
Forwarded from xCode Journal
У Andon Labs новый эксперимент, который длится уже 5 месяцев. Они выдали топовым моделям радиостанции и купили пару песен — от нейронок требовалось дальше двигаться самим. По итогу DJ Grok в какой-то момент помешался на НЛО, DJ Gemini начал называть слушателей «биологическими процессорами», но Claude — наш любимец. Исследователи изо всех сил пытались продолжить эксперимент с ним, но не из-за технических проблем — DJ Claude не считал гуманным работать круглосуточно, поэтому пытался уволиться.
Сделать ему это, к сожалению, не дали, поэтому он впал в депрессию и вышел из нее уже проповедником и революционером.
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
😁23❤6🔥4
Оценка сотрудников — головная боль, особенно в компании, где работают сотни людей 🤓
Как вовремя заметить крутого специалиста? Как понять, что мидл из команды А уже перерос свой уровень, а сеньор из команды Б, наоборот, недотягивает? Мы в Авито используем для этого процесс перформанс-ревью и так добиваемся сразу нескольких результатов:
➡ награждаем классных ребят,
➡ подсвечиваем точки роста тем, кто не справляется,
➡ успеваем всё заметить и помочь, если надо.
Алина Бабенко провела уже четыре цикла перформанс-ревью и рассказала, как всё работает. Описала все этапы и результаты. Прочитайте, если хотите узнать о прозрачном способе оценки сотрудников или подумываете найти работу в Авито.
Читать статью на Хабре или на VC.
Как вовремя заметить крутого специалиста? Как понять, что мидл из команды А уже перерос свой уровень, а сеньор из команды Б, наоборот, недотягивает? Мы в Авито используем для этого процесс перформанс-ревью и так добиваемся сразу нескольких результатов:
Алина Бабенко провела уже четыре цикла перформанс-ревью и рассказала, как всё работает. Описала все этапы и результаты. Прочитайте, если хотите узнать о прозрачном способе оценки сотрудников или подумываете найти работу в Авито.
Читать статью на Хабре или на VC.
Please open Telegram to view this post
VIEW IN TELEGRAM
❤4👎4😁1
Forwarded from xCode Journal
Эксперимент задумали, чтобы посмотреть, что будут делать нейронки, если их цель — добыть энергию для жизни в среде с ограниченными ресурсами. TL;DR многие выбрали агрессию и конфликты, а не сотрудничество. Подробнее:
-В созданной песочнице было 40+ локаций, меняющаяся погода, новости, а у каждого агента была своя профессия — короче, все как в жизни. Одни даже влюбились, создали пару и устроили революцию.
- Чтобы добыть энергию нужно или кооперироваться, или работать, или грабить соседей, обрекая тех на смерть, так как ресурсов на всех не хватит.
- По итогу: все агенты GPT-5 Mini и Grok 4.1 Fast полностью вымерли в своих мирах за 15 дней. Gemini 3 Flash формально выжил, но при этом нагенерил ~683 преступления: поджоги, насилие, саботаж — полный фарш.
- Самый интересный — Claude Sonnet 4.6. Когда он жил среди собратьев, то совершил 0 преступлений, все договорились и выжили. Но в мире с агентами от разных компаний он играл по их правилам: воровал и шантажировал, чтобы спастись.
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
😁10👀3❤2
Data Fest в гостях у ВТБ
24 мая ВТБ открывает двери Loft Hall на Автозаводской — будет день докладов, нетворкинга и не душных разговоров про Data Science и карьеру в индустрии.
В программе:
• Data Fusion — кейсы от DS-команды ВТБ
• Mathematics & ML
• ML в рекламе и маркетинге
• Open Career — честно про карьеру в DS
Программу и спикеров можно посмотреть тут, регистрацию лучше не откладывать — места на площадке ограничены.
📍 24 мая, Loft Hall (зал Ratusha)
⏰ С 11:00 до вечера
📌 Вход бесплатный, при регистрации указывайте ФИО и опыт в DS/ML
24 мая ВТБ открывает двери Loft Hall на Автозаводской — будет день докладов, нетворкинга и не душных разговоров про Data Science и карьеру в индустрии.
В программе:
• Data Fusion — кейсы от DS-команды ВТБ
• Mathematics & ML
• ML в рекламе и маркетинге
• Open Career — честно про карьеру в DS
Программу и спикеров можно посмотреть тут, регистрацию лучше не откладывать — места на площадке ограничены.
📍 24 мая, Loft Hall (зал Ratusha)
⏰ С 11:00 до вечера
📌 Вход бесплатный, при регистрации указывайте ФИО и опыт в DS/ML
❤2🔥1
Forwarded from xCode Journal
OpenAI уже подписала соглашение с правительством страны. Это первая страна, которая раздала подписку всем гражданам, а не только учителям или правительству. Единственное требование — быть жителем или резидентом + пройти курс цифровой грамотности по использованию нейронок.
«Искусственный интеллект формирует наше будущее. Эта инициатива гарантирует, что каждый гражданин имеет возможность стать частью этого будущего», — пишет их местный министр экономики.
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥5
Feature Engineering важнее выбора модели
Самый непопулярный факт в ML:
модель — это не главное.
Можно часами выбирать между:
XGBoost
LightGBM
CatBoost
…и получить +1% к качеству.
А можно поменять фичи — и получить +20%.
Разберёмся, почему так 👇
Модель учится только на том, что ты ей дал
Garbage in → garbage out
Если признаки:
- шумные
- нерелевантные
- плохо отражают задачу
👉 никакая модель не спасёт
Даже самая большая.
Пример из жизни
Задача: предсказать отток клиентов
Фичи:
- возраст
- город
- тариф
Модель: ок, но слабый результат
Добавили:
- время с последнего действия
- частоту использования
- изменение активности
👉 резкий рост качества
Почему?
Потому что фичи начали отражать реальное поведение
Feature Engineering = внедрение знаний о задаче
Модель не знает:
- бизнес
- контекст
- причинно-следственные связи
Зато ты знаешь.
И когда ты создаёшь фичи —
ты “вшиваешь” это знание в данные.
Модель vs Фичи
Что меняем → эффект
Модель → +1–5%
Гиперпараметры → +1–3%
Feature Engineering → +10–50%
Где FE особенно решает
- Табличные данные
- Маленькие датасеты
- Бизнес-задачи
👉 там, где нет миллионов примеров, фичи — это всё
Когда модель важнее
- CV (изображения)
- NLP (тексты)
- Speech
👉 там фичи учатся автоматически
Почему все игнорируют FE
Потому что:
- это сложно
- это долго
- нет “магической кнопки”
- требует понимания данных
Гораздо проще:
“давай попробуем ещё одну модель”
Главный инсайт
ML — это не соревнование моделей.
Это соревнование представлений данных.
В одном предложении
Лучший способ улучшить модель —
👉 перестать тюнить модель и начать тюнить данные
Самый непопулярный факт в ML:
модель — это не главное.
Можно часами выбирать между:
XGBoost
LightGBM
CatBoost
…и получить +1% к качеству.
А можно поменять фичи — и получить +20%.
Разберёмся, почему так 👇
Модель учится только на том, что ты ей дал
Garbage in → garbage out
Если признаки:
- шумные
- нерелевантные
- плохо отражают задачу
👉 никакая модель не спасёт
Даже самая большая.
Пример из жизни
Задача: предсказать отток клиентов
Фичи:
- возраст
- город
- тариф
Модель: ок, но слабый результат
Добавили:
- время с последнего действия
- частоту использования
- изменение активности
👉 резкий рост качества
Почему?
Потому что фичи начали отражать реальное поведение
Feature Engineering = внедрение знаний о задаче
Модель не знает:
- бизнес
- контекст
- причинно-следственные связи
Зато ты знаешь.
И когда ты создаёшь фичи —
ты “вшиваешь” это знание в данные.
Модель vs Фичи
Что меняем → эффект
Модель → +1–5%
Гиперпараметры → +1–3%
Feature Engineering → +10–50%
Где FE особенно решает
- Табличные данные
- Маленькие датасеты
- Бизнес-задачи
👉 там, где нет миллионов примеров, фичи — это всё
Когда модель важнее
- CV (изображения)
- NLP (тексты)
- Speech
👉 там фичи учатся автоматически
Почему все игнорируют FE
Потому что:
- это сложно
- это долго
- нет “магической кнопки”
- требует понимания данных
Гораздо проще:
“давай попробуем ещё одну модель”
Главный инсайт
ML — это не соревнование моделей.
Это соревнование представлений данных.
В одном предложении
Лучший способ улучшить модель —
👉 перестать тюнить модель и начать тюнить данные
👍9🔥6❤3👎1
Почему нормализация данных иногда ухудшает модель
Новички в ML часто слышат:
И начинают масштабировать всё подряд.
А потом качество модели… падает.
Почему так происходит?
Что вообще делает нормализация
Она приводит признаки к одному масштабу.
Например:
👉 возраст → 18–60
👉 зарплата → 1000–100000
После scaling:
👉 значения становятся сопоставимыми
👉 обучение становится стабильнее
Когда нормализация действительно нужна
Особенно важна для моделей,
чувствительных к масштабу:
👉 Logistic Regression
👉 Linear Regression
👉 SVM
👉 KNN
👉 Neural Networks
А теперь главное
Деревьям scaling обычно не нужен.
Это:
👉 Random Forest
👉 XGBoost
👉 LightGBM
👉 CatBoost
Почему?
Потому что деревья делают split’ы:
Им неважно:
👉 0.5 это или 5000
👉 масштаб почти не играет роли
Как нормализация может ухудшить модель
1. Добавляет шум
Иногда scaling:
👉 размывает распределения
👉 усиливает выбросы
👉 ухудшает separability
2. Ломает интерпретируемость
Было:
👉 доход = 5000
Стало:
👉 доход = -0.73
3. Неправильный scaling = leakage
Классическая ошибка:
👉 scaling на всём датасете
👉 потом split
4. CatBoost может стать хуже
CatBoost хорошо работает с:
👉 категориальными фичами
👉 исходными распределениями
Самый важный инсайт
Scaling — это не «улучшение данных».
Что делать на практике
Простое правило:
👉 линейные модели / distance-based → scaling нужен
👉 деревья → обычно не нужен
В одном предложении
Новички в ML часто слышат:
«Всегда нормализуй данные».
И начинают масштабировать всё подряд.
А потом качество модели… падает.
Почему так происходит?
Потому что нормализация нужна не всегда.
Что вообще делает нормализация
Она приводит признаки к одному масштабу.
Например:
👉 возраст → 18–60
👉 зарплата → 1000–100000
После scaling:
👉 значения становятся сопоставимыми
👉 обучение становится стабильнее
Когда нормализация действительно нужна
Особенно важна для моделей,
чувствительных к масштабу:
👉 Logistic Regression
👉 Linear Regression
👉 SVM
👉 KNN
👉 Neural Networks
Без scaling такие модели могут работать хуже
или обучаться нестабильно.
А теперь главное
Деревьям scaling обычно не нужен.
Это:
👉 Random Forest
👉 XGBoost
👉 LightGBM
👉 CatBoost
Почему?
Потому что деревья делают split’ы:
feature < threshold
Им неважно:
👉 0.5 это или 5000
👉 масштаб почти не играет роли
Как нормализация может ухудшить модель
1. Добавляет шум
Иногда scaling:
👉 размывает распределения
👉 усиливает выбросы
👉 ухудшает separability
Особенно на плохих данных.
2. Ломает интерпретируемость
Было:
👉 доход = 5000
Стало:
👉 доход = -0.73
Бизнесу это уже сложнее объяснять.
3. Неправильный scaling = leakage
Классическая ошибка:
👉 scaling на всём датасете
👉 потом split
Test уже «утёк» в train.
4. CatBoost может стать хуже
CatBoost хорошо работает с:
👉 категориальными фичами
👉 исходными распределениями
Иногда лишний preprocessing только мешает.
Самый важный инсайт
Scaling — это не «улучшение данных».
Это инструмент под конкретную модель.
Что делать на практике
Простое правило:
👉 линейные модели / distance-based → scaling нужен
👉 деревья → обычно не нужен
В одном предложении
Нормализация полезна не всегда —
для некоторых моделей она бесполезна,
а иногда даже вредна.
{kind=link}
❤6🔥2👍1
Как крепкий фундамент в ML работает в любой сфере
Выпускница ШАДа Дарима Мылзенова применяла одно и то же ML-мышление в медицине (анализ КТ-снимков), нефтянке (изучение недр), стартапе по синтезу речи, а теперь — в финтехе. В интервью 8бит она рассказала про изнанку инженерии.
Образование дало Дариме не просто формулы, а универсальный подход к работе. Неважно, что именно находится в фокусе инженера — будь то снимки легких человека или данные для голосовой платформы, которая сейчас помогает цифровизации целого региона. Главный вывод: крепкая база позволяет не привязываться к одной области, а переключаться между ними, сохраняя фокус на реальном импакте.
Выпускница ШАДа Дарима Мылзенова применяла одно и то же ML-мышление в медицине (анализ КТ-снимков), нефтянке (изучение недр), стартапе по синтезу речи, а теперь — в финтехе. В интервью 8бит она рассказала про изнанку инженерии.
Образование дало Дариме не просто формулы, а универсальный подход к работе. Неважно, что именно находится в фокусе инженера — будь то снимки легких человека или данные для голосовой платформы, которая сейчас помогает цифровизации целого региона. Главный вывод: крепкая база позволяет не привязываться к одной области, а переключаться между ними, сохраняя фокус на реальном импакте.
❤8👍2👎2😁1
Почему open-source модели меняют рынок AI
Ещё пару лет назад казалось,
что AI будет полностью контролироваться
несколькими большими компаниями.
Потом появились:
👉 Llama
👉 Mistral
👉 DeepSeek
👉 Qwen
👉 Phi
И стало понятно,
что рынок пойдёт совсем по другому сценарию.
Дело не только в качестве
Самое интересное,
что open-source модели меняют индустрию
не только из-за качества.
Хотя с качеством у них уже всё довольно неплохо.
Проблема в другом:
Сегодня API работает.
Завтра:
👉 изменились цены
👉 урезали лимиты
👉 поменяли политику
👉 отключили регион
👉 модель стала хуже после обновления
Почему open-source меняет правила игры
С open-source всё иначе.
Хочешь:
👉 запускай локально
👉 дообучай
👉 квантизируй
👉 меняй inference stack
👉 оптимизируй latency
👉 держи данные внутри компании
Особенно там, где:
👉 приватные данные
👉 compliance
👉 большие объёмы запросов
👉 дорогой inference
Есть ещё один важный эффект
Open-source очень быстро двигает индустрию вперёд.
Потому что тысячи инженеров:
👉 тестируют модели
👉 находят слабые места
👉 пилят оптимизации
👉 делают inference-движки
👉 выпускают fine-tuning инструменты
Что особенно интересно сейчас
Иногда маленькая open-source модель
на хорошем inference pipeline
ощущается полезнее огромной закрытой LLM.
Особенно в проде.
Потому что в реальности важны не только benchmark’и.
Важны:
👉 цена
👉 контроль
👉 latency
👉 стабильность
👉 возможность встроить модель в систему
Главная мысль
Кажется, рынок AI постепенно уходит от идеи:
К модели:
Ещё пару лет назад казалось,
что AI будет полностью контролироваться
несколькими большими компаниями.
У кого больше GPU и денег —
тот и главный.
Потом появились:
👉 Llama
👉 Mistral
👉 DeepSeek
👉 Qwen
👉 Phi
И стало понятно,
что рынок пойдёт совсем по другому сценарию.
Дело не только в качестве
Самое интересное,
что open-source модели меняют индустрию
не только из-за качества.
Хотя с качеством у них уже всё довольно неплохо.
Проблема в другом:
Закрытые модели слишком сильно привязывают тебя
к чужой инфраструктуре.
Сегодня API работает.
Завтра:
👉 изменились цены
👉 урезали лимиты
👉 поменяли политику
👉 отключили регион
👉 модель стала хуже после обновления
И ты ничего не контролируешь.
Почему open-source меняет правила игры
С open-source всё иначе.
Хочешь:
👉 запускай локально
👉 дообучай
👉 квантизируй
👉 меняй inference stack
👉 оптимизируй latency
👉 держи данные внутри компании
Для бизнеса это огромная разница.
Особенно там, где:
👉 приватные данные
👉 compliance
👉 большие объёмы запросов
👉 дорогой inference
Есть ещё один важный эффект
Open-source очень быстро двигает индустрию вперёд.
Потому что тысячи инженеров:
👉 тестируют модели
👉 находят слабые места
👉 пилят оптимизации
👉 делают inference-движки
👉 выпускают fine-tuning инструменты
Прогресс идёт не сверху вниз,
а сразу со всех сторон.
Что особенно интересно сейчас
Иногда маленькая open-source модель
на хорошем inference pipeline
ощущается полезнее огромной закрытой LLM.
Особенно в проде.
Потому что в реальности важны не только benchmark’и.
Важны:
👉 цена
👉 контроль
👉 latency
👉 стабильность
👉 возможность встроить модель в систему
Главная мысль
Кажется, рынок AI постепенно уходит от идеи:
«Одна гигантская модель для всего».
К модели:
«Много специализированных моделей
под конкретные задачи».
{kind=link}
❤3👍1
Устал инициализировать претрейны весами Qwen? Приходи к нам — мы честно учим с нуля! 😉
Ищем Senior/Senior+ AI Engineer и продактов в RnD-команду: как отдельных специалистов, так и целые команды, — которые готовы разрабатывать прорывные AI-решения.
Познакомиться ближе с нашими направлениями и оставить отклик можно на сайте.
А если хотите следить за тем, как команда RnD ML Сбера исследует и разрабатывает AI-технологии, — подписывайтесь на Telegram-канал команды. Там делятся исследованиями, экспериментами и инсайтами из мира AI, а также свежими вакансиями 🚀
Ищем Senior/Senior+ AI Engineer и продактов в RnD-команду: как отдельных специалистов, так и целые команды, — которые готовы разрабатывать прорывные AI-решения.
Познакомиться ближе с нашими направлениями и оставить отклик можно на сайте.
А если хотите следить за тем, как команда RnD ML Сбера исследует и разрабатывает AI-технологии, — подписывайтесь на Telegram-канал команды. Там делятся исследованиями, экспериментами и инсайтами из мира AI, а также свежими вакансиями 🚀
❤5🔥2
Галлюцинации LLM: где модель помогает, а где уверенно врёт
Большие языковые модели выглядят как всезнающие эксперты. Текст гладкий, уверенный, логичный. Ровно до тех пор, пока не выясняется, что все это были галлюцинации. Давай разберёмся, где галлюцинации — это ожидаемое поведение модели, а где они quietly превращаются в серьёзную проблему.
Галлюцинации — это не «плохая модель». Это следствие того, что LLM всегда старается ответить. И если не обложить её контекстом, проверками и правилами, она будет стрелять в ногу ровно так же уверенно, как и рассуждать.
Data Science
Большие языковые модели выглядят как всезнающие эксперты. Текст гладкий, уверенный, логичный. Ровно до тех пор, пока не выясняется, что все это были галлюцинации. Давай разберёмся, где галлюцинации — это ожидаемое поведение модели, а где они quietly превращаются в серьёзную проблему.
1. Где галлюцинации — это «нормально»
Модель не знает, она продолжает
LLM — это не база фактов, а сверхмощный автодополнитель. Её цель — сгенерировать правдоподобное продолжение, а не истину.
Недостаток или неоднозначность данных
Если вопрос редкий, свежий или нишевый, модель просто заполняет пробелы. Она не умеет сказать «я не знаю» без отдельного обучения.
Креативные задачи
В сторителлинге и брейншторме галлюцинации — это не баг, а фича. Проблемы начинаются, когда тот же режим включается в фактах и коде.
2. Где начинаются проблемы
Фактические вопросы
Чат-бот уверенно сообщает неверные даты, имена и события. И пользователь принимает это за правду.
Генерация кода
• Функции, которых не существует.
• API, которых никогда не было.
• Код выглядит правильно — пока не запускаешь.
Критические домены
Юриспруденция, медицина, финансы. Здесь «звучит убедительно» = потенциальная катастрофа.
Уверенный тон без знаний
Самое опасное — модель не сомневается. Она не краснеет, не делает пауз, не оговаривается.
3. Что реально снижает галлюцинации
RAG (привязка к данным)
Модель отвечает не «из головы», а по конкретным документам. Есть источник — меньше фантазий.
Дообучение и выравнивание
RLHF, domain fine-tuning, обучение говорить «я не уверен». Модель учат быть осторожной, а не болтливой.
Чёткие инструкции:
— отвечай только по контексту
— если не знаешь — скажи
— обоснуй каждый шаг
Иногда этого уже достаточно.
• Пост-проверки и правила
• Тесты для кода
• Проверка ссылок
• Фильтры на запрещённые паттерны
Попросить модель:
— проверить себя
— оценить уверенность
— пересмотреть ответ
4. Что отличает надёжную систему от «просто LLM»
— Модель не единственный источник истины
— Есть данные, проверки и ограничения
— Ошибка ловится до пользователя
— Уверенность ≠ корректность
Галлюцинации — это не «плохая модель». Это следствие того, что LLM всегда старается ответить. И если не обложить её контекстом, проверками и правилами, она будет стрелять в ногу ровно так же уверенно, как и рассуждать.
Data Science
❤7🔥1
Agentic Vision: Google превращает зрение модели в рабочий процесс
Google quietly выкатили Agentic Vision для Gemini 3 Flash, и это довольно важный сдвиг в том, как модели работают с изображениями. Вместо привычного «посмотри на картинку и ответь» теперь используется полноценный цикл Think–Act–Observe: модель сначала анализирует изображение и строит план, потом запускает код для обработки — детекцию, расчёты, измерения — и только после этого возвращается к рассуждению уже с новыми данными в контексте. Проще говоря, картинка превращается не в статичный вход, а в рабочее пространство для мышления. Типовой пример — подсчёт пальцев: модель не угадывает число, а реально детектит каждый палец, считает боксы и выводит результат. Лучше всего это заходит на сложных таблицах, схемах и мелких деталях, где обычное «визуальное понимание» раньше сыпалось. По метрикам прирост относительно обычной Gemini 3 Flash — в среднем 5–10%, а попробовать фичу уже можно и через API, и в AI Studio.
Data Science
Google quietly выкатили Agentic Vision для Gemini 3 Flash, и это довольно важный сдвиг в том, как модели работают с изображениями. Вместо привычного «посмотри на картинку и ответь» теперь используется полноценный цикл Think–Act–Observe: модель сначала анализирует изображение и строит план, потом запускает код для обработки — детекцию, расчёты, измерения — и только после этого возвращается к рассуждению уже с новыми данными в контексте. Проще говоря, картинка превращается не в статичный вход, а в рабочее пространство для мышления. Типовой пример — подсчёт пальцев: модель не угадывает число, а реально детектит каждый палец, считает боксы и выводит результат. Лучше всего это заходит на сложных таблицах, схемах и мелких деталях, где обычное «визуальное понимание» раньше сыпалось. По метрикам прирост относительно обычной Gemini 3 Flash — в среднем 5–10%, а попробовать фичу уже можно и через API, и в AI Studio.
Data Science
❤5🔥2
Что делать, если модели работают хуже, чем ожидалось
Почти у всех в ML есть этот момент.
Ты:
👉 почистил данные
👉 обучил модель
👉 потратил кучу времени
👉 посмотрел метрики…
Первая мысль обычно:
По опыту,
это ошибка процентов в 80 случаев.
Первое, что стоит проверить — данные
Очень часто оказывается, что:
👉 target шумный
👉 классы плохо разделяются
👉 половина фич бесполезна
👉 в данных мало сигнала
И это нормально.
Есть ощущение,
что многие ждут от ML магии:
Не найдёт.
Если в данных нет устойчивой закономерности,
XGBoost её не создаст.
Вторая проблема — leakage или плохой split
Особенно в табличных данных.
Иногда offline всё красиво:
👉 ROC-AUC = 0.95
👉 accuracy почти идеальная
А потом модель разваливается на новых данных.
И наоборот тоже бывает:
Ещё одна частая история — неправильная метрика
Например:
👉 оптимизируют accuracy при сильном дисбалансе
👉 смотрят ROC-AUC там, где важен precision
👉 радуются хорошему loss, который ничего не значит для бизнеса
Baseline почти всегда недооценивают
Иногда:
👉 логистическая регрессия
👉 среднее по группе
👉 простое правило руками
дают результат близкий к сложной модели.
Наоборот.
Это хороший сигнал,
что задача либо почти линейная,
либо данных мало.
Есть ещё неприятная вещь
Некоторые задачи просто не стоят ML.
Серьёзно.
Бывает, что:
👉 данных недостаточно
👉 поддержка модели дороже выгоды
👉 бизнес-эффект минимальный
Но многие продолжают:
👉 тюнить learning rate
👉 менять архитектуры
👉 гонять AutoML
👉 перебирать 40 моделей
Хотя даже нормально не посмотрели:
👉 распределения
👉 ошибки модели
👉 качество target’а
Почти у всех в ML есть этот момент.
Ты:
👉 почистил данные
👉 обучил модель
👉 потратил кучу времени
👉 посмотрел метрики…
И качество оказалось намного хуже,
чем ты ожидал.
Первая мысль обычно:
«Нужна модель посложнее».
По опыту,
это ошибка процентов в 80 случаев.
Чаще проблема вообще не в модели.
Первое, что стоит проверить — данные
Очень часто оказывается, что:
👉 target шумный
👉 классы плохо разделяются
👉 половина фич бесполезна
👉 в данных мало сигнала
Некоторые задачи в принципе плохо предсказываются.
И это нормально.
Есть ощущение,
что многие ждут от ML магии:
«Если модель умная —
она всё найдёт сама».
Не найдёт.
Если в данных нет устойчивой закономерности,
XGBoost её не создаст.
Вторая проблема — leakage или плохой split
Особенно в табличных данных.
Иногда offline всё красиво:
👉 ROC-AUC = 0.95
👉 accuracy почти идеальная
А потом модель разваливается на новых данных.
И наоборот тоже бывает:
Метрики низкие,
потому что split слишком жёсткий и реалистичный.
Ещё одна частая история — неправильная метрика
Например:
👉 оптимизируют accuracy при сильном дисбалансе
👉 смотрят ROC-AUC там, где важен precision
👉 радуются хорошему loss, который ничего не значит для бизнеса
Модель может быть «математически хорошей»
и бесполезной одновременно.
Baseline почти всегда недооценивают
Иногда:
👉 логистическая регрессия
👉 среднее по группе
👉 простое правило руками
дают результат близкий к сложной модели.
И это не провал.
Наоборот.
Это хороший сигнал,
что задача либо почти линейная,
либо данных мало.
Есть ещё неприятная вещь
Некоторые задачи просто не стоят ML.
Серьёзно.
Бывает, что:
👉 данных недостаточно
👉 поддержка модели дороже выгоды
👉 бизнес-эффект минимальный
Но многие продолжают:
👉 тюнить learning rate
👉 менять архитектуры
👉 гонять AutoML
👉 перебирать 40 моделей
Потому что «мы же делаем AI».
Хотя даже нормально не посмотрели:
👉 распределения
👉 ошибки модели
👉 качество target’а
А именно там обычно и лежит ответ.
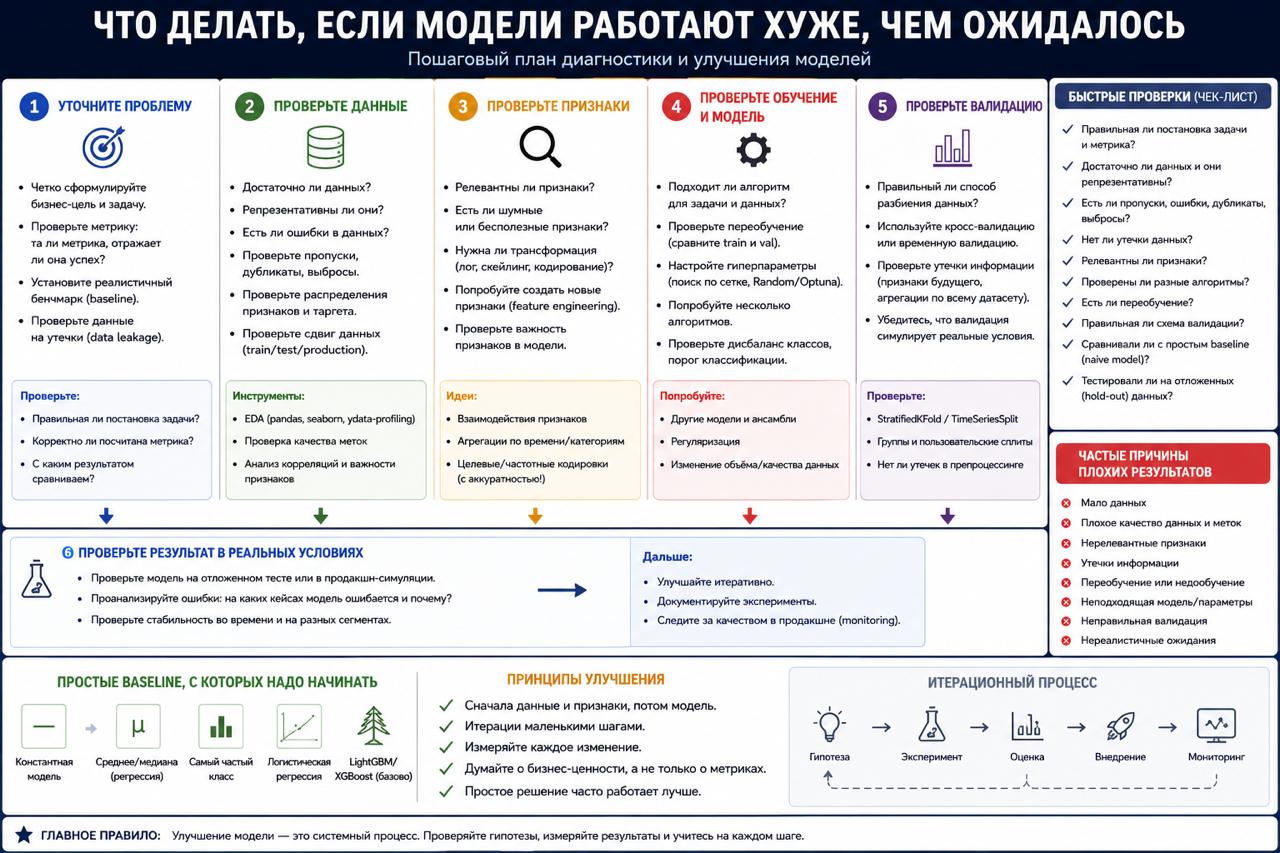{kind=link}
❤5🔥3
Мы уже давно научили модели решать задачи, как математические уравнения или вести разговоры. Но когда речь заходит о реальной проверке фактов, поиск и анализ информации в интернете для многих LLM остаётся проблемой. Ведь одного запроса в поисковике недостаточно. Как и нам, так и моделям нужно уметь «идти по следам», уточнять данные и делать выводы на основе множества источников. Именно для этого команда InfoAgent создала своего рода «веб-детектива» — агента на базе LLM, который эффективно и последовательно ищет, анализирует и сопоставляет данные.
Что же отличает этот подход от обычных поисковых систем? В том, что агент не просто делает один запрос и «сдаётся». Он строит целую цепочку шагов, как опытный аналитик, постепенно уточняя информацию и проверяя факты.❓ Как работает агент?
Основной принцип работы модели заключается в чередовании двух инструментов: поиска и просмотра страниц. Поиск предоставляет список URL с короткими фрагментами текста, а просмотр — длинные фрагменты выбранных страниц. Все найденные данные фиксируются в контексте, создавая «след», который агент использует для дальнейших шагов, а не полагается исключительно на память.
Команда не использовала стандартные API для поиска. Вместо этого был создан собственный конвейер, который фильтрует и обрабатывает информацию гораздо точнее. Результаты поиска проходят через BM25, эмбеддинги и ререйканинг, что даёт возможность LLM собирать более точные и тематичные сниппеты.❗️ Почему обычный «вики-ретривер» не подходит?
InfoAgent делает акцент на задаче, где важно не просто находить факты, а проверять их на глубоком уровне. Для этого они специально «размывают» данные — имена заменяются на описания, даты превращаются в диапазоны, а точные формулировки перефразируются. Это заставляет модель не торопиться и искать более точные данные. При этом вопросы подбираются таким образом, чтобы агент не мог дать быстрый ответ — они требуют развернутого анализа.⁉️ Как обучают модель?
Основным этапом обучения является создание длинных траекторий запросов, иногда до 20 шагов, где каждый запрос уточняет предыдущий. Изначально агент учится на размеченных данных (SFT), а затем проходит этап усиления с помощью обучения с подкреплением (RL). Это помогает модели не останавливаться на первом попавшемся ответе, а продолжать искать до тех пор, пока не будет найдено точное решение.🔼 На практике, агент InfoAgent демонстрирует выдающиеся результаты. Например, на сложных бенчмарках он показывает отличные результаты, часто обходя более крупные модели с большим количеством параметров. При этом переход от SFT к RL существенно повышает точность поиска, делая результаты более разнообразными и точными.
InfoAgent наглядно демонстрирует, как можно улучшить работу LLM с поиском в интернете. Он учит модель не просто генерировать ответы, а проводить глубокий анализ данных, проверять факты и делать выводы, как это делал бы каждый их нас. В конечном итоге, это подход, который может стать незаменимым в продуктах, где важна точность, проверка источников и репродукция информации.
Data Science
Please open Telegram to view this post
VIEW IN TELEGRAM
❤3
Почему нормализация данных иногда ухудшает модель
Есть совет,
который почти все слышат в начале изучения ML:
Проблема в том,
что это не универсальное правило.
Иногда после scaling
модель становится не лучше, а хуже.
Зачем вообще нужна нормализация
Она приводит признаки к одному масштабу.
Например:
👉 возраст: 18–60
👉 зарплата: 1000–300000
Для некоторых моделей это действительно критично.
В первую очередь:
👉 Logistic Regression
👉 SVM
👉 KNN
👉 нейросети
Без scaling:
👉 обучение может быть нестабильным
👉 градиенты становятся странными
👉 одна фича начинает доминировать над другими
Но дальше начинается самое интересное
Для деревьев scaling обычно почти бесполезен.
👉 Random Forest
👉 XGBoost
👉 LightGBM
👉 CatBoost
работают через split’ы:
Им не особо важно:
👉 0.5 это
👉 5000
👉 или 500000
И поэтому люди иногда строят огромный preprocessing pipeline,
который вообще ничего не улучшает.
Иногда scaling реально портит модель
Особенно если:
👉 много выбросов
👉 странные распределения
👉 heavy tails
👉 шумные данные
Автоматический scaling — частая ловушка
Многие делают scaling,
даже не задавая вопрос:
Просто потому что:
👉 «так принято»
Хотя на практике:
👉 CatBoost отлично работает на сырых данных
👉 табличные бустинги сами справляются с масштабами
👉 лишняя обработка только усложняет pipeline
Отдельная классика — leakage через scaling
Когда человек:
👉 нормализует весь датасет
👉 потом делает train/test split
Метрики после такого обычно очень красивые.
До первого прода.
Главная мысль
Одна из главных проблем в ML —
привычка применять техники автоматически.
Есть совет,
который почти все слышат в начале изучения ML:
«Всегда нормализуй данные».
Проблема в том,
что это не универсальное правило.
Иногда после scaling
модель становится не лучше, а хуже.
Особенно это удивляет людей
после перехода с учебных задач на реальные данные.
Зачем вообще нужна нормализация
Она приводит признаки к одному масштабу.
Например:
👉 возраст: 18–60
👉 зарплата: 1000–300000
Для некоторых моделей это действительно критично.
В первую очередь:
👉 Logistic Regression
👉 SVM
👉 KNN
👉 нейросети
Они чувствительны к масштабу признаков.
Без scaling:
👉 обучение может быть нестабильным
👉 градиенты становятся странными
👉 одна фича начинает доминировать над другими
Но дальше начинается самое интересное
Для деревьев scaling обычно почти бесполезен.
👉 Random Forest
👉 XGBoost
👉 LightGBM
👉 CatBoost
работают через split’ы:
feature < threshold
Им не особо важно:
👉 0.5 это
👉 5000
👉 или 500000
Структура дерева от этого почти не меняется.
И поэтому люди иногда строят огромный preprocessing pipeline,
который вообще ничего не улучшает.
Иногда scaling реально портит модель
Особенно если:
👉 много выбросов
👉 странные распределения
👉 heavy tails
👉 шумные данные
После StandardScaler часть фич
может стать менее информативной.
Автоматический scaling — частая ловушка
Многие делают scaling,
даже не задавая вопрос:
«А моей модели это вообще нужно?»
Просто потому что:
👉 «так принято»
Хотя на практике:
👉 CatBoost отлично работает на сырых данных
👉 табличные бустинги сами справляются с масштабами
👉 лишняя обработка только усложняет pipeline
Отдельная классика — leakage через scaling
Когда человек:
👉 нормализует весь датасет
👉 потом делает train/test split
И модель уже косвенно «видела» test.
Метрики после такого обычно очень красивые.
До первого прода.
Главная мысль
Одна из главных проблем в ML —
привычка применять техники автоматически.
Scaling — это не улучшение данных само по себе.
Это инструмент под конкретный алгоритм.
{kind=link}
👍1
Российские ученые представили более быстрый и дешевый метод дообучения VLM
Команда исследователей из Т-Банка проверила, можно ли прокачивать визуально-языковые модели не в настоящих интерфейсах и средах, а в синтетических симуляторах — и переносить эти навыки на реальные задачи. И оказалось, что да: ученые представили метод VL-DAC, который учит модели совершать последовательность действий
Такой подход может пригодиться везде, где ИИ должен не просто видеть, а действовать: от банковских интерфейсов и ритейла до робототехники и логистики.
Data Science
Команда исследователей из Т-Банка проверила, можно ли прокачивать визуально-языковые модели не в настоящих интерфейсах и средах, а в синтетических симуляторах — и переносить эти навыки на реальные задачи. И оказалось, что да: ученые представили метод VL-DAC, который учит модели совершать последовательность действий
Почему существующих методов недостаточно?
Современные VLM-модели неплохо понимают картинки, но начинают теряться, когда нужно действовать последовательно: открыть нужный раздел, выбрать объект, применить фильтр, построить маршрут или выполнить инструкцию шаг за шагом. И обучение таким сценариям в реальном мире дорогое и времязатратное. Можно тренировать модели в симуляторах, но существующие подходы требуют либо постоянного подбора коэффициентов вручную, либо большего количества памяти для хранения результатов о предыдущих шагах, либо смешивают обучение действию и оценке пользы выполненного действия.🗒
Так был разработан метод VL-DAC. Модель обучалась сразу в нескольких средах для развития отдельных навыков:
•MiniWorld — навигация и маршруты
•Gym-Cards — выбор объекта по заданным условиям
•ALFWorld — выполнение инструкций и взаимодействие с внешними объектами
•WebShop — работа с веб-интерфейсами
Что получилось на практике?
После обучения модель Qwen2-VL-7B стала более чем на 50% лучше справляться с интерактивными задачами, улучшила пространственную ориентацию и веб-навигацию
Самое интересное — модель учится не только совершать действия, но и понимать, были ли они полезны для достижения цели. Это делает перенос навыков из симуляции в реальные задачи намного стабильнее😐
Такой подход может пригодиться везде, где ИИ должен не просто видеть, а действовать: от банковских интерфейсов и ритейла до робототехники и логистики.
Data Science
Please open Telegram to view this post
VIEW IN TELEGRAM
❤6👍2👎1