
Forwarded from Малоизвестное интересное
В сегодняшнем «безумном» мире есть только 2 страны: США и Китай.
Это Инь и Ян «безумного» мира. Остальных же здесь просто нет.
Будущее мира «безумно». В том смысле, что его технологической базой будет MAD (машинное обучение, ИИ и данные). По сути, MAD превращается в единую горизонтальную супер-индустрию, состоящую из двух ключевых сегментов:
• Международные MAD киты (Google, Misrisoft etc)
• Примерно 3 тыс. ведущих стартапов мирового MAD-ландшафта
Про впечатляющие прорывы первых постоянно слышится из любого утюга.
Про вторых мы слышим не часто (в основном, когда их на корню скупают первые).
Однако будущее «безумного» мира зависит от вторых ничуть не меньше, чем первых.
И потому столь важным для анализа происходящего в MAD-мире является проект «MAD ландшафт», структурирующий MAD-мир и позволяющий его анализировать.
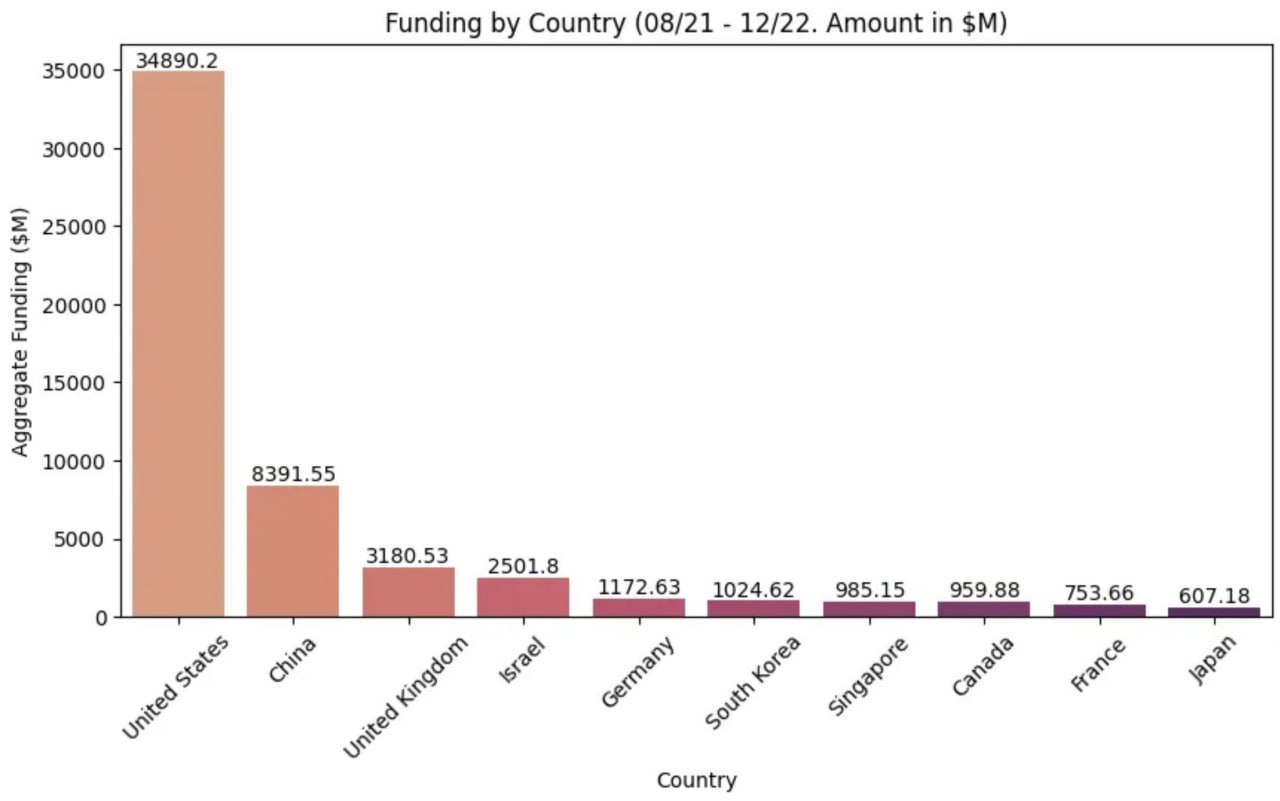
Пример такого анализа приведен на картинке этого поста, сравнивающей объемы венчурного финансирования главных мировых «регионов MAD ландшафта»:
• почти $35B у США
• у Китая в 4+ раза меньше
• у остальных вообще крохи (можете представить, как выглядят непоказанные страны, если столбики Франции и Японии плохо различимы?)
В аналитической записке проекта «MAD ландшафт» анализируется - почему Китай так отстает, имея немеряно денег?
Ответ весьма интересен – потому что у Китая, не смотря на все шумные заверения, на деле, другие приоритеты.
Сравните сами – это просто Инь и Ян приоритетов венчурного финансирования.
Кто-то еще хочет спросить, почему Китай так отстал в больших языковых моделях?
#MAD #Китай #США
Это Инь и Ян «безумного» мира. Остальных же здесь просто нет.
Будущее мира «безумно». В том смысле, что его технологической базой будет MAD (машинное обучение, ИИ и данные). По сути, MAD превращается в единую горизонтальную супер-индустрию, состоящую из двух ключевых сегментов:
• Международные MAD киты (Google, Misrisoft etc)
• Примерно 3 тыс. ведущих стартапов мирового MAD-ландшафта
Про впечатляющие прорывы первых постоянно слышится из любого утюга.
Про вторых мы слышим не часто (в основном, когда их на корню скупают первые).
Однако будущее «безумного» мира зависит от вторых ничуть не меньше, чем первых.
И потому столь важным для анализа происходящего в MAD-мире является проект «MAD ландшафт», структурирующий MAD-мир и позволяющий его анализировать.
Пример такого анализа приведен на картинке этого поста, сравнивающей объемы венчурного финансирования главных мировых «регионов MAD ландшафта»:
• почти $35B у США
• у Китая в 4+ раза меньше
• у остальных вообще крохи (можете представить, как выглядят непоказанные страны, если столбики Франции и Японии плохо различимы?)
В аналитической записке проекта «MAD ландшафт» анализируется - почему Китай так отстает, имея немеряно денег?
Ответ весьма интересен – потому что у Китая, не смотря на все шумные заверения, на деле, другие приоритеты.
Сравните сами – это просто Инь и Ян приоритетов венчурного финансирования.
Кто-то еще хочет спросить, почему Китай так отстал в больших языковых моделях?
#MAD #Китай #США
{kind=link}
Нашли кое-что интересное для CTO, которым нужен свежий диалог с коллегами, и для тех, кто только собирается разбить стеклянный потолок до C-Level.
⚡️ South HUB — кэмп настоящих и будущих CTO, который пройдет с 19 по 23 июня в Сочи
Кэмп — про развитие в work-life-balance. Программа включает в себя обширную контентную часть, вечеринки в горах, отдельный день спорта и настоящую детскую научно-исследовательскую конференцию.
Конференц-часть пройдет на трех площадках:
“Для настоящих CTO” – прямой диалог с C-Level из бизнеса, коммерции, маркетинга, логистики, стратегии и HR, чтобы говорить на одном языке.
“Для будущих CTO” — опытные CTO расскажут, как дорасти до C-Level и подготовиться к “шишкам” на профессиональном пути.
Workshop Day — фокус на диалог, погружение в реальные кейсы от спикеров и совместная генерация решений.
И, конечно, дискуссионные клубы в пентхаусе и ночные научпоп лекции.
Где встречаемся?
На высоте 960 всесезонного горного курорта Красная Поляна⛰
Вся информация тут: https://www.southhub.ru/?utm_source=telegram&utm_medium=post_cdoclub&utm_campaign=announcement
⚡️ South HUB — кэмп настоящих и будущих CTO, который пройдет с 19 по 23 июня в Сочи
Кэмп — про развитие в work-life-balance. Программа включает в себя обширную контентную часть, вечеринки в горах, отдельный день спорта и настоящую детскую научно-исследовательскую конференцию.
Конференц-часть пройдет на трех площадках:
“Для настоящих CTO” – прямой диалог с C-Level из бизнеса, коммерции, маркетинга, логистики, стратегии и HR, чтобы говорить на одном языке.
“Для будущих CTO” — опытные CTO расскажут, как дорасти до C-Level и подготовиться к “шишкам” на профессиональном пути.
Workshop Day — фокус на диалог, погружение в реальные кейсы от спикеров и совместная генерация решений.
И, конечно, дискуссионные клубы в пентхаусе и ночные научпоп лекции.
Где встречаемся?
На высоте 960 всесезонного горного курорта Красная Поляна⛰
Вся информация тут: https://www.southhub.ru/?utm_source=telegram&utm_medium=post_cdoclub&utm_campaign=announcement
southhub.ru
South HUB 2025
Вышло интересное интервью Романа Нестера (основателя компании Сегменто) про данные в рекламе и в целом про рынок маркетинга, рекламы и его соприкосновении с технологиями.
Поскольку Роман сейчас не является бенефициаром коммерческий компаний, работающих на этом рынке, его максимально независимая, не предвзятая и глубокая экспертная оценка является довольно редкой для рынка и максимально ценна. В основном спикерами на эту тему выступают ангажированные люди, а тут прям "все правда" 🙂
Ну кроме гипотетических рассуждений участников про Сбер, с коими наша редакция в полной мере согласиться не может 🙂 Но рассказ про историю Сегменто и Сбера очень интересен.
Что касается данных: вот я полностью согласен, что использование таргетов в рекламе - себя не оправдало на Российском рынке. Нет у нас борьбы за эти 10% точности и эффективности, у нас другими методами пользуются для конкурентной борьбы, это мы и в CleverData проходили. Хорошо, что мы сразу пошли по пути не продажи данных, а реализовали стратегию технологического вендора и развиваем и продаем платформу для работы с данными в прямом маркетинге, а не рекламе - и это помогло построить устойчивый бизнес.
Ну и в целом много интересных обсуждений про сбор, использование данных, вопросы этики как в области данных, так и в области технологий вообще и тд.
Посмотрите
https://www.youtube.com/watch?v=hzT7Zen7oA8
Поскольку Роман сейчас не является бенефициаром коммерческий компаний, работающих на этом рынке, его максимально независимая, не предвзятая и глубокая экспертная оценка является довольно редкой для рынка и максимально ценна. В основном спикерами на эту тему выступают ангажированные люди, а тут прям "все правда" 🙂
Ну кроме гипотетических рассуждений участников про Сбер, с коими наша редакция в полной мере согласиться не может 🙂 Но рассказ про историю Сегменто и Сбера очень интересен.
Что касается данных: вот я полностью согласен, что использование таргетов в рекламе - себя не оправдало на Российском рынке. Нет у нас борьбы за эти 10% точности и эффективности, у нас другими методами пользуются для конкурентной борьбы, это мы и в CleverData проходили. Хорошо, что мы сразу пошли по пути не продажи данных, а реализовали стратегию технологического вендора и развиваем и продаем платформу для работы с данными в прямом маркетинге, а не рекламе - и это помогло построить устойчивый бизнес.
Ну и в целом много интересных обсуждений про сбор, использование данных, вопросы этики как в области данных, так и в области технологий вообще и тд.
Посмотрите
https://www.youtube.com/watch?v=hzT7Zen7oA8
Опубликованы презентации с мероприятия BigData&AI2023, о посещении которого писал выше.
Мне мероприятие очень понравилось, прям хорошая и актуальная была повестка. Спикеры говорили очень предметные вещи, реальные кейсы/проблемы и решения. Не было совсем ощущения "маркетингово булшита" как это в последние годы складывалось 🙂 Даже выступления вендоров были вполне интересными и не рекламными.
Конечно, основная тема была "импортозамещение" и многие компании рассказывали о своем опыте и выборе решений. Много обзоров решений в области BI и Каталога данных (продолжает быть горячим трендом).
Качайте, смотрите: https://www.osp.ru/lp/bigdata2023/presentations
Мне мероприятие очень понравилось, прям хорошая и актуальная была повестка. Спикеры говорили очень предметные вещи, реальные кейсы/проблемы и решения. Не было совсем ощущения "маркетингово булшита" как это в последние годы складывалось 🙂 Даже выступления вендоров были вполне интересными и не рекламными.
Конечно, основная тема была "импортозамещение" и многие компании рассказывали о своем опыте и выборе решений. Много обзоров решений в области BI и Каталога данных (продолжает быть горячим трендом).
Качайте, смотрите: https://www.osp.ru/lp/bigdata2023/presentations
www.osp.ru
Материалы конференции BIG DATA&AI 2023
Деловой форум BIG DATA&AI 2023: все главные темы о данных как главном драйвере развития – общества, бизнеса, государства
Forwarded from Блуждающий нерв
The New England Journal of Medicine, один из самых влиятельных медицинских журналов в мире, открывает серию статей «ИИ в медицине», первые публикации уже появились в свежем номере. Далее, в 2024 будет запущен дочерний журнал NEJM AI, целиком посвященный этой теме. Летом этого года начнут принимать статьи на рецензирование.
В преамбуле есть ремарка о “трансформации медицины”, что похоже на осознание и принятие неизбежного. Передовая наука без ИИ уже не представима, в медицину это придет с задержкой, но тренд обозначен. К слову, в 2024-м уже все используют GPT-5.
Интересно, как будут уживаться прежняя “доказательная” медицина и новая “ИИ-ведомая”, если их прогнозы и рекомендации, допустим, начнут расходиться. В NEJM один взгляд, а в NEJM AI другой на ту же проблему — такой сценарий не исключен. Придется выбирать, чему доверять больше.
В преамбуле есть ремарка о “трансформации медицины”, что похоже на осознание и принятие неизбежного. Передовая наука без ИИ уже не представима, в медицину это придет с задержкой, но тренд обозначен. К слову, в 2024-м уже все используют GPT-5.
Интересно, как будут уживаться прежняя “доказательная” медицина и новая “ИИ-ведомая”, если их прогнозы и рекомендации, допустим, начнут расходиться. В NEJM один взгляд, а в NEJM AI другой на ту же проблему — такой сценарий не исключен. Придется выбирать, чему доверять больше.
The New England Journal of Medicine
Artificial Intelligence in Medicine | NEJM
The editors announce both a series of articles focusing on AI and machine learning
in health care and the 2024 launch of a new journal, NEJM AI, a forum for evidence,
resource sharing, and discussi...
in health care and the 2024 launch of a new journal, NEJM AI, a forum for evidence,
resource sharing, and discussi...
Если вы пропустили появление такого явления, как Foundation Models, то NVidia подготовила для вас хороший экскурс в историю
https://blogs.nvidia.com/blog/2023/03/13/what-are-foundation-models/?nvid=nv-int-bnr-463583#new_tab
https://blogs.nvidia.com/blog/2023/03/13/what-are-foundation-models/?nvid=nv-int-bnr-463583#new_tab
NVIDIA Blog
What Are Foundation Models?
Foundation models are AI neural networks trained on massive unlabeled datasets to handle a wide variety of jobs from translating text to analyzing medical images.
Forwarded from Sber Developer News
Вышла новая версия генеративной модели Сбера Kandinsky 2.1
Создавать изображения можно в телеграм-боте @kandinsky21_bot, а также на умных устройствах Sber и в мобильном приложении Салют, сказав: «Запусти художника».
Модель может:
🔹Объединять изображения и текст
🔹 Генерировать изображения, похожие на заданное
🔹 Дорисовывать недостающие части картинки
🔹Объединять несколько рисунков
🔹Изменять изображения
🔹Формировать изображения в режиме бесконечного полотна
Протестируйте обновлённую модель в боте или на сайте (там расширенная функциональность, будет интересно).
Оцените работу нашей команды и делитесь результатами в комментариях.
Создавать изображения можно в телеграм-боте @kandinsky21_bot, а также на умных устройствах Sber и в мобильном приложении Салют, сказав: «Запусти художника».
Модель может:
🔹Объединять изображения и текст
🔹 Генерировать изображения, похожие на заданное
🔹 Дорисовывать недостающие части картинки
🔹Объединять несколько рисунков
🔹Изменять изображения
🔹Формировать изображения в режиме бесконечного полотна
Протестируйте обновлённую модель в боте или на сайте (там расширенная функциональность, будет интересно).
Оцените работу нашей команды и делитесь результатами в комментариях.
ЛитРес сделали очень интересную подборку книг про киберпанк.
Есть у кого чем дополнить?
В духе «Бегущего по лезвию»: топ-25 книг в жанре киберпанк https://litres.ru/journal/v-dukhe-begushchego-po-lezviiu-top-25-knig-v-zhanre-kiberpank/
Есть у кого чем дополнить?
В духе «Бегущего по лезвию»: топ-25 книг в жанре киберпанк https://litres.ru/journal/v-dukhe-begushchego-po-lezviiu-top-25-knig-v-zhanre-kiberpank/
Литрес
В духе «Бегущего по лезвию»: топ-25 книг в жанре киберпанк
Предлагаем вашему вниманию статью на тему: В духе «Бегущего по лезвию»: топ-25 книг в жанре киберпанк
Дайджест статей
The Kappa Architecture: A Cutting-Edge Approach for Data Engineering
https://dzone.com/articles/the-kappa-architecture-a-cutting-edge-approach-for
Data Mesh Architecture: A Paradigm Shift in Data Engineering
https://dzone.com/articles/data-mesh-architecture-a-paradigm-shift-in-data-en
Enterprise Data Is Broken – Here’s How to Fix It
https://www.datasciencecentral.com/enterprise-data-is-broken-heres-how-to-fix-it/
How Data-Driven Analytics Can Improve Workplace Safety
https://www.datasciencecentral.com/how-data-driven-analytics-can-improve-workplace-safety/
Deep Learning Neural Networks: Revolutionising Software Test Case Generation and Optimization
https://dzone.com/articles/deep-learning-neural-networks-revolutionizing-soft
A Guide to Data Labeling and Annotating: Importance, Types, and Best Practices
https://dzone.com/articles/a-guide-to-data-labeling-and-annotating-importance
The Data Streaming Landscape
https://dzone.com/articles/the-data-streaming-landscape-2023
Пять причин, по которым вам нужны синтетические данные
https://habr.com/ru/articles/725810/
Стриминговая аналитика с применением Apache Pulsar и структурированные потоки Spark
https://habr.com/ru/companies/timeweb/articles/727166/
Основные инструменты для работы в Data Engineering: введение для начинающих Data Engineer'ов
https://habr.com/ru/articles/727560/
The Kappa Architecture: A Cutting-Edge Approach for Data Engineering
https://dzone.com/articles/the-kappa-architecture-a-cutting-edge-approach-for
Data Mesh Architecture: A Paradigm Shift in Data Engineering
https://dzone.com/articles/data-mesh-architecture-a-paradigm-shift-in-data-en
Enterprise Data Is Broken – Here’s How to Fix It
https://www.datasciencecentral.com/enterprise-data-is-broken-heres-how-to-fix-it/
How Data-Driven Analytics Can Improve Workplace Safety
https://www.datasciencecentral.com/how-data-driven-analytics-can-improve-workplace-safety/
Deep Learning Neural Networks: Revolutionising Software Test Case Generation and Optimization
https://dzone.com/articles/deep-learning-neural-networks-revolutionizing-soft
A Guide to Data Labeling and Annotating: Importance, Types, and Best Practices
https://dzone.com/articles/a-guide-to-data-labeling-and-annotating-importance
The Data Streaming Landscape
https://dzone.com/articles/the-data-streaming-landscape-2023
Пять причин, по которым вам нужны синтетические данные
https://habr.com/ru/articles/725810/
Стриминговая аналитика с применением Apache Pulsar и структурированные потоки Spark
https://habr.com/ru/companies/timeweb/articles/727166/
Основные инструменты для работы в Data Engineering: введение для начинающих Data Engineer'ов
https://habr.com/ru/articles/727560/
DZone
The Kappa Architecture: A Cutting-Edge Approach for Data Engineering
Kappa Architecture and its key features that make it a cutting-edge approach for data engineering.
Коллеги, 18 апреля на площадке Центра событий РБК (г. Москва, Космодамианская набережная, 52, стр. 7) пройдет First Russian Data Forum — конференция о роли данных в цифровом развитии России, где первые лица отрасли обсудят вопросы цифровой трансформации государства, бизнеса и общества. Организаторами форума являются Ассоциация больших данных и АНО «Цифровая экономика».
Программа форума будет одинаково интересна как для топ-менеджмента организаций, связанных с развитием и использованием big data в бизнесе, чиновников и GR-экспертов, так и для практикующих специалистов в ИТ, искусственном интеллекте и больших данных. Спикерами First Russian Data Forum станут эксперты из Ассоциации больших данных, АНО «Цифровая экономика», Минцифры России Минэкономразвития России, Центра стратегических разработок, ПАО “Ростелеком”, ПАО «МТС», ПАО “Сбербанк”, Тинькофф, QIWI, Яндекс, VK, Авито и другие.
Я так же планирую принять участие в работе формума в виде небольшоего доклада и обсуждения тендеций развития рынка данных. Приходите на форум или смотрите трансляцию онлайн.
Зарегистрироваться и купить билеты можно на сайте - https://data-forum.ru/
Программа форума будет одинаково интересна как для топ-менеджмента организаций, связанных с развитием и использованием big data в бизнесе, чиновников и GR-экспертов, так и для практикующих специалистов в ИТ, искусственном интеллекте и больших данных. Спикерами First Russian Data Forum станут эксперты из Ассоциации больших данных, АНО «Цифровая экономика», Минцифры России Минэкономразвития России, Центра стратегических разработок, ПАО “Ростелеком”, ПАО «МТС», ПАО “Сбербанк”, Тинькофф, QIWI, Яндекс, VK, Авито и другие.
Я так же планирую принять участие в работе формума в виде небольшоего доклада и обсуждения тендеций развития рынка данных. Приходите на форум или смотрите трансляцию онлайн.
Зарегистрироваться и купить билеты можно на сайте - https://data-forum.ru/
data-forum.ru
First Russian Data Forum
Data Forum — новая, современная, интерактивная площадка публичного диалога между регулирующими органами и бизнес-сообществом о планах цифрового развития России, государственной политики и роли данных в цифровой трансформации бизнеса и общества
Forwarded from Все о блокчейн/мозге/space/WEB 3.0 в России и мире
🔥Deepmind выпустили исчерпывающий обзор архитектур и алгоритмов трансформеров
Предлагаем прочитать всем, кто хочет понять языковые модели. В обзоре рассказывается, что они из себя представляют, как их обучают, для чего используются и их ключевые архитектурные компоненты.
Предлагаем прочитать всем, кто хочет понять языковые модели. В обзоре рассказывается, что они из себя представляют, как их обучают, для чего используются и их ключевые архитектурные компоненты.
С появлением ChatGPT во всем мире активизировались регуляторы и пытаются разобраться, что теперь делать с этим явлением. Очевидно, что возможности, которые неожиданно для всех дали людям технологии - требуют реакции с их стороны. И если ранее к вопросу "регулирования ИИ" относились несколько пассивно, заявляя о его необходимости, но в тоже время не делая конкретных шагов, то сейчас все переходит в активную фазу.
В то время, как, например, Италия, полностью запретила ChatGPT, регулятор UK демонстрирует вполне здравые идеи и предложения.
В частности, намеревается "регулировать не технологии, а их использование"
Явная тенденция в Великобритании - это отступление от существующих мер защиты, поскольку правительство стремится расстелить красный ковер для "инноваций", основанных на ИИ, не задумываясь о том, что это может означать для таких важных вещей, как безопасность или справедливость - и, следовательно, надежность.
Посмотрим, кто окажется прав :)
https://techcrunch.com/2023/03/29/uk-ai-white-paper/
В то время, как, например, Италия, полностью запретила ChatGPT, регулятор UK демонстрирует вполне здравые идеи и предложения.
В частности, намеревается "регулировать не технологии, а их использование"
Явная тенденция в Великобритании - это отступление от существующих мер защиты, поскольку правительство стремится расстелить красный ковер для "инноваций", основанных на ИИ, не задумываясь о том, что это может означать для таких важных вещей, как безопасность или справедливость - и, следовательно, надежность.
Посмотрим, кто окажется прав :)
https://techcrunch.com/2023/03/29/uk-ai-white-paper/
TechCrunch
UK to avoid fixed rules for AI – in favor of ‘context-specific guidance’
The U.K. isn’t going to be setting hard rules for AI any time soon.
Ведущий исследователь Озлем Гарибай, доцент кафедры промышленной инженерии и систем управления UCF, говорит, что технология стала занимать более заметное место во многих аспектах нашей жизни, породив множество проблем, которые необходимо тщательно изучить.
Например, грядущая повсеместная интеграция искусственного интеллекта может существенно повлиять на жизнь человека таким образом, который ещё не до конца понятен, говорит Гарибай, работающая над применением ИИ в разработке и открытии материалов и лекарств, а также над тем, как ИИ влияет на социальные системы.
Гарибай и группа исследователей определили шесть важных задач, которые необходимо будет решить.
- Благополучие человека: ИИ должен уметь находить возможности, повышающие благополучие людей. Он также должен быть внимателен к благополучию пользователя, взаимодействующего с ИИ.
- Ответственность: Преимущества ИИ должны использоваться таким образом, чтобы соответствовать человеческим ценностям и приоритетам, а также снижать риск непредвиденных последствий или нарушений этических норм.
- Конфиденциальность: Сбор, использование и распространение данных в системах ИИ должны быть тщательно продуманы для обеспечения защиты частной жизни людей и предотвращения вредного использования против отдельных лиц или групп.
- Проектирование: В основе ИИ должен лежать фреймворк, который позволит разделять ИИ с низким риском, ИИ не требующий специальных мер, ИИ с высоким риском и ИИ, который не следует реализовывать вообще.
- Управление и надзор: Необходима система управления, учитывающая весь жизненный цикл ИИ — от концепции до разработки и внедрения.
- Взаимодействие человека и ИИ: Для формирования этичных и справедливых отношений между людьми и системами ИИ необходимо, чтобы взаимодействие основывалось на фундаментальном принципе уважения когнитивных способностей человека. В частности, люди должны сохранять полный контроль над поведением и результатами работы систем ИИ и нести за них ответственность.
В исследовании, которое проводилось в течение 20 месяцев, учитывались мнения 26 международных экспертов, имеющих различный опыт работы в области технологий ИИ.
https://www.eurekalert.org/news-releases/984019
Например, грядущая повсеместная интеграция искусственного интеллекта может существенно повлиять на жизнь человека таким образом, который ещё не до конца понятен, говорит Гарибай, работающая над применением ИИ в разработке и открытии материалов и лекарств, а также над тем, как ИИ влияет на социальные системы.
Гарибай и группа исследователей определили шесть важных задач, которые необходимо будет решить.
- Благополучие человека: ИИ должен уметь находить возможности, повышающие благополучие людей. Он также должен быть внимателен к благополучию пользователя, взаимодействующего с ИИ.
- Ответственность: Преимущества ИИ должны использоваться таким образом, чтобы соответствовать человеческим ценностям и приоритетам, а также снижать риск непредвиденных последствий или нарушений этических норм.
- Конфиденциальность: Сбор, использование и распространение данных в системах ИИ должны быть тщательно продуманы для обеспечения защиты частной жизни людей и предотвращения вредного использования против отдельных лиц или групп.
- Проектирование: В основе ИИ должен лежать фреймворк, который позволит разделять ИИ с низким риском, ИИ не требующий специальных мер, ИИ с высоким риском и ИИ, который не следует реализовывать вообще.
- Управление и надзор: Необходима система управления, учитывающая весь жизненный цикл ИИ — от концепции до разработки и внедрения.
- Взаимодействие человека и ИИ: Для формирования этичных и справедливых отношений между людьми и системами ИИ необходимо, чтобы взаимодействие основывалось на фундаментальном принципе уважения когнитивных способностей человека. В частности, люди должны сохранять полный контроль над поведением и результатами работы систем ИИ и нести за них ответственность.
В исследовании, которое проводилось в течение 20 месяцев, учитывались мнения 26 международных экспертов, имеющих различный опыт работы в области технологий ИИ.
https://www.eurekalert.org/news-releases/984019
EurekAlert!
Researchers identify 6 challenges humans face with artificial intelligence
A UCF professor and 26 other researchers have published a study identifying the challenges humans must overcome to ensure that artificial intelligence is reliable, safe, trustworthy and compatible with human values. The study, “Six Human-Centered Artificial…