
PCA — это метод снижения размерности, который преобразует исходные переменные в новый набор переменных (компонент), сохраняя как можно больше информации. Он помогает ускорить обучение моделей и уменьшить переобучение.
import numpy as np
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
# Загрузка данных
data = load_iris()
X = data.data
# Применение PCA для снижения размерности до 2 компонент
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
print(X_pca[:5]) # Преобразованные данные
🗣️ В этом примере PCA снижает размерность данных Iris с 4 до 2 компонент. Это позволяет визуализировать данные и ускорить работу моделей, сохраняя основную информацию.
Please open Telegram to view this post
VIEW IN TELEGRAM
❤3⚡1
В этой статье я расскажу, что такое Veo 3 Fast, как получить к ней доступ и использовать, а также покажу примеры видео и выскажу свои соображения.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤2
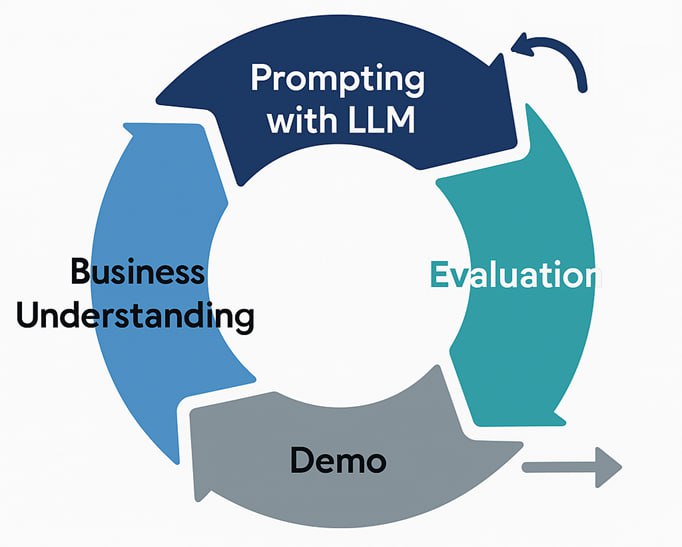
Рассказывается про CRISP-DM Light — фреймворк, который помогает быстро проверять ML-гипотезы и не сливать бюджеты впустую. Меньше бюрократии, больше пользы — и шанс дойти до прода.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤5⚡1
Вам дана матрица
X — список списков с числовыми признаками. Один или несколько признаков были случайно сгенерированы, и не несут полезной информации (то есть, они не коррелируют ни с одним другим).Нужно реализовать функцию
drop_random_features(X, threshold=0.05), которая вернёт индексы признаков, слабо коррелирующих со всеми остальными (по модулю корреляции Пирсона).Если признак не коррелирует ни с одним другим больше, чем на
threshold, он считается псевдослучайным и подлежит удалению.Цель:
Найти признаки, которые не имеют статистической связи с другими и потенциально являются шумом. Возвращать нужно их индексы.
Решение задачи
import numpy as np
def drop_random_features(X, threshold=0.05):
X = np.array(X)
n_features = X.shape[1]
to_drop = []
for i in range(n_features):
max_corr = 0
for j in range(n_features):
if i != j:
corr = abs(np.corrcoef(X[:, i], X[:, j])[0, 1])
max_corr = max(max_corr, corr)
if max_corr < threshold:
to_drop.append(i)
return to_drop
# Пример использования
np.random.seed(42)
X = np.column_stack([
np.linspace(1, 10, 100), # линейный
np.linspace(10, 1, 100), # обратный
np.random.rand(100), # шум
np.linspace(5, 50, 100) + np.random.rand(100) * 0.1 # почти линейный
])
print(drop_random_features(X, threshold=0.2))
# Ожидаемый результат: [2] — третий признак случайный
Please open Telegram to view this post
VIEW IN TELEGRAM
👍4🔥4
• Реализация подобия Apple Vision Pro
• Почему LLM так плохо играют в шахматы (и что с этим делать)
• LLM будут врать вечно
• Как мы создали LLM-модель Cotype Nano
• Человек и LLM: как построить метрики для оценки моделей
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤4👎1🔥1
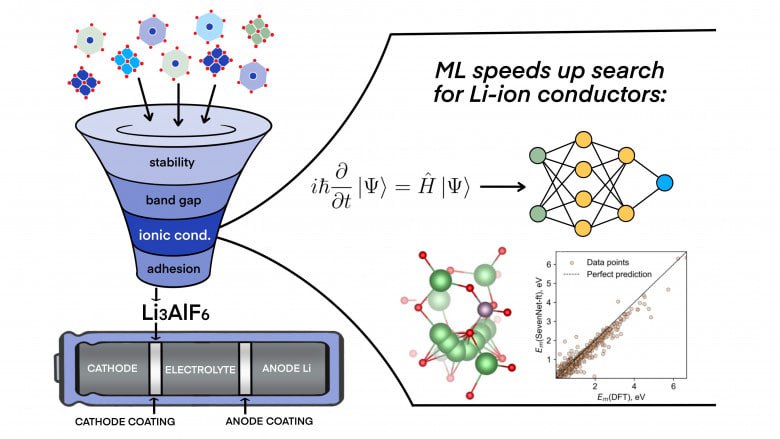
Рассказываю, как мы с помощью ML искали литий-ионные проводники и покрытия для катодов. Материалы, потенциалы, немного науки и много практики — без занудства.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤6
Разбирался, как ИИ «собирается» нас всех заменить. Спойлер: не спешит. Но уже сейчас кое-что делает лучше нас — и это не только котиков генерировать.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤3
{kind=link}
Покажу, как мы в Positive Technologies заменили формальные правила машинкой — чтобы чувствительные данные находились не по шаблону, а по смыслу. Меньше false negative, больше пользы.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤3
logging в Python?logging — это встроенный модуль Python для создания логов, которые помогают отлаживать и мониторить работу приложений.import logging
# Настройка базового уровня логирования
logging.basicConfig(level=logging.INFO)
# Создание лога
logging.info("Приложение запущено")
logging.warning("Это предупреждение!")
logging.error("Произошла ошибка")
🗣️ В этом примере модуль logging создаёт сообщения разного уровня важности. Логирование позволяет отслеживать работу приложений и находить проблемы в коде.
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥6👍1
Пытаюсь вычленить шаблоны, по которым палятся тексты от нейросетей: гладкие, пустые, «умные». И придумать способ автоматом понять — писал ли это ИИ или просто скучный человек.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤5👍3
Показываю, как модель с динамической силой команд предсказывает исходы матчей лучше классики. Не угадываю счёт, но выигрываю на ставках. У букмекеров шансы тают.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
🔥6🐳2
Есть соблазн показать уровень, написав сложную, многослойную, «умную» реализацию. Но это оружие против команды.
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥14❤5
Создайте модель на датасете Iris, обучите классификатор
KNeighborsClassifier и сделайте предсказание. Это классическая задача для первых шагов в машинном обучении.Решение задачи
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# Загружаем данные
iris = load_iris()
X, y =iris.data , iris.target
# Делим на обучающую и тестовую выборки
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Обучаем модель
model = KNeighborsClassifier(n_neighbors=3)model.fit (X_train, y_train)
# Предсказание
y_pred = model.predict(X_test)
# Оценка качества
print(f"Точность: {accuracy_score(y_test, y_pred):.2f}")
Please open Telegram to view this post
VIEW IN TELEGRAM
❤4
Эта статья не ответит на все вопросы, но мы пробежимся по всем основам глубокого машинного обучения, что бы создать примерную начальную картину без сильного углубления в детали.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤3⚡1🔥1🐳1
Создайте функцию
plot_distributions, которая принимает DataFrame и автоматически определяет числовые и категориальные признаки. Затем строит гистограммы или bar-графики в зависимости от типа данных. Это удобно для EDA (исследовательского анализа данных).Решение задачи
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
def plot_distributions(df, max_categories=10):
for column in df.columns:
plt.figure(figsize=(6, 4))
if pd.api.types.is_numeric_dtype(df[column]):
sns.histplot(df[column].dropna(), kde=True)
plt.title(f'Гистограмма: {column}')
elif df[column].nunique() <= max_categories:
df[column].value_counts().plot(kind='bar')
plt.title(f'Категории: {column}')
else:
print(f'Пропущен {column}: слишком много уникальных категорий')
continue
plt.tight_layout()
plt.show ()
# Пример использования
df = pd.DataFrame({
'age': [23, 45, 31, 35, 62, 44, 23],
'gender': ['male', 'female', 'female', 'male', 'male', 'female', 'female'],
'income': [40000, 50000, 45000, 52000, 61000, 48000, 46000]
})
plot_distributions(df)
Please open Telegram to view this post
VIEW IN TELEGRAM
❤3🔥3
Эта статья — не очередной «гайд по ML для новичков». Это мой личный взгляд на то, как бы я подошёл к обучению, если бы начинал с нуля уже сегодня , учитывая свой опыт работы в крупных компаниях, проваленные проекты, ошибки и победы..
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤9⚡1
У вас есть категориальный признак (например,
"A", "B", "C"), который был закодирован в виде One-Hot Encoding, а затем данные были искажены случайным шумом.Реализуйте функцию
recover_category(matrix, labels), которая по входной матрице matrix (список списков, где каждая строка — вектор с плавающими значениями после шума) и списку labels (названия категорий в нужном порядке) должна восстановить название исходной категории для каждой строки — ту, у которой была 1 до добавления шума.Шум малый, но может нарушать точные значения (например, 1.0 становится 0.91, 0.0 — 0.08 и т.п.).
Решение задачи
def recover_category(matrix, labels):
result = []
for row in matrix:
max_index = row.index(max(row))
result.append(labels[max_index])
return result
# Пример использования
matrix = [
[0.05, 0.92, 0.03],
[0.89, 0.06, 0.12],
[0.12, 0.08, 0.83]
]
labels = ["A", "B", "C"]
print(recover_category(matrix, labels))
# Ожидаемый результат: ['B', 'A', 'C']
Please open Telegram to view this post
VIEW IN TELEGRAM
❤5🐳2👍1
Расскажу, как из одного кадра получить свободную 3D-прогулку: доращиваем панорамы, меняем проекции и крутим ракурсы в VR с помощью кастомного модуля для ComfyUI.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤4
2025 год подходит к экватору, поэтому самое время посмотреть, как поменялись позиции крупнейших компаний-разработчиков. Но для начала предлагаю посмотреть на две иллюстрации. Первая — рейтинг ИИ от ресурса LMArena.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤2