
Autoload (автозагрузчик)
На всякий случай начнём с основ, т.к. не все знают, как это работает.
👉 Все мы ежедневно создаём классы, которые помещаем в отдельные файлы. Внутри класса мы можем использовать другие классы. И для того, чтобы наш интерпретатор знал о используемом классе, мы должны подключить (
❗️ PHP позволяет тебе зарегистрировать автозагрузчик
Сразу пример, как это сделать с помощью функции spl_autoload_register(). Можно зарегистрировать любое число автозагрузчиков (то есть много раз объявить эту самую функцию). Например, если ты подключаешь стороннюю библиотеку, то она может зарегистрировать свой автозагрузчик для загрузки своих классов. Таким образом, каждая библиотека может самостоятельно решать, как она будет искать и подключать файлы.
📁 Если ни один автозагрузчик не подключит файл с вызываемым классом, то будет выведена ошибка об обращении к несуществующему классу. Вот примеры, когда автозагрузчик будет вызван, а когда нет.
👍 Несколько правил, если нужно написать автозагрузчик самостоятельно:
📌 Aвтозагрузчик не должен выдавать ошибку, если он не может найти файл с классом — может быть, этот класс подгрузит следующий автозагрузчик.
📌 Нужно писать автозагрузчик только для своих файлов и не использовать файлы сторонних библиотек.
📌 Не нужно изобретать свои правила сопоставления имен классов и файлов, лучше всего использовать общепринятый стандарт PSR-4 (о нем поговорим позже).
#php #autoload #junior #source
На всякий случай начнём с основ, т.к. не все знают, как это работает.
👉 Все мы ежедневно создаём классы, которые помещаем в отдельные файлы. Внутри класса мы можем использовать другие классы. И для того, чтобы наш интерпретатор знал о используемом классе, мы должны подключить (
require) файл, в котором описан используемый класс. Пока вроде просто. Когда число классов увеличивается, писать все эти require_once становится неудобно. Но выход есть!❗️ PHP позволяет тебе зарегистрировать автозагрузчик
Сразу пример, как это сделать с помощью функции spl_autoload_register(). Можно зарегистрировать любое число автозагрузчиков (то есть много раз объявить эту самую функцию). Например, если ты подключаешь стороннюю библиотеку, то она может зарегистрировать свой автозагрузчик для загрузки своих классов. Таким образом, каждая библиотека может самостоятельно решать, как она будет искать и подключать файлы.
📁 Если ни один автозагрузчик не подключит файл с вызываемым классом, то будет выведена ошибка об обращении к несуществующему классу. Вот примеры, когда автозагрузчик будет вызван, а когда нет.
👍 Несколько правил, если нужно написать автозагрузчик самостоятельно:
📌 Aвтозагрузчик не должен выдавать ошибку, если он не может найти файл с классом — может быть, этот класс подгрузит следующий автозагрузчик.
📌 Нужно писать автозагрузчик только для своих файлов и не использовать файлы сторонних библиотек.
📌 Не нужно изобретать свои правила сопоставления имен классов и файлов, лучше всего использовать общепринятый стандарт PSR-4 (о нем поговорим позже).
#php #autoload #junior #source
{kind=link}
❓Опросник❓
👉 Ребзя, хочу улучшить контент, который я выкладываю в этом канале, в связи с чем, сделал этот опросник.
Внутри всего 5 вопросов, которые могут помочь мне лучше понять, что за подписчики тут тусуются, а следовательно лучше адаптировать материал под вас :)
👍 Четыре вопроса обязательных, но там достаточно быстро тыкнуть мышкой. Последний — для творческого полёта мыслей и на него необязательно отвечать, но я буду очень благодарен тем людям, которые там напишут хотя-бы 1-2 предложения.
Короче, залетай, заполняй, помоги автору делать топовый контент!
👉 Ребзя, хочу улучшить контент, который я выкладываю в этом канале, в связи с чем, сделал этот опросник.
Внутри всего 5 вопросов, которые могут помочь мне лучше понять, что за подписчики тут тусуются, а следовательно лучше адаптировать материал под вас :)
👍 Четыре вопроса обязательных, но там достаточно быстро тыкнуть мышкой. Последний — для творческого полёта мыслей и на него необязательно отвечать, но я буду очень благодарен тем людям, которые там напишут хотя-бы 1-2 предложения.
Короче, залетай, заполняй, помоги автору делать топовый контент!
PSR-4 и Composer autoload
А пока полным ходом идёт заполнение опросника, спешу продолжить тему автозагрузчика. Кстати, реально спасибо всем, кто заполнил опросник. Я не ожидал, что будет столько отклика и полезных ответов. Позже обязательно сведу все результаты и поделюсь с вами, а пока перейдем к материалу =)
😢 Вообще тема PSR достаточно болезненна. Не многие знают, что это не только "правила кодстайла", но и вполне универсальные, стандартизированные концепции, для переиспользования в абсолютно разных проектах.
👉 Начало было положено в 2010 с PSR-0 (Autoloading Standard), который ни много ни мало стал первым шагом к объединению фреймворков, а также безболезненной возможности установки пакетов в ваше приложение (напр. composer в 2012). Однако уже в 2014 ему на смену пришел PSR-4, а PSR-0 был объявлен deprecated.
📌 Согласно PSR-4 мы должны называть файл, взяв название класса и добавив к нему расширение
📌 Наш файл должен лежать в каталоге, путь которого совпадает с частями нашего namespace. Например
Обычно в качестве неймспейса верхнего уровня выбирают название приложения / пакета, иногда вместе с названием компании или ником разработчика (например в фреймворке Symfony все классы лежат внутри неймспейса Symfony). По мере роста пакета добавляются дополнительные уровни вложенности и получится что-то вроде
Composer autoload
👍 Но, чтобы не писать свой автозагрузчик руками - можно использовать
❗️ Нужно обратить внимание, что:
1. Важно писать
2. В качестве разделителя использовать двойной бекслеш
3. В конце неймспейса также следует указывать
📌 Также есть возможность указать fallback каталог, в котором будет искаться любое пространство имён, для этого оставляем неймспейс пустым.
🔗 Все ссылки будут объеденены во время
🤝 Вам остается только подключить файл в свой проект с помощью
Также напоминаю, что обсудить любую тему и прокомментировать пост можно в нашем чатике, так что присоединяйся 🍺
#php #psr #autoload #composer #junior #source
А пока полным ходом идёт заполнение опросника, спешу продолжить тему автозагрузчика. Кстати, реально спасибо всем, кто заполнил опросник. Я не ожидал, что будет столько отклика и полезных ответов. Позже обязательно сведу все результаты и поделюсь с вами, а пока перейдем к материалу =)
😢 Вообще тема PSR достаточно болезненна. Не многие знают, что это не только "правила кодстайла", но и вполне универсальные, стандартизированные концепции, для переиспользования в абсолютно разных проектах.
👉 Начало было положено в 2010 с PSR-0 (Autoloading Standard), который ни много ни мало стал первым шагом к объединению фреймворков, а также безболезненной возможности установки пакетов в ваше приложение (напр. composer в 2012). Однако уже в 2014 ему на смену пришел PSR-4, а PSR-0 был объявлен deprecated.
📌 Согласно PSR-4 мы должны называть файл, взяв название класса и добавив к нему расширение
.php, при этом регистр названия класса и файла должны полностью совпадать.📌 Наш файл должен лежать в каталоге, путь которого совпадает с частями нашего namespace. Например
MyModule\Sub\SomeClass будет лежать по пути MyModule/Sub/SomeClass.php.Обычно в качестве неймспейса верхнего уровня выбирают название приложения / пакета, иногда вместе с названием компании или ником разработчика (например в фреймворке Symfony все классы лежат внутри неймспейса Symfony). По мере роста пакета добавляются дополнительные уровни вложенности и получится что-то вроде
\Symfony\Component\HttpFoundation\Request.Composer autoload
👍 Но, чтобы не писать свой автозагрузчик руками - можно использовать
composer.json. Для этого в нём следует создать директиву autoload, во внутри которого прописать "psr-4" и правила, по которым следует сопоставить корневой неймспейс с корневой папкой проекта. Это будет выглядеть так.❗️ Нужно обратить внимание, что:
1. Важно писать
psr-4 именно в нижнем регистре.2. В качестве разделителя использовать двойной бекслеш
\\ — это особенность json, первый он воспринимает как экранирование.3. В конце неймспейса также следует указывать
\\
📌 Есть возможность поиска определенного неймспейса сразу в нескольких директориях, для этого их нужно указать как массив.📌 Также есть возможность указать fallback каталог, в котором будет искаться любое пространство имён, для этого оставляем неймспейс пустым.
🔗 Все ссылки будут объеденены во время
install / update / dump-autoload в один массив, который композер положит в сгенерированный файл vendor/composer/autoload_psr4.php и пробросит путь к нему в основной файл автозагрузки vendor/autoload.php (там могут быть подключены и другие файлы типа psr-0, classmap и т.д.)🤝 Вам остается только подключить файл в свой проект с помощью
require_once __DIR__ . '/vendor/autoload.php'; и можно избавить себя от необходимости писать собственный автозагрузчик.Также напоминаю, что обсудить любую тему и прокомментировать пост можно в нашем чатике, так что присоединяйся 🍺
#php #psr #autoload #composer #junior #source
{kind=link}
Идемпотентные операции
Идемпотентность помогает проектировать более надёжные системы. На самом деле это математическая концепция, которая гласит: идемпотентная операция — это операция, которая не имеет дополнительного эффекта, если она вызывается более одного раза с одними и теми же входными параметрами. Другими словами, если вы выполните одну и ту же операцию несколько раз подряд, то результат не изменится.
Например умножение на 0 и на 1 — идемпотентная операция:
📌 Migrations
👉 Представьте ситуацию: Ваше приложение растёт и перед вами поставили задачу разделить сущность/таблицу Users на данные для доступа Access (напр. login, password, token) и профиля Profile (name, surname, address и т.д.).
❓ Вам нужно написать миграцию, которая создаст 2 новые таблицы в них скопирует необходимые данные пользователей, после чего исходную таблицу переименует в deprecated. Но что если посреди копирования миграция крашнется? Что произойдёт если запустить миграцию еще раз?
👍 Чтобы не беспокоиться об этом — позаботьтесь об идемпотентности ваших миграций. Если ваша БД поддерживает транзакции этих операций — не забудьте их использовать. Если у ваc MySQL, где для операций DDL (
📌 Message Queues
👉 Другой пример: Вам надо отправить письма определенной группе пользователей, но посреди отправки вы понимаете, что что-то пошло не так, у вас проблемы с SMTP и ваши письма перестали отправляться. После того как работа SMTP была восстановлена — вам нужно продолжить отправку. Но что будет, если вы запустите команду второй раз?
👍 Для решения — используйте очереди, которые гарантируют доставку. Если по какой-то причине нет такой возможности, то помечайте в базе кому уже письма были отправлены, чтобы они не принимали участия в следующей выборке.
С одной стороны вроде описанные вещи достаточно очевидны, с другой нельзя забывать о них во время проектирования. Всегда старайтесь думать о том, что будет если вам нужно будет повторно выполнить одну и ту же операцию, какие могут быть риски и как избежать головной боли =)
Позже рассмотрим идемпотентность HTTP-методов
#junior #php #architecture #source
Идемпотентность помогает проектировать более надёжные системы. На самом деле это математическая концепция, которая гласит: идемпотентная операция — это операция, которая не имеет дополнительного эффекта, если она вызывается более одного раза с одними и теми же входными параметрами. Другими словами, если вы выполните одну и ту же операцию несколько раз подряд, то результат не изменится.
Например умножение на 0 и на 1 — идемпотентная операция:
x * 1 == x * 1 * 1Присваивание — тоже идемпотентная, хотя первый вызов присваивания, можно сказать, имеет побочный эффект, но повторное выполнение не приведет ни к чему другому:
x * 0 == x * 0 * 0
x := 4Но при чем тут Веб-приложения?
📌 Migrations
👉 Представьте ситуацию: Ваше приложение растёт и перед вами поставили задачу разделить сущность/таблицу Users на данные для доступа Access (напр. login, password, token) и профиля Profile (name, surname, address и т.д.).
❓ Вам нужно написать миграцию, которая создаст 2 новые таблицы в них скопирует необходимые данные пользователей, после чего исходную таблицу переименует в deprecated. Но что если посреди копирования миграция крашнется? Что произойдёт если запустить миграцию еще раз?
👍 Чтобы не беспокоиться об этом — позаботьтесь об идемпотентности ваших миграций. Если ваша БД поддерживает транзакции этих операций — не забудьте их использовать. Если у ваc MySQL, где для операций DDL (
CREATE, ALTER, DROP) нет возможности сделать транзакцию, позаботьтесь о том, чтобы использовать CREATE TABLE IF NOT EXISTS, а данные для копирования не просто выбирались полностью (SELECT * FROM USERS), а брались только те, у которых еще нет ряда в Profiles.📌 Message Queues
👉 Другой пример: Вам надо отправить письма определенной группе пользователей, но посреди отправки вы понимаете, что что-то пошло не так, у вас проблемы с SMTP и ваши письма перестали отправляться. После того как работа SMTP была восстановлена — вам нужно продолжить отправку. Но что будет, если вы запустите команду второй раз?
👍 Для решения — используйте очереди, которые гарантируют доставку. Если по какой-то причине нет такой возможности, то помечайте в базе кому уже письма были отправлены, чтобы они не принимали участия в следующей выборке.
С одной стороны вроде описанные вещи достаточно очевидны, с другой нельзя забывать о них во время проектирования. Всегда старайтесь думать о том, что будет если вам нужно будет повторно выполнить одну и ту же операцию, какие могут быть риски и как избежать головной боли =)
Позже рассмотрим идемпотентность HTTP-методов
#junior #php #architecture #source
{kind=link}
Symfony .env и как его готовить
Чем больше я сталкиваюсь с проектами, тем больше вижу, что мало кто использует .env в Symfony так, как это рекомендуют в документации фреймворка. Решил остановиться на этом подробнее.
❓Как было всегда?
В Symfony до 2018 года и во многих других фреймворках мы использовали комбинацию
С какими проблемами можно столкнуться?
📌 При развертке проекта. Не смотря на то, что названия переменных есть, но сами значения надо где-то взять. Приходится что-то придумывать, у кого-то спрашивать, лезть в разные конфиги, что не очень удобно. Конечно многие выкручиваются тем, что добавляют их прямо в dist, а потом перезаписывают руками.
📌 При добавлении новой переменной всем разработчикам следует сразу добавить её в свой
👉 В целом со всем этим можно жить и нет критических проблем, но что предлагают ребята из Symfony?
❗️ Первое, что бросается в глаза, это коммитить(!)
❓ А если даже для локалки не все данные можно коммитить?
👉 Для этого необходимо создать файл
👉 Для каждой среды вы можете сделать свои файлы, например
👍 Фишки:
📌 При установке некоторых пакетов заботливый Symfony Flex будет сразу добавлять в ваш
📌 Реальные переменные окружения (export) имеют преимущество над переменными из файлов. Если нужно — вы можете спокойно экспортировать переменные или сделать source .env и отказаться от использования файла.
📌 Чтобы ускорить продакшн можно использовать
📌 Вы можете переиспользовать уже объявленные переменные внутри своего
Чем больше я сталкиваюсь с проектами, тем больше вижу, что мало кто использует .env в Symfony так, как это рекомендуют в документации фреймворка. Решил остановиться на этом подробнее.
❓Как было всегда?
В Symfony до 2018 года и во многих других фреймворках мы использовали комбинацию
.env и .env.dist (или .env.example). При этом сам .env не коммится в репозиторий (что логично), а .env.dist имел, как правило, только набор переменных и пустых значений.С какими проблемами можно столкнуться?
📌 При развертке проекта. Не смотря на то, что названия переменных есть, но сами значения надо где-то взять. Приходится что-то придумывать, у кого-то спрашивать, лезть в разные конфиги, что не очень удобно. Конечно многие выкручиваются тем, что добавляют их прямо в dist, а потом перезаписывают руками.
📌 При добавлении новой переменной всем разработчикам следует сразу добавить её в свой
.env, иначе при использовании в контейнере мы быстро отловим Exception. Конечно это тоже можно обойти и задать дефолтные значения прямо в yml.👉 В целом со всем этим можно жить и нет критических проблем, но что предлагают ребята из Symfony?
❗️ Первое, что бросается в глаза, это коммитить(!)
.env. Но спокойно, это сделано, чтобы в данный файл можно было внести настройки по-умолчанию для локальной разработки. ❓ А если даже для локалки не все данные можно коммитить?
👉 Для этого необходимо создать файл
.env.local, который будет иметь более высокий приоритет, чем .env, а значит переопределит заданные переменные. Там можно перезаписать необходимые переменные. Все файлы ".local" не коммитятся, то есть для каждого отдельного сервака/компа можно создать и использовать свой .env.local.👉 Для каждой среды вы можете сделать свои файлы, например
.env.dev, .env.test, .env.prod, они также переопределять дефолтные значения, но только в рамках заданного окружения. Эти файлы также коммитятся. Таким образом можно выстроить гибкую иерархию дефолтных значений на все случаи жизни.👍 Фишки:
📌 При установке некоторых пакетов заботливый Symfony Flex будет сразу добавлять в ваш
.env файл необходимые переменные, чтобы вы не забыли об этом. Например после установки Sentry composer require sentry/sentry-symfony, в env появятся вот такие строки.📌 Реальные переменные окружения (export) имеют преимущество над переменными из файлов. Если нужно — вы можете спокойно экспортировать переменные или сделать source .env и отказаться от использования файла.
📌 Чтобы ускорить продакшн можно использовать
composer dump-env prod, который создаст .env.local.php. Это позволит не тратить лишние ресурсы на парсинг .env файла при каждом запросе.📌 Вы можете переиспользовать уже объявленные переменные внутри своего
.env, например:DB_USER=root#php #symfony #env #middle #source
DB_PASS=${DB_USER}-password # присвоит значение root-password
{kind=link}
🔥1
Введение в Opcode и Opcache
Во время нескольких последних собеседований, которые я проводил, задавал кандидатам на Middle позицию вопрос: Можешь в общих чертах рассказать что такое Opcache, зачем он нужен и как он работает? К сожалению ни один из них даже не попытался. Я был крайне удивлён, ведь в последнее время эта тема была на слуху, благодаря preload и JIT. Но практика показывает обратное. Подумал, что стоит посвятить короткий пост (не вдаваясь в подробности выделяемой памяти и работы ZMM) этой теме.
👉 Все мы знаем, что PHP — интерпретируемый язык. Но что на самом деле происходит с нашим PHP скриптом?
📌 Изначально наш код читается, происходит его разбор и преобразование в так называемые "токены". Это позволяет нашему интерпретатору разбить код на фрагменты, понять где они находятся. Этот процесс называется токенизация или лексирование.
📌 Дальше, имея токены, происходит синтаксический анализ (он также называется parsing), который генерирует абстрактное синтаксическое дерево (Abstract Syntax Tree — AST) для того чтобы было проще понять какие есть операции и какой у них приоритет. На этом этапе приходит анализ тех самых токенов. Уверен, что каждый из вас хоть раз видел ошибку типа:
📌 Дальше происходит компиляция (преобразование) AST в операционный код (Opcode), который наконец и сможет быть выполнен. Не стоит путать, преобразование происходит не в команды ассемблера (очень низкоуровневые), это именно опкоды для виртуальной машины PHP, в них гораздо больше логики.
📌 Далее, виртуальный движок Zend VM (Virtual Machine) получает список наших Opcode и выполняет их! Вот схема всего процесса.
❗️Но после выполнения опкоды немедленно уничтожаются. Возникает вопрос: зачем нам каждый раз токенизирвоать, парсить и компилировать PHP код?
Очень маловероятно, что на production-серверах PHP-код изменится между выполнением нескольких запросов, а значит и Opcode будет точно таким же.
👍 В связи с этим было разработано расширение для кэширования опкодов — Opcache. Его главная задача — единожды скомпилировать каждый PHP-скрипт и закэшировать получившиеся опкоды в общую память, чтобы их мог считать и выполнить каждый рабочий процесс PHP из вашего пула (PHP-FPM). Вот схема с учетом использования Opcache. Расширение Opcache поставляется с PHP.
👌 В результате на запуск скрипта уходит как минимум вдвое меньше времени (сильно зависит от самого скрипта). Чем сложнее приложение, тем выше эффективность этой оптимизации.
#php #middle #opcache #source
Во время нескольких последних собеседований, которые я проводил, задавал кандидатам на Middle позицию вопрос: Можешь в общих чертах рассказать что такое Opcache, зачем он нужен и как он работает? К сожалению ни один из них даже не попытался. Я был крайне удивлён, ведь в последнее время эта тема была на слуху, благодаря preload и JIT. Но практика показывает обратное. Подумал, что стоит посвятить короткий пост (не вдаваясь в подробности выделяемой памяти и работы ZMM) этой теме.
👉 Все мы знаем, что PHP — интерпретируемый язык. Но что на самом деле происходит с нашим PHP скриптом?
📌 Изначально наш код читается, происходит его разбор и преобразование в так называемые "токены". Это позволяет нашему интерпретатору разбить код на фрагменты, понять где они находятся. Этот процесс называется токенизация или лексирование.
📌 Дальше, имея токены, происходит синтаксический анализ (он также называется parsing), который генерирует абстрактное синтаксическое дерево (Abstract Syntax Tree — AST) для того чтобы было проще понять какие есть операции и какой у них приоритет. На этом этапе приходит анализ тех самых токенов. Уверен, что каждый из вас хоть раз видел ошибку типа:
Parse error: syntax error, unexpected token "==", expecting "(" in script.php on line 10.
и задавался вопросом "что за token"? Теперь тайна раскрыта :)📌 Дальше происходит компиляция (преобразование) AST в операционный код (Opcode), который наконец и сможет быть выполнен. Не стоит путать, преобразование происходит не в команды ассемблера (очень низкоуровневые), это именно опкоды для виртуальной машины PHP, в них гораздо больше логики.
📌 Далее, виртуальный движок Zend VM (Virtual Machine) получает список наших Opcode и выполняет их! Вот схема всего процесса.
❗️Но после выполнения опкоды немедленно уничтожаются. Возникает вопрос: зачем нам каждый раз токенизирвоать, парсить и компилировать PHP код?
Очень маловероятно, что на production-серверах PHP-код изменится между выполнением нескольких запросов, а значит и Opcode будет точно таким же.
👍 В связи с этим было разработано расширение для кэширования опкодов — Opcache. Его главная задача — единожды скомпилировать каждый PHP-скрипт и закэшировать получившиеся опкоды в общую память, чтобы их мог считать и выполнить каждый рабочий процесс PHP из вашего пула (PHP-FPM). Вот схема с учетом использования Opcache. Расширение Opcache поставляется с PHP.
👌 В результате на запуск скрипта уходит как минимум вдвое меньше времени (сильно зависит от самого скрипта). Чем сложнее приложение, тем выше эффективность этой оптимизации.
#php #middle #opcache #source
{kind=link}
🔥2
Хеш-таблицы, HashTables (part-1)
Ну что, отпуск окончен, теперь с новыми силами пришла пора приступить к статьям :) Здесь речь пойдёт именно о структуре данных. То есть пока мы не будем вдаваться во внутренности php (например под капотом языка массивы реализованы именно с помощью хеш-таблиц).
👉 Хеш-таблица — это структура данных для хранения пар ключ-значение. Проще всего представить себе хеш-таблицу в виде массива. Важно то, что местоположение элемента зависит от самого элемента. Связь между значением элемента и его позицией в хеш-таблице задает хеш-функция.
Пока звучит сложно, но сейчас попробуем разобраться ;) Для начала определимся с тем, что такое хеширование.
👉 Хеширование — операция, которая преобразует любые входные данные в строку (реже число) фиксированной длины. Функция, реализующая алгоритм преобразования, называется "хеш-функцией", а результат называют "хешем" или "хеш-суммой". Наиболее известны CRC32, MD5 и SHA (много разновидностей). Также стоит упомянуть, что хеш не имеет возможности быть преобразованным обратно в исходные данные.
Для решения нашей задачи хеш-функция принимает в качестве аргумента какой-то элемент (который нужно вставить в хеш-таблицу), а в результате выдает позицию заданного элемента в хеш-таблицы (то есть индекс). Любая операция внутри хеш-таблицы начинается с того, что ключ каким-либо образом преобразуется в индекс обычного массива.
❗️ Например, на картинке выше мы видим, что хеш-функция сопоставила ключ
Для получения индекса нужно выполнить два действия: найти хеш и привести его к индексу (например, через остаток от деления).
❗️ Главное, что ваша хеш-функция должна:
1. Быстро вычислять хеш (индекс), в разных источниках можно встретить понятие "адрес", это одно и то же;
2. Всегда возвращать один и тот же адрес для одного и того же ключа;
3. Использует все адресное пространство с одинаковой вероятностью;
❓ Зачем так всё усложнять?
👍 Вся прелесть этой структуры данных заключается в скорости выполнения операций, но об этом мы поговорим в следующей части. Если забыли о том, что такое О-большое, то вот напоминалка ;)
#middle #algorithm #source
Ну что, отпуск окончен, теперь с новыми силами пришла пора приступить к статьям :) Здесь речь пойдёт именно о структуре данных. То есть пока мы не будем вдаваться во внутренности php (например под капотом языка массивы реализованы именно с помощью хеш-таблиц).
👉 Хеш-таблица — это структура данных для хранения пар ключ-значение. Проще всего представить себе хеш-таблицу в виде массива. Важно то, что местоположение элемента зависит от самого элемента. Связь между значением элемента и его позицией в хеш-таблице задает хеш-функция.
Пока звучит сложно, но сейчас попробуем разобраться ;) Для начала определимся с тем, что такое хеширование.
👉 Хеширование — операция, которая преобразует любые входные данные в строку (реже число) фиксированной длины. Функция, реализующая алгоритм преобразования, называется "хеш-функцией", а результат называют "хешем" или "хеш-суммой". Наиболее известны CRC32, MD5 и SHA (много разновидностей). Также стоит упомянуть, что хеш не имеет возможности быть преобразованным обратно в исходные данные.
Для решения нашей задачи хеш-функция принимает в качестве аргумента какой-то элемент (который нужно вставить в хеш-таблицу), а в результате выдает позицию заданного элемента в хеш-таблицы (то есть индекс). Любая операция внутри хеш-таблицы начинается с того, что ключ каким-либо образом преобразуется в индекс обычного массива.
❗️ Например, на картинке выше мы видим, что хеш-функция сопоставила ключ
John Smith с индексом 873, а далее в хеш-таблицу под этим индексом было записано значение, а если быть точным, то комплексный объект, содержащий исходный ключ и значение (в нашем случае номер телефона).Для получения индекса нужно выполнить два действия: найти хеш и привести его к индексу (например, через остаток от деления).
$key = 'John Doe';📌 В данном примере мы используем так называемое "адресное пространство", которое задаёт размеры нашей хеш-таблицы. Так как мы получаем остаток от деления на 1000, то все значения нашего индекса будут лежать в диапазоне от 0 до 999. Возникает вопрос "может ли случиться так, что для разных ключей будет рассчитан один и тот же индекс?" — может, но это не значит, что значения затрутся. Структура таблицы станет чуть сложнее, незначительно вырастет вычислительная сложность, но подробнее об этом в следующем посте ;)
$index = crc32($key) % 1000; // по модулю
print_r($index); // => 434
❗️ Главное, что ваша хеш-функция должна:
1. Быстро вычислять хеш (индекс), в разных источниках можно встретить понятие "адрес", это одно и то же;
2. Всегда возвращать один и тот же адрес для одного и того же ключа;
3. Использует все адресное пространство с одинаковой вероятностью;
❓ Зачем так всё усложнять?
👍 Вся прелесть этой структуры данных заключается в скорости выполнения операций, но об этом мы поговорим в следующей части. Если забыли о том, что такое О-большое, то вот напоминалка ;)
#middle #algorithm #source
{kind=link}
Хеш-таблицы, Hash Tables (part 2)
В данной части мы немного подробнее поговорим о вычислительной скорости (О большое) и о том, как там всё происходит под капотом.
👉 Ранее мы рассматривали бинарный поиск по телефонному справочнику. Хоть он работает достаточно быстро, но всё равно занимает время
❓ Но при чем тут хеш-таблица?
Продолжим рассматривать пример из предыдущего поста. Представим, что у нас есть пустой массив
👍 Теперь, когда вам понадобится номер телефона, искать в массиве ничего не нужно — просто передайте строку в хеш функцию и она укажет вам, что номер хранится в массиве с определенным индексом:
❗️ Так как количество элементов в хеш-таблице ограничено (в нашем примере адресное пространство от 0 до 999), а множество всех возможных ключей — бесконечно, то не для всех входных данных найдётся уникальный хеш. На каком-то этапе возможно появление дублей (когда для разных значений получается один и тот же хеш). Такую ситуацию принято называть коллизией.
👌 Для решения подобных ситуаций можно использовать метод цепочек:
Суть этого способа заключается в том, что каждая ячейка хеш-таблицы является ссылкой на связный список. Каждый новый элемент добавляется в конец этого списка. Коллизии приводят к тому, что в таблице появляются списки, которые содержат несколько элементов.
То есть, если ячейка с хешем уже занята, но новый ключ отличается от уже имеющегося, то новый элемент вставляется в список в виде пары ключ-значение.
Если выбран метод цепочек, то вставка нового элемента происходит за
😅 Cтруктур хэш-таблиц огромное множество, и ни один из них не совершенен, в каждом есть компромиссы. Одни варианты лучше при добавлении данных, другие — при поиске и т. д. Выбирайте реализацию в зависимости от того, что для вас важнее.
В данной части мы немного подробнее поговорим о вычислительной скорости (О большое) и о том, как там всё происходит под капотом.
👉 Ранее мы рассматривали бинарный поиск по телефонному справочнику. Хоть он работает достаточно быстро, но всё равно занимает время
O(log n). Теперь представьте, что есть человек с феноменальной памятью, который смог запомнить все записи из этого справочника и вместо того, чтобы искать телефон в книге — вам достаточно назвать имя и фамилию, а этот человек мгновенно предоставит номер телефона. Получается, что в этом случае он может назвать номер телефона за время О(1), независимо от размера справочника. То есть этот алгоритм работает еще быстрее, чем бинарный поиск.❓ Но при чем тут хеш-таблица?
Продолжим рассматривать пример из предыдущего поста. Представим, что у нас есть пустой массив
$phones = []; В котором и будут храниться все номера телефонов. Передаём "Sam Doe" в нашу хеш-функцию, получаем 998, сохраняем номер телефона в элементе массива с индексом 998:$phones = [];По аналогии добавим туда и других абонентов, пока наш массив не будет заполнен всеми номерами справочника.
$index = someHashFunction('Sam Doe');
$phones[$index] = '+1-555-5030';
👍 Теперь, когда вам понадобится номер телефона, искать в массиве ничего не нужно — просто передайте строку в хеш функцию и она укажет вам, что номер хранится в массиве с определенным индексом:
$index = someHashFunction('Lisa Smith'); // 1
$phone = $phones[$index];
Соответственно мы сразу знаем где находится элемент, а значит, что скорость выполнения операции поиска (а также вставки и удаления) равна O(1). Но сразу оговорюсь, что это не совсем так. ❗️ Так как количество элементов в хеш-таблице ограничено (в нашем примере адресное пространство от 0 до 999), а множество всех возможных ключей — бесконечно, то не для всех входных данных найдётся уникальный хеш. На каком-то этапе возможно появление дублей (когда для разных значений получается один и тот же хеш). Такую ситуацию принято называть коллизией.
$index = someHashFunction('Sam Doe'); // 234
$index = someHashFunction('Jack Duck'); // 234 👌 Для решения подобных ситуаций можно использовать метод цепочек:
Суть этого способа заключается в том, что каждая ячейка хеш-таблицы является ссылкой на связный список. Каждый новый элемент добавляется в конец этого списка. Коллизии приводят к тому, что в таблице появляются списки, которые содержат несколько элементов.
То есть, если ячейка с хешем уже занята, но новый ключ отличается от уже имеющегося, то новый элемент вставляется в список в виде пары ключ-значение.
Если выбран метод цепочек, то вставка нового элемента происходит за
O(1), а время поиска зависит от длины списка и в худшем случае равно O(n). Если количество ключей n, а распределяем по m-ячейкам, то соотношение n/m будет коэффициентом заполнения.😅 Cтруктур хэш-таблиц огромное множество, и ни один из них не совершенен, в каждом есть компромиссы. Одни варианты лучше при добавлении данных, другие — при поиске и т. д. Выбирайте реализацию в зависимости от того, что для вас важнее.
{kind=link}
👍1
Атрибуты (part 1, что это такое?)
Сейчас много разговоров о PHP 8, ещё больше о 8.1. Есть куча крутых фишек, есть спорные, а есть те, с которыми лень разбираться. Одна из таких атрибуты. К сожалению только несколько человек из тех, кого я собеседовал, смогли ответить на вопрос — что это такое. Причины могут быть разные (еще не перешли на 8 / долго и лениво читать / оно как-то работает и пусть), но для тех, кто всё же хочет чуть-чуть разобраться я пишу этот пост.
👉 Сама концепция уже давно известна, мы много лет используем аннотации (докблоки) для добавления каких-то метаданных к классам, свойствам, методам, переменным и т.д. Думаю всем давно известны примеры из PHPUnit, Doctrine ORM, Assert и многих других либок и фреймворков.
❓ Как это работало раньше?
В PHP докблоки «рефлексивны»: к ним можно получить доступ с помощью метода API Reflection getDocComment() на уровне функции, класса, метода и атрибута. Сначала нужно было получить комментарии класса и метода(ов), затем с помощью регулярных выражений распарсить необходимые аннотации. Код выглядел примерно так.
❓ Как это работает сейчас и в чём разница?
📌 Атрибуты дают фактически те-же возможности, однако этот способ конфигурации встроен непосредственно в язык, что даёт преимущество в скорости и читабельности. Если раньше некоторые не использовали аннотации, аргументируя это тем, что аннотации - по сути комментарии и не могут быть кодом для выполнения, а так же, функционал, который их использует, сложно распространять, то сейчас это часть языка. Вот так это может выглядеть теперь.
📌 Также можно (а согласно документации даже очень нужно) создавать классы атрибутов для этого нужно использовать атрибут
👌 В следующей части рассмотрим ограничения, повторяющиеся атрибуты, класс
#php #middle #source
Сейчас много разговоров о PHP 8, ещё больше о 8.1. Есть куча крутых фишек, есть спорные, а есть те, с которыми лень разбираться. Одна из таких атрибуты. К сожалению только несколько человек из тех, кого я собеседовал, смогли ответить на вопрос — что это такое. Причины могут быть разные (еще не перешли на 8 / долго и лениво читать / оно как-то работает и пусть), но для тех, кто всё же хочет чуть-чуть разобраться я пишу этот пост.
👉 Сама концепция уже давно известна, мы много лет используем аннотации (докблоки) для добавления каких-то метаданных к классам, свойствам, методам, переменным и т.д. Думаю всем давно известны примеры из PHPUnit, Doctrine ORM, Assert и многих других либок и фреймворков.
❓ Как это работало раньше?
В PHP докблоки «рефлексивны»: к ним можно получить доступ с помощью метода API Reflection getDocComment() на уровне функции, класса, метода и атрибута. Сначала нужно было получить комментарии класса и метода(ов), затем с помощью регулярных выражений распарсить необходимые аннотации. Код выглядел примерно так.
❓ Как это работает сейчас и в чём разница?
📌 Атрибуты дают фактически те-же возможности, однако этот способ конфигурации встроен непосредственно в язык, что даёт преимущество в скорости и читабельности. Если раньше некоторые не использовали аннотации, аргументируя это тем, что аннотации - по сути комментарии и не могут быть кодом для выполнения, а так же, функционал, который их использует, сложно распространять, то сейчас это часть языка. Вот так это может выглядеть теперь.
📌 Также можно (а согласно документации даже очень нужно) создавать классы атрибутов для этого нужно использовать атрибут
#[Attribute], который можно импортировать из глобального пространства имён с помощью оператора use. Они могут быть пустыми, но так-же могут содержать дополнительную информацию, в виде параметров которую также легко можно прочитать:$attributes = $reflection->getAttributes(MyAttribute::class);
foreach ($attributes as $attribute) {
$attribute->getArguments();
}
Как вы поняли из примера, параметры будут переданы в конструктор класса MyAttribute. Параметры могут быть простыми скалярными типами, массивами, константами и т.д. 👌 В следующей части рассмотрим ограничения, повторяющиеся атрибуты, класс
ReflectionAttribute и фильтрацию ;)#php #middle #source
{kind=link}
👍1
Битовые операции (часть 1, сдвиг влево и вправо)
📌 В мире PHP эти операции встречаются редко, однако в статьях, книгах, либках и других источниках легко можно встретить запись типа:
❓ Чё сдвигается, куда? Зачем вообще оно надо? Давайте разбираться.
Думаю многие знают, что число в двоичной (бинарной) системе исчисления представляет собой набор нулей и единиц. Например число 6 будет представлено как 00000110.
👍 Побитовый сдвиг в PHP - это арифметическая операция. Биты, сдвинутые за границы числа, отбрасываются. Сдвиг влево дополняет число нулями справа, сдвигая в то же время знаковый бит числа влево, что означает что знак операнда не сохраняется. Сдвиг вправо сохраняет копию сдвинутого знакового бита слева, что означает что знак операнда сохраняется.
Возвращаемся к нашему оператору
❗️ Стоп. Да это же степени двойки!
Возвращаясь к нашему первому примеру
#php #junior #source
📌 В мире PHP эти операции встречаются редко, однако в статьях, книгах, либках и других источниках легко можно встретить запись типа:
~
$memory = memory_get_usage() >> 20;
И тут наступает ступор, что за ">>"? Лезешь в доку а там $a >> $b — Сдвиг вправо. Все биты переменной $a сдвигаются на $b позиций вправо (каждая позиция подразумевает "деление на 2").❓ Чё сдвигается, куда? Зачем вообще оно надо? Давайте разбираться.
Думаю многие знают, что число в двоичной (бинарной) системе исчисления представляет собой набор нулей и единиц. Например число 6 будет представлено как 00000110.
👍 Побитовый сдвиг в PHP - это арифметическая операция. Биты, сдвинутые за границы числа, отбрасываются. Сдвиг влево дополняет число нулями справа, сдвигая в то же время знаковый бит числа влево, что означает что знак операнда не сохраняется. Сдвиг вправо сохраняет копию сдвинутого знакового бита слева, что означает что знак операнда сохраняется.
Возвращаемся к нашему оператору
>> $n = 6; // 00000110👉 Здесь четко видно, что мы отбросили самый правый бит, а слева дополнили нулём. Соответственно запись 00000011 в двоичном представлении равна 3 в десятичном. То есть фактически сдвинув один бит — мы поделили на 2, а если сдвинем на 2 бита, то еще раз поделим на 2 (то есть на 4), на 3 бита — получится что на 8.
$k = $n >> 1; // 00000011
❗️ Стоп. Да это же степени двойки!
Возвращаясь к нашему первому примеру
>> 20, получится, что мы делим наше исходное значение на 2 в степени 20. Легко запомнить, что 2^10 = 1024. Тогда: $memory = memory_get_usage() / (1024 * 1024);Так как функция
memory_get_usage() возвращает значение в байтах, то мы всего-лишь перевели всё в Мб. Получается достаточно удобно:>> 10 приводит в КбВ то время как сдвиг вправо означает деление, то сдвиг влево — умножение.
>> 20 приводит в Мб
>> 30 приводит в Гб
$y = 5; // 000000101
echo $y << 2; // 000010100 (5 * 4 = 20)
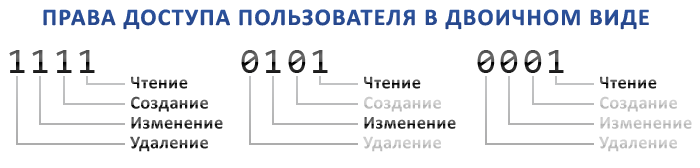
❤️ Однако, самое вкусное использование побитовых операций заключается не в умножении и делении, а именно в использовании побитовой маски, например для разграничений прав доступа, или других подобных операций:define('U_READ', 1 << 0); // 0001
define('U_CREATE', 1 << 1); // 0010
define('U_EDIT', 1 << 2); // 0100
define('U_DELETE', 1 << 3); // 1000
define('U_ALL', U_READ | U_CREATE | U_EDIT | U_DELETE); // 1111
Выглядит интересно, но об этом и других битовых операциях мы поговорим в следующей части :)#php #junior #source
{kind=link}
❤4
Битовые операции (часть 2)
В прошлой части мы рассмотрели побитовые сдвиги влево и вправо, сегодня рассмотрим остальные 4 операции — AND & , OR | , XOR ^, NOT ~.
Для примера рассмотрим простую систему разграничения прав доступа к сайту.
📌 У нас будут доступны следующие права доступа: Чтение, Создание, Редактирование, Удаление. То есть всего 4 значения, их можно представить в виде 4-х битного числа, в котором 1 — означает, что у пользователя есть данное право, а 0 — нет. Разберем код из предыдущей части:
define('U_READ', 1 << 0); // 0001
define('U_CREATE', 1 << 1); // 0010
define('U_EDIT', 1 << 2); // 0100
define('U_DELETE', 1 << 3); // 1000
define('U_ALL', U_READ | U_CREATE | U_EDIT | U_DELETE); // 1111
В первых 4 строках мы задали константы с помощью сдвига влево. А в пятой строке использовали оператор OR |. Он выполняет операцию над каждым битом своих операндов. Бит результата устанавливается, если соответствующий бит установлен хотя бы в одном операнде. Например:
$x = 3; // 0011
$y = 5; // 0101
echo $x | $y; // 0111 (7)
Таким образом мы можем задать любые разрешения для пользователя:
$userPermission = U_READ; // только право чтения
$userPermission = U_READ | U_CREATE; // можно читать и создавать
$userPermission = U_ALL ^ U_DELETE; // все права кроме удаления
$userPermission = U_ALL & ~ U_DELETE; // тоже все права кроме удаления
📌 В данном примере мы видим XOR ^ (исключающее или). Бит устанавливается, если соответствующий бит установлен в одном (но не в обоих) из двух операндов.
$x = 3; // 0011
$y = 5; // 0101
echo $x ^ $y; // 0110 (6)
В нашем случае:
U_ALL 1111
U_DELETE 1000
RESULT 0111
📌 В следующей строке сразу 2 оператора AND & и NOT ~. Оператор & выполняет операцию логическое И над каждым битом своих операндов. Бит результата устанавливается, если соответствующий бит установлен в обоих операндах:
$x = 3; // 0011
$y = 5; // 0101
echo $x & $y; // 0001 (1)
📌 Оператор NOT ~ представляет собой унарный оператор, указываемый перед своим единственным операндом. Он выполняет инверсию всех битов операнда. Из-за способа представления целых со знаком в PHP применение оператора ~ к значению эквивалентно изменению его знака и вычитанию 1.
$y = 5; // 0101
echo ~$y; // 1010 (-6)
Таким образом в нашем примере сначала сработает оператор NOT. U_DELETE из 1000 станет 0111, а затем вызовется оператор &
U_ALL 1111
~ U_DELETE 0111
RESULT 0111
❗️ Разница между этими вариантами в том, что в первом случае просто переключается бит, если был 1, то станет 0, и наоборот. Второй же вариант делает бит равным 0, независимо от его текущего значения.
Если мы хотим убрать какое-нибудь право доступа, то пишем так:
$userPermission &= ~ U_DELETE; // запретить удаление
👉 Для проверки битов (в нашем случае прав доступа) можно использовать следующие конструкции.
if ($userPermission & U_READ) // есть ли право чтения?
if ($userPermission & (U_READ | U_DELETE)) // есть ли право чтения и/или удаления
Еще один пример:
// Вместо
if ($error['type'] == E_ERROR || $error['type'] == E_PARSE || $error['type'] == E_COMPILE_ERROR) {}
// Или
if (in_array($error['type'], [E_ERROR, E_PARSE, E_COMPILE_ERROR])) {}
// Можно использовать
if ($error['type'] & (E_ERROR | E_PARSE | E_COMPILE_ERROR)) {}
👍 Несмотря на то, что коды ошибок в PHP специально заточены под битовые операции, тем не менее, достаточно часто для проверки кодов ошибок используются обычные операторы сравнения. Но теперь вы знаете, что можно сравнивать и побитово ;)
#php #junior #source
В прошлой части мы рассмотрели побитовые сдвиги влево и вправо, сегодня рассмотрим остальные 4 операции — AND & , OR | , XOR ^, NOT ~.
Для примера рассмотрим простую систему разграничения прав доступа к сайту.
📌 У нас будут доступны следующие права доступа: Чтение, Создание, Редактирование, Удаление. То есть всего 4 значения, их можно представить в виде 4-х битного числа, в котором 1 — означает, что у пользователя есть данное право, а 0 — нет. Разберем код из предыдущей части:
define('U_READ', 1 << 0); // 0001
define('U_CREATE', 1 << 1); // 0010
define('U_EDIT', 1 << 2); // 0100
define('U_DELETE', 1 << 3); // 1000
define('U_ALL', U_READ | U_CREATE | U_EDIT | U_DELETE); // 1111
В первых 4 строках мы задали константы с помощью сдвига влево. А в пятой строке использовали оператор OR |. Он выполняет операцию над каждым битом своих операндов. Бит результата устанавливается, если соответствующий бит установлен хотя бы в одном операнде. Например:
$x = 3; // 0011
$y = 5; // 0101
echo $x | $y; // 0111 (7)
Таким образом мы можем задать любые разрешения для пользователя:
$userPermission = U_READ; // только право чтения
$userPermission = U_READ | U_CREATE; // можно читать и создавать
$userPermission = U_ALL ^ U_DELETE; // все права кроме удаления
$userPermission = U_ALL & ~ U_DELETE; // тоже все права кроме удаления
📌 В данном примере мы видим XOR ^ (исключающее или). Бит устанавливается, если соответствующий бит установлен в одном (но не в обоих) из двух операндов.
$x = 3; // 0011
$y = 5; // 0101
echo $x ^ $y; // 0110 (6)
В нашем случае:
U_ALL 1111
U_DELETE 1000
RESULT 0111
📌 В следующей строке сразу 2 оператора AND & и NOT ~. Оператор & выполняет операцию логическое И над каждым битом своих операндов. Бит результата устанавливается, если соответствующий бит установлен в обоих операндах:
$x = 3; // 0011
$y = 5; // 0101
echo $x & $y; // 0001 (1)
📌 Оператор NOT ~ представляет собой унарный оператор, указываемый перед своим единственным операндом. Он выполняет инверсию всех битов операнда. Из-за способа представления целых со знаком в PHP применение оператора ~ к значению эквивалентно изменению его знака и вычитанию 1.
$y = 5; // 0101
echo ~$y; // 1010 (-6)
Таким образом в нашем примере сначала сработает оператор NOT. U_DELETE из 1000 станет 0111, а затем вызовется оператор &
U_ALL 1111
~ U_DELETE 0111
RESULT 0111
❗️ Разница между этими вариантами в том, что в первом случае просто переключается бит, если был 1, то станет 0, и наоборот. Второй же вариант делает бит равным 0, независимо от его текущего значения.
Если мы хотим убрать какое-нибудь право доступа, то пишем так:
$userPermission &= ~ U_DELETE; // запретить удаление
👉 Для проверки битов (в нашем случае прав доступа) можно использовать следующие конструкции.
if ($userPermission & U_READ) // есть ли право чтения?
if ($userPermission & (U_READ | U_DELETE)) // есть ли право чтения и/или удаления
Еще один пример:
// Вместо
if ($error['type'] == E_ERROR || $error['type'] == E_PARSE || $error['type'] == E_COMPILE_ERROR) {}
// Или
if (in_array($error['type'], [E_ERROR, E_PARSE, E_COMPILE_ERROR])) {}
// Можно использовать
if ($error['type'] & (E_ERROR | E_PARSE | E_COMPILE_ERROR)) {}
👍 Несмотря на то, что коды ошибок в PHP специально заточены под битовые операции, тем не менее, достаточно часто для проверки кодов ошибок используются обычные операторы сравнения. Но теперь вы знаете, что можно сравнивать и побитово ;)
#php #junior #source
❤1
Локальная разработка пакетов (composer + phpstorm)
Буквально пару дней назад мой коллега спросил "а как ты работаешь с мультирепозиториями?", "О чём ты?" — спросил я, "Ну вот тебе нужно сделать sdk и сразу протестить внутри приложения, что ты делаешь?". И вот уже через несколько часов я действительно разбирался с этой проблемой, решением которой захотел поделиться.
👉 Представим, что у вас есть проект и вы решили сделать отдельный пакет, который будет решать какую-то задачу внутри проекта. Например собственное SDK для внешнего API, которое хотите внедрить и тестить прямо в своём проекте. С чего начать?
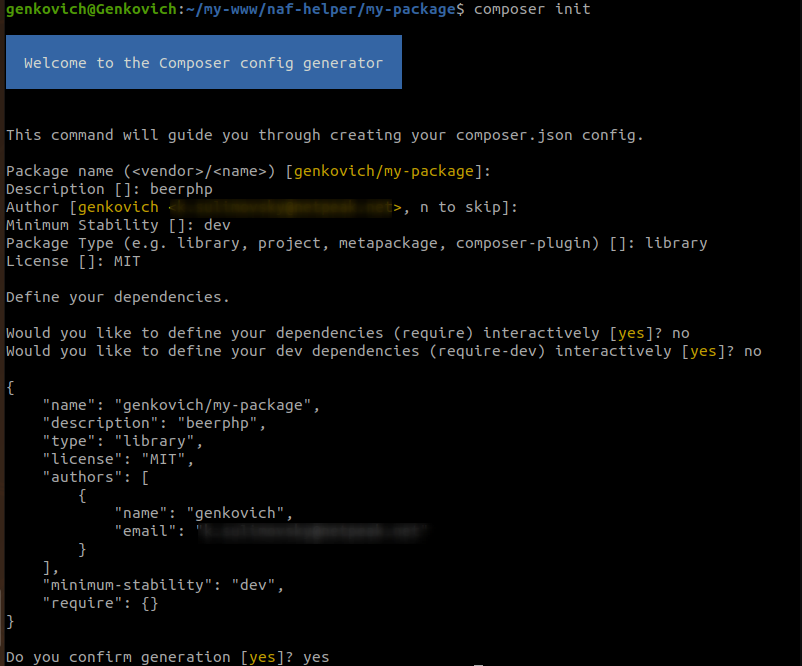
0. создаете папку
1. в ней composer init
2. создать структуру папок и прописать psr-4 (вот пост с подробностями)
3. не забудьте
❓Дальше начинается самое интересное. Как же подключить наш локальный пакет к существующему
Оказывается всё достаточно просто. Нужно добавить в
👍 Дальше делаем
💁♂️ Ну, а для того чтобы во время разработки не прыгать между окнами, достаточно добавить в
#middle #phpstorm #packages
Буквально пару дней назад мой коллега спросил "а как ты работаешь с мультирепозиториями?", "О чём ты?" — спросил я, "Ну вот тебе нужно сделать sdk и сразу протестить внутри приложения, что ты делаешь?". И вот уже через несколько часов я действительно разбирался с этой проблемой, решением которой захотел поделиться.
👉 Представим, что у вас есть проект и вы решили сделать отдельный пакет, который будет решать какую-то задачу внутри проекта. Например собственное SDK для внешнего API, которое хотите внедрить и тестить прямо в своём проекте. С чего начать?
0. создаете папку
1. в ней composer init
2. создать структуру папок и прописать psr-4 (вот пост с подробностями)
3. не забудьте
git init :) точно пригодится❓Дальше начинается самое интересное. Как же подключить наш локальный пакет к существующему
vendor? Оказывается всё достаточно просто. Нужно добавить в
composer.json директорию repositories, добавить запись с типом path, а урл — относительный путь в директорию с пакетом:"repositories": [и не забыть понизить
{
"type": "path",
"url": "../my-package"
}
],
"minimum-stability": "dev"
minimum-stability до dev. Выглядит вот так.👍 Дальше делаем
composer require package/name и вуаля! Теперь мы можем смело править файлы пакета, без дополнительных коммитов, пуша в удаленный репозиторий и прочих прелестей. Всё потому, что фактически композер сделал симлинку и подтягивает изменённые файлы напрямую.💁♂️ Ну, а для того чтобы во время разработки не прыгать между окнами, достаточно добавить в
PHPStorm -> Settings -> Version Control тот самый локальный репозиторий, затем открыть папку проекта и выбрать attach. После этого находясь в одном окне вы можете спокойно править файлы и проекта и пакета, при этом каждый будет, пуллиться, фетчится и даже коммититься в свой гит репозиторий :)#middle #phpstorm #packages
{kind=link}
Decorator pattern
Не подумайте, меня не покусал Егор Бугаенко (для тех кто в теме, кто нет — погуглите), мои взгляды не настолько радикальны, однако я действительно считаю, что этому паттерну уделяют мало внимания. Потому решил познакомить с ним тех, кто не знаком и освежить в памяти для тех, кто уже давно им пользуется.
Декоратор — (wiki) структурный шаблон проектирования, предназначенный для динамического подключения дополнительного поведения к объекту.
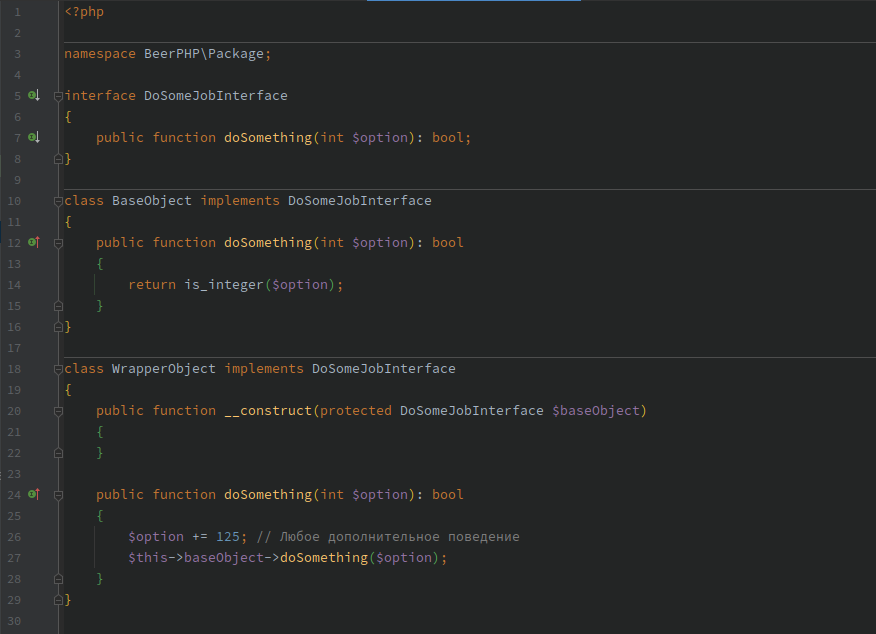
👉 Если простым языком, то суть данного паттерна заключается в "оборачивании" существующего объекта новым функционалом, при этом оригинальный интерфейс объекта остается неизменным. В данном примере
❓ В чем преимущества?
1. Его не получится просто так создать без существования базового класса.
2. Так как базовый класс и класс обертка имплементируют один интерфейс — то они взаимозаменяемы.
3. Мы расширяем поведение без изменения исходного кода.
Стоп, да это же прям Open-Closed Principle! И да, это отличная альтернатива наследованию. Также вы можете использовать несколько разных обёрток одновременно.
❗️ Да, клиентский код выглядит не круто, да и искать все места где вызывается базовый класс, чтобы прицепить обёртку бывает проблематично (особенно в долгоживущих проектах). Однако в фреймворках этот вопрос легко решается. Например в Symfony достаточно добавить всего несколько строк:
Представим, что у нас есть какой-то Mailer, который мы описали в services.yaml и теперь мы хотим логировать отправку всей почты. Для этого у контейнера есть директива decorates. Подобная запись подменит основной
👍 Но что если мы хотим не только логировать, но и отправлять наши письма через очередь? Нет проблем, мы можем добавить еще одну запись. Но как задать порядок в котором будут вызваны декораторы? Для этого существует директива
Не подумайте, меня не покусал Егор Бугаенко (для тех кто в теме, кто нет — погуглите), мои взгляды не настолько радикальны, однако я действительно считаю, что этому паттерну уделяют мало внимания. Потому решил познакомить с ним тех, кто не знаком и освежить в памяти для тех, кто уже давно им пользуется.
Декоратор — (wiki) структурный шаблон проектирования, предназначенный для динамического подключения дополнительного поведения к объекту.
👉 Если простым языком, то суть данного паттерна заключается в "оборачивании" существующего объекта новым функционалом, при этом оригинальный интерфейс объекта остается неизменным. В данном примере
WrapperObject и есть наш декоратор. ❓ В чем преимущества?
1. Его не получится просто так создать без существования базового класса.
2. Так как базовый класс и класс обертка имплементируют один интерфейс — то они взаимозаменяемы.
3. Мы расширяем поведение без изменения исходного кода.
Стоп, да это же прям Open-Closed Principle! И да, это отличная альтернатива наследованию. Также вы можете использовать несколько разных обёрток одновременно.
❗️ Да, клиентский код выглядит не круто, да и искать все места где вызывается базовый класс, чтобы прицепить обёртку бывает проблематично (особенно в долгоживущих проектах). Однако в фреймворках этот вопрос легко решается. Например в Symfony достаточно добавить всего несколько строк:
Представим, что у нас есть какой-то Mailer, который мы описали в services.yaml и теперь мы хотим логировать отправку всей почты. Для этого у контейнера есть директива decorates. Подобная запись подменит основной
mailer на mailer_logger и наши письма начнут начнут логироваться. Для ссылки на исходный класс нужно использовать decorating_service_id + .inner (или просто '@.inner' начиная с Symfony 5.1).👍 Но что если мы хотим не только логировать, но и отправлять наши письма через очередь? Нет проблем, мы можем добавить еще одну запись. Но как задать порядок в котором будут вызваны декораторы? Для этого существует директива
decoration_priority (по умолчанию 0). Соответственно чем выше приоритет — тем раньше применится декоратор (всё логично). Например такой код сначала залогирует (1), а потом уже отправит в очередь (2) наше сообщение: $this->services['mailer'] = new LoggerDecorator(new QueueDecorator(new Mailler()));#php #oop #patterns #middle
{kind=link}
👍2❤1
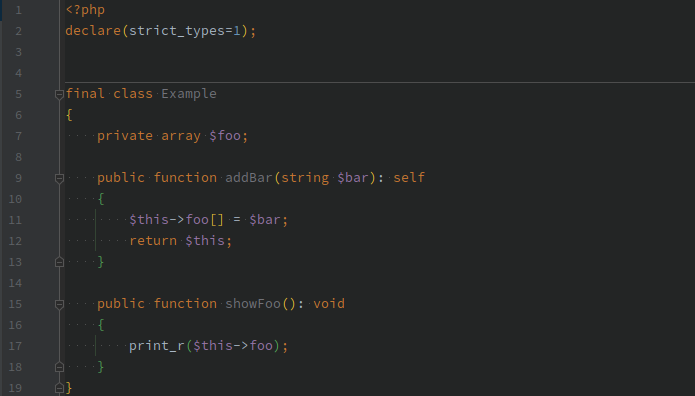
DRY (Don't Repeat Yourself)
Буквально сегодня сидел и смотрел на пачку похожих классов, код которых на 98,2% одинаков. Очень сильно подмывало схлопнуть это всё, но как правильно это сделать? Давайте разберемся подробнее.
👉 Многие считают, что DRY запрещает дублировать код, но это не так. Вся суть таится немного глубже. Давайте разберемся с определением:
"Каждая часть знания должна иметь единственное, непротиворечивое и авторитетное представление в рамках системы"
❓ Вся тайна кроется как раз в определении "часть знания". Что же это такое?
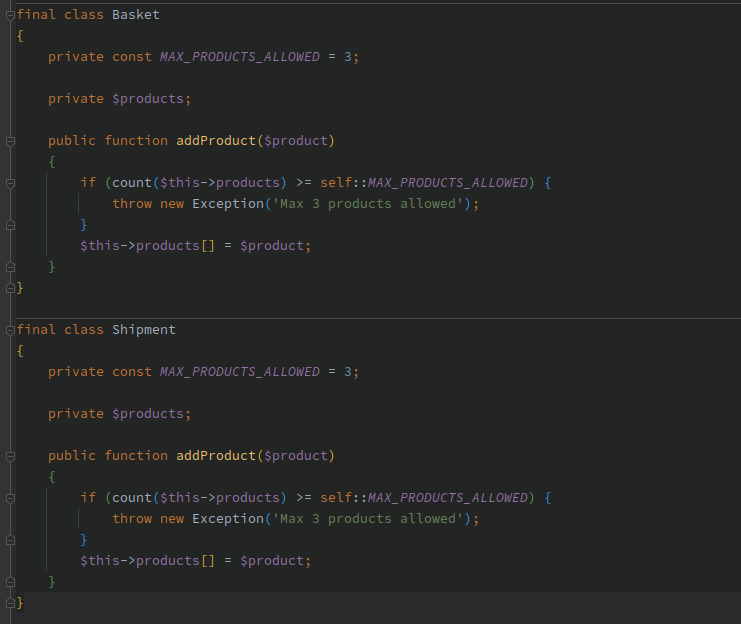
👍 Речь идёт не о написанном коде, а о знаниях в "предметной области" или "бизнес правилах". Давайте рассмотрим пример { pic | gist }
В данном случае код выглядит одинаково, однако, это может продиктовано абсолютно разными требованиями бизнеса:
📌Мы ограничиваем корзину тремя единицами товара из-за высокого спроса, а нам выгодно продать его как можно большему кол-ву покупателей.
📌В то же время мы ограничиваем доставку тремя единицами, потому что наш транспорт физически не может вместить большего объема.
Подсознательно нам хочется взять и вынести дублирующийся код в один источник, но что если какое-то из правил изменится? Например мы купили новый транспорт для доставки и теперь можем доставлять до 10 единиц товара?
❗️ Очень важно, чтобы у вашего кода могла быть только "одна причина для изменения" (прямо как в SRP), ведь правила вашего бизнеса в одной предметной области могут (и должны) меняться независимо от другой.
💡 Когда-то М. Фаулер популяризировал так называемое Rule of three. Звучит примерно так: "Два экземпляра аналогичного кода не требуют рефакторинга, но, когда аналогичный код используется три раза, его следует извлечь в новую процедуру." Это правило, в первую очередь, отлично помогает избежать преждевременного обобщения, когда с виду похожие вещи имеют разные зоны ответственности и потому не являются дублированием.
👌 DRY — это принцип, однако принципы — не правила. Они лишь инструменты, помогающие идти в правильном направлении. Очевидно, что не стоит везде повторять бизнес-логику, но также не нужно и объединять всё подряд. Необходимо искать баланс, который зависит от текущей ситуации.
#php #junior #source
Буквально сегодня сидел и смотрел на пачку похожих классов, код которых на 98,2% одинаков. Очень сильно подмывало схлопнуть это всё, но как правильно это сделать? Давайте разберемся подробнее.
👉 Многие считают, что DRY запрещает дублировать код, но это не так. Вся суть таится немного глубже. Давайте разберемся с определением:
"Каждая часть знания должна иметь единственное, непротиворечивое и авторитетное представление в рамках системы"
❓ Вся тайна кроется как раз в определении "часть знания". Что же это такое?
👍 Речь идёт не о написанном коде, а о знаниях в "предметной области" или "бизнес правилах". Давайте рассмотрим пример { pic | gist }
В данном случае код выглядит одинаково, однако, это может продиктовано абсолютно разными требованиями бизнеса:
📌Мы ограничиваем корзину тремя единицами товара из-за высокого спроса, а нам выгодно продать его как можно большему кол-ву покупателей.
📌В то же время мы ограничиваем доставку тремя единицами, потому что наш транспорт физически не может вместить большего объема.
Подсознательно нам хочется взять и вынести дублирующийся код в один источник, но что если какое-то из правил изменится? Например мы купили новый транспорт для доставки и теперь можем доставлять до 10 единиц товара?
❗️ Очень важно, чтобы у вашего кода могла быть только "одна причина для изменения" (прямо как в SRP), ведь правила вашего бизнеса в одной предметной области могут (и должны) меняться независимо от другой.
💡 Когда-то М. Фаулер популяризировал так называемое Rule of three. Звучит примерно так: "Два экземпляра аналогичного кода не требуют рефакторинга, но, когда аналогичный код используется три раза, его следует извлечь в новую процедуру." Это правило, в первую очередь, отлично помогает избежать преждевременного обобщения, когда с виду похожие вещи имеют разные зоны ответственности и потому не являются дублированием.
👌 DRY — это принцип, однако принципы — не правила. Они лишь инструменты, помогающие идти в правильном направлении. Очевидно, что не стоит везде повторять бизнес-логику, но также не нужно и объединять всё подряд. Необходимо искать баланс, который зависит от текущей ситуации.
#php #junior #source
{kind=link}
❤1
CGI, FastCGI, php-fpm
Уверен, многие из вас видели эти аббревиатуры, но, как оказалось, не все знают, как они связаны и что обозначают. Конечно, эта тема может быть более актуальна тем, кто занимается настройкой ПО (типа DevOps), но считаю, что хотя-бы общее представление должно быть у всех, кто так или иначе занимается разработкой на PHP, потому решил поверхностно описать эти вопросы.
👉 CGI
Common Gateway Interface — это стандарт (протокол, спецификация, соглашение, набор правил), который описывает, как веб-сервер должен запускать скрипты (в т.ч. PHP, а также другие программы), как должен передавать им параметры HTTP-запроса и как скрипты должны передавать результаты своей работы веб-серверу. То есть CGI был разработан для того, чтобы расширить возможности веб-сервера и дать возможность создания и обработки динамического контента.
👉 FastCGI
По факту это дальнейшее развитие технологии CGI, является более производительным и безопасным. В чем же главное отличие?
В CGI-режиме на каждый запрос создается отдельный процесс, "умирающий" после окончания обработки. В FastCGI процесс работает в качестве демона, то есть один и тот же процесс обрабатывает различные HTTP запросы один за другим. PHP из коробки умеет работать и в FastCGI режиме.
👉 PHP-FPM
FastCGI Process Manager — альтернативная реализация PHP FastCGI, которая позволяет вам достаточно гибко настраивать те самые процессы, о которых я писал выше.
❓ Как это работает?
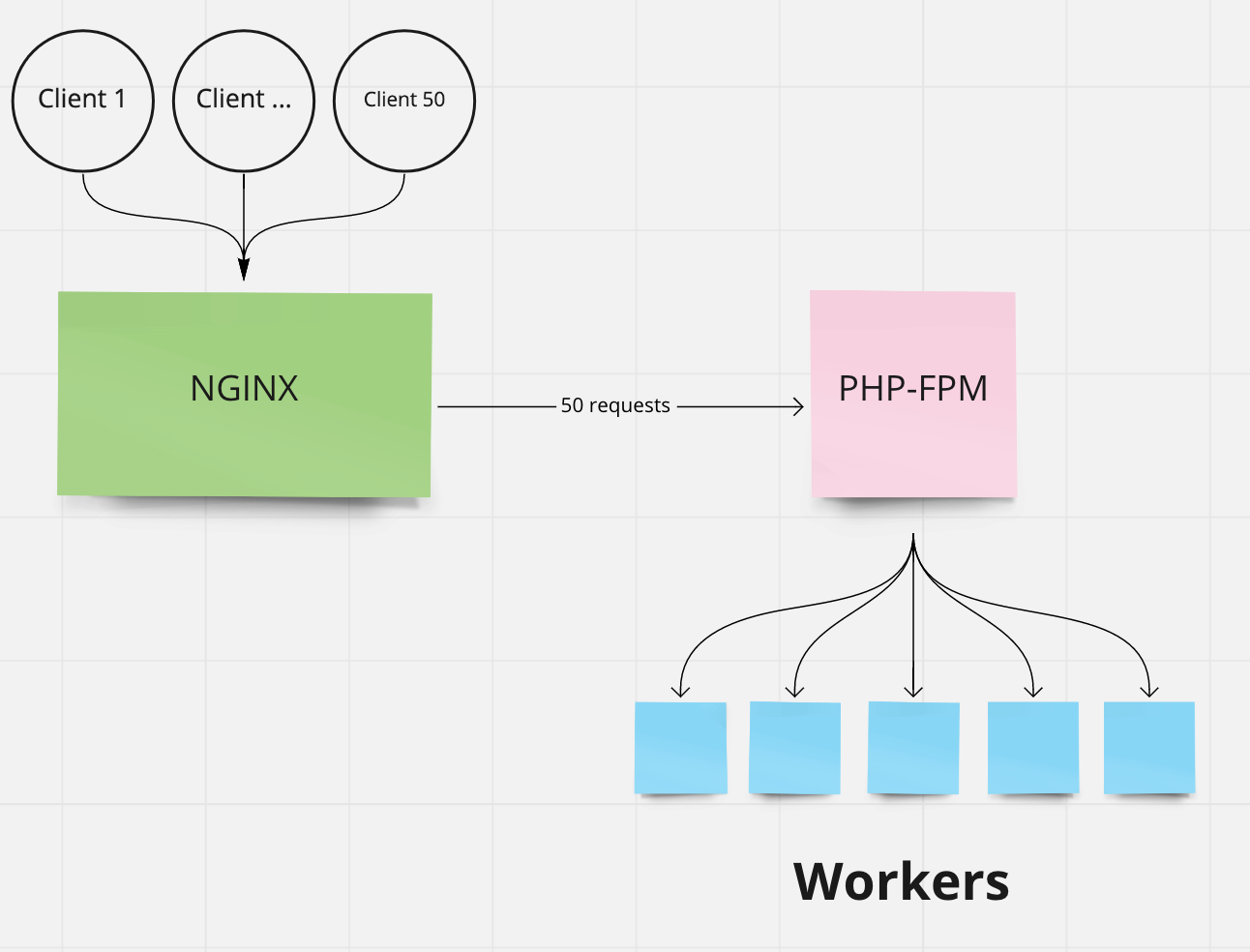
📌 Представим, что в наше приложение одновременно приходит 50 клиентов. Сначала они обращаются в наш NGINX, который по факту пробрасывает запросы сквозь себя на PHP-FPM (за исключением запросов за статическими ресурсами/файлами), а дальше PHP-FPM пытается обработать все запросы с помощью своих процессов (воркеров).
📌 Допустим у нас запущено 5 воркеров, как на картинке. В таком случае во время одновременного запроса первые 5 клиентов будут обрабатываться сразу, а остальные 45 становятся в очередь и ждут, когда первые 5 закончат обработку. PHP-FPM позволяет задавать настройки в зависимости от ваших потребностей, будь то динамическое увеличение воркеров для того чтобы клиенты не ждали в очереди или экономия ресурсов с целью ускорения обработки запросов со статическим кол-вом воркеров.
👍 Если интересно более подробно почитать про настройку php-fpm, то ставь 🍺. Надеюсь стало немного понятнее и теперь никто не будет впадать в ступор при виде этих аббревиатур. 😉
#php #server #source
Уверен, многие из вас видели эти аббревиатуры, но, как оказалось, не все знают, как они связаны и что обозначают. Конечно, эта тема может быть более актуальна тем, кто занимается настройкой ПО (типа DevOps), но считаю, что хотя-бы общее представление должно быть у всех, кто так или иначе занимается разработкой на PHP, потому решил поверхностно описать эти вопросы.
👉 CGI
Common Gateway Interface — это стандарт (протокол, спецификация, соглашение, набор правил), который описывает, как веб-сервер должен запускать скрипты (в т.ч. PHP, а также другие программы), как должен передавать им параметры HTTP-запроса и как скрипты должны передавать результаты своей работы веб-серверу. То есть CGI был разработан для того, чтобы расширить возможности веб-сервера и дать возможность создания и обработки динамического контента.
👉 FastCGI
По факту это дальнейшее развитие технологии CGI, является более производительным и безопасным. В чем же главное отличие?
В CGI-режиме на каждый запрос создается отдельный процесс, "умирающий" после окончания обработки. В FastCGI процесс работает в качестве демона, то есть один и тот же процесс обрабатывает различные HTTP запросы один за другим. PHP из коробки умеет работать и в FastCGI режиме.
👉 PHP-FPM
FastCGI Process Manager — альтернативная реализация PHP FastCGI, которая позволяет вам достаточно гибко настраивать те самые процессы, о которых я писал выше.
❓ Как это работает?
📌 Представим, что в наше приложение одновременно приходит 50 клиентов. Сначала они обращаются в наш NGINX, который по факту пробрасывает запросы сквозь себя на PHP-FPM (за исключением запросов за статическими ресурсами/файлами), а дальше PHP-FPM пытается обработать все запросы с помощью своих процессов (воркеров).
📌 Допустим у нас запущено 5 воркеров, как на картинке. В таком случае во время одновременного запроса первые 5 клиентов будут обрабатываться сразу, а остальные 45 становятся в очередь и ждут, когда первые 5 закончат обработку. PHP-FPM позволяет задавать настройки в зависимости от ваших потребностей, будь то динамическое увеличение воркеров для того чтобы клиенты не ждали в очереди или экономия ресурсов с целью ускорения обработки запросов со статическим кол-вом воркеров.
👍 Если интересно более подробно почитать про настройку php-fpm, то ставь 🍺. Надеюсь стало немного понятнее и теперь никто не будет впадать в ступор при виде этих аббревиатур. 😉
#php #server #source
{kind=link}
👍2❤1
Fluent interface. Evil or not?
Ну а пока я готовлю материал по теме настройки fpm (оказалось не очень просто вместить его в небольшой и понятный пост), решил поднять довольно старую тему, о которой не так уж много сказано.
Прежде всего давайте синхронизируемся что же такое fluent interface?
Каждый из вас наверняка видел конструкцию наподобие:
На первый взгляд выглядит отлично, достаточно удобно и позволяет писать меньше кода. Однако, не всё так радужно, как кажется на первый взгляд.
📌 Первая проблема — подобные конструкции начинают вставлять везде, где только можно. Возьмём пример с какой-нибудь сущностью
❌ Что мы делаем? Правильно, мы берем и просто добавляем еще 3 метода, потому что нам хочется вызывать их цепочкой. Затем мы хотим добавить инфу о получателе и добавляем еще 5 методов, инфу о скидках — еще 4 и т.д. В итоге наша сущность раздувается до нереальных размеров, данные никак не разбиты на логические (бизнесовые) куски (смотри whole objects).
К нам приходит менеджер и говорит — "Нельзя, чтобы описание товара было заполнено без тайтла, а адрес не должен быть указан без страны и города". И тут начинается веселье, в котором в сеттеры добавляются проверки, а у нашего fluent interface появляется необходимость вызывать методы в определенной очереди, которая совсем не очевидна другому разработчику. Чем больше правил — тем больше хаоса, рано или поздно кто-то таки выстрелит себе в ногу.
📌 Второе — декорирование. Давайте представим, что мы хотим расширить наш класс
📌 Третье — их сложнее мокать. Не секрет, что мокая объект мы создаем
👍 Есть места, где использование данного похода достаточно хорошо себя показывает и это билдеры (в множестве их проявлений):
Сам по себе данный подход ни в коем случае не является абсолютным злом, однако, прежде чем его использовать вам следует хорошо подумать:
1. Не создаёте ли вы себе дополнительных проблем?
2. В какой момент и что пошло не так, если в Entity вам нужно засэтить десяток полей?
3. Точно ли всё очевидно?
Хорошо и правильно, если данный подход вы используете с умом, там где это уместно. Тогда fluent interface действительно сделает ваш код лаконичнее, а не породит несколько мест для новых багов.
#php #junior #source
Ну а пока я готовлю материал по теме настройки fpm (оказалось не очень просто вместить его в небольшой и понятный пост), решил поднять довольно старую тему, о которой не так уж много сказано.
Прежде всего давайте синхронизируемся что же такое fluent interface?
Каждый из вас наверняка видел конструкцию наподобие:
$example = Example::create()->addFoo()->deleteBar()->build();
👉 А добиться этого можно с помощью вот такого нехитрого фокуса [pic | code ]. При такой реализации мы сможем добавлять в массив строки не вызывая каждый раз переменную [pic | code ].На первый взгляд выглядит отлично, достаточно удобно и позволяет писать меньше кода. Однако, не всё так радужно, как кажется на первый взгляд.
📌 Первая проблема — подобные конструкции начинают вставлять везде, где только можно. Возьмём пример с какой-нибудь сущностью
Order. Предположим у вас есть сеттеры (об этом зле у нас будет отдельный разговор, но потом. Пока предположим, что у вас они есть) setId(), setTitle(), setDescription(). Всё выглядит достаточно удобно, в сущности всего 3 метода, мы можем вызывать их цепочкой. Однако, представим, что нам нужно добавить информацию о доставке setCountry(), setCity(), setAddress(). ❌ Что мы делаем? Правильно, мы берем и просто добавляем еще 3 метода, потому что нам хочется вызывать их цепочкой. Затем мы хотим добавить инфу о получателе и добавляем еще 5 методов, инфу о скидках — еще 4 и т.д. В итоге наша сущность раздувается до нереальных размеров, данные никак не разбиты на логические (бизнесовые) куски (смотри whole objects).
К нам приходит менеджер и говорит — "Нельзя, чтобы описание товара было заполнено без тайтла, а адрес не должен быть указан без страны и города". И тут начинается веселье, в котором в сеттеры добавляются проверки, а у нашего fluent interface появляется необходимость вызывать методы в определенной очереди, которая совсем не очевидна другому разработчику. Чем больше правил — тем больше хаоса, рано или поздно кто-то таки выстрелит себе в ногу.
📌 Второе — декорирование. Давайте представим, что мы хотим расширить наш класс
Example и добавить логирование [pic | code ]. На первый взгляд всё выглядит логично, но сколько раз вызовется логгер? Один(!). А всё потому, что нашу обёртку теперь тоже нужно сделать "текучей", что тоже не сразу очевидно и часто бывает местом для багов.📌 Третье — их сложнее мокать. Не секрет, что мокая объект мы создаем
Null Object, где все методы являются заглушками. Чтобы протестировать логику и случайно не оборвать нашу цепочку — нам придётся описывать КАЖДЫЙ метод (а напомню, что в примере с Order их больше 20) примерно такой конструкцией, даже если на самом деле его вызов ни на что не влияет в нашем тесте.$example📌 Если копнуть еще глубже, то можно найти проблемы с обратной совместимостью, нарушением инкапсуляции, сложностью с отслеживанием изменений, однако не всё так плохо.
->expects($this->any())
->method('addBar')
->willReturnSelf();
👍 Есть места, где использование данного похода достаточно хорошо себя показывает и это билдеры (в множестве их проявлений):
$queryBuilder❓ Так зло или нет?!
->select('u')
->from('User u')
->where('u.id = :identifier')
->orderBy('u.name', 'ASC')
->setParameter('identifier', 100);
Сам по себе данный подход ни в коем случае не является абсолютным злом, однако, прежде чем его использовать вам следует хорошо подумать:
1. Не создаёте ли вы себе дополнительных проблем?
2. В какой момент и что пошло не так, если в Entity вам нужно засэтить десяток полей?
3. Точно ли всё очевидно?
Хорошо и правильно, если данный подход вы используете с умом, там где это уместно. Тогда fluent interface действительно сделает ваш код лаконичнее, а не породит несколько мест для новых багов.
#php #junior #source
{kind=link}
❤6👍3
Настройка PHP-FPM (part 1)
Ну что, вы просто не оставили мне выбора, почти 400 🍺, круто! Сразу оговорюсь, что материал, который здесь приведен — очень сухая и субъективная выжимка, потому как материала слишком много (и уже получилось несколько частей), но я не стал углубляться в дебри. Постарался сделать так, чтобы было понятно откуда ноги растут и куда копать, если что.
👉 Давайте по порядку. В конфигурации нас будут интересовать 2 места:
• основной файл конфигурации
⚡️Разделение приложений по пулам позволяет предотвратить ситуацию, когда один высоконагруженный сервис постоянно держит занятыми процессы-обработчики, не давая нормально работать другим, более лёгким приложениям
Для того чтобы создать несколько отдельных пулов, внутри директории
✅ На что следует обратить внимание, это то как проходят данные от веб-сервера к вашим php процессам. Это отражено в директиве listen:
❓ Помните в прошлом посте был пример про "очередь", в которой будет ожидать наш запрос, если он еще не обрабатывается каким-то процессом?
Так вот, параметр listen.backlog отвечает за размер очереди одновременно ожидающих подключений к нашему сокету. В зависимости от версии и операционной системы вы можете увидеть значение по умолчанию 511, 128, 65535, -1 (подразумевая неограниченно, но это не так) и т.д.
Какое значение установить? Зависит от задачи которую вы решаете:
❗️Если значение слишком большое, а php-fpm не успевает обрабатывать все запросы, то nginx дождется тайм-аута и отключится, выкинув 504 ошибку.
❗️Если это значение установлено слишком маленьким, то с одной стороны клиентские запросы, вообще не могут попасть в очередь и выдается сообщение об ошибке 502, однако ваш сервер не тратит лишние ресурсы на хранение запросов в очереди.
👌 Лучший метод расчета — определить размер в соответствии с QPS (query per second) у вашего production сервера, накинуть 30-50%, и убедиться, что железо справляется с таким кол-вом запросов. Тогда во время пиковой нагрузки (черная пятница/новый год) вы конечно рискуете, что некоторые из пользователей отвалятся получая 502, но не потеряете всех из-за зависшего железа.
🧐 Думаю на сегодня достаточно, в следующей части рассмотрим настройки самого Process Manager (pm), узнаем, какие стратегии лучше использовать для решения различных задач. Если у вас есть вопросы — их можно обсудить со мной и другими подписчиками в нашем чатике.
#php #server #middle #source
Ну что, вы просто не оставили мне выбора, почти 400 🍺, круто! Сразу оговорюсь, что материал, который здесь приведен — очень сухая и субъективная выжимка, потому как материала слишком много (и уже получилось несколько частей), но я не стал углубляться в дебри. Постарался сделать так, чтобы было понятно откуда ноги растут и куда копать, если что.
👉 Давайте по порядку. В конфигурации нас будут интересовать 2 места:
• основной файл конфигурации
/etc/php/(версия)/fpm/php-fpm.conf
• и файлы пулов /etc/php/(версия)/fpm/pool.d/
📌 С понятием Pool вы будете сталкиваться достаточно часто. Pool – это группа процессов, выделенная для обработки запросов, поступающих на определённый порт или unix-socket. В PHP-FPM возможно настраивать (и использовать) сразу несколько пулов, для решения разных, отдельных задач.⚡️Разделение приложений по пулам позволяет предотвратить ситуацию, когда один высоконагруженный сервис постоянно держит занятыми процессы-обработчики, не давая нормально работать другим, более лёгким приложениям
Для того чтобы создать несколько отдельных пулов, внутри директории
pool.d следует создать отдельный файл под каждый пул. Сразу скажу, что настройки в этих файлах будут иметь приоритет выше, чем те, что в php.ini. По умолчанию у нас описан пул в файле www.conf. Открыв его мы сразу видим [www], это и есть наше имя пула. В зависимости от потребностей вы можете создать пул с любым именем. Например вы можете настроить отдельными пулами [backend] и [frontend]. Имя пула должно быть в самом верху в квадратных скобках.✅ На что следует обратить внимание, это то как проходят данные от веб-сервера к вашим php процессам. Это отражено в директиве listen:
listen = /var/run/php8-fpm.sockПо факту, таким образом в нашей операционной системе мы задаём адрес (socket или host:port) , который будет принимать FastCGI-запросы. И затем уже в нашем nginx конфиге мы указываем по какому адресу нам стоит обращаться, а следовательно какой пулл с какими настройками будет использован:
### nginx config ###🔨 Коротко про права доступа: Чтобы кто попало не писал в наш сокет - запрещаем это делать путём указания прав доступа к нему. Для этого предназначены строчки
location ~ \.php$ {
...
fastcgi_pass unix:/var/run/php8-fpm.sock;
...
}
listen.owner, listen.group и listen.mode. По умолчанию стоит группа и пользователь www-data (как у вашего веб-сервера) и права 0660, что означает, что владелец и пользователь могут читать и редактировать, а все остальные не могут делать ничего. ❓ Помните в прошлом посте был пример про "очередь", в которой будет ожидать наш запрос, если он еще не обрабатывается каким-то процессом?
Так вот, параметр listen.backlog отвечает за размер очереди одновременно ожидающих подключений к нашему сокету. В зависимости от версии и операционной системы вы можете увидеть значение по умолчанию 511, 128, 65535, -1 (подразумевая неограниченно, но это не так) и т.д.
Какое значение установить? Зависит от задачи которую вы решаете:
❗️Если значение слишком большое, а php-fpm не успевает обрабатывать все запросы, то nginx дождется тайм-аута и отключится, выкинув 504 ошибку.
❗️Если это значение установлено слишком маленьким, то с одной стороны клиентские запросы, вообще не могут попасть в очередь и выдается сообщение об ошибке 502, однако ваш сервер не тратит лишние ресурсы на хранение запросов в очереди.
👌 Лучший метод расчета — определить размер в соответствии с QPS (query per second) у вашего production сервера, накинуть 30-50%, и убедиться, что железо справляется с таким кол-вом запросов. Тогда во время пиковой нагрузки (черная пятница/новый год) вы конечно рискуете, что некоторые из пользователей отвалятся получая 502, но не потеряете всех из-за зависшего железа.
🧐 Думаю на сегодня достаточно, в следующей части рассмотрим настройки самого Process Manager (pm), узнаем, какие стратегии лучше использовать для решения различных задач. Если у вас есть вопросы — их можно обсудить со мной и другими подписчиками в нашем чатике.
#php #server #middle #source
{kind=link}
❤6👍4
Настройка PHP-FPM (part 2)
Окей, вот мы переходим к самому интересному, по моему мнению, разделу: управление процессами.
👉 С помощью параметра
📌 Static — гарантирует, что обработка запросов всегда доступна фиксированному количеству дочерних процессов (кол-во которых устанавливается с помощью
❓ Как посчитать значение
Один из способов — от оперативной памяти. Безопаснее всего когда ваш
Для этого определяем сколько памяти кушает каждый наш процесс (найдите для вашей ОС, вот пример для Ubuntu):
⚡️ От себя рекомендую получившееся число изначально разделить еще на 2 и двигаться дальше от этой отправной точки эмпирическим путём, внимательно наблюдая за метриками сервера.
📌 Dynamic — регулирует количество дочерних процессов в зависимости от нагрузки исходя из значений конфигурационного файла. Данный пул больше всего подходит когда нужна экономия ресурсов (за счет уменьшения дочерних процессов при простое), но при этом бывают пиковые всплески, которые необходимо обработать.
Помимо
👍 Как вы уже догадались, вас ждёт 3я часть из данного цикла. Если вам есть что добавить — обязательно пишите мне лично или добавляйтесь в наш уютный чатик :)
#php #server #middle #source
Окей, вот мы переходим к самому интересному, по моему мнению, разделу: управление процессами.
👉 С помощью параметра
pm можно настроить стратегию запуска дочерних процессов. Всего есть 3 режима работы.📌 Static — гарантирует, что обработка запросов всегда доступна фиксированному количеству дочерних процессов (кол-во которых устанавливается с помощью
pm.max_children). При такой схеме кол-во дочерних процессов не меняется, а значит они всегда занимают определенный объем ОЗУ и в случае пиковых нагрузок у вас могут быть сложности (клиенты будут становиться в очередь). С другой стороны — запросам не нужно ждать запуска новых процессов, а значит на это не тратятся дополнительные ресурсы, что делает static самым быстрым подходом. Такую стратегию лучше использовать когда у вас постоянная высокая нагрузка и большой объём оперативной памяти. pm.max_children — очень важный параметр, который работает для всех трёх режимов, означает максимально возможное количество дочерних процессов, если значение будет слишком маленьким, то при возрастании нагрузки, лимит исчерпается и ваш сайт начнёт тупить, если слишком большим - исчерпается оперативная память и что-то упадёт;❓ Как посчитать значение
pm.max_children? Один из способов — от оперативной памяти. Безопаснее всего когда ваш
fpm работает изолировано, например в контейнере, и ему выделен определенный ресурс. В противном случае высока вероятность что-то не учесть, а конкурирующие процессы будут недовольны таким положением дел. Для этого определяем сколько памяти кушает каждый наш процесс (найдите для вашей ОС, вот пример для Ubuntu):
ps --no-headers -o "rss,cmd" -C php-fpm | awk '{ sum+=$1 } END { printf ("%d%s\n", sum/NR/1024,"Mb") }'
Например я получил, что в среднем один процесс кушает 60 МБайт. Допустим у меня на серваке всего 16 ГБайт, 8 из них уже использует БД (кеши и прочее), еще 2 другие приложения, остаётся 6. Какой-то запас необходимо оставить, итого 4 ГБ / 60 МБ = 66 процессов. ⚡️ От себя рекомендую получившееся число изначально разделить еще на 2 и двигаться дальше от этой отправной точки эмпирическим путём, внимательно наблюдая за метриками сервера.
📌 Dynamic — регулирует количество дочерних процессов в зависимости от нагрузки исходя из значений конфигурационного файла. Данный пул больше всего подходит когда нужна экономия ресурсов (за счет уменьшения дочерних процессов при простое), но при этом бывают пиковые всплески, которые необходимо обработать.
Помимо
pm.max_children в настройке этой стратегии принимают участие еще 3 параметра:✅ pm.start_servers — количество процессов, запускаемых при старте PHP-FPM. Видел 2 рекомендации по подсчёту: Значение равно кол-ву ядер (но не нашел информации где это обоснованно) или 25% от pm.max_children, который считается также, как для static.✅ pm.min_spare_servers — минимальное количество бездействующих дочерних процессов. Чтобы новый процесс не создавался прямо в момент подключения нового клиента — PHP-FPM создаёт процессы заранее. Например на старте у нас было 10 процессов, и значение min_spare_servers мы установили равным 10. Пришел клиент и сразу подключился к одному из поднятых процессов, а в это время заботливый FPM создаёт еще один 11й процесс, чтобы бездействующих снова стало 10. Когда общее кол-во процессов упирается в pm.max_children, то новые свободные процессы не создаются (что логично). Также рекомендуют брать значение 25% от pm.max_children. ✅ pm.max_spare_servers — максимальное количество бездействующих дочерних процессов. При падении нагрузки, PHP-FPM будет убивать лишние процессы высвобождая ресурсы. Если значение свободных процессов больше, чем pm.max_spare_servers, то главному процессу будет отправлен SIGCHLD, чтобы он сократил кол-во дочерних процессов и они всегда находились в пределе между pm.min_spare_servers и pm.max_spare_servers. Считают как 75% от pm.max_children.👍 Как вы уже догадались, вас ждёт 3я часть из данного цикла. Если вам есть что добавить — обязательно пишите мне лично или добавляйтесь в наш уютный чатик :)
#php #server #middle #source
{kind=link}
❤7👍4
Настройка PHP-FPM (part 3)
Ранее мы рассмотрели 2 стратегии запуска дочерних процессов процессов и проговорили об основах работы самого fpm.
Итак третья стратегия:
📌 Ondemand — на старте у вас есть 0 (ноль, зеро) рабочих процессов. Процессы создаются когда появляются новые запросы. Такая стратегия подойдет для проекта с низким трафиком и ограниченным ресурсом. С одной стороны у вас не будет запущено лишних процессов, с другой клиентам придётся немного подождать, пока
❗️Ни в коем случае не стоит использовать, если у вас постоянные скачки трафика. На постоянное создание у уничтожение процессов будет тратиться очень много лишних мощностей.
Для настройки этого режима используется 2 параметра — уже хорошо известный нам
⚡️И еще несколько полезных параметров:
❓Как же подобрать оптимальное значение
Раз уж начал, то стоит и упомянуть и
❓Как помочь освободить память?
👉 Также достаточно полезным инструментом для анализа может быть
🍻 Ну что, с циклом статей по PHP-FPM будем заканчивать. Не забывайте следить за показателями на своём серваке, анализировать и настраивать на основе именно вашей нагрузки.
#php #server #middle #source
Ранее мы рассмотрели 2 стратегии запуска дочерних процессов процессов и проговорили об основах работы самого fpm.
Итак третья стратегия:
📌 Ondemand — на старте у вас есть 0 (ноль, зеро) рабочих процессов. Процессы создаются когда появляются новые запросы. Такая стратегия подойдет для проекта с низким трафиком и ограниченным ресурсом. С одной стороны у вас не будет запущено лишних процессов, с другой клиентам придётся немного подождать, пока
fpm создаст для них процесс. ❗️Ни в коем случае не стоит использовать, если у вас постоянные скачки трафика. На постоянное создание у уничтожение процессов будет тратиться очень много лишних мощностей.
Для настройки этого режима используется 2 параметра — уже хорошо известный нам
pm.max_children и pm.process_idle_timeout. Второй параметр устанавливает время через которое нужно убить ваш дочерний процесс, если тот свободен и простаивает. Маленькое значение конечно поможет вам быстро высвободить память, но если у вас есть скачки трафика, то лучше заменить стандартные 10 секунда на несколько минут, а может и несколько десятков минут.⚡️И еще несколько полезных параметров:
❓Как же подобрать оптимальное значение
pm.max_children в процессе использования? Для этого можно посмотреть статистику в реальном времени воспользовавшись параметром pm.status_path, который задаст адрес для просмотра страницы. Сколько процессов запущено, сколько из них находится в ожидании, а также какая длина очереди ожидающих выполнения запросов и всё что вас интересует — можно здесь найти. Данные значения можно отображать в xml, json, html, что может быть полезно в разных ситуациях (например если вы собираете данные с помощью prometeus). Раз уж начал, то стоит и упомянуть и
ping.path, в которой также можно указать адрес страницы. С её помощью можно убедиться, что FPM жив и отвечает. Вам будет отдаваться ответ с кодом 200, а контент страницы можно задать в ping.response, по умолчанию увидите pong. Почему не использовать status page? Просто потому, что этот вариант требует меньшего ресурса и его можно чаще опрашивать т.к. ему не нужно проводить дополнительных манипуляций. ❓Как помочь освободить память?
pm.max_requests — это максимальное количество запросов, которое обработает дочерний процесс, прежде чем будет уничтожен. Принудительное уничтожение процесса позволяет избежать ситуации в которой память дочернего процесса "разбухнет" по причине утечек (т.к процесс продолжает работу после от запроса к запросу). С другой стороны, слишком маленькое значение приведет к частым перезапускам, что приведет к потерям в производительности. По умолчанию стоит 0, но стоит с ним поиграться. Для стратегии static под большими нагрузками я бы начал со значения в 50000, ведь мы специально её выбрали, чтобы не тратить ресурсы на работу с процессами. Для dynamic и ondemand нужно выбирать меньшее значение.request_terminate_timeout — устанавливает максимальное время выполнения дочернего процесса, прежде чем он будет уничтожен. Это позволяет избегать долгих запросов, если по какой-либо причине было изменено значение max_execution_time в настройках интерпретатора. Значение стоит установить исходя из логики обрабатываемых приложений, скажем 60s (1 минута).👉 Также достаточно полезным инструментом для анализа может быть
slowlog. request_slowlog_timeout = 5sТаким образом мы указали файл, в который будет писаться журнал всех запросов, которые выполнялись дольше 5 секунд. Не забудьте — память на сервере не резиновая :)
slowlog = /var/log/php-fpm/slowlog-site.log
🍻 Ну что, с циклом статей по PHP-FPM будем заканчивать. Не забывайте следить за показателями на своём серваке, анализировать и настраивать на основе именно вашей нагрузки.
#php #server #middle #source
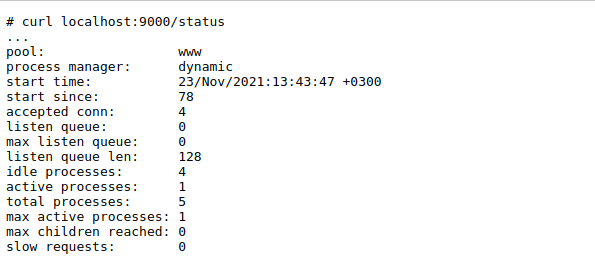{kind=link}
❤8👍6🔥4
DateTimeImmutable vs DateTimeInterface
Очень давно не выходили посты, пора возвращаться в строй и вот один из черновиков, который я таки добил.
Все мы знаем (надеюсь), что для работы с датой и временем в PHP cуществует класс
📌 Используйте только DateTimeImmutable
Изначально
👍 Вместо того, чтобы добавлять костыли для предотвращения неожиданных изменений, используйте
📌 Не используйте DateTimeInterface
Но почему? Да, я и сам его использовал до недавнего времени, но спасибо коллегам по работе за подсказку. В PHP изначально появился класс
👉 А как же завязываться на абстракции, а не на реализации? Во-первых, вы просто не можете создать пользовательский класс, который бы имплементировал этот интефейс. Во-вторых необходимость в интерфейсах для Value Object's крайне спорная затея. Также были намерения по выпилу данного интефейса. Ну и согласно PSR-20 (за который проголосовали но еще не зарелизили) мы будем завязаны именно на реализации
📌 Всегда используйте информацию о часовом поясе
Не нужно от неё абстрагироваться, да и в большинстве случаев не получится. Это хорошо соотносится с whole value concept, то есть работать с временем без часового пояса равнозначна работе с деньгами без валюты. Есть несколько нюансов как правильно это делать, но это уже совсем другая история ☺️.
—————
И да, так как в телеграмм появились реакции, которые можно использовать вместе с комментариями (но нет 🍺 и 🐒), то попробуем заюзать их в тестовом формате. Так что ставьте 🔥и пишите комменты :)
#php #datetime #junior
Очень давно не выходили посты, пора возвращаться в строй и вот один из черновиков, который я таки добил.
Все мы знаем (надеюсь), что для работы с датой и временем в PHP cуществует класс
DateTime. Однако, даже работая с этим классом, в котором решены многие проблемы, мы можем набить себе кучу шишек. И вот как избежать некоторых из них: 📌 Используйте только DateTimeImmutable
Изначально
DateTime задумывался как Value Object, а одним из главных принципов создания VO является иммутабельность. Думаю, что никому не будет приятно попадать в подобные ситуации, когда создавая один объект, мы случайно аффектим и второй [pic ]. Ведь именно такие замечаешь не сразу т.к. на первый взгляд всё логично написано. Конечно можно решить это использовав clone, но зачем? 👍 Вместо того, чтобы добавлять костыли для предотвращения неожиданных изменений, используйте
DateTimeImmutable, который является тем самым иммутабельным Value Object'ом, а значит под капотом, будет создавать новый объект, то есть сделает clone за вас.📌 Не используйте DateTimeInterface
Но почему? Да, я и сам его использовал до недавнего времени, но спасибо коллегам по работе за подсказку. В PHP изначально появился класс
DateTime. Очевидно, это удобный инструмент, который стали использовать в большом кол-ве проектов, но быстро поняли, что мутабельность это ошибка. Тогда для соблюдения обратной совместимости и более плавного перехода прогеров на DateTimeImmutable — выпустили "патч" в виде DateTimeInterface. 👉 А как же завязываться на абстракции, а не на реализации? Во-первых, вы просто не можете создать пользовательский класс, который бы имплементировал этот интефейс. Во-вторых необходимость в интерфейсах для Value Object's крайне спорная затея. Также были намерения по выпилу данного интефейса. Ну и согласно PSR-20 (за который проголосовали но еще не зарелизили) мы будем завязаны именно на реализации
DateTimeImmutable.📌 Всегда используйте информацию о часовом поясе
Не нужно от неё абстрагироваться, да и в большинстве случаев не получится. Это хорошо соотносится с whole value concept, то есть работать с временем без часового пояса равнозначна работе с деньгами без валюты. Есть несколько нюансов как правильно это делать, но это уже совсем другая история ☺️.
—————
И да, так как в телеграмм появились реакции, которые можно использовать вместе с комментариями (но нет 🍺 и 🐒), то попробуем заюзать их в тестовом формате. Так что ставьте 🔥и пишите комменты :)
#php #datetime #junior
{kind=link}
🔥226❤16👍8😱3
👉 Так совпало, что когда CrosserBot запостил своё сообщение у меня в канале, я бежал по воздушной тревоге в укрытие.
❗️Хочу донести до вас несколько месседжей:
1. Я из Украины. Я родился и вырос в Донецке. Я был вынужден выехать из своего любимого города.
2. То, что сделали CrosserBot — они сделали необдуманно, хотя я сильно благодарен им за смелость, за их позицию, которую я разделяю и поддерживаю.
3. Я верю, что в нашем комьюнити все здраво и критически мыслящие люди, которые способны на DYOR (do your own research).
4. От себя лично я прошу воздержаться от резких высказываний с одной и с другой стороны. Это не поможет. Это вызывает ненависть, которая на самом деле никому не нужна.
5. Все войны заканчиваются. Эта не будет исключением.
⭕️ Что касается моей позиции:
1. Войска РФ вторглись на территорию суверенного государства. В результате этого действия гибнут люди с двух сторон. Этому нет оправдания.
2. Сейчас в РФ не может быть позиции "я вне политики". Политика коснулась каждого. Сегодня в РФ пора это принять. Или бояться автозаков и смериться с тем, что происходит с экономикой или бороться с этим.
3. Если вы боитесь сесть на 15 лет, я вас не осуждаю, это нормально. Только нужно принять тот факт, что вам угрожают не украинцы, а власти РФ.
‼️ Итог:
Я временно закрываю комментарии, чтобы не раздувать вражду и не вызывать ненависть с обоих сторон. Точно знаю, что словесные перепалки делают только хуже. Несколько дней назад я сделал отдельный канал, в котором делаю посты о текущей ситуации, сам проверяю инфу на предмет правдивости. Если вам не хватает политической информации — Welcome.
———————————————————
Если бы 2 недели назад мне сказали, что я буду писать этот текст я бы посмеялся этому человеку в лицо. Я горжусь тем, что родился и вырос в Украине, горжусь нашими людьми, армией и силой духа.
Все буде Україна 🇺🇦❤️
❗️Хочу донести до вас несколько месседжей:
1. Я из Украины. Я родился и вырос в Донецке. Я был вынужден выехать из своего любимого города.
2. То, что сделали CrosserBot — они сделали необдуманно, хотя я сильно благодарен им за смелость, за их позицию, которую я разделяю и поддерживаю.
3. Я верю, что в нашем комьюнити все здраво и критически мыслящие люди, которые способны на DYOR (do your own research).
4. От себя лично я прошу воздержаться от резких высказываний с одной и с другой стороны. Это не поможет. Это вызывает ненависть, которая на самом деле никому не нужна.
5. Все войны заканчиваются. Эта не будет исключением.
⭕️ Что касается моей позиции:
1. Войска РФ вторглись на территорию суверенного государства. В результате этого действия гибнут люди с двух сторон. Этому нет оправдания.
2. Сейчас в РФ не может быть позиции "я вне политики". Политика коснулась каждого. Сегодня в РФ пора это принять. Или бояться автозаков и смериться с тем, что происходит с экономикой или бороться с этим.
3. Если вы боитесь сесть на 15 лет, я вас не осуждаю, это нормально. Только нужно принять тот факт, что вам угрожают не украинцы, а власти РФ.
‼️ Итог:
Я временно закрываю комментарии, чтобы не раздувать вражду и не вызывать ненависть с обоих сторон. Точно знаю, что словесные перепалки делают только хуже. Несколько дней назад я сделал отдельный канал, в котором делаю посты о текущей ситуации, сам проверяю инфу на предмет правдивости. Если вам не хватает политической информации — Welcome.
———————————————————
Если бы 2 недели назад мне сказали, что я буду писать этот текст я бы посмеялся этому человеку в лицо. Я горжусь тем, что родился и вырос в Украине, горжусь нашими людьми, армией и силой духа.
Все буде Україна 🇺🇦❤️
❤315💩48🔥18👍10