
Годнота про то как сделать один сервер Jupyter доступным для кучи пользователей с разграничением доступов https://habrahabr.ru/company/yandex/blog/353546/. От туда узнал про nbgrader - систему для оценки заданий с помощью Jupyter (https://github.com/jupyter/nbgrader).
Habr
JupyterHub, или как управлять сотнями пользователей Python. Лекция Яндекса
Платформа Jupyter позволяет начинающим разработчикам, аналитикам данных и студентам быстрее начать программировать на Python. Предположим, ваша команда растёт — в ней теперь не только программисты, но...
Как-то я раньше не знал о существовании чудесного фреймворка Dash https://github.com/plotly/dash от Plotly для создания собственных аналитических веб-приложений на Питоне. Упрощенно говоря, на выходе получаются дэшборды в виде отдельных веб-сервисов, которые можно кастомизировать как душе угодно. Если кто-то видел Shiny для R, то это его аналог, но для Python. И всё это опенсорсненько. Пример дэшборда: https://dash-stock-tickers.plot.ly/
GitHub
GitHub - plotly/dash: Data Apps & Dashboards for Python. No JavaScript Required.
Data Apps & Dashboards for Python. No JavaScript Required. - plotly/dash

Интересный формат. Автор планирует туториал из 8 эпизодов для тех аналитиков, кто пытался когда-то изучать Python, но забросил. Бросают обычно из-за того, что люди начинают изучение с синтаксиса, а лучше начинать с решения легких практических задач, избавляя себя от рутины и сразу же чувствуя как Python улучшает рабочий процесс. https://changhsinlee.com/pyderpuffgirls-ep1/
Chang Hsin Lee
A Python Tutorial for the Bored Me—PyderPuffGirls Episode 1
This is the Episode 1 of the PyderPuffGirls†—a tutorial on automating the boring parts of data analysis that we are going through in the next 8 weeks. I’m writing this tutorial for people that had at least one false start in learning Python, just like me…
Добавляйтесь в мою группу на Facebook. Делитесь интересными ссылками, задавайте вопросы по анализу данных, по возможности буду отвечать или отвечайте на вопросы других участников. Давайте сообща развивать культуру анализа данных на Python! 🐍
Из статьи на vc.ru узнал о том, что Amazon выкатил в паблик свои курсы по машинному обучению. Бесплатненько. Для курсов выбран любопытный подход, когда различные курсы объединены в обучающие пути. Например, есть обучающий путь для разработчиков ML или для дата-сайентистов.
vc.ru
Amazon открыла доступ к внутренним курсам по машинному обучению для всех желающих — Образование на vc.ru
Каждый может пройти программу, по которой готовятся разработчики крупнейшего онлайн-ритейлера.
На сайте издательства Apress до 30 ноября действует акция Cyberweek: продают книги по 7 евро. Среди ассортимента встречается много книг по Python, например, Персональные финансы с помощью Python.💰 Есть книги, где на Github размещено много исходного кода (например). Так что можно даже не покупать, а просто поисследовать что там за код 😏
www.apress.com
We build strong partnerships with our authors. Apress offers authors the chance to work with a publisher with the marketing, distribution, and
Первая часть большого и подробного гайда про веб-скрэпинг (парсинг информации с веб-сайтов) с помощью библиотеки BeautifulSoup на Python на примере анализа данных о политических новостях https://www.learndatasci.com/tutorials/ultimate-guide-web-scraping-w-python-requests-and-beautifulsoup/ 🇬🇧
Learndatasci
Ultimate Guide to Web Scraping with Python Part 1: Requests and BeautifulSoup
Request and wrangling HTML using two of the most popular Python libraries for web scraping: requests and BeautifulSoup.
https://www.marsja.se/pandas-read-csv-tutorial-to-csv/
Очень детальное руководство по работе с CSV-файлами в Pandas. Освещена куча насущных вопросов о том как:
⚪️ прочитать CSV и заменить названия колонок,
⚪️ задать индексную колонку,
⚪️ загрузить только заранее определенные колонки,
⚪️ массово удалить колонки без названий, работать с пустыми значениями,
⚪️ пропустить несколько строк при загрузке,
⚪️ загрузить несколько CSV в один датафрейм
Масса полезных и простых советов. Рекомендую
Очень детальное руководство по работе с CSV-файлами в Pandas. Освещена куча насущных вопросов о том как:
⚪️ прочитать CSV и заменить названия колонок,
⚪️ задать индексную колонку,
⚪️ загрузить только заранее определенные колонки,
⚪️ массово удалить колонки без названий, работать с пустыми значениями,
⚪️ пропустить несколько строк при загрузке,
⚪️ загрузить несколько CSV в один датафрейм
Масса полезных и простых советов. Рекомендую
Erik Marsja
Pandas Read CSV Tutorial: How to Read and Write
Learn how to use Pandas to read CSV & write CSV files. Learn how to combine, handle missing, data, with a link to .ipynb containing examples.
Занятная статья про пирамиду потребностей аналитики. Идеология тут такая же как и в пирамиде Маслоу: пока не удовлетворены базовые потребности, компания не может испытывать потребности более высокого уровня. Простой пример: если у тебя нет данных, то ты может и хочешь заниматься предиктивной моделью, но физически не можешь. Где-то там высоко (ближе к верхушке) также находятся метрики, ведь прежде чем считать метрики мы должны быть уверены в корректности полученных данных https://hackernoon.com/the-ai-hierarchy-of-needs-18f111fcc007
Hackernoon
The AI Hierarchy of Needs | HackerNoon
As is usually the case with fast-advancing technologies, AI has inspired massive <a href="https://en.wikipedia.org/wiki/Fear_of_missing_out" target="_blank">FOMO</a> , <a href="https://en.wikipedia.org/wiki/Fear,_uncertainty_and_doubt" target="_blank">FUD</a>…
Ноутбук с мастер-класса Александра Швеца из DigitalGod на конференции "Матемаркетинг-2018". Александр разбирает использование Logs API Яндекс.Метрики для анализа длины цепочек посещений, а также показывает интересный пример динамической атрибуции на основе данных того же Logs API, загнанных в Clickhouse https://github.com/ashwets/conferences/blob/master/matemarketing_2018.ipynb
digitalgod.be
Digital God — Горизонт возможностей на стыке твоей профессии и программирования
Программирование открывает новые горизонты профессионального развития, позволяя один раз написать скрипт и больше к этому не возвращаться или посчитать аудиторию и загрузить её в рекламную систему по API. Это более чем реально!
Лично я не очень люблю Matplotlib из-за достаточно сложного синтаксиса. Разбираться в его документации - то ещё удовольствие, поэтому чаще приходится лезть в Stackoverflow и искать среди ответов что-то подходящее. Но нужно признать должное: если нужен комбайн для сложных визуализаций, то вряд ли найдется что-то лучше Matplotlib среди Python-библиотек. Я бы сравнил его с d3.js на JavaScript по уровню кастомизируемости. Статья по ссылке это подтверждает, там 50 мощных визуализаций с примерами кода https://www.machinelearningplus.com/plots/top-50-matplotlib-visualizations-the-master-plots-python/
Machine Learning Plus
Top 50 matplotlib Visualizations – The Master Plots (with full python code)
Learn Data Science (AI/ML/Gen AI) Online
https://changhsinlee.com/pyderpuffgirls-ep2/ Вторая часть серии туториалов про изучение Python для аналитиков. На этот раз про вытаскивание данных из БД на примере PostgreSQL. Первая часть
Chang Hsin Lee
How to Query a Database in Python—PyderPuffGirls Episode 2
In PyderPuffGirl Episode 1, I showed you how to open a SQL query in Python. How can I submit said query through Python to a database? Moreover, how can I get the result of the query as a file in Python?
Статья о том как с помощью pandas можно разными способами выбирать сэмплы из данных. Может быть полезным, если хотите делать сэмплирование с использованием groupby (чтобы выбрать по N строк из каждой группы), а также делать выборки с фиксированным "псевдо-случайным" числом, чтобы сэмплированная выборка всегда получалась одинаковая (полезно, когда нужно добиться воспроизводимости исследований). https://www.marsja.se/pandas-sample-randomly-select-rows/
Erik Marsja
How to use Pandas Sample to Select Rows and Columns
Here we will learn how to use Pandas Sample to select rows, set a random seed, sample by group, using weights, and conditions, among other useful things
Есть много странных рейтингов. Нашел вот рейтинг популярности систем управления базами данных. Судя по нему, PostgreSQL занимает 4е место и показывает хорошие темпы роста. К этому бесполезному факту выкладываю ссылку на отличную статью про то как вытаскивать данные из PostgreSQL в Питоне с помощью psycopg2 https://khashtamov.com/ru/postgresql-python-psycopg2/
Forwarded from Vlad Flaks
Выложили на Github наши скрипты для импорта данных в Google BigQuery из mysql, ftp, https, intercom: https://www.owox.com/c/github-bigquery-integrations.
Все написано на Python для Google Cloud Functions. То есть отдельный сервер для запуска не нужен и проблем с ресурсами как у App Script нет. Инструкции на русском языке, разберется даже маркетолог 🙂
Все написано на Python для Google Cloud Functions. То есть отдельный сервер для запуска не нужен и проблем с ресурсами как у App Script нет. Инструкции на русском языке, разберется даже маркетолог 🙂
https://changhsinlee.com/pyderpuffgirls-ep3/ Третья часть серии туториалов про изучение Python для аналитиков. Про то, как запускать свои скрипты по расписанию и наслаждаться результатом, попивая кофе и закусывая маффином. Автор показывает один из самых простых способов планирования задач в Python - модуль schedule. На практике, к такому способу прибегают редко, т.к. нужно постоянно держать запущенным питоновский скрипт. Так что решение из статьи по первому времени сгодится, а потом я бы рекомендовал использовать cron или Airflow. В конце статьи - ссылки на две предыдущих части
Chang Hsin Lee
Don't Wait, Schedule and Relax Instead—PyderPuffGirls Episode 3
The purpose of automation is to let machine do things while us humans rest. In this post, I will show you how to schedule a job with a Python module schedule.
https://www.dataschool.io/future-of-pandas/
Статья про будущее библиотеки Pandas. Автор основывается на докладе одного из ключевых разработчиков Pandas на митапе PyData 2018 (кстати, рекомендую канал PyData на YouTube, где размещается куча полезного контента). Из интересного: хотят сделать почти все методы такими, чтобы была поддержка chaining, когда весь процесс обработки данных можно описать однострочной длинной последовательностью вызываемых друг за другом методов; уберут из методов поддержку параметра inplace; Apache Arrow будет бэкендом для Pandas, что повлияет на скорость обработки больших датасетов; появятся кастомные типы, например int с поддержкой nan 🎉 (сейчас только float из численных типов поддерживает nan); уберут поддержку обращения к строкам dataframe через ix. В общем, светлое будущее. Версия 0.25, в которой все это будет, запланирована на начало 2019. А следом из 0.25 сделают мажорную версию 1.0, убрав из 0.25 все устаревшие (deprecated) методы.
Статья про будущее библиотеки Pandas. Автор основывается на докладе одного из ключевых разработчиков Pandas на митапе PyData 2018 (кстати, рекомендую канал PyData на YouTube, где размещается куча полезного контента). Из интересного: хотят сделать почти все методы такими, чтобы была поддержка chaining, когда весь процесс обработки данных можно описать однострочной длинной последовательностью вызываемых друг за другом методов; уберут из методов поддержку параметра inplace; Apache Arrow будет бэкендом для Pandas, что повлияет на скорость обработки больших датасетов; появятся кастомные типы, например int с поддержкой nan 🎉 (сейчас только float из численных типов поддерживает nan); уберут поддержку обращения к строкам dataframe через ix. В общем, светлое будущее. Версия 0.25, в которой все это будет, запланирована на начало 2019. А следом из 0.25 сделают мажорную версию 1.0, убрав из 0.25 все устаревшие (deprecated) методы.
Data School
What's the future of the pandas library?
pandas is a very popular Python library for data analysis, manipulation, and visualization, but it still hasn't reached version 1.0. What's next for pandas?
Forwarded from BigQuery Insights
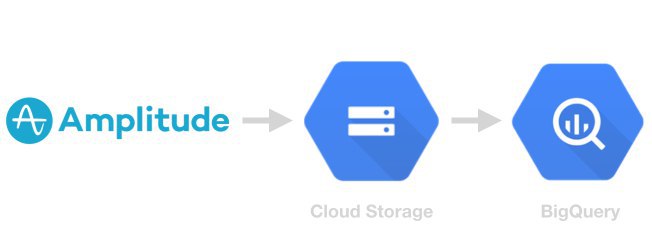
В сети появился скрипт для ежедневного экспорта данных Amplitude в BigQuery через Google Cloud Storage
via @BigQuery
via @BigQuery
{kind=link}
https://tqdm.github.io/
Иногда всяческие приятные мелочи сильно упрощают жизнь. Например, tqdm - очень минималистичная библиотека, единственная функция которой - отображать красивый информативный прогресс бар
Иногда всяческие приятные мелочи сильно упрощают жизнь. Например, tqdm - очень минималистичная библиотека, единственная функция которой - отображать красивый информативный прогресс бар
Написал в свой блог короткую статейку о том как через Python загружать или получать данные из BigQuery сразу в пандасовский датафрейм. Также немного рассматривается как с помощью нативной питоновской библиотеки bigquery можно управлять датасетами и таблицами. http://datalytics.ru/all/kak-ispolzovat-google-bigquery-s-pomoschyu-python/
www.datalytics.ru
Как использовать Google BigQuery с помощью Python
Google BigQuery — это безсерверное масштабируемое хранилище данных