
Нашёл на Kaggle микрокурс по изучению Pandas, оформленный в виде ноутбуков. Включает в себя разбор всех базовых функций, так что для ознакомления с возможностями библиотеки отлично подходит
https://www.kaggle.com/learn/pandas
https://www.kaggle.com/learn/pandas
Kaggle
Learn Pandas Tutorials
Solve short hands-on challenges to perfect your data manipulation skills.
Статья про байесовский подход к оценке результатов A/B-тестирования. Хорошо и доступно описывается сам подход и его преимущества. Также в статье есть примеры кода, которые будут полезны для собственных проектов
https://towardsdatascience.com/why-you-should-try-the-bayesian-approach-of-a-b-testing-38b8079ea33a
https://towardsdatascience.com/why-you-should-try-the-bayesian-approach-of-a-b-testing-38b8079ea33a
Medium
Why you should try the Bayesian approach of A/B testing
The intuitive way of A/B testing. The advantages of the Bayesian approach and how to do it.
Запись доклада про производительность Pandas с PyData Fest Amsterdam 2020 от Ian Ozsvald, одного из авторов книги High Performance Python
Большие датасеты не всегда помещаются в память, но что делать если хочется проанализировать их с помощью Pandas? Сначала в видео рассматриваются методы сжатия данных. Далее разбираются некоторые "хитрые" способы ускорить выполнение обычных операций в датафреймах, включая переход на numpy и более оптимальный выбор функций для операций с данными. Рассмотренные приёмы позволят уменьшить размер датафреймов и ускорить обработку данных.
https://youtu.be/N4pj3CS857c
Большие датасеты не всегда помещаются в память, но что делать если хочется проанализировать их с помощью Pandas? Сначала в видео рассматриваются методы сжатия данных. Далее разбираются некоторые "хитрые" способы ускорить выполнение обычных операций в датафреймах, включая переход на numpy и более оптимальный выбор функций для операций с данными. Рассмотренные приёмы позволят уменьшить размер датафреймов и ускорить обработку данных.
https://youtu.be/N4pj3CS857c
YouTube
Ian Ozsvald - Making Pandas Fly | PyData Fest Amsterdam 2020
PyData is excited to announce PyData Global, November 11th - 15th! Tickets are now available: https://global.pydata.org/pages/tickets.html#pricing-and-ticket-purchases
Part of an underrepresented group in tech? PyData Global is offering Diversity Scholarships.…
Part of an underrepresented group in tech? PyData Global is offering Diversity Scholarships.…
Forwarded from LEFT JOIN
Диалог @a_nikushin и @data_karpov о доступном образовании для аналитиков на Youtube вдохновил меня рассказать одну свою историю и поделиться ссылками.
Так сложилось, что в Университете мне очень повезло с преподавателями (от линейной алгебры до баз данных и языков программирования). Один из них, В. Л. Аббакумов, разжег настоящую страсть к методам анализа данных своими лекциями и лабораторными заданиями. В. Л. — практик и был моим научным руководителем по дипломной работе (мы делали кластеризацию данных Ленты), а затем и по кандидатской диссертации (строили нейронную сеть специальной архитектуры, тогда еще в Matlab).
Уже несколько лет назад в рамках ШАД и Computer Science Яндекса у него был записан курс Анализ данных на Python в примерах и задачах в двух частях. Настало время поделиться ссылками на первый и второй плейлисты на Youtube.
Первая часть посвящена описательным статистикам, проверке статистических гипотез, иерархическому кластерному анализу и кластерному анализу методом к-средних, классификационным моделям (деревья, Random Forest, GBM). В целом, весь плейлист достоин внимания без отрыва 🤓
Во второй части более глубокое погружение в нейронные сети, keras, deep learning, xgboost и снова все лекции крайне рекомендованы.🎖
Смотреть можно смело на 1.5x.
Материалы к видео:
— Часть 1. Занятия и материалы
— Часть 2. Занятия и материалы
Так сложилось, что в Университете мне очень повезло с преподавателями (от линейной алгебры до баз данных и языков программирования). Один из них, В. Л. Аббакумов, разжег настоящую страсть к методам анализа данных своими лекциями и лабораторными заданиями. В. Л. — практик и был моим научным руководителем по дипломной работе (мы делали кластеризацию данных Ленты), а затем и по кандидатской диссертации (строили нейронную сеть специальной архитектуры, тогда еще в Matlab).
Уже несколько лет назад в рамках ШАД и Computer Science Яндекса у него был записан курс Анализ данных на Python в примерах и задачах в двух частях. Настало время поделиться ссылками на первый и второй плейлисты на Youtube.
Первая часть посвящена описательным статистикам, проверке статистических гипотез, иерархическому кластерному анализу и кластерному анализу методом к-средних, классификационным моделям (деревья, Random Forest, GBM). В целом, весь плейлист достоин внимания без отрыва 🤓
Во второй части более глубокое погружение в нейронные сети, keras, deep learning, xgboost и снова все лекции крайне рекомендованы.🎖
Смотреть можно смело на 1.5x.
Материалы к видео:
— Часть 1. Занятия и материалы
— Часть 2. Занятия и материалы
YouTube
Лекция 1. Описательные статистики. Квантили, квартили. Гистограммы
https://compscicenter.ru/
Описательные статистики. Квантили, квартили. Гистограммы. Ядерные оценки плотности.
Лекция №1 в курсе "Анализ данных на Python в примерах и задачах. Часть 1" (весна 2018).
Преподаватель курса: Вадим Леонардович Аббакумов
Описательные статистики. Квантили, квартили. Гистограммы. Ядерные оценки плотности.
Лекция №1 в курсе "Анализ данных на Python в примерах и задачах. Часть 1" (весна 2018).
Преподаватель курса: Вадим Леонардович Аббакумов
Наткнулся на библиотеку для работы с временными рядами Darts. В неё встроены не только популярные инструменты прогнозирования временных рядов (ARIMA, Prophet), но и различные вспомогательные функции, например, процессинг ряда для разделения на сезонную и трендовую компоненты, утилиты для бэктестинга (проверки модели на исторических данных). В общем, любопытная штука, для тех кто работает с временными рядами - будет полезно
https://medium.com/unit8-machine-learning-publication/darts-time-series-made-easy-in-python-5ac2947a8878
@datalytx
https://medium.com/unit8-machine-learning-publication/darts-time-series-made-easy-in-python-5ac2947a8878
@datalytx
Medium
Darts: Time Series Made Easy in Python
Time series simply represent data points over time. They are thus everywhere in nature and in business: temperatures, heartbeats, births…
Forwarded from This is Data
Наконец-то закончил статью на одну из самых сложных для понимания тем - оконные функции в SQL.
На ее написание ушло почти пять месяцев с перерывом на отпуск :)
В статье на простых примерах с картинками разбирается принцип работы данных функций, а в конце вас ждут кейсы с расчетом моделей атрибуции «Первый клик» и «С учетом давности взаимодействий».
На ее написание ушло почти пять месяцев с перерывом на отпуск :)
В статье на простых примерах с картинками разбирается принцип работы данных функций, а в конце вас ждут кейсы с расчетом моделей атрибуции «Первый клик» и «С учетом давности взаимодействий».
{kind=link}
Интересная статья с большим количеством примеров, рассказывающая про индексы в Pandas. Для тех кто всегда делает
https://towardsdatascience.com/understand-pandas-indexes-1b94f5c078c6
reset_index(), боясь заморачиваться с текстовыми индексами🙃https://towardsdatascience.com/understand-pandas-indexes-1b94f5c078c6
Medium
Understand Pandas Indexes
To efficiently use of Pandas, ignore its documentation and learn the truth about indexes
Retentioneering — это библиотека, которая помогает продуктовым и маркетинговым аналитикам обрабатывать логи событий и траектории пользователей в мобильных приложениях, веб-сайтах и других цифровых продуктов. С помощью этого фреймворка можно сегментировать пользователей, строить ML-пайплайны для прогнозирования категории пользователей или определения вероятности совершения целевого действия, основываясь на исторических данных.
Недавно у ребят вышел большой апдейт https://github.com/retentioneering/retentioneering-tools
Попробовать можно слету в Google Colab без установки, все стало очень просто.
Добавлен инструмент простого A/B-тестирования, ускорены более чем в десять раз скорость кластеризации, переработан функционал step-матриц.
P.S. Очень важное дополнение - различные варианты нормировки и развесовки ребер графа. Теперь можно четко видеть сколько пользователей сделало переход, либо сколько сессий с таким переходом было, либо сколько событий переходов во всем датасете. Можно явно выбирать как вы хотите это нормировать - на общее число пользователей или переходов, или на количество переходов из конкретного узла - получаются разные инсайты на графе и в матрицах переходов.
Вопросы по библиотеке можно задать в Телеграм чате @retentioneering_support
Недавно у ребят вышел большой апдейт https://github.com/retentioneering/retentioneering-tools
Попробовать можно слету в Google Colab без установки, все стало очень просто.
Добавлен инструмент простого A/B-тестирования, ускорены более чем в десять раз скорость кластеризации, переработан функционал step-матриц.
P.S. Очень важное дополнение - различные варианты нормировки и развесовки ребер графа. Теперь можно четко видеть сколько пользователей сделало переход, либо сколько сессий с таким переходом было, либо сколько событий переходов во всем датасете. Можно явно выбирать как вы хотите это нормировать - на общее число пользователей или переходов, или на количество переходов из конкретного узла - получаются разные инсайты на графе и в матрицах переходов.
Вопросы по библиотеке можно задать в Телеграм чате @retentioneering_support
GitHub
GitHub - retentioneering/retentioneering-tools: Retentioneering: product analytics, data-driven CJM optimization, marketing analytics…
Retentioneering: product analytics, data-driven CJM optimization, marketing analytics, web analytics, transaction analytics, graph visualization, process mining, and behavioral segmentation in Pyth...
Дисбаланс в A/B-тестах. Есть ли разница между 99/1 % и 50/50 % в экспериментах?
Ребята из Experiment Fest провели небольшое исследование и написали статью про несбалансированные A/B-тестирования. Как оказалось, проводя A/B на несбалансированных выборках, существенно возрастает вероятность упустить значимые различия, если они есть. Результаты анализа и выводы представлены в статье
Читать статью на Медиуме
Подписаться на канал Experiment Fest
Ребята из Experiment Fest провели небольшое исследование и написали статью про несбалансированные A/B-тестирования. Как оказалось, проводя A/B на несбалансированных выборках, существенно возрастает вероятность упустить значимые различия, если они есть. Результаты анализа и выводы представлены в статье
Читать статью на Медиуме
Подписаться на канал Experiment Fest
Таблицы иногда говорят больше, чем графики. Особенно для тех, кто умеет с ними работать. При этом процесс интерпретации таблиц должен быть быстрым и комфортным. Например, в excel для этого используется условное форматирование и спарклайны. В этой статье рассматривается как визуализировать данные с помощью Python и библиотеки pandas, используя свойства DataFrame.style и Options and settings
https://habr.com/ru/post/521894/
https://habr.com/ru/post/521894/
Хабр
Формат таблиц в pandas
Если вы пока ещё не знаете как транслировать данные напрямую заказчику в подсознание или, на худой конец, текст сообщения в slack, вам пригодится информация о то...
Пример разведочного анализа данных (EDA) на датасете из 450к записей с Пикабу. Получился хороший блокнот, освещающий основные этапы: заполнение пропущенных значений, удаление дубликатов, описательные статистики, анализ взаимосвязей между признаки и визуализация. Если кому-то захочется самостоятельно покопаться с данными — ближе к концу статьи есть ссылка на датасет
https://habr.com/ru/post/519054/
https://habr.com/ru/post/519054/
Хабр
Pikabu-dataset
Предлагается взглянуть на dataset постов с pikabu.ru c точки зрения датастатистики. Сам датасет в составе 450к штук собран лучшими круглосуточными парсерами, обработан отдушками, убирающими дубликаты...
Forwarded from Пристанище Дата Сайентиста
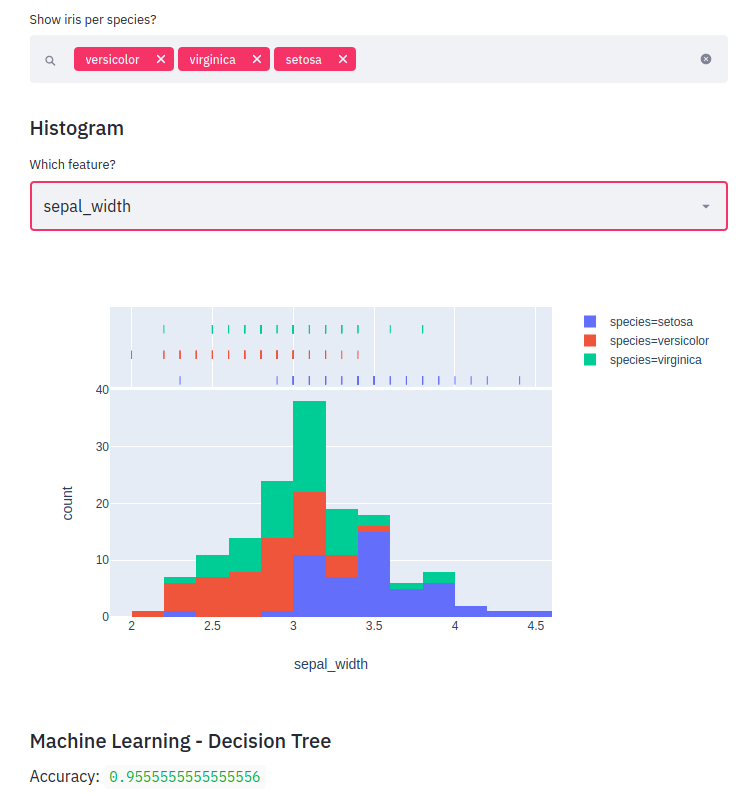
Streamlit - быстрый способ создать приложение для работы с данными
Допустим вам нужно быстро создать приложение для работы с данными. Оно может включать в себя дэшборд и работу с моделью. Или если вам нужен быстрый прототип для показа заказчику, который можно сделать за несколько часов и бесплатно.
Streamlit отлично подходит под эти задачи. Все на чистом Python. Нужно будет освоить только интерактивные компоненты для создания фильтров/ чекбоксов/ полей ввода/ загрузки файлов.
Разберём функционал на уже знакомом примере Ирисов Фишера. Сделаем очень простой дэшборд с выбором вида Ирисов и построением гистограмм. Так же в Streamlit можно обучать и делать инференс моделей.
Дополнительный материал:
Сайт Streamlit - https://www.streamlit.io/
Код с Docker - https://github.com/alimbekovKZ/ML-DL-in-production/tree/master/streamlit
Допустим вам нужно быстро создать приложение для работы с данными. Оно может включать в себя дэшборд и работу с моделью. Или если вам нужен быстрый прототип для показа заказчику, который можно сделать за несколько часов и бесплатно.
Streamlit отлично подходит под эти задачи. Все на чистом Python. Нужно будет освоить только интерактивные компоненты для создания фильтров/ чекбоксов/ полей ввода/ загрузки файлов.
Разберём функционал на уже знакомом примере Ирисов Фишера. Сделаем очень простой дэшборд с выбором вида Ирисов и построением гистограмм. Так же в Streamlit можно обучать и делать инференс моделей.
import streamlit as stimport pandas as pdimport numpy as npimport plotly.express as pximport seaborn as snsimport matplotlib.pyplot as pltimport plotly.graph_objects as gost.title('Iris')df = pd.read_csv("iris.csv")st.subheader('Scatter plot')species = st.multiselect('Show iris per species?', df['species'].unique())new_df = df[(df['species'].isin(species))]st.subheader('Histogram')feature = st.selectbox('Which feature?', df.columns[0:4])new_df2 = df[(df['species'].isin(species))][feature]fig2 = px.histogram(new_df, x=feature, color="species", marginal="rug")st.plotly_chart(fig2)st.subheader('Machine Learning - Decision Tree')from sklearn.model_selection import train_test_splitfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.metrics import confusion_matrixfeatures= df[['sepal_length', 'sepal_width', 'petal_length', 'petal_width']].valueslabels = df['species'].valuesX_train,X_test, y_train, y_test = train_test_split(features, labels, train_size=0.7, random_state=1)dtc = DecisionTreeClassifier()dtc.fit(X_train, y_train)acc = dtc.score(X_test, y_test)st.write('Accuracy: ', acc)pred_dtc = dtc.predict(X_test)cm_dtc=confusion_matrix(y_test,pred_dtc)st.write('Confusion matrix: ', cm_dtc)Дополнительный материал:
Сайт Streamlit - https://www.streamlit.io/
Код с Docker - https://github.com/alimbekovKZ/ML-DL-in-production/tree/master/streamlit
{kind=link}
Подробный гайд про визуализацию данных с помощью Plotnine
Если вы любите ggplot2 из R за лаконичный синтаксис и простоту использования, и вам не хватает этого в питоновских библиотеках для визуализации, то Plotnine — отличное решение. Эта библиотека позволяет строить ggplot-визуализации в Python
https://realpython.com/ggplot-python/
Если вы любите ggplot2 из R за лаконичный синтаксис и простоту использования, и вам не хватает этого в питоновских библиотеках для визуализации, то Plotnine — отличное решение. Эта библиотека позволяет строить ggplot-визуализации в Python
https://realpython.com/ggplot-python/
Realpython
Using ggplot in Python: Visualizing Data With plotnine – Real Python
In this tutorial, you'll learn how to use ggplot in Python to build data visualizations with plotnine. You'll discover what a grammar of graphics is and how it can help you create plots in a very concise and consistent way.
Хорошая статья про то как автоматизировать работу с Excel-файлами с помощью Python
Forwarded from data fm
Если вы вчера решили, что я ничего не выложу — вы были правы 😁
Я тоже так думала, ровно до 20.00, потому что я поняла, что день подходит к концу, а доверие тихонечко ускользает.
В общем, если вы решите, что материал бестолковый или скучный, я всё прощу) Но не перестану говорить, что продолжение будет. Учиться на ошибках тоже нужно.
А пока я нашла в себе силы побороть себя, расскажу о том, что мысль вести 100500 каналов — так себе мысль. Вы никогда не сможете успеть делать всё, только если у вас один контент-план на все площадки)
Так вот, эксель — это то с чего всё начиналось, это такая простая вещь, что кажется.. а что может быть проще? Там столько всего можно сделать, что даже грустно от мысли, что я решила даже его автоматизировать 😭
Но не смотря на такое грустное начало, выкладываю первую часть автоматизации и надеюсь, что больше я не буду так тянуть резину.
Читать, подписываться и хлопать на медиуме можно, нужно и очень жду, а еще пишите комментарии тут.
Я тоже так думала, ровно до 20.00, потому что я поняла, что день подходит к концу, а доверие тихонечко ускользает.
В общем, если вы решите, что материал бестолковый или скучный, я всё прощу) Но не перестану говорить, что продолжение будет. Учиться на ошибках тоже нужно.
А пока я нашла в себе силы побороть себя, расскажу о том, что мысль вести 100500 каналов — так себе мысль. Вы никогда не сможете успеть делать всё, только если у вас один контент-план на все площадки)
Так вот, эксель — это то с чего всё начиналось, это такая простая вещь, что кажется.. а что может быть проще? Там столько всего можно сделать, что даже грустно от мысли, что я решила даже его автоматизировать 😭
Но не смотря на такое грустное начало, выкладываю первую часть автоматизации и надеюсь, что больше я не буду так тянуть резину.
Читать, подписываться и хлопать на медиуме можно, нужно и очень жду, а еще пишите комментарии тут.
Medium
Автоматизация Excel с помощью Python
Часть 1
Анализ выживаемости (survival analysis) — класс статистических моделей, позволяющих оценить вероятность наступления события. Своё название он получил из-за того, что этот анализ широко применяется в медицинской сфере для оценки продолжительности жизни в ходе исследований методов лечения. С его помощью можно понять какие факторы увеличивают вероятность наступления события, а какие уменьшают
Этот метод применяется и за рамками медицины, например, можно предсказывать время использования (lifetime) клиентов в сервисе
Для того, чтобы провести анализ выживаемости с помощью Python существует библиотека lifelines, которая предоставляет набор простых в использовании методов для оценки вероятности наступления событий во времени
Документация у библиотеки подробная и с множеством примеров, например, тут описывается процесс создания предсказательной функции на примере длительности существования политических режимов
https://github.com/CamDavidsonPilon/lifelines
Этот метод применяется и за рамками медицины, например, можно предсказывать время использования (lifetime) клиентов в сервисе
Для того, чтобы провести анализ выживаемости с помощью Python существует библиотека lifelines, которая предоставляет набор простых в использовании методов для оценки вероятности наступления событий во времени
Документация у библиотеки подробная и с множеством примеров, например, тут описывается процесс создания предсказательной функции на примере длительности существования политических режимов
https://github.com/CamDavidsonPilon/lifelines
GitHub
GitHub - CamDavidsonPilon/lifelines: Survival analysis in Python
Survival analysis in Python. Contribute to CamDavidsonPilon/lifelines development by creating an account on GitHub.
Приглашаю всех на онлайн конференцию Матемаркетинг, где 11-го ноября я участвую в обсуждении собеседований в мире аналитики и пробую понять, нужны ли на них вопросы по теорверу. Мой коллега, Марк Сысоев, тоже участвует в конфе и расскажет про жизненный цикл аналитики в организации.
Посмотрите доклад прошлого года, в котором Марк поделился тем, как он занимался анализом пользовательского опыта учеников SkyEng с помощью customer journey map и как делать это на бесплатных инструментах:
https://www.youtube.com/watch?v=A9TIOFrEwN4
В 18-м году еще был крутой доклад Павла Левчука (Senior Product Manager Social Tech) с конкретными примерами того, как продуктовому аналитику победить churn (когорты, Life-Cycle Grid, реактивация, вовлечение, кластеризация, ретеншен): https://www.youtube.com/watch?v=JNgzuZuepV0
Матемаркетинг-2020 - это самая большая российская конференция по маркетинговой и продуктовой аналитике, монетизации и решениях, основанным на данных. Она пройдет с 9 по 13 ноября, подробности тут:
https://bit.ly/348bLwy
Специально для подписчиков организаторы подготовили промокод -
Посмотрите доклад прошлого года, в котором Марк поделился тем, как он занимался анализом пользовательского опыта учеников SkyEng с помощью customer journey map и как делать это на бесплатных инструментах:
https://www.youtube.com/watch?v=A9TIOFrEwN4
В 18-м году еще был крутой доклад Павла Левчука (Senior Product Manager Social Tech) с конкретными примерами того, как продуктовому аналитику победить churn (когорты, Life-Cycle Grid, реактивация, вовлечение, кластеризация, ретеншен): https://www.youtube.com/watch?v=JNgzuZuepV0
Матемаркетинг-2020 - это самая большая российская конференция по маркетинговой и продуктовой аналитике, монетизации и решениях, основанным на данных. Она пройдет с 9 по 13 ноября, подробности тут:
https://bit.ly/348bLwy
Специально для подписчиков организаторы подготовили промокод -
datalytics на скидку в 10%YouTube
Марк Сысоев, SkyEng - Customer Journey Mapping с помощью цепей Маркова.
Совсем скоро Матемаркетинг-22, 17-18 ноября
Подробности: https://matemarketing.ru/
Программа: https://clck.ru/y6jEV
Купить билет: https://matemarketing.ru/
Марк Сысоев рассказывает, как он занимался анализом пользовательского опыта учеников
онлайн-школы…
Подробности: https://matemarketing.ru/
Программа: https://clck.ru/y6jEV
Купить билет: https://matemarketing.ru/
Марк Сысоев рассказывает, как он занимался анализом пользовательского опыта учеников
онлайн-школы…
Статья, в которой подробно разбирается задача визуализации пересекающихся множеств, а также демонстрируется библиотека supervenn, которая позволяет в удобной форме анализировать пересечение множеств. Это может быть полезным в работе аналитике, например, если вы захотите оценить какие товарные категории чаще всего пересекаются между собой в корзинах покупателей интернет-магазина
https://habr.com/ru/company/yandex/blog/501924/
https://habr.com/ru/company/yandex/blog/501924/
Хабр
Как построить диаграмму Венна с 50 кругами? Визуализация множеств и история моего Python-проекта с открытым кодом
Всем привет, меня зовут Фёдор Индукаев, я работаю аналитиком в Яндекс.Маршрутизации. Сегодня хочу рассказать вам про задачу визуализации пересекающихся множеств и про пакет для Python с открытым кодом...
Forwarded from местный датасасер ☮️
Вчера вышел Python 3.9! 🥳
Лично я по питону сильно соскучился, ибо уже второй месяц пишу только на C и плюсах, а тут еще и обнова подъехала 😎
Итак, что нового и действительно интересного:
1. Новые операторы для словарей: finally можно нормально их мержить:
Отдельный респект за очередную отсылку к Монти Пайтону на странице обновы
Лично я по питону сильно соскучился, ибо уже второй месяц пишу только на C и плюсах, а тут еще и обнова подъехала 😎
Итак, что нового и действительно интересного:
1. Новые операторы для словарей: finally можно нормально их мержить:
dict1 = {'x': 1, 'y': 2}
dict2 = {'x': 4, 'z': 5}
print(dict1 | dict2) # выведет {'x': 4, 'y': 2, 'z': 5}
2. Методы строк, позволяющие получить строку без указанного префикса/суффикса: "abcdef".removeprefix("abc") # выведет def
"abcdef".removesuffix("def") # выведет abc
3. Более удобные декораторы, теперь там можно делать что-то такое:@buttons[0].clicked.connect📗 Также добавили плюшек в аннотации, обновили поддержку Юникода и много других мелочей, о которых можно почитать на официальном сайте.
def spam():
...
Отдельный респект за очередную отсылку к Монти Пайтону на странице обновы
Дмитрий Федеров перевёл официальные туториалы по Pandas на русский язык. Теперь это один из тех (немногочисленных) русскоязычных материалов, которые я могу смело рекомендовать любому, кто начинает изучать Pandas
http://dfedorov.spb.ru/pandas/
http://dfedorov.spb.ru/pandas/
В Телеграме очень много каналов про аналитику, в определенный момент я задался странным желанием собрать их все. У меня вообще страсть к коллекционированию информации. Я выискиваю даже самые небольшие каналы джунов/начинающих и подписываюсь на них, чтобы понять какие проблемы их волнуют.
И вот я в своём расстройстве зашёл так далеко, что решил спарсить все посты из этих каналов, да ещё и с указанием количества просмотров. Появилась небольшая такая таблица на 11000 записей. Да, я из тех людей, которые сначала соберут тьму данных, а потом решают, что с ними делать.
Сидел-сидел и понял, что хочу сделать так, чтобы информация из каналов в Телеграме приобретала вторую жизнь, просмотры набирали бы не только свежие посты, но и старые/проверенные/новые с небольшим числом просмотров. Сначала думал вручную собрать посты в коллекции (например, про АБ-тесты, про SQL, про визуализацию и т.д.) и разместить на отдельных страничках через embed-виджеты. Получились бы такие небольшие базы знаний. Но мне стало немного лениво/скучно/тревожно при мысли о том, чтобы вручную отбирать хорошие посты и классифицировать их. Поэтому я неумело сделал препроцессинг текстов постов и теперь готов к классификации с использованием ARTIFICIAL INTELLIGENCE!!!
Что дальше?
Дальше хочу сделать небольшой сервис, где выбираешь интересующую тематику, например, "Продуктовые метрики" и тебе подсовываются рандомно-хорошие посты из разных каналов на эту (или семантически-похожую) тему.
Поэтому ищу руки-ноги-головы, готовые помочь с:
а) Алгоритмом кластеризации/классификации (нужно сначала выделить потенциальные классы, предполагаю, что лучше всего каким-нибудь LDA, а затем обучить модельку)
б) Простенькой mobile-first веб-мордой
Пишите в комментах
И вот я в своём расстройстве зашёл так далеко, что решил спарсить все посты из этих каналов, да ещё и с указанием количества просмотров. Появилась небольшая такая таблица на 11000 записей. Да, я из тех людей, которые сначала соберут тьму данных, а потом решают, что с ними делать.
Сидел-сидел и понял, что хочу сделать так, чтобы информация из каналов в Телеграме приобретала вторую жизнь, просмотры набирали бы не только свежие посты, но и старые/проверенные/новые с небольшим числом просмотров. Сначала думал вручную собрать посты в коллекции (например, про АБ-тесты, про SQL, про визуализацию и т.д.) и разместить на отдельных страничках через embed-виджеты. Получились бы такие небольшие базы знаний. Но мне стало немного лениво/скучно/тревожно при мысли о том, чтобы вручную отбирать хорошие посты и классифицировать их. Поэтому я неумело сделал препроцессинг текстов постов и теперь готов к классификации с использованием ARTIFICIAL INTELLIGENCE!!!
Что дальше?
Дальше хочу сделать небольшой сервис, где выбираешь интересующую тематику, например, "Продуктовые метрики" и тебе подсовываются рандомно-хорошие посты из разных каналов на эту (или семантически-похожую) тему.
Поэтому ищу руки-ноги-головы, готовые помочь с:
а) Алгоритмом кластеризации/классификации (нужно сначала выделить потенциальные классы, предполагаю, что лучше всего каким-нибудь LDA, а затем обучить модельку)
б) Простенькой mobile-first веб-мордой
Пишите в комментах