
Дмитрий Федеров перевёл официальные туториалы по Pandas на русский язык. Теперь это один из тех (немногочисленных) русскоязычных материалов, которые я могу смело рекомендовать любому, кто начинает изучать Pandas
http://dfedorov.spb.ru/pandas/
http://dfedorov.spb.ru/pandas/
В Телеграме очень много каналов про аналитику, в определенный момент я задался странным желанием собрать их все. У меня вообще страсть к коллекционированию информации. Я выискиваю даже самые небольшие каналы джунов/начинающих и подписываюсь на них, чтобы понять какие проблемы их волнуют.
И вот я в своём расстройстве зашёл так далеко, что решил спарсить все посты из этих каналов, да ещё и с указанием количества просмотров. Появилась небольшая такая таблица на 11000 записей. Да, я из тех людей, которые сначала соберут тьму данных, а потом решают, что с ними делать.
Сидел-сидел и понял, что хочу сделать так, чтобы информация из каналов в Телеграме приобретала вторую жизнь, просмотры набирали бы не только свежие посты, но и старые/проверенные/новые с небольшим числом просмотров. Сначала думал вручную собрать посты в коллекции (например, про АБ-тесты, про SQL, про визуализацию и т.д.) и разместить на отдельных страничках через embed-виджеты. Получились бы такие небольшие базы знаний. Но мне стало немного лениво/скучно/тревожно при мысли о том, чтобы вручную отбирать хорошие посты и классифицировать их. Поэтому я неумело сделал препроцессинг текстов постов и теперь готов к классификации с использованием ARTIFICIAL INTELLIGENCE!!!
Что дальше?
Дальше хочу сделать небольшой сервис, где выбираешь интересующую тематику, например, "Продуктовые метрики" и тебе подсовываются рандомно-хорошие посты из разных каналов на эту (или семантически-похожую) тему.
Поэтому ищу руки-ноги-головы, готовые помочь с:
а) Алгоритмом кластеризации/классификации (нужно сначала выделить потенциальные классы, предполагаю, что лучше всего каким-нибудь LDA, а затем обучить модельку)
б) Простенькой mobile-first веб-мордой
Пишите в комментах
И вот я в своём расстройстве зашёл так далеко, что решил спарсить все посты из этих каналов, да ещё и с указанием количества просмотров. Появилась небольшая такая таблица на 11000 записей. Да, я из тех людей, которые сначала соберут тьму данных, а потом решают, что с ними делать.
Сидел-сидел и понял, что хочу сделать так, чтобы информация из каналов в Телеграме приобретала вторую жизнь, просмотры набирали бы не только свежие посты, но и старые/проверенные/новые с небольшим числом просмотров. Сначала думал вручную собрать посты в коллекции (например, про АБ-тесты, про SQL, про визуализацию и т.д.) и разместить на отдельных страничках через embed-виджеты. Получились бы такие небольшие базы знаний. Но мне стало немного лениво/скучно/тревожно при мысли о том, чтобы вручную отбирать хорошие посты и классифицировать их. Поэтому я неумело сделал препроцессинг текстов постов и теперь готов к классификации с использованием ARTIFICIAL INTELLIGENCE!!!
Что дальше?
Дальше хочу сделать небольшой сервис, где выбираешь интересующую тематику, например, "Продуктовые метрики" и тебе подсовываются рандомно-хорошие посты из разных каналов на эту (или семантически-похожую) тему.
Поэтому ищу руки-ноги-головы, готовые помочь с:
а) Алгоритмом кластеризации/классификации (нужно сначала выделить потенциальные классы, предполагаю, что лучше всего каким-нибудь LDA, а затем обучить модельку)
б) Простенькой mobile-first веб-мордой
Пишите в комментах
Замечаете, что данные окружают вас повсюду и постоянно ищите между ними взаимосвязи? Этой осенью проект Digital Leader при поддержке Intel, VMware и Hewlett Packard Enterprise проведет онлайн-хакатон для датасайентистов, мыслящих вне рамок и шаблонов.
Для участия в конкурсном отборе необходимо сформулировать оригинальную/смешную/креативную гипотезу, протестировать ее на существующем датасете, ярко визуализировать результаты и прислать работу организаторам до 10 ноября.
Победитель получит денежный приз, а все участники – возможность завоевать признание профессионального сообщества. Победителя в режиме онлайн определит жюри, состоящее из экспертов Яндекса, СберМаркетинга, КРОК и других компаний, а также всех посетителей отчетного ивента уже 19 ноября!
Подробнее про онлайн-хакатон New Data Tech, условия участия, призы и т.д. – по ссылке https://clck.ru/RmwYL
Для участия в конкурсном отборе необходимо сформулировать оригинальную/смешную/креативную гипотезу, протестировать ее на существующем датасете, ярко визуализировать результаты и прислать работу организаторам до 10 ноября.
Победитель получит денежный приз, а все участники – возможность завоевать признание профессионального сообщества. Победителя в режиме онлайн определит жюри, состоящее из экспертов Яндекса, СберМаркетинга, КРОК и других компаний, а также всех посетителей отчетного ивента уже 19 ноября!
Подробнее про онлайн-хакатон New Data Tech, условия участия, призы и т.д. – по ссылке https://clck.ru/RmwYL
Forwarded from Ivan Begtin (Ivan Begtin)
Для тех кто работает с данными постоянно, выбирает инструменты для экспериментов, создает методологии и исполняемые статьи (executive papers) подборка инструментов для автоматизации работы:
Проекты с открытым кодом:
- Jupyter Notebook и JupyterLab [1] - стандарт де-факто, используется в большинстве проектов
- Apache Zeppelin [2] - система записных книжек с поддержкой SQL и Scala, с открытым кодом
- BeakerX [3] - расширения для Jupyter Notebook с дополнительными возможностями, такими как интерактивными таблицами
- Polynote [4] - платформа для записных книжек на Scala от Netflix
- Elyra [5] - расширения для Jupyter Notebook для работа с AI
Внутри редакторов кода
- Pycharm [6] - поддерживает Jupyter Notebook прямо в среде разработки. Коммерческий
- Hydrogen [7] - поддержка Jupyter Notebook внутри редактора Atom. Открытый и бесплатный
Облачные коммерческие продукты:
- DeepNote [8] - коммерческий продукт совместимый с Jupyter
- franchise [9] - облачные записные книжки для работы с SQL
- Starboard [10] - записные книжки с поддержкой Markdown, Latex, Javascript и Python. Стартап
- Google Colab [11] - облачные записные книжки на базе Jupyter от Google
- Microsoft Azure Notebooks [12] - облачные записные книжки на базе Jupyter от Microsoft
- Wolfram Notebooks [13] - специализированные научные блокноты на базе языка Wolfram
Корпоративные продукты:
- DataIku [14] - комплексный продукт организации работы data scientist'ов
Список наверняка неполный и его ещё не раз можно пополнять.
Ссылки:
[1] http://jupyter.org
[2] https://zeppelin.apache.org/
[3] http://beakerx.com/
[4] https://polynote.org
[5] https://elyra.readthedocs.io/en/latest/
[6] https://www.jetbrains.com/help/pycharm/jupyter-notebook-support.html
[7] https://nteract.io/atom
[8] https://deepnote.com
[9] https://franchise.cloud/
[10] https://starboard.gg
[11] https://colab.research.google.com
[12] https://notebooks.azure.com/
[13] https://www.wolfram.com/notebooks/
[14] http://dataiku.com/
#datascience #tools
Проекты с открытым кодом:
- Jupyter Notebook и JupyterLab [1] - стандарт де-факто, используется в большинстве проектов
- Apache Zeppelin [2] - система записных книжек с поддержкой SQL и Scala, с открытым кодом
- BeakerX [3] - расширения для Jupyter Notebook с дополнительными возможностями, такими как интерактивными таблицами
- Polynote [4] - платформа для записных книжек на Scala от Netflix
- Elyra [5] - расширения для Jupyter Notebook для работа с AI
Внутри редакторов кода
- Pycharm [6] - поддерживает Jupyter Notebook прямо в среде разработки. Коммерческий
- Hydrogen [7] - поддержка Jupyter Notebook внутри редактора Atom. Открытый и бесплатный
Облачные коммерческие продукты:
- DeepNote [8] - коммерческий продукт совместимый с Jupyter
- franchise [9] - облачные записные книжки для работы с SQL
- Starboard [10] - записные книжки с поддержкой Markdown, Latex, Javascript и Python. Стартап
- Google Colab [11] - облачные записные книжки на базе Jupyter от Google
- Microsoft Azure Notebooks [12] - облачные записные книжки на базе Jupyter от Microsoft
- Wolfram Notebooks [13] - специализированные научные блокноты на базе языка Wolfram
Корпоративные продукты:
- DataIku [14] - комплексный продукт организации работы data scientist'ов
Список наверняка неполный и его ещё не раз можно пополнять.
Ссылки:
[1] http://jupyter.org
[2] https://zeppelin.apache.org/
[3] http://beakerx.com/
[4] https://polynote.org
[5] https://elyra.readthedocs.io/en/latest/
[6] https://www.jetbrains.com/help/pycharm/jupyter-notebook-support.html
[7] https://nteract.io/atom
[8] https://deepnote.com
[9] https://franchise.cloud/
[10] https://starboard.gg
[11] https://colab.research.google.com
[12] https://notebooks.azure.com/
[13] https://www.wolfram.com/notebooks/
[14] http://dataiku.com/
#datascience #tools
jupyter.org
Project Jupyter
The Jupyter Notebook is a web-based interactive computing platform. The notebook combines live code, equations, narrative text, visualizations, interactive dashboards and other media.
Отличная статья о том как выстроена машина экспериментов в Flo Health. Статья в меньшей степени рассказывает про особенности статистической оценки результатов тестирования, а освещает вопросы построения архитектуры обработки данных для автоматизации экспериментов
https://medium.com/flo-engineering/how-flo-conducts-experiments-5ee35fc3327f
https://medium.com/flo-engineering/how-flo-conducts-experiments-5ee35fc3327f
Medium
How Flo Conducts Experiments
Let’s take a deep dive into the experiments from an engineering point of view.
📊Статистика, прогнозирование, эксперименты и AB-тестирования🔬
**Эксперименты**
Расчёт каннибализации на основе классического A/B-теста и метод bootstrap’а
Множественные эксперименты: теория и практика
🔥 Подборка от Vit Cheremisinov и Iskandar Mirmakhmadov
Простой гид по байесовскому А/B-тестированию на Python
Краткое руководство по реализации A/B тестов на Python
Математика A/B-тестирования с примером кода на Python
Байесовский подход к оценке результатов A/B-тестирования
A/B-тесты на несбалансированных выборках
Про архитектуру экспериментов в Flo Health [data engineering]
**Методики**
Разбор и несколько примеров расчёта effect size (величины эффекта)
Метод оценки максимального правдоподобия (MLE)
Кластеризация последовательности значений с помощью метода оптимизации Дженкса
Predictive Power Score для линейной и нелинейной зависимости
**Туториалы**
🔥 Тестирование статистических гипотез с помощью Python
🔥 Сборник готовых рецептов для практического применения статистических методов
Пример использования критерия хи-квадрат
Виды распределений вероятностей
🔥Расчет доверительных интервалов с помощью Bootstrap
Анализ time-series данных с помощью Pandas
Гайд по работе с временными рядами в Python
Основы описательной статистики с помощью Python
**Библиотеки**
Библиотека `pingouin` для статистического анализа
Работа с вероятностными моделями в `pomegranate`
Библиотека `atspy` для прогнозирования временных рядов
Работа с временными рядами в библиотеке `darts`
Анализ выживаемости с помощью библиотеки `lifelines`
**Эксперименты**
Расчёт каннибализации на основе классического A/B-теста и метод bootstrap’а
Множественные эксперименты: теория и практика
🔥 Подборка от Vit Cheremisinov и Iskandar Mirmakhmadov
Простой гид по байесовскому А/B-тестированию на Python
Краткое руководство по реализации A/B тестов на Python
Математика A/B-тестирования с примером кода на Python
Байесовский подход к оценке результатов A/B-тестирования
A/B-тесты на несбалансированных выборках
Про архитектуру экспериментов в Flo Health [data engineering]
**Методики**
Разбор и несколько примеров расчёта effect size (величины эффекта)
Метод оценки максимального правдоподобия (MLE)
Кластеризация последовательности значений с помощью метода оптимизации Дженкса
Predictive Power Score для линейной и нелинейной зависимости
**Туториалы**
🔥 Тестирование статистических гипотез с помощью Python
🔥 Сборник готовых рецептов для практического применения статистических методов
Пример использования критерия хи-квадрат
Виды распределений вероятностей
🔥Расчет доверительных интервалов с помощью Bootstrap
Анализ time-series данных с помощью Pandas
Гайд по работе с временными рядами в Python
Основы описательной статистики с помощью Python
**Библиотеки**
Библиотека `pingouin` для статистического анализа
Работа с вероятностными моделями в `pomegranate`
Библиотека `atspy` для прогнозирования временных рядов
Работа с временными рядами в библиотеке `darts`
Анализ выживаемости с помощью библиотеки `lifelines`
Datalytics pinned «📊Статистика, прогнозирование, эксперименты и AB-тестирования🔬 **Эксперименты** Расчёт каннибализации на основе классического A/B-теста и метод bootstrap’а Множественные эксперименты: теория и практика 🔥 Подборка от Vit Cheremisinov и Iskandar Mirmakhmadov…»
🐼 Pandas (part I) 📈
**Для начинающих**
Руководство по Pandas для начинающих
Курс по работе с Pandas
Визуальный гайд по работе с Pandas
Русскоязычный гайд про Pandas
Видеолекция Ильи Щурова про Pandas
Обзорная статья про Pandas
🔥 Русскоязычный гайд по Pandas от Алексея Куличевского
🔥 Введение в pandas: анализ данных на Python (на русском)
Как устроены Series в Pandas
Советы о том как выбирать колонки датафрейма в Pandas
Всеобъемлющий туториал по Pandas
Иллюстрированная статья про функции объединения в pandas
Чтение файлов csv, создание dataframe и фильтрация данных
100 полезных приёмов и хаков в Pandas от Kevin Markham, собранные в одном ноутбуке
Агрегация и группировка данных с помощью pandas
Мини-курс по Pandas на Kaggle
🔥 Перевод официальных туториалов Pandas на русский
**Оформление**
Вывод датафреймов с помощью styling
Форматирование таблиц в Pandas
Как создать оформленную HTML таблицу из pandas DataFrame
**Методы**
Обзор метода read_csv
Выбор сэмпла из датафрейма с помощью sample
Метод query
Трансформация данных (pivot, stack, unstack)
Как сделать ВПР (VLOOKUP) в Pandas
Map и replace
Выбор данных (slicing)
Почему Method Chaining — это хорошо
Melt в pandas
Apply и lambda
Как работают группировки
Новые методы в pandas 0.25.0
iterrows() vs itertuples()
Методы трансформации данных
Методы loc и iloc для индексации по датафрейму
Как разбить данные на диапазоны в pandas: cut и qcut
Метод resample для изменения группировки данных, содержащих дату-время
Три метода Pandas, о которых вы, возможно, не знали
4 крутых функции Numpy
Обзор пяти простых, но эффективных, методов pandas: shift, mask, value_counts, nlargest, nsmallest
Обзор нескольких новых функций в Pandas 1.0
**Для начинающих**
Руководство по Pandas для начинающих
Курс по работе с Pandas
Визуальный гайд по работе с Pandas
Русскоязычный гайд про Pandas
Видеолекция Ильи Щурова про Pandas
Обзорная статья про Pandas
🔥 Русскоязычный гайд по Pandas от Алексея Куличевского
🔥 Введение в pandas: анализ данных на Python (на русском)
Как устроены Series в Pandas
Советы о том как выбирать колонки датафрейма в Pandas
Всеобъемлющий туториал по Pandas
Иллюстрированная статья про функции объединения в pandas
Чтение файлов csv, создание dataframe и фильтрация данных
100 полезных приёмов и хаков в Pandas от Kevin Markham, собранные в одном ноутбуке
Агрегация и группировка данных с помощью pandas
Мини-курс по Pandas на Kaggle
🔥 Перевод официальных туториалов Pandas на русский
**Оформление**
Вывод датафреймов с помощью styling
Форматирование таблиц в Pandas
Как создать оформленную HTML таблицу из pandas DataFrame
**Методы**
Обзор метода read_csv
Выбор сэмпла из датафрейма с помощью sample
Метод query
Трансформация данных (pivot, stack, unstack)
Как сделать ВПР (VLOOKUP) в Pandas
Map и replace
Выбор данных (slicing)
Почему Method Chaining — это хорошо
Melt в pandas
Apply и lambda
Как работают группировки
Новые методы в pandas 0.25.0
iterrows() vs itertuples()
Методы трансформации данных
Методы loc и iloc для индексации по датафрейму
Как разбить данные на диапазоны в pandas: cut и qcut
Метод resample для изменения группировки данных, содержащих дату-время
Три метода Pandas, о которых вы, возможно, не знали
4 крутых функции Numpy
Обзор пяти простых, но эффективных, методов pandas: shift, mask, value_counts, nlargest, nsmallest
Обзор нескольких новых функций в Pandas 1.0
Datalytics pinned «🐼 Pandas (part I) 📈 **Для начинающих** Руководство по Pandas для начинающих Курс по работе с Pandas Визуальный гайд по работе с Pandas Русскоязычный гайд про Pandas Видеолекция Ильи Щурова про Pandas Обзорная статья про Pandas 🔥 Русскоязычный гайд…»
Forwarded from Войти в IT
Андрей Дорожный со своей командой дата-журналистов запустили проекты по обучению визуализации в Tableau и программированию на языке Python. Ссылка на Мастерскую важных историй.
YouTube
Мастерская Важных историй
Мастерская — это образовательный проект «Важных историй» (istories.media) для журналистов, в котором мы рассказываем о крутых инструментах для сбора, анализа и визуализации данных.
Мы хотим, чтобы как можно больше журналистов в России знали, как делать качественные…
Мы хотим, чтобы как можно больше журналистов в России знали, как делать качественные…
🐼 Pandas (part II) 📊
Tips & Tricks
Шпаргалка по Pandas 1
Шпаргалка по Pandas 2
Набор небольших советов
Обзор различных хаков Pandas
Подборка полезных сниппетов 1
Подборка полезных сниппетов 2
Шпаргалка по работе с различными форматами файлов (csv, xml, json и многие другие)
Другое
Выгрузка файла csv из Jupyter Notebook через браузер
Как в Pandas разбить одну колонку на несколько
Сборник упражнений по Pandas
Примеры использования нестандартных команд в Pandas
Туториал по обработке данных
Советы для эффективной обработки данных в Pandas
Импорт данных в Pandas
Очистка и подготовка данных
Статья про индексы в датафреймах
Что под капотом у фильтрации в Pandas
Как трансформировать JSON с множественными уровнями вложенности в DataFrame
Как ухаживать за пандами [видео]
Как сделать исключение одного датафрейма из другого
Обработка данных в разных форматах
Regex with Pandas and Named Groups
Что принёс нам Pandas 1.0
Примеры использования pandas для тестирования алгоритмов сбора и обработки данных
Как использовать if-else конструкции для формирования новых колонок в pandas
Библиотека sidetable — value_counts() на стериодах
Про преобразование значений из численного в категориальный
Индексы в Pandas
Производительность
Сравнение производительности функций
Руководство по использованию pandas для анализа больших датасетов
Организация циклов через iterrows и apply
Почему каждый Data Scientist должен знать Dask
Производительность циклов в pandas
Оптимизация памяти при работе с pandas
Советы как снизить потребление памяти в Pandas
Как анализировать большой объем данных с помощью библиотеки vaex
Ускорение обработки больших датасетов с помощью dask и parquet
Добавляем параллельные вычисления в Pandas с pandarallel
Ian Ozsvald - Making Pandas Fly
Tips & Tricks
Шпаргалка по Pandas 1
Шпаргалка по Pandas 2
Набор небольших советов
Обзор различных хаков Pandas
Подборка полезных сниппетов 1
Подборка полезных сниппетов 2
Шпаргалка по работе с различными форматами файлов (csv, xml, json и многие другие)
Другое
Выгрузка файла csv из Jupyter Notebook через браузер
Как в Pandas разбить одну колонку на несколько
Сборник упражнений по Pandas
Примеры использования нестандартных команд в Pandas
Туториал по обработке данных
Советы для эффективной обработки данных в Pandas
Импорт данных в Pandas
Очистка и подготовка данных
Статья про индексы в датафреймах
Что под капотом у фильтрации в Pandas
Как трансформировать JSON с множественными уровнями вложенности в DataFrame
Как ухаживать за пандами [видео]
Как сделать исключение одного датафрейма из другого
Обработка данных в разных форматах
Regex with Pandas and Named Groups
Что принёс нам Pandas 1.0
Примеры использования pandas для тестирования алгоритмов сбора и обработки данных
Как использовать if-else конструкции для формирования новых колонок в pandas
Библиотека sidetable — value_counts() на стериодах
Про преобразование значений из численного в категориальный
Индексы в Pandas
Производительность
Сравнение производительности функций
Руководство по использованию pandas для анализа больших датасетов
Организация циклов через iterrows и apply
Почему каждый Data Scientist должен знать Dask
Производительность циклов в pandas
Оптимизация памяти при работе с pandas
Советы как снизить потребление памяти в Pandas
Как анализировать большой объем данных с помощью библиотеки vaex
Ускорение обработки больших датасетов с помощью dask и parquet
Добавляем параллельные вычисления в Pandas с pandarallel
Ian Ozsvald - Making Pandas Fly
Datalytics pinned «🐼 Pandas (part II) 📊 Tips & Tricks Шпаргалка по Pandas 1 Шпаргалка по Pandas 2 Набор небольших советов Обзор различных хаков Pandas Подборка полезных сниппетов 1 Подборка полезных сниппетов 2 Шпаргалка по работе с различными форматами файлов (csv, xml…»
📊 Визуализация данных 🧑🎨
**Туториалы matplotlib**
50 визуализаций с помощью matplotlib
Шпаргалка по matplotlib
Anatomy of figure in matplotlib
🔥 50 примеров крутых графиков на Matplotlib и Seaborn
Способы создания гистограмм с помощью Python
Введение в визуализацию данных с помощью Matplotlib
**Туториалы Seaborn**
Подробный гайд по визуализации с помощью Seaborn
Визуализация данных в Seaborn
🔥 Русскоязычный гайд про визуализацию данных с помощью Seaborn
**Туториалы Plotly**
Статистический анализ с использованием Plotly
Многомерные графики в Python
Шпаргалка по визуализации данных в Python с помощью Plotly
**Туториалы по визуализации с Pandas**
Создание гистограм с помощью встроенных методов pandas
Как строить визуализации с помощью методов, встроенных в ацессор plot в Pandas
**Другие туториалы**
Визуализация с помощью Altair
Визуализация геоданных с помощью Folium
Туториал по визуализации с использованием Bokeh
🔥 Complete Guide to Data Visualization with Python
Визуализация данных с помощью Altair
Как делать интерактивные визуализации с помощью Bokeh в одну строчку с библиотекой `Pandas-Boken`
**Библиотеки**
Библиотека manim для создания научных анимаций
Визуализация геопространственных данных с помощью библиотеки geoviews
Библиотека для создания анимированных гифок с помощью matplotlib
Графики как в ggplot (R) с помощью библиотеки `plotnine`
Библиотека `supervenn` для визуализации пересекающихся множеств
**Книги и курсы**
Книга на русском языке по Matplotlib от DevPractice
**Другое**
15 роликов про визуализацию на matplotlib
**Туториалы matplotlib**
50 визуализаций с помощью matplotlib
Шпаргалка по matplotlib
Anatomy of figure in matplotlib
🔥 50 примеров крутых графиков на Matplotlib и Seaborn
Способы создания гистограмм с помощью Python
Введение в визуализацию данных с помощью Matplotlib
**Туториалы Seaborn**
Подробный гайд по визуализации с помощью Seaborn
Визуализация данных в Seaborn
🔥 Русскоязычный гайд про визуализацию данных с помощью Seaborn
**Туториалы Plotly**
Статистический анализ с использованием Plotly
Многомерные графики в Python
Шпаргалка по визуализации данных в Python с помощью Plotly
**Туториалы по визуализации с Pandas**
Создание гистограм с помощью встроенных методов pandas
Как строить визуализации с помощью методов, встроенных в ацессор plot в Pandas
**Другие туториалы**
Визуализация с помощью Altair
Визуализация геоданных с помощью Folium
Туториал по визуализации с использованием Bokeh
🔥 Complete Guide to Data Visualization with Python
Визуализация данных с помощью Altair
Как делать интерактивные визуализации с помощью Bokeh в одну строчку с библиотекой `Pandas-Boken`
**Библиотеки**
Библиотека manim для создания научных анимаций
Визуализация геопространственных данных с помощью библиотеки geoviews
Библиотека для создания анимированных гифок с помощью matplotlib
Графики как в ggplot (R) с помощью библиотеки `plotnine`
Библиотека `supervenn` для визуализации пересекающихся множеств
**Книги и курсы**
Книга на русском языке по Matplotlib от DevPractice
**Другое**
15 роликов про визуализацию на matplotlib
Datalytics pinned «📊 Визуализация данных 🧑🎨 **Туториалы matplotlib** 50 визуализаций с помощью matplotlib Шпаргалка по matplotlib Anatomy of figure in matplotlib 🔥 50 примеров крутых графиков на Matplotlib и Seaborn Способы создания гистограмм с помощью Python Введение…»
Forwarded from Reveal the Data
Женя Козлов, построивший с нуля отдел аналитики Яндекс.Такси в сотню человек, написал лонгрид об оценке профессионального уровня аналитиков данных.
Ещё Женя любит применять аналитические подходы и к повседневной жизни, пишет об этом в своем телеграм-канале
#ссылка
Ещё Женя любит применять аналитические подходы и к повседневной жизни, пишет об этом в своем телеграм-канале
#ссылка
GoPractice
ᐈ Навыки и требования к аналитикам данных на разных уровнях в «Яндексе». Профессия аналитика данных
Какими бывают уровни аналитика данных, как развиваться в профессии и какие компетенции нужны топовым аналитикам
Дмитрий Федоров перевёл гайд "Pandas за 10 минут" из официальной документации. Ещё один отличный русскоязычный материал, который можно смело рекомендовать для изучения Pandas. Скажем Дмитрию огромное спасибо (а ещё лучше подписывайтесь на его канал)!
http://dfedorov.spb.ru/pandas/Pandas%20%D0%B7%D0%B0%2010%20%D0%BC%D0%B8%D0%BD%D1%83%D1%82.html
http://dfedorov.spb.ru/pandas/Pandas%20%D0%B7%D0%B0%2010%20%D0%BC%D0%B8%D0%BD%D1%83%D1%82.html
Forwarded from Пристанище Дата Сайентиста
pycaret - библиотека для автоматизации рабочих процессов машинного обучения
PyCaret одна из самых простых AutoML библиотек. AutoML — это процесс автоматизации сквозного процесса применения машинного обучения. AutoML бибилиотеки позволяют ускорить цикл экспериментов и тестирование гипотез.
PyCaret по сути, оболочка Python для нескольких библиотек и фреймворков машинного обучения, таких как scikit-learn, XGBoost, LightGBM, CatBoost, spaCy, Optuna, Hyperopt, Ray и многих других. Этот инструмент может заменить сотни строк кода всего несколькими.
С помощью этой библиотеки можно решать следующие задачи:
- Классификация
- Регрессия
- Кластеризация
- Детекция Аномалий
- Natural Language Processing
- Подготовка ассоциативных правил
Установка:
Пример использования:
Из еще крутых возможностей PyCaret
Деплой моделей на AWS S3:
Логирование экспериментов:
Работа с признаками:
Рекомендую обратить внимание на эту библиотеку. Особенно если построение ML моделей не ваше основная работа.
PyCaret одна из самых простых AutoML библиотек. AutoML — это процесс автоматизации сквозного процесса применения машинного обучения. AutoML бибилиотеки позволяют ускорить цикл экспериментов и тестирование гипотез.
PyCaret по сути, оболочка Python для нескольких библиотек и фреймворков машинного обучения, таких как scikit-learn, XGBoost, LightGBM, CatBoost, spaCy, Optuna, Hyperopt, Ray и многих других. Этот инструмент может заменить сотни строк кода всего несколькими.
С помощью этой библиотеки можно решать следующие задачи:
- Классификация
- Регрессия
- Кластеризация
- Детекция Аномалий
- Natural Language Processing
- Подготовка ассоциативных правил
Установка:
pip install pycaretПример использования:
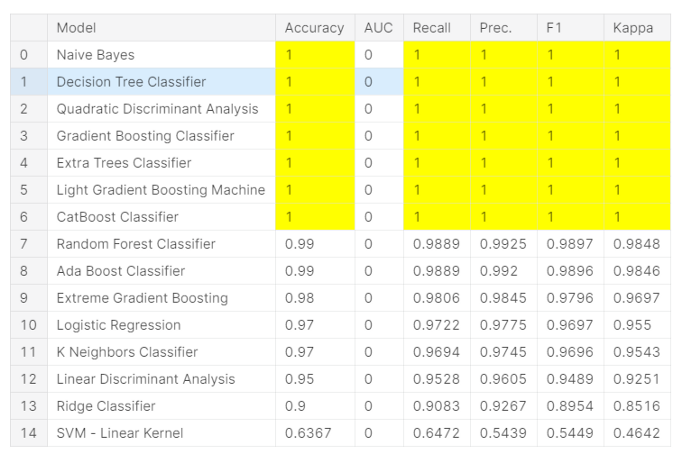
from pycaret.classification import * # импортируем pycaret classification методыexp = setup(data = data, target = 'Species', session_id=77 ) # указываем данные, таргет и random seedcompare_models() # сравним различные модели метриками - accuracy,F1 и другимиnb_model = create_model('nb', fold = 10) # создаем модель Naives Byes на 10 фолдахplot_model(nb_model, plot = 'auc') # построим ROC AUCplot_model(nb_model, plot = 'confusion_matrix') # построим confusion matrixnew_prediction = predict_model(nb_model, data=data_unseen) # делаем предсказания на новых данныхИз еще крутых возможностей PyCaret
Деплой моделей на AWS S3:
deploy_model(final_lr, model_name = 'lr_aws', platform = 'aws', authentication = { 'bucket' : 'pycaret-test' })Логирование экспериментов:
from pycaret.classification import *clf1 = setup(data, target = 'Class variable', log_experiment = True, experiment_name = 'diabetes1')top5 = compare_models()logs = get_logs(save=True)Работа с признаками:
reg1 = setup(data = insurance, target = 'charges', feature_interaction = True, feature_ratio = True)reg1 = setup(data = insurance, target = 'charges', trigonometry_features = True)clf1 = setup(data = juice, target = 'Purchase', polynomial_features = True)clf1 = setup(data = credit, target = 'default', group_features = ['BILL_AMT1', 'BILL_AMT2', 'BILL_AMT3', 'BILL_AMT4', 'BILL_AMT5', 'BILL_AMT6'])Рекомендую обратить внимание на эту библиотеку. Особенно если построение ML моделей не ваше основная работа.
{kind=link}
👍2
🚀 Автоматизация 🤖
**Автоматизация рутины**
Туториал из 8 эпизодов про автоматизацию рутинных задач
Запуск скриптов по расписанию
Отправка email сообщений
Как писать приложения с command-line interfaces
Создание YAML конфигов для выполнения задач
Работа с API Google Drive
Туториал про создание бота для Телеграм на основе данных BigQuery
Инструмент для анализа данных из командной строки
Рассуждения на тему автоматизации рутины с помощью Python
Автоматизация формирования отчетности с помощью Papermill 1
Автоматизация формирования отчетности с помощью Papermill 2
Cоздание пайплайнов обработки данных в датафреймах
7 Simple Python Functions to Clean Your Data
**Excel и Google Sheets**
Как сравнить два Excel-файла
Форматирование ячеек в Excel-файлах
Как вставлять рисунки, диаграммы и формулы в книгу Excel через Python
Загрузка данных из датафрейма в Google Sheets
Соединение нескольких листов в один на Python
Руководство по работе с openpyxl
Обзор возможностей библиотек pandas, openpyxl, xlrd, xlutils и pyexcel для работы с Excel-файлами из Python
**Интерактивные дашборды и data-applications**
Создание web-дашбордов с библиотекой Panel
Библиотека для создания standalone-приложений на основе данных Voila
Краткое руководство по Dash
Metabase с поддержкой Clickhouse
Видеолекция Алексея Куличевского про Metabase
Создание интерактивного дашборда в Dash
Обзор библиотеки Streamlit
Interactive spreadsheets in Jupyter
Cоздание интерактивных дашбордов с помощью Plotly и Voila
Отображение датафрейма в удобной таблице с возможностью сортировки и фильтрации с помощью D-Tale
Делаем Dashboard для авиакомпании: Dash и не только
Создание приложения с помощью `Streamlit`
**Автоматизация рутины**
Туториал из 8 эпизодов про автоматизацию рутинных задач
Запуск скриптов по расписанию
Отправка email сообщений
Как писать приложения с command-line interfaces
Создание YAML конфигов для выполнения задач
Работа с API Google Drive
Туториал про создание бота для Телеграм на основе данных BigQuery
Инструмент для анализа данных из командной строки
Рассуждения на тему автоматизации рутины с помощью Python
Автоматизация формирования отчетности с помощью Papermill 1
Автоматизация формирования отчетности с помощью Papermill 2
Cоздание пайплайнов обработки данных в датафреймах
7 Simple Python Functions to Clean Your Data
**Excel и Google Sheets**
Как сравнить два Excel-файла
Форматирование ячеек в Excel-файлах
Как вставлять рисунки, диаграммы и формулы в книгу Excel через Python
Загрузка данных из датафрейма в Google Sheets
Соединение нескольких листов в один на Python
Руководство по работе с openpyxl
Обзор возможностей библиотек pandas, openpyxl, xlrd, xlutils и pyexcel для работы с Excel-файлами из Python
**Интерактивные дашборды и data-applications**
Создание web-дашбордов с библиотекой Panel
Библиотека для создания standalone-приложений на основе данных Voila
Краткое руководство по Dash
Metabase с поддержкой Clickhouse
Видеолекция Алексея Куличевского про Metabase
Создание интерактивного дашборда в Dash
Обзор библиотеки Streamlit
Interactive spreadsheets in Jupyter
Cоздание интерактивных дашбордов с помощью Plotly и Voila
Отображение датафрейма в удобной таблице с возможностью сортировки и фильтрации с помощью D-Tale
Делаем Dashboard для авиакомпании: Dash и не только
Создание приложения с помощью `Streamlit`
👍2
Datalytics pinned «🚀 Автоматизация 🤖 **Автоматизация рутины** Туториал из 8 эпизодов про автоматизацию рутинных задач Запуск скриптов по расписанию Отправка email сообщений Как писать приложения с command-line interfaces Создание YAML конфигов для выполнения задач Работа…»
Forwarded from Этюды для программистов на Python (Дима Федоров)
Перевод статьи Криса Моффитта о сводных таблицах (pivot_table) в pandas 🥳🐍 http://dfedorov.spb.ru/pandas/%D0%A1%D0%B2%D0%BE%D0%B4%D0%BD%D0%B0%D1%8F%20%D1%82%D0%B0%D0%B1%D0%BB%D0%B8%D1%86%D0%B0%20%D0%B2%20pandas.html