
This media is not supported in your browser
VIEW IN TELEGRAM
One more example of a synthesised image by the paper mentioned above.
This media is not supported in your browser
VIEW IN TELEGRAM
Rethinking Style Transfer: From Pixels to Parameterized Brushstrokes
[Another recent "style transfer with brushstrokes" paper from my colleagues in Heidelberg University ]
In this paper, images are stylized by optimizing parameterized brush strokes instead of pixels as well. In order to backpropagate teh error through the rendered brushstrokes, the authors came up with a simple differentiable rendering of strokes, each of which is parameterized with a Bezier curve.
The results are excellent. You can also add constraints to the shape of your brush strokes by drawing a couple of lines over the photo. The only drawback is that it works for a rather long time (10-20 minutes per 1MP picture), since this is an iterative optimization, and at each iteration a forward-pass through VGG-16 newtwork is required.
🌀 Project website
🛠 Source code
[Another recent "style transfer with brushstrokes" paper from my colleagues in Heidelberg University ]
In this paper, images are stylized by optimizing parameterized brush strokes instead of pixels as well. In order to backpropagate teh error through the rendered brushstrokes, the authors came up with a simple differentiable rendering of strokes, each of which is parameterized with a Bezier curve.
The results are excellent. You can also add constraints to the shape of your brush strokes by drawing a couple of lines over the photo. The only drawback is that it works for a rather long time (10-20 minutes per 1MP picture), since this is an iterative optimization, and at each iteration a forward-pass through VGG-16 newtwork is required.
🌀 Project website
🛠 Source code
This media is not supported in your browser
VIEW IN TELEGRAM
Here's another example of how the algorithm mentioned above works. The horse is stylized in Kirchner's style.
The differences with the classic pixel-by-pixel method by Gatys et al. are very explicit. The new method, of course, significantly perturbs the content in contrast to Gatys, but the style really looks more similar to the German expressionist Kirchner and we see prominent brush strokes.
The differences with the classic pixel-by-pixel method by Gatys et al. are very explicit. The new method, of course, significantly perturbs the content in contrast to Gatys, but the style really looks more similar to the German expressionist Kirchner and we see prominent brush strokes.
This media is not supported in your browser
VIEW IN TELEGRAM
🔥StyleGAN3 by NVIDIA!
Do you remember the awesome smooth results by Alias-Free GAN I wrote about earlier? The authors have finally posted the code and now you can build your amazing projects on it.
I don't know about you, but my hands are already itching to try it out.
🛠 Source code
🌀 Project page
⚙️ Colab
Do you remember the awesome smooth results by Alias-Free GAN I wrote about earlier? The authors have finally posted the code and now you can build your amazing projects on it.
I don't know about you, but my hands are already itching to try it out.
🛠 Source code
🌀 Project page
⚙️ Colab
On Neural Rendering
What is Neural Rendering? In a nutshell, neural rendering is when we take classic algorithms for image rendering from computer graphics and replace a part of the pipeline with neural networks (stupid, but effective). Neural rendering learns to render and represent a scene from one or more input photos by simulating the physical process of a camera that captures the scene. A key property of 3D neural rendering is the disentanglement of the camera capturing process (i.e., the projection and image formation) and the representation of a 3D scene during training. That is, we learn an explicit (voxels, point clouds, parametric surfaces) or an implicit (signed distance function) representation of a 3D scene. For training, we use observations of the scene from several camera viewpoints. The network is trained on these observations by rendering the estimated 3D scene from the training viewpoints, and minimizing the difference between the rendered and observed images. This learned scene representation can be rendered from any virtual camera in order to synthesize novel views. It is important for learning that the entire rendering pipeline is differentiable.
You may have noticed, that the topic of neural rendering, including all sorts of nerfs-schmerfs, is now a big hype in computer vision. You might say that neural rendering is very slow, and you'd be right. A typical training session on a small scene with ~ 50 input photos takes about 5.5 hours for the fastest method on a single GPU, but neural rendering methods have made significant progress in the last year improving both fidelity and efficiency. To catch up on all the recent developments in this direction, I highly recommend reading this SOTA report "Advances in Neural Rendering".
The gif is from Volume Rendering of Neural Implicit Surfaces paper.
What is Neural Rendering? In a nutshell, neural rendering is when we take classic algorithms for image rendering from computer graphics and replace a part of the pipeline with neural networks (stupid, but effective). Neural rendering learns to render and represent a scene from one or more input photos by simulating the physical process of a camera that captures the scene. A key property of 3D neural rendering is the disentanglement of the camera capturing process (i.e., the projection and image formation) and the representation of a 3D scene during training. That is, we learn an explicit (voxels, point clouds, parametric surfaces) or an implicit (signed distance function) representation of a 3D scene. For training, we use observations of the scene from several camera viewpoints. The network is trained on these observations by rendering the estimated 3D scene from the training viewpoints, and minimizing the difference between the rendered and observed images. This learned scene representation can be rendered from any virtual camera in order to synthesize novel views. It is important for learning that the entire rendering pipeline is differentiable.
You may have noticed, that the topic of neural rendering, including all sorts of nerfs-schmerfs, is now a big hype in computer vision. You might say that neural rendering is very slow, and you'd be right. A typical training session on a small scene with ~ 50 input photos takes about 5.5 hours for the fastest method on a single GPU, but neural rendering methods have made significant progress in the last year improving both fidelity and efficiency. To catch up on all the recent developments in this direction, I highly recommend reading this SOTA report "Advances in Neural Rendering".
The gif is from Volume Rendering of Neural Implicit Surfaces paper.
I'm back people! After some pause I decided to continue posting in this channel. I promise to select the most interesting papers and write at least 1-2 posts per week.
Cheers,
Artsiom
Cheers,
Artsiom
🇨🇳 Chinese researchers brought deepfakes to the next level by changing the entire head
We have all seen deepfakes where faces are swapped. This paper went further, they substitute the driving head entirely. Miracles of Chinese engineering skills and a lot of losses do the job 🤓.
Compared to the usual "face swap", the new method exhibits better transfer of the personality from the target photo to the driving video, preserving the hair, eyebrows, and other important attributes. A slight improvement of the temporal stability is needed though - the edges of the head are a little twitchy. There is no code yet, but the authors promised to upload it soon.
❱❱ Few-Shot Head Swapping in the Wild CVPR 2022, Oral
We have all seen deepfakes where faces are swapped. This paper went further, they substitute the driving head entirely. Miracles of Chinese engineering skills and a lot of losses do the job 🤓.
Compared to the usual "face swap", the new method exhibits better transfer of the personality from the target photo to the driving video, preserving the hair, eyebrows, and other important attributes. A slight improvement of the temporal stability is needed though - the edges of the head are a little twitchy. There is no code yet, but the authors promised to upload it soon.
❱❱ Few-Shot Head Swapping in the Wild CVPR 2022, Oral
Neural 3D Reconstruction in the Wild”
[SIGGRAPH 2022]
When will neural-based approaches beat COLMAP in terms of both speed and quality of the surface reconstruction? Here is the Neural Rendering method tackling the quality part.
Authors show that with a clever sampling strategy, neural-based 3D reconstruction for large scenes in the wild can be better and faster than COLMAP.
The method is built on top of NeuS (2 MLPs for prediction color and SDF for (x,y,z) loсation). The main contribution is a hybrid voxel- and surface guided sampling technique that allows for more efficient ray sampling around surfaces and leads to significant improvements in
reconstruction quality (see figure attached).
❱❱ Project page
Code is coming soon
@Artem Gradient
[SIGGRAPH 2022]
When will neural-based approaches beat COLMAP in terms of both speed and quality of the surface reconstruction? Here is the Neural Rendering method tackling the quality part.
Authors show that with a clever sampling strategy, neural-based 3D reconstruction for large scenes in the wild can be better and faster than COLMAP.
The method is built on top of NeuS (2 MLPs for prediction color and SDF for (x,y,z) loсation). The main contribution is a hybrid voxel- and surface guided sampling technique that allows for more efficient ray sampling around surfaces and leads to significant improvements in
reconstruction quality (see figure attached).
❱❱ Project page
Code is coming soon
@Artem Gradient
Image Inpainting: Partial Convolution vs Gated Convolution
Let’s talk about some essential components of the image inpainting networks - convolutions. #fundamentals
It is common in image inpainting model to feed a corrupted image (with some parts masked out) to the generator network. But we don’t want the network layers to rely on empty regions when features are computed. There is a straightforward solutions to this problem (Partial Convolutions) and a more elegant one (gated convolution).
🔻Partial Convolutions make the convolutions dependent only on valid pixels. They are like normal convolutions, but with hard mask multiplication applied to each output feature map. The first map is computed from occluded image directly or provided as an input from user. Masks for every next partial convolution are computed by finding non-zero elements in the input feature maps.
- Partial convolution heuristically classifies all spatial locations to be either valid or invalid. The mask in next layer will be set to ones no matter how many pixels are covered by the filter range in previous layer (for example, for a 3x3 conv, 1 valid pixel and 9 valid pixels are treated as same to update current mask).
- For partial convolution the invalid pixels will progressively disappear in deep layers, gradually converting all mask values to ones.
- partial convolution is incompatible with additional user inputs. However, we would like to be able to utilize extra user inputs for conditional generation (for example, sparse sketch inside the mask).
- All channels in each layer share the same mask, which limits the flexibility. Essentially, partial convolution can be viewed as un-learnable single-channel feature hard-gating.
🔻Gated convolutions. Instead of hard-gating mask updated with rules, gated convolutions learn soft mask automatically from data. It has a “Soft gating” block (consists of one convolutional layer) which takes an input feature map and predicts an appropriate soft mask which is applied to the output of the convolution.
- Can take any extra user guidance (e.g., mask, sketch) as input. They can be all concatenated with the corrupted image and fed to the first gated convolution.
- Learns a dynamic feature selection mechanism for each channel and each spatial
location.
- Interestingly, visualization of intermediate gating values show that it learns to select the feature not only according to background, mask, sketch, but also considering semantic segmentation in some channels.
- Even in deep layers, gated convolution learns to highlight the masked regions and sketch information in separate channels to better generate inpainting results.
@gradientdude
Let’s talk about some essential components of the image inpainting networks - convolutions. #fundamentals
It is common in image inpainting model to feed a corrupted image (with some parts masked out) to the generator network. But we don’t want the network layers to rely on empty regions when features are computed. There is a straightforward solutions to this problem (Partial Convolutions) and a more elegant one (gated convolution).
🔻Partial Convolutions make the convolutions dependent only on valid pixels. They are like normal convolutions, but with hard mask multiplication applied to each output feature map. The first map is computed from occluded image directly or provided as an input from user. Masks for every next partial convolution are computed by finding non-zero elements in the input feature maps.
- Partial convolution heuristically classifies all spatial locations to be either valid or invalid. The mask in next layer will be set to ones no matter how many pixels are covered by the filter range in previous layer (for example, for a 3x3 conv, 1 valid pixel and 9 valid pixels are treated as same to update current mask).
- For partial convolution the invalid pixels will progressively disappear in deep layers, gradually converting all mask values to ones.
- partial convolution is incompatible with additional user inputs. However, we would like to be able to utilize extra user inputs for conditional generation (for example, sparse sketch inside the mask).
- All channels in each layer share the same mask, which limits the flexibility. Essentially, partial convolution can be viewed as un-learnable single-channel feature hard-gating.
🔻Gated convolutions. Instead of hard-gating mask updated with rules, gated convolutions learn soft mask automatically from data. It has a “Soft gating” block (consists of one convolutional layer) which takes an input feature map and predicts an appropriate soft mask which is applied to the output of the convolution.
- Can take any extra user guidance (e.g., mask, sketch) as input. They can be all concatenated with the corrupted image and fed to the first gated convolution.
- Learns a dynamic feature selection mechanism for each channel and each spatial
location.
- Interestingly, visualization of intermediate gating values show that it learns to select the feature not only according to background, mask, sketch, but also considering semantic segmentation in some channels.
- Even in deep layers, gated convolution learns to highlight the masked regions and sketch information in separate channels to better generate inpainting results.
@gradientdude
{kind=link}
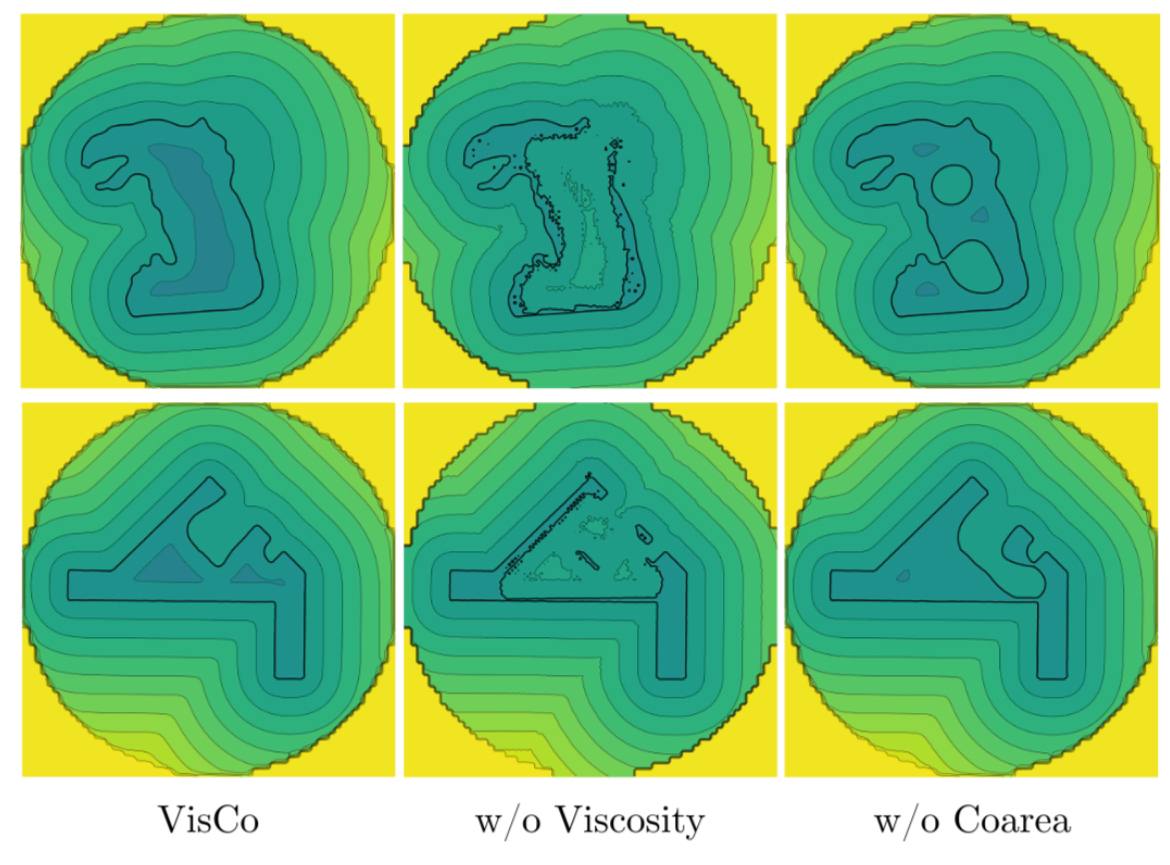
VisCo Grids: Surface Reconstruction with Viscosity and Coarea Grids
The goal of this work it show that network-free grid-based implicit representations can achieve INR (Implicit Neural Representation)-level 3D reconstructions when incorporating suitable priors.
VisCo Grids is a grid-based surface reconstruction algorithm that incorporates well-defined geometric priors: Viscosity and Coarea.
The viscosity loss, is replacing the Eikonal loss used in INRs for optimizing Signed Distance Functions (SDF). The Eikonal loss posses many bad minimal solution that are avoided in the INR setting due to the network’s inductive bias, but are present in the grid parametrization (see attached Figure, middle). The viscosity loss regularizes the Eikonal loss and provides well defined smooth solution that converges to the "correct" viscosity SDF solution. The viscosity loss provides smooth SDF solution but do not punish excessive or "ghost" surface parts (see the Figure, right).
Therefore, a second useful prior is the Coarea loss, directly controlling the surface’s area, and encourages it to be smaller. The coarea loss is defined using a "squashing" function applied to the viscosity SDF making it approximately an indicator function, and then integrates its gradient norm over the domain.
VisCo grids have instant inference, and even with our current rather naive implementation are faster to train than INRs. Considerable training time improvement are expected with a more efficient implementation.
We tested VisCo Grids on a standard 3D reconstruction dataset, and achieved comparable accuracy to the state-of-the-art INR methods.
❱❱ Paper
❱❱ Code is coming soon.
@gradientdude
The goal of this work it show that network-free grid-based implicit representations can achieve INR (Implicit Neural Representation)-level 3D reconstructions when incorporating suitable priors.
VisCo Grids is a grid-based surface reconstruction algorithm that incorporates well-defined geometric priors: Viscosity and Coarea.
The viscosity loss, is replacing the Eikonal loss used in INRs for optimizing Signed Distance Functions (SDF). The Eikonal loss posses many bad minimal solution that are avoided in the INR setting due to the network’s inductive bias, but are present in the grid parametrization (see attached Figure, middle). The viscosity loss regularizes the Eikonal loss and provides well defined smooth solution that converges to the "correct" viscosity SDF solution. The viscosity loss provides smooth SDF solution but do not punish excessive or "ghost" surface parts (see the Figure, right).
Therefore, a second useful prior is the Coarea loss, directly controlling the surface’s area, and encourages it to be smaller. The coarea loss is defined using a "squashing" function applied to the viscosity SDF making it approximately an indicator function, and then integrates its gradient norm over the domain.
VisCo grids have instant inference, and even with our current rather naive implementation are faster to train than INRs. Considerable training time improvement are expected with a more efficient implementation.
We tested VisCo Grids on a standard 3D reconstruction dataset, and achieved comparable accuracy to the state-of-the-art INR methods.
❱❱ Paper
❱❱ Code is coming soon.
@gradientdude
{kind=link}
I will be presenting our VisCo Grids paper at NeurIPS tomorrow at 11:00-13:00 in Hall J.
Feel free to come to poster #527 to learn more details if you are attending the conference!
@gradientdude
Feel free to come to poster #527 to learn more details if you are attending the conference!
@gradientdude
This media is not supported in your browser
VIEW IN TELEGRAM
🦿Avatars Grow Legs
I'm thrilled to share with you my latest research paper (CVPR 2023)! This was a joint effort with my intern at Meta Reality Labs before our team transitioned to GenAI.
Our innovative method, dubbed Avatars Grow Legs (AGRoL), aims to control a 3D avatar's entire body in VR without the need for extra sensors. Typically in VR, your interaction is limited to a headset and two handheld joysticks, leaving out any direct input from your legs. This limitation persists despite the Quest's downward-facing cameras, as they rarely capture the unocludded view of the legs.
To tackle this, we've introduced a novel solution based on a diffusion model. Our model synthesizes the 3D movement of the whole body conditioned solely on the tracking data from the hands and the head, circumventing the need for direct observation of the legs.
Moreover, we've designed AGRoL with an efficient architecture
enabling 30 FPS synthsis on a V100 GPU.
❱❱ Code and weights
❱❱ Paper
❱❱ Project Page
@gradientdude
I'm thrilled to share with you my latest research paper (CVPR 2023)! This was a joint effort with my intern at Meta Reality Labs before our team transitioned to GenAI.
Our innovative method, dubbed Avatars Grow Legs (AGRoL), aims to control a 3D avatar's entire body in VR without the need for extra sensors. Typically in VR, your interaction is limited to a headset and two handheld joysticks, leaving out any direct input from your legs. This limitation persists despite the Quest's downward-facing cameras, as they rarely capture the unocludded view of the legs.
To tackle this, we've introduced a novel solution based on a diffusion model. Our model synthesizes the 3D movement of the whole body conditioned solely on the tracking data from the hands and the head, circumventing the need for direct observation of the legs.
Moreover, we've designed AGRoL with an efficient architecture
enabling 30 FPS synthsis on a V100 GPU.
❱❱ Code and weights
❱❱ Paper
❱❱ Project Page
@gradientdude
Media is too big
VIEW IN TELEGRAM
Demo of our Avatars Grow Legs model that synthesizes the full 3D body motion based on sparse tracking inputs from the head and the wrists.
More details are in the paper.
@gradientdude
More details are in the paper.
@gradientdude
This media is not supported in your browser
VIEW IN TELEGRAM
Today I will be presenting our CVPR2023 poster "Avatars Grow Legs: Generating Smooth Human Motion from Sparse Tracking Inputs with Diffusion Model".
Learn how to synthesize full body motion based on 3 known points only (head and wrists)!
❱❱ Detailed post about the paper.
Come to chat with me today at 10:30-12:30 PDT, poster #46 if you are at CVPR.
@gradientdude
Learn how to synthesize full body motion based on 3 known points only (head and wrists)!
❱❱ Detailed post about the paper.
Come to chat with me today at 10:30-12:30 PDT, poster #46 if you are at CVPR.
@gradientdude