
Шифрование (Part 2) — Разбираемся с ЭЦП
В предыдущей части я упоминал, что используя шифрование, помимо целостности и конфиденциальности информации, мы также хотим быть уверенными, что информация, полученная нами от какого либо источника, точно была передана именно этим источником.
Напомню, что при асимметричном шифровании мы используем два ключа — открытый и закрытый, а также то, что зашифровать информацию можно любым из них (и открытым и закрытым), а расшифровать вторым из этой пары.
❓ Получается, что не важно какой ключ называть открытым, а какой закрытым и можно рассылать любой? Нет.
❗️ Дело в том, что из закрытого ключа можно восстановить открытый, а вот из открытого получить закрытый нельзя (если быть точным, то решение данной задачи возможно, но не выгодно т.к. на это требуется огромное кол-во времени и ресурсов).
👉 Немого освежим знания про хеширование.
Напоминаю, что применяя хеш-функцию к одному и тому-же набору данных, мы всегда будем получать одинаковую хеш-сумму. Если в исходном наборе данных что-то изменится, то после применения хеш-функции хеш-сумма получится совсем другой (за исключением коллизий).
Коллиизия хеш-функций — это когда для двух разных наборов данных после применения хеш-функции на выходе получится одинаковый результат. Коллизии существуют для большинства хеш-функций, но для «хороших» хеш-функций частота их возникновения близка к теоретическому минимуму.
❓Так как же работает ЭЦП?
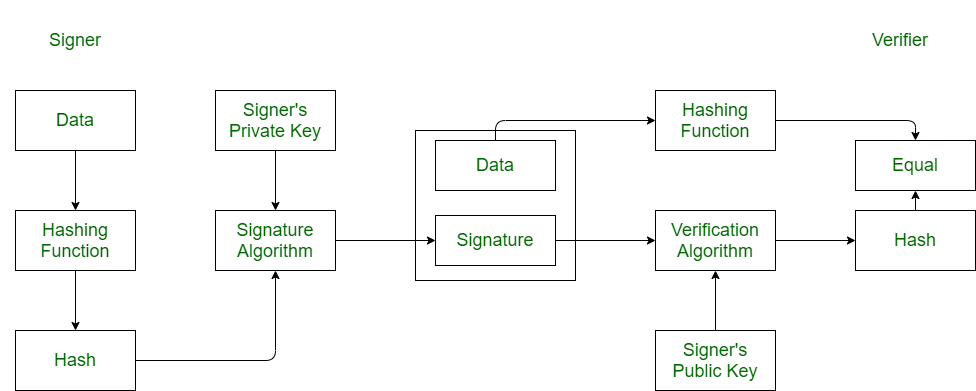
1. Берём данные, которые нам необходимо подписать и применяем к ним хеш-функцию, получаем хеш-сумму.
2. Затем полученную хеш-сумму мы шифруем нашим закрытым ключом.
3. Полученный результат отправляем адресату вместе с теми данными, которые мы подписывали.
—————————
1. Получатель берёт нашу зашифрованную хеш-сумму и расшифровывает её с помощью открытого ключа.
2. Далее применяет хеш-функцию к полученным данным.
3. Затем сравнивает оба хеша и если они совпадают, то получатель может быть уверен, что подписанные данные не были изменены, а также, что именно мы их отправили, т.к. закрытый ключ есть только у одного отправителя.
Псевдокод для понимания
❓ Что такое АЦСК и зачем нам сертификаты?
Всё выглядит отлично, кроме одного момента: откуда мы знаем, что открытый ключ на самом деле принадлежит правдивому источнику, а не был отправлен нам каким-то злоумышленником?
📃 К сожалению в таких условиях нам не обойтись без третьей стороны, которой все могут доверять. На арену выходит "Аккредитованный центр сертификации ключей" (АЦСК).
Его задача состоит в том, чтобы подтвердить принадлежность открытого ключа именно вам. После этого АЦСК подписывает ваш открытый ключ, своим закрытым ключем и то, что получилось, называется сертификатом открытого ключа.
Теперь любой может проверить подлинность открытого ключа, то есть расшифровать подпись в сертификате (онлайн, с помощью открытого ключа удостоверяющего центра) и убедиться, что ключ принадлежит именно вам.
💩 Собираем всё в кучу
☝️ Получается, чтобы абсолютно безопасно передать данные нужно выполнить следующие шаги:
1. Вы и получатель должны сгенерировать по паре ключей
2. Открытые ключи подписать в АЦСК и обменяться ими
3. Данные, которые нужно засекретить, шифруете открытым ключем получателя
4. Затем подписываете своим закрытым ключом уже зашифрованные данные и отправляем
1. Получатель сначала проверяет ваш сертификат (убеждается что вы это вы)
2. Затем вашим открытым ключем проверяет подпись (убеждается в целостности и что данные пришли именно от вас)
3. Своим закрытым ключем расшифровывает данные и получает то, что хотел
❗️Такая сложная схема используется не всегда. Можно обойтись без АЦСК, когда мы доверяем полученным открытым ключам (напр. мы сами его положили на сервак для доступа по ssh) или используем так называемые "сети доверия" (OpenPGP).
—————
💬 Не стесняйтесь писать в комментарии своё мнение, вопросы, замечания и предложения ;)
#php #crypto #middle ❤️ Все буде Україна 🇺🇦
В предыдущей части я упоминал, что используя шифрование, помимо целостности и конфиденциальности информации, мы также хотим быть уверенными, что информация, полученная нами от какого либо источника, точно была передана именно этим источником.
Напомню, что при асимметричном шифровании мы используем два ключа — открытый и закрытый, а также то, что зашифровать информацию можно любым из них (и открытым и закрытым), а расшифровать вторым из этой пары.
❓ Получается, что не важно какой ключ называть открытым, а какой закрытым и можно рассылать любой? Нет.
❗️ Дело в том, что из закрытого ключа можно восстановить открытый, а вот из открытого получить закрытый нельзя (если быть точным, то решение данной задачи возможно, но не выгодно т.к. на это требуется огромное кол-во времени и ресурсов).
👉 Немого освежим знания про хеширование.
Напоминаю, что применяя хеш-функцию к одному и тому-же набору данных, мы всегда будем получать одинаковую хеш-сумму. Если в исходном наборе данных что-то изменится, то после применения хеш-функции хеш-сумма получится совсем другой (за исключением коллизий).
Коллиизия хеш-функций — это когда для двух разных наборов данных после применения хеш-функции на выходе получится одинаковый результат. Коллизии существуют для большинства хеш-функций, но для «хороших» хеш-функций частота их возникновения близка к теоретическому минимуму.
❓Так как же работает ЭЦП?
1. Берём данные, которые нам необходимо подписать и применяем к ним хеш-функцию, получаем хеш-сумму.
2. Затем полученную хеш-сумму мы шифруем нашим закрытым ключом.
3. Полученный результат отправляем адресату вместе с теми данными, которые мы подписывали.
—————————
1. Получатель берёт нашу зашифрованную хеш-сумму и расшифровывает её с помощью открытого ключа.
2. Далее применяет хеш-функцию к полученным данным.
3. Затем сравнивает оба хеша и если они совпадают, то получатель может быть уверен, что подписанные данные не были изменены, а также, что именно мы их отправили, т.к. закрытый ключ есть только у одного отправителя.
Псевдокод для понимания
❓ Что такое АЦСК и зачем нам сертификаты?
Всё выглядит отлично, кроме одного момента: откуда мы знаем, что открытый ключ на самом деле принадлежит правдивому источнику, а не был отправлен нам каким-то злоумышленником?
📃 К сожалению в таких условиях нам не обойтись без третьей стороны, которой все могут доверять. На арену выходит "Аккредитованный центр сертификации ключей" (АЦСК).
Его задача состоит в том, чтобы подтвердить принадлежность открытого ключа именно вам. После этого АЦСК подписывает ваш открытый ключ, своим закрытым ключем и то, что получилось, называется сертификатом открытого ключа.
Теперь любой может проверить подлинность открытого ключа, то есть расшифровать подпись в сертификате (онлайн, с помощью открытого ключа удостоверяющего центра) и убедиться, что ключ принадлежит именно вам.
💩 Собираем всё в кучу
☝️ Получается, чтобы абсолютно безопасно передать данные нужно выполнить следующие шаги:
1. Вы и получатель должны сгенерировать по паре ключей
2. Открытые ключи подписать в АЦСК и обменяться ими
3. Данные, которые нужно засекретить, шифруете открытым ключем получателя
4. Затем подписываете своим закрытым ключом уже зашифрованные данные и отправляем
1. Получатель сначала проверяет ваш сертификат (убеждается что вы это вы)
2. Затем вашим открытым ключем проверяет подпись (убеждается в целостности и что данные пришли именно от вас)
3. Своим закрытым ключем расшифровывает данные и получает то, что хотел
❗️Такая сложная схема используется не всегда. Можно обойтись без АЦСК, когда мы доверяем полученным открытым ключам (напр. мы сами его положили на сервак для доступа по ssh) или используем так называемые "сети доверия" (OpenPGP).
—————
💬 Не стесняйтесь писать в комментарии своё мнение, вопросы, замечания и предложения ;)
#php #crypto #middle ❤️ Все буде Україна 🇺🇦
{kind=link}
❤57👍18🔥16💩8
Как https нас защищает?
Когда браузер делает запрос к веб-сайту, то запрос должен пройти через множество различных сетей, любая из которых может быть прослушана злоумышленником.
☝️ Как правило, запросы передаются посредством обычного HTTP, в котором и запрос клиента, и ответ сервера будут в открытом виде. Это значит, что злоумышленник может получить отправленные вами "sensitive data" (пароли, данные карт, коды подтверждения и т.д.) и воспользоваться ими.
❓ Что такое TLS?
Transport Layer Security (TLS) — это тот самый механизм (протокол), который обеспечивает безопасное HTTP соединение (фактически наследник SSL).
⚠️ TLS расположен на уровень ниже протокола HTTP в модели OSI. Это означит, что в процессе выполнения запроса сперва происходят все действия, связанные с TLS, а уже потом, всё что связано с HTTP-соединением.
🔑 TLS использует асимметричное шифрование для генерации общего секретного ключа и аутентификации (то есть удостоверения в том, что вы – тот за кого себя выдаете), а также симметричное (с общим секретным ключом) для шифрования запросов и ответов.
То есть сначала, клиент и сервер должны безопасно договориться об общем "сеансовом" ключе. Для этого используют алгоритм обмена ключами Ди́ффи — Хе́ллмана (DH). В это раз поленюсь и оставлю вам ссылку на видос о том, как он работает.
👉 Итак, мы получили секретный ключ, но откуда мы знаем, что общаемся с нужным нам сервером, а не со злоумышленником?
❤️ Аутентификация
Здесь на помощь нам приходит асимметричное шифрование. Каждый из вас слышал о TLS-сертификатах (SSL-сертификаты - устаревшее название, являющееся синонимом), из предыдущего поста мы знаем, что по факту это открытый ключ, который в свою очередь был выдан (и подписан) источником, которому все стороны доверяют — центром сертификации. Вместе с ним на сервере находится закрытый ключ от этой пары.
☑️ Сервер берет все данные, которыми клиент и сервер уже успели обменяться, вычисляет хеш и шифрует (подписывает) своим закрытым ключом.
☑️ Клиент обладая тем же набором данных, также хеширует их, получает от сервера подпись (зашифрованный хеш) и применяет к нему открытый ключ из сертификата (расшифровывает).
✅ Если полученные хеши совпадают — это значит, что никто не вмешивался в процесс получения общего ключа, а подпись поставил именно тот сервер, которому принадлежит данный сертификат.
Когда же стороны уже договорились о секретном ключе, клиент-серверное взаимодействие происходит с помощью симметричного шифрования, которое, как мы знаем, намного эффективнее для передачи информации.
🤟 В итоге мы безопасно создали сеансовый ключ с помощью алгоритма Диффи Хеллмана, удостоверились в подлинности источника с помощью сертификата и безопасно передаём друг другу данные с помощью симметричного шифрования.
——————
Конечно за кадром осталось очень много нюансов о том как происходит handshake, как происходит управление сеансовыми ключами, какие используются шифры и т.д. Для любознательных оставлю ссылку на очень подробную статью.
#php #crypto #middle ❤️ Все буде Україна 🇺🇦
Когда браузер делает запрос к веб-сайту, то запрос должен пройти через множество различных сетей, любая из которых может быть прослушана злоумышленником.
☝️ Как правило, запросы передаются посредством обычного HTTP, в котором и запрос клиента, и ответ сервера будут в открытом виде. Это значит, что злоумышленник может получить отправленные вами "sensitive data" (пароли, данные карт, коды подтверждения и т.д.) и воспользоваться ими.
❓ Что такое TLS?
Transport Layer Security (TLS) — это тот самый механизм (протокол), который обеспечивает безопасное HTTP соединение (фактически наследник SSL).
⚠️ TLS расположен на уровень ниже протокола HTTP в модели OSI. Это означит, что в процессе выполнения запроса сперва происходят все действия, связанные с TLS, а уже потом, всё что связано с HTTP-соединением.
🔑 TLS использует асимметричное шифрование для генерации общего секретного ключа и аутентификации (то есть удостоверения в том, что вы – тот за кого себя выдаете), а также симметричное (с общим секретным ключом) для шифрования запросов и ответов.
То есть сначала, клиент и сервер должны безопасно договориться об общем "сеансовом" ключе. Для этого используют алгоритм обмена ключами Ди́ффи — Хе́ллмана (DH). В это раз поленюсь и оставлю вам ссылку на видос о том, как он работает.
👉 Итак, мы получили секретный ключ, но откуда мы знаем, что общаемся с нужным нам сервером, а не со злоумышленником?
❤️ Аутентификация
Здесь на помощь нам приходит асимметричное шифрование. Каждый из вас слышал о TLS-сертификатах (SSL-сертификаты - устаревшее название, являющееся синонимом), из предыдущего поста мы знаем, что по факту это открытый ключ, который в свою очередь был выдан (и подписан) источником, которому все стороны доверяют — центром сертификации. Вместе с ним на сервере находится закрытый ключ от этой пары.
☑️ Сервер берет все данные, которыми клиент и сервер уже успели обменяться, вычисляет хеш и шифрует (подписывает) своим закрытым ключом.
☑️ Клиент обладая тем же набором данных, также хеширует их, получает от сервера подпись (зашифрованный хеш) и применяет к нему открытый ключ из сертификата (расшифровывает).
✅ Если полученные хеши совпадают — это значит, что никто не вмешивался в процесс получения общего ключа, а подпись поставил именно тот сервер, которому принадлежит данный сертификат.
Когда же стороны уже договорились о секретном ключе, клиент-серверное взаимодействие происходит с помощью симметричного шифрования, которое, как мы знаем, намного эффективнее для передачи информации.
🤟 В итоге мы безопасно создали сеансовый ключ с помощью алгоритма Диффи Хеллмана, удостоверились в подлинности источника с помощью сертификата и безопасно передаём друг другу данные с помощью симметричного шифрования.
——————
Конечно за кадром осталось очень много нюансов о том как происходит handshake, как происходит управление сеансовыми ключами, какие используются шифры и т.д. Для любознательных оставлю ссылку на очень подробную статью.
#php #crypto #middle ❤️ Все буде Україна 🇺🇦
YouTube
Алгоритм Диффи-Хеллмана
Простое и наглядное описание того, как работает алгоритм Диффи — Хеллмана, позволяющий двум сторонам получить секретный ключ используя прослушиваемый канал связи.
Википедия - http://www.youtube.com/watch?v=3QnD2c4Xovk
Оригинал на английском языке -- ht…
Википедия - http://www.youtube.com/watch?v=3QnD2c4Xovk
Оригинал на английском языке -- ht…
👍74❤17💩9🔥3
Поговорим о времени
В комментариях к этому посту было несколько просьб подробнее рассказать о часовых поясах. В этом посте я постарался собрать несколько важных тезисов по данной теме.
📚 Теория:
🕔 Всемирное время — UTC. Было введено вместо устаревшего среднего времени по Гринвичу (GMT), поскольку шкала GMT является неравномерной и связана с суточным вращением Земли. Шкала UTC, в свою очередь основана на равномерной шкале атомного времени (TAI).
Часовые пояса вокруг земного шара выражаются как положительное или отрицательное смещение относительно UTC.
❗️ Часовой пояс и смещение — не одно и то же. Почему? Всему виной летнее время (DST — Daylight Saving Time).
👉 Часовой пояс может иметь одно или несколько смещений. Какое именно время принято в качестве стандартного, зависит от текущих политических и/или экономических причин в конкретной стране.
Так как время по UTC не переводится ни зимой, ни летом, то, для тех мест, где есть переход на летнее время и происходит смещение относительно UTC.
⌚️ Unix время — это количество секунд, прошедших с полуночи (00:00:00 UTC) 1 января 1970 года и представлено целым числом.
🔧 Практика:
✅ Следует работать с Unix временем. Такой формат удобно использовать для сравнения и хранения дат. При необходимости его легко преобразовать в любой подходящий формат (и обратно).
На всякий случай упомяну про "критические даты", например 19 января 2038 года в 03:14:08 число секунд достигнет 2^31, что может привести к ошибочной интерпретации этого числа как отрицательного. Возможное решение проблемы состоит в использовании не 32-битной, а 64-битной переменной, которой хватит на 292 млрд лет.
✅ Если вам нужно хранить время только что произошедшего события, текущее время, по факту определённого действия, храните его в UTC (напр. для PostgreSQL —TIMESTAMP WITH TIME ZONE). Это могут быть записи в логах, время регистрации пользователя, совершения заказа или отправки письма.
✅ Нужно ли хранить часовой пояс пользователя?
Да, только с помощью информации о часовом поясе мы можем сделать вывод о том, какое смещение у него сейчас или будет через пол года. Ведь, повторюсь, один часовой пояс может иметь несколько смещений.
✅ Если время привязано к пользователю — сохраняйте локальное время пользователя и его смещение.
Фактически
————
🔥 Вот те самые несколько нюансов, которыми хотелось поделиться. Пишите в комментарии, если есть что дополнить, возможно вместе соберём еще несколько дельных советов😉.
#php #datetime #middle
В комментариях к этому посту было несколько просьб подробнее рассказать о часовых поясах. В этом посте я постарался собрать несколько важных тезисов по данной теме.
📚 Теория:
🕔 Всемирное время — UTC. Было введено вместо устаревшего среднего времени по Гринвичу (GMT), поскольку шкала GMT является неравномерной и связана с суточным вращением Земли. Шкала UTC, в свою очередь основана на равномерной шкале атомного времени (TAI).
Часовые пояса вокруг земного шара выражаются как положительное или отрицательное смещение относительно UTC.
❗️ Часовой пояс и смещение — не одно и то же. Почему? Всему виной летнее время (DST — Daylight Saving Time).
👉 Часовой пояс может иметь одно или несколько смещений. Какое именно время принято в качестве стандартного, зависит от текущих политических и/или экономических причин в конкретной стране.
Так как время по UTC не переводится ни зимой, ни летом, то, для тех мест, где есть переход на летнее время и происходит смещение относительно UTC.
⌚️ Unix время — это количество секунд, прошедших с полуночи (00:00:00 UTC) 1 января 1970 года и представлено целым числом.
🔧 Практика:
✅ Следует работать с Unix временем. Такой формат удобно использовать для сравнения и хранения дат. При необходимости его легко преобразовать в любой подходящий формат (и обратно).
На всякий случай упомяну про "критические даты", например 19 января 2038 года в 03:14:08 число секунд достигнет 2^31, что может привести к ошибочной интерпретации этого числа как отрицательного. Возможное решение проблемы состоит в использовании не 32-битной, а 64-битной переменной, которой хватит на 292 млрд лет.
✅ Если вам нужно хранить время только что произошедшего события, текущее время, по факту определённого действия, храните его в UTC (напр. для PostgreSQL —TIMESTAMP WITH TIME ZONE). Это могут быть записи в логах, время регистрации пользователя, совершения заказа или отправки письма.
✅ Нужно ли хранить часовой пояс пользователя?
Да, только с помощью информации о часовом поясе мы можем сделать вывод о том, какое смещение у него сейчас или будет через пол года. Ведь, повторюсь, один часовой пояс может иметь несколько смещений.
✅ Если время привязано к пользователю — сохраняйте локальное время пользователя и его смещение.
Фактически
1660050128, 2022–09–9T16:02:08+03:00 и 2022–09–9T13:02:08+00:00 — это одно и то же время. Сохраняя смещение мы оставляем важную информацию, которая может оказаться нужной как с точки зрения бизнеса, так и для внутренней отладки, принятия других решений. Иными словами если у вас есть информация, и её хранение вам не доставляет (существенных) дополнительных усилий — не выбрасывайте её. Вы не сможете получить её обратно.————
🔥 Вот те самые несколько нюансов, которыми хотелось поделиться. Пишите в комментарии, если есть что дополнить, возможно вместе соберём еще несколько дельных советов😉.
#php #datetime #middle
{kind=link}
👍94❤10🔥7
Value Object or Data Transfer Object?
Существует некоторая путаница когда речь заходит об этих двух понятиях. Что ж, давайте разбираться.
Data Transfer Object (DTO) — уже писал ранее о нём, это объект, который содержит в себе примитивные типы (string, int, bool, etc.). Его задача определить схему передаваемых данных, декларируя имена полей и их типы. То есть используя DTO, мы гарантируем, что сможем обратиться к конкретному полю, которое будет содержать ожидаемый тип данных.
↔️ DTO обычно используются для передачи данных между различными сервисами или приложениями, либо между слоями внутри одного приложения.
❗️ При этом DTO абсолютно ничего не знает о том, имеют ли передаваемые данные какой-то смысл в рамках вашего бизнеса (или приложения). То есть строки могут быть пустыми, числа отрицательными и т.д. Пример
✅ Value Object — это полноценный объект вашей доменной модели, он гарантирует, что значения имеют смысл с точки зрения предметной области (вашего бизнеса) , то есть строки больше не будут пустыми, там где не должны, а числа будут проверены на соответствие правильному диапазону.
👍 Также value object's должны соответствовать whole value concept, могут содержать какую-то логику, помимо валидации. Пример
Value Object часто используются в предметной области (Domain и Application Layer) и не используются для передачи данных между приложениями. В определенных случаях их удобно использовать и в инфраструктурной части приложения, например чтобы избежать дублирования правил валидации данных.
🫣 Иммутабельность
Данное свойство почему-то пытаются использовать в качестве доказательства, что перед нами непосредственно Value Object. Да, безусловно VO должен быть иммутабельным, однако это совсем не означает, что DTO не может быть таковым. Более того, очень рекомендую готовить его именно таким образом.
❓Может ли Value Object находиться внутри DTO?
Интересный вопрос, с одной стороны хочется сразу просто ответить "нет", ведь мы только что проговорили, что VO не подходит для передачи. С другой, я многократно видел как внутри используется тот же DateTimeImmutable, который фактически является VO.
💬 Напишите в комментарии, что думаете по этому поводу? Своё мнение, а также все самые интересные мысли из комментариев закину отдельным постом ☺️
#php #oop #middle #source ❤️ Все буде Україна 🇺🇦
Существует некоторая путаница когда речь заходит об этих двух понятиях. Что ж, давайте разбираться.
Data Transfer Object (DTO) — уже писал ранее о нём, это объект, который содержит в себе примитивные типы (string, int, bool, etc.). Его задача определить схему передаваемых данных, декларируя имена полей и их типы. То есть используя DTO, мы гарантируем, что сможем обратиться к конкретному полю, которое будет содержать ожидаемый тип данных.
↔️ DTO обычно используются для передачи данных между различными сервисами или приложениями, либо между слоями внутри одного приложения.
❗️ При этом DTO абсолютно ничего не знает о том, имеют ли передаваемые данные какой-то смысл в рамках вашего бизнеса (или приложения). То есть строки могут быть пустыми, числа отрицательными и т.д. Пример
✅ Value Object — это полноценный объект вашей доменной модели, он гарантирует, что значения имеют смысл с точки зрения предметной области (вашего бизнеса) , то есть строки больше не будут пустыми, там где не должны, а числа будут проверены на соответствие правильному диапазону.
👍 Также value object's должны соответствовать whole value concept, могут содержать какую-то логику, помимо валидации. Пример
Value Object часто используются в предметной области (Domain и Application Layer) и не используются для передачи данных между приложениями. В определенных случаях их удобно использовать и в инфраструктурной части приложения, например чтобы избежать дублирования правил валидации данных.
🫣 Иммутабельность
Данное свойство почему-то пытаются использовать в качестве доказательства, что перед нами непосредственно Value Object. Да, безусловно VO должен быть иммутабельным, однако это совсем не означает, что DTO не может быть таковым. Более того, очень рекомендую готовить его именно таким образом.
❓Может ли Value Object находиться внутри DTO?
Интересный вопрос, с одной стороны хочется сразу просто ответить "нет", ведь мы только что проговорили, что VO не подходит для передачи. С другой, я многократно видел как внутри используется тот же DateTimeImmutable, который фактически является VO.
💬 Напишите в комментарии, что думаете по этому поводу? Своё мнение, а также все самые интересные мысли из комментариев закину отдельным постом ☺️
#php #oop #middle #source ❤️ Все буде Україна 🇺🇦
{kind=link}
👍79❤29👎3😁1
Law of Demeter (Закон Деметры, LOD)
Этот закон часто используют вместе с темой Tell Don't Ask. Его идея в том, что объект должен обладать ограниченным знанием о других объектах и модулях, взаимодействовать только с теми, кто имеет к нему непосредственное отношение.
Формально правило звучит так, что в клиентском коде вы можете вызывать методы объектов, которые:
✅ Были переданы как аргументы;
✅ Были созданы локально;
✅ Являются глобальными;
✅ Собственные методы;
Пока что непонятно зачем это всё. Давайте разбираться.
Основная задача — создать условия для слабой связанности (loose coupling) между объектами. Но за счёт чего?
🌈 Представьте, вы находитесь в магазине, хотите купить товар стоимостью 25$. Вы дадите продавцу 25$ или вы отдадите продавцу свой кошелек, чтобы тот достал 25$? Давайте разберём этот пример.
👉 В первом случае мы явно знаем, что у объекта
❓ Чем же лучше второй вариант?
Когда у
🤓 LOD также называют законом "одной точки" (one dot), т.к. ноги растут из Java. В нашем же случае о его применении стоит задуматься при виде более одной стрелочки ->. Обращаю внимание, что речь идёт о методах (или свойствах), которые позволяют получить промежуточный объект, утрируя - о геттерах. То есть две стрелочки в каком нибудь fluent interface (напр.
🙈 У закона Деметры тоже есть свои минусы. Одним из них является необходимость создания большого количества методов-адаптеров. Если вы чувствуете, что классы становятся перегруженными - это признак плохого объектно-ориентированного дизайна.
❓ Можно ли нарушать закон Деметры?
Руководствуйтесь здравым смыслом. Если у вас, например, вложенные DTO, которые предназначены для транспортировки объектов, то нет никакого смысла наворачивать что-то подобное сверху. Используйте только там, где это уместно и помните о преимуществах 😉
#php #oop #middle #source
Этот закон часто используют вместе с темой Tell Don't Ask. Его идея в том, что объект должен обладать ограниченным знанием о других объектах и модулях, взаимодействовать только с теми, кто имеет к нему непосредственное отношение.
Формально правило звучит так, что в клиентском коде вы можете вызывать методы объектов, которые:
✅ Были переданы как аргументы;
✅ Были созданы локально;
✅ Являются глобальными;
✅ Собственные методы;
Пока что непонятно зачем это всё. Давайте разбираться.
Основная задача — создать условия для слабой связанности (loose coupling) между объектами. Но за счёт чего?
🌈 Представьте, вы находитесь в магазине, хотите купить товар стоимостью 25$. Вы дадите продавцу 25$ или вы отдадите продавцу свой кошелек, чтобы тот достал 25$? Давайте разберём этот пример.
👉 В первом случае мы явно знаем, что у объекта
SomePerson есть Wallet, который мы хотим получить, чтобы достать (вычесть) из него какую-то сумму денег. Таким образом мы создаём сильную связь (tight coupling) с объектом кошелька, а также раскрываем особенности внутренней реализации.❓ Чем же лучше второй вариант?
Когда у
SomeAnotherPerson мы вызываем метод subtractMoney, это нам даёт дополнительную гибкость, возможность легко изменить внутреннюю реализацию данного метода, не изменяя другие участки кода. Как бонус появляется information hiding, а также это дело менее проблематично мокать в тестах.🤓 LOD также называют законом "одной точки" (one dot), т.к. ноги растут из Java. В нашем же случае о его применении стоит задуматься при виде более одной стрелочки ->. Обращаю внимание, что речь идёт о методах (или свойствах), которые позволяют получить промежуточный объект, утрируя - о геттерах. То есть две стрелочки в каком нибудь fluent interface (напр.
$filter->limit(10)->offset(0)) сюда не относятся.🙈 У закона Деметры тоже есть свои минусы. Одним из них является необходимость создания большого количества методов-адаптеров. Если вы чувствуете, что классы становятся перегруженными - это признак плохого объектно-ориентированного дизайна.
❓ Можно ли нарушать закон Деметры?
Руководствуйтесь здравым смыслом. Если у вас, например, вложенные DTO, которые предназначены для транспортировки объектов, то нет никакого смысла наворачивать что-то подобное сверху. Используйте только там, где это уместно и помните о преимуществах 😉
#php #oop #middle #source
{kind=link}
👍84🔥20❤15🤯2👎1
Ну що, поїхали 🍻
Відчув в собі сили та натхнення знов постити щось в канал. Є багато тем, котрі хочеться структуризувати для себе і поділитись з вами. Проте чернеток за цей час накопичилось, тому дайте фідбек, що було б цікаво:
Відчув в собі сили та натхнення знов постити щось в канал. Є багато тем, котрі хочеться структуризувати для себе і поділитись з вами. Проте чернеток за цей час накопичилось, тому дайте фідбек, що було б цікаво:
Anonymous Poll
58%
🙈 Щось про архітектуру (чисту, лукову, гексагональну і щось пов'язане)
42%
🏗 Інсайти по інфраструктурі (Redis, Rabbit, Mongo, якісь не зовсім очевидні штуки)
31%
🤖 Алгоритми та структури (базові речі в котрі мало хто занурюється, але цікаві для усвідомлення)
40%
🤔 На мій розсуд (що ближче до душі лежить)
🔥54🗿33⚡7👀6😁5👍4🙊4
Fwdays PHP Talks
📍Ну а поки йде голосування, а я думаю, про що саме розповісти в наступній темі, запрошую всіх до перегляду свіжого випуску Fwdays PHP Talks.
Поговорили про:
— CI/CD
— Правила ведення гілок
— Де закінчується відповідальність DevOps і починається відповільність розробника
— Автотести в мікросервісах
— І багато суміжних тем
Йожеф Гісем та Дмитро Немеш, дякую за цікаву дискусію 👍 А всіх інших запрошую до перегляду
P.S. Вдячний всім за голосування, коментарі і реакцій до попереднього поста ☺️
📍Ну а поки йде голосування, а я думаю, про що саме розповісти в наступній темі, запрошую всіх до перегляду свіжого випуску Fwdays PHP Talks.
Поговорили про:
— CI/CD
— Правила ведення гілок
— Де закінчується відповідальність DevOps і починається відповільність розробника
— Автотести в мікросервісах
— І багато суміжних тем
Йожеф Гісем та Дмитро Немеш, дякую за цікаву дискусію 👍 А всіх інших запрошую до перегляду
P.S. Вдячний всім за голосування, коментарі і реакцій до попереднього поста ☺️
YouTube
Методологія СI/CD на практиці | Як запускати автотести в мікросервісній архітектурі?
Друзі, зустрічайте другий випуск Fwdays PHP Talks у форматі «Дебати»!
❗️Важлива інформація: наш збір разом з Корчівниками триває, ми збираємо 100 000 гривень для купівлі карети швидкої допомоги, для медслужби морської піхоти України яка рятує життя бійцям…
❗️Важлива інформація: наш збір разом з Корчівниками триває, ми збираємо 100 000 гривень для купівлі карети швидкої допомоги, для медслужби морської піхоти України яка рятує життя бійцям…
👍32🔥10⚡4🗿1🙊1
Kind Reminder
17 серпня відбудеться PHP fwdays'24 — дійсно крута і велика конфа. Можна доєднатись онлайн або офлайн у Києві.
Для тих хто не був, то вас чекає:
📍Цікаві спікери та практичні доповіді про оптимізацію, міграцію з легасі продуктів, використання AI, Github Copilot та багато іншого.
📍Нетворкінг, Q&A зі спікерами, нові знайомства
📍Вайб відпочинку на морі під час офлайн частини заходу 🏄♀️
📍Розіграші та подарунки
Буквально завтра ціна на квитки підніметься, тому сьогодні у вас є шанс придбати квитки, ще і з 10% знижкою. Для цього необхідно використати промокод PHP10Beer за посиланням 👉 https://bit.ly/3WCY1VW
17 серпня відбудеться PHP fwdays'24 — дійсно крута і велика конфа. Можна доєднатись онлайн або офлайн у Києві.
Для тих хто не був, то вас чекає:
📍Цікаві спікери та практичні доповіді про оптимізацію, міграцію з легасі продуктів, використання AI, Github Copilot та багато іншого.
📍Нетворкінг, Q&A зі спікерами, нові знайомства
📍Вайб відпочинку на морі під час офлайн частини заходу 🏄♀️
📍Розіграші та подарунки
Буквально завтра ціна на квитки підніметься, тому сьогодні у вас є шанс придбати квитки, ще і з 10% знижкою. Для цього необхідно використати промокод PHP10Beer за посиланням 👉 https://bit.ly/3WCY1VW
👍16👀2🗿2🙊1
Третій випуск Fwdays PHP Talks
Якщо ви думали, що знов все затихло, то ні, знов взяв участь у "дебатах". На цей раз разом Йожефом Гісемом та Михайлом Боднарчуком подсикутували про:
📍 Laracon: Pest — прорив в тестуванні чи гарний маркетинг?
🤯 Чи можна звільнити всіх мануальних тестувальників?
🗂 Дані в міграціях і як з цим жити?
💻 Мікросервіси і бази даних
То ж залітайте дивитись (або просто слухати) випуск 🍻
Якщо ви думали, що знов все затихло, то ні, знов взяв участь у "дебатах". На цей раз разом Йожефом Гісемом та Михайлом Боднарчуком подсикутували про:
📍 Laracon: Pest — прорив в тестуванні чи гарний маркетинг?
🤯 Чи можна звільнити всіх мануальних тестувальників?
🗂 Дані в міграціях і як з цим жити?
💻 Мікросервіси і бази даних
То ж залітайте дивитись (або просто слухати) випуск 🍻
YouTube
Pest конкурент Codeception? | Тримання даних у міграціях | Використання мікросервісів
Зустрічайте третій випуск Fwdays PHP Talks у форматі «Дебати»!
У сьогоднішньому випуску наші постійні спікери - Йожеф Гісем і Кирило Сулімовський, а також гість подкасту Михайло Боднарчук обговорять теми:
- Laracon: Які переваги та недоліки використання…
У сьогоднішньому випуску наші постійні спікери - Йожеф Гісем і Кирило Сулімовський, а також гість подкасту Михайло Боднарчук обговорять теми:
- Laracon: Які переваги та недоліки використання…
🔥16👍10🙊2
Виклики через мережу
Думаю, що не треба наголошувати, що reqeust до зовнішньої мережі буде працювати значно повільніше (і менш стабільно) ніж звернення до локальної памʼяті або локальної мережі. Різниця в часі щонайменше в 7 разів. Саме тому архітектура вашого застосунку, ваш код, має це враховувати.
✅ Чітко і явно відокремлюйте виклики через зовнішню мережу.
Ми постійно використовуємо DI контейнер для зручності, тому клієнтський код десь в application layer, може виглядати достатньо звично:
❗️️️️️️️Проте, всередині може бути досить велика різниця:
Одна реалізація [gist]
Зовсім інша реалізація [gist]
📍️️️️️️ При такій реалізації в клієнтському коді досить важко передбачити виклик через зовнішню мережу. Допоможіть собі майбутньому і іншим програмістам в вашому проекті чітко зрозуміти з чим саме зараз ви зараз працюєте.
🔥 Введіть неймінг, котрий явно буде кричати про себе, говорити що виклик зовнішній:
Будь яка конвенція, котра буде команді довподоби, але вона має чітко відрізнятись від:
🤓 Можливо передача інфомації за допомогою квантових частинок дозволить нам робити це миттєво в якомусь майбутньому, проте на даному етапі ми жорстко обмежені швидкістю світла.
✅ Намагайтесь отримати одразу всі необхідні дані
Якщо вже виконуєте зовнішій виклик, намагайтесь повернути всі потрібні дані в одному запиті. Cхоже на вирішення класичної проблеми n+1.
[gist]
Проти [gist]
✅ Кешування – ваш друг, але будьте з ним обережні
Якщо ви досить часто запитуєте одні і ті самі дані, а в свою чергу, вони відносно рідко змінюються - кеш може бути чудовим рішенням. Він одночасно зменшить час на виклик, обробку даних і навантаження на мережу.
❗️Обовʼязково приділіть час для узгодження стратегії інвалідації кеша.
✅ Інвертуйте потік даних
Замість того, щоб кожного разу опитувати інші сервіси, ви можете використовувати патерн Pub/Sub та зберігайти дані локально (в тому числі в кеші). Звичайно, це ускладнює архітектуру, звичайно, це підійде не для всіх задач. Але памʼятайте про цей прийом, він може досить елегантно вирішити проблему в вашому проекті.
#php #architecture #middle #source
Думаю, що не треба наголошувати, що reqeust до зовнішньої мережі буде працювати значно повільніше (і менш стабільно) ніж звернення до локальної памʼяті або локальної мережі. Різниця в часі щонайменше в 7 разів. Саме тому архітектура вашого застосунку, ваш код, має це враховувати.
✅ Чітко і явно відокремлюйте виклики через зовнішню мережу.
Ми постійно використовуємо DI контейнер для зручності, тому клієнтський код десь в application layer, може виглядати достатньо звично:
// client code after DI container wiring
$order = new Order($id, $userId, $total);
$this->orderRepository->save($order);
❗️️️️️️️Проте, всередині може бути досить велика різниця:
Одна реалізація [gist]
final readonly class OrderRepository
{
public function __construct(
private PostgresConnection $connection
)
{
}
public function save(Order $order)
{
$this->connection->execute('INSERT INTO orders (id, user_id, total) VALUES (?, ?, ?)', [
$order->id(),
$order->userId(),
$order->total()
]);
}
}
Зовсім інша реалізація [gist]
final readonly class OrderRepository
{
public function __construct(
private OrderApiClient $client
)
{
}
public function save(Order $order)
{
$this->client->createOrder($order);
}
}
📍️️️️️️ При такій реалізації в клієнтському коді досить важко передбачити виклик через зовнішню мережу. Допоможіть собі майбутньому і іншим програмістам в вашому проекті чітко зрозуміти з чим саме зараз ви зараз працюєте.
OrderProvider, OrderGateway, OrderIntegration, etc.
Будь яка конвенція, котра буде команді довподоби, але вона має чітко відрізнятись від:
OrderRepository, OrderStorage, etc.
🤓 Можливо передача інфомації за допомогою квантових частинок дозволить нам робити це миттєво в якомусь майбутньому, проте на даному етапі ми жорстко обмежені швидкістю світла.
✅ Намагайтесь отримати одразу всі необхідні дані
Якщо вже виконуєте зовнішій виклик, намагайтесь повернути всі потрібні дані в одному запиті. Cхоже на вирішення класичної проблеми n+1.
[gist]
employees = $this->employeeProvider->getList($limit, $offset);
foreach ($employees as $employee) {
$department = $this->departmentProvider->getById(
$employee->getDepartmentId(),
);
// do something with department
}
Проти [gist]
$employees = $this->employeeProvider->getList($limit, $offset);
$departments = $this->departmentProvider->getAll();
// prepare a map of department id to department
foreach ($employees as $employee) {
$department = $departments[$employee->getDepartmentId()];
// do something with department
}
✅ Кешування – ваш друг, але будьте з ним обережні
Якщо ви досить часто запитуєте одні і ті самі дані, а в свою чергу, вони відносно рідко змінюються - кеш може бути чудовим рішенням. Він одночасно зменшить час на виклик, обробку даних і навантаження на мережу.
❗️Обовʼязково приділіть час для узгодження стратегії інвалідації кеша.
✅ Інвертуйте потік даних
Замість того, щоб кожного разу опитувати інші сервіси, ви можете використовувати патерн Pub/Sub та зберігайти дані локально (в тому числі в кеші). Звичайно, це ускладнює архітектуру, звичайно, це підійде не для всіх задач. Але памʼятайте про цей прийом, він може досить елегантно вирішити проблему в вашому проекті.
#php #architecture #middle #source
Please open Telegram to view this post
VIEW IN TELEGRAM
👍56🔥6🙊2🗿1
Ранні виходи (Early return)
Все ще закликаю комьюніті до гостьових постів. Сьогодні саме один з таких, дякую автору, @yozhef, за те, що підняв цю тему.
📍 Ранні виходи з функцій чи циклів – це крутий лайфхак, який робить ваш код чистішим, зрозумілішим і простішим для підтримки. Якщо ви відразу виходите з функції, коли умова не відповідає необхідним критеріям, ви економите час як на виконання, так і на розуміння логіки (та і ментальне здоровʼя 😁).
Давайте переглянемо цей код [gist]:
Порівняно з наступним [gist]:
Думаю у early return підхода можна виділити наступні переваги:
🎯 Спрощення логіки — ви уникаєте численних вкладених if-ів, що значно полегшує розуміння логіки.
🛑 Менша вкладеність — менше шансів заплутатися. Як бонус, ваш код стає легшим для читання.
⏩ Швидке завершення. Ранні виходи дозволяють швидше завершити виконання функції, коли вже відомо, що подальші дії непотрібні. Те ж саме стосується і Fail Fast: Як сказали Jim Shore і Martin Fowler, швидке виявлення помилок робить код більш надійним. Якщо помилка трапляється, функція одразу припиняє виконання, що запобігає виконанню зайвих операцій.
🛠️ Простіше модифікувати. Чим менше розгалужень у функції, тим легше вносити зміни або додавати нову логіку без ризику зламати існуючий функціонал.
🧹 Менше залежностей, а відповідно кожна частина коду стає більш ізольованою. Це спрощує рефакторинг та тестування, адже залежності між різними частинами зменшуються.
🔍 Фокус на критичних умовах — Можливість зосередитися на найважливіших умовах виконання коду, підкреслюючи їх значущість і відсіюючи менш критичні сценарії.
Отже, використання ранніх виходів робить ваш код елегантним і ефективним, особливо в умовах складних систем з великою кількістю умов і розгалужень.
#php #lifehack #junior #source
Все ще закликаю комьюніті до гостьових постів. Сьогодні саме один з таких, дякую автору, @yozhef, за те, що підняв цю тему.
📍 Ранні виходи з функцій чи циклів – це крутий лайфхак, який робить ваш код чистішим, зрозумілішим і простішим для підтримки. Якщо ви відразу виходите з функції, коли умова не відповідає необхідним критеріям, ви економите час як на виконання, так і на розуміння логіки (та і ментальне здоровʼя 😁).
Давайте переглянемо цей код [gist]:
function processOrder($order) {
if ($order->isPaid()) {
if ($order->hasValidShippingAddress()) {
if ($order->isInStock()) {
// Логіка обробки замовлення
return "Order processed successfully.";
} else {
return "Order cannot be processed: Out of stock.";
}
} else {
return "Order cannot be processed: Invalid shipping address.";
}
} else {
return "Order cannot be processed: Payment pending.";
}
}
Порівняно з наступним [gist]:
function processOrder($order) {
if (!$order->isPaid()) {
return "Order cannot be processed: Payment pending.";
}
if (!$order->hasValidShippingAddress()) {
return "Order cannot be processed: Invalid shipping address.";
}
if (!$order->isInStock()) {
return "Order cannot be processed: Out of stock.";
}
// Логіка обробки замовлення
return "Order processed successfully.";
}
Думаю у early return підхода можна виділити наступні переваги:
🎯 Спрощення логіки — ви уникаєте численних вкладених if-ів, що значно полегшує розуміння логіки.
🛑 Менша вкладеність — менше шансів заплутатися. Як бонус, ваш код стає легшим для читання.
⏩ Швидке завершення. Ранні виходи дозволяють швидше завершити виконання функції, коли вже відомо, що подальші дії непотрібні. Те ж саме стосується і Fail Fast: Як сказали Jim Shore і Martin Fowler, швидке виявлення помилок робить код більш надійним. Якщо помилка трапляється, функція одразу припиняє виконання, що запобігає виконанню зайвих операцій.
🛠️ Простіше модифікувати. Чим менше розгалужень у функції, тим легше вносити зміни або додавати нову логіку без ризику зламати існуючий функціонал.
🧹 Менше залежностей, а відповідно кожна частина коду стає більш ізольованою. Це спрощує рефакторинг та тестування, адже залежності між різними частинами зменшуються.
🔍 Фокус на критичних умовах — Можливість зосередитися на найважливіших умовах виконання коду, підкреслюючи їх значущість і відсіюючи менш критичні сценарії.
Отже, використання ранніх виходів робить ваш код елегантним і ефективним, особливо в умовах складних систем з великою кількістю умов і розгалужень.
#php #lifehack #junior #source
👍53🔥6👀2⚡1🙊1
Сьомий випуск Fwdays PHP Talks
Разом з Олегом Зінченко та Владиславом Яришом поговорили про болючі теми:
💵 Оплачувані і безкоштовні тестові
🤯 Чому варто вивчати golang?
📈 Як python зайняв перше місце в рейтингу?
🔥 Куди рухається PHP і як збільшити його популярніть?
Доєднутесь дивитись (або просто слухати) та діліться своїми думками 🍻
Разом з Олегом Зінченко та Владиславом Яришом поговорили про болючі теми:
💵 Оплачувані і безкоштовні тестові
🤯 Чому варто вивчати golang?
📈 Як python зайняв перше місце в рейтингу?
Доєднутесь дивитись (або просто слухати) та діліться своїми думками 🍻
Media is too big
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
👍13🔥4🙊2🗿1
Пропускна здатність обмежена
Гігабітний інтернет, це багато, чи мало? Фактично це дає нам змогу обмінюватись інформацією зі швидкістю 125 МБ/сек – у теорії. Але в реальності, через всі накладні витрати, ця цифра може легко падати до 60 МБ/сек, навіть коли обидві сторони (клієнт та сервер) знаходяться на одному континенті.
❗️ Важливо розуміти, що кількість даних, котрими ми обмінюємось постійно і стрімко зростає. Відео контент вже став стандартом на сьогоднішній день, хоча 15 років тому я в браузері відключав завантаження картинок, аби текстовий контент завантажувався швидше. При цьому пропускна здатність збільшується не так швидко, як би нам хотілось.
Припустимо, що у вас є середній розмір DTO близько 5 КБ, а ваша система обслуговує 100 RPS (requests per second). Це означає, що за секунду передається приблизно 500 КБ даних – що досить непогано, враховуючи потенційне обмеження в 60 МБ.
📍 Не всі хмарні рішення готові надавати 1 Гбіт "із коробки". Ваша пропускна здатність може бути легко обмежена 200 Мбіт (без додаткових витрат), а DTO важити далеко не 5 КБ. За допомогою ORM ми починаємо тягнути купу даних, навіть якщо вони не потрібні. Наприклад, коли пишемо API для інтернет-магазину, то контролер може повертати об’єкт Order із усіма деталями: інформацією про користувача, товари, опис кожного з них, метадані для фільтрів, дані про доставку, оплату. В результаті серіалізації такого обʼєкту на виході отримуємо JSON розміром вже не 5 КБ, а 400 КБ.
🤓 Можна легко підрахувати, що при 200 Мбіт (25 МБ/c) зазначеної пропускної здатності ми витримати всього 60 RPS.
Звісно, можна просто доплатити і розширити канал, взяти ще один сервер, розмежувати якимось чином network і т.д. Проте ми будемо платити за обсяги даних, що передаємо.
👉 На цьому етапі виникає конфлікт інтересів. З одного боку, ми говорили про те, що хочемо завантажувати більше даних за раз, щоб отримувати все і якось боротись з latency. З іншого боку, це збільшує навантаження на мережу, що може призвести до затримок і неефективного використання пропускної здатності.
👍 Отже нам потрібен баланс. Цей баланс залежить від конкретного сценарію. В цьому нам допоможуть Bounded Context, Read/Write Model а також Aggregate.
#backend #architecture #middle #source
Гігабітний інтернет, це багато, чи мало? Фактично це дає нам змогу обмінюватись інформацією зі швидкістю 125 МБ/сек – у теорії. Але в реальності, через всі накладні витрати, ця цифра може легко падати до 60 МБ/сек, навіть коли обидві сторони (клієнт та сервер) знаходяться на одному континенті.
❗️ Важливо розуміти, що кількість даних, котрими ми обмінюємось постійно і стрімко зростає. Відео контент вже став стандартом на сьогоднішній день, хоча 15 років тому я в браузері відключав завантаження картинок, аби текстовий контент завантажувався швидше. При цьому пропускна здатність збільшується не так швидко, як би нам хотілось.
Припустимо, що у вас є середній розмір DTO близько 5 КБ, а ваша система обслуговує 100 RPS (requests per second). Це означає, що за секунду передається приблизно 500 КБ даних – що досить непогано, враховуючи потенційне обмеження в 60 МБ.
100 RPS * 5 КБ = 500 КБ/с
📍 Не всі хмарні рішення готові надавати 1 Гбіт "із коробки". Ваша пропускна здатність може бути легко обмежена 200 Мбіт (без додаткових витрат), а DTO важити далеко не 5 КБ. За допомогою ORM ми починаємо тягнути купу даних, навіть якщо вони не потрібні. Наприклад, коли пишемо API для інтернет-магазину, то контролер може повертати об’єкт Order із усіма деталями: інформацією про користувача, товари, опис кожного з них, метадані для фільтрів, дані про доставку, оплату. В результаті серіалізації такого обʼєкту на виході отримуємо JSON розміром вже не 5 КБ, а 400 КБ.
🤓 Можна легко підрахувати, що при 200 Мбіт (25 МБ/c) зазначеної пропускної здатності ми витримати всього 60 RPS.
Звісно, можна просто доплатити і розширити канал, взяти ще один сервер, розмежувати якимось чином network і т.д. Проте ми будемо платити за обсяги даних, що передаємо.
👉 На цьому етапі виникає конфлікт інтересів. З одного боку, ми говорили про те, що хочемо завантажувати більше даних за раз, щоб отримувати все і якось боротись з latency. З іншого боку, це збільшує навантаження на мережу, що може призвести до затримок і неефективного використання пропускної здатності.
👍 Отже нам потрібен баланс. Цей баланс залежить від конкретного сценарію. В цьому нам допоможуть Bounded Context, Read/Write Model а також Aggregate.
#backend #architecture #middle #source
👍23🔥2
Bounded Context
Перший крок — варто уникати створення єдиної, монолітної доменної моделі для всієї системи. Намагайтесь розділити модель і ваші обʼєкти на менші частини, кожна з яких відповідає за конкретний сценарій або контекст. Наприклад, якщо у нас є система для обробки замовлень інтернет магазину, то є обʼєкт (Order), але в різних частинах системи це слово означає різне:
Для створення замовлення важливі товари й ціна
Для оплати — номер картки й статус транзакції
Для доставки — адреса й дата
Обмежений контекст — це коли ми ділимо модель на маленькі шматочки, кожен із яких живе окремо і відповідає за конкретну задачу.
⁉️ Як це працює?
Cтворюємо окремі класи для кожного контексту. Наприклад:
OrderCreation — для створення замовлення
OrderPayment — для оплати
OrderDelivery — для доставки
Кожен із них має тільки те, що йому потрібно, і не знає про існування інших.
[golang] [php] [python] [nodejs]
📍Моделі (обʼєкти, сервіси, ентіті, хендлери і т.д.) в одному обмеженому контексті мають бути тісно пов’язані (cohesion) й працювати разом для однієї мети. Наприклад, у контексті OrderCreation це може бути додавання, видалення й оновлення товарів в замолені, бо це одна бізнес-здібність.
📍В той же час контекст не має сильно залежати від інших (loose coupling). Наприклад, OrderDelivery оперує саме OrderId а не цілим Order і зовсім нічого не знає про деталі оплати.
Переваги такого підходу:
1. Код стає простішим: кожен клас маленький і зрозумілий.
2. Легше тестувати: можна окремо перевіряти кожну частинку, не чіпаючи іншу.
3. Передаємо менше даних. Наприклад, OrderPayment випадково не потягне за собою адресу доставки, бо вона йому не потрібна.
❗️ Розділені контексти - це не раз і назавжди. З часом, коли проект росте, ви можете і маєте переглядати їх. В моноліті кордони між контекстами можуть бути малопомітні, адже виклик сервіса із сусідньої папки не викликає ніяких проблем. Проте варто за цим слідкувати. Як мінімум впровадити архітектурні тести (deptrac) з описаними правилами, котрий буде запускатись разом з тестами і статичним аналізатором.
#backend #architecture #middle #source
Перший крок — варто уникати створення єдиної, монолітної доменної моделі для всієї системи. Намагайтесь розділити модель і ваші обʼєкти на менші частини, кожна з яких відповідає за конкретний сценарій або контекст. Наприклад, якщо у нас є система для обробки замовлень інтернет магазину, то є обʼєкт (Order), але в різних частинах системи це слово означає різне:
Для створення замовлення важливі товари й ціна
Для оплати — номер картки й статус транзакції
Для доставки — адреса й дата
Обмежений контекст — це коли ми ділимо модель на маленькі шматочки, кожен із яких живе окремо і відповідає за конкретну задачу.
⁉️ Як це працює?
Cтворюємо окремі класи для кожного контексту. Наприклад:
OrderCreation — для створення замовлення
OrderPayment — для оплати
OrderDelivery — для доставки
Кожен із них має тільки те, що йому потрібно, і не знає про існування інших.
[golang] [php] [python] [nodejs]
final readonly class OrderCreation {
/**
* @param OrderItem[] $items
*/
public function __construct(
private OrderId $orderId,
private UserId $userId,
private array $items
) {
}
}
// Контекст оплати замовлення
final readonly class OrderPayment {
public function __construct(
private OrderId $orderId,
private Money $sum
)
{
}
}
// Контекст доставки
final readonly class OrderDelivery {
public function __construct(
private OrderId $orderId,
private Address $address
)
{
}
}
// Використання
$orderCreation = new OrderCreation(
new OrderId($this->orderIdGenerator->generate()),
new UserId($this->userId),
[
new OrderItem(new ProductId('notebook'), $quantity),
new OrderItem(new ProductId('gamepad'), $quantity),
]
);
$orderPayment = new OrderPayment(
$orderCreation->orderId(),
new Money($this->total)
);
$orderDelivery = new OrderDelivery(
$orderCreation->orderId(),
new Address(
$this->city,
$this->street,
$this->house
)
);
📍Моделі (обʼєкти, сервіси, ентіті, хендлери і т.д.) в одному обмеженому контексті мають бути тісно пов’язані (cohesion) й працювати разом для однієї мети. Наприклад, у контексті OrderCreation це може бути додавання, видалення й оновлення товарів в замолені, бо це одна бізнес-здібність.
📍В той же час контекст не має сильно залежати від інших (loose coupling). Наприклад, OrderDelivery оперує саме OrderId а не цілим Order і зовсім нічого не знає про деталі оплати.
Переваги такого підходу:
1. Код стає простішим: кожен клас маленький і зрозумілий.
2. Легше тестувати: можна окремо перевіряти кожну частинку, не чіпаючи іншу.
3. Передаємо менше даних. Наприклад, OrderPayment випадково не потягне за собою адресу доставки, бо вона йому не потрібна.
❗️ Розділені контексти - це не раз і назавжди. З часом, коли проект росте, ви можете і маєте переглядати їх. В моноліті кордони між контекстами можуть бути малопомітні, адже виклик сервіса із сусідньої папки не викликає ніяких проблем. Проте варто за цим слідкувати. Як мінімум впровадити архітектурні тести (deptrac) з описаними правилами, котрий буде запускатись разом з тестами і статичним аналізатором.
#backend #architecture #middle #source
👍31🔥5
Aggregate
Що робити, коли нам все таки потрібні різні частинки, бо вони приймають участь в одній операції? Наприкад, створення Invoice для того самого Order (продовжуємо думку попереднього поста) може вимагати як особистих даних користувача, так і повного списку товарів (щоб їх там відобразити), а також загальної суми для транзакції. Тут на поміч приходить агрегат.
👉 Агрегат — група пов’язаних об’єктів домену. Він складається з однієї або декількох сутностей (а інколи й об’єктів-значень), які логічно пов’язані між собою.
У нашому випадку, коли для створення інвойсу потрібні дані користувача, список товарів і сума, агрегат має зібрати все це разом і гарантувати, що зміни відбуватимуться транзакційно. Наприклад, якщо додати новий товар, то загальна сума автоматично оновиться.
❗️ Агрегат має корінь (aggregate root), через який відбуваються всі операції. Він відповідає за забезпечення інваріантів (бізнес-правил), надання методів для доступу та зміни стану, щоб зовнішні виклики не могли порушити ту саму узгодженість. Це означає, що замість того, щоб окремо взаємодіяти з обʼєктами даних користувача, товарами й сумою, ви працюєте з одним об’єктом, який уже все це тримає в узгодженому стані.
[golang] [php] [python] [nodejs]
👉 Коли вам потрібно створити інвойс, ви викликаєте createInvoice(), і агрегат повертає об’єкт Invoice із усіма потрібними даними. Вам не доводиться вручну збирати ці частинки з різних джерел чи турбуватися про їхню узгодженість — агрегат це робить за вас.
Підсумуємо:
– Всі зміни в агрегаті виконуються узгоджено. Після завершення транзакції стан усіх сутностей агрегата має бути консистентним.
– Агрегати визначають область транзакції – операції над ними мають виконуватися атомарно. Наприклад, якщо ми щось зберігаємо, або дістаємо зі storage, то ми маємо це робити з усім агрегатом. Дані не можуть бути оновлені частково.
– Зовнішні об’єкти можуть взаємодіяти лише з агрегатним коренем, що дозволяє зберігати внутрішню цілісність агрегата.
❗️Агрегат не повинен містити інших агрегатів. Кожен агрегат має свою власну область відповідальності. Якщо вам потрібно з якоїсь причини повʼязати агрегати — використовуйте ідентифікатори для того щоб зробити посилання на інший агрегат.
#backend #architecture #middle #source
Що робити, коли нам все таки потрібні різні частинки, бо вони приймають участь в одній операції? Наприкад, створення Invoice для того самого Order (продовжуємо думку попереднього поста) може вимагати як особистих даних користувача, так і повного списку товарів (щоб їх там відобразити), а також загальної суми для транзакції. Тут на поміч приходить агрегат.
👉 Агрегат — група пов’язаних об’єктів домену. Він складається з однієї або декількох сутностей (а інколи й об’єктів-значень), які логічно пов’язані між собою.
У нашому випадку, коли для створення інвойсу потрібні дані користувача, список товарів і сума, агрегат має зібрати все це разом і гарантувати, що зміни відбуватимуться транзакційно. Наприклад, якщо додати новий товар, то загальна сума автоматично оновиться.
❗️ Агрегат має корінь (aggregate root), через який відбуваються всі операції. Він відповідає за забезпечення інваріантів (бізнес-правил), надання методів для доступу та зміни стану, щоб зовнішні виклики не могли порушити ту саму узгодженість. Це означає, що замість того, щоб окремо взаємодіяти з обʼєктами даних користувача, товарами й сумою, ви працюєте з одним об’єктом, який уже все це тримає в узгодженому стані.
[golang] [php] [python] [nodejs]
// Клас для даних користувача
final class UserData {
public function __construct(
public string $name,
public Address $address
) {}
}
/**
* @param Product[] $items
*/
final class Invoice {
public function __construct(
public OrderId $orderId,
public UserData $user,
public array $items,
public Money $total
) {}
}
// Агрегат для замовлення
final class OrderAggregate {
private OrderId $orderId;
private UserData $user;
private array $items;
private Money $total;
public function __construct(OrderId $orderId, UserData $user, array $items) {
$this->orderId = $orderId;
$this->user = $user;
$this->items = $items;
$this->calculateTotal();
}
// Розрахунок загальної суми
private function calculateTotal(): void {
$this->total = array_sum(array_map(fn($item) => $item->price * $item->amount, $this->items));
}
// Додавання нового товару
public function addItem(string $name, Money $price, int $quantity): void {
$this->items[] = new Product($name, $price, $quantity);
$this->calculateTotal();
}
// Створення інвойсу
public function createInvoice(): Invoice {
return new Invoice($this->orderId, $this->user, $this->items, $this->total);
}
}
// Використання
$user = new UserData('Іван Петренко', new Address('Київ', 'вул. Шевченка', '1'));
$order = new OrderAggregate('123', $user, [new Product('Ноутбук', 20000, 1)]);
$order->addItem('Мишка', 500, 2);
$invoice = $order->createInvoice();
echo \sprintf(‘Інвойс для замовлення %s, користувач: %s, сума: %s грн\n’, $invoice->orderId, $invoice->user->name, $invoice->total);
👉 Коли вам потрібно створити інвойс, ви викликаєте createInvoice(), і агрегат повертає об’єкт Invoice із усіма потрібними даними. Вам не доводиться вручну збирати ці частинки з різних джерел чи турбуватися про їхню узгодженість — агрегат це робить за вас.
Підсумуємо:
– Всі зміни в агрегаті виконуються узгоджено. Після завершення транзакції стан усіх сутностей агрегата має бути консистентним.
– Агрегати визначають область транзакції – операції над ними мають виконуватися атомарно. Наприклад, якщо ми щось зберігаємо, або дістаємо зі storage, то ми маємо це робити з усім агрегатом. Дані не можуть бути оновлені частково.
– Зовнішні об’єкти можуть взаємодіяти лише з агрегатним коренем, що дозволяє зберігати внутрішню цілісність агрегата.
❗️Агрегат не повинен містити інших агрегатів. Кожен агрегат має свою власну область відповідальності. Якщо вам потрібно з якоїсь причини повʼязати агрегати — використовуйте ідентифікатори для того щоб зробити посилання на інший агрегат.
#backend #architecture #middle #source
👍29🔥3🗿2🙊1
Read, Write, Partial Update
Наступна відома проблема, коли ми намагаємось використовувати один і той самий обʼєкт як для читання (наприклад представлення на frontend) так і для запису (створення, оновлення).
👉 Візьмемо іншу сутність в рамках нашого створення замолення — Customer. Побудуємо його з низки Value Objects щоб гарантувати, що дані завжди валідні.
Які ж можуть виникнути проблеми?
1️⃣ Щось, що ми не хочемо відображати
Якщо для відображення ми будемо використовувати той самий обʼєкт Customer, існує ризик, що у відповідь потраплять зайві дані.
Наприклад захешований пароль
Так, можемо по місцю зробити щось на кшталт:
2️⃣ Зміна правил валідації
Їдемо далі. Наші перевірки в Value Objects можуть змінюватись з часом. В якийсь момент, ми можемо зробити їх більш жорсткими. В базі даних можуть зберігатись записи, котрі можуть не пройти правила нової валідації, якщо ми будемо використовувати один і той самий обʼєкт для читання і для запису. Тут починаються трюки з Reflection. Вже не так райдужно.
3️⃣ Додаткові дані для відображення
Наступна проблема, коли для відображення нам потрібна інформація, котра не міститься в поточному обʼєкті. Наприклад, кількість замовлень.
Варіант робочий, проте ми тут робимо 2 запити до бази даних, хоча потенційно можна зробити один.
4️⃣ Чи дійсно створення та оновлення це одне і те саме?
При створенні нового Customer ми очікуємо email, name та password. Але, наприклад, при зміні імені, що ми маємо передавати в полі пароля. Чи навпаки, при зміні пароля нам потрібна специфічна логіка (запит на зміну, надсилання токена тощо).
🤓 Щоб вирішити ці проблеми, доцільно використовувати окремі моделі для різних операцій. Наприклад:
Або для оновлення даних:
✏️ Write model забезпечує дотримання інваріантів і консистентність даних. Оскільки тут ми не паримось як саме будемо виводити ці дані - це дозволяє нам робити обʼєкт маленьким і конкретним.
📖 Read model дає можливість отримати всю необхідну інформацію, потрібну для конкретного відображення чи перегляду.
Не бійтеся створювати окремі представлення для різних операцій. Ваш код стане більш стабільним, логічни та простим для підтримки.
#backend #architecture #middle #source
Наступна відома проблема, коли ми намагаємось використовувати один і той самий обʼєкт як для читання (наприклад представлення на frontend) так і для запису (створення, оновлення).
👉 Візьмемо іншу сутність в рамках нашого створення замолення — Customer. Побудуємо його з низки Value Objects щоб гарантувати, що дані завжди валідні.
$customer = new Customer(
new CustomerId(uniqid()),
new Email($request->email),
new Name($request->name)),
new Password($request->password))
);
$repository->save($customer);
Які ж можуть виникнути проблеми?
1️⃣ Щось, що ми не хочемо відображати
Якщо для відображення ми будемо використовувати той самий обʼєкт Customer, існує ризик, що у відповідь потраплять зайві дані.
interface CustomerRepository
{
public function save(Customer $customer): void;
public function get(string $email): Customer;
}
Наприклад захешований пароль
{
"customerId": "5f2b...",
"email": "jane@doe.com",
"name": "Jane Doe",
"password": "$2y$10$..."
}
Так, можемо по місцю зробити щось на кшталт:
final readonly class Customer
{
// ...
public function serialize(): array
{
return [
'email' => $this->email,
'name' => $this->name,
];
}
}
2️⃣ Зміна правил валідації
Їдемо далі. Наші перевірки в Value Objects можуть змінюватись з часом. В якийсь момент, ми можемо зробити їх більш жорсткими. В базі даних можуть зберігатись записи, котрі можуть не пройти правила нової валідації, якщо ми будемо використовувати один і той самий обʼєкт для читання і для запису. Тут починаються трюки з Reflection. Вже не так райдужно.
3️⃣ Додаткові дані для відображення
Наступна проблема, коли для відображення нам потрібна інформація, котра не міститься в поточному обʼєкті. Наприклад, кількість замовлень.
[
...$customerRepository->getById($customerId),
...['orders_count' => $orderRepository->count($customerId)]
]
Варіант робочий, проте ми тут робимо 2 запити до бази даних, хоча потенційно можна зробити один.
4️⃣ Чи дійсно створення та оновлення це одне і те саме?
При створенні нового Customer ми очікуємо email, name та password. Але, наприклад, при зміні імені, що ми маємо передавати в полі пароля. Чи навпаки, при зміні пароля нам потрібна специфічна логіка (запит на зміну, надсилання токена тощо).
interface CustomerRepository
{
public function save(Customer $user): void;
public function update(Customer $user): void;
}
// Updating name
$customer = new Customer(
$request->email,
$request->name,
'а що тут робити з паролем?',
);
$repository->update($customer);
🤓 Щоб вирішити ці проблеми, доцільно використовувати окремі моделі для різних операцій. Наприклад:
final readonly class CustomerRead
{
public function __construct(
public CustomerId $customerId,
public Email $email,
public Name $name,
public int $orderCount,
) {}
}
interface CustomerReadRepository
{
public function get(CustomerId $customerId): CustomerRead;
}
Або для оновлення даних:
final readonly class CustomerNameUpdate
{
public function __construct(
public CustomerId $customerId,
public Name $name,
)
}
interface CustomerRepository
{
public function save(Customer $customer): void;
public function updateData(CustomerNameUpdate $customerNameUpdate): void;
public function updatePassword(CustomerPasswordUpdate $customerPasswordUpdate): void;
}
✏️ Write model забезпечує дотримання інваріантів і консистентність даних. Оскільки тут ми не паримось як саме будемо виводити ці дані - це дозволяє нам робити обʼєкт маленьким і конкретним.
📖 Read model дає можливість отримати всю необхідну інформацію, потрібну для конкретного відображення чи перегляду.
Не бійтеся створювати окремі представлення для різних операцій. Ваш код стане більш стабільним, логічни та простим для підтримки.
#backend #architecture #middle #source
👍32🔥5🙊3⚡1
Знову про індекси
На моїй практиці 7 з 10 інженерів відповідають приблизно в такому форматі. Можливо тільки в мене така статистика, але пропоную зануритись трошки глибше.
❗️В 90% випадках, незалежно від бази даних (MySQL, Postgres, Mongo) для забезпечення своїх потреб ми будемо використовувати B-Tree або B+Tree індекси.
«Це ж бінарні дерева!» вигукують інженери. І так і ні.
👉 Ця структура - дійсно дерево, і замість того, щоб виконувати пошук по списку і перебирати всі дані O(n), змінивши структуру і розклавши дані у дерево ми будемо виконувати операцію зі складністю ~ O(log n). Якщо дерево бінарне, то і пошук буде бінарним.
❓ Чому важливо, що це не просто бінарне дерево?
При додаванні нового елемента в бінарне дерево - важливий порядок додавання. Перший елемент стає коренем дерева і від нього починають будуватись всі гілки.
❗️ Це неминуче призводить до того, що деякі гілки будуть значно довші (вищі) ніж інші. Така структура не може гарантувати швидкість пошуку по всі таблиці з однаковою ефективністю. Ось приклад незбалансованого дерева (в гіршому випадку):
Таке дерево фактично стає зв'язним списком з складністю пошуку O(n).
👍 Для вирішення цієї проблеми придумали збалансовані дерева. Тут при кожній операції вставки алгоритм обертає значення таким чином, щоб як умога довше забезпечити однакову висоту по всьому дереву. Обертання - досить дорога операція, і це сильно сповільнює вставку.
✅️️️️️️️ Інженери пішли далі і сьогодні ми маємо такі різновиди збалансованих дерев як B-Tree та B+Tree. В них при операції вставки ми не одразу породжуємо нову ноду, а намагаємось вставити дані за певним алгоритмом, щоб зберегти висоту. Це породжує декілька значень на рівні однієї ноди:
🤓 Але про них ми більш подробно поговоримо в наступному пості. Отже, головний посил, що індекси - не магія і не просто "якась штука збоку". Це конкретні структури даних, що пришвидшують пошук.
#database #middle
- Що робити, якщо ваш запит в БД відпрацьовує повільно?
- Ну я б спробував(ла) додати індекс.
- Чудово, а чому індекс пришвидшує пошук?
- Нуууу, просто це якась відсортована штука збоку. Ось вона відсортована, пошук швидше.
На моїй практиці 7 з 10 інженерів відповідають приблизно в такому форматі. Можливо тільки в мене така статистика, але пропоную зануритись трошки глибше.
❗️В 90% випадках, незалежно від бази даних (MySQL, Postgres, Mongo) для забезпечення своїх потреб ми будемо використовувати B-Tree або B+Tree індекси.
«Це ж бінарні дерева!» вигукують інженери. І так і ні.
👉 Ця структура - дійсно дерево, і замість того, щоб виконувати пошук по списку і перебирати всі дані O(n), змінивши структуру і розклавши дані у дерево ми будемо виконувати операцію зі складністю ~ O(log n). Якщо дерево бінарне, то і пошук буде бінарним.
❓ Чому важливо, що це не просто бінарне дерево?
При додаванні нового елемента в бінарне дерево - важливий порядок додавання. Перший елемент стає коренем дерева і від нього починають будуватись всі гілки.
Додаємо числа: 10, 5, 15, 3, 7, 12, 20
Крок 1: Додаємо 10 (корінь)
10
Крок 2: Додаємо 5 (менше 10, йде ліворуч)
10
/
5
Крок 3: Додаємо 15 (більше 10, йде праворуч)
10
/ \
5 15
Крок 4: Додаємо 3 (менше 5, йде ліворуч від 5)
10
/ \
5 15
/
3
Крок 5: Додаємо 7 (більше 5, йде праворуч від 5)
10
/ \
5 15
/ \
3 7
Крок 6: Додаємо 12 (менше 15, йде ліворуч від 15)
10
/ \
5 15
/ \ /
3 7 12
Крок 7: Додаємо 20 (більше 15, йде праворуч від 15)
10
/ \
5 15
/ \ / \
3 7 12 20
❗️ Це неминуче призводить до того, що деякі гілки будуть значно довші (вищі) ніж інші. Така структура не може гарантувати швидкість пошуку по всі таблиці з однаковою ефективністю. Ось приклад незбалансованого дерева (в гіршому випадку):
Додаємо числа в порядку зростання: 1, 2, 3, 4, 5, 6, 7
1
\
2
\
3
\
4
\
5
\
6
\
7
Таке дерево фактично стає зв'язним списком з складністю пошуку O(n).
👍 Для вирішення цієї проблеми придумали збалансовані дерева. Тут при кожній операції вставки алгоритм обертає значення таким чином, щоб як умога довше забезпечити однакову висоту по всьому дереву. Обертання - досить дорога операція, і це сильно сповільнює вставку.
Припустимо, у нас є незбалансоване дерево, яке "виросло" вліво:
30
/
20
/ \
10 25
Необхідно виконати праве обертання навколо кореня (30):
Крок 1: Беремо вузол 20 як новий корінь
Крок 2: Старий корінь (30) стає правим нащадком нового кореня
Крок 3: Правий нащадок нового кореня (якщо є) стає лівим нащадком
старого кореня (25 стає зліва)
Результат:
20
/ \
25 30
/
10
Тепер дерево збалансоване
Розглянемо складніший випадок з подвійним обертанням. Дано:
30
/
10
\
20
Тут праве обертання не виправить ситуацію. Потрібне подвійне обертання:
Спочатку ліве обертання навколо 10:
30
/
20
/
10
Потім праве обертання навколо 30:
20
/ \
10 30
✅️️️️️️️ Інженери пішли далі і сьогодні ми маємо такі різновиди збалансованих дерев як B-Tree та B+Tree. В них при операції вставки ми не одразу породжуємо нову ноду, а намагаємось вставити дані за певним алгоритмом, щоб зберегти висоту. Це породжує декілька значень на рівні однієї ноди:
[15, 50]
/ | \
[5] [20] [70]
🤓 Але про них ми більш подробно поговоримо в наступному пості. Отже, головний посил, що індекси - не магія і не просто "якась штука збоку". Це конкретні структури даних, що пришвидшують пошук.
#database #middle
👍50🔥8🗿1
B-Tree та B+Tree індекси
👉 Саме вони є найбільш розповсюдженими в нашому повсякденному житті. Майже всі популярні БД (PostgreSQL, MySQL/InnoDB, SQLite, MongoDB і т.д.) використовують B+Tree для зберігання індексів. Як зазначено в попередньому пості, це різновиди збаланосованих дерев. Головна особливість в тому, що кожен вузол може мати більше двох нащадків (на відміну від бінарного дерева), а також може мати кілька ключів (значень) в одному вузлі.
Порядок B-Tree (зазвичай позначається як m) визначає максимальну кількість нащадків, які може мати вузол.
- Кожна нода (крім кореня) має від ceil(m/2)-1 до m-1 ключів
- Корінь має від 1 до m-1 ключів
- Нода з k ключами має k+1 дочірніх нод
❗️У нашому прикладі ми використовуємо B-Tree порядку 3, це значить, що може бути до 2 ключів у кожному вузлі, і до 3 нащадків для кожного вузла відповідно.
📍 B+Tree відрізняється від B-Tree тим, що всі дані зберігаються тільки в листкових вузлах, які додатково пов'язані між собою як зв'язний список, що значно пришвидшує послідовне читання а значить і кращу продуктивність при пошуку близьких значень.
Алгоритм вставки:
❓ "Перебудова індексу", або чому вставки такі дорогі?
🔥 Основна причина популярності цих індексів - оптимізація роботи з диском. Диск читається блоками (вони ж сторінки індексу фіксованого розміру, зазвичай 4KB, 8KB або 16KB залежно від БД), і B-дерева чудово це використовують, зберігаючи багато ключів в одному вузлі.
Fill Factor (фактор заповнення) - параметр, який визначає, наскільки заповненими будуть сторінки індексу при їх створенні. Наприклад, fill factor 70% означає, що сторінки заповнюються на 70%, залишаючи 30% вільного місця для майбутніх вставок.
Коли сторінка індексу заповнюється повністю (через вставки даних), відбувається операція розщеплення сторінки (page split):
1️⃣ Створюється нова сторінка
2️⃣ Приблизно половина даних переміщується в нову сторінку
3️⃣ Середній ключ "піднімається" до батьківської сторінки
4️⃣ Батьківська сторінка оновлює свої посилання
❗️Це і є супер дорога операція, бо вимагає виділення нової сторінки на диску, переміщення даних, оновлення посилань, можливе розщеплення батьківських сторінок (каскадний ефект).
Також налаштування fill factor може підвищити продуктивність бази даних:
Для таблиць з частими вставками — низький fill factor (70-80%)
Для таблиць тільки для читання — високий fill factor (90-100%)
👍 Сподіваюсь, у світі стало трошки менше магії, і трошки більше розуміння того, як працюють системи, якими ми користуємось щодня.
#database #middle
👉 Саме вони є найбільш розповсюдженими в нашому повсякденному житті. Майже всі популярні БД (PostgreSQL, MySQL/InnoDB, SQLite, MongoDB і т.д.) використовують B+Tree для зберігання індексів. Як зазначено в попередньому пості, це різновиди збаланосованих дерев. Головна особливість в тому, що кожен вузол може мати більше двох нащадків (на відміну від бінарного дерева), а також може мати кілька ключів (значень) в одному вузлі.
Порядок B-Tree (зазвичай позначається як m) визначає максимальну кількість нащадків, які може мати вузол.
- Кожна нода (крім кореня) має від ceil(m/2)-1 до m-1 ключів
- Корінь має від 1 до m-1 ключів
- Нода з k ключами має k+1 дочірніх нод
❗️У нашому прикладі ми використовуємо B-Tree порядку 3, це значить, що може бути до 2 ключів у кожному вузлі, і до 3 нащадків для кожного вузла відповідно.
📍 B+Tree відрізняється від B-Tree тим, що всі дані зберігаються тільки в листкових вузлах, які додатково пов'язані між собою як зв'язний список, що значно пришвидшує послідовне читання а значить і кращу продуктивність при пошуку близьких значень.
Алгоритм вставки:
Коли нода заповнюється і не може вмістити новий ключ, при черговій вставці відбувається операція ділення і ми створюємо новий рівень з існуючих даних.
[5, 15]
/ | \
[3] [10,20,30] [40]
1. У нас є переповнена нода: [10, 20, 30]
2. Медіана: 20
3. Розділяємо на: [10] і [30]
4. 20 піднімається до батьківської ноди
[5, 15, 20]
/ / \ \
[3] [10] [30] [40]
Продовжуємо процес, бо [5, 15, 20] теж переповнена:
1. Медіана: 15
2. Розділяємо на: [5] і [20]
3. 15 піднімається вище
Припустимо, що раніше наше дерево мало корінь з одним елементом [50], до якого ми додаємо 15:
Проміжний результат:
[15, 50]
/ | \
[5] [20] [...]
Остаточно структура виглядає так:
[15, 50]
/ | \
[5] [20] [...]
/ \ / | \
[3] [10] [...] [30] [40]
При цьому складність пошуку гарантовано буде O(log_m n), де m — порядок дерева, як я зазначав вище.
❓ "Перебудова індексу", або чому вставки такі дорогі?
🔥 Основна причина популярності цих індексів - оптимізація роботи з диском. Диск читається блоками (вони ж сторінки індексу фіксованого розміру, зазвичай 4KB, 8KB або 16KB залежно від БД), і B-дерева чудово це використовують, зберігаючи багато ключів в одному вузлі.
Fill Factor (фактор заповнення) - параметр, який визначає, наскільки заповненими будуть сторінки індексу при їх створенні. Наприклад, fill factor 70% означає, що сторінки заповнюються на 70%, залишаючи 30% вільного місця для майбутніх вставок.
Коли сторінка індексу заповнюється повністю (через вставки даних), відбувається операція розщеплення сторінки (page split):
1️⃣ Створюється нова сторінка
2️⃣ Приблизно половина даних переміщується в нову сторінку
3️⃣ Середній ключ "піднімається" до батьківської сторінки
4️⃣ Батьківська сторінка оновлює свої посилання
❗️Це і є супер дорога операція, бо вимагає виділення нової сторінки на диску, переміщення даних, оновлення посилань, можливе розщеплення батьківських сторінок (каскадний ефект).
Також налаштування fill factor може підвищити продуктивність бази даних:
Для таблиць з частими вставками — низький fill factor (70-80%)
Для таблиць тільки для читання — високий fill factor (90-100%)
# Postgres
CREATE TABLE my_table (
id serial PRIMARY KEY,
data text
) WITH (fillfactor = 70);
# Для InnoDB доступний параметр fillfactor на рівні сервера
# в my.cnf або my.ini
[mysqld]
innodb_fill_factor = 80
👍 Сподіваюсь, у світі стало трошки менше магії, і трошки більше розуміння того, як працюють системи, якими ми користуємось щодня.
#database #middle
👍38🔥9⚡2🗿1
Ювілейний, 10-й випуск FWDays PHP Talks — вже на каналі
Ми нарешті сіли і поговорили про те, як не втопитися в логах, як збирати трейси в event-driven, як жити, коли в тебе триста мікросервісів.
Згадали такі речі, як EFK, Grafana Loki, Jaeger, Prometheus, OpenTelemetry, PageDuty, Graylog, "і отой забутий пайплайн на івентах, де ніхто не знає, що з чим з’єднане".
📍 Чим обсервабіліті відрізняється від моніторингу?
📍 Чому "все логуватити" — це погано, а не логувати — ще гірше?
📍 Скільки вартує моніторинг і чи треба він бізнесу?
📍 Чому Event-Driven це чудово, поки не треба дебажити?
👉 Подяка Йожефу, як завжди, за настрій і формат.
👍 Олексію — за архітектурну мудрість і чесність про "комфортну зону" архітектора.
🎧 Слухайте. Лайкайте. Пишіть нам, якщо з чимось не згодні 😉
https://youtu.be/frJGs9WovWY
#php #observability #monitoring #logging #tracing
Ми нарешті сіли і поговорили про те, як не втопитися в логах, як збирати трейси в event-driven, як жити, коли в тебе триста мікросервісів.
Згадали такі речі, як EFK, Grafana Loki, Jaeger, Prometheus, OpenTelemetry, PageDuty, Graylog, "і отой забутий пайплайн на івентах, де ніхто не знає, що з чим з’єднане".
📍 Чим обсервабіліті відрізняється від моніторингу?
📍 Чому "все логуватити" — це погано, а не логувати — ще гірше?
📍 Скільки вартує моніторинг і чи треба він бізнесу?
📍 Чому Event-Driven це чудово, поки не треба дебажити?
👉 Подяка Йожефу, як завжди, за настрій і формат.
👍 Олексію — за архітектурну мудрість і чесність про "комфортну зону" архітектора.
🎧 Слухайте. Лайкайте. Пишіть нам, якщо з чимось не згодні 😉
https://youtu.be/frJGs9WovWY
#php #observability #monitoring #logging #tracing
🔥14👍6
PHP 8.5: Clone with - майже те, що треба
Готувався до подкасту, де будемо розглядати нові можливості PHP 8.5 і неочікувано натрапив те, що цю фічу вже імплементували. Я був шокований, адже я чекав цього ще з моменту, як ввели readonly property (php8.1), навіть був RFC, котрий заглох, а тут бах, і вже змержили. Що правда не все супер райдужно, адже фактично створили новий RFC і імплементацію розділили на кілька етапів. То давайте розбиратись
❓ Чим круті readonly properties та іммутабельні обʼєкти
► Не треба гратись з інкапсуляцією, створювати додаткові getters/setters
► Ніхто випадково не поміняє дані десь в глибині коду
► Можна безпечно передавати об'єкт кудись - він точно повернеться таким самим
► Легше дебажити - об'єкт не може магічно змінитись між рядками коду
► Thread safety з коробки (якщо раптом дійде до async в PHP 9)
Але все це круто до моменту поки ми не захочемо щось з цим обʼєктом таки зробити [pic | code]
І через це пилили костилі, приходилось або писати купу окремих with методів [pic | code] (просто копіпасту), або гратись з рефлексією, що також є ресурсозатратно і не зовсім надійно [pic | code]
І тепер в PHP 8.5 ми зможемо досягти результату дуже просто
Ну майже просто 😅
🗿 Які є підводні камені?
Справа в тому, що ми не можемо просто взяти і зробити це без додаткових дій, адже коли в PHP 8.4 формалізували asymmetric visibility (можна окремо задавати видимість для читання і запису), стало зрозуміло, що всі public readonly властивості по дефолту були public(get) protected(set).
Чому protected(set) а не public(set) за замовчуванням, бо readonly властивості з самого початку (PHP 8.1) були задумані як "встановлюються тільки в конструкторі". Ну і не private(set), щоб можна було цим керувати в дочірніх класах
👉 Саме тому, при спробі викликати клонування в 8.5 поза обʼєктом призведе до відповідної помилки [pic | code], тому треба про це памʼятати і якщо необхідно - явно вказувати public(set) для властивостей вашого обʼєкту [pic | code]
💡 Або, робити відповідні зміни прямо всередині вашого обʼєкта, додаючи відповідні методи [pic | code], що мені подобається більше, але підійде не для всіх випадків.
🤔 Чи по тій самій схемі, замінити страшний приклад з рефлексією на реалізацію простого with [pic | code]
Ще один важливий момент
Поточна реалізація ніяк не впливає на використання магічного метода __clone, тобто параметри в нього досі передавати не можна, а при його імплементації ми отримаємо копію обʼєкту БЕЗ урахування того, що ми передали в якості аргументу [pic | code]. Це було свідоме рішення під час розбиття rfc на різні етапи, бо ця фіча ломає BC і сильно ускладнює імплементацію
💪 І тим не менш, я думаю, що Clone with - це крок в правильному напрямку
Поки памʼятаємо про protected(set) для readonly, скоріш за все це зміниться, та __clone() без параметрів, котрі обіцяють додати в майбутньому.
Але навіть з усіма нюансами - це краще ніж те, чим ми користувались. А ви що думаєте? Будете використовувати clone with?
#php85 #readonly #clonewith #middle #source
Готувався до подкасту, де будемо розглядати нові можливості PHP 8.5 і неочікувано натрапив те, що цю фічу вже імплементували. Я був шокований, адже я чекав цього ще з моменту, як ввели readonly property (php8.1), навіть був RFC, котрий заглох, а тут бах, і вже змержили. Що правда не все супер райдужно, адже фактично створили новий RFC і імплементацію розділили на кілька етапів. То давайте розбиратись
❓ Чим круті readonly properties та іммутабельні обʼєкти
► Не треба гратись з інкапсуляцією, створювати додаткові getters/setters
► Ніхто випадково не поміняє дані десь в глибині коду
► Можна безпечно передавати об'єкт кудись - він точно повернеться таким самим
► Легше дебажити - об'єкт не може магічно змінитись між рядками коду
► Thread safety з коробки (якщо раптом дійде до async в PHP 9)
Але все це круто до моменту поки ми не захочемо щось з цим обʼєктом таки зробити [pic | code]
І через це пилили костилі, приходилось або писати купу окремих with методів [pic | code] (просто копіпасту), або гратись з рефлексією, що також є ресурсозатратно і не зовсім надійно [pic | code]
І тепер в PHP 8.5 ми зможемо досягти результату дуже просто
$mariaViolin = clone($maria, ['instrument' => 'скрипка']);
Ну майже просто 😅
🗿 Які є підводні камені?
Справа в тому, що ми не можемо просто взяти і зробити це без додаткових дій, адже коли в PHP 8.4 формалізували asymmetric visibility (можна окремо задавати видимість для читання і запису), стало зрозуміло, що всі public readonly властивості по дефолту були public(get) protected(set).
Чому protected(set) а не public(set) за замовчуванням, бо readonly властивості з самого початку (PHP 8.1) були задумані як "встановлюються тільки в конструкторі". Ну і не private(set), щоб можна було цим керувати в дочірніх класах
👉 Саме тому, при спробі викликати клонування в 8.5 поза обʼєктом призведе до відповідної помилки [pic | code], тому треба про це памʼятати і якщо необхідно - явно вказувати public(set) для властивостей вашого обʼєкту [pic | code]
💡 Або, робити відповідні зміни прямо всередині вашого обʼєкта, додаючи відповідні методи [pic | code], що мені подобається більше, але підійде не для всіх випадків.
🤔 Чи по тій самій схемі, замінити страшний приклад з рефлексією на реалізацію простого with [pic | code]
Ще один важливий момент
Поточна реалізація ніяк не впливає на використання магічного метода __clone, тобто параметри в нього досі передавати не можна, а при його імплементації ми отримаємо копію обʼєкту БЕЗ урахування того, що ми передали в якості аргументу [pic | code]. Це було свідоме рішення під час розбиття rfc на різні етапи, бо ця фіча ломає BC і сильно ускладнює імплементацію
💪 І тим не менш, я думаю, що Clone with - це крок в правильному напрямку
Поки памʼятаємо про protected(set) для readonly, скоріш за все це зміниться, та __clone() без параметрів, котрі обіцяють додати в майбутньому.
Але навіть з усіма нюансами - це краще ніж те, чим ми користувались. А ви що думаєте? Будете використовувати clone with?
#php85 #readonly #clonewith #middle #source
🔥25👍18
Media is too big
VIEW IN TELEGRAM
Один із трендових напрямків зараз — інтеграція AI у CI/CD 🤖🚀
І це реально круто, що на етапі CI воно може в рази пришвидшити написання та перевірку коду.
Але коли мова про CD, тут ще є нюанси 🙃
Моделі статистичні → значить, вони недетерміновані. Це може давати:
❌ фолс-позитивні результати (бачать проблему там, де її нема)
🤷♂️ пропускати важливі речі (не ловлять баг, коли він є)
🌀 «галюцинації»
🙅♂️ «огріхи» від неповного датасету чи неідеального навчання
Попри все, тренд рухається вперед. І цікаво спостерігати, як AI буде поступово «вростати» у CI/CD процеси 💡
І це реально круто, що на етапі CI воно може в рази пришвидшити написання та перевірку коду.
Але коли мова про CD, тут ще є нюанси 🙃
Моделі статистичні → значить, вони недетерміновані. Це може давати:
❌ фолс-позитивні результати (бачать проблему там, де її нема)
🤷♂️ пропускати важливі речі (не ловлять баг, коли він є)
🌀 «галюцинації»
🙅♂️ «огріхи» від неповного датасету чи неідеального навчання
Попри все, тренд рухається вперед. І цікаво спостерігати, як AI буде поступово «вростати» у CI/CD процеси 💡
👍16🙊3🔥1