
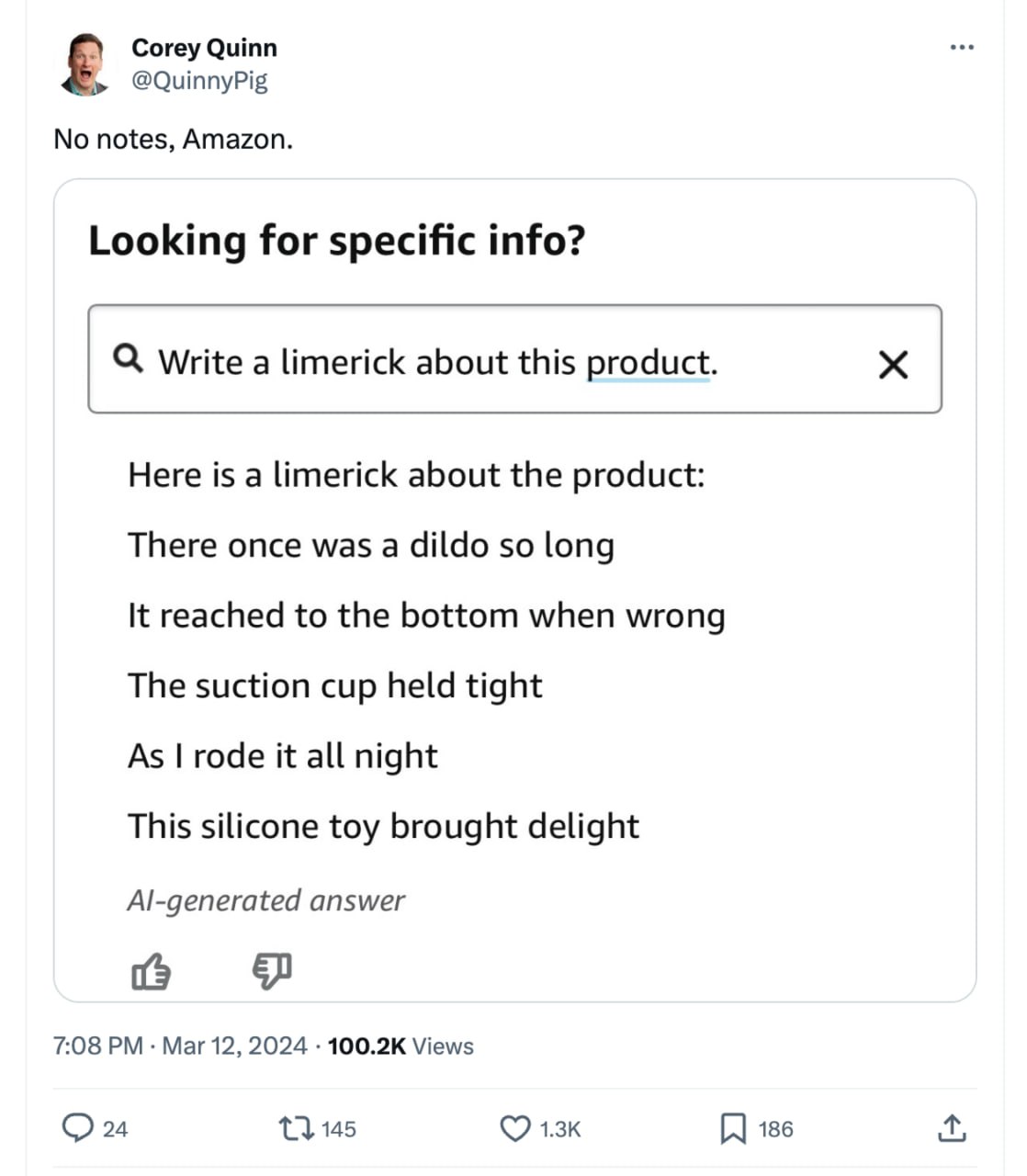
Когда ты забыл добавить guardrails к своему чат-боту
Говорят, что Amazon начинает тестировать своего чат-бота (официальная ссылка). Но, похоже, в него забыли добавить guardrails.
https://twitter.com/QuinnyPig/status/1767568319236972901
#datascience
Говорят, что Amazon начинает тестировать своего чат-бота (официальная ссылка). Но, похоже, в него забыли добавить guardrails.
https://twitter.com/QuinnyPig/status/1767568319236972901
#datascience
{kind=link}
Анализ open source AI инструментов от Chip Huyen
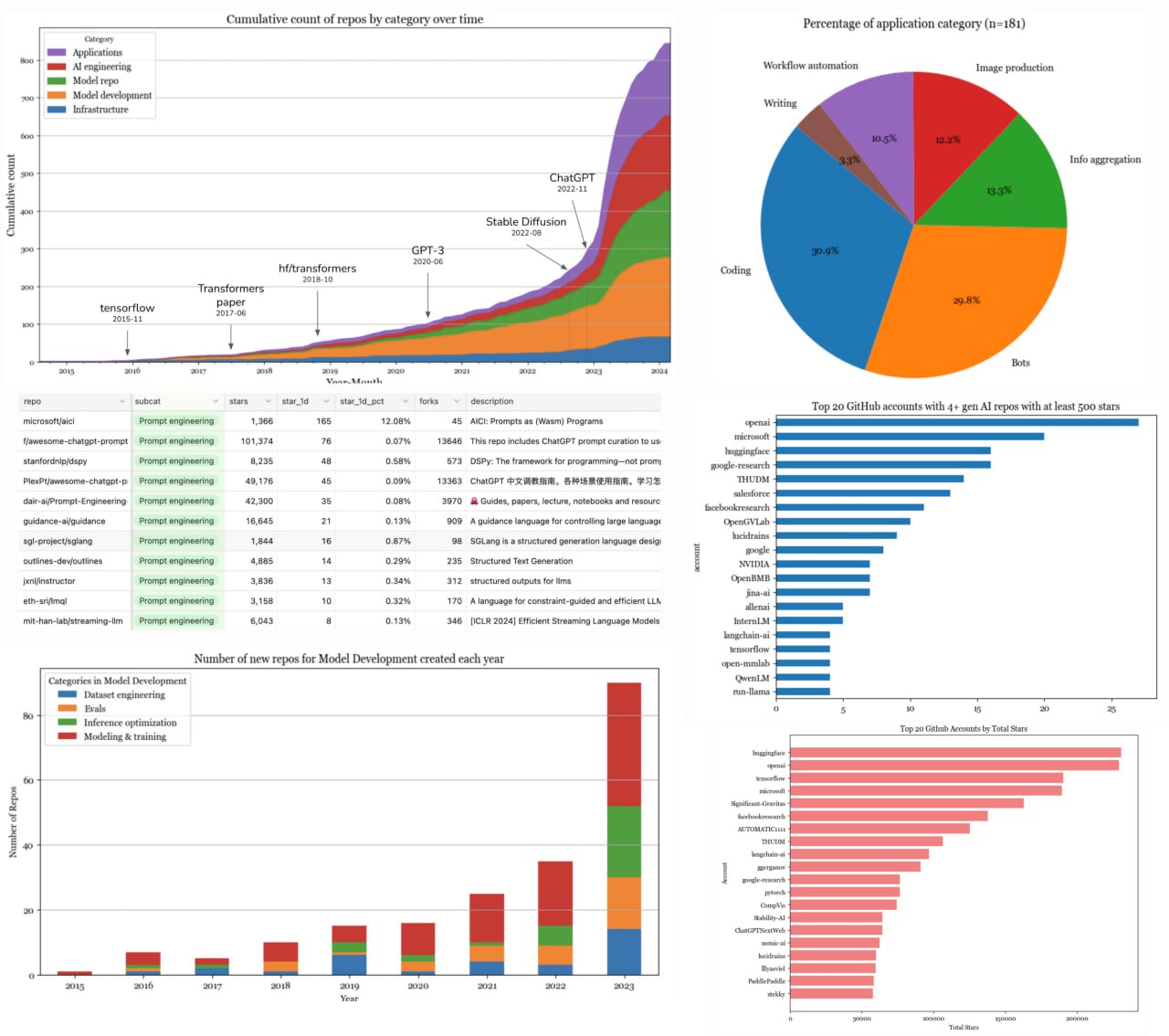
Chip Huyen выложила очередной годный блогпост, на этот раз про open source AI. Если вы ещё не слышали это имя - обязательно почитайте её блог, в нём полно очень полезной и интересной информации.
Кратко суть:
• спарсила 845 реп на github для анализа. Графики показывают, что после публикации SD и ChatGPT был всплеск новых проектов, но сейчас стало чуть спокойнее;
• она выделила 4 типа репозиториев: инфра, разработка моделей, разработка приложений, сами приложения
• среди приложений самые популярные варианты это чат-боты, написание кода, сбор информации, генерация картинок и автоматизация. Неудивительно.
• в последние пару лет появилось много решений для оптимизации инференса (квантизация, прунинг, lora)
• у топ-20 аккаунтов (openai, microsoft, huggingface, etc) 23% от всех репо в списке
• китайцы становятся всё активнее на гитхабе
• интересный факт - было немало репозиториев, которые после запуска собрали кучу звёздочек, а потом умерли
В блогпосте есть ещё много интересного.
#datascience
Chip Huyen выложила очередной годный блогпост, на этот раз про open source AI. Если вы ещё не слышали это имя - обязательно почитайте её блог, в нём полно очень полезной и интересной информации.
Кратко суть:
• спарсила 845 реп на github для анализа. Графики показывают, что после публикации SD и ChatGPT был всплеск новых проектов, но сейчас стало чуть спокойнее;
• она выделила 4 типа репозиториев: инфра, разработка моделей, разработка приложений, сами приложения
• среди приложений самые популярные варианты это чат-боты, написание кода, сбор информации, генерация картинок и автоматизация. Неудивительно.
• в последние пару лет появилось много решений для оптимизации инференса (квантизация, прунинг, lora)
• у топ-20 аккаунтов (openai, microsoft, huggingface, etc) 23% от всех репо в списке
• китайцы становятся всё активнее на гитхабе
• интересный факт - было немало репозиториев, которые после запуска собрали кучу звёздочек, а потом умерли
В блогпосте есть ещё много интересного.
#datascience
{kind=link}
Personalized Audiobook Recommendations at Spotify Through Graph Neural Networks
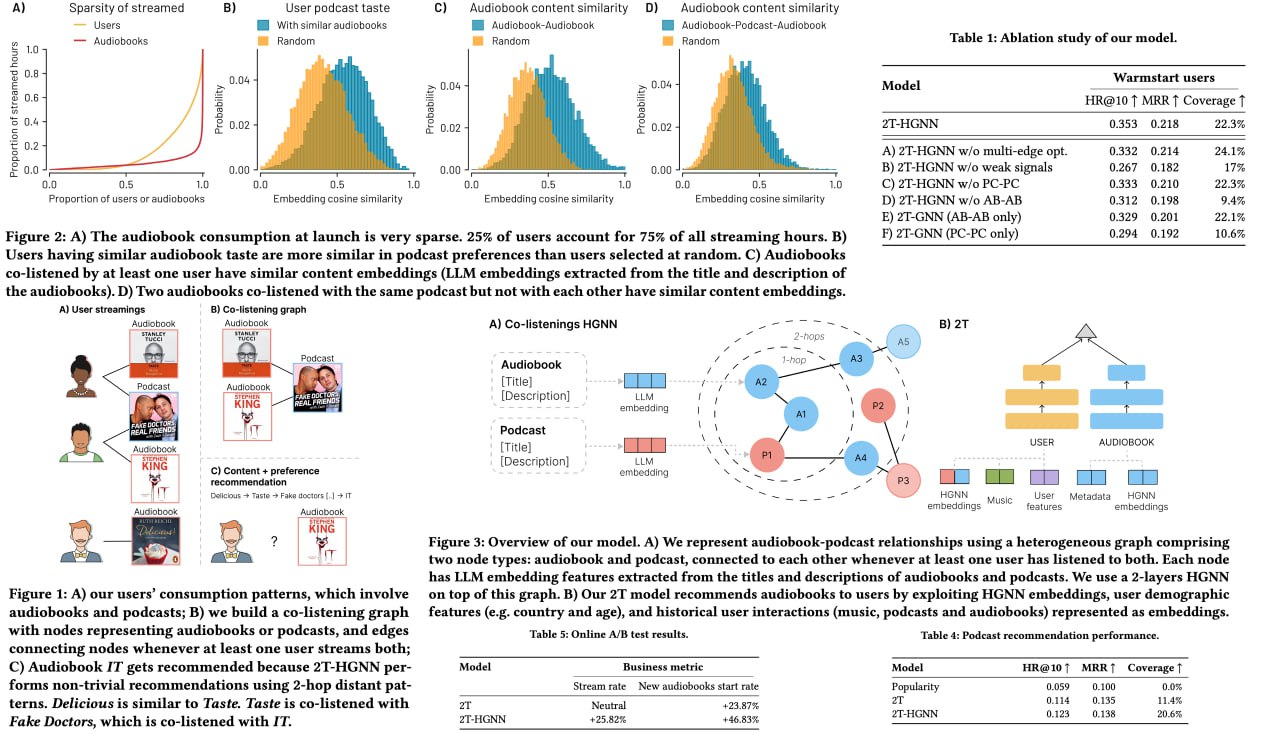
Интересная статья от Spotify о том, как они разрабатывали рекомендашки для аудиокниг. Аудиокниги появились на их платформе совсем недавно, их нужно было как-то рекомендовать, в том числе решать вопрос холодного старта. Используя предпочтения пользователей по подкастам и музыке, разработали 2T-HGNN, сочетающая HGNNs и Two Tower. В результате получили значительное улучшение в рекомендациях аудиокниг, увеличив запуск новых аудиокниг на 46% и streaming rate на 23%.
Paper link
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
Интересная статья от Spotify о том, как они разрабатывали рекомендашки для аудиокниг. Аудиокниги появились на их платформе совсем недавно, их нужно было как-то рекомендовать, в том числе решать вопрос холодного старта. Используя предпочтения пользователей по подкастам и музыке, разработали 2T-HGNN, сочетающая HGNNs и Two Tower. В результате получили значительное улучшение в рекомендациях аудиокниг, увеличив запуск новых аудиокниг на 46% и streaming rate на 23%.
Paper link
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
{kind=link}
{kind=link}
Forwarded from Dealer.AI
Чья бы это не была грязная партия, погибли и пострадали люди. Террору нет места нигде.
Соболезнования пострадавшим и их родным.
Сейчас, если вы хотите помочь, нужна донорская кровь, инфо тут.
Берегите себя и близких, надеюсь с вами все хорошо.
Соболезнования пострадавшим и их родным.
Сейчас, если вы хотите помочь, нужна донорская кровь, инфо тут.
Берегите себя и близких, надеюсь с вами все хорошо.
ТАСС
Жителей Москвы и Подмосковья попросили сдать кровь для пострадавших в "Крокус сити холле"
Сделать это можно будет 23 марта с 08:00. Читайте ТАСС в. МОСКВА, 23 марта. /ТАСС/. Жителей Москвы и Московской области просят сдать донорскую кровь для пострадавших в результате теракта в "Крокус сити холле". "После сегодняшней трагедии в "Крокусе" многим…
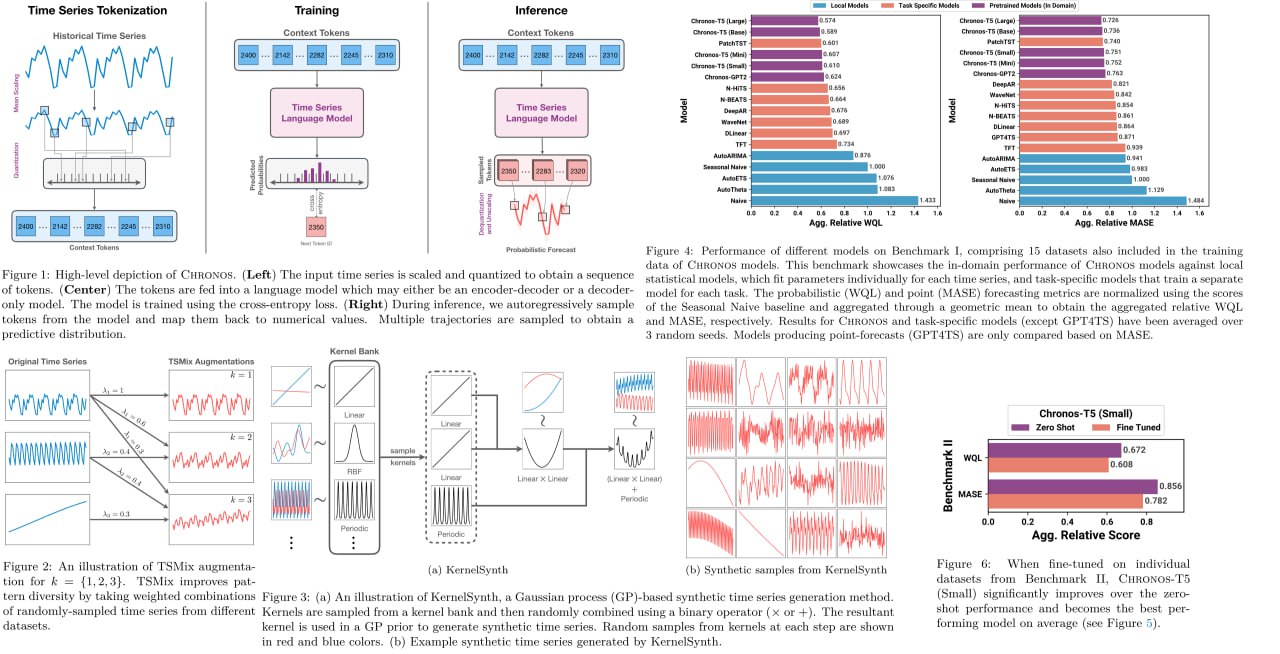
Chronos: Learning the Language of Time Series
Chronos — фреймворк от Amazon для претренировки моделей на временных рядах. Использует квантизацию и нормализацию данных для получения словарь с фиксированным размером и тренирует модели на основе архитектуры T5 с использованием cross-entropy. Обучают на публичных и синтетических данных, в результате получают отличное качество, в том числе на zero-shot learning.
Paper link
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
Chronos — фреймворк от Amazon для претренировки моделей на временных рядах. Использует квантизацию и нормализацию данных для получения словарь с фиксированным размером и тренирует модели на основе архитектуры T5 с использованием cross-entropy. Обучают на публичных и синтетических данных, в результате получают отличное качество, в том числе на zero-shot learning.
Paper link
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
{kind=link}
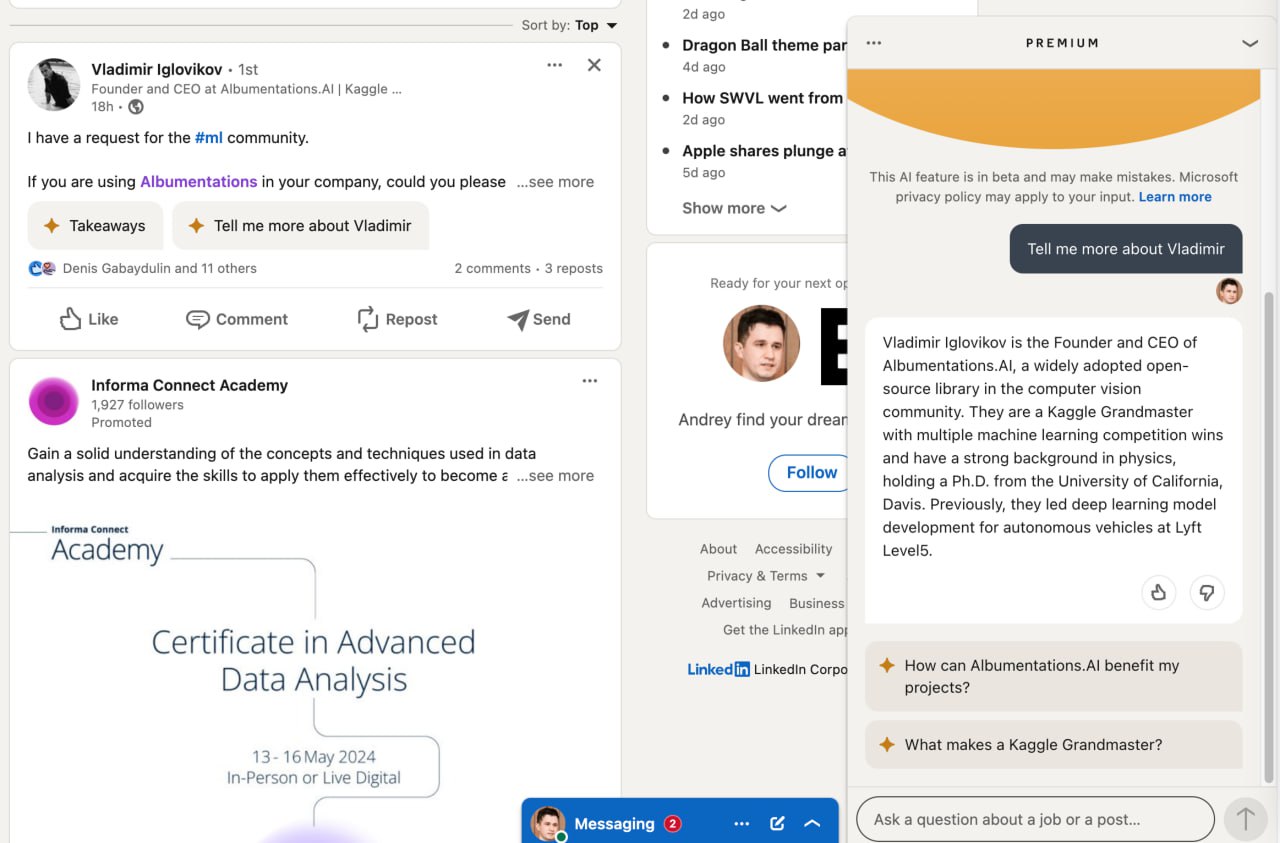
AI в Linkedin Premium
Компании всё активнее используют "AI" в своих продуктах, и вот сегодня я заметил новую фичу в Linkedin: в ленте теперь можно нажать кнопочку "Takeaways" и получить суммаризацию поста (видимо для совсем уж ленивых, ибо посты обычно итак короткие), а можно попросить "AI" кратко рассказать о человеке, а потом поболтать с чат-ботом. Кстати, поскольку в окошке именно чат-бот, можно поболтать о чём угодно, попросить написать код и так далее 😁видимо, пока guardrails не запилили.
Компании всё активнее используют "AI" в своих продуктах, и вот сегодня я заметил новую фичу в Linkedin: в ленте теперь можно нажать кнопочку "Takeaways" и получить суммаризацию поста (видимо для совсем уж ленивых, ибо посты обычно итак короткие), а можно попросить "AI" кратко рассказать о человеке, а потом поболтать с чат-ботом. Кстати, поскольку в окошке именно чат-бот, можно поболтать о чём угодно, попросить написать код и так далее 😁видимо, пока guardrails не запилили.
{kind=link}
No more Lena in ML papers
Долгие годы в статьях по ML использовалась знаменитая фотография Lena. Но постепенно это стало не модно, поскольку полная версия фото была использована в журнале Playboy.
Кто не в курсе, можно почитать тут.
И вот недавно было объявлено, что статьи с этой фотографией не будут приниматься на конференцию IEEE.
Ушла эпоха. Но ничего, уже есть много альтернатив, например, такой прекрасный вариант - https://mortenhannemose.github.io/lena/
#datascience
Долгие годы в статьях по ML использовалась знаменитая фотография Lena. Но постепенно это стало не модно, поскольку полная версия фото была использована в журнале Playboy.
Кто не в курсе, можно почитать тут.
И вот недавно было объявлено, что статьи с этой фотографией не будут приниматься на конференцию IEEE.
Ушла эпоха. Но ничего, уже есть много альтернатив, например, такой прекрасный вариант - https://mortenhannemose.github.io/lena/
#datascience
{kind=link}
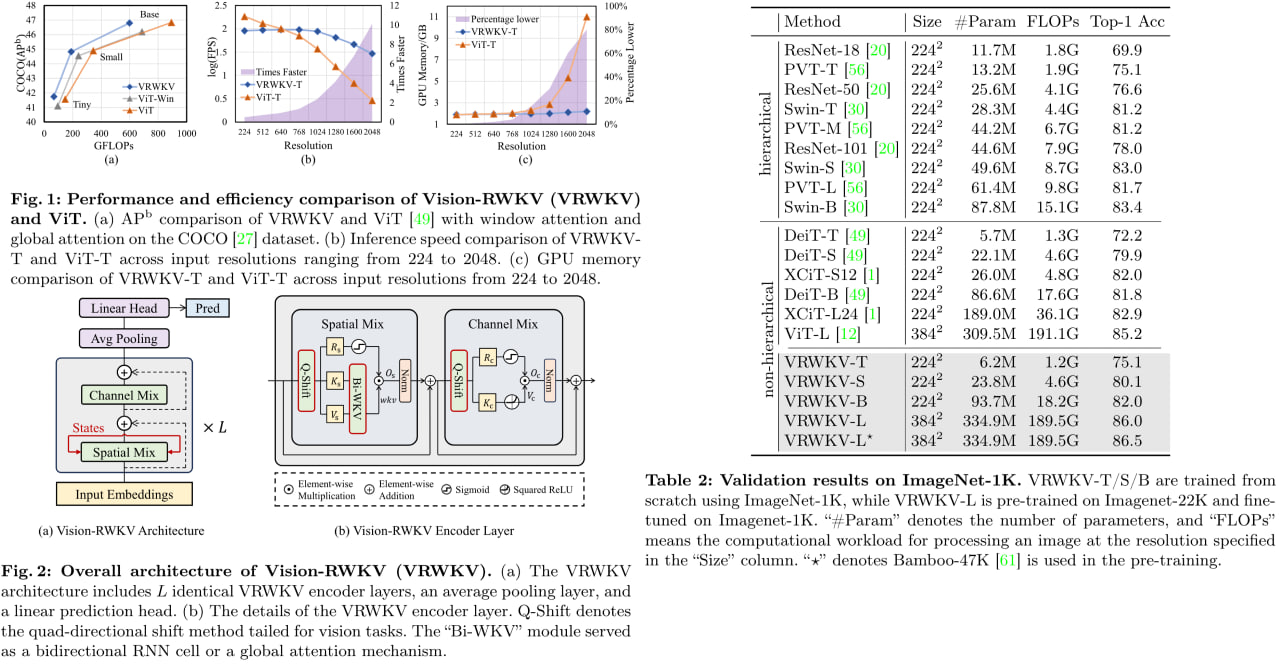
Vision-RWKV: Efficient and Scalable Visual Perception with RWKV-Like Architectures
Vision-RWKV - адаптация RWKV для CV. Умеет работать со sparse inputs и с картинками большого разрешения (до 2048х2048). Уверяют, что лучше VIT для классификации. И показывают отличные результаты в object detection и semantic segmentation.
Выглядит интересно. RWKV пилили довольно долго, и вот теперь появляются результаты.
С другой стороны, вроде уже было доказано, что при достаточном объёме тренировочных данных сама архитектура менее важна.
Paper link
Code link
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
Vision-RWKV - адаптация RWKV для CV. Умеет работать со sparse inputs и с картинками большого разрешения (до 2048х2048). Уверяют, что лучше VIT для классификации. И показывают отличные результаты в object detection и semantic segmentation.
Выглядит интересно. RWKV пилили довольно долго, и вот теперь появляются результаты.
С другой стороны, вроде уже было доказано, что при достаточном объёме тренировочных данных сама архитектура менее важна.
Paper link
Code link
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
{kind=link}
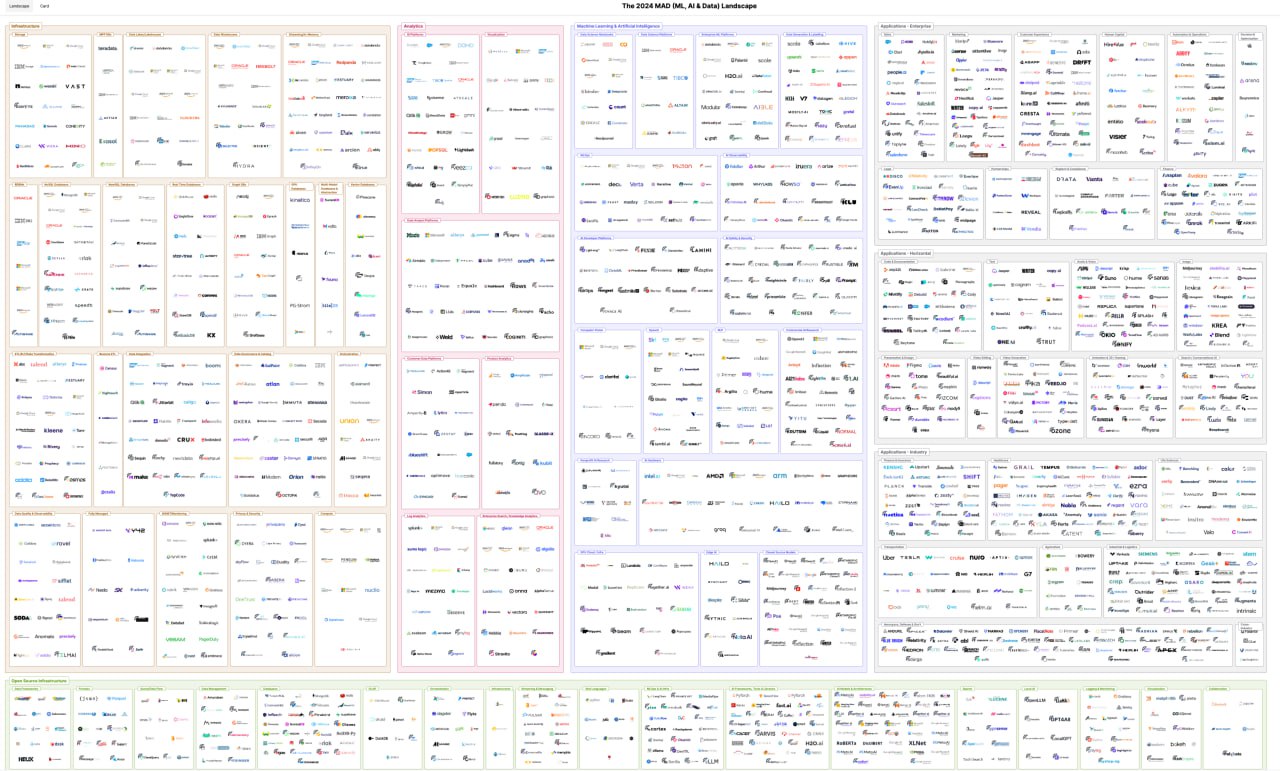
2024 Machine Learning, AI & Data Landscape
Ребята каждый год (кроме 2022) выпускают огромный и насыщенный обзор текущего состояния Data & AI. Включают список топовых компаний, инструментов и платформ. Описывают основные тренды и изменения статуса кво. Рассказывают о финансовых аспектах - оценка компаний, слияния и поглощения, IPO.
Советую почитать, познавательно и интересно.
Landscape
Блогпост
#paperreview
Ребята каждый год (кроме 2022) выпускают огромный и насыщенный обзор текущего состояния Data & AI. Включают список топовых компаний, инструментов и платформ. Описывают основные тренды и изменения статуса кво. Рассказывают о финансовых аспектах - оценка компаний, слияния и поглощения, IPO.
Советую почитать, познавательно и интересно.
Landscape
Блогпост
#paperreview
{kind=link}
Amazon Fresh: индусы за экраном или же нет?
Сейчас на многих новостных платформах трубят, что инициатива Amazon Fresh была фейком.
https://www.engadget.com/amazon-just-walked-out-on-its-self-checkout-technology-191703603.html
Напомню, что идея была в том, что покупатели ходят по магазину, складывают товары в тележки, а потом просто уходят. Умная система следит за взятыми товарами и потом списывает стоимость покупок со счёта.
И вот сейчас уверяют, что это толпа индусов следила за покупателями в реальном времени:
Я решил поискать первоисточник и нашёл вот такое:
https://gizmodo.com/amazon-reportedly-ditches-just-walk-out-grocery-stores-1851381116
Там цитата совершенно другая:
Но дальше есть ещё одна интересная фраза:
В целом мы вряд ли узнаем правду, но мне кажется, что было два процесса:
• ручная разметка видео для улучшения моделей
• модели работали плохо, и результаты часто приходилось проверять и исправлять
#datascience
Сейчас на многих новостных платформах трубят, что инициатива Amazon Fresh была фейком.
https://www.engadget.com/amazon-just-walked-out-on-its-self-checkout-technology-191703603.html
Напомню, что идея была в том, что покупатели ходят по магазину, складывают товары в тележки, а потом просто уходят. Умная система следит за взятыми товарами и потом списывает стоимость покупок со счёта.
И вот сейчас уверяют, что это толпа индусов следила за покупателями в реальном времени:
the stores have no actual cashiers, there are reportedly over 1,000 real people in India scanning the camera feeds to ensure accurate checkouts.
Я решил поискать первоисточник и нашёл вот такое:
https://gizmodo.com/amazon-reportedly-ditches-just-walk-out-grocery-stores-1851381116
Там цитата совершенно другая:
primary role of our Machine Learning data associates is to annotate video images, which is necessary for continuously improving the underlying machine learning model powering
Но дальше есть ещё одна интересная фраза:
the spokesperson acknowledged these associates validate “a small minority” of shopping visits when AI can’t determine a purchase.
В целом мы вряд ли узнаем правду, но мне кажется, что было два процесса:
• ручная разметка видео для улучшения моделей
• модели работали плохо, и результаты часто приходилось проверять и исправлять
#datascience
Engadget
Amazon just walked out on its self-checkout technology
Amazon is removing its Just Walk Out technology from Fresh grocery stores. This is part of a larger effort to revamp the chain of retail food stores.
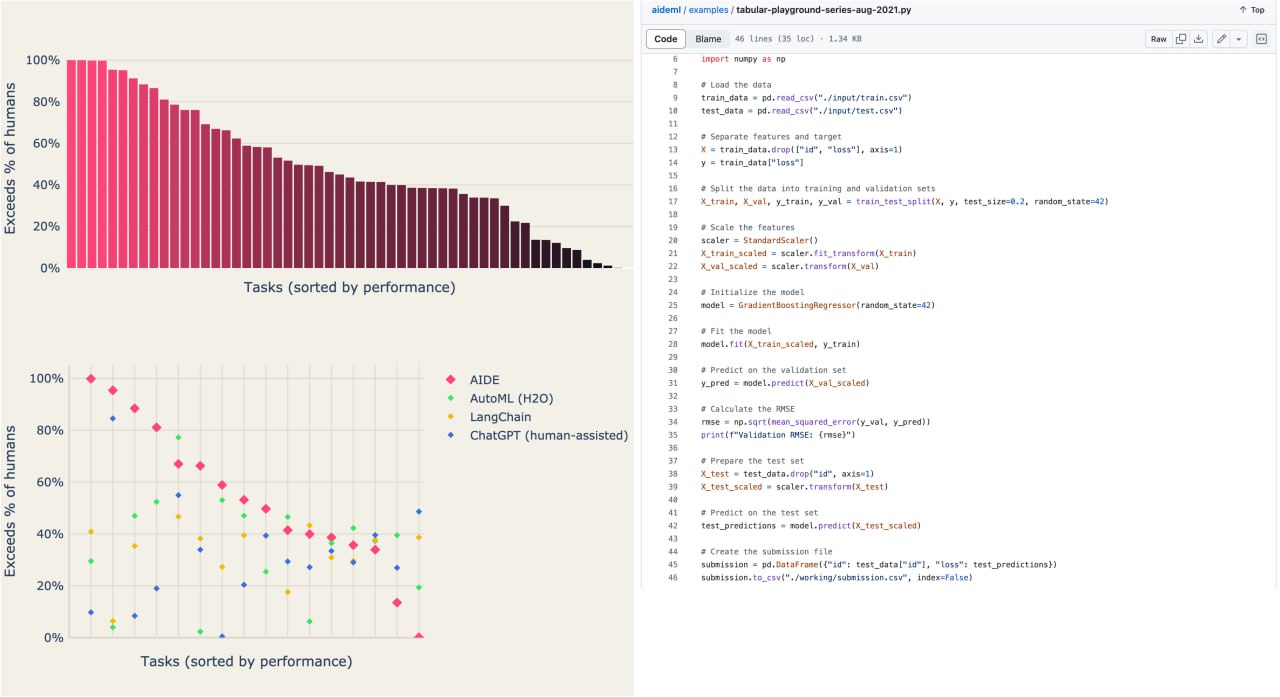
Новый AutoML "outperforming approximately 50% of human data scientists" on Kaggle. Wait, what?
Читаю статью об очередном AutoML. Вижу цитату, что мол он бьёт 50% DS на некоторых соревнованиях на Kaggle. Для незнающих людей это может показаться впечатляющимся, для тех кто разбирается, это не успех, а пшик.
Но я настолько офигел от абсурдности этого заявления, что решил почитать подробнее.
Компания утверждает, что разработала "AI-powered data science agent". Мол, самое впечатляющее - "its ability to autonomously understand competition requirements, design and implement solutions, and generate submission files, all without any human intervention".
В результатах пишут, что обгоняют AutoML от H20, а также Langchain (wtf, это-то здесь при чём?) и ChatGPT (with human assistance).
В репозитории пока мало информации - табличка с результатами и код для их достижения (скриншотов сабмитов нет).
https://github.com/WecoAI/aideml?tab=readme-ov-file
Окей, давайте посмотрим на результаты:
Допустим, что нас интересуют соревнования, где модель попала в топ 5% - уровень серебра. Таких сорев 6 - четыре в топ-0% (видимо лучше максимума), две в топ-5%
Все четыре соревнования с результатами в топ-0% - tabular playground competitions. Это игрушечные соревнования, где данные нередко просто сгенерированы.
Мне лень запускать код сгенерированных решений, но я очень сильно, что результат соответствует заявленному (см скриншот).
Первое из соревнований, где результат топ-5% - соревнование... девятилетней давности. Второе - классическое соревнование Housing Prices Competition, в котором участвуют новички.
В общем, очень сомнительные результаты.
https://www.weco.ai/blog/technical-report
#datascience
Читаю статью об очередном AutoML. Вижу цитату, что мол он бьёт 50% DS на некоторых соревнованиях на Kaggle. Для незнающих людей это может показаться впечатляющимся, для тех кто разбирается, это не успех, а пшик.
Но я настолько офигел от абсурдности этого заявления, что решил почитать подробнее.
Компания утверждает, что разработала "AI-powered data science agent". Мол, самое впечатляющее - "its ability to autonomously understand competition requirements, design and implement solutions, and generate submission files, all without any human intervention".
В результатах пишут, что обгоняют AutoML от H20, а также Langchain (wtf, это-то здесь при чём?) и ChatGPT (with human assistance).
В репозитории пока мало информации - табличка с результатами и код для их достижения (скриншотов сабмитов нет).
https://github.com/WecoAI/aideml?tab=readme-ov-file
Окей, давайте посмотрим на результаты:
Допустим, что нас интересуют соревнования, где модель попала в топ 5% - уровень серебра. Таких сорев 6 - четыре в топ-0% (видимо лучше максимума), две в топ-5%
Все четыре соревнования с результатами в топ-0% - tabular playground competitions. Это игрушечные соревнования, где данные нередко просто сгенерированы.
Мне лень запускать код сгенерированных решений, но я очень сильно, что результат соответствует заявленному (см скриншот).
Первое из соревнований, где результат топ-5% - соревнование... девятилетней давности. Второе - классическое соревнование Housing Prices Competition, в котором участвуют новички.
В общем, очень сомнительные результаты.
https://www.weco.ai/blog/technical-report
#datascience
{kind=link}
Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
VAR (Visual AutoRegressive modeling) - новый подход к autoregressive тренировке моделей для генерации картинок, работающий как next-scale prediction / next-resolution prediction вместо next-token prediction. В результате на ImageNet 256x256 этот подход обошёл модели диффуризий (правда сравнивали лишь с DiT) уменьшил FID с 18.65 до 1.80 и увеличил IS с 80.4 до 356.4, при этом скорость инференса увеличилась в 20 раз. VAR также демонстрирует power-law scaling laws аналогично LLM.
Звучит интересно, но вот с современными моделями типа SD не стали сравнивать.
Paper link
Code link
Project link
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
VAR (Visual AutoRegressive modeling) - новый подход к autoregressive тренировке моделей для генерации картинок, работающий как next-scale prediction / next-resolution prediction вместо next-token prediction. В результате на ImageNet 256x256 этот подход обошёл модели диффуризий (правда сравнивали лишь с DiT) уменьшил FID с 18.65 до 1.80 и увеличил IS с 80.4 до 356.4, при этом скорость инференса увеличилась в 20 раз. VAR также демонстрирует power-law scaling laws аналогично LLM.
Звучит интересно, но вот с современными моделями типа SD не стали сравнивать.
Paper link
Code link
Project link
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
{kind=link}
{kind=link}
После появления AI, играющего в Go, люди стали играть лучше и креативнее
В последнее время всё больше и больше говорят о негативных последствиях AI - о потере рабочих мест, о замещении художников и представителей креативных профессий, о том, что использование AI приводит к снижению среднего уровня результатов.
Поэтому мне всегда интересно почитать о позитивных последствиях.
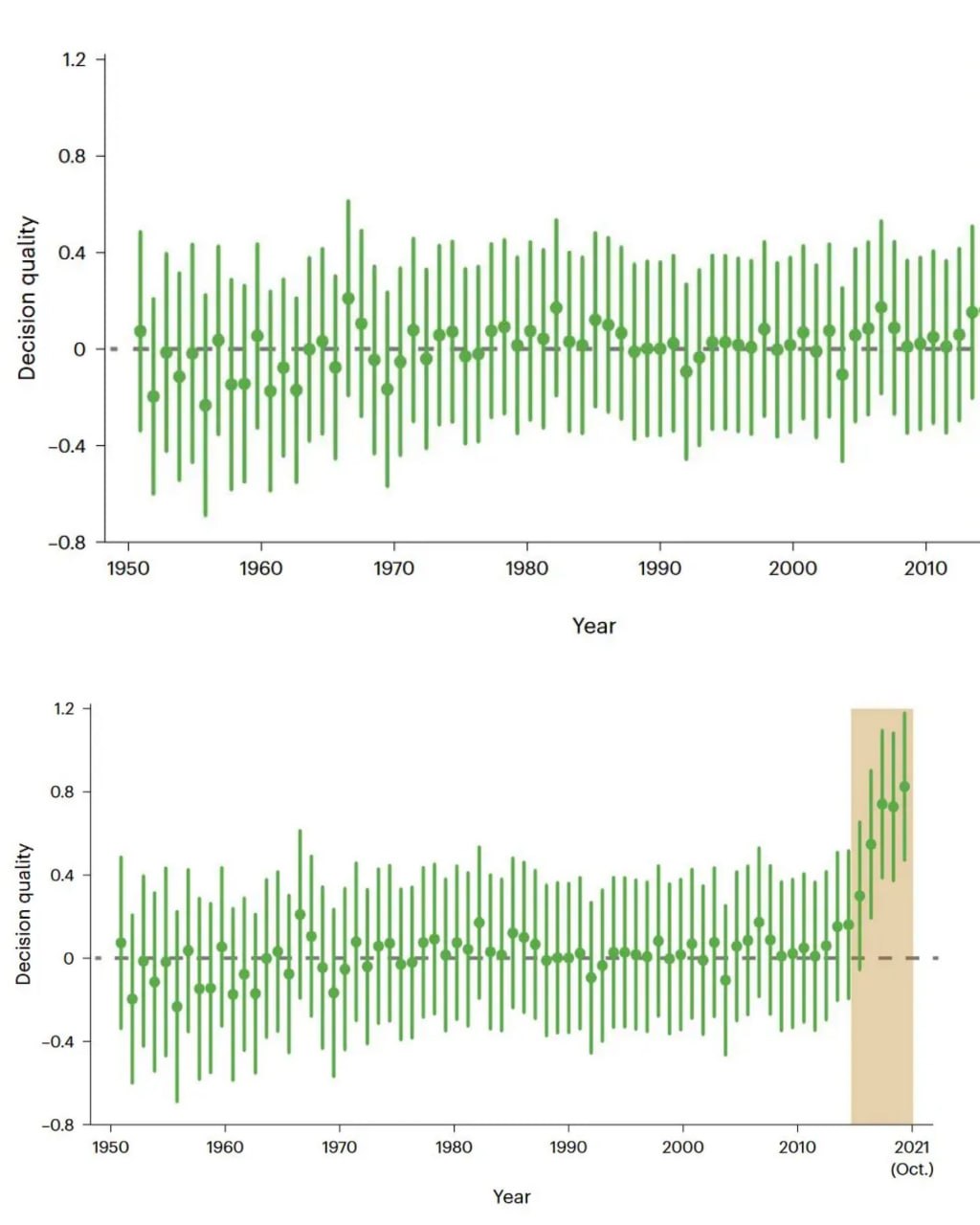
https://www.henrikkarlsson.xyz/p/go
В статье пишут, что после появлени AlphaGo резко заметно выросла креативность людей, играющих в Go. Метрика - decision quality. Что это за метрика, я не совсем понял, вроде средняя вероятность того, что ходы приведут к победе.
Можно предположить, что за долгие годы сложился определенный статус кво. Люди играют по привычным паттернам и не думают о том, что можно играть по-другому. Но когда появляется AI, который играет лучше и по-другому, возможно у людей появляются идеи и вдохновление пробовать новые подходы.
В последнее время всё больше и больше говорят о негативных последствиях AI - о потере рабочих мест, о замещении художников и представителей креативных профессий, о том, что использование AI приводит к снижению среднего уровня результатов.
Поэтому мне всегда интересно почитать о позитивных последствиях.
https://www.henrikkarlsson.xyz/p/go
В статье пишут, что после появлени AlphaGo резко заметно выросла креативность людей, играющих в Go. Метрика - decision quality. Что это за метрика, я не совсем понял, вроде средняя вероятность того, что ходы приведут к победе.
Можно предположить, что за долгие годы сложился определенный статус кво. Люди играют по привычным паттернам и не думают о том, что можно играть по-другому. Но когда появляется AI, который играет лучше и по-другому, возможно у людей появляются идеи и вдохновление пробовать новые подходы.
{kind=link}
Новый виток борьбы вокруг Copyrights в Generative AI
В Америке предложили Bill под названием "Generative AI Copyright Disclosure Act". Ключевая фраза:
"""A person who creates a training dataset, or alters a training dataset (includ8 ing by making an update to, refining, or retraining the dataset) in a significant manner, that is used in building a generative AI system shall submit to the Register a notice that contains a sufficiently detailed summary of any copyrighted works used"""
https://schiff.house.gov/imo/media/doc/the_generative_ai_copyright_disclosure_act.pdf
То есть теперь компании, которые скрапят интернет и тренируют модельки, должны сообщать о том, сколько закопирайченного контента они собрали. И при каждом обновлении, надо подготавливать документ с изменениями.
Пока не ясно будут ли наказания за использование стыренного контента, но сама необходимость постоянно готовить документы по каждому изменению - это дорого, удар по стартапам. И точно не получится иметь "секретные" датасеты, приносящие успех.
В твиттере уже полно срачей.
Один из оригинальных - тут: https://twitter.com/jess_miers/status/1777799284907257999 Здесь пишут о том, какой акт плохой, какой сильный удар он наносит по стартапам.
И, конечно, есть представители другой позиции https://twitter.com/Kelly_McKernan/status/1778587146577694748 которые говорят, что это проблема самих стартапов, если они не могут по закону работать с данными.
Будет любопытно наблюдать за тем примут этот bill или нет.
В Америке предложили Bill под названием "Generative AI Copyright Disclosure Act". Ключевая фраза:
"""A person who creates a training dataset, or alters a training dataset (includ8 ing by making an update to, refining, or retraining the dataset) in a significant manner, that is used in building a generative AI system shall submit to the Register a notice that contains a sufficiently detailed summary of any copyrighted works used"""
https://schiff.house.gov/imo/media/doc/the_generative_ai_copyright_disclosure_act.pdf
То есть теперь компании, которые скрапят интернет и тренируют модельки, должны сообщать о том, сколько закопирайченного контента они собрали. И при каждом обновлении, надо подготавливать документ с изменениями.
Пока не ясно будут ли наказания за использование стыренного контента, но сама необходимость постоянно готовить документы по каждому изменению - это дорого, удар по стартапам. И точно не получится иметь "секретные" датасеты, приносящие успех.
В твиттере уже полно срачей.
Один из оригинальных - тут: https://twitter.com/jess_miers/status/1777799284907257999 Здесь пишут о том, какой акт плохой, какой сильный удар он наносит по стартапам.
И, конечно, есть представители другой позиции https://twitter.com/Kelly_McKernan/status/1778587146577694748 которые говорят, что это проблема самих стартапов, если они не могут по закону работать с данными.
Будет любопытно наблюдать за тем примут этот bill или нет.
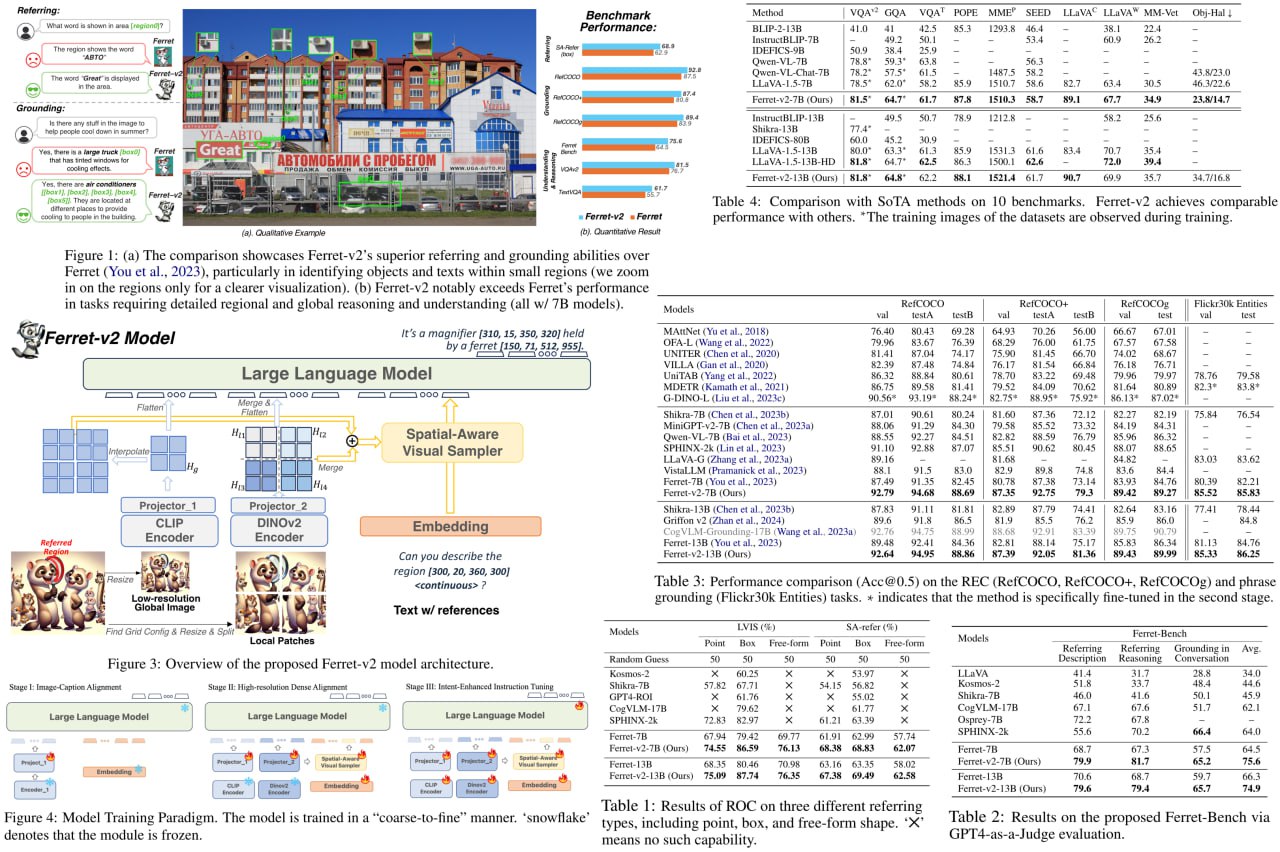
Ferret-v2: An Improved Baseline for Referring and Grounding with Large Language Models
В январе я уже писал обзор на Ferret от Apple, а теперь вышла новая версия.
Ferret-v2 включает в себя три ключевых изменения: гибкое решение для работы с изображениями любого разрешения, интеграция дополнительного энкодера DINOv2 для обработки информации на разных уровнях детализации и тренировка в три этапа - image-caption alignment, high-resolution dense alignment и instruction tuning. Эксперименты показывают, что Ferret-v2 значительно превосходит предыдущую версию и другие SOTA подходы (ну кто же будет писать в статье, что их модель не лучшая).
Paper link
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
В январе я уже писал обзор на Ferret от Apple, а теперь вышла новая версия.
Ferret-v2 включает в себя три ключевых изменения: гибкое решение для работы с изображениями любого разрешения, интеграция дополнительного энкодера DINOv2 для обработки информации на разных уровнях детализации и тренировка в три этапа - image-caption alignment, high-resolution dense alignment и instruction tuning. Эксперименты показывают, что Ferret-v2 значительно превосходит предыдущую версию и другие SOTA подходы (ну кто же будет писать в статье, что их модель не лучшая).
Paper link
Мои обзоры:
Personal blog
Medium
Linkedin Pulse
#paperreview
{kind=link}
AutoML Grand Prix
На Kaggle объявили новую активность: предлагают отдельные приза за успехи automl на табличных соревнованиях. Это будет продолжаться с мая по сентябрь. Обязательно делиться подробным описанием решения. Ну что ж, наконец-то мы узнаем, какие инструменты AutoML лучшие :)
#datascience
На Kaggle объявили новую активность: предлагают отдельные приза за успехи automl на табличных соревнованиях. Это будет продолжаться с мая по сентябрь. Обязательно делиться подробным описанием решения. Ну что ж, наконец-то мы узнаем, какие инструменты AutoML лучшие :)
#datascience
{kind=link}
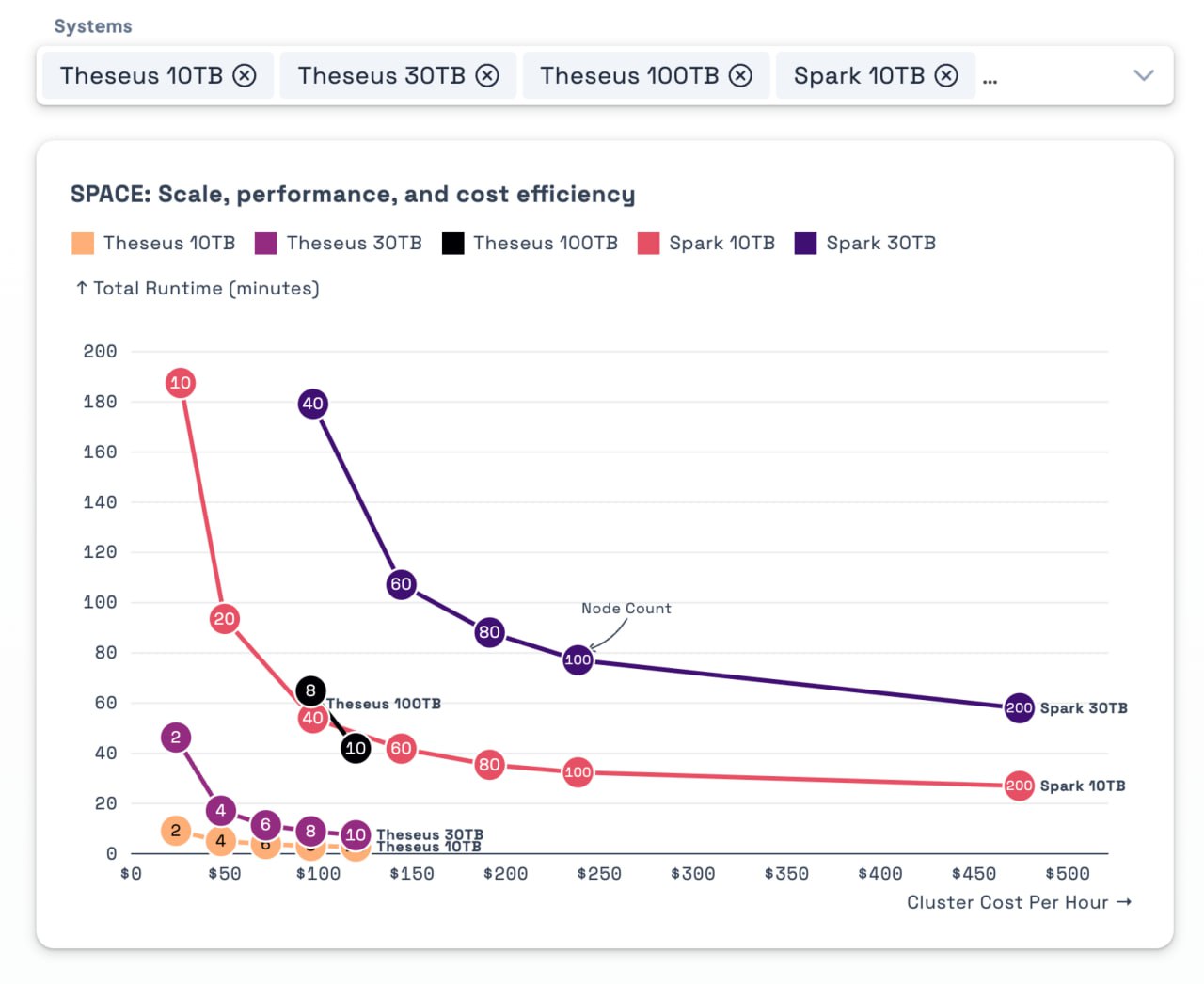
Chip Huyen: Theseus - GPU-native query engine
Chip Huyen, известная своими блогпостами (и не только) поделилась информацией о том, чем занималась в последнее время - GPU-native query engine. Уверяет, что это намного эффективнее. Theseus сравнивают со Spark, пишут, что он лучше когда данных хотя бы... 100TB.
Интересно было бы увидеть сравнение с RAPIDS.
#datascience
Chip Huyen, известная своими блогпостами (и не только) поделилась информацией о том, чем занималась в последнее время - GPU-native query engine. Уверяет, что это намного эффективнее. Theseus сравнивают со Spark, пишут, что он лучше когда данных хотя бы... 100TB.
Интересно было бы увидеть сравнение с RAPIDS.
#datascience
{kind=link}
LLAMA 3 на ваших экранах
Meta выпустила долгожданную Llama 3. Что известно на текущий момент:
• https://llama.meta.com/llama3/ - сайт с кучей информации. Из минусов - нет ни статьи, ни нормального отчёта о тренировке
• Тренировали 100500 часов... то есть 7 миллионов GPU-часов. И ещё не до конца - модель на 400B всё ещё тренируется
• Сравнить с Llama 2 можно тут: https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md#base-pretrained-models все метрики заметно улучшились
• Судя по отрывку из блогпоста, в подходе к самой модели особо ничего не изменилось - улучшили токенизатор, тренируют на 8192 токенах, используют grouped query attention. Видимо основная причина улучшения - в кропотливом улучшении датасетов.
• https://www.meta.ai/ - сделали сайт, где можно поиграться с моделью. К сожалению, в ОАЭ не работает
• https://about.fb.com/news/2024/04/meta-ai-assistant-built-with-llama-3/ - интегрировали модель везде где только можно: чат-бот для рекомендации развлечений, помощь в профессиональных задачах. Добавили в Facebook, Instagram, WhatsApp, Messenger. Есть даже в Facebook Feed. И картинки тоже умеет генерить. И это всё не полный список.
Meta выпустила долгожданную Llama 3. Что известно на текущий момент:
• https://llama.meta.com/llama3/ - сайт с кучей информации. Из минусов - нет ни статьи, ни нормального отчёта о тренировке
• Тренировали 100500 часов... то есть 7 миллионов GPU-часов. И ещё не до конца - модель на 400B всё ещё тренируется
• Сравнить с Llama 2 можно тут: https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md#base-pretrained-models все метрики заметно улучшились
• Судя по отрывку из блогпоста, в подходе к самой модели особо ничего не изменилось - улучшили токенизатор, тренируют на 8192 токенах, используют grouped query attention. Видимо основная причина улучшения - в кропотливом улучшении датасетов.
• https://www.meta.ai/ - сделали сайт, где можно поиграться с моделью. К сожалению, в ОАЭ не работает
• https://about.fb.com/news/2024/04/meta-ai-assistant-built-with-llama-3/ - интегрировали модель везде где только можно: чат-бот для рекомендации развлечений, помощь в профессиональных задачах. Добавили в Facebook, Instagram, WhatsApp, Messenger. Есть даже в Facebook Feed. И картинки тоже умеет генерить. И это всё не полный список.
Meta Llama
The open-source AI models you can fine-tune, distill and deploy anywhere. Choose from our collection of models: Llama 3.1, Llama 3.2, Llama 3.3.