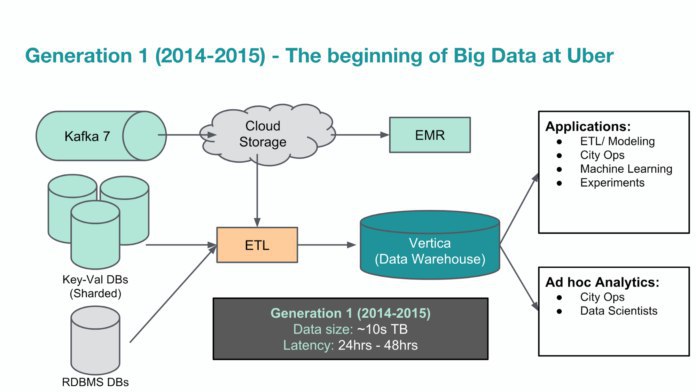
В корпоративном блоге Uber Engineering вышла крутая статья с обзором инфраструктуры для хранения, обработки и анализа данных компании Uber. На минуточку, у них сейчас под рукой более 100 петабайт данных → https://eng.uber.com/uber-big-data-platform/
{kind=link}
Доклад на Kafka Summit SF 2018 от Martin Kleppmann (автор книги Designing Data-Intensive Applications) под названием "Is Kafka a Database?": http://martin.kleppmann.com/2018/10/17/kafka-summit.html
{kind=link}
В блоге Insight Data Science вышла вводная статья про Apache Airflow. Хорошее руководство для начинающих свой путь в построении batch processing jobs → http://bit.ly/2NSWRiF
Forwarded from DevBrain
Нашел солидный вводный курс в экосистему Amazon Web Services на русском языке.
Сейчас без опыта работы хотя бы с одной из облачных систем (AWS, Google Cloud, MS Azure) сложно разрабатывать масштабируемые приложения.
Советую к просмотру, автор проделал титанический труд → http://bit.ly/2yWCJGD
Сейчас без опыта работы хотя бы с одной из облачных систем (AWS, Google Cloud, MS Azure) сложно разрабатывать масштабируемые приложения.
Советую к просмотру, автор проделал титанический труд → http://bit.ly/2yWCJGD
{kind=link}
Jack Vanlightly открывает серию постов про внутреннее устройство распределенной Pub-Sub (брокер сообщений) системы под названием Apache Pulsar.
Apache Pulsar была разработана в стенах компании Yahoo, а позже передана под патронаж Apache Foundation. На данный момент выпущена уже 2-я версия системы.
Читать → http://bit.ly/2S51IQX
Apache Pulsar была разработана в стенах компании Yahoo, а позже передана под патронаж Apache Foundation. На данный момент выпущена уже 2-я версия системы.
Читать → http://bit.ly/2S51IQX
Jack Vanlightly
Understanding How Apache Pulsar Works — Jack Vanlightly
I will be writing a series of blog posts about Apache Pulsar, including some Kafka vs Pulsar posts. First up though I will be running some chaos tests on a Pulsar cluster like I have done with RabbitMQ and Kafka to see what failure modes it has and its…