
{kind=link}
Synonyms in Elasticsearch
Синоним — слово, которое означает точно или почти то же самое, что и другое слово.
В этом коротком посте демонстрация реализации синонимов в Elasticsearch, например, сопоставление людей по имени «Anne» при поиске «Ann».
Синоним — слово, которое означает точно или почти то же самое, что и другое слово.
В этом коротком посте демонстрация реализации синонимов в Elasticsearch, например, сопоставление людей по имени «Anne» при поиске «Ann».
{kind=link}
Как упростить жизнь разработчиков, которые пишут приложение, работающее с Elasticsearch?
Elasticsearch умеет создавать поисковые запросы в виде поисковых шаблонов (search templates), которые потом можно вызывать с параметрами. Использую готовые шаблоны, разработчики могут не добавлять в код излишние сущности..
Статья с описанием механизма
Страница документации
Elasticsearch умеет создавать поисковые запросы в виде поисковых шаблонов (search templates), которые потом можно вызывать с параметрами. Использую готовые шаблоны, разработчики могут не добавлять в код излишние сущности..
Статья с описанием механизма
Страница документации
{kind=link}
Storing 50 million events per second in Elasticsearch: How we did it
Несколько цифр: наш кластер хранит более 150 ТБ данных, 15 триллионов событий в 60 миллиардах документов, разбросанных по 3 000 индексов и 15 000 шардов на 80 узлах. Каждый документ хранит 250 событий в отдельном поле.
Каждый день во время пиковой нагрузки наш кластер Elasticsearch записывает более 200 000 документов в секунду и имеет скорость поиска более 20 000 запросов в секунду.
Наши индексы основаны на ежедневной основе, и у нас есть один индекс для каждого клиента, чтобы обеспечить логическое разделение данных.
И как оптимизировать производительность такого кластера?
Несколько цифр: наш кластер хранит более 150 ТБ данных, 15 триллионов событий в 60 миллиардах документов, разбросанных по 3 000 индексов и 15 000 шардов на 80 узлах. Каждый документ хранит 250 событий в отдельном поле.
Каждый день во время пиковой нагрузки наш кластер Elasticsearch записывает более 200 000 документов в секунду и имеет скорость поиска более 20 000 запросов в секунду.
Наши индексы основаны на ежедневной основе, и у нас есть один индекс для каждого клиента, чтобы обеспечить логическое разделение данных.
И как оптимизировать производительность такого кластера?
{kind=link}
👍1
Top 10 Elasticsearch Metrics to Monitor - статья о том, за какими показателями Elasticsearch стоит следить, чтобы кластер был здоров и могуч.
👉 Cluster Health: Shards and Node Availability
👉 Search Query Performance Metrics: Request Rate and Latency
👉 Indexing Performance Metrics: Refresh and Merge Times
👉 Node Health: Memory, Disk, and CPU Metrics
👉 Caching: Field Data, Node Query and Shard Query Cache
👉 JVM Health Metrics: Heap, GC, and Pool Size
Статья.
👉 Cluster Health: Shards and Node Availability
👉 Search Query Performance Metrics: Request Rate and Latency
👉 Indexing Performance Metrics: Refresh and Merge Times
👉 Node Health: Memory, Disk, and CPU Metrics
👉 Caching: Field Data, Node Query and Shard Query Cache
👉 JVM Health Metrics: Heap, GC, and Pool Size
Статья.
{kind=link}
👍1
Известно, что заменой Logstash может быть ingest-нода Elasticsearch. Действительно, зачем поддерживать несколько разных решений в стэке, если можно ограничиться одним. Если нет специфичных задач по интеграции или обработке данных именно так мы и советуем поступать нашим клиентам. В статье по ссылке ниже сравнение производительности одного и того же процессора grok в Logstash и в ingest-ноде Elasticsearch. Угадайте, кто показывает лучшую эффективность работы.
Elasticsearch Ingest Node vs Logstash Performance
Elasticsearch Ingest Node vs Logstash Performance
{kind=link}
How I Discovered Thousands of Open Databases on AWS
Последнее китайское предупреждение о том, что безопасность кластера Elastic — первоочередная задача, которую нужно решить. Даже если кластер находится внутри периметра компании. В этой статье рассказ о том, как 1 человек за 1 день обнаружил тысячи открытых данных в Elasticsearch. Читать дальше.
На прикрепленном скриншоте данные чьего-то банковского счёта.
Последнее китайское предупреждение о том, что безопасность кластера Elastic — первоочередная задача, которую нужно решить. Даже если кластер находится внутри периметра компании. В этой статье рассказ о том, как 1 человек за 1 день обнаружил тысячи открытых данных в Elasticsearch. Читать дальше.
На прикрепленном скриншоте данные чьего-то банковского счёта.
{kind=link}
How to properly handle Elasticsearch ingest pipelines failures
В Logstash есть специальный функционал для обработки сбоев и защита от удаления документов — Dead Letter Queue. В этой статье вы узнаете как использовать Elasticsearch и его ingest pipeline для:
⚡️ обработки сбоев
⚡️ хранения неудачно отправленных документов
⚡️ повторной отправки документов
В Logstash есть специальный функционал для обработки сбоев и защита от удаления документов — Dead Letter Queue. В этой статье вы узнаете как использовать Elasticsearch и его ingest pipeline для:
⚡️ обработки сбоев
⚡️ хранения неудачно отправленных документов
⚡️ повторной отправки документов
Too many fields! 3 ways to prevent mapping explosion in Elasticsearch
В этой статье методика по эффективной работе с полями документов, чтобы их типы и количество не влияли на утилизацию аппаратных ресурсов и, в конечном итоге, на производительность кластера Elasticsearch.
В этой статье методика по эффективной работе с полями документов, чтобы их типы и количество не влияли на утилизацию аппаратных ресурсов и, в конечном итоге, на производительность кластера Elasticsearch.
Если хотите разобраться с возможностями APM в Elasticsearch, в этой статье разбор установки тестового приложения и настройки его работы с Elastic Stack.
{kind=link}
В блоге Pascal Thalmann вы найдете несколько воркшопов по компонентам Elastic Stack. Перейти в блог.
{kind=link}
Elasticsearch Indexing Strategy in Asset Management Platform (AMP)
Статья о подходе Netflix к хранению каталога данных в Elasticsearch.
Статья о подходе Netflix к хранению каталога данных в Elasticsearch.
{kind=link}
Data Pipeline from Kafka To Elastic-search using logstash
В этой статье о настройке logstash для ввода из топиков Kafka, трансформации данных и их публикации в индексе Elasticsearch.
В этой статье о настройке logstash для ввода из топиков Kafka, трансформации данных и их публикации в индексе Elasticsearch.
{kind=link}
Do you need ElasticSearch when you have PostgreSQL?
Когда Elasticsearch ту мач и когда будет достаточно PostgreSQL. В этой статье опыт компании Qonto и их небольшой ресерч производительности обоих конкурсантов.
Когда Elasticsearch ту мач и когда будет достаточно PostgreSQL. В этой статье опыт компании Qonto и их небольшой ресерч производительности обоих конкурсантов.
{kind=link}
Forwarded from Мониторим ИТ
Monitor Elasticsearch with Kube-Prometheus
В этой статье:
⚡️How to monitor Elasticsearch with Kube-Prometheus
⚡️Elasticsearch Exporter
⚡️Elasticsearch Exporter — Helm
⚡️Elasticsearch Exporter and Terraform
⚡️Deploy Elasticsearch Exporter using Terraform
⚡️Kubernetes Servicemonitor
Читать дальше.
В этой статье:
⚡️How to monitor Elasticsearch with Kube-Prometheus
⚡️Elasticsearch Exporter
⚡️Elasticsearch Exporter — Helm
⚡️Elasticsearch Exporter and Terraform
⚡️Deploy Elasticsearch Exporter using Terraform
⚡️Kubernetes Servicemonitor
Читать дальше.
{kind=link}
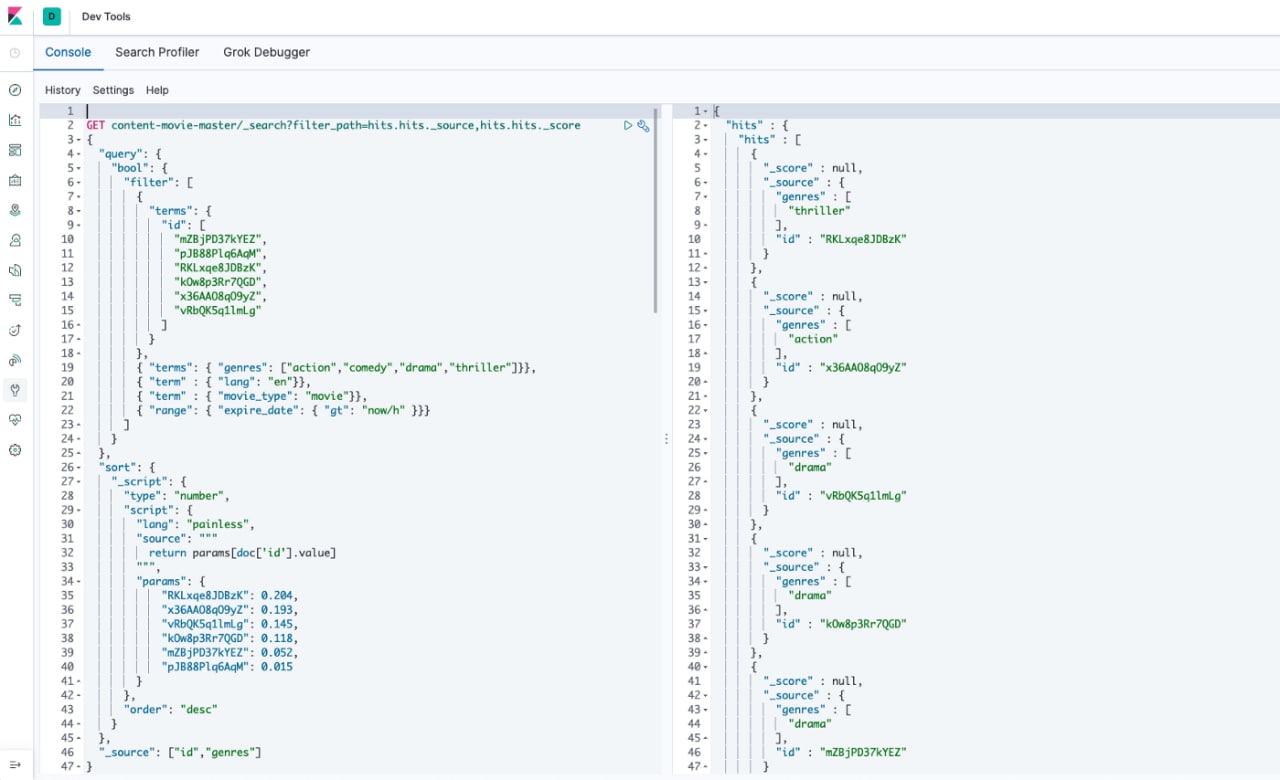
Elasticsearch custom sorting script
В этой статье о сортировке результатов поиска при помощи painless
В этой статье о сортировке результатов поиска при помощи painless
{kind=link}
How to Change Sharding of Existing Indices on an Elasticsearch Cluster
«Бэст прэктис» рекомендует поддерживать размер шардов в пределах от 10 до 50 Гб, чтобы был баланс между слишком большим количеством шардов, вызывающих перегрузку кластера, и наличием больших шардов, затрудняющих восстановление кластера. В дополнение к этому, поддержание одинакового размера шарда и количества шардов, кратного узлам, поможет равномерно распределить сегменты, уменьшив перекосы в хранении и производительности.
Ссылка.
«Бэст прэктис» рекомендует поддерживать размер шардов в пределах от 10 до 50 Гб, чтобы был баланс между слишком большим количеством шардов, вызывающих перегрузку кластера, и наличием больших шардов, затрудняющих восстановление кластера. В дополнение к этому, поддержание одинакового размера шарда и количества шардов, кратного узлам, поможет равномерно распределить сегменты, уменьшив перекосы в хранении и производительности.
Ссылка.
{kind=link}
{kind=link}
В этой статье о том, как использовать Kubernetes Operator для автомасштабирования кластеров Elasticsearch.
Autoscaling Elasticsearch/OpenSearch Clusters for Logs: Using a Kubernetes Operator to Scale Up or Down
Autoscaling Elasticsearch/OpenSearch Clusters for Logs: Using a Kubernetes Operator to Scale Up or Down
{kind=link}
Выбор шипперов/обработчиков для ElasticSearch/OpenSearch состоит не из полутора инструментов. Их достаточно много и каждый обладает определенным преимуществом. В этой статье краткий обзор Logstash, Fluentd, FluentBit и Vector.
Logstash, Fluentd, Fluent Bit, or Vector? How to Choose the Right Open-Source Log Collector
Logstash, Fluentd, Fluent Bit, or Vector? How to Choose the Right Open-Source Log Collector