
Regular Expression
При виде слова "RegExp" у разработчиков начинает дергаться глаз. Ведь каждый из на с помнит десятки потраченных часов, ради того, чтобы покрыть все возможные кейсы и таки сделать регулярку, которая будет работать. Здесь я опишу пару советов о том, как немного упростить себе жизнь при написании RegExp.
👉 Выберите удобный разделитель (delimiter)
Речь идет о символах, в которые мы оборачиваем наше выражение. Чаще всего в примерах используется slash "
❓ Но зачем выбирать другой разделитель? Всё дело в том, что все вхождения символа разделителя в выражение должны быть экранированы, потому на выходе мы получаем:
Скобочными группами называется то, что находится внутри () скобок. Найденные результаты будут переданы в $matches.
👉 Используйте символьные классы
Это также поможет сделать ваше выражение более читабельным. Самый распространенный класс
👌 Так-же следует упомянуть, что при использовании выражений с поддержкой unicode (флаг
Весь перечень можно посмотреть здесь.
#junior #regexp #source
При виде слова "RegExp" у разработчиков начинает дергаться глаз. Ведь каждый из на с помнит десятки потраченных часов, ради того, чтобы покрыть все возможные кейсы и таки сделать регулярку, которая будет работать. Здесь я опишу пару советов о том, как немного упростить себе жизнь при написании RegExp.
👉 Выберите удобный разделитель (delimiter)
Речь идет о символах, в которые мы оборачиваем наше выражение. Чаще всего в примерах используется slash "
/"/(foo|bar)/i❗️На самом деле для разделителя можно выбрать любой символ, например
~,!, @, #, $. Разделителями НЕ могут быть буквенно-цифровые символы (AZ, az и 0-9), многобайтовые символы (Такие как Emojis 😢) и обратная косая черта (\). ❓ Но зачем выбирать другой разделитель? Всё дело в том, что все вхождения символа разделителя в выражение должны быть экранированы, потому на выходе мы получаем:
preg_match('/^https:\/\/example.com\/path/i', $uri);
// или
preg_match('~^https://example.com/path~i', $uri);
👉 Именуйте скобочные группы (группы захвата)Скобочными группами называется то, что находится внутри () скобок. Найденные результаты будут переданы в $matches.
$pattern = '~Price: (£|€)(\d+)~';Именуя скобочные группы, мы сразу получаем два преимущества: это упростит чтение регулярного выражения, а также имена будут отображены в $matches;
// или
$pattern = '~Price: (?<currency>£|€)(?<price>\d+)~';
👉 Используйте символьные классы
Это также поможет сделать ваше выражение более читабельным. Самый распространенный класс
\d - представляет собой одну цифру (эквивалентно [0-9]), при этом \D (в верхнем регистре) эквивалентно [^0-9] то есть не является цифрой. То есть использование верхнего регистра является обратным основному выражению.\w соответствует слову (может состоять из букв, цифр и подчёркивания) A-Za-z0-9_\s соответствует символу пробела (включая табуляцию и прерывание строки). соответствует любому символу👌 Так-же следует упомянуть, что при использовании выражений с поддержкой unicode (флаг
/u), вы можете использовать еще огромное количество символьных классов \p{}. Например:\p{Sc} — любой знак валюты\p{P} — любой знак пунктуации\p{L} — любая буква из любого языкаВесь перечень можно посмотреть здесь.
#junior #regexp #source
{kind=link}
👍1
The Everybody Poops Rule (Все какают)
👉 Как мне кажется отличная аллегория, которая применима к программированию. Все мы постоянно сталкиваемся с ситуациями, когда в коде приходится идти на компромиссы. Иногда из-за нехватки времени, иногда для избежания оверинжиниринга, иногда из-за несовершенства системы, нехватки знаний и т.д. И мы сознательно оставляем в коде "дерьмо", ведь не каждая часть нашего приложения должна быть идеальной.
📌 Все какают. Но дома это делают не в каждой комнате. У вас есть специальная комната, в которой вы какаете, ставите дверь, и только там это делаете.
Да, звучит странно, но зато хорошо запоминается 😂
❗️ Важно понимать, что этот процесс управляемый. Данное правило как раз помогает с этим жить при помощи сокрытия и инкапсуляции. Если код изолирован — не важно, что скрывается за интерфейсом. Главное, что мы гадим в определенных частях и "держим дверь закрытой".
👍 Конечно, у подобных мест тоже следует определить стандарты. То есть нельзя совсем забить и втулить туда какой-то
❗️ Также то, что вы можете всё изолировать — не значит, что это нужно делать всегда и везде. Прежде чем это сделать задайте себе несколько вопросов:
• Как часто код будет использоваться?
• Как долго его можно не трогать?
• Является ли это основным доменом в вашей компании? (здесь лучше этого не делать)
👍 Еще круче — сразу планировать возможный рефакторинг. То, что сегодня вы изолировали может понадобиться бизнесу в будущем или где-то аукнуться в самый неподходящий момент. Круто быть к этому готовым. Лучше всего это место задокументировать, чтобы точно знать о всех отклонениях.
#junior #oop #source
👉 Как мне кажется отличная аллегория, которая применима к программированию. Все мы постоянно сталкиваемся с ситуациями, когда в коде приходится идти на компромиссы. Иногда из-за нехватки времени, иногда для избежания оверинжиниринга, иногда из-за несовершенства системы, нехватки знаний и т.д. И мы сознательно оставляем в коде "дерьмо", ведь не каждая часть нашего приложения должна быть идеальной.
📌 Все какают. Но дома это делают не в каждой комнате. У вас есть специальная комната, в которой вы какаете, ставите дверь, и только там это делаете.
Да, звучит странно, но зато хорошо запоминается 😂
❗️ Важно понимать, что этот процесс управляемый. Данное правило как раз помогает с этим жить при помощи сокрытия и инкапсуляции. Если код изолирован — не важно, что скрывается за интерфейсом. Главное, что мы гадим в определенных частях и "держим дверь закрытой".
👍 Конечно, у подобных мест тоже следует определить стандарты. То есть нельзя совсем забить и втулить туда какой-то
God Object с методами в 1000 строк, вызывающие запросы к БД в foreach. Здесь важно найти баланс. Это тоже непростая работа. Помните, положив код "за дверь" он не становится лучше, а значит учитывайте риски того, что вам придётся его переписывать.❗️ Также то, что вы можете всё изолировать — не значит, что это нужно делать всегда и везде. Прежде чем это сделать задайте себе несколько вопросов:
• Как часто код будет использоваться?
• Как долго его можно не трогать?
• Является ли это основным доменом в вашей компании? (здесь лучше этого не делать)
👍 Еще круче — сразу планировать возможный рефакторинг. То, что сегодня вы изолировали может понадобиться бизнесу в будущем или где-то аукнуться в самый неподходящий момент. Круто быть к этому готовым. Лучше всего это место задокументировать, чтобы точно знать о всех отклонениях.
#junior #oop #source
{kind=link}
👍1
Data Transfer Object (DTO) и как его готовить?
В предыдущих постах я уже упоминал что это, но хочу остановиться на нём немного подробнее, чтобы закрыть часто задаваемые вопросы.
❓ Зачем он нужен?
Для упрощения рассмотрим всё тот-же кейс передачи данных между слоями внутри приложения.
Основная идея, что мы можем отделить логику нашего бизнеса от инфраструктуры фреймворка и дело тут вовсе не в том, что мы когда-нибудь захотим переехать на новый фреймворк (хотя полностью исключать этого не стоит), а в том, чтобы иметь возможность переиспользовать существующее поведение в независимости от того, откуда оно дергается.
Для примера рассмотрим контроллер и консольную команду внутри которых мы пытаемся вызывать уже существующий сервис (или command handler) для смены адреса доставки. И
Как раз здесь нам на помощь и приходит DTO, который позволит отделить слои друг от друга.
❓ Должен ли DTO содержать валидацию?
👉 Нет.
Внутри вообще ничего не должно быть, кроме примитивных данных. Оставьте первый этап валидации вашему фронтенду (или валидатору фреймворка), а второй уже самому доменному слою (
❗️ Называйте ваши DTO по их намерениям (действиям)
👍 Если данные будут использоваться для изменения адреса доставки заказа (как в примерах выше), назовите его
#junior #php #dto #source
В предыдущих постах я уже упоминал что это, но хочу остановиться на нём немного подробнее, чтобы закрыть часто задаваемые вопросы.
❓ Зачем он нужен?
Для упрощения рассмотрим всё тот-же кейс передачи данных между слоями внутри приложения.
Основная идея, что мы можем отделить логику нашего бизнеса от инфраструктуры фреймворка и дело тут вовсе не в том, что мы когда-нибудь захотим переехать на новый фреймворк (хотя полностью исключать этого не стоит), а в том, чтобы иметь возможность переиспользовать существующее поведение в независимости от того, откуда оно дергается.
Для примера рассмотрим контроллер и консольную команду внутри которых мы пытаемся вызывать уже существующий сервис (или command handler) для смены адреса доставки. И
Request и Input являются частью инфраструктуры фреймворка, на которую мы не можем повлиять, при этом они имеют разный интерфейс. Плюс ко всему это делает нашу бизнес логику зависимой от той самой инфраструктуры.Как раз здесь нам на помощь и приходит DTO, который позволит отделить слои друг от друга.
❓ Должен ли DTO содержать валидацию?
👉 Нет.
Внутри вообще ничего не должно быть, кроме примитивных данных. Оставьте первый этап валидации вашему фронтенду (или валидатору фреймворка), а второй уже самому доменному слою (
Value Object, Entity и т.д.). То есть DTO не должен выбрасывать никаких исключений. Всё что вам нужно, это привести данные к правильным типам, присвоить полям их значения или null (если в вашем случае это допустимо). Это оставит знания о том, как работать с объектами домена внутри ядра приложения, а не в коде инфраструктуры.❗️ Называйте ваши DTO по их намерениям (действиям)
👍 Если данные будут использоваться для изменения адреса доставки заказа (как в примерах выше), назовите его
ChangeDeliveryAddress (а не DeliveryAddressDTO). Во первых это уменьшит путаницу, т.к. разные действия, чаще всего будут иметь разный набор данных. Например DTO для создания адреса доставки может не содержать ID, а для изменения он уже обязателен.#junior #php #dto #source
{kind=link}
Validation (part 1). Валидация внутри доменного слоя приложения
Уже несколько раз меня просили написать заметку по этой теме и вот, после нескольких подготовительных постов, на которые я буду ссылаться наконец можно приступить. Чуть позже мы рассмотрим и пользовательскую валидацию и поговорим про ограничения в базе данных, но начнем мы сразу с доменного слоя нашего приложения, то есть с той самой бизнес логики.
📌 Валидация сущности (Entity).
Рано или поздно, пользовательские данные переданные в наше приложение попадают во внутрь
❌ Не нужно создавать для
👍 Конструктор должен принимать все обязательные для существования сущности параметры и валидировать их перед тем, как присвоить значение свойству. Все необязательные параметры могут быть заданы значениями по-умолчанию и/или быть присвоенными отдельными методами, в которых также следует добавлять проверки перед присваиванием. В случае если нас что-то не устраивает — кидаем
❓ Но ведь мы же не будем показывать пользователям исключения?
Всё правильно, исключения не для пользователей.
📌 Используйте Value Objects для проверки отдельных значений.
Данный подход позволяет и делегировать проверки, и переиспользовать их в дальнейшем в других частях нашего приложения.
👍 Из предыдущего примера мы можем отдельно вынести AccountNumber, переместив в него всю валидацию, отдельно выделить
👉 Тема очень обширная, так что ставь 🍺 если интересна информация про валидацию пользовательских данных, взаимодействие с БД, а также про Incomplete, Invalid и Inconsistent объекты.
#php #oop #junior #source
Уже несколько раз меня просили написать заметку по этой теме и вот, после нескольких подготовительных постов, на которые я буду ссылаться наконец можно приступить. Чуть позже мы рассмотрим и пользовательскую валидацию и поговорим про ограничения в базе данных, но начнем мы сразу с доменного слоя нашего приложения, то есть с той самой бизнес логики.
📌 Валидация сущности (Entity).
Рано или поздно, пользовательские данные переданные в наше приложение попадают во внутрь
Entity. В одном из предыдущих постов, я уже писал, что сущность сама должна защищать свои инварианты, хранить в себе только валидные данные и при этом валидировать данные самостоятельно. ❌ Не нужно создавать для
Entity сервисы валидации. Вам придется делать бесконечные и ненужные геттеры внутри Entity, следить за тем что нужно обновить сервис в случае изменения самой сущности и не забывать его вызвать каждый раз при её создании. 👍 Конструктор должен принимать все обязательные для существования сущности параметры и валидировать их перед тем, как присвоить значение свойству. Все необязательные параметры могут быть заданы значениями по-умолчанию и/или быть присвоенными отдельными методами, в которых также следует добавлять проверки перед присваиванием. В случае если нас что-то не устраивает — кидаем
Exception. Пример❓ Но ведь мы же не будем показывать пользователям исключения?
Всё правильно, исключения не для пользователей.
Exceptions, трассировка и контекст должны быть видны только разработчикам. Все исключения выброшенные разработчиком должны быть обработаны перед тем как вывести пользователю что-то на экран. Но об этом чуть позже.📌 Используйте Value Objects для проверки отдельных значений.
Данный подход позволяет и делегировать проверки, и переиспользовать их в дальнейшем в других частях нашего приложения.
👍 Из предыдущего примера мы можем отдельно вынести AccountNumber, переместив в него всю валидацию, отдельно выделить
Value Object Money, который также может взять на себя операцию сложения для логики пополнения счета. Тогда наша Entity будет иметь примерно следующий вид. Так как в основной сущности мы уже работаем с валидными Value Objects, то нет необходимости проверять что-то дополнительно внутри сущности, мы и так всё затайпхинтили.👉 Тема очень обширная, так что ставь 🍺 если интересна информация про валидацию пользовательских данных, взаимодействие с БД, а также про Incomplete, Invalid и Inconsistent объекты.
#php #oop #junior #source
{kind=link}
Бинарный поиск и "О-большое"
К сожалению, в последнее время встречаю всё больше людей, которые совсем не знакомы с темой алгоритмов. Аргументируют это тем, что "да зачем мне это нужно, если я пилю крадики" и они правы. Разница только в том, что с таким подходом далеко не уедешь и велика вероятность так и пилить крадики до конца своей карьеры. Лично я считаю, что действительно не стоит сразу слишком глубоко копать в эту тему, но базовые принципы знать обязательно. Как минимум базовые понятия встречаются во многих книгах, статьях и видео. И чтобы правильно понять, что до вас хочет донести автор — нужно чуть-чуть разобраться.
Представьте, что ваш друг загадал число, от 1 до 100, а вам нужно его отгадать. При каждой попытке друг будет давать вам один из трёх ответов "Мало" , "Много", "В точку!". Если перебирать все варианты подряд (1, 2, 3, 4... то есть прямым поиском), то вы рискуете использовать 100 попыток, при самом плохом случае.
👌 Но что если вы сразу ударите в середину и назовете число 50? "Мало", и вы сразу отсекли половину вариантов. Затем "75" — "Много", и еще половина вариантов ушла. Именно так и работает бинарный поиск.
❗️Важно, что бинарный поиск работает только в том случае, если список отсортирован.
📌 Время выполнения и "О-большое"
💁♂️ Возможно вы забыли что такое логарифм, но точно помните, что такое возведение в степень. Так вот, запись
"О-большое" описывает, насколько быстро работает алгоритм. Простой поиск должен проверить каждый элемент. Для списка из 4 миллиардов (или любое другое n) чисел потребуется до 4 миллиардов попыток. Таким образом, максимальное количество попыток совпадает с размером списка. Такое время выполнения называется линейным и обозначается
С бинарным поиском дело обстоит иначе. Для списка из 4 миллиардов элементов, потребуется не более более 32 попыток. Впечатляет, да? Бинарный поиск выполняется за логарифмическое время и его сложность описывается как
❓ Если это время, то где же секунды?
А их здесь нет. "О-большое" не сообщает время в секундах, а позволяет сравнить количество операций. Оно указывает, насколько быстро возрастает время выполнения алгоритма. А время в секундах уже будет зависеть от размера исходных данных, вычислительных мощностей и т.д.
❗️ "О-большое" определяет время выполнения в худшем случае.
То есть если ваш друг, загадал число "1", то при прямом поиске вы угадаете его моментально, так как оно стоит на первом месте
👍 Надеюсь стало немного понятнее и теперь, когда в разных книгах или статьях вы встретите записи типа
#junior #algorithm #source
К сожалению, в последнее время встречаю всё больше людей, которые совсем не знакомы с темой алгоритмов. Аргументируют это тем, что "да зачем мне это нужно, если я пилю крадики" и они правы. Разница только в том, что с таким подходом далеко не уедешь и велика вероятность так и пилить крадики до конца своей карьеры. Лично я считаю, что действительно не стоит сразу слишком глубоко копать в эту тему, но базовые принципы знать обязательно. Как минимум базовые понятия встречаются во многих книгах, статьях и видео. И чтобы правильно понять, что до вас хочет донести автор — нужно чуть-чуть разобраться.
Представьте, что ваш друг загадал число, от 1 до 100, а вам нужно его отгадать. При каждой попытке друг будет давать вам один из трёх ответов "Мало" , "Много", "В точку!". Если перебирать все варианты подряд (1, 2, 3, 4... то есть прямым поиском), то вы рискуете использовать 100 попыток, при самом плохом случае.
👌 Но что если вы сразу ударите в середину и назовете число 50? "Мало", и вы сразу отсекли половину вариантов. Затем "75" — "Много", и еще половина вариантов ушла. Именно так и работает бинарный поиск.
❗️Важно, что бинарный поиск работает только в том случае, если список отсортирован.
📌 Время выполнения и "О-большое"
💁♂️ Возможно вы забыли что такое логарифм, но точно помните, что такое возведение в степень. Так вот, запись
log(2) 8 означает, в какую степень нужно возвести 2, чтобы получить 8, итак log(2) 8 = 3."О-большое" описывает, насколько быстро работает алгоритм. Простой поиск должен проверить каждый элемент. Для списка из 4 миллиардов (или любое другое n) чисел потребуется до 4 миллиардов попыток. Таким образом, максимальное количество попыток совпадает с размером списка. Такое время выполнения называется линейным и обозначается
O(n). С бинарным поиском дело обстоит иначе. Для списка из 4 миллиардов элементов, потребуется не более более 32 попыток. Впечатляет, да? Бинарный поиск выполняется за логарифмическое время и его сложность описывается как
O(log n). ❓ Если это время, то где же секунды?
А их здесь нет. "О-большое" не сообщает время в секундах, а позволяет сравнить количество операций. Оно указывает, насколько быстро возрастает время выполнения алгоритма. А время в секундах уже будет зависеть от размера исходных данных, вычислительных мощностей и т.д.
❗️ "О-большое" определяет время выполнения в худшем случае.
То есть если ваш друг, загадал число "1", то при прямом поиске вы угадаете его моментально, так как оно стоит на первом месте
O(1). Но простой поиск всё равно выполняется за время O(n), фактически это утверждение о том, что в худшем случае придется перебрать все числа.👍 Надеюсь стало немного понятнее и теперь, когда в разных книгах или статьях вы встретите записи типа
O(n), O(n!), O(n log n) вы не будете впадать в ступор, а будете осознанно понимать, что автор хочет до вас донести.#junior #algorithm #source
{kind=link}
Validation (part 2). Всё еще внутри доменного слоя приложения
Продолжаем рассматривать тему из предыдущего поста. Мы остановились на том, что валидируем сущность перед её созданием, то есть добиваемся того, чтобы в нашей системе все объекты были валидны. Но какие правила туда вообще нужно помещать? От чего объект должен защищать свое состояние?
❗️Объект должен гарантировать что его данные должны быть полными, действительными и консистентными.
📌 Данные неполные (Incomplete) , если для выполнения простых задач отсутствует их логический кусок. Например для Money, если бы у нас была сумма, но отсутствовала валюта. В таком случае мы бы не смогли корректно производить сложение. Более подробно про эту проблему я писал в этом посте.
📌 Недействительные данные (Invalid) — которые имеют правильный тип, но обладают не всеми нужными качествами. Будет проще на примере. Возьмем тот же Money, на данный момент в конструктор мы можем передать любую строку, которая будет обозначать валюту, а это значит, что пользователь может создать объект с несуществующей валютой или той, которая никак не относится к нашему бизнесу (например вы не работает с криптой, а вам передали биткоин). Для выхода из сложившейся ситуации можно (надеемся в php 8.1 уже будет из коробки) использовать Enum (пример для более ранних версий), чтобы убедиться, в корректности переданного значения.
📌 Неконсистентные (Inconsistent) — когда два и более куска данных противоречат друг другу. Например заказ нельзя перевести в статус "
👉 Связь с другой сущностью по ID
Если в качестве связи с другой сущностью в метод или в конструктор мы передаём
👍 Правильным решением будет — достать сущность из её репозитория, в случае если её не существует мы об этом узнаем. Да и чаще всего нам нужно знать куда больше, чем просто факт существования сущности. Нам будут нужны какие-то её свойства, потому логично будет передавать её в другой объект.
❗️Но не всё так просто. Всё зависит от данных, которые может предоставить
👍 А пока главный месседж — отношения лучше выстраивать с помощью идентификаторов, а не по ссылкам на объект. Во первых таким образом мы понижаем связанность (
Вроде по доменной всё. На очереди пользовательская валидация.
#middle #php #oop #source
Продолжаем рассматривать тему из предыдущего поста. Мы остановились на том, что валидируем сущность перед её созданием, то есть добиваемся того, чтобы в нашей системе все объекты были валидны. Но какие правила туда вообще нужно помещать? От чего объект должен защищать свое состояние?
❗️Объект должен гарантировать что его данные должны быть полными, действительными и консистентными.
📌 Данные неполные (Incomplete) , если для выполнения простых задач отсутствует их логический кусок. Например для Money, если бы у нас была сумма, но отсутствовала валюта. В таком случае мы бы не смогли корректно производить сложение. Более подробно про эту проблему я писал в этом посте.
📌 Недействительные данные (Invalid) — которые имеют правильный тип, но обладают не всеми нужными качествами. Будет проще на примере. Возьмем тот же Money, на данный момент в конструктор мы можем передать любую строку, которая будет обозначать валюту, а это значит, что пользователь может создать объект с несуществующей валютой или той, которая никак не относится к нашему бизнесу (например вы не работает с криптой, а вам передали биткоин). Для выхода из сложившейся ситуации можно (надеемся в php 8.1 уже будет из коробки) использовать Enum (пример для более ранних версий), чтобы убедиться, в корректности переданного значения.
📌 Неконсистентные (Inconsistent) — когда два и более куска данных противоречат друг другу. Например заказ нельзя перевести в статус "
доставляется", если нет адреса доставки. То есть помимо текущего состояния объект также несет ответственность за переход между состояниями. Например если заказ оплачен и доставлен — его нельзя просто так "отменить" (подробнее в этом посте).👉 Связь с другой сущностью по ID
Если в качестве связи с другой сущностью в метод или в конструктор мы передаём
ID, то мы наверняка не можем быть уверенны, что Entity с таким ID существует в рамках нашей системы, ведь на входе мы можем убедиться лишь в том, что ID соответствует определенному шаблону (например UUID).👍 Правильным решением будет — достать сущность из её репозитория, в случае если её не существует мы об этом узнаем. Да и чаще всего нам нужно знать куда больше, чем просто факт существования сущности. Нам будут нужны какие-то её свойства, потому логично будет передавать её в другой объект.
❗️Но не всё так просто. Всё зависит от данных, которые может предоставить
Read Model, но это уже совсем другая история, которую позже мы обязательно разберем. 👍 А пока главный месседж — отношения лучше выстраивать с помощью идентификаторов, а не по ссылкам на объект. Во первых таким образом мы понижаем связанность (
Low Coupling), а также убираем возможность нежелательных изменений, которые могут происходить внутри связанной сущности.Вроде по доменной всё. На очереди пользовательская валидация.
#middle #php #oop #source
Repositories (Репозитории)
Каждая сущность (Entity) должна иметь репозиторий. Именно он выступает неким "адаптером" между внешним хранилищем (например БД) и нашим доменным слоем. Но вот проблема.
❌ Если мы будем вызывать реализацию репозитория внутри нашего Application слоя, то нарушим правило разделения приложения, которое гласит, что внешние слои могут зависеть от внутренних, а не наоборот (
👉 Для решения этой проблемы достаточно создать абстракцию (интерфейс), который и будет принадлежать доменному слою, на который и может быть завязан сервис или юзкейс.
❓ Почему интерфейс репозитория принадлежит доменному слою, а сам репозиторий нет?
Вашему бизнесовому коду всё равно, будете вы использовать базу данных, файловую систему или InMemory для хранения и получения данных, ему важно чтобы были методы с определенными именами, принимали конкретные параметры и возвращали нужные типы данных. Именно это и позволяет оставлять наш код независимым от конкретной реализации, таким образом реализация остаётся в инфраструктурном слое.
❗️ Держите код Repository в чистоте
❌ Очень частое упрощение — весь код, который работает с базой выносим в репозиторий. В итоге получаем, что в репозитории у нас 2 метода, которые мы используем постоянно (например
👍 Если вам нужен объект из репозитория с ограниченным или наоборот расширенным набором данных только для чтения (то есть вы не предполагаете внесение изменений), то не надо делать этот метод в том-же репозитории. Скорее всего вам нужен
📌 Ваши view не всегда нужны все данные ваших
📌 Вам не придётся делать ненужные
📌 Ваши
📌 В конце концов вы можете разделить источники данных, в то время как
#php #oop #repository #middle #source
Каждая сущность (Entity) должна иметь репозиторий. Именно он выступает неким "адаптером" между внешним хранилищем (например БД) и нашим доменным слоем. Но вот проблема.
❌ Если мы будем вызывать реализацию репозитория внутри нашего Application слоя, то нарушим правило разделения приложения, которое гласит, что внешние слои могут зависеть от внутренних, а не наоборот (
Infrastructure -> Application -> Domain).👉 Для решения этой проблемы достаточно создать абстракцию (интерфейс), который и будет принадлежать доменному слою, на который и может быть завязан сервис или юзкейс.
❓ Почему интерфейс репозитория принадлежит доменному слою, а сам репозиторий нет?
Вашему бизнесовому коду всё равно, будете вы использовать базу данных, файловую систему или InMemory для хранения и получения данных, ему важно чтобы были методы с определенными именами, принимали конкретные параметры и возвращали нужные типы данных. Именно это и позволяет оставлять наш код независимым от конкретной реализации, таким образом реализация остаётся в инфраструктурном слое.
❗️ Держите код Repository в чистоте
❌ Очень частое упрощение — весь код, который работает с базой выносим в репозиторий. В итоге получаем, что в репозитории у нас 2 метода, которые мы используем постоянно (например
getById() и save()) и 5 методов, которые у нас узконаправлены (например используются для каких-то частных выборок типа отчетов). Здесь вообще стоит немного углубиться в тему Read Model, но пока обойдемся более простой идеей. 👍 Если вам нужен объект из репозитория с ограниченным или наоборот расширенным набором данных только для чтения (то есть вы не предполагаете внесение изменений), то не надо делать этот метод в том-же репозитории. Скорее всего вам нужен
Finder, который сразу может вернуть вам удобные структуры данных (тех же DTO). Это удобно как минимум потому, что:📌 Ваши view не всегда нужны все данные ваших
Entity / Агрегатов.📌 Вам не придётся делать ненужные
getters в вашей основной Entity.📌 Ваши
Entity не должны содержать весь список данных "на всякий случай", со всеми ссылками на другие сущности (например Customer со всеми заказами, со всеми данными этих заказов).📌 В конце концов вы можете разделить источники данных, в то время как
Entity могут работать с реляционной, то View могут быть получены из того же Redis, для ускорения получения данных (вопрос консистентности тоже рассмотрим отдельно).#php #oop #repository #middle #source
{kind=link}
🥳🥳🥳 Чатик Beer::PHP 🍺
Я получил уже несколько десятков запросов о создании чата для комментирования статей и обсуждения вопросов. Также иногда я просто не успеваю отвечать на вопросы в личке, так что чатик может стать отличным местом, куда я буду заглядывать с целью ответить, если другой участник не сделает это раньше меня ;)
😢 Грустно это признавать, но наше СНГ-прогерское комьюнити достаточно токсично. В связи с этим в чатах (правда не во всех) много грубых ответов, троллинга, спама и оффтопа, а вот чётких коротких или развернутых ответов на вопросы — мало и их сложно найти за кучей сообщений.
👉 К сожалению в связи с дефицитом времени практически нет возможности его модерировать. Однако, я нашел выход :)
👍👍👍 Вступить в чат можно за символическую (часто просто неподъемную для программиста) подписку 1$ в месяц. Оплата внедрена с целью нажиться на подписч... кхм.. максимально отфильтровать людей и оставить только действительно заинтересованных.
🔨 Если что-то не получается — вот подробная инструкция.
📃 Также выкатил короткий свод правил чатика.
Вступай в чатик, общайся с коллегами и делись своим опытом, мы тебя ждём! ❤️
Я получил уже несколько десятков запросов о создании чата для комментирования статей и обсуждения вопросов. Также иногда я просто не успеваю отвечать на вопросы в личке, так что чатик может стать отличным местом, куда я буду заглядывать с целью ответить, если другой участник не сделает это раньше меня ;)
😢 Грустно это признавать, но наше СНГ-прогерское комьюнити достаточно токсично. В связи с этим в чатах (правда не во всех) много грубых ответов, троллинга, спама и оффтопа, а вот чётких коротких или развернутых ответов на вопросы — мало и их сложно найти за кучей сообщений.
👉 К сожалению в связи с дефицитом времени практически нет возможности его модерировать. Однако, я нашел выход :)
👍👍👍 Вступить в чат можно за символическую (часто просто неподъемную для программиста) подписку 1$ в месяц. Оплата внедрена с целью нажиться на подписч... кхм.. максимально отфильтровать людей и оставить только действительно заинтересованных.
🔨 Если что-то не получается — вот подробная инструкция.
📃 Также выкатил короткий свод правил чатика.
Вступай в чатик, общайся с коллегами и делись своим опытом, мы тебя ждём! ❤️
paywall.pw
Чат Beer::PHP 🍺
Это чат подписчиков канала Beer::PHP 🍺, который создан с целью обсуждения материала, комментирования постов и статей.
😢 Грустно это признавать, но наше СНГ-прогерское комьюнити достаточно токсично. В связи с этим в чатах (правда не во всех) много грубых…
😢 Грустно это признавать, но наше СНГ-прогерское комьюнити достаточно токсично. В связи с этим в чатах (правда не во всех) много грубых…
Validation (part 3). Валидация пользовательских данных
В предыдущих частях (раз, два) мы уже добились того, что наша доменная модель полностью защищена и в случае попадания невалдиных данных наше приложение будет кидать
❗️ Это круто работает если нам надо прервать какую-то операцию, но не слишком удобно, если мы хотим показать пользователю ошибки, особенно если их несколько (например при заполнении формы).
❌ Первое, что приходит в голову, это добавить валидацию в контроллер. При этом у нас уже есть готовые
С одной стороны мы убрали дублирование, с другой нет. Мы начинаем переносить всю бизнес логику в контроллер и подсознание говорит, что мы делаем что-то не так. И не надо так делать!
📌 Нам надо просто убедиться, что пользователь не ошибся при вводе данных
👉 Мы должны сделать всё от нас зависящее, чтобы помочь пользователю это сделать. Пока пользователь вводит свои данные — вы уже можете выдать предупреждение, что
👍 Такую валидацию вы можете доверить фронтовой части вашего приложения (да-да, вообще убрать из контроллера❗️), если работаете c
📌 Но есть более сложные бизнес требования
👉 Например во время заказа, вам нужно проверить, что на складе всё еще есть хотя-бы одна единица товара, которую заказывает пользователь (ведь пока он чехлился, кто-то другой мог забрать последнюю единицу первее чем он нажал кнопку). Такие проверки должны выполняться в application слое приложения и отлавливаться через
📌 Исключения обязательно нужно контролировать
Некоторые, должны быть видны только разработчикам, потому как раскрытие этих данных пользователю сразу создаёт угрозу безопасности. Другие, такие как исключения бизнес логики, должны быть информативными для ваших пользователей.
📌 Вам обязательно нужно различать их в своём коде.
💁♂️ Первые могут возникать, когда кто-то пытается абузить ваше приложение, например отправляет рандомные данные
Чтобы не дублировать подобный код в каждом контроллере — настройте перехватчик в
👍 Для вторых круто будет создать пользовательские классы исключений, которые можно отлавливать вместе с другими ошибками формы и отправлять на вывод пользователю. Логированием таких ошибок можно пренебречь, но опять же, всё зависит от вашей задачи.
👉 Использование исключений для пользовательской валидации не должно быть в приоритете. Помощь пользователю при работе с пользовательским интерфейсом — лучший способ пользовательской валидации 😉.
#php #oop #validation #middle #source
В предыдущих частях (раз, два) мы уже добились того, что наша доменная модель полностью защищена и в случае попадания невалдиных данных наше приложение будет кидать
Exception в любой непонятной ситуации. ❗️ Это круто работает если нам надо прервать какую-то операцию, но не слишком удобно, если мы хотим показать пользователю ошибки, особенно если их несколько (например при заполнении формы).
❌ Первое, что приходит в голову, это добавить валидацию в контроллер. При этом у нас уже есть готовые
Value Object's, которые используются и доменном слое! Что нам мешает провалидировать Email? Мы точно будем знать, что изменив правила валидации в одном месте, они изменятся везде. С одной стороны мы убрали дублирование, с другой нет. Мы начинаем переносить всю бизнес логику в контроллер и подсознание говорит, что мы делаем что-то не так. И не надо так делать!
📌 Нам надо просто убедиться, что пользователь не ошибся при вводе данных
👉 Мы должны сделать всё от нас зависящее, чтобы помочь пользователю это сделать. Пока пользователь вводит свои данные — вы уже можете выдать предупреждение, что
email выглядит некорректно.👍 Такую валидацию вы можете доверить фронтовой части вашего приложения (да-да, вообще убрать из контроллера❗️), если работаете c
Vue, React, etc..., или доверить встроенным валидаторам фреймворка, если используете twig, blade, etc... Главное помните, что ваша задача помочь пользователю, а не ввести его в ступор своими правилами.📌 Но есть более сложные бизнес требования
👉 Например во время заказа, вам нужно проверить, что на складе всё еще есть хотя-бы одна единица товара, которую заказывает пользователь (ведь пока он чехлился, кто-то другой мог забрать последнюю единицу первее чем он нажал кнопку). Такие проверки должны выполняться в application слое приложения и отлавливаться через
Exception'ы.📌 Исключения обязательно нужно контролировать
Некоторые, должны быть видны только разработчикам, потому как раскрытие этих данных пользователю сразу создаёт угрозу безопасности. Другие, такие как исключения бизнес логики, должны быть информативными для ваших пользователей.
📌 Вам обязательно нужно различать их в своём коде.
💁♂️ Первые могут возникать, когда кто-то пытается абузить ваше приложение, например отправляет рандомные данные
POST в обход формы. Такие ошибки должны быть отловлены в инфрастуктурном слое, информация обязательно отправлена в логи, а на фронт выброшен 400 (или более подходящий) ответ без какой-то конкретики. Чтобы не дублировать подобный код в каждом контроллере — настройте перехватчик в
production среде на уровне вашего фреймворка (для development окружения их "глушить" не нужно).👍 Для вторых круто будет создать пользовательские классы исключений, которые можно отлавливать вместе с другими ошибками формы и отправлять на вывод пользователю. Логированием таких ошибок можно пренебречь, но опять же, всё зависит от вашей задачи.
👉 Использование исключений для пользовательской валидации не должно быть в приоритете. Помощь пользователю при работе с пользовательским интерфейсом — лучший способ пользовательской валидации 😉.
#php #oop #validation #middle #source
{kind=link}
Autoload (автозагрузчик)
На всякий случай начнём с основ, т.к. не все знают, как это работает.
👉 Все мы ежедневно создаём классы, которые помещаем в отдельные файлы. Внутри класса мы можем использовать другие классы. И для того, чтобы наш интерпретатор знал о используемом классе, мы должны подключить (
❗️ PHP позволяет тебе зарегистрировать автозагрузчик
Сразу пример, как это сделать с помощью функции spl_autoload_register(). Можно зарегистрировать любое число автозагрузчиков (то есть много раз объявить эту самую функцию). Например, если ты подключаешь стороннюю библиотеку, то она может зарегистрировать свой автозагрузчик для загрузки своих классов. Таким образом, каждая библиотека может самостоятельно решать, как она будет искать и подключать файлы.
📁 Если ни один автозагрузчик не подключит файл с вызываемым классом, то будет выведена ошибка об обращении к несуществующему классу. Вот примеры, когда автозагрузчик будет вызван, а когда нет.
👍 Несколько правил, если нужно написать автозагрузчик самостоятельно:
📌 Aвтозагрузчик не должен выдавать ошибку, если он не может найти файл с классом — может быть, этот класс подгрузит следующий автозагрузчик.
📌 Нужно писать автозагрузчик только для своих файлов и не использовать файлы сторонних библиотек.
📌 Не нужно изобретать свои правила сопоставления имен классов и файлов, лучше всего использовать общепринятый стандарт PSR-4 (о нем поговорим позже).
#php #autoload #junior #source
На всякий случай начнём с основ, т.к. не все знают, как это работает.
👉 Все мы ежедневно создаём классы, которые помещаем в отдельные файлы. Внутри класса мы можем использовать другие классы. И для того, чтобы наш интерпретатор знал о используемом классе, мы должны подключить (
require) файл, в котором описан используемый класс. Пока вроде просто. Когда число классов увеличивается, писать все эти require_once становится неудобно. Но выход есть!❗️ PHP позволяет тебе зарегистрировать автозагрузчик
Сразу пример, как это сделать с помощью функции spl_autoload_register(). Можно зарегистрировать любое число автозагрузчиков (то есть много раз объявить эту самую функцию). Например, если ты подключаешь стороннюю библиотеку, то она может зарегистрировать свой автозагрузчик для загрузки своих классов. Таким образом, каждая библиотека может самостоятельно решать, как она будет искать и подключать файлы.
📁 Если ни один автозагрузчик не подключит файл с вызываемым классом, то будет выведена ошибка об обращении к несуществующему классу. Вот примеры, когда автозагрузчик будет вызван, а когда нет.
👍 Несколько правил, если нужно написать автозагрузчик самостоятельно:
📌 Aвтозагрузчик не должен выдавать ошибку, если он не может найти файл с классом — может быть, этот класс подгрузит следующий автозагрузчик.
📌 Нужно писать автозагрузчик только для своих файлов и не использовать файлы сторонних библиотек.
📌 Не нужно изобретать свои правила сопоставления имен классов и файлов, лучше всего использовать общепринятый стандарт PSR-4 (о нем поговорим позже).
#php #autoload #junior #source
{kind=link}
❓Опросник❓
👉 Ребзя, хочу улучшить контент, который я выкладываю в этом канале, в связи с чем, сделал этот опросник.
Внутри всего 5 вопросов, которые могут помочь мне лучше понять, что за подписчики тут тусуются, а следовательно лучше адаптировать материал под вас :)
👍 Четыре вопроса обязательных, но там достаточно быстро тыкнуть мышкой. Последний — для творческого полёта мыслей и на него необязательно отвечать, но я буду очень благодарен тем людям, которые там напишут хотя-бы 1-2 предложения.
Короче, залетай, заполняй, помоги автору делать топовый контент!
👉 Ребзя, хочу улучшить контент, который я выкладываю в этом канале, в связи с чем, сделал этот опросник.
Внутри всего 5 вопросов, которые могут помочь мне лучше понять, что за подписчики тут тусуются, а следовательно лучше адаптировать материал под вас :)
👍 Четыре вопроса обязательных, но там достаточно быстро тыкнуть мышкой. Последний — для творческого полёта мыслей и на него необязательно отвечать, но я буду очень благодарен тем людям, которые там напишут хотя-бы 1-2 предложения.
Короче, залетай, заполняй, помоги автору делать топовый контент!
PSR-4 и Composer autoload
А пока полным ходом идёт заполнение опросника, спешу продолжить тему автозагрузчика. Кстати, реально спасибо всем, кто заполнил опросник. Я не ожидал, что будет столько отклика и полезных ответов. Позже обязательно сведу все результаты и поделюсь с вами, а пока перейдем к материалу =)
😢 Вообще тема PSR достаточно болезненна. Не многие знают, что это не только "правила кодстайла", но и вполне универсальные, стандартизированные концепции, для переиспользования в абсолютно разных проектах.
👉 Начало было положено в 2010 с PSR-0 (Autoloading Standard), который ни много ни мало стал первым шагом к объединению фреймворков, а также безболезненной возможности установки пакетов в ваше приложение (напр. composer в 2012). Однако уже в 2014 ему на смену пришел PSR-4, а PSR-0 был объявлен deprecated.
📌 Согласно PSR-4 мы должны называть файл, взяв название класса и добавив к нему расширение
📌 Наш файл должен лежать в каталоге, путь которого совпадает с частями нашего namespace. Например
Обычно в качестве неймспейса верхнего уровня выбирают название приложения / пакета, иногда вместе с названием компании или ником разработчика (например в фреймворке Symfony все классы лежат внутри неймспейса Symfony). По мере роста пакета добавляются дополнительные уровни вложенности и получится что-то вроде
Composer autoload
👍 Но, чтобы не писать свой автозагрузчик руками - можно использовать
❗️ Нужно обратить внимание, что:
1. Важно писать
2. В качестве разделителя использовать двойной бекслеш
3. В конце неймспейса также следует указывать
📌 Также есть возможность указать fallback каталог, в котором будет искаться любое пространство имён, для этого оставляем неймспейс пустым.
🔗 Все ссылки будут объеденены во время
🤝 Вам остается только подключить файл в свой проект с помощью
Также напоминаю, что обсудить любую тему и прокомментировать пост можно в нашем чатике, так что присоединяйся 🍺
#php #psr #autoload #composer #junior #source
А пока полным ходом идёт заполнение опросника, спешу продолжить тему автозагрузчика. Кстати, реально спасибо всем, кто заполнил опросник. Я не ожидал, что будет столько отклика и полезных ответов. Позже обязательно сведу все результаты и поделюсь с вами, а пока перейдем к материалу =)
😢 Вообще тема PSR достаточно болезненна. Не многие знают, что это не только "правила кодстайла", но и вполне универсальные, стандартизированные концепции, для переиспользования в абсолютно разных проектах.
👉 Начало было положено в 2010 с PSR-0 (Autoloading Standard), который ни много ни мало стал первым шагом к объединению фреймворков, а также безболезненной возможности установки пакетов в ваше приложение (напр. composer в 2012). Однако уже в 2014 ему на смену пришел PSR-4, а PSR-0 был объявлен deprecated.
📌 Согласно PSR-4 мы должны называть файл, взяв название класса и добавив к нему расширение
.php, при этом регистр названия класса и файла должны полностью совпадать.📌 Наш файл должен лежать в каталоге, путь которого совпадает с частями нашего namespace. Например
MyModule\Sub\SomeClass будет лежать по пути MyModule/Sub/SomeClass.php.Обычно в качестве неймспейса верхнего уровня выбирают название приложения / пакета, иногда вместе с названием компании или ником разработчика (например в фреймворке Symfony все классы лежат внутри неймспейса Symfony). По мере роста пакета добавляются дополнительные уровни вложенности и получится что-то вроде
\Symfony\Component\HttpFoundation\Request.Composer autoload
👍 Но, чтобы не писать свой автозагрузчик руками - можно использовать
composer.json. Для этого в нём следует создать директиву autoload, во внутри которого прописать "psr-4" и правила, по которым следует сопоставить корневой неймспейс с корневой папкой проекта. Это будет выглядеть так.❗️ Нужно обратить внимание, что:
1. Важно писать
psr-4 именно в нижнем регистре.2. В качестве разделителя использовать двойной бекслеш
\\ — это особенность json, первый он воспринимает как экранирование.3. В конце неймспейса также следует указывать
\\
📌 Есть возможность поиска определенного неймспейса сразу в нескольких директориях, для этого их нужно указать как массив.📌 Также есть возможность указать fallback каталог, в котором будет искаться любое пространство имён, для этого оставляем неймспейс пустым.
🔗 Все ссылки будут объеденены во время
install / update / dump-autoload в один массив, который композер положит в сгенерированный файл vendor/composer/autoload_psr4.php и пробросит путь к нему в основной файл автозагрузки vendor/autoload.php (там могут быть подключены и другие файлы типа psr-0, classmap и т.д.)🤝 Вам остается только подключить файл в свой проект с помощью
require_once __DIR__ . '/vendor/autoload.php'; и можно избавить себя от необходимости писать собственный автозагрузчик.Также напоминаю, что обсудить любую тему и прокомментировать пост можно в нашем чатике, так что присоединяйся 🍺
#php #psr #autoload #composer #junior #source
{kind=link}
Идемпотентные операции
Идемпотентность помогает проектировать более надёжные системы. На самом деле это математическая концепция, которая гласит: идемпотентная операция — это операция, которая не имеет дополнительного эффекта, если она вызывается более одного раза с одними и теми же входными параметрами. Другими словами, если вы выполните одну и ту же операцию несколько раз подряд, то результат не изменится.
Например умножение на 0 и на 1 — идемпотентная операция:
📌 Migrations
👉 Представьте ситуацию: Ваше приложение растёт и перед вами поставили задачу разделить сущность/таблицу Users на данные для доступа Access (напр. login, password, token) и профиля Profile (name, surname, address и т.д.).
❓ Вам нужно написать миграцию, которая создаст 2 новые таблицы в них скопирует необходимые данные пользователей, после чего исходную таблицу переименует в deprecated. Но что если посреди копирования миграция крашнется? Что произойдёт если запустить миграцию еще раз?
👍 Чтобы не беспокоиться об этом — позаботьтесь об идемпотентности ваших миграций. Если ваша БД поддерживает транзакции этих операций — не забудьте их использовать. Если у ваc MySQL, где для операций DDL (
📌 Message Queues
👉 Другой пример: Вам надо отправить письма определенной группе пользователей, но посреди отправки вы понимаете, что что-то пошло не так, у вас проблемы с SMTP и ваши письма перестали отправляться. После того как работа SMTP была восстановлена — вам нужно продолжить отправку. Но что будет, если вы запустите команду второй раз?
👍 Для решения — используйте очереди, которые гарантируют доставку. Если по какой-то причине нет такой возможности, то помечайте в базе кому уже письма были отправлены, чтобы они не принимали участия в следующей выборке.
С одной стороны вроде описанные вещи достаточно очевидны, с другой нельзя забывать о них во время проектирования. Всегда старайтесь думать о том, что будет если вам нужно будет повторно выполнить одну и ту же операцию, какие могут быть риски и как избежать головной боли =)
Позже рассмотрим идемпотентность HTTP-методов
#junior #php #architecture #source
Идемпотентность помогает проектировать более надёжные системы. На самом деле это математическая концепция, которая гласит: идемпотентная операция — это операция, которая не имеет дополнительного эффекта, если она вызывается более одного раза с одними и теми же входными параметрами. Другими словами, если вы выполните одну и ту же операцию несколько раз подряд, то результат не изменится.
Например умножение на 0 и на 1 — идемпотентная операция:
x * 1 == x * 1 * 1Присваивание — тоже идемпотентная, хотя первый вызов присваивания, можно сказать, имеет побочный эффект, но повторное выполнение не приведет ни к чему другому:
x * 0 == x * 0 * 0
x := 4Но при чем тут Веб-приложения?
📌 Migrations
👉 Представьте ситуацию: Ваше приложение растёт и перед вами поставили задачу разделить сущность/таблицу Users на данные для доступа Access (напр. login, password, token) и профиля Profile (name, surname, address и т.д.).
❓ Вам нужно написать миграцию, которая создаст 2 новые таблицы в них скопирует необходимые данные пользователей, после чего исходную таблицу переименует в deprecated. Но что если посреди копирования миграция крашнется? Что произойдёт если запустить миграцию еще раз?
👍 Чтобы не беспокоиться об этом — позаботьтесь об идемпотентности ваших миграций. Если ваша БД поддерживает транзакции этих операций — не забудьте их использовать. Если у ваc MySQL, где для операций DDL (
CREATE, ALTER, DROP) нет возможности сделать транзакцию, позаботьтесь о том, чтобы использовать CREATE TABLE IF NOT EXISTS, а данные для копирования не просто выбирались полностью (SELECT * FROM USERS), а брались только те, у которых еще нет ряда в Profiles.📌 Message Queues
👉 Другой пример: Вам надо отправить письма определенной группе пользователей, но посреди отправки вы понимаете, что что-то пошло не так, у вас проблемы с SMTP и ваши письма перестали отправляться. После того как работа SMTP была восстановлена — вам нужно продолжить отправку. Но что будет, если вы запустите команду второй раз?
👍 Для решения — используйте очереди, которые гарантируют доставку. Если по какой-то причине нет такой возможности, то помечайте в базе кому уже письма были отправлены, чтобы они не принимали участия в следующей выборке.
С одной стороны вроде описанные вещи достаточно очевидны, с другой нельзя забывать о них во время проектирования. Всегда старайтесь думать о том, что будет если вам нужно будет повторно выполнить одну и ту же операцию, какие могут быть риски и как избежать головной боли =)
Позже рассмотрим идемпотентность HTTP-методов
#junior #php #architecture #source
{kind=link}
Symfony .env и как его готовить
Чем больше я сталкиваюсь с проектами, тем больше вижу, что мало кто использует .env в Symfony так, как это рекомендуют в документации фреймворка. Решил остановиться на этом подробнее.
❓Как было всегда?
В Symfony до 2018 года и во многих других фреймворках мы использовали комбинацию
С какими проблемами можно столкнуться?
📌 При развертке проекта. Не смотря на то, что названия переменных есть, но сами значения надо где-то взять. Приходится что-то придумывать, у кого-то спрашивать, лезть в разные конфиги, что не очень удобно. Конечно многие выкручиваются тем, что добавляют их прямо в dist, а потом перезаписывают руками.
📌 При добавлении новой переменной всем разработчикам следует сразу добавить её в свой
👉 В целом со всем этим можно жить и нет критических проблем, но что предлагают ребята из Symfony?
❗️ Первое, что бросается в глаза, это коммитить(!)
❓ А если даже для локалки не все данные можно коммитить?
👉 Для этого необходимо создать файл
👉 Для каждой среды вы можете сделать свои файлы, например
👍 Фишки:
📌 При установке некоторых пакетов заботливый Symfony Flex будет сразу добавлять в ваш
📌 Реальные переменные окружения (export) имеют преимущество над переменными из файлов. Если нужно — вы можете спокойно экспортировать переменные или сделать source .env и отказаться от использования файла.
📌 Чтобы ускорить продакшн можно использовать
📌 Вы можете переиспользовать уже объявленные переменные внутри своего
Чем больше я сталкиваюсь с проектами, тем больше вижу, что мало кто использует .env в Symfony так, как это рекомендуют в документации фреймворка. Решил остановиться на этом подробнее.
❓Как было всегда?
В Symfony до 2018 года и во многих других фреймворках мы использовали комбинацию
.env и .env.dist (или .env.example). При этом сам .env не коммится в репозиторий (что логично), а .env.dist имел, как правило, только набор переменных и пустых значений.С какими проблемами можно столкнуться?
📌 При развертке проекта. Не смотря на то, что названия переменных есть, но сами значения надо где-то взять. Приходится что-то придумывать, у кого-то спрашивать, лезть в разные конфиги, что не очень удобно. Конечно многие выкручиваются тем, что добавляют их прямо в dist, а потом перезаписывают руками.
📌 При добавлении новой переменной всем разработчикам следует сразу добавить её в свой
.env, иначе при использовании в контейнере мы быстро отловим Exception. Конечно это тоже можно обойти и задать дефолтные значения прямо в yml.👉 В целом со всем этим можно жить и нет критических проблем, но что предлагают ребята из Symfony?
❗️ Первое, что бросается в глаза, это коммитить(!)
.env. Но спокойно, это сделано, чтобы в данный файл можно было внести настройки по-умолчанию для локальной разработки. ❓ А если даже для локалки не все данные можно коммитить?
👉 Для этого необходимо создать файл
.env.local, который будет иметь более высокий приоритет, чем .env, а значит переопределит заданные переменные. Там можно перезаписать необходимые переменные. Все файлы ".local" не коммитятся, то есть для каждого отдельного сервака/компа можно создать и использовать свой .env.local.👉 Для каждой среды вы можете сделать свои файлы, например
.env.dev, .env.test, .env.prod, они также переопределять дефолтные значения, но только в рамках заданного окружения. Эти файлы также коммитятся. Таким образом можно выстроить гибкую иерархию дефолтных значений на все случаи жизни.👍 Фишки:
📌 При установке некоторых пакетов заботливый Symfony Flex будет сразу добавлять в ваш
.env файл необходимые переменные, чтобы вы не забыли об этом. Например после установки Sentry composer require sentry/sentry-symfony, в env появятся вот такие строки.📌 Реальные переменные окружения (export) имеют преимущество над переменными из файлов. Если нужно — вы можете спокойно экспортировать переменные или сделать source .env и отказаться от использования файла.
📌 Чтобы ускорить продакшн можно использовать
composer dump-env prod, который создаст .env.local.php. Это позволит не тратить лишние ресурсы на парсинг .env файла при каждом запросе.📌 Вы можете переиспользовать уже объявленные переменные внутри своего
.env, например:DB_USER=root#php #symfony #env #middle #source
DB_PASS=${DB_USER}-password # присвоит значение root-password
{kind=link}
🔥1
Введение в Opcode и Opcache
Во время нескольких последних собеседований, которые я проводил, задавал кандидатам на Middle позицию вопрос: Можешь в общих чертах рассказать что такое Opcache, зачем он нужен и как он работает? К сожалению ни один из них даже не попытался. Я был крайне удивлён, ведь в последнее время эта тема была на слуху, благодаря preload и JIT. Но практика показывает обратное. Подумал, что стоит посвятить короткий пост (не вдаваясь в подробности выделяемой памяти и работы ZMM) этой теме.
👉 Все мы знаем, что PHP — интерпретируемый язык. Но что на самом деле происходит с нашим PHP скриптом?
📌 Изначально наш код читается, происходит его разбор и преобразование в так называемые "токены". Это позволяет нашему интерпретатору разбить код на фрагменты, понять где они находятся. Этот процесс называется токенизация или лексирование.
📌 Дальше, имея токены, происходит синтаксический анализ (он также называется parsing), который генерирует абстрактное синтаксическое дерево (Abstract Syntax Tree — AST) для того чтобы было проще понять какие есть операции и какой у них приоритет. На этом этапе приходит анализ тех самых токенов. Уверен, что каждый из вас хоть раз видел ошибку типа:
📌 Дальше происходит компиляция (преобразование) AST в операционный код (Opcode), который наконец и сможет быть выполнен. Не стоит путать, преобразование происходит не в команды ассемблера (очень низкоуровневые), это именно опкоды для виртуальной машины PHP, в них гораздо больше логики.
📌 Далее, виртуальный движок Zend VM (Virtual Machine) получает список наших Opcode и выполняет их! Вот схема всего процесса.
❗️Но после выполнения опкоды немедленно уничтожаются. Возникает вопрос: зачем нам каждый раз токенизирвоать, парсить и компилировать PHP код?
Очень маловероятно, что на production-серверах PHP-код изменится между выполнением нескольких запросов, а значит и Opcode будет точно таким же.
👍 В связи с этим было разработано расширение для кэширования опкодов — Opcache. Его главная задача — единожды скомпилировать каждый PHP-скрипт и закэшировать получившиеся опкоды в общую память, чтобы их мог считать и выполнить каждый рабочий процесс PHP из вашего пула (PHP-FPM). Вот схема с учетом использования Opcache. Расширение Opcache поставляется с PHP.
👌 В результате на запуск скрипта уходит как минимум вдвое меньше времени (сильно зависит от самого скрипта). Чем сложнее приложение, тем выше эффективность этой оптимизации.
#php #middle #opcache #source
Во время нескольких последних собеседований, которые я проводил, задавал кандидатам на Middle позицию вопрос: Можешь в общих чертах рассказать что такое Opcache, зачем он нужен и как он работает? К сожалению ни один из них даже не попытался. Я был крайне удивлён, ведь в последнее время эта тема была на слуху, благодаря preload и JIT. Но практика показывает обратное. Подумал, что стоит посвятить короткий пост (не вдаваясь в подробности выделяемой памяти и работы ZMM) этой теме.
👉 Все мы знаем, что PHP — интерпретируемый язык. Но что на самом деле происходит с нашим PHP скриптом?
📌 Изначально наш код читается, происходит его разбор и преобразование в так называемые "токены". Это позволяет нашему интерпретатору разбить код на фрагменты, понять где они находятся. Этот процесс называется токенизация или лексирование.
📌 Дальше, имея токены, происходит синтаксический анализ (он также называется parsing), который генерирует абстрактное синтаксическое дерево (Abstract Syntax Tree — AST) для того чтобы было проще понять какие есть операции и какой у них приоритет. На этом этапе приходит анализ тех самых токенов. Уверен, что каждый из вас хоть раз видел ошибку типа:
Parse error: syntax error, unexpected token "==", expecting "(" in script.php on line 10.
и задавался вопросом "что за token"? Теперь тайна раскрыта :)📌 Дальше происходит компиляция (преобразование) AST в операционный код (Opcode), который наконец и сможет быть выполнен. Не стоит путать, преобразование происходит не в команды ассемблера (очень низкоуровневые), это именно опкоды для виртуальной машины PHP, в них гораздо больше логики.
📌 Далее, виртуальный движок Zend VM (Virtual Machine) получает список наших Opcode и выполняет их! Вот схема всего процесса.
❗️Но после выполнения опкоды немедленно уничтожаются. Возникает вопрос: зачем нам каждый раз токенизирвоать, парсить и компилировать PHP код?
Очень маловероятно, что на production-серверах PHP-код изменится между выполнением нескольких запросов, а значит и Opcode будет точно таким же.
👍 В связи с этим было разработано расширение для кэширования опкодов — Opcache. Его главная задача — единожды скомпилировать каждый PHP-скрипт и закэшировать получившиеся опкоды в общую память, чтобы их мог считать и выполнить каждый рабочий процесс PHP из вашего пула (PHP-FPM). Вот схема с учетом использования Opcache. Расширение Opcache поставляется с PHP.
👌 В результате на запуск скрипта уходит как минимум вдвое меньше времени (сильно зависит от самого скрипта). Чем сложнее приложение, тем выше эффективность этой оптимизации.
#php #middle #opcache #source
{kind=link}
🔥2
Хеш-таблицы, HashTables (part-1)
Ну что, отпуск окончен, теперь с новыми силами пришла пора приступить к статьям :) Здесь речь пойдёт именно о структуре данных. То есть пока мы не будем вдаваться во внутренности php (например под капотом языка массивы реализованы именно с помощью хеш-таблиц).
👉 Хеш-таблица — это структура данных для хранения пар ключ-значение. Проще всего представить себе хеш-таблицу в виде массива. Важно то, что местоположение элемента зависит от самого элемента. Связь между значением элемента и его позицией в хеш-таблице задает хеш-функция.
Пока звучит сложно, но сейчас попробуем разобраться ;) Для начала определимся с тем, что такое хеширование.
👉 Хеширование — операция, которая преобразует любые входные данные в строку (реже число) фиксированной длины. Функция, реализующая алгоритм преобразования, называется "хеш-функцией", а результат называют "хешем" или "хеш-суммой". Наиболее известны CRC32, MD5 и SHA (много разновидностей). Также стоит упомянуть, что хеш не имеет возможности быть преобразованным обратно в исходные данные.
Для решения нашей задачи хеш-функция принимает в качестве аргумента какой-то элемент (который нужно вставить в хеш-таблицу), а в результате выдает позицию заданного элемента в хеш-таблицы (то есть индекс). Любая операция внутри хеш-таблицы начинается с того, что ключ каким-либо образом преобразуется в индекс обычного массива.
❗️ Например, на картинке выше мы видим, что хеш-функция сопоставила ключ
Для получения индекса нужно выполнить два действия: найти хеш и привести его к индексу (например, через остаток от деления).
❗️ Главное, что ваша хеш-функция должна:
1. Быстро вычислять хеш (индекс), в разных источниках можно встретить понятие "адрес", это одно и то же;
2. Всегда возвращать один и тот же адрес для одного и того же ключа;
3. Использует все адресное пространство с одинаковой вероятностью;
❓ Зачем так всё усложнять?
👍 Вся прелесть этой структуры данных заключается в скорости выполнения операций, но об этом мы поговорим в следующей части. Если забыли о том, что такое О-большое, то вот напоминалка ;)
#middle #algorithm #source
Ну что, отпуск окончен, теперь с новыми силами пришла пора приступить к статьям :) Здесь речь пойдёт именно о структуре данных. То есть пока мы не будем вдаваться во внутренности php (например под капотом языка массивы реализованы именно с помощью хеш-таблиц).
👉 Хеш-таблица — это структура данных для хранения пар ключ-значение. Проще всего представить себе хеш-таблицу в виде массива. Важно то, что местоположение элемента зависит от самого элемента. Связь между значением элемента и его позицией в хеш-таблице задает хеш-функция.
Пока звучит сложно, но сейчас попробуем разобраться ;) Для начала определимся с тем, что такое хеширование.
👉 Хеширование — операция, которая преобразует любые входные данные в строку (реже число) фиксированной длины. Функция, реализующая алгоритм преобразования, называется "хеш-функцией", а результат называют "хешем" или "хеш-суммой". Наиболее известны CRC32, MD5 и SHA (много разновидностей). Также стоит упомянуть, что хеш не имеет возможности быть преобразованным обратно в исходные данные.
Для решения нашей задачи хеш-функция принимает в качестве аргумента какой-то элемент (который нужно вставить в хеш-таблицу), а в результате выдает позицию заданного элемента в хеш-таблицы (то есть индекс). Любая операция внутри хеш-таблицы начинается с того, что ключ каким-либо образом преобразуется в индекс обычного массива.
❗️ Например, на картинке выше мы видим, что хеш-функция сопоставила ключ
John Smith с индексом 873, а далее в хеш-таблицу под этим индексом было записано значение, а если быть точным, то комплексный объект, содержащий исходный ключ и значение (в нашем случае номер телефона).Для получения индекса нужно выполнить два действия: найти хеш и привести его к индексу (например, через остаток от деления).
$key = 'John Doe';📌 В данном примере мы используем так называемое "адресное пространство", которое задаёт размеры нашей хеш-таблицы. Так как мы получаем остаток от деления на 1000, то все значения нашего индекса будут лежать в диапазоне от 0 до 999. Возникает вопрос "может ли случиться так, что для разных ключей будет рассчитан один и тот же индекс?" — может, но это не значит, что значения затрутся. Структура таблицы станет чуть сложнее, незначительно вырастет вычислительная сложность, но подробнее об этом в следующем посте ;)
$index = crc32($key) % 1000; // по модулю
print_r($index); // => 434
❗️ Главное, что ваша хеш-функция должна:
1. Быстро вычислять хеш (индекс), в разных источниках можно встретить понятие "адрес", это одно и то же;
2. Всегда возвращать один и тот же адрес для одного и того же ключа;
3. Использует все адресное пространство с одинаковой вероятностью;
❓ Зачем так всё усложнять?
👍 Вся прелесть этой структуры данных заключается в скорости выполнения операций, но об этом мы поговорим в следующей части. Если забыли о том, что такое О-большое, то вот напоминалка ;)
#middle #algorithm #source
{kind=link}
Хеш-таблицы, Hash Tables (part 2)
В данной части мы немного подробнее поговорим о вычислительной скорости (О большое) и о том, как там всё происходит под капотом.
👉 Ранее мы рассматривали бинарный поиск по телефонному справочнику. Хоть он работает достаточно быстро, но всё равно занимает время
❓ Но при чем тут хеш-таблица?
Продолжим рассматривать пример из предыдущего поста. Представим, что у нас есть пустой массив
👍 Теперь, когда вам понадобится номер телефона, искать в массиве ничего не нужно — просто передайте строку в хеш функцию и она укажет вам, что номер хранится в массиве с определенным индексом:
❗️ Так как количество элементов в хеш-таблице ограничено (в нашем примере адресное пространство от 0 до 999), а множество всех возможных ключей — бесконечно, то не для всех входных данных найдётся уникальный хеш. На каком-то этапе возможно появление дублей (когда для разных значений получается один и тот же хеш). Такую ситуацию принято называть коллизией.
👌 Для решения подобных ситуаций можно использовать метод цепочек:
Суть этого способа заключается в том, что каждая ячейка хеш-таблицы является ссылкой на связный список. Каждый новый элемент добавляется в конец этого списка. Коллизии приводят к тому, что в таблице появляются списки, которые содержат несколько элементов.
То есть, если ячейка с хешем уже занята, но новый ключ отличается от уже имеющегося, то новый элемент вставляется в список в виде пары ключ-значение.
Если выбран метод цепочек, то вставка нового элемента происходит за
😅 Cтруктур хэш-таблиц огромное множество, и ни один из них не совершенен, в каждом есть компромиссы. Одни варианты лучше при добавлении данных, другие — при поиске и т. д. Выбирайте реализацию в зависимости от того, что для вас важнее.
В данной части мы немного подробнее поговорим о вычислительной скорости (О большое) и о том, как там всё происходит под капотом.
👉 Ранее мы рассматривали бинарный поиск по телефонному справочнику. Хоть он работает достаточно быстро, но всё равно занимает время
O(log n). Теперь представьте, что есть человек с феноменальной памятью, который смог запомнить все записи из этого справочника и вместо того, чтобы искать телефон в книге — вам достаточно назвать имя и фамилию, а этот человек мгновенно предоставит номер телефона. Получается, что в этом случае он может назвать номер телефона за время О(1), независимо от размера справочника. То есть этот алгоритм работает еще быстрее, чем бинарный поиск.❓ Но при чем тут хеш-таблица?
Продолжим рассматривать пример из предыдущего поста. Представим, что у нас есть пустой массив
$phones = []; В котором и будут храниться все номера телефонов. Передаём "Sam Doe" в нашу хеш-функцию, получаем 998, сохраняем номер телефона в элементе массива с индексом 998:$phones = [];По аналогии добавим туда и других абонентов, пока наш массив не будет заполнен всеми номерами справочника.
$index = someHashFunction('Sam Doe');
$phones[$index] = '+1-555-5030';
👍 Теперь, когда вам понадобится номер телефона, искать в массиве ничего не нужно — просто передайте строку в хеш функцию и она укажет вам, что номер хранится в массиве с определенным индексом:
$index = someHashFunction('Lisa Smith'); // 1
$phone = $phones[$index];
Соответственно мы сразу знаем где находится элемент, а значит, что скорость выполнения операции поиска (а также вставки и удаления) равна O(1). Но сразу оговорюсь, что это не совсем так. ❗️ Так как количество элементов в хеш-таблице ограничено (в нашем примере адресное пространство от 0 до 999), а множество всех возможных ключей — бесконечно, то не для всех входных данных найдётся уникальный хеш. На каком-то этапе возможно появление дублей (когда для разных значений получается один и тот же хеш). Такую ситуацию принято называть коллизией.
$index = someHashFunction('Sam Doe'); // 234
$index = someHashFunction('Jack Duck'); // 234 👌 Для решения подобных ситуаций можно использовать метод цепочек:
Суть этого способа заключается в том, что каждая ячейка хеш-таблицы является ссылкой на связный список. Каждый новый элемент добавляется в конец этого списка. Коллизии приводят к тому, что в таблице появляются списки, которые содержат несколько элементов.
То есть, если ячейка с хешем уже занята, но новый ключ отличается от уже имеющегося, то новый элемент вставляется в список в виде пары ключ-значение.
Если выбран метод цепочек, то вставка нового элемента происходит за
O(1), а время поиска зависит от длины списка и в худшем случае равно O(n). Если количество ключей n, а распределяем по m-ячейкам, то соотношение n/m будет коэффициентом заполнения.😅 Cтруктур хэш-таблиц огромное множество, и ни один из них не совершенен, в каждом есть компромиссы. Одни варианты лучше при добавлении данных, другие — при поиске и т. д. Выбирайте реализацию в зависимости от того, что для вас важнее.
{kind=link}
👍1
Атрибуты (part 1, что это такое?)
Сейчас много разговоров о PHP 8, ещё больше о 8.1. Есть куча крутых фишек, есть спорные, а есть те, с которыми лень разбираться. Одна из таких атрибуты. К сожалению только несколько человек из тех, кого я собеседовал, смогли ответить на вопрос — что это такое. Причины могут быть разные (еще не перешли на 8 / долго и лениво читать / оно как-то работает и пусть), но для тех, кто всё же хочет чуть-чуть разобраться я пишу этот пост.
👉 Сама концепция уже давно известна, мы много лет используем аннотации (докблоки) для добавления каких-то метаданных к классам, свойствам, методам, переменным и т.д. Думаю всем давно известны примеры из PHPUnit, Doctrine ORM, Assert и многих других либок и фреймворков.
❓ Как это работало раньше?
В PHP докблоки «рефлексивны»: к ним можно получить доступ с помощью метода API Reflection getDocComment() на уровне функции, класса, метода и атрибута. Сначала нужно было получить комментарии класса и метода(ов), затем с помощью регулярных выражений распарсить необходимые аннотации. Код выглядел примерно так.
❓ Как это работает сейчас и в чём разница?
📌 Атрибуты дают фактически те-же возможности, однако этот способ конфигурации встроен непосредственно в язык, что даёт преимущество в скорости и читабельности. Если раньше некоторые не использовали аннотации, аргументируя это тем, что аннотации - по сути комментарии и не могут быть кодом для выполнения, а так же, функционал, который их использует, сложно распространять, то сейчас это часть языка. Вот так это может выглядеть теперь.
📌 Также можно (а согласно документации даже очень нужно) создавать классы атрибутов для этого нужно использовать атрибут
👌 В следующей части рассмотрим ограничения, повторяющиеся атрибуты, класс
#php #middle #source
Сейчас много разговоров о PHP 8, ещё больше о 8.1. Есть куча крутых фишек, есть спорные, а есть те, с которыми лень разбираться. Одна из таких атрибуты. К сожалению только несколько человек из тех, кого я собеседовал, смогли ответить на вопрос — что это такое. Причины могут быть разные (еще не перешли на 8 / долго и лениво читать / оно как-то работает и пусть), но для тех, кто всё же хочет чуть-чуть разобраться я пишу этот пост.
👉 Сама концепция уже давно известна, мы много лет используем аннотации (докблоки) для добавления каких-то метаданных к классам, свойствам, методам, переменным и т.д. Думаю всем давно известны примеры из PHPUnit, Doctrine ORM, Assert и многих других либок и фреймворков.
❓ Как это работало раньше?
В PHP докблоки «рефлексивны»: к ним можно получить доступ с помощью метода API Reflection getDocComment() на уровне функции, класса, метода и атрибута. Сначала нужно было получить комментарии класса и метода(ов), затем с помощью регулярных выражений распарсить необходимые аннотации. Код выглядел примерно так.
❓ Как это работает сейчас и в чём разница?
📌 Атрибуты дают фактически те-же возможности, однако этот способ конфигурации встроен непосредственно в язык, что даёт преимущество в скорости и читабельности. Если раньше некоторые не использовали аннотации, аргументируя это тем, что аннотации - по сути комментарии и не могут быть кодом для выполнения, а так же, функционал, который их использует, сложно распространять, то сейчас это часть языка. Вот так это может выглядеть теперь.
📌 Также можно (а согласно документации даже очень нужно) создавать классы атрибутов для этого нужно использовать атрибут
#[Attribute], который можно импортировать из глобального пространства имён с помощью оператора use. Они могут быть пустыми, но так-же могут содержать дополнительную информацию, в виде параметров которую также легко можно прочитать:$attributes = $reflection->getAttributes(MyAttribute::class);
foreach ($attributes as $attribute) {
$attribute->getArguments();
}
Как вы поняли из примера, параметры будут переданы в конструктор класса MyAttribute. Параметры могут быть простыми скалярными типами, массивами, константами и т.д. 👌 В следующей части рассмотрим ограничения, повторяющиеся атрибуты, класс
ReflectionAttribute и фильтрацию ;)#php #middle #source
{kind=link}
👍1
Битовые операции (часть 1, сдвиг влево и вправо)
📌 В мире PHP эти операции встречаются редко, однако в статьях, книгах, либках и других источниках легко можно встретить запись типа:
❓ Чё сдвигается, куда? Зачем вообще оно надо? Давайте разбираться.
Думаю многие знают, что число в двоичной (бинарной) системе исчисления представляет собой набор нулей и единиц. Например число 6 будет представлено как 00000110.
👍 Побитовый сдвиг в PHP - это арифметическая операция. Биты, сдвинутые за границы числа, отбрасываются. Сдвиг влево дополняет число нулями справа, сдвигая в то же время знаковый бит числа влево, что означает что знак операнда не сохраняется. Сдвиг вправо сохраняет копию сдвинутого знакового бита слева, что означает что знак операнда сохраняется.
Возвращаемся к нашему оператору
❗️ Стоп. Да это же степени двойки!
Возвращаясь к нашему первому примеру
#php #junior #source
📌 В мире PHP эти операции встречаются редко, однако в статьях, книгах, либках и других источниках легко можно встретить запись типа:
~
$memory = memory_get_usage() >> 20;
И тут наступает ступор, что за ">>"? Лезешь в доку а там $a >> $b — Сдвиг вправо. Все биты переменной $a сдвигаются на $b позиций вправо (каждая позиция подразумевает "деление на 2").❓ Чё сдвигается, куда? Зачем вообще оно надо? Давайте разбираться.
Думаю многие знают, что число в двоичной (бинарной) системе исчисления представляет собой набор нулей и единиц. Например число 6 будет представлено как 00000110.
👍 Побитовый сдвиг в PHP - это арифметическая операция. Биты, сдвинутые за границы числа, отбрасываются. Сдвиг влево дополняет число нулями справа, сдвигая в то же время знаковый бит числа влево, что означает что знак операнда не сохраняется. Сдвиг вправо сохраняет копию сдвинутого знакового бита слева, что означает что знак операнда сохраняется.
Возвращаемся к нашему оператору
>> $n = 6; // 00000110👉 Здесь четко видно, что мы отбросили самый правый бит, а слева дополнили нулём. Соответственно запись 00000011 в двоичном представлении равна 3 в десятичном. То есть фактически сдвинув один бит — мы поделили на 2, а если сдвинем на 2 бита, то еще раз поделим на 2 (то есть на 4), на 3 бита — получится что на 8.
$k = $n >> 1; // 00000011
❗️ Стоп. Да это же степени двойки!
Возвращаясь к нашему первому примеру
>> 20, получится, что мы делим наше исходное значение на 2 в степени 20. Легко запомнить, что 2^10 = 1024. Тогда: $memory = memory_get_usage() / (1024 * 1024);Так как функция
memory_get_usage() возвращает значение в байтах, то мы всего-лишь перевели всё в Мб. Получается достаточно удобно:>> 10 приводит в КбВ то время как сдвиг вправо означает деление, то сдвиг влево — умножение.
>> 20 приводит в Мб
>> 30 приводит в Гб
$y = 5; // 000000101
echo $y << 2; // 000010100 (5 * 4 = 20)
❤️ Однако, самое вкусное использование побитовых операций заключается не в умножении и делении, а именно в использовании побитовой маски, например для разграничений прав доступа, или других подобных операций:define('U_READ', 1 << 0); // 0001
define('U_CREATE', 1 << 1); // 0010
define('U_EDIT', 1 << 2); // 0100
define('U_DELETE', 1 << 3); // 1000
define('U_ALL', U_READ | U_CREATE | U_EDIT | U_DELETE); // 1111
Выглядит интересно, но об этом и других битовых операциях мы поговорим в следующей части :)#php #junior #source
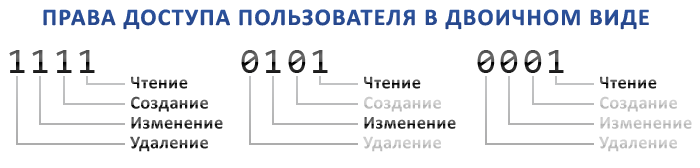{kind=link}
❤4
Битовые операции (часть 2)
В прошлой части мы рассмотрели побитовые сдвиги влево и вправо, сегодня рассмотрим остальные 4 операции — AND & , OR | , XOR ^, NOT ~.
Для примера рассмотрим простую систему разграничения прав доступа к сайту.
📌 У нас будут доступны следующие права доступа: Чтение, Создание, Редактирование, Удаление. То есть всего 4 значения, их можно представить в виде 4-х битного числа, в котором 1 — означает, что у пользователя есть данное право, а 0 — нет. Разберем код из предыдущей части:
define('U_READ', 1 << 0); // 0001
define('U_CREATE', 1 << 1); // 0010
define('U_EDIT', 1 << 2); // 0100
define('U_DELETE', 1 << 3); // 1000
define('U_ALL', U_READ | U_CREATE | U_EDIT | U_DELETE); // 1111
В первых 4 строках мы задали константы с помощью сдвига влево. А в пятой строке использовали оператор OR |. Он выполняет операцию над каждым битом своих операндов. Бит результата устанавливается, если соответствующий бит установлен хотя бы в одном операнде. Например:
$x = 3; // 0011
$y = 5; // 0101
echo $x | $y; // 0111 (7)
Таким образом мы можем задать любые разрешения для пользователя:
$userPermission = U_READ; // только право чтения
$userPermission = U_READ | U_CREATE; // можно читать и создавать
$userPermission = U_ALL ^ U_DELETE; // все права кроме удаления
$userPermission = U_ALL & ~ U_DELETE; // тоже все права кроме удаления
📌 В данном примере мы видим XOR ^ (исключающее или). Бит устанавливается, если соответствующий бит установлен в одном (но не в обоих) из двух операндов.
$x = 3; // 0011
$y = 5; // 0101
echo $x ^ $y; // 0110 (6)
В нашем случае:
U_ALL 1111
U_DELETE 1000
RESULT 0111
📌 В следующей строке сразу 2 оператора AND & и NOT ~. Оператор & выполняет операцию логическое И над каждым битом своих операндов. Бит результата устанавливается, если соответствующий бит установлен в обоих операндах:
$x = 3; // 0011
$y = 5; // 0101
echo $x & $y; // 0001 (1)
📌 Оператор NOT ~ представляет собой унарный оператор, указываемый перед своим единственным операндом. Он выполняет инверсию всех битов операнда. Из-за способа представления целых со знаком в PHP применение оператора ~ к значению эквивалентно изменению его знака и вычитанию 1.
$y = 5; // 0101
echo ~$y; // 1010 (-6)
Таким образом в нашем примере сначала сработает оператор NOT. U_DELETE из 1000 станет 0111, а затем вызовется оператор &
U_ALL 1111
~ U_DELETE 0111
RESULT 0111
❗️ Разница между этими вариантами в том, что в первом случае просто переключается бит, если был 1, то станет 0, и наоборот. Второй же вариант делает бит равным 0, независимо от его текущего значения.
Если мы хотим убрать какое-нибудь право доступа, то пишем так:
$userPermission &= ~ U_DELETE; // запретить удаление
👉 Для проверки битов (в нашем случае прав доступа) можно использовать следующие конструкции.
if ($userPermission & U_READ) // есть ли право чтения?
if ($userPermission & (U_READ | U_DELETE)) // есть ли право чтения и/или удаления
Еще один пример:
// Вместо
if ($error['type'] == E_ERROR || $error['type'] == E_PARSE || $error['type'] == E_COMPILE_ERROR) {}
// Или
if (in_array($error['type'], [E_ERROR, E_PARSE, E_COMPILE_ERROR])) {}
// Можно использовать
if ($error['type'] & (E_ERROR | E_PARSE | E_COMPILE_ERROR)) {}
👍 Несмотря на то, что коды ошибок в PHP специально заточены под битовые операции, тем не менее, достаточно часто для проверки кодов ошибок используются обычные операторы сравнения. Но теперь вы знаете, что можно сравнивать и побитово ;)
#php #junior #source
В прошлой части мы рассмотрели побитовые сдвиги влево и вправо, сегодня рассмотрим остальные 4 операции — AND & , OR | , XOR ^, NOT ~.
Для примера рассмотрим простую систему разграничения прав доступа к сайту.
📌 У нас будут доступны следующие права доступа: Чтение, Создание, Редактирование, Удаление. То есть всего 4 значения, их можно представить в виде 4-х битного числа, в котором 1 — означает, что у пользователя есть данное право, а 0 — нет. Разберем код из предыдущей части:
define('U_READ', 1 << 0); // 0001
define('U_CREATE', 1 << 1); // 0010
define('U_EDIT', 1 << 2); // 0100
define('U_DELETE', 1 << 3); // 1000
define('U_ALL', U_READ | U_CREATE | U_EDIT | U_DELETE); // 1111
В первых 4 строках мы задали константы с помощью сдвига влево. А в пятой строке использовали оператор OR |. Он выполняет операцию над каждым битом своих операндов. Бит результата устанавливается, если соответствующий бит установлен хотя бы в одном операнде. Например:
$x = 3; // 0011
$y = 5; // 0101
echo $x | $y; // 0111 (7)
Таким образом мы можем задать любые разрешения для пользователя:
$userPermission = U_READ; // только право чтения
$userPermission = U_READ | U_CREATE; // можно читать и создавать
$userPermission = U_ALL ^ U_DELETE; // все права кроме удаления
$userPermission = U_ALL & ~ U_DELETE; // тоже все права кроме удаления
📌 В данном примере мы видим XOR ^ (исключающее или). Бит устанавливается, если соответствующий бит установлен в одном (но не в обоих) из двух операндов.
$x = 3; // 0011
$y = 5; // 0101
echo $x ^ $y; // 0110 (6)
В нашем случае:
U_ALL 1111
U_DELETE 1000
RESULT 0111
📌 В следующей строке сразу 2 оператора AND & и NOT ~. Оператор & выполняет операцию логическое И над каждым битом своих операндов. Бит результата устанавливается, если соответствующий бит установлен в обоих операндах:
$x = 3; // 0011
$y = 5; // 0101
echo $x & $y; // 0001 (1)
📌 Оператор NOT ~ представляет собой унарный оператор, указываемый перед своим единственным операндом. Он выполняет инверсию всех битов операнда. Из-за способа представления целых со знаком в PHP применение оператора ~ к значению эквивалентно изменению его знака и вычитанию 1.
$y = 5; // 0101
echo ~$y; // 1010 (-6)
Таким образом в нашем примере сначала сработает оператор NOT. U_DELETE из 1000 станет 0111, а затем вызовется оператор &
U_ALL 1111
~ U_DELETE 0111
RESULT 0111
❗️ Разница между этими вариантами в том, что в первом случае просто переключается бит, если был 1, то станет 0, и наоборот. Второй же вариант делает бит равным 0, независимо от его текущего значения.
Если мы хотим убрать какое-нибудь право доступа, то пишем так:
$userPermission &= ~ U_DELETE; // запретить удаление
👉 Для проверки битов (в нашем случае прав доступа) можно использовать следующие конструкции.
if ($userPermission & U_READ) // есть ли право чтения?
if ($userPermission & (U_READ | U_DELETE)) // есть ли право чтения и/или удаления
Еще один пример:
// Вместо
if ($error['type'] == E_ERROR || $error['type'] == E_PARSE || $error['type'] == E_COMPILE_ERROR) {}
// Или
if (in_array($error['type'], [E_ERROR, E_PARSE, E_COMPILE_ERROR])) {}
// Можно использовать
if ($error['type'] & (E_ERROR | E_PARSE | E_COMPILE_ERROR)) {}
👍 Несмотря на то, что коды ошибок в PHP специально заточены под битовые операции, тем не менее, достаточно часто для проверки кодов ошибок используются обычные операторы сравнения. Но теперь вы знаете, что можно сравнивать и побитово ;)
#php #junior #source
❤1