
Категория выражений xvalue
Да кто этот ваш
Появление этой категории обусловлено некоторыми издержками копирования, которые свойственны выражениям других категорий.
Как уже было сказано однажды, к категории
Все это звучит как-то абстрактно, давайте глянем пример:
1. Существует временный объект класса string, который хранит 10 Мб текста на куче.
2. Строчку хотят сохранить в другом объекте, а временный объект удалить.
В прямой постановке задачи, мы как раз оперируем категориями
Но неужели мы реально будем копировать 10 Мб текста с кучи в другое место, чтобы потом удалить исходные данные? То есть мы сделаем лишний системный вызов на выделение 10 Мб памяти, потом будем посимвольно копировать 10 000 000 байт, а затем мы просто удалим источник?...
По сути, это и есть те накладные расходы, которые тормозят нашу программу. Кажется, что этого можно избежать. Например, можно сказать другому объекту, что теперь он новый владелец данных временного объекта! То есть мы передадим другому объекту указатель на текст и сделаем так, чтобы временный объект его не удалял. Новый объект сможет дальше продолжить пользоваться текстом, возможно, очень долго, когда старый уже исчезнет. Формально, поменяется лишь оболочка над текстом.
Исходя из этой логики пример может быть эффективно решен следующей последовательностью действий:
1. Инициализируем новый объект string, скопировав указатель на текст и счетчики размера из временного объекта.
3. Во временном объекте установим указатель на текст
4. Разрушим временный объект.
5. Радуемся новому объекту, которых хранит ресурсы временного объекта!
Таким образом, мы сэкономили время на выделении памяти и его копировании, и даже ни в чем не проиграли. Мы можем написать отдельную функцию или метод, который будет выполнять этот алгоритм передачи данных. Однако, удобно ли нам вызывать такую функцию каждый раз? Будет ли этот механизм удобно использовать во всем проекте?
Начиная с C++11 вводится специальная категория выражений для обработки таких временных объектов —
⚠️ Ранее мы использовали
Тип
Теперь каждый класс может определять внутри себя логику передачи владения ресурсом. Таким образом, получилось интегрировать нововведения в действующую языковую модель.
Обратите внимание, как легко и непринужденно тут проявляется идиома RAII. Жизненный цикл объекта остается неизменным и предсказуемым, а ресурсы передаются между объектами: один создал строчку, а другой её удалит.
Будь я на вашем месте, мне бы стало непонятно, как же использовать всю эту лабуду? Продолжение в комментарии!
#cppcore #memory #algorithm
Да кто этот ваш
xvalue?! В продолжение к предыдущим постам.Появление этой категории обусловлено некоторыми издержками копирования, которые свойственны выражениям других категорий.
Как уже было сказано однажды, к категории
xvalue относятся временные выражения, ресурс которых можно перераспределить после их уничтожения. Все это звучит как-то абстрактно, давайте глянем пример:
1. Существует временный объект класса string, который хранит 10 Мб текста на куче.
2. Строчку хотят сохранить в другом объекте, а временный объект удалить.
В прямой постановке задачи, мы как раз оперируем категориями
lvalue и rvalue:
std::string nstr = tstr;
// ~~^~~ ~~^~~
// lvalue lvalue -> rvalue
// Then destroy temporary string 'tstr'
Но неужели мы реально будем копировать 10 Мб текста с кучи в другое место, чтобы потом удалить исходные данные? То есть мы сделаем лишний системный вызов на выделение 10 Мб памяти, потом будем посимвольно копировать 10 000 000 байт, а затем мы просто удалим источник?...
По сути, это и есть те накладные расходы, которые тормозят нашу программу. Кажется, что этого можно избежать. Например, можно сказать другому объекту, что теперь он новый владелец данных временного объекта! То есть мы передадим другому объекту указатель на текст и сделаем так, чтобы временный объект его не удалял. Новый объект сможет дальше продолжить пользоваться текстом, возможно, очень долго, когда старый уже исчезнет. Формально, поменяется лишь оболочка над текстом.
Исходя из этой логики пример может быть эффективно решен следующей последовательностью действий:
1. Инициализируем новый объект string, скопировав указатель на текст и счетчики размера из временного объекта.
3. Во временном объекте установим указатель на текст
nullptr и занулим счетчики размера строки, чтобы при вызове деструктора наши данные не потёрлись.4. Разрушим временный объект.
5. Радуемся новому объекту, которых хранит ресурсы временного объекта!
Таким образом, мы сэкономили время на выделении памяти и его копировании, и даже ни в чем не проиграли. Мы можем написать отдельную функцию или метод, который будет выполнять этот алгоритм передачи данных. Однако, удобно ли нам вызывать такую функцию каждый раз? Будет ли этот механизм удобно использовать во всем проекте?
Начиная с C++11 вводится специальная категория выражений для обработки таких временных объектов —
xvalue. Так же вводится специальный тип rvalue reference, для которого можно добавить перегрузки операторов и конструкторов:class string
{
public:
// Constructor for
// rvalue reference of string 'other'
string(string &&other) noexcept
{ ... }
// Assign operator for
// rvalue reference of string 'other'
string& operator=(string &&other) noexcept
{ ... }
};
⚠️ Ранее мы использовали
rvalue, как имя категории выражений. Теперь появляется ТИП rvalue reference, который относится к категории выражения xvalue. Не путайтесь, пожалуйста! Я считаю это неудачной терминологией стандарта, которую надо просто запомнить.Тип
rvalue reference задаётся с помощью && перед именем класса. Например:std::string &&value = other;
// ~~^~~
// rvalue reference
Теперь каждый класс может определять внутри себя логику передачи владения ресурсом. Таким образом, получилось интегрировать нововведения в действующую языковую модель.
Обратите внимание, как легко и непринужденно тут проявляется идиома RAII. Жизненный цикл объекта остается неизменным и предсказуемым, а ресурсы передаются между объектами: один создал строчку, а другой её удалит.
Будь я на вашем месте, мне бы стало непонятно, как же использовать всю эту лабуду? Продолжение в комментарии!
#cppcore #memory #algorithm
{kind=link}
Идиома Remove-Erase устарела?
Снова вспомним про эту идиому. В прошлых частях тык и тык(кто не видел эту серию постов, то после первого нужно еще вот этот посмотреть) говорили о том, зачем что это такое, какую проблему решает, и как работает. А в этой части я расскажу, что это все не нужно)
Точнее будет не нужно, после того, как ваши проекты полностью перейдут на С++20.
Дело в том, что этот релиз подарил нам 2 прекрасные шаблонные функции: std::erase и std::erase_if. Чем они занимаются в контексте идиомы? А занимаются они ровно тем же, только намного красивее. Если раньше нам приходилось использовать 2 алгоритма, чтобы удалить нужные элементы из вектора, то здесь нужна всего одна функция.
std::vector<int> myVec = {1, 2, 3, 4, 5};
std::erase(myVec, 2);
И все. Больше ничего не нужно городить. И даже убрали этот некрасивый интерфейс с итераторами (по сути интерфейс крутой и функциональный, но слишком много букав писать надо). Да, для ренджей придется использовать идиому по старинке, но случаи, когда это реально необходимо, очень редки.
Вся прелесть этих функции в том, что они шаблонные. То есть могут принимать на вход любые контейнеры стандартной библиотеки. Примечательно, что для большинства контейнеров эти функции частично специализированы под этот конкретный контейнер. Писать обобщенный код теперь стало еще проще.
Stay updated. Stay cool.
#cpp20 #STL #algorithms
Снова вспомним про эту идиому. В прошлых частях тык и тык(кто не видел эту серию постов, то после первого нужно еще вот этот посмотреть) говорили о том, зачем что это такое, какую проблему решает, и как работает. А в этой части я расскажу, что это все не нужно)
Точнее будет не нужно, после того, как ваши проекты полностью перейдут на С++20.
Дело в том, что этот релиз подарил нам 2 прекрасные шаблонные функции: std::erase и std::erase_if. Чем они занимаются в контексте идиомы? А занимаются они ровно тем же, только намного красивее. Если раньше нам приходилось использовать 2 алгоритма, чтобы удалить нужные элементы из вектора, то здесь нужна всего одна функция.
std::vector<int> myVec = {1, 2, 3, 4, 5};
std::erase(myVec, 2);
И все. Больше ничего не нужно городить. И даже убрали этот некрасивый интерфейс с итераторами (по сути интерфейс крутой и функциональный, но слишком много букав писать надо). Да, для ренджей придется использовать идиому по старинке, но случаи, когда это реально необходимо, очень редки.
Вся прелесть этих функции в том, что они шаблонные. То есть могут принимать на вход любые контейнеры стандартной библиотеки. Примечательно, что для большинства контейнеров эти функции частично специализированы под этот конкретный контейнер. Писать обобщенный код теперь стало еще проще.
Stay updated. Stay cool.
#cpp20 #STL #algorithms
{kind=link}
Постинкремент vs преинкремент
В С++ есть замечательные операторы инкремента(например вот в питоне их нет). Преинкремент увеличивает значение числа на единицу и возвращает ссылку на него. А постинкремент по идее создает временную переменную равную текущему значению числа, увеличивает число на единицу и возвращает по значению временную переменную. Поэтому кстати результат преинкремента - lvalue(возвращается как бы rvalue, но потом приводится к lvalue, потому что ссылка), то есть его можно использовать слева от знака равно, а постинкремента - rvalue, и его уже нельзя использовать слева от равно. Последнее верно в любом случае, это семантика языка. Но вот что насчет реализации?
И когда мы учили язык, нам говорили, что в циклах использовать нужно преинкремент, потому что постинкремент ко всему прочему создает временную переменную и это снижает перформанс. Реально ли компилятор генерирует такой код?
Возьмем простенький пример:
int main()
{
for ( int i = 0; i < 10; ++i) {}
return 0;
}
Казалось бы, конкретно для этого примера от перестановки мест слагаемых, сумма не меняется. Мы можем использовать и тот и другой оператор, результат будет тем же. Может компилятору хватит мозгов, чтобы выяснить это и не генерировать неэффективный код?
И реально, мозгов хватает.
movl $0, -4(%rbp)
.L3:
cmpl $9, -4(%rbp)
jg .L2
addl $1, -4(%rbp)
jmp .L3
.L2:
movl $0, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
Такой ассемблер компилятор генерирует о обоих случаях. И это даже без оптимизаций!! С оптимизациями код был бы пустым, потому что мы ничего полезного не делаем. Но я проверял для более сложных случаев, когда код цикла реально генерировался, и с оптимизациями. Все одинаково.
Кладем нолик в память для i, сравниваем его с девяткой, если девятка больше или равна i, то прибавляем единичку и прыгаем обратно в цикл. Если девятка меньше чем i, то прыгаем на выход из main.
Так что, если у вас были предубеждения насчет использования этих операторов конкретно в таких сценариях, когда нужно просто проитерироваться, то оставьте эти предубеждения. Пишите, как удобно. Пример конечно суперпростой, но это чтобы глаза не вытекали у вас от ассемблера. Более сложные примеры логично будут более сложными для понимания.
Безусловно, когда от выбора оператора зависит результат операции, то компилятор сгенерирует разный код для разных случаев. По-другому и быть не может.
Stay relaxed. Stay cool.
В С++ есть замечательные операторы инкремента(например вот в питоне их нет). Преинкремент увеличивает значение числа на единицу и возвращает ссылку на него. А постинкремент по идее создает временную переменную равную текущему значению числа, увеличивает число на единицу и возвращает по значению временную переменную. Поэтому кстати результат преинкремента - lvalue(возвращается как бы rvalue, но потом приводится к lvalue, потому что ссылка), то есть его можно использовать слева от знака равно, а постинкремента - rvalue, и его уже нельзя использовать слева от равно. Последнее верно в любом случае, это семантика языка. Но вот что насчет реализации?
И когда мы учили язык, нам говорили, что в циклах использовать нужно преинкремент, потому что постинкремент ко всему прочему создает временную переменную и это снижает перформанс. Реально ли компилятор генерирует такой код?
Возьмем простенький пример:
int main()
{
for ( int i = 0; i < 10; ++i) {}
return 0;
}
Казалось бы, конкретно для этого примера от перестановки мест слагаемых, сумма не меняется. Мы можем использовать и тот и другой оператор, результат будет тем же. Может компилятору хватит мозгов, чтобы выяснить это и не генерировать неэффективный код?
И реально, мозгов хватает.
movl $0, -4(%rbp)
.L3:
cmpl $9, -4(%rbp)
jg .L2
addl $1, -4(%rbp)
jmp .L3
.L2:
movl $0, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
Такой ассемблер компилятор генерирует о обоих случаях. И это даже без оптимизаций!! С оптимизациями код был бы пустым, потому что мы ничего полезного не делаем. Но я проверял для более сложных случаев, когда код цикла реально генерировался, и с оптимизациями. Все одинаково.
Кладем нолик в память для i, сравниваем его с девяткой, если девятка больше или равна i, то прибавляем единичку и прыгаем обратно в цикл. Если девятка меньше чем i, то прыгаем на выход из main.
Так что, если у вас были предубеждения насчет использования этих операторов конкретно в таких сценариях, когда нужно просто проитерироваться, то оставьте эти предубеждения. Пишите, как удобно. Пример конечно суперпростой, но это чтобы глаза не вытекали у вас от ассемблера. Более сложные примеры логично будут более сложными для понимания.
Безусловно, когда от выбора оператора зависит результат операции, то компилятор сгенерирует разный код для разных случаев. По-другому и быть не может.
Stay relaxed. Stay cool.
{kind=link}
500
Поздравляю всех причастных с очередным достижением на нашем канале!🎉🎊🎁💥
500 человек - это уже солидная цифра, потихоньку наш канал обретает вес в плюсовом сообществе телеграмма. Спасибо всем вам за то, что доверились нашим стараниям, подписываетесь, ставите реакции и комментируете посты. Это все очень помогает развитию канала и админам очень радует глаз)
Может это не всем понятно, но банальный рост статов, то есть просто циферок на экране по факту, очень сильно мотивирует делать контент и делать его все качественнее. Знали бы сколько раз на дню я захожу в статистику канала....
Мы сами многому научились и во многих тонкостях разобрались. Я надеюсь, что наши посты также помогают вам расширять границы своих познаний. Но впереди нас ждут еще большие дебри плюсов и computer science в целом, поэтому давайте проходить через них вместе.
Всем замечательного дня!!
Поздравляю всех причастных с очередным достижением на нашем канале!🎉🎊🎁💥
500 человек - это уже солидная цифра, потихоньку наш канал обретает вес в плюсовом сообществе телеграмма. Спасибо всем вам за то, что доверились нашим стараниям, подписываетесь, ставите реакции и комментируете посты. Это все очень помогает развитию канала и админам очень радует глаз)
Может это не всем понятно, но банальный рост статов, то есть просто циферок на экране по факту, очень сильно мотивирует делать контент и делать его все качественнее. Знали бы сколько раз на дню я захожу в статистику канала....
Мы сами многому научились и во многих тонкостях разобрались. Я надеюсь, что наши посты также помогают вам расширять границы своих познаний. Но впереди нас ждут еще большие дебри плюсов и computer science в целом, поэтому давайте проходить через них вместе.
Всем замечательного дня!!
Универсальные ссылки
Вообще говоря, вся эта серия постов началась с просьбы нашего подписчика Сергея Нефедова объяснить зачем нужны универсальные ссылки. Дождались! 🤩
В предыдущей статье я сделал акцент:
Тип rvalue reference задаётся с помощью && перед именем класса.
ОДНО БОЛЬШОЕ НО! Вместо имени класса может быть установлен параметр-тип шаблона:
Ожидается, что из него будет выведен тип
В своё время Scott Meyers, придумал такой термин как универсальные ссылки, чтобы объяснить некоторые тонкости языка. Рассмотрим на примере вышеупомянутой
Оба вызова функции
Универсальная ссылка (т.н. universal reference) — это переменная или параметр, которая имеет тип T&& для выведенного типа T. Из неё будет выведен тип rvalue reference, либо lvalue reference. Это так же касается auto переменных, т.к. их тип тоже выводится.
Расставляем точки над i вместе со Scott Meyers:
В соответствии с этим маленьким нюансом поведение может меняться внутри функции
Я немного изменил предыдущий пример: https://compiler-explorer.com/z/EzddYhjdv. В зависимости от выведенного типа, строка будет либо скопирована, либо перемещена. Соответственно, в области видимости функции
Причем, это не работает, если
Пример: https://compiler-explorer.com/z/We4qzG5xG
Получается, что в универсальные ссылки заложен дуализм поведения. Зачем же так было сделано? А за тем, что существуют
Как мы видим, разные аргументы вызова
Кстати, если не знать и не пытаться в эти тонкости, то можно вполне спокойно использовать стандартные структуры. Если говорить с натяжкой, то можно, конечно, сказать, что такая универсальность может снижать порог вхождения в C++. Не знаешь — пишешь просто рабочий код, а знаешь — пишешь ещё и эффективный.
Другое дело, непонятно, почему нельзя было для универсальных ссылок сделать отдельный синтаксис? Например, добавить
Я думаю, что нам еще нужны посты на разбор этой темы, чтобы это в голове уложилось. А пока будем развивать тему в сторону move семантики. Не забываем об исключениях в перемещающем конструкторе, а так же про оптимизации RVO/NRVO.
#cppcore #memory #algorithm #hardcore
Вообще говоря, вся эта серия постов началась с просьбы нашего подписчика Сергея Нефедова объяснить зачем нужны универсальные ссылки. Дождались! 🤩
В предыдущей статье я сделал акцент:
Тип rvalue reference задаётся с помощью && перед именем класса.
ОДНО БОЛЬШОЕ НО! Вместо имени класса может быть установлен параметр-тип шаблона:
template<typename T>
void foo(T &&message)
{
...
}
Ожидается, что из него будет выведен тип
rvalue reference, но это не всегда так. Такие ссылки позволяют с одной стороны определить поведения для работы с xvalue, а с другой, неожиданно, для lvalue.В своё время Scott Meyers, придумал такой термин как универсальные ссылки, чтобы объяснить некоторые тонкости языка. Рассмотрим на примере вышеупомянутой
foo:std::string str = "blah blah blah";
// Передает lvalue
foo(str);
// Передает xvalue (rvalue reference)
foo(std::move(str));
Оба вызова функции
foo будут корректны, если не брать во внимание реализацию foo. Живой примерУниверсальная ссылка (т.н. universal reference) — это переменная или параметр, которая имеет тип T&& для выведенного типа T. Из неё будет выведен тип rvalue reference, либо lvalue reference. Это так же касается auto переменных, т.к. их тип тоже выводится.
Расставляем точки над i вместе со Scott Meyers:
Widget &&var1 = someWidget;
// ~~^~~
// rvalue reference
auto &&var2 = var1;
// ~~^~~
// universal reference
template<typename T>
void f(std::vector<T> &¶m);
// ~~^~~
// rvalue reference
template<typename T>
void f(T &¶m);
// ~~^~~
// universal reference
В соответствии с этим маленьким нюансом поведение может меняться внутри функции
foo. Банально, можно накодить тормозящее копирование вместо производительной передачи ресурса.Я немного изменил предыдущий пример: https://compiler-explorer.com/z/EzddYhjdv. В зависимости от выведенного типа, строка будет либо скопирована, либо перемещена. Соответственно, в области видимости функции
main объект либо выводит текст, либо нет (т.к. ресурс был передан другому объекту внутри foo).Причем, это не работает, если
T — параметр-тип шаблонного класса:template<class T>
class mycontainer
{
public:
void push_back(T &&other) { ... }
~~~^~~~
rvalue reference
...
};
Пример: https://compiler-explorer.com/z/We4qzG5xG
Получается, что в универсальные ссылки заложен дуализм поведения. Зачем же так было сделано? А за тем, что существуют
template parameter pack:template<class... Ts>
void foo(Ts... args)
{
bar(args...);
}
foo(std::move(string), value);
~~~~^~~~ ~~^~~~
xvalue lvalue
Как мы видим, разные аргументы вызова
foo могут относиться к разным категориям выражений.Кстати, если не знать и не пытаться в эти тонкости, то можно вполне спокойно использовать стандартные структуры. Если говорить с натяжкой, то можно, конечно, сказать, что такая универсальность может снижать порог вхождения в C++. Не знаешь — пишешь просто рабочий код, а знаешь — пишешь ещё и эффективный.
Другое дело, непонятно, почему нельзя было для универсальных ссылок сделать отдельный синтаксис? Например, добавить
T &&&. Т.к. сейчас это рушит всю концептуальную целостность системы типов. Если это планировалось как гибкий механизм, то он граничит с полной дезориентацией разработчиков 😊Я думаю, что нам еще нужны посты на разбор этой темы, чтобы это в голове уложилось. А пока будем развивать тему в сторону move семантики. Не забываем об исключениях в перемещающем конструкторе, а так же про оптимизации RVO/NRVO.
#cppcore #memory #algorithm #hardcore
{kind=link}
Еще про именование сущностей
В прошлом мы поговорили о том, что нужно создавать абстракции из деталей реализации. Не нужно тащить везде вместе кучу разных переменных. Нужно их объединить в именованный класс. Это повышает читаемость кода и скрывает ненужную на данном уровне понимания информацию.
Однако мы не всегда можем это сделать. Классы должны быть неделимыми с архитектурной точки зрения. Не нужно объединять все в одно. Но даже когда мы имеем завершенный и правильно спроектированный класс, встает проблема, что в названии множества из таких классов не записано их предназначение. Ну тут как бы все логично. Разработчики класса матрицы не знают, как конкретно будет использоваться их класс. С их точки зрения они предоставляют инструмент, кирпичик, который потом ляжет в основу программ пользователей. Проблема проявляется именно на уровне пользовательского кода. Представим, что полноценная программа - это часовой механизм. Неведомая куча каких-то шестеренок, пружинок и прочих финтифлюшек. Глядя на каждый компонент механизма, я понимаю, что он из себя представляет. Но я не понимаю главного: Нахера он нужен именно в этом месте? Какую роль выполняет? Вот также с сущностями в коде. Конечно, давать обстоятельные имена объектам - дело благородное и богоугодное. Но хотелось бы всегда давать имена классам, которые мы используем. Чисто как еще один инструмент для превращения кода в текст на естественном языке. И в плюсах так делать можно!
Алиасинг типов, введенный в С++11, дает нам удобный механизм определения синонимов типов. Это как typedef, только на стероидах. Не будем сейчас говорить о их различиях. Нам важна суть. Мы можем написать:
using ResponseFrequencyByInstance = std::unordered_map<instance_id, size_t>;
И получим человеческое название для структуры, которая хранит частоту ответов, присылаемых от разных инстансов сервиса. И нам уже не важно, что конкретно лежит в основе этой структуры. По названию видно ее предназначение, а нам только это и нужно. А имена этих объектов могут включать уже другую информацию, такую как: единицу измерения отрезка времени(секунды, миллисекунды) или указание конкретного сервиса, для которого собирается статистика. Конечно, всегда рядом с именем объекта мы постоянно должны будем помнить его тип, чтобы получить всю информацию о нем. Однако современные IDE сильно облегчили нашу жизнь в этом плане. Простым наведением курсора на объект мы увидим плашку с типом этого объекта.
Теперь мы можем давать понятные имена любым классам на свой выбор, если видим потребность в более детальной проработке смыслов.
Новичков скорее всего будет отпугивать обилие использование этих алиасов, но это фактически необходимость для поддержания ясности кода и действительно рабочая вещь.
Stay helpful. Stay cool.
#cpp11 #design #goodpractice
В прошлом мы поговорили о том, что нужно создавать абстракции из деталей реализации. Не нужно тащить везде вместе кучу разных переменных. Нужно их объединить в именованный класс. Это повышает читаемость кода и скрывает ненужную на данном уровне понимания информацию.
Однако мы не всегда можем это сделать. Классы должны быть неделимыми с архитектурной точки зрения. Не нужно объединять все в одно. Но даже когда мы имеем завершенный и правильно спроектированный класс, встает проблема, что в названии множества из таких классов не записано их предназначение. Ну тут как бы все логично. Разработчики класса матрицы не знают, как конкретно будет использоваться их класс. С их точки зрения они предоставляют инструмент, кирпичик, который потом ляжет в основу программ пользователей. Проблема проявляется именно на уровне пользовательского кода. Представим, что полноценная программа - это часовой механизм. Неведомая куча каких-то шестеренок, пружинок и прочих финтифлюшек. Глядя на каждый компонент механизма, я понимаю, что он из себя представляет. Но я не понимаю главного: Нахера он нужен именно в этом месте? Какую роль выполняет? Вот также с сущностями в коде. Конечно, давать обстоятельные имена объектам - дело благородное и богоугодное. Но хотелось бы всегда давать имена классам, которые мы используем. Чисто как еще один инструмент для превращения кода в текст на естественном языке. И в плюсах так делать можно!
Алиасинг типов, введенный в С++11, дает нам удобный механизм определения синонимов типов. Это как typedef, только на стероидах. Не будем сейчас говорить о их различиях. Нам важна суть. Мы можем написать:
using ResponseFrequencyByInstance = std::unordered_map<instance_id, size_t>;
И получим человеческое название для структуры, которая хранит частоту ответов, присылаемых от разных инстансов сервиса. И нам уже не важно, что конкретно лежит в основе этой структуры. По названию видно ее предназначение, а нам только это и нужно. А имена этих объектов могут включать уже другую информацию, такую как: единицу измерения отрезка времени(секунды, миллисекунды) или указание конкретного сервиса, для которого собирается статистика. Конечно, всегда рядом с именем объекта мы постоянно должны будем помнить его тип, чтобы получить всю информацию о нем. Однако современные IDE сильно облегчили нашу жизнь в этом плане. Простым наведением курсора на объект мы увидим плашку с типом этого объекта.
Теперь мы можем давать понятные имена любым классам на свой выбор, если видим потребность в более детальной проработке смыслов.
Новичков скорее всего будет отпугивать обилие использование этих алиасов, но это фактически необходимость для поддержания ясности кода и действительно рабочая вещь.
Stay helpful. Stay cool.
#cpp11 #design #goodpractice
{kind=link}
Идеальная передача — perfect forwarding
В продолжение к предыдущему посту.
Мы теперь знаем, что универсальные ссылки могут работать с разными категориями выражений
Конечно, как вы уже знаете, мы можем детектировать тип
Функция
В данном примере во временный объект
То есть
Отлично, где же нам такая радость может пригодиться? Конечно же, при использовании универсальных ссылок. В основном, при написании оберток над чем-то.
Пример I. Инициализация объекта по универсальной ссылке:
Пример II. При работе с контейнерами STL я предпочитаю использовать семейство функций
Передачу аргументов таким способом называют идеальной передачей (т.н. perfect forwarding), потому что она позволяет не создавать копии временных объектов.
Не забываем об исключениях в перемещающем конструкторе, а так же про оптимизации RVO/NRVO.
#cppcore #memory #algorithm
В продолжение к предыдущему посту.
Мы теперь знаем, что универсальные ссылки могут работать с разными категориями выражений
lvalue и xvalue. При написании кода шаблонной функции мы можем не знать, какие аргументы могут быть переданы в неё. Соответственно, мы не знаем, можем ли мы распоряжаться её внутренними ресурсами. Всё это сильно влияет на производительность нашего решения. Что же делать в такой ситуации?Конечно, как вы уже знаете, мы можем детектировать тип
rvalue reference. И да, мы можем написать два разных участка кода для двух разных категорий выражений. Можно, но нужно ли? Это противоречит дублированию кода.Функция
std::forward используется для так называемой идеальной передачи аргументов при вызове других методов, конструкторов и функций:template<typename T>
void foo(T &&message)
{
T tmp(std::forward<T>(message));
...
}
В данном примере во временный объект
tmp будет передано либо lvalue, либо xvalue. Следовательно, мы либо скопируем строку, либо переместим. Это зависит от того, как вызвали foo:std::string str = "blah blah blah";
// Передает lvalue => std::string tmp(str);
foo(str);
// Передает xvalue => std::string tmp(std::move(str));
foo(std::move(str));
То есть
std::forward выполняет проброс информации о категории выражения внутрь. Отсюда и название: forward, т.е. дальше.Отлично, где же нам такая радость может пригодиться? Конечно же, при использовании универсальных ссылок. В основном, при написании оберток над чем-то.
Пример I. Инициализация объекта по универсальной ссылке:
template<class T>
class wrapper
{
std::vector<T> m_data;
public:
template<class Y>
wrapper(Y &&data)
: m_data(std::forward<Y>(data))
{
// make a copy from `data` or move resources from `data`
}
};
Пример II. При работе с контейнерами STL я предпочитаю использовать семейство функций
emplace, т.к. они предоставляют возможность сконструировать объект сразу там, где он будет потом храниться. В основе таких методов лежит std::forward, который пробрасывает аргументы вплоть до конструкторов. Смотрите сами тут.Передачу аргументов таким способом называют идеальной передачей (т.н. perfect forwarding), потому что она позволяет не создавать копии временных объектов.
Не забываем об исключениях в перемещающем конструкторе, а так же про оптимизации RVO/NRVO.
#cppcore #memory #algorithm
{kind=link}
Преинкремент vs постинкремент
Особо бесцельный пост, просто чтобы вы просто посмотрели на то, какой машинный код компилятор генерирует для одного и другого оператора для знакового числа, когда их различия влияют на поведение программы. Иногда полезно залезать в ассемблер, чтобы понимать, как вещи реально работают на практике. Потому что, как мы убедились, не всегда то, что декларируется, реально осуществляется на практике. А мы, как плюсовики, должны докапываться до истины и никому не верить на слово!
Возьмем опять простенькую программу:
int main()
{
int i = 0;
int a = ++i; //i++;
return 0;
}
В первом случае я буду использовать преинкремент, во втором - постинкремент. Компилировать буду с g++ на x86-64 и без оптимизаций, потому что для такого примера просто не сгенерируется никакого кода, так как ничего полезного мы не делаем. Ну а на чуть более сложных примерах, компилятор понимает, что мы хотим сделать и просто засунет уже готовые числа по нужным адресам. Хочу продемонстрировать такую базовую хрестоматийную версию, о которой пишут в книжках.
Ассемблер для первой версии:
movl $0, -8(%rbp)
addl $1, -8(%rbp)
movl -8(%rbp), %eax
movl %eax, -4(%rbp)
Я сознательно опускаю всю обвязку и тут только суть. Кладем нолик в память со сдвигом 8 от rbp(этой ячейке памяти соответствует переменная i), добавляем к нему единичку, и через eax кладем это значение во вторую локальную переменную a со сдвигом 4 от rbp. eax - регистр-аккумулятор, в нем сохраняются промежуточные результаты арифметических вычислений, поэтому операция инкремента проходит через него. Интересно, что переменная a находится ближе к base pointer'у, хотя она объявлена позже. Это просто следствие того, что компилятор сам выбирает, как ему удобнее расположить локальные переменные на стеке и на это никак нельзя повлиять.
Теперь посмотрим на код постинкремента:
movl $0, -8(%rbp)
movl -8(%rbp), %eax
leal 1(%rax), %edx
movl %edx, -8(%rbp)
movl %eax, -4(%rbp)
Поменялось немногое, но различия уже заметны. Инструкцией leal мы складываем единичку с младшими 32-м битами в регистре rax(кто знает, почему не eax, напишите в комментах) и кладем это значение в edx, не трогая eax. Получается, что в edx создержится инкремент, а в eax - старое значение. Ну и дальше раскидываем их по правильным адресам на стеке. Обратите внимание, что в этом случае мы используем дополнительную память, а именно регистр edx, который не фигурировал в прошлом примере. Именно про это все говорят, когда объясняют, что постинкремент использует дополнительное копирование. Вот вам наглядное представление, как это утверждение ложится на уровень машинного кода.
Ставьте лайк, если нравятся такие низкоуровневые штуки и их на канале будет больше)
Stay hardwared. Stay cool
#hardcore #cppcore
Особо бесцельный пост, просто чтобы вы просто посмотрели на то, какой машинный код компилятор генерирует для одного и другого оператора для знакового числа, когда их различия влияют на поведение программы. Иногда полезно залезать в ассемблер, чтобы понимать, как вещи реально работают на практике. Потому что, как мы убедились, не всегда то, что декларируется, реально осуществляется на практике. А мы, как плюсовики, должны докапываться до истины и никому не верить на слово!
Возьмем опять простенькую программу:
int main()
{
int i = 0;
int a = ++i; //i++;
return 0;
}
В первом случае я буду использовать преинкремент, во втором - постинкремент. Компилировать буду с g++ на x86-64 и без оптимизаций, потому что для такого примера просто не сгенерируется никакого кода, так как ничего полезного мы не делаем. Ну а на чуть более сложных примерах, компилятор понимает, что мы хотим сделать и просто засунет уже готовые числа по нужным адресам. Хочу продемонстрировать такую базовую хрестоматийную версию, о которой пишут в книжках.
Ассемблер для первой версии:
movl $0, -8(%rbp)
addl $1, -8(%rbp)
movl -8(%rbp), %eax
movl %eax, -4(%rbp)
Я сознательно опускаю всю обвязку и тут только суть. Кладем нолик в память со сдвигом 8 от rbp(этой ячейке памяти соответствует переменная i), добавляем к нему единичку, и через eax кладем это значение во вторую локальную переменную a со сдвигом 4 от rbp. eax - регистр-аккумулятор, в нем сохраняются промежуточные результаты арифметических вычислений, поэтому операция инкремента проходит через него. Интересно, что переменная a находится ближе к base pointer'у, хотя она объявлена позже. Это просто следствие того, что компилятор сам выбирает, как ему удобнее расположить локальные переменные на стеке и на это никак нельзя повлиять.
Теперь посмотрим на код постинкремента:
movl $0, -8(%rbp)
movl -8(%rbp), %eax
leal 1(%rax), %edx
movl %edx, -8(%rbp)
movl %eax, -4(%rbp)
Поменялось немногое, но различия уже заметны. Инструкцией leal мы складываем единичку с младшими 32-м битами в регистре rax(кто знает, почему не eax, напишите в комментах) и кладем это значение в edx, не трогая eax. Получается, что в edx создержится инкремент, а в eax - старое значение. Ну и дальше раскидываем их по правильным адресам на стеке. Обратите внимание, что в этом случае мы используем дополнительную память, а именно регистр edx, который не фигурировал в прошлом примере. Именно про это все говорят, когда объясняют, что постинкремент использует дополнительное копирование. Вот вам наглядное представление, как это утверждение ложится на уровень машинного кода.
Ставьте лайк, если нравятся такие низкоуровневые штуки и их на канале будет больше)
Stay hardwared. Stay cool
#hardcore #cppcore
{kind=link}
Исключения в перемещающем конструкторе
Продолжаем серию постов. Как вы могли заметить, во всех примерах с перемещающим конструктором был поставлен спецификатор
И неспроста я это делал! Я бы даже сказал, что где-то это является очень важным требованием.
Возьмем в качестве примера всем нам известный
Когда же есть возможность переместить объект? Оказывается, наличие обычного перемещающего конструктора — это недостаточное условие! Необходимо гарантировать, что перемещение будет выполнено успешно и без исключений.
Про исключения мы пока не успели написать, но в рамках этой статьи можно считать, что это специальный способ сообщить об ошибке, которую можно обработать без падения программы.
Представим ситуацию, что МЫ - ВЕКТОР. Вот мы выделили новую память и начали туда перемещать объекты. И где-то на середине процесса получаем исключение при перемещении одного из объектов. Что нам делать-то с этим? Вообще говоря, надо разрушить все что переместили в новой памяти и сообщить об этом пользователю. Т.е. откатить все назад. НО! Назад дороги нет 😅 Разрушать объекты из новой области памяти нельзя — их ресурсы перемещены из старой памяти. Обратно перемещать тоже нельзя — вдруг опять исключение прилетит? Брать на себя ответственность сделать что-то одно тоже нельзя — мы вектор из стандартной библиотеки. В общем, встаем в аналитический ступор...
Таким образом, мы приходим к выводу, что перемещать можно, если есть явные гарантии от пользовательского класса. И это действительно так, взгляните на живой пример 1.
Конечно, если копирующий конструктор запрещен (например), то будет вызван хоть какой-то, т.е. перемещающий с исключениями: живой пример 2. Тут важно отметить стремление разработчиков STL обезопаситься там, где это возможно.
Если мы тоже хотим по возможности не нести ответственность за касяки стороннего класса, то нам приходит на помощь функция:
Она делает всё то же самое, что и классическая
Пользовательские классы очень и очень часто засовывают в стандартные контейнеры. Порой это происходит не сразу, через долгое время. Следовательно, если производительность в проекте важна, то побеспокоиться о гарантиях работы без исключений при перемещении есть смысл сразу, как только был написан наш класс. Либо же есть другой путь — копировать всё подряд, но это тема другого поста 😊
Надеюсь, что мне удалось вас убедить в важности
#cppcore #memory #algorithm
Продолжаем серию постов. Как вы могли заметить, во всех примерах с перемещающим конструктором был поставлен спецификатор
noexcept:class string
{
public:
string(string &&other) noexcept
{ ... }
};
И неспроста я это делал! Я бы даже сказал, что где-то это является очень важным требованием.
Возьмем в качестве примера всем нам известный
std::vector. Одним из свойств этой структуры данных является перевыделение памяти большего размера, при увеличении количества объектов. При этом старые объекты отправляются в новый участок памяти. Логично задаться вопросом — как? И логично ответить, что в целях повышенной производительности нужно выполнять перемещение каждого объекта, а не копирование, если есть возможность.Когда же есть возможность переместить объект? Оказывается, наличие обычного перемещающего конструктора — это недостаточное условие! Необходимо гарантировать, что перемещение будет выполнено успешно и без исключений.
Про исключения мы пока не успели написать, но в рамках этой статьи можно считать, что это специальный способ сообщить об ошибке, которую можно обработать без падения программы.
Представим ситуацию, что МЫ - ВЕКТОР. Вот мы выделили новую память и начали туда перемещать объекты. И где-то на середине процесса получаем исключение при перемещении одного из объектов. Что нам делать-то с этим? Вообще говоря, надо разрушить все что переместили в новой памяти и сообщить об этом пользователю. Т.е. откатить все назад. НО! Назад дороги нет 😅 Разрушать объекты из новой области памяти нельзя — их ресурсы перемещены из старой памяти. Обратно перемещать тоже нельзя — вдруг опять исключение прилетит? Брать на себя ответственность сделать что-то одно тоже нельзя — мы вектор из стандартной библиотеки. В общем, встаем в аналитический ступор...
Таким образом, мы приходим к выводу, что перемещать можно, если есть явные гарантии от пользовательского класса. И это действительно так, взгляните на живой пример 1.
Конечно, если копирующий конструктор запрещен (например), то будет вызван хоть какой-то, т.е. перемещающий с исключениями: живой пример 2. Тут важно отметить стремление разработчиков STL обезопаситься там, где это возможно.
Если мы тоже хотим по возможности не нести ответственность за касяки стороннего класса, то нам приходит на помощь функция:
std::move_if_noexcept(object);
Она делает всё то же самое, что и классическая
std::move, но только если перемещающий конструктор помечен как noexcept (или кроме перемещающего конструктора нет альтернатив). А вот если внутри метода, помеченного noexcept, исключение всё таки будет брошено, то будет все очень очень плохо... Скажу по опыту, такое отладить достаточно тяжело. Поговорим об этом, когда наступит время серии постов про исключения 😉Пользовательские классы очень и очень часто засовывают в стандартные контейнеры. Порой это происходит не сразу, через долгое время. Следовательно, если производительность в проекте важна, то побеспокоиться о гарантиях работы без исключений при перемещении есть смысл сразу, как только был написан наш класс. Либо же есть другой путь — копировать всё подряд, но это тема другого поста 😊
Надеюсь, что мне удалось вас убедить в важности
noexcept в перемещающем конструкторе. Осталось совсем немного - оптимизации RVO/NRVO.#cppcore #memory #algorithm
{kind=link}
Инициализация вектора
Под вот этим постом в комментах завелась небольшая дискуссия по поводу целесообразности использования круглых скобок для инициализации объектов. Мол универсальная инициализация предпочтительнее и от круглых скобок можно вообще отказаться. На канале уже есть пост про то, что с вектором универсальную инициализацию использовать не получится из-за того, что у вектора есть конструктор от initializer_list и из-за этого вместо того, чтобы передавать объекты из {} в конструктор, компилятор рассматривает {} и все внутри них как один аргумент - initializer_list. И появляются приколы, что хочешь создать массив на 100 элементов, заполненных нулями, а получаешь массив на 2 элемента: 100 и 0.
Однако был выдвинут интересный вопрос. Что эффективнее: создавать массив и инициализировать его в конструкторе через круглые скобки или дефолтно создать массив, а потом использовать resize и std::fill. Сегодня мы это и проверим.
Мое изначальное предположение было в том, что 3 вызова хуже одного в плане перфоманса. Прост исходя из логики, что отдельно взятый метод стандартной библиотеки очень оптимизирован. И если делать ту же самую работу, только руками, даже через другие вызовы из std, то мы как бы лишаем компилятор некоторых оптимизаций, которые могли бы быть сделаны внутри одного вызова.
Снова наклепал простенький бенчмарк. Скомпилировал это дело 11-м гцц с 20-ми плюсами и O2 оптимизациями. Результаты можно увидеть на картинке к посту.
Специально проверял несколько случаев: создание массива чисел с заданным размером и с дефолтным значением элементов, далее с кастомным значением чисел и для интереса со строками.
В целом, моя гипотеза подтвердилась. Создание массива чисел через круглые скобки быстрее на 20-30%, чем через последовательность конструктор-ресайз-филл. Но это с чиселками. Со строками последовательный вариант проигрывает уже почти в 2 раза. Хз, с чем это связано. Видимо как раз в этих самых межвызовных оптимизациях. Кто очень хорошо за асемблер шарит, наверное может подсказать причину.
Можете сами поиграться с примером в голдболде. Правда там иногда странные результаты, так что придется потыкаться в версии и опции.
Поэтому, думаю, что инициализации с круглыми скобками быть! Не надо отказываться от инструментов только из-за того, что мода на них прошла. Нужно понимать, что и где выгоднее использовать, и проверять свои предположения.
Measure your performance. Stay cool.
#compiler #optimization #cpp11
Под вот этим постом в комментах завелась небольшая дискуссия по поводу целесообразности использования круглых скобок для инициализации объектов. Мол универсальная инициализация предпочтительнее и от круглых скобок можно вообще отказаться. На канале уже есть пост про то, что с вектором универсальную инициализацию использовать не получится из-за того, что у вектора есть конструктор от initializer_list и из-за этого вместо того, чтобы передавать объекты из {} в конструктор, компилятор рассматривает {} и все внутри них как один аргумент - initializer_list. И появляются приколы, что хочешь создать массив на 100 элементов, заполненных нулями, а получаешь массив на 2 элемента: 100 и 0.
Однако был выдвинут интересный вопрос. Что эффективнее: создавать массив и инициализировать его в конструкторе через круглые скобки или дефолтно создать массив, а потом использовать resize и std::fill. Сегодня мы это и проверим.
Мое изначальное предположение было в том, что 3 вызова хуже одного в плане перфоманса. Прост исходя из логики, что отдельно взятый метод стандартной библиотеки очень оптимизирован. И если делать ту же самую работу, только руками, даже через другие вызовы из std, то мы как бы лишаем компилятор некоторых оптимизаций, которые могли бы быть сделаны внутри одного вызова.
Снова наклепал простенький бенчмарк. Скомпилировал это дело 11-м гцц с 20-ми плюсами и O2 оптимизациями. Результаты можно увидеть на картинке к посту.
Специально проверял несколько случаев: создание массива чисел с заданным размером и с дефолтным значением элементов, далее с кастомным значением чисел и для интереса со строками.
В целом, моя гипотеза подтвердилась. Создание массива чисел через круглые скобки быстрее на 20-30%, чем через последовательность конструктор-ресайз-филл. Но это с чиселками. Со строками последовательный вариант проигрывает уже почти в 2 раза. Хз, с чем это связано. Видимо как раз в этих самых межвызовных оптимизациях. Кто очень хорошо за асемблер шарит, наверное может подсказать причину.
Можете сами поиграться с примером в голдболде. Правда там иногда странные результаты, так что придется потыкаться в версии и опции.
Поэтому, думаю, что инициализации с круглыми скобками быть! Не надо отказываться от инструментов только из-за того, что мода на них прошла. Нужно понимать, что и где выгоднее использовать, и проверять свои предположения.
Measure your performance. Stay cool.
#compiler #optimization #cpp11
{kind=link}
shared_ptr и потокобезопасность
Использование шареного указателя для менеджмента ресурсов в многопоточных приложениях де-факто - стандарт. Ничего другого адекватного нет для совместного использования ресурсов несколькими потоками одновременно. Есть конечно глобальные объекты, но это практически всегда зло и не очень хочется с этим связываться. И возникает вопрос - а безопасно ли использоваться std::shared_ptr в многопоточном контексте?
Тут есть на самом деле, о чем порассуждать. Потому что размножение вашего объекта и чтение его данных - thread-safe. С чтением все понятно, никто ничего не меняет, поэтому и гонок быть не может. Но вот размножение почему? Дело в атомарном счетчике ссылок. Каждый вызов конструктора и деструктора инкрементирует или декрементирует общий для всех объектов указателя счетчик ссылок. Однако эти операции выполняются атомарно. То есть ни один поток не может увидеть промежуточный результат таких операций. Поэтому размножение и смерть объектов умного указателя - потокобезопасны..
Но вряд ли часто появляются кейсы, когда везде с собой нужно таскать объект, который никто не будет изменять. Потоки для того и работают с общими данными, чтобы и читать их, и изменять.
Ну и конечно, шаренный указатель не предоставляет из коробки потокобезопасное использование объектов, на которые он указывает. Тут работает один из базовых принципов С++ - не плати за то, чем не пользуешься. Потокобезопасность - это всегда дополнительные расходы памяти и производительности. И внедрение этой фичи замедлило бы приложения, которые этой фичей не пользовались.
Так что вызов изменяющих методов объектов, для которых не позаботились о их безопасности, в разных тредах - гарантированные трудноотловмые многопоточные проблемы. Какие? Да вообще любые. Пусть вы храните какую-нибудь мапу и передаете ее везде в виде шаред поинтера. Как только к эту мапу захочет записать какой-нибудь поток, начнет это делать и через писечную долю секунды придет читающий поток, то он увидит данные в неконсистентном состоянии. Только что на ваших глазах произошла так называемая гонка данных. И это самая тривиальная проблема. Баги могут быть намного более изощренными.
Поэтому критически важно синхронизировать доступ потоков для объектов, которые будут использоваться множеством потоков.
Stay safe. Stay cool.
#multitasking #cpp11
Использование шареного указателя для менеджмента ресурсов в многопоточных приложениях де-факто - стандарт. Ничего другого адекватного нет для совместного использования ресурсов несколькими потоками одновременно. Есть конечно глобальные объекты, но это практически всегда зло и не очень хочется с этим связываться. И возникает вопрос - а безопасно ли использоваться std::shared_ptr в многопоточном контексте?
Тут есть на самом деле, о чем порассуждать. Потому что размножение вашего объекта и чтение его данных - thread-safe. С чтением все понятно, никто ничего не меняет, поэтому и гонок быть не может. Но вот размножение почему? Дело в атомарном счетчике ссылок. Каждый вызов конструктора и деструктора инкрементирует или декрементирует общий для всех объектов указателя счетчик ссылок. Однако эти операции выполняются атомарно. То есть ни один поток не может увидеть промежуточный результат таких операций. Поэтому размножение и смерть объектов умного указателя - потокобезопасны..
Но вряд ли часто появляются кейсы, когда везде с собой нужно таскать объект, который никто не будет изменять. Потоки для того и работают с общими данными, чтобы и читать их, и изменять.
Ну и конечно, шаренный указатель не предоставляет из коробки потокобезопасное использование объектов, на которые он указывает. Тут работает один из базовых принципов С++ - не плати за то, чем не пользуешься. Потокобезопасность - это всегда дополнительные расходы памяти и производительности. И внедрение этой фичи замедлило бы приложения, которые этой фичей не пользовались.
Так что вызов изменяющих методов объектов, для которых не позаботились о их безопасности, в разных тредах - гарантированные трудноотловмые многопоточные проблемы. Какие? Да вообще любые. Пусть вы храните какую-нибудь мапу и передаете ее везде в виде шаред поинтера. Как только к эту мапу захочет записать какой-нибудь поток, начнет это делать и через писечную долю секунды придет читающий поток, то он увидит данные в неконсистентном состоянии. Только что на ваших глазах произошла так называемая гонка данных. И это самая тривиальная проблема. Баги могут быть намного более изощренными.
Поэтому критически важно синхронизировать доступ потоков для объектов, которые будут использоваться множеством потоков.
Stay safe. Stay cool.
#multitasking #cpp11
{kind=link}
Самая программистская математическая задачка
Есть одна задачка, которая вскружила мне голову элегантностью своего решения. Сформулирована она как обычная задачка на логику, но по сути своей очень программистская. Для людей с очень «низкоуровневым мышлением». Поэтому и решил с вами ей поделиться. Кажется плюсовый канал - подходящее место для таких задачек. Может я преувеличиваю, но я художник, я так чувствую.
Собсна формулировка. Жил был король. Хорошо король правил своей страной, богатая она была. И король соответственно тоже жил в большой роскоши. Появился у этого короля завистник среди придворной интеллигенции и захотел он убить короля. Думал про разные способы убийства и вспомнил одну деталь. Король очень любит вино и в погребе дворца есть 1000 бутылок его самого любимого вина, которое он пьет каждый день. И решил завистник отравить вино. Послал вместо себя убийцу в погреб, чтобы он отравил бутылки. Однако убийцу быстро нашли и поймали до того, как он отравил все бутылки. По правде говоря, он успел только одну из них отравить.
И теперь перед королем стоит задача - определить отравленное вино, потому что убийца не сознается.
Чтобы не травить людей, король приказал принести ему 10 кроликов. По задумке кролики будут пить вина из каждой бутылки и рано и поздно, найдется отравленная. Каждый кролик может пить неограниченное количество вина. То что он будет вдрызг пьяный, не значит, что он мертвый 😁
Чтобы убить живое существо, яду нужно примерно 24 часа.
Имея 10 кроликов и 1000 бутылок, королю нужно за минимальное время определить, какая из бутылок отравленная, чтобы продолжить пить свое любимое вино.
Решением задачи будет стратегия, придерживаясь которой гарантированно определяется нужная бутылка за минимальное количество времени.
Кидайте свои варианты в комменты. Если знаете реальное решение, то прошу не писать его, чтобы другие могли хорошенько подумать.
Кажется, что тут даже можно что-то пообсуждать, поэтому оставлю вас без решения пока. Ответ напишу в комментах к завтрашнему посту. Не гуглите решение, чтобы не испортить себе впечатление. Так что подрубаем уведомления, скорее всего вы сильно удивитесь решению.
Solve problems. Stay cool.
#fun
Есть одна задачка, которая вскружила мне голову элегантностью своего решения. Сформулирована она как обычная задачка на логику, но по сути своей очень программистская. Для людей с очень «низкоуровневым мышлением». Поэтому и решил с вами ей поделиться. Кажется плюсовый канал - подходящее место для таких задачек. Может я преувеличиваю, но я художник, я так чувствую.
Собсна формулировка. Жил был король. Хорошо король правил своей страной, богатая она была. И король соответственно тоже жил в большой роскоши. Появился у этого короля завистник среди придворной интеллигенции и захотел он убить короля. Думал про разные способы убийства и вспомнил одну деталь. Король очень любит вино и в погребе дворца есть 1000 бутылок его самого любимого вина, которое он пьет каждый день. И решил завистник отравить вино. Послал вместо себя убийцу в погреб, чтобы он отравил бутылки. Однако убийцу быстро нашли и поймали до того, как он отравил все бутылки. По правде говоря, он успел только одну из них отравить.
И теперь перед королем стоит задача - определить отравленное вино, потому что убийца не сознается.
Чтобы не травить людей, король приказал принести ему 10 кроликов. По задумке кролики будут пить вина из каждой бутылки и рано и поздно, найдется отравленная. Каждый кролик может пить неограниченное количество вина. То что он будет вдрызг пьяный, не значит, что он мертвый 😁
Чтобы убить живое существо, яду нужно примерно 24 часа.
Имея 10 кроликов и 1000 бутылок, королю нужно за минимальное время определить, какая из бутылок отравленная, чтобы продолжить пить свое любимое вино.
Решением задачи будет стратегия, придерживаясь которой гарантированно определяется нужная бутылка за минимальное количество времени.
Кидайте свои варианты в комменты. Если знаете реальное решение, то прошу не писать его, чтобы другие могли хорошенько подумать.
Кажется, что тут даже можно что-то пообсуждать, поэтому оставлю вас без решения пока. Ответ напишу в комментах к завтрашнему посту. Не гуглите решение, чтобы не испортить себе впечатление. Так что подрубаем уведомления, скорее всего вы сильно удивитесь решению.
Solve problems. Stay cool.
#fun
{kind=link}
Линковка констант
Сегодня начнем затрагивать вопрос линковки переменных, линковки в целом и тонкости этого процесса. На эту тему несколько постов, плавно перетекающих друг в друга.
Давайте предположим, что у нас есть некоторый набор констант. Пусть это будут тривиальные физические константы, типа скорости света, числа авагадро и тд. И мы хотим использовать эти константы в разных единицах трансляции. Очевидный вариант - вынести их в какой-нибудь хэдер и подключать его всякий раз при необходимости. Получаем что-то типа такого:
Используем здесь constexpr для появления возможности использования этих констант в compile-time вычислениях.
Почему это вообще работает? Мы ведь здесь подключаем одно и то же определение в разные юниты трансляции. ODR должно нам запретить такое делать.
Дело в том, что все константы имеют по умолчанию внутреннее связывание. То же самое и для constexpr. Внутреннее связывание гарантирует, что в каждом юните трансляции будет использоваться своя копия этих переменных и ни из какого другого юнита нельзя будет получить доступ к ним. То есть определение этих констант везде будет свое. И ODR не будет нарушаться.
Если пометить константы как static, то ничего толком не изменится, потому что они и так неявно статические. То есть с внутренним связыванием.
У такого подхода есть проблемы.
Каждый раз, когда мы включаем заголовочный файл с константами в файл с кодом, каждая из этих переменных копируется в файл с кодом. Поэтому, если constants.hpp включается в 20 различных файлов кода, каждая из этих переменных дублируется 20 раз. Из этого следует следующее:
1️⃣ Изменение одной константы потребует перекомпиляции каждого файла, использующего константы(даже если измененная константа там не используется!), что делает компиляцию долгой для крупных проектов.
2️⃣ Если константы имеют большой размер и не могут быть оптимизированы, это приведёт к нежелательному расходу памяти.
Какое здесь решение? Подождать следующего поста, там будут объяснения)
Solve the problems. Stay cool.
#cppcore #compiler
Сегодня начнем затрагивать вопрос линковки переменных, линковки в целом и тонкости этого процесса. На эту тему несколько постов, плавно перетекающих друг в друга.
Давайте предположим, что у нас есть некоторый набор констант. Пусть это будут тривиальные физические константы, типа скорости света, числа авагадро и тд. И мы хотим использовать эти константы в разных единицах трансляции. Очевидный вариант - вынести их в какой-нибудь хэдер и подключать его всякий раз при необходимости. Получаем что-то типа такого:
// constants.hpp
#pragma once
namespace constants
{
constexpr unsigned light_speed { 299 792 458 };
constexpr double avogadro { 6.0221413e23 };
// ... other related constants
}
Используем здесь constexpr для появления возможности использования этих констант в compile-time вычислениях.
Почему это вообще работает? Мы ведь здесь подключаем одно и то же определение в разные юниты трансляции. ODR должно нам запретить такое делать.
Дело в том, что все константы имеют по умолчанию внутреннее связывание. То же самое и для constexpr. Внутреннее связывание гарантирует, что в каждом юните трансляции будет использоваться своя копия этих переменных и ни из какого другого юнита нельзя будет получить доступ к ним. То есть определение этих констант везде будет свое. И ODR не будет нарушаться.
Если пометить константы как static, то ничего толком не изменится, потому что они и так неявно статические. То есть с внутренним связыванием.
У такого подхода есть проблемы.
Каждый раз, когда мы включаем заголовочный файл с константами в файл с кодом, каждая из этих переменных копируется в файл с кодом. Поэтому, если constants.hpp включается в 20 различных файлов кода, каждая из этих переменных дублируется 20 раз. Из этого следует следующее:
1️⃣ Изменение одной константы потребует перекомпиляции каждого файла, использующего константы(даже если измененная константа там не используется!), что делает компиляцию долгой для крупных проектов.
2️⃣ Если константы имеют большой размер и не могут быть оптимизированы, это приведёт к нежелательному расходу памяти.
Какое здесь решение? Подождать следующего поста, там будут объяснения)
Solve the problems. Stay cool.
#cppcore #compiler
{kind=link}
Как это всегда со мной бывает, я забыл вставить решение вчерашней задачи, поэтому решил сделать это сейчас
То есть решение будет в первом комменте к этому посту
То есть решение будет в первом комменте к этому посту
Линковка констант Ч2
Мы узнали один из вариантов, как можно подключать константы в свои файлы с кодом. Однако у него были проблемы, которые мы попытаемся решить сегодня.
Все проблемы прошлого варианта по сути сводится к последствиям внутренней линковки.
Если у нас будет только одно определение переменной и весь остальной код будет только ссылаться на него, то решится проблема с перекомпиляцией. Потому что задача подстановки символов будет решаться при линковке. Во всех единицах трансляции будет просто заглушка для этой константы. И реальное значение будет подставляться компановщиком. А значит ничего не нужно заново компилировать.
Одно определение также решит вопрос нежелательного расхода памяти, так как экземпляр константы будет один и занимать одну условную единицу памяти. Никакого дублирования не будет.
Как мы можем добиться, чтобы определение констант было всего одно?
Обеспечить им внешнее связывание. С помощью ключевого слова extern.
Теперь константы будут создаваться только один раз (в единице трансляции соотвествующей constants.cpp), а не каждый раз при включении constants.h, и все использования будут просто ссылаться на версию в constants.cpp. Любые внесенные изменения в constants.cpp потребуют только перекомпиляции constants.cpp.
Однако и у этого метода есть несколько недостатков(да штож такое).
1️⃣ Эти константы теперь могут считаться константами времени компиляции только в файле, в котором они фактически определены (constants.cpp), а не где-либо еще. Это означает, что вне constants.cpp они не могут быть использованы нигде, где требуются вычисления в compile-time. Печально.
2️⃣ В принципе оптимизировать их использование компилятору сложнее, потому что он не имеет доступа к настоящему значению.
3️⃣ Неудобно просто. Каждый раз нужно ходить в реализацию, чтобы удостовериться в значении константы - такое себе. Да, современные IDE могут решить этот вопрос. А могут и не решить. Плюс нужно или мышку наводить или кнопки какие-то нажимать. Слишком много действий!
Шучу конечно. Но намного удобнее определение держать в хэдере.
Учитывая вышеперечисленные недостатки, хочется определять константы в заголовочном файле. Наконец-то мы подбираемся к самой мякотке. Но об этом - в следующих постах)
Stay in touch. Stay cool.
#cppcore #compiler
Мы узнали один из вариантов, как можно подключать константы в свои файлы с кодом. Однако у него были проблемы, которые мы попытаемся решить сегодня.
Все проблемы прошлого варианта по сути сводится к последствиям внутренней линковки.
Если у нас будет только одно определение переменной и весь остальной код будет только ссылаться на него, то решится проблема с перекомпиляцией. Потому что задача подстановки символов будет решаться при линковке. Во всех единицах трансляции будет просто заглушка для этой константы. И реальное значение будет подставляться компановщиком. А значит ничего не нужно заново компилировать.
Одно определение также решит вопрос нежелательного расхода памяти, так как экземпляр константы будет один и занимать одну условную единицу памяти. Никакого дублирования не будет.
Как мы можем добиться, чтобы определение констант было всего одно?
Обеспечить им внешнее связывание. С помощью ключевого слова extern.
//constant.cpp
#include "constant.hpp"
namespace constants
{
const unsigned light_speed { 299'792'458 };
const double avogadro { 6.0221413e23 };
// ... other related constants
}
//constant.hpp
#pragma once
namespace constants
{
extern const unsigned light_speed;
extern const double avogadro;
// ... other related constants
}
Теперь константы будут создаваться только один раз (в единице трансляции соотвествующей constants.cpp), а не каждый раз при включении constants.h, и все использования будут просто ссылаться на версию в constants.cpp. Любые внесенные изменения в constants.cpp потребуют только перекомпиляции constants.cpp.
Однако и у этого метода есть несколько недостатков(да штож такое).
1️⃣ Эти константы теперь могут считаться константами времени компиляции только в файле, в котором они фактически определены (constants.cpp), а не где-либо еще. Это означает, что вне constants.cpp они не могут быть использованы нигде, где требуются вычисления в compile-time. Печально.
2️⃣ В принципе оптимизировать их использование компилятору сложнее, потому что он не имеет доступа к настоящему значению.
3️⃣ Неудобно просто. Каждый раз нужно ходить в реализацию, чтобы удостовериться в значении константы - такое себе. Да, современные IDE могут решить этот вопрос. А могут и не решить. Плюс нужно или мышку наводить или кнопки какие-то нажимать. Слишком много действий!
Шучу конечно. Но намного удобнее определение держать в хэдере.
Учитывая вышеперечисленные недостатки, хочется определять константы в заголовочном файле. Наконец-то мы подбираемся к самой мякотке. Но об этом - в следующих постах)
Stay in touch. Stay cool.
#cppcore #compiler
{kind=link}
Реальное предназначение inline
В этом посте мы говорили о том, почему встраивание функций - важная задача для перформанса приложения. И что ключевое слово inline изначально предназначалось для того, чтобы указывать компилятору, какую функцию ему нужно встроить. Но программы уже давно намного умнее людей в очень специфических задачах. И компилятор стал настолько умным, что он теперь без нашего прямого указания может самостоятельно встраивать функции, которые даже не помечены inline. А также имеет полное право игнорировать наши прямые указания на встраивание. В случае прямого указания он обязан выполнить проверку возможности встраивания, но при оптимизациях компилятор и так это делает.
Но тогда смысл ключевого слова inline несколько теряется в тумане. Все равно все используют оптимизации в продакшене. Тогда есть ли реальная польза от использования inline?
Есть! Сейчас все разберем.
В чем прикол. Прикол в том, что для того, чтобы компилятор смог встроить функцию, ее определение ОБЯЗАНО быть видно в той единице трансляции, в которой она используется. Именно на этапе компиляции. Как можно встроить код, которого нет сейчас в доступе?
Почему это нельзя сделать на этапе линковки? Линкер резолвит проблему символов. Он сопоставляет имена с их содержимым. Линкер от слова link - связка. Для встраивания функции нужно иметь доступ к ее исходникам и информации вокруг вызова функции. Такого доступа у линкера нет. Да и задачи кодогенерации у него нет.
Что нужно, чтобы на этапе компиляции, компилятор видел определение функции? Ее можно определить в цппшнике, тогда все будет четко. Но такую функцию нельзя переиспользовать. Она будет тупо скрыта от всех других единиц трансляции. Ее можно было бы переиспользовать. Тогда нужно было бы везде forward declaration вставлять, что очень неудобно. И она видна будет только во время линковки. Во время компиляции ни одна другая единица трансляции ее не увидит. Поэтому нам это не подходит.
Тогда второй способ с потенциальной возможностью переиспользования: вынести определение в хэдер. Тогда всем единицам трансляции, которые подключают хэдер, будет доступно определение нашей функции. Но вот есть проблема - тогда во всех единицах трансляции будет определение нашей функции. А это нарушение ODR.
Как выходить из ситуации? Можно пометить функцию как static. Тогда в каждой единице трансляции будет своя копия функции. Но это ведет к дублированию кода функции и увеличению размера бинарника. Это нам не подходит.
Выходит, что у нас только одно решение. Разрешить inline функциям находиться в хэдерах и не нарушать ODR! Тогда нам нужны некоторые оговорки: мы разрешаем определению одной и той же inline функции быть в разных единицах трансляции, но тогда все эти определения должны быть идентичные. Потому что как бы предполагается, что они все определены в одном месте КОДА. Линкер потом объединяет все определения функции в одно(на самом деле выбирает одно из них, а другие откидывает). И вот у нас уже один экземпляр функции на всю программу.
Что мы имеем по итогу. Если мы хотим поместить определение обычной функции в хэдэр, то нам настучит по башке линкер со своим multiple definition и мы уйдем грустные в закат. Но теперь у нас есть другой вид функций, которые как бы должны быть встроены, но никто этого не гарантирует, и которые можно определять в хэдерах. Такие функции могут быть встроены с той же вероятностью, что и все остальные, поэтому от этой части смысла никакого нет. Получается, что мы можем пометить нашу функцию inline и тогда она ее просто можно будет определять в заголовочниках. Гениально.
Ох и непростая тема! Советую пару раз прочитать этот пост, чтобы хорошо все усвоить. Информация очень глубокая и фундаментальная. Пишите в комментах, что непонятно. И замечания тоже пишите.
Dig deeper. Stay cool.
#cppcore #compiler #hardcore #design #howitworks
В этом посте мы говорили о том, почему встраивание функций - важная задача для перформанса приложения. И что ключевое слово inline изначально предназначалось для того, чтобы указывать компилятору, какую функцию ему нужно встроить. Но программы уже давно намного умнее людей в очень специфических задачах. И компилятор стал настолько умным, что он теперь без нашего прямого указания может самостоятельно встраивать функции, которые даже не помечены inline. А также имеет полное право игнорировать наши прямые указания на встраивание. В случае прямого указания он обязан выполнить проверку возможности встраивания, но при оптимизациях компилятор и так это делает.
Но тогда смысл ключевого слова inline несколько теряется в тумане. Все равно все используют оптимизации в продакшене. Тогда есть ли реальная польза от использования inline?
Есть! Сейчас все разберем.
В чем прикол. Прикол в том, что для того, чтобы компилятор смог встроить функцию, ее определение ОБЯЗАНО быть видно в той единице трансляции, в которой она используется. Именно на этапе компиляции. Как можно встроить код, которого нет сейчас в доступе?
Почему это нельзя сделать на этапе линковки? Линкер резолвит проблему символов. Он сопоставляет имена с их содержимым. Линкер от слова link - связка. Для встраивания функции нужно иметь доступ к ее исходникам и информации вокруг вызова функции. Такого доступа у линкера нет. Да и задачи кодогенерации у него нет.
Что нужно, чтобы на этапе компиляции, компилятор видел определение функции? Ее можно определить в цппшнике, тогда все будет четко. Но такую функцию нельзя переиспользовать. Она будет тупо скрыта от всех других единиц трансляции. Ее можно было бы переиспользовать. Тогда нужно было бы везде forward declaration вставлять, что очень неудобно. И она видна будет только во время линковки. Во время компиляции ни одна другая единица трансляции ее не увидит. Поэтому нам это не подходит.
Тогда второй способ с потенциальной возможностью переиспользования: вынести определение в хэдер. Тогда всем единицам трансляции, которые подключают хэдер, будет доступно определение нашей функции. Но вот есть проблема - тогда во всех единицах трансляции будет определение нашей функции. А это нарушение ODR.
Как выходить из ситуации? Можно пометить функцию как static. Тогда в каждой единице трансляции будет своя копия функции. Но это ведет к дублированию кода функции и увеличению размера бинарника. Это нам не подходит.
Выходит, что у нас только одно решение. Разрешить inline функциям находиться в хэдерах и не нарушать ODR! Тогда нам нужны некоторые оговорки: мы разрешаем определению одной и той же inline функции быть в разных единицах трансляции, но тогда все эти определения должны быть идентичные. Потому что как бы предполагается, что они все определены в одном месте КОДА. Линкер потом объединяет все определения функции в одно(на самом деле выбирает одно из них, а другие откидывает). И вот у нас уже один экземпляр функции на всю программу.
Что мы имеем по итогу. Если мы хотим поместить определение обычной функции в хэдэр, то нам настучит по башке линкер со своим multiple definition и мы уйдем грустные в закат. Но теперь у нас есть другой вид функций, которые как бы должны быть встроены, но никто этого не гарантирует, и которые можно определять в хэдерах. Такие функции могут быть встроены с той же вероятностью, что и все остальные, поэтому от этой части смысла никакого нет. Получается, что мы можем пометить нашу функцию inline и тогда она ее просто можно будет определять в заголовочниках. Гениально.
Ох и непростая тема! Советую пару раз прочитать этот пост, чтобы хорошо все усвоить. Информация очень глубокая и фундаментальная. Пишите в комментах, что непонятно. И замечания тоже пишите.
Dig deeper. Stay cool.
#cppcore #compiler #hardcore #design #howitworks
{kind=link}
Определение статических полей класса
Если вы хоть раз пытались наивно инициализировать статический член класса внутри самого класса, то явно знаете, о чем речь пойдет. А для тех, кто не знает, скажу, что произойдет дальше. Компилятор выдаст ошибку типа: ISO C++ forbids in-class initialization of non-const static member. Стандарт запрещает неконстантным статическим полям инициализироваться внутри класса. Ранее стандартной практикой для решения этой проблемы был вынос определения этого поля в цпп файл. Решение довольно неудобное, ибо каждый раз нужно лезть в файл реализации, чтобы посмотреть инициализатор. Да и писать это не очень удобно. В потенциале для такой инициализации нужно дополнительно написать в 1.5 раза больше букав, чем при удобной in-class инициализации. Если это так неудобно, то почему такое правило вообще введено?
Давайте небольшой рекап для статических членов. Статическое поле класса - по сути глобальный объект, который как бы присоединен к классу. Любой объект класса может получить доступ к одному и тому же инстансу статической переменной. Как и любой код, который может создать объект класса, сможет использовать его статический член через имя класса. Типа такого ClassType::static_field. То есть, несмотря на то, что поле объявлено как static, оно имеет внешнее связывание. То есть существует лишь один инстанс этого поля, который виден всему коду, имеющему доступ к классу. И для такой сущности применяется One Definition Rule(ODR), которое говорит, что у переменной или функции(за некоторыми исключениями) внутри ВСЕЙ программы может быть сколько угодно объявлений, но только одно определение. Ща поясню, к чему это приводит.
Вот у вас есть описание класса в каком-то хэдере. Как использовать этот класс? Заинклюдить этот хэдер в нужный файлик. А что делает иклюд? Правильно, на этапе препроцессора он просто заменяется на текст подключаемого файла. Поэтому если у вас определение статического поля находится в хэдере, значит у вас есть определение этого поля во всех единицах трансляции, куда попало описание класса. А это прямое нарушение ODR.
Описания классов обычно находятся в хэдэрах, поэтому проще просто запретить определять статические поля внутри классов.
Как меняет ситуацию определение поля вне класса в цпп файле? Это позволяет не нарушать ODR, все просто) Ну если чуть подробнее, то во всех единицах трансляции, куда мы подключили описание класса, будет только объявление нашего поля. И только одно определение будет браться из нашего цпп файлика.
И кстати в файле реализации нельзя приписывать определению переменной пометку static. Это путает компилятор. Обычно для переменных static значит статическое время жизни и внутреннюю линковку, а нам здесь нужна внешняя линковка.
Это кстати довольно важно подсветить: static для обычных глобальных переменных меняет их тип линковки на внутреннюю, а внутри класса static обозначает внешнюю линковку(что с методами, что с полями).
Но начиная с 17-х плюсов есть намного более изящный способ обойти ODR в этом конкретном случае. Постоянные читатели или просто знающие люди уже понимают, о чем речь. Но пост об этом будет позже)
Define yourself. Stay cool.
#cppcore
Если вы хоть раз пытались наивно инициализировать статический член класса внутри самого класса, то явно знаете, о чем речь пойдет. А для тех, кто не знает, скажу, что произойдет дальше. Компилятор выдаст ошибку типа: ISO C++ forbids in-class initialization of non-const static member. Стандарт запрещает неконстантным статическим полям инициализироваться внутри класса. Ранее стандартной практикой для решения этой проблемы был вынос определения этого поля в цпп файл. Решение довольно неудобное, ибо каждый раз нужно лезть в файл реализации, чтобы посмотреть инициализатор. Да и писать это не очень удобно. В потенциале для такой инициализации нужно дополнительно написать в 1.5 раза больше букав, чем при удобной in-class инициализации. Если это так неудобно, то почему такое правило вообще введено?
Давайте небольшой рекап для статических членов. Статическое поле класса - по сути глобальный объект, который как бы присоединен к классу. Любой объект класса может получить доступ к одному и тому же инстансу статической переменной. Как и любой код, который может создать объект класса, сможет использовать его статический член через имя класса. Типа такого ClassType::static_field. То есть, несмотря на то, что поле объявлено как static, оно имеет внешнее связывание. То есть существует лишь один инстанс этого поля, который виден всему коду, имеющему доступ к классу. И для такой сущности применяется One Definition Rule(ODR), которое говорит, что у переменной или функции(за некоторыми исключениями) внутри ВСЕЙ программы может быть сколько угодно объявлений, но только одно определение. Ща поясню, к чему это приводит.
Вот у вас есть описание класса в каком-то хэдере. Как использовать этот класс? Заинклюдить этот хэдер в нужный файлик. А что делает иклюд? Правильно, на этапе препроцессора он просто заменяется на текст подключаемого файла. Поэтому если у вас определение статического поля находится в хэдере, значит у вас есть определение этого поля во всех единицах трансляции, куда попало описание класса. А это прямое нарушение ODR.
Описания классов обычно находятся в хэдэрах, поэтому проще просто запретить определять статические поля внутри классов.
Как меняет ситуацию определение поля вне класса в цпп файле? Это позволяет не нарушать ODR, все просто) Ну если чуть подробнее, то во всех единицах трансляции, куда мы подключили описание класса, будет только объявление нашего поля. И только одно определение будет браться из нашего цпп файлика.
И кстати в файле реализации нельзя приписывать определению переменной пометку static. Это путает компилятор. Обычно для переменных static значит статическое время жизни и внутреннюю линковку, а нам здесь нужна внешняя линковка.
Это кстати довольно важно подсветить: static для обычных глобальных переменных меняет их тип линковки на внутреннюю, а внутри класса static обозначает внешнюю линковку(что с методами, что с полями).
Но начиная с 17-х плюсов есть намного более изящный способ обойти ODR в этом конкретном случае. Постоянные читатели или просто знающие люди уже понимают, о чем речь. Но пост об этом будет позже)
Define yourself. Stay cool.
#cppcore
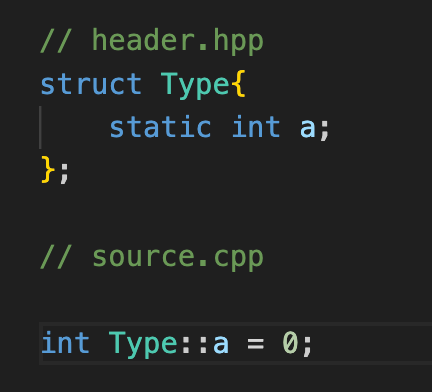{kind=link}
inline переменные
Так, ну это уже перебор. inline для функций окей, можем встроить ее код в место вызова. Но что значит встроенная переменная? Мы же в месте, где используется переменная просто ссылаемся на оригинал переменной через указатель(адресом переменной для динамических объектов или отступом от регистра для локальных). Переменная - это же память. Не понятно, что значит встроить память в код. Это в принципе не имеет смысла. Разве что можно встроить какие-нибудь чиселки в непосредственное место их использования как один из операндов. Но компилятор уже это и так делает, без наших просьб. В чем тогда смысл?
Мы уже поговорили о том, что смысл ключевого слова inline для функций в современных реалиях С++ - это уже совсем не про inline expansion, а про обеспечение обхода ODR. Это позволяет определять функцию прямо в хэдере. При этом линкер не обидится на нас и даже прогарантирует, что объединит все определения в одно и тогда в места вызова функции будет даже один и тот же адрес подставляться.
И вот именно эту семантику и перенимают переменные в С++17, которые теперь могут быть помечены ключевым словом inline. Какие конкретно преимущества теперь получают переменные?
Теперь мы прямо в заголовочнике можем определить значение для переменной, например, константы. Компоновщик просто потом объединит все определения в одно. То есть будет всего один оригинал переменной и гарантируется, что она будет создана только один раз и совместно будет использоваться во всех файлах с кодом.
Что это нам дает?
1️⃣ Внешнее связывание inline дает нам преимущества компактности размера скомпилированного кода.
2️⃣ Компилятор может оптимизировать переменные как он хочет, потому что видит определение на момент компиляции.
3️⃣ По той же причине, все compile-time вычисления имеют место быть.
4️⃣ Нет перекомпиляции за неиспользованные переменные.
5️⃣ Определение находится в хэдере и это удобно смотреть.
Все проблемы отсюда и отсюда решены!! Магия вне Хогвартса!
На картинке показано, как с новыми знаниями можно определять константы в хэдерах.
Stay satisfied. Stay cool.
#cppcore #compiler #cpp17
Так, ну это уже перебор. inline для функций окей, можем встроить ее код в место вызова. Но что значит встроенная переменная? Мы же в месте, где используется переменная просто ссылаемся на оригинал переменной через указатель(адресом переменной для динамических объектов или отступом от регистра для локальных). Переменная - это же память. Не понятно, что значит встроить память в код. Это в принципе не имеет смысла. Разве что можно встроить какие-нибудь чиселки в непосредственное место их использования как один из операндов. Но компилятор уже это и так делает, без наших просьб. В чем тогда смысл?
Мы уже поговорили о том, что смысл ключевого слова inline для функций в современных реалиях С++ - это уже совсем не про inline expansion, а про обеспечение обхода ODR. Это позволяет определять функцию прямо в хэдере. При этом линкер не обидится на нас и даже прогарантирует, что объединит все определения в одно и тогда в места вызова функции будет даже один и тот же адрес подставляться.
И вот именно эту семантику и перенимают переменные в С++17, которые теперь могут быть помечены ключевым словом inline. Какие конкретно преимущества теперь получают переменные?
Теперь мы прямо в заголовочнике можем определить значение для переменной, например, константы. Компоновщик просто потом объединит все определения в одно. То есть будет всего один оригинал переменной и гарантируется, что она будет создана только один раз и совместно будет использоваться во всех файлах с кодом.
Что это нам дает?
1️⃣ Внешнее связывание inline дает нам преимущества компактности размера скомпилированного кода.
2️⃣ Компилятор может оптимизировать переменные как он хочет, потому что видит определение на момент компиляции.
3️⃣ По той же причине, все compile-time вычисления имеют место быть.
4️⃣ Нет перекомпиляции за неиспользованные переменные.
5️⃣ Определение находится в хэдере и это удобно смотреть.
Все проблемы отсюда и отсюда решены!! Магия вне Хогвартса!
На картинке показано, как с новыми знаниями можно определять константы в хэдерах.
Stay satisfied. Stay cool.
#cppcore #compiler #cpp17
{kind=link}
Нормальное определение статических полей класса
Здесь мы посмотрели на проблему, которая стоит перед нами, когда мы пытаемся определить статическое поле класса. А проблема такова, что статические поля класса имеют внешнее связывание. За объяснением этого утверждения можете перейти по ссылке на тот пост, а мы продолжим.
Мы никак не можем обойти это ограничение вплоть до С++17. ODR требует, чтобы мы определяли статические поля вне класса и хэдера. Можно было бы поставить квалификатор const, но это уже другой разговор. Это не всегда нужно. И это совершенно не подходит для случая, когда нам нужно изменять наш объект. Да и статические константные поля можно инициализировать внутри класса только если это тривиальные типы.
Но! В C++17 завезли нам прекрасную фичу - inline переменные. Мы теперь можем определять символы с внешним связыванием во множестве единиц трансляции! И это как раз то, что нам нужно!
Мы просто берем и в хэдере определяем статическое поле, помечаем его inline и все готово. Никто на нас не ругается и все работает, как часы. Можем теперь как белые люди все писать в хэдерах. Это намного более удобно и не требует больших затрат. 8 дополнительных символов и Доби свободен!
Берите на заметку. Это прикольное и, главное, реально полезное приложение inline, которым вы будете довольно часто пользоваться.
Be free. Stay cool.
#cpp17 #compiler
Здесь мы посмотрели на проблему, которая стоит перед нами, когда мы пытаемся определить статическое поле класса. А проблема такова, что статические поля класса имеют внешнее связывание. За объяснением этого утверждения можете перейти по ссылке на тот пост, а мы продолжим.
Мы никак не можем обойти это ограничение вплоть до С++17. ODR требует, чтобы мы определяли статические поля вне класса и хэдера. Можно было бы поставить квалификатор const, но это уже другой разговор. Это не всегда нужно. И это совершенно не подходит для случая, когда нам нужно изменять наш объект. Да и статические константные поля можно инициализировать внутри класса только если это тривиальные типы.
Но! В C++17 завезли нам прекрасную фичу - inline переменные. Мы теперь можем определять символы с внешним связыванием во множестве единиц трансляции! И это как раз то, что нам нужно!
Мы просто берем и в хэдере определяем статическое поле, помечаем его inline и все готово. Никто на нас не ругается и все работает, как часы. Можем теперь как белые люди все писать в хэдерах. Это намного более удобно и не требует больших затрат. 8 дополнительных символов и Доби свободен!
Берите на заметку. Это прикольное и, главное, реально полезное приложение inline, которым вы будете довольно часто пользоваться.
Be free. Stay cool.
#cpp17 #compiler
{kind=link}
Оптимизации RVO / NRVO
Всем привет! Настало время завершающего поста этой серии. Сегодня мы поговорим об одной из самых нетривиальных оптимизаций в С++.
Я очень удивлюсь, если встречу человека, который по мере изучения стандартных контейнеров никогда не задумывался, что эти ребята слишком «жирные», чтобы их просто так возвращать в качестве результата функции или метода:
...и приходили к мысли, что нужно заполнять уже существующий объект:
Эта мысль волновала всех с давних времен... Поэтому она нашла поддержку от разработчиков компиляторов.
Существует такие древние оптимизации, как RVO (Return Value Optimization) и NRVO (Named Return Value Optimization). Они призваны избавить нас от потенциально избыточных и лишних вызовов конструктора копирования для объектов на стеке. Например, в таких ситуациях:
Давайте взглянем на живой пример 1, в котором вызов конструктора копирования явно пропускается. Вообще говоря, эта информация немного выбивается в контексте постов, посвященных move семантике C++11, т.к. это работает даже на C++98. Вот поэтому я её называю древней 😉
Немного теории. При вызове функции резервируется место на стеке, куда должно быть записано возвращаемое значение функции. Если компилятор может гарантировать, что функция возвращает единственный локальный объект, тип которого совпадает с
Иными словами, компилятор пытается понять, можно ли "подсунуть" область памяти
В конце поста потом почитайте ассемблерный код в комментариях, а пока продолжим.
RVO отличается NRVO тем, что в первом случае выполняется оптимизация для объекта, который создается при выходе из функции в
А во втором для возвращаемого именованного объекта:
Но при этом замысел и суть остаются такими же! Тут важно отметить, что и вам, и компилятору, по объективным причинам, намного проще доказать корректность RVO, чем NRVO.
Давайте покажу, когда NRVO может не сработать и почему. Рассмотрим кусочек из живого примера 2:
Оптимизация NRVO не выполнится. В данном примере компилятору будет неясно, какой именно из объектов
Продолжение в комментариях!
#cppcore #memory #algorithm #hardcore
Всем привет! Настало время завершающего поста этой серии. Сегодня мы поговорим об одной из самых нетривиальных оптимизаций в С++.
Я очень удивлюсь, если встречу человека, который по мере изучения стандартных контейнеров никогда не задумывался, что эти ребята слишком «жирные», чтобы их просто так возвращать в качестве результата функции или метода:
std::string get_very_long_string();
...и приходили к мысли, что нужно заполнять уже существующий объект:
void fill_very_long_string(std::string &);
Эта мысль волновала всех с давних времен... Поэтому она нашла поддержку от разработчиков компиляторов.
Существует такие древние оптимизации, как RVO (Return Value Optimization) и NRVO (Named Return Value Optimization). Они призваны избавить нас от потенциально избыточных и лишних вызовов конструктора копирования для объектов на стеке. Например, в таких ситуациях:
// RVO example
Foo f()
{
return Foo();
}
// NRVO example
Foo f()
{
Foo named_object;
return named_object;
}
// Foo no coping
Foo obj = f();
Давайте взглянем на живой пример 1, в котором вызов конструктора копирования явно пропускается. Вообще говоря, эта информация немного выбивается в контексте постов, посвященных move семантике C++11, т.к. это работает даже на C++98. Вот поэтому я её называю древней 😉
Немного теории. При вызове функции резервируется место на стеке, куда должно быть записано возвращаемое значение функции. Если компилятор может гарантировать, что функция возвращает единственный локальный объект, тип которого совпадает с
lvalue, тогда он может сразу сконструировать этот объект напрямую в ожидаемом месте вызывающего кода. Допустимо отличаться на константность.Иными словами, компилятор пытается понять, можно ли "подсунуть" область памяти
lvalue при вычислении rvalue и гарантировать, что мы получим тот же результат, что и при обычном копировании. Можно считать, что компилятор преобразует код в следующий:void f(Foo *address)
{
// construct an object Foo
// in memory at address
new (address) Foo();
}
int main()
{
auto *address = reinterpret_cast<Foo *>(
// allocate memory directly on stack!
alloca(sizeof(Foo))
);
f(address);
}
В конце поста потом почитайте ассемблерный код в комментариях, а пока продолжим.
RVO отличается NRVO тем, что в первом случае выполняется оптимизация для объекта, который создается при выходе из функции в
return:// RVO example
Foo f()
{
return Foo();
}
А во втором для возвращаемого именованного объекта:
// NRVO example
Foo f()
{
Foo named_object;
return named_object;
}
Но при этом замысел и суть остаются такими же! Тут важно отметить, что и вам, и компилятору, по объективным причинам, намного проще доказать корректность RVO, чем NRVO.
Давайте покажу, когда NRVO может не сработать и почему. Рассмотрим кусочек из живого примера 2:
// NRVO failed!
Foo f(bool value)
{
Foo a, b;
if (value)
return a;
else
return b;
}
Оптимизация NRVO не выполнится. В данном примере компилятору будет неясно, какой именно из объектов
a или b будет возвращен. Несмотря на то, что объекты БУКВАЛЬНО одинаковые, нельзя гарантировать применимость NRVO. До if (value) можно было по-разному поменять каждый из объектов и их память. Или вдруг у вас в конструкторе Foo зашит генератор случайных чисел? 😉 Следовательно, компилятору может быть непонятно куда надо конструировать объект напрямую из этих двух. Тут будет применено копирование.Продолжение в комментариях!
#cppcore #memory #algorithm #hardcore
{kind=link}
Static
Ключевое слово static не зря вызывает столько вопросов. Его можно применять к куче разных сущностей и везде поведение будет разным. Поэтому поначалу это все довольно сложно усвоить. Будем потихоньку разбирать каждый аспект применения static в подробностях, но сейчас соберу все вместе и кратко расскажу о ключевых особенностях каждого.
Всего есть 5 возможных способа применить static:
👉🏿 К глобальным переменным. Есть у вас файлик и вы в нем определили глобальную переменную std::string ж = "опа";. Такой неконстантной глобальной переменной автоматически присваивается внешнее связывание. То есть все единицы трансляции могут увидеть эту переменную и использовать ее(через forward declaration). Как только вы пометите ее как static, тип связывания изменится на внутреннее. Это значит, что никакие другие единицы трансляции не смогут получить доступ к конкретно этому экземпляру строки. Время жизни переменной в этом случае не особо меняется.
👉🏿 К локальным переменным функции. В этом случае переменная будет продолжать принадлежать функции, но теперь ее время жизни с автоматического изменится на статическое. То есть переменная будет продолжать жить между вызовами функции и сохранять свое значение с предыдущего вызова. Такие переменные гарантированно инициализируются атомарно и один раз при самом первом вызове функции.
👉🏿 К полям класса. В отличии от обычных членов класса, для доступа к которым нужен объект, для статических полей объект не нужен. Представьте, что это глобальная переменная, которая "присоединена" к классу. Это поле видно всем, кому доступно определение класса, и к нему можно обратиться с помощью имени класса, типа такого Type::static_member. Также такие поля доступны в методах класса. Короче. Ничего особенного, просто глобальная переменная принадлежащая классу.
👉🏿 К свободным функциям. Ситуация очень похожа на ситуацию с глобальными переменными. По сути изменяется только тип связывания. Такую функцию нельзя увидеть из другой единицы трансляции.
👉🏿 К методам класса. Ситуация похожа на применение static к полям класса. Это свободная функция, которая присоединена к классу. Однако у нее есть еще одно преимущество, что такие методы имеют возможность доступа ко всем полям класса. Если каким-то образом заиметь объект того же самого класса внутри статического метода, то можно пользоваться плюшками доступа ко всем полям.
Как видно, что прошлись сильно по верхам. Я специально не затрагивал нюансы и описывал все крупными мазками. Нюансы будут, когда будем все подробно разбирать.
Вот такая многогранная вещь этот static. Ждите следующих частей, будет жарко🔥.
Stay hot. Stay cool.
#cppcore #howitworks
Ключевое слово static не зря вызывает столько вопросов. Его можно применять к куче разных сущностей и везде поведение будет разным. Поэтому поначалу это все довольно сложно усвоить. Будем потихоньку разбирать каждый аспект применения static в подробностях, но сейчас соберу все вместе и кратко расскажу о ключевых особенностях каждого.
Всего есть 5 возможных способа применить static:
👉🏿 К глобальным переменным. Есть у вас файлик и вы в нем определили глобальную переменную std::string ж = "опа";. Такой неконстантной глобальной переменной автоматически присваивается внешнее связывание. То есть все единицы трансляции могут увидеть эту переменную и использовать ее(через forward declaration). Как только вы пометите ее как static, тип связывания изменится на внутреннее. Это значит, что никакие другие единицы трансляции не смогут получить доступ к конкретно этому экземпляру строки. Время жизни переменной в этом случае не особо меняется.
👉🏿 К локальным переменным функции. В этом случае переменная будет продолжать принадлежать функции, но теперь ее время жизни с автоматического изменится на статическое. То есть переменная будет продолжать жить между вызовами функции и сохранять свое значение с предыдущего вызова. Такие переменные гарантированно инициализируются атомарно и один раз при самом первом вызове функции.
👉🏿 К полям класса. В отличии от обычных членов класса, для доступа к которым нужен объект, для статических полей объект не нужен. Представьте, что это глобальная переменная, которая "присоединена" к классу. Это поле видно всем, кому доступно определение класса, и к нему можно обратиться с помощью имени класса, типа такого Type::static_member. Также такие поля доступны в методах класса. Короче. Ничего особенного, просто глобальная переменная принадлежащая классу.
👉🏿 К свободным функциям. Ситуация очень похожа на ситуацию с глобальными переменными. По сути изменяется только тип связывания. Такую функцию нельзя увидеть из другой единицы трансляции.
👉🏿 К методам класса. Ситуация похожа на применение static к полям класса. Это свободная функция, которая присоединена к классу. Однако у нее есть еще одно преимущество, что такие методы имеют возможность доступа ко всем полям класса. Если каким-то образом заиметь объект того же самого класса внутри статического метода, то можно пользоваться плюшками доступа ко всем полям.
Как видно, что прошлись сильно по верхам. Я специально не затрагивал нюансы и описывал все крупными мазками. Нюансы будут, когда будем все подробно разбирать.
Вот такая многогранная вещь этот static. Ждите следующих частей, будет жарко🔥.
Stay hot. Stay cool.
#cppcore #howitworks
{kind=link}