
Полезный пост с описанием моментов по созданию мультирегиональных приложений:
https://aws.amazon.com/blogs/architecture/creating-a-multi-region-application-with-aws-services-part-2-data-and-replication/
#design
https://aws.amazon.com/blogs/architecture/creating-a-multi-region-application-with-aws-services-part-2-data-and-replication/
When building a distributed system, consider the consistency, availability, partition tolerance (CAP) theorem. This theorem states that an application can only pick 2 out of the 3, and tradeoffs should be considered.▫️ Consistency – all clients always have the same view of data▫️ Availability – all clients can always read and write data▫️ Partition Tolerance – the system will continue to work despite physical partitions#design
Amazon
Creating a Multi-Region Application with AWS Services – Part 2, Data and Replication | Amazon Web Services
Data is at the center of stateful applications. Data consistency models will vary when choosing in-Region vs. multi-Region. In this post, part 2 of 3, we continue to filter through AWS services to focus on data-centric services with native features to help…
Хорошая статья-сравнение параллельного запуска Lambda, App Runner и Fargate:
https://nathanpeck.com/concurrency-compared-lambda-fargate-app-runner/
🔸 Concurrency
🔹 Scaling
Lambda
🔸
🔹
App Runner
🔸
🔹
Fargate
🔸
🔹
#design
https://nathanpeck.com/concurrency-compared-lambda-fargate-app-runner/
🔸 Concurrency
🔹 Scaling
Lambda
🔸
Single concurrent request per Lambda function instance, but many separate Lambda function instances🔹
Fully managed by AWS Lambda, default limit of 1000 concurrent executions. Scale out more function instances in under a second.App Runner
🔸
Multiple concurrent requests per container, enforces a configurable hard limit such as 100 concurrent reqs/container🔹
Fully managed by App Runner. Configure a concurrency limit per containerized process. Scale out more container instances in less than 1 min.Fargate
🔸
Multiple concurrent requests per container, no built-in limits on concurrency per container🔹
Managed by you. Scale out more container instances based on your desired metric: CPU, concurrency, or a custom metric. Scale out in less than 1 min.#design
Nathan Peck
Concurrency Compared: AWS Lambda, AWS App Runner, and AWS Fargate
Concurrency is one of the core principles of modern computing. When concurrency is combined with the cloud, it becomes even more powerful. In this article you’ll learn about how concurrency works across three of the compute options available on Amazon Web…
Network Infrastructure Security Guidance:
https://media.defense.gov/2022/Mar/01/2002947139/-1/-1/0/CTR_NSA_NETWORK_INFRASTRUCTURE_SECURITY_GUIDANCE_20220301.PDF
#security #network #design
https://media.defense.gov/2022/Mar/01/2002947139/-1/-1/0/CTR_NSA_NETWORK_INFRASTRUCTURE_SECURITY_GUIDANCE_20220301.PDF
Contents1. Introduction2. Network architecture and design3. Security maintenance4. Authentication, authorization, and accounting5. Administrator accounts and passwords6. Remote logging and monitoring7. Remote administration and network services8. Routing9. Interface ports10. Notification banners11. Conclusion#security #network #design
AWS drawing and diagramming tools:
https://aws.amazon.com/architecture/icons/#Drawing_and_diagramming_tools
#design
https://aws.amazon.com/architecture/icons/#Drawing_and_diagramming_tools
#design
{kind=link}
Бесконечно можно смотреть на 🔥 огонь и обсуждать, как на ☁️ AWS установить 🗒️ Wordpress:
https://www.youtube.com/watch?v=PYyAl2RPdhM
#design #Wordpress
https://www.youtube.com/watch?v=PYyAl2RPdhM
#design #Wordpress
YouTube
Whiteboard Architecture: WordPress
Начинаем новую рубрику Whiteboard Architecture, и начинаем рассмотрение с довольно простого и популярного решения это Wordpress. Рассмотрели в трех фазах ка...
Twitter architecture 2012 vs 2022 — what has changed in the last 10 years?
#design
2012 — https://www.infoq.com/presentations/Real-Time-Delivery-Twitter/2022 — https://twitter.com/elonmusk/status/1593899029531803649#design
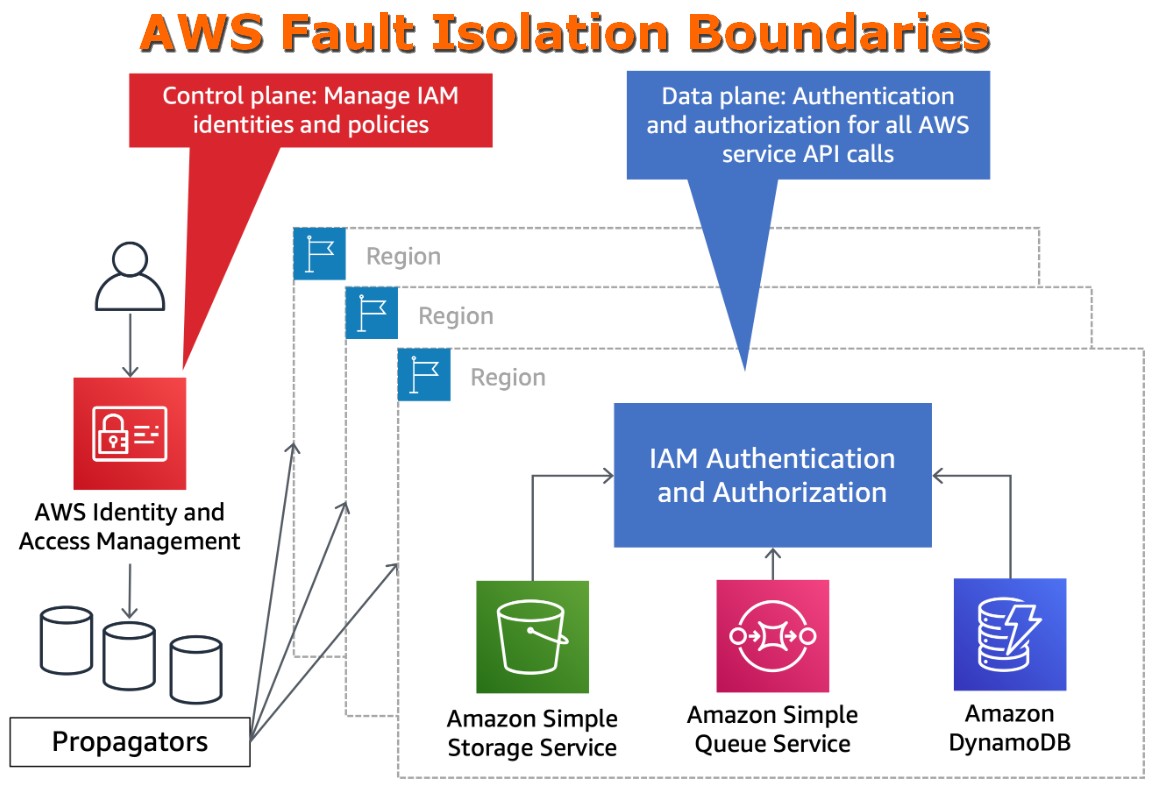
📓 AWS Fault Isolation Boundaries:
https://docs.aws.amazon.com/whitepapers/latest/aws-fault-isolation-boundaries/abstract-and-introduction.html
Очень полезный для понимания работы AWS на глобальном уровне документ. Важный при проектировании архитектуры и принципиально важный при построении Disaster Recovery схемы.
Основная мысль такая. Если падает
В переводе на сервисы это означает следующее.
🔹 Route 53
Route 53 задействован под капотом самого AWS при создании многих сервисов, которым он должен сделать DNS собственные записи, в том числе хелсчеки, поэтому при проблемах в
▪️ API Gateway
▪️ CloudFront
▪️ DynamoDB Accelerator (DAX)
▪️ Global Accelerator
▪️ ECS with DNS-based Service Discovery
▪️ EKS Kubernetes control plane
▪️ ElastiCache
▪️ ELB load balancers
▪️ Lambda URLs
▪️ MemoryDB for Redis
▪️ Neptune
▪️ OpenSearch
▪️ PrivateLink VPC endpoints
▪️ RDS/Aurora
👉 Рекомендация: для критичных Disaster Recovery схем нужно создавать ресурсы заранее. Не получится во время проблем в
🔸 S3
S3 региональный сервис, но из-за того, что у S3 все имена должны быть уникальные, то не получится создать или удалить бакет во время проблем в
👉 Рекомендация: для критичных DR схем создавать S3 бакеты заранее. Не получится во время проблем в
🔹 CloudFront
CloudFront используется для API Gateway with edge-optimized endpoints.
👉 Рекомендация: создавать заранее все нужные API Gateway with edge-optimized endpoints.
🔸 AWS STS
IAM сервис глобальный, получить временные credentials через STS можно из любого региона. Если у вас захардкожен
👉 Рекомендация: изменить в AWS CLI / AWS SDK захардкоженный
🔹 IAM Identity Center (AWS SSO) / Federated SAML
SSO может пострадать, если в том регионе, где он настроен, проблемы.
👉 Рекомендация: создайте IAM юзеров на случай, если вы, как я, слишком уж стараетесь соблюдать security best practices. По-другому зайти в систему во время проблем с SSO не получится, потому для критических случаев нужно создать рабочекрестьянского IAM user-а.
Ужас какой. Короче, типа — WiFi это конечно очень круто, но бухту кабеля и обжим всё-таки пока не выбрасывайте.
🔸 S3 Storage Lens
Дефолтная борда и её метрики располагаются в
👉 Рекомендация: если для вас критичны S3 Storage Lens, то нужно создать свои собственные дашборды, указав при создании свой регион.
#design
https://docs.aws.amazon.com/whitepapers/latest/aws-fault-isolation-boundaries/abstract-and-introduction.html
Очень полезный для понимания работы AWS на глобальном уровне документ. Важный при проектировании архитектуры и принципиально важный при построении Disaster Recovery схемы.
Основная мысль такая. Если падает
us-east-1, где располагается control plane большинства глобальных сервисов, то операции по их созданию, изменению, удалению перестанут работать (могут перестать, полагаться на это нельзя). При этом сервисы в регионах с нагрузками будут работать. Поэтому нужно планировать Disaster Recovery схему так, чтобы она не зависела от control plane.В переводе на сервисы это означает следующее.
🔹 Route 53
Route 53 задействован под капотом самого AWS при создании многих сервисов, которым он должен сделать DNS собственные записи, в том числе хелсчеки, поэтому при проблемах в
us-east-1 у Route 53 может не быть возможности создать нужные записи и потому запросы на создание большинства популярных ресурсов вернут ошибку. Это верно как минимум для следующего списка (список не полный):▪️ API Gateway
▪️ CloudFront
▪️ DynamoDB Accelerator (DAX)
▪️ Global Accelerator
▪️ ECS with DNS-based Service Discovery
▪️ EKS Kubernetes control plane
▪️ ElastiCache
▪️ ELB load balancers
▪️ Lambda URLs
▪️ MemoryDB for Redis
▪️ Neptune
▪️ OpenSearch
▪️ PrivateLink VPC endpoints
▪️ RDS/Aurora
👉 Рекомендация: для критичных Disaster Recovery схем нужно создавать ресурсы заранее. Не получится во время проблем в
us-east-1 поднять RDS базу данных из бэкапа. Не получится создать балансеры, Redis или CloudFront.🔸 S3
S3 региональный сервис, но из-за того, что у S3 все имена должны быть уникальные, то не получится создать или удалить бакет во время проблем в
us-east-1. Кроме того все операции по изменению конфигурации бакета (bucket policy, настройки CORS, ACL, шифрования, репликации, логирования и др.) тоже зависят от us-east-1.👉 Рекомендация: для критичных DR схем создавать S3 бакеты заранее. Не получится во время проблем в
us-east-1 создать новый S3 бакет или срочно прикрутить к нему репликацию.🔹 CloudFront
CloudFront используется для API Gateway with edge-optimized endpoints.
👉 Рекомендация: создавать заранее все нужные API Gateway with edge-optimized endpoints.
🔸 AWS STS
IAM сервис глобальный, получить временные credentials через STS можно из любого региона. Если у вас захардкожен
us-east-1, то когда у него проблемы, вы получите ошибки, в то время как региональный STS будет работать.👉 Рекомендация: изменить в AWS CLI / AWS SDK захардкоженный
us-east-1 на регион с нагрузкой.🔹 IAM Identity Center (AWS SSO) / Federated SAML
SSO может пострадать, если в том регионе, где он настроен, проблемы.
👉 Рекомендация: создайте IAM юзеров на случай, если вы, как я, слишком уж стараетесь соблюдать security best practices. По-другому зайти в систему во время проблем с SSO не получится, потому для критических случаев нужно создать рабочекрестьянского IAM user-а.
Ужас какой. Короче, типа — WiFi это конечно очень круто, но бухту кабеля и обжим всё-таки пока не выбрасывайте.
🔸 S3 Storage Lens
Дефолтная борда и её метрики располагаются в
us-east-1, поэтому при проблемах они могут быть не доступны.👉 Рекомендация: если для вас критичны S3 Storage Lens, то нужно создать свои собственные дашборды, указав при создании свой регион.
#design
{kind=link}
📄 AWS Whitepaper — AWS Multi-Region Fundamentals:
https://docs.aws.amazon.com/pdfs/whitepapers/latest/aws-multi-region-fundamentals/aws-multi-region-fundamentals.pdf
🔹 This paper focuses on high availability and continuity of operations requirements, and helps you navigate the considerations for adopting a multi-Region architecture for a workload.
🔸 It describes fundamental concepts that apply to design, development, and deployment of a multi-Region workload, along with a prescriptive framework to help you determine whether a multi-Region architecture is the right choice for a particular workload.
🔹 You need to ensure a multi-Region architecture is the right choice for your workload, because these architectures are challenging, and it’s possible that, if not done correctly, the overall availability of the workload can decrease.
#design
https://docs.aws.amazon.com/pdfs/whitepapers/latest/aws-multi-region-fundamentals/aws-multi-region-fundamentals.pdf
🔹 This paper focuses on high availability and continuity of operations requirements, and helps you navigate the considerations for adopting a multi-Region architecture for a workload.
🔸 It describes fundamental concepts that apply to design, development, and deployment of a multi-Region workload, along with a prescriptive framework to help you determine whether a multi-Region architecture is the right choice for a particular workload.
🔹 You need to ensure a multi-Region architecture is the right choice for your workload, because these architectures are challenging, and it’s possible that, if not done correctly, the overall availability of the workload can decrease.
#design
{kind=link}
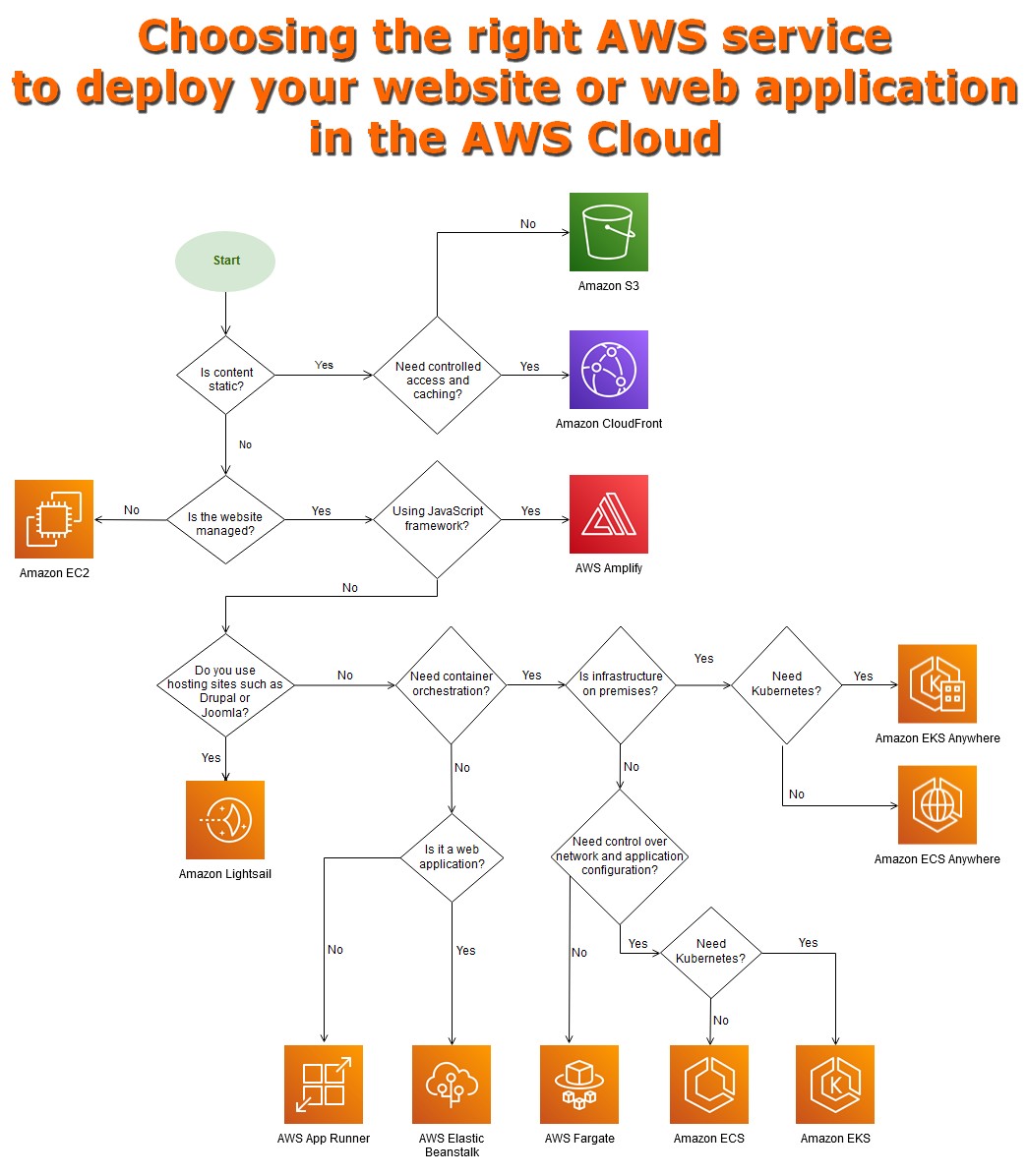
📓 Choosing the right AWS service to deploy your website or web application in the AWS Cloud — AWS Prescriptive Guidance:
https://docs.aws.amazon.com/prescriptive-guidance/latest/website-deployment-services
▫️ Static: S3 + CloudFront
▫️ JS framework + CI/CD: Amplify
▫️ Serverless + low-cost: API Gateway + Lambda + S3
▫️ WordPress/Drupal/Joomla: LightSail
▫️ Containers: App Runner or ECS or Fargate
▫️ Kubernetes: EKS
▫️ On-premises: EKS Anywhere or ECS Anywhere
▫️ Old-style managed environment: Beanstalk
▫️ Self-managed: EC2
#design
https://docs.aws.amazon.com/prescriptive-guidance/latest/website-deployment-services
▫️ Static: S3 + CloudFront
▫️ JS framework + CI/CD: Amplify
▫️ Serverless + low-cost: API Gateway + Lambda + S3
▫️ WordPress/Drupal/Joomla: LightSail
▫️ Containers: App Runner or ECS or Fargate
▫️ Kubernetes: EKS
▫️ On-premises: EKS Anywhere or ECS Anywhere
▫️ Old-style managed environment: Beanstalk
▫️ Self-managed: EC2
#design
{kind=link}
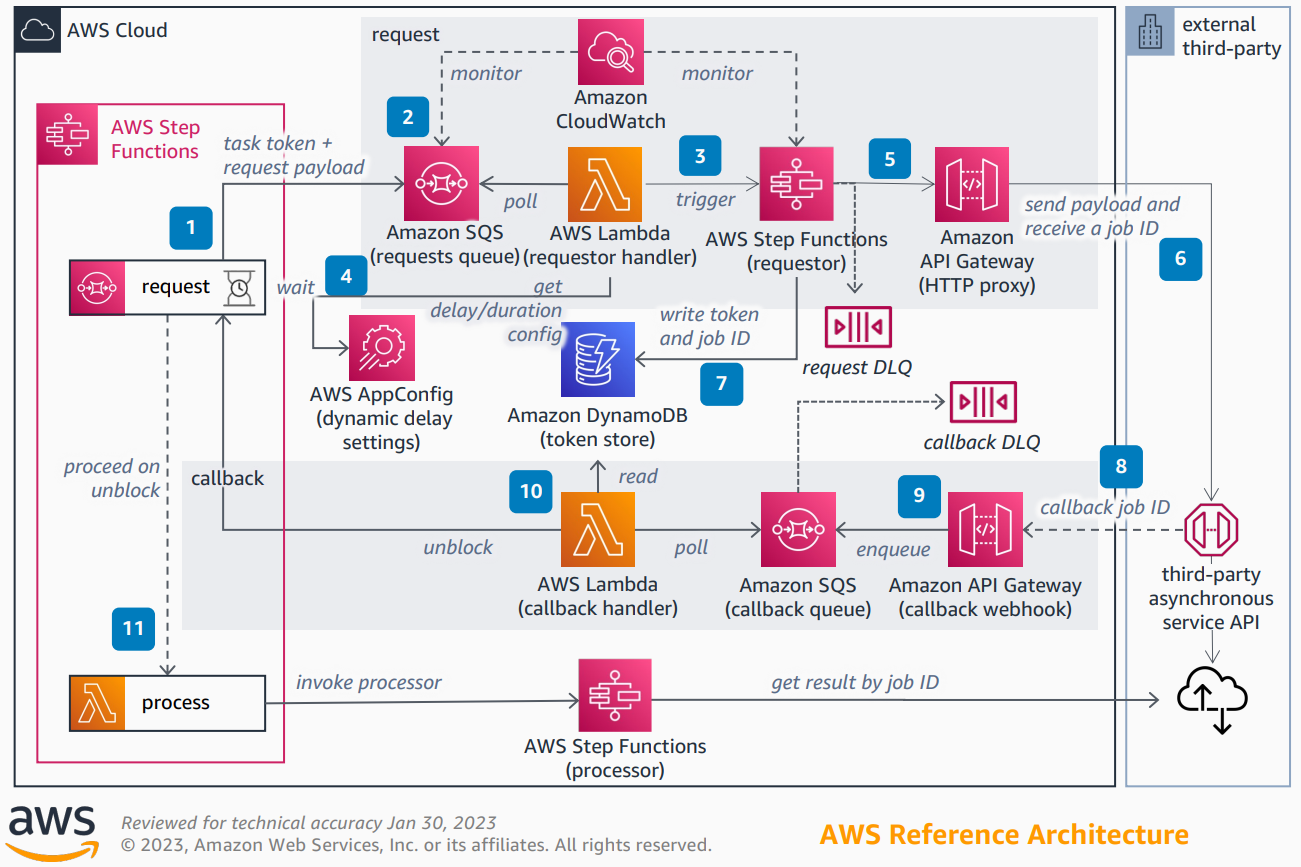
📘 AWS Reference Architecture — Invoking Asynchronous External APIs:
https://d1.awsstatic.com/architecture-diagrams/ArchitectureDiagrams/invoking-asynchronous-external-apis-ra.pdf
1️⃣ Set up Step Functions
2️⃣ Send the task token and the request payload
3️⃣ Use Lambda to poll SQS and trigger an express Step Functions workflow
4️⃣ (Optionally) Add dynamic delay inside Lambda controlled by AppConfig
5️⃣ Step Function invokes an API Gateway HTTP proxy API
6️⃣ Invoke the external third-party asynchronous service API
7️⃣ Store the workflow’s task token and the received job ID in DynamoDB
8️⃣ Receive the completed job ID in a callback webhook endpoint
9️⃣ Transform the external callbacks with API Gateway
🔟 Use Lambda to poll the callback SQS
1️⃣1️⃣ Pass the job ID to the next step, and invoke a Step Function processor to fetch the job’s results
#design
https://d1.awsstatic.com/architecture-diagrams/ArchitectureDiagrams/invoking-asynchronous-external-apis-ra.pdf
1️⃣ Set up Step Functions
2️⃣ Send the task token and the request payload
3️⃣ Use Lambda to poll SQS and trigger an express Step Functions workflow
4️⃣ (Optionally) Add dynamic delay inside Lambda controlled by AppConfig
5️⃣ Step Function invokes an API Gateway HTTP proxy API
6️⃣ Invoke the external third-party asynchronous service API
7️⃣ Store the workflow’s task token and the received job ID in DynamoDB
8️⃣ Receive the completed job ID in a callback webhook endpoint
9️⃣ Transform the external callbacks with API Gateway
🔟 Use Lambda to poll the callback SQS
1️⃣1️⃣ Pass the job ID to the next step, and invoke a Step Function processor to fetch the job’s results
#design
{kind=link}
Микросервисы → Монолит
Статья от Amazon Prime Video, где рассказывается, как удалось уменьшить расходы в десять раз после перехода с микросервисов на монолитную архитектуру:
https://www.primevideotech.com/video-streaming/scaling-up-the-prime-video-audio-video-monitoring-service-and-reducing-costs-by-90
Статья достаточно скудная на факты, потому попробую изложить свою версию развития событий исходя из данного текста.
v.0.0.0
— Привет, Дмитро. Тут задача срочная прилетела — клиенту нужно запилить сервис по проверке качества роликов. А вы, помню, уже как-то что-то делали для тестирования видео?
— Было дело, накрапали костылик для внутренних нужд, чтобы отчёты слать аналитикам.
— Вот и отлично, приступайте.
— А какая нагрузка планируется?
— Подробностей не знаю, если что, чего-нибудь помощней поставим.
— Не, мы ж на Лямбдах всё написали.
— О, отлично, передам маркетингу — у нас будет Serverless-решение!
v.0.1.0
— Макс, что по нагрузке?
— Всё должно работать рилтайм и в перспективе держать тысячи параллельных задач на обработку.
— <censored>! Мы ж никогда пробовали на таких объёмах.
— Поздно, уже всё продано, продолжайте делать.
— А денег у клиента хватит?
— Деньги не проблема, главное сделать быстро!
v.1.0.0
— Дмитро, у нас проблемы. Клиент увидел счёт за прошлый месяц и офигел.
— Я предупреждал. И это лишь 5% от полной нагрузки.
— А почему так дорого?
— Так мы ж каждый кадр видео на S3 гоняем Лямбдами по несколько раз с помощью дорогущих Step Functions.
— И как это исправить?
— Никак, нужно всё переделывать. Проанализировать результаты под нагрузкой, попробовать различные варианты, спроектировать...
— ...А если нужно вчера?
— Ну, можно всё тупо засунуть в один контейнер и масштабировать как монолит с помощью ECS. Ещё и дешевле получится.
— О, супер, так и сделаем. И продадим как версию 2.0. А я напишу маркетингу, пусть они статейку накатают, как мы сэкономили клиенту кучу денег, перейдя на монолит с микросервисов. Все будут обсуждать только это и никто не вспомнит, как мы облажались с первой версией.
#serverless #monolith #design
Статья от Amazon Prime Video, где рассказывается, как удалось уменьшить расходы в десять раз после перехода с микросервисов на монолитную архитектуру:
https://www.primevideotech.com/video-streaming/scaling-up-the-prime-video-audio-video-monitoring-service-and-reducing-costs-by-90
Статья достаточно скудная на факты, потому попробую изложить свою версию развития событий исходя из данного текста.
v.0.0.0
— Привет, Дмитро. Тут задача срочная прилетела — клиенту нужно запилить сервис по проверке качества роликов. А вы, помню, уже как-то что-то делали для тестирования видео?
— Было дело, накрапали костылик для внутренних нужд, чтобы отчёты слать аналитикам.
— Вот и отлично, приступайте.
— А какая нагрузка планируется?
— Подробностей не знаю, если что, чего-нибудь помощней поставим.
— Не, мы ж на Лямбдах всё написали.
— О, отлично, передам маркетингу — у нас будет Serverless-решение!
v.0.1.0
— Макс, что по нагрузке?
— Всё должно работать рилтайм и в перспективе держать тысячи параллельных задач на обработку.
— <censored>! Мы ж никогда пробовали на таких объёмах.
— Поздно, уже всё продано, продолжайте делать.
— А денег у клиента хватит?
— Деньги не проблема, главное сделать быстро!
v.1.0.0
— Дмитро, у нас проблемы. Клиент увидел счёт за прошлый месяц и офигел.
— Я предупреждал. И это лишь 5% от полной нагрузки.
— А почему так дорого?
— Так мы ж каждый кадр видео на S3 гоняем Лямбдами по несколько раз с помощью дорогущих Step Functions.
— И как это исправить?
— Никак, нужно всё переделывать. Проанализировать результаты под нагрузкой, попробовать различные варианты, спроектировать...
— ...А если нужно вчера?
— Ну, можно всё тупо засунуть в один контейнер и масштабировать как монолит с помощью ECS. Ещё и дешевле получится.
— О, супер, так и сделаем. И продадим как версию 2.0. А я напишу маркетингу, пусть они статейку накатают, как мы сэкономили клиенту кучу денег, перейдя на монолит с микросервисов. Все будут обсуждать только это и никто не вспомнит, как мы облажались с первой версией.
#serverless #monolith #design
US About Amazon
Entertainment
We create and provide access to world-class entertainment through Amazon Originals, Prime Video, Audible, Amazon Games, Twitch, Amazon Music, Prime Gaming, and more. Amazon’s digital entertainment products enable customers to access the latest apps and games…
Анализ статьи Amazon Prime Video
Во-первых, мои поздравления команде маркетинга Amazon — браво, великолепная работа! Кратко, минимум информации, точно в больное место и в результате каждый может сделать для себя (не)правильные выводы.
Во-вторых, если у вас есть сомнения в компетенциях управляющих процессом разработки в Amazon, то сначала спросите, что по этому поводу думаетGoogle ChatGPT или просто посмотрите список самых успешных IT компаний.
Целью команды Amazon Prime Video было максимально быстро получить рабочий вариант. С отлаженным процессом разработки на Serverless можно выдавать готовые решения за несколько спринтов, в том числе для сложных и нагруженных систем.
Главный плюс Serverless — не условная "бесплатность", это уже побочный эффект. Главный плюс — скорость разработки и возможность справляться с неизвестной или непрогнозируемой нагрузкой.
Анализ статьи с цитатами из текста
1️⃣ Была задача получить решение максимально быстро и они сделали это. Serverless прекрасно вписывается в этот подход и команда имеет опыт разработки Serverless решений.
«We designed our initial solution as a distributed system using serverless components (for example, AWS Step Functions or AWS Lambda), which was a good choice for building the service quickly.»
2️⃣ Они получили опыт эксплуатации первой тестовой версии и реальные данные по нагрузке. Выяснилось, что быстро разработанное Serverless-решение имеет ограничения по масштабированию да при этом ещё и дорогое.
«In theory, this would allow us to scale each service component independently. However, the way we used some components caused us to hit a hard scaling limit at around 5% of the expected load. Also, the overall cost of all the building blocks was too high to accept the solution at a large scale.»
3️⃣ На основе полученных данных они получили возможность сформировать конкретные требования как по масштабированию, так и по стоимости. В результате чего переработали решение, выбрав монолитную архитектуру вместо распределённой.
«We initially considered fixing problems separately to reduce cost and increase scaling capabilities. We experimented and took a bold decision: we decided to rearchitect our infrastructure.
We realized that distributed approach wasn’t bringing a lot of benefits in our specific use case, so we packed all of the components into a single process. This eliminated the need for the S3 bucket as the intermediate storage for video frames because our data transfer now happened in the memory. We also implemented orchestration that controls components within a single instance.»
4️⃣ Изменения затронули лишь исполнительную часть, общая схема не изменилась, поэтому переход Serverless → ECS был быстрым.
«Conceptually, the high-level architecture remained the same. We still have exactly the same components as we had in the initial design (media conversion, detectors, or orchestration). This allowed us to reuse a lot of code and quickly migrate to a new architecture.»
Выводы
Имея свободу в изменении в том числе архитектурного решения, можно и быстро разрабатывать, и получать эффективные проекты.
Однако каждый может сделать и свои выводы — ещё раз респект маркетингу Amazon. Кстати, им точно стоит развить успех и помочь коллегам из AWS с придумыванием адекватных названий для сервисов.
P.S. Самая уместная (из немногих) статья по данной теме:
https://adrianco.medium.com/so-many-bad-takes-what-is-there-to-learn-from-the-prime-video-microservices-to-monolith-story-4bd0970423d4
#design #development #marketing
Во-первых, мои поздравления команде маркетинга Amazon — браво, великолепная работа! Кратко, минимум информации, точно в больное место и в результате каждый может сделать для себя (не)правильные выводы.
Во-вторых, если у вас есть сомнения в компетенциях управляющих процессом разработки в Amazon, то сначала спросите, что по этому поводу думает
Целью команды Amazon Prime Video было максимально быстро получить рабочий вариант. С отлаженным процессом разработки на Serverless можно выдавать готовые решения за несколько спринтов, в том числе для сложных и нагруженных систем.
Главный плюс Serverless — не условная "бесплатность", это уже побочный эффект. Главный плюс — скорость разработки и возможность справляться с неизвестной или непрогнозируемой нагрузкой.
Анализ статьи с цитатами из текста
1️⃣ Была задача получить решение максимально быстро и они сделали это. Serverless прекрасно вписывается в этот подход и команда имеет опыт разработки Serverless решений.
«We designed our initial solution as a distributed system using serverless components (for example, AWS Step Functions or AWS Lambda), which was a good choice for building the service quickly.»
2️⃣ Они получили опыт эксплуатации первой тестовой версии и реальные данные по нагрузке. Выяснилось, что быстро разработанное Serverless-решение имеет ограничения по масштабированию да при этом ещё и дорогое.
«In theory, this would allow us to scale each service component independently. However, the way we used some components caused us to hit a hard scaling limit at around 5% of the expected load. Also, the overall cost of all the building blocks was too high to accept the solution at a large scale.»
3️⃣ На основе полученных данных они получили возможность сформировать конкретные требования как по масштабированию, так и по стоимости. В результате чего переработали решение, выбрав монолитную архитектуру вместо распределённой.
«We initially considered fixing problems separately to reduce cost and increase scaling capabilities. We experimented and took a bold decision: we decided to rearchitect our infrastructure.
We realized that distributed approach wasn’t bringing a lot of benefits in our specific use case, so we packed all of the components into a single process. This eliminated the need for the S3 bucket as the intermediate storage for video frames because our data transfer now happened in the memory. We also implemented orchestration that controls components within a single instance.»
4️⃣ Изменения затронули лишь исполнительную часть, общая схема не изменилась, поэтому переход Serverless → ECS был быстрым.
«Conceptually, the high-level architecture remained the same. We still have exactly the same components as we had in the initial design (media conversion, detectors, or orchestration). This allowed us to reuse a lot of code and quickly migrate to a new architecture.»
Выводы
Имея свободу в изменении в том числе архитектурного решения, можно и быстро разрабатывать, и получать эффективные проекты.
Однако каждый может сделать и свои выводы — ещё раз респект маркетингу Amazon. Кстати, им точно стоит развить успех и помочь коллегам из AWS с придумыванием адекватных названий для сервисов.
P.S. Самая уместная (из немногих) статья по данной теме:
https://adrianco.medium.com/so-many-bad-takes-what-is-there-to-learn-from-the-prime-video-microservices-to-monolith-story-4bd0970423d4
#design #development #marketing
Medium
So many bad takes — What is there to learn from the Prime Video microservices to monolith story
The Prime Video team published this story: Scaling up the audio/video monitoring service and reducing costs by 90%, and the internet piled…
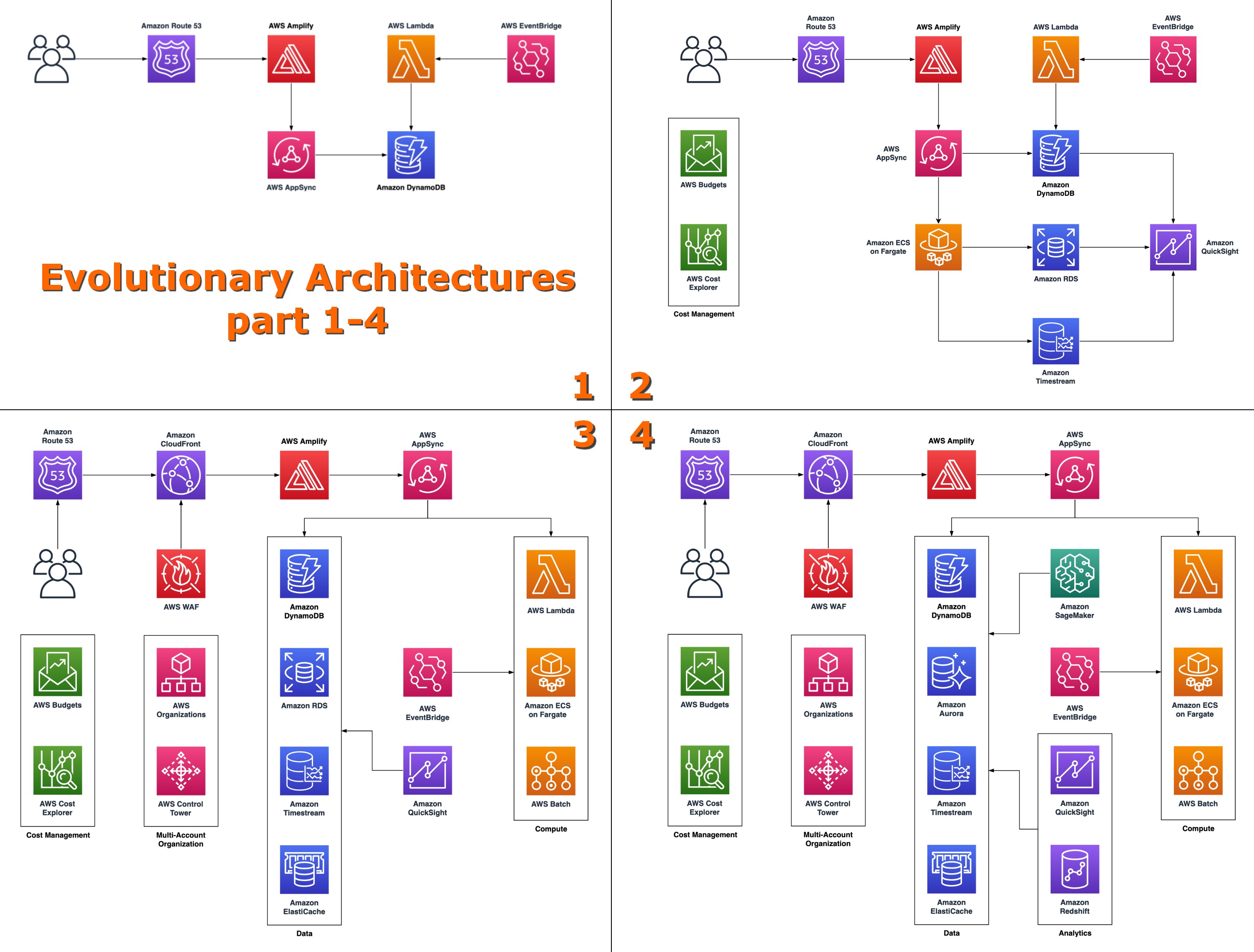
🔢 «Evolutionary Architectures» is a four-part blog series that shows how solution designs and decisions evolve as companies go through the different stages of the startups lifecycle.
1️⃣ «I’ve got this great idea!» — MVP:
https://aws.amazon.com/blogs/startups/evolutionary-architectures-series-part-1/
2️⃣ «I think we may be onto something» — evolving technical solution:
https://aws.amazon.com/blogs/startups/evolutionary-architectures-series-part-2/
3️⃣ «To the moon 🚀» — evolving architecture:
https://aws.amazon.com/blogs/startups/evolutionary-architectures-series-part-3/
4️⃣ «Would you like coffee with that?» — formalizing security and backup posture to meet various compliance standards:
https://aws.amazon.com/blogs/startups/evolutionary-architectures-series-part-4/
#design
1️⃣ «I’ve got this great idea!» — MVP:
https://aws.amazon.com/blogs/startups/evolutionary-architectures-series-part-1/
2️⃣ «I think we may be onto something» — evolving technical solution:
https://aws.amazon.com/blogs/startups/evolutionary-architectures-series-part-2/
3️⃣ «To the moon 🚀» — evolving architecture:
https://aws.amazon.com/blogs/startups/evolutionary-architectures-series-part-3/
4️⃣ «Would you like coffee with that?» — formalizing security and backup posture to meet various compliance standards:
https://aws.amazon.com/blogs/startups/evolutionary-architectures-series-part-4/
#design
{kind=link}
{kind=link}
📚 Два главных документа которые должен знать каждый грамотный AWS DevOps Engineer:
1️⃣ AWS CAF (AWS Cloud Adoption Framework)
2️⃣ AWS WAF (Well-Architected Framework)
Это немалый объём и в реальности не два документа. Но это база. © Настоящая база, которая не про айноды. 😁
Можно спорить про применимость это для начинающих, хотя WAF (не который firewall) точно показан с самого начала и в режиме pocket book на все случаи.
Обязательно рекомендуется продвинутым. Особенно, если нужно прокачаться в ширину, а не глубину.
#design #CAF #WAF #devops
1️⃣ AWS CAF (AWS Cloud Adoption Framework)
2️⃣ AWS WAF (Well-Architected Framework)
Это немалый объём и в реальности не два документа. Но это база. © Настоящая база, которая не про айноды. 😁
Можно спорить про применимость это для начинающих, хотя WAF (не который firewall) точно показан с самого начала и в режиме pocket book на все случаи.
Обязательно рекомендуется продвинутым. Особенно, если нужно прокачаться в ширину, а не глубину.
#design #CAF #WAF #devops
Amazon
AWS Cloud Adoption Framework
The AWS Cloud Adoption Framework helps enterprises effectively adopt the AWS cloud
AWS Notes
📚 Два главных документа которые должен знать каждый грамотный AWS DevOps Engineer: 1️⃣ AWS CAF (AWS Cloud Adoption Framework) 2️⃣ AWS WAF (Well-Architected Framework) Это немалый объём и в реальности не два документа. Но это база. © Настоящая база, которая…
AWS Cloud Adoption Framework на русском.
https://d1.awsstatic.com/whitepapers/ru_RU/aws-cloud-adoption-framework.pdf
#design
https://d1.awsstatic.com/whitepapers/ru_RU/aws-cloud-adoption-framework.pdf
#design
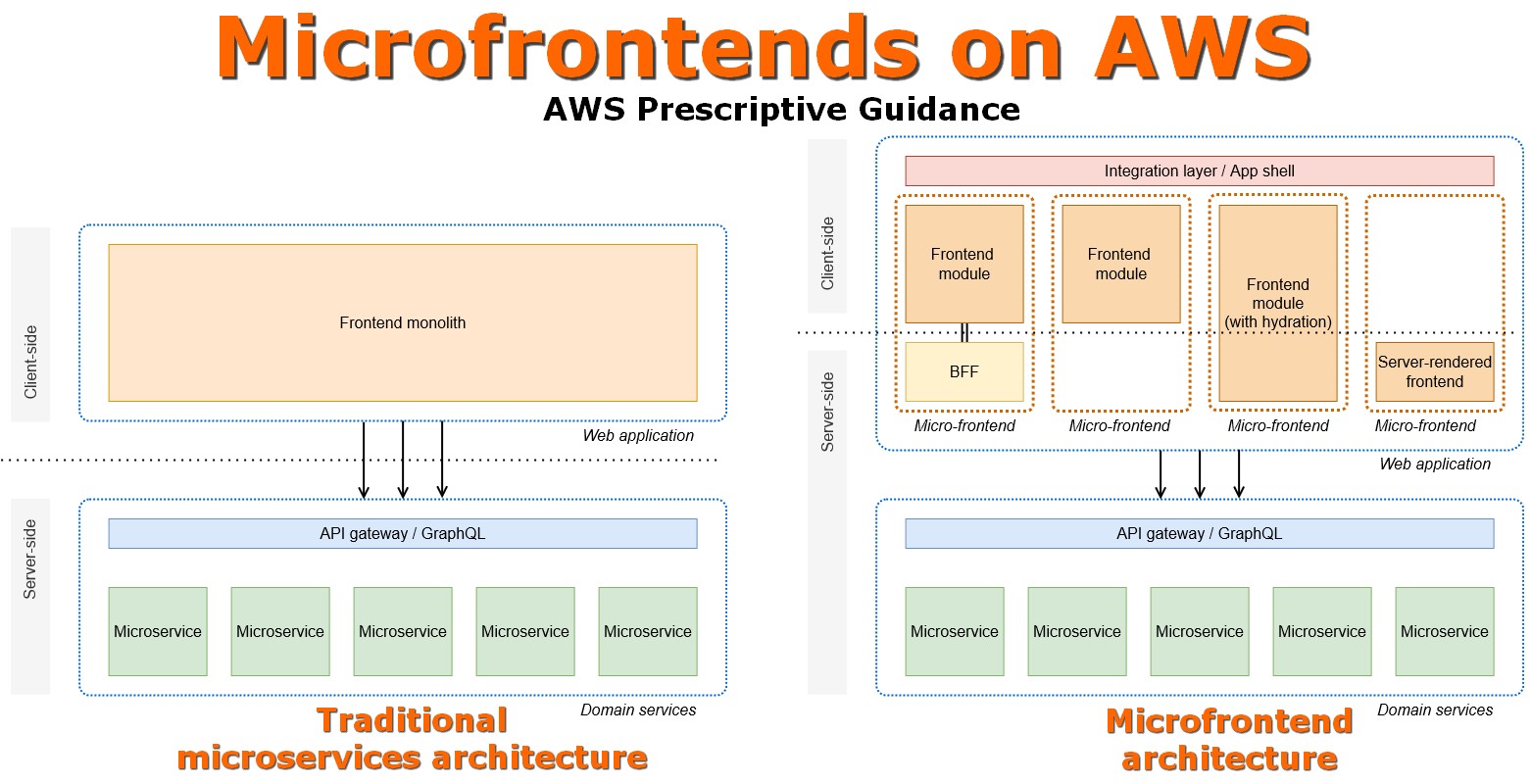
Microfrontends on AWS
https://docs.aws.amazon.com/prescriptive-guidance/latest/micro-frontends-aws/introduction.html
• Foundational concepts
• Alternative architectures
• Architectural decisions
• Frameworks and tools
• API integration ‒ BFF
• Styling and CSS
• Organization
• Governance
• Platform team
#design
https://docs.aws.amazon.com/prescriptive-guidance/latest/micro-frontends-aws/introduction.html
• Foundational concepts
• Alternative architectures
• Architectural decisions
• Frameworks and tools
• API integration ‒ BFF
• Styling and CSS
• Organization
• Governance
• Platform team
#design
{kind=link}