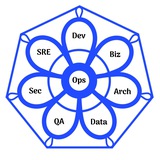
Путь развития разработчика в Infrastructure as Code
Недавно вышли новые роадмапы профессионального развития на https://roadmap.sh/ и они на мой взгляд очень хорошо помогают прояснить мой предыдущий пост про то, что подход Infrastructure as Code — это особая форма разработки. Я не уверен, что согласен с названиями роадмапов, но разделение на роадмапы мне кажется очень хорошо сделанным:
- Software Architect — список навыков указывают, что основные задачи это построение систем, состоящих из множества отдельно разрабатываемых компонентов (и интеграция этих компонентов между собой), коммуникация с разработчиками, другими архитекторами и руководством компании, и организация проекта. Одним словом, чтобы множество команд разработки и программные сервисы которые они разрабатывают интегрировались друг с другом и при этом решали бизнес-задачи. Нужны ли эти практики в подходе Infrastructure as Code? Не уверен, скорее всего если выходишь на такой уровень в организации тебе уже не нужен IaC, но вместе с тем практически все эти темы в той или иной мере затрагиваются если ты занимаешься методологией DevOps.
- Software Design and Architecture (напомню, что “design” переводится как “проектирование”) — список навыков указывает, что основные задачи это структурирование программного кода, разбиение на модули и интеграция между ними. Одним словом, все то, что нужно для того, чтобы код в рамках одного сервиса был не лапшой, а был поддерживаемым, тестируемым, изменяемым, надежным и т.п. Нужны ли эти практики в подходе Infrastructure as Code? Несомненно. Если размер инфраструктурного кода десятки тысяч строк, применение всех этих практик и концептов поможет справиться со сложностью и в декларативных языках — сложность в них с ростом кодовой базы растет медленнее чем в императивных, но все же растет. Отдельные принципы скорее всего неприменимы, но не столько неприменимы сами по себе, сколько по причине относительно более простой и относительно маленькой кодовой базы в случае инфраструктуры, и относительно стабильного пространства понятий которые мы при помощи IaC описываем.
- Backend Developer — здесь говорится об инструментах и концепциях применяемых собственно в процессе разработки. Что-то из этого если находимся в контексте инфраструктуры мы знаем и так, что-то становится применимо сразу же как-только мы начинаем заниматься SRE, а не только писать код. В целом кажется применимым не столько к IaC, сколько к SRE.
Напомню свой тезис, который прозвучал в начале: практика Infrastructure as Code является не чем иным как программированием в “особой” доменной области на “особом” языке. Примерно так же как современное фронтенд-программирование имеет довольно мало общего с тем программированием на языке Паскаль, которое мы изучали в школе. Основные отличия находятся в решаемой проблематике и в конкретных языках программирования, которые применяются для решения задач.
Есть ли что-то, что я упустил в рассуждениях?
Недавно вышли новые роадмапы профессионального развития на https://roadmap.sh/ и они на мой взгляд очень хорошо помогают прояснить мой предыдущий пост про то, что подход Infrastructure as Code — это особая форма разработки. Я не уверен, что согласен с названиями роадмапов, но разделение на роадмапы мне кажется очень хорошо сделанным:
- Software Architect — список навыков указывают, что основные задачи это построение систем, состоящих из множества отдельно разрабатываемых компонентов (и интеграция этих компонентов между собой), коммуникация с разработчиками, другими архитекторами и руководством компании, и организация проекта. Одним словом, чтобы множество команд разработки и программные сервисы которые они разрабатывают интегрировались друг с другом и при этом решали бизнес-задачи. Нужны ли эти практики в подходе Infrastructure as Code? Не уверен, скорее всего если выходишь на такой уровень в организации тебе уже не нужен IaC, но вместе с тем практически все эти темы в той или иной мере затрагиваются если ты занимаешься методологией DevOps.
- Software Design and Architecture (напомню, что “design” переводится как “проектирование”) — список навыков указывает, что основные задачи это структурирование программного кода, разбиение на модули и интеграция между ними. Одним словом, все то, что нужно для того, чтобы код в рамках одного сервиса был не лапшой, а был поддерживаемым, тестируемым, изменяемым, надежным и т.п. Нужны ли эти практики в подходе Infrastructure as Code? Несомненно. Если размер инфраструктурного кода десятки тысяч строк, применение всех этих практик и концептов поможет справиться со сложностью и в декларативных языках — сложность в них с ростом кодовой базы растет медленнее чем в императивных, но все же растет. Отдельные принципы скорее всего неприменимы, но не столько неприменимы сами по себе, сколько по причине относительно более простой и относительно маленькой кодовой базы в случае инфраструктуры, и относительно стабильного пространства понятий которые мы при помощи IaC описываем.
- Backend Developer — здесь говорится об инструментах и концепциях применяемых собственно в процессе разработки. Что-то из этого если находимся в контексте инфраструктуры мы знаем и так, что-то становится применимо сразу же как-только мы начинаем заниматься SRE, а не только писать код. В целом кажется применимым не столько к IaC, сколько к SRE.
Напомню свой тезис, который прозвучал в начале: практика Infrastructure as Code является не чем иным как программированием в “особой” доменной области на “особом” языке. Примерно так же как современное фронтенд-программирование имеет довольно мало общего с тем программированием на языке Паскаль, которое мы изучали в школе. Основные отличия находятся в решаемой проблематике и в конкретных языках программирования, которые применяются для решения задач.
Есть ли что-то, что я упустил в рассуждениях?
roadmap.sh
Developer Roadmaps - roadmap.sh
Community driven roadmaps, articles and guides for developers to grow in their career.
Исследование DORA и его проблемы
Кажется, спустя полтора года после прочтения книги Accelerate наконец удалось кратко и компактно сформулировать в чем проблема с отчетом State Of Devops.
Проблема в том, что в книге и отчете выпячивается та несомненно большая сложная часть работы по статистическим предсказаниям, которая однако по факту никому не нужна, и которая не имеет смысла.
1. DORA статистически показали, что использование CI/CD приводит ("предсказывает") к сокращению Lead Time, увеличению частоты поставки и снижению количества ошибок при развертывании.
На деле же это и есть основная функция CI/CD — он строится как раз для того, чтобы именно это и происходило.
Если ваш процесс CI/CD не приводит к ускорению поставки он не выполняет свою основную функцию, и скорее всего вы что-то делаете не так, и это можно сказать без исследований.
Ждем горячих заголовков "Доказано научно: передвигаться на велосипеде быстрее чем пешком".
2. Аналогичная ошибка просматривается относительно выводов "высокая частота релизов приводит к высокой производительности разработки, а та в свою очередь приводит к господствующему положению на рынке".
Здесь тоже зависимость обратная. Если компания постоянно меняется и адаптируется к рынку, постоянно выпускает новые фичи (которые технически могут ломать старые), то без высокопроизводительного IT ей делать нечего. А "быстрый процесс поставки" — это как мы уже заметили, функция внутри IT (также как и сам IT это функция внутри бизнеса).
Т.е. и здесь перевернули все с ног на голову.
При этом у них получаются действительно интересные выводы об анализе аудитории, трендах и других полезных вещах, но они тонут в огромном количестве научных рассуждений о статистике и т.д. К моей большой радости, последние год-два к работе подключилось большое количество новых людей и они начали делать то, что у них получается хорошо — кластерный и когортный анализ, и история с выводами через статистику начала идти на спад.
Кажется, спустя полтора года после прочтения книги Accelerate наконец удалось кратко и компактно сформулировать в чем проблема с отчетом State Of Devops.
Проблема в том, что в книге и отчете выпячивается та несомненно большая сложная часть работы по статистическим предсказаниям, которая однако по факту никому не нужна, и которая не имеет смысла.
1. DORA статистически показали, что использование CI/CD приводит ("предсказывает") к сокращению Lead Time, увеличению частоты поставки и снижению количества ошибок при развертывании.
На деле же это и есть основная функция CI/CD — он строится как раз для того, чтобы именно это и происходило.
Если ваш процесс CI/CD не приводит к ускорению поставки он не выполняет свою основную функцию, и скорее всего вы что-то делаете не так, и это можно сказать без исследований.
Ждем горячих заголовков "Доказано научно: передвигаться на велосипеде быстрее чем пешком".
2. Аналогичная ошибка просматривается относительно выводов "высокая частота релизов приводит к высокой производительности разработки, а та в свою очередь приводит к господствующему положению на рынке".
Здесь тоже зависимость обратная. Если компания постоянно меняется и адаптируется к рынку, постоянно выпускает новые фичи (которые технически могут ломать старые), то без высокопроизводительного IT ей делать нечего. А "быстрый процесс поставки" — это как мы уже заметили, функция внутри IT (также как и сам IT это функция внутри бизнеса).
Т.е. и здесь перевернули все с ног на голову.
При этом у них получаются действительно интересные выводы об анализе аудитории, трендах и других полезных вещах, но они тонут в огромном количестве научных рассуждений о статистике и т.д. К моей большой радости, последние год-два к работе подключилось большое количество новых людей и они начали делать то, что у них получается хорошо — кластерный и когортный анализ, и история с выводами через статистику начала идти на спад.
Релизы и деплои
Периодически поднимается тема того, чем отличается deploy от release, и на это есть элегантный ответ в недавно вышедшей новой версии стандарта IT4IT от The Open Group.
- Deploy — это собственно инсталляция новой версии продукта на продакшн (сюда же включают и удаление старых версий с продакшна). В этот процесс входят и все стратегии деплоя — в том числе canary deploy, раскатка на какую-то небольшую часть аудитории, или деплой функциональности вообще прикрытой через feature flags и недоступной никому.
- Release — это предоставление новой версии сервиса (или услуги, если вспомнить ITIL) потребителям. При этом всякие хотфиксы в релиз закономерно не войдут, да и кажется далеко не каждый мажорный релиз по такой классификации можно будет назвать релизом.
Но релизом станет, например, изменение SLA сервиса при неизменной функциональности или изменение стоимости подписки на него.
Еще один пример релиза — в софте не меняется вообще ничего, меняются только гарантии на LTS поддержку (см Terraform 1.0 который от 0.15 отличается только гарантиями долговременной поддержки).
А еще точнее, получается что релиз всегда привязан к сегменту потребителей, и это во многом маркетинговая штука. Рефакторинг софта, который ничего для пользователя не меняет, но даёт возможность писать фичи быстрее — это релиз для разработчиков, но не релиз для пользователей. Для первых релиз есть, для вторых его нет, хотя софт один и тот же.
Что это значит для нас?
- В первую очередь в том, призыв “релизиться чаще” должен вызывать ответный вопрос “для каких пользователей?” (естественно, сегменты пользователей для своих цифровых продуктов нужно выявить сразу же как только мы с начинаем работать со своим продуктом). И мы тут же понимаем, что с одной стороны нельзя всем угодить, а с другой стороны есть пользователи разного приоритета и важности, и пауза в релизах на подготовку к единственному долгому и важному релизу может оказаться для нас важнее, чем выпуск серии релизов низкой важности.
- На мой взгляд, нельзя релизиться чаще чем раз в месяц, потому что каждый релиз это стресс для пользователя. И уж точно не стоит планировать релизиться каждый день. Как часто вы предпочитаете обновлять операционную систему на своем компьютере или в своем телефоне?
Если же вы успешно релизитесь чаще (вспоминаем отличия релиза от деплоя), значит постоянная эволюция и развитие вашего сервиса — часть вашего сервисного предложения и вероятно является вашим конкурентным преимуществом. И тогда важно “частоту релизов” отслеживать именно для отслеживания состояния этого самого конкурентного преимущества, а не потому что DORA предсказала. И не важно идет ли речь про SaaS или про устанавливаемый софт — вспомните каким релизом вашего броузера вы пользуетесь.
Если же постоянное непрерывное и быстрое развитие продукта для вас таким конкурентным преимуществом по той или иной причине не является (например, у вас другая стратегия), поддерживать актуальным в течение длительного времени сервисное предложение “наш продукт постоянно значимо и заметно развивается и улучшается” скорее всего окажется слишком дорого.
- Частота деплоев не важна вообще. Для оценки качества работы CI/CD может оказаться важна частота запуска пайплайнов (и в этом случае деплой входит в пайплайн, и будет одним из результатов его выполнения), для кросс-командной работы — частота релизов для внутренних пользователей (разработчиков). А что дает частота деплоев сама по себе? Ну разве что ее можно померять для определения предельно допустимых нагрузок на инструмент деплоя.
DORA выбрали частоту деплоев в качестве метрики лишь по той причине, что это единственный подходящий показатель, который можно более-менее убедительно измерить через опросник рассылаемый веером по интернету (с частотой релизов и частотой запуска пайплайнов это сложнее), и они явно про это говорили в книге Accelerate.
В сообществе регулярно ставят под сомнение пользу измерения частоты деплоев (вот пример, если у вас есть другие — смело присылайте).
Но тем не менее все прикладывают усилия чтобы “релизиться чаще”.
Почему?
Периодически поднимается тема того, чем отличается deploy от release, и на это есть элегантный ответ в недавно вышедшей новой версии стандарта IT4IT от The Open Group.
- Deploy — это собственно инсталляция новой версии продукта на продакшн (сюда же включают и удаление старых версий с продакшна). В этот процесс входят и все стратегии деплоя — в том числе canary deploy, раскатка на какую-то небольшую часть аудитории, или деплой функциональности вообще прикрытой через feature flags и недоступной никому.
- Release — это предоставление новой версии сервиса (или услуги, если вспомнить ITIL) потребителям. При этом всякие хотфиксы в релиз закономерно не войдут, да и кажется далеко не каждый мажорный релиз по такой классификации можно будет назвать релизом.
Но релизом станет, например, изменение SLA сервиса при неизменной функциональности или изменение стоимости подписки на него.
Еще один пример релиза — в софте не меняется вообще ничего, меняются только гарантии на LTS поддержку (см Terraform 1.0 который от 0.15 отличается только гарантиями долговременной поддержки).
А еще точнее, получается что релиз всегда привязан к сегменту потребителей, и это во многом маркетинговая штука. Рефакторинг софта, который ничего для пользователя не меняет, но даёт возможность писать фичи быстрее — это релиз для разработчиков, но не релиз для пользователей. Для первых релиз есть, для вторых его нет, хотя софт один и тот же.
Что это значит для нас?
- В первую очередь в том, призыв “релизиться чаще” должен вызывать ответный вопрос “для каких пользователей?” (естественно, сегменты пользователей для своих цифровых продуктов нужно выявить сразу же как только мы с начинаем работать со своим продуктом). И мы тут же понимаем, что с одной стороны нельзя всем угодить, а с другой стороны есть пользователи разного приоритета и важности, и пауза в релизах на подготовку к единственному долгому и важному релизу может оказаться для нас важнее, чем выпуск серии релизов низкой важности.
- На мой взгляд, нельзя релизиться чаще чем раз в месяц, потому что каждый релиз это стресс для пользователя. И уж точно не стоит планировать релизиться каждый день. Как часто вы предпочитаете обновлять операционную систему на своем компьютере или в своем телефоне?
Если же вы успешно релизитесь чаще (вспоминаем отличия релиза от деплоя), значит постоянная эволюция и развитие вашего сервиса — часть вашего сервисного предложения и вероятно является вашим конкурентным преимуществом. И тогда важно “частоту релизов” отслеживать именно для отслеживания состояния этого самого конкурентного преимущества, а не потому что DORA предсказала. И не важно идет ли речь про SaaS или про устанавливаемый софт — вспомните каким релизом вашего броузера вы пользуетесь.
Если же постоянное непрерывное и быстрое развитие продукта для вас таким конкурентным преимуществом по той или иной причине не является (например, у вас другая стратегия), поддерживать актуальным в течение длительного времени сервисное предложение “наш продукт постоянно значимо и заметно развивается и улучшается” скорее всего окажется слишком дорого.
- Частота деплоев не важна вообще. Для оценки качества работы CI/CD может оказаться важна частота запуска пайплайнов (и в этом случае деплой входит в пайплайн, и будет одним из результатов его выполнения), для кросс-командной работы — частота релизов для внутренних пользователей (разработчиков). А что дает частота деплоев сама по себе? Ну разве что ее можно померять для определения предельно допустимых нагрузок на инструмент деплоя.
DORA выбрали частоту деплоев в качестве метрики лишь по той причине, что это единственный подходящий показатель, который можно более-менее убедительно измерить через опросник рассылаемый веером по интернету (с частотой релизов и частотой запуска пайплайнов это сложнее), и они явно про это говорили в книге Accelerate.
В сообществе регулярно ставят под сомнение пользу измерения частоты деплоев (вот пример, если у вас есть другие — смело присылайте).
Но тем не менее все прикладывают усилия чтобы “релизиться чаще”.
Почему?
Методология, дисциплины, практики (часть 1)
Существует мнение, что тяжеловесные подходы проектирования (ITIL, TOGAF, ГОСТ34 и т.д.) несовместимы с быстрыми частыми релизами и изменениями. А следовательно, зачем их изучать? Это верно только отчасти.
Во-первых вспомним всем известную методологическую максиму, которая упрощенно звучит как: “практика = дисциплина + технология”. И далее эта самая практика адаптируется под вполне конкретный контекст организации.
Дисциплина описывает мотивацию, взаимоотношения с окружающим миром, онтологию и принципы. К примеру, CI/CD предназначен для ускорения поставки разрабатываемого софта в продакшн, состоит из последовательной цепочки преобразований, которую проходит описание фичи до продакшна (в процессе превращаясь в код, затем в некий набор артефактов), подразумевает активное участие команды в процессах этой цепочки, и наконец можно говорить о принципах Shift Left и Fail Fast как примере более частных описаний.
Технология описывает конкретные инструменты — например, Gitlab CI или Jenkins.
И наконец, практика
Таким образом, практика — это конкретный вид деятельности, который осуществляется для реализации дисциплины с использованием технологии.
Что здесь еще важно рассмотреть? Рассмотреть как практика будет вписываться в реальную организацию — в частности, есть ли у человека ее исполняющего необходимые компетенции, да даже есть ли у него необходимые средства для этого. Если человеку нужно писать многокилобайтные YAML для Kubernetes, а ему отдел ИБ не разрешает поставить редактор с поддержкой YAML, то практика
И наконец мы подходим к самому важному, что обычно обсуждается в контексте Devops, различных трансформаций и подобных темах — к интеграции наших практик в нашу организацию, с тем чтобы достичь целей описываемых дисциплиной. Если разрабатываемое приложение — сильносвязанный монолит с высокой интенсивностью разработки и низкой частотой релизов (т.е. не соответствует ни мотивации, ни принципам дисциплины CI/CD), то польза от практики
Здесь у нас встает важный вопрос: почему эта организация такая? Или: почему приложение такое? Наверняка именно такой дизайн преследовал целью некоторую вполне конкретную мотивацию? К примеру, разделение людей по функциональным колодцам это неплохой способ снижения затрат при относительно низком количестве и низкой сложности поставляемых изменений.
И сопутствующий вопрос — изменилась ли с тех пор мотивация? Что нам важнее сейчас — поставлять изменения быстро, или же сократить затраты? В достаточно большом спектре решений это цели противоположные, и возможно только поставлять изменения быстро и как-то контролировать затраты, либо же сократить затраты и как-то контролировать скорость поставки изменений. Какой должна быть компания, чтобы следовать этим целям и каким должно быть приложение?
(продолжение)
Существует мнение, что тяжеловесные подходы проектирования (ITIL, TOGAF, ГОСТ34 и т.д.) несовместимы с быстрыми частыми релизами и изменениями. А следовательно, зачем их изучать? Это верно только отчасти.
Во-первых вспомним всем известную методологическую максиму, которая упрощенно звучит как: “практика = дисциплина + технология”. И далее эта самая практика адаптируется под вполне конкретный контекст организации.
Дисциплина описывает мотивацию, взаимоотношения с окружающим миром, онтологию и принципы. К примеру, CI/CD предназначен для ускорения поставки разрабатываемого софта в продакшн, состоит из последовательной цепочки преобразований, которую проходит описание фичи до продакшна (в процессе превращаясь в код, затем в некий набор артефактов), подразумевает активное участие команды в процессах этой цепочки, и наконец можно говорить о принципах Shift Left и Fail Fast как примере более частных описаний.
Технология описывает конкретные инструменты — например, Gitlab CI или Jenkins.
И наконец, практика
"CI/CD на базе Gitlab" будет описывать типовые паттерны применения данной технологии для реализации задач, которые задаются дисциплиной. Некоторые авторы практику не делают специфичной по отношению к инструменту, что на мой взгляд неверно — если ты умеешь делать отличные пайплайны на Gitlab-CI не факт, что ты вообще что-то вразумительное сможешь сделать под Jenkins. Или другой пример для дисциплины "программирование": если ты будучи программистом отлично умеешь писать код на Python далеко не факт, что ты будешь успешно исполнять практику "программирование на Java".Таким образом, практика — это конкретный вид деятельности, который осуществляется для реализации дисциплины с использованием технологии.
Что здесь еще важно рассмотреть? Рассмотреть как практика будет вписываться в реальную организацию — в частности, есть ли у человека ее исполняющего необходимые компетенции, да даже есть ли у него необходимые средства для этого. Если человеку нужно писать многокилобайтные YAML для Kubernetes, а ему отдел ИБ не разрешает поставить редактор с поддержкой YAML, то практика
"развертывание приложений в кластере Kubernetes" будет в этой компании работать со скрипом.И наконец мы подходим к самому важному, что обычно обсуждается в контексте Devops, различных трансформаций и подобных темах — к интеграции наших практик в нашу организацию, с тем чтобы достичь целей описываемых дисциплиной. Если разрабатываемое приложение — сильносвязанный монолит с высокой интенсивностью разработки и низкой частотой релизов (т.е. не соответствует ни мотивации, ни принципам дисциплины CI/CD), то польза от практики
"CI/CD на базе Gitlab", конечно будет, но ее будет очень немого. Подобная же история будет если разработчики, тестировщики и эксплуатация сидят по разным функциональным колодцам и не спешат из них вылезать. Иными словами, чтобы реализовать всего одну конкретную практику DevOps требуется полная перестройка приложения, либо полная перестройка организации, а часто и то и другое одновременно. Именно над этим в контексте DevOps бьются светлейшие умы всего мира.Здесь у нас встает важный вопрос: почему эта организация такая? Или: почему приложение такое? Наверняка именно такой дизайн преследовал целью некоторую вполне конкретную мотивацию? К примеру, разделение людей по функциональным колодцам это неплохой способ снижения затрат при относительно низком количестве и низкой сложности поставляемых изменений.
И сопутствующий вопрос — изменилась ли с тех пор мотивация? Что нам важнее сейчас — поставлять изменения быстро, или же сократить затраты? В достаточно большом спектре решений это цели противоположные, и возможно только поставлять изменения быстро и как-то контролировать затраты, либо же сократить затраты и как-то контролировать скорость поставки изменений. Какой должна быть компания, чтобы следовать этим целям и каким должно быть приложение?
(продолжение)
Методология, дисциплины, практики (часть 2)
(начало)
Мне кажется, в таких примерах в какой-то момент истории их развития незаметно изменилась мотивация, а в след за ней должна была измениться архитектура организации и приложения. А архитектуру сложно изменить по самому определению архитектуры:
Вариантов определений множество но суть у всех примерно такая.
При этом по причине того, что в прошлом такое архитектурное проектирование велось с применением подходов предлагаемых, например, ITIL или ГОСТ34 публика такую неудачу автоматически приписывают им.
(я знаю, что ни то ни другое не является методом архитектурного проектирования в строгом смысле этого понятия, но для целей статьи это различие не играет значимой роли)
Но давайте вспомним взаимоотношения организации, применяемых в ней практик, дисциплин и технологий, про которые мы говорили в начале статьи, и попробуем разобраться что из этого является неотъемлемой частью этих подходов проектирования, а что — особенностью реализации.
Конкретные практики, которые применяются в организации (например,
При этом, в настоящее время чаще применяется совсем другая практика, а именно,
Из дополнительных обстоятельств — наверняка разные версии дисциплин будут по-разному совместимы с разными архитектурами приложения и разными архитектурами организации.
Старые версии подходов проектирования конечно же могут быть несовместимы с современными архитектурами, но я не могу считать, что разработчики этих подходов живут в вакууме и не пытаются в новых релизах их адаптировать к новым реалиям.
Итого собирается следующая картина:
- Применимость тех или иных подходов проектирования к каждому конкретному случаю определяется мотивацией содержащейся в этом подходе (“для чего он предназначен”), и эта мотивация достаточно легко верифицируется (хоть и далеко не всегда легко выявляется).
- Любой подход проектирования требует адаптации к архитектуре конкретной организации и конкретного приложения. Важно использовать самую современную версию дисциплины изложенной в конкретных подходах проектирования и проверять современность предлагаемых практик в условиях окружающей действительности. Более того — при необходимости заменять их на более современные (при этом оставаться в рамках дисциплины).
При этом, если мы на секунду забудем обо всем, что мы только что обсуждали и посмотрим на относительно легковесные и простые практики DevOps или SRE — их адаптация к реалиям конкретных организаций часто тоже является очень болезненным процессом. При этом достаточно часто проблемы адаптации состоят в том, что напрочь игнорируется мотивационная часть (“— Для чего нам Kubernetes? — Потому что сейчас все его используют”), а нередко при применении DevOps игнорируют и его фундаментальные понятия и принципы с закономерно плачевным результатом.
(окончание)
(начало)
Мне кажется, в таких примерах в какой-то момент истории их развития незаметно изменилась мотивация, а в след за ней должна была измениться архитектура организации и приложения. А архитектуру сложно изменить по самому определению архитектуры:
Архитектура — это принципиальные инженерные решения, изменение хотя бы одного из которых приводит к существенному изменению всей конструкции.
Вариантов определений множество но суть у всех примерно такая.
При этом по причине того, что в прошлом такое архитектурное проектирование велось с применением подходов предлагаемых, например, ITIL или ГОСТ34 публика такую неудачу автоматически приписывают им.
Но давайте вспомним взаимоотношения организации, применяемых в ней практик, дисциплин и технологий, про которые мы говорили в начале статьи, и попробуем разобраться что из этого является неотъемлемой частью этих подходов проектирования, а что — особенностью реализации.
Конкретные практики, которые применяются в организации (например,
"Управление изменениями через собрание CAB") раскладываются на дисциплину "Управление изменениями" и технологию "Собрание CAB".При этом, в настоящее время чаще применяется совсем другая практика, а именно,
"Управление изменениями через планирование спринта и Pull Request". Но изменилась ли при этом сама дисциплина "Управление изменениями" (т.е. в первую очередь, изменились ли мотивация и принципы) от того, что мы одну технологию "Собрание CAB" заменили на другую технологию "Pull-request в Github"? Изменилась ли дисциплина "Управление инцидентами" от того, что в современном мире маленьких кросс-функциональных команд практика "Триаж инцидентов сервисдеском" чаще всего не очень нужна и алерты когда они происходят обычно считаются критическими? Изменилась ли мотивация этой дисциплины, взаимоотношения с внешним миром, содержание ключевых понятий, и выводимые в ней принципы? Что-то наверняка изменилось, но вспомним что у многих стандартов, методик и фреймворков регулярно выходят обновления в которых это может быть учтено на уровне самих дисциплин. Технологии же и практики применения этих дисциплин наверняка меняются намного чаще, чем сами дисциплины.Из дополнительных обстоятельств — наверняка разные версии дисциплин будут по-разному совместимы с разными архитектурами приложения и разными архитектурами организации.
Старые версии подходов проектирования конечно же могут быть несовместимы с современными архитектурами, но я не могу считать, что разработчики этих подходов живут в вакууме и не пытаются в новых релизах их адаптировать к новым реалиям.
Итого собирается следующая картина:
- Применимость тех или иных подходов проектирования к каждому конкретному случаю определяется мотивацией содержащейся в этом подходе (“для чего он предназначен”), и эта мотивация достаточно легко верифицируется (хоть и далеко не всегда легко выявляется).
- Любой подход проектирования требует адаптации к архитектуре конкретной организации и конкретного приложения. Важно использовать самую современную версию дисциплины изложенной в конкретных подходах проектирования и проверять современность предлагаемых практик в условиях окружающей действительности. Более того — при необходимости заменять их на более современные (при этом оставаться в рамках дисциплины).
При этом, если мы на секунду забудем обо всем, что мы только что обсуждали и посмотрим на относительно легковесные и простые практики DevOps или SRE — их адаптация к реалиям конкретных организаций часто тоже является очень болезненным процессом. При этом достаточно часто проблемы адаптации состоят в том, что напрочь игнорируется мотивационная часть (“— Для чего нам Kubernetes? — Потому что сейчас все его используют”), а нередко при применении DevOps игнорируют и его фундаментальные понятия и принципы с закономерно плачевным результатом.
(окончание)
Методология, дисциплины, практики (часть 3)
(начало)
При осмыслении всего вышесказанного у меня возникают вопросы:
- Действительно ли вместе с переизобретением практик на базе новых технологий необходимо переизобретать и дисциплины? Почему chatops и автоматизированное создание алертов нельзя обсуждать в контексте классической дисциплины
- Что мешает использовать классические детально проработанные (но адаптированные под современность! это важно!) методы проектирования для построения практик на базе современного тулчейна и современных архитектур как организации, так и приложений?
- И, наконец, можно ли при проектировании целевого видения процессов в организации игнорировать решения принятые много лет назад? И если нет, как их встраивать процесс проектирования?
Как на это смотрите вы?
.
(начало)
При осмыслении всего вышесказанного у меня возникают вопросы:
- Действительно ли вместе с переизобретением практик на базе новых технологий необходимо переизобретать и дисциплины? Почему chatops и автоматизированное создание алертов нельзя обсуждать в контексте классической дисциплины
"Управление инцидентами", которая появилась еще задолго до появления компьютеров?- Что мешает использовать классические детально проработанные (но адаптированные под современность! это важно!) методы проектирования для построения практик на базе современного тулчейна и современных архитектур как организации, так и приложений?
- И, наконец, можно ли при проектировании целевого видения процессов в организации игнорировать решения принятые много лет назад? И если нет, как их встраивать процесс проектирования?
Как на это смотрите вы?
.
Telegram
Об DevOps и архитектуру
Методология, дисциплины, практики (часть 1)
Существует мнение, что тяжеловесные подходы проектирования (ITIL, TOGAF, ГОСТ34 и т.д.) несовместимы с быстрыми частыми релизами и изменениями. А следовательно, зачем их изучать? Это верно только отчасти.
Во-первых…
Существует мнение, что тяжеловесные подходы проектирования (ITIL, TOGAF, ГОСТ34 и т.д.) несовместимы с быстрыми частыми релизами и изменениями. А следовательно, зачем их изучать? Это верно только отчасти.
Во-первых…
❤1
5 бизнес-процессов в разработке
Меня периодически спрашивают каким образом строить инфраструктуру для небольших проектов, когда в команде еще нет компетенций админа/девопс-инженера ни у руководителя или программистов, ни в в виде выделенного человека.
Что при этом выбрать — выделенные сервера, облако или Kubernetes? Я сейчас не буду делать какие-то технологические рекомендации, но опишу на что нужно обратить внимание организационно, чтобы можно было сделать такой выбор.
При планировании развертывания любого приложения для продакшна важно всегда в том или ином виде продумывать как минимум следующие 5 бизнес-процессов / Value stream:
- процесс разработки приложений
- процесс конфигурирования приложений
- процесс настройки и конфигурирование серверов (или других сред выполнения)
- процесс настройки и конфигурирования самого процесса сборки и деплоя
- процесс настройки и конфигурирования вспомогательных сервисов (например, мониторинга, бэкапов и т.д.), сюда же я запишу базы данных, кэши, очереди и т.п.
(см рис.1)
Любая инсталляция, которая выходит за пределы ноутбука разработчика будет состоять как минимум из компонентов указанных на иллюстрации (стикеры синего и зеленого цвета).
Каждый из этих компонентов каким-то образом настраивается первоначально, в него каким-то образом регулярно вносятся изменения, ну и когда-то каждый из этих компонент скорее всего будет выведен из эксплуатации и заменен на какой-то другой. Также в том или ином виде происходит текущая поддержка каждого из этих компонентов — обеспечение работоспособности и реакция на инциденты.
(см рис.2)
Это составляющие каждого из наших 5 основных процессов, итого у нас получается не меньше 20 типовых операций или процессов, которые присутствуют в абсолютно любой современной инсталляции.
Соотвественно необходимо продумать каким именно образом это будет происходить, как будут происходить эти операции. Конечно, если мы хотим в той или иной мере сохранять контроль над нашей инсталляцией.
А в первую очередь как во все эти компоненты будут вноситься изменения, и как будет происходить текущая поддержка — т.к. эти операции и процессы ключевые для работающей системы и выполняются чаще всего.
В начале статьи я намеренно написал "бизнес-процессы / Value Streams", т.к. что именно это будет определяем мы как технический руководитель. Это могут быть классические инструкции в виде чеклиста или BPMN-диаграммы, в этом случае про них уместно говорить как о "бизнес-процессах". Это могут быть насквозь автоматизированные Software Defined Processes и в этом случае мы о них скорее всего будем говорить как о Value Stream. Часто противопоставляя DevOps и "классическое IT" имеют в виду смену именно этой парадигмы — замену "бизнес-процессов" на "Value Stream".
Ну либо мы можем полностью делегировать этот процесс некоему сотруднику (сисадмину, либо Devops-инженеру) не задумываясь о том, что в этом процессе происходит, и надеяться, что когда рано или поздно этот сотрудник уйдет, новый сотрудник на его замену сможет в этом хозяйстве разобраться. Если мы принимаем этот риск, то в этом случае строго говоря нам действительно не важно как этот сотрудник работает — копипастит ли артефакты через FTP, или же пишет портянки кода на Ansible и Terraform.
Ключевое здесь в том, что для того чтобы наш продакшн и разработка вели себя предсказуемо для нас необходимо:
- Выделить компоненты, которые участвуют в процессе разработки-поставки-эксплуатации. Один из примеров такого компонентного разбиения приведен на картинке.
- Для каждого из компонентов определиться каким образом будут в него вноситься изменения, кто за это отвечает, и сколько ответственности делегировать этим людям или скриптам.
- Следить за тем, что если у нас появляются новые компоненты, для каждого из них мы будем принимать эти же решения.
Меня периодически спрашивают каким образом строить инфраструктуру для небольших проектов, когда в команде еще нет компетенций админа/девопс-инженера ни у руководителя или программистов, ни в в виде выделенного человека.
Что при этом выбрать — выделенные сервера, облако или Kubernetes? Я сейчас не буду делать какие-то технологические рекомендации, но опишу на что нужно обратить внимание организационно, чтобы можно было сделать такой выбор.
При планировании развертывания любого приложения для продакшна важно всегда в том или ином виде продумывать как минимум следующие 5 бизнес-процессов / Value stream:
- процесс разработки приложений
- процесс конфигурирования приложений
- процесс настройки и конфигурирование серверов (или других сред выполнения)
- процесс настройки и конфигурирования самого процесса сборки и деплоя
- процесс настройки и конфигурирования вспомогательных сервисов (например, мониторинга, бэкапов и т.д.), сюда же я запишу базы данных, кэши, очереди и т.п.
(см рис.1)
Любая инсталляция, которая выходит за пределы ноутбука разработчика будет состоять как минимум из компонентов указанных на иллюстрации (стикеры синего и зеленого цвета).
Каждый из этих компонентов каким-то образом настраивается первоначально, в него каким-то образом регулярно вносятся изменения, ну и когда-то каждый из этих компонент скорее всего будет выведен из эксплуатации и заменен на какой-то другой. Также в том или ином виде происходит текущая поддержка каждого из этих компонентов — обеспечение работоспособности и реакция на инциденты.
(см рис.2)
Это составляющие каждого из наших 5 основных процессов, итого у нас получается не меньше 20 типовых операций или процессов, которые присутствуют в абсолютно любой современной инсталляции.
Соотвественно необходимо продумать каким именно образом это будет происходить, как будут происходить эти операции. Конечно, если мы хотим в той или иной мере сохранять контроль над нашей инсталляцией.
А в первую очередь как во все эти компоненты будут вноситься изменения, и как будет происходить текущая поддержка — т.к. эти операции и процессы ключевые для работающей системы и выполняются чаще всего.
В начале статьи я намеренно написал "бизнес-процессы / Value Streams", т.к. что именно это будет определяем мы как технический руководитель. Это могут быть классические инструкции в виде чеклиста или BPMN-диаграммы, в этом случае про них уместно говорить как о "бизнес-процессах". Это могут быть насквозь автоматизированные Software Defined Processes и в этом случае мы о них скорее всего будем говорить как о Value Stream. Часто противопоставляя DevOps и "классическое IT" имеют в виду смену именно этой парадигмы — замену "бизнес-процессов" на "Value Stream".
Ну либо мы можем полностью делегировать этот процесс некоему сотруднику (сисадмину, либо Devops-инженеру) не задумываясь о том, что в этом процессе происходит, и надеяться, что когда рано или поздно этот сотрудник уйдет, новый сотрудник на его замену сможет в этом хозяйстве разобраться. Если мы принимаем этот риск, то в этом случае строго говоря нам действительно не важно как этот сотрудник работает — копипастит ли артефакты через FTP, или же пишет портянки кода на Ansible и Terraform.
Ключевое здесь в том, что для того чтобы наш продакшн и разработка вели себя предсказуемо для нас необходимо:
- Выделить компоненты, которые участвуют в процессе разработки-поставки-эксплуатации. Один из примеров такого компонентного разбиения приведен на картинке.
- Для каждого из компонентов определиться каким образом будут в него вноситься изменения, кто за это отвечает, и сколько ответственности делегировать этим людям или скриптам.
- Следить за тем, что если у нас появляются новые компоненты, для каждого из них мы будем принимать эти же решения.
👍1
Для сложных инсталляций, естественно, компонентов может быть больше. Например из "Конфигурации приложения" зачастую можно выделить "Секреты", "Endpoints" и "Функциональную конфигурацию" (относящуюся к логике приложения). Или "Среда выполнения" может состоять как из "Виртуальных серверов", так и "Оркестратора".
Для каждого из таких компонентов них необходимо тоже прорабатывать соответствующий процесс внесения изменения. Как мы уже говорили выше, в зависимости от того какой дорогой мы выбрали идти это могут быть как развесистые инструкции, так и скрипты автоматизации. Либо вообще у нас будут отдельные сервисы — они будут управлять этими компонентами и возьмут на себя всю сложность. К примеру, если держать секреты в Vault весь процесс внесения изменений в секреты будет состоять из минимум двух шагов:
- Меняем секрет через UI Vault
- Наши скрипты автоматизации раскатывают эти секреты по всем сервисам.
Но тут встает интересный вопрос: что делать с внесением изменений в эту самую автоматизацию? Ответ простой — автоматизация это по сути код, мы применяем подход Infrastructure as Code. А точнее, у нас появляется Infrastructure as Code как процесс разработки, и это не то же самое, что Infrastructure as Scripts как очень часто бывает. Соответственно, для упрощения планирования и работы мы начинаем применять классические практики разработки: прорабатываем компонентную модель кода, описывающего нашу инфраструктуру, прорабатываем форматы и последовательности обмена сообщениями в нашей инфре (например, какой скрипт какие хуки дергает и что передает), строим релизный процесс для инфраструктурного кода, прорабатываем бэклог фич — одним словом, работаем с инфраструктурой так, как будто это еще один компонент приложения.
И наконец мы приходим к главному вопросу: что со всем этим знанием делать?
Если у вас маленькая инсталляция и небольшая частота изменений в инфраструктуре:
- прописать упомянутые 5 процессов в том виде, в каком они по факту используются. Это может быть одна строчка "собираем всю команду и решаем как и что будем делать", и это нормально
- подумать не пропустили ли чего, и можно ли эти процессы улучшить
- прикинуть сколько мы сможем жить с такими процессами и когда начнем упираться в их эффективность
Если у вас инсталляция большая и изменений в инфраструктуре много:
- развитие инфраструктурных компонентов осуществлять через практики разработки софта (классические "описание фичи -> бэклог -> разработка -> тестирование -> релиз -> стейджинг -> продакшн")
- выделить компоненты данных в инфраструктуре и прописать процесс работы с ними (это могут быть, например, конфигурация, секреты и т.д.). Возможно в результате этого у вас появятся задачи в бэклог инфраструктурной разработки
- выделить оставшиеся компоненты и процессы, для которых мы не применяем IaC (например "восстановление из бэкапа", или "реакция на инцидент") и прописать процесс работы с ними
Для каждого из таких компонентов них необходимо тоже прорабатывать соответствующий процесс внесения изменения. Как мы уже говорили выше, в зависимости от того какой дорогой мы выбрали идти это могут быть как развесистые инструкции, так и скрипты автоматизации. Либо вообще у нас будут отдельные сервисы — они будут управлять этими компонентами и возьмут на себя всю сложность. К примеру, если держать секреты в Vault весь процесс внесения изменений в секреты будет состоять из минимум двух шагов:
- Меняем секрет через UI Vault
- Наши скрипты автоматизации раскатывают эти секреты по всем сервисам.
Но тут встает интересный вопрос: что делать с внесением изменений в эту самую автоматизацию? Ответ простой — автоматизация это по сути код, мы применяем подход Infrastructure as Code. А точнее, у нас появляется Infrastructure as Code как процесс разработки, и это не то же самое, что Infrastructure as Scripts как очень часто бывает. Соответственно, для упрощения планирования и работы мы начинаем применять классические практики разработки: прорабатываем компонентную модель кода, описывающего нашу инфраструктуру, прорабатываем форматы и последовательности обмена сообщениями в нашей инфре (например, какой скрипт какие хуки дергает и что передает), строим релизный процесс для инфраструктурного кода, прорабатываем бэклог фич — одним словом, работаем с инфраструктурой так, как будто это еще один компонент приложения.
И наконец мы приходим к главному вопросу: что со всем этим знанием делать?
Если у вас маленькая инсталляция и небольшая частота изменений в инфраструктуре:
- прописать упомянутые 5 процессов в том виде, в каком они по факту используются. Это может быть одна строчка "собираем всю команду и решаем как и что будем делать", и это нормально
- подумать не пропустили ли чего, и можно ли эти процессы улучшить
- прикинуть сколько мы сможем жить с такими процессами и когда начнем упираться в их эффективность
Если у вас инсталляция большая и изменений в инфраструктуре много:
- развитие инфраструктурных компонентов осуществлять через практики разработки софта (классические "описание фичи -> бэклог -> разработка -> тестирование -> релиз -> стейджинг -> продакшн")
- выделить компоненты данных в инфраструктуре и прописать процесс работы с ними (это могут быть, например, конфигурация, секреты и т.д.). Возможно в результате этого у вас появятся задачи в бэклог инфраструктурной разработки
- выделить оставшиеся компоненты и процессы, для которых мы не применяем IaC (например "восстановление из бэкапа", или "реакция на инцидент") и прописать процесс работы с ними
👍1
Есть ли какие-то типовые процессы, которые важно реализовать, но которые я здесь не учел?
Большие статьи в телеге читать и писать неудобно, особенно если в статье картинки, поэтому скорее всего на большие статьи в следующий раз буду давать только ссылки на другие площадки.
Сейчас кросспост этой статьи здесь:
- https://habr.com/ru/post/708930/
- https://timurb.ru/kb/5-devops-processes/
- https://timurbatyrshin.medium.com/ef3f97406d99
Сейчас кросспост этой статьи здесь:
- https://habr.com/ru/post/708930/
- https://timurb.ru/kb/5-devops-processes/
- https://timurbatyrshin.medium.com/ef3f97406d99
Хабр
5 бизнес-процессов в разработке
Меня периодически спрашивают каким образом строить инфраструктуру для небольших проектов, когда в команде еще нет компетенций админа/девопс-инженера ни у руководителя или программистов, ни в в виде...
Платформенный подход и трансакционные издержки
В начале 20 века английский экономист Рональд Коуз изучал причину появления фирм на свободном рынке, и в своей статье Природа фирм он пришел к следующему:
- Трансакционные издержки (расходы на поиск и взаимодействие контрагентов и их контрактацию) внутри фирмы ниже, чем трансакционные издержки на рынке, и поэтому найм может оказаться дешевле чем аутсорсинг. Контракт с сотрудником обслуживать дешевле, чем контракт с внешней организацией (даже если это рамочный контракт).
- В противном случая аутсорсинг дешевле, т.к. внешний подрядчик оптимизирует работу своей компании для того, чтобы стать более конкурентоспособным, и поэтому будет более эффективным чем внутренний сотрудник.
- Одновременно с этим при росте компании растут издержки на управление самой компанией, увеличивается количество ошибок управления и т.д.
- Размер компании определяется оптимумом между расходами на трансакционные издержки и расходами на издержки управления.
Подробнее предлагаю прочитать в википедии, либо в первоисточнике — я мог недостаточно четко пересказать основные мысли оттуда.
В этом контексте кажется можно рассматривать экосистемы и компании состоящие из самоорганизующихся команд как промежуточное звено между фирмами по Коузу и свободным рынком:
- Трансакционные издержки между командами внутри компании ниже, чем трансакционные издержки между компанией и внешним рынком
- В то же самое время расходы на управление такой компанией ниже, чем для “плановой экономики” с централизованным управлением
Почему же далеко не все идут в эту сторону несмотря на модный тренд? Для этого должна быть другая архитектура постановки задач и контроля, да и по большому счету вся архитектура взаимодействия с сотрудниками и подразделениями.
Команды должны быть либо максимально независимыми, вертикальными и достаточно узкими (Платформенный подход):
- с одной стороны для оптимизации команды вокруг предоставляемого сервиса (качества и стоимости для потребителя, в т.ч. трансакционной стоимости)
- с другой — для снижения управленческих издержек внутри самой этой команды
Либо команды должны быть горизонтальными, с максимально полностью делегированной ответственностью за сквозной Value Stream — для оптимизации команды вокруг пропорции “доставляемая до клиента ценность к running cost” этого стрима. При этом, чтобы не было роста управленческих издержек внутри команды вся непрофильная активность этого стрима будет аутсорситься на внешних вендоров (по отношению к команде, не к компании!), т.е. на платформенные и развивающие (enabling) команды.
Интересной особенностью здесь становится то, что мы можем в число поставщиков без особых проблем вносить и внешних вендоров если они будут соответствовать некоторым критериям, которым соответствуют все наши внутренние вендоры (платформенные команды). Подход “Private cloud” во многом как раз призван решить именно эту задачу — упростить онбординг партнеров и внешних вендоров внутрь ландшафта компании. На всех крупных заводах немалые площади выделены именно для компаний-партнеров для обеспечения локальности производства.
Чего не хватает в этой картине? Финансирования, т.е. циклов обратной связи между платформенной командой и “внутренним рынком”, и горизонтальной командой (но не компанией целиком!) и “внешним рынком”. Какие-то зачатки такой обратной связи предлагаются в практиках “error budget” и “security budget” и абстрактных отсылках к “продуктовому подходу” без конкретики, но их явно недостаточно.
Встречались ли кому-то еще какие-то материалы на эту тему?
В начале 20 века английский экономист Рональд Коуз изучал причину появления фирм на свободном рынке, и в своей статье Природа фирм он пришел к следующему:
- Трансакционные издержки (расходы на поиск и взаимодействие контрагентов и их контрактацию) внутри фирмы ниже, чем трансакционные издержки на рынке, и поэтому найм может оказаться дешевле чем аутсорсинг. Контракт с сотрудником обслуживать дешевле, чем контракт с внешней организацией (даже если это рамочный контракт).
- В противном случая аутсорсинг дешевле, т.к. внешний подрядчик оптимизирует работу своей компании для того, чтобы стать более конкурентоспособным, и поэтому будет более эффективным чем внутренний сотрудник.
- Одновременно с этим при росте компании растут издержки на управление самой компанией, увеличивается количество ошибок управления и т.д.
- Размер компании определяется оптимумом между расходами на трансакционные издержки и расходами на издержки управления.
Подробнее предлагаю прочитать в википедии, либо в первоисточнике — я мог недостаточно четко пересказать основные мысли оттуда.
В этом контексте кажется можно рассматривать экосистемы и компании состоящие из самоорганизующихся команд как промежуточное звено между фирмами по Коузу и свободным рынком:
- Трансакционные издержки между командами внутри компании ниже, чем трансакционные издержки между компанией и внешним рынком
- В то же самое время расходы на управление такой компанией ниже, чем для “плановой экономики” с централизованным управлением
Почему же далеко не все идут в эту сторону несмотря на модный тренд? Для этого должна быть другая архитектура постановки задач и контроля, да и по большому счету вся архитектура взаимодействия с сотрудниками и подразделениями.
Команды должны быть либо максимально независимыми, вертикальными и достаточно узкими (Платформенный подход):
- с одной стороны для оптимизации команды вокруг предоставляемого сервиса (качества и стоимости для потребителя, в т.ч. трансакционной стоимости)
- с другой — для снижения управленческих издержек внутри самой этой команды
Либо команды должны быть горизонтальными, с максимально полностью делегированной ответственностью за сквозной Value Stream — для оптимизации команды вокруг пропорции “доставляемая до клиента ценность к running cost” этого стрима. При этом, чтобы не было роста управленческих издержек внутри команды вся непрофильная активность этого стрима будет аутсорситься на внешних вендоров (по отношению к команде, не к компании!), т.е. на платформенные и развивающие (enabling) команды.
Интересной особенностью здесь становится то, что мы можем в число поставщиков без особых проблем вносить и внешних вендоров если они будут соответствовать некоторым критериям, которым соответствуют все наши внутренние вендоры (платформенные команды). Подход “Private cloud” во многом как раз призван решить именно эту задачу — упростить онбординг партнеров и внешних вендоров внутрь ландшафта компании. На всех крупных заводах немалые площади выделены именно для компаний-партнеров для обеспечения локальности производства.
Чего не хватает в этой картине? Финансирования, т.е. циклов обратной связи между платформенной командой и “внутренним рынком”, и горизонтальной командой (но не компанией целиком!) и “внешним рынком”. Какие-то зачатки такой обратной связи предлагаются в практиках “error budget” и “security budget” и абстрактных отсылках к “продуктовому подходу” без конкретики, но их явно недостаточно.
Встречались ли кому-то еще какие-то материалы на эту тему?
Об формальные и неформальные нотации
Если сравнивать "просто стикеры" в миро и Archimate, то Archimate удобнее тем, что мы в нем получаем "встроенную" валидацию типов, которую в случае стикеров приходится выполнять более явно.
Скорее всего это применимо и для других формальных языков описаний (BPMN, UML и т.д.) в сравнении со "свободными" рассуждениями.
С другой стороны, если понимания типов у человека нет все нотации мгновенно становятся бессмысленными.
А для коммуникации нужны именно типы, пространство понятий, а не нотация.
Таким образом одна из важнейших задач в любой архитектуре это установление коммуникации — выбор или создание языка на котором будут разговаривать разные представители стейкхолдеров.
Кажется, здесь появляется интересный момент в том, что в результате этого немалую часть архитектурных артефактов стейкхолдеры смогут создать самостоятельно без участия собственно архитектора.
Или это не так?
Если сравнивать "просто стикеры" в миро и Archimate, то Archimate удобнее тем, что мы в нем получаем "встроенную" валидацию типов, которую в случае стикеров приходится выполнять более явно.
Скорее всего это применимо и для других формальных языков описаний (BPMN, UML и т.д.) в сравнении со "свободными" рассуждениями.
С другой стороны, если понимания типов у человека нет все нотации мгновенно становятся бессмысленными.
А для коммуникации нужны именно типы, пространство понятий, а не нотация.
Таким образом одна из важнейших задач в любой архитектуре это установление коммуникации — выбор или создание языка на котором будут разговаривать разные представители стейкхолдеров.
Кажется, здесь появляется интересный момент в том, что в результате этого немалую часть архитектурных артефактов стейкхолдеры смогут создать самостоятельно без участия собственно архитектора.
Или это не так?
В понедельник на конференции DevOpsConf буду рассказывать про применение практик из разработки в подходе Infrastructure as Code
Forwarded from DevOpsConf Channel
⠀
📋 https://bit.ly/3ka2Vck
⠀
За более чем 10 лет DevOps было сформировано много практик, которые помогают ускорять разработку.
Обычно говорят про CI/CD и контейнеры, но это всего лишь одна сторона вопроса.
Другая важная составляющая — изменение модульности и интеграционных паттернов в самих приложениях.
Третья составляющая — описание инфраструктурных компонентов в виде кода.
⠀
Встает интересный вопрос — прошли ли практики написания инфраструктурного кода такую же трансформацию разработки, какая произошла в разработке?
Или все по-прежнему пишут инфраструктурные монолиты, которые запускаются, только если всей командой взяться за руки?
Кто на самом деле являлся драйвером DevOps-трансформации?
⠀
Поговорим об этом на докладе.
⠀
Ждем вас 13 и 14 марта на DevOpsConf 2023 в Москве 🖐
⠀
Please open Telegram to view this post
VIEW IN TELEGRAM
❤1🔥1
Написал новую статью "Об Модифицирующие Команды".
Как обычно, кросспост в несколько мест:
- https://habr.com/ru/post/723410/
- https://timurbatyrshin.medium.com/41db803e1875
- https://timurb.ru/kb/ob-enabling-team/
Как обычно, кросспост в несколько мест:
- https://habr.com/ru/post/723410/
- https://timurbatyrshin.medium.com/41db803e1875
- https://timurb.ru/kb/ob-enabling-team/
Хабр
О модифицирующих командах
На волне нынешнего хайпа про инфраструктурные платформы, наверное каждый слышал о книге Team Topologies . Я ее сейчас пересказывать не буду, поэтому если какие-то термины или рассуждения ниже вам...
❤5
Написал новую статью "Ситуационная инженерия метода".
Длинные посты в телеграм не влезают, поэтому как обычно, только кросспост в несколько мест:
- https://timurbatyrshin.medium.com/1b9f246a1cd9
- https://timurb.ru/kb/situational-method-engineering/
Комментарии можно оставлять как здесь, так и по любой из ссылок.
Длинные посты в телеграм не влезают, поэтому как обычно, только кросспост в несколько мест:
- https://timurbatyrshin.medium.com/1b9f246a1cd9
- https://timurb.ru/kb/situational-method-engineering/
Комментарии можно оставлять как здесь, так и по любой из ссылок.
Medium
Ситуационная инженерия метода
При старте нового проекта (или авральном подключении к существующему) руководителю нужно выполнить большое количество шагов планирования и…
👍2👎1
Друзья, для меня очень ценна обратная связь. Если для вас что-то кажется спорным, прошу: пишите текстом.
Можно личным сообщением (@TimurBatyrshin) если не хотите выносить в общий чат.
Можно личным сообщением (@TimurBatyrshin) если не хотите выносить в общий чат.
Об разницу между Waterfall и Agile
(из неопубликованных архивов)
Некоторое время назад нашел простое и потрясающее объяснение того, когда нужно выбирать waterfall, когда scrum, а когда еще что-то другое.
Цитата (отсюда https://sebokwiki.org/wiki/System_Lifecycle_Models):
There are a large number of potential life cycle process models. They fall into three major categories:
1. primarily pre-specified and sequential processes (e.g. the single-step waterfall model)
2. primarily evolutionary and concurrent processes (e.g. lean development, the agile unified process, and various forms of the vee and spiral models)
3. primarily interpersonal and emergent processes (e.g. agile development, scrum, extreme programming (XP), the dynamic system development method, and innovation-based processes)
Перевожу на простой человеческий язык:
1. Если вам нужно строить что-то ровно один раз, без параллелизации работ, или доработок вообще, или же нужен жесткий процесс с контролем выходов на каждой стадии — waterfall ваш выбор.
2. Если вам нужно разрабатывать несколько фич параллельно, или процесс будет дорабатываться (но сам процесс есть) — выбирайте второй вариант.
3. Если вы выясните процесс работы по ходу в процессе личного взаимодействия — выбирайте третий вариант.
Казалось бы, где тут откровения? Но давайте представим, какие последствия будут при выборе каждого из вариантов.
1. Waterfall: Пока пилим фичи баги исправлять не будем (и наоборот). Если потребуется в процессе внести какие-то изменения это будет очень тяжело.
2. Эволюционные/параллельные процессы: Нужно прописать и как-то контролировать процесс работы, и как дорабатывать его самого. Нужно определить как нам не мешать друг другу при параллельной разработке.
3. Межличностные и эмерджентные процессы: Ребята у нас умные, как-нибудь сами обо всем договорятся. В том числе и с заказчиками и внешними стейкхолдерами (спонсор, регуляторы, команды-смежники, внешние провайдеры, в т.ч. коммерческие и т.д.).
Какой из вариантов лучше всего подходит к вашему проекту?
(из неопубликованных архивов)
Некоторое время назад нашел простое и потрясающее объяснение того, когда нужно выбирать waterfall, когда scrum, а когда еще что-то другое.
Цитата (отсюда https://sebokwiki.org/wiki/System_Lifecycle_Models):
There are a large number of potential life cycle process models. They fall into three major categories:
1. primarily pre-specified and sequential processes (e.g. the single-step waterfall model)
2. primarily evolutionary and concurrent processes (e.g. lean development, the agile unified process, and various forms of the vee and spiral models)
3. primarily interpersonal and emergent processes (e.g. agile development, scrum, extreme programming (XP), the dynamic system development method, and innovation-based processes)
Перевожу на простой человеческий язык:
1. Если вам нужно строить что-то ровно один раз, без параллелизации работ, или доработок вообще, или же нужен жесткий процесс с контролем выходов на каждой стадии — waterfall ваш выбор.
2. Если вам нужно разрабатывать несколько фич параллельно, или процесс будет дорабатываться (но сам процесс есть) — выбирайте второй вариант.
3. Если вы выясните процесс работы по ходу в процессе личного взаимодействия — выбирайте третий вариант.
Казалось бы, где тут откровения? Но давайте представим, какие последствия будут при выборе каждого из вариантов.
1. Waterfall: Пока пилим фичи баги исправлять не будем (и наоборот). Если потребуется в процессе внести какие-то изменения это будет очень тяжело.
2. Эволюционные/параллельные процессы: Нужно прописать и как-то контролировать процесс работы, и как дорабатывать его самого. Нужно определить как нам не мешать друг другу при параллельной разработке.
3. Межличностные и эмерджентные процессы: Ребята у нас умные, как-нибудь сами обо всем договорятся. В том числе и с заказчиками и внешними стейкхолдерами (спонсор, регуляторы, команды-смежники, внешние провайдеры, в т.ч. коммерческие и т.д.).
Какой из вариантов лучше всего подходит к вашему проекту?