
сижу в отпуске , пью смузи и читаю " ИИ скандалы, интриги, расследования" 🍿
Оказывается это все вранье😱 чтобы набрать классы 🤨
https://x.com/digital_ninjaaa/status/1760564832216981684?s=20
Оказывается это все вранье
https://x.com/digital_ninjaaa/status/1760564832216981684?s=20
Please open Telegram to view this post
VIEW IN TELEGRAM
X (formerly Twitter)
Digital Ниндзя (@digital_ninjaaa) on X
Помните тред про то, как чувак познакомился с 5239 девушками через Tinder? Он набрал 8.3 миллиона просмотров. Этот тред — выдумка.
У автора, Александра Жадана, Нейро-Казановы, не было технического решения. Я провёл своё расследование и поговорил с ним.
…
У автора, Александра Жадана, Нейро-Казановы, не было технического решения. Я провёл своё расследование и поговорил с ним.
…
😁9👍6🍌2
Токенизируй меня полностью.
Наверняка, вы уже посмотрели замечательное видео от Карпаты про токенизацию в языковых моделях. Если нет, бегом смотреть.
Далее, советую ознакомиться с еще одной мерой описания информации на токен - фертильность. Понятие старое, придуманное еще IBM в далекие 90-е, в рамках машинного перевода. Основная интуиция, лежащая в основе манипуляций с фертильностью, заключалась в том, что одно понятие может быть выражено на английском языке множеством непересекающихся слов. То же справедливо, конечно и для ру языка.
Вопрос:
В языковых моделях мы можем рассматривать число сабвордов/токенов на одно реальное слово. Тогда для словаря только из лексем (реальных слов) фертильность будет равна 1, тк один токен = 1 реальное слово. Но у слов есть словоформы зависящие от числа рода и падежа и тп. Так словарь будет разбухать от сингл лексем, будет пухнуть эмб матрица -> расти модель, время на обучение и тп.
Эффективнее разумеется переходить к сабвордам, тк из их комбинаций можно собрать много слов. Таким образом, вся эта токенизация при помощи bpe/bbpe/wpiece/spiece и др. предстает перед нами с другой стороны. И как мы оцениваем нормальность LLM через перплексию, так мы можем оценить эффективность словаря добавив еще и фертильность. Для примера, в данной работе, авторы при создании многоязычного словаря и токенизатора к нему, проводят непрямое расширение словаря. Для этого они заменяют низкочастотные лексемы одного языка на соответствующие частотные другого, устремляя фертильность расширенного словаря к изначальному монолингвальному (тут я еще сам осознаю как это работает, ибо не лингвист).
Что дальше?
А дальше, можно потыкать вот такую тулзу на HF для демо работы токенизации: https://huggingface.co/spaces/Xenova/the-tokenizer-playground
Посмотреть обзор multiling-bert словаря на предмет покрытия токенов, в тч с расчетом фертильности:
https://juditacs.github.io/2019/02/19/bert-tokenization-stats.html
Почитать про фертильность "мохнатого" года статью.
Наверняка, вы уже посмотрели замечательное видео от Карпаты про токенизацию в языковых моделях. Если нет, бегом смотреть.
Далее, советую ознакомиться с еще одной мерой описания информации на токен - фертильность. Понятие старое, придуманное еще IBM в далекие 90-е, в рамках машинного перевода. Основная интуиция, лежащая в основе манипуляций с фертильностью, заключалась в том, что одно понятие может быть выражено на английском языке множеством непересекающихся слов. То же справедливо, конечно и для ру языка.
Вопрос:
Зачем нужна фертильность? Ответ: Для оценки эффективности словаря. В языковых моделях мы можем рассматривать число сабвордов/токенов на одно реальное слово. Тогда для словаря только из лексем (реальных слов) фертильность будет равна 1, тк один токен = 1 реальное слово. Но у слов есть словоформы зависящие от числа рода и падежа и тп. Так словарь будет разбухать от сингл лексем, будет пухнуть эмб матрица -> расти модель, время на обучение и тп.
Эффективнее разумеется переходить к сабвордам, тк из их комбинаций можно собрать много слов. Таким образом, вся эта токенизация при помощи bpe/bbpe/wpiece/spiece и др. предстает перед нами с другой стороны. И как мы оцениваем нормальность LLM через перплексию, так мы можем оценить эффективность словаря добавив еще и фертильность. Для примера, в данной работе, авторы при создании многоязычного словаря и токенизатора к нему, проводят непрямое расширение словаря. Для этого они заменяют низкочастотные лексемы одного языка на соответствующие частотные другого, устремляя фертильность расширенного словаря к изначальному монолингвальному (тут я еще сам осознаю как это работает, ибо не лингвист).
Что дальше?
А дальше, можно потыкать вот такую тулзу на HF для демо работы токенизации: https://huggingface.co/spaces/Xenova/the-tokenizer-playground
Посмотреть обзор multiling-bert словаря на предмет покрытия токенов, в тч с расчетом фертильности:
https://juditacs.github.io/2019/02/19/bert-tokenization-stats.html
Почитать про фертильность "мохнатого" года статью.
huggingface.co
The Tokenizer Playground - a Hugging Face Space by Xenova
Experiment with and compare different tokenizers
❤15🔥3
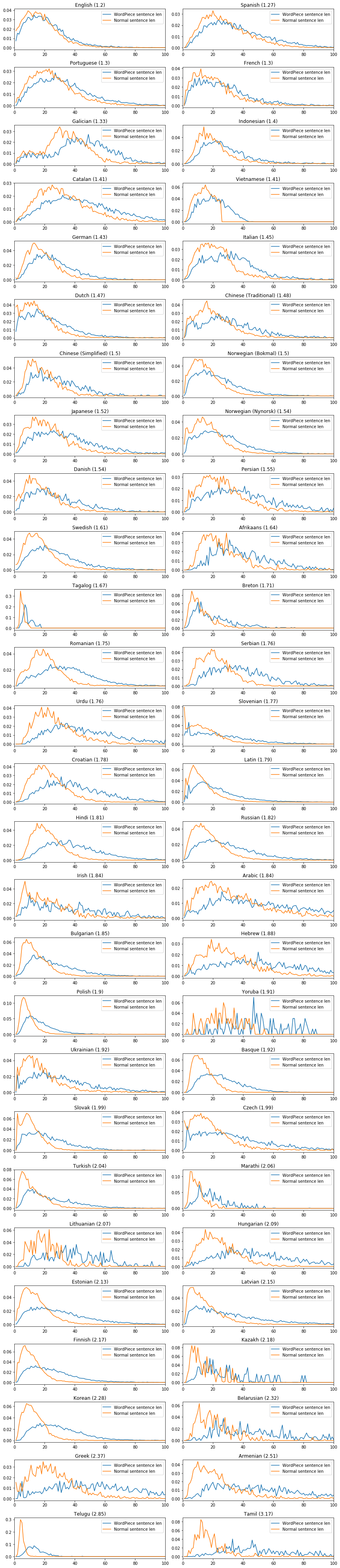
много картинок про фертильность
multiling-bert словаря для разных языков.
Фертильность указана над графиком.
https://juditacs.github.io/assets/bert_vocab/bert_sent_len_full_fertility_sorted.png
multiling-bert словаря для разных языков.
Фертильность указана над графиком.
https://juditacs.github.io/assets/bert_vocab/bert_sent_len_full_fertility_sorted.png
{kind=link}
❤5
MarksRemarks
Достаточно интересное с точки зрения денег соревнование на Кагле – Home Credit - Credit Risk Model Stability TLDR: Задача – предсказать кредитный дефолт Метрика – сложная на основе gini, falling rate, residuals Денег – 105к$ Данные – очень много табличек…
Говорят, стопнули сореву, косяк с метрикой
https://www.kaggle.com/competitions/home-credit-credit-risk-model-stability/discussion/476867
https://www.kaggle.com/competitions/home-credit-credit-risk-model-stability/discussion/476867
Kaggle
Home Credit - Credit Risk Model Stability
Create a model measured against feature stability over time
🤡14😁6
Балалайка, березка, Matryoshka.
Выпустили концептуальный гайд по эмбам матрехи на hf. Красивые картиносы матрех и схемы, концепты теории и примеры на sentence-transformers.
Ну че тут рассказывать? Все просто берем embs и вдоль dim нарезаем по нарастающей, сводим саб эмбы и эмбы в конвеере metric learning на нужной датке в NLI, STS или qa задачках. Хочешь сводишь все на одном и том же, хочешь каждому эмбу из нарезки сообщаешь свою таску.
В чем польза?
1. Меньше индекс - на поверхности.
2. Возможность строить быстрые каскадные пайпы ранжирования. Преранк, например, на full index с маленьким эмбом (так быстрее), далее сложные примеры на more big эмбах, итоговый реранк в топ1 на жирнючем.
Код в блоге присутствует. Поэтому дерзайте.
Выпустили концептуальный гайд по эмбам матрехи на hf. Красивые картиносы матрех и схемы, концепты теории и примеры на sentence-transformers.
Ну че тут рассказывать? Все просто берем embs и вдоль dim нарезаем по нарастающей, сводим саб эмбы и эмбы в конвеере metric learning на нужной датке в NLI, STS или qa задачках. Хочешь сводишь все на одном и том же, хочешь каждому эмбу из нарезки сообщаешь свою таску.
В чем польза?
1. Меньше индекс - на поверхности.
2. Возможность строить быстрые каскадные пайпы ранжирования. Преранк, например, на full index с маленьким эмбом (так быстрее), далее сложные примеры на more big эмбах, итоговый реранк в топ1 на жирнючем.
Код в блоге присутствует. Поэтому дерзайте.
huggingface.co
🪆 Introduction to Matryoshka Embedding Models
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
👍18🔥2🦄2❤1
Dealer.AI
Photo
Telegram
gonzo-обзоры ML статей
Мистраль выкатил свою большую модель Mistral Large, доступна на La Plateforme и Azure.
32k контекст, мультиязычная, умеет function calling.
Также выкатили оптимизированную Mistral Small, которая лучше Mixtral 8x7B (https://t.me/gonzo_ML/2162).
https:/…
32k контекст, мультиязычная, умеет function calling.
Также выкатили оптимизированную Mistral Small, которая лучше Mixtral 8x7B (https://t.me/gonzo_ML/2162).
https:/…
👍4
Forwarded from AbstractDL
Do Large Language Models Latently Perform Multi-Hop Reasoning? (by Google)
Авторы обнаружили, что если вопрос сформулирован неявно, то LLM уже во время его чтения "пытаются" подставить промежуточный шаг рассуждений в латентном пространстве. Например, для эмбеддингов последних токенов этого вопроса
растут логиты, соответствующие слову "Стамбул".
Выходит, что на промежуточных слоях происходит multi-hop reasoning. Пока авторы нашли подтверждение этому максимум до 2 шагов рассуждений, причём качество первого шага растёт по мере увеличения модели, а вот второй шаг размазывается по всем слоям и почему-то не сильно зависит от размеров LLM.
Статья
Авторы обнаружили, что если вопрос сформулирован неявно, то LLM уже во время его чтения "пытаются" подставить промежуточный шаг рассуждений в латентном пространстве. Например, для эмбеддингов последних токенов этого вопроса
Сколько людей живут в крупнейшем городе Европы?
растут логиты, соответствующие слову "Стамбул".
Выходит, что на промежуточных слоях происходит multi-hop reasoning. Пока авторы нашли подтверждение этому максимум до 2 шагов рассуждений, причём качество первого шага растёт по мере увеличения модели, а вот второй шаг размазывается по всем слоям и почему-то не сильно зависит от размеров LLM.
Статья
👍12🔥7❤2🤔1
Forwarded from Сергей Марков: машинное обучение, искусство и шитпостинг
Генеративные модели достигли в программировании уровня сеньоров
😁62
Сергей Марков: машинное обучение, искусство и шитпостинг
Генеративные модели достигли в программировании уровня сеньоров
Добавлю комментарии источника:
"зелёное написал человек, а Copilot предлагает продолжение в виде серого текста".
Вот так еще веселее)
Надеюсь там нет кода: "не запускай - убьет" или "я бы не лез сюда, ты еще молодой ... ".
"зелёное написал человек, а Copilot предлагает продолжение в виде серого текста".
Вот так еще веселее)
Надеюсь там нет кода: "не запускай - убьет" или "я бы не лез сюда, ты еще молодой ... ".
😁4
Forwarded from Complete AI (Andrey Kuznetsov)
⚡⚡⚡Вот и статья про Sora пожаловала от OpenAI
(А точнее от Lehigh University и Microsoft Research)
Сделать разбор статьи о том, что внутри?
PDF
@complete_ai
(А точнее от Lehigh University и Microsoft Research)
Сделать разбор статьи о том, что внутри?
@complete_ai
💯53👍4🥴1
Complete AI
⚡⚡⚡Вот и статья про Sora пожаловала от OpenAI (А точнее от Lehigh University и Microsoft Research) Сделать разбор статьи о том, что внутри? PDF @complete_ai
Ну че, почитали одни фантазии, читаем другие
https://habr.com/ru/articles/794566/
p. s. Кста подписчики на пост выше сделали норм пояснение , что это чисто преломление одного ума чела из microsoft.
https://habr.com/ru/articles/794566/
p. s. Кста подписчики на пост выше сделали норм пояснение , что это чисто преломление одного ума чела из microsoft.
Хабр
Настоящее предназначение OpenAI SORA: как и зачем симулировать «Матрицу» для ChatGPT
Ну что, уже успели прочитать восхищения небывалым качеством видео от нейросетки SORA у всех блогеров и новостных изданий? А теперь мы вам расскажем то, о чем не написал никто: чего на самом деле...
🔥9😁3❤🔥1
Последний день этого отпуска. Читал Макиавелли. Принцип лисы и льва: "лиса обойдет ловушки, а лев даст бой, если нужно".
А я блин пока медвед с балалайкой.
А кто вы?
А я блин пока медвед с балалайкой.
А кто вы?
😁18❤1👎1
Восстанови промт, если сможешь.
Новое соревнование на kaggle:
LLM Prompt Recovery | Kaggle
По уже новой традиции соревок с LLM (к примеру LLM detect):
- Трейна неть (ходите генерите сами)🤨
- Тест 1400 семплов, но мы его вам не дадим, у вас докУментов нету🤣
Из плюсов понятна моделька, из которой все это безобразие* идет: Gemma2b или все же 7/9b?😀
Не ясны параметры генерации (врубаем брутфорс перебор).
Че там наделали с ней? Взяли исходный промпт кожАных, переписали его с Gemma, далее получили по этому промпту конечную генерацию. Воть, далее извольте определить, измененный промпт из теста и генерация совместны или нет.
Метрика косинус между векторным представлением промпта вашего решения и верным ответом. Эмбы получают с помощью sentence-t5 модели.
Подстава в том, что у нас нет опорных затравок для переписывания промпта с Gemma. Следовательно, придется выдумывать самому (трансферить стиль на 1 данном примере с LLM я как-то не вижу смысла).
* gemma в последнее время = безобразие ;)
Новое соревнование на kaggle:
LLM Prompt Recovery | Kaggle
По уже новой традиции соревок с LLM (к примеру LLM detect):
- Трейна неть (ходите генерите сами)
- Тест 1400 семплов, но мы его вам не дадим, у вас докУментов нету
Из плюсов понятна моделька, из которой все это безобразие* идет: Gemma2b или все же 7/9b?
Не ясны параметры генерации (врубаем брутфорс перебор).
Че там наделали с ней? Взяли исходный промпт кожАных, переписали его с Gemma, далее получили по этому промпту конечную генерацию. Воть, далее извольте определить, измененный промпт из теста и генерация совместны или нет.
Метрика косинус между векторным представлением промпта вашего решения и верным ответом. Эмбы получают с помощью sentence-t5 модели.
Подстава в том, что у нас нет опорных затравок для переписывания промпта с Gemma. Следовательно, придется выдумывать самому (трансферить стиль на 1 данном примере с LLM я как-то не вижу смысла).
* gemma в последнее время = безобразие ;)
Please open Telegram to view this post
VIEW IN TELEGRAM
Kaggle
LLM Prompt Recovery
Recover the prompt used to transform a given text
Обещанного 3 года июля ждут
https://www.reuters.com/technology/meta-plans-launch-new-ai-language-model-llama-3-july-information-reports-2024-02-28
https://www.reuters.com/technology/meta-plans-launch-new-ai-language-model-llama-3-july-information-reports-2024-02-28
😁1
This media is not supported in your browser
VIEW IN TELEGRAM
Знаю, кому понравится этот видос...
Спасибо подписчикам.
Спасибо подписчикам.
😁56🔥5❤3🍌1
Dealer.AI
Знаю, кому понравится этот видос... Спасибо подписчикам.
блин, как же хорошо в отпуск сходил.
продолжаем👇
продолжаем👇
🔥6😁1
Forwarded from Все о блокчейн/мозге/space/WEB 3.0 в России и мире
⚡️Маск: OpenAI уже достигли AGI и подал в суд против Open AI и Сэма Альтмана за нарушение контракта.
Илон Маск подал иск против OpenAI за нарушение контракта, фидуциарных обязанностей и недобросовестную деловую практику и просит OpenAI вернуться к открытому исходному коду и поделиться всеми своими исследованиями на благо человечества.
Маск утверждает, что OpenAI уже достигли AGI и, таким образом, выходят за рамки соглашения с Microsoft, которое применимо только к технологиям, предшествующим AGI.
По сути, Маск утверждает, что с GPT-4 они уже достигли порога AGI, и, не открывая исходный код GPT-4, они нарушают Учредительное соглашение.
«Похоже, что Q* может сейчас или в будущем стать частью 6, еще более ясного и яркого примера общего искусственного интеллекта, разработанного OpenAI».
Интересно, что Маск требует судебного решения по аргументу о том, что GPT-4, Q* и «LLM следующего поколения, находящиеся в настоящее время в разработке», представляют собой AGI.
Илон Маск подал иск против OpenAI за нарушение контракта, фидуциарных обязанностей и недобросовестную деловую практику и просит OpenAI вернуться к открытому исходному коду и поделиться всеми своими исследованиями на благо человечества.
Маск утверждает, что OpenAI уже достигли AGI и, таким образом, выходят за рамки соглашения с Microsoft, которое применимо только к технологиям, предшествующим AGI.
По сути, Маск утверждает, что с GPT-4 они уже достигли порога AGI, и, не открывая исходный код GPT-4, они нарушают Учредительное соглашение.
«Похоже, что Q* может сейчас или в будущем стать частью 6, еще более ясного и яркого примера общего искусственного интеллекта, разработанного OpenAI».
Интересно, что Маск требует судебного решения по аргументу о том, что GPT-4, Q* и «LLM следующего поколения, находящиеся в настоящее время в разработке», представляют собой AGI.
😁17👍9🔥3🤡3🦄1