
Unfun fact. Оказывается Batch-norm layer, необходимый слой в большинстве используемых претренированных неиронных сетей, запатентован:
https://patents.google.com/patent/US20160217368A1/en
Технически почти все, кто применяет неиросети, нарушают закон. Или нет. Откуда мне знать, я не лоер. Я думаю даже лоеры тут ничего не понимают. Я точно ничего не понимаю.
https://patents.google.com/patent/US20160217368A1/en
Технически почти все, кто применяет неиросети, нарушают закон. Или нет. Откуда мне знать, я не лоер. Я думаю даже лоеры тут ничего не понимают. Я точно ничего не понимаю.
Google
US20160217368A1 - Batch normalization layers
- Google Patents
- Google Patents
Methods, systems, and apparatus, including computer programs encoded on computer storage media, for processing inputs using a neural network system that includes a batch normalization layer. One of the methods includes receiving a respective first layer output…
Forwarded from Серёга Бомбит
Однажды Эрнест Хемингуэй поспорил, что сможет написать самый короткий рассказ, способный растрогать любого. Он выиграл спор: «Kernel died, restarting»
🔥1
Общался с учеными-эпидемиологами только что. Один из них: "Говорят, что у нас будет свой штамм коронавируса. Идеологически неправильно, если у нас будет британский штамм"
Недавно закончился Kaggle контест Cassava Leaf Disease Classification, в котором я участвовал. Задача соревнования была в том, чтобы натренировать модель определять по фотографиям болеют растения или нет. Я сделал себе пометку посмотреть решение тех, кто занял первое место, когда его опубликуют. И не пожалел!
Смотрим на решение 14 места:
https://www.kaggle.com/c/cassava-leaf-disease-classification/discussion/220751
Видим: огромный ансамбль. Семнадцать EfficientNet, 14 ResNext, 2 ViT. Хитрости с лейблами: часть моделей предсказывает не тип болезни, а бинарной здоровый/нездоровй, а одна модель вообще предсказывает ImageNet классы. Потом ещё всё это стакается, сверху Lightgbm. Страшно представить, сколько всего эти ребята перепробовали по части параметрво моделей, аугментаций, исправления шума в данных.
For the record, мой пайплайн решения был менее огромным, более креативным, но всё равно довольно сложным.
Все места от третьего и ниже, вплоть до того дна, где очутился я, выглядят как-то так. Много моделей, много всего попробовано. Кому-то хватило интуиции найти нужную комбинацию всех переменных и залететь в призовые места, кому-то нет.
Но всё это не имело никакого значения!
Смотрим второе место:
https://www.kaggle.com/c/cassava-leaf-disease-classification/discussion/220898
Парень залетел в соревнование в последний момент, сделал 3 сабмита (у всех остальных на лидерборде 100 и больше), взял второе место. Он гений? Нет, просто он нашел CropNet: модель, которая была претрейнута на листьях cassava для какой-то научной статьи, и использовал её. Никаких безумных ансамблей. Пришел, сабмитнул, победил.
Смотрим первое место:
https://www.kaggle.com/c/cassava-leaf-disease-classification/discussion/221957
Мы видим небольшой ансамбль. Ничего такого, что бы сделало его намного лучше 14 места или большинства других. Но есть ещё кое-что: CropNet. И всё, ребята побеждают с огромным отрывом от всех.
Вывод? Всё кроме CropNet не имело значения. Люди задаются вопросами, как же мелкий CropNet может давать такой прирост, чтобы гарантировать победу? Возможно он просто видел тестовые данные? Скорее всего.
Вот из-за таких приколов Kaggle бывает жутко фрустрирующим. Ты меряешься размером ансамбля с толпой ребят у которых больше GPU, чем у тебя, а потом кто-то достает свой CropNet. И всё, оказывается зря тысяча команд по всему миру нагревала атмосферу. Не всегда так бывает конечно - я участвовал в соревновании, где победило самое умное решение, а не мега-ансамбль или утечка в данных.
Смотрим на решение 14 места:
https://www.kaggle.com/c/cassava-leaf-disease-classification/discussion/220751
Видим: огромный ансамбль. Семнадцать EfficientNet, 14 ResNext, 2 ViT. Хитрости с лейблами: часть моделей предсказывает не тип болезни, а бинарной здоровый/нездоровй, а одна модель вообще предсказывает ImageNet классы. Потом ещё всё это стакается, сверху Lightgbm. Страшно представить, сколько всего эти ребята перепробовали по части параметрво моделей, аугментаций, исправления шума в данных.
For the record, мой пайплайн решения был менее огромным, более креативным, но всё равно довольно сложным.
Все места от третьего и ниже, вплоть до того дна, где очутился я, выглядят как-то так. Много моделей, много всего попробовано. Кому-то хватило интуиции найти нужную комбинацию всех переменных и залететь в призовые места, кому-то нет.
Но всё это не имело никакого значения!
Смотрим второе место:
https://www.kaggle.com/c/cassava-leaf-disease-classification/discussion/220898
Парень залетел в соревнование в последний момент, сделал 3 сабмита (у всех остальных на лидерборде 100 и больше), взял второе место. Он гений? Нет, просто он нашел CropNet: модель, которая была претрейнута на листьях cassava для какой-то научной статьи, и использовал её. Никаких безумных ансамблей. Пришел, сабмитнул, победил.
Смотрим первое место:
https://www.kaggle.com/c/cassava-leaf-disease-classification/discussion/221957
Мы видим небольшой ансамбль. Ничего такого, что бы сделало его намного лучше 14 места или большинства других. Но есть ещё кое-что: CropNet. И всё, ребята побеждают с огромным отрывом от всех.
Вывод? Всё кроме CropNet не имело значения. Люди задаются вопросами, как же мелкий CropNet может давать такой прирост, чтобы гарантировать победу? Возможно он просто видел тестовые данные? Скорее всего.
Вот из-за таких приколов Kaggle бывает жутко фрустрирующим. Ты меряешься размером ансамбля с толпой ребят у которых больше GPU, чем у тебя, а потом кто-то достает свой CropNet. И всё, оказывается зря тысяча команд по всему миру нагревала атмосферу. Не всегда так бывает конечно - я участвовал в соревновании, где победило самое умное решение, а не мега-ансамбль или утечка в данных.
Kaggle
Cassava Leaf Disease Classification
Identify the type of disease present on a Cassava Leaf image
Дисклеймер: я не в призах не потому, что кто-то нашел CropNet, а потому, что забил на контест за месяц до конца. Даже удачно получилось: было бы обидно ещё месяц поработать и узнать, что шанса выиграть изначально не было
Forwarded from Machinelearning
👔 Virtual Try-on via Distilling Appearance Flows, CVPR 2021
Github: https://github.com/geyuying/PF-AFN
Paper: https://arxiv.org/abs/2103.04559
@ai_machinelearning_big_data
Github: https://github.com/geyuying/PF-AFN
Paper: https://arxiv.org/abs/2103.04559
@ai_machinelearning_big_data
Forwarded from CGIT_Vines (CGIT_Vines)
This media is not supported in your browser
VIEW IN TELEGRAM
Отличный способ расслабиться после тяжёлого трудового дня - посидеть в тепле с бокальчиком вина, поиграть и поорать.
Вышел пост на VC про Spaced Repetition. Но вы получили этот контент эксклюзивно и заранее. Однако если вдруг не прочитали, то очень советую познакомиться с этим инструментом!
https://vc.ru/otus/219674-spaced-repetition
https://vc.ru/otus/219674-spaced-repetition
vc.ru
Spaced Repetition — Otus на vc.ru
Вы проходите курс, сдаете экзамен, а через месяц с трудом вспоминаете название предмета, не говоря уже о материале. Было такое? В университете мне говорили, что так должно быть: “Зато остается интуиция, и ты знаешь, где посмотреть!” Теперь я уверен: всё это…
Forwarded from Data Science by ODS.ai 🦜
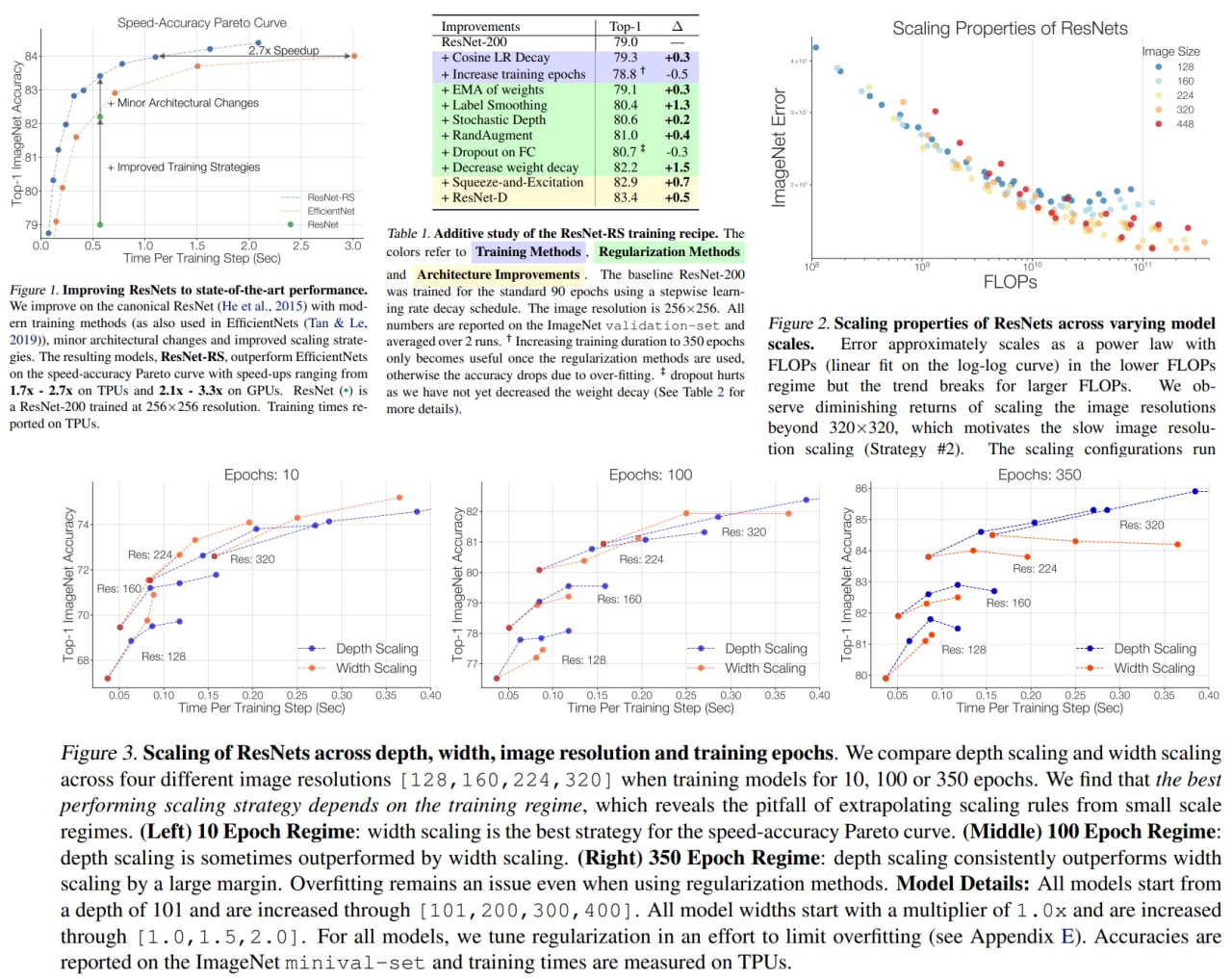
Revisiting ResNets: Improved Training and Scaling Strategies
The authors of the paper (from Google Brain and UC Berkeley) have decided to analyze the effects of the model architecture, training, and scaling strategies separately and concluded that these strategies might have a higher impact on the score than the architecture.
They offer two new strategies:
- scale model depth if overfitting is possible, scale model width otherwise
- increase image resolution slower than recommended in previous papers
Based on these ideas, the new architecture ResNet-RS was developed. It is 2.1x–3.3x faster than EfficientNets on GPU while reaching similar accuracy on ImageNet.
In semi-supervised learning, ResNet-RS achieves 86.2% top-1 ImageNet accuracy while being 4.7x faster than EfficientNet-NoisyStudent.
Transfer learning on downstream tasks also has improved performance.
The authors suggest using these ResNet-RS as a baseline for further research.
Paper: https://arxiv.org/abs/2103.07579
Code and checkpoints are available in TensorFlow:
https://github.com/tensorflow/models/tree/master/official/vision/beta
https://github.com/tensorflow/tpu/tree/master/models/official/resnet/resnet_rs
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-resnetsr
#deeplearning #computervision #sota
The authors of the paper (from Google Brain and UC Berkeley) have decided to analyze the effects of the model architecture, training, and scaling strategies separately and concluded that these strategies might have a higher impact on the score than the architecture.
They offer two new strategies:
- scale model depth if overfitting is possible, scale model width otherwise
- increase image resolution slower than recommended in previous papers
Based on these ideas, the new architecture ResNet-RS was developed. It is 2.1x–3.3x faster than EfficientNets on GPU while reaching similar accuracy on ImageNet.
In semi-supervised learning, ResNet-RS achieves 86.2% top-1 ImageNet accuracy while being 4.7x faster than EfficientNet-NoisyStudent.
Transfer learning on downstream tasks also has improved performance.
The authors suggest using these ResNet-RS as a baseline for further research.
Paper: https://arxiv.org/abs/2103.07579
Code and checkpoints are available in TensorFlow:
https://github.com/tensorflow/models/tree/master/official/vision/beta
https://github.com/tensorflow/tpu/tree/master/models/official/resnet/resnet_rs
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-resnetsr
#deeplearning #computervision #sota
{kind=link}
Я делаю для друзей аудит IT-проекта. Они наняли команду на аутсорсе писать им проект очень даже весомого масштаба. Аутсорсеры что-то пилят годами, приближается срок сдачи проекта, но непонятно, нормально они всё делают или внутри полная лажа. Поэтому наняли меня в качестве аудитора, аутсорсеры со скрипом дали доступ к коду, и я стал изучать. В итоге мои выводы помогут торговаться с исполнителем на тему правок и сэкономить килотонны денег.
Если с ресерчем в ML не получится, то буду как Елена Летучая для IT проектов. Сидят программисты в подвале, хрумкают печенье "Юблиейное" без шоколадной глазури, ничто не предвещает беды. И тут врываюсь я с камерами: "Здравствуйте. Посмотрим, что тут у нас: показывайте свой репозиторий. Это что у вас, меркуриал? Вы что, из 19 века? Ладно, покажите маркировку коммита. Да, да, показывайте. Так, что это за протухший прошлогодний пулл-реквест? Позовите мне тимлида! Вы знаете, что у вас тестов нет? Вы код ревью вообще делаете? Так, погодите. Что это за запах? Вот этот запах, чем воняет? У вас что, MongoDB?"
Если с ресерчем в ML не получится, то буду как Елена Летучая для IT проектов. Сидят программисты в подвале, хрумкают печенье "Юблиейное" без шоколадной глазури, ничто не предвещает беды. И тут врываюсь я с камерами: "Здравствуйте. Посмотрим, что тут у нас: показывайте свой репозиторий. Это что у вас, меркуриал? Вы что, из 19 века? Ладно, покажите маркировку коммита. Да, да, показывайте. Так, что это за протухший прошлогодний пулл-реквест? Позовите мне тимлида! Вы знаете, что у вас тестов нет? Вы код ревью вообще делаете? Так, погодите. Что это за запах? Вот этот запах, чем воняет? У вас что, MongoDB?"
👍1
Телеграм канал ОТУС выложил мой пост про Spaced Reptition. Если благодаря этому вы попали в мой канал, то вот обещанные подробности о том, как делать Anki карточки:
https://t.me/boris_again/239
https://t.me/boris_again/239
Telegram
OTUS News
#expert
🧠Всем привет! Сегодня у нас в гостях Борис Цейтлин - выпускник магистратуры "Науки о данных" ФКН ВШЭ, работал machine learning инженером в Mindsdb, в настоящее время преподаёт в OTUS на курсах по машинному обучению.
Поговорили с Борисом о том, как…
🧠Всем привет! Сегодня у нас в гостях Борис Цейтлин - выпускник магистратуры "Науки о данных" ФКН ВШЭ, работал machine learning инженером в Mindsdb, в настоящее время преподаёт в OTUS на курсах по машинному обучению.
Поговорили с Борисом о том, как…
Там парень на реддите запустил сервис аренды VPS с GPU для машинного обучения, и цены в три раза ниже чем на AWS. Сам не проверял, но звучит очень круто:
https://gpu.land/
UPD. ещё и описал в пару строк как создать такой сервис:
https://www.reddit.com/r/MachineLearning/comments/m73sy7/p_my_side_project_cloud_gpus_for_13_the_cost_of/gr9sy8v?utm_source=share&utm_medium=web2x&context=3
https://gpu.land/
UPD. ещё и описал в пару строк как создать такой сервис:
https://www.reddit.com/r/MachineLearning/comments/m73sy7/p_my_side_project_cloud_gpus_for_13_the_cost_of/gr9sy8v?utm_source=share&utm_medium=web2x&context=3
Reddit
xepo3abp's comment on "[P] My side project: Cloud GPUs for 1/3 the cost of AWS/GCP"
Explore this conversation and more from the MachineLearning community
👍1
Forwarded from нёрд хаб
This media is not supported in your browser
VIEW IN TELEGRAM
#AR
Приложение-помощник при ремонте, для выбора цвета стен. Обратите внимание, как виртуальная поверхность отражает свет
https://twitter.com/heyadam/status/1369342211771428864?s=19
Приложение-помощник при ремонте, для выбора цвета стен. Обратите внимание, как виртуальная поверхность отражает свет
https://twitter.com/heyadam/status/1369342211771428864?s=19
Неиронные клеточные автоматы + Майнкрафт:
https://twitter.com/risi1979/status/1372158321256456198
Это как обычные клеточные автоматы, но правило апдейта задается неиронной сетью. Все блоки структуры используют только локальную информацию о своих соседях. Каждый в отдельности ничего не знает о глобальной структуре. Так блоки коммуницируют между собой, и каждый приходит к выводу о том, какую часть в общей структуре он занимает. Результаты крутые: блоки собираются в здания, в живых существ, в механизмы на рэдстоуне. Если отломать часть здания, то она отрастет обратно.
https://twitter.com/risi1979/status/1372158321256456198
Это как обычные клеточные автоматы, но правило апдейта задается неиронной сетью. Все блоки структуры используют только локальную информацию о своих соседях. Каждый в отдельности ничего не знает о глобальной структуре. Так блоки коммуницируют между собой, и каждый приходит к выводу о том, какую часть в общей структуре он занимает. Результаты крутые: блоки собираются в здания, в живых существ, в механизмы на рэдстоуне. Если отломать часть здания, то она отрастет обратно.
Twitter
Sebastian Risi
Excited to share our work on Morphogenesis in Minecraft! We show that neural cellular automata can learn to grow not only complex 3D artifacts with over 3,000 blocks but also functional Minecraft machines that can regenerate when cut in half 🐛🔪=🐛🐛 PDF:ar…
Раньше меня очень поразила серия статей на эту тему на distill:
https://distill.pub/2020/growing-ca/
https://distill.pub/2020/selforg/mnist/
Там тоже самое, но вместо блоков пиксели. Вся суть в том, что пиксели могут собираться в сложные структуры и могут восстанавливать повреждения. Причем структуры получаются устойчивые к поворотам и изменениям координат. Пиксели могут коммуницировать между собой и решить, какой рисунок они представляют.
Авторы предполагают, что однажды мы сможем так выращивать живые органы. Один раз учишь алгоритм для апдейта клетки, а дальше много клеток следуя этому алгоритму собираются в искусственную почку.
Всё это настолько круто, что я бы с удовольствем сделал это темой PhD. И пусть неизвестно, будет это реально применимо или нет
https://distill.pub/2020/growing-ca/
https://distill.pub/2020/selforg/mnist/
Там тоже самое, но вместо блоков пиксели. Вся суть в том, что пиксели могут собираться в сложные структуры и могут восстанавливать повреждения. Причем структуры получаются устойчивые к поворотам и изменениям координат. Пиксели могут коммуницировать между собой и решить, какой рисунок они представляют.
Авторы предполагают, что однажды мы сможем так выращивать живые органы. Один раз учишь алгоритм для апдейта клетки, а дальше много клеток следуя этому алгоритму собираются в искусственную почку.
Всё это настолько круто, что я бы с удовольствем сделал это темой PhD. И пусть неизвестно, будет это реально применимо или нет
Distill
Growing Neural Cellular Automata
Training an end-to-end differentiable, self-organising cellular automata model of morphogenesis, able to both grow and regenerate specific patterns.