
Wazuh-Rules. Репозиторий на Гитхабе с правилами для Wazuh, которые можно взять и использовать в Elasticsearch. Ознакомиться.
👍1🔥1
{kind=link}
Исследование нагрузки на ELK stack и тюнинг Logstash. В этой статье автор расскажет про то, как столкнувшись с многократно увеличившейся нагрузкой на ELK stack сначала было диагностировано узкое место, а после произведён его тюнинг. Хоть и в заголовке статьи уже есть спойлер что произведен только тюнинг Logstash, но тем не менее. Читать.
{kind=link}
👍6👎1
Overview of Syslog Parsing with Fluentd
Syslog - это широко используемый метод сбора и хранения данных. Это стандарт, который поддерживается многими приложениями и платформами. В этой статье рассмотрены основы разбора syslog с помощью Fluentd.
Syslog - это широко используемый метод сбора и хранения данных. Это стандарт, который поддерживается многими приложениями и платформами. В этой статье рассмотрены основы разбора syslog с помощью Fluentd.
👍2
Run Elastic Stack on Kubernetes
Это руководство по развертыванию стека Elastic на Kubernetes. В этом руководстве используется оператор ECK для создания всех связанных с Elastic ресурсов на Kubernetes.
Это руководство по развертыванию стека Elastic на Kubernetes. В этом руководстве используется оператор ECK для создания всех связанных с Elastic ресурсов на Kubernetes.
👍2
Elastic SIEM fleet server implementation
Fleet Server, который отвечает за управление Elastic-агентами на хостах, является одним из основных элементов Elastic SIEM. В этой статье рассказано о том как устроен и какими возможностями обладает Fleet Server для Elastic SIEM.
Fleet Server, который отвечает за управление Elastic-агентами на хостах, является одним из основных элементов Elastic SIEM. В этой статье рассказано о том как устроен и какими возможностями обладает Fleet Server для Elastic SIEM.
{kind=link}
👍3
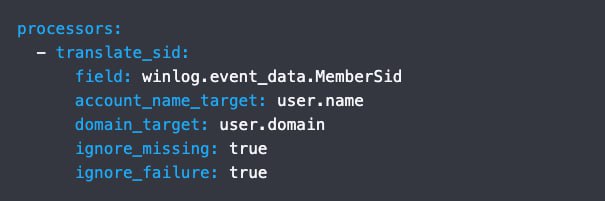
Если вы используете Elastic в качестве SIEM-системы, обратите внимание на процессор translate_sid для Winlogbeat. Процессор извлекает имя учетной записи, связанной с SID, первый домен, в котором найден SID и тип учетной записи.
Каждой учетной записи в домене присваивается уникальный идентификатор SID при первом создании. Внутренние процессы в Windows обращаются к SID учетной записи, а не к имени пользователя или группы, и именно эти значения появляются в журналах Windows.
Описание процессора translate_sid в документации
Каждой учетной записи в домене присваивается уникальный идентификатор SID при первом создании. Внутренние процессы в Windows обращаются к SID учетной записи, а не к имени пользователя или группы, и именно эти значения появляются в журналах Windows.
Описание процессора translate_sid в документации
{kind=link}
👍2
Рассказали в нашем блоге о роли координирующей ноды в кластере Elasticsearch. Прочитайте эту статью, если задумываетесь нужна ли она вам.
gals.software
Координирующая нода (Coordinating Node) Elasticsearch: когда она нужна
Разберем что такое координирующая нода, когда она нужна и принципы её работы.
👍3👎1
Задачи миграции индексов между кластерами достаточно часто встают перед администраторами Elasticsearch. В этой статье на Медиуме разобрана миграция кластера при помощи утилит elasticsearch-dump, Minio и хранилища S3.
👍3
Что нового в OpenSearch 2.6
28 февраля вышла новая минорная версия OpenSearch. Давайте посмотрим какие обновления она получила.
⚡️ В OpenSearch 2.6.0 появилась функциональность, упрощающая администрирование кластера. Это обновление позволяет создавать, просматривать и управлять потоками данных непосредственно из пользовательского интерфейса. Также появилась возможность выполнять операции ручного переноса индексов или потоков данных, а также принудительного слияния индексов или потоков из пользовательского интерфейса.
⚡️При создании детекций угроз в OpenSearch 2.6.0 теперь можно использовать несколько индексов или шаблонов индексов для построения детекции, а не только один индекс. Пять новых интеграций доступны для обнаружения угроз, теперь их общее количество достигло 13. Новые интеграции включают в себя Google Workspace, GitHub Actions, логи Microsoft 365, события Okta и логи Microsoft Azure. Кроме того, многие типы детекций теперь включают готовые панели, предназначенные для визуализации логов, которые они отслеживают.
⚡️Версия 2.6.0 включает новую панель здоровья ML-моделей в качестве экспериментальной функции, позволяющей просматривать местоположение и состояние ML-моделей в кластере.
⚡️Появились карты в OpenSearch Dashboards. Ранее карты можно было создавать и отображать только в плагине Maps; теперь вы можете получить доступ к картам для визуализации и анализа, не выходя из Dashboards.
⚡️OpenSearch 2.6.0 поддерживает OpenSearch Reporting CLI. Новый CLI предоставляет готовый способ программно генерировать и загружать отчеты непосредственно из OpenSearch Dashboards. Можно использовать Reporting CLI для создания отчетов в формате PDF, PNG или CSV и распространения их в виде файла в системах передачи сообщений.
⚡️OpenSearch использует встроенный механизм для определения ресурсоемких поисковых запросов и сбрасывает их, когда нагрузка на ноде превышает лимит ресурсов. В новом релизе OpenSearch запросы теперь сбрасываются на уровне ноды-координатора и, таким образом, обеспечивается более эффективная защита от скачков нагрузки, возникающая из-за небольшого количества ресурсоемких запросов.
Подробнее об обновления можно узнать в блоге OpenSearch.
28 февраля вышла новая минорная версия OpenSearch. Давайте посмотрим какие обновления она получила.
⚡️ В OpenSearch 2.6.0 появилась функциональность, упрощающая администрирование кластера. Это обновление позволяет создавать, просматривать и управлять потоками данных непосредственно из пользовательского интерфейса. Также появилась возможность выполнять операции ручного переноса индексов или потоков данных, а также принудительного слияния индексов или потоков из пользовательского интерфейса.
⚡️При создании детекций угроз в OpenSearch 2.6.0 теперь можно использовать несколько индексов или шаблонов индексов для построения детекции, а не только один индекс. Пять новых интеграций доступны для обнаружения угроз, теперь их общее количество достигло 13. Новые интеграции включают в себя Google Workspace, GitHub Actions, логи Microsoft 365, события Okta и логи Microsoft Azure. Кроме того, многие типы детекций теперь включают готовые панели, предназначенные для визуализации логов, которые они отслеживают.
⚡️Версия 2.6.0 включает новую панель здоровья ML-моделей в качестве экспериментальной функции, позволяющей просматривать местоположение и состояние ML-моделей в кластере.
⚡️Появились карты в OpenSearch Dashboards. Ранее карты можно было создавать и отображать только в плагине Maps; теперь вы можете получить доступ к картам для визуализации и анализа, не выходя из Dashboards.
⚡️OpenSearch 2.6.0 поддерживает OpenSearch Reporting CLI. Новый CLI предоставляет готовый способ программно генерировать и загружать отчеты непосредственно из OpenSearch Dashboards. Можно использовать Reporting CLI для создания отчетов в формате PDF, PNG или CSV и распространения их в виде файла в системах передачи сообщений.
⚡️OpenSearch использует встроенный механизм для определения ресурсоемких поисковых запросов и сбрасывает их, когда нагрузка на ноде превышает лимит ресурсов. В новом релизе OpenSearch запросы теперь сбрасываются на уровне ноды-координатора и, таким образом, обеспечивается более эффективная защита от скачков нагрузки, возникающая из-за небольшого количества ресурсоемких запросов.
Подробнее об обновления можно узнать в блоге OpenSearch.
{kind=link}
👍6
Данные Elasticsearch-сервера оператора связи «Авантелеком», включая логи общения с клиентами, оказались открыты всем
В комментариях компания пишет, что это был взлом, однако, часто бывает, что кластер Elasticsearch начинает быть открытым всему интернету просто по недосмотру. У нас уже был пост про безопасность Elasticsearch в docker-контейнера. Обратите пристальное внимание на особенность работы Docker с iptables.
В комментариях компания пишет, что это был взлом, однако, часто бывает, что кластер Elasticsearch начинает быть открытым всему интернету просто по недосмотру. У нас уже был пост про безопасность Elasticsearch в docker-контейнера. Обратите пристальное внимание на особенность работы Docker с iptables.
👍2
Test Logstash Pipelines/Filters before Implementation
Эта статья намекает, что logstash можно запустить с ключом -f и протестировать конфигурацию перед запуском.
Эта статья намекает, что logstash можно запустить с ключом -f и протестировать конфигурацию перед запуском.
👍3
How to Upgrade Elasticsearch from Version 7 to Version 8
Если очень нужно, то вот пошаговая инструкция по обновлению.
Если очень нужно, то вот пошаговая инструкция по обновлению.
👍6
What are the best Elasticsearch GUI clients?
Перечень GUI-клиентов для Elasticsearch
Перечень GUI-клиентов для Elasticsearch
👍3
Яндекс Облако сегодня проводили вебинар по OpenSearch. Рассказали об отличиях с Elasticsearch, как выполнить миграцию в OpenSearch и, конечно, о своём управляемом сервисе.
{kind=link}
👍6
Paginate Your Search Result with Elasticsearch and Go
В этой статье примеры кода на Go для поисковых запросов с пагинацией в Elasticsearch. Описаны два типа пагинаций: по количеству ответов и бесконечная.
В этой статье примеры кода на Go для поисковых запросов с пагинацией в Elasticsearch. Описаны два типа пагинаций: по количеству ответов и бесконечная.
👍2
Elasticsearch reindex - How to decrease the reindex time by more than 90% and simplify reindex process
В этой статье обзор существующих решений для Elasticsearch и решение с открытым исходным кодом, которое помогает упростить процесс переиндексации. Судя по контрольным показателям, использование этого приложения сэкономит до 90% времени!
В этой статье обзор существующих решений для Elasticsearch и решение с открытым исходным кодом, которое помогает упростить процесс переиндексации. Судя по контрольным показателям, использование этого приложения сэкономит до 90% времени!
{kind=link}
👍2
Внедряем и сопровождаем 🔎ElasticSearch 🔎OpenSearch
Разбираемся в кейсах безопасности, логирования, поиска и APM-мониторинга.
На базе одной из этих бесплатных систем создадим для вас систему управления событиями информационной безопасности.
Вы всегда будете знать:
⚡️ кто и когда создал удалил новую учетную запись или группу в AD или Linux
⚡️ кто открывал, создавал или удалял файлы на файловом хранилище
⚡️ кто и когда подключался к 1С, веб-ресурсам компании, рабочим станциям, серверам или по VPN
⚡️ какие веб-ресурсы посещали пользователи (например, по данным прокси Касперского)
⚡️ когда происходит подбор пароля
⚡️ и о многих других событиях.
Все собранные данные мы аккуратно визуализируем в Kibana/OpenSearch Dashboards, чтобы вы могли видеть полную картину происходящего. По каждому событию настроим уведомления в почту или телеграм. Также мы проконсультируем по эффективному использованию этих систем в качестве SIEM-системы.
Если у вас уже есть в эксплуатации ElasticSearch/OpenSearch, мы займёмся его развитием и сопровождением или проведем для вас обучение на специализированных курсах по ElasticSearch и OpenSearch.
Запрос можно оставить через форму обратной связи на нашем сайте, отправить в адрес welcome@gals.software либо написать в телеграм @galssoftware.
Разбираемся в кейсах безопасности, логирования, поиска и APM-мониторинга.
На базе одной из этих бесплатных систем создадим для вас систему управления событиями информационной безопасности.
Вы всегда будете знать:
⚡️ кто и когда создал удалил новую учетную запись или группу в AD или Linux
⚡️ кто открывал, создавал или удалял файлы на файловом хранилище
⚡️ кто и когда подключался к 1С, веб-ресурсам компании, рабочим станциям, серверам или по VPN
⚡️ какие веб-ресурсы посещали пользователи (например, по данным прокси Касперского)
⚡️ когда происходит подбор пароля
⚡️ и о многих других событиях.
Все собранные данные мы аккуратно визуализируем в Kibana/OpenSearch Dashboards, чтобы вы могли видеть полную картину происходящего. По каждому событию настроим уведомления в почту или телеграм. Также мы проконсультируем по эффективному использованию этих систем в качестве SIEM-системы.
Если у вас уже есть в эксплуатации ElasticSearch/OpenSearch, мы займёмся его развитием и сопровождением или проведем для вас обучение на специализированных курсах по ElasticSearch и OpenSearch.
Запрос можно оставить через форму обратной связи на нашем сайте, отправить в адрес welcome@gals.software либо написать в телеграм @galssoftware.
👍3
Некоторое время назад у одного из заказчиков столкнулись с ситуацией периодического выпадения ноды в кластере EkasticSearch. Были сетевые проблемы. В конфигурации ноды есть специальный параметр, который позволяет настроить задержку распределения потерянных шардов и не тратить на это аппаратные ресурсы.
Когда одна из дата- нод покидает кластер, мастер-нода реагирует следующим образом:
⛵️ Повышает реплика-шарды до праймари-шардов, чтобы заместить все праймари, которые были на потерянной ноде.
⛵️Распределяет реплика-шарды для замены потерянных реплик (при условии, что имеется достаточное количество нод).
⛵️Выполняет перераспределение шардов поровну между оставшимися нодами.
Эти действия направлены на защиту кластера от потери данных путем обеспечения полной репликации каждого шарда.
Переезд шардов создаёт дополнительную нагрузку на кластер, которую можно избежать, если нода выпала из кластера на короткое время. Рассмотрим следующий сценарий:
⛵️Нода теряет сетевое соединение.
⛵️Мастер-нода переводит реплика-шарды в праймари для каждого праймари-шарда, находившегося на выпавшей ноде.
⛵️Мастер распределяет новые реплики по другим нодам кластера.
⛵️Каждая новая реплика создает полную копию праймари-шарда.
⛵️Шарды ребалансируются на другие ноды кластера.
⛵️Потерянная нода возвращается через несколько минут.
⛵️Мастер-нода восстанавливает баланс кластера, выделяя шарды потерянной ноде.
Если бы мастер-нода подождала несколько минут, то потерянные шарды можно было бы перераспределить на потерянную ноду с минимальным сетевым трафиком.
Распределение реплик-шардов, которые становятся нераспределенными из-за отключения ноды, может быть отложено с помощью настройки index.unassigned.node_left.delayed_timeout, которая по умолчанию равна 1минуте. Этот параметр может быть обновлен без перезагрузки.
⛵️Нода теряет сетевое подключение.
⛵️Мастер-нода переводит реплика-шарды в праймари для каждого праймари-шарда, который находился на выпавшей ноде.
⛵️Мастер-нода регистрирует сообщение о том, что распределение неназначенных шардов было отложено и на какой срок.
⛵️Кластер остается желтым, потому что есть нераспределенные шарды-реплики.
⛵️Потерянная нода возвращается через несколько минут, до истечения тайм-аута.
⛵️Потерянные реплики повторно распределяются на выпадавшую ноду.
Эта настройка не влияет на повышение реплика-шардов до праймари, равно как и на назначение реплик, которые не были назначены ранее. Тут всё без изменений.
Если время отложенного распределения истекло, мастер-нода запускает процесс по первому сценарию.
Сталкивались ли вы с проблемами периодического кратковременного выпадения ноды из кластера?
Когда одна из дата- нод покидает кластер, мастер-нода реагирует следующим образом:
⛵️ Повышает реплика-шарды до праймари-шардов, чтобы заместить все праймари, которые были на потерянной ноде.
⛵️Распределяет реплика-шарды для замены потерянных реплик (при условии, что имеется достаточное количество нод).
⛵️Выполняет перераспределение шардов поровну между оставшимися нодами.
Эти действия направлены на защиту кластера от потери данных путем обеспечения полной репликации каждого шарда.
Переезд шардов создаёт дополнительную нагрузку на кластер, которую можно избежать, если нода выпала из кластера на короткое время. Рассмотрим следующий сценарий:
⛵️Нода теряет сетевое соединение.
⛵️Мастер-нода переводит реплика-шарды в праймари для каждого праймари-шарда, находившегося на выпавшей ноде.
⛵️Мастер распределяет новые реплики по другим нодам кластера.
⛵️Каждая новая реплика создает полную копию праймари-шарда.
⛵️Шарды ребалансируются на другие ноды кластера.
⛵️Потерянная нода возвращается через несколько минут.
⛵️Мастер-нода восстанавливает баланс кластера, выделяя шарды потерянной ноде.
Если бы мастер-нода подождала несколько минут, то потерянные шарды можно было бы перераспределить на потерянную ноду с минимальным сетевым трафиком.
Распределение реплик-шардов, которые становятся нераспределенными из-за отключения ноды, может быть отложено с помощью настройки index.unassigned.node_left.delayed_timeout, которая по умолчанию равна 1минуте. Этот параметр может быть обновлен без перезагрузки.
PUT _all/_settingsПри включенном отложенном распределении вышеописанный сценарий выглядит следующим образом:
{
"settings": {
"index.unassigned.node_left.delayed_timeout": "5m"
}
}
⛵️Нода теряет сетевое подключение.
⛵️Мастер-нода переводит реплика-шарды в праймари для каждого праймари-шарда, который находился на выпавшей ноде.
⛵️Мастер-нода регистрирует сообщение о том, что распределение неназначенных шардов было отложено и на какой срок.
⛵️Кластер остается желтым, потому что есть нераспределенные шарды-реплики.
⛵️Потерянная нода возвращается через несколько минут, до истечения тайм-аута.
⛵️Потерянные реплики повторно распределяются на выпадавшую ноду.
Эта настройка не влияет на повышение реплика-шардов до праймари, равно как и на назначение реплик, которые не были назначены ранее. Тут всё без изменений.
Если время отложенного распределения истекло, мастер-нода запускает процесс по первому сценарию.
Сталкивались ли вы с проблемами периодического кратковременного выпадения ноды из кластера?
👍14
Поле text на минималках или как сэкономить до 10% дискового пространства
Начиная с версии 7.14 в Elasticsearch появился новый тип поля
⚡️Оценка релевантности рассчитывается как количество совпадающих выражений.
⚡️Span-запросы не поддерживаются. Все остальные типы запросов, которые поддерживаются для полей типа text, также поддерживаются для полей match_only_text.
⚡️Фразовые и интервальные запросы выполняются медленнее, чем в текстовых полях, но намного быстрее, чем линейное сканирование. Другие типы запросов выполняются так же быстро.
Так за счет чего достигается оптимизация хранения?
⚡️коэффициенты нормализации длины
⚡️частотности выражений
⚡️позиции в выдаче
Коэффициент нормализации длины и частотности выражений используются только для вычисления скоринга, поэтому отказ от их использования очевидный шаг, учитывая, что оценка релевантности обычно бесполезна для логов, т.к. события обычно сортируются по убыванию временной метки, а не по релевантности.
P.S. Про 10% Elastic заявляет в своей статье блога. Для оптимизации хранения мы рекомендуем использовать поля типа
Приходилось ли вам использовать поле типа
Начиная с версии 7.14 в Elasticsearch появился новый тип поля
match_only_text, который может быть использован в качестве замены поля типа text. Тип поля match_only_text обладает следующими характеристиками:⚡️Оценка релевантности рассчитывается как количество совпадающих выражений.
⚡️Span-запросы не поддерживаются. Все остальные типы запросов, которые поддерживаются для полей типа text, также поддерживаются для полей match_only_text.
⚡️Фразовые и интервальные запросы выполняются медленнее, чем в текстовых полях, но намного быстрее, чем линейное сканирование. Другие типы запросов выполняются так же быстро.
Так за счет чего достигается оптимизация хранения?
match_only_text — это тип поля, который отсекает некоторые характерные типу text вещи:⚡️коэффициенты нормализации длины
⚡️частотности выражений
⚡️позиции в выдаче
Коэффициент нормализации длины и частотности выражений используются только для вычисления скоринга, поэтому отказ от их использования очевидный шаг, учитывая, что оценка релевантности обычно бесполезна для логов, т.к. события обычно сортируются по убыванию временной метки, а не по релевантности.
P.S. Про 10% Elastic заявляет в своей статье блога. Для оптимизации хранения мы рекомендуем использовать поля типа
keyword и удалять поле message после того как вы вытащили оттуда всё необходимое. В целом, match_only_text выглядит как некий компромисс, который вроде бы и не особо нужен при работе с текстовыми логами.Приходилось ли вам использовать поле типа
match_only_text в ваших индексах?