

A short article by Julia Evans about why OSI model doesn't map to TCP/IP really well. And why sometimes it's just easier to say things like "TCP load balancer" or "Ethernet switch" rather than "later 4", "layer 2", etc.
tl;dr: primarily, because OSI is old.
Also, there is a diagram of your usual network packet as a bonus.
tl;dr: primarily, because OSI is old.
Also, there is a diagram of your usual network packet as a bonus.
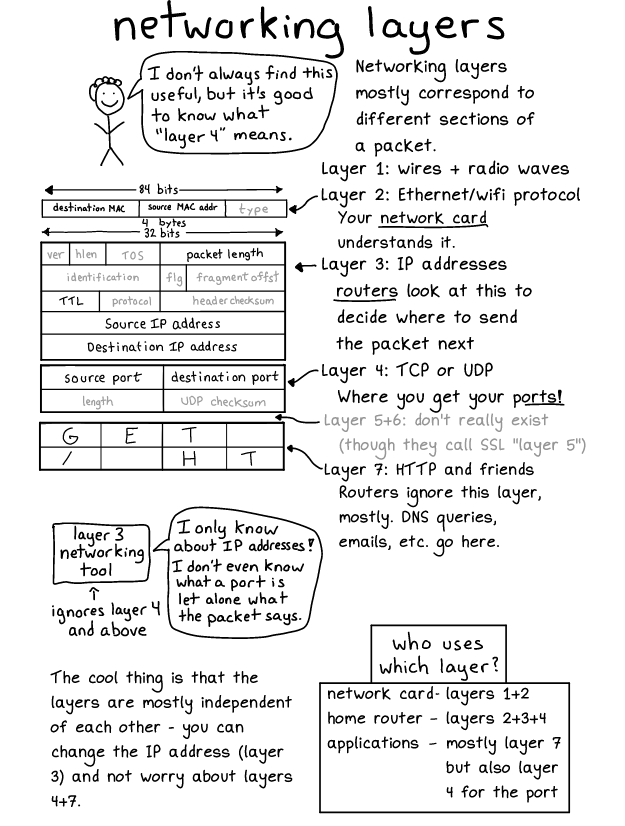{kind=link}
Some time ago we had some weird network timeouts in our Kubernetes clusters. It was also pretty strange that not all service owners reported timeouts and according to the monitoring graphs, these issues usually happened during the day.
A colleague of mine dig into this problem and, well, found a bug in AWS. He described the process of his debug in this article, which steps he took and in what sequence, as well as some tools he used to debug this.
Happy reading!
#kubernetes #aws
A colleague of mine dig into this problem and, well, found a bug in AWS. He described the process of his debug in this article, which steps he took and in what sequence, as well as some tools he used to debug this.
Happy reading!
#kubernetes #aws
N26
N26 engineering team solves Kubernetes challenge
At N26, our engineering team attacks problems head-on. Here, we tell the story of how we investigated and resolved a mysterious connectivity issue.
The Serverless Rules are a compilation of rules to validate infrastructure as code templates for AWS against recommended practices.
They are available as
#aws #serverless
They are available as
cfn-lint or tflint plugins. So, you can check your CloudFormation or Terraform code against them.#aws #serverless
GitHub
GitHub - awslabs/serverless-rules: Compilation of rules to validate infrastructure-as-code templates against recommended practices…
Compilation of rules to validate infrastructure-as-code templates against recommended practices for serverless applications. - GitHub - awslabs/serverless-rules: Compilation of rules to validate in...
I like it when articles on the Web start discussions. Although, sometimes such articles are just click bait, but you can figure it out based discussions they ignite.
Steve Smith wrote an article called "GitOps is a placebo", where he argues that GitOps haven't bought anything new to the table, because all its core concepts already existed in form of Continuous Delivery and Infrastructure as Code.
And here is the reply to this article by Carlos Sanchez in the form of a Twitter thread.
Feel free to share your own thoughts on GitOps in our chat
#cicd #iac #gitops
Steve Smith wrote an article called "GitOps is a placebo", where he argues that GitOps haven't bought anything new to the table, because all its core concepts already existed in form of Continuous Delivery and Infrastructure as Code.
And here is the reply to this article by Carlos Sanchez in the form of a Twitter thread.
Feel free to share your own thoughts on GitOps in our chat
#cicd #iac #gitops
Twitter
Carlos Sanchez
"GitOps is a placebo" Interesting take but let me disagree with some points, a 🧵 twitter.com/SteveSmith_Tec…
Forwarded from Roman Siewko
Identified - The issue has been identified and a fix is being implemented.
Jun 8, 10:44 UTChttps://status.fastly.com/
So, first big announcements from HashiConf Europe, which is happening right now.
Terraform goes 1.0 at last!!
People were expecting this release for a long time. Also, it seems like there gonna be less jokes about Terraform's production readiness from now on.
#hashicorp #terraform
Terraform goes 1.0 at last!!
People were expecting this release for a long time. Also, it seems like there gonna be less jokes about Terraform's production readiness from now on.
#hashicorp #terraform
HashiCorp
Announcing HashiCorp Terraform 1.0 General Availability
Terraform 1.0 — now generally available — marks a major milestone for interoperability, ease of upgrades, and maintenance for your automation workflows.
Fastly has published a report of yesterday's incident
Not much there, to be honest. In the mid May they introduced a bug, which could be triggered by a specific configuration which is valid on its own.
And yesterday, on the 8th of June, someone submitted such configuration eventually.
These are basically all the details they reveal. The good part is that the whole incident lasted for just 49 minutes. And full downtime was much shorter.
So, it's seems like the Internet has got its 3rd problem.
Not much there, to be honest. In the mid May they introduced a bug, which could be triggered by a specific configuration which is valid on its own.
And yesterday, on the 8th of June, someone submitted such configuration eventually.
These are basically all the details they reveal. The good part is that the whole incident lasted for just 49 minutes. And full downtime was much shorter.
So, it's seems like the Internet has got its 3rd problem.
{kind=link}
You can use multi-line RUN commands in Dockerfiles now.
It's not like you couldn't, it's just became more human readable.
To use this feature, set Dockerfile version to labs channel. Currently this feature is only available in docker/dockerfile-upstream:master-labs image.
#docker
It's not like you couldn't, it's just became more human readable.
To use this feature, set Dockerfile version to labs channel. Currently this feature is only available in docker/dockerfile-upstream:master-labs image.
# syntax=docker/dockerfile-upstream:master-labs
# syntax = docker/dockerfile-upstream:master-labs
FROM debian
RUN <<eot bash
apt-get update
apt-get install -y vim
eot
#docker
GitHub
buildkit/frontend/dockerfile/docs/syntax.md at master · moby/buildkit
concurrent, cache-efficient, and Dockerfile-agnostic builder toolkit - moby/buildkit
Kris Nova's recent write up on Infrastructure as Code vs Infrastructure as Software
(also available on GitHub)
In short, we are used to manage our infrastructure with Turing incomplete configs like YAML. Since configs are too static, people invented some tooling on top of it. So, now you have a lot of templating for this.
On another hand, we can simply use modern day programming languages like Go, TypeScript, Python, etc. In this scenario infrastructure engineers can benefit from the entire ecosystem of a given language like test suites, IDE plugins, package management and so on.
In fact, these concepts are already used in various CDKs and Pulumi.
This article is not yet a definitive guide, rather just a thoughts material. You can join the discussion
- on Twitter
- on Reddit
#iac
(also available on GitHub)
In short, we are used to manage our infrastructure with Turing incomplete configs like YAML. Since configs are too static, people invented some tooling on top of it. So, now you have a lot of templating for this.
On another hand, we can simply use modern day programming languages like Go, TypeScript, Python, etc. In this scenario infrastructure engineers can benefit from the entire ecosystem of a given language like test suites, IDE plugins, package management and so on.
In fact, these concepts are already used in various CDKs and Pulumi.
This article is not yet a definitive guide, rather just a thoughts material. You can join the discussion
- on Twitter
- on Reddit
#iac
CNCF Security Technical Advisory Group published The Software Supply Chain Security Paper last month
This paper is intended to be a living document guided by the community. It provides general recommendations, tooling options, and design guidances on how to reduce the risk of a supply chain attack.
This document has more that 40 pages and covers topics like: securing the software and materials, securing pipelines, artifacts and deployments, etc.
#security
This paper is intended to be a living document guided by the community. It provides general recommendations, tooling options, and design guidances on how to reduce the risk of a supply chain attack.
This document has more that 40 pages and covers topics like: securing the software and materials, securing pipelines, artifacts and deployments, etc.
#security
GitHub
tag-security/supply-chain-security/supply-chain-security-paper/CNCF_SSCP_v1.pdf at main · cncf/tag-security
🔐CNCF Security Technical Advisory Group -- secure access, policy control, privacy, auditing, explainability and more! - cncf/tag-security
A few announcements from AWS, which I personally find interesting. Ofc, there are usually tons of AWS announcements.
1. AWS KMS multi-Region keys. So, now you can define global KMS keys and that's awesome! Previously, it was always cumbersome to create a cross-regional backup for encrypted data. Looking forward to trying it!
2. AWS Step Functions Workflow Studio. Now you can design a state machine in a visual editor.
3. AWS Proton became generally available. Proton is a tool or rather a toolchain that helps you to build a custom PaaS for your internal product teams on top of AWS.
And one more thing. Short manual on how to stop and RDS on schedule with a Lambda function. Could be interesting for those, who are willing to save some money in their non-production environments.
#aws
1. AWS KMS multi-Region keys. So, now you can define global KMS keys and that's awesome! Previously, it was always cumbersome to create a cross-regional backup for encrypted data. Looking forward to trying it!
2. AWS Step Functions Workflow Studio. Now you can design a state machine in a visual editor.
3. AWS Proton became generally available. Proton is a tool or rather a toolchain that helps you to build a custom PaaS for your internal product teams on top of AWS.
And one more thing. Short manual on how to stop and RDS on schedule with a Lambda function. Could be interesting for those, who are willing to save some money in their non-production environments.
#aws
Amazon
Encrypt global data client-side with AWS KMS multi-Region keys | Amazon Web Services
Today, AWS Key Management Service (AWS KMS) is introducing multi-Region keys, a new capability that lets you replicate keys from one Amazon Web Services (AWS) Region into another. Multi-Region keys are designed to simplify management of client-side encryption…
An experiment ran by Corey Quinn: what would happen once you pushed your AWS keys to a public repository.
He summarized it in a Twitter thread
tl;dr: AWS contacted him about leaked credentials and refused to close the case before he rotated the keys even though these keys had no permissions.
Also, there's an interesting reply from a person who is working in GitHub. GitHub have a monitoring for leaked credentials. However, they notify AWS directly rather than a customer in such occasions. The reason for that is a lot of false-positives at the time such monitoring was just introduced. So, they decided not to bother their customers in vain.
P.S. Last time I had to scan a repository for leaked credentials, I used TruffelHog tool it searches not only for AWS secrets, but actually for any high-entropy strings. Also, it works quite well even for large repositories.
#security #aws #github #toolz
He summarized it in a Twitter thread
tl;dr: AWS contacted him about leaked credentials and refused to close the case before he rotated the keys even though these keys had no permissions.
Also, there's an interesting reply from a person who is working in GitHub. GitHub have a monitoring for leaked credentials. However, they notify AWS directly rather than a customer in such occasions. The reason for that is a lot of false-positives at the time such monitoring was just introduced. So, they decided not to bother their customers in vain.
P.S. Last time I had to scan a repository for leaked credentials, I used TruffelHog tool it searches not only for AWS secrets, but actually for any high-entropy strings. Also, it works quite well even for large repositories.
#security #aws #github #toolz
Twitter
Corey Quinn
Let's do an @awscloud experiment with our friends at @github. I have pushed a set of API credentials to a public repository. Oh no! Specifically at Mon Jun 21 23:08:12 UTC 2021.
In addition to our last post.
An article on what happens if you push secrets into a public repository with some advices on how to mitigate that risk.
This article was sent to me by one of our subscribers. Big thanks for it! If you want to share interesting stuff as well, you can either send it to our chat or admins directly.
#security
An article on what happens if you push secrets into a public repository with some advices on how to mitigate that risk.
This article was sent to me by one of our subscribers. Big thanks for it! If you want to share interesting stuff as well, you can either send it to our chat or admins directly.
#security
If you work with Open Policy Agent, you probably want to test the policies you write.
Lucky there is an ability to write test suites for Rego.
However, these tests suits are not always very obvious as well as Rego policies themselves. Here is an article by Dustin Specker on how to write tests for your policies. This article helped a lot me personally. And I hope it will be helpful for you too.
#opa #kubernetes #testing
Lucky there is an ability to write test suites for Rego.
However, these tests suits are not always very obvious as well as Rego policies themselves. Here is an article by Dustin Specker on how to write tests for your policies. This article helped a lot me personally. And I hope it will be helpful for you too.
#opa #kubernetes #testing
Open Policy Agent
Policy Testing
Policy-based control for cloud native environments
Speaking of Infrastructure as Software from the previous post
Kris Nova has created naml - a framework to replace Kubernetes YAML with Go.
Obviously, this project is in a very early stage. However, the industry is clearly moving in the direction of IaS with products like Pulumi, various CDKs, and this one.
So, it's a good time to start learning software engineering practices, if you haven't already.
#kubernetes #ias
Kris Nova has created naml - a framework to replace Kubernetes YAML with Go.
Obviously, this project is in a very early stage. However, the industry is clearly moving in the direction of IaS with products like Pulumi, various CDKs, and this one.
So, it's a good time to start learning software engineering practices, if you haven't already.
#kubernetes #ias
Telegram
CatOps
Kris Nova's recent write up on Infrastructure as Code vs Infrastructure as Software
(also available on GitHub)
In short, we are used to manage our infrastructure with Turing incomplete configs like YAML. Since configs are too static, people invented some…
(also available on GitHub)
In short, we are used to manage our infrastructure with Turing incomplete configs like YAML. Since configs are too static, people invented some…
A post of irony :)
We have created an internal toolset to manage the lifecycle of Kubernetes clusters in my company. It allows us to create clusters, upgrade them, destroy, as well as manage some plugins like CNI, Ingress, and other core plugins as we call them.
Just yesterday, I had a thought that this could be one's business model - create an OSS-core tool to manage ready-to-use clusters and then sell support, or some enhancement plugins, or some additional functionality like automagical cluster upgrades.
And also yesterday, Flant has released the source code for their Deckhouse project! This is a project aimed to manage cluster lifecycle, and it was used in Flant internally for quite some time already.
Also, it looks like they're going to build the business around this tool as well. At least they have a website dedicated to it, but unfortunately not much info there. Unfortunately, I haven't found any blogposts or press releases about this tool in English. However, I did find a few reports on the Internet that people tried it out, and it works. At least, it creates a cluster.
I personally would say that this is too early to tell what the future of this tool would look like, but I like the general idea. I personally think that Kubernetes goes the same way Linux kernel went earlier: there is an OSS core and then there are tons of distributions managed by different companies. With RedHat being the first to jump on this train, of course.
So, brace yourself! More distro wars to come!
#kubernetes
We have created an internal toolset to manage the lifecycle of Kubernetes clusters in my company. It allows us to create clusters, upgrade them, destroy, as well as manage some plugins like CNI, Ingress, and other core plugins as we call them.
Just yesterday, I had a thought that this could be one's business model - create an OSS-core tool to manage ready-to-use clusters and then sell support, or some enhancement plugins, or some additional functionality like automagical cluster upgrades.
And also yesterday, Flant has released the source code for their Deckhouse project! This is a project aimed to manage cluster lifecycle, and it was used in Flant internally for quite some time already.
Also, it looks like they're going to build the business around this tool as well. At least they have a website dedicated to it, but unfortunately not much info there. Unfortunately, I haven't found any blogposts or press releases about this tool in English. However, I did find a few reports on the Internet that people tried it out, and it works. At least, it creates a cluster.
I personally would say that this is too early to tell what the future of this tool would look like, but I like the general idea. I personally think that Kubernetes goes the same way Linux kernel went earlier: there is an OSS core and then there are tons of distributions managed by different companies. With RedHat being the first to jump on this train, of course.
So, brace yourself! More distro wars to come!
#kubernetes
GitHub
GitHub - deckhouse/deckhouse: Kubernetes platform from Flant
Kubernetes platform from Flant. Contribute to deckhouse/deckhouse development by creating an account on GitHub.
A blog post by AWS about how to create a LIFO (last in first out) queue using DynamoDB and Lambda
AWS SQS provides FIFO (first in first out) queues out of the box. However, LIFO queues could be useful in throughput constrained environments like IoT, for example.
This article shows how to create a LIFO queue and an example worker using DynamoDB, Lambda, and SAM framework to deploy all these things.
#aws
AWS SQS provides FIFO (first in first out) queues out of the box. However, LIFO queues could be useful in throughput constrained environments like IoT, for example.
This article shows how to create a LIFO queue and an example worker using DynamoDB, Lambda, and SAM framework to deploy all these things.
#aws
Amazon
Implementing a LIFO task queue using AWS Lambda and Amazon DynamoDB | Amazon Web Services
This post was written by Diggory Briercliffe, Senior IoT Architect. When implementing a task queue, you can use Amazon SQS standard or FIFO (First-In-First-Out) queue types. Both queue types give priority to tasks created earlier over tasks that are created…
Kinda longread about optimizations of JS code in the environments, where JIT compilation is not available e.g. iOS, gaming consoles, serverless environments, etc.
The main idea is to run JS inside WebAssembly instance.
Wizer pre-initializer is used as an example here.
Even though, information from here might be not very useful for the people, who run JS in a "traditional" way I.e. in a browser. However, I personally think this is an interesting read for those who build JS-powered serverless services as well as those who deploy JS code to portable devices.
Also, it's important to mark that such an approach could be used for other run other runtimes like Python, Ruby, or Lua.
#programming
The main idea is to run JS inside WebAssembly instance.
Wizer pre-initializer is used as an example here.
Even though, information from here might be not very useful for the people, who run JS in a "traditional" way I.e. in a browser. However, I personally think this is an interesting read for those who build JS-powered serverless services as well as those who deploy JS code to portable devices.
Also, it's important to mark that such an approach could be used for other run other runtimes like Python, Ruby, or Lua.
#programming
Bytecode Alliance
Making JavaScript run fast on WebAssembly
JavaScript in the browser runs many times faster than it did two decades ago. And that happened because the browser vendors spent that time working on intensive performance optimizations.