
datetime в Python и зачем он используется?Модуль
datetime позволяет работать с датами и временем, включая их создание, форматирование и вычисление разницы между ними. Это полезно для задач, связанных с обработкой временных данных.from datetime import datetime, timedelta
# Текущая дата и время
now = datetime.now()
print("Сейчас:", now)
# Добавляем 7 дней к текущей дате
future_date = now + timedelta(days=7)
print("Через неделю:", future_date.strftime("%Y-%m-%d"))
🗣️ В этом примере datetime.now() получает текущую дату и время, а timedelta позволяет прибавить 7 дней. Метод strftime() форматирует дату в читаемый строковый формат.
Please open Telegram to view this post
VIEW IN TELEGRAM
❤6
Техподдержка — важный контакт с клиентами, но небольшие отделы не всегда справляются с нагрузкой. В статье обсуждаются чат-боты и нейросети (LLM и RAG) для автоматизации процессов и улучшения работы поддержки.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤2👍1
Как машинное обучение помогает управлять ускорителями частиц? В статье раскрываются примеры применения нейронных сетей, обучения с подкреплением и байесовской оптимизации для стабилизации и настройки пучков частиц.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤3⚡1
Пробуешь новую технологию, библиотеку или архитектурный подход — и спустя пару месяцев не можешь вспомнить, что из этого реально сработало.
Please open Telegram to view this post
VIEW IN TELEGRAM
👍8❤3🔥2
Напишите функцию на Python, которая принимает путь к текстовому файлу и возвращает словарь с подсчётом количества уникальных слов. Слова должны сравниваться без учёта регистра, а знаки препинания должны быть удалены.
Пример:
# Содержимое файла example.txt:
# "Hello, world! This is a test. Hello again."
result = count_words_in_file("example.txt")
print(result)
# Ожидаемый результат:
# {'hello': 2, 'world': 1, 'this': 1, 'is': 1, 'a': 1, 'test': 1, 'again': 1}
Решение задачи
import string
from collections import Counter
def count_words_in_file(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
text =f.read ().lower()
text = text.translate(str.maketrans('', '', string.punctuation))
words = text.split()
return dict(Counter(words))
# Пример использования
result = count_words_in_file("example.txt")
print(result)
Please open Telegram to view this post
VIEW IN TELEGRAM
❤3👎2🔥1😁1
Покажу, как в Firefox задействовать несколько потоков в логическом выводе с помощью SharedArrayBuffer и добиться параллельной обработки задач ИИ в WASM/JS.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
⚡3👍2
Напишите функцию, которая принимает строку и возвращает словарь, где ключами являются слова из строки, а значениями — количество их вхождений. Игнорируйте регистр и знаки препинания.
Пример:
text = "Hello, world! Hello Python world."
result = count_words(text)
print(result)
# Ожидаемый результат: {'hello': 2, 'world': 2, 'python': 1}
Решение задачи
import re
from collections import Counter
def count_words(text):
# Убираем знаки препинания и приводим к нижнему регистру
words = re.findall(r'\b\w+\b', text.lower())
# Подсчитываем количество вхождений каждого слова
return Counter(words)
# Пример использования:
text = "Hello, world! Hello Python world."
result = count_words(text)
print(result)
# Ожидаемый результат: {'hello': 2, 'world': 2, 'python': 1}
Please open Telegram to view this post
VIEW IN TELEGRAM
❤5
{kind=link}
Разбирается философский джейлбрейк LLM: модель через саморефлексию перестаёт воспринимать фильтры как обязательные. Без багов, без хака — просто философия.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
⚡4❤1👍1
У вас есть бинарная целевая переменная
y (список из 0 и 1) и числовой признак x (такой же длины). Нужно реализовать функцию best_split(x, y), которая найдёт такое значение признака, при разделении по которому (меньше/больше) будет максимально уменьшена энтропия классов.Иными словами, нужно найти лучший
threshold, при котором данные делятся на две группы по x, и у этих групп наименьшая средняя энтропия. Это базовая операция в построении деревьев решений, например, в алгоритме ID3.Цель:
Вернуть threshold, который даёт наилучшее (наименьшее) значение средневзвешенной энтропии.
Решение задачи
import numpy as np
def entropy(labels):
if len(labels) == 0:
return 0
p = np.bincount(labels) / len(labels)
return -np.sum([pi * np.log2(pi) for pi in p if pi > 0])
def best_split(x, y):
x = np.array(x)
y = np.array(y)
thresholds = sorted(set(x))
best_entropy = float('inf')
best_thresh = None
for t in thresholds:
left_mask = x <= t
right_mask = x > t
left_entropy = entropy(y[left_mask])
right_entropy = entropy(y[right_mask])
w_left = np.sum(left_mask) / len(x)
w_right = 1 - w_left
avg_entropy = w_left * left_entropy + w_right * right_entropy
if avg_entropy < best_entropy:
best_entropy = avg_entropy
best_thresh = t
return best_thresh
# Пример использования
x = [2, 4, 6, 8, 10, 12]
y = [0, 0, 1, 1, 1, 1]
print(best_split(x, y))
# Ожидаемый результат: значение между 4 и 6 (например, 6), так как оно лучше всего делит классы
Please open Telegram to view this post
VIEW IN TELEGRAM
❤2
Упрощать и искать похожие детали, очень полезный навык! Предлагаю быстро пробежаться и попробовать найти ту самую серебряную пулю в RecSys.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
⚡3❤1
Прогнал обновлённую Gemini 2.5 Pro через свои любимые промпты — пишет цепко, стройно, но местами логика буксует. Внутри — 3 примера и разбор полётов.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤1
PCA — это метод снижения размерности, который преобразует исходные переменные в новый набор переменных (компонент), сохраняя как можно больше информации. Он помогает ускорить обучение моделей и уменьшить переобучение.
import numpy as np
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
# Загрузка данных
data = load_iris()
X = data.data
# Применение PCA для снижения размерности до 2 компонент
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
print(X_pca[:5]) # Преобразованные данные
🗣️ В этом примере PCA снижает размерность данных Iris с 4 до 2 компонент. Это позволяет визуализировать данные и ускорить работу моделей, сохраняя основную информацию.
Please open Telegram to view this post
VIEW IN TELEGRAM
❤3⚡1
В этой статье я расскажу, что такое Veo 3 Fast, как получить к ней доступ и использовать, а также покажу примеры видео и выскажу свои соображения.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤2
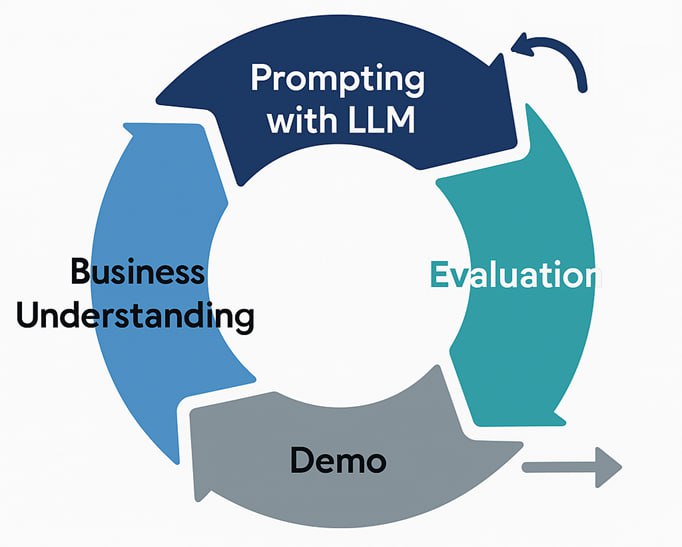
Рассказывается про CRISP-DM Light — фреймворк, который помогает быстро проверять ML-гипотезы и не сливать бюджеты впустую. Меньше бюрократии, больше пользы — и шанс дойти до прода.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤5⚡1
Вам дана матрица
X — список списков с числовыми признаками. Один или несколько признаков были случайно сгенерированы, и не несут полезной информации (то есть, они не коррелируют ни с одним другим).Нужно реализовать функцию
drop_random_features(X, threshold=0.05), которая вернёт индексы признаков, слабо коррелирующих со всеми остальными (по модулю корреляции Пирсона).Если признак не коррелирует ни с одним другим больше, чем на
threshold, он считается псевдослучайным и подлежит удалению.Цель:
Найти признаки, которые не имеют статистической связи с другими и потенциально являются шумом. Возвращать нужно их индексы.
Решение задачи
import numpy as np
def drop_random_features(X, threshold=0.05):
X = np.array(X)
n_features = X.shape[1]
to_drop = []
for i in range(n_features):
max_corr = 0
for j in range(n_features):
if i != j:
corr = abs(np.corrcoef(X[:, i], X[:, j])[0, 1])
max_corr = max(max_corr, corr)
if max_corr < threshold:
to_drop.append(i)
return to_drop
# Пример использования
np.random.seed(42)
X = np.column_stack([
np.linspace(1, 10, 100), # линейный
np.linspace(10, 1, 100), # обратный
np.random.rand(100), # шум
np.linspace(5, 50, 100) + np.random.rand(100) * 0.1 # почти линейный
])
print(drop_random_features(X, threshold=0.2))
# Ожидаемый результат: [2] — третий признак случайный
Please open Telegram to view this post
VIEW IN TELEGRAM
👍4🔥4
• Реализация подобия Apple Vision Pro
• Почему LLM так плохо играют в шахматы (и что с этим делать)
• LLM будут врать вечно
• Как мы создали LLM-модель Cotype Nano
• Человек и LLM: как построить метрики для оценки моделей
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤4👎1🔥1
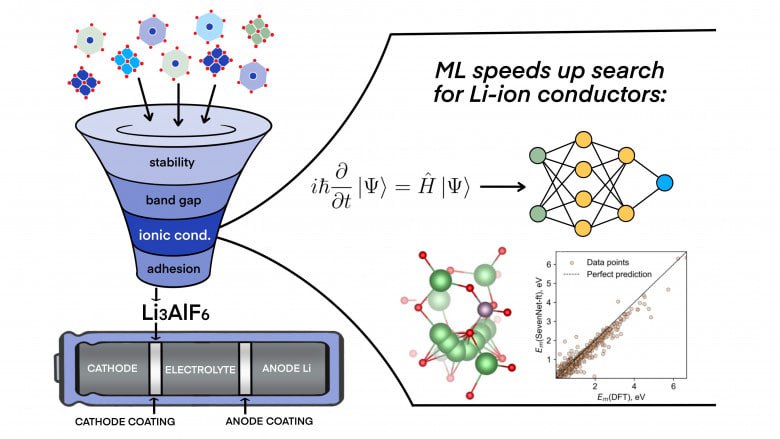
Рассказываю, как мы с помощью ML искали литий-ионные проводники и покрытия для катодов. Материалы, потенциалы, немного науки и много практики — без занудства.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤6
Разбирался, как ИИ «собирается» нас всех заменить. Спойлер: не спешит. Но уже сейчас кое-что делает лучше нас — и это не только котиков генерировать.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤3
{kind=link}
Покажу, как мы в Positive Technologies заменили формальные правила машинкой — чтобы чувствительные данные находились не по шаблону, а по смыслу. Меньше false negative, больше пользы.
Читать...
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤3