
OpenAI disbands its robotics research team. This is exactly the same team that, for example, taught a robotic arm to solve a Rubik's cube using Reinforcement Learning. This decision was made because the company considers more promising research in areas where physical equipment is not required (except for servers, of course), and there is already a lot of data available. And also for economic reasons, since Software as a Services is a business with a much higher margin. Yes, the joke is that the non-profit organization OpenAI is considered more and more about profit. This is understandable because it takes a lot of money to create general artificial intelligence (AGI) that can learn all the tasks that a person can do and even more.
It's no secret that research in the field of robotics is also a very costly activity that requires a lot of investment. Therefore, there are not so many companies involved in this. Among the large and successful, only Boston Dynamics comes to mind, which has already changed several owners. Did you know that in 2013 Google acquired Boston Dynamics, then Google also scaled down its robotics research program, and in 2017 sold Boston Dynamic to the Japanese firm SoftBank. The adventures of Boston Dynamics did not end there, and in December 2020 SoftBank resold 80% of the shares (a controlling stake) to the automaker Hyundai. This looks somehow fishy as if every company understands after a few years that it is still difficult to make a profit from Boston Dynamics and sells it to another patsy.
In any case, it is very interesting to observe which focus areas are chosen by the titans of AI research. But I'm a bit sad that robots are still lagging behind.
It's no secret that research in the field of robotics is also a very costly activity that requires a lot of investment. Therefore, there are not so many companies involved in this. Among the large and successful, only Boston Dynamics comes to mind, which has already changed several owners. Did you know that in 2013 Google acquired Boston Dynamics, then Google also scaled down its robotics research program, and in 2017 sold Boston Dynamic to the Japanese firm SoftBank. The adventures of Boston Dynamics did not end there, and in December 2020 SoftBank resold 80% of the shares (a controlling stake) to the automaker Hyundai. This looks somehow fishy as if every company understands after a few years that it is still difficult to make a profit from Boston Dynamics and sells it to another patsy.
In any case, it is very interesting to observe which focus areas are chosen by the titans of AI research. But I'm a bit sad that robots are still lagging behind.
VentureBeat
OpenAI disbands its robotics research team
OpenAI has disbanded its robotics team in what might be a reflection of economic and commercial realities.
Researchers from NVIDIA (in particular Tero Karras) have once again "solved" image generation.
This time, the scientists were able to remove aliasing in the generator. In a nutshell, then the reason for the artifacts was careless signal processing in the CNN resulting in incorrect discretization. The signal could not be accurately reconstructed, which led to unnatural "jerks" noticeable in the video. The authors have modified the generator to prevent these negative sampling effects.
The resulting networks match the FID of StyleGAN2 but differ dramatically in their internal representations, and they are fully equivariant to translation and rotation even at subpixel scales.
The code is not available yet, but I'm sure NVIDIA will release it soon.
Read more about Alias-Free GAN here.
This time, the scientists were able to remove aliasing in the generator. In a nutshell, then the reason for the artifacts was careless signal processing in the CNN resulting in incorrect discretization. The signal could not be accurately reconstructed, which led to unnatural "jerks" noticeable in the video. The authors have modified the generator to prevent these negative sampling effects.
The resulting networks match the FID of StyleGAN2 but differ dramatically in their internal representations, and they are fully equivariant to translation and rotation even at subpixel scales.
The code is not available yet, but I'm sure NVIDIA will release it soon.
Read more about Alias-Free GAN here.
German startup aims to become "Europe's OpenAI"
The German startup Aleph Alpha, which is based in Heidelberg, Germany (the city where I did my PhD), recently raised $ 27M in a Series A round. The task, they set themselves ambitious (even too much) - they want to create another breakthrough in AI, something similar to OpenAI GPT-3.
The company was founded in 2019, and, strangely, I discovered it only today. I looked at their ML team. And I have not found a single person with any major scientific achievements (say on the level of Professor). I got disappointed. Their ML team includes 3 recent PhD students and Connor Leahy, who is known for co-founding EleutherAI. EleutherAI is a non-profit organization that was created to reproduce and open-source GPT-3 model. Perhaps they bet on Connor, but, frankly speaking, Connor is not a researcher, he has no scientific publications, and EleutherAI is simply reproducing results of OpenAI. When OpenAI was founded, it was immediately clear that they got a stellar team, which would certainly produce something cool.
My impressions are controversial. Aleph Alpha has partnerships with German government agencies. They promote themselves in the style of "we are Europe's last chance claim a place in the field of AI", "we will be based purely in Europe and will be pushing European values and ethical standards." They also promise to be more open than OpenAI (lol) and commit to open-source. Although, perhaps, they will just create some kind of large platform with AI solutions and sit on the government funding. It will be a kind of AI consulting, they even have a job posted on their website for this purpose - AI Delivery & Consulting. The whole affair smacks of a government cover-up like in the case of Palantir (at least partially).
I'm not a startup expert, but it seems like Europe is very hungry for innovation. They want to keep up with the United States and China. Therefore, they give out the bucks at the first opportunity, especially if the company promises to work closely with the government. What do you think about this, gentlemen?
The German startup Aleph Alpha, which is based in Heidelberg, Germany (the city where I did my PhD), recently raised $ 27M in a Series A round. The task, they set themselves ambitious (even too much) - they want to create another breakthrough in AI, something similar to OpenAI GPT-3.
The company was founded in 2019, and, strangely, I discovered it only today. I looked at their ML team. And I have not found a single person with any major scientific achievements (say on the level of Professor). I got disappointed. Their ML team includes 3 recent PhD students and Connor Leahy, who is known for co-founding EleutherAI. EleutherAI is a non-profit organization that was created to reproduce and open-source GPT-3 model. Perhaps they bet on Connor, but, frankly speaking, Connor is not a researcher, he has no scientific publications, and EleutherAI is simply reproducing results of OpenAI. When OpenAI was founded, it was immediately clear that they got a stellar team, which would certainly produce something cool.
My impressions are controversial. Aleph Alpha has partnerships with German government agencies. They promote themselves in the style of "we are Europe's last chance claim a place in the field of AI", "we will be based purely in Europe and will be pushing European values and ethical standards." They also promise to be more open than OpenAI (lol) and commit to open-source. Although, perhaps, they will just create some kind of large platform with AI solutions and sit on the government funding. It will be a kind of AI consulting, they even have a job posted on their website for this purpose - AI Delivery & Consulting. The whole affair smacks of a government cover-up like in the case of Palantir (at least partially).
I'm not a startup expert, but it seems like Europe is very hungry for innovation. They want to keep up with the United States and China. Therefore, they give out the bucks at the first opportunity, especially if the company promises to work closely with the government. What do you think about this, gentlemen?
TechCrunch
German startup Aleph Alpha raises $27M Series A round to build ‘Europe’s OpenAI’
With Microsoft now being an investor in OpenAI the field is more open for new insurgents into the open-source AI arena. Now a German company hopes to take on the next AI mantle and produce something akin to the success of the GPT-3 AI model.
This media is not supported in your browser
VIEW IN TELEGRAM
Paint Transformer: Feed Forward Neural Painting with Stroke Prediction
Earlier I wrote about a style transfer that, instead of optimizing pixels, optimizes directly parameterized brush strokes. A new work has been released, it uses Transformer architecture to predict stroke parameters using one (well, almost one) forward-pass of the network. In fact, their transformer is made in the spirit of a recurrent network.
Four forward passes of the original image in different resolutions are made through the network, starting from downsapled 16 times to the original one. At each next forward puss, a rendered canvas with strokes predicted in the previous passes is also added to the input as well as the original image in a higher resolution. Thus, the network gradually adds new strokes to the canvas, starting with larger ones (they are painted on a low resolution canvas), and ending with smaller ones (on a high resolution canvas). The network is trained on synthetic data generated online.
📝 Paper
🛠 Code
Earlier I wrote about a style transfer that, instead of optimizing pixels, optimizes directly parameterized brush strokes. A new work has been released, it uses Transformer architecture to predict stroke parameters using one (well, almost one) forward-pass of the network. In fact, their transformer is made in the spirit of a recurrent network.
Four forward passes of the original image in different resolutions are made through the network, starting from downsapled 16 times to the original one. At each next forward puss, a rendered canvas with strokes predicted in the previous passes is also added to the input as well as the original image in a higher resolution. Thus, the network gradually adds new strokes to the canvas, starting with larger ones (they are painted on a low resolution canvas), and ending with smaller ones (on a high resolution canvas). The network is trained on synthetic data generated online.
📝 Paper
🛠 Code
This media is not supported in your browser
VIEW IN TELEGRAM
One more example of a synthesised image by the paper mentioned above.
This media is not supported in your browser
VIEW IN TELEGRAM
Rethinking Style Transfer: From Pixels to Parameterized Brushstrokes
[Another recent "style transfer with brushstrokes" paper from my colleagues in Heidelberg University ]
In this paper, images are stylized by optimizing parameterized brush strokes instead of pixels as well. In order to backpropagate teh error through the rendered brushstrokes, the authors came up with a simple differentiable rendering of strokes, each of which is parameterized with a Bezier curve.
The results are excellent. You can also add constraints to the shape of your brush strokes by drawing a couple of lines over the photo. The only drawback is that it works for a rather long time (10-20 minutes per 1MP picture), since this is an iterative optimization, and at each iteration a forward-pass through VGG-16 newtwork is required.
🌀 Project website
🛠 Source code
[Another recent "style transfer with brushstrokes" paper from my colleagues in Heidelberg University ]
In this paper, images are stylized by optimizing parameterized brush strokes instead of pixels as well. In order to backpropagate teh error through the rendered brushstrokes, the authors came up with a simple differentiable rendering of strokes, each of which is parameterized with a Bezier curve.
The results are excellent. You can also add constraints to the shape of your brush strokes by drawing a couple of lines over the photo. The only drawback is that it works for a rather long time (10-20 minutes per 1MP picture), since this is an iterative optimization, and at each iteration a forward-pass through VGG-16 newtwork is required.
🌀 Project website
🛠 Source code
This media is not supported in your browser
VIEW IN TELEGRAM
Here's another example of how the algorithm mentioned above works. The horse is stylized in Kirchner's style.
The differences with the classic pixel-by-pixel method by Gatys et al. are very explicit. The new method, of course, significantly perturbs the content in contrast to Gatys, but the style really looks more similar to the German expressionist Kirchner and we see prominent brush strokes.
The differences with the classic pixel-by-pixel method by Gatys et al. are very explicit. The new method, of course, significantly perturbs the content in contrast to Gatys, but the style really looks more similar to the German expressionist Kirchner and we see prominent brush strokes.
This media is not supported in your browser
VIEW IN TELEGRAM
🔥StyleGAN3 by NVIDIA!
Do you remember the awesome smooth results by Alias-Free GAN I wrote about earlier? The authors have finally posted the code and now you can build your amazing projects on it.
I don't know about you, but my hands are already itching to try it out.
🛠 Source code
🌀 Project page
⚙️ Colab
Do you remember the awesome smooth results by Alias-Free GAN I wrote about earlier? The authors have finally posted the code and now you can build your amazing projects on it.
I don't know about you, but my hands are already itching to try it out.
🛠 Source code
🌀 Project page
⚙️ Colab
On Neural Rendering
What is Neural Rendering? In a nutshell, neural rendering is when we take classic algorithms for image rendering from computer graphics and replace a part of the pipeline with neural networks (stupid, but effective). Neural rendering learns to render and represent a scene from one or more input photos by simulating the physical process of a camera that captures the scene. A key property of 3D neural rendering is the disentanglement of the camera capturing process (i.e., the projection and image formation) and the representation of a 3D scene during training. That is, we learn an explicit (voxels, point clouds, parametric surfaces) or an implicit (signed distance function) representation of a 3D scene. For training, we use observations of the scene from several camera viewpoints. The network is trained on these observations by rendering the estimated 3D scene from the training viewpoints, and minimizing the difference between the rendered and observed images. This learned scene representation can be rendered from any virtual camera in order to synthesize novel views. It is important for learning that the entire rendering pipeline is differentiable.
You may have noticed, that the topic of neural rendering, including all sorts of nerfs-schmerfs, is now a big hype in computer vision. You might say that neural rendering is very slow, and you'd be right. A typical training session on a small scene with ~ 50 input photos takes about 5.5 hours for the fastest method on a single GPU, but neural rendering methods have made significant progress in the last year improving both fidelity and efficiency. To catch up on all the recent developments in this direction, I highly recommend reading this SOTA report "Advances in Neural Rendering".
The gif is from Volume Rendering of Neural Implicit Surfaces paper.
What is Neural Rendering? In a nutshell, neural rendering is when we take classic algorithms for image rendering from computer graphics and replace a part of the pipeline with neural networks (stupid, but effective). Neural rendering learns to render and represent a scene from one or more input photos by simulating the physical process of a camera that captures the scene. A key property of 3D neural rendering is the disentanglement of the camera capturing process (i.e., the projection and image formation) and the representation of a 3D scene during training. That is, we learn an explicit (voxels, point clouds, parametric surfaces) or an implicit (signed distance function) representation of a 3D scene. For training, we use observations of the scene from several camera viewpoints. The network is trained on these observations by rendering the estimated 3D scene from the training viewpoints, and minimizing the difference between the rendered and observed images. This learned scene representation can be rendered from any virtual camera in order to synthesize novel views. It is important for learning that the entire rendering pipeline is differentiable.
You may have noticed, that the topic of neural rendering, including all sorts of nerfs-schmerfs, is now a big hype in computer vision. You might say that neural rendering is very slow, and you'd be right. A typical training session on a small scene with ~ 50 input photos takes about 5.5 hours for the fastest method on a single GPU, but neural rendering methods have made significant progress in the last year improving both fidelity and efficiency. To catch up on all the recent developments in this direction, I highly recommend reading this SOTA report "Advances in Neural Rendering".
The gif is from Volume Rendering of Neural Implicit Surfaces paper.
I'm back people! After some pause I decided to continue posting in this channel. I promise to select the most interesting papers and write at least 1-2 posts per week.
Cheers,
Artsiom
Cheers,
Artsiom
🇨🇳 Chinese researchers brought deepfakes to the next level by changing the entire head
We have all seen deepfakes where faces are swapped. This paper went further, they substitute the driving head entirely. Miracles of Chinese engineering skills and a lot of losses do the job 🤓.
Compared to the usual "face swap", the new method exhibits better transfer of the personality from the target photo to the driving video, preserving the hair, eyebrows, and other important attributes. A slight improvement of the temporal stability is needed though - the edges of the head are a little twitchy. There is no code yet, but the authors promised to upload it soon.
❱❱ Few-Shot Head Swapping in the Wild CVPR 2022, Oral
We have all seen deepfakes where faces are swapped. This paper went further, they substitute the driving head entirely. Miracles of Chinese engineering skills and a lot of losses do the job 🤓.
Compared to the usual "face swap", the new method exhibits better transfer of the personality from the target photo to the driving video, preserving the hair, eyebrows, and other important attributes. A slight improvement of the temporal stability is needed though - the edges of the head are a little twitchy. There is no code yet, but the authors promised to upload it soon.
❱❱ Few-Shot Head Swapping in the Wild CVPR 2022, Oral
Neural 3D Reconstruction in the Wild”
[SIGGRAPH 2022]
When will neural-based approaches beat COLMAP in terms of both speed and quality of the surface reconstruction? Here is the Neural Rendering method tackling the quality part.
Authors show that with a clever sampling strategy, neural-based 3D reconstruction for large scenes in the wild can be better and faster than COLMAP.
The method is built on top of NeuS (2 MLPs for prediction color and SDF for (x,y,z) loсation). The main contribution is a hybrid voxel- and surface guided sampling technique that allows for more efficient ray sampling around surfaces and leads to significant improvements in
reconstruction quality (see figure attached).
❱❱ Project page
Code is coming soon
@Artem Gradient
[SIGGRAPH 2022]
When will neural-based approaches beat COLMAP in terms of both speed and quality of the surface reconstruction? Here is the Neural Rendering method tackling the quality part.
Authors show that with a clever sampling strategy, neural-based 3D reconstruction for large scenes in the wild can be better and faster than COLMAP.
The method is built on top of NeuS (2 MLPs for prediction color and SDF for (x,y,z) loсation). The main contribution is a hybrid voxel- and surface guided sampling technique that allows for more efficient ray sampling around surfaces and leads to significant improvements in
reconstruction quality (see figure attached).
❱❱ Project page
Code is coming soon
@Artem Gradient
Image Inpainting: Partial Convolution vs Gated Convolution
Let’s talk about some essential components of the image inpainting networks - convolutions. #fundamentals
It is common in image inpainting model to feed a corrupted image (with some parts masked out) to the generator network. But we don’t want the network layers to rely on empty regions when features are computed. There is a straightforward solutions to this problem (Partial Convolutions) and a more elegant one (gated convolution).
🔻Partial Convolutions make the convolutions dependent only on valid pixels. They are like normal convolutions, but with hard mask multiplication applied to each output feature map. The first map is computed from occluded image directly or provided as an input from user. Masks for every next partial convolution are computed by finding non-zero elements in the input feature maps.
- Partial convolution heuristically classifies all spatial locations to be either valid or invalid. The mask in next layer will be set to ones no matter how many pixels are covered by the filter range in previous layer (for example, for a 3x3 conv, 1 valid pixel and 9 valid pixels are treated as same to update current mask).
- For partial convolution the invalid pixels will progressively disappear in deep layers, gradually converting all mask values to ones.
- partial convolution is incompatible with additional user inputs. However, we would like to be able to utilize extra user inputs for conditional generation (for example, sparse sketch inside the mask).
- All channels in each layer share the same mask, which limits the flexibility. Essentially, partial convolution can be viewed as un-learnable single-channel feature hard-gating.
🔻Gated convolutions. Instead of hard-gating mask updated with rules, gated convolutions learn soft mask automatically from data. It has a “Soft gating” block (consists of one convolutional layer) which takes an input feature map and predicts an appropriate soft mask which is applied to the output of the convolution.
- Can take any extra user guidance (e.g., mask, sketch) as input. They can be all concatenated with the corrupted image and fed to the first gated convolution.
- Learns a dynamic feature selection mechanism for each channel and each spatial
location.
- Interestingly, visualization of intermediate gating values show that it learns to select the feature not only according to background, mask, sketch, but also considering semantic segmentation in some channels.
- Even in deep layers, gated convolution learns to highlight the masked regions and sketch information in separate channels to better generate inpainting results.
@gradientdude
Let’s talk about some essential components of the image inpainting networks - convolutions. #fundamentals
It is common in image inpainting model to feed a corrupted image (with some parts masked out) to the generator network. But we don’t want the network layers to rely on empty regions when features are computed. There is a straightforward solutions to this problem (Partial Convolutions) and a more elegant one (gated convolution).
🔻Partial Convolutions make the convolutions dependent only on valid pixels. They are like normal convolutions, but with hard mask multiplication applied to each output feature map. The first map is computed from occluded image directly or provided as an input from user. Masks for every next partial convolution are computed by finding non-zero elements in the input feature maps.
- Partial convolution heuristically classifies all spatial locations to be either valid or invalid. The mask in next layer will be set to ones no matter how many pixels are covered by the filter range in previous layer (for example, for a 3x3 conv, 1 valid pixel and 9 valid pixels are treated as same to update current mask).
- For partial convolution the invalid pixels will progressively disappear in deep layers, gradually converting all mask values to ones.
- partial convolution is incompatible with additional user inputs. However, we would like to be able to utilize extra user inputs for conditional generation (for example, sparse sketch inside the mask).
- All channels in each layer share the same mask, which limits the flexibility. Essentially, partial convolution can be viewed as un-learnable single-channel feature hard-gating.
🔻Gated convolutions. Instead of hard-gating mask updated with rules, gated convolutions learn soft mask automatically from data. It has a “Soft gating” block (consists of one convolutional layer) which takes an input feature map and predicts an appropriate soft mask which is applied to the output of the convolution.
- Can take any extra user guidance (e.g., mask, sketch) as input. They can be all concatenated with the corrupted image and fed to the first gated convolution.
- Learns a dynamic feature selection mechanism for each channel and each spatial
location.
- Interestingly, visualization of intermediate gating values show that it learns to select the feature not only according to background, mask, sketch, but also considering semantic segmentation in some channels.
- Even in deep layers, gated convolution learns to highlight the masked regions and sketch information in separate channels to better generate inpainting results.
@gradientdude
{kind=link}
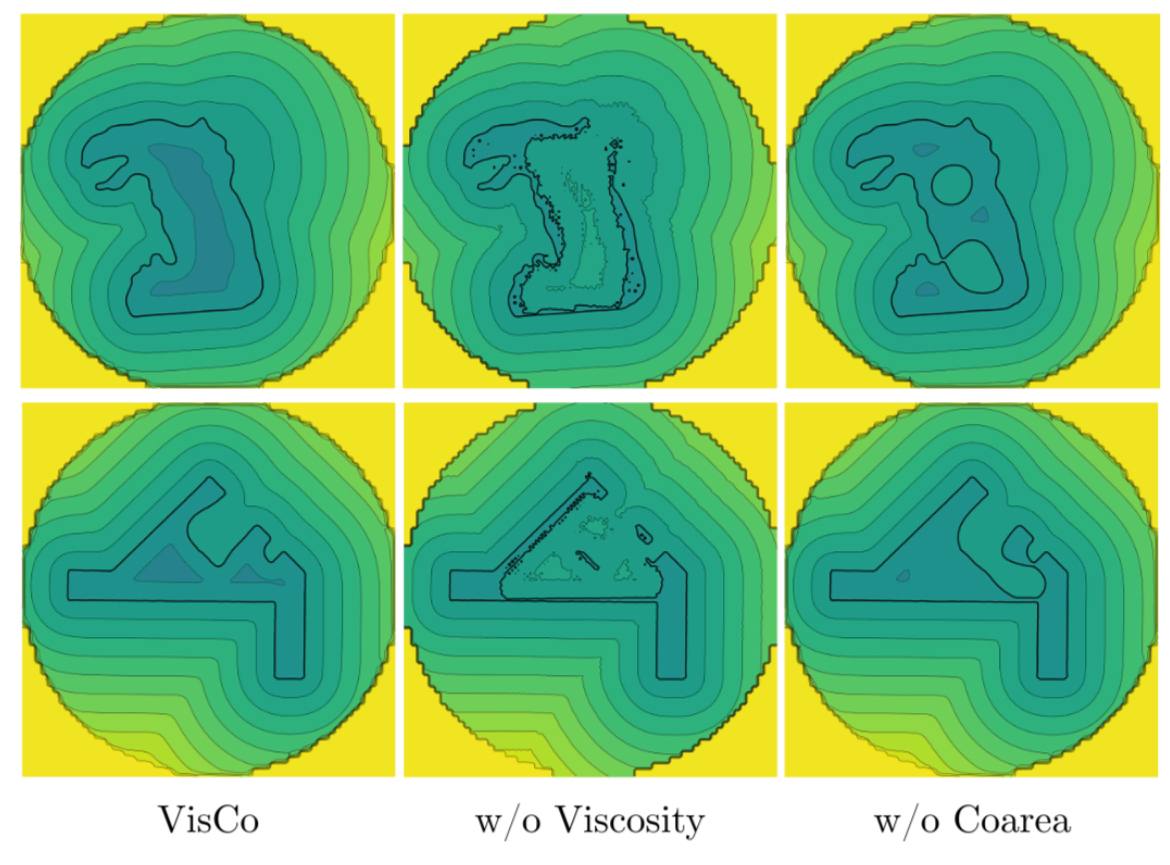
VisCo Grids: Surface Reconstruction with Viscosity and Coarea Grids
The goal of this work it show that network-free grid-based implicit representations can achieve INR (Implicit Neural Representation)-level 3D reconstructions when incorporating suitable priors.
VisCo Grids is a grid-based surface reconstruction algorithm that incorporates well-defined geometric priors: Viscosity and Coarea.
The viscosity loss, is replacing the Eikonal loss used in INRs for optimizing Signed Distance Functions (SDF). The Eikonal loss posses many bad minimal solution that are avoided in the INR setting due to the network’s inductive bias, but are present in the grid parametrization (see attached Figure, middle). The viscosity loss regularizes the Eikonal loss and provides well defined smooth solution that converges to the "correct" viscosity SDF solution. The viscosity loss provides smooth SDF solution but do not punish excessive or "ghost" surface parts (see the Figure, right).
Therefore, a second useful prior is the Coarea loss, directly controlling the surface’s area, and encourages it to be smaller. The coarea loss is defined using a "squashing" function applied to the viscosity SDF making it approximately an indicator function, and then integrates its gradient norm over the domain.
VisCo grids have instant inference, and even with our current rather naive implementation are faster to train than INRs. Considerable training time improvement are expected with a more efficient implementation.
We tested VisCo Grids on a standard 3D reconstruction dataset, and achieved comparable accuracy to the state-of-the-art INR methods.
❱❱ Paper
❱❱ Code is coming soon.
@gradientdude
The goal of this work it show that network-free grid-based implicit representations can achieve INR (Implicit Neural Representation)-level 3D reconstructions when incorporating suitable priors.
VisCo Grids is a grid-based surface reconstruction algorithm that incorporates well-defined geometric priors: Viscosity and Coarea.
The viscosity loss, is replacing the Eikonal loss used in INRs for optimizing Signed Distance Functions (SDF). The Eikonal loss posses many bad minimal solution that are avoided in the INR setting due to the network’s inductive bias, but are present in the grid parametrization (see attached Figure, middle). The viscosity loss regularizes the Eikonal loss and provides well defined smooth solution that converges to the "correct" viscosity SDF solution. The viscosity loss provides smooth SDF solution but do not punish excessive or "ghost" surface parts (see the Figure, right).
Therefore, a second useful prior is the Coarea loss, directly controlling the surface’s area, and encourages it to be smaller. The coarea loss is defined using a "squashing" function applied to the viscosity SDF making it approximately an indicator function, and then integrates its gradient norm over the domain.
VisCo grids have instant inference, and even with our current rather naive implementation are faster to train than INRs. Considerable training time improvement are expected with a more efficient implementation.
We tested VisCo Grids on a standard 3D reconstruction dataset, and achieved comparable accuracy to the state-of-the-art INR methods.
❱❱ Paper
❱❱ Code is coming soon.
@gradientdude
{kind=link}