
Когда исправляешь баг, проверь, не скрывается ли за ним системная проблема.
Please open Telegram to view this post
VIEW IN TELEGRAM
❤8👍1
Product Analyst
Data Quality Analyst (Financial Data)
Senior Python Developer
Please open Telegram to view this post
VIEW IN TELEGRAM
❤3🐳1
Статья описывает разработку «умного» помощника для клиентской поддержки интернет-магазина. Рассматриваются проблемы, с которыми сталкивался клиент, и пути их решения с помощью ИИ.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
👍8❤2
Напишите функцию, которая принимает
pandas.DataFrame и название столбца, а затем возвращает новый DataFrame, в котором выбросы (значения, выходящие за пределы 1.5 межквартильного размаха) удалены.Пример:
import pandas as pd
data = pd.DataFrame({
"values": [10, 12, 15, 100, 14, 13, 11, 102, 16]
})
cleaned_data = remove_outliers(data, "values")
print(cleaned_data)
# Ожидаемый результат:
# values
# 0 10
# 1 12
# 2 15
# 4 14
# 5 13
# 6 11
# 8 16
Решение задачи
import pandas as pd
def remove_outliers(df, column):
Q1 = df[column].quantile(0.25)
Q3 = df[column].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
return df[(df[column] >= lower_bound) & (df[column] <= upper_bound)]
# Пример использования:
data = pd.DataFrame({
"values": [10, 12, 15, 100, 14, 13, 11, 102, 16]
})
cleaned_data = remove_outliers(data, "values")
print(cleaned_data)
Please open Telegram to view this post
VIEW IN TELEGRAM
👍12❤3🐳2🔥1
• Построение базы знаний компании и поиска документов на LLM и RAG
• Что побуждает LLM врать и как этого избежать в своих продуктах
• Ломаем капчу 4Chan
• На чём учатся современные модели машинного перевода: опыт команды Яндекс Переводчика
• Gemini вырывается вперед, Китай спамит моделями, в Minecraft запустили AI-агентов: главные события ноября в сфере ИИ
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤2🔥1
Статья объясняет, как внедрить ML-модель, обученную на Python, в сервис на Go, используя ONNX. Рассматривается пример работы с моделью seara/rubert-tiny2-russian-sentiment для анализа сентимента текста.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
👍3❤1
Напишите функцию, которая принимает
pandas.DataFrame и возвращает новый DataFrame, где все пропущенные значения (NaN) в числовых столбцах заменены на медиану соответствующего столбца.Пример:
import pandas as pd
data = pd.DataFrame({
'age': [25, 30, None, 45, 50],
'salary': [50000, 60000, 55000, None, 65000],
'city': ['NY', 'LA', 'NY', 'SF', 'LA']
})
cleaned_data = fill_missing_with_median(data)
print(cleaned_data)
age salary city
0 25.0 50000.0 NY
1 30.0 60000.0 LA
2 37.5 55000.0 NY
3 45.0 57500.0 SF
4 50.0 65000.0 LA
Решение задачи
import pandas as pd
def fill_missing_with_median(df):
df_filled = df.copy()
for col in df_filled.select_dtypes(include='number').columns:
median = df_filled[col].median()
df_filled[col].fillna(median, inplace=True)
return df_filled
# Пример использования:
data = pd.DataFrame({
'age': [25, 30, None, 45, 50],
'salary': [50000, 60000, 55000, None, 65000],
'city': ['NY', 'LA', 'NY', 'SF', 'LA']
})
cleaned_data = fill_missing_with_median(data)
print(cleaned_data)
Please open Telegram to view this post
VIEW IN TELEGRAM
👍6❤2
Junior/Middle Data Engineer
Junior Data Engineer
Специалист по сбору данных/ Junior data analyst
Please open Telegram to view this post
VIEW IN TELEGRAM
❤1👍1
В этой статье я привел базовые сведения о логистической регрессии и показал как сделать модель с нуля на чистом Python. Логистическая функция, обучение, метрики качества для модели классификации, реализация и небольшой разбор обучения весов.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤4👍1
shutil в Python и зачем он используется?Модуль
shutil предоставляет функции для работы с файлами и директориями, такие как копирование, перемещение и удаление. Он полезен для автоматизации задач управления файлами.import shutil
# Копирование файла
shutil.copy('source.txt', 'destination.txt')
# Перемещение файла
shutil.move('destination.txt', 'folder/destination.txt')
🗣️ В этом примере shutil.copy копирует файл, а shutil.move перемещает его в другую директорию. Это облегчает выполнение операций с файлами и папками.
Please open Telegram to view this post
VIEW IN TELEGRAM
👍6🐳2❤1
Data Scientist
• Python, SQL, MS SQL Server, PostgreSQL, A/B тестирование, ML-модели, Ad-Hoc аналитика• Уровень дохода не указан | Средний (Middle)Data Scientist (Моделирование РБ)
• Python, Spark, SQL, ML, DL, NLP, Apache Spark• Уровень дохода не указан | Средний (Middle)ML Engineer / Инженер машинного обучения
• Python, PyTorch, PostgreSQL, FastAPI, LLM, MLOps, Git, Docker, AirFlow• Уровень дохода не указан | Средний (Middle)Python разработчик
• Python, FastAPI, PostgreSQL, React• от 150 000 ₽ | Средний (Middle)Python разработчик
• Python, Flask, FastAPI, PostgreSQL, MySQL• Уровень дохода не указан | Средний (Middle)Please open Telegram to view this post
VIEW IN TELEGRAM
❤2👍1
Компания OpenAI представила свою ИИ-модель для генерации видео — Sora. В статье обсуждаются ожидания, доступность и сравнительный анализ с конкурентами, такими как Kling AI и Runway Gen-3.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤2👍2
Напишите функцию, которая принимает текстовую строку и возвращает наиболее часто встречающееся слово и количество его вхождений. Игнорируйте регистр и знаки препинания.
Пример:
text = "Python is great, and Python is fun! Learning Python is rewarding."
result = most_common_word(text)
print(result)
# Ожидаемый результат: ('python', 3)
Решение задачи
import re
from collections import Counter
def most_common_word(text):
words = re.findall(r'\b\w+\b', text.lower())
counter = Counter(words)
return counter.most_common(1)[0]
# Пример использования:
text = "Python is great, and Python is fun! Learning Python is rewarding."
result = most_common_word(text)
print(result)
Please open Telegram to view this post
VIEW IN TELEGRAM
❤6👍2👎1
Статья расскажет, как машинное обучение помогает улучшить процесс производства железорудных окатышей, снизив зависимость от человеческого фактора, и о примерах, когда технологии сталкиваются с реальными проблемами.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
🐳5❤1
Статья рассказывает, как Pydantic помогает бизнесу гибко управлять наградами для пользователей. Описаны преимущества Pydantic в валидации и преобразовании данных по сравнению с dataclass.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤2🔥1
💾 Онлайн-доски теперь в on-premise!
Яндекс 360 для бизнеса выкатил корпоративный сервис для совместной работы. Можно строить схемы, вести проекты, разбирать user flow и визуализировать данные.
🛠 Что под капотом?
• On-premise-развертывание — все данные остаются внутри компании.
• Гибкое управление доступами — настройка через админку.
• Безопасность — данные зашифрованы, работают в закрытом контуре.
📡 В будущем добавят облачную версию, но пока онли self-hosted. Лицензия уже доступна.
Яндекс 360 для бизнеса выкатил корпоративный сервис для совместной работы. Можно строить схемы, вести проекты, разбирать user flow и визуализировать данные.
🛠 Что под капотом?
• On-premise-развертывание — все данные остаются внутри компании.
• Гибкое управление доступами — настройка через админку.
• Безопасность — данные зашифрованы, работают в закрытом контуре.
📡 В будущем добавят облачную версию, но пока онли self-hosted. Лицензия уже доступна.
{kind=link}
❤3🔥3🐳3👎2👍1
• Эволюция архитектур нейросетей в компьютерном зрении: сегментация изображений
• Заяц не вырастет в акулу. Или секреты гибкой инженерной культуры от Александра Бындю
• Все, пора увольняться: что я поняла после работы в токсичных командах
• Базовое программирование, или Почему джуны не могут пройти к нам собеседование
• Я стал аналитиком, потому что не смог быть программистом
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
👍6❤2🐳2
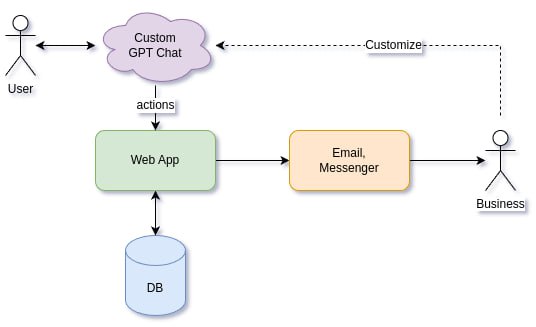
Статья исследует возможность аутентификации пользователей GPT-чата во внешних приложениях. Рассматривается голосовое взаимодействие и альтернативный способ аутентификации через пароли вместо OAuth 2.0.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤3👍1🐳1
Статья объясняет, как управлять зависимостями и изолировать проекты в Python. Рассматриваются виртуальные окружения, работа с разными версиями Python, примеры из практики и лучшие подходы для разработки.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤4
{kind=link}