
Can Vision Transformers Learn without Natural Images? YES!🔥
This is very exciting. It was shown that we can pretrain Vision Transformers purely on synthetic fractal dataset w/o any manual annotations and achieve similar performance on downstream tasks as self-supervised pretraining on ImageNet and similar performance to supervised pretraining on other datasets like Places.
Authors also pretrained regular ResNets on their fractal synthetic data. It works pretty well too, although DeiT Transformers are better.
Overall, this is good news. If we can come up with clever approaches to synthetic data generation, then we can generate arbitrarily large datasets for free!
📖 Paper
🌐 Proj page
📦 Fractal dataset is described in this paper.
This is very exciting. It was shown that we can pretrain Vision Transformers purely on synthetic fractal dataset w/o any manual annotations and achieve similar performance on downstream tasks as self-supervised pretraining on ImageNet and similar performance to supervised pretraining on other datasets like Places.
Authors also pretrained regular ResNets on their fractal synthetic data. It works pretty well too, although DeiT Transformers are better.
Overall, this is good news. If we can come up with clever approaches to synthetic data generation, then we can generate arbitrarily large datasets for free!
📖 Paper
🌐 Proj page
📦 Fractal dataset is described in this paper.
More results and the visualized attention maps. Models pretrained of Fractal dataset tend to focus on object edges.
Positional Encodings and Positional Embeddings for Self-Attention Explained
Vanilla Transformers are permutation-invariant models. By default, the output of the model will not change if you permute all words in the input sentence. But this is really bad for language modeling and for Image recognition, as sentences and images have a specific structure and the order of words and pixels do change the semantic meaning.
Consequently, for successful learning, there is a need to incorporate the order of the words/pixels in the input sequence into our self-attention model. This can be done by explicitly attaching the information about the order to every element in a sequence before feeding it to the model. The most widely used approaches are Precomputed Sinusoidal Positional Encodings and Learnable Positional Embeddings.
🟡 In the case of Sinusoidal Positional Encodings, position
🟢 In the case of Positional Embeddings, for every possible position
To learn more details about Positional Encodings and Embeddings and how to implement them, refer to the following blogposts:
📜 Positional Encodings
📃 Positional Embeddings
Vanilla Transformers are permutation-invariant models. By default, the output of the model will not change if you permute all words in the input sentence. But this is really bad for language modeling and for Image recognition, as sentences and images have a specific structure and the order of words and pixels do change the semantic meaning.
Consequently, for successful learning, there is a need to incorporate the order of the words/pixels in the input sequence into our self-attention model. This can be done by explicitly attaching the information about the order to every element in a sequence before feeding it to the model. The most widely used approaches are Precomputed Sinusoidal Positional Encodings and Learnable Positional Embeddings.
🟡 In the case of Sinusoidal Positional Encodings, position
i is encoded by a series of K sine-cosine pairs (sin(w_k t), cos(w_k t)) with decreasing frequencies w_k, k=1, K.🟢 In the case of Positional Embeddings, for every possible position
i we randomly initialize a learnable d-dimensional embedding p_i and concatenate it to every element in the input sequence.To learn more details about Positional Encodings and Embeddings and how to implement them, refer to the following blogposts:
📜 Positional Encodings
📃 Positional Embeddings
{kind=link}
PlenOctrees For Real-time Rendering of Neural Radiance Fields
And yet another speed-up of NERF. Exactly the same idea as in FastNeRF and NEX (predict spherical harmonics coefficients k) - incredible! It's the first time I see so many concurrent papers sharig the same idea. But this one has code at least, which makes it the best!
📝 Paper arxiv.org/abs/2103.14024
🌐Project page alexyu.net/plenoctrees/
🛠Code github.com/sxyu/volrend
And yet another speed-up of NERF. Exactly the same idea as in FastNeRF and NEX (predict spherical harmonics coefficients k) - incredible! It's the first time I see so many concurrent papers sharig the same idea. But this one has code at least, which makes it the best!
📝 Paper arxiv.org/abs/2103.14024
🌐Project page alexyu.net/plenoctrees/
🛠Code github.com/sxyu/volrend
Most of the Recent Advancements in Transformers are Useless😱
Google Research
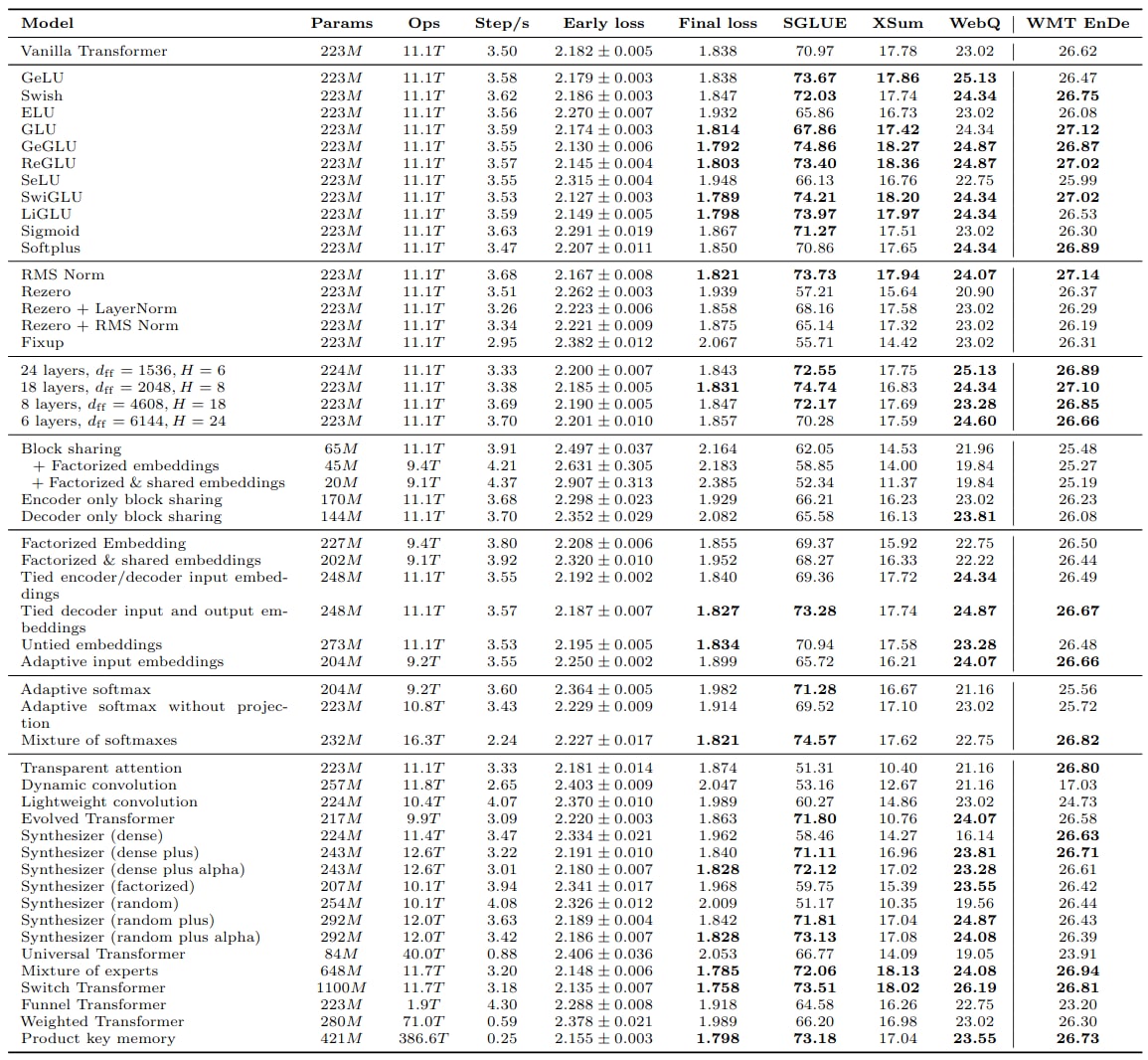
Google study shows Transformer Modifications Fail To Transfer Across Implementations and Applications.
The researchers began by reimplementing and evaluating a variety of transformer variants on the tasks where they are most commonly applied. As a baseline, they used the original transformer model with two modifications: applying layer normalization before the self-attention and feed-forward blocks instead of after, and using relative attention with shared biases instead of sinusoidal positional embeddings.
👀 Surprise!
Most architecture modifications they looked at do not meaningfully improve performance on downstream NLP tasks - they fail to transfer across implementations and applications. See the table below👇 with results for transfer learning based on T5, and supervised machine translation on the WMT'14 English-German benchmark.
😅 Simple ideas are always the best, and more compute never hurts!
Modifications that were proved to improve performance are either (1) relatively simple (e.g. a change in activation function) , or (2) rely on increase in parameter count or FLOPs (e.g. the Switch Transformer or Universal Transformer). And this makes total sense to me.
My take on the reasons for such results is that researchers are often pressured by the urge to publishing new papers every year. This spurs cherry-picking of the results, overstated claims, and spurious architectural modifications. The performance increase shown in many papers is just a result of overfitting over a specific benchmark or more accurate hyperparameter selection compared to the previous work. And such phenomenon is not only inherent for transformer and NLP papers but for other subfields of Deep Learning research as well.
📝 Arxiv paper
Thanks @ai_newz for the pointer!
Google Research
Google study shows Transformer Modifications Fail To Transfer Across Implementations and Applications.
The researchers began by reimplementing and evaluating a variety of transformer variants on the tasks where they are most commonly applied. As a baseline, they used the original transformer model with two modifications: applying layer normalization before the self-attention and feed-forward blocks instead of after, and using relative attention with shared biases instead of sinusoidal positional embeddings.
👀 Surprise!
Most architecture modifications they looked at do not meaningfully improve performance on downstream NLP tasks - they fail to transfer across implementations and applications. See the table below👇 with results for transfer learning based on T5, and supervised machine translation on the WMT'14 English-German benchmark.
😅 Simple ideas are always the best, and more compute never hurts!
Modifications that were proved to improve performance are either (1) relatively simple (e.g. a change in activation function) , or (2) rely on increase in parameter count or FLOPs (e.g. the Switch Transformer or Universal Transformer). And this makes total sense to me.
My take on the reasons for such results is that researchers are often pressured by the urge to publishing new papers every year. This spurs cherry-picking of the results, overstated claims, and spurious architectural modifications. The performance increase shown in many papers is just a result of overfitting over a specific benchmark or more accurate hyperparameter selection compared to the previous work. And such phenomenon is not only inherent for transformer and NLP papers but for other subfields of Deep Learning research as well.
📝 Arxiv paper
Thanks @ai_newz for the pointer!
{kind=link}
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
It's Sunday! So for your attention is Sparky, a robodog from Australia🇦🇺.
Looks like he is a decent competitor for Spot from Boston Dynamics.
Looks like he is a decent competitor for Spot from Boston Dynamics.
Swin Transformer: New SOTA backbone for Computer Vision🔥
MS Research Asia
👉 What?
New vision Transformer architecture called Swin Transformer that can serve as a backbone in computer vision instead of CNNs.
❓Why?
There are two main problems with the usage of Transformers for computer vision.
1. Existing Transformer-based models have tokens of a fixed scale. However, in contrast to the word tokens, visual elements can be different in scale (e.g. objects of varying sizes on the scene)
2. Regular self-attention requires quadratic of the image size number of operations, limiting applications in computer vision where high resolution is necessary (e.g., instance segmentation).
🥊 The main ideas of the Swin Transformers:
1. Hierarchical feature maps where at each level of hierarchy Self-attention is applied within local non-overlapping windows. The size of the windows is progressively increased with the network depth (inspired by CNNs). This enables building architectures similar to feature pyramid networks (FPN) or U-Net for dense pixel-level tasks.
2. Window-based Self-attention reduces the computational overhead.
⚙️ Overall Architecture consists of repeating the following blocks:
- Split RGB image into non-overlapping patches (tokens).
- Apply MLP to translate raw features into an arbitrary dimension.
- Apply 2 consecutive Swin Transformer blocks with Window self-attention: both blocks have the same window size, but the second block uses shifted by `patch_size/2` windows which allows information flow between non-overlapping windows.
- Downsampling layer: Reduce the number of tokens by merging neighboring patches in a 2x2 window, and double the feature depth.
🦾 Results
+ Outperforms SOTA by a significant margin on COCO segmentation and detection tasks and ADE20K segmentation.
+ Comparable accuracy to the EfficientNet family on ImageNet-1K classification, while being faster.
👌🏻Conclusion
While Transformers are super flexible, researchers start to inject in Transformers inductive biases similar to those in CNNs, e.g., local connectivity, feature hierarchies. And this seems to help tremendously!
📝 Paper
⚒ Code (promissed soon)
🌐 TL;DR blogpost
MS Research Asia
👉 What?
New vision Transformer architecture called Swin Transformer that can serve as a backbone in computer vision instead of CNNs.
❓Why?
There are two main problems with the usage of Transformers for computer vision.
1. Existing Transformer-based models have tokens of a fixed scale. However, in contrast to the word tokens, visual elements can be different in scale (e.g. objects of varying sizes on the scene)
2. Regular self-attention requires quadratic of the image size number of operations, limiting applications in computer vision where high resolution is necessary (e.g., instance segmentation).
🥊 The main ideas of the Swin Transformers:
1. Hierarchical feature maps where at each level of hierarchy Self-attention is applied within local non-overlapping windows. The size of the windows is progressively increased with the network depth (inspired by CNNs). This enables building architectures similar to feature pyramid networks (FPN) or U-Net for dense pixel-level tasks.
2. Window-based Self-attention reduces the computational overhead.
⚙️ Overall Architecture consists of repeating the following blocks:
- Split RGB image into non-overlapping patches (tokens).
- Apply MLP to translate raw features into an arbitrary dimension.
- Apply 2 consecutive Swin Transformer blocks with Window self-attention: both blocks have the same window size, but the second block uses shifted by `patch_size/2` windows which allows information flow between non-overlapping windows.
- Downsampling layer: Reduce the number of tokens by merging neighboring patches in a 2x2 window, and double the feature depth.
🦾 Results
+ Outperforms SOTA by a significant margin on COCO segmentation and detection tasks and ADE20K segmentation.
+ Comparable accuracy to the EfficientNet family on ImageNet-1K classification, while being faster.
👌🏻Conclusion
While Transformers are super flexible, researchers start to inject in Transformers inductive biases similar to those in CNNs, e.g., local connectivity, feature hierarchies. And this seems to help tremendously!
📝 Paper
⚒ Code (promissed soon)
🌐 TL;DR blogpost
{kind=link}