shared_ptr и потокобезопасность
Использование шареного указателя для менеджмента ресурсов в многопоточных приложениях де-факто - стандарт. Ничего другого адекватного нет для совместного использования ресурсов несколькими потоками одновременно. Есть конечно глобальные объекты, но это практически всегда зло и не очень хочется с этим связываться. И возникает вопрос - а безопасно ли использоваться std::shared_ptr в многопоточном контексте?
Тут есть на самом деле, о чем порассуждать. Потому что размножение вашего объекта и чтение его данных - thread-safe. С чтением все понятно, никто ничего не меняет, поэтому и гонок быть не может. Но вот размножение почему? Дело в атомарном счетчике ссылок. Каждый вызов конструктора и деструктора инкрементирует или декрементирует общий для всех объектов указателя счетчик ссылок. Однако эти операции выполняются атомарно. То есть ни один поток не может увидеть промежуточный результат таких операций. Поэтому размножение и смерть объектов умного указателя - потокобезопасны..
Но вряд ли часто появляются кейсы, когда везде с собой нужно таскать объект, который никто не будет изменять. Потоки для того и работают с общими данными, чтобы и читать их, и изменять.
Ну и конечно, шаренный указатель не предоставляет из коробки потокобезопасное использование объектов, на которые он указывает. Тут работает один из базовых принципов С++ - не плати за то, чем не пользуешься. Потокобезопасность - это всегда дополнительные расходы памяти и производительности. И внедрение этой фичи замедлило бы приложения, которые этой фичей не пользовались.
Так что вызов изменяющих методов объектов, для которых не позаботились о их безопасности, в разных тредах - гарантированные трудноотловмые многопоточные проблемы. Какие? Да вообще любые. Пусть вы храните какую-нибудь мапу и передаете ее везде в виде шаред поинтера. Как только к эту мапу захочет записать какой-нибудь поток, начнет это делать и через писечную долю секунды придет читающий поток, то он увидит данные в неконсистентном состоянии. Только что на ваших глазах произошла так называемая гонка данных. И это самая тривиальная проблема. Баги могут быть намного более изощренными.
Поэтому критически важно синхронизировать доступ потоков для объектов, которые будут использоваться множеством потоков.
Stay safe. Stay cool.
#multitasking #cpp11
Использование шареного указателя для менеджмента ресурсов в многопоточных приложениях де-факто - стандарт. Ничего другого адекватного нет для совместного использования ресурсов несколькими потоками одновременно. Есть конечно глобальные объекты, но это практически всегда зло и не очень хочется с этим связываться. И возникает вопрос - а безопасно ли использоваться std::shared_ptr в многопоточном контексте?
Тут есть на самом деле, о чем порассуждать. Потому что размножение вашего объекта и чтение его данных - thread-safe. С чтением все понятно, никто ничего не меняет, поэтому и гонок быть не может. Но вот размножение почему? Дело в атомарном счетчике ссылок. Каждый вызов конструктора и деструктора инкрементирует или декрементирует общий для всех объектов указателя счетчик ссылок. Однако эти операции выполняются атомарно. То есть ни один поток не может увидеть промежуточный результат таких операций. Поэтому размножение и смерть объектов умного указателя - потокобезопасны..
Но вряд ли часто появляются кейсы, когда везде с собой нужно таскать объект, который никто не будет изменять. Потоки для того и работают с общими данными, чтобы и читать их, и изменять.
Ну и конечно, шаренный указатель не предоставляет из коробки потокобезопасное использование объектов, на которые он указывает. Тут работает один из базовых принципов С++ - не плати за то, чем не пользуешься. Потокобезопасность - это всегда дополнительные расходы памяти и производительности. И внедрение этой фичи замедлило бы приложения, которые этой фичей не пользовались.
Так что вызов изменяющих методов объектов, для которых не позаботились о их безопасности, в разных тредах - гарантированные трудноотловмые многопоточные проблемы. Какие? Да вообще любые. Пусть вы храните какую-нибудь мапу и передаете ее везде в виде шаред поинтера. Как только к эту мапу захочет записать какой-нибудь поток, начнет это делать и через писечную долю секунды придет читающий поток, то он увидит данные в неконсистентном состоянии. Только что на ваших глазах произошла так называемая гонка данных. И это самая тривиальная проблема. Баги могут быть намного более изощренными.
Поэтому критически важно синхронизировать доступ потоков для объектов, которые будут использоваться множеством потоков.
Stay safe. Stay cool.
#multitasking #cpp11
{kind=link}
Самая программистская математическая задачка
Есть одна задачка, которая вскружила мне голову элегантностью своего решения. Сформулирована она как обычная задачка на логику, но по сути своей очень программистская. Для людей с очень «низкоуровневым мышлением». Поэтому и решил с вами ей поделиться. Кажется плюсовый канал - подходящее место для таких задачек. Может я преувеличиваю, но я художник, я так чувствую.
Собсна формулировка. Жил был король. Хорошо король правил своей страной, богатая она была. И король соответственно тоже жил в большой роскоши. Появился у этого короля завистник среди придворной интеллигенции и захотел он убить короля. Думал про разные способы убийства и вспомнил одну деталь. Король очень любит вино и в погребе дворца есть 1000 бутылок его самого любимого вина, которое он пьет каждый день. И решил завистник отравить вино. Послал вместо себя убийцу в погреб, чтобы он отравил бутылки. Однако убийцу быстро нашли и поймали до того, как он отравил все бутылки. По правде говоря, он успел только одну из них отравить.
И теперь перед королем стоит задача - определить отравленное вино, потому что убийца не сознается.
Чтобы не травить людей, король приказал принести ему 10 кроликов. По задумке кролики будут пить вина из каждой бутылки и рано и поздно, найдется отравленная. Каждый кролик может пить неограниченное количество вина. То что он будет вдрызг пьяный, не значит, что он мертвый 😁
Чтобы убить живое существо, яду нужно примерно 24 часа.
Имея 10 кроликов и 1000 бутылок, королю нужно за минимальное время определить, какая из бутылок отравленная, чтобы продолжить пить свое любимое вино.
Решением задачи будет стратегия, придерживаясь которой гарантированно определяется нужная бутылка за минимальное количество времени.
Кидайте свои варианты в комменты. Если знаете реальное решение, то прошу не писать его, чтобы другие могли хорошенько подумать.
Кажется, что тут даже можно что-то пообсуждать, поэтому оставлю вас без решения пока. Ответ напишу в комментах к завтрашнему посту. Не гуглите решение, чтобы не испортить себе впечатление. Так что подрубаем уведомления, скорее всего вы сильно удивитесь решению.
Solve problems. Stay cool.
#fun
Есть одна задачка, которая вскружила мне голову элегантностью своего решения. Сформулирована она как обычная задачка на логику, но по сути своей очень программистская. Для людей с очень «низкоуровневым мышлением». Поэтому и решил с вами ей поделиться. Кажется плюсовый канал - подходящее место для таких задачек. Может я преувеличиваю, но я художник, я так чувствую.
Собсна формулировка. Жил был король. Хорошо король правил своей страной, богатая она была. И король соответственно тоже жил в большой роскоши. Появился у этого короля завистник среди придворной интеллигенции и захотел он убить короля. Думал про разные способы убийства и вспомнил одну деталь. Король очень любит вино и в погребе дворца есть 1000 бутылок его самого любимого вина, которое он пьет каждый день. И решил завистник отравить вино. Послал вместо себя убийцу в погреб, чтобы он отравил бутылки. Однако убийцу быстро нашли и поймали до того, как он отравил все бутылки. По правде говоря, он успел только одну из них отравить.
И теперь перед королем стоит задача - определить отравленное вино, потому что убийца не сознается.
Чтобы не травить людей, король приказал принести ему 10 кроликов. По задумке кролики будут пить вина из каждой бутылки и рано и поздно, найдется отравленная. Каждый кролик может пить неограниченное количество вина. То что он будет вдрызг пьяный, не значит, что он мертвый 😁
Чтобы убить живое существо, яду нужно примерно 24 часа.
Имея 10 кроликов и 1000 бутылок, королю нужно за минимальное время определить, какая из бутылок отравленная, чтобы продолжить пить свое любимое вино.
Решением задачи будет стратегия, придерживаясь которой гарантированно определяется нужная бутылка за минимальное количество времени.
Кидайте свои варианты в комменты. Если знаете реальное решение, то прошу не писать его, чтобы другие могли хорошенько подумать.
Кажется, что тут даже можно что-то пообсуждать, поэтому оставлю вас без решения пока. Ответ напишу в комментах к завтрашнему посту. Не гуглите решение, чтобы не испортить себе впечатление. Так что подрубаем уведомления, скорее всего вы сильно удивитесь решению.
Solve problems. Stay cool.
#fun
{kind=link}
Линковка констант
Сегодня начнем затрагивать вопрос линковки переменных, линковки в целом и тонкости этого процесса. На эту тему несколько постов, плавно перетекающих друг в друга.
Давайте предположим, что у нас есть некоторый набор констант. Пусть это будут тривиальные физические константы, типа скорости света, числа авагадро и тд. И мы хотим использовать эти константы в разных единицах трансляции. Очевидный вариант - вынести их в какой-нибудь хэдер и подключать его всякий раз при необходимости. Получаем что-то типа такого:
Используем здесь constexpr для появления возможности использования этих констант в compile-time вычислениях.
Почему это вообще работает? Мы ведь здесь подключаем одно и то же определение в разные юниты трансляции. ODR должно нам запретить такое делать.
Дело в том, что все константы имеют по умолчанию внутреннее связывание. То же самое и для constexpr. Внутреннее связывание гарантирует, что в каждом юните трансляции будет использоваться своя копия этих переменных и ни из какого другого юнита нельзя будет получить доступ к ним. То есть определение этих констант везде будет свое. И ODR не будет нарушаться.
Если пометить константы как static, то ничего толком не изменится, потому что они и так неявно статические. То есть с внутренним связыванием.
У такого подхода есть проблемы.
Каждый раз, когда мы включаем заголовочный файл с константами в файл с кодом, каждая из этих переменных копируется в файл с кодом. Поэтому, если constants.hpp включается в 20 различных файлов кода, каждая из этих переменных дублируется 20 раз. Из этого следует следующее:
1️⃣ Изменение одной константы потребует перекомпиляции каждого файла, использующего константы(даже если измененная константа там не используется!), что делает компиляцию долгой для крупных проектов.
2️⃣ Если константы имеют большой размер и не могут быть оптимизированы, это приведёт к нежелательному расходу памяти.
Какое здесь решение? Подождать следующего поста, там будут объяснения)
Solve the problems. Stay cool.
#cppcore #compiler
Сегодня начнем затрагивать вопрос линковки переменных, линковки в целом и тонкости этого процесса. На эту тему несколько постов, плавно перетекающих друг в друга.
Давайте предположим, что у нас есть некоторый набор констант. Пусть это будут тривиальные физические константы, типа скорости света, числа авагадро и тд. И мы хотим использовать эти константы в разных единицах трансляции. Очевидный вариант - вынести их в какой-нибудь хэдер и подключать его всякий раз при необходимости. Получаем что-то типа такого:
// constants.hpp
#pragma once
namespace constants
{
constexpr unsigned light_speed { 299 792 458 };
constexpr double avogadro { 6.0221413e23 };
// ... other related constants
}
Используем здесь constexpr для появления возможности использования этих констант в compile-time вычислениях.
Почему это вообще работает? Мы ведь здесь подключаем одно и то же определение в разные юниты трансляции. ODR должно нам запретить такое делать.
Дело в том, что все константы имеют по умолчанию внутреннее связывание. То же самое и для constexpr. Внутреннее связывание гарантирует, что в каждом юните трансляции будет использоваться своя копия этих переменных и ни из какого другого юнита нельзя будет получить доступ к ним. То есть определение этих констант везде будет свое. И ODR не будет нарушаться.
Если пометить константы как static, то ничего толком не изменится, потому что они и так неявно статические. То есть с внутренним связыванием.
У такого подхода есть проблемы.
Каждый раз, когда мы включаем заголовочный файл с константами в файл с кодом, каждая из этих переменных копируется в файл с кодом. Поэтому, если constants.hpp включается в 20 различных файлов кода, каждая из этих переменных дублируется 20 раз. Из этого следует следующее:
1️⃣ Изменение одной константы потребует перекомпиляции каждого файла, использующего константы(даже если измененная константа там не используется!), что делает компиляцию долгой для крупных проектов.
2️⃣ Если константы имеют большой размер и не могут быть оптимизированы, это приведёт к нежелательному расходу памяти.
Какое здесь решение? Подождать следующего поста, там будут объяснения)
Solve the problems. Stay cool.
#cppcore #compiler
{kind=link}
Как это всегда со мной бывает, я забыл вставить решение вчерашней задачи, поэтому решил сделать это сейчас
То есть решение будет в первом комменте к этому посту
То есть решение будет в первом комменте к этому посту
Линковка констант Ч2
Мы узнали один из вариантов, как можно подключать константы в свои файлы с кодом. Однако у него были проблемы, которые мы попытаемся решить сегодня.
Все проблемы прошлого варианта по сути сводится к последствиям внутренней линковки.
Если у нас будет только одно определение переменной и весь остальной код будет только ссылаться на него, то решится проблема с перекомпиляцией. Потому что задача подстановки символов будет решаться при линковке. Во всех единицах трансляции будет просто заглушка для этой константы. И реальное значение будет подставляться компановщиком. А значит ничего не нужно заново компилировать.
Одно определение также решит вопрос нежелательного расхода памяти, так как экземпляр константы будет один и занимать одну условную единицу памяти. Никакого дублирования не будет.
Как мы можем добиться, чтобы определение констант было всего одно?
Обеспечить им внешнее связывание. С помощью ключевого слова extern.
Теперь константы будут создаваться только один раз (в единице трансляции соотвествующей constants.cpp), а не каждый раз при включении constants.h, и все использования будут просто ссылаться на версию в constants.cpp. Любые внесенные изменения в constants.cpp потребуют только перекомпиляции constants.cpp.
Однако и у этого метода есть несколько недостатков(да штож такое).
1️⃣ Эти константы теперь могут считаться константами времени компиляции только в файле, в котором они фактически определены (constants.cpp), а не где-либо еще. Это означает, что вне constants.cpp они не могут быть использованы нигде, где требуются вычисления в compile-time. Печально.
2️⃣ В принципе оптимизировать их использование компилятору сложнее, потому что он не имеет доступа к настоящему значению.
3️⃣ Неудобно просто. Каждый раз нужно ходить в реализацию, чтобы удостовериться в значении константы - такое себе. Да, современные IDE могут решить этот вопрос. А могут и не решить. Плюс нужно или мышку наводить или кнопки какие-то нажимать. Слишком много действий!
Шучу конечно. Но намного удобнее определение держать в хэдере.
Учитывая вышеперечисленные недостатки, хочется определять константы в заголовочном файле. Наконец-то мы подбираемся к самой мякотке. Но об этом - в следующих постах)
Stay in touch. Stay cool.
#cppcore #compiler
Мы узнали один из вариантов, как можно подключать константы в свои файлы с кодом. Однако у него были проблемы, которые мы попытаемся решить сегодня.
Все проблемы прошлого варианта по сути сводится к последствиям внутренней линковки.
Если у нас будет только одно определение переменной и весь остальной код будет только ссылаться на него, то решится проблема с перекомпиляцией. Потому что задача подстановки символов будет решаться при линковке. Во всех единицах трансляции будет просто заглушка для этой константы. И реальное значение будет подставляться компановщиком. А значит ничего не нужно заново компилировать.
Одно определение также решит вопрос нежелательного расхода памяти, так как экземпляр константы будет один и занимать одну условную единицу памяти. Никакого дублирования не будет.
Как мы можем добиться, чтобы определение констант было всего одно?
Обеспечить им внешнее связывание. С помощью ключевого слова extern.
//constant.cpp
#include "constant.hpp"
namespace constants
{
const unsigned light_speed { 299'792'458 };
const double avogadro { 6.0221413e23 };
// ... other related constants
}
//constant.hpp
#pragma once
namespace constants
{
extern const unsigned light_speed;
extern const double avogadro;
// ... other related constants
}
Теперь константы будут создаваться только один раз (в единице трансляции соотвествующей constants.cpp), а не каждый раз при включении constants.h, и все использования будут просто ссылаться на версию в constants.cpp. Любые внесенные изменения в constants.cpp потребуют только перекомпиляции constants.cpp.
Однако и у этого метода есть несколько недостатков(да штож такое).
1️⃣ Эти константы теперь могут считаться константами времени компиляции только в файле, в котором они фактически определены (constants.cpp), а не где-либо еще. Это означает, что вне constants.cpp они не могут быть использованы нигде, где требуются вычисления в compile-time. Печально.
2️⃣ В принципе оптимизировать их использование компилятору сложнее, потому что он не имеет доступа к настоящему значению.
3️⃣ Неудобно просто. Каждый раз нужно ходить в реализацию, чтобы удостовериться в значении константы - такое себе. Да, современные IDE могут решить этот вопрос. А могут и не решить. Плюс нужно или мышку наводить или кнопки какие-то нажимать. Слишком много действий!
Шучу конечно. Но намного удобнее определение держать в хэдере.
Учитывая вышеперечисленные недостатки, хочется определять константы в заголовочном файле. Наконец-то мы подбираемся к самой мякотке. Но об этом - в следующих постах)
Stay in touch. Stay cool.
#cppcore #compiler
{kind=link}
Реальное предназначение inline
В этом посте мы говорили о том, почему встраивание функций - важная задача для перформанса приложения. И что ключевое слово inline изначально предназначалось для того, чтобы указывать компилятору, какую функцию ему нужно встроить. Но программы уже давно намного умнее людей в очень специфических задачах. И компилятор стал настолько умным, что он теперь без нашего прямого указания может самостоятельно встраивать функции, которые даже не помечены inline. А также имеет полное право игнорировать наши прямые указания на встраивание. В случае прямого указания он обязан выполнить проверку возможности встраивания, но при оптимизациях компилятор и так это делает.
Но тогда смысл ключевого слова inline несколько теряется в тумане. Все равно все используют оптимизации в продакшене. Тогда есть ли реальная польза от использования inline?
Есть! Сейчас все разберем.
В чем прикол. Прикол в том, что для того, чтобы компилятор смог встроить функцию, ее определение ОБЯЗАНО быть видно в той единице трансляции, в которой она используется. Именно на этапе компиляции. Как можно встроить код, которого нет сейчас в доступе?
Почему это нельзя сделать на этапе линковки? Линкер резолвит проблему символов. Он сопоставляет имена с их содержимым. Линкер от слова link - связка. Для встраивания функции нужно иметь доступ к ее исходникам и информации вокруг вызова функции. Такого доступа у линкера нет. Да и задачи кодогенерации у него нет.
Что нужно, чтобы на этапе компиляции, компилятор видел определение функции? Ее можно определить в цппшнике, тогда все будет четко. Но такую функцию нельзя переиспользовать. Она будет тупо скрыта от всех других единиц трансляции. Ее можно было бы переиспользовать. Тогда нужно было бы везде forward declaration вставлять, что очень неудобно. И она видна будет только во время линковки. Во время компиляции ни одна другая единица трансляции ее не увидит. Поэтому нам это не подходит.
Тогда второй способ с потенциальной возможностью переиспользования: вынести определение в хэдер. Тогда всем единицам трансляции, которые подключают хэдер, будет доступно определение нашей функции. Но вот есть проблема - тогда во всех единицах трансляции будет определение нашей функции. А это нарушение ODR.
Как выходить из ситуации? Можно пометить функцию как static. Тогда в каждой единице трансляции будет своя копия функции. Но это ведет к дублированию кода функции и увеличению размера бинарника. Это нам не подходит.
Выходит, что у нас только одно решение. Разрешить inline функциям находиться в хэдерах и не нарушать ODR! Тогда нам нужны некоторые оговорки: мы разрешаем определению одной и той же inline функции быть в разных единицах трансляции, но тогда все эти определения должны быть идентичные. Потому что как бы предполагается, что они все определены в одном месте КОДА. Линкер потом объединяет все определения функции в одно(на самом деле выбирает одно из них, а другие откидывает). И вот у нас уже один экземпляр функции на всю программу.
Что мы имеем по итогу. Если мы хотим поместить определение обычной функции в хэдэр, то нам настучит по башке линкер со своим multiple definition и мы уйдем грустные в закат. Но теперь у нас есть другой вид функций, которые как бы должны быть встроены, но никто этого не гарантирует, и которые можно определять в хэдерах. Такие функции могут быть встроены с той же вероятностью, что и все остальные, поэтому от этой части смысла никакого нет. Получается, что мы можем пометить нашу функцию inline и тогда она ее просто можно будет определять в заголовочниках. Гениально.
Ох и непростая тема! Советую пару раз прочитать этот пост, чтобы хорошо все усвоить. Информация очень глубокая и фундаментальная. Пишите в комментах, что непонятно. И замечания тоже пишите.
Dig deeper. Stay cool.
#cppcore #compiler #hardcore #design #howitworks
В этом посте мы говорили о том, почему встраивание функций - важная задача для перформанса приложения. И что ключевое слово inline изначально предназначалось для того, чтобы указывать компилятору, какую функцию ему нужно встроить. Но программы уже давно намного умнее людей в очень специфических задачах. И компилятор стал настолько умным, что он теперь без нашего прямого указания может самостоятельно встраивать функции, которые даже не помечены inline. А также имеет полное право игнорировать наши прямые указания на встраивание. В случае прямого указания он обязан выполнить проверку возможности встраивания, но при оптимизациях компилятор и так это делает.
Но тогда смысл ключевого слова inline несколько теряется в тумане. Все равно все используют оптимизации в продакшене. Тогда есть ли реальная польза от использования inline?
Есть! Сейчас все разберем.
В чем прикол. Прикол в том, что для того, чтобы компилятор смог встроить функцию, ее определение ОБЯЗАНО быть видно в той единице трансляции, в которой она используется. Именно на этапе компиляции. Как можно встроить код, которого нет сейчас в доступе?
Почему это нельзя сделать на этапе линковки? Линкер резолвит проблему символов. Он сопоставляет имена с их содержимым. Линкер от слова link - связка. Для встраивания функции нужно иметь доступ к ее исходникам и информации вокруг вызова функции. Такого доступа у линкера нет. Да и задачи кодогенерации у него нет.
Что нужно, чтобы на этапе компиляции, компилятор видел определение функции? Ее можно определить в цппшнике, тогда все будет четко. Но такую функцию нельзя переиспользовать. Она будет тупо скрыта от всех других единиц трансляции. Ее можно было бы переиспользовать. Тогда нужно было бы везде forward declaration вставлять, что очень неудобно. И она видна будет только во время линковки. Во время компиляции ни одна другая единица трансляции ее не увидит. Поэтому нам это не подходит.
Тогда второй способ с потенциальной возможностью переиспользования: вынести определение в хэдер. Тогда всем единицам трансляции, которые подключают хэдер, будет доступно определение нашей функции. Но вот есть проблема - тогда во всех единицах трансляции будет определение нашей функции. А это нарушение ODR.
Как выходить из ситуации? Можно пометить функцию как static. Тогда в каждой единице трансляции будет своя копия функции. Но это ведет к дублированию кода функции и увеличению размера бинарника. Это нам не подходит.
Выходит, что у нас только одно решение. Разрешить inline функциям находиться в хэдерах и не нарушать ODR! Тогда нам нужны некоторые оговорки: мы разрешаем определению одной и той же inline функции быть в разных единицах трансляции, но тогда все эти определения должны быть идентичные. Потому что как бы предполагается, что они все определены в одном месте КОДА. Линкер потом объединяет все определения функции в одно(на самом деле выбирает одно из них, а другие откидывает). И вот у нас уже один экземпляр функции на всю программу.
Что мы имеем по итогу. Если мы хотим поместить определение обычной функции в хэдэр, то нам настучит по башке линкер со своим multiple definition и мы уйдем грустные в закат. Но теперь у нас есть другой вид функций, которые как бы должны быть встроены, но никто этого не гарантирует, и которые можно определять в хэдерах. Такие функции могут быть встроены с той же вероятностью, что и все остальные, поэтому от этой части смысла никакого нет. Получается, что мы можем пометить нашу функцию inline и тогда она ее просто можно будет определять в заголовочниках. Гениально.
Ох и непростая тема! Советую пару раз прочитать этот пост, чтобы хорошо все усвоить. Информация очень глубокая и фундаментальная. Пишите в комментах, что непонятно. И замечания тоже пишите.
Dig deeper. Stay cool.
#cppcore #compiler #hardcore #design #howitworks
{kind=link}
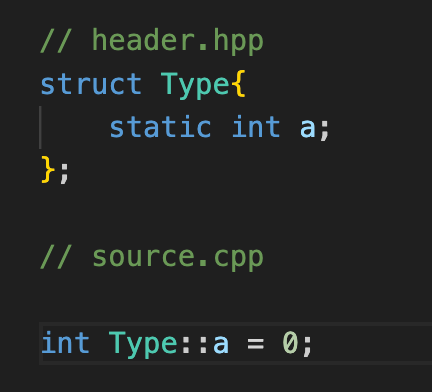
Определение статических полей класса
Если вы хоть раз пытались наивно инициализировать статический член класса внутри самого класса, то явно знаете, о чем речь пойдет. А для тех, кто не знает, скажу, что произойдет дальше. Компилятор выдаст ошибку типа: ISO C++ forbids in-class initialization of non-const static member. Стандарт запрещает неконстантным статическим полям инициализироваться внутри класса. Ранее стандартной практикой для решения этой проблемы был вынос определения этого поля в цпп файл. Решение довольно неудобное, ибо каждый раз нужно лезть в файл реализации, чтобы посмотреть инициализатор. Да и писать это не очень удобно. В потенциале для такой инициализации нужно дополнительно написать в 1.5 раза больше букав, чем при удобной in-class инициализации. Если это так неудобно, то почему такое правило вообще введено?
Давайте небольшой рекап для статических членов. Статическое поле класса - по сути глобальный объект, который как бы присоединен к классу. Любой объект класса может получить доступ к одному и тому же инстансу статической переменной. Как и любой код, который может создать объект класса, сможет использовать его статический член через имя класса. Типа такого ClassType::static_field. То есть, несмотря на то, что поле объявлено как static, оно имеет внешнее связывание. То есть существует лишь один инстанс этого поля, который виден всему коду, имеющему доступ к классу. И для такой сущности применяется One Definition Rule(ODR), которое говорит, что у переменной или функции(за некоторыми исключениями) внутри ВСЕЙ программы может быть сколько угодно объявлений, но только одно определение. Ща поясню, к чему это приводит.
Вот у вас есть описание класса в каком-то хэдере. Как использовать этот класс? Заинклюдить этот хэдер в нужный файлик. А что делает иклюд? Правильно, на этапе препроцессора он просто заменяется на текст подключаемого файла. Поэтому если у вас определение статического поля находится в хэдере, значит у вас есть определение этого поля во всех единицах трансляции, куда попало описание класса. А это прямое нарушение ODR.
Описания классов обычно находятся в хэдэрах, поэтому проще просто запретить определять статические поля внутри классов.
Как меняет ситуацию определение поля вне класса в цпп файле? Это позволяет не нарушать ODR, все просто) Ну если чуть подробнее, то во всех единицах трансляции, куда мы подключили описание класса, будет только объявление нашего поля. И только одно определение будет браться из нашего цпп файлика.
И кстати в файле реализации нельзя приписывать определению переменной пометку static. Это путает компилятор. Обычно для переменных static значит статическое время жизни и внутреннюю линковку, а нам здесь нужна внешняя линковка.
Это кстати довольно важно подсветить: static для обычных глобальных переменных меняет их тип линковки на внутреннюю, а внутри класса static обозначает внешнюю линковку(что с методами, что с полями).
Но начиная с 17-х плюсов есть намного более изящный способ обойти ODR в этом конкретном случае. Постоянные читатели или просто знающие люди уже понимают, о чем речь. Но пост об этом будет позже)
Define yourself. Stay cool.
#cppcore
Если вы хоть раз пытались наивно инициализировать статический член класса внутри самого класса, то явно знаете, о чем речь пойдет. А для тех, кто не знает, скажу, что произойдет дальше. Компилятор выдаст ошибку типа: ISO C++ forbids in-class initialization of non-const static member. Стандарт запрещает неконстантным статическим полям инициализироваться внутри класса. Ранее стандартной практикой для решения этой проблемы был вынос определения этого поля в цпп файл. Решение довольно неудобное, ибо каждый раз нужно лезть в файл реализации, чтобы посмотреть инициализатор. Да и писать это не очень удобно. В потенциале для такой инициализации нужно дополнительно написать в 1.5 раза больше букав, чем при удобной in-class инициализации. Если это так неудобно, то почему такое правило вообще введено?
Давайте небольшой рекап для статических членов. Статическое поле класса - по сути глобальный объект, который как бы присоединен к классу. Любой объект класса может получить доступ к одному и тому же инстансу статической переменной. Как и любой код, который может создать объект класса, сможет использовать его статический член через имя класса. Типа такого ClassType::static_field. То есть, несмотря на то, что поле объявлено как static, оно имеет внешнее связывание. То есть существует лишь один инстанс этого поля, который виден всему коду, имеющему доступ к классу. И для такой сущности применяется One Definition Rule(ODR), которое говорит, что у переменной или функции(за некоторыми исключениями) внутри ВСЕЙ программы может быть сколько угодно объявлений, но только одно определение. Ща поясню, к чему это приводит.
Вот у вас есть описание класса в каком-то хэдере. Как использовать этот класс? Заинклюдить этот хэдер в нужный файлик. А что делает иклюд? Правильно, на этапе препроцессора он просто заменяется на текст подключаемого файла. Поэтому если у вас определение статического поля находится в хэдере, значит у вас есть определение этого поля во всех единицах трансляции, куда попало описание класса. А это прямое нарушение ODR.
Описания классов обычно находятся в хэдэрах, поэтому проще просто запретить определять статические поля внутри классов.
Как меняет ситуацию определение поля вне класса в цпп файле? Это позволяет не нарушать ODR, все просто) Ну если чуть подробнее, то во всех единицах трансляции, куда мы подключили описание класса, будет только объявление нашего поля. И только одно определение будет браться из нашего цпп файлика.
И кстати в файле реализации нельзя приписывать определению переменной пометку static. Это путает компилятор. Обычно для переменных static значит статическое время жизни и внутреннюю линковку, а нам здесь нужна внешняя линковка.
Это кстати довольно важно подсветить: static для обычных глобальных переменных меняет их тип линковки на внутреннюю, а внутри класса static обозначает внешнюю линковку(что с методами, что с полями).
Но начиная с 17-х плюсов есть намного более изящный способ обойти ODR в этом конкретном случае. Постоянные читатели или просто знающие люди уже понимают, о чем речь. Но пост об этом будет позже)
Define yourself. Stay cool.
#cppcore
{kind=link}
inline переменные
Так, ну это уже перебор. inline для функций окей, можем встроить ее код в место вызова. Но что значит встроенная переменная? Мы же в месте, где используется переменная просто ссылаемся на оригинал переменной через указатель(адресом переменной для динамических объектов или отступом от регистра для локальных). Переменная - это же память. Не понятно, что значит встроить память в код. Это в принципе не имеет смысла. Разве что можно встроить какие-нибудь чиселки в непосредственное место их использования как один из операндов. Но компилятор уже это и так делает, без наших просьб. В чем тогда смысл?
Мы уже поговорили о том, что смысл ключевого слова inline для функций в современных реалиях С++ - это уже совсем не про inline expansion, а про обеспечение обхода ODR. Это позволяет определять функцию прямо в хэдере. При этом линкер не обидится на нас и даже прогарантирует, что объединит все определения в одно и тогда в места вызова функции будет даже один и тот же адрес подставляться.
И вот именно эту семантику и перенимают переменные в С++17, которые теперь могут быть помечены ключевым словом inline. Какие конкретно преимущества теперь получают переменные?
Теперь мы прямо в заголовочнике можем определить значение для переменной, например, константы. Компоновщик просто потом объединит все определения в одно. То есть будет всего один оригинал переменной и гарантируется, что она будет создана только один раз и совместно будет использоваться во всех файлах с кодом.
Что это нам дает?
1️⃣ Внешнее связывание inline дает нам преимущества компактности размера скомпилированного кода.
2️⃣ Компилятор может оптимизировать переменные как он хочет, потому что видит определение на момент компиляции.
3️⃣ По той же причине, все compile-time вычисления имеют место быть.
4️⃣ Нет перекомпиляции за неиспользованные переменные.
5️⃣ Определение находится в хэдере и это удобно смотреть.
Все проблемы отсюда и отсюда решены!! Магия вне Хогвартса!
На картинке показано, как с новыми знаниями можно определять константы в хэдерах.
Stay satisfied. Stay cool.
#cppcore #compiler #cpp17
Так, ну это уже перебор. inline для функций окей, можем встроить ее код в место вызова. Но что значит встроенная переменная? Мы же в месте, где используется переменная просто ссылаемся на оригинал переменной через указатель(адресом переменной для динамических объектов или отступом от регистра для локальных). Переменная - это же память. Не понятно, что значит встроить память в код. Это в принципе не имеет смысла. Разве что можно встроить какие-нибудь чиселки в непосредственное место их использования как один из операндов. Но компилятор уже это и так делает, без наших просьб. В чем тогда смысл?
Мы уже поговорили о том, что смысл ключевого слова inline для функций в современных реалиях С++ - это уже совсем не про inline expansion, а про обеспечение обхода ODR. Это позволяет определять функцию прямо в хэдере. При этом линкер не обидится на нас и даже прогарантирует, что объединит все определения в одно и тогда в места вызова функции будет даже один и тот же адрес подставляться.
И вот именно эту семантику и перенимают переменные в С++17, которые теперь могут быть помечены ключевым словом inline. Какие конкретно преимущества теперь получают переменные?
Теперь мы прямо в заголовочнике можем определить значение для переменной, например, константы. Компоновщик просто потом объединит все определения в одно. То есть будет всего один оригинал переменной и гарантируется, что она будет создана только один раз и совместно будет использоваться во всех файлах с кодом.
Что это нам дает?
1️⃣ Внешнее связывание inline дает нам преимущества компактности размера скомпилированного кода.
2️⃣ Компилятор может оптимизировать переменные как он хочет, потому что видит определение на момент компиляции.
3️⃣ По той же причине, все compile-time вычисления имеют место быть.
4️⃣ Нет перекомпиляции за неиспользованные переменные.
5️⃣ Определение находится в хэдере и это удобно смотреть.
Все проблемы отсюда и отсюда решены!! Магия вне Хогвартса!
На картинке показано, как с новыми знаниями можно определять константы в хэдерах.
Stay satisfied. Stay cool.
#cppcore #compiler #cpp17
{kind=link}
Нормальное определение статических полей класса
Здесь мы посмотрели на проблему, которая стоит перед нами, когда мы пытаемся определить статическое поле класса. А проблема такова, что статические поля класса имеют внешнее связывание. За объяснением этого утверждения можете перейти по ссылке на тот пост, а мы продолжим.
Мы никак не можем обойти это ограничение вплоть до С++17. ODR требует, чтобы мы определяли статические поля вне класса и хэдера. Можно было бы поставить квалификатор const, но это уже другой разговор. Это не всегда нужно. И это совершенно не подходит для случая, когда нам нужно изменять наш объект. Да и статические константные поля можно инициализировать внутри класса только если это тривиальные типы.
Но! В C++17 завезли нам прекрасную фичу - inline переменные. Мы теперь можем определять символы с внешним связыванием во множестве единиц трансляции! И это как раз то, что нам нужно!
Мы просто берем и в хэдере определяем статическое поле, помечаем его inline и все готово. Никто на нас не ругается и все работает, как часы. Можем теперь как белые люди все писать в хэдерах. Это намного более удобно и не требует больших затрат. 8 дополнительных символов и Доби свободен!
Берите на заметку. Это прикольное и, главное, реально полезное приложение inline, которым вы будете довольно часто пользоваться.
Be free. Stay cool.
#cpp17 #compiler
Здесь мы посмотрели на проблему, которая стоит перед нами, когда мы пытаемся определить статическое поле класса. А проблема такова, что статические поля класса имеют внешнее связывание. За объяснением этого утверждения можете перейти по ссылке на тот пост, а мы продолжим.
Мы никак не можем обойти это ограничение вплоть до С++17. ODR требует, чтобы мы определяли статические поля вне класса и хэдера. Можно было бы поставить квалификатор const, но это уже другой разговор. Это не всегда нужно. И это совершенно не подходит для случая, когда нам нужно изменять наш объект. Да и статические константные поля можно инициализировать внутри класса только если это тривиальные типы.
Но! В C++17 завезли нам прекрасную фичу - inline переменные. Мы теперь можем определять символы с внешним связыванием во множестве единиц трансляции! И это как раз то, что нам нужно!
Мы просто берем и в хэдере определяем статическое поле, помечаем его inline и все готово. Никто на нас не ругается и все работает, как часы. Можем теперь как белые люди все писать в хэдерах. Это намного более удобно и не требует больших затрат. 8 дополнительных символов и Доби свободен!
Берите на заметку. Это прикольное и, главное, реально полезное приложение inline, которым вы будете довольно часто пользоваться.
Be free. Stay cool.
#cpp17 #compiler
{kind=link}
Оптимизации RVO / NRVO
Всем привет! Настало время завершающего поста этой серии. Сегодня мы поговорим об одной из самых нетривиальных оптимизаций в С++.
Я очень удивлюсь, если встречу человека, который по мере изучения стандартных контейнеров никогда не задумывался, что эти ребята слишком «жирные», чтобы их просто так возвращать в качестве результата функции или метода:
...и приходили к мысли, что нужно заполнять уже существующий объект:
Эта мысль волновала всех с давних времен... Поэтому она нашла поддержку от разработчиков компиляторов.
Существует такие древние оптимизации, как RVO (Return Value Optimization) и NRVO (Named Return Value Optimization). Они призваны избавить нас от потенциально избыточных и лишних вызовов конструктора копирования для объектов на стеке. Например, в таких ситуациях:
Давайте взглянем на живой пример 1, в котором вызов конструктора копирования явно пропускается. Вообще говоря, эта информация немного выбивается в контексте постов, посвященных move семантике C++11, т.к. это работает даже на C++98. Вот поэтому я её называю древней 😉
Немного теории. При вызове функции резервируется место на стеке, куда должно быть записано возвращаемое значение функции. Если компилятор может гарантировать, что функция возвращает единственный локальный объект, тип которого совпадает с
Иными словами, компилятор пытается понять, можно ли "подсунуть" область памяти
В конце поста потом почитайте ассемблерный код в комментариях, а пока продолжим.
RVO отличается NRVO тем, что в первом случае выполняется оптимизация для объекта, который создается при выходе из функции в
А во втором для возвращаемого именованного объекта:
Но при этом замысел и суть остаются такими же! Тут важно отметить, что и вам, и компилятору, по объективным причинам, намного проще доказать корректность RVO, чем NRVO.
Давайте покажу, когда NRVO может не сработать и почему. Рассмотрим кусочек из живого примера 2:
Оптимизация NRVO не выполнится. В данном примере компилятору будет неясно, какой именно из объектов
Продолжение в комментариях!
#cppcore #memory #algorithm #hardcore
Всем привет! Настало время завершающего поста этой серии. Сегодня мы поговорим об одной из самых нетривиальных оптимизаций в С++.
Я очень удивлюсь, если встречу человека, который по мере изучения стандартных контейнеров никогда не задумывался, что эти ребята слишком «жирные», чтобы их просто так возвращать в качестве результата функции или метода:
std::string get_very_long_string();
...и приходили к мысли, что нужно заполнять уже существующий объект:
void fill_very_long_string(std::string &);
Эта мысль волновала всех с давних времен... Поэтому она нашла поддержку от разработчиков компиляторов.
Существует такие древние оптимизации, как RVO (Return Value Optimization) и NRVO (Named Return Value Optimization). Они призваны избавить нас от потенциально избыточных и лишних вызовов конструктора копирования для объектов на стеке. Например, в таких ситуациях:
// RVO example
Foo f()
{
return Foo();
}
// NRVO example
Foo f()
{
Foo named_object;
return named_object;
}
// Foo no coping
Foo obj = f();
Давайте взглянем на живой пример 1, в котором вызов конструктора копирования явно пропускается. Вообще говоря, эта информация немного выбивается в контексте постов, посвященных move семантике C++11, т.к. это работает даже на C++98. Вот поэтому я её называю древней 😉
Немного теории. При вызове функции резервируется место на стеке, куда должно быть записано возвращаемое значение функции. Если компилятор может гарантировать, что функция возвращает единственный локальный объект, тип которого совпадает с
lvalue, тогда он может сразу сконструировать этот объект напрямую в ожидаемом месте вызывающего кода. Допустимо отличаться на константность.Иными словами, компилятор пытается понять, можно ли "подсунуть" область памяти
lvalue при вычислении rvalue и гарантировать, что мы получим тот же результат, что и при обычном копировании. Можно считать, что компилятор преобразует код в следующий:void f(Foo *address)
{
// construct an object Foo
// in memory at address
new (address) Foo();
}
int main()
{
auto *address = reinterpret_cast<Foo *>(
// allocate memory directly on stack!
alloca(sizeof(Foo))
);
f(address);
}
В конце поста потом почитайте ассемблерный код в комментариях, а пока продолжим.
RVO отличается NRVO тем, что в первом случае выполняется оптимизация для объекта, который создается при выходе из функции в
return:// RVO example
Foo f()
{
return Foo();
}
А во втором для возвращаемого именованного объекта:
// NRVO example
Foo f()
{
Foo named_object;
return named_object;
}
Но при этом замысел и суть остаются такими же! Тут важно отметить, что и вам, и компилятору, по объективным причинам, намного проще доказать корректность RVO, чем NRVO.
Давайте покажу, когда NRVO может не сработать и почему. Рассмотрим кусочек из живого примера 2:
// NRVO failed!
Foo f(bool value)
{
Foo a, b;
if (value)
return a;
else
return b;
}
Оптимизация NRVO не выполнится. В данном примере компилятору будет неясно, какой именно из объектов
a или b будет возвращен. Несмотря на то, что объекты БУКВАЛЬНО одинаковые, нельзя гарантировать применимость NRVO. До if (value) можно было по-разному поменять каждый из объектов и их память. Или вдруг у вас в конструкторе Foo зашит генератор случайных чисел? 😉 Следовательно, компилятору может быть непонятно куда надо конструировать объект напрямую из этих двух. Тут будет применено копирование.Продолжение в комментариях!
#cppcore #memory #algorithm #hardcore
{kind=link}
Static
Ключевое слово static не зря вызывает столько вопросов. Его можно применять к куче разных сущностей и везде поведение будет разным. Поэтому поначалу это все довольно сложно усвоить. Будем потихоньку разбирать каждый аспект применения static в подробностях, но сейчас соберу все вместе и кратко расскажу о ключевых особенностях каждого.
Всего есть 5 возможных способа применить static:
👉🏿 К глобальным переменным. Есть у вас файлик и вы в нем определили глобальную переменную std::string ж = "опа";. Такой неконстантной глобальной переменной автоматически присваивается внешнее связывание. То есть все единицы трансляции могут увидеть эту переменную и использовать ее(через forward declaration). Как только вы пометите ее как static, тип связывания изменится на внутреннее. Это значит, что никакие другие единицы трансляции не смогут получить доступ к конкретно этому экземпляру строки. Время жизни переменной в этом случае не особо меняется.
👉🏿 К локальным переменным функции. В этом случае переменная будет продолжать принадлежать функции, но теперь ее время жизни с автоматического изменится на статическое. То есть переменная будет продолжать жить между вызовами функции и сохранять свое значение с предыдущего вызова. Такие переменные гарантированно инициализируются атомарно и один раз при самом первом вызове функции.
👉🏿 К полям класса. В отличии от обычных членов класса, для доступа к которым нужен объект, для статических полей объект не нужен. Представьте, что это глобальная переменная, которая "присоединена" к классу. Это поле видно всем, кому доступно определение класса, и к нему можно обратиться с помощью имени класса, типа такого Type::static_member. Также такие поля доступны в методах класса. Короче. Ничего особенного, просто глобальная переменная принадлежащая классу.
👉🏿 К свободным функциям. Ситуация очень похожа на ситуацию с глобальными переменными. По сути изменяется только тип связывания. Такую функцию нельзя увидеть из другой единицы трансляции.
👉🏿 К методам класса. Ситуация похожа на применение static к полям класса. Это свободная функция, которая присоединена к классу. Однако у нее есть еще одно преимущество, что такие методы имеют возможность доступа ко всем полям класса. Если каким-то образом заиметь объект того же самого класса внутри статического метода, то можно пользоваться плюшками доступа ко всем полям.
Как видно, что прошлись сильно по верхам. Я специально не затрагивал нюансы и описывал все крупными мазками. Нюансы будут, когда будем все подробно разбирать.
Вот такая многогранная вещь этот static. Ждите следующих частей, будет жарко🔥.
Stay hot. Stay cool.
#cppcore #howitworks
Ключевое слово static не зря вызывает столько вопросов. Его можно применять к куче разных сущностей и везде поведение будет разным. Поэтому поначалу это все довольно сложно усвоить. Будем потихоньку разбирать каждый аспект применения static в подробностях, но сейчас соберу все вместе и кратко расскажу о ключевых особенностях каждого.
Всего есть 5 возможных способа применить static:
👉🏿 К глобальным переменным. Есть у вас файлик и вы в нем определили глобальную переменную std::string ж = "опа";. Такой неконстантной глобальной переменной автоматически присваивается внешнее связывание. То есть все единицы трансляции могут увидеть эту переменную и использовать ее(через forward declaration). Как только вы пометите ее как static, тип связывания изменится на внутреннее. Это значит, что никакие другие единицы трансляции не смогут получить доступ к конкретно этому экземпляру строки. Время жизни переменной в этом случае не особо меняется.
👉🏿 К локальным переменным функции. В этом случае переменная будет продолжать принадлежать функции, но теперь ее время жизни с автоматического изменится на статическое. То есть переменная будет продолжать жить между вызовами функции и сохранять свое значение с предыдущего вызова. Такие переменные гарантированно инициализируются атомарно и один раз при самом первом вызове функции.
👉🏿 К полям класса. В отличии от обычных членов класса, для доступа к которым нужен объект, для статических полей объект не нужен. Представьте, что это глобальная переменная, которая "присоединена" к классу. Это поле видно всем, кому доступно определение класса, и к нему можно обратиться с помощью имени класса, типа такого Type::static_member. Также такие поля доступны в методах класса. Короче. Ничего особенного, просто глобальная переменная принадлежащая классу.
👉🏿 К свободным функциям. Ситуация очень похожа на ситуацию с глобальными переменными. По сути изменяется только тип связывания. Такую функцию нельзя увидеть из другой единицы трансляции.
👉🏿 К методам класса. Ситуация похожа на применение static к полям класса. Это свободная функция, которая присоединена к классу. Однако у нее есть еще одно преимущество, что такие методы имеют возможность доступа ко всем полям класса. Если каким-то образом заиметь объект того же самого класса внутри статического метода, то можно пользоваться плюшками доступа ко всем полям.
Как видно, что прошлись сильно по верхам. Я специально не затрагивал нюансы и описывал все крупными мазками. Нюансы будут, когда будем все подробно разбирать.
Вот такая многогранная вещь этот static. Ждите следующих частей, будет жарко🔥.
Stay hot. Stay cool.
#cppcore #howitworks
{kind=link}
Static глобальные переменные
Начнем разбирать тонкие моменты применения static. В контексте глобальных переменных.
Я конечно базово негативно настроен на применение глобальные переменных и объектов, но не важно, что я думаю. Статические глобальные переменные используются и еще очень долго будут использоваться. И если средствами ООП этого почти всегда можно избежать при хорошей архитектуре, то например в какой-нибудь сишечке, где довольно ограниченные возможности по хранению стейта модуля, это довольно частое явление. Поэтому давайте разбираться.
Первое, что стоит понимать - static обозначает определенный цикл жизни объекта. Например, цикл жизни объекта на стеке - от создания до выхода из скоупа. А для статических глобальных переменных их цикл жизни начинается до захода в main(причем порядок инициализации глобальных объектов не определен), сохраняется в течение всего времени существования программы и заканчивается после выхода из main.
Второе - static указывает на место хранения. Статические глобальные переменные хранятся в сегменте данных - .data segment. Это место в адресном пространстве, где находятся все глобальные и статические переменные. Также это Read-Write сегмент, поэтому мы спокойно можем изменять данные, которые в нем находятся(в отличие от .rodata segment).
Третье - это ключевое слово определяет тип линковки для сущности. В данном случае у объекта появляется внутреннее связывание. Это значит, что объект будет недоступным для других единиц трансляции. Никто другой его не увидит. И даже если такой объект будет определен в хэдере, который будет подключаться в разные единицы трансляции, то в каждой из них будет создаваться своя копия этого объекта и эти копии будут уникальными для своего юнита. И это будут именно копии, то есть несколько экземпляров. А значит памяти все это дело будет занимать больше.
Расскажу чуть подробнее про линковочный аспект. Каждая единица трансляции компилируется независимо от остальных. На этом этапе компилятору может не хватать данных(например у него есть только объявление сущности), поэтому он вставляет в такие места заглушки. Эти заглушки заменяет на ссылки на реальные символы уже линкер. Так вот. У каждой единицы трансляции создается свой .data segment и там лежат глобальные и статические переменные, определенные в этом юните. Когда вы в хэдере определяете статическую переменную, это ее определение попадает в ту единицу трансляции, куда этот хэдер был включен. Соотвественно, в каждом таком юните будет свой сегмент данных, каждый из которых будет содержать свою копию. И у каждой из них даже скорее всего имя будет одинаковым.
Но потом приходит компоновщик и объединяет все юниты трансляции в один исполняемый файл и, в том числе, он объединяет сегменты данных. Поэтому в объединенном .data segment у вас будут 2 объекта с потенциально одинаковым символьным представлением(хотя с чего они должны быть разными). Например, для целочисленной переменной с именем qwerty, ее внутреннее представление может иметь примерно такое имя - _ZL6qwerty. Разные могут быть варианты манглинга, но что-то похожее на это так или иначе будет. И вот такие экземпляров будет 2. Только у них разные адреса будут и каждая из них будет относится только к своему "модулю" программы. А конфликтовать они не будут, потому что линкер по очереди обрабатывает эти единицы трансляции и жестко привязывает символы к адресам в памяти.
Вроде довольно подробно рассказал. Задавайте вопросы, если что-то непонятно. Поправляйте, если что не так описал. В общем, ждем в комментах)
Stay based. Stay cool.
#compiler #cppcore #hardcore
Начнем разбирать тонкие моменты применения static. В контексте глобальных переменных.
Я конечно базово негативно настроен на применение глобальные переменных и объектов, но не важно, что я думаю. Статические глобальные переменные используются и еще очень долго будут использоваться. И если средствами ООП этого почти всегда можно избежать при хорошей архитектуре, то например в какой-нибудь сишечке, где довольно ограниченные возможности по хранению стейта модуля, это довольно частое явление. Поэтому давайте разбираться.
Первое, что стоит понимать - static обозначает определенный цикл жизни объекта. Например, цикл жизни объекта на стеке - от создания до выхода из скоупа. А для статических глобальных переменных их цикл жизни начинается до захода в main(причем порядок инициализации глобальных объектов не определен), сохраняется в течение всего времени существования программы и заканчивается после выхода из main.
Второе - static указывает на место хранения. Статические глобальные переменные хранятся в сегменте данных - .data segment. Это место в адресном пространстве, где находятся все глобальные и статические переменные. Также это Read-Write сегмент, поэтому мы спокойно можем изменять данные, которые в нем находятся(в отличие от .rodata segment).
Третье - это ключевое слово определяет тип линковки для сущности. В данном случае у объекта появляется внутреннее связывание. Это значит, что объект будет недоступным для других единиц трансляции. Никто другой его не увидит. И даже если такой объект будет определен в хэдере, который будет подключаться в разные единицы трансляции, то в каждой из них будет создаваться своя копия этого объекта и эти копии будут уникальными для своего юнита. И это будут именно копии, то есть несколько экземпляров. А значит памяти все это дело будет занимать больше.
Расскажу чуть подробнее про линковочный аспект. Каждая единица трансляции компилируется независимо от остальных. На этом этапе компилятору может не хватать данных(например у него есть только объявление сущности), поэтому он вставляет в такие места заглушки. Эти заглушки заменяет на ссылки на реальные символы уже линкер. Так вот. У каждой единицы трансляции создается свой .data segment и там лежат глобальные и статические переменные, определенные в этом юните. Когда вы в хэдере определяете статическую переменную, это ее определение попадает в ту единицу трансляции, куда этот хэдер был включен. Соотвественно, в каждом таком юните будет свой сегмент данных, каждый из которых будет содержать свою копию. И у каждой из них даже скорее всего имя будет одинаковым.
Но потом приходит компоновщик и объединяет все юниты трансляции в один исполняемый файл и, в том числе, он объединяет сегменты данных. Поэтому в объединенном .data segment у вас будут 2 объекта с потенциально одинаковым символьным представлением(хотя с чего они должны быть разными). Например, для целочисленной переменной с именем qwerty, ее внутреннее представление может иметь примерно такое имя - _ZL6qwerty. Разные могут быть варианты манглинга, но что-то похожее на это так или иначе будет. И вот такие экземпляров будет 2. Только у них разные адреса будут и каждая из них будет относится только к своему "модулю" программы. А конфликтовать они не будут, потому что линкер по очереди обрабатывает эти единицы трансляции и жестко привязывает символы к адресам в памяти.
Вроде довольно подробно рассказал. Задавайте вопросы, если что-то непонятно. Поправляйте, если что не так описал. В общем, ждем в комментах)
Stay based. Stay cool.
#compiler #cppcore #hardcore
{kind=link}
Пропуск конструкторов копирования и перемещения
Недавно был опубликован пост про RVO/NRVO. Какой еще можно сделать вывод из этой статьи?
Конструкторы копирования/перемещения не всегда могут быть вызваны! И если вы туда засовываете, например, какие-то счетчики, которые должны влиять на внешний код, то будьте готовы, что они могут остаться нетронуты.
Вообще говоря, никогда не стоит определять никаких сайд эффектов в конструкторах / деструкторах / операторах, если вы на них рассчитываете. Иначе может случиться вот это.
Конечно же, такую оптимизацию можно отменить с помощью флага компиляции:
Тогда всё всегда будет вызываться, но при этом с потерей производительности. С другой стороны, это в принципе кажется странным — конструкторы не должны менять ничего снаружи себя. Соблюдайте это правило, и всё будет хорошо!
#cppcore #algorithm #hardcore
Недавно был опубликован пост про RVO/NRVO. Какой еще можно сделать вывод из этой статьи?
Конструкторы копирования/перемещения не всегда могут быть вызваны! И если вы туда засовываете, например, какие-то счетчики, которые должны влиять на внешний код, то будьте готовы, что они могут остаться нетронуты.
Вообще говоря, никогда не стоит определять никаких сайд эффектов в конструкторах / деструкторах / операторах, если вы на них рассчитываете. Иначе может случиться вот это.
Конечно же, такую оптимизацию можно отменить с помощью флага компиляции:
-fno-elide-constructors
Тогда всё всегда будет вызываться, но при этом с потерей производительности. С другой стороны, это в принципе кажется странным — конструкторы не должны менять ничего снаружи себя. Соблюдайте это правило, и всё будет хорошо!
#cppcore #algorithm #hardcore
{kind=link}
static inline
Мы с вами уже немного знаем про эти две вещи в отдельности. А сегодня мы разберем одну интересную вещь: что будет, если соединить эти два ключевых слова? Как изменится поведение сущностей в таком случае?
И как это обычно бывает, все разделяется на кучу вариантов использования: в хэдере или в цппшнике, для переменной или функции, для поля класса или метода. Не знаю, хватит ли тут места для них всех и нужно ли это. Но погнали.
Рассмотрим static inline свободные функции. inline говорит компилятору, что эту функцию неплохо бы встроить, и это дает ей внешнее связывание. Теперь функцию можно определять во всех единицах трансляции единожды. И итоге код для всех этих определений объединится и будет один экземпляр функции в бинарнике. А вот static говорит, что у функции теперь внутреннее связывание и в каждой единице трансляции будет своя копия функции.
Нихера не клеится. Эти ключевые слова задают практически противоположное поведение. Как же они будут сочетаться?
static победит. И в каждой единице трансляции будет своя копия функции. inline здесь будет всего лишь подсказкой к встраиванию функции.
Однако здесь есть один интересный момент. Лишь для статической функции компилятор может попробовать встроить все ее вызовы и вообще не генерировать код для нее. Потому что static - гарантия того, что за пределами юнита трансляции никто не будет пробовать вызвать эту функцию. А значит, если получится в текущем юните встроить все вызовы, то и код функции вообще генерировать не нужно. Он просто никому не понадобиться. Для функций с внешней линковкой такой трюк не провернуть. Компилятор обязан для них генерировать код, потому что линкер потом может сослаться на вызов этой функции. И придется делать call, который должен перепрыгивать в тело функции.
Для глобальных переменных применимо все то же самое, что и в предыдущем случае, за исключением возможности встраивания. inline переменные, введенные вместе с 17-м стандартом, повторяют только линковочную семантику inline функций, поэтому static inline переменная также будет иметь копии в каждой единице трансляции, куда она попала.
К тому же это все справедливо и для хэдеров, и для цппшников.
Теперь про методы класса. Для них static не имеет того же значения, что и для предыдущих случаев. Статические методы - это по факту обычные свободные функции с внешним связыванием, которые имеют доступ ко всем полям класса. Поэтому в этом случае добавление inline просто будет явным намеком компилятору, что метод можно встроить. Хотя смысла от этого намека немного, ибо при этом всем, все статические методы, определенные внутри описания класса, неявно помечены inline, чтобы иметь возможность определять такие методы сразу в хэдерах и обходить odr.
И для полей класса. Мы кстати разбирали уже этот случай в этом посте. Пометив статическое поле inline, мы получаем возможность определять это поле внутри описания класса и не беспокоиться по поводу линкера и odr. Собственно, как и в случае с методами.
Даже компактно справился. Надо конечно запоминать все эти тонкости линковки, чтобы связывать такие довольно сложные конструкции вместе. Надеюсь, что эти посты помогают что-то структурировать в голове.
Combine things together. Stay cool.
#cpp17 #compiler #optimization
Мы с вами уже немного знаем про эти две вещи в отдельности. А сегодня мы разберем одну интересную вещь: что будет, если соединить эти два ключевых слова? Как изменится поведение сущностей в таком случае?
И как это обычно бывает, все разделяется на кучу вариантов использования: в хэдере или в цппшнике, для переменной или функции, для поля класса или метода. Не знаю, хватит ли тут места для них всех и нужно ли это. Но погнали.
Рассмотрим static inline свободные функции. inline говорит компилятору, что эту функцию неплохо бы встроить, и это дает ей внешнее связывание. Теперь функцию можно определять во всех единицах трансляции единожды. И итоге код для всех этих определений объединится и будет один экземпляр функции в бинарнике. А вот static говорит, что у функции теперь внутреннее связывание и в каждой единице трансляции будет своя копия функции.
Нихера не клеится. Эти ключевые слова задают практически противоположное поведение. Как же они будут сочетаться?
static победит. И в каждой единице трансляции будет своя копия функции. inline здесь будет всего лишь подсказкой к встраиванию функции.
Однако здесь есть один интересный момент. Лишь для статической функции компилятор может попробовать встроить все ее вызовы и вообще не генерировать код для нее. Потому что static - гарантия того, что за пределами юнита трансляции никто не будет пробовать вызвать эту функцию. А значит, если получится в текущем юните встроить все вызовы, то и код функции вообще генерировать не нужно. Он просто никому не понадобиться. Для функций с внешней линковкой такой трюк не провернуть. Компилятор обязан для них генерировать код, потому что линкер потом может сослаться на вызов этой функции. И придется делать call, который должен перепрыгивать в тело функции.
Для глобальных переменных применимо все то же самое, что и в предыдущем случае, за исключением возможности встраивания. inline переменные, введенные вместе с 17-м стандартом, повторяют только линковочную семантику inline функций, поэтому static inline переменная также будет иметь копии в каждой единице трансляции, куда она попала.
К тому же это все справедливо и для хэдеров, и для цппшников.
Теперь про методы класса. Для них static не имеет того же значения, что и для предыдущих случаев. Статические методы - это по факту обычные свободные функции с внешним связыванием, которые имеют доступ ко всем полям класса. Поэтому в этом случае добавление inline просто будет явным намеком компилятору, что метод можно встроить. Хотя смысла от этого намека немного, ибо при этом всем, все статические методы, определенные внутри описания класса, неявно помечены inline, чтобы иметь возможность определять такие методы сразу в хэдерах и обходить odr.
И для полей класса. Мы кстати разбирали уже этот случай в этом посте. Пометив статическое поле inline, мы получаем возможность определять это поле внутри описания класса и не беспокоиться по поводу линкера и odr. Собственно, как и в случае с методами.
Даже компактно справился. Надо конечно запоминать все эти тонкости линковки, чтобы связывать такие довольно сложные конструкции вместе. Надеюсь, что эти посты помогают что-то структурировать в голове.
Combine things together. Stay cool.
#cpp17 #compiler #optimization
{kind=link}
inline constexpr
В прошлом мы уже обсуждали, что удобно определять константы в заголовочнике и помечать их inline constexpr. Я бы сегодня хотел поговорить в целом про два этих ключевых слова и рассмотреть, как они друг на друга влияют.
Как мы знаем, inline - теперь это больше про линковку, а про эту сторону inline мы знаем уже довольно много. Куча постов было про это за последний месяц. Базово inline обеспечивает внешнее связывание и предоставляет компилятору партийный билет на нарушение odr, который дает право иметь по одному определению сущности на одну единицу трансляции, а не на всю программу, как обычные смертные.
Теперь нужно посмотреть, какие особенности линковки у constexpr сущностей, чтобы понять, как они с inline взаимодействуют.
У нас опять куча вариантов, какие сущности мы можем пометить constexpr. Но в разрезе линковки их всего 2, поэтому будет полегче.
Первая группа - спецификатор используется при определении объектов. В этом случае подразумевается, что эти объекты помечены const. А это уже значит, что они базово имеют внутреннюю линковку. Кстати, константы можно помечать extern, чтобы у них сменился вид линковки с внутренней на внешнюю. А вот constexpr объекты - нельзя. Потому что связка объявления символа с его значением при внешнем связывании происходит на этапе линковки. А constexpr требует, чтобы значение было известно на этапе компиляции.
Вторая группа - функции и статические члены класса. В этом случае подразумевается, что они неявно помечены inline. На это есть весьма веские причины(по-другому и не делается). Функции, которые могут выполнять вычисления в compile-time, должны быть видны на этом самом этапе компиляции всем единицам трансляции. Так что extern мы сразу отбрасываем, такого не может быть. Они могли бы помечаться static, но тогда потенциально будет дублироваться код функции во всех единицах трансляции. А inline решает все проблемы. Функцию видно во всех единицах трансляции, куда она подключается. А код на этапе линковки объединяется в одно определение и никакого дублирования.
Для статических полей класса похожая схема. Раз их определение должно быть видно всем единицам трансляции, которые видят этот класс, то их нужно определять внутри описания класса. А это(за исключением пары случаев) можно сделать только, если пометить статический член как inline.
Получается, что нет смысла писать inline constexpr для любого рода функций(которые в принципе могут быть constexpr) и для статических поле классов. Это можно сделать, чтобы подсветить эту конкретную особенность и намерение(?), но, на самом деле, непонятно, что это изменит.
А вот глобальные объекты есть смысл помечать inline. Чтобы избежать издержек внутренней линковки объектов. Поэтому в примере из прошлого поста именно так и было сделано.
Продолжаем штудировать тему inline и линковки. Если вы устали от этой однотипной тематики, то ставьте реакцию🗿, постараемся разбавить эту духоту. Хочется просто сделать связный рассказ, чтобы вы из контекста не выпадали. Но если это мешает, то поменяем тактику.
Dig to the core. Stay cool.
#cpp11 #cpp17 #cppcore #compiler
В прошлом мы уже обсуждали, что удобно определять константы в заголовочнике и помечать их inline constexpr. Я бы сегодня хотел поговорить в целом про два этих ключевых слова и рассмотреть, как они друг на друга влияют.
Как мы знаем, inline - теперь это больше про линковку, а про эту сторону inline мы знаем уже довольно много. Куча постов было про это за последний месяц. Базово inline обеспечивает внешнее связывание и предоставляет компилятору партийный билет на нарушение odr, который дает право иметь по одному определению сущности на одну единицу трансляции, а не на всю программу, как обычные смертные.
Теперь нужно посмотреть, какие особенности линковки у constexpr сущностей, чтобы понять, как они с inline взаимодействуют.
У нас опять куча вариантов, какие сущности мы можем пометить constexpr. Но в разрезе линковки их всего 2, поэтому будет полегче.
Первая группа - спецификатор используется при определении объектов. В этом случае подразумевается, что эти объекты помечены const. А это уже значит, что они базово имеют внутреннюю линковку. Кстати, константы можно помечать extern, чтобы у них сменился вид линковки с внутренней на внешнюю. А вот constexpr объекты - нельзя. Потому что связка объявления символа с его значением при внешнем связывании происходит на этапе линковки. А constexpr требует, чтобы значение было известно на этапе компиляции.
Вторая группа - функции и статические члены класса. В этом случае подразумевается, что они неявно помечены inline. На это есть весьма веские причины(по-другому и не делается). Функции, которые могут выполнять вычисления в compile-time, должны быть видны на этом самом этапе компиляции всем единицам трансляции. Так что extern мы сразу отбрасываем, такого не может быть. Они могли бы помечаться static, но тогда потенциально будет дублироваться код функции во всех единицах трансляции. А inline решает все проблемы. Функцию видно во всех единицах трансляции, куда она подключается. А код на этапе линковки объединяется в одно определение и никакого дублирования.
Для статических полей класса похожая схема. Раз их определение должно быть видно всем единицам трансляции, которые видят этот класс, то их нужно определять внутри описания класса. А это(за исключением пары случаев) можно сделать только, если пометить статический член как inline.
Получается, что нет смысла писать inline constexpr для любого рода функций(которые в принципе могут быть constexpr) и для статических поле классов. Это можно сделать, чтобы подсветить эту конкретную особенность и намерение(?), но, на самом деле, непонятно, что это изменит.
А вот глобальные объекты есть смысл помечать inline. Чтобы избежать издержек внутренней линковки объектов. Поэтому в примере из прошлого поста именно так и было сделано.
Продолжаем штудировать тему inline и линковки. Если вы устали от этой однотипной тематики, то ставьте реакцию🗿, постараемся разбавить эту духоту. Хочется просто сделать связный рассказ, чтобы вы из контекста не выпадали. Но если это мешает, то поменяем тактику.
Dig to the core. Stay cool.
#cpp11 #cpp17 #cppcore #compiler
{kind=link}
Ретроспектива
Ретроспективой называют регулярные встречи разработчиков для анализа процессов, возникших неудобств и проблем. Это помогает не только выявить и исправить текущие проблемы, улучшить процессы, но и закрепить успешные практики.
«Нормальные люди… считают, что если не сломано – не чини. Инженеры считают, что если не сломано – значит недостаточно улучшено» – Скотт Адамс.
Я глубоко убежден, что всё находится в вечной градации: либо развивается, либо деградирует. Причем, деградация – это неявно определенное поведение по умолчанию компилятором жизни 😅 В основном, потому что развивается что-то другое, более естественное, чем разработка ПО. Следовательно, необходимо явно определять поведение, влияющее на наше развитие в контексте коллективной разработки.
Одним из таких инструментов самоорганизации является ретроспектива. Какие преимущества она несёт?
• Улучшение процессов
Нет смысла тратить время зря, если это не является целью встречи. Возможно, это другое собрание.
• Укрепление команды
Общие психотравмы объединяют 🤣 На самом деле, открытое общение помогает лучше понимать друг друга и доверять. Так же, это помогает вовлечь в процесс новых сотрудников.
• Целеполагание
Умение четко формулировать цели и находить пути к их достижению - это двигатель развития людей.
• Извлечение уроков и закрепление практик
Распространение ценных единиц информации, т.е. мемов, является важной составляющей в теории эволюции. Давайте учиться не только на своих, но и на чужих ошибках, а так же сбережем ближнего.
Следствием всех этих действий становится сокращение эмоционально истощающих неудобств, стрессов и фрустраций; избавление от рутины, которая так хорошо замыливает глаза.
В книге «То как мы работаем, – не работает» Tony Schwartz пишет, что умение экономить силы на работе и эффективно их восполнять во время отдыха НАПРЯМУЮ определяет вашу продуктивность. Я полностью согласен с этим утверждением.
Если что-то идет туго, скорее всего, надо пересмотреть способ достижения результата. Чем раньше это сделаешь, тем меньше разочаруешься в будущем.
А вы проводите ретро у себя в команде? Помогает ли вам это?
#goodpractice
Ретроспективой называют регулярные встречи разработчиков для анализа процессов, возникших неудобств и проблем. Это помогает не только выявить и исправить текущие проблемы, улучшить процессы, но и закрепить успешные практики.
«Нормальные люди… считают, что если не сломано – не чини. Инженеры считают, что если не сломано – значит недостаточно улучшено» – Скотт Адамс.
Я глубоко убежден, что всё находится в вечной градации: либо развивается, либо деградирует. Причем, деградация – это неявно определенное поведение по умолчанию компилятором жизни 😅 В основном, потому что развивается что-то другое, более естественное, чем разработка ПО. Следовательно, необходимо явно определять поведение, влияющее на наше развитие в контексте коллективной разработки.
Одним из таких инструментов самоорганизации является ретроспектива. Какие преимущества она несёт?
• Улучшение процессов
Нет смысла тратить время зря, если это не является целью встречи. Возможно, это другое собрание.
• Укрепление команды
Общие психотравмы объединяют 🤣 На самом деле, открытое общение помогает лучше понимать друг друга и доверять. Так же, это помогает вовлечь в процесс новых сотрудников.
• Целеполагание
Умение четко формулировать цели и находить пути к их достижению - это двигатель развития людей.
• Извлечение уроков и закрепление практик
Распространение ценных единиц информации, т.е. мемов, является важной составляющей в теории эволюции. Давайте учиться не только на своих, но и на чужих ошибках, а так же сбережем ближнего.
Следствием всех этих действий становится сокращение эмоционально истощающих неудобств, стрессов и фрустраций; избавление от рутины, которая так хорошо замыливает глаза.
В книге «То как мы работаем, – не работает» Tony Schwartz пишет, что умение экономить силы на работе и эффективно их восполнять во время отдыха НАПРЯМУЮ определяет вашу продуктивность. Я полностью согласен с этим утверждением.
Если что-то идет туго, скорее всего, надо пересмотреть способ достижения результата. Чем раньше это сделаешь, тем меньше разочаруешься в будущем.
А вы проводите ретро у себя в команде? Помогает ли вам это?
#goodpractice
{kind=link}
static inline constexpr
Когда-то давно @Igorlamerger попросил нас рассказать про inline, static inline и static inline constexpr. Отчасти эта большая серия постов и была предназначена как ответ на просьбу подписчика. И хотя мы уже столько всего обсудили, что, в целом, вы и так можете сказать, когда и как можно писать inline static constexpr. Но на всякий случай сегодняшний пост будет про это.
Был у нас уже вчера пост про inline constexpr, поэтому нам осталось только добавить к этому всему немного статичности)
Как мы знаем, constexpr для статических методов и полей класса подразумевает inline. Следовательно в этих случаях static обозначает принадлежность свободной функции или глобальной переменной к классу, а не объекту, и внешнюю линковку. constexpr здесь отвечает за возможность использования сущности в вычислениях времени компиляции, а inline обеспечивает эту возможность. Чтобы все единицы трансляции получили определение сущности во время компиляции.
Далее свободные функции и методы класса. Для них constexpr тоже подразумевает inline. Если к методу класса приписать static, то он будет уже не методом, а статической функцией, кейс которой мы обсуждали выше. Если для свободной, по факту уже, inline constexpr функции дописать static, то static кинет на прогиб ваш inline и навяжет свои правила. Эту функцию также можно будет продолжать использовать для compile-time вычислений, но в каждой единице трансляции будет своя копия этой функции. То есть тип линковки изменится с внешней на внутренюю.
Ну и теперь глобальные переменные. С ними ситуация почти такая же, как и со свободными функциями. Только здесь constexpr раскрывается в просто const и дает внутреннее связывание. inline говорит, что нихера подобного, пусть все тебя видят. И дает внешнее связывание. Но приходит static и в честном, бесконтактном бою закидывает невидимыми энергоударами инлайн и побеждает его. Связывание будет внутренним.
Такой вот небольшой пост. Но думаю, что теперь вы мастера спорта по линковке и связанными с ней ключевыми словами. И сможете сами спокойно пояснить за любую их комбинацию и как это будет влиять на сущность. Осталось еще несколько моментов, которые мы не разобрали, поэтому сериал "Линковка в большом городе" продолжается.
Be a master of your specialty. Stay cool.
#cppcore #cpp11 #cpp17 #compiler
Когда-то давно @Igorlamerger попросил нас рассказать про inline, static inline и static inline constexpr. Отчасти эта большая серия постов и была предназначена как ответ на просьбу подписчика. И хотя мы уже столько всего обсудили, что, в целом, вы и так можете сказать, когда и как можно писать inline static constexpr. Но на всякий случай сегодняшний пост будет про это.
Был у нас уже вчера пост про inline constexpr, поэтому нам осталось только добавить к этому всему немного статичности)
Как мы знаем, constexpr для статических методов и полей класса подразумевает inline. Следовательно в этих случаях static обозначает принадлежность свободной функции или глобальной переменной к классу, а не объекту, и внешнюю линковку. constexpr здесь отвечает за возможность использования сущности в вычислениях времени компиляции, а inline обеспечивает эту возможность. Чтобы все единицы трансляции получили определение сущности во время компиляции.
Далее свободные функции и методы класса. Для них constexpr тоже подразумевает inline. Если к методу класса приписать static, то он будет уже не методом, а статической функцией, кейс которой мы обсуждали выше. Если для свободной, по факту уже, inline constexpr функции дописать static, то static кинет на прогиб ваш inline и навяжет свои правила. Эту функцию также можно будет продолжать использовать для compile-time вычислений, но в каждой единице трансляции будет своя копия этой функции. То есть тип линковки изменится с внешней на внутренюю.
Ну и теперь глобальные переменные. С ними ситуация почти такая же, как и со свободными функциями. Только здесь constexpr раскрывается в просто const и дает внутреннее связывание. inline говорит, что нихера подобного, пусть все тебя видят. И дает внешнее связывание. Но приходит static и в честном, бесконтактном бою закидывает невидимыми энергоударами инлайн и побеждает его. Связывание будет внутренним.
Такой вот небольшой пост. Но думаю, что теперь вы мастера спорта по линковке и связанными с ней ключевыми словами. И сможете сами спокойно пояснить за любую их комбинацию и как это будет влиять на сущность. Осталось еще несколько моментов, которые мы не разобрали, поэтому сериал "Линковка в большом городе" продолжается.
Be a master of your specialty. Stay cool.
#cppcore #cpp11 #cpp17 #compiler
Ретроспектива с подписчиками #1
Буквально вчера был опубликован пост про ретроспективу. Естественно, это был прогрев 😃 Мы бы хотели провести своё собственное открытое ретро с подписчиками, большая надежда на ваш отклик! 😌
Напомню цель: необходимо закрепить хорошее, выявить и исправить плохое. Желательно подкрепить замечания какими-то фактами или наблюдениями, чтобы нам была понятна мотивация. Это может быть готовое предложение, наблюдение или вопрос.
Это может касаться абсолютно всего, что связано с каналом. Например:
- Управление: время публикаций, частота публикаций;
- Наполненность: план публикаций, сложность материала, глубина погружения в тему, душность, объём публикаций;
- Общение: время отклика, качество ответов, живость, вежливость;
- Поиск материала: сложность поиска, группировка постов, подготовка гайдов (т.е. методичек, сборников статей по теме);
Голосовать за важность чьей либо идеи предлагаем просто пальцами: 👍или👎. Так мы поймем, что действительно важно для нас. Данный тред будет актуален до следующей ретроспективы. Погнали! 👨💻
#retro
Буквально вчера был опубликован пост про ретроспективу. Естественно, это был прогрев 😃 Мы бы хотели провести своё собственное открытое ретро с подписчиками, большая надежда на ваш отклик! 😌
Напомню цель: необходимо закрепить хорошее, выявить и исправить плохое. Желательно подкрепить замечания какими-то фактами или наблюдениями, чтобы нам была понятна мотивация. Это может быть готовое предложение, наблюдение или вопрос.
Это может касаться абсолютно всего, что связано с каналом. Например:
- Управление: время публикаций, частота публикаций;
- Наполненность: план публикаций, сложность материала, глубина погружения в тему, душность, объём публикаций;
- Общение: время отклика, качество ответов, живость, вежливость;
- Поиск материала: сложность поиска, группировка постов, подготовка гайдов (т.е. методичек, сборников статей по теме);
Голосовать за важность чьей либо идеи предлагаем просто пальцами: 👍или👎. Так мы поймем, что действительно важно для нас. Данный тред будет актуален до следующей ретроспективы. Погнали! 👨💻
#retro
{kind=link}
Почему нельзя объявлять нестатические поля класса constexpr?
В прошлом посте мы задели особенности линковки constexpr сущностей. Однако я не упомянул про нестатические поля класса. И не зря. Потому что нельзя нестатические поля объявлять constexpr. Но почему?
Давайте немного подумаем, что значит constexpr. В глобальном смысле подразумевается, что мы что-то можем вычислить во время компиляции. Для это придуманы константы времени компиляции(constexpr variables) и функции, которые способны делать вычисления в compile-time.
Причем на константы времени компиляции накладываются жесткие ограничения. Их инициализатор должен быть известен во время компилятору на этом самом этапе компиляции(или конструктор класса помечен constexpr). Только тогда можно создать такой объект.
И теперь взглянем на поле класса. Когда оно инициализируется? Правильно, в конструкторе. То есть мы должны начать создавать объект, чтобы инициализировать поле. А создаются объекты во время исполнения. Получается, что наше constexpr поле принадлежит сущности, которой вообще не существует до момента создания экземпляра класса. И как оно тогда может быть константой времени компиляции? Ведь если constexpr variable и создается, то создается только в compile time. А это просто невозможно в таком случае.
На самом деле поле класса может быть constexpr. Но неявно. Когда объект, в котором содержится это поле, сам является constexpr.
Посмотрите на пример на картинке. Там определяется класс с constexpr конструкторами и затем создается constexpr экземпляр этого класса. Чтобы проверить, действительно ли поле a является константой времени компиляции, можно попробовать вызвать шаблонную функцию с интовым шаблонным параметром. Так как шаблонный параметр - часть типа, то его значение должно быть известно на этапе компиляции. Поэтому, если все получится, то это докажет, что a - константа времени компиляции. И действительно, все работает. constexpr объект делает его поля constexpr.
Если мы попробуем разрешить помечать поля класса constexpr, даже одно единственное поле, значит нам нужно гарантировать, чтобы все поля становились constexpr(если это будет делаться неявно, то это явно кринж), и все объекты данного класса могли создаваться только в compile-time. Зачем это нужно? Да вроде как не за чем. В этом очень мало смысла. Можно выделить constexpr интерфейс и жить себе прекрасно в compile-time. И пользоваться полноценным интерфейсом во время выполнения. Слишком много неуверенности в полезности этой фичи. Поэтому и не разрешают так делать.
Вот такие интересности скрываются в таких, казалось бы, привычных темах. Вряд ли эта информация вам когда-нибудь понадобится, но понимание таких вещей выводит ваше осознание происходящих процессов на иной уровень.
Reach new levels. Stay cool.
#cpp11 #compiler
В прошлом посте мы задели особенности линковки constexpr сущностей. Однако я не упомянул про нестатические поля класса. И не зря. Потому что нельзя нестатические поля объявлять constexpr. Но почему?
Давайте немного подумаем, что значит constexpr. В глобальном смысле подразумевается, что мы что-то можем вычислить во время компиляции. Для это придуманы константы времени компиляции(constexpr variables) и функции, которые способны делать вычисления в compile-time.
Причем на константы времени компиляции накладываются жесткие ограничения. Их инициализатор должен быть известен во время компилятору на этом самом этапе компиляции(или конструктор класса помечен constexpr). Только тогда можно создать такой объект.
И теперь взглянем на поле класса. Когда оно инициализируется? Правильно, в конструкторе. То есть мы должны начать создавать объект, чтобы инициализировать поле. А создаются объекты во время исполнения. Получается, что наше constexpr поле принадлежит сущности, которой вообще не существует до момента создания экземпляра класса. И как оно тогда может быть константой времени компиляции? Ведь если constexpr variable и создается, то создается только в compile time. А это просто невозможно в таком случае.
На самом деле поле класса может быть constexpr. Но неявно. Когда объект, в котором содержится это поле, сам является constexpr.
Посмотрите на пример на картинке. Там определяется класс с constexpr конструкторами и затем создается constexpr экземпляр этого класса. Чтобы проверить, действительно ли поле a является константой времени компиляции, можно попробовать вызвать шаблонную функцию с интовым шаблонным параметром. Так как шаблонный параметр - часть типа, то его значение должно быть известно на этапе компиляции. Поэтому, если все получится, то это докажет, что a - константа времени компиляции. И действительно, все работает. constexpr объект делает его поля constexpr.
Если мы попробуем разрешить помечать поля класса constexpr, даже одно единственное поле, значит нам нужно гарантировать, чтобы все поля становились constexpr(если это будет делаться неявно, то это явно кринж), и все объекты данного класса могли создаваться только в compile-time. Зачем это нужно? Да вроде как не за чем. В этом очень мало смысла. Можно выделить constexpr интерфейс и жить себе прекрасно в compile-time. И пользоваться полноценным интерфейсом во время выполнения. Слишком много неуверенности в полезности этой фичи. Поэтому и не разрешают так делать.
Вот такие интересности скрываются в таких, казалось бы, привычных темах. Вряд ли эта информация вам когда-нибудь понадобится, но понимание таких вещей выводит ваше осознание происходящих процессов на иной уровень.
Reach new levels. Stay cool.
#cpp11 #compiler
{kind=link}
Inline под капотом
Мы уже знаем, что inline позволяет находится определению одних и тех же сущностей в разных единицах трансляции. А потом на этапе линковки, компоновщик объединяет все эти определения в одно. Но как конкретно он это делает? Как устроен этот механизм в деталях? Сегодня будем в этом разбираться.
Вернемся к примерам из вот этого поста(продублирую его в прикрепленной картинке к этому посту), но только уберем constexpr, чтобы компилятор не просто вставлял значение переменной в место ее использования, а прям создал эту переменную в секции .data, чтобы ее можно было видеть. Ну и пометим их static, чтобы на нас линкер не ругался. Да, это глобальная переменная, так нельзя делать, и ля ля ля. Но пример учебный, просто для понимания.
Как будет выглядеть переменная light_speed в единице трансляции, соответствующей файлу first.cpp?
Рассмотрим по порядку, что здесь происходит. Начинается сегмент данных, которые выровнены на 4 байта. Говорим, что наш символ _ZN9constantsL11light_speedE - это объект с размером 4 байта. И определяем этом символ, говорим, что он типа long со значением 299792458.
И в результирующем бинарнике у нас будет 2 экземпляра семантически одной переменной в разных единицах трансляции.
0000000000004010 d _ZN9constantsL11light_speedE
0000000000004020 d _ZN9constantsL11light_speedE
Что конечно может хорошенько подпортить жизнь трудноотловимыми багами. Не нужно объявлять в хэдерах изменяющиеся переменные как static. Но повторю, что это только учебный пример, чтобы показать интересности линковки inline. Много циферок - виртуальный адрес символа, а d значит, что символ инициализирован.
Теперь, что будет, если мы static заменим на inline.
Здесь определяется слабый символ _ZN9constants11light_speedE. Слабый символ может быть переписан другим определением. Дальше идет секция данных и очень много страшных букв, но нам важно только последнее слово "comdat". Оно значит: "Здарова братишка, компоновщик! Не в службу, а в дружбу, не конкатенируй определения для символа _ZN9constants11light_speedE, а просто выбери из них всех одно и вставь в финальный бинарь. Мое увожение!". Это и есть тот маркер, по которому линкер определяет inline сущности. Ну и это все идет с компании с типом @gnu_unique_object, который должен быть уникальным во всех программе и это предотвращает дупликацию кода.
Тогда в бинарнике будет только одна запись на эту переменную.
0000000000004018 u _ZN9constants11light_speedE
u здесь значит, что символ глобальный и уникальный для всей программы.
Кстати, можно заметить пару деталей. В первом случае символ имел имя _ZN9constantsL11light_speedE, а во втором случае _ZN9constants11light_speedE.
Их объединяет то, что в оба имя включено название их нэймспейса. В С++ каждый символ имеет свое замангленное имя, которое может включать много всяких интересностей. Такое имя сильно облегчает компилятору и линкеру работу по разрешению вызовов и сопоставлению символов. Так что имя неймспейса включено в это расширенное имя объекта.
Но можно заметить и разницу. После имени неймспейса в случае статических переменных мы имеем заглавную L. Так компилятор помечает символ с внутренним связыванием.
Всё равно все рано или поздно начинают смотреть в ассемблер, поэтому, если вы еще не мастак в этом ремесле, то важно постепенно и безболезненно впитывать особенности того, как там все работает, и потихоньку приобщатся к коду.
А для остальных этот пост, надеюсь, подарил пару интересных и новых моментов.
Stay hardcore. Stay cool.
#cppcore #hardcore #cpp17 #compiler
Мы уже знаем, что inline позволяет находится определению одних и тех же сущностей в разных единицах трансляции. А потом на этапе линковки, компоновщик объединяет все эти определения в одно. Но как конкретно он это делает? Как устроен этот механизм в деталях? Сегодня будем в этом разбираться.
Вернемся к примерам из вот этого поста(продублирую его в прикрепленной картинке к этому посту), но только уберем constexpr, чтобы компилятор не просто вставлял значение переменной в место ее использования, а прям создал эту переменную в секции .data, чтобы ее можно было видеть. Ну и пометим их static, чтобы на нас линкер не ругался. Да, это глобальная переменная, так нельзя делать, и ля ля ля. Но пример учебный, просто для понимания.
Как будет выглядеть переменная light_speed в единице трансляции, соответствующей файлу first.cpp?
.data
.align 4
.type _ZN9constantsL11light_speedE, @object
.size _ZN9constantsL11light_speedE, 4
_ZN9constantsL11light_speedE:
.long 299792458
Рассмотрим по порядку, что здесь происходит. Начинается сегмент данных, которые выровнены на 4 байта. Говорим, что наш символ _ZN9constantsL11light_speedE - это объект с размером 4 байта. И определяем этом символ, говорим, что он типа long со значением 299792458.
И в результирующем бинарнике у нас будет 2 экземпляра семантически одной переменной в разных единицах трансляции.
0000000000004010 d _ZN9constantsL11light_speedE
0000000000004020 d _ZN9constantsL11light_speedE
Что конечно может хорошенько подпортить жизнь трудноотловимыми багами. Не нужно объявлять в хэдерах изменяющиеся переменные как static. Но повторю, что это только учебный пример, чтобы показать интересности линковки inline. Много циферок - виртуальный адрес символа, а d значит, что символ инициализирован.
Теперь, что будет, если мы static заменим на inline.
.weak _ZN9constants11light_speedE
.section .data._ZN9constants11light_speedE,"awG",@progbits,_ZN9constants11light_speedE,comdat
.align 4
.type _ZN9constants11light_speedE, @gnu_unique_object
.size _ZN9constants11light_speedE, 4
_ZN9constants11light_speedE:
.long 299792458
Здесь определяется слабый символ _ZN9constants11light_speedE. Слабый символ может быть переписан другим определением. Дальше идет секция данных и очень много страшных букв, но нам важно только последнее слово "comdat". Оно значит: "Здарова братишка, компоновщик! Не в службу, а в дружбу, не конкатенируй определения для символа _ZN9constants11light_speedE, а просто выбери из них всех одно и вставь в финальный бинарь. Мое увожение!". Это и есть тот маркер, по которому линкер определяет inline сущности. Ну и это все идет с компании с типом @gnu_unique_object, который должен быть уникальным во всех программе и это предотвращает дупликацию кода.
Тогда в бинарнике будет только одна запись на эту переменную.
0000000000004018 u _ZN9constants11light_speedE
u здесь значит, что символ глобальный и уникальный для всей программы.
Кстати, можно заметить пару деталей. В первом случае символ имел имя _ZN9constantsL11light_speedE, а во втором случае _ZN9constants11light_speedE.
Их объединяет то, что в оба имя включено название их нэймспейса. В С++ каждый символ имеет свое замангленное имя, которое может включать много всяких интересностей. Такое имя сильно облегчает компилятору и линкеру работу по разрешению вызовов и сопоставлению символов. Так что имя неймспейса включено в это расширенное имя объекта.
Но можно заметить и разницу. После имени неймспейса в случае статических переменных мы имеем заглавную L. Так компилятор помечает символ с внутренним связыванием.
Всё равно все рано или поздно начинают смотреть в ассемблер, поэтому, если вы еще не мастак в этом ремесле, то важно постепенно и безболезненно впитывать особенности того, как там все работает, и потихоньку приобщатся к коду.
А для остальных этот пост, надеюсь, подарил пару интересных и новых моментов.
Stay hardcore. Stay cool.
#cppcore #hardcore #cpp17 #compiler
{kind=link}
Vector vs List
Знание алгоритмов и структур данных - критично для нашей профессии. Ведь в принципе все, что мы делаем - это берем какие-то явления реального мира, создаем их представления в программе и управляем ими. От нашего понимания эффективного представления данных в памяти компьютера и управления ими зависит количество ресурсов, которое требуется на предоставление какой-то услуги, а значит и доход заказчика. Чем лучше мы знаем эти вещи, тем дешевле предоставлять услугу и тем больше мы ценны как специалисты. И наши доходы растут. Но computer science намного обширнее, чем абстрактные вещи типа теории алгоритмов или архитектуры ПО. Это еще и знание и понимание работы конкретного железа, на котором наш софт выполняется. Что важнее - непонятно. Но только в синергии можно получить топовые результаты.
Согласно теории, проход по массиву и двунаправленному списку происходит за одинаковое алгоритмическое время. O(n). То есть время прохода линейно зависит от количества элементов в структуре. И без применения знаний о принципах работы железа, можно подумать, что они взаимозаменяемы. Просто в одном случае элементы лежат рядом, а в другом - связаны ссылками. А на практике получается, что не совсем линейно и совсем не взаимозаменяемы. Расскажу подробнее о последнем.
Дело в существовании кэша у процессора. Когда мы запрашиваем доступ к одной ячейке памяти, процессор верно предполагает, что нам скорее всего будут нужны и соседние ячейки тоже. Поэтому он копирует целый интервал в памяти, называемый кэш-строкой, в свой промежуточный буфер. А доступ к этому буферу происходит намного быстрее, чем к оперативной памяти. И процессору не нужно ходить за этими рядом лежащими данными в ОЗУ, он их просто берет из кэша.
Элементы же списка хранятся в разных участках памяти и связаны между собой ссылками. В общем виде нет никакой гарантии, что они будут лежать рядом. Если конечно вы не используете кастомный аллокатор. Поэтому за каждым элементом листа процессору приходится ходит в ОЗУ.
Вот и получается, что обработка элементов списка будет происходит медленнее, чем элементов массива.
Написал простенькую программку, которая проверит разницу во времени прохода.
Получилось, что для 100кк чисел в массиве и в листе, время отличается от 1.5 до 2 раз на разных машинах. Нихрена себе такая разница. И это без оптимизаций!
С ними разница вообще 6-8 раз. Это кстати еще один повод для того, чтобы понимать, как именно мы работаем на уровне железа и какие структуры данных хорошо ложатся на разные оптимизации.
Конечно, в реальных приложениях обработка - обычно более дорогая операция, чем просто инкремент и в процентном соотношении затраты на доступ к элементам будут другие. Но для того и пишутся такие тесты, чтобы максимально подсветить проблему.
Stay based. Stay cool.
#STL #algorithms #cppcore
Знание алгоритмов и структур данных - критично для нашей профессии. Ведь в принципе все, что мы делаем - это берем какие-то явления реального мира, создаем их представления в программе и управляем ими. От нашего понимания эффективного представления данных в памяти компьютера и управления ими зависит количество ресурсов, которое требуется на предоставление какой-то услуги, а значит и доход заказчика. Чем лучше мы знаем эти вещи, тем дешевле предоставлять услугу и тем больше мы ценны как специалисты. И наши доходы растут. Но computer science намного обширнее, чем абстрактные вещи типа теории алгоритмов или архитектуры ПО. Это еще и знание и понимание работы конкретного железа, на котором наш софт выполняется. Что важнее - непонятно. Но только в синергии можно получить топовые результаты.
Согласно теории, проход по массиву и двунаправленному списку происходит за одинаковое алгоритмическое время. O(n). То есть время прохода линейно зависит от количества элементов в структуре. И без применения знаний о принципах работы железа, можно подумать, что они взаимозаменяемы. Просто в одном случае элементы лежат рядом, а в другом - связаны ссылками. А на практике получается, что не совсем линейно и совсем не взаимозаменяемы. Расскажу подробнее о последнем.
Дело в существовании кэша у процессора. Когда мы запрашиваем доступ к одной ячейке памяти, процессор верно предполагает, что нам скорее всего будут нужны и соседние ячейки тоже. Поэтому он копирует целый интервал в памяти, называемый кэш-строкой, в свой промежуточный буфер. А доступ к этому буферу происходит намного быстрее, чем к оперативной памяти. И процессору не нужно ходить за этими рядом лежащими данными в ОЗУ, он их просто берет из кэша.
Элементы же списка хранятся в разных участках памяти и связаны между собой ссылками. В общем виде нет никакой гарантии, что они будут лежать рядом. Если конечно вы не используете кастомный аллокатор. Поэтому за каждым элементом листа процессору приходится ходит в ОЗУ.
Вот и получается, что обработка элементов списка будет происходит медленнее, чем элементов массива.
Написал простенькую программку, которая проверит разницу во времени прохода.
Получилось, что для 100кк чисел в массиве и в листе, время отличается от 1.5 до 2 раз на разных машинах. Нихрена себе такая разница. И это без оптимизаций!
С ними разница вообще 6-8 раз. Это кстати еще один повод для того, чтобы понимать, как именно мы работаем на уровне железа и какие структуры данных хорошо ложатся на разные оптимизации.
Конечно, в реальных приложениях обработка - обычно более дорогая операция, чем просто инкремент и в процентном соотношении затраты на доступ к элементам будут другие. Но для того и пишутся такие тесты, чтобы максимально подсветить проблему.
Stay based. Stay cool.
#STL #algorithms #cppcore
{kind=link}