
https://www.dataschool.io/future-of-pandas/
Статья про будущее библиотеки Pandas. Автор основывается на докладе одного из ключевых разработчиков Pandas на митапе PyData 2018 (кстати, рекомендую канал PyData на YouTube, где размещается куча полезного контента). Из интересного: хотят сделать почти все методы такими, чтобы была поддержка chaining, когда весь процесс обработки данных можно описать однострочной длинной последовательностью вызываемых друг за другом методов; уберут из методов поддержку параметра inplace; Apache Arrow будет бэкендом для Pandas, что повлияет на скорость обработки больших датасетов; появятся кастомные типы, например int с поддержкой nan 🎉 (сейчас только float из численных типов поддерживает nan); уберут поддержку обращения к строкам dataframe через ix. В общем, светлое будущее. Версия 0.25, в которой все это будет, запланирована на начало 2019. А следом из 0.25 сделают мажорную версию 1.0, убрав из 0.25 все устаревшие (deprecated) методы.
Статья про будущее библиотеки Pandas. Автор основывается на докладе одного из ключевых разработчиков Pandas на митапе PyData 2018 (кстати, рекомендую канал PyData на YouTube, где размещается куча полезного контента). Из интересного: хотят сделать почти все методы такими, чтобы была поддержка chaining, когда весь процесс обработки данных можно описать однострочной длинной последовательностью вызываемых друг за другом методов; уберут из методов поддержку параметра inplace; Apache Arrow будет бэкендом для Pandas, что повлияет на скорость обработки больших датасетов; появятся кастомные типы, например int с поддержкой nan 🎉 (сейчас только float из численных типов поддерживает nan); уберут поддержку обращения к строкам dataframe через ix. В общем, светлое будущее. Версия 0.25, в которой все это будет, запланирована на начало 2019. А следом из 0.25 сделают мажорную версию 1.0, убрав из 0.25 все устаревшие (deprecated) методы.
Data School
What's the future of the pandas library?
pandas is a very popular Python library for data analysis, manipulation, and visualization, but it still hasn't reached version 1.0. What's next for pandas?
Forwarded from BigQuery Insights
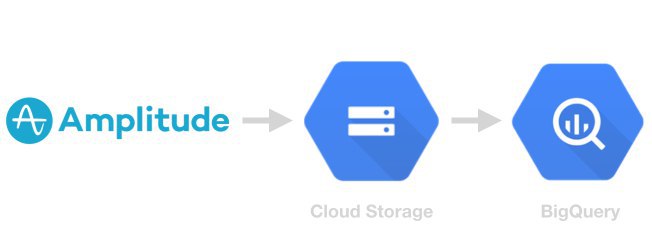
В сети появился скрипт для ежедневного экспорта данных Amplitude в BigQuery через Google Cloud Storage
via @BigQuery
via @BigQuery
{kind=link}
https://tqdm.github.io/
Иногда всяческие приятные мелочи сильно упрощают жизнь. Например, tqdm - очень минималистичная библиотека, единственная функция которой - отображать красивый информативный прогресс бар
Иногда всяческие приятные мелочи сильно упрощают жизнь. Например, tqdm - очень минималистичная библиотека, единственная функция которой - отображать красивый информативный прогресс бар
Написал в свой блог короткую статейку о том как через Python загружать или получать данные из BigQuery сразу в пандасовский датафрейм. Также немного рассматривается как с помощью нативной питоновской библиотеки bigquery можно управлять датасетами и таблицами. http://datalytics.ru/all/kak-ispolzovat-google-bigquery-s-pomoschyu-python/
www.datalytics.ru
Как использовать Google BigQuery с помощью Python
Google BigQuery — это безсерверное масштабируемое хранилище данных
https://changhsinlee.com/pyderpuffgirls-ep4/ Новая часть серии постов про автоматизацию всяческой рутины на Python. В этот раз про то как отправлять email, да не простые, а с аттачментами и эмоджи! В конце статьи - ссылки на предыдущие части
Chang Hsin Lee
Filling Up Your Inbox with Goodies—PyderPuffGirls Episode 4
In the previous posts, I covered how to set up scheduled jobs for SQL queries. How can I get a note when things go wrong? How can I send the result to myself? Email, of course! So, in this post, I will show you how to send emails with Python.
Подробное руководство по Pandas для начинающих. Освещает вопросы загрузки данных, очистки и подготовки данных, применения условий для фильтрации. https://www.learndatasci.com/tutorials/python-pandas-tutorial-complete-introduction-for-beginners/
Learndatasci
Python Pandas Tutorial: A Complete Introduction for Beginners
Learn some of the most important pandas features for exploring, cleaning, transforming, visualizing, and learning from data.
Наткнулся на метод в pandas, который до сих пор мне был не известен, но очень пригодился, когда захотелось порефакторить свой старый ноутбук, чтобы повысить удобочитаемость. Это метод query. Он дает возможность выбрать строки датафрейма, исходя из определенного условия, но при этом не ссылаясь на сам датафрейм, что позволяет оформлять обработку данных в стиле method chaining.
К примеру, я хочу смерджить два датафрейма, а затем отфильтровать полученный результат по колонке из второго датафрейма.
Можно сделать это двумя отдельными командами:
К примеру, я хочу смерджить два датафрейма, а затем отфильтровать полученный результат по колонке из второго датафрейма.
Можно сделать это двумя отдельными командами:
df = df1.merge(df2,on='key',how='left')А вот как можно сделать это с помощью query:
df = df[df['column_from_df2'] == 1]
df = df1.merge(df2,on='key',how='left').query("column_from_df2==1")
Также в query можно использовать переменные:some_value = 1
df = df1.merge(df2,on='key',how='left').query("column_from_df2==@some_value")
Такие дела❗️В дополнение к этому каналу решил завести чатик @pydata_chat. В нем можно (и нужно) задавать всяческие вопросы на тему применения Python для анализа данных, в особенности для различного рода автоматизации и аналитики. Также рад буду, если участники будут делиться полезными материалами. Как минимум, там есть я, так что вопросы про pandas точно не останутся без ответа🙂
Если вы сомневаетесь ставить ли вам пробелы после оператора &, нужен ли пробел после наименования функции до аргументов, то рекомендации из PEP8 помогут развеять ваши сомнения. Это официальный гайдлайд о том как писать читабельный код. Статья по ссылке освещает важные моменты из PEP8 https://realpython.com/python-pep8/
Realpython
How to Write Beautiful Python Code With PEP 8 – Real Python
Learn how to write high-quality, readable code by using the Python style guidelines laid out in PEP 8. Following these guidelines helps you make a great impression when sharing your work with potential employers and collaborators.
Не совсем в тему канала, так как изначально ориентируюсь на аудиторию тех, кто использует Python для анализа данных, но без Machine Learning. Но наткнулся на отличную подборку материалов по ML и такой штукой грех не поделиться: https://github.com/demidovakatya/vvedenie-mashinnoe-obuchenie
GitHub
GitHub - demidovakatya/vvedenie-mashinnoe-obuchenie: :memo: Подборка ресурсов по машинному обучению
:memo: Подборка ресурсов по машинному обучению. Contribute to demidovakatya/vvedenie-mashinnoe-obuchenie development by creating an account on GitHub.
Datalytics pinned «❗️В дополнение к этому каналу решил завести чатик @pydata_chat. В нем можно (и нужно) задавать всяческие вопросы на тему применения Python для анализа данных, в особенности для различного рода автоматизации и аналитики. Также рад буду, если участники будут…»
Канал выбирается из зимней спячки. И первый пост в новом году будет про Pandas. Когда вы долго и регулярно пользуетесь Pandas, то у вас обычно набирается несколько стандартных кусочков кода (сниппетов), из которых формируется пайплайн обработки данных. Jeff Delaney делится своими сниппетами. Есть и банальности вроде "как прочитать csv", но бывают и интересные, например, о том как сделать разбивку числовых значений на диапазоны, или как загрузить большой csv последовательными маленькими чанками. https://jeffdelaney.me/blog/useful-snippets-in-pandas/
jeffdelaney.me
19 Essential Snippets in Pandas
A compilation of Python Pandas snippets for data science. After playing around with Pandas for about a month, I've compiled a pretty large list of useful sni...
Хорошее руководство по написанию CLI (command-line interfaces) - интерфейсов командной строки. Автор разбирает использование модулей стандартной библиотеки
https://blog.sicara.com/perfect-python-command-line-interfaces-7d5d4efad6a2?fbclid=IwAR2MEXJyPhYOgGpfwxf8ZeYskQF-8cWjtnEhezCS6OpYRXYf1iVQarpCJwM
sys.argv и argparse, а затем знакомит нас со сторонней библиотекой click, с помощью которой просто создавать очень мощные CLI, а код при этом выглядит простым и понятным.https://blog.sicara.com/perfect-python-command-line-interfaces-7d5d4efad6a2?fbclid=IwAR2MEXJyPhYOgGpfwxf8ZeYskQF-8cWjtnEhezCS6OpYRXYf1iVQarpCJwM
Sicara's blog
How to Write Perfect Python Command-line Interfaces — Learn by Example
Improve your productivity by making your scripts as handy and straightforward as possible
Если кто много работает с семантическими ядрами, ключевыми словами или обработкой текста, то может пригодится библиотека rutermextract, которая позволяет извлекать ключевые слова из текста, основываясь на частях речи и частоте употребления.
GitHub
GitHub - igor-shevchenko/rutermextract: Term extraction for Russian language
Term extraction for Russian language. Contribute to igor-shevchenko/rutermextract development by creating an account on GitHub.
Курс, включающий 11 уроков по работе с Pandas. Всё очень детально и подробно. Каждый урок представлен в виде отдельного ноутбука. Есть даже урок, освещающий stack и unstack, с которыми у многих возникают проблемы, а чаще всего их просто не используют 🙃https://bitbucket.org/hrojas/learn-pandas
Новый эпизод из серии постов про автоматизацию всяческой рутины с помощью Python. На этот раз речь пойдет о том как эффективно создавать SQL-запросы с помощью шаблонизатора Jinja. Такой подход позволяет делать собственные шаблоны для запросов, что делает скрипты для обработки данных из БД более универсальными, т.к. можно чаще использовать уже готовые скрипты для новых задач. Ссылки на предыдущие части - в конце поста. https://changhsinlee.com/pyderpuffgirls-ep5/
Chang Hsin Lee
Untangle the SQL Mess with Jinja—PyderPuffGirls Episode 5
Writing and maintaining complex SQL query sucks. How can I use Python to make my life easier?
Нет лучшего способа контролировать ход выполнения алгоритма, чем логирование. Можно конечно всё обвешать print'ами😀 но это будет жуть как неудобно, когда ваши скрипты будут разрастаться, всё больше скриптов будет запускаться по расписанию и нужно будет разбираться что вообще происходит. На RealPython есть хороший туториал по логированию, как раз для тех, кто хочет перестать всё обвешивать print и делать как "серьёзные" программисты😎https://realpython.com/python-logging/
Realpython
Logging in Python – Real Python
If you use Python's print() function to get information about the flow of your programs, logging is the natural next step. Create your first logs and curate them to grow with your projects.
Хорошая статья про функции pivot, stack и unstack в Pandas. С pivot, наверняка, многие работали, а вот stack и unstack применяют не так часто. Тем не менее, функции очень полезные для трансформации данных. https://nikgrozev.com/2015/07/01/reshaping-in-pandas-pivot-pivot-table-stack-and-unstack-explained-with-pictures/
Nikgrozev
Reshaping in Pandas - Pivot, Pivot-Table, Stack, and Unstack explained with Pictures
In this post, I'll exemplify some of the most common Pandas reshaping functions and will depict their work with diagrams ...
Решил в своём блоге начать выкладывать не только гайды в стиле how-to, но и делиться примерами решения задач из области анализа данных, с которыми я сталкиваюсь. Надеюсь, что такие статьи помогут аналитикам узнать новые приёмы для себя, которые они перенесут в свою деятельность. Также я буду крайне рад, если подписчики будут предлагать свои решения.
Первая задача, которую я хочу рассмотреть - это преобразование одной колонки с данными в несколько. Может пригодится, если входные данные кривоваты, как в моём случае. http://datalytics.ru/all/kak-v-pandas-razbit-kolonku-na-neskolko-kolonok/
Первая задача, которую я хочу рассмотреть - это преобразование одной колонки с данными в несколько. Может пригодится, если входные данные кривоваты, как в моём случае. http://datalytics.ru/all/kak-v-pandas-razbit-kolonku-na-neskolko-kolonok/
www.datalytics.ru
Как в Pandas разбить одну колонку на несколько
Решил начать рассматривать нетривиальные кейсы в Pandas, с которыми иногда сталкиваюсь при работе с данными
В продолжение вчерашнего поста. Читатель предложил собственное решение задачи, использующее регулярные выражения. Получилось просто и эффективно 👍🏻Добавил решение в статью: http://datalytics.ru/all/kak-v-pandas-razbit-kolonku-na-neskolko-kolonok/
www.datalytics.ru
Как в Pandas разбить одну колонку на несколько
Решил начать рассматривать нетривиальные кейсы в Pandas, с которыми иногда сталкиваюсь при работе с данными
Крайне советую канал @ohmypy, в котором автор раскрывает возможности стандартной библиотеки Python, о которых вам лучше бы знать. Тут и про кортежи, и про
enum, и про Counter из collections, и про сравнение похожести строк с помощью SequenceMatcher. В общем, куча полезных советов, которые помогут сделать код эффективным и опрятным https://t.me/ohmypyTelegram
Oh My Py
Все о чистом коде на Python // antonz.ru