5 бизнес-процессов в разработке
Меня периодически спрашивают каким образом строить инфраструктуру для небольших проектов, когда в команде еще нет компетенций админа/девопс-инженера ни у руководителя или программистов, ни в в виде выделенного человека.
Что при этом выбрать — выделенные сервера, облако или Kubernetes? Я сейчас не буду делать какие-то технологические рекомендации, но опишу на что нужно обратить внимание организационно, чтобы можно было сделать такой выбор.
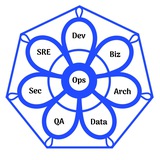
При планировании развертывания любого приложения для продакшна важно всегда в том или ином виде продумывать как минимум следующие 5 бизнес-процессов / Value stream:
- процесс разработки приложений
- процесс конфигурирования приложений
- процесс настройки и конфигурирование серверов (или других сред выполнения)
- процесс настройки и конфигурирования самого процесса сборки и деплоя
- процесс настройки и конфигурирования вспомогательных сервисов (например, мониторинга, бэкапов и т.д.), сюда же я запишу базы данных, кэши, очереди и т.п.
(см рис.1)
Любая инсталляция, которая выходит за пределы ноутбука разработчика будет состоять как минимум из компонентов указанных на иллюстрации (стикеры синего и зеленого цвета).
Каждый из этих компонентов каким-то образом настраивается первоначально, в него каким-то образом регулярно вносятся изменения, ну и когда-то каждый из этих компонент скорее всего будет выведен из эксплуатации и заменен на какой-то другой. Также в том или ином виде происходит текущая поддержка каждого из этих компонентов — обеспечение работоспособности и реакция на инциденты.
(см рис.2)
Это составляющие каждого из наших 5 основных процессов, итого у нас получается не меньше 20 типовых операций или процессов, которые присутствуют в абсолютно любой современной инсталляции.
Соотвественно необходимо продумать каким именно образом это будет происходить, как будут происходить эти операции. Конечно, если мы хотим в той или иной мере сохранять контроль над нашей инсталляцией.
А в первую очередь как во все эти компоненты будут вноситься изменения, и как будет происходить текущая поддержка — т.к. эти операции и процессы ключевые для работающей системы и выполняются чаще всего.
В начале статьи я намеренно написал "бизнес-процессы / Value Streams", т.к. что именно это будет определяем мы как технический руководитель. Это могут быть классические инструкции в виде чеклиста или BPMN-диаграммы, в этом случае про них уместно говорить как о "бизнес-процессах". Это могут быть насквозь автоматизированные Software Defined Processes и в этом случае мы о них скорее всего будем говорить как о Value Stream. Часто противопоставляя DevOps и "классическое IT" имеют в виду смену именно этой парадигмы — замену "бизнес-процессов" на "Value Stream".
Ну либо мы можем полностью делегировать этот процесс некоему сотруднику (сисадмину, либо Devops-инженеру) не задумываясь о том, что в этом процессе происходит, и надеяться, что когда рано или поздно этот сотрудник уйдет, новый сотрудник на его замену сможет в этом хозяйстве разобраться. Если мы принимаем этот риск, то в этом случае строго говоря нам действительно не важно как этот сотрудник работает — копипастит ли артефакты через FTP, или же пишет портянки кода на Ansible и Terraform.
Ключевое здесь в том, что для того чтобы наш продакшн и разработка вели себя предсказуемо для нас необходимо:
- Выделить компоненты, которые участвуют в процессе разработки-поставки-эксплуатации. Один из примеров такого компонентного разбиения приведен на картинке.
- Для каждого из компонентов определиться каким образом будут в него вноситься изменения, кто за это отвечает, и сколько ответственности делегировать этим людям или скриптам.
- Следить за тем, что если у нас появляются новые компоненты, для каждого из них мы будем принимать эти же решения.
Меня периодически спрашивают каким образом строить инфраструктуру для небольших проектов, когда в команде еще нет компетенций админа/девопс-инженера ни у руководителя или программистов, ни в в виде выделенного человека.
Что при этом выбрать — выделенные сервера, облако или Kubernetes? Я сейчас не буду делать какие-то технологические рекомендации, но опишу на что нужно обратить внимание организационно, чтобы можно было сделать такой выбор.
При планировании развертывания любого приложения для продакшна важно всегда в том или ином виде продумывать как минимум следующие 5 бизнес-процессов / Value stream:
- процесс разработки приложений
- процесс конфигурирования приложений
- процесс настройки и конфигурирование серверов (или других сред выполнения)
- процесс настройки и конфигурирования самого процесса сборки и деплоя
- процесс настройки и конфигурирования вспомогательных сервисов (например, мониторинга, бэкапов и т.д.), сюда же я запишу базы данных, кэши, очереди и т.п.
(см рис.1)
Любая инсталляция, которая выходит за пределы ноутбука разработчика будет состоять как минимум из компонентов указанных на иллюстрации (стикеры синего и зеленого цвета).
Каждый из этих компонентов каким-то образом настраивается первоначально, в него каким-то образом регулярно вносятся изменения, ну и когда-то каждый из этих компонент скорее всего будет выведен из эксплуатации и заменен на какой-то другой. Также в том или ином виде происходит текущая поддержка каждого из этих компонентов — обеспечение работоспособности и реакция на инциденты.
(см рис.2)
Это составляющие каждого из наших 5 основных процессов, итого у нас получается не меньше 20 типовых операций или процессов, которые присутствуют в абсолютно любой современной инсталляции.
Соотвественно необходимо продумать каким именно образом это будет происходить, как будут происходить эти операции. Конечно, если мы хотим в той или иной мере сохранять контроль над нашей инсталляцией.
А в первую очередь как во все эти компоненты будут вноситься изменения, и как будет происходить текущая поддержка — т.к. эти операции и процессы ключевые для работающей системы и выполняются чаще всего.
В начале статьи я намеренно написал "бизнес-процессы / Value Streams", т.к. что именно это будет определяем мы как технический руководитель. Это могут быть классические инструкции в виде чеклиста или BPMN-диаграммы, в этом случае про них уместно говорить как о "бизнес-процессах". Это могут быть насквозь автоматизированные Software Defined Processes и в этом случае мы о них скорее всего будем говорить как о Value Stream. Часто противопоставляя DevOps и "классическое IT" имеют в виду смену именно этой парадигмы — замену "бизнес-процессов" на "Value Stream".
Ну либо мы можем полностью делегировать этот процесс некоему сотруднику (сисадмину, либо Devops-инженеру) не задумываясь о том, что в этом процессе происходит, и надеяться, что когда рано или поздно этот сотрудник уйдет, новый сотрудник на его замену сможет в этом хозяйстве разобраться. Если мы принимаем этот риск, то в этом случае строго говоря нам действительно не важно как этот сотрудник работает — копипастит ли артефакты через FTP, или же пишет портянки кода на Ansible и Terraform.
Ключевое здесь в том, что для того чтобы наш продакшн и разработка вели себя предсказуемо для нас необходимо:
- Выделить компоненты, которые участвуют в процессе разработки-поставки-эксплуатации. Один из примеров такого компонентного разбиения приведен на картинке.
- Для каждого из компонентов определиться каким образом будут в него вноситься изменения, кто за это отвечает, и сколько ответственности делегировать этим людям или скриптам.
- Следить за тем, что если у нас появляются новые компоненты, для каждого из них мы будем принимать эти же решения.
👍1
Для сложных инсталляций, естественно, компонентов может быть больше. Например из "Конфигурации приложения" зачастую можно выделить "Секреты", "Endpoints" и "Функциональную конфигурацию" (относящуюся к логике приложения). Или "Среда выполнения" может состоять как из "Виртуальных серверов", так и "Оркестратора".
Для каждого из таких компонентов них необходимо тоже прорабатывать соответствующий процесс внесения изменения. Как мы уже говорили выше, в зависимости от того какой дорогой мы выбрали идти это могут быть как развесистые инструкции, так и скрипты автоматизации. Либо вообще у нас будут отдельные сервисы — они будут управлять этими компонентами и возьмут на себя всю сложность. К примеру, если держать секреты в Vault весь процесс внесения изменений в секреты будет состоять из минимум двух шагов:
- Меняем секрет через UI Vault
- Наши скрипты автоматизации раскатывают эти секреты по всем сервисам.
Но тут встает интересный вопрос: что делать с внесением изменений в эту самую автоматизацию? Ответ простой — автоматизация это по сути код, мы применяем подход Infrastructure as Code. А точнее, у нас появляется Infrastructure as Code как процесс разработки, и это не то же самое, что Infrastructure as Scripts как очень часто бывает. Соответственно, для упрощения планирования и работы мы начинаем применять классические практики разработки: прорабатываем компонентную модель кода, описывающего нашу инфраструктуру, прорабатываем форматы и последовательности обмена сообщениями в нашей инфре (например, какой скрипт какие хуки дергает и что передает), строим релизный процесс для инфраструктурного кода, прорабатываем бэклог фич — одним словом, работаем с инфраструктурой так, как будто это еще один компонент приложения.
И наконец мы приходим к главному вопросу: что со всем этим знанием делать?
Если у вас маленькая инсталляция и небольшая частота изменений в инфраструктуре:
- прописать упомянутые 5 процессов в том виде, в каком они по факту используются. Это может быть одна строчка "собираем всю команду и решаем как и что будем делать", и это нормально
- подумать не пропустили ли чего, и можно ли эти процессы улучшить
- прикинуть сколько мы сможем жить с такими процессами и когда начнем упираться в их эффективность
Если у вас инсталляция большая и изменений в инфраструктуре много:
- развитие инфраструктурных компонентов осуществлять через практики разработки софта (классические "описание фичи -> бэклог -> разработка -> тестирование -> релиз -> стейджинг -> продакшн")
- выделить компоненты данных в инфраструктуре и прописать процесс работы с ними (это могут быть, например, конфигурация, секреты и т.д.). Возможно в результате этого у вас появятся задачи в бэклог инфраструктурной разработки
- выделить оставшиеся компоненты и процессы, для которых мы не применяем IaC (например "восстановление из бэкапа", или "реакция на инцидент") и прописать процесс работы с ними
Для каждого из таких компонентов них необходимо тоже прорабатывать соответствующий процесс внесения изменения. Как мы уже говорили выше, в зависимости от того какой дорогой мы выбрали идти это могут быть как развесистые инструкции, так и скрипты автоматизации. Либо вообще у нас будут отдельные сервисы — они будут управлять этими компонентами и возьмут на себя всю сложность. К примеру, если держать секреты в Vault весь процесс внесения изменений в секреты будет состоять из минимум двух шагов:
- Меняем секрет через UI Vault
- Наши скрипты автоматизации раскатывают эти секреты по всем сервисам.
Но тут встает интересный вопрос: что делать с внесением изменений в эту самую автоматизацию? Ответ простой — автоматизация это по сути код, мы применяем подход Infrastructure as Code. А точнее, у нас появляется Infrastructure as Code как процесс разработки, и это не то же самое, что Infrastructure as Scripts как очень часто бывает. Соответственно, для упрощения планирования и работы мы начинаем применять классические практики разработки: прорабатываем компонентную модель кода, описывающего нашу инфраструктуру, прорабатываем форматы и последовательности обмена сообщениями в нашей инфре (например, какой скрипт какие хуки дергает и что передает), строим релизный процесс для инфраструктурного кода, прорабатываем бэклог фич — одним словом, работаем с инфраструктурой так, как будто это еще один компонент приложения.
И наконец мы приходим к главному вопросу: что со всем этим знанием делать?
Если у вас маленькая инсталляция и небольшая частота изменений в инфраструктуре:
- прописать упомянутые 5 процессов в том виде, в каком они по факту используются. Это может быть одна строчка "собираем всю команду и решаем как и что будем делать", и это нормально
- подумать не пропустили ли чего, и можно ли эти процессы улучшить
- прикинуть сколько мы сможем жить с такими процессами и когда начнем упираться в их эффективность
Если у вас инсталляция большая и изменений в инфраструктуре много:
- развитие инфраструктурных компонентов осуществлять через практики разработки софта (классические "описание фичи -> бэклог -> разработка -> тестирование -> релиз -> стейджинг -> продакшн")
- выделить компоненты данных в инфраструктуре и прописать процесс работы с ними (это могут быть, например, конфигурация, секреты и т.д.). Возможно в результате этого у вас появятся задачи в бэклог инфраструктурной разработки
- выделить оставшиеся компоненты и процессы, для которых мы не применяем IaC (например "восстановление из бэкапа", или "реакция на инцидент") и прописать процесс работы с ними
👍1
Есть ли какие-то типовые процессы, которые важно реализовать, но которые я здесь не учел?
Большие статьи в телеге читать и писать неудобно, особенно если в статье картинки, поэтому скорее всего на большие статьи в следующий раз буду давать только ссылки на другие площадки.
Сейчас кросспост этой статьи здесь:
- https://habr.com/ru/post/708930/
- https://timurb.ru/kb/5-devops-processes/
- https://timurbatyrshin.medium.com/ef3f97406d99
Сейчас кросспост этой статьи здесь:
- https://habr.com/ru/post/708930/
- https://timurb.ru/kb/5-devops-processes/
- https://timurbatyrshin.medium.com/ef3f97406d99
Хабр
5 бизнес-процессов в разработке
Меня периодически спрашивают каким образом строить инфраструктуру для небольших проектов, когда в команде еще нет компетенций админа/девопс-инженера ни у руководителя или программистов, ни в в виде...
Платформенный подход и трансакционные издержки
В начале 20 века английский экономист Рональд Коуз изучал причину появления фирм на свободном рынке, и в своей статье Природа фирм он пришел к следующему:
- Трансакционные издержки (расходы на поиск и взаимодействие контрагентов и их контрактацию) внутри фирмы ниже, чем трансакционные издержки на рынке, и поэтому найм может оказаться дешевле чем аутсорсинг. Контракт с сотрудником обслуживать дешевле, чем контракт с внешней организацией (даже если это рамочный контракт).
- В противном случая аутсорсинг дешевле, т.к. внешний подрядчик оптимизирует работу своей компании для того, чтобы стать более конкурентоспособным, и поэтому будет более эффективным чем внутренний сотрудник.
- Одновременно с этим при росте компании растут издержки на управление самой компанией, увеличивается количество ошибок управления и т.д.
- Размер компании определяется оптимумом между расходами на трансакционные издержки и расходами на издержки управления.
Подробнее предлагаю прочитать в википедии, либо в первоисточнике — я мог недостаточно четко пересказать основные мысли оттуда.
В этом контексте кажется можно рассматривать экосистемы и компании состоящие из самоорганизующихся команд как промежуточное звено между фирмами по Коузу и свободным рынком:
- Трансакционные издержки между командами внутри компании ниже, чем трансакционные издержки между компанией и внешним рынком
- В то же самое время расходы на управление такой компанией ниже, чем для “плановой экономики” с централизованным управлением
Почему же далеко не все идут в эту сторону несмотря на модный тренд? Для этого должна быть другая архитектура постановки задач и контроля, да и по большому счету вся архитектура взаимодействия с сотрудниками и подразделениями.
Команды должны быть либо максимально независимыми, вертикальными и достаточно узкими (Платформенный подход):
- с одной стороны для оптимизации команды вокруг предоставляемого сервиса (качества и стоимости для потребителя, в т.ч. трансакционной стоимости)
- с другой — для снижения управленческих издержек внутри самой этой команды
Либо команды должны быть горизонтальными, с максимально полностью делегированной ответственностью за сквозной Value Stream — для оптимизации команды вокруг пропорции “доставляемая до клиента ценность к running cost” этого стрима. При этом, чтобы не было роста управленческих издержек внутри команды вся непрофильная активность этого стрима будет аутсорситься на внешних вендоров (по отношению к команде, не к компании!), т.е. на платформенные и развивающие (enabling) команды.
Интересной особенностью здесь становится то, что мы можем в число поставщиков без особых проблем вносить и внешних вендоров если они будут соответствовать некоторым критериям, которым соответствуют все наши внутренние вендоры (платформенные команды). Подход “Private cloud” во многом как раз призван решить именно эту задачу — упростить онбординг партнеров и внешних вендоров внутрь ландшафта компании. На всех крупных заводах немалые площади выделены именно для компаний-партнеров для обеспечения локальности производства.
Чего не хватает в этой картине? Финансирования, т.е. циклов обратной связи между платформенной командой и “внутренним рынком”, и горизонтальной командой (но не компанией целиком!) и “внешним рынком”. Какие-то зачатки такой обратной связи предлагаются в практиках “error budget” и “security budget” и абстрактных отсылках к “продуктовому подходу” без конкретики, но их явно недостаточно.
Встречались ли кому-то еще какие-то материалы на эту тему?
В начале 20 века английский экономист Рональд Коуз изучал причину появления фирм на свободном рынке, и в своей статье Природа фирм он пришел к следующему:
- Трансакционные издержки (расходы на поиск и взаимодействие контрагентов и их контрактацию) внутри фирмы ниже, чем трансакционные издержки на рынке, и поэтому найм может оказаться дешевле чем аутсорсинг. Контракт с сотрудником обслуживать дешевле, чем контракт с внешней организацией (даже если это рамочный контракт).
- В противном случая аутсорсинг дешевле, т.к. внешний подрядчик оптимизирует работу своей компании для того, чтобы стать более конкурентоспособным, и поэтому будет более эффективным чем внутренний сотрудник.
- Одновременно с этим при росте компании растут издержки на управление самой компанией, увеличивается количество ошибок управления и т.д.
- Размер компании определяется оптимумом между расходами на трансакционные издержки и расходами на издержки управления.
Подробнее предлагаю прочитать в википедии, либо в первоисточнике — я мог недостаточно четко пересказать основные мысли оттуда.
В этом контексте кажется можно рассматривать экосистемы и компании состоящие из самоорганизующихся команд как промежуточное звено между фирмами по Коузу и свободным рынком:
- Трансакционные издержки между командами внутри компании ниже, чем трансакционные издержки между компанией и внешним рынком
- В то же самое время расходы на управление такой компанией ниже, чем для “плановой экономики” с централизованным управлением
Почему же далеко не все идут в эту сторону несмотря на модный тренд? Для этого должна быть другая архитектура постановки задач и контроля, да и по большому счету вся архитектура взаимодействия с сотрудниками и подразделениями.
Команды должны быть либо максимально независимыми, вертикальными и достаточно узкими (Платформенный подход):
- с одной стороны для оптимизации команды вокруг предоставляемого сервиса (качества и стоимости для потребителя, в т.ч. трансакционной стоимости)
- с другой — для снижения управленческих издержек внутри самой этой команды
Либо команды должны быть горизонтальными, с максимально полностью делегированной ответственностью за сквозной Value Stream — для оптимизации команды вокруг пропорции “доставляемая до клиента ценность к running cost” этого стрима. При этом, чтобы не было роста управленческих издержек внутри команды вся непрофильная активность этого стрима будет аутсорситься на внешних вендоров (по отношению к команде, не к компании!), т.е. на платформенные и развивающие (enabling) команды.
Интересной особенностью здесь становится то, что мы можем в число поставщиков без особых проблем вносить и внешних вендоров если они будут соответствовать некоторым критериям, которым соответствуют все наши внутренние вендоры (платформенные команды). Подход “Private cloud” во многом как раз призван решить именно эту задачу — упростить онбординг партнеров и внешних вендоров внутрь ландшафта компании. На всех крупных заводах немалые площади выделены именно для компаний-партнеров для обеспечения локальности производства.
Чего не хватает в этой картине? Финансирования, т.е. циклов обратной связи между платформенной командой и “внутренним рынком”, и горизонтальной командой (но не компанией целиком!) и “внешним рынком”. Какие-то зачатки такой обратной связи предлагаются в практиках “error budget” и “security budget” и абстрактных отсылках к “продуктовому подходу” без конкретики, но их явно недостаточно.
Встречались ли кому-то еще какие-то материалы на эту тему?
Об формальные и неформальные нотации
Если сравнивать "просто стикеры" в миро и Archimate, то Archimate удобнее тем, что мы в нем получаем "встроенную" валидацию типов, которую в случае стикеров приходится выполнять более явно.
Скорее всего это применимо и для других формальных языков описаний (BPMN, UML и т.д.) в сравнении со "свободными" рассуждениями.
С другой стороны, если понимания типов у человека нет все нотации мгновенно становятся бессмысленными.
А для коммуникации нужны именно типы, пространство понятий, а не нотация.
Таким образом одна из важнейших задач в любой архитектуре это установление коммуникации — выбор или создание языка на котором будут разговаривать разные представители стейкхолдеров.
Кажется, здесь появляется интересный момент в том, что в результате этого немалую часть архитектурных артефактов стейкхолдеры смогут создать самостоятельно без участия собственно архитектора.
Или это не так?
Если сравнивать "просто стикеры" в миро и Archimate, то Archimate удобнее тем, что мы в нем получаем "встроенную" валидацию типов, которую в случае стикеров приходится выполнять более явно.
Скорее всего это применимо и для других формальных языков описаний (BPMN, UML и т.д.) в сравнении со "свободными" рассуждениями.
С другой стороны, если понимания типов у человека нет все нотации мгновенно становятся бессмысленными.
А для коммуникации нужны именно типы, пространство понятий, а не нотация.
Таким образом одна из важнейших задач в любой архитектуре это установление коммуникации — выбор или создание языка на котором будут разговаривать разные представители стейкхолдеров.
Кажется, здесь появляется интересный момент в том, что в результате этого немалую часть архитектурных артефактов стейкхолдеры смогут создать самостоятельно без участия собственно архитектора.
Или это не так?
В понедельник на конференции DevOpsConf буду рассказывать про применение практик из разработки в подходе Infrastructure as Code
Forwarded from DevOpsConf Channel
⠀
📋 https://bit.ly/3ka2Vck
⠀
За более чем 10 лет DevOps было сформировано много практик, которые помогают ускорять разработку.
Обычно говорят про CI/CD и контейнеры, но это всего лишь одна сторона вопроса.
Другая важная составляющая — изменение модульности и интеграционных паттернов в самих приложениях.
Третья составляющая — описание инфраструктурных компонентов в виде кода.
⠀
Встает интересный вопрос — прошли ли практики написания инфраструктурного кода такую же трансформацию разработки, какая произошла в разработке?
Или все по-прежнему пишут инфраструктурные монолиты, которые запускаются, только если всей командой взяться за руки?
Кто на самом деле являлся драйвером DevOps-трансформации?
⠀
Поговорим об этом на докладе.
⠀
Ждем вас 13 и 14 марта на DevOpsConf 2023 в Москве 🖐
⠀
Please open Telegram to view this post
VIEW IN TELEGRAM
❤1🔥1
Написал новую статью "Об Модифицирующие Команды".
Как обычно, кросспост в несколько мест:
- https://habr.com/ru/post/723410/
- https://timurbatyrshin.medium.com/41db803e1875
- https://timurb.ru/kb/ob-enabling-team/
Как обычно, кросспост в несколько мест:
- https://habr.com/ru/post/723410/
- https://timurbatyrshin.medium.com/41db803e1875
- https://timurb.ru/kb/ob-enabling-team/
Хабр
О модифицирующих командах
На волне нынешнего хайпа про инфраструктурные платформы, наверное каждый слышал о книге Team Topologies . Я ее сейчас пересказывать не буду, поэтому если какие-то термины или рассуждения ниже вам...
❤5
Написал новую статью "Ситуационная инженерия метода".
Длинные посты в телеграм не влезают, поэтому как обычно, только кросспост в несколько мест:
- https://timurbatyrshin.medium.com/1b9f246a1cd9
- https://timurb.ru/kb/situational-method-engineering/
Комментарии можно оставлять как здесь, так и по любой из ссылок.
Длинные посты в телеграм не влезают, поэтому как обычно, только кросспост в несколько мест:
- https://timurbatyrshin.medium.com/1b9f246a1cd9
- https://timurb.ru/kb/situational-method-engineering/
Комментарии можно оставлять как здесь, так и по любой из ссылок.
Medium
Ситуационная инженерия метода
При старте нового проекта (или авральном подключении к существующему) руководителю нужно выполнить большое количество шагов планирования и…
👍2👎1
Друзья, для меня очень ценна обратная связь. Если для вас что-то кажется спорным, прошу: пишите текстом.
Можно личным сообщением (@TimurBatyrshin) если не хотите выносить в общий чат.
Можно личным сообщением (@TimurBatyrshin) если не хотите выносить в общий чат.
Об разницу между Waterfall и Agile
(из неопубликованных архивов)
Некоторое время назад нашел простое и потрясающее объяснение того, когда нужно выбирать waterfall, когда scrum, а когда еще что-то другое.
Цитата (отсюда https://sebokwiki.org/wiki/System_Lifecycle_Models):
There are a large number of potential life cycle process models. They fall into three major categories:
1. primarily pre-specified and sequential processes (e.g. the single-step waterfall model)
2. primarily evolutionary and concurrent processes (e.g. lean development, the agile unified process, and various forms of the vee and spiral models)
3. primarily interpersonal and emergent processes (e.g. agile development, scrum, extreme programming (XP), the dynamic system development method, and innovation-based processes)
Перевожу на простой человеческий язык:
1. Если вам нужно строить что-то ровно один раз, без параллелизации работ, или доработок вообще, или же нужен жесткий процесс с контролем выходов на каждой стадии — waterfall ваш выбор.
2. Если вам нужно разрабатывать несколько фич параллельно, или процесс будет дорабатываться (но сам процесс есть) — выбирайте второй вариант.
3. Если вы выясните процесс работы по ходу в процессе личного взаимодействия — выбирайте третий вариант.
Казалось бы, где тут откровения? Но давайте представим, какие последствия будут при выборе каждого из вариантов.
1. Waterfall: Пока пилим фичи баги исправлять не будем (и наоборот). Если потребуется в процессе внести какие-то изменения это будет очень тяжело.
2. Эволюционные/параллельные процессы: Нужно прописать и как-то контролировать процесс работы, и как дорабатывать его самого. Нужно определить как нам не мешать друг другу при параллельной разработке.
3. Межличностные и эмерджентные процессы: Ребята у нас умные, как-нибудь сами обо всем договорятся. В том числе и с заказчиками и внешними стейкхолдерами (спонсор, регуляторы, команды-смежники, внешние провайдеры, в т.ч. коммерческие и т.д.).
Какой из вариантов лучше всего подходит к вашему проекту?
(из неопубликованных архивов)
Некоторое время назад нашел простое и потрясающее объяснение того, когда нужно выбирать waterfall, когда scrum, а когда еще что-то другое.
Цитата (отсюда https://sebokwiki.org/wiki/System_Lifecycle_Models):
There are a large number of potential life cycle process models. They fall into three major categories:
1. primarily pre-specified and sequential processes (e.g. the single-step waterfall model)
2. primarily evolutionary and concurrent processes (e.g. lean development, the agile unified process, and various forms of the vee and spiral models)
3. primarily interpersonal and emergent processes (e.g. agile development, scrum, extreme programming (XP), the dynamic system development method, and innovation-based processes)
Перевожу на простой человеческий язык:
1. Если вам нужно строить что-то ровно один раз, без параллелизации работ, или доработок вообще, или же нужен жесткий процесс с контролем выходов на каждой стадии — waterfall ваш выбор.
2. Если вам нужно разрабатывать несколько фич параллельно, или процесс будет дорабатываться (но сам процесс есть) — выбирайте второй вариант.
3. Если вы выясните процесс работы по ходу в процессе личного взаимодействия — выбирайте третий вариант.
Казалось бы, где тут откровения? Но давайте представим, какие последствия будут при выборе каждого из вариантов.
1. Waterfall: Пока пилим фичи баги исправлять не будем (и наоборот). Если потребуется в процессе внести какие-то изменения это будет очень тяжело.
2. Эволюционные/параллельные процессы: Нужно прописать и как-то контролировать процесс работы, и как дорабатывать его самого. Нужно определить как нам не мешать друг другу при параллельной разработке.
3. Межличностные и эмерджентные процессы: Ребята у нас умные, как-нибудь сами обо всем договорятся. В том числе и с заказчиками и внешними стейкхолдерами (спонсор, регуляторы, команды-смежники, внешние провайдеры, в т.ч. коммерческие и т.д.).
Какой из вариантов лучше всего подходит к вашему проекту?
Об гиперпространственные тоннели между деятельностными мирами
Меня очень вдохновляет язык моделирования Archimate (https://www.cfin.ru/itm/EA_ArchiMate.shtml) при всех его недостатках. Я не особенно задумывался почему -- на нем удобно отображать связи и взаимодействие между людьми, процессами, приложениями, технологиями, но кажется этого недостаточно чтобы служить вдохновением.
Сегодня я понял в чем дело: за счет его метамодели у нас в рассуждениях появляется интерфейс, связывающий между собой понятия из самых разных областей.
Метамодель Archimate очень простая, это формула "cубъект -- выполняет действия -- с объектом", и в дополнение представление ее же во внешний мир в виде сервисов и интерфейсов.
Что здесь примечательно, так это то, что мы можем за счет этого одновременно описывать несколько миров: мир практик и отношений между практиками, мир субъектов и их должностей, и мир объектов и их использования. Фактически эта формула выступает неким гиперпространственным тоннелем, который позволяет нам мгновенно переходить между рассуждениями в каждом из этих миров и связывать между собой факты, которые внешне никак не связаны.
Если Вася -- столяр, а столяр выполняет практику "изготовление табуретки", и в ее процессе превращает древесину в табуретку, то мы через эту формулу можем легко отследить, что Вася превращает древесину в табуретку. Это для известных доменов знаний звучит просто, но для неизвестной области это не так: сможете ли вы утверждать, каким образом при помощи бубузятора получаются хрямзики и что еще для этого нужно? Только через определение процесса получения хрямзиков, указание его входов, выходов, роли исполняющей этот процесс и через назначение бубузятора роль выполняющую этот процесс.
В дополнение к этому деятельностному гиперпространственному тонелю Archimate вводит еще несколько таких гиперпространственных тоннелей, связывающих между собой пространство предприятия (бизнес-процессы и бизнес-функции, исполнители, ответственные лица, материальные активы), пространство ИТ-приложений (ИТ-компоненты, объекты данных, программные процессы), пространство технологий (артефакты, узлы, сети) и дополнительные пространства для обсуждения мотивации, стратегии и проектной деятельности.
Т.е. если мы проводим например, анализ "какие материальные артефакты нам понадобятся для стратегии "захват рынка", мы можем в каждом из миров построить архитектуру некоего решения, и через связку этих гиперпространственных тоннелей связать материальные объекты которые мы можем потрогать рукой с неким намерением, о котором договорились ключевые стейкхолдеры предприятия реализующего стратегию "захват рынка".
Сегодняшнее открытие состоит как раз в обнаружении этих самых гиперпространственных тоннелей.
Тоннель появляется в момент сопоставления объектов из нескольких миров в едином материальном объекте который они репрезентируют. Это знание позволяет искать эти тоннели целенаправленно -- достаточно знание о существовании некоего мира и законах этого мира.
Так, "проект" может быть одновременно:
- набором работ, который нужно исполнить к определенному сроку
- командой людей и ресурсов, которые требуют обеспечения финансами
- транзакцией между организациями
- движением прогресса отношений между организациями в достижении некоей цели
и объектами множества других миров
В ISO 42010 / ГОСТ Р 57100 точки входа в такие тоннели называются Architecture Viewpoint.
Описываются они в стандартах и нотациях моделирования.
Если их освоить и гармонизировать между собой появляется возможность быстро путешествовать в любую точку мира.
Меня очень вдохновляет язык моделирования Archimate (https://www.cfin.ru/itm/EA_ArchiMate.shtml) при всех его недостатках. Я не особенно задумывался почему -- на нем удобно отображать связи и взаимодействие между людьми, процессами, приложениями, технологиями, но кажется этого недостаточно чтобы служить вдохновением.
Сегодня я понял в чем дело: за счет его метамодели у нас в рассуждениях появляется интерфейс, связывающий между собой понятия из самых разных областей.
Метамодель Archimate очень простая, это формула "cубъект -- выполняет действия -- с объектом", и в дополнение представление ее же во внешний мир в виде сервисов и интерфейсов.
Что здесь примечательно, так это то, что мы можем за счет этого одновременно описывать несколько миров: мир практик и отношений между практиками, мир субъектов и их должностей, и мир объектов и их использования. Фактически эта формула выступает неким гиперпространственным тоннелем, который позволяет нам мгновенно переходить между рассуждениями в каждом из этих миров и связывать между собой факты, которые внешне никак не связаны.
Если Вася -- столяр, а столяр выполняет практику "изготовление табуретки", и в ее процессе превращает древесину в табуретку, то мы через эту формулу можем легко отследить, что Вася превращает древесину в табуретку. Это для известных доменов знаний звучит просто, но для неизвестной области это не так: сможете ли вы утверждать, каким образом при помощи бубузятора получаются хрямзики и что еще для этого нужно? Только через определение процесса получения хрямзиков, указание его входов, выходов, роли исполняющей этот процесс и через назначение бубузятора роль выполняющую этот процесс.
В дополнение к этому деятельностному гиперпространственному тонелю Archimate вводит еще несколько таких гиперпространственных тоннелей, связывающих между собой пространство предприятия (бизнес-процессы и бизнес-функции, исполнители, ответственные лица, материальные активы), пространство ИТ-приложений (ИТ-компоненты, объекты данных, программные процессы), пространство технологий (артефакты, узлы, сети) и дополнительные пространства для обсуждения мотивации, стратегии и проектной деятельности.
Т.е. если мы проводим например, анализ "какие материальные артефакты нам понадобятся для стратегии "захват рынка", мы можем в каждом из миров построить архитектуру некоего решения, и через связку этих гиперпространственных тоннелей связать материальные объекты которые мы можем потрогать рукой с неким намерением, о котором договорились ключевые стейкхолдеры предприятия реализующего стратегию "захват рынка".
Сегодняшнее открытие состоит как раз в обнаружении этих самых гиперпространственных тоннелей.
Тоннель появляется в момент сопоставления объектов из нескольких миров в едином материальном объекте который они репрезентируют. Это знание позволяет искать эти тоннели целенаправленно -- достаточно знание о существовании некоего мира и законах этого мира.
Так, "проект" может быть одновременно:
- набором работ, который нужно исполнить к определенному сроку
- командой людей и ресурсов, которые требуют обеспечения финансами
- транзакцией между организациями
- движением прогресса отношений между организациями в достижении некоей цели
и объектами множества других миров
В ISO 42010 / ГОСТ Р 57100 точки входа в такие тоннели называются Architecture Viewpoint.
Описываются они в стандартах и нотациях моделирования.
Если их освоить и гармонизировать между собой появляется возможность быстро путешествовать в любую точку мира.
👍4
Во вторник, 5 марта, на конференции DevOpsConf делаю доклад для инженеров и начинающих тимлидов о том как подключаться к новым проектам.
Если вы вдруг хотите купить билет, но почему-то этого еще не сделали, у меня для вас есть промокод на скидку 7%:
https://devopsconf.io/moscow/2024/abstracts/11628
Если вы вдруг хотите купить билет, но почему-то этого еще не сделали, у меня для вас есть промокод на скидку 7%:
DevOpsMoscow_2024https://devopsconf.io/moscow/2024/abstracts/11628
devopsconf.io
Тимур Батыршин на DevOpsConf 2024
Представьте ситуацию, что вы пришли на проект в большой компании. Вы пишете код или настраиваете сервисы, но все вокруг недовольны и им нужно непонятно что. Приоритеты постоянно меняются, и все горит.В своем докладе я расскажу о нескольких простых шагах,…
👍3
Экспериментирую с пропусканием текстов через ChatGPT и последующей доработкой напильником
"Цель DevOps — это переход от документоориентированных (document-centric) процессов управления разработкой ПО и процессов управления IT-сервисами к кодоориентированным (software-defined).
При этом методы управления всеми этими процессами могут быть различными — как использование единого инструмента для оркестрации всех процессов и активностей, так и интеграция различных инструментов и сервисов в единую распределенную систему."
"Цель DevOps — это переход от документоориентированных (document-centric) процессов управления разработкой ПО и процессов управления IT-сервисами к кодоориентированным (software-defined).
При этом методы управления всеми этими процессами могут быть различными — как использование единого инструмента для оркестрации всех процессов и активностей, так и интеграция различных инструментов и сервисов в единую распределенную систему."
❤1👍1
Выложили видео моего доклада на конференции DevOpsConf, которая происходила 4 и 5 марта 2024г.
Я делал доклад для инженеров и начинающих лидов — о том как ускорить свою производительность и снизить количество возникающих пожаров.
Ключевые слова: GTD, Meeting notes, Decision records
Поделитесь с теми ребятами у себя в команде, кто не очень хорошо справляется с организацией собственных дел
https://youtu.be/t_jZMmXRjGM
Я делал доклад для инженеров и начинающих лидов — о том как ускорить свою производительность и снизить количество возникающих пожаров.
Ключевые слова: GTD, Meeting notes, Decision records
Поделитесь с теми ребятами у себя в команде, кто не очень хорошо справляется с организацией собственных дел
https://youtu.be/t_jZMmXRjGM
YouTube
Как навести порядок в горящем проекте / Тимур Батыршин (Axenix)
Приглашаем на DevOpsConf 2025, которая пройдет 7 и 8 апреля 2025 в Сколково в Москве.
Программа, подробности и билеты по ссылке: https://devopsconf.io/moscow/2025
Конференция для инженеров и всех, кто должен понимать инженеров DevOpsConf 2024
Презентация…
Программа, подробности и билеты по ссылке: https://devopsconf.io/moscow/2025
Конференция для инженеров и всех, кто должен понимать инженеров DevOpsConf 2024
Презентация…
👍2🔥2
Об DevOps и архитектуру
Цель DevOps — это переход от документоориентированных (document-centric) процессов управления разработкой ПО и процессов управления IT-сервисами к кодоориентированным (software-defined).
В противопоставлении document-centric и software-defined подходов я намеренно опустил один важный момент.
Представим, что нас интересует некий целевой процесс в организации, который будет давать нужный нам результат. Например, быструю и надежную доставку фич в продакшн. Или снижение рутины у команд сопровождения. Или повышение надежности релизов.
Мы проектируем этот процесс, чтобы получить этот самый результат — например, описываем чеклисты для перехода между активностями в этом процессе, или выделяем стадии для контроля качества доставляемой фичи.
Мы можем каждую из активностей в этом процесе описать в виде подробного документа, дать с ним ознакомиться сотрудникам, проводить регулярное обучение и адаптировать в виде инструкций.
Либо можно для каждой из активностей написать портянку YAML, написать тесты и CI/CD для раскатки этого YAML, перевести на разработанные скрипты автоматизации все процессы разработки.
Для каждой активности назначить ответственного сотрудника, который будет регулярно обновлять и дорабатывать регламенты (в случае документоцентричного подхода) или дописывать новый YAML по запросу разработчиков (в случае кодоцентричного подхода).
Только что я намеренно еще раз пропустил тот же самый важный момент. В обоих случаях нас интересует не просто регламентация или автоматизация шагов процесса, а тот результат, который мы получаем в итоге.
Вместо методологии DevOps появились devops-инженеры ровно в тот момент когда мы из software-defined процессов убрали ориентацию на результат и заменили ее автоматизацией отдельных шагов.
Представим, что нас интересует некий целевой процесс в организации, который будет давать нужный нам результат. Например, быструю и надежную доставку фич в продакшн. Или снижение рутины у команд сопровождения. Или повышение надежности релизов.
Мы проектируем этот процесс, чтобы получить этот самый результат — например, описываем чеклисты для перехода между активностями в этом процессе, или выделяем стадии для контроля качества доставляемой фичи.
Мы можем каждую из активностей в этом процесе описать в виде подробного документа, дать с ним ознакомиться сотрудникам, проводить регулярное обучение и адаптировать в виде инструкций.
Либо можно для каждой из активностей написать портянку YAML, написать тесты и CI/CD для раскатки этого YAML, перевести на разработанные скрипты автоматизации все процессы разработки.
Для каждой активности назначить ответственного сотрудника, который будет регулярно обновлять и дорабатывать регламенты (в случае документоцентричного подхода) или дописывать новый YAML по запросу разработчиков (в случае кодоцентричного подхода).
Только что я намеренно еще раз пропустил тот же самый важный момент. В обоих случаях нас интересует не просто регламентация или автоматизация шагов процесса, а тот результат, который мы получаем в итоге.
Вместо методологии DevOps появились devops-инженеры ровно в тот момент когда мы из software-defined процессов убрали ориентацию на результат и заменили ее автоматизацией отдельных шагов.
🔥2
В продолжение предыдущего поста и обсуждения в комментариях, давайте попробуем разобраться почему происходит описанное в нем, а именно почему исчезает "ориентация на результат", или почему в компании нет "высокой проектной культуры".
Для этого рассмотрим какое место отдельные описанные элементы занимают в цельной картине.
Предположим, некий "devops-инженер" пишет разнообразную автоматизацию пайплайна SDLC для своей команды разработки.
- Его видимая работа состоит в написании различных автоматизаций на YAML. Эти задачи можно положить в таск-трекер и проконтролировать их выполнение.
- Следующий слой работы состоит в интеграции отдельных шагов пайплайна так, чтобы артефакты между ними передавались правильно и без ошибок. Эти задачи в таск трекер положить можно, но только либо в виде самого описания или definition of done задачи по реализации шага пайплайна, либо в виде багов — когда один шаг вроде бы интегрирован с другим, но дает неверные результаты. Причем, технически эту задачу отделить от первого шага вполне реально — я часто советую ребятам сделать два эти шага по отдельности, когда они буксуют над подобной составной задачей
- Слоем глубже находится построение поведения пайплайна, состоящего из нескольких шагов. Например, мы сперва публикуем контейнер в хранилище, дальше этот контейнер сканируем на уязвимости и подписываем ключом, и в конце разрешаем запуск контейнеров на средах только если они подписаны. Эту задачу можно положить в таск-трекер как набор отдельных задач, но для того чтобы реализовалась именно функциональность "разрешить запуск только контейнеров просканированных на уязвимости" нужно эти задачи или объединить в какой-нибудь эпик, или тщательно описать что должно происходить для каждой из задач, или описать весь процесс отдельным документом и прикрепить его к каждой из задач. Создание такого описания и декомпозиция его на тикеты может быть отдельной задачей перед собственно написанием автоматизации на YAML, и задачей окажется довольно немаленькой.
Ну или можно завести одну большую задачу "реализовать проверку подписи контейнеров", подразумевая всю эту цепочку, и отдать выяснять детали самому инженеру. Но тогда как состояние выполнения этой довольно немаленькой задачи, так и собственно способ ее реализации становятся плохо верифицируемыми для стороннего наблюдателя. Иными словами, если мы ставим такие достаточно большие составные задачи (или мини-проекты) мы должны быть уверены в том, что сотрудник умеет их решать, и решает их хорошо.
- Если идти еще глубже, мы приходим к построению принципов и стандартов работы пайплайна самого по себе, и как они будут интегрироваться с рабочим процессом команд разработки. Из этих принципов у нас появляются задачи на реализацию элементов функциональности пайплайна — т.е. задачи предыдущего слоя. Такой вид задач требует как знания предметной области ("как правильно строить пайплайны") с одной стороны, так и совершенно нетехнических компетенций с другой стороны — навыков анализа систем, планирования процессов и декомпозиции решений на элементарные задачи.
Все это хорошо, но какая здесь связь с DevOps?
Дело в том, что ориентация на результат, анализ сложных систем и планирование их реализации — это набор необходимых характеристик любого технического руководителя. Декомпозиция целевого решения на отдельные задачи тоже.
Вся суть "методологии DevOps" состоит в том, чтобы включать в активности по проектированию целевой системы не только функциональные и нефункциональные требования заказчика, но также и части системы связанные с Инфраструктурой и SDLC. Это не столько "методология" или "философия", сколько домен знания наподобие "проектирования интерфейсов" или "построения даталейков".
Скорее всего будучи руководителем, реализацию различных частей системы ты отдашь сотрудникам с соответствующей квалификацией.
В этот момент и возникает потребность в devops-инженерах, которые на деле являются такими же разработчиками как фронтендеры, тестировщики или разработчики на Java.
Для этого рассмотрим какое место отдельные описанные элементы занимают в цельной картине.
Предположим, некий "devops-инженер" пишет разнообразную автоматизацию пайплайна SDLC для своей команды разработки.
- Его видимая работа состоит в написании различных автоматизаций на YAML. Эти задачи можно положить в таск-трекер и проконтролировать их выполнение.
- Следующий слой работы состоит в интеграции отдельных шагов пайплайна так, чтобы артефакты между ними передавались правильно и без ошибок. Эти задачи в таск трекер положить можно, но только либо в виде самого описания или definition of done задачи по реализации шага пайплайна, либо в виде багов — когда один шаг вроде бы интегрирован с другим, но дает неверные результаты. Причем, технически эту задачу отделить от первого шага вполне реально — я часто советую ребятам сделать два эти шага по отдельности, когда они буксуют над подобной составной задачей
- Слоем глубже находится построение поведения пайплайна, состоящего из нескольких шагов. Например, мы сперва публикуем контейнер в хранилище, дальше этот контейнер сканируем на уязвимости и подписываем ключом, и в конце разрешаем запуск контейнеров на средах только если они подписаны. Эту задачу можно положить в таск-трекер как набор отдельных задач, но для того чтобы реализовалась именно функциональность "разрешить запуск только контейнеров просканированных на уязвимости" нужно эти задачи или объединить в какой-нибудь эпик, или тщательно описать что должно происходить для каждой из задач, или описать весь процесс отдельным документом и прикрепить его к каждой из задач. Создание такого описания и декомпозиция его на тикеты может быть отдельной задачей перед собственно написанием автоматизации на YAML, и задачей окажется довольно немаленькой.
Ну или можно завести одну большую задачу "реализовать проверку подписи контейнеров", подразумевая всю эту цепочку, и отдать выяснять детали самому инженеру. Но тогда как состояние выполнения этой довольно немаленькой задачи, так и собственно способ ее реализации становятся плохо верифицируемыми для стороннего наблюдателя. Иными словами, если мы ставим такие достаточно большие составные задачи (или мини-проекты) мы должны быть уверены в том, что сотрудник умеет их решать, и решает их хорошо.
- Если идти еще глубже, мы приходим к построению принципов и стандартов работы пайплайна самого по себе, и как они будут интегрироваться с рабочим процессом команд разработки. Из этих принципов у нас появляются задачи на реализацию элементов функциональности пайплайна — т.е. задачи предыдущего слоя. Такой вид задач требует как знания предметной области ("как правильно строить пайплайны") с одной стороны, так и совершенно нетехнических компетенций с другой стороны — навыков анализа систем, планирования процессов и декомпозиции решений на элементарные задачи.
Все это хорошо, но какая здесь связь с DevOps?
Дело в том, что ориентация на результат, анализ сложных систем и планирование их реализации — это набор необходимых характеристик любого технического руководителя. Декомпозиция целевого решения на отдельные задачи тоже.
Вся суть "методологии DevOps" состоит в том, чтобы включать в активности по проектированию целевой системы не только функциональные и нефункциональные требования заказчика, но также и части системы связанные с Инфраструктурой и SDLC. Это не столько "методология" или "философия", сколько домен знания наподобие "проектирования интерфейсов" или "построения даталейков".
Скорее всего будучи руководителем, реализацию различных частей системы ты отдашь сотрудникам с соответствующей квалификацией.
В этот момент и возникает потребность в devops-инженерах, которые на деле являются такими же разработчиками как фронтендеры, тестировщики или разработчики на Java.