
Розігруємо подарунок під ялиночку — теплий та класний світшот ❄️ Розіграш відбувається у Facebook та Instagram
Умови участі у розіграші:
1. Бути підписаним на сторінку Data Science UA
2. Зробити репост цього допису до себе на сторінку. Публікація повинна бути у відкритому доступі.
Інструкція із застосування 😊:
- нядягати у холодну погоду
- нядягати, коли сумно
- надягати, коли хочеш відчути присутність Data Science спільноти поруч 😀
Переможця оберемо 28 грудня.
#datascienceua #datascience
Умови участі у розіграші:
1. Бути підписаним на сторінку Data Science UA
2. Зробити репост цього допису до себе на сторінку. Публікація повинна бути у відкритому доступі.
Інструкція із застосування 😊:
- нядягати у холодну погоду
- нядягати, коли сумно
- надягати, коли хочеш відчути присутність Data Science спільноти поруч 😀
Переможця оберемо 28 грудня.
#datascienceua #datascience
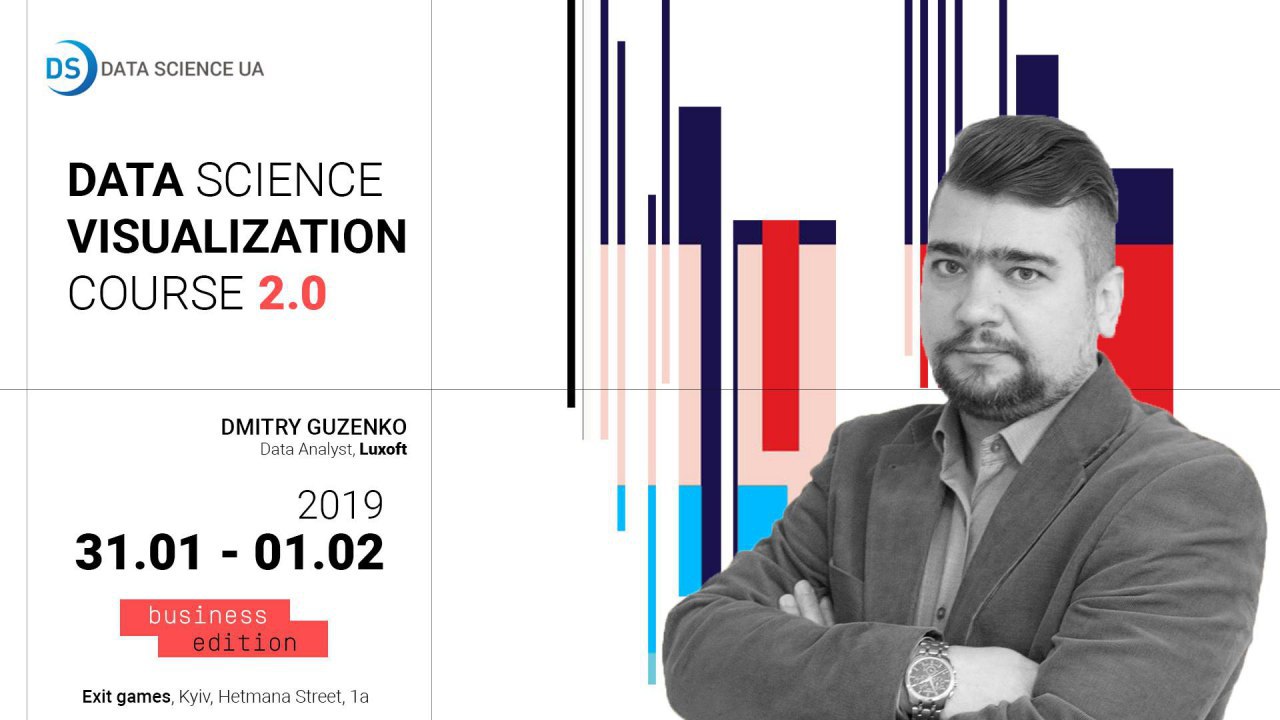
Data Science Visualization Course — повторення очікуваного курсу.
Встигніть потрапити на курс цього разу.
Кількість місць обмежено — 24 учасники.
31 січня та 1 лютого Дмитро Гусенко, Data Analyst, Luxoft проведе дводенний курс Data Science Visualization.
Дмитро має більше 20-років досвіду роботи в галузі автоматизації бізнес-процесів та впровадження систем ERP, 10-річний досвід роботи в системному аналізі та архітектурі бізнес-моделей, 3-річна експертиза управління даними для підвищення ефективності роботи компанії.
Має досвід роботи в галузі архітектури рішень, найкращих практик аналізу бізнес-аналізу для підвищення цінності для інвесторів.
Запрошені експерти:
Олександр Васильєв - Використання мови R для візуалізації даних
Дмитро Пациляндра - Використання мови Python для візуалізації даних
⚡️ Зміст курсу ⚡️
• Введення в візуалізацію даних
• Кращі практики та методи візуалізації
• Порівняння безкоштовних платформ для візуалізації даних
• Воркшоп в групах: моделювання візуалізації на підставі вимог бізнесу
• Практична робота: розробка та публікація візуалізацій, виконаних з використанням MS Power BI Desktop, Tableau Desktop Public Edition
• Практична робота: розробка візуалізації з R, бібліотеки ggplot2, RGL, Plotly
• Практична робота: розробка візуалізації з Python, бібліотеки matplotlib, plotly, bokeh
✓ На курсі ви знайдете відповіді на запитання ✓:
- Практики і підходи для якісної візуалізації. Яких помилок слід уникати? Як зробити так, щоб дані говорили самі за себе і показували необхідні бізнесу інсайти?
- Огляд систем Self BI
- Як зробити візуалізацію швидко, без програмування і надати доступ іншим до створеної візуалізації, в рамках організації або навіть за її межами?
- Як зробити це такими інструментами, за використання яких компанії б не довелося платити гроші, або вартість була б дуже доступною?
Ви отримаєте практичні навички роботи у Microsoft Power BI і Tableau.
Також для проектів Data Science і машинного навчання необхідний більш глибокий аналіз даних, який реалізується за допомогою R та Python. Частина курсу присвячена вивченню деяких базових можливостей для візуалізації з використанням популярних бібліотек R та Python.
З 1-го січня вартість квитка на курс зросте!
Встигніть потрапити на курс цього разу.
Кількість місць обмежено — 24 учасники.
31 січня та 1 лютого Дмитро Гусенко, Data Analyst, Luxoft проведе дводенний курс Data Science Visualization.
Дмитро має більше 20-років досвіду роботи в галузі автоматизації бізнес-процесів та впровадження систем ERP, 10-річний досвід роботи в системному аналізі та архітектурі бізнес-моделей, 3-річна експертиза управління даними для підвищення ефективності роботи компанії.
Має досвід роботи в галузі архітектури рішень, найкращих практик аналізу бізнес-аналізу для підвищення цінності для інвесторів.
Запрошені експерти:
Олександр Васильєв - Використання мови R для візуалізації даних
Дмитро Пациляндра - Використання мови Python для візуалізації даних
⚡️ Зміст курсу ⚡️
• Введення в візуалізацію даних
• Кращі практики та методи візуалізації
• Порівняння безкоштовних платформ для візуалізації даних
• Воркшоп в групах: моделювання візуалізації на підставі вимог бізнесу
• Практична робота: розробка та публікація візуалізацій, виконаних з використанням MS Power BI Desktop, Tableau Desktop Public Edition
• Практична робота: розробка візуалізації з R, бібліотеки ggplot2, RGL, Plotly
• Практична робота: розробка візуалізації з Python, бібліотеки matplotlib, plotly, bokeh
✓ На курсі ви знайдете відповіді на запитання ✓:
- Практики і підходи для якісної візуалізації. Яких помилок слід уникати? Як зробити так, щоб дані говорили самі за себе і показували необхідні бізнесу інсайти?
- Огляд систем Self BI
- Як зробити візуалізацію швидко, без програмування і надати доступ іншим до створеної візуалізації, в рамках організації або навіть за її межами?
- Як зробити це такими інструментами, за використання яких компанії б не довелося платити гроші, або вартість була б дуже доступною?
Ви отримаєте практичні навички роботи у Microsoft Power BI і Tableau.
Також для проектів Data Science і машинного навчання необхідний більш глибокий аналіз даних, який реалізується за допомогою R та Python. Частина курсу присвячена вивченню деяких базових можливостей для візуалізації з використанням популярних бібліотек R та Python.
З 1-го січня вартість квитка на курс зросте!
{kind=link}
ТОП 5 бібліотек для візуалізації даних:
1. D3 - це JavaScript бібліотека для керування документами на основі даних.
D3 дозволяє легко працювати з великими датасетами.
2. React-vis
Ця бібліотека створена Uber. З її допомогою можна легко створювати загальні діаграми (стовпчикові, кругові, карти дерев та багато іншого).
3. Chart.js
Ще одна бібліотека, яка серед інших має перевагу — невеликий розмір. Chart.js дає 8 типів візуалізації.
4. VX
Тут можна знайти величезну кількість графіків.
5. Recharts
Бібліотека, побудована на react-компонентах.
Більше інформації за посиланням: https://www.kdnuggets.com/2019/01/five-best-data-visualization-libraries.html
31 січня і 1 лютого разом з Дмитро Гузенко ми проводимо Data Science Visualization Course: 2.0, де й дізнаємось більше про візуалізацію!
#datascienceua #datascience
1. D3 - це JavaScript бібліотека для керування документами на основі даних.
D3 дозволяє легко працювати з великими датасетами.
2. React-vis
Ця бібліотека створена Uber. З її допомогою можна легко створювати загальні діаграми (стовпчикові, кругові, карти дерев та багато іншого).
3. Chart.js
Ще одна бібліотека, яка серед інших має перевагу — невеликий розмір. Chart.js дає 8 типів візуалізації.
4. VX
Тут можна знайти величезну кількість графіків.
5. Recharts
Бібліотека, побудована на react-компонентах.
Більше інформації за посиланням: https://www.kdnuggets.com/2019/01/five-best-data-visualization-libraries.html
31 січня і 1 лютого разом з Дмитро Гузенко ми проводимо Data Science Visualization Course: 2.0, де й дізнаємось більше про візуалізацію!
#datascienceua #datascience
{kind=link}
Data Science UA Conference
Знання та нетворкінг, що створюють переваги
16 березня вже вшосте разом зберуться кращі розробники та інженери з data science, machine learning, NLP, computer vision та AI.
Data Science UA — конференція про технології, що створюють майбутнє вже сьогодні. Саме тут думки формуються в ідеї, учасники стають партнерами, а інсайти перетворюються на досвід.
Станьте частиною справжнього data science community в України на Data Science UA Conference 2019.
Data Science UA - це:
- 400 учасників
- 18 спікерів
- 3 потоки
- 10 годин нетворкінгу
Одночасно 3 потоки:
- технічний потік
- бізнес потік
- воркшопи
Інформація і квитки за посиланням
Знання та нетворкінг, що створюють переваги
16 березня вже вшосте разом зберуться кращі розробники та інженери з data science, machine learning, NLP, computer vision та AI.
Data Science UA — конференція про технології, що створюють майбутнє вже сьогодні. Саме тут думки формуються в ідеї, учасники стають партнерами, а інсайти перетворюються на досвід.
Станьте частиною справжнього data science community в України на Data Science UA Conference 2019.
Data Science UA - це:
- 400 учасників
- 18 спікерів
- 3 потоки
- 10 годин нетворкінгу
Одночасно 3 потоки:
- технічний потік
- бізнес потік
- воркшопи
Інформація і квитки за посиланням
{kind=link}
Ми розігруємо квиток на 6-ту конференцію Data Science UA на нашій сторінці у Facebook
Data Science UA - це:
- Три потоки: бізнес, технічний і воркшопи.
- Корисні і цікаві доповіді.
- Нетворкінг.
Умови участі у публікації
Data Science UA - це:
- Три потоки: бізнес, технічний і воркшопи.
- Корисні і цікаві доповіді.
- Нетворкінг.
Умови участі у публікації
Facebook
Data Science UA
🔥 Розіграш квитка на Data Science UA Conference 🔥 Якщо ви уважно слідкуєте за новинами нашої спільноти, то знаєте, що 16 березня відбудеться шоста конференція Data Science UA. - Три потоки: бізнес,...
Залишилося менше одного дня до подорожчання квитків на Data Science UA Conference. Встигніть придбати квитки за пропозицією "Early Birds"!
Ми вже анонсували імена 19 спікерів на сайті. Дізнатися більше і придбати квиток на Data Science UA Conference: https://bit.ly/2FSUsnC
#datascienceua #datascience #dsuaconference
Ми вже анонсували імена 19 спікерів на сайті. Дізнатися більше і придбати квиток на Data Science UA Conference: https://bit.ly/2FSUsnC
#datascienceua #datascience #dsuaconference
{kind=link}
Рекомендуємо фільм на вечір — «Тау».
Сюжет:
Джулія заробляє на життя мілкими крадіжками. Одного дня її викрадають і вона прокидається у камері з двома людьми. Джулія робить спробу втекти, але вона потрапляє лише в іншу кімнату, а сусідів по камері вбивають. Усі спроби вийти за межі кімнати припиняються штучним інтелектом Тау...
#datascienceua #datascience
Сюжет:
Джулія заробляє на життя мілкими крадіжками. Одного дня її викрадають і вона прокидається у камері з двома людьми. Джулія робить спробу втекти, але вона потрапляє лише в іншу кімнату, а сусідів по камері вбивають. Усі спроби вийти за межі кімнати припиняються штучним інтелектом Тау...
#datascienceua #datascience
{kind=link}
MIT Technology Review проаналізували 16,625 документів, щоб з'ясувати, куди AI рухається далі.
Вони виявили три основні тенденції: перехід до машинного навчання в кінці 1990-х і на початку 2000-х років, зростання популярності нейронних мереж, що починається на початку 2010-х років, і зростання reinforcement learning за останні кілька років.
То що ж чекає нас у найближчі роки?
#datascienceua #datascience
Вони виявили три основні тенденції: перехід до машинного навчання в кінці 1990-х і на початку 2000-х років, зростання популярності нейронних мереж, що починається на початку 2010-х років, і зростання reinforcement learning за останні кілька років.
То що ж чекає нас у найближчі роки?
#datascienceua #datascience
MIT Technology Review
We analyzed 16,625 papers to figure out where AI is headed next
Our study of 25 years of artificial-intelligence research suggests the era of deep learning may come to an end.
Золоті медалісти Kaggle — про потрапляння в топ на змаганнях з ML та чому в Україні проблеми з машинним навчанням 🧐
Читайте про змагання Kaggle в інтерв'ю з Ігорем Крашеним, Senior Research Engineer в Ciklum, і Денисом Саквою, старшим аналітиком в Dragon Capital
#datascienceua #datascience
Читайте про змагання Kaggle в інтерв'ю з Ігорем Крашеним, Senior Research Engineer в Ciklum, і Денисом Саквою, старшим аналітиком в Dragon Capital
#datascienceua #datascience
ДОУ
Золоті медалісти Kaggle — про потрапляння в топ на змаганнях з ML та чому в Україні проблеми з машинним навчанням
Ігор Крашений та Денис Саква наприкінці 2018 року здобули золото в змаганнях на Kaggle - платформі для тих, хто цікавиться аналізом даних, машинним навчанням, прогнозуванням. В інтерв'ю вони розповіли про завдання на змаганнях, як вивчати ML та в яких сферах…
Вже п’ятниця, а отже час подумати про своє дозвілля! 🙂
Сьогодні ми хочемо порекомендувати фільм Стівена Спілберга «Особлива думка». У головних ролях Том Круз, Колін Фарел та ін.
Сюжет:
Події відбуваються у 2054 році. Людство навчилося передбачати навмисні вбивства і створило для цього спеціальне агенство.
Агент Джонні Андертон — палкий прихильник своєї справи — розкриває наміри злочинців і арештовує їх.
Але що робити, коли у списку вбивць бачиш своє ім’я?
#datascience #datascienceua
Сьогодні ми хочемо порекомендувати фільм Стівена Спілберга «Особлива думка». У головних ролях Том Круз, Колін Фарел та ін.
Сюжет:
Події відбуваються у 2054 році. Людство навчилося передбачати навмисні вбивства і створило для цього спеціальне агенство.
Агент Джонні Андертон — палкий прихильник своєї справи — розкриває наміри злочинців і арештовує їх.
Але що робити, коли у списку вбивць бачиш своє ім’я?
#datascience #datascienceua
{kind=link}
8 книг про штучний інтелект, які радить The Verge:
- «Риси майбутнього», Артур Кларк
- «The Book of Why», Дана Маккензі і Джуда Перл
- «Вибори», Айзек Азімов
- «Вбивчі Великі дані», Кеті О'Ніл
- «Алмазне століття, або Буквар для шляхетних дівчат», Ніл Стівенсон
- «Машинне навчання для людей», Вишал Маін і Самір Сабрі
- «Sorting Things Out: Classification and Its Consequences», Джеффрі Боукер і Сьюзан Лі Стар
- «Верховний алгоритм», Педро Домінгос
Читайте більше за посиланням
- «Риси майбутнього», Артур Кларк
- «The Book of Why», Дана Маккензі і Джуда Перл
- «Вибори», Айзек Азімов
- «Вбивчі Великі дані», Кеті О'Ніл
- «Алмазне століття, або Буквар для шляхетних дівчат», Ніл Стівенсон
- «Машинне навчання для людей», Вишал Маін і Самір Сабрі
- «Sorting Things Out: Classification and Its Consequences», Джеффрі Боукер і Сьюзан Лі Стар
- «Верховний алгоритм», Педро Домінгос
Читайте більше за посиланням
The Verge
An AI reading list — from practical primers to sci-fi short stories
The best books on AI recommended by the experts
🔸Розшукуємо таланти 🔸
8 вакансій і основні вимоги до кандидатів нижче
R Engineer
- BS/MS/PhD degree in computer science or related
- R development experience
- Practical experience with SQL
- Data processing (data.table, dplyr, RODBC, etc)
- Visualization (ggplot2, plot.ly)
- UI (Shiny framework, shinyproxy)
- Understanding of ML techniques and concepts
QA Automation (Scala)
- Experience from 1 year (automation)
- Scala (or Java);
- Shell scripting;
- Experience in performance testing;
- Experience in backend automation;
- Load testing tools (JMeter, Gatling);
- QA experience in a Linux environment;
- Docker
DevOps
- Willingness to master unfamiliar technologies
- Non-abstract large system design skills: distributed network applications, capacity planning
- Containerization tools, 12-factor application practices
- Ability to diagnose performance issues in distributed systems
- Careful attention to details in the task specification
- Basic Computer Science qualifications
Machine learning engineer
- Have a Bachelor degree in Machine Learning, Computer Science, Mathematics, Statistics or equivalent experience
- Experience with applying predictive modeling using sophisticated algorithms such as Decision Trees, Deep Learning… etc. to solve real world case.
- Experience with multiple ML/AI (research papers, kaggle, open source implementations, etc.)
- Expertise in one or more specific areas of ML (Neural Nets/Deep Learning, Text Mining/NLP, etc.)
- Experience with large scale distributed programming and distributed computing platforms
Full Stack Developer
Position requirement:
- At least 3 years in software development;
- Node.js (express framework or similar)
- React.js (with redux or mobxjs)
- PostgreSQL; Unix; Git;
- Good experience with Promise/A+; async/await is must;
- Good experience with lodash is strong plus.
Python Back-End Engineer
- Experience in writing production quality code in Python (1,5+ years of experience)
- Ability to conduct performance analysis and optimization for features and systems.
- Experience of working with high load scalable systems.
- Hands-on experience with either SQL (e.g. MySQL, PostgreSQL).
- Experience with unit testing, load testing and end-to-end testing methodologies.
- Experience with frameworks such as OpenCV, Numpy and PyTorch.
Embedded Engineer
- Linux, ARM-based
- Worked with embedded bootloaders (u-boot, etc.)
- Experience with Yocto/Buildroot or similar
- HW bring-up skills
- Target platform - Xilinx Zynq Ultrascale
- Experience with video sensors/still image
Data Science Engineer
- Python DS libraries Keras, Tensorflow, Pytorch, Caffe2, scikit-learn, numpy, matplotlib,
- Darknet Worked with object detection, keypoint detection
- Semantic segmentation, Instance segmentation
- Object tracking, gesture recognition, scene understanding, movement / action prediction
- Perspective transformation, fast fourier transform, low pass filters, high pass filters
- Experience with data preparation - Data augmentation, annotation, labeling
🔺Резюме надсилайте на пошту cv@data-science.com.ua
8 вакансій і основні вимоги до кандидатів нижче
R Engineer
- BS/MS/PhD degree in computer science or related
- R development experience
- Practical experience with SQL
- Data processing (data.table, dplyr, RODBC, etc)
- Visualization (ggplot2, plot.ly)
- UI (Shiny framework, shinyproxy)
- Understanding of ML techniques and concepts
QA Automation (Scala)
- Experience from 1 year (automation)
- Scala (or Java);
- Shell scripting;
- Experience in performance testing;
- Experience in backend automation;
- Load testing tools (JMeter, Gatling);
- QA experience in a Linux environment;
- Docker
DevOps
- Willingness to master unfamiliar technologies
- Non-abstract large system design skills: distributed network applications, capacity planning
- Containerization tools, 12-factor application practices
- Ability to diagnose performance issues in distributed systems
- Careful attention to details in the task specification
- Basic Computer Science qualifications
Machine learning engineer
- Have a Bachelor degree in Machine Learning, Computer Science, Mathematics, Statistics or equivalent experience
- Experience with applying predictive modeling using sophisticated algorithms such as Decision Trees, Deep Learning… etc. to solve real world case.
- Experience with multiple ML/AI (research papers, kaggle, open source implementations, etc.)
- Expertise in one or more specific areas of ML (Neural Nets/Deep Learning, Text Mining/NLP, etc.)
- Experience with large scale distributed programming and distributed computing platforms
Full Stack Developer
Position requirement:
- At least 3 years in software development;
- Node.js (express framework or similar)
- React.js (with redux or mobxjs)
- PostgreSQL; Unix; Git;
- Good experience with Promise/A+; async/await is must;
- Good experience with lodash is strong plus.
Python Back-End Engineer
- Experience in writing production quality code in Python (1,5+ years of experience)
- Ability to conduct performance analysis and optimization for features and systems.
- Experience of working with high load scalable systems.
- Hands-on experience with either SQL (e.g. MySQL, PostgreSQL).
- Experience with unit testing, load testing and end-to-end testing methodologies.
- Experience with frameworks such as OpenCV, Numpy and PyTorch.
Embedded Engineer
- Linux, ARM-based
- Worked with embedded bootloaders (u-boot, etc.)
- Experience with Yocto/Buildroot or similar
- HW bring-up skills
- Target platform - Xilinx Zynq Ultrascale
- Experience with video sensors/still image
Data Science Engineer
- Python DS libraries Keras, Tensorflow, Pytorch, Caffe2, scikit-learn, numpy, matplotlib,
- Darknet Worked with object detection, keypoint detection
- Semantic segmentation, Instance segmentation
- Object tracking, gesture recognition, scene understanding, movement / action prediction
- Perspective transformation, fast fourier transform, low pass filters, high pass filters
- Experience with data preparation - Data augmentation, annotation, labeling
🔺Резюме надсилайте на пошту cv@data-science.com.ua
{kind=link}
Для тих, хто хоче побудувати кар’єру у data science і суміжних професіях, ми створили новий напрямок — менторство 😊.
У залежності від вашого досвіду, освіти, навичок та бажань ми:
- підберемо вам ментора;
- проконсультуємо з побудови кар’єрного шляху і розвитку необхідних навичок;
- надамо супровід у комфортному режимі (онлайн чи особисто);
- за бажанням створимо групи для спільного навчання.
🔸ВАЖЛИВО🔸: це не офлайн навчальна група, це створення індивідуального плану для самостійного навчання або плану для самостійного навчання маленької групи.
Зацікавились? Пишіть нашому community manager @h31ga
#datascienceua #datascience
У залежності від вашого досвіду, освіти, навичок та бажань ми:
- підберемо вам ментора;
- проконсультуємо з побудови кар’єрного шляху і розвитку необхідних навичок;
- надамо супровід у комфортному режимі (онлайн чи особисто);
- за бажанням створимо групи для спільного навчання.
🔸ВАЖЛИВО🔸: це не офлайн навчальна група, це створення індивідуального плану для самостійного навчання або плану для самостійного навчання маленької групи.
Зацікавились? Пишіть нашому community manager @h31ga
#datascienceua #datascience
{kind=link}
Усе життя ми проводимо з іншими людьми — колегами, друзями, коханими та родичами. Від дитячого садочку до технічних конференцій.
Лише 14 лютого купуйте 2 квитки на Data Science UA Conference за ціною 2900 грн. Адже разом ми здатні на більше, разом ми — команда.
More information about Data Science UA Conference: https://data-science.com.ua/conferences/conference-6/
#datascienceua #datascience #dsuaconference
Лише 14 лютого купуйте 2 квитки на Data Science UA Conference за ціною 2900 грн. Адже разом ми здатні на більше, разом ми — команда.
More information about Data Science UA Conference: https://data-science.com.ua/conferences/conference-6/
#datascienceua #datascience #dsuaconference
{kind=link}
28 лютого в Creative Quarter Олесь Петрів і Назар Шматко проведуть воркшоп 'How to control GANgsters. Controlled image synthesis'.
Олесь Петрів, CTO, NeoCortext/ML Lead, Videogorillas
Олесь активно займається дослідженнями і розробкою систем комп’ютерного зору й обробки природної мови. Він є автором курсу з машинного навчання на Prometheus, а також курсу з глибокого навчання в ARVI Lab. Олесь має великий досвід роботи в обробці відео із використанням методів Deep learning для виявлення об’єктів і дiй, генерацій субтитрів до зображень та відео для кіностудій Голлівуду.
Назар Шматко, VP of engineering, NeoCortext
Назар, як фахівець в області машинного навчання, має досвід роботи в сферах комп'ютерного зору, обробки природної мови та прикладні знання в healthcare-сфері. Зараз активно працює з генеративними моделями для проекту із переносу рис обличчя.
Воркшоп поділений на 2 частини:
Доповідь — 1 година.
У доповіді поговоримо про базову теорію глибоких генеративних моделей і розглянемо принципи роботи змагальних мереж (GAN). Обговоримо основні проблеми з якими стикаються дослідники під час тренування таких моделей і способи їх вирішення. Зробимо огляд існуючих досягнень генеративних моделей і області їх практичного застосування.
Воркшоп — 1,5 год.
Ми розглянемо загальний метод, що дозволяє використовувати натреновану генеративную модель для синтезу даних, які мають заздалегідь визначені атрибути. Для прикладу будемо використовувати натреновану модель GAN, що генерує довільні обличчя з шуму. Натренуємо модель, яка шляхом зміни латентного вектора на вході буде регулювати стать і вік згенерованої особи. Для того, щоб дати розуміння нейромережі, що таке стать і вік ми додатково натренуємо допоміжну модель, що відповідає за передбачення цих атрибутів. Обговоримо переваги і недоліки розглянутих методів і межі їх застосувань.
Коли: 28 лютого, 19:00-22:00
Де: Creative Quarter, 11 поверх
БЦ Gulliver, Спортивна площа, 1А, 01023 Київ, Україна
Вартість:
15-20 лютого — 700 грн
21-28 лютого — 850 грн
Знижки:
від 3 квитків — 10%
від 5 квитків — 15%
студентам — 25%
Квитки за посиланням https://goo.gl/MBVrc2
---------------------------------
Кількість місць обмежено — 20 учасників
---------------------------------
Вимоги до програмного забезпечення:
- операційна система Linux
- бажано, але не критично мати окрему відеокарту
- CUDA
- CUDNN
Необхідне ПО для воркшопу:
imageio
ipython
jupyter
matplotlib
numpy
opencv-python
Pillow
scikit-image
scikit-learn
scipy
sklearn
tensorboard
tensorboardX
tensorflow
torch
torchfile
torchvision
tqdm
Олесь Петрів, CTO, NeoCortext/ML Lead, Videogorillas
Олесь активно займається дослідженнями і розробкою систем комп’ютерного зору й обробки природної мови. Він є автором курсу з машинного навчання на Prometheus, а також курсу з глибокого навчання в ARVI Lab. Олесь має великий досвід роботи в обробці відео із використанням методів Deep learning для виявлення об’єктів і дiй, генерацій субтитрів до зображень та відео для кіностудій Голлівуду.
Назар Шматко, VP of engineering, NeoCortext
Назар, як фахівець в області машинного навчання, має досвід роботи в сферах комп'ютерного зору, обробки природної мови та прикладні знання в healthcare-сфері. Зараз активно працює з генеративними моделями для проекту із переносу рис обличчя.
Воркшоп поділений на 2 частини:
Доповідь — 1 година.
У доповіді поговоримо про базову теорію глибоких генеративних моделей і розглянемо принципи роботи змагальних мереж (GAN). Обговоримо основні проблеми з якими стикаються дослідники під час тренування таких моделей і способи їх вирішення. Зробимо огляд існуючих досягнень генеративних моделей і області їх практичного застосування.
Воркшоп — 1,5 год.
Ми розглянемо загальний метод, що дозволяє використовувати натреновану генеративную модель для синтезу даних, які мають заздалегідь визначені атрибути. Для прикладу будемо використовувати натреновану модель GAN, що генерує довільні обличчя з шуму. Натренуємо модель, яка шляхом зміни латентного вектора на вході буде регулювати стать і вік згенерованої особи. Для того, щоб дати розуміння нейромережі, що таке стать і вік ми додатково натренуємо допоміжну модель, що відповідає за передбачення цих атрибутів. Обговоримо переваги і недоліки розглянутих методів і межі їх застосувань.
Коли: 28 лютого, 19:00-22:00
Де: Creative Quarter, 11 поверх
БЦ Gulliver, Спортивна площа, 1А, 01023 Київ, Україна
Вартість:
15-20 лютого — 700 грн
21-28 лютого — 850 грн
Знижки:
від 3 квитків — 10%
від 5 квитків — 15%
студентам — 25%
Квитки за посиланням https://goo.gl/MBVrc2
---------------------------------
Кількість місць обмежено — 20 учасників
---------------------------------
Вимоги до програмного забезпечення:
- операційна система Linux
- бажано, але не критично мати окрему відеокарту
- CUDA
- CUDNN
Необхідне ПО для воркшопу:
imageio
ipython
jupyter
matplotlib
numpy
opencv-python
Pillow
scikit-image
scikit-learn
scipy
sklearn
tensorboard
tensorboardX
tensorflow
torch
torchfile
torchvision
tqdm
{kind=link}
Сайт https://thispersondoesnotexist.com/ генерує реалістичні людські обличчя. Більшість є дуже реалістичними 😏
Як це все працює можна прочитати у статті: https://arxiv.org/pdf/1812.04948.pdf
#datascienceua #datascience
Як це все працює можна прочитати у статті: https://arxiv.org/pdf/1812.04948.pdf
#datascienceua #datascience
Нейромережа, що пише сама тексти 🤨
OpenAI натренувала нейромережу на 8 мільйонах веб-сторінок. І, як стверджують, тексти виходять доволі непоганої якості 😏
Компанія поки що пропонує лише демо-версію, через низку побоювань
OpenAI натренувала нейромережу на 8 мільйонах веб-сторінок. І, як стверджують, тексти виходять доволі непоганої якості 😏
Компанія поки що пропонує лише демо-версію, через низку побоювань
AIN.UA
OpenAI создала нейросеть, которая самостоятельно пишет тексты. Ее боятся выпускать
Некоммерческая компания OpenAI, которая занимается исследованиями в сфере искусственного интеллекта, создала нейросеть GPT-2, которая может самостоятельно писать тексты по определенной теме. Впрочем, в OpenAI сообщили, что не будут публиковать полную версию…
Найбільш часті проблеми, що виникають при роботі з TensorFlow і як їх вирішувати 🙃
Галина Олійник, Natural language processing engineer в 1touch.io поділилась своїми порадами у статті.
Якщо в тебе виникнуть нові труднощі і питання, то зможеш запитати в Галини про них особисто на Data Science UA Conference 😃
Читай статтю: https://dou.ua/lenta/articles/debug-on-tensorflow/?from=tg&fbclid=IwAR27teR84qn9hYKhm3Ufs7GPhAt1WDF22rFkoemdCGLYCm01Ol2Vx1--qTk
Галина Олійник, Natural language processing engineer в 1touch.io поділилась своїми порадами у статті.
Якщо в тебе виникнуть нові труднощі і питання, то зможеш запитати в Галини про них особисто на Data Science UA Conference 😃
Читай статтю: https://dou.ua/lenta/articles/debug-on-tensorflow/?from=tg&fbclid=IwAR27teR84qn9hYKhm3Ufs7GPhAt1WDF22rFkoemdCGLYCm01Ol2Vx1--qTk
ДОУ
Как дебажить код на TensorFlow: болезненные ошибки и их решения
Привет, меня зовут Галина Олейник, я занимаюсь решением задач в сфере NLP в компании 1touch.io. Сегодня я хотела бы рассказать о работе data scientist’а с фреймворком TensorFlow, а также углубиться в детали решения наиболее частых проблем, которые возникают…
Робочий тиждень вже майже закінчився і, когось більше, когось менше, виснажив 😲
А ось наша команда не перестає працювати, щоб організувати круту конференцію Data Science UA для вас. І ми вирішили подарувати промокоди на 50% знижку на конференцію першим двом щасливцям ☺️
🔸 DSUA_Friday
🔸 DSUA_Fun
Скоріше переходьте на сайт, щоб активувати один з промокодів!
А ось наша команда не перестає працювати, щоб організувати круту конференцію Data Science UA для вас. І ми вирішили подарувати промокоди на 50% знижку на конференцію першим двом щасливцям ☺️
🔸 DSUA_Friday
🔸 DSUA_Fun
Скоріше переходьте на сайт, щоб активувати один з промокодів!
{kind=link}
Юххуу, 15 хвилин і двоє щасливчиків придбали квитки на конференцію Data Science UA зі знижкою 50% 😀
Програма конференції вже на сайті!
Ви вже вирішили, які доповіди будете слухати? 😃
Шукайте програму Data Science UA Conference за посиланням: https://bit.ly/2FSUsnC
#datascienceua #datascience #dsuaconference
Ви вже вирішили, які доповіди будете слухати? 😃
Шукайте програму Data Science UA Conference за посиланням: https://bit.ly/2FSUsnC
#datascienceua #datascience #dsuaconference
{kind=link}