
📊 Визуализация данных 🧑🎨
**Туториалы matplotlib**
50 визуализаций с помощью matplotlib
Шпаргалка по matplotlib
Anatomy of figure in matplotlib
🔥 50 примеров крутых графиков на Matplotlib и Seaborn
Способы создания гистограмм с помощью Python
Введение в визуализацию данных с помощью Matplotlib
**Туториалы Seaborn**
Подробный гайд по визуализации с помощью Seaborn
Визуализация данных в Seaborn
🔥 Русскоязычный гайд про визуализацию данных с помощью Seaborn
**Туториалы Plotly**
Статистический анализ с использованием Plotly
Многомерные графики в Python
Шпаргалка по визуализации данных в Python с помощью Plotly
**Туториалы по визуализации с Pandas**
Создание гистограм с помощью встроенных методов pandas
Как строить визуализации с помощью методов, встроенных в ацессор plot в Pandas
**Другие туториалы**
Визуализация с помощью Altair
Визуализация геоданных с помощью Folium
Туториал по визуализации с использованием Bokeh
🔥 Complete Guide to Data Visualization with Python
Визуализация данных с помощью Altair
Как делать интерактивные визуализации с помощью Bokeh в одну строчку с библиотекой `Pandas-Boken`
**Библиотеки**
Библиотека manim для создания научных анимаций
Визуализация геопространственных данных с помощью библиотеки geoviews
Библиотека для создания анимированных гифок с помощью matplotlib
Графики как в ggplot (R) с помощью библиотеки `plotnine`
Библиотека `supervenn` для визуализации пересекающихся множеств
**Книги и курсы**
Книга на русском языке по Matplotlib от DevPractice
**Другое**
15 роликов про визуализацию на matplotlib
**Туториалы matplotlib**
50 визуализаций с помощью matplotlib
Шпаргалка по matplotlib
Anatomy of figure in matplotlib
🔥 50 примеров крутых графиков на Matplotlib и Seaborn
Способы создания гистограмм с помощью Python
Введение в визуализацию данных с помощью Matplotlib
**Туториалы Seaborn**
Подробный гайд по визуализации с помощью Seaborn
Визуализация данных в Seaborn
🔥 Русскоязычный гайд про визуализацию данных с помощью Seaborn
**Туториалы Plotly**
Статистический анализ с использованием Plotly
Многомерные графики в Python
Шпаргалка по визуализации данных в Python с помощью Plotly
**Туториалы по визуализации с Pandas**
Создание гистограм с помощью встроенных методов pandas
Как строить визуализации с помощью методов, встроенных в ацессор plot в Pandas
**Другие туториалы**
Визуализация с помощью Altair
Визуализация геоданных с помощью Folium
Туториал по визуализации с использованием Bokeh
🔥 Complete Guide to Data Visualization with Python
Визуализация данных с помощью Altair
Как делать интерактивные визуализации с помощью Bokeh в одну строчку с библиотекой `Pandas-Boken`
**Библиотеки**
Библиотека manim для создания научных анимаций
Визуализация геопространственных данных с помощью библиотеки geoviews
Библиотека для создания анимированных гифок с помощью matplotlib
Графики как в ggplot (R) с помощью библиотеки `plotnine`
Библиотека `supervenn` для визуализации пересекающихся множеств
**Книги и курсы**
Книга на русском языке по Matplotlib от DevPractice
**Другое**
15 роликов про визуализацию на matplotlib
Datalytics pinned «📊 Визуализация данных 🧑🎨 **Туториалы matplotlib** 50 визуализаций с помощью matplotlib Шпаргалка по matplotlib Anatomy of figure in matplotlib 🔥 50 примеров крутых графиков на Matplotlib и Seaborn Способы создания гистограмм с помощью Python Введение…»
Forwarded from Reveal the Data
Женя Козлов, построивший с нуля отдел аналитики Яндекс.Такси в сотню человек, написал лонгрид об оценке профессионального уровня аналитиков данных.
Ещё Женя любит применять аналитические подходы и к повседневной жизни, пишет об этом в своем телеграм-канале
#ссылка
Ещё Женя любит применять аналитические подходы и к повседневной жизни, пишет об этом в своем телеграм-канале
#ссылка
GoPractice
ᐈ Навыки и требования к аналитикам данных на разных уровнях в «Яндексе». Профессия аналитика данных
Какими бывают уровни аналитика данных, как развиваться в профессии и какие компетенции нужны топовым аналитикам
Дмитрий Федоров перевёл гайд "Pandas за 10 минут" из официальной документации. Ещё один отличный русскоязычный материал, который можно смело рекомендовать для изучения Pandas. Скажем Дмитрию огромное спасибо (а ещё лучше подписывайтесь на его канал)!
http://dfedorov.spb.ru/pandas/Pandas%20%D0%B7%D0%B0%2010%20%D0%BC%D0%B8%D0%BD%D1%83%D1%82.html
http://dfedorov.spb.ru/pandas/Pandas%20%D0%B7%D0%B0%2010%20%D0%BC%D0%B8%D0%BD%D1%83%D1%82.html
Forwarded from Пристанище Дата Сайентиста
pycaret - библиотека для автоматизации рабочих процессов машинного обучения
PyCaret одна из самых простых AutoML библиотек. AutoML — это процесс автоматизации сквозного процесса применения машинного обучения. AutoML бибилиотеки позволяют ускорить цикл экспериментов и тестирование гипотез.
PyCaret по сути, оболочка Python для нескольких библиотек и фреймворков машинного обучения, таких как scikit-learn, XGBoost, LightGBM, CatBoost, spaCy, Optuna, Hyperopt, Ray и многих других. Этот инструмент может заменить сотни строк кода всего несколькими.
С помощью этой библиотеки можно решать следующие задачи:
- Классификация
- Регрессия
- Кластеризация
- Детекция Аномалий
- Natural Language Processing
- Подготовка ассоциативных правил
Установка:
Пример использования:
Из еще крутых возможностей PyCaret
Деплой моделей на AWS S3:
Логирование экспериментов:
Работа с признаками:
Рекомендую обратить внимание на эту библиотеку. Особенно если построение ML моделей не ваше основная работа.
PyCaret одна из самых простых AutoML библиотек. AutoML — это процесс автоматизации сквозного процесса применения машинного обучения. AutoML бибилиотеки позволяют ускорить цикл экспериментов и тестирование гипотез.
PyCaret по сути, оболочка Python для нескольких библиотек и фреймворков машинного обучения, таких как scikit-learn, XGBoost, LightGBM, CatBoost, spaCy, Optuna, Hyperopt, Ray и многих других. Этот инструмент может заменить сотни строк кода всего несколькими.
С помощью этой библиотеки можно решать следующие задачи:
- Классификация
- Регрессия
- Кластеризация
- Детекция Аномалий
- Natural Language Processing
- Подготовка ассоциативных правил
Установка:
pip install pycaretПример использования:
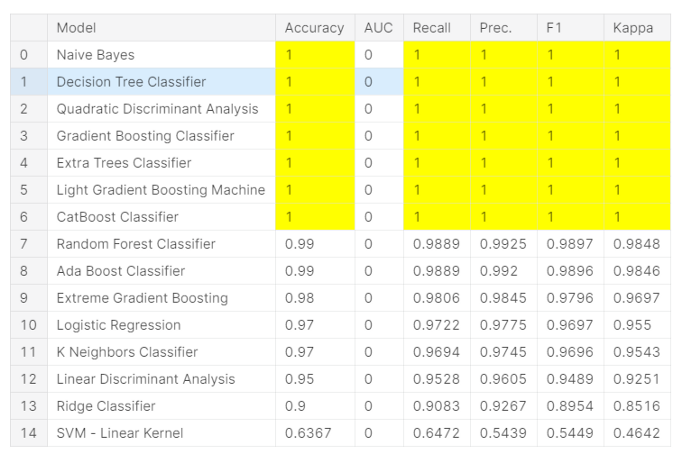
from pycaret.classification import * # импортируем pycaret classification методыexp = setup(data = data, target = 'Species', session_id=77 ) # указываем данные, таргет и random seedcompare_models() # сравним различные модели метриками - accuracy,F1 и другимиnb_model = create_model('nb', fold = 10) # создаем модель Naives Byes на 10 фолдахplot_model(nb_model, plot = 'auc') # построим ROC AUCplot_model(nb_model, plot = 'confusion_matrix') # построим confusion matrixnew_prediction = predict_model(nb_model, data=data_unseen) # делаем предсказания на новых данныхИз еще крутых возможностей PyCaret
Деплой моделей на AWS S3:
deploy_model(final_lr, model_name = 'lr_aws', platform = 'aws', authentication = { 'bucket' : 'pycaret-test' })Логирование экспериментов:
from pycaret.classification import *clf1 = setup(data, target = 'Class variable', log_experiment = True, experiment_name = 'diabetes1')top5 = compare_models()logs = get_logs(save=True)Работа с признаками:
reg1 = setup(data = insurance, target = 'charges', feature_interaction = True, feature_ratio = True)reg1 = setup(data = insurance, target = 'charges', trigonometry_features = True)clf1 = setup(data = juice, target = 'Purchase', polynomial_features = True)clf1 = setup(data = credit, target = 'default', group_features = ['BILL_AMT1', 'BILL_AMT2', 'BILL_AMT3', 'BILL_AMT4', 'BILL_AMT5', 'BILL_AMT6'])Рекомендую обратить внимание на эту библиотеку. Особенно если построение ML моделей не ваше основная работа.
{kind=link}
👍2
🚀 Автоматизация 🤖
**Автоматизация рутины**
Туториал из 8 эпизодов про автоматизацию рутинных задач
Запуск скриптов по расписанию
Отправка email сообщений
Как писать приложения с command-line interfaces
Создание YAML конфигов для выполнения задач
Работа с API Google Drive
Туториал про создание бота для Телеграм на основе данных BigQuery
Инструмент для анализа данных из командной строки
Рассуждения на тему автоматизации рутины с помощью Python
Автоматизация формирования отчетности с помощью Papermill 1
Автоматизация формирования отчетности с помощью Papermill 2
Cоздание пайплайнов обработки данных в датафреймах
7 Simple Python Functions to Clean Your Data
**Excel и Google Sheets**
Как сравнить два Excel-файла
Форматирование ячеек в Excel-файлах
Как вставлять рисунки, диаграммы и формулы в книгу Excel через Python
Загрузка данных из датафрейма в Google Sheets
Соединение нескольких листов в один на Python
Руководство по работе с openpyxl
Обзор возможностей библиотек pandas, openpyxl, xlrd, xlutils и pyexcel для работы с Excel-файлами из Python
**Интерактивные дашборды и data-applications**
Создание web-дашбордов с библиотекой Panel
Библиотека для создания standalone-приложений на основе данных Voila
Краткое руководство по Dash
Metabase с поддержкой Clickhouse
Видеолекция Алексея Куличевского про Metabase
Создание интерактивного дашборда в Dash
Обзор библиотеки Streamlit
Interactive spreadsheets in Jupyter
Cоздание интерактивных дашбордов с помощью Plotly и Voila
Отображение датафрейма в удобной таблице с возможностью сортировки и фильтрации с помощью D-Tale
Делаем Dashboard для авиакомпании: Dash и не только
Создание приложения с помощью `Streamlit`
**Автоматизация рутины**
Туториал из 8 эпизодов про автоматизацию рутинных задач
Запуск скриптов по расписанию
Отправка email сообщений
Как писать приложения с command-line interfaces
Создание YAML конфигов для выполнения задач
Работа с API Google Drive
Туториал про создание бота для Телеграм на основе данных BigQuery
Инструмент для анализа данных из командной строки
Рассуждения на тему автоматизации рутины с помощью Python
Автоматизация формирования отчетности с помощью Papermill 1
Автоматизация формирования отчетности с помощью Papermill 2
Cоздание пайплайнов обработки данных в датафреймах
7 Simple Python Functions to Clean Your Data
**Excel и Google Sheets**
Как сравнить два Excel-файла
Форматирование ячеек в Excel-файлах
Как вставлять рисунки, диаграммы и формулы в книгу Excel через Python
Загрузка данных из датафрейма в Google Sheets
Соединение нескольких листов в один на Python
Руководство по работе с openpyxl
Обзор возможностей библиотек pandas, openpyxl, xlrd, xlutils и pyexcel для работы с Excel-файлами из Python
**Интерактивные дашборды и data-applications**
Создание web-дашбордов с библиотекой Panel
Библиотека для создания standalone-приложений на основе данных Voila
Краткое руководство по Dash
Metabase с поддержкой Clickhouse
Видеолекция Алексея Куличевского про Metabase
Создание интерактивного дашборда в Dash
Обзор библиотеки Streamlit
Interactive spreadsheets in Jupyter
Cоздание интерактивных дашбордов с помощью Plotly и Voila
Отображение датафрейма в удобной таблице с возможностью сортировки и фильтрации с помощью D-Tale
Делаем Dashboard для авиакомпании: Dash и не только
Создание приложения с помощью `Streamlit`
👍2
Datalytics pinned «🚀 Автоматизация 🤖 **Автоматизация рутины** Туториал из 8 эпизодов про автоматизацию рутинных задач Запуск скриптов по расписанию Отправка email сообщений Как писать приложения с command-line interfaces Создание YAML конфигов для выполнения задач Работа…»
Forwarded from Этюды для программистов на Python (Дима Федоров)
Перевод статьи Криса Моффитта о сводных таблицах (pivot_table) в pandas 🥳🐍 http://dfedorov.spb.ru/pandas/%D0%A1%D0%B2%D0%BE%D0%B4%D0%BD%D0%B0%D1%8F%20%D1%82%D0%B0%D0%B1%D0%BB%D0%B8%D1%86%D0%B0%20%D0%B2%20pandas.html
Начал собирать список вредных советов при написании pandas-кода. Вот что делать НЕ стоит:
- Выводить датафрейм через функцию
- Использовать параметр
- Удалять колонки через
- Делать однотипные операции с колонками не через цикл, а каждую на своей строке
- Использовать пробелы, кириллицу и спецсимволы (напр. '$') в названиях колонок
- Проходится циклом по строкам датафрейма
- Использовать метод
- Тоже вкусовщина: делать поочередные манипуляции с одной и той же колонкой на отдельных строках (например, вместо
- Использовать вызов методов внутри
- Использовать
- Всегда оставлять MultiIndex (даже если он в колонках и в строках одновременно)
- Использовать
А какие вы посоветуете вредные советы? 😉
- Выводить датафрейм через функцию
print() вместо display()
- Использовать built-in функции Python вместо методов pandas (например, sum(df['column']) вместо df['column'].sum())- Использовать параметр
inplace при вызове методов- Удалять колонки через
del
- Изменять названия колонок через атрибут columns или метод set_axis()
- Вызывать колонки через attribute-like запись (df.genre) вместо dict-like записи (df['genre'])- Делать однотипные операции с колонками не через цикл, а каждую на своей строке
- Использовать пробелы, кириллицу и спецсимволы (напр. '$') в названиях колонок
- Проходится циклом по строкам датафрейма
- Использовать метод
merge() без параметров how и on
- Это вкусовщина: использовать вызов методов из библиотеки, а не из инстанса DataFrame (например, pd.pivot_table() вместо df.pivot_table())- Тоже вкусовщина: делать поочередные манипуляции с одной и той же колонкой на отдельных строках (например, вместо
df['column'].fillna(0).astype(int) сделать на отдельных строках .fillna(0) и .astype(int)
- Часто использовать абсолютную индексацию (например, iloc или выбирать колонки с помощью slice)- Использовать вызов методов внутри
query() (например, df.query('value.notna()'))- Использовать
notnull() и isnull() вместо notna() и isna() (для соблюдения читаемости, учитывая, что существуют методы drop_na() и fillna())- Всегда оставлять MultiIndex (даже если он в колонках и в строках одновременно)
- Использовать
pivot_table() там где можно обойтись groupby()
Многие пункты — это скорее вкусовщина, они почти ни на что не влияют с точки зрения производительности или функциональности, но зато код смотрится опрятнее, а также позволяет при ревью проектов добиться от студентов более однотипного стиля, что снижает когнитивную нагрузку у ревьюеров.А какие вы посоветуете вредные советы? 😉
Forwarded from Этюды для программистов на Python (Дима Федоров)
🔥 Завершил перевод "Подробного руководства по группировке и агрегированию с помощью pandas" от Криса Моффитта (по ссылке Блокнот и Colab): https://vk.cc/bJOuIc
Все переводы доступны на странице: http://dfedorov.spb.ru/pandas/
Все переводы доступны на странице: http://dfedorov.spb.ru/pandas/
Forwarded from Этюды для программистов на Python (Дима Федоров)
Перевел две интересные статьи! 🥳
👉 Обзор типов данных pandas (по ссылке Блокнот и Colab): https://vk.cc/bVq3KU
👉 Очистка данных о валюте с помощью pandas (по ссылке Блокнот и Colab): https://vk.cc/bVq3Ua
Все переводы доступны на странице 🐍 http://dfedorov.spb.ru/pandas/
👉 Обзор типов данных pandas (по ссылке Блокнот и Colab): https://vk.cc/bVq3KU
👉 Очистка данных о валюте с помощью pandas (по ссылке Блокнот и Colab): https://vk.cc/bVq3Ua
Все переводы доступны на странице 🐍 http://dfedorov.spb.ru/pandas/
This media is not supported in your browser
VIEW IN TELEGRAM
А что, если вы не просто умеете стучать по клавиатуре? 😉 Что, если вы понимаете основы баз данных, составления SQL-запросов и умеете разрабатывать ПО? IT-команда Совкомбанка, одного из самых технологичных банков России, если кто вдруг не знал, ищет системного аналитика на проект OpenApi. В команде знают и любят Agile, помогают коллегам развиваться и платят приличные деньги. Никаких дресс-кодов, гибкий график, расширенный ДМС и адекватные тимлиды прилагаются. Локация для вакансии — Саратов. Узнать больше можно здесь: https://bit.ly/3lUeL5p
Эмели Драль и Лена Самуйлова опубликовали на Github легковесную библиотеку для генерации интерактивных отчетов по анализу датасетов для ML моделей. Это полноценный MVP, который сегодня умеет оценивать только Data Drift, а совсем скоро научится делать ещё массу всего полезного, например, ассеcсмент ML модели, а дальше полноценный мониторинг
https://evidentlyai.com/blog/evidently-001-open-source-tool-to-analyze-data-drift
Ссылка на github
https://evidentlyai.com/blog/evidently-001-open-source-tool-to-analyze-data-drift
Ссылка на github
Evidentlyai
Introducing Evidently 0.0.1 Release: Open-Source Tool To Analyze Data Drift
We are excited to announce our first release. You can now use Evidently open-source python package to estimate and explore data drift for machine learning models.
Хорошее русскоязычное руководство по Matplotlib. Отдельно стоит отметить, что это не просто сборник готовых рецептов по построению стандартных диаграмм, а качественный образовательный материал, объясняющий простым языком принципы построения самых разнообразных диаграмм (в том числе комбинированных, например, scatterplot + line plot). Большое внимание уделяется компонентам фигуры (см. Anatomy of a figure), что позволяет гибко настраивать внешний вид визуализации под свои нужды
Когда я только знакомился с анализом данных на Python, то matplotlib я не любил из-за постоянно возникающего ощущения, что для создания хорошей визуализации нужно много танцев с бубном, но по-тихоньку моё отношение к нему менялось. На мой взгляд, обманчивая сложность освоения в первую очередь связана с тем, что самый распространенный способ создания визуализаций в matplotlib — это pyplot API, которое базируется на состояниях (state-based API), а после объектно-ориентированного подхода это немного дезориентирует. Вот хороший ответ на stackoverflow, объясняющий принцип состояний в matplotlib
Итого: секрет успешного освоения matplotlib — понимание компонентов фигуры + принципа state-based API. Зная компоненты становится яснее какие компоненты нужно изменять, а умея работать с состояниями — изменять эти компоненты
https://pyprog.pro/mpl/mpl_short_guide.html
Когда я только знакомился с анализом данных на Python, то matplotlib я не любил из-за постоянно возникающего ощущения, что для создания хорошей визуализации нужно много танцев с бубном, но по-тихоньку моё отношение к нему менялось. На мой взгляд, обманчивая сложность освоения в первую очередь связана с тем, что самый распространенный способ создания визуализаций в matplotlib — это pyplot API, которое базируется на состояниях (state-based API), а после объектно-ориентированного подхода это немного дезориентирует. Вот хороший ответ на stackoverflow, объясняющий принцип состояний в matplotlib
Итого: секрет успешного освоения matplotlib — понимание компонентов фигуры + принципа state-based API. Зная компоненты становится яснее какие компоненты нужно изменять, а умея работать с состояниями — изменять эти компоненты
https://pyprog.pro/mpl/mpl_short_guide.html
MACAUSLOT88 Login Link Alternatif Dan Daftar Terbaru 2025
MACAUSLOT88 Login Link Alternatif Dan Daftar Terbaru 2025 telah kami sediakan supaya kamu bisa ngeslot dengan aman serta mendaptakan promo terbaru kami gratis!
Forwarded from oleg_log (Oleg Kovalov)
# lang: python
def is_unique(l):
return len(set(l)) == len(l)
Forwarded from oleg_log (Oleg Kovalov)
Google создали рейтинг критически важных open-source проектов. В расчёте метрики критичности участвует много разных показателей, свидетельствующих о влиянии и значимости проекта, например, количество контрибьютров и частота коммитов на Github. Отдельного внимания заслуживает документ, рассказывающий о методологии расчёта. На мой взгляд, это интересный пример расчёта аналитической метрики, позволяющей ранжировать данные, опираясь на независимые показатели
На основе данных, представленных Google, оказывается, что наиболее критичный open-source проект среди всех — это
На картинке топ-10 Python-проектов. А ещё можете сами поковырять файлик, в который сведены данные по ссылке выше: 6 списков по 6 языкам (C, C++, Java, JS, Python, Rust)
На основе данных, представленных Google, оказывается, что наиболее критичный open-source проект среди всех — это
Node.js. А среди проектов, написанных на Python — Ansible. Ну и замечу, что всеми нами любимый Pandas находится на 4 строчке среди Python-проектов и на 19 месте среди всех проектовНа картинке топ-10 Python-проектов. А ещё можете сами поковырять файлик, в который сведены данные по ссылке выше: 6 списков по 6 языкам (C, C++, Java, JS, Python, Rust)
Forwarded from addmeto (Grigory Bakunov)
Пятничное: ребята из ClickHouse загрузили в базу кучу статистики про GitHub и сделали кучу готовых запросов, очень много рассказывающих про культуру и опенсорс вцелом. Если вас интересует эта тема - обязательно посмотрите, много неожиданных открытий. Например теперь понятно, какая компания делает самый популярный опенсорс. Или какой контент на гитхабе самый популярный вообще https://gh.clickhouse.tech/explorer/
Для отслеживания самых заметных мероприятий посвященных Big Data, Machine Learning, Data Science, Data Engineering, BI/DWH и другим направлениям, связанным с обработкой данных, рекомендую подписаться на канал "Data online events & Moscow meetups"
Предложить свой ивент можно, написав @NikolayKrupiy, @Ajvol
👉🏻 Подписаться на t.me/data_events
Предложить свой ивент можно, написав @NikolayKrupiy, @Ajvol
👉🏻 Подписаться на t.me/data_events
Telegram
Data Events
Ивенты по Big Data, DE, BI, AI, ML, DS, DA, etc
Спец подканалы:
@AI_meetups
@DE_events
@BI_events
@datathons
@data_career
@devetups
см также @agile_events
#Календарь bit.ly/3oLMmDc
tgstat.ru/channel/@data_events
contacts: @black_titmouse
Спец подканалы:
@AI_meetups
@DE_events
@BI_events
@datathons
@data_career
@devetups
см также @agile_events
#Календарь bit.ly/3oLMmDc
tgstat.ru/channel/@data_events
contacts: @black_titmouse
Статья, в которой приводится несколько простых советов о том как организовывать эффективные и надежные пайплайны обработки данных. Если вкратце, то вот они:
- Разделяйте пайплайн на изолированные и тестируемые маленькие шаги;
- Старайтесь делать шаги атомарными (обработка данных как атомарные транзакции)
- Запущенный этап ETL должен при повторном запуске выдавать тот же результат на идентичных входных данных (правило идемпотентности)
- Избыточность (храните raw-data так долго как это представляется возможным)
https://habr.com/en/company/badoo/blog/531912/
- Разделяйте пайплайн на изолированные и тестируемые маленькие шаги;
- Старайтесь делать шаги атомарными (обработка данных как атомарные транзакции)
- Запущенный этап ETL должен при повторном запуске выдавать тот же результат на идентичных входных данных (правило идемпотентности)
- Избыточность (храните raw-data так долго как это представляется возможным)
https://habr.com/en/company/badoo/blog/531912/
Habr
The Rules for Data Processing Pipeline Builders
"Come, let us make bricks, and burn them thoroughly." – legendary buildersYou may have noticed by 2020 that data is eating the world. And whenever any r...
Forwarded from Этюды для программистов на Python (Дима Федоров)
У меня две новости и обе хорошие 🥳
1) Добавил несколько кейсов и упражнений по Pandas и NumPy (можно прокачать скиллы по анализу товаров): https://dfedorov.spb.ru/pandas/
2) Завершил перевод статьи "Типичные задачи Excel, продемонстрированные в pandas": https://dfedorov.spb.ru/pandas/%D0%A2%D0%B8%D0%BF%D0%B8%D1%87%D0%BD%D1%8B%D0%B5%20%D0%B7%D0%B0%D0%B4%D0%B0%D1%87%D0%B8%20Excel,%20%D0%BF%D1%80%D0%BE%D0%B4%D0%B5%D0%BC%D0%BE%D0%BD%D1%81%D1%82%D1%80%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D1%8B%D0%B5%20%D0%B2%20pandas.html
1) Добавил несколько кейсов и упражнений по Pandas и NumPy (можно прокачать скиллы по анализу товаров): https://dfedorov.spb.ru/pandas/
2) Завершил перевод статьи "Типичные задачи Excel, продемонстрированные в pandas": https://dfedorov.spb.ru/pandas/%D0%A2%D0%B8%D0%BF%D0%B8%D1%87%D0%BD%D1%8B%D0%B5%20%D0%B7%D0%B0%D0%B4%D0%B0%D1%87%D0%B8%20Excel,%20%D0%BF%D1%80%D0%BE%D0%B4%D0%B5%D0%BC%D0%BE%D0%BD%D1%81%D1%82%D1%80%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D1%8B%D0%B5%20%D0%B2%20pandas.html