
Визуализация бюджетов земель Германии в проекте Offener Haushalt [1] с открытым кодом [2]. Полезная особенность что весь проект сделан на Jekyll и собирается в статический сайт. Выглядит очень неплохо.
Полевое руководство Open Up Field Guide о том как планировать публикацию открытых данных [3] от Open Data Charter.
Открытые данные по матчам чемпионата мира по футболу 2018 года [4] в рамках проекта Open Football [5]
Ссылки:
[1] https://offenerhaushalt.de/
[2] https://github.com/okfde/offenerhaushalt.de
[3] https://drive.google.com/file/d/1itEjUOzSdn35K0o7VLoxrYzKHEwASYKV/view
[4] https://github.com/openfootball/world-cup
[5] https://github.com/openfootball
#opendata
Полевое руководство Open Up Field Guide о том как планировать публикацию открытых данных [3] от Open Data Charter.
Открытые данные по матчам чемпионата мира по футболу 2018 года [4] в рамках проекта Open Football [5]
Ссылки:
[1] https://offenerhaushalt.de/
[2] https://github.com/okfde/offenerhaushalt.de
[3] https://drive.google.com/file/d/1itEjUOzSdn35K0o7VLoxrYzKHEwASYKV/view
[4] https://github.com/openfootball/world-cup
[5] https://github.com/openfootball
#opendata
GitHub
okfde/offenerhaushalt.de
Visualize budgets from various levels of the German government; based on the OpenSpending API - okfde/offenerhaushalt.de
Мне не верят, но это так - я не только занимаюсь общественными и коммерческими проектами, но и стараюсь находить время на то чтобы напрограммировать чего-нибудь простого и полезного.
Одна из таких штук - это @FeedRetranslatorBot (https://t.me/@FeedRetranslatorBot), агрегатор новостей превращающий их в каналы в Телеграм.
В своё время я делал его для того чтобы не самому искать новости, а так чтобы новости находили меня. Учитывая что на множество телеграм каналов и так подписываешься и читаешь то и логично выглядело создать несколько каналов по тематикам и собирать туда новости регулярно.
Так вот @FeedRetranslatorBot именно это и делает. Создаёшь канал, добавляешь его туда с правами на делать посты, добавляешь ему этот канал командой /channel и добавляешь в туда подписки командой /add
Все это описано в его справке вызываемой по /help
Особенность бота в том что он поддерживает новостные ресурсы без RSS. То есть ему можно скормить и RSS ленту. Например RSS лента сайта Правительства http://government.ru/all/rss/, а можно и дать ссылку на раздел с новостям, но без RSS. Пример, сайт ЦСРа http://csr.ru
Если RSS ленты нет то в сервисе срабатывает мой давний алгоритм "Скиур", он умеет извлекать новости из HTML.
С помощью этого бота работают такие каналы как:
- Правительственный дайджест https://t.me/govdigest
- Контрактная система https://t.me/gzcontracts
- Open Government Digest https://t.me/opengovdigest
- Open Data Digest https://t.me/opendatadigest
- Data is Good https://t.me/dataisgood
- Госфинансы https://t.me/govfin
Они все не про популярное, а скорее в форме канала заменяющего подписки на RSS. Общедоступного канала.
Так же работает и канал Инфокультуры https://t.me/infoculture туда транслируются все новости Инфокультуры со всех проектов - Госзатраты, Открытая полиция, сайт ИК и тд.
Так что бот это бесплатный и общедоступный сервис, им уже пользуются другие и создают свои каналы.
А это же и пример почему экосистема телеграма так удобна, я думал о том как воспроизвести это всё в других мессенжерах и никак не выходит, они просто не дают такой возможности.
#open
Одна из таких штук - это @FeedRetranslatorBot (https://t.me/@FeedRetranslatorBot), агрегатор новостей превращающий их в каналы в Телеграм.
В своё время я делал его для того чтобы не самому искать новости, а так чтобы новости находили меня. Учитывая что на множество телеграм каналов и так подписываешься и читаешь то и логично выглядело создать несколько каналов по тематикам и собирать туда новости регулярно.
Так вот @FeedRetranslatorBot именно это и делает. Создаёшь канал, добавляешь его туда с правами на делать посты, добавляешь ему этот канал командой /channel и добавляешь в туда подписки командой /add
Все это описано в его справке вызываемой по /help
Особенность бота в том что он поддерживает новостные ресурсы без RSS. То есть ему можно скормить и RSS ленту. Например RSS лента сайта Правительства http://government.ru/all/rss/, а можно и дать ссылку на раздел с новостям, но без RSS. Пример, сайт ЦСРа http://csr.ru
Если RSS ленты нет то в сервисе срабатывает мой давний алгоритм "Скиур", он умеет извлекать новости из HTML.
С помощью этого бота работают такие каналы как:
- Правительственный дайджест https://t.me/govdigest
- Контрактная система https://t.me/gzcontracts
- Open Government Digest https://t.me/opengovdigest
- Open Data Digest https://t.me/opendatadigest
- Data is Good https://t.me/dataisgood
- Госфинансы https://t.me/govfin
Они все не про популярное, а скорее в форме канала заменяющего подписки на RSS. Общедоступного канала.
Так же работает и канал Инфокультуры https://t.me/infoculture туда транслируются все новости Инфокультуры со всех проектов - Госзатраты, Открытая полиция, сайт ИК и тд.
Так что бот это бесплатный и общедоступный сервис, им уже пользуются другие и создают свои каналы.
А это же и пример почему экосистема телеграма так удобна, я думал о том как воспроизвести это всё в других мессенжерах и никак не выходит, они просто не дают такой возможности.
#open
Счётная Палата опубликовала результаты проверки "Карты Российской науки" [1] с ожидаемыми выводами о серьёзных нарушениях и множестве других не менее интересных фактов о том как этот проект делался.
О проекте ещё в 2013 году писали коллеги из Киберленинки, а настойчиво защищала его Екатерина Шапочка [2], с 2012 года партнёр PwC в России [3], но выступавшая на заседании в Минобре от Правкомиссии по открытости.
Конфликты интересов не такое уж сложное явление, интересно сколько ещё их вылезет за эти годы? Вернее, сколько из них выйдут на свет.
Ссылки:
[1] http://audit.gov.ru/press_center/news/33645
[2] https://habr.com/company/cyberleninka/blog/205394/
[3] https://www.rvc.ru/about/governance/consult/shapochka/
#opengov
О проекте ещё в 2013 году писали коллеги из Киберленинки, а настойчиво защищала его Екатерина Шапочка [2], с 2012 года партнёр PwC в России [3], но выступавшая на заседании в Минобре от Правкомиссии по открытости.
Конфликты интересов не такое уж сложное явление, интересно сколько ещё их вылезет за эти годы? Вернее, сколько из них выйдут на свет.
Ссылки:
[1] http://audit.gov.ru/press_center/news/33645
[2] https://habr.com/company/cyberleninka/blog/205394/
[3] https://www.rvc.ru/about/governance/consult/shapochka/
#opengov
audit.gov.ru
ИС «Карта российской науки» за 450 миллионов рублей не функционирует из-за многочисленных нарушений
Официальный сайт Счетной палаты Российской Федерации
В догонку к теме карты российской науки, сайт проекта давно закрыт, но архивная копия нами сохранена - https://hubofdata.ru/dataset/mapofscience-org-2013-12-10
hubofdata.ru
Архив сайта mapofscience.org на 2013-12-10 - Хаб открытых данных
Копия страниц и файлов сайта 2013-12-10 на mapofscience.org.
Сделано в формате WARC с использованием wget, с сохранением поддоменов и веб-страниц
Сделано в формате WARC с использованием wget, с сохранением поддоменов и веб-страниц
Forwarded from Brodetskyi. Tech, VC, Startups
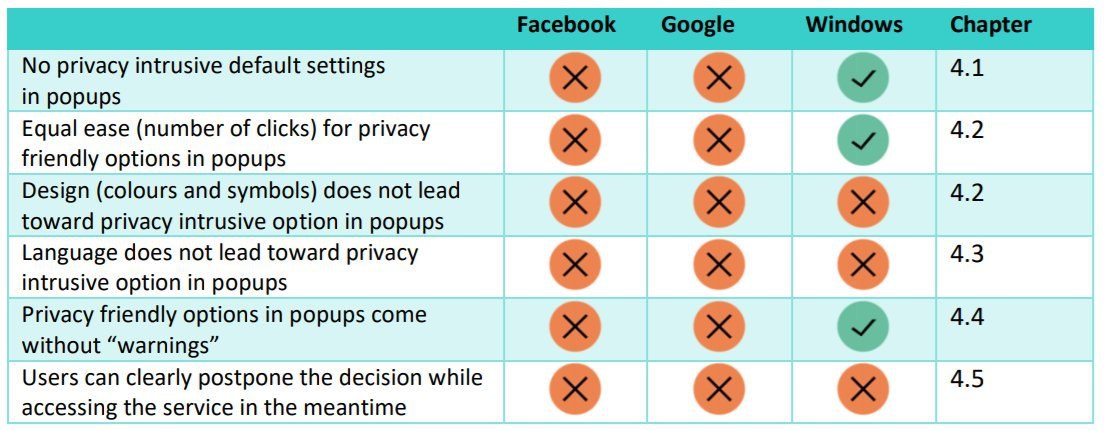
Dark patterns - это уловки в интерфейсе, с помощью которых разработчики управляют поведением пользователей. Условия, прописанные мелким шрифтом; большая кнопка "Принять" и маленькая "Отклонить"; включение настроек по умолчанию, автовоспроизведение следующего трека/ролика и так далее. Если вы когда-нибудь пытались отписаться от почтовой рассылки Linkedin, вы понимаете о чём речь.
Норвежский Совет по защите потребителей выпустил отчёт с критикой dark patterns, которые угрожают приватности данных пользователей. Под раздачу попали интернет-гиганты - Google, Facebook и Microsoft. Очень познавательный документ, почитайте.
Хитрые дизайнеры Гугла и Фейсбука делают поп-апы с яркой кнопкой "Принять" и бледной "Подробнее", нужные настройки включают по умолчанию, используют тонкие формулировки, за которыми сложно распознать реальную их суть - и всё ради того, чтобы получить от пользователей согласие на сбор и обработку персональных данных. Кстати, у Microsoft в этом плане дизайн менее обманчивый.
Норвежским защитникам потребителей респект - хороший отчёт сделали, интересно почитать. Скандинавская дотошность! Ну а от гуглофейсбуков ничего другого и не ждёшь, только хитростей и уловок ради увеличения прибыли.
Кстати, если вдруг не видели, почитайте нашумевший текст бывшего сотрудника Google про 10 приёмов хитрого дизайна, которые технологические сервисы используют, чтобы украсть наше внимание и время.
Норвежский Совет по защите потребителей выпустил отчёт с критикой dark patterns, которые угрожают приватности данных пользователей. Под раздачу попали интернет-гиганты - Google, Facebook и Microsoft. Очень познавательный документ, почитайте.
Хитрые дизайнеры Гугла и Фейсбука делают поп-апы с яркой кнопкой "Принять" и бледной "Подробнее", нужные настройки включают по умолчанию, используют тонкие формулировки, за которыми сложно распознать реальную их суть - и всё ради того, чтобы получить от пользователей согласие на сбор и обработку персональных данных. Кстати, у Microsoft в этом плане дизайн менее обманчивый.
Норвежским защитникам потребителей респект - хороший отчёт сделали, интересно почитать. Скандинавская дотошность! Ну а от гуглофейсбуков ничего другого и не ждёшь, только хитростей и уловок ради увеличения прибыли.
Кстати, если вдруг не видели, почитайте нашумевший текст бывшего сотрудника Google про 10 приёмов хитрого дизайна, которые технологические сервисы используют, чтобы украсть наше внимание и время.
{kind=link}
О том как создавать востребованные data порталы и вовлекать НКО и госструктуры в публикацию данных.
Проект HumData [1] - это центр, стандарты и портал по раскрытию информации о гуманитарных катастрофах и усилиях по их предотвращению.
Созданный управление по координации гуманитарных вопросов ООН (UN OCHA) проект представляет собой центр по работе с гуманитарными данными [2] в рамках которого создаётся портал для обмена данными, стандарты раскрытия информации и координация получателей поддержки и участников инициатив по публикацию собранных ими данных.
Его важное отличие в том что это НЕ портал раскрытия информации о деятельности ООН и НЕ портал открытости НКО, это коллаборативный ресурс где кроме данных НКО и кроме данных структур ООН публикуются ещё и все те данные которые им самим нужны в работе.
Поэтому там можно найти данные из проектов OpenStreetMap [3], проекта OurAirports [4] и многое другое. Данные разделены не по организациям, а по группам и темам.
Так, там можно найти данные разделённые по странам [5] и по ситуациям затрагивающим множество стран [6].
Пример этого проекта - это одна из наиболее зрелых инициатив по работе с открытыми данными, поскольку она следует важному принципу сформулированному в Open Data Charter - "Publishing with a purpose". Публикация с заранее определенной целью.
HDX - это портал с заранее определенной целью, содействие кооперации в совместном предотвращении гуманитарных катастроф.
Ссылки:
[1] https://data.humdata.org
[2] https://centre.humdata.org/
[3] https://data.humdata.org/organization/hot
[4] https://data.humdata.org/organization/ourairports
[5] https://data.humdata.org/group
[6] https://data.humdata.org/ebola
#opendata
Проект HumData [1] - это центр, стандарты и портал по раскрытию информации о гуманитарных катастрофах и усилиях по их предотвращению.
Созданный управление по координации гуманитарных вопросов ООН (UN OCHA) проект представляет собой центр по работе с гуманитарными данными [2] в рамках которого создаётся портал для обмена данными, стандарты раскрытия информации и координация получателей поддержки и участников инициатив по публикацию собранных ими данных.
Его важное отличие в том что это НЕ портал раскрытия информации о деятельности ООН и НЕ портал открытости НКО, это коллаборативный ресурс где кроме данных НКО и кроме данных структур ООН публикуются ещё и все те данные которые им самим нужны в работе.
Поэтому там можно найти данные из проектов OpenStreetMap [3], проекта OurAirports [4] и многое другое. Данные разделены не по организациям, а по группам и темам.
Так, там можно найти данные разделённые по странам [5] и по ситуациям затрагивающим множество стран [6].
Пример этого проекта - это одна из наиболее зрелых инициатив по работе с открытыми данными, поскольку она следует важному принципу сформулированному в Open Data Charter - "Publishing with a purpose". Публикация с заранее определенной целью.
HDX - это портал с заранее определенной целью, содействие кооперации в совместном предотвращении гуманитарных катастроф.
Ссылки:
[1] https://data.humdata.org
[2] https://centre.humdata.org/
[3] https://data.humdata.org/organization/hot
[4] https://data.humdata.org/organization/ourairports
[5] https://data.humdata.org/group
[6] https://data.humdata.org/ebola
#opendata
data.humdata.org
Welcome - Humanitarian Data Exchange
По поводу формирования нового-старого правительства.
Вот объясните мне почему:
1. До сих пор нет сайта "Министерства высшего образования и науки"
2. На сайте министерства образования и науки минобрнауки.рф до сих пор публикуются новости, а в сайт Министерства просвещения он не преобразован
Оба органа власти нарушают положения 8-ФЗ "Об обеспечении доступа к информации о деятельности государственных органов и органов местного самоуправления" от 09.02.2009 и ряд других нормативно-правовых актов следующих из этого закона.
И я впервые такое вижу что через полтора месяца после решения о создании ФОИВов их сайтов всё ещё нет.
Напомню что надзор за соблюдение 8-ФЗ осуществляет Генеральная прокуратура
Вот объясните мне почему:
1. До сих пор нет сайта "Министерства высшего образования и науки"
2. На сайте министерства образования и науки минобрнауки.рф до сих пор публикуются новости, а в сайт Министерства просвещения он не преобразован
Оба органа власти нарушают положения 8-ФЗ "Об обеспечении доступа к информации о деятельности государственных органов и органов местного самоуправления" от 09.02.2009 и ряд других нормативно-правовых актов следующих из этого закона.
И я впервые такое вижу что через полтора месяца после решения о создании ФОИВов их сайтов всё ещё нет.
Напомню что надзор за соблюдение 8-ФЗ осуществляет Генеральная прокуратура
Сразу много новостей о государственных информационных системах.
Минфином России подготовлен проект закона, устанавливающего основы систематизации и гармонизации информации в РФ [1]. Если законопроект примут то Минфин станет не только финансовым мегарегулятором, но и мегарегулятором в управлении данными. Особенно интересно появление всероссийского реестра информационных ресурсов упомянутого в статье 13.
Единый государственный реестр заключений экспертизы проектной документации объектов капитального строительства [2] пока непонятно содержит ли что-то поскольку поиск не даёт результатов, но выглядит как новая ГИС. При том что в реестре ФГИС её найти не удалось.
Обновился ФГИС Координация информатизации [3] включая их открытые данные [4], но внутри не работает поиск по ФГИС, а информация о ФГИС введена даже без форматирования текстов, пример Государственная интегрированная информационная система управления общественными финансами "Электронный бюджет" в разделе " Cведения об источниках финансирования создания, эксплуатации, модернизации ФГИС: "
Ссылки:
[1] http://regulation.gov.ru/projects#npa=80844
[2] http://egrz.ru
[3] https://portal.eskigov.ru/
[4] https://portal.eskigov.ru/opendata
[5] https://portal.eskigov.ru/fgis/336
#opendata #data
Минфином России подготовлен проект закона, устанавливающего основы систематизации и гармонизации информации в РФ [1]. Если законопроект примут то Минфин станет не только финансовым мегарегулятором, но и мегарегулятором в управлении данными. Особенно интересно появление всероссийского реестра информационных ресурсов упомянутого в статье 13.
Единый государственный реестр заключений экспертизы проектной документации объектов капитального строительства [2] пока непонятно содержит ли что-то поскольку поиск не даёт результатов, но выглядит как новая ГИС. При том что в реестре ФГИС её найти не удалось.
Обновился ФГИС Координация информатизации [3] включая их открытые данные [4], но внутри не работает поиск по ФГИС, а информация о ФГИС введена даже без форматирования текстов, пример Государственная интегрированная информационная система управления общественными финансами "Электронный бюджет" в разделе " Cведения об источниках финансирования создания, эксплуатации, модернизации ФГИС: "
Ссылки:
[1] http://regulation.gov.ru/projects#npa=80844
[2] http://egrz.ru
[3] https://portal.eskigov.ru/
[4] https://portal.eskigov.ru/opendata
[5] https://portal.eskigov.ru/fgis/336
#opendata #data
Для тех кто всерьёз задумывается о коммерческих проектах на базе открытых данных, на сайте ODINe, Европейского инкубатора стартапов на базе Open Data есть раздел где собрано много бизнес моделей стартапов [1] отрисованных по схеме Остервальдера Business Model Canvas.
Второй источник вдохновения - это каталог OpenData 500 [2], с большой коллекцией компаний создавших бизнес используя открытые данные.
Открытые данные - это, конечно же, часть экосистемы данных вообще и часть экосистемы открытости куда входят ещё и открытый код, открытые знания и многое другое.
Коммерческие проекты часто возникают на стыке открытых данных и данных непубличных. О том какие бизнес модели существуют подробнее есть в докладе Deloitte 2014 года [3]
Ссылки:
[1] https://opendataincubator.eu/resources/
[2] http://www.opendata500.com/
[3] https://ec.europa.eu/futurium/sites/futurium/files/deloitte_pov_-_new_business_models_with_data.pdf
#opendata #business #data
Второй источник вдохновения - это каталог OpenData 500 [2], с большой коллекцией компаний создавших бизнес используя открытые данные.
Открытые данные - это, конечно же, часть экосистемы данных вообще и часть экосистемы открытости куда входят ещё и открытый код, открытые знания и многое другое.
Коммерческие проекты часто возникают на стыке открытых данных и данных непубличных. О том какие бизнес модели существуют подробнее есть в докладе Deloitte 2014 года [3]
Ссылки:
[1] https://opendataincubator.eu/resources/
[2] http://www.opendata500.com/
[3] https://ec.europa.eu/futurium/sites/futurium/files/deloitte_pov_-_new_business_models_with_data.pdf
#opendata #business #data
Opendata500
Open Data 500
The OD500 Global Network is an international network of organizations that seek to study the use and impact of open data.
Ещё вчера поиск Яндекса выдавал множество интереснейших результатов при поиске по общедоступным документам в Google Documents (docs.google.com), например, многие находили там общедоступные списки паролей, паспортные данные и списки ДСП и иных непубличных документов.
Всё это происходило по причине того Google позволял индексировать эти документы [1], а Яндекс выдавал эти результаты. Сработала комбинация факторов, начиная с пользователей кто делал общедоступными по ссылке документы, и продолжая поисковиками которые, с ненулевой вероятностью, получали эти ссылки не интернет-краулинга, а из истории посещений браузеров и из ссылок при переписке по электронной почте.
Сейчас поиск по "passwords site:docs.google.com" уже не работает [2], по крайней мере на утро 5 июля.
То что вскрылось сейчас это не единственный такой случай. Какое-то время назад аналогично и гугл индексировал disk.yandex.ru, yadi.sk и другие домены Яндекс.Диска с содержащимися там файлами и находки там были ничуть не менее нелестными, но не получили публичного освещения.
Всё это совсем не новость для всех кто более-менее серьёзно занимался темой Open Source Intelligence. Индексы поисковых систем - это один из источников информации при составлении досье, анализе информации о компании или о человеке и не только.
Большинство тех кто знает такие механизмы утечки информации не афишируют свои знания, используют их по мере практической необходимости.
Для Google даже существует Google Hacking Database (GHDB) [3] с большой коллекцией запросов по поиску уязвимостей в серверах и устройствах и утечек данных на сайтах. Для Яндекса я ничего подобного и публичного не встречал, отчасти из-за значительно более слабого общедоступного языка запросов к поисковому индексу (внутри то я не сомневаюсь возможностей гораздо больше).
Надо помнить что такие утечки не редкость. Один из малоизученных пока каналов утечки - это сканы документов. Google, Яндекс, Bing и остальные поисковики постепенно учатся индексировать текст с картинок, из PDF'ов состоящих из изображений, заглядывают в файлы архивов и вообще вгрызаются в ранее не индексируемые документы. Это вытаскивает на свет документы содержащие персональные данные и много другой чувствительной информации.
Увы, те кто до сих пор публикуют сканы документов этого не понимают. Впрочем и без сканированных документов и даже на государственных сайтах часто исполнители просто не проверяют что они публикуют и в открытом доступе оказываются документы и другие материалы которых там не должно было бы быть никогда.
Ссылки:
[1] https://docs.google.com/robots.txt
[2] https://yandex.ru/search/?text=passwords&lr=213&site=docs.google.com
[3] https://www.exploit-db.com/google-hacking-database/
#opendata #osint #security #privacy
Всё это происходило по причине того Google позволял индексировать эти документы [1], а Яндекс выдавал эти результаты. Сработала комбинация факторов, начиная с пользователей кто делал общедоступными по ссылке документы, и продолжая поисковиками которые, с ненулевой вероятностью, получали эти ссылки не интернет-краулинга, а из истории посещений браузеров и из ссылок при переписке по электронной почте.
Сейчас поиск по "passwords site:docs.google.com" уже не работает [2], по крайней мере на утро 5 июля.
То что вскрылось сейчас это не единственный такой случай. Какое-то время назад аналогично и гугл индексировал disk.yandex.ru, yadi.sk и другие домены Яндекс.Диска с содержащимися там файлами и находки там были ничуть не менее нелестными, но не получили публичного освещения.
Всё это совсем не новость для всех кто более-менее серьёзно занимался темой Open Source Intelligence. Индексы поисковых систем - это один из источников информации при составлении досье, анализе информации о компании или о человеке и не только.
Большинство тех кто знает такие механизмы утечки информации не афишируют свои знания, используют их по мере практической необходимости.
Для Google даже существует Google Hacking Database (GHDB) [3] с большой коллекцией запросов по поиску уязвимостей в серверах и устройствах и утечек данных на сайтах. Для Яндекса я ничего подобного и публичного не встречал, отчасти из-за значительно более слабого общедоступного языка запросов к поисковому индексу (внутри то я не сомневаюсь возможностей гораздо больше).
Надо помнить что такие утечки не редкость. Один из малоизученных пока каналов утечки - это сканы документов. Google, Яндекс, Bing и остальные поисковики постепенно учатся индексировать текст с картинок, из PDF'ов состоящих из изображений, заглядывают в файлы архивов и вообще вгрызаются в ранее не индексируемые документы. Это вытаскивает на свет документы содержащие персональные данные и много другой чувствительной информации.
Увы, те кто до сих пор публикуют сканы документов этого не понимают. Впрочем и без сканированных документов и даже на государственных сайтах часто исполнители просто не проверяют что они публикуют и в открытом доступе оказываются документы и другие материалы которых там не должно было бы быть никогда.
Ссылки:
[1] https://docs.google.com/robots.txt
[2] https://yandex.ru/search/?text=passwords&lr=213&site=docs.google.com
[3] https://www.exploit-db.com/google-hacking-database/
#opendata #osint #security #privacy
Exploit-Db
OffSec’s Exploit Database Archive
The GHDB is an index of search queries (we call them dorks) used to find publicly available information, intended for pentesters and security researchers.
Через 5 дней, с 10-го по 15 июля я на https://ostrov.2035.university в рамках программы по подготовке Chief Data Officers буду много рассказывать о работе с данными, в особенности о том как устроены данные в России, как они публикуются, где их искать, как они устроены и многое другое.
Мне там надо будет работать довольно много, буквально с утра до вечера в несколько потоков, но это и хорошо поскольку наконец-то в России созрела отдельная большая категория потребителей данных - это региональные чиновники и госслужащие.
В ситуации когда огромные объёмы данных в России концентрируются в федеральных государственных информационных системах возникает ситуация когда решать какие-либо региональные задачи невозможно в полной мере не зная как эти данные получать. И тут уже не работают механизмы вроде СМЭВа, тут оказывается что практика публикации именно открытых данных востребована более чем закрытые механизмы обмена данными (которые или не работают хорошо или не работают вообще).
#opendata #data
Мне там надо будет работать довольно много, буквально с утра до вечера в несколько потоков, но это и хорошо поскольку наконец-то в России созрела отдельная большая категория потребителей данных - это региональные чиновники и госслужащие.
В ситуации когда огромные объёмы данных в России концентрируются в федеральных государственных информационных системах возникает ситуация когда решать какие-либо региональные задачи невозможно в полной мере не зная как эти данные получать. И тут уже не работают механизмы вроде СМЭВа, тут оказывается что практика публикации именно открытых данных востребована более чем закрытые механизмы обмена данными (которые или не работают хорошо или не работают вообще).
#opendata #data
В Евросоюзе сейчас идёт большая кампания в защиту Интернета от статьи 13 в защиту копирайта [1]. 20 июня профильный комитет Европарламент проголосовал 15 против 10 за принятие этой статьи и если сегодня 5 июля Европарламент проголосует за, то практически все онлайн платформы работающие с европейскими потребителями будут обязаны фильтровать контент загружаемый пользователями на предмет нарушения владельцев прав на интеллектуальную собственность.
У свободы много граней и свободный обмен знаниями - одна из важнейших. На мой взгляд запреты копирайта даже хуже политической цензуры. Но в современном мире у нас мало возможностей в выборе между разными видами свободы, наш выбор сводится к разным формам несвободы.
Ссылки:
[1] https://saveyourinternet.eu/
#saveyourinternet
У свободы много граней и свободный обмен знаниями - одна из важнейших. На мой взгляд запреты копирайта даже хуже политической цензуры. Но в современном мире у нас мало возможностей в выборе между разными видами свободы, наш выбор сводится к разным формам несвободы.
Ссылки:
[1] https://saveyourinternet.eu/
#saveyourinternet
#SaveYourInternet
Home
You can still stop #Article13 (aka #Article17)! #Copyright #CensorshipMachine
Многие знают о Europeana [1], крупнейшем онлайн музее/архиве/выставке Евросоюза основанном на партнёрстве и оцифровке материалов более чем 3,500 музеев, галерей, библиотек и архивов Европы, но мало кто знает о Канадиане [2] и схожего масштаба проект Trove [3] в Австралии, как поисковая машина и краудсорсинговый проект по оцифровке и разметке исторических материалов.
Но это государственные инициативы, а немало проектов по сохранению цифрового наследия существует и без государства. Как некоммерческие и коммерческие частные проекты.
Например:
- Software Heritage [4] спонсируемая Microsoft, Intel, Google и многими другими компаниями инициатива по долгосрочному сохранению открытого исходного кода. Они выкачивают его из github'а, gitlab'а и других источников и хранят все версии и все релизы.
- Old Version [5] большой краудсорсинговый проект архива старого ПО
- Common Crawl [6] огромный репозиторий веб-страниц собранных веб-краулерами и с возможностью ретроспективы.
- Archive Team [7] - команда волонтёров архивирующая погибающие (гигантские) сайты совместной работой над выгрузкой всего контента который может исчезнуть
И многие другие проекты. Чем больше данных и знаний создает человечество, тем больше нужно усилий по их сохранению.
Ссылки:
[1] http://europeana.eu/
[2] http://www.canadiana.ca/
[3] https://trove.nla.gov.au
[4] https://www.softwareheritage.org
[5] http://www.oldversion.com/
[6] http://commoncrawl.org/
[7] https://www.archiveteam.org/
#open #digitalpreservation
Но это государственные инициативы, а немало проектов по сохранению цифрового наследия существует и без государства. Как некоммерческие и коммерческие частные проекты.
Например:
- Software Heritage [4] спонсируемая Microsoft, Intel, Google и многими другими компаниями инициатива по долгосрочному сохранению открытого исходного кода. Они выкачивают его из github'а, gitlab'а и других источников и хранят все версии и все релизы.
- Old Version [5] большой краудсорсинговый проект архива старого ПО
- Common Crawl [6] огромный репозиторий веб-страниц собранных веб-краулерами и с возможностью ретроспективы.
- Archive Team [7] - команда волонтёров архивирующая погибающие (гигантские) сайты совместной работой над выгрузкой всего контента который может исчезнуть
И многие другие проекты. Чем больше данных и знаний создает человечество, тем больше нужно усилий по их сохранению.
Ссылки:
[1] http://europeana.eu/
[2] http://www.canadiana.ca/
[3] https://trove.nla.gov.au
[4] https://www.softwareheritage.org
[5] http://www.oldversion.com/
[6] http://commoncrawl.org/
[7] https://www.archiveteam.org/
#open #digitalpreservation
www.europeana.eu
Discover Europe’s digital cultural heritage
Search, save and share art, books, films and music from thousands of cultural institutions
Forwarded from Эшер II A+
https://mobile.twitter.com/espectalll/status/1014814409162620928 Европарламент отклонил директиву об авторском праве в интернете. Бог есть
Twitter
Francisco Gómez
Good news, the directive proposal on Internet copyright has been rejected! Thank you everyone!
Дайджест новостей об открытых данных и открытости государства вцелом:
- What if people were paid for their data? статья в The Economist [1] о неравенстве в использовании данных и о том смогли бы существовать нынешние дата-корпорации если бы платили пользователям за использование их данных.
- Hope for Democracy, вышла онлайн книга "Надежда на демократию" о 30 годах применения партисипаторного, в России, инициативного бюджетирования. Книга бесплатна, написана на английском языке интернациональной командов авторов и, самое неожиданное, _This publication is supported by the Ministry of Finance of the Russian Federation within the joint project with the World Bank “Strengthening participatory budgeting in the Russian Federation”._
Будем надеяться что и на русском языке она тоже будет.
- UN Biodiversity Lab, ещё один проект и каталог данных от ООН, на сей раз по биоразнообразию [3]. У ООН уже очень многие подразделения работают с большими и открытыми данными.
- ARCGis продвигает идею Geohub'ов, порталов открытых данных с акцентом на геоданные, на примере города Брамптона, Канада [4]
Ссылки:
[1] https://www.economist.com/the-world-if/2018/07/07/what-if-people-were-paid-for-their-data
[2] https://www.oficina.org.pt/hopefordemocracy.html
[3] https://otr-online.ru/programmy/segodnya-v-rossii/ivan-begtin-32511.html
[4] http://geohub.brampton.ca/
#opendata #opengov
- What if people were paid for their data? статья в The Economist [1] о неравенстве в использовании данных и о том смогли бы существовать нынешние дата-корпорации если бы платили пользователям за использование их данных.
- Hope for Democracy, вышла онлайн книга "Надежда на демократию" о 30 годах применения партисипаторного, в России, инициативного бюджетирования. Книга бесплатна, написана на английском языке интернациональной командов авторов и, самое неожиданное, _This publication is supported by the Ministry of Finance of the Russian Federation within the joint project with the World Bank “Strengthening participatory budgeting in the Russian Federation”._
Будем надеяться что и на русском языке она тоже будет.
- UN Biodiversity Lab, ещё один проект и каталог данных от ООН, на сей раз по биоразнообразию [3]. У ООН уже очень многие подразделения работают с большими и открытыми данными.
- ARCGis продвигает идею Geohub'ов, порталов открытых данных с акцентом на геоданные, на примере города Брамптона, Канада [4]
Ссылки:
[1] https://www.economist.com/the-world-if/2018/07/07/what-if-people-were-paid-for-their-data
[2] https://www.oficina.org.pt/hopefordemocracy.html
[3] https://otr-online.ru/programmy/segodnya-v-rossii/ivan-begtin-32511.html
[4] http://geohub.brampton.ca/
#opendata #opengov
The Economist
What if people were paid for their data?
Advocates of “data as labour” think users should be paid for using online services
В РБК вышла моя колонка "Поиск виновного: почему стала возможной утечка данных из Google Docs" https://www.rbc.ru/opinions/technology_and_media/09/07/2018/5b3f505e9a794748ac73914f
Даже не знаю что добавить, я там как мог максимально детально старался описать.
#privacy
Даже не знаю что добавить, я там как мог максимально детально старался описать.
#privacy
РБК
Поиск виновного: почему стала возможной утечка данных из Google Docs
Когда в 1990-е годы создавались известные нам поисковики, считалось, что если кто-то что-то опубликовал в Сети, значит, он заинтересован в привлечении внимания. Современный интернет устроен сложнее
Свежее исследование Google о гендерных различиях (и дискриминации) в кинематорграфе на основе анализа 100 фильмов за 2014-2016 годы [1] и тут я не могу не напомнить об исследовании Five Thirty Eight [2] о том что Bechdel Test измеряющий гендерное неравенство - это не единственный тест на равенство мужчин и женщин в кинематографе. В исследовании они предлагают около десятка тестов охватывающих и роль женщин как протагонистов, состав поддерживающей команды, состав команды съемок и многое другое.
Кстати два фильма проходящих минимум гендерных тестов - это Доктор Стрендж и Дедпул. Поэтому эти тесты - не тесты качества, это тесты гендерного равенства.
Ещё один отличный проект по визуализации гендерного неравенства в кино была визуализация Hollywood's gender divide and it's effect on films [3] от The Pudding.
Журналисткам (и журналистам) на заметку - никто такого анализа российских фильмов никогда не проводил. Хотя бы по Bechdel test, не говоря уже о большем числе сложных тестов из статьи в Five Thirty Five.
Ссылки:
[1] https://www.google.com/about/main/gender-equality-films/
[2] https://projects.fivethirtyeight.com/next-bechdel/
[3] https://pudding.cool/2017/03/bechdel/
#opendata
Кстати два фильма проходящих минимум гендерных тестов - это Доктор Стрендж и Дедпул. Поэтому эти тесты - не тесты качества, это тесты гендерного равенства.
Ещё один отличный проект по визуализации гендерного неравенства в кино была визуализация Hollywood's gender divide and it's effect on films [3] от The Pudding.
Журналисткам (и журналистам) на заметку - никто такого анализа российских фильмов никогда не проводил. Хотя бы по Bechdel test, не говоря уже о большем числе сложных тестов из статьи в Five Thirty Five.
Ссылки:
[1] https://www.google.com/about/main/gender-equality-films/
[2] https://projects.fivethirtyeight.com/next-bechdel/
[3] https://pudding.cool/2017/03/bechdel/
#opendata
about.google
Using technology to address gender bias in film - Google
Hollywood’s missing women: how Google is helping uncover gender bias in film with machine learning →
Немного быстрой рефлексии по Университету НТИ 20.35 и интенсиву по Chief Data Officers на Острове Русский
1. Ожидаемо подтвердилось что всем нужна цельная госполитика по работе с данными и есть пока легкое замешательство, мало кто знает в какую сторону и кто в итоге будет её определять.
2. Организаторы выступили в роли "патерналистичного государства" дав датчики всем участникам и отслеживая их активность. При этом рефлексия самих участников по поводу этого была не так уж сильна. Во всяком случае многие команды прорабатывая кейсы с персональными образовательными траекториями, поддержкой талантливых детей или же персонификацией социальной помощи не рефлексировали это на себя в текущей ситуации.
3. Самое востребованное оказалось консультирование по кейсам команд. Я свои презентации и выступления адаптировал на ходу, доделывая под аудиторию в процессе. Все же практически вопросы были о том как и что можно сделать в России и особенно о том как и где находятся те или иные данные.
4. Фактически все участники так или иначе работают с открытыми данными. СМЭВ не предоставляет инструментов доступа к данным, а иной инфраструктуры для этого за все эти годы не создавалась и в итоге многие региональные госслужащие и чиновники работают как и бизнес с открытыми данными из федеральных информационных систем.
5. Сложный вопрос по работе с персональными данными. Многие сложные кейсы по разработке алгоритмов и системам поддержки принятия решения требуют обезличивания данных и тем они сложнее с точки зрения существующего российского регулирования. Особенно в части передачи персональных данных между федеральными и региональными системами.
6. Скажу честно, преподавание для уже состоявшихся людей в возрасте 30-45 непростая задача. Где-то я могу подсказать участникам, а каждый из участников во многих предметных областях разбирался гораздо больше чем я. Поэтому это было всегда очень познавательное общение.
Программа продлится до 21 июля, я на это время буду в Москве и помогать участникам дистанционно.
На всякий случай продублирую информацию о том где и как меня найти:
- мой канал в телеграм: https://t.me/begtin
- личный блог https://begtin.tech
- второй блог https://medium.com/@ibegtin
- мои презентации https://www.slideshare.net/ivbeg/
- сайт Инфокультуры http://infoculture.ru
- коммерческий проект в рамках которого мы инвентаризируем публичные (и не очень) базы данных и даём API для доступа к данным - http://apicrafter.ru
Проекты к которым имею отношение я и Инфокультура:
- Госзатраты https://clearspending.ru
- Открытая полиция http://openpolice.ru
- Хаб открытых данных https://hubofdata.ru
и многие другие на сайте Инфокультуры
#opendata #opengov #cdo #data
1. Ожидаемо подтвердилось что всем нужна цельная госполитика по работе с данными и есть пока легкое замешательство, мало кто знает в какую сторону и кто в итоге будет её определять.
2. Организаторы выступили в роли "патерналистичного государства" дав датчики всем участникам и отслеживая их активность. При этом рефлексия самих участников по поводу этого была не так уж сильна. Во всяком случае многие команды прорабатывая кейсы с персональными образовательными траекториями, поддержкой талантливых детей или же персонификацией социальной помощи не рефлексировали это на себя в текущей ситуации.
3. Самое востребованное оказалось консультирование по кейсам команд. Я свои презентации и выступления адаптировал на ходу, доделывая под аудиторию в процессе. Все же практически вопросы были о том как и что можно сделать в России и особенно о том как и где находятся те или иные данные.
4. Фактически все участники так или иначе работают с открытыми данными. СМЭВ не предоставляет инструментов доступа к данным, а иной инфраструктуры для этого за все эти годы не создавалась и в итоге многие региональные госслужащие и чиновники работают как и бизнес с открытыми данными из федеральных информационных систем.
5. Сложный вопрос по работе с персональными данными. Многие сложные кейсы по разработке алгоритмов и системам поддержки принятия решения требуют обезличивания данных и тем они сложнее с точки зрения существующего российского регулирования. Особенно в части передачи персональных данных между федеральными и региональными системами.
6. Скажу честно, преподавание для уже состоявшихся людей в возрасте 30-45 непростая задача. Где-то я могу подсказать участникам, а каждый из участников во многих предметных областях разбирался гораздо больше чем я. Поэтому это было всегда очень познавательное общение.
Программа продлится до 21 июля, я на это время буду в Москве и помогать участникам дистанционно.
На всякий случай продублирую информацию о том где и как меня найти:
- мой канал в телеграм: https://t.me/begtin
- личный блог https://begtin.tech
- второй блог https://medium.com/@ibegtin
- мои презентации https://www.slideshare.net/ivbeg/
- сайт Инфокультуры http://infoculture.ru
- коммерческий проект в рамках которого мы инвентаризируем публичные (и не очень) базы данных и даём API для доступа к данным - http://apicrafter.ru
Проекты к которым имею отношение я и Инфокультура:
- Госзатраты https://clearspending.ru
- Открытая полиция http://openpolice.ru
- Хаб открытых данных https://hubofdata.ru
и многие другие на сайте Инфокультуры
#opendata #opengov #cdo #data
Telegram
Ivan Begtin
I write about Open Data, Data Engineering, Government, Privacy, Digital Preservation and other gov related and tech stuff.
Founder of Dateno https://dateno.io
Telegram @ibegtin
Facebook - https://facebook.com/ibegtin
Secure contacts ivan@begtin.tech
Founder of Dateno https://dateno.io
Telegram @ibegtin
Facebook - https://facebook.com/ibegtin
Secure contacts ivan@begtin.tech
Тем временем Счетная палата, насколько я знаю, первым из центральных и конституционных органов власти организует свою работу через публичную разработку стратегии. Первое её обсуждение прошло 14 июля [1].
Ссылки:
[1] http://audit.gov.ru/press_center/news/33788
#opengov
Ссылки:
[1] http://audit.gov.ru/press_center/news/33788
#opengov
audit.gov.ru
Счетная палата обсуждает стратегию
Официальный сайт Счетной палаты Российской Федерации
Главный продукт производства государства - это законы и все остальные документы которые в России именуют НПА (Нормативно правовые акты).
Проект Crowd.Law [1] от The GovLab посвящён инициативам по сонаписанию законов гражданами и законодателями.
Сейчас открылся каталог проектов по Crowd Law в котором собрано более 100 примеров внедрения такого подхода [2]
Там необоснованно мало российских проектов, представлены только crowd.mos.ru и Активный гражданин. Да и те не про законотворчество, а про идеи и опросы. В России проектов больше, во всяком случае было больше ещё недавно.
В то же время много проектов в США, Мексике и Испании.
Каталог будет полезен всем кто изучает трансформацию законотворчества в мире и вовлечение граждан в решение государственных вопросов.
Ссылки:
[1] https://crowd.law/
[2] https://catalog.crowd.law/
#opengov
Проект Crowd.Law [1] от The GovLab посвящён инициативам по сонаписанию законов гражданами и законодателями.
Сейчас открылся каталог проектов по Crowd Law в котором собрано более 100 примеров внедрения такого подхода [2]
Там необоснованно мало российских проектов, представлены только crowd.mos.ru и Активный гражданин. Да и те не про законотворчество, а про идеи и опросы. В России проектов больше, во всяком случае было больше ещё недавно.
В то же время много проектов в США, Мексике и Испании.
Каталог будет полезен всем кто изучает трансформацию законотворчества в мире и вовлечение граждан в решение государственных вопросов.
Ссылки:
[1] https://crowd.law/
[2] https://catalog.crowd.law/
#opengov
CrowdLaw-Online Public Participation in Lawmaking
Using public engagement to improve the quality, effectiveness and legitimacy of the lawmaking process. This is a draft version 1.0 of the report (dated October 12, 2017 ) and will be updated in November.