
Массивы (часть 1, использование массивов как списков)
Как бы мы не хотели использовать только объекты, это удобно далеко не всегда, да и часто может являться оверинженирингом. На помощь приходят любимые массивы. Вот некоторые рекомендации, которые могут помочь при использовании массивов в виде списков:
❗️Все элементы массива должны быть одного типа
Это касается как использования объектов внутри списков, так и простых типов (int, string и т.д.).
❗️Старайтесь не использовать индекс вашего списка.
Не стоит полагаться на индексы, которые автоматически генерирует PHP или использовать их напрямую. Вам должно быть достаточно того, что массив итерируемый (
❗️Вместо удаления элементов используйте фильтр.
Это правило вытекает из предыдущего. Вы можете удалить элементы из списка по их индексу (
Эти правила помогут вам избавиться от лишних
#php #array #junior #source
Как бы мы не хотели использовать только объекты, это удобно далеко не всегда, да и часто может являться оверинженирингом. На помощь приходят любимые массивы. Вот некоторые рекомендации, которые могут помочь при использовании массивов в виде списков:
❗️Все элементы массива должны быть одного типа
@var array <TypeOfElement>. Это касается как использования объектов внутри списков, так и простых типов (int, string и т.д.).
❗️Старайтесь не использовать индекс вашего списка.
Не стоит полагаться на индексы, которые автоматически генерирует PHP или использовать их напрямую. Вам должно быть достаточно того, что массив итерируемый (
foreach) и его кол-во элементов можно посчитать (count()). Следовательно нужно стараться избегать конструкции for.❗️Вместо удаления элементов используйте фильтр.
Это правило вытекает из предыдущего. Вы можете удалить элементы из списка по их индексу (
unset()), но вместо этого лучше использовать array_filter() для создания нового списка без нежелательных элементов. Также не нужно использовать флаги, которые позволяют внутри array_filter() работать с индексами.Эти правила помогут вам избавиться от лишних
if, повысят читабельность и предсказуемость, а что нам еще надо то? :)#php #array #junior #source
{kind=link}
Где определять ID сущности (entity)?
Здесь мы опустим часть, в которой мы сравниваем автоинкременты из БД и генерируемые
Мы знаем 2 правила:
1. Сущности (Entity) должны иметь идентификатор.
2. Объекты должны создаваться валидными.
❌ Исходя из этого вроде логично добавить генерацию
❌ Отлично, выносим за пределы, на уровень Application, выглядит неплохо. Но есть ощущение, что что-то не так. Код будет повторяться, к тому же лежит он здесь как-то нелогично.
📌 Чтобы не разбрасывать по всему проекту код самой генерации - его можно вынести в репозиторий сущности.
Сразу получим несколько преимуществ:
1. Концептуально логично: Репозиторий управляет сущностями и их id.
2. В случае необходимости - легко подменить реализацию т.к. код генерации в одном месте.
3. Можете даже использовать инкрементные id, если БД поддреживает последовательности (sequences, напр. postgresql).
4. Всё на своих местах, интерфейс и сущность в доменном уровне, uuid в инфраструктуре, как и полагается зависимым от даты / времени и случайных данных строкам.
#php #middle #advice #source
Здесь мы опустим часть, в которой мы сравниваем автоинкременты из БД и генерируемые
id (uuid) и сразу перейдем ко вторым. Если останутся вопросы, то обязательно пробежимся и по теме сравнения.Мы знаем 2 правила:
1. Сущности (Entity) должны иметь идентификатор.
2. Объекты должны создаваться валидными.
❌ Исходя из этого вроде логично добавить генерацию
uuid в конструктор. Но создание uuid основывается на текущей дате / времени и ранее сгенерированных случайных данных, а значит, нам не стоит относить его к уровню домена. Плюс ко всему сущность должна знать только о себе и не должна смотреть за пределы своих границ, чтобы узнать, действительно ли id уникален (а это одна из распространенных проблем). Получается этот процесс должен быть вне сущности.❌ Отлично, выносим за пределы, на уровень Application, выглядит неплохо. Но есть ощущение, что что-то не так. Код будет повторяться, к тому же лежит он здесь как-то нелогично.
📌 Чтобы не разбрасывать по всему проекту код самой генерации - его можно вынести в репозиторий сущности.
Сразу получим несколько преимуществ:
1. Концептуально логично: Репозиторий управляет сущностями и их id.
2. В случае необходимости - легко подменить реализацию т.к. код генерации в одном месте.
3. Можете даже использовать инкрементные id, если БД поддреживает последовательности (sequences, напр. postgresql).
4. Всё на своих местах, интерфейс и сущность в доменном уровне, uuid в инфраструктуре, как и полагается зависимым от даты / времени и случайных данных строкам.
#php #middle #advice #source
{kind=link}
Когда следует использовать коллекции?
В этой статье мы говорили о том как быстро приготовить коллекцию, но стоит разобраться в каких именно случаях она нужна. Безусловно, их использование это крутой подход, но в то же время это отнимает больше времени, ведь вам нужно написать больше кода, покрыть его тестами, заниматься его отладкой и т.д.
Поэтому стоит соблюдать некоторый баланс, ведь часто использования простого массива с некоторыми аннотациями вполне достаточно для решения той или иной задачи.
Как понять, что лучше всё таки использовать коллекцию, а не массив?
📌 Если у вас есть дублирующаяся логика, использующая этот массив. Например вы видите, что в клиентском коде, в нескольких местах у вас есть повторяющаяся логика, которая фильтрует/сокращает/выбирает и т.д. данные массива, вы можете вынести её в метод класса коллекции. Плюс данного подхода также в том, что вы даете осознанное имя определенной логике, которую прячете в метод, что сильно повышает читабельность кода.
📌 Когда какой-то объект работает с массивом, перебирает его, извлекает какие-то данные, что-то с ними делает, то объект становится сильно связанным с этим массивом и изменение данных в массиве легко может нарушить работу клиента. Таким образом следует вынести наш массив в коллекцию, дать коллекции выполнить необходимые вычисления внутри и предоставить объекту готовый результат, таким образом снизив связанность.
#PHP #junior #source
В этой статье мы говорили о том как быстро приготовить коллекцию, но стоит разобраться в каких именно случаях она нужна. Безусловно, их использование это крутой подход, но в то же время это отнимает больше времени, ведь вам нужно написать больше кода, покрыть его тестами, заниматься его отладкой и т.д.
Поэтому стоит соблюдать некоторый баланс, ведь часто использования простого массива с некоторыми аннотациями вполне достаточно для решения той или иной задачи.
Как понять, что лучше всё таки использовать коллекцию, а не массив?
📌 Если у вас есть дублирующаяся логика, использующая этот массив. Например вы видите, что в клиентском коде, в нескольких местах у вас есть повторяющаяся логика, которая фильтрует/сокращает/выбирает и т.д. данные массива, вы можете вынести её в метод класса коллекции. Плюс данного подхода также в том, что вы даете осознанное имя определенной логике, которую прячете в метод, что сильно повышает читабельность кода.
📌 Когда какой-то объект работает с массивом, перебирает его, извлекает какие-то данные, что-то с ними делает, то объект становится сильно связанным с этим массивом и изменение данных в массиве легко может нарушить работу клиента. Таким образом следует вынести наш массив в коллекцию, дать коллекции выполнить необходимые вычисления внутри и предоставить объекту готовый результат, таким образом снизив связанность.
#PHP #junior #source
{kind=link}
Как сохранять Value Objects (VO) в Doctrine?
📌 Первое, что приходит на ум — использовать
Этот подход может показаться странным, но если присмотреться — он вполне оптимальный, ведь для внешнего мира объект выглядит идеально.
📌 Вариант чуть сложнее - использовать DBAL Types, для этого руками для такого типа нужно описать 2 метода:
📌 Embeddables
Данный подход, позволяет встраивать класс, не являющийся сущностью, внутрь сущности. Кажется она просто предназначена для хранения объектов-значений!
❗️ Конечно, существует еще такой способ, как сериализация. Как и в первом варианте с простыми типами, пока это внутри модели, это не большая проблема для всей бизнесовой логики. Недостатком является то, что вы не можете эффективно запрашивать эти данные. То есть вы можете сериализовать значения в свою базу данных, но только тогда, когда на 100% уверенны, что никогда не захотите выполнять запросы к ним или изменять данные.
🤦♀️ С одной стороны последний метод с использованием Embeddables выглядит очень громоздким, с другой первый метод хоть и простой, но мы внутри сущности добавляем поведение лишь для того, чтобы сохранить state (не криминально, но вызывает двоякие чувства). Кто-то обязательно скажет насчет аннотаций в сущности, которые "смешивают слои" (хотя я считаю, что т.к. аннотации это по сути комментарии, то сущность от этого не страдает), что стоит хранить подобное описание в XML или YAML.
👍 Это нормально использовать симбиоз вышеописанных подходов. Всё зависит от задачи, времени на разработку и ваших договоренностей в команде.
#PHP #middle #source
📌 Первое, что приходит на ум — использовать
VO только на границах (входе и выходе), а внутри самой Entity использовать простые типы.Этот подход может показаться странным, но если присмотреться — он вполне оптимальный, ведь для внешнего мира объект выглядит идеально.
📌 Вариант чуть сложнее - использовать DBAL Types, для этого руками для такого типа нужно описать 2 метода:
convertToDatabaseValue($value, AbstractPlatform $platform)Этот метод отлично подходит, если ваш
convertToPHPValue($value, AbstractPlatform $platform)
VO хранит в себе одно значение, которое вам нужно вписать в одну колонку. Но что, если их несколько?📌 Embeddables
Данный подход, позволяет встраивать класс, не являющийся сущностью, внутрь сущности. Кажется она просто предназначена для хранения объектов-значений!
❗️ Конечно, существует еще такой способ, как сериализация. Как и в первом варианте с простыми типами, пока это внутри модели, это не большая проблема для всей бизнесовой логики. Недостатком является то, что вы не можете эффективно запрашивать эти данные. То есть вы можете сериализовать значения в свою базу данных, но только тогда, когда на 100% уверенны, что никогда не захотите выполнять запросы к ним или изменять данные.
🤦♀️ С одной стороны последний метод с использованием Embeddables выглядит очень громоздким, с другой первый метод хоть и простой, но мы внутри сущности добавляем поведение лишь для того, чтобы сохранить state (не криминально, но вызывает двоякие чувства). Кто-то обязательно скажет насчет аннотаций в сущности, которые "смешивают слои" (хотя я считаю, что т.к. аннотации это по сути комментарии, то сущность от этого не страдает), что стоит хранить подобное описание в XML или YAML.
👍 Это нормально использовать симбиоз вышеописанных подходов. Всё зависит от задачи, времени на разработку и ваших договоренностей в команде.
#PHP #middle #source
{kind=link}
Как хранить UUID в MySQL?
К сожалению реалии таковы, что просто написать "никак" не получится, т.к. MySQL всё еще занимает лидирующие позиции по использованию в веб разработке, не смотря на все его недостатки.
🙈 Многие по-умолчанию сохраняют
Хранить как BINARY.
🔨 Благо с выходом 8й версии MySQL часть танцев с бубном была перенесена в коробку и
❗️Для этого можно использовать
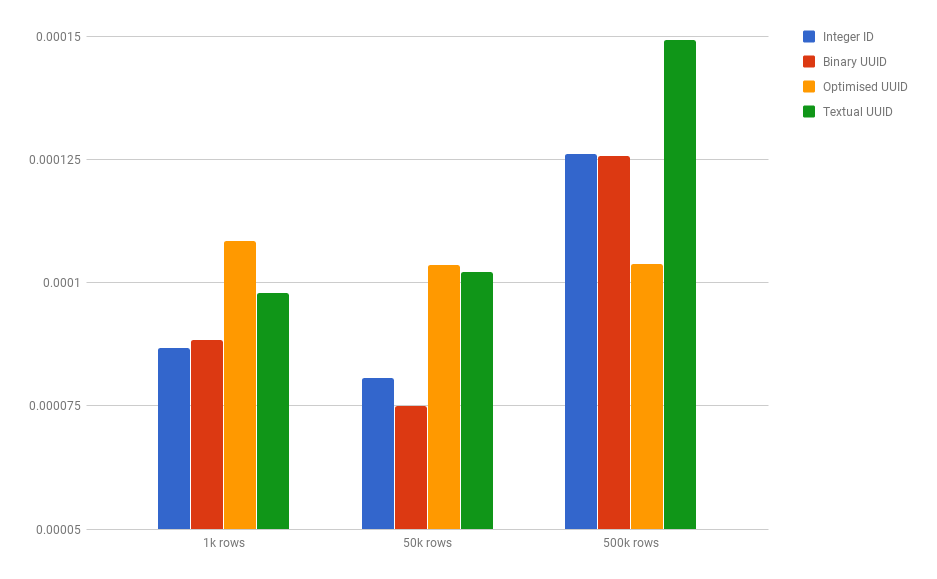
📊 Ну и самое интересное — сравнение!
📌 Выходит, что при малом кол-ве записей, наш оптимизированный
Безусловно, генерируемые id — довольно удобный инструмент, но всегда следует хорошо спроектировать решение в голове, прежде чем внедрить.
#PHP #MySQL #middle #source
К сожалению реалии таковы, что просто написать "никак" не получится, т.к. MySQL всё еще занимает лидирующие позиции по использованию в веб разработке, не смотря на все его недостатки.
🙈 Многие по-умолчанию сохраняют
UUID в CHAR(36) и не переживают по этому поводу. Действительно, если кол-во записей в вашей таблице < 50к, то вы скорее всего не заметите никаких проблем. Но что если в какой-то из таблиц их больше полумиллиона?Хранить как BINARY.
🔨 Благо с выходом 8й версии MySQL часть танцев с бубном была перенесена в коробку и
UUID_TO_BIN / BIN_TO_UUID уже делают всё за тебя. Они производят сжатие 32 символов (36 или более с разделителями) до 16-битного формата или обратно до формата, который снова можно прочесть.INSERT INTO t VALUES(UUID_TO_BIN(UUID()));👍 Мы уже получим буст, и очень неплохой, т.к. MySQL отлично индексирует
SELECT BIN_TO_UUID(id) FROM t;
BINARY, даже лучше, чем привычный автоинкрементный INT. И всё бы ничего, если бы не кластерный индекс, который как раз и используется у PRIMARY KEY. Это значит, что для его оптимизации мы должны иметь и упорядоченные UUID в базе. Но как это сделать?❗️Для этого можно использовать
UUID первой версии, в которой содержатся биты связанные со временем. А во время использования UUID_TO_BIN / BIN_TO_UUID использовать второй (необязательный, логический) аргумент:INSERT INTO t VALUES (UUID_TO_BIN (UUID (), true));Именно он переупорядочит биты, связанные со временем, так, чтобы последовательные сгенерированные значения были упорядочены и в индексе.
📊 Ну и самое интересное — сравнение!
📌 Выходит, что при малом кол-ве записей, наш оптимизированный
UUID работает медленнее остальных, при этом при 500к он обгоняет по показателям INT. И здесь возникает совсем другая история, а именно кол-во потребляемой памяти для большого кол-ва записей :) Безусловно, генерируемые id — довольно удобный инструмент, но всегда следует хорошо спроектировать решение в голове, прежде чем внедрить.
#PHP #MySQL #middle #source
{kind=link}
Сегодня спешу вас порадовать первым гостевым постом (не рекламой). Надеюсь, что этот эксперимент будет успешным и время от времени здесь будут публиковаться и интересные материалы от подписчиков.
Unit testing (предисловие, part - 0)
❗️ Основная цель юнит тестирования — обеспечение стабильного роста проекта. Не быстрого, не сверхнадёжного, а стабильного.
В начале жизни продукта, писать его очень легко. Фичи пилятся, запускаются и интегрируется в код быстро, пользователи довольны, бизнес считает прибыль. Но со временем, сложность проекта растет, внедрение фич занимает всё больше времени, а руки при релизе начинают дрожать.
🙈 Чем больше вы пишете кода, тем сильнее растет так называемая "программная энтропия" (научный термин между прочим!) — степень беспорядка в системе. Соответственно скорость разработки продукта падает, потому как каждый раз когда вы трогаете код, энтропия увеличивается.
Что делать? Есть 2 варианта.
👉 Можно забить если это:
1. Проверка идеи или MVP продукта, который слеплен из веток и сами знаете чего.
2. Сайт лендинг / визитка / каталог в которому не требуется длительный саппорт.
3. Проект, который существует только у вас на компе и не пойдет в продакшен.
👉 Нужно контролировать если:
1. Продукт прошел стадию MVP и перерос в бизнес.
2. Нужен длительный саппорт.
Причем тут тесты? Они помогают контролировать. Как? Об этом в следующем посте.
#intern #unit #testing #author
Unit testing (предисловие, part - 0)
❗️ Основная цель юнит тестирования — обеспечение стабильного роста проекта. Не быстрого, не сверхнадёжного, а стабильного.
В начале жизни продукта, писать его очень легко. Фичи пилятся, запускаются и интегрируется в код быстро, пользователи довольны, бизнес считает прибыль. Но со временем, сложность проекта растет, внедрение фич занимает всё больше времени, а руки при релизе начинают дрожать.
🙈 Чем больше вы пишете кода, тем сильнее растет так называемая "программная энтропия" (научный термин между прочим!) — степень беспорядка в системе. Соответственно скорость разработки продукта падает, потому как каждый раз когда вы трогаете код, энтропия увеличивается.
Что делать? Есть 2 варианта.
👉 Можно забить если это:
1. Проверка идеи или MVP продукта, который слеплен из веток и сами знаете чего.
2. Сайт лендинг / визитка / каталог в которому не требуется длительный саппорт.
3. Проект, который существует только у вас на компе и не пойдет в продакшен.
👉 Нужно контролировать если:
1. Продукт прошел стадию MVP и перерос в бизнес.
2. Нужен длительный саппорт.
Причем тут тесты? Они помогают контролировать. Как? Об этом в следующем посте.
#intern #unit #testing #author
{kind=link}
Сеть — ненадёжна
👉 Давайте договоримся о том, что "Сеть — ненадёжна", примем это как аксиому, как фундаментальное правило, как гравитацию. Сегодня, в эпоху (микро)сервисов, огромного кол-ва сторонних решений вызываемых по API это очень важная аксиома.
• Что делать, если я пошлю команду на изменение и не получу ответ?
• Является ли данный вызов идемпотентным?
• etc.
Что делать, раз вызов по сети может зафейлиться?
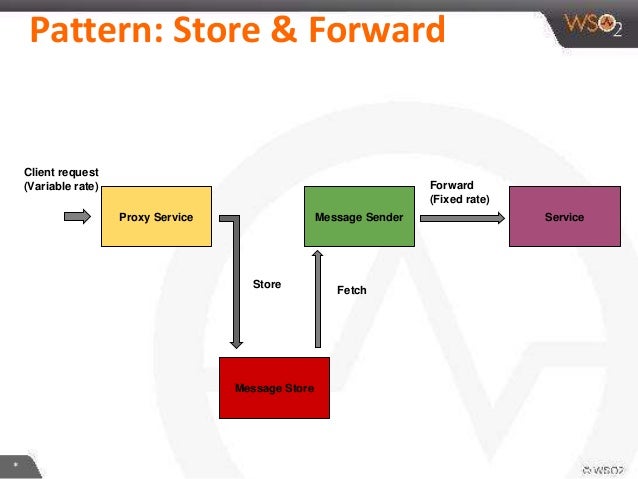
👍 Мы должны обеспечить автоматический retry. Для этого отлично подходят системы управления очередями.
Такое взаимодействие называется store and forward, при котором информация попадает в промежуточное хранилище и позднее отправляется в конечный пункт назначения. Он также помогает обеспечить гарантированную доставку, поскольку сообщения сохраняются и никогда не теряются. Если наш получатель находится offline или возникли любые другие сетевые проблемы — система очередей должна попробовать повторить отправку сообщения.
❗️Конечно стоит помнить об особенностях данного подхода. Для конечного пользователя взаимодействие перестанет быть синхронным. С одной стороны, нам не нужно заставлять пользователя ждать, пока выполнятся все наши сетевые вызовы, но с другой мы не можем сразу вывести пользователю конечный результат. То есть мы переходим от привычного Request/Response к Fire and Forget паттерну.
🔨 Получается, что, решая проблему инфраструктуры, асинхронный обмен сообщениями вынуждает нас изменить логическую схему приложения, переосмыслить подход к написанию кода и осмыслить границы в нашей системе.
#middle #architecture #source
👉 Давайте договоримся о том, что "Сеть — ненадёжна", примем это как аксиому, как фундаментальное правило, как гравитацию. Сегодня, в эпоху (микро)сервисов, огромного кол-ва сторонних решений вызываемых по API это очень важная аксиома.
Во время разработки нужно об этом помнить и задавать себе вопросы:• А что если я получу HTTP timeout exception?
• Что делать, если я пошлю команду на изменение и не получу ответ?
• Является ли данный вызов идемпотентным?
• etc.
Что делать, раз вызов по сети может зафейлиться?
👍 Мы должны обеспечить автоматический retry. Для этого отлично подходят системы управления очередями.
Такое взаимодействие называется store and forward, при котором информация попадает в промежуточное хранилище и позднее отправляется в конечный пункт назначения. Он также помогает обеспечить гарантированную доставку, поскольку сообщения сохраняются и никогда не теряются. Если наш получатель находится offline или возникли любые другие сетевые проблемы — система очередей должна попробовать повторить отправку сообщения.
❗️Конечно стоит помнить об особенностях данного подхода. Для конечного пользователя взаимодействие перестанет быть синхронным. С одной стороны, нам не нужно заставлять пользователя ждать, пока выполнятся все наши сетевые вызовы, но с другой мы не можем сразу вывести пользователю конечный результат. То есть мы переходим от привычного Request/Response к Fire and Forget паттерну.
🔨 Получается, что, решая проблему инфраструктуры, асинхронный обмен сообщениями вынуждает нас изменить логическую схему приложения, переосмыслить подход к написанию кода и осмыслить границы в нашей системе.
#middle #architecture #source
{kind=link}
Использование индексов в MySQL
Чем больше мы пользуемся ORM, тем меньше задумываемся об оптимизации БД, до тех пор пока не прижмёт. В простых кейсах для ускорения запроса проблем не возникает, но если случай чуть сложнее чем "добавить индекс", то разработчики часто не знают за что хвататься. Здесь хочу оставить пару заметок, которые могут натолкнуть на различные решения в подобной ситуации.
👉 Все мы знаем, что индексы используются для быстрого поиска строк с определенными значениями столбцов. Без индекса MySQL будет начинать поиск с первой строки, а затем читать всю таблицу. Чем больше таблица, тем дороже эта операция.
❓ На что обратить внимание при оптимизации?
• Не исключен случай когда одна колонка используется в нескольких индексах. В таком случае MySQL выбирает индекс который вернет наименьшее кол-во строк (наиболее избирательный).
• При использовании составного (композитного) индекса помните, что он может использоваться и в более простых выборках, но только по столбцам перечисленным слева направо. Например индекс
🤝 Для получения строк из других таблиц при
• MySQL может использовать индексы более эффективно, если они одного и того же типа и размера. В этом контексте
Сравнение столбцов разного типа (например,
🙈 Не слишком очевидное
• Индексы менее важны для маленьких таблиц или для больших, из которых нам нужно извлечь все данные или большую их часть. В таком случае последовательное чтение выполняется быстрее, чем при работе с индексом. Всё потому, что последовательное чтение минимизируют поиск на диске, даже если нам нужны не абсолютно все строки.
• Оптимизатору можно задать подсказку по выбору или игнорированию индекса.
#MySQL #junior #source
Чем больше мы пользуемся ORM, тем меньше задумываемся об оптимизации БД, до тех пор пока не прижмёт. В простых кейсах для ускорения запроса проблем не возникает, но если случай чуть сложнее чем "добавить индекс", то разработчики часто не знают за что хвататься. Здесь хочу оставить пару заметок, которые могут натолкнуть на различные решения в подобной ситуации.
👉 Все мы знаем, что индексы используются для быстрого поиска строк с определенными значениями столбцов. Без индекса MySQL будет начинать поиск с первой строки, а затем читать всю таблицу. Чем больше таблица, тем дороже эта операция.
❓ На что обратить внимание при оптимизации?
• Не исключен случай когда одна колонка используется в нескольких индексах. В таком случае MySQL выбирает индекс который вернет наименьшее кол-во строк (наиболее избирательный).
• При использовании составного (композитного) индекса помните, что он может использоваться и в более простых выборках, но только по столбцам перечисленным слева направо. Например индекс
(col1, col2, col3) будет работать для выборок (col1), (col1, col2), и (col1, col2, col3), но не будет для (col2, col3) или (col3).🤝 Для получения строк из других таблиц при
JOIN
• Для сравнения строковых столбцов оба столбца должны использовать одну и ту же кодировку. Например, сравнение столбца utf8 со столбцом latin1 исключает использование индекса.• MySQL может использовать индексы более эффективно, если они одного и того же типа и размера. В этом контексте
VARCHAR и CHAR считаются одинаковыми, если они объявлены с одинаковым размером. Например, VARCHAR (10) и CHAR (10) имеют одинаковый размер, а VARCHAR (10) и CHAR (15) - нет.Сравнение столбцов разного типа (например,
VARCHAR с DATETIME или INT) может препятствовать использованию индексов, если при этом необходимо преобразование. Например в одной таблице у вас INT 1, а в другой VARCHAR ' 1' или '00001'.🙈 Не слишком очевидное
• Индексы менее важны для маленьких таблиц или для больших, из которых нам нужно извлечь все данные или большую их часть. В таком случае последовательное чтение выполняется быстрее, чем при работе с индексом. Всё потому, что последовательное чтение минимизируют поиск на диске, даже если нам нужны не абсолютно все строки.
• Оптимизатору можно задать подсказку по выбору или игнорированию индекса.
SELECT * FROM table1 USE INDEX (col1_index,col2_index)👍 Ставь 🍺 если было полезно и если хочешь еще заметок по этой теме.
WHERE col1=1 AND col2=2 AND col3=3;
SELECT * FROM table1 IGNORE INDEX (col3_index)
WHERE col1=1 AND col2=2 AND col3=3;
#MySQL #junior #source
{kind=link}
Статические анонимные функции 😱
❓ Буквально на днях пришел вопрос от одного из подписчиков касательно контента этого поста. Звучал он так: "
📄 Из документации:
При объявлении в контексте класса, текущий класс будет автоматически связан с ним, делая $this доступным внутри функций класса. Если вы не хотите автоматического связывания с текущим классом, используйте статические анонимные функции.
Выходит, что когда
❗️На первый взгляд "да и чёрт с ним", но стоит копнуть чуть глубже.
Замыкание, содержащее ссылку на
👉 Если подвести короткий итог, то анонимные функции без
#php #middle #memory #source
❓ Буквально на днях пришел вопрос от одного из подписчиков касательно контента этого поста. Звучал он так: "
А зачем делать callback’и в функции сортировки (usort), статическими?" И я подумал, что это действительно хороший вопрос, на который стоит обратить внимание.📄 Из документации:
При объявлении в контексте класса, текущий класс будет автоматически связан с ним, делая $this доступным внутри функций класса. Если вы не хотите автоматического связывания с текущим классом, используйте статические анонимные функции.
Выходит, что когда
closure объявляется в контексте класса, то класс автоматически привязывается к замыканию. Это означает, что $this доступен внутри области анонимной функции. Вот такой вот пример.❗️На первый взгляд "да и чёрт с ним", но стоит копнуть чуть глубже.
Замыкание, содержащее ссылку на
$this, может предотвратить сборку мусора для этого объекта, что, в свою очередь, может существенно повлиять на производительность. Вот примеры с использованием static и без него. Ну и gist, чтобы самостоятельно поиграться.👉 Если подвести короткий итог, то анонимные функции без
static стоит использовать если вам необходимо привязать объект к области видимости выполнения функции. Во всех остальных случаях можно использовать static, как минимум, чтобы случайно не выстрелить себе в ногу.#php #middle #memory #source
{kind=link}
Whole value concept (Quantity pattern)
Я часто вижу, что этому концепту уделяют мало внимания при проектировании Value Objects, потому решил отдельно на нём остановиться.
❗️Следует создавать и использовать объекты, которые имеют значение в рамках вашего бизнеса.
👉 Идея простая. Представим, что у нас есть геопозиция. Чтобы понять где именно находится точка нам нужна и широта и долгота. Поскольку сами по себе "широта" или "долгота" не имеют смысла друг без друга, значит они должны находиться в одном месте, внутри одного объекта. Другими словами не нужно создавать отдельные VO, если сами по себе они ничего не значат, а только являются составляющей другого объекта.
👉 Другой пример. У нас есть сумма денег, которую нам нужно сложить с другой суммой. Чтобы принять решение можем ли мы сложить две amount, мы должны проверить currency. Поскольку currency напрямую влияет на логику вычислений, то оно должно находиться там-же, где и amount.
Это может быть что угодно, такие штуки как валюта, координаты, календарный период, номер телефона, расстояние, вес и т.д.
📌 То есть если у нас есть данные которые влияют на логику - они должны быть частью состояния объекта где эта логика реализована. Да-да, вычисления(логика) также должны находиться внутри (например сложение/вычитание денег или вычисление расстояния в случае с гео).
📌 Если же в объекте хранятся данные которые на логику реализованную в этом объекте никак не влияют - было бы неплохо эти данные оттуда вынести что бы не мешали.
❌ Это не значит, что нужно совсем перестать оборачивать примитивные типы (строки, числа и т.д.). Это значит, что при проектировании стоит задумываться о целесообразности того или иного объекта в вашей предметной области.
#php #oop #middle #source
Я часто вижу, что этому концепту уделяют мало внимания при проектировании Value Objects, потому решил отдельно на нём остановиться.
❗️Следует создавать и использовать объекты, которые имеют значение в рамках вашего бизнеса.
👉 Идея простая. Представим, что у нас есть геопозиция. Чтобы понять где именно находится точка нам нужна и широта и долгота. Поскольку сами по себе "широта" или "долгота" не имеют смысла друг без друга, значит они должны находиться в одном месте, внутри одного объекта. Другими словами не нужно создавать отдельные VO, если сами по себе они ничего не значат, а только являются составляющей другого объекта.
👉 Другой пример. У нас есть сумма денег, которую нам нужно сложить с другой суммой. Чтобы принять решение можем ли мы сложить две amount, мы должны проверить currency. Поскольку currency напрямую влияет на логику вычислений, то оно должно находиться там-же, где и amount.
Это может быть что угодно, такие штуки как валюта, координаты, календарный период, номер телефона, расстояние, вес и т.д.
📌 То есть если у нас есть данные которые влияют на логику - они должны быть частью состояния объекта где эта логика реализована. Да-да, вычисления(логика) также должны находиться внутри (например сложение/вычитание денег или вычисление расстояния в случае с гео).
📌 Если же в объекте хранятся данные которые на логику реализованную в этом объекте никак не влияют - было бы неплохо эти данные оттуда вынести что бы не мешали.
❌ Это не значит, что нужно совсем перестать оборачивать примитивные типы (строки, числа и т.д.). Это значит, что при проектировании стоит задумываться о целесообразности того или иного объекта в вашей предметной области.
#php #oop #middle #source
{kind=link}
Правила по проектированию Entity (part 1)
🗒 В предыдущих статьях я уже несколько раз ссылался на понятие сущности Entity. Разные авторы (напр. Эванс, Нобак, Вернон) дают немного разные определения этого понятия, но суть сильно от этого не меняется.
И вот несколько правил, которые помогут вам проектировать такие объекты:
📌 Сущность всегда должна защищать свои доменные инварианты и следить за тем, чтобы она находилась в согласованном состоянии. Она не должна существовать в вашем приложении если внутри неполные или невалидные данные.
Для этого в конструкторе необходимо проверять, что данные адекватны, например, что значения находятся в допустимом диапазоне, все значения присутствуют и т.д. В случае если что-то не так - вы должны выбрасывать исключения.
📌 Когда обновление определенного поля фактически представляет действие, выполняемое над объектом, определите для него метод в самой сущности. Задача такого метода также заключается в проверке предоставленных ему данных, он должен убедиться, что можно обновить данные, учитывая текущее состояние объекта.
Например вы работаете с заказами. Заказ товара может быть отменен, если он не доставлен. Вместо того чтобы где-то во вне сущности делать:
📌 Не думайте всё время о базе данных.
Стоит оговориться, что речь идёт именно о проектировании структуры и самой сущности. Конечно, есть много случаев, когда нам нужно считаться с нашей базой (высокая конкуренция запросов, deadlocks и т.д.), но идея в том, чтобы перестроить мышление и думать об объектах, как о вещах в реальном мире, а не как о данных в таблице. Просто примите для себя, что маппинг данных в БД это отдельная задача.
👉 Еще несколько правил, касающихся ID, построения связей с другими сущностями, фишки с использованием репозиториев будут во второй части.
#php #oop #junior #entity #source
🗒 В предыдущих статьях я уже несколько раз ссылался на понятие сущности Entity. Разные авторы (напр. Эванс, Нобак, Вернон) дают немного разные определения этого понятия, но суть сильно от этого не меняется.
Сущности — это объекты, которые хранят состояние вашего приложения. Но не "просто хранят".И вот несколько правил, которые помогут вам проектировать такие объекты:
📌 Сущность всегда должна защищать свои доменные инварианты и следить за тем, чтобы она находилась в согласованном состоянии. Она не должна существовать в вашем приложении если внутри неполные или невалидные данные.
Для этого в конструкторе необходимо проверять, что данные адекватны, например, что значения находятся в допустимом диапазоне, все значения присутствуют и т.д. В случае если что-то не так - вы должны выбрасывать исключения.
📌 Когда обновление определенного поля фактически представляет действие, выполняемое над объектом, определите для него метод в самой сущности. Задача такого метода также заключается в проверке предоставленных ему данных, он должен убедиться, что можно обновить данные, учитывая текущее состояние объекта.
Например вы работаете с заказами. Заказ товара может быть отменен, если он не доставлен. Вместо того чтобы где-то во вне сущности делать:
$order->getStatus(),Определите метод
// isn't delivered
$order->setCancel()
cancel(), который будет выполнять проверки внутри сущности и если всё согласовано — менять её состояние.📌 Не думайте всё время о базе данных.
Стоит оговориться, что речь идёт именно о проектировании структуры и самой сущности. Конечно, есть много случаев, когда нам нужно считаться с нашей базой (высокая конкуренция запросов, deadlocks и т.д.), но идея в том, чтобы перестроить мышление и думать об объектах, как о вещах в реальном мире, а не как о данных в таблице. Просто примите для себя, что маппинг данных в БД это отдельная задача.
👉 Еще несколько правил, касающихся ID, построения связей с другими сущностями, фишки с использованием репозиториев будут во второй части.
#php #oop #junior #entity #source
{kind=link}
Использование индексов в MySQL (part 2)
Вот еще несколько важных заметок, которые являются дополнением этого поста.
📌 Повторяющиеся индексы могут не замедлить запросы SELECT, но вполне могут замедлить запросы на INSERT (а в некоторых случаях и UPDATE). В целом рекомендуется избегать дублирования ключей. Например если в одной таблице 2 индекса:
👉 Вот тулза, которая может вам помочь найти подобные случаи и решить, как с ними поступать.
📌 Обратная ситуация, неиспользуемые индексы также следует удалять т.к. это дополнительные расходы памяти и времени на вставку и апдейт. Для этого есть еще одна тулза, которая может вам помочь найти подобные кейсы, но после нахождения обязательно перепроверьте вручную, чтобы не удалить лишнего.
📌 Начиная с версии 8+, MySQL поддерживает индексы по убыванию (нисходящие, DESC), что означает, что он может хранить индексы в порядке убывания. Это может пригодиться, когда у вас есть выборки где надо получать последние добавленные данные.
👍 Если вернуться к первым двум пунктам этой заметки, то следует упомянуть, что у Percona Toolkit очень большой набор инструментов, с которым рекомендую как минимум ознакомиться ;) Если и этот пост наберет много 🍺, то напишу короткую заметку о самых интересных на мой взгляд.
#MySQL #junior #source
Вот еще несколько важных заметок, которые являются дополнением этого поста.
📌 Повторяющиеся индексы могут не замедлить запросы SELECT, но вполне могут замедлить запросы на INSERT (а в некоторых случаях и UPDATE). В целом рекомендуется избегать дублирования ключей. Например если в одной таблице 2 индекса:
KEY `firstname` (`firstname`),то
KEY `firstname_lastname_id` (`firstname`,`lastname`,`id`)
firstname является дубликатом firstname_lastname_id, так как firstname является первым столбцом индекса firstname_lastname_id.👉 Вот тулза, которая может вам помочь найти подобные случаи и решить, как с ними поступать.
📌 Обратная ситуация, неиспользуемые индексы также следует удалять т.к. это дополнительные расходы памяти и времени на вставку и апдейт. Для этого есть еще одна тулза, которая может вам помочь найти подобные кейсы, но после нахождения обязательно перепроверьте вручную, чтобы не удалить лишнего.
📌 Начиная с версии 8+, MySQL поддерживает индексы по убыванию (нисходящие, DESC), что означает, что он может хранить индексы в порядке убывания. Это может пригодиться, когда у вас есть выборки где надо получать последние добавленные данные.
CREATE TABLE t (📌 Также у вас могут быть таблицы с данными, которые не нужны вам в выборке или вообще нужны редко. Подумайте о том, чтобы разделить такую таблицу (логически или по необходимости использования данных). Это также ускорит выборку и снизит потребление CPU.
c1 INT, c2 INT,
INDEX idx1 (c1 ASC, c2 ASC),
INDEX idx2 (c1 ASC, c2 DESC),
INDEX idx3 (c1 DESC, c2 ASC),
INDEX idx4 (c1 DESC, c2 DESC)
);
👍 Если вернуться к первым двум пунктам этой заметки, то следует упомянуть, что у Percona Toolkit очень большой набор инструментов, с которым рекомендую как минимум ознакомиться ;) Если и этот пост наберет много 🍺, то напишу короткую заметку о самых интересных на мой взгляд.
#MySQL #junior #source
{kind=link}
Tell, Don't Ask (TDA)
Еще в 1997 году А. Шарп сформулировал такой принцип:
📃 Процедурный код сначала получает информацию, а затем принимает решения. Объектно-ориентированный код говорит объектам, что нужно делать.
То, что мы принимаем решения за пределами объектов — нарушает их information hiding. В этом примере мы скрыли детали реализации. Это упростило понимание и поддержку нашего кода, а также сделало наш объект более осознанным.
❗️ Внимание, обычно в этом месте кто-то вспоминает про "анемичную модель", а кто-то про "god objects" и начинается дикий срач, так что будьте готовы, если хотите с кем-то обсудить эту тему ;)
👉 Принципы — это не истина последней инстанции. Безусловно, мы должны держать TDA в голове, но не слепо ему следовать. Да он может привести к:
🔹 Раздутию классов и увеличения их сложности;
🔹 Увеличению coupling из-за того что у объекта много ответственности;
🔹 Нарушению SRP (single responsibility principle) в конце концов;
❓ С другой стороны, если для регистрации
Конечно многое зависит от задачи и контекста, но в любом случае стоит придерживаться здравого смысла.
#oop #middle #source
Еще в 1997 году А. Шарп сформулировал такой принцип:
📃 Процедурный код сначала получает информацию, а затем принимает решения. Объектно-ориентированный код говорит объектам, что нужно делать.
То, что мы принимаем решения за пределами объектов — нарушает их information hiding. В этом примере мы скрыли детали реализации. Это упростило понимание и поддержку нашего кода, а также сделало наш объект более осознанным.
❗️ Внимание, обычно в этом месте кто-то вспоминает про "анемичную модель", а кто-то про "god objects" и начинается дикий срач, так что будьте готовы, если хотите с кем-то обсудить эту тему ;)
👉 Принципы — это не истина последней инстанции. Безусловно, мы должны держать TDA в голове, но не слепо ему следовать. Да он может привести к:
🔹 Раздутию классов и увеличения их сложности;
🔹 Увеличению coupling из-за того что у объекта много ответственности;
🔹 Нарушению SRP (single responsibility principle) в конце концов;
❓ С другой стороны, если для регистрации
User вам нужны только email и password, которые совсем не принимают участия в других процессах, то действительно ли всё должно быть в одном объекте? Или это совсем другой объект напр. Credentials? Конечно многое зависит от задачи и контекста, но в любом случае стоит придерживаться здравого смысла.
#oop #middle #source
{kind=link}
Regular Expression
При виде слова "RegExp" у разработчиков начинает дергаться глаз. Ведь каждый из на с помнит десятки потраченных часов, ради того, чтобы покрыть все возможные кейсы и таки сделать регулярку, которая будет работать. Здесь я опишу пару советов о том, как немного упростить себе жизнь при написании RegExp.
👉 Выберите удобный разделитель (delimiter)
Речь идет о символах, в которые мы оборачиваем наше выражение. Чаще всего в примерах используется slash "
❓ Но зачем выбирать другой разделитель? Всё дело в том, что все вхождения символа разделителя в выражение должны быть экранированы, потому на выходе мы получаем:
Скобочными группами называется то, что находится внутри () скобок. Найденные результаты будут переданы в $matches.
👉 Используйте символьные классы
Это также поможет сделать ваше выражение более читабельным. Самый распространенный класс
👌 Так-же следует упомянуть, что при использовании выражений с поддержкой unicode (флаг
Весь перечень можно посмотреть здесь.
#junior #regexp #source
При виде слова "RegExp" у разработчиков начинает дергаться глаз. Ведь каждый из на с помнит десятки потраченных часов, ради того, чтобы покрыть все возможные кейсы и таки сделать регулярку, которая будет работать. Здесь я опишу пару советов о том, как немного упростить себе жизнь при написании RegExp.
👉 Выберите удобный разделитель (delimiter)
Речь идет о символах, в которые мы оборачиваем наше выражение. Чаще всего в примерах используется slash "
/"/(foo|bar)/i❗️На самом деле для разделителя можно выбрать любой символ, например
~,!, @, #, $. Разделителями НЕ могут быть буквенно-цифровые символы (AZ, az и 0-9), многобайтовые символы (Такие как Emojis 😢) и обратная косая черта (\). ❓ Но зачем выбирать другой разделитель? Всё дело в том, что все вхождения символа разделителя в выражение должны быть экранированы, потому на выходе мы получаем:
preg_match('/^https:\/\/example.com\/path/i', $uri);
// или
preg_match('~^https://example.com/path~i', $uri);
👉 Именуйте скобочные группы (группы захвата)Скобочными группами называется то, что находится внутри () скобок. Найденные результаты будут переданы в $matches.
$pattern = '~Price: (£|€)(\d+)~';Именуя скобочные группы, мы сразу получаем два преимущества: это упростит чтение регулярного выражения, а также имена будут отображены в $matches;
// или
$pattern = '~Price: (?<currency>£|€)(?<price>\d+)~';
👉 Используйте символьные классы
Это также поможет сделать ваше выражение более читабельным. Самый распространенный класс
\d - представляет собой одну цифру (эквивалентно [0-9]), при этом \D (в верхнем регистре) эквивалентно [^0-9] то есть не является цифрой. То есть использование верхнего регистра является обратным основному выражению.\w соответствует слову (может состоять из букв, цифр и подчёркивания) A-Za-z0-9_\s соответствует символу пробела (включая табуляцию и прерывание строки). соответствует любому символу👌 Так-же следует упомянуть, что при использовании выражений с поддержкой unicode (флаг
/u), вы можете использовать еще огромное количество символьных классов \p{}. Например:\p{Sc} — любой знак валюты\p{P} — любой знак пунктуации\p{L} — любая буква из любого языкаВесь перечень можно посмотреть здесь.
#junior #regexp #source
{kind=link}
👍1
The Everybody Poops Rule (Все какают)
👉 Как мне кажется отличная аллегория, которая применима к программированию. Все мы постоянно сталкиваемся с ситуациями, когда в коде приходится идти на компромиссы. Иногда из-за нехватки времени, иногда для избежания оверинжиниринга, иногда из-за несовершенства системы, нехватки знаний и т.д. И мы сознательно оставляем в коде "дерьмо", ведь не каждая часть нашего приложения должна быть идеальной.
📌 Все какают. Но дома это делают не в каждой комнате. У вас есть специальная комната, в которой вы какаете, ставите дверь, и только там это делаете.
Да, звучит странно, но зато хорошо запоминается 😂
❗️ Важно понимать, что этот процесс управляемый. Данное правило как раз помогает с этим жить при помощи сокрытия и инкапсуляции. Если код изолирован — не важно, что скрывается за интерфейсом. Главное, что мы гадим в определенных частях и "держим дверь закрытой".
👍 Конечно, у подобных мест тоже следует определить стандарты. То есть нельзя совсем забить и втулить туда какой-то
❗️ Также то, что вы можете всё изолировать — не значит, что это нужно делать всегда и везде. Прежде чем это сделать задайте себе несколько вопросов:
• Как часто код будет использоваться?
• Как долго его можно не трогать?
• Является ли это основным доменом в вашей компании? (здесь лучше этого не делать)
👍 Еще круче — сразу планировать возможный рефакторинг. То, что сегодня вы изолировали может понадобиться бизнесу в будущем или где-то аукнуться в самый неподходящий момент. Круто быть к этому готовым. Лучше всего это место задокументировать, чтобы точно знать о всех отклонениях.
#junior #oop #source
👉 Как мне кажется отличная аллегория, которая применима к программированию. Все мы постоянно сталкиваемся с ситуациями, когда в коде приходится идти на компромиссы. Иногда из-за нехватки времени, иногда для избежания оверинжиниринга, иногда из-за несовершенства системы, нехватки знаний и т.д. И мы сознательно оставляем в коде "дерьмо", ведь не каждая часть нашего приложения должна быть идеальной.
📌 Все какают. Но дома это делают не в каждой комнате. У вас есть специальная комната, в которой вы какаете, ставите дверь, и только там это делаете.
Да, звучит странно, но зато хорошо запоминается 😂
❗️ Важно понимать, что этот процесс управляемый. Данное правило как раз помогает с этим жить при помощи сокрытия и инкапсуляции. Если код изолирован — не важно, что скрывается за интерфейсом. Главное, что мы гадим в определенных частях и "держим дверь закрытой".
👍 Конечно, у подобных мест тоже следует определить стандарты. То есть нельзя совсем забить и втулить туда какой-то
God Object с методами в 1000 строк, вызывающие запросы к БД в foreach. Здесь важно найти баланс. Это тоже непростая работа. Помните, положив код "за дверь" он не становится лучше, а значит учитывайте риски того, что вам придётся его переписывать.❗️ Также то, что вы можете всё изолировать — не значит, что это нужно делать всегда и везде. Прежде чем это сделать задайте себе несколько вопросов:
• Как часто код будет использоваться?
• Как долго его можно не трогать?
• Является ли это основным доменом в вашей компании? (здесь лучше этого не делать)
👍 Еще круче — сразу планировать возможный рефакторинг. То, что сегодня вы изолировали может понадобиться бизнесу в будущем или где-то аукнуться в самый неподходящий момент. Круто быть к этому готовым. Лучше всего это место задокументировать, чтобы точно знать о всех отклонениях.
#junior #oop #source
{kind=link}
👍1
Data Transfer Object (DTO) и как его готовить?
В предыдущих постах я уже упоминал что это, но хочу остановиться на нём немного подробнее, чтобы закрыть часто задаваемые вопросы.
❓ Зачем он нужен?
Для упрощения рассмотрим всё тот-же кейс передачи данных между слоями внутри приложения.
Основная идея, что мы можем отделить логику нашего бизнеса от инфраструктуры фреймворка и дело тут вовсе не в том, что мы когда-нибудь захотим переехать на новый фреймворк (хотя полностью исключать этого не стоит), а в том, чтобы иметь возможность переиспользовать существующее поведение в независимости от того, откуда оно дергается.
Для примера рассмотрим контроллер и консольную команду внутри которых мы пытаемся вызывать уже существующий сервис (или command handler) для смены адреса доставки. И
Как раз здесь нам на помощь и приходит DTO, который позволит отделить слои друг от друга.
❓ Должен ли DTO содержать валидацию?
👉 Нет.
Внутри вообще ничего не должно быть, кроме примитивных данных. Оставьте первый этап валидации вашему фронтенду (или валидатору фреймворка), а второй уже самому доменному слою (
❗️ Называйте ваши DTO по их намерениям (действиям)
👍 Если данные будут использоваться для изменения адреса доставки заказа (как в примерах выше), назовите его
#junior #php #dto #source
В предыдущих постах я уже упоминал что это, но хочу остановиться на нём немного подробнее, чтобы закрыть часто задаваемые вопросы.
❓ Зачем он нужен?
Для упрощения рассмотрим всё тот-же кейс передачи данных между слоями внутри приложения.
Основная идея, что мы можем отделить логику нашего бизнеса от инфраструктуры фреймворка и дело тут вовсе не в том, что мы когда-нибудь захотим переехать на новый фреймворк (хотя полностью исключать этого не стоит), а в том, чтобы иметь возможность переиспользовать существующее поведение в независимости от того, откуда оно дергается.
Для примера рассмотрим контроллер и консольную команду внутри которых мы пытаемся вызывать уже существующий сервис (или command handler) для смены адреса доставки. И
Request и Input являются частью инфраструктуры фреймворка, на которую мы не можем повлиять, при этом они имеют разный интерфейс. Плюс ко всему это делает нашу бизнес логику зависимой от той самой инфраструктуры.Как раз здесь нам на помощь и приходит DTO, который позволит отделить слои друг от друга.
❓ Должен ли DTO содержать валидацию?
👉 Нет.
Внутри вообще ничего не должно быть, кроме примитивных данных. Оставьте первый этап валидации вашему фронтенду (или валидатору фреймворка), а второй уже самому доменному слою (
Value Object, Entity и т.д.). То есть DTO не должен выбрасывать никаких исключений. Всё что вам нужно, это привести данные к правильным типам, присвоить полям их значения или null (если в вашем случае это допустимо). Это оставит знания о том, как работать с объектами домена внутри ядра приложения, а не в коде инфраструктуры.❗️ Называйте ваши DTO по их намерениям (действиям)
👍 Если данные будут использоваться для изменения адреса доставки заказа (как в примерах выше), назовите его
ChangeDeliveryAddress (а не DeliveryAddressDTO). Во первых это уменьшит путаницу, т.к. разные действия, чаще всего будут иметь разный набор данных. Например DTO для создания адреса доставки может не содержать ID, а для изменения он уже обязателен.#junior #php #dto #source
{kind=link}
Validation (part 1). Валидация внутри доменного слоя приложения
Уже несколько раз меня просили написать заметку по этой теме и вот, после нескольких подготовительных постов, на которые я буду ссылаться наконец можно приступить. Чуть позже мы рассмотрим и пользовательскую валидацию и поговорим про ограничения в базе данных, но начнем мы сразу с доменного слоя нашего приложения, то есть с той самой бизнес логики.
📌 Валидация сущности (Entity).
Рано или поздно, пользовательские данные переданные в наше приложение попадают во внутрь
❌ Не нужно создавать для
👍 Конструктор должен принимать все обязательные для существования сущности параметры и валидировать их перед тем, как присвоить значение свойству. Все необязательные параметры могут быть заданы значениями по-умолчанию и/или быть присвоенными отдельными методами, в которых также следует добавлять проверки перед присваиванием. В случае если нас что-то не устраивает — кидаем
❓ Но ведь мы же не будем показывать пользователям исключения?
Всё правильно, исключения не для пользователей.
📌 Используйте Value Objects для проверки отдельных значений.
Данный подход позволяет и делегировать проверки, и переиспользовать их в дальнейшем в других частях нашего приложения.
👍 Из предыдущего примера мы можем отдельно вынести AccountNumber, переместив в него всю валидацию, отдельно выделить
👉 Тема очень обширная, так что ставь 🍺 если интересна информация про валидацию пользовательских данных, взаимодействие с БД, а также про Incomplete, Invalid и Inconsistent объекты.
#php #oop #junior #source
Уже несколько раз меня просили написать заметку по этой теме и вот, после нескольких подготовительных постов, на которые я буду ссылаться наконец можно приступить. Чуть позже мы рассмотрим и пользовательскую валидацию и поговорим про ограничения в базе данных, но начнем мы сразу с доменного слоя нашего приложения, то есть с той самой бизнес логики.
📌 Валидация сущности (Entity).
Рано или поздно, пользовательские данные переданные в наше приложение попадают во внутрь
Entity. В одном из предыдущих постов, я уже писал, что сущность сама должна защищать свои инварианты, хранить в себе только валидные данные и при этом валидировать данные самостоятельно. ❌ Не нужно создавать для
Entity сервисы валидации. Вам придется делать бесконечные и ненужные геттеры внутри Entity, следить за тем что нужно обновить сервис в случае изменения самой сущности и не забывать его вызвать каждый раз при её создании. 👍 Конструктор должен принимать все обязательные для существования сущности параметры и валидировать их перед тем, как присвоить значение свойству. Все необязательные параметры могут быть заданы значениями по-умолчанию и/или быть присвоенными отдельными методами, в которых также следует добавлять проверки перед присваиванием. В случае если нас что-то не устраивает — кидаем
Exception. Пример❓ Но ведь мы же не будем показывать пользователям исключения?
Всё правильно, исключения не для пользователей.
Exceptions, трассировка и контекст должны быть видны только разработчикам. Все исключения выброшенные разработчиком должны быть обработаны перед тем как вывести пользователю что-то на экран. Но об этом чуть позже.📌 Используйте Value Objects для проверки отдельных значений.
Данный подход позволяет и делегировать проверки, и переиспользовать их в дальнейшем в других частях нашего приложения.
👍 Из предыдущего примера мы можем отдельно вынести AccountNumber, переместив в него всю валидацию, отдельно выделить
Value Object Money, который также может взять на себя операцию сложения для логики пополнения счета. Тогда наша Entity будет иметь примерно следующий вид. Так как в основной сущности мы уже работаем с валидными Value Objects, то нет необходимости проверять что-то дополнительно внутри сущности, мы и так всё затайпхинтили.👉 Тема очень обширная, так что ставь 🍺 если интересна информация про валидацию пользовательских данных, взаимодействие с БД, а также про Incomplete, Invalid и Inconsistent объекты.
#php #oop #junior #source
{kind=link}
Бинарный поиск и "О-большое"
К сожалению, в последнее время встречаю всё больше людей, которые совсем не знакомы с темой алгоритмов. Аргументируют это тем, что "да зачем мне это нужно, если я пилю крадики" и они правы. Разница только в том, что с таким подходом далеко не уедешь и велика вероятность так и пилить крадики до конца своей карьеры. Лично я считаю, что действительно не стоит сразу слишком глубоко копать в эту тему, но базовые принципы знать обязательно. Как минимум базовые понятия встречаются во многих книгах, статьях и видео. И чтобы правильно понять, что до вас хочет донести автор — нужно чуть-чуть разобраться.
Представьте, что ваш друг загадал число, от 1 до 100, а вам нужно его отгадать. При каждой попытке друг будет давать вам один из трёх ответов "Мало" , "Много", "В точку!". Если перебирать все варианты подряд (1, 2, 3, 4... то есть прямым поиском), то вы рискуете использовать 100 попыток, при самом плохом случае.
👌 Но что если вы сразу ударите в середину и назовете число 50? "Мало", и вы сразу отсекли половину вариантов. Затем "75" — "Много", и еще половина вариантов ушла. Именно так и работает бинарный поиск.
❗️Важно, что бинарный поиск работает только в том случае, если список отсортирован.
📌 Время выполнения и "О-большое"
💁♂️ Возможно вы забыли что такое логарифм, но точно помните, что такое возведение в степень. Так вот, запись
"О-большое" описывает, насколько быстро работает алгоритм. Простой поиск должен проверить каждый элемент. Для списка из 4 миллиардов (или любое другое n) чисел потребуется до 4 миллиардов попыток. Таким образом, максимальное количество попыток совпадает с размером списка. Такое время выполнения называется линейным и обозначается
С бинарным поиском дело обстоит иначе. Для списка из 4 миллиардов элементов, потребуется не более более 32 попыток. Впечатляет, да? Бинарный поиск выполняется за логарифмическое время и его сложность описывается как
❓ Если это время, то где же секунды?
А их здесь нет. "О-большое" не сообщает время в секундах, а позволяет сравнить количество операций. Оно указывает, насколько быстро возрастает время выполнения алгоритма. А время в секундах уже будет зависеть от размера исходных данных, вычислительных мощностей и т.д.
❗️ "О-большое" определяет время выполнения в худшем случае.
То есть если ваш друг, загадал число "1", то при прямом поиске вы угадаете его моментально, так как оно стоит на первом месте
👍 Надеюсь стало немного понятнее и теперь, когда в разных книгах или статьях вы встретите записи типа
#junior #algorithm #source
К сожалению, в последнее время встречаю всё больше людей, которые совсем не знакомы с темой алгоритмов. Аргументируют это тем, что "да зачем мне это нужно, если я пилю крадики" и они правы. Разница только в том, что с таким подходом далеко не уедешь и велика вероятность так и пилить крадики до конца своей карьеры. Лично я считаю, что действительно не стоит сразу слишком глубоко копать в эту тему, но базовые принципы знать обязательно. Как минимум базовые понятия встречаются во многих книгах, статьях и видео. И чтобы правильно понять, что до вас хочет донести автор — нужно чуть-чуть разобраться.
Представьте, что ваш друг загадал число, от 1 до 100, а вам нужно его отгадать. При каждой попытке друг будет давать вам один из трёх ответов "Мало" , "Много", "В точку!". Если перебирать все варианты подряд (1, 2, 3, 4... то есть прямым поиском), то вы рискуете использовать 100 попыток, при самом плохом случае.
👌 Но что если вы сразу ударите в середину и назовете число 50? "Мало", и вы сразу отсекли половину вариантов. Затем "75" — "Много", и еще половина вариантов ушла. Именно так и работает бинарный поиск.
❗️Важно, что бинарный поиск работает только в том случае, если список отсортирован.
📌 Время выполнения и "О-большое"
💁♂️ Возможно вы забыли что такое логарифм, но точно помните, что такое возведение в степень. Так вот, запись
log(2) 8 означает, в какую степень нужно возвести 2, чтобы получить 8, итак log(2) 8 = 3."О-большое" описывает, насколько быстро работает алгоритм. Простой поиск должен проверить каждый элемент. Для списка из 4 миллиардов (или любое другое n) чисел потребуется до 4 миллиардов попыток. Таким образом, максимальное количество попыток совпадает с размером списка. Такое время выполнения называется линейным и обозначается
O(n). С бинарным поиском дело обстоит иначе. Для списка из 4 миллиардов элементов, потребуется не более более 32 попыток. Впечатляет, да? Бинарный поиск выполняется за логарифмическое время и его сложность описывается как
O(log n). ❓ Если это время, то где же секунды?
А их здесь нет. "О-большое" не сообщает время в секундах, а позволяет сравнить количество операций. Оно указывает, насколько быстро возрастает время выполнения алгоритма. А время в секундах уже будет зависеть от размера исходных данных, вычислительных мощностей и т.д.
❗️ "О-большое" определяет время выполнения в худшем случае.
То есть если ваш друг, загадал число "1", то при прямом поиске вы угадаете его моментально, так как оно стоит на первом месте
O(1). Но простой поиск всё равно выполняется за время O(n), фактически это утверждение о том, что в худшем случае придется перебрать все числа.👍 Надеюсь стало немного понятнее и теперь, когда в разных книгах или статьях вы встретите записи типа
O(n), O(n!), O(n log n) вы не будете впадать в ступор, а будете осознанно понимать, что автор хочет до вас донести.#junior #algorithm #source
{kind=link}
Validation (part 2). Всё еще внутри доменного слоя приложения
Продолжаем рассматривать тему из предыдущего поста. Мы остановились на том, что валидируем сущность перед её созданием, то есть добиваемся того, чтобы в нашей системе все объекты были валидны. Но какие правила туда вообще нужно помещать? От чего объект должен защищать свое состояние?
❗️Объект должен гарантировать что его данные должны быть полными, действительными и консистентными.
📌 Данные неполные (Incomplete) , если для выполнения простых задач отсутствует их логический кусок. Например для Money, если бы у нас была сумма, но отсутствовала валюта. В таком случае мы бы не смогли корректно производить сложение. Более подробно про эту проблему я писал в этом посте.
📌 Недействительные данные (Invalid) — которые имеют правильный тип, но обладают не всеми нужными качествами. Будет проще на примере. Возьмем тот же Money, на данный момент в конструктор мы можем передать любую строку, которая будет обозначать валюту, а это значит, что пользователь может создать объект с несуществующей валютой или той, которая никак не относится к нашему бизнесу (например вы не работает с криптой, а вам передали биткоин). Для выхода из сложившейся ситуации можно (надеемся в php 8.1 уже будет из коробки) использовать Enum (пример для более ранних версий), чтобы убедиться, в корректности переданного значения.
📌 Неконсистентные (Inconsistent) — когда два и более куска данных противоречат друг другу. Например заказ нельзя перевести в статус "
👉 Связь с другой сущностью по ID
Если в качестве связи с другой сущностью в метод или в конструктор мы передаём
👍 Правильным решением будет — достать сущность из её репозитория, в случае если её не существует мы об этом узнаем. Да и чаще всего нам нужно знать куда больше, чем просто факт существования сущности. Нам будут нужны какие-то её свойства, потому логично будет передавать её в другой объект.
❗️Но не всё так просто. Всё зависит от данных, которые может предоставить
👍 А пока главный месседж — отношения лучше выстраивать с помощью идентификаторов, а не по ссылкам на объект. Во первых таким образом мы понижаем связанность (
Вроде по доменной всё. На очереди пользовательская валидация.
#middle #php #oop #source
Продолжаем рассматривать тему из предыдущего поста. Мы остановились на том, что валидируем сущность перед её созданием, то есть добиваемся того, чтобы в нашей системе все объекты были валидны. Но какие правила туда вообще нужно помещать? От чего объект должен защищать свое состояние?
❗️Объект должен гарантировать что его данные должны быть полными, действительными и консистентными.
📌 Данные неполные (Incomplete) , если для выполнения простых задач отсутствует их логический кусок. Например для Money, если бы у нас была сумма, но отсутствовала валюта. В таком случае мы бы не смогли корректно производить сложение. Более подробно про эту проблему я писал в этом посте.
📌 Недействительные данные (Invalid) — которые имеют правильный тип, но обладают не всеми нужными качествами. Будет проще на примере. Возьмем тот же Money, на данный момент в конструктор мы можем передать любую строку, которая будет обозначать валюту, а это значит, что пользователь может создать объект с несуществующей валютой или той, которая никак не относится к нашему бизнесу (например вы не работает с криптой, а вам передали биткоин). Для выхода из сложившейся ситуации можно (надеемся в php 8.1 уже будет из коробки) использовать Enum (пример для более ранних версий), чтобы убедиться, в корректности переданного значения.
📌 Неконсистентные (Inconsistent) — когда два и более куска данных противоречат друг другу. Например заказ нельзя перевести в статус "
доставляется", если нет адреса доставки. То есть помимо текущего состояния объект также несет ответственность за переход между состояниями. Например если заказ оплачен и доставлен — его нельзя просто так "отменить" (подробнее в этом посте).👉 Связь с другой сущностью по ID
Если в качестве связи с другой сущностью в метод или в конструктор мы передаём
ID, то мы наверняка не можем быть уверенны, что Entity с таким ID существует в рамках нашей системы, ведь на входе мы можем убедиться лишь в том, что ID соответствует определенному шаблону (например UUID).👍 Правильным решением будет — достать сущность из её репозитория, в случае если её не существует мы об этом узнаем. Да и чаще всего нам нужно знать куда больше, чем просто факт существования сущности. Нам будут нужны какие-то её свойства, потому логично будет передавать её в другой объект.
❗️Но не всё так просто. Всё зависит от данных, которые может предоставить
Read Model, но это уже совсем другая история, которую позже мы обязательно разберем. 👍 А пока главный месседж — отношения лучше выстраивать с помощью идентификаторов, а не по ссылкам на объект. Во первых таким образом мы понижаем связанность (
Low Coupling), а также убираем возможность нежелательных изменений, которые могут происходить внутри связанной сущности.Вроде по доменной всё. На очереди пользовательская валидация.
#middle #php #oop #source
Repositories (Репозитории)
Каждая сущность (Entity) должна иметь репозиторий. Именно он выступает неким "адаптером" между внешним хранилищем (например БД) и нашим доменным слоем. Но вот проблема.
❌ Если мы будем вызывать реализацию репозитория внутри нашего Application слоя, то нарушим правило разделения приложения, которое гласит, что внешние слои могут зависеть от внутренних, а не наоборот (
👉 Для решения этой проблемы достаточно создать абстракцию (интерфейс), который и будет принадлежать доменному слою, на который и может быть завязан сервис или юзкейс.
❓ Почему интерфейс репозитория принадлежит доменному слою, а сам репозиторий нет?
Вашему бизнесовому коду всё равно, будете вы использовать базу данных, файловую систему или InMemory для хранения и получения данных, ему важно чтобы были методы с определенными именами, принимали конкретные параметры и возвращали нужные типы данных. Именно это и позволяет оставлять наш код независимым от конкретной реализации, таким образом реализация остаётся в инфраструктурном слое.
❗️ Держите код Repository в чистоте
❌ Очень частое упрощение — весь код, который работает с базой выносим в репозиторий. В итоге получаем, что в репозитории у нас 2 метода, которые мы используем постоянно (например
👍 Если вам нужен объект из репозитория с ограниченным или наоборот расширенным набором данных только для чтения (то есть вы не предполагаете внесение изменений), то не надо делать этот метод в том-же репозитории. Скорее всего вам нужен
📌 Ваши view не всегда нужны все данные ваших
📌 Вам не придётся делать ненужные
📌 Ваши
📌 В конце концов вы можете разделить источники данных, в то время как
#php #oop #repository #middle #source
Каждая сущность (Entity) должна иметь репозиторий. Именно он выступает неким "адаптером" между внешним хранилищем (например БД) и нашим доменным слоем. Но вот проблема.
❌ Если мы будем вызывать реализацию репозитория внутри нашего Application слоя, то нарушим правило разделения приложения, которое гласит, что внешние слои могут зависеть от внутренних, а не наоборот (
Infrastructure -> Application -> Domain).👉 Для решения этой проблемы достаточно создать абстракцию (интерфейс), который и будет принадлежать доменному слою, на который и может быть завязан сервис или юзкейс.
❓ Почему интерфейс репозитория принадлежит доменному слою, а сам репозиторий нет?
Вашему бизнесовому коду всё равно, будете вы использовать базу данных, файловую систему или InMemory для хранения и получения данных, ему важно чтобы были методы с определенными именами, принимали конкретные параметры и возвращали нужные типы данных. Именно это и позволяет оставлять наш код независимым от конкретной реализации, таким образом реализация остаётся в инфраструктурном слое.
❗️ Держите код Repository в чистоте
❌ Очень частое упрощение — весь код, который работает с базой выносим в репозиторий. В итоге получаем, что в репозитории у нас 2 метода, которые мы используем постоянно (например
getById() и save()) и 5 методов, которые у нас узконаправлены (например используются для каких-то частных выборок типа отчетов). Здесь вообще стоит немного углубиться в тему Read Model, но пока обойдемся более простой идеей. 👍 Если вам нужен объект из репозитория с ограниченным или наоборот расширенным набором данных только для чтения (то есть вы не предполагаете внесение изменений), то не надо делать этот метод в том-же репозитории. Скорее всего вам нужен
Finder, который сразу может вернуть вам удобные структуры данных (тех же DTO). Это удобно как минимум потому, что:📌 Ваши view не всегда нужны все данные ваших
Entity / Агрегатов.📌 Вам не придётся делать ненужные
getters в вашей основной Entity.📌 Ваши
Entity не должны содержать весь список данных "на всякий случай", со всеми ссылками на другие сущности (например Customer со всеми заказами, со всеми данными этих заказов).📌 В конце концов вы можете разделить источники данных, в то время как
Entity могут работать с реляционной, то View могут быть получены из того же Redis, для ускорения получения данных (вопрос консистентности тоже рассмотрим отдельно).#php #oop #repository #middle #source
{kind=link}
🥳🥳🥳 Чатик Beer::PHP 🍺
Я получил уже несколько десятков запросов о создании чата для комментирования статей и обсуждения вопросов. Также иногда я просто не успеваю отвечать на вопросы в личке, так что чатик может стать отличным местом, куда я буду заглядывать с целью ответить, если другой участник не сделает это раньше меня ;)
😢 Грустно это признавать, но наше СНГ-прогерское комьюнити достаточно токсично. В связи с этим в чатах (правда не во всех) много грубых ответов, троллинга, спама и оффтопа, а вот чётких коротких или развернутых ответов на вопросы — мало и их сложно найти за кучей сообщений.
👉 К сожалению в связи с дефицитом времени практически нет возможности его модерировать. Однако, я нашел выход :)
👍👍👍 Вступить в чат можно за символическую (часто просто неподъемную для программиста) подписку 1$ в месяц. Оплата внедрена с целью нажиться на подписч... кхм.. максимально отфильтровать людей и оставить только действительно заинтересованных.
🔨 Если что-то не получается — вот подробная инструкция.
📃 Также выкатил короткий свод правил чатика.
Вступай в чатик, общайся с коллегами и делись своим опытом, мы тебя ждём! ❤️
Я получил уже несколько десятков запросов о создании чата для комментирования статей и обсуждения вопросов. Также иногда я просто не успеваю отвечать на вопросы в личке, так что чатик может стать отличным местом, куда я буду заглядывать с целью ответить, если другой участник не сделает это раньше меня ;)
😢 Грустно это признавать, но наше СНГ-прогерское комьюнити достаточно токсично. В связи с этим в чатах (правда не во всех) много грубых ответов, троллинга, спама и оффтопа, а вот чётких коротких или развернутых ответов на вопросы — мало и их сложно найти за кучей сообщений.
👉 К сожалению в связи с дефицитом времени практически нет возможности его модерировать. Однако, я нашел выход :)
👍👍👍 Вступить в чат можно за символическую (часто просто неподъемную для программиста) подписку 1$ в месяц. Оплата внедрена с целью нажиться на подписч... кхм.. максимально отфильтровать людей и оставить только действительно заинтересованных.
🔨 Если что-то не получается — вот подробная инструкция.
📃 Также выкатил короткий свод правил чатика.
Вступай в чатик, общайся с коллегами и делись своим опытом, мы тебя ждём! ❤️
paywall.pw
Чат Beer::PHP 🍺
Это чат подписчиков канала Beer::PHP 🍺, который создан с целью обсуждения материала, комментирования постов и статей.
😢 Грустно это признавать, но наше СНГ-прогерское комьюнити достаточно токсично. В связи с этим в чатах (правда не во всех) много грубых…
😢 Грустно это признавать, но наше СНГ-прогерское комьюнити достаточно токсично. В связи с этим в чатах (правда не во всех) много грубых…