
Кроме того, я решил радикально переделать язык шаблонов LHX и уйти от awk-style разбивки строчек по заранее заданному разделителю. Хочу дать возможность описывать разбиения строки ввода по подстроке, регуляркой, по индексу и давать обращаться из шаблона к каждому разбиению, в том числе и к нескольким сразу. Чтобы можно было написать "разбить по запятым, взять второй элемент, разобрать его как дату (Y, m, d), взять последний элемент, ...":
Всё это можно закешировать в виде префиксного дерева, чтобы повторные обращения к одной и той же цепочке в рамках одного шаблона не делали уже выполненную работу повторно. Вот где простор-то!
csv=re-split:\s*,\s*
ymd=re:\d{4}\.\d{2}\.\d{2}
$date=csv:2:ymd
---
$date:1;-$date:2;-$date:3; - $csv:1;
Всё это можно закешировать в виде префиксного дерева, чтобы повторные обращения к одной и той же цепочке в рамках одного шаблона не делали уже выполненную работу повторно. Вот где простор-то!
👍8
Мде, докатился, завёл второй канал. Чтобы туда писать неструктурированные мысли (подразумевается, что тут они структурированные (нет?)).
Хотел сделать блог в очередной раз, с разделами "TIL" и "мои проекты" — специально чтобы писать ради написания, а не корпеть над каждой статьёй. Но предвкушение мук по настройке пока что не даёт снова окунуться в блоговодство вне silos, пусть даже в виде умолчательной автоматики GH Pages.
Потому что даже в случае Pages нужно что-то запускать, генерить какие-то
Не уверен, что это вообще стоит кому-то читать, но ссылку всё равно дам: https://t.me/brain_leakage_etc Повторюсь, если тут я пишу не всё подряд, что в голову приходит, то там всё будет сильно более сумбурное вроде тех самых TIL и просто ссылок на всё подряд с моими комментариями (в основном для будущего меня самого).
Хотел сделать блог в очередной раз, с разделами "TIL" и "мои проекты" — специально чтобы писать ради написания, а не корпеть над каждой статьёй. Но предвкушение мук по настройке пока что не даёт снова окунуться в блоговодство вне silos, пусть даже в виде умолчательной автоматики GH Pages.
Потому что даже в случае Pages нужно что-то запускать, генерить какие-то
.md, заполнять какие-то front matters. Хочу отправлять по нажатию Enter и всё тут. Поэтому канал. Потом перенесу может быть. Как только придумаю, как из Org Roam публиковать просто навешиванием тега на заметку (опять программировать нужно, но пока не хочется).Не уверен, что это вообще стоит кому-то читать, но ссылку всё равно дам: https://t.me/brain_leakage_etc Повторюсь, если тут я пишу не всё подряд, что в голову приходит, то там всё будет сильно более сумбурное вроде тех самых TIL и просто ссылок на всё подряд с моими комментариями (в основном для будущего меня самого).
Telegram
brain_leakage_etc
Не мысли, но мыслишки некоего @astynax. Можно сказать то, что не получилось дописать до средней длины публикаций в @brain_dump_etc
👍4
Давече я задумался, а как бы мне запускать внешние программы из #Emacs — ну знаете, нужно иногда PDF reader открыть или окно терминала, связанные с ткущим проектом.
Да, у emacs есть возможность запускать процессы синхронно и не очень, в shell и без. Вот только мне не хотелось, чтобы запущенные программы продолжали быть связаны с Emacs как его подпроцессы. Но чьи-то дочки это должны быть! Вот бы иметь процесс, который всегда запущен и которому можно скомандовать "запусти-ка вот это вот". И такой процесс у меня есть: systemd!
Ага, знаю, многие systemd не любят, но мне-то он как раз подходит: он и так запускает тот же Emacs server. Но делать по unit на каждую программу, которую я когда-либо захочу запускать, мне точно было бы лень. Так родился basher.bash — скрипт, который командует соответствующему basher@.service запустить себя же, но в режиме "замени себя такой-то программой".
Замещающая программа при этом запускается в той директории, из которой был интерактивно запущен
В довесок я получаю логирование запущенных программ, поскольку systemd это умеет. Может быть я потом получу кучку мусорных логов. Но пока меня это не сильно беспокоит. А как начнёт, сделаю service, который будет чистить логи
Да, у emacs есть возможность запускать процессы синхронно и не очень, в shell и без. Вот только мне не хотелось, чтобы запущенные программы продолжали быть связаны с Emacs как его подпроцессы. Но чьи-то дочки это должны быть! Вот бы иметь процесс, который всегда запущен и которому можно скомандовать "запусти-ка вот это вот". И такой процесс у меня есть: systemd!
Ага, знаю, многие systemd не любят, но мне-то он как раз подходит: он и так запускает тот же Emacs server. Но делать по unit на каждую программу, которую я когда-либо захочу запускать, мне точно было бы лень. Так родился basher.bash — скрипт, который командует соответствующему basher@.service запустить себя же, но в режиме "замени себя такой-то программой".
Замещающая программа при этом запускается в той директории, из которой был интерактивно запущен
basher.bash — это дело я пробрасываю через временный файл с переменными окружения. Да, костыльненько, но зато а) работает, б) позволяет посмотреть, что за программа была запущена и в какой директории. Второе возможно потому, что каждый файл получает UUID в качестве имени и этот же UUID становится частью имени запущенного сервиса. А уникальные имена сервисов нужны для того, чтобы можно было иметь запущенными несколько экземпляров одновременно.В довесок я получаю логирование запущенных программ, поскольку systemd это умеет. Может быть я потом получу кучку мусорных логов. Но пока меня это не сильно беспокоит. А как начнёт, сделаю service, который будет чистить логи
:) Вот такое велосипедостроение! Зато хоть systemd потрогал наконец.---UPD: оказалось, что велосипед изобретать не стоило, а нужно было просто взять
systemd-run. Ну да ладно, зато я покопался в разном для меня новом и нескучно провёл время! Ссылки поправил на исторические, потому что велосипед свой удалю из dotfilles, но в анналах истории пусть остаётся :)👍7
Так уж вышло, что есть у меня сколько-то программ, написанных на Python, которые если и дебианизированы, то в виде пакетов обновляются сильно позже/реже, чем на PyPI.
Например, youtube-dl можно поставить силами
Как же устанавливать всякое околопитоновое? Авторы пакетов часто предлагают делать "
Да, существуют всякие надстройки над pip вроде pipx и pipsi — эти создают по виртуальному окружению (это такие питоновские песочницы) на каждое приложение и обновлять в последствии. Более того, pipx вообще, можно сказать, "официальный" инструмент — развивается силами pypa, а это те же люди, которые сделали сам pip!
Я сам использовал pipsi, а потом и pipx и вполне успешно. Но в какой-то момент понял, что собственно напитонового ПО у меня в принципе мало, чтобы иметь отдельный инструмент для установки. Это когда-то раньше я ставил десятка два всяких percol — и не пользовался ни разу
Вот только на очередном витке эволюции я решил "минимально, но достаточно автоматизировать" обслуживание. Запилил venv&run, теперь этот скрипт создаёт venvs и устанавливает туда пакеты. Но веселье тут в том, как вы добавляете новое ПО: вы делаете symlink на этот скрипт, называя так, как будет называться устанавливаемая программа — скажем, "dogesay", а потом скрипт уже видит, что имя у него новое, и запускает нужную программу (заменяет себя оной через
Не обошлось и без неприятных сюрпризов. Когда учил скрипт создавать симлинки, то оказалось, что если запустить себя, а потом в пытаться создать venv, то директории создаются, но файлы не копируются, в итоге песочница получается без песка. Пока не понял, почему так. Так что моё suckless решение пока kinda sucks, но не настолько сильно, чтобы не пользоваться
Например, youtube-dl можно поставить силами
apt, но версия будет не самая свежая, вот только это как раз та программа, которую вы захотите иметь максимально свежей — "API" разных платформ меняются часто и код, отвечающий за скачивание, устаревает быстро. Более того, yt-dlp — форк такой, более активный, чем оригинал — всё ещё не дебианизирован.Как же устанавливать всякое околопитоновое? Авторы пакетов часто предлагают делать "
pip install ..." иногда даже с применением sudo. Но этот вариант ничем не лучше "sudo make install"! Даже если знать, что можно использовать флаг --user и ставить всё "только себе", то конфликты версий пакетов вы получите довольно быстро, потому что пользовательское окружение — это всё ещё глобальное окружение, пусть и "чуть менее".Да, существуют всякие надстройки над pip вроде pipx и pipsi — эти создают по виртуальному окружению (это такие питоновские песочницы) на каждое приложение и обновлять в последствии. Более того, pipx вообще, можно сказать, "официальный" инструмент — развивается силами pypa, а это те же люди, которые сделали сам pip!
Я сам использовал pipsi, а потом и pipx и вполне успешно. Но в какой-то момент понял, что собственно напитонового ПО у меня в принципе мало, чтобы иметь отдельный инструмент для установки. Это когда-то раньше я ставил десятка два всяких percol — и не пользовался ни разу
:Р В итоге я решил отдаться тяге к suckless в данном конкретном случае и просто создавать venvs руками и пакеты ставить и обновлять руками же. С тех пор всё лежит у меня в ~/.software, доступно в PATH через symlinks в ~/.local/bin, есть не просит.Вот только на очередном витке эволюции я решил "минимально, но достаточно автоматизировать" обслуживание. Запилил venv&run, теперь этот скрипт создаёт venvs и устанавливает туда пакеты. Но веселье тут в том, как вы добавляете новое ПО: вы делаете symlink на этот скрипт, называя так, как будет называться устанавливаемая программа — скажем, "dogesay", а потом скрипт уже видит, что имя у него новое, и запускает нужную программу (заменяет себя оной через
execv). Чтобы создать venv и установить пакет или обновить его, нужно новую команду запустить в виде "INSTALL=t dogesay". Вот такой вот минимализм ради минимализма, дёшево-сердито :)Не обошлось и без неприятных сюрпризов. Когда учил скрипт создавать симлинки, то оказалось, что если запустить себя, а потом в пытаться создать venv, то директории создаются, но файлы не копируются, в итоге песочница получается без песка. Пока не понял, почему так. Так что моё suckless решение пока kinda sucks, но не настолько сильно, чтобы не пользоваться
:P{kind=link}
👍6🤔1
Дослушиваю выпуск Changelog Podcast "A guided tour through ID3 esoterica". Ведущие беседуют с автором библиотеки для Elixir, работающей с ID3 тегами. Причём разработку библиотеки авторы подкаста же и заказали, чтобы иметь возможность размечать главы в записях подкастов — да, в ID3 есть и такое! Но спешу отметить, что выпуск интересен сам по себе в отрыве от Elixir, потому что позволяет погрузиться в историю и прощупать глубины тегирования MP3 — там есть, на что посмотреть!
Например, знали ли вы, что есть тег, отвечающий за количество прослушиваний конкретного файла? Предполагалось, что проигрыватели будут инкрементить этот счётчик при каждом прослушивании! Так же есть теги, касающиеся монетизации контента. А ещё есть возможность приложить произвольный файл. Который в свою очередь может быть MP3-файлом или даже целым альбомом! Словом, подкаст получился и познавательно-развлекательный, и рассуждательно-юмористический — отличная альтернатива типичным "новостям мира АйТи".
Мне было слушать особенно интересно, потому что я летом добил таки Practical Common Lisp, а в книге приличная часть выделена на разработку библиотеки для работы со всё теми же ID3-тегами. Глава очень мощная, включает и реализацию DSL для описания фреймов c тегами, и matching по заголовкам с помощью мультиметодов — именно за это книгу и любят, ведь она показывает практическое применение тех довольно необычных возможностей языка, которые в иных источниках упоминают вскользь.
И пусть я приличную часть книги читал, держа в голове мысль "да, круто, конечно, но я точно не захочу это использовать сам!", но в целом про работу с бинарными данными, предполагающими разные кодировки и разную компоновку в зависимости от версии формата было интересно даже просто пролистывать. Я даже задавался мыслью "а насколько удобнее такие штуки матчить в Erlang?", так что упомянутый выпуск подкаста попал в благодатную почву :)
Например, знали ли вы, что есть тег, отвечающий за количество прослушиваний конкретного файла? Предполагалось, что проигрыватели будут инкрементить этот счётчик при каждом прослушивании! Так же есть теги, касающиеся монетизации контента. А ещё есть возможность приложить произвольный файл. Который в свою очередь может быть MP3-файлом или даже целым альбомом! Словом, подкаст получился и познавательно-развлекательный, и рассуждательно-юмористический — отличная альтернатива типичным "новостям мира АйТи".
Мне было слушать особенно интересно, потому что я летом добил таки Practical Common Lisp, а в книге приличная часть выделена на разработку библиотеки для работы со всё теми же ID3-тегами. Глава очень мощная, включает и реализацию DSL для описания фреймов c тегами, и matching по заголовкам с помощью мультиметодов — именно за это книгу и любят, ведь она показывает практическое применение тех довольно необычных возможностей языка, которые в иных источниках упоминают вскользь.
И пусть я приличную часть книги читал, держа в голове мысль "да, круто, конечно, но я точно не захочу это использовать сам!", но в целом про работу с бинарными данными, предполагающими разные кодировки и разную компоновку в зависимости от версии формата было интересно даже просто пролистывать. Я даже задавался мыслью "а насколько удобнее такие штуки матчить в Erlang?", так что упомянутый выпуск подкаста попал в благодатную почву :)
👍9
Есть такая программка — jq. Используется для работы с JSON, делает выборки данных из глубоко вложенных структур, может что-то подменять на лету. Применяется, как правило, в сценариях автоматизации. Думаю, что слышали про неё многие. Казалось бы, ну что тут такого нового и интересного? Вот и я так думал до сегодняшнего дня.
Да, я слышал, что язык скриптов jq достаточно богат. Но оказалось, что это неслабое преуменьшение. У jq приличная часть встроенных функций написана на jq же, имеется оптимизация хвостовых вызовов, всякие генераторы, ввод-вывод, система модулей.
То есть сегодня jq — это вполне себе язык большой программирования! На Rosetta Code можно найти реализацию алгоритма Дейкстры и некоторого подобия алгебраических типов данных, помимо прочего.
Для jq есть "среды разработки" с живыми предпросмотром результатов, интерактивные построители запросов, интегрируемые в ваш zsh, внутрибраузерная версия, работающая на базе настоящего jq, скомпилированного в WebAssembly. Вот соответствующий "awesome list" разных штук в экосистеме jq — да, уже можно сказать, что таковая имеется. Из интересного для себя отметил:
- jc — препроцессор "выхлопа" разных популярных программ, преобразующий всё в JSON, который уже можно обрабатывать силами jq
- fq — "jq для бинарных форматов", позволяет делать запросы по EXIF и ID3 тегам, сообщениям Protobuf, и тому подобным штукам, которые jq не переваривает самостоятельно
- jqt — шаблонизатор, размещающий данные из JSON внутри шаблонов — да, можно сайтик написать на jq теперь
Решил ли я научиться писать на jq и делать всё с его помощью? Нет, конечно
Да, я слышал, что язык скриптов jq достаточно богат. Но оказалось, что это неслабое преуменьшение. У jq приличная часть встроенных функций написана на jq же, имеется оптимизация хвостовых вызовов, всякие генераторы, ввод-вывод, система модулей.
То есть сегодня jq — это вполне себе язык большой программирования! На Rosetta Code можно найти реализацию алгоритма Дейкстры и некоторого подобия алгебраических типов данных, помимо прочего.
Для jq есть "среды разработки" с живыми предпросмотром результатов, интерактивные построители запросов, интегрируемые в ваш zsh, внутрибраузерная версия, работающая на базе настоящего jq, скомпилированного в WebAssembly. Вот соответствующий "awesome list" разных штук в экосистеме jq — да, уже можно сказать, что таковая имеется. Из интересного для себя отметил:
- jc — препроцессор "выхлопа" разных популярных программ, преобразующий всё в JSON, который уже можно обрабатывать силами jq
- fq — "jq для бинарных форматов", позволяет делать запросы по EXIF и ID3 тегам, сообщениям Protobuf, и тому подобным штукам, которые jq не переваривает самостоятельно
- jqt — шаблонизатор, размещающий данные из JSON внутри шаблонов — да, можно сайтик написать на jq теперь
Решил ли я научиться писать на jq и делать всё с его помощью? Нет, конечно
:) Но знать о том, какие задачи теперь можно решать с помощью jq, будет полезно!👍25🔥6🤔1😱1
Рубрика "минутка прекрасного"! https://trondal.com/sid/ — внутрибраузерный плеер авторской подборки музыки для чипа SID, который использовался в Commodore 64 и других ретро-железках. Причём плеер в реальном времени показывает то, что играют все три канала. Включать сразу рекомендую "Monty on the Run (1/19)" (находится по ключевому слову "monty") — отличная демонстрация возможностей чипа в умелых руках.
Ещё раз напомню, что вся эта музыка сыграна на трёх каналах, частотой и формой сигнала которых можно программно управлять. Заметьте, это не вывод оцифрованного звука, потому что Commodore 64 и его современники просто физически не могли выдавать таковой при своих скромных ресурсах. Так что это натуральное программирование музыки!
Именно SID-чипы во многом определили направление музыки, которое сейчас называется Chiptune. Кстати, путать оное с трекерной музыкой не следует, потому что в трекерной музыке при тех же трёх-четырёх, скажем, дорожках вы оперируете сэмплами, то есть предзаписанными кусочками цифрового звука, а это уже совсем другая история!
Если вдруг вам захочется послушать больше коммодоровского чиптюна, но в осовремененом виде, то можете сходить на SLAYRadio (старое-доброе Internet-radio, да-да) или на Remix.Kwed.Org, где народ делится ремиксами и прочими каверами на известные и не очень SID-треки. Советую скачивать сразу архивами за такие-то года — получите много всего, не копаясь в сайте и не слушая композиции по одной!
А я всё надеюсь как-нибудь добыть SID-чип и сделать аппаратный плеер треков. Вот только чипы эти нынче крайне редки, так что легче купить электрически совместимый "новодел" на базе FPGA, пусть это и подуменьшит ауру retro будущего проекта
Ещё раз напомню, что вся эта музыка сыграна на трёх каналах, частотой и формой сигнала которых можно программно управлять. Заметьте, это не вывод оцифрованного звука, потому что Commodore 64 и его современники просто физически не могли выдавать таковой при своих скромных ресурсах. Так что это натуральное программирование музыки!
Именно SID-чипы во многом определили направление музыки, которое сейчас называется Chiptune. Кстати, путать оное с трекерной музыкой не следует, потому что в трекерной музыке при тех же трёх-четырёх, скажем, дорожках вы оперируете сэмплами, то есть предзаписанными кусочками цифрового звука, а это уже совсем другая история!
Если вдруг вам захочется послушать больше коммодоровского чиптюна, но в осовремененом виде, то можете сходить на SLAYRadio (старое-доброе Internet-radio, да-да) или на Remix.Kwed.Org, где народ делится ремиксами и прочими каверами на известные и не очень SID-треки. Советую скачивать сразу архивами за такие-то года — получите много всего, не копаясь в сайте и не слушая композиции по одной!
А я всё надеюсь как-нибудь добыть SID-чип и сделать аппаратный плеер треков. Вот только чипы эти нынче крайне редки, так что легче купить электрически совместимый "новодел" на базе FPGA, пусть это и подуменьшит ауру retro будущего проекта
:){kind=link}
🔥3
Я веду свои заметки в Org Mode, потихоньку перетаскиваю то, что раньше просто лежало в огромных файлах, в карточки Org Roam, линкую всё это дело.
То, что пишу в канал (уже в каналы), веду в больших файлах в виде outline со списком опубликованных записей и идей на будущее. Опубликованные записи помечены как DONE и имеют дату публикации. Отсортированы в порядке публикации. "Идеи" идут следом. Не идеально, но "мне удобно".
Для побочного канала решил минимально уменьшить количество препятствий, отделяющих меня от записывания мыслей. Для этого прямо в inbox-файле завёл поддерево "brain_leakage_etc" — у меня этот файл открывается по хоткею, удобно сразу мочь начать писать. Но ведь ветки в дерево нужно добавлять, проставлять дату — это всё излишнее трение!
"Нужно автоматизировать", подумал как-то я — "вот бы мне «кнопку» — ту самую «сделать хорошо»". И положил прямо в дерево исполняемый блок кода на Emacs Lisp, ведь Org Mode такое тоже умеет. Вот такой код:
Теперь я встаю курсором на это блок кода, жму
Да, можно было сложить весь код в
Отдельно хочу отметить, что все функции я нашёл через встроенную справку, просто поискав, что делают функции с похожими на нужные мне именами. Интернет не понадобился, проще говоря. Эта возможность быстро "подпрограммировать" редактор, иной раз даже не имея даже доступа в Интернет, меня лично очень греет.
Если кому всё ещё интересно, что за
А если нажать только
Иногда встречаются действия с "альтернативными альтернативами" (очень редко, к счастью), и
То, что пишу в канал (уже в каналы), веду в больших файлах в виде outline со списком опубликованных записей и идей на будущее. Опубликованные записи помечены как DONE и имеют дату публикации. Отсортированы в порядке публикации. "Идеи" идут следом. Не идеально, но "мне удобно".
Для побочного канала решил минимально уменьшить количество препятствий, отделяющих меня от записывания мыслей. Для этого прямо в inbox-файле завёл поддерево "brain_leakage_etc" — у меня этот файл открывается по хоткею, удобно сразу мочь начать писать. Но ведь ветки в дерево нужно добавлять, проставлять дату — это всё излишнее трение!
"Нужно автоматизировать", подумал как-то я — "вот бы мне «кнопку» — ту самую «сделать хорошо»". И положил прямо в дерево исполняемый блок кода на Emacs Lisp, ведь Org Mode такое тоже умеет. Вот такой код:
(org-get-heading)Собственно, выбирается ветка-родитель — а это дерево с записями в канал. В ней выбирается первый ребёнок, затем добавляется новый узел на том же уровне. В этот узел уже пишется "IN-PROGRESS дата", следом идёт перевод строки и narrowing. narrowing — это возможность оставить видимой только интересующую нас часть файла с убиранием всяких лишних отступов и прочего отвлекающего от сути шума.
(org-goto-first-child)
(org-insert-heading '(16)) ;; C-u C-u
(insert "IN-PROGRESS ")
(insert (format-time-string "[%Y-%m-%d] "))
(insert "\n")
(org-narrow-to-subtree)
Теперь я встаю курсором на это блок кода, жму
Ctrl+C Ctrl+C и оказываюсь в режиме написания нового текста!Да, можно было сложить весь код в
(progn) и сделать elisp-ссылку, которая работала бы точно так же, но я пока ещё отлаживаю flow, так что мне не мешает видеть этот кусочек кода (его всё равно можно свернуть). Можно даже было в конфиг мой функцию положить. Вот только мне приятно, что я могу именно в этом конкретном документе запрограммировать нужное мне поведение!Отдельно хочу отметить, что все функции я нашёл через встроенную справку, просто поискав, что делают функции с похожими на нужные мне именами. Интернет не понадобился, проще говоря. Эта возможность быстро "подпрограммировать" редактор, иной раз даже не имея даже доступа в Интернет, меня лично очень греет.
Если кому всё ещё интересно, что за
'(16), могу рассказать. У Emacs есть возможность параметризовать действие числовым аргументом, который обычно означает количество повторов действия. Скажем, если сочетание M-d (это Alt+D по-имаксовски) удаляет слово под курсором, то C-u 8 M-d удалит 8 слов.А если нажать только
C-u (Ctrl+U), то это означает "повторить четыре раза". Почему 4? Так исторически сложилось. Но это же одиночное C-u часто используется просто как указание выполнить "слегка альтернативное действие": открыть ссылку не во внутреннем браузере, а во внешнем и тому подобное.Иногда встречаются действия с "альтернативными альтернативами" (очень редко, к счастью), и
org-insert-heading — как раз такое. Без модификаторов новый узел outline вставляется над текущим, с одиночным модификатором узел вставляется под текущим, а с двойным модификатором — в конце списка узлов родительского узла. Вот только мне-то функцию нужно было вызывать из кода. В таких случаях нужно передавать "число повторов" как синглтон-список. А "четырежды четыре повтора", это как раз те самые 16 :)🔥7🤔2
Вчера поизучал то, что пишут про Bangle JS 2 — это такие часы на базе ARM от Nordic, с немножко цветным memory LCD как у приснопамятных Pebble, GPS, датчиком пульса и прочими прелестями.
Программируются часики на JS, увы. Зато прямо из браузера. Да и Espruino — тамошний интерпретатор JS — нынче довольно стабильный, вроде как. Да и inline C можно вставлять в код, так что можно писать что-то экономичное. Часы, как говорят, могут жить на одной зарядке неделю-две, что очень даже достойно. Есть возможность подключать часы к телефону и использовать с популярными программами вроде GadgetBridge. И в целом всё, что можно было открыть, открыто, что внушает некоторые надежды на то, что устройство проживёт дольше, чем прожили Pebble.
На сабреддите Bangle JS 2 сравнивают с PineTime (c Pebble тоже сравнивают) PineTime — это уже часы от Pine64, которые знамениты своими подчёркнуто открытыми железками вроде телефонов, читалок, ноутбуков. Как реддитовцы отмечают, у Pine64 лучше обстоят дела с качеством производства, часы более "вылизаны". Да и FreeRTOS внутри PineTime выглядит более серьёзно (а ещё там LVGL интерфейсы рисует и вообще стек интересный). Но вот экран у PineTime — IPS. И вот это меня очень печалит, потому что на носимых девайсах трансфлексивные memory LCD мне гораздо больше нравятся!
Из интересных проектов есть ещё Sensor Watch, но это уже совершенно другой весовой категории штука. Это новая "материнская плата" для очень популярных классических часов Casio F-91W (и другой модели с совместимой начинкой). Используется оригинальный сегментный экран, оригинальные кнопки, даже батарейка используется та же. Зато можно напрограммировать себе таймеров, секундомеров, фаз луны, генераторов ключей для TOTP. Ещё есть возможность добавить сенсор вроде температурного, но нет уверенности, что сенсоров таких будет много. Такой себе проектик для больших любителей Casio, желающих немного покастомизировать часы, сохранив олдскульность
Вот такие проблемы выбора. А пока я продолжаю ходить со своим MiBand и ждать идеальной лично для меня замены для Pebble.
Программируются часики на JS, увы. Зато прямо из браузера. Да и Espruino — тамошний интерпретатор JS — нынче довольно стабильный, вроде как. Да и inline C можно вставлять в код, так что можно писать что-то экономичное. Часы, как говорят, могут жить на одной зарядке неделю-две, что очень даже достойно. Есть возможность подключать часы к телефону и использовать с популярными программами вроде GadgetBridge. И в целом всё, что можно было открыть, открыто, что внушает некоторые надежды на то, что устройство проживёт дольше, чем прожили Pebble.
На сабреддите Bangle JS 2 сравнивают с PineTime (c Pebble тоже сравнивают) PineTime — это уже часы от Pine64, которые знамениты своими подчёркнуто открытыми железками вроде телефонов, читалок, ноутбуков. Как реддитовцы отмечают, у Pine64 лучше обстоят дела с качеством производства, часы более "вылизаны". Да и FreeRTOS внутри PineTime выглядит более серьёзно (а ещё там LVGL интерфейсы рисует и вообще стек интересный). Но вот экран у PineTime — IPS. И вот это меня очень печалит, потому что на носимых девайсах трансфлексивные memory LCD мне гораздо больше нравятся!
Из интересных проектов есть ещё Sensor Watch, но это уже совершенно другой весовой категории штука. Это новая "материнская плата" для очень популярных классических часов Casio F-91W (и другой модели с совместимой начинкой). Используется оригинальный сегментный экран, оригинальные кнопки, даже батарейка используется та же. Зато можно напрограммировать себе таймеров, секундомеров, фаз луны, генераторов ключей для TOTP. Ещё есть возможность добавить сенсор вроде температурного, но нет уверенности, что сенсоров таких будет много. Такой себе проектик для больших любителей Casio, желающих немного покастомизировать часы, сохранив олдскульность
:)Вот такие проблемы выбора. А пока я продолжаю ходить со своим MiBand и ждать идеальной лично для меня замены для Pebble.
{kind=link}
👍11🤔1
Я тут завтра буду стримить Котлин, внезапно. Буду на Jetpack Compose делать десктопное приложение — игру 2048 реализую.
Цель состоит в том, чтобы показать, что на Котлине не только вебчик пишут и не всегда на Spring :Р
Правда котлинист из меня странный, поэтому писать буду так, как мне нравится :)
Цель состоит в том, чтобы показать, что на Котлине не только вебчик пишут и не всегда на Spring :Р
Правда котлинист из меня странный, поэтому писать буду так, как мне нравится :)
Telegram
Канал клуба московских программистов in Международный Клуб Московских Программистов
https://youtu.be/V2YqLtD3HoU
1 декабря 19:00-20:30
Знакомство с языками программирования бывает разным. Можно погрузиться в серьёзных проект, в котором, помимо языка, нужно держать в голове тестирование, архитектуру, системную библиотеку и даже, вероятно…
1 декабря 19:00-20:30
Знакомство с языками программирования бывает разным. Можно погрузиться в серьёзных проект, в котором, помимо языка, нужно держать в голове тестирование, архитектуру, системную библиотеку и даже, вероятно…
👍8🔥3🤔2
Постримил Котлин вчера нормально, мне кажется. Хоть без грабель и не обошлось даже там, где, казалось бы, соломки достаточно подстелено было :) В описании к видео можете найти ссылку на код.
А ещё сегодня второй день Advent of Code '2022, если ещё не начали участвовать, зову присоединяться! Я уже который год участвую, правда, с переменным успехом: не каждый раз получается найти время в двадцатых числах октября, а там как раз задачки посложнее начинаются, так что у меня бывали бодрые начала, но уходил в итоге не дальше середины :)
Если вдруг кто решил/решит на #Haskell решать задачи, советую пробежаться глазами по этой статье: Some tips and tricks for doing Advent of Code with Haskell Советы в ней даются совсем новичковые, но тем не менее, кое-какие из упомянутых практик я сам открыл для себя за годы участия.
А ещё сегодня второй день Advent of Code '2022, если ещё не начали участвовать, зову присоединяться! Я уже который год участвую, правда, с переменным успехом: не каждый раз получается найти время в двадцатых числах октября, а там как раз задачки посложнее начинаются, так что у меня бывали бодрые начала, но уходил в итоге не дальше середины :)
Если вдруг кто решил/решит на #Haskell решать задачи, советую пробежаться глазами по этой статье: Some tips and tricks for doing Advent of Code with Haskell Советы в ней даются совсем новичковые, но тем не менее, кое-какие из упомянутых практик я сам открыл для себя за годы участия.
🔥5👍2
Недавно в одном из чатов вспоминал, когда же я пользовался Windows нормально, а не только для запуска Steam. Где-то года с 2010 я на Linux перешёл в качестве домашней ОС, а до этого сидел на WinXP, но даже тогда у меня был очень странный Windows. Классическая тема оформления. Ни одного ярлыка на Dеsktop. Total Commander — вот что было моей настоящей оболочкой! Я вообще жил в двухпанельных файловых менеджерах, начиная с MS-DOS в середине 90-х и заканчивая началом нулевых уже на Windows. Так что вспомнить про TC было приятно: я не просто его использовал, я регулярно дорабатывал TC, чтобы тот соответствовал моему пониманию "идеальной ОС"!
Но для начала я признаюсь кое-в-чём: я TC так и не купил
Со временем launcher научился запускать "ровно одну копию" TC, потом добавилась возможность открывать директорию во вкладке уже запущенного коммандера, если лаунчер получал путь в качестве параметра — при drag'n'drop на иконку на панели задач или через отправку в "Send to…". Тесная интеграция с ОС!
Ещё у моего TC были переключаемые панели инструментов, потому что на одну все кнопки уже не влезали. А работало переключение потому, что показывал новую панель инструментов при нажатии на кнопку на оригинальной панели, если вместо программы для запуска вы кнопке назначали файл новой панели — настоящее инженерное решение
И что было особенно приятно, даже тогда, когда добавилась поддержка Windows Registry, TotalCommander позволял себя настраивать через INI-файл, в том числе лежащий в заданной вами директории. Достаточно было указать файл конфигурации в командной строке — этим тоже мой launcher занимался. В какой-то момент появилась поддержка разделяемых файлов конфигурации и мой большущий конфиг был успешно распилен на десяток отдельных файлов!
Эх, сколько всего было ещё понакручено… Выбиралка редактора по расширению, например. Сам TC тогда ещё вызывал один редактор для всего, хотя просмотрщики были настраиваемыми. Ещё я использовал подкрашивание файлов и директорий более яркими цветами, если в описании файла или директории в файле
В какой-то момент в мой набор портативного софта добавились mplayer и даже GVim — я, сам того не зная, приблизился к Linux максимально
Но для начала я признаюсь кое-в-чём: я TC так и не купил
:( Всё откладывал до "первой зарплаты", чтобы, наконец-то, заказать себе фирменную дискетку. Сперва использовал ключик с дисков с софтом, а затем и из интернетов. Но в какой-то момент воспользовался тем, что Гислер (автор программы) разрешил бедным студентам использовать безвозмездно — коль скоро те не будут добывать ключи, а продолжат при запуске программы нажимать те самые кнопки "1", "2" и "3" (напомню, при запуске программа просила нажать выбранную ею случайно кнопку — одну из трёх на выбор). Ну так вот, нажимал я, нажимал кнопки эти какое-то время, а потом решил это действие автоматизировать :)
Написал свой launcher, который ждал, пока TC запустится и покажет окошко с кнопками, искал элемент управления, который содержал название выбранной кнопки, а потом, собственно, нажимал кнопку. Минимум жонглирования WinAPI и вы даже не видите то самое окно, а сразу начинаете работать! Писал я этот лаунчер на Delphi, как тогда у меня водилось, и тогда я уже освоил кое-что из WinAPI и программировал на "сыром Delphi language" без формочек и прочего мышиного программирования.Со временем launcher научился запускать "ровно одну копию" TC, потом добавилась возможность открывать директорию во вкладке уже запущенного коммандера, если лаунчер получал путь в качестве параметра — при drag'n'drop на иконку на панели задач или через отправку в "Send to…". Тесная интеграция с ОС!
Ещё у моего TC были переключаемые панели инструментов, потому что на одну все кнопки уже не влезали. А работало переключение потому, что показывал новую панель инструментов при нажатии на кнопку на оригинальной панели, если вместо программы для запуска вы кнопке назначали файл новой панели — настоящее инженерное решение
:). Когда мой TC оброс кучкой portable software, такие панели пригодились! Правда, пришлось понарисовать изрядное количество пиктограмм.И что было особенно приятно, даже тогда, когда добавилась поддержка Windows Registry, TotalCommander позволял себя настраивать через INI-файл, в том числе лежащий в заданной вами директории. Достаточно было указать файл конфигурации в командной строке — этим тоже мой launcher занимался. В какой-то момент появилась поддержка разделяемых файлов конфигурации и мой большущий конфиг был успешно распилен на десяток отдельных файлов!
Эх, сколько всего было ещё понакручено… Выбиралка редактора по расширению, например. Сам TC тогда ещё вызывал один редактор для всего, хотя просмотрщики были настраиваемыми. Ещё я использовал подкрашивание файлов и директорий более яркими цветами, если в описании файла или директории в файле
descript.ion встречался соответствующий тег. Это позволяло, скажем, отмечать текущий эпизод сериала, чтобы в следующий раз начать с того же места.В какой-то момент в мой набор портативного софта добавились mplayer и даже GVim — я, сам того не зная, приблизился к Linux максимально
:) Собственно, во многом поэтому было проще соскакивать с Windows, ведь я практически не пользовался рекомендованными производителем средствами. А уже на Linux я пробовал использовать TC под Wine, но в какой-то момент понял, что большой менеджер файлов мне не нужен, а когда изредка нужно бывает что-то поменеджить, нынче я беру ranger.Ghisler
Total Commander - home
Homepage of Total Commander, a file manager replacement for
Windows 95/98/NT/2000/XP/Vista/7/8/8.1/10/11
Windows 95/98/NT/2000/XP/Vista/7/8/8.1/10/11
👍15🔥6
Я уже который год участвую в Advent of Code. Планирую в этот раз дойти до конца, тогда это будет мой второй успешный финиш.
Пока решаю как обычно на Haskell. И параллельно на Common Lisp, раз уж книжек по нему почитал в этом году — практикую
Надеюсь дотащить оба языка до конца, но решать приходится два раза: на Haskell как обычно зипперы и иммутабельность, а вот на CL процедурщина, мутации, деструктивные присваивания в многомерные массивы. Но тем и интереснее. На Python, например, тоже мог бы решать, но не тянет — что я, апдейтов словарей словарей списков на нём не делал?
Вот стримить решения я пока не пробовал. Но может быть позовут показательно решить для "Контура": у них бодро идёт процесс, день-в-день, с решениями от разных авторов на разных языках!
У JetBrains тоже есть плейлист с решениями на Kotlin и последующие дни даже анонсированы — умеют же в привлечение внимания подписчиков!
А тут можно посмотреть на решения задач первых двух дней на Clojure, причём с использованием не только стандартной библиотеки, но и пакета specter — это такая "пост-стандартная библиотека" для всяческих сложных трансформаций над сложносоставными данными. Я specter себе "закладывал", но сам пока не добрался, успел только упомянуть в докладе, так что мне лично было интересно посмотреть на применение пакетика на практике.
Забавно было увидеть, как автор видео из предыдущего абзаца автоматизировал себе загрузку данных. У него файлы с данными скачиваются скриптом через передачу session cookie, я до такого ещё не дошёл. Но зато в Emacs в
Пока решаю как обычно на Haskell. И параллельно на Common Lisp, раз уж книжек по нему почитал в этом году — практикую
loop, а вчера даже ООП, макросами обмазанный применил :)Надеюсь дотащить оба языка до конца, но решать приходится два раза: на Haskell как обычно зипперы и иммутабельность, а вот на CL процедурщина, мутации, деструктивные присваивания в многомерные массивы. Но тем и интереснее. На Python, например, тоже мог бы решать, но не тянет — что я, апдейтов словарей словарей списков на нём не делал?
Вот стримить решения я пока не пробовал. Но может быть позовут показательно решить для "Контура": у них бодро идёт процесс, день-в-день, с решениями от разных авторов на разных языках!
У JetBrains тоже есть плейлист с решениями на Kotlin и последующие дни даже анонсированы — умеют же в привлечение внимания подписчиков!
А тут можно посмотреть на решения задач первых двух дней на Clojure, причём с использованием не только стандартной библиотеки, но и пакета specter — это такая "пост-стандартная библиотека" для всяческих сложных трансформаций над сложносоставными данными. Я specter себе "закладывал", но сам пока не добрался, успел только упомянуть в докладе, так что мне лично было интересно посмотреть на применение пакетика на практике.
Забавно было увидеть, как автор видео из предыдущего абзаца автоматизировал себе загрузку данных. У него файлы с данными скачиваются скриптом через передачу session cookie, я до такого ещё не дошёл. Но зато в Emacs в
.org-файлике, который у меня как Inbox работает, я сделал выполняемые блоки, один из которых берёт ~/Downloads/input и под нужным именем кладёт в два репозитория, попутно создавая болванки для программок, а ещё два скрипта открывают по инстансу Emacs в каждом из проектов. Я даже темплейты для commit messages в .git подложил, чтобы не писать руками "add: solution for the day #"! Вот так и развлекаюсь :P{kind=link}
🔥16👍3
Ну вот я и закончил Advent of Code с 50 звёздами! В первый раз дошёл до конца и даже вовремя, с чем себя и поздравляю
Что я могу сказать… в этом году было проще, чем бывало раньше. Да, я буксовал пару так, что приходилось переписывать решение задачи по пять раз и даже прогонять чужие решения на моих данных, чтобы найти баги. А вот именно решения чужие я не подсматривал, только пару раз заглянул уже после того, как своё получил. И лучше бы не заглядывал, очень уж там страшненький код встречается
По качеству заданий могу тоже сказать "бывало и интереснее". Я уж молчу про 2019 год, когда нужно было свой интерпретатор выдуманного языка реализовывать и расширять его функциональность от задачи к задаче. Но и в целом были дежурные задачи на клеточные автоматы, интервалы, модульную арифметику — с одной стороны это то самое "знаем и (не)любим" (люблю КА, не люблю формулы), с другой именно новизны не хватило в этот раз. Впрочем, парочка задач действительно понравилась, так что в целом я доволен!
Второй набор решений тех же задач, но на Common Lisp я не дотянул, остановился дне на восемнадцатом, кажется. Однако пользу от "набивания руки" на жонглировании лисповыми
На будущий год решил попробовать решить сколько-то задач на Emacs Lisp (параллельно с Haskell, само собой). Тут уже мне хочется посмотреть, каково это — использовать в роли "структуры данных" обычный имаксовый буфер со всеми возможностями вроде "переместить курсор на три слова вперёд" и "искать следующее вхождение подстроки". Я посмотрел, как Gavin Freeborn решает первую задачку, и захотелось тоже попробовать.
:)Что я могу сказать… в этом году было проще, чем бывало раньше. Да, я буксовал пару так, что приходилось переписывать решение задачи по пять раз и даже прогонять чужие решения на моих данных, чтобы найти баги. А вот именно решения чужие я не подсматривал, только пару раз заглянул уже после того, как своё получил. И лучше бы не заглядывал, очень уж там страшненький код встречается
;)По качеству заданий могу тоже сказать "бывало и интереснее". Я уж молчу про 2019 год, когда нужно было свой интерпретатор выдуманного языка реализовывать и расширять его функциональность от задачи к задаче. Но и в целом были дежурные задачи на клеточные автоматы, интервалы, модульную арифметику — с одной стороны это то самое "знаем и (не)любим" (люблю КА, не люблю формулы), с другой именно новизны не хватило в этот раз. Впрочем, парочка задач действительно понравилась, так что в целом я доволен!
Второй набор решений тех же задач, но на Common Lisp я не дотянул, остановился дне на восемнадцатом, кажется. Однако пользу от "набивания руки" на жонглировании лисповыми
loop я получил. И даже микро-библиотечку парсер-комбинаторов написал в процессе! В будущем какие-то задачи я добью, возможно: интересно порешать их именно императивно, на изменяемых массивах (уже предвкушаю чад отладки) и ООП в лице CLOS.На будущий год решил попробовать решить сколько-то задач на Emacs Lisp (параллельно с Haskell, само собой). Тут уже мне хочется посмотреть, каково это — использовать в роли "структуры данных" обычный имаксовый буфер со всеми возможностями вроде "переместить курсор на три слова вперёд" и "искать следующее вхождение подстроки". Я посмотрел, как Gavin Freeborn решает первую задачку, и захотелось тоже попробовать.
{kind=link}
🔥25👍10
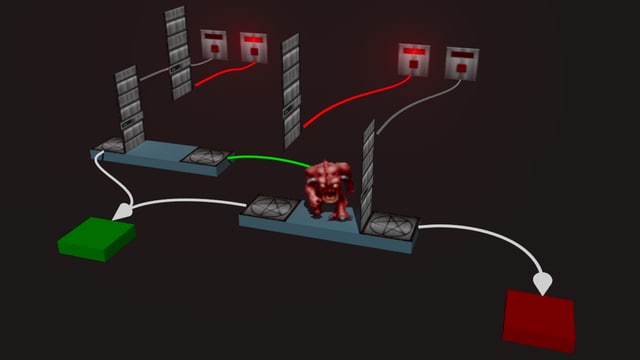
Под конец прошлого года вышла статья про то, как автор сделал карту для Doom, которая содержит машину, складывающую десятичные числа. И работает этот своеобразный калькулятор не только на современных вариантах оригинального движка Doom, но даже на Vanilla Doom 2 без каких либо дополнений и модификаций!
При этом не используются никакие трюки вроде эксплойта, который позволяет запускать произвольный код и даёт возможность запустить Doom в Doom (ссылка на этот эксперимент есть в статье). Логические элементы, из которых собран калькулятор, реализованы в виде сети из маленьких комнат, которые соединены в бинарные диаграммы решений, а внутри имеют управляемые извне дверями и телепортами. Роль носителей информации выполняют монстры, которые проходят через двери и телепортируются.
Даже про само по себе кодирование булевой логики читать интересно, но автор не пожалел времени и снабдил статью не только иллюстрациями и анимациями, но и приложил интерактивный симулятор, показывающий то, как происходит суммирование и формирование ответа на "сегментированном индикаторе" — красота!
А ещё кому-то будет интересно почитать про то, как автор генерировал WAD-файл с картой, а делал он это с помощью… #Clojure, которая позволила и DSL использовать для описания диаграмм решений, и на ней же был реализован оптимизатор "кода", позволяющий сэкономить место на карте.
При этом не используются никакие трюки вроде эксплойта, который позволяет запускать произвольный код и даёт возможность запустить Doom в Doom (ссылка на этот эксперимент есть в статье). Логические элементы, из которых собран калькулятор, реализованы в виде сети из маленьких комнат, которые соединены в бинарные диаграммы решений, а внутри имеют управляемые извне дверями и телепортами. Роль носителей информации выполняют монстры, которые проходят через двери и телепортируются.
Даже про само по себе кодирование булевой логики читать интересно, но автор не пожалел времени и снабдил статью не только иллюстрациями и анимациями, но и приложил интерактивный симулятор, показывающий то, как происходит суммирование и формирование ответа на "сегментированном индикаторе" — красота!
А ещё кому-то будет интересно почитать про то, как автор генерировал WAD-файл с картой, а делал он это с помощью… #Clojure, которая позволила и DSL использовать для описания диаграмм решений, и на ней же был реализован оптимизатор "кода", позволяющий сэкономить место на карте.
{kind=link}
🔥22
Буквально позавчера в Steam вышла игра Kandria. По стилистике игра напоминает классику вроде Flashback) и Another World), а в плане игрового процесса это "нарративный платформер" в атмосфере постапокалипсиса. Придётся немножко подраться и множко попрыгать и полазить по стенам пещер и остовов домов.
"Ну игра и игра", спросите вы, зачем я про неё пишу здесь? Отвечаю: потому что игра написана на… Common Lisp! Да, хорошо (для indie, как минимум) выглядящая и звучащая игра доделана и выпущена в Steam. И создана Kandria буквально одним человеком — и движок, и код игры (Open Source!), и даже графика! Вот такие смельчаки ходят среди нас
"Ну игра и игра", спросите вы, зачем я про неё пишу здесь? Отвечаю: потому что игра написана на… Common Lisp! Да, хорошо (для indie, как минимум) выглядящая и звучащая игра доделана и выпущена в Steam. И создана Kandria буквально одним человеком — и движок, и код игры (Open Source!), и даже графика! Вот такие смельчаки ходят среди нас
:)Steampowered
Save 65% on Kandria on Steam
Explore a ruined open world of caverns and settlements. Hack and slash your way through missions: patrol, repair, scavenge - choose your quests and dialogue. Or go fishing, forage mushrooms, and race the clock! The old world is gone - the future is up to…
🔥19👍1
Я тут немножко записываю то, как решаю задачки Advent of Code 2016 на Common Lisp. Навёрстываю упущенное, так сказать. Пока хватает стандартной библиотеки, но может быть свой парсер притащу в итоге — получился вполне удобным. Ещё надо будет поиграться с альтернативными наборами батареек вроде Radical Utilities, пусть даже большая часть подобных библиотек — оголтелая вкусовщина
Кстати, если вам нравится читать всякие истории из жизни программистов старой школы, можете глянуть на эту статью: "Lisping at JPL Revisited". Автор пишет о том, что он думает о прошлом себе, написавшем оригинальную статью "Lisping at JPL" в начале нулевых, и как эволюционировали его (автора) отношения с Common Lisp. И оригинальную статью почитайте тоже: она рассказывает про программирование марсианских роверов на Lisp.
А кстати эта статья приходится потому, что Rondam Ramblings (так автора зовут) программирует вот уже почти сорок лет на своём языке, который он построил на основе CL — очень "лисперская" история и тоже вся наполнена вкусовщиной. При этом автор считает, что именно такие личные истории и привели к тому, что экосистема у Common Lisp ныне сильно фрагментирована. Так что "критику лиспов от лица лиспера" вы в статье тоже найдёте.
P.S. В процессе записывания процесса решения у меня пока обнаруживаются всякие проблемы вроде пропадания кадров в записях стримов силами Telegram, с которым раньше не было проблем. Но в принципе оно смотрибельно, да и с третьего видео я перешёл на локальную запись с помощью OBS, так что пропуски кадров должны уйти в прошлое. И OBS хотя бы не вставляет заглушки свои в ролик, как это телеграм делает.
:)Кстати, если вам нравится читать всякие истории из жизни программистов старой школы, можете глянуть на эту статью: "Lisping at JPL Revisited". Автор пишет о том, что он думает о прошлом себе, написавшем оригинальную статью "Lisping at JPL" в начале нулевых, и как эволюционировали его (автора) отношения с Common Lisp. И оригинальную статью почитайте тоже: она рассказывает про программирование марсианских роверов на Lisp.
А кстати эта статья приходится потому, что Rondam Ramblings (так автора зовут) программирует вот уже почти сорок лет на своём языке, который он построил на основе CL — очень "лисперская" история и тоже вся наполнена вкусовщиной. При этом автор считает, что именно такие личные истории и привели к тому, что экосистема у Common Lisp ныне сильно фрагментирована. Так что "критику лиспов от лица лиспера" вы в статье тоже найдёте.
P.S. В процессе записывания процесса решения у меня пока обнаруживаются всякие проблемы вроде пропадания кадров в записях стримов силами Telegram, с которым раньше не было проблем. Но в принципе оно смотрибельно, да и с третьего видео я перешёл на локальную запись с помощью OBS, так что пропуски кадров должны уйти в прошлое. И OBS хотя бы не вставляет заглушки свои в ролик, как это телеграм делает.
{kind=link}
👍9🤔2🔥1
Раз уж я тут с Common Lisp играюсь в последнее время и сюда об этом пишу, то прорекламирую один YouTubeканал: "IT Муравейник".
Автор недавно начал рассказывать про то, как вообще живётся в мире CL, как его готовить и с чем вприкуску есть. А сегодня Александр выложил ролик про библиотечку cl-reex в формате "сегодня я поковырял вот это вот" — у автора раньше уже был заход в "рассматривание по библиотеке в день" и очень даже длинный, в 220 дней (мне бы так)!
Так вот, у меня от
Потом я, правда, видал примеры "серьёзного" использования Rx, и они мне понравились не так сильно. Мне гораздо больше нравится FRP, с тех пор, как я с ним поигрался в Elm, даже доклады делал про это всё. А потом был не рад, когда FRP из Elm выплили. Но это, как говорится, уже совсем другая история.
Однако, не могу не отметить, что в контексте с CL реактивщина в стиле Rx смотрится неплохо! Потому что язык процедурный, мутировать состояние очень даже принято. Вот и сеть подписок строится путём оформления подписок для существующих наблюдателей. Зато макросы позволяют довольно приятно разгрузить синтаксис:
Надо будет попробовать написать какую-нибудь игрушку с логикой на cl-reex. Только сначала нужно найти библиотеку, которая с канвой работает не слишком многословно. Может быть в "IT Муравейнике" проскользнёт?
Автор недавно начал рассказывать про то, как вообще живётся в мире CL, как его готовить и с чем вприкуску есть. А сегодня Александр выложил ролик про библиотечку cl-reex в формате "сегодня я поковырял вот это вот" — у автора раньше уже был заход в "рассматривание по библиотеке в день" и очень даже длинный, в 220 дней (мне бы так)!
Так вот, у меня от
cl-reex возник тот самый "вьетнамский флешбэк": вспомнилось, как я проходил на Coursera курс "Functional Program Design in Scala", когда он только появился, в 2012 (!) — с отличием закончил, между прочим! Курс до сих пор существует и в одной из частей знакомит с реактивщиной в Rxстиле с наблюдателями и подписками. Мне тогда эта идея вполне понравилась, во многом потому, что в курсе подавалась интересно.Потом я, правда, видал примеры "серьёзного" использования Rx, и они мне понравились не так сильно. Мне гораздо больше нравится FRP, с тех пор, как я с ним поигрался в Elm, даже доклады делал про это всё. А потом был не рад, когда FRP из Elm выплили. Но это, как говорится, уже совсем другая история.
Однако, не могу не отметить, что в контексте с CL реактивщина в стиле Rx смотрится неплохо! Потому что язык процедурный, мутировать состояние очень даже принято. Вот и сеть подписок строится путём оформления подписок для существующих наблюдателей. Зато макросы позволяют довольно приятно разгрузить синтаксис:
(defparameter observerНикаких вложенных вызовов, даже лямбды спрятаны за клозами вроде
(rx:make-observer
(rx:on-next (x) (print x))
(rx:on-error (x) (format t "error: ~S~%" x))
(rx:on-completed () (print "completed")) ))
rx:on-next — DSL в лучшем виде, если вы вообще любите такое, конечно.Надо будет попробовать написать какую-нибудь игрушку с логикой на cl-reex. Только сначала нужно найти библиотеку, которая с канвой работает не слишком многословно. Может быть в "IT Муравейнике" проскользнёт?
:)👍11
У меня на той неделе намечается стрим. Будет не столько сложная вёрстка какая-то, сколько просто разработка под браузер в целом: приложение с состоянием, local storage, походами в публичный API за данными. Так что будет не то чтобы очень красиво, но зато разнообразно :Р
А надумал я про это порассказывать потому, что сейчас книжку пишу про ClojureScript. Не то чтобы большую книгу про язык в целом, общо и широко, а в стиле "семи языков за семь недель" — познавательно-развлекательно с показом в первую очередь интересных особенностей языка и присущих ему подходов к проектированию приложений.
Изначально планировалась книга про три языка: TS, ClJS и PureScript, но мои соавторы пока не готовы публиковать свои порции, а я уже написал достаточно, чтобы имело смысл выложить в виде GitBook. Может ещё и Patreon какой-нить прикручу — вдруг кому понравится. А большая книга про три языка выйдет, когда выйдет. Может быть я сам, когда часть про ClJS добью, попробую помочь коллегам с TS или PS.
А надумал я про это порассказывать потому, что сейчас книжку пишу про ClojureScript. Не то чтобы большую книгу про язык в целом, общо и широко, а в стиле "семи языков за семь недель" — познавательно-развлекательно с показом в первую очередь интересных особенностей языка и присущих ему подходов к проектированию приложений.
Изначально планировалась книга про три языка: TS, ClJS и PureScript, но мои соавторы пока не готовы публиковать свои порции, а я уже написал достаточно, чтобы имело смысл выложить в виде GitBook. Может ещё и Patreon какой-нить прикручу — вдруг кому понравится. А большая книга про три языка выйдет, когда выйдет. Может быть я сам, когда часть про ClJS добью, попробую помочь коллегам с TS или PS.
YouTube
Функциональный фронтенд. ClojureScript — Часть 1 из 5
Исходный код проекта: https://github.com/astynax/cljs-pokedex
Алексей Пирогов на getmentor: https://getmentor.dev/mentor/aleksei-pirogov-3568
00:00 - заставка
04:50 - начало - вводное слово от Марка
06:45 - вводная от Алексея про Clojure и ClojureScript…
Алексей Пирогов на getmentor: https://getmentor.dev/mentor/aleksei-pirogov-3568
00:00 - заставка
04:50 - начало - вводное слово от Марка
06:45 - вводная от Алексея про Clojure и ClojureScript…
🔥19👍5🤔1
Постримил вторую часть приключений с ClojureScript. Сделал забор данных о покемонах через GraphQL, уложил оные в DataScript, попробовал погонять запросы. Естественно, наступил на половину граблей, даже REPL подвесил разок, но в целом доволен. Теперь нужно придумать, как many-to-many связи между "моделями" разложить на тройки, но это я в фоне попилю к следующему вторнику, когда третий стрим будет.
Кстати, backend у PokeAPI на Python/Django написан. А GraphQL делается силами Hasura, а это, на минуточку, уже проект, реализованный на Haskell! (Если что, Hasura — это такая штука, превращающая вашу базу в *PostgreSQL* в GraphQL endpoint с админкой и правами). Вместе с моим проектом на ClJS получается настоящий зоопарк
Кстати, backend у PokeAPI на Python/Django написан. А GraphQL делается силами Hasura, а это, на минуточку, уже проект, реализованный на Haskell! (Если что, Hasura — это такая штука, превращающая вашу базу в *PostgreSQL* в GraphQL endpoint с админкой и правами). Вместе с моим проектом на ClJS получается настоящий зоопарк
:){kind=link}
🔥10
Третью часть вчера постримил. Как всегда, не без граблей :) На этот раз подвёл PokeAPI — у них прилег GraphQL backend, о чём мне радостно сообщил CloudFlare прямо перед стримом.
А ведь я хотел сдампить себе выдачу, чтобы локальную копию иметь и не нагружать сервис лишний раз! Но, как в анекдоте про бэкапы, пришлось перейти из лагеря тех, кто ещё не делает, в лагерь тех, кто уже делает :)
Я даже пытался по-быстрому сдампить то, что у меня было сохранено на другим компе в запущенном REPL. Но в случае ClJS не так-то просто взять и что-то осмысленное сделать со структурой в несколько мегабайт. Я пробовал воткнуть в DOM ноду с
В процессе мокания наткнулся на пресловутый nil punning: когда спуск вглубь структуры натыкается на nil, вы не получаете ошибку, а вместо этого получаете nil в качестве результата. Это удобно, когда ты того хочешь, и неудобно, когда не хочешь. Но уж таков путь (в Clojure, как минимум). Да, кложуристы сказали бы (кое-кто таки сказал
В любом случае, я сделал таки тестовые данные. Это позволило порешать проблему с дублированием строк в выборке, предполагающей JOIN "табличек" в Datascript, связанных как "один-ко-многим". Силами БД я это не стал решать, просто пожонглировал мапками, но на то у нас и Data-Oriented Programming, чтобы обходиться обобщёнными структурами данных и превращать неудобные внешние данные в удобные внутренние посредством манипуляций над этими самыми структурами!
А ведь я хотел сдампить себе выдачу, чтобы локальную копию иметь и не нагружать сервис лишний раз! Но, как в анекдоте про бэкапы, пришлось перейти из лагеря тех, кто ещё не делает, в лагерь тех, кто уже делает :)
Я даже пытался по-быстрому сдампить то, что у меня было сохранено на другим компе в запущенном REPL. Но в случае ClJS не так-то просто взять и что-то осмысленное сделать со структурой в несколько мегабайт. Я пробовал воткнуть в DOM ноду с
<pre></pre>, чтобы потом скопипастить содержимое в файл. Но вставка выдала копию значения в REPL в качестве эха и это был конец: REPL помер в попытке вывести эти самые мегабайты — и со стороны Emacs, и в консоли браузера. Иными словами, не получилось сдампить, так что пришлось мокать.В процессе мокания наткнулся на пресловутый nil punning: когда спуск вглубь структуры натыкается на nil, вы не получаете ошибку, а вместо этого получаете nil в качестве результата. Это удобно, когда ты того хочешь, и неудобно, когда не хочешь. Но уж таков путь (в Clojure, как минимум). Да, кложуристы сказали бы (кое-кто таки сказал
;)), мол, надо было сразу спеку cделать. Да, надо было. Может быть и сделаю в следующей серии!В любом случае, я сделал таки тестовые данные. Это позволило порешать проблему с дублированием строк в выборке, предполагающей JOIN "табличек" в Datascript, связанных как "один-ко-многим". Силами БД я это не стал решать, просто пожонглировал мапками, но на то у нас и Data-Oriented Programming, чтобы обходиться обобщёнными структурами данных и превращать неудобные внешние данные в удобные внутренние посредством манипуляций над этими самыми структурами!
{kind=link}
🔥8👍1