
Интересная статья, раскрывающая многие аспекты работы аналитика: Никита Башун из "Везёт" рассказывает о создании системы антифрода. Отличный пример создания быстрого MVP, который за минимум времени разработки закрывает серьёзную проблему. Из инструментов: PostgreSQL, Airflow и Google Spreadsheets.
https://habr.com/ru/post/512752/
https://habr.com/ru/post/512752/
Хабр
Создание системы антифрода в такси с нуля
Добрый день. Меня зовут Никита Башун, работаю дата-аналитиком в группе компаний «Везёт». Мой рассказ будет о том, как мы командой из трёх человек с нуля создавал...
Forwarded from Data Analytics Jobs
🚂«Первая Грузовая Компания» (ПГК) — крупнейший частный оператор грузовых железнодорожных перевозок России в поиске Senior/Middle data scientist
🔈Слово предоставляется ребятам из ПГК:
Мы видим высокий потенциал в применении различных математических, ML и оптимизационных алгоритмов для создания решений в виде цифровых подсказчиков и инструментов автоматизации бизнес-процессов. Есть беклог на 7 продуктов от стратегического планирования до фактического исполнения грузовых ЖД перевозок. Расчет оптимального плана перевозок, выбор лучших маршрутов и подходящих вагонов, оптимальная передислокация вагонов в онлайн режиме, баланс парка и много другое.
Прямо сейчас мы создаем ядро команды продуктовой разработки. Есть возможность реализовать свои амбиции в части выстраивания процессов разработки и применяемых инструментов с нуля.
Стек: Python, SQL, математический солвер Gurobi.
Круто, если у тебя есть опыт в том, с чем мы еще не работаем и ты нас этому научишь.
📝Откликнуться на вакансию: @dkrupenin (Дима Крупенин)
🔗Ссылка на вакансию: https://hh.ru/vacancy/38174454
#moscow #remote #fulltime #senior #middle #data_analyst
🔈Слово предоставляется ребятам из ПГК:
Мы видим высокий потенциал в применении различных математических, ML и оптимизационных алгоритмов для создания решений в виде цифровых подсказчиков и инструментов автоматизации бизнес-процессов. Есть беклог на 7 продуктов от стратегического планирования до фактического исполнения грузовых ЖД перевозок. Расчет оптимального плана перевозок, выбор лучших маршрутов и подходящих вагонов, оптимальная передислокация вагонов в онлайн режиме, баланс парка и много другое.
Прямо сейчас мы создаем ядро команды продуктовой разработки. Есть возможность реализовать свои амбиции в части выстраивания процессов разработки и применяемых инструментов с нуля.
Стек: Python, SQL, математический солвер Gurobi.
Круто, если у тебя есть опыт в том, с чем мы еще не работаем и ты нас этому научишь.
📝Откликнуться на вакансию: @dkrupenin (Дима Крупенин)
🔗Ссылка на вакансию: https://hh.ru/vacancy/38174454
#moscow #remote #fulltime #senior #middle #data_analyst
Я заметил, что некоторые посты из этого канала репостят небольшие телеграм-каналы, которые рассказывают про работу с данными. Значит, появляется много новых каналов про аналитику данных. И это круто, потому что создание новых каналов — сигнал растущего интереса к этой теме. К тому же завести свой канал — отличный метод систематизации информации и может ускорить профессиональное развитие.
Захотелось привести на эти каналы побольше подписчиков, чтобы мотивировать авторов активнее писать и не бросать это дело. У меня небольшая просьба: если вы ведёте телеграм-канал про анализ данных и у вас немного подписчиков (до 500) — поделитесь ссылкой на канал в личном сообщении. Я соберу их в один пост и размещу тут.
Захотелось привести на эти каналы побольше подписчиков, чтобы мотивировать авторов активнее писать и не бросать это дело. У меня небольшая просьба: если вы ведёте телеграм-канал про анализ данных и у вас немного подписчиков (до 500) — поделитесь ссылкой на канал в личном сообщении. Я соберу их в один пост и размещу тут.
Статья про конкурентный анализ средствами Python. Я уже кидал предыдущую часть статьи, в которой рассматривались особенности парсинга. В этой же части автор рассказывает об организации хранения полученных данных с помощью простой SQLite-базы
https://habr.com/ru/post/512208/
https://habr.com/ru/post/512208/
Хабр
Как проанализировать рынок фотостудий с помощью Python (2/3). База данных
В предыдущей статье в рамках коммерческого проекта по анализу рынка фотостудий рассмотрел создание парсинга: выгрузка списка фотостудий, списка залов, данных по...
Как и обещал, делюсь ссылками на каналы в сфере анализа данных, только начинающие свой путь, а также некоторые каналы, которые существуют уже давно, но по какой-то причине не набрали ещё много подписчиков:
🔷Канал Саши Михайлова, не только про аналитику, но и про неё тоже
🔶What does data mean? — Поток полезных ссылок для изучения data science и анализа данных
🔷Аналитика. Это просто — Канал про аналитику данных
🔶Продуктовая аналитика для чайников — Канал о тернистом пути в продуктовую аналитику: ссылки, авторские заметки и статьи
🔷Я у мамы аналитик — Записная книжка по Business Intelligence, аналитике, инструментам и методам анализа
🔶Fsecrets.ru — Подборка интересных материалов с трендами продвинутой аналитики, реальными кейсами применения
🔷data fm — Канал Анастасии Шушуриной про возможности python в анализе данных, разработке и data science
🔶Just Yet Another Channel — Канал Дарьи Чиркиной про продвинутую аналитику данных
🔷datadrivendecisions — Канал Даниила Ханина о том, как принимать решения на основе данных, юнит-экономике, метриках и поисках точек кратного роста
🔶Пристанище Дата Сайентиста — Канал Рената Алимбекова про карьеру, применение и обучение Data Science
🔷LEFT JOIN — Канал Николая Валиотти про аналитику данных
🔶Business Intelligence HeadHunter — Канал с вакансиями Power BI, Tableau
Не пожалейте времени пробежаться и подписаться на интересные вам каналы
🔷Канал Саши Михайлова, не только про аналитику, но и про неё тоже
🔶What does data mean? — Поток полезных ссылок для изучения data science и анализа данных
🔷Аналитика. Это просто — Канал про аналитику данных
🔶Продуктовая аналитика для чайников — Канал о тернистом пути в продуктовую аналитику: ссылки, авторские заметки и статьи
🔷Я у мамы аналитик — Записная книжка по Business Intelligence, аналитике, инструментам и методам анализа
🔶Fsecrets.ru — Подборка интересных материалов с трендами продвинутой аналитики, реальными кейсами применения
🔷data fm — Канал Анастасии Шушуриной про возможности python в анализе данных, разработке и data science
🔶Just Yet Another Channel — Канал Дарьи Чиркиной про продвинутую аналитику данных
🔷datadrivendecisions — Канал Даниила Ханина о том, как принимать решения на основе данных, юнит-экономике, метриках и поисках точек кратного роста
🔶Пристанище Дата Сайентиста — Канал Рената Алимбекова про карьеру, применение и обучение Data Science
🔷LEFT JOIN — Канал Николая Валиотти про аналитику данных
🔶Business Intelligence HeadHunter — Канал с вакансиями Power BI, Tableau
Не пожалейте времени пробежаться и подписаться на интересные вам каналы
Статья про сравнение двух инструментов (Power BI и Python) для выполнения одной и той же задачи — когортного анализа. Лично я сторонник такого подхода, что для обработки данных нужно использовать тот инструмент, который исключает необходимость что-то тюнить и настраивать вручную, а для визуализации — инструмент с наибольшими возможностями гибкой фильтрации и предоставления self-service аналитики. Поэтому я бы комбинировал эти инструменты: строить сами когорты и определять количество дней жизни когорты в Python, а визуализировать (строить "косынки" и когортную таблицу) в BI-инструменте
https://habr.com/ru/post/501492/
https://habr.com/ru/post/501492/
Хабр
Повторяем когортный анализ, выполненный в Power BI, силами Python
Добрый день уважаемые читатели! Поводом для написания данной публикации послужил вебинар, который я посмотрел на Youtube. Он был посвящен когортному анализу прод...
Forwarded from Data Analytics Jobs
👷♂️Profi.ru ищет Middle Data Engineer в команду «BI»
🔈Слово предоставляется тимлиду команды «BI»:
Наша команда раскладывает и визуализирует данные так, чтобы аналитики могли строить дашборды, а бизнес — делать выводы и принимать решения на их основе.
Сейчас мы открываем направление «Аналитика в реальном времени», но для полноценного погружения нам не хватает data-инженера, который подхватит запросы от аналитиков и бизнеса, поддержит текущее развитие хранилища данных и поможет построить хранилище для маркетинговых данных.
Стек: Vertica, Clickhouse, MySQL, Redis, Python, Java, NodeJS, Apache Airflow, Apache Flink.
💬Откликнуться: @natashaprofi
🔗Посмотреть вакансию: https://profi.ru/vacancies/middle_engineer/
#moscow #fulltime #remote_first #middle #data_engineer
🔈Слово предоставляется тимлиду команды «BI»:
Наша команда раскладывает и визуализирует данные так, чтобы аналитики могли строить дашборды, а бизнес — делать выводы и принимать решения на их основе.
Сейчас мы открываем направление «Аналитика в реальном времени», но для полноценного погружения нам не хватает data-инженера, который подхватит запросы от аналитиков и бизнеса, поддержит текущее развитие хранилища данных и поможет построить хранилище для маркетинговых данных.
Стек: Vertica, Clickhouse, MySQL, Redis, Python, Java, NodeJS, Apache Airflow, Apache Flink.
💬Откликнуться: @natashaprofi
🔗Посмотреть вакансию: https://profi.ru/vacancies/middle_engineer/
#moscow #fulltime #remote_first #middle #data_engineer
Predictive Power Score (PPS) — это метрика, позволяющая определять степень линейной и нелинейной зависимости между двумя колонками, в том числе для ассиметричной зависимости. Эта метрика может быть отличной заменой коэффициента корреляции Пирсона. Пример реализации подсчета Predictive Power Score на Python и сравнение с Пирсоном:
https://www.kaggle.com/frtgnn/predictive-power-score-vs-correlation
Также рекомендую почитать статью про PPS:
https://towardsdatascience.com/rip-correlation-introducing-the-predictive-power-score-3d90808b9598
Вдохновлено постом https://t.me/ProductAnalytics/249
https://www.kaggle.com/frtgnn/predictive-power-score-vs-correlation
Также рекомендую почитать статью про PPS:
https://towardsdatascience.com/rip-correlation-introducing-the-predictive-power-score-3d90808b9598
Вдохновлено постом https://t.me/ProductAnalytics/249
В этом году исполнилось 35 лет с первого релиза Microsoft Excel.
Это программа, которая, без преувеличения, изменила мир. Про себя могу сказать, что знакомство и тщательное изучение Excel определили то, что я буду заниматься аналитикой. Можно сказать, что именно благодаря этой программе я начал совершать первые робки шаги в анализе данных.
Нашёл перевод интересной статьи, которая прославляет Excel и рассказывает про его историю и влияние на бизнес:
Посмотрите как эволюционировал Excel за эти 35 лет: https://www.versionmuseum.com/history-of/microsoft-excel
Это программа, которая, без преувеличения, изменила мир. Про себя могу сказать, что знакомство и тщательное изучение Excel определили то, что я буду заниматься аналитикой. Можно сказать, что именно благодаря этой программе я начал совершать первые робки шаги в анализе данных.
Нашёл перевод интересной статьи, которая прославляет Excel и рассказывает про его историю и влияние на бизнес:
Появление MS Excel определило эпоху — он «создал тысячи стартапов и стимулировал миллионы увольнений». Благодаря этой программе появлялись совершенно новые отрасли промышленности. Только посмотрите, какое количество новых должностей появилось в мире бизнес-аналитики — даже та, на которой я проработал большую часть 2015-го. Этих профессий не существовало, пока Excel не подарил нам возможность обрабатывать и визуализировать данные — играть в «что будет, если…».https://habr.com/ru/company/it-grad/blog/507114/
Посмотрите как эволюционировал Excel за эти 35 лет: https://www.versionmuseum.com/history-of/microsoft-excel
Хабр
Ода Excel: 34 года волшебства
Примечание: статья была написана в 2019 году, а в этом Microsoft Excel отмечает уже 35-летний юбилей. Чему инструмент, выдержавший проверку временем, может нау...
Нашёл на Kaggle микрокурс по изучению Pandas, оформленный в виде ноутбуков. Включает в себя разбор всех базовых функций, так что для ознакомления с возможностями библиотеки отлично подходит
https://www.kaggle.com/learn/pandas
https://www.kaggle.com/learn/pandas
Kaggle
Learn Pandas Tutorials
Solve short hands-on challenges to perfect your data manipulation skills.
Статья про байесовский подход к оценке результатов A/B-тестирования. Хорошо и доступно описывается сам подход и его преимущества. Также в статье есть примеры кода, которые будут полезны для собственных проектов
https://towardsdatascience.com/why-you-should-try-the-bayesian-approach-of-a-b-testing-38b8079ea33a
https://towardsdatascience.com/why-you-should-try-the-bayesian-approach-of-a-b-testing-38b8079ea33a
Medium
Why you should try the Bayesian approach of A/B testing
The intuitive way of A/B testing. The advantages of the Bayesian approach and how to do it.
Запись доклада про производительность Pandas с PyData Fest Amsterdam 2020 от Ian Ozsvald, одного из авторов книги High Performance Python
Большие датасеты не всегда помещаются в память, но что делать если хочется проанализировать их с помощью Pandas? Сначала в видео рассматриваются методы сжатия данных. Далее разбираются некоторые "хитрые" способы ускорить выполнение обычных операций в датафреймах, включая переход на numpy и более оптимальный выбор функций для операций с данными. Рассмотренные приёмы позволят уменьшить размер датафреймов и ускорить обработку данных.
https://youtu.be/N4pj3CS857c
Большие датасеты не всегда помещаются в память, но что делать если хочется проанализировать их с помощью Pandas? Сначала в видео рассматриваются методы сжатия данных. Далее разбираются некоторые "хитрые" способы ускорить выполнение обычных операций в датафреймах, включая переход на numpy и более оптимальный выбор функций для операций с данными. Рассмотренные приёмы позволят уменьшить размер датафреймов и ускорить обработку данных.
https://youtu.be/N4pj3CS857c
YouTube
Ian Ozsvald - Making Pandas Fly | PyData Fest Amsterdam 2020
PyData is excited to announce PyData Global, November 11th - 15th! Tickets are now available: https://global.pydata.org/pages/tickets.html#pricing-and-ticket-purchases
Part of an underrepresented group in tech? PyData Global is offering Diversity Scholarships.…
Part of an underrepresented group in tech? PyData Global is offering Diversity Scholarships.…
Forwarded from LEFT JOIN
Диалог @a_nikushin и @data_karpov о доступном образовании для аналитиков на Youtube вдохновил меня рассказать одну свою историю и поделиться ссылками.
Так сложилось, что в Университете мне очень повезло с преподавателями (от линейной алгебры до баз данных и языков программирования). Один из них, В. Л. Аббакумов, разжег настоящую страсть к методам анализа данных своими лекциями и лабораторными заданиями. В. Л. — практик и был моим научным руководителем по дипломной работе (мы делали кластеризацию данных Ленты), а затем и по кандидатской диссертации (строили нейронную сеть специальной архитектуры, тогда еще в Matlab).
Уже несколько лет назад в рамках ШАД и Computer Science Яндекса у него был записан курс Анализ данных на Python в примерах и задачах в двух частях. Настало время поделиться ссылками на первый и второй плейлисты на Youtube.
Первая часть посвящена описательным статистикам, проверке статистических гипотез, иерархическому кластерному анализу и кластерному анализу методом к-средних, классификационным моделям (деревья, Random Forest, GBM). В целом, весь плейлист достоин внимания без отрыва 🤓
Во второй части более глубокое погружение в нейронные сети, keras, deep learning, xgboost и снова все лекции крайне рекомендованы.🎖
Смотреть можно смело на 1.5x.
Материалы к видео:
— Часть 1. Занятия и материалы
— Часть 2. Занятия и материалы
Так сложилось, что в Университете мне очень повезло с преподавателями (от линейной алгебры до баз данных и языков программирования). Один из них, В. Л. Аббакумов, разжег настоящую страсть к методам анализа данных своими лекциями и лабораторными заданиями. В. Л. — практик и был моим научным руководителем по дипломной работе (мы делали кластеризацию данных Ленты), а затем и по кандидатской диссертации (строили нейронную сеть специальной архитектуры, тогда еще в Matlab).
Уже несколько лет назад в рамках ШАД и Computer Science Яндекса у него был записан курс Анализ данных на Python в примерах и задачах в двух частях. Настало время поделиться ссылками на первый и второй плейлисты на Youtube.
Первая часть посвящена описательным статистикам, проверке статистических гипотез, иерархическому кластерному анализу и кластерному анализу методом к-средних, классификационным моделям (деревья, Random Forest, GBM). В целом, весь плейлист достоин внимания без отрыва 🤓
Во второй части более глубокое погружение в нейронные сети, keras, deep learning, xgboost и снова все лекции крайне рекомендованы.🎖
Смотреть можно смело на 1.5x.
Материалы к видео:
— Часть 1. Занятия и материалы
— Часть 2. Занятия и материалы
YouTube
Лекция 1. Описательные статистики. Квантили, квартили. Гистограммы
https://compscicenter.ru/
Описательные статистики. Квантили, квартили. Гистограммы. Ядерные оценки плотности.
Лекция №1 в курсе "Анализ данных на Python в примерах и задачах. Часть 1" (весна 2018).
Преподаватель курса: Вадим Леонардович Аббакумов
Описательные статистики. Квантили, квартили. Гистограммы. Ядерные оценки плотности.
Лекция №1 в курсе "Анализ данных на Python в примерах и задачах. Часть 1" (весна 2018).
Преподаватель курса: Вадим Леонардович Аббакумов
Наткнулся на библиотеку для работы с временными рядами Darts. В неё встроены не только популярные инструменты прогнозирования временных рядов (ARIMA, Prophet), но и различные вспомогательные функции, например, процессинг ряда для разделения на сезонную и трендовую компоненты, утилиты для бэктестинга (проверки модели на исторических данных). В общем, любопытная штука, для тех кто работает с временными рядами - будет полезно
https://medium.com/unit8-machine-learning-publication/darts-time-series-made-easy-in-python-5ac2947a8878
@datalytx
https://medium.com/unit8-machine-learning-publication/darts-time-series-made-easy-in-python-5ac2947a8878
@datalytx
Medium
Darts: Time Series Made Easy in Python
Time series simply represent data points over time. They are thus everywhere in nature and in business: temperatures, heartbeats, births…
Forwarded from This is Data
Наконец-то закончил статью на одну из самых сложных для понимания тем - оконные функции в SQL.
На ее написание ушло почти пять месяцев с перерывом на отпуск :)
В статье на простых примерах с картинками разбирается принцип работы данных функций, а в конце вас ждут кейсы с расчетом моделей атрибуции «Первый клик» и «С учетом давности взаимодействий».
На ее написание ушло почти пять месяцев с перерывом на отпуск :)
В статье на простых примерах с картинками разбирается принцип работы данных функций, а в конце вас ждут кейсы с расчетом моделей атрибуции «Первый клик» и «С учетом давности взаимодействий».
{kind=link}
Интересная статья с большим количеством примеров, рассказывающая про индексы в Pandas. Для тех кто всегда делает
https://towardsdatascience.com/understand-pandas-indexes-1b94f5c078c6
reset_index(), боясь заморачиваться с текстовыми индексами🙃https://towardsdatascience.com/understand-pandas-indexes-1b94f5c078c6
Medium
Understand Pandas Indexes
To efficiently use of Pandas, ignore its documentation and learn the truth about indexes
Retentioneering — это библиотека, которая помогает продуктовым и маркетинговым аналитикам обрабатывать логи событий и траектории пользователей в мобильных приложениях, веб-сайтах и других цифровых продуктов. С помощью этого фреймворка можно сегментировать пользователей, строить ML-пайплайны для прогнозирования категории пользователей или определения вероятности совершения целевого действия, основываясь на исторических данных.
Недавно у ребят вышел большой апдейт https://github.com/retentioneering/retentioneering-tools
Попробовать можно слету в Google Colab без установки, все стало очень просто.
Добавлен инструмент простого A/B-тестирования, ускорены более чем в десять раз скорость кластеризации, переработан функционал step-матриц.
P.S. Очень важное дополнение - различные варианты нормировки и развесовки ребер графа. Теперь можно четко видеть сколько пользователей сделало переход, либо сколько сессий с таким переходом было, либо сколько событий переходов во всем датасете. Можно явно выбирать как вы хотите это нормировать - на общее число пользователей или переходов, или на количество переходов из конкретного узла - получаются разные инсайты на графе и в матрицах переходов.
Вопросы по библиотеке можно задать в Телеграм чате @retentioneering_support
Недавно у ребят вышел большой апдейт https://github.com/retentioneering/retentioneering-tools
Попробовать можно слету в Google Colab без установки, все стало очень просто.
Добавлен инструмент простого A/B-тестирования, ускорены более чем в десять раз скорость кластеризации, переработан функционал step-матриц.
P.S. Очень важное дополнение - различные варианты нормировки и развесовки ребер графа. Теперь можно четко видеть сколько пользователей сделало переход, либо сколько сессий с таким переходом было, либо сколько событий переходов во всем датасете. Можно явно выбирать как вы хотите это нормировать - на общее число пользователей или переходов, или на количество переходов из конкретного узла - получаются разные инсайты на графе и в матрицах переходов.
Вопросы по библиотеке можно задать в Телеграм чате @retentioneering_support
GitHub
GitHub - retentioneering/retentioneering-tools: Retentioneering: product analytics, data-driven CJM optimization, marketing analytics…
Retentioneering: product analytics, data-driven CJM optimization, marketing analytics, web analytics, transaction analytics, graph visualization, process mining, and behavioral segmentation in Pyth...
Дисбаланс в A/B-тестах. Есть ли разница между 99/1 % и 50/50 % в экспериментах?
Ребята из Experiment Fest провели небольшое исследование и написали статью про несбалансированные A/B-тестирования. Как оказалось, проводя A/B на несбалансированных выборках, существенно возрастает вероятность упустить значимые различия, если они есть. Результаты анализа и выводы представлены в статье
Читать статью на Медиуме
Подписаться на канал Experiment Fest
Ребята из Experiment Fest провели небольшое исследование и написали статью про несбалансированные A/B-тестирования. Как оказалось, проводя A/B на несбалансированных выборках, существенно возрастает вероятность упустить значимые различия, если они есть. Результаты анализа и выводы представлены в статье
Читать статью на Медиуме
Подписаться на канал Experiment Fest
Таблицы иногда говорят больше, чем графики. Особенно для тех, кто умеет с ними работать. При этом процесс интерпретации таблиц должен быть быстрым и комфортным. Например, в excel для этого используется условное форматирование и спарклайны. В этой статье рассматривается как визуализировать данные с помощью Python и библиотеки pandas, используя свойства DataFrame.style и Options and settings
https://habr.com/ru/post/521894/
https://habr.com/ru/post/521894/
Хабр
Формат таблиц в pandas
Если вы пока ещё не знаете как транслировать данные напрямую заказчику в подсознание или, на худой конец, текст сообщения в slack, вам пригодится информация о то...
Пример разведочного анализа данных (EDA) на датасете из 450к записей с Пикабу. Получился хороший блокнот, освещающий основные этапы: заполнение пропущенных значений, удаление дубликатов, описательные статистики, анализ взаимосвязей между признаки и визуализация. Если кому-то захочется самостоятельно покопаться с данными — ближе к концу статьи есть ссылка на датасет
https://habr.com/ru/post/519054/
https://habr.com/ru/post/519054/
Хабр
Pikabu-dataset
Предлагается взглянуть на dataset постов с pikabu.ru c точки зрения датастатистики. Сам датасет в составе 450к штук собран лучшими круглосуточными парсерами, обработан отдушками, убирающими дубликаты...
Forwarded from Пристанище Дата Сайентиста
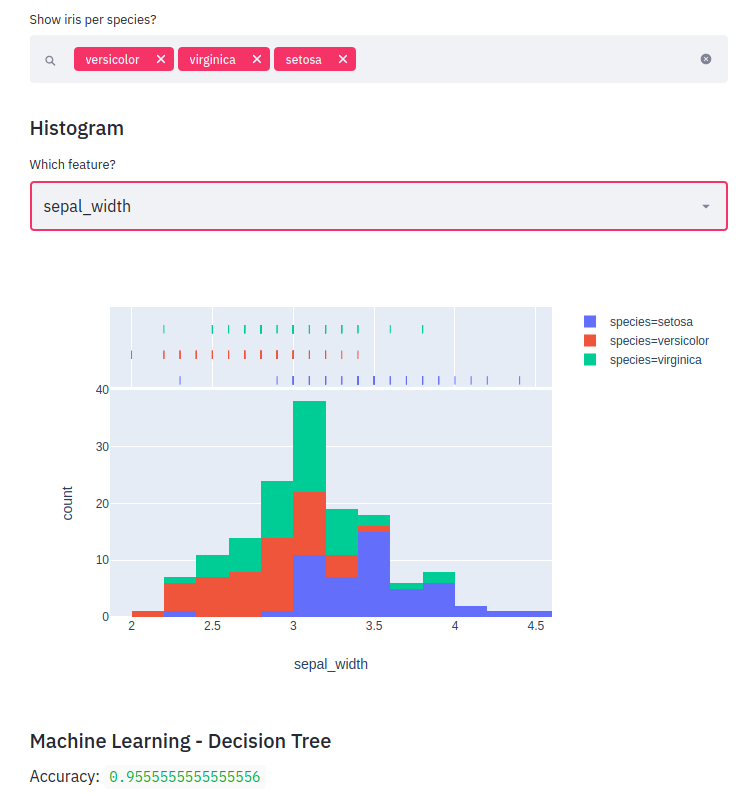
Streamlit - быстрый способ создать приложение для работы с данными
Допустим вам нужно быстро создать приложение для работы с данными. Оно может включать в себя дэшборд и работу с моделью. Или если вам нужен быстрый прототип для показа заказчику, который можно сделать за несколько часов и бесплатно.
Streamlit отлично подходит под эти задачи. Все на чистом Python. Нужно будет освоить только интерактивные компоненты для создания фильтров/ чекбоксов/ полей ввода/ загрузки файлов.
Разберём функционал на уже знакомом примере Ирисов Фишера. Сделаем очень простой дэшборд с выбором вида Ирисов и построением гистограмм. Так же в Streamlit можно обучать и делать инференс моделей.
Дополнительный материал:
Сайт Streamlit - https://www.streamlit.io/
Код с Docker - https://github.com/alimbekovKZ/ML-DL-in-production/tree/master/streamlit
Допустим вам нужно быстро создать приложение для работы с данными. Оно может включать в себя дэшборд и работу с моделью. Или если вам нужен быстрый прототип для показа заказчику, который можно сделать за несколько часов и бесплатно.
Streamlit отлично подходит под эти задачи. Все на чистом Python. Нужно будет освоить только интерактивные компоненты для создания фильтров/ чекбоксов/ полей ввода/ загрузки файлов.
Разберём функционал на уже знакомом примере Ирисов Фишера. Сделаем очень простой дэшборд с выбором вида Ирисов и построением гистограмм. Так же в Streamlit можно обучать и делать инференс моделей.
import streamlit as stimport pandas as pdimport numpy as npimport plotly.express as pximport seaborn as snsimport matplotlib.pyplot as pltimport plotly.graph_objects as gost.title('Iris')df = pd.read_csv("iris.csv")st.subheader('Scatter plot')species = st.multiselect('Show iris per species?', df['species'].unique())new_df = df[(df['species'].isin(species))]st.subheader('Histogram')feature = st.selectbox('Which feature?', df.columns[0:4])new_df2 = df[(df['species'].isin(species))][feature]fig2 = px.histogram(new_df, x=feature, color="species", marginal="rug")st.plotly_chart(fig2)st.subheader('Machine Learning - Decision Tree')from sklearn.model_selection import train_test_splitfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.metrics import confusion_matrixfeatures= df[['sepal_length', 'sepal_width', 'petal_length', 'petal_width']].valueslabels = df['species'].valuesX_train,X_test, y_train, y_test = train_test_split(features, labels, train_size=0.7, random_state=1)dtc = DecisionTreeClassifier()dtc.fit(X_train, y_train)acc = dtc.score(X_test, y_test)st.write('Accuracy: ', acc)pred_dtc = dtc.predict(X_test)cm_dtc=confusion_matrix(y_test,pred_dtc)st.write('Confusion matrix: ', cm_dtc)Дополнительный материал:
Сайт Streamlit - https://www.streamlit.io/
Код с Docker - https://github.com/alimbekovKZ/ML-DL-in-production/tree/master/streamlit
{kind=link}