книжки Information Dashboard Design https://www.uxmatters.com/mt/archives/2007/04/book-review-information-dashboard-design.php
Там явно многое устарело, но я бы хотел подчеркнуть, что хотелось бы отойти от немного альбомного формата коллекции странных вещей Тафти: смотреть на них интересно, но вот вынести что-то полезное, мне кажется, сложно. Сама книжка следующим постом на канале.
Опять-таки не забываем кидать пост в личку друзьям дата-аналитикам, дата-инженерам и дата-журналистам, а также дата-продактам. Дата-пролетарии всех стран соединяйтесь!
Скачал несколько книг, начиная с классического Эдварда Тафти (основатель информационной архитектуры), который еще жив и пишет настоящие палимпсесты из слоев иллюстраций и диаграмм, и заканчивая модной девушкой Джорджией Лупи из Facebook, которая написала книгу «Dear Data» в стилистике пастельных феминистических рисунков карандашом.
Выглядят они, конечно, круто, но сколько помню знакомых дата-инженеров и членов команд дата-продуктов — не поймут. Зато нашел https://datavizproject.com/ проект с визардами, где можно подобрать визуализацию и диаграмму по типу паттерна в эксельке и удобренную примерами использования такой визуализации. Наверное, для чуваков, которые умеют работать с визуальными данными это не проблема. Такой же каталог есть и тут https://datavizcatalogue.com/index.html
В старой статье на UX matters достаточно занятный обзор книжки Information Dashboard Design https://www.uxmatters.com/mt/archives/2007/04/book-review-information-dashboard-design.php
Там явно многое устарело, но я бы хотел подчеркнуть, что хотелось бы отойти от немного альбомного формата коллекции странных вещей Тафти: смотреть на них интересно, но вот вынести что-то полезное, мне кажется, сложно. Сама книжка следующим постом на канале.
Опять-таки не забываем кидать пост в личку друзьям дата-аналитикам, дата-инженерам и дата-журналистам, а также дата-продактам. Дата-пролетарии всех стран соединяйтесь!
Datavizcatalogue
The Data Visualisation Catalogue
A handy guide and library of different data visualization techniques, tools, and a learning resource for data visualization.
👍2
Stephen_Few_Information_Dashboard_Design_The_Effective_Visual_Communication.pdf
8.3 MB
Information Dashboard Design
А вот это уже полезная
А вот это уже полезная
Grounded Theory Method. Концептуализация данных.
Grounded theory, которую иногда переводят на русский как «обоснованную теорию» или «приемы обоснованной теории», популярный и фундаментальный момент в современных исследованиях. Строгий способ исследования области и внятные критерии тестирования — сильные стороны GTM. Вообще, речь скорее идет не о одной единой теории, а о целом семействе методов или подходов, которые добавляют объяснительной силы изучению эргономики.
GTM отличается от многих теорий еще и тем, что не предлагает конкретный набор конкретных процедур, при этом оставаясь «объективным» методом. GTM предполагает, что люди являются активными и познающими агентами, которые минуют стадии сбора данных перед использованием интерфейса, часто сравнивают разные типы данных из разных областей и в своей основе прагматики (или скорее уж прагматицисты). О чем идет речь?
Абдукция как третий метод.
Основная концепция GTM состоит в том, что пользователи используют «логику открытий» при взаимодействии с интерфейсами: эта логика абдукции выражается в виде поиска новых интерпретаций (теорий) для данных, которые не соответствуют старым идеям. GTM была вызвана к жизни некоторой усталостью социологов от позитивизма 70-ых годов в общественных науках в США.
Тандем социологов Ансельма Страусса и Барни Глейзера предложил метод в исследовании смертельно больных: постоянные ссылки на качественные исследования и строгие процедуры работы с качественными данными могли ответить на этот вызов адептов измеримых и количественных методов. Для этого предлагалось использовать кодирование — выделение первичных аналитических понятий (кодов) непосредственно из текста интервью или другого источника данных. Читая массив текстов, исследователи строчка за строчкой выделяли коды и основные понятия предметной области в ментальной модели респондентов. По мере формирования кодов-понятий они объединяются в большие категории и сама эта процедура стала называться интерактивной, т.е. развивающийся. Теории создаются ad hoc, т.е. методологически по факту существующих данных. Это практично, может понравится бизнесу, и не понравится академическим исследованиям. Креативность в итерации кодов почти всегда заслуга исследователя, который обладает теоретической чувствительностью, те очень личными характеристиками.
Итак, GTM начинается не с теории. Она начинается с даты. Данные обрабатываются кодами, а когда коды используются повторно в более разнообразных ситуациях, они получают объяснительную силу. Код - это дескриптор некоторого аспекта конкретной ситуации (сайт, информатор или группа информаторов, эпизод, разговорный поворот, действие и т.д.). Давайте попробуем понять на примере, который я возьму из книги отцов-основателей.
Предположим, вы находитесь в довольно дорогом, но популярном ресторане. Пока вы ждете своего ужина, вы замечаете даму в красном. Вы отмечаете, что она внимательно осматривает площадь кухни, рабочее место, фиксируя в уме, что там происходит. Вы задаете себе вопрос, что она здесь делает ? Затем вы присваиваете ярлык ее занятию — наблюдение. Наблюдение за чем? За работой кухни.
Далее, кто-то входит и задает ей вопрос. Она отвечает. Это действие иное, чем наблюдение, поэтому вы кодируете его как передачу информации.
Кажется, она замечает все. Вы называете это внимательностью.
По-видимому, она отслеживает все и всех, мониторинг. Но мониторинг чего? Будучи проницательным наблюдателем, вы замечаете, что она осуществляет мониторинг качества обслуживания, как официант взаимодействует и отвечает клиенту; *время обслуживания*, сколько времени проходит между посадкой клиента, заказом и подачей пищи; какова реакция клиента и его удовлетворенность обслуживанием.
Официант приходит с заказом для большого вечера, она идет ему на помощь, предоставление помощи.
Женщина выглядит знающей и компетентной в том, что она делает, опытной.
Этого примера должно быть для вас достаточно, чтобы понять, что мы подразумеваем под наклеиванием ярлыков на феномены.
Grounded theory, которую иногда переводят на русский как «обоснованную теорию» или «приемы обоснованной теории», популярный и фундаментальный момент в современных исследованиях. Строгий способ исследования области и внятные критерии тестирования — сильные стороны GTM. Вообще, речь скорее идет не о одной единой теории, а о целом семействе методов или подходов, которые добавляют объяснительной силы изучению эргономики.
GTM отличается от многих теорий еще и тем, что не предлагает конкретный набор конкретных процедур, при этом оставаясь «объективным» методом. GTM предполагает, что люди являются активными и познающими агентами, которые минуют стадии сбора данных перед использованием интерфейса, часто сравнивают разные типы данных из разных областей и в своей основе прагматики (или скорее уж прагматицисты). О чем идет речь?
Абдукция как третий метод.
Основная концепция GTM состоит в том, что пользователи используют «логику открытий» при взаимодействии с интерфейсами: эта логика абдукции выражается в виде поиска новых интерпретаций (теорий) для данных, которые не соответствуют старым идеям. GTM была вызвана к жизни некоторой усталостью социологов от позитивизма 70-ых годов в общественных науках в США.
Тандем социологов Ансельма Страусса и Барни Глейзера предложил метод в исследовании смертельно больных: постоянные ссылки на качественные исследования и строгие процедуры работы с качественными данными могли ответить на этот вызов адептов измеримых и количественных методов. Для этого предлагалось использовать кодирование — выделение первичных аналитических понятий (кодов) непосредственно из текста интервью или другого источника данных. Читая массив текстов, исследователи строчка за строчкой выделяли коды и основные понятия предметной области в ментальной модели респондентов. По мере формирования кодов-понятий они объединяются в большие категории и сама эта процедура стала называться интерактивной, т.е. развивающийся. Теории создаются ad hoc, т.е. методологически по факту существующих данных. Это практично, может понравится бизнесу, и не понравится академическим исследованиям. Креативность в итерации кодов почти всегда заслуга исследователя, который обладает теоретической чувствительностью, те очень личными характеристиками.
Итак, GTM начинается не с теории. Она начинается с даты. Данные обрабатываются кодами, а когда коды используются повторно в более разнообразных ситуациях, они получают объяснительную силу. Код - это дескриптор некоторого аспекта конкретной ситуации (сайт, информатор или группа информаторов, эпизод, разговорный поворот, действие и т.д.). Давайте попробуем понять на примере, который я возьму из книги отцов-основателей.
Предположим, вы находитесь в довольно дорогом, но популярном ресторане. Пока вы ждете своего ужина, вы замечаете даму в красном. Вы отмечаете, что она внимательно осматривает площадь кухни, рабочее место, фиксируя в уме, что там происходит. Вы задаете себе вопрос, что она здесь делает ? Затем вы присваиваете ярлык ее занятию — наблюдение. Наблюдение за чем? За работой кухни.
Далее, кто-то входит и задает ей вопрос. Она отвечает. Это действие иное, чем наблюдение, поэтому вы кодируете его как передачу информации.
Кажется, она замечает все. Вы называете это внимательностью.
По-видимому, она отслеживает все и всех, мониторинг. Но мониторинг чего? Будучи проницательным наблюдателем, вы замечаете, что она осуществляет мониторинг качества обслуживания, как официант взаимодействует и отвечает клиенту; *время обслуживания*, сколько времени проходит между посадкой клиента, заказом и подачей пищи; какова реакция клиента и его удовлетворенность обслуживанием.
Официант приходит с заказом для большого вечера, она идет ему на помощь, предоставление помощи.
Женщина выглядит знающей и компетентной в том, что она делает, опытной.
Этого примера должно быть для вас достаточно, чтобы понять, что мы подразумеваем под наклеиванием ярлыков на феномены.
❤1👍1