
Какие AWS сервисы используют Security groups?
Решили расчистить заброшенный аккаунт от ненужного и обнаружили сотню-другую неизвестно чьих и используемых ли security groups?
Зачистка
Самый простой способ почистить ненужные-неиспользуемые #sg - просто взять и удалить. Вот так просто выделить все и удалить.
Эту операцию особо приятно проделывать на проде, быстренько нажав подтверждение Yes в присутствии кого-нибудь важного. Вы-то знаете, что все хоть как-то задействованные sg-группы останутся и удалятся лишь бесхозные, не прикреплённые ни к какому сервису и на которые никто не ссылается. А лицезрящий ваш самоубиственный поступок руководитель - нет.
Прополка
Если вас ещё не уволили, то далее предстоит поиск используемых кем-то заведомо ненужных sg-групп. То бишь тех, что вы хотите удалить, а не получается. Не получается по нескольким причинам.
Либо на группу кто-то ссылается (в том числе она сама на себя - см.картинку). Либо её использует какой-то инстанс, в том числе остановленный. Или даже некоторое время (до получаса бывает) удалённый.
Сервисы
Когда инстансы прошерстили и всё равно не удаляется - вспоминаем, что sg используется не только в EC2, но и в RDS! Точно, находим таким образом забытые сто лет жрущие деньги никому не нужные базы данных, гасим, гордимся собой за сэкономленным в будущем казёные деньги и снова удаляем.
Часть удалилось, но часть нет. Какие же сервисы ещё используют security groups? Напрягаем логику и вспоминаем про Лямбду (умеющую ходить в VPC) и что у нас бесхозный Redis в углу завалялся из ElastiCache, который тоже имеет security group. StackOverflow подсказывает, что sg ещё есть у EMR и Redshift. Всё?
А вот и не всё. Вот полный список сервисов, использующих security groups:
AppStream
Batch
CodeBuild
DAX
DMS
DocDB
EC2 (AutoScaling, ELB, ALB, NLB)
ECS
EFS
EKS
ElastiCache
Elasticsearch
EMR
Events
FSx
Glue
Lambda
MediaLive
MSK
Neptune
OpsWorks
RDS
Redshift
Route53 (Route53Resolver)
SageMaker
Удачной борьбы с сорняками!
#security_groups
Решили расчистить заброшенный аккаунт от ненужного и обнаружили сотню-другую неизвестно чьих и используемых ли security groups?
Зачистка
Самый простой способ почистить ненужные-неиспользуемые #sg - просто взять и удалить. Вот так просто выделить все и удалить.
Эту операцию особо приятно проделывать на проде, быстренько нажав подтверждение Yes в присутствии кого-нибудь важного. Вы-то знаете, что все хоть как-то задействованные sg-группы останутся и удалятся лишь бесхозные, не прикреплённые ни к какому сервису и на которые никто не ссылается. А лицезрящий ваш самоубиственный поступок руководитель - нет.
Прополка
Если вас ещё не уволили, то далее предстоит поиск используемых кем-то заведомо ненужных sg-групп. То бишь тех, что вы хотите удалить, а не получается. Не получается по нескольким причинам.
Либо на группу кто-то ссылается (в том числе она сама на себя - см.картинку). Либо её использует какой-то инстанс, в том числе остановленный. Или даже некоторое время (до получаса бывает) удалённый.
Сервисы
Когда инстансы прошерстили и всё равно не удаляется - вспоминаем, что sg используется не только в EC2, но и в RDS! Точно, находим таким образом забытые сто лет жрущие деньги никому не нужные базы данных, гасим, гордимся собой за сэкономленным в будущем казёные деньги и снова удаляем.
Часть удалилось, но часть нет. Какие же сервисы ещё используют security groups? Напрягаем логику и вспоминаем про Лямбду (умеющую ходить в VPC) и что у нас бесхозный Redis в углу завалялся из ElastiCache, который тоже имеет security group. StackOverflow подсказывает, что sg ещё есть у EMR и Redshift. Всё?
А вот и не всё. Вот полный список сервисов, использующих security groups:
AppStream
Batch
CodeBuild
DAX
DMS
DocDB
EC2 (AutoScaling, ELB, ALB, NLB)
ECS
EFS
EKS
ElastiCache
Elasticsearch
EMR
Events
FSx
Glue
Lambda
MediaLive
MSK
Neptune
OpsWorks
RDS
Redshift
Route53 (Route53Resolver)
SageMaker
Удачной борьбы с сорняками!
#security_groups
{kind=link}
Поиск по IAM политикам
Для этого есть очень хороший секретный ресурс:
https://iam.cloudonaut.io/reference
Здесь находится список всех #IAM политик на текущий момент с возможностью разнообразного поиска.
Например, для поиска tag-supported сервисов в поле Conditions задаём ResourceTag и получаем актуальный список для такой манипуляции.
#info
Для этого есть очень хороший секретный ресурс:
https://iam.cloudonaut.io/reference
Здесь находится список всех #IAM политик на текущий момент с возможностью разнообразного поиска.
Например, для поиска tag-supported сервисов в поле Conditions задаём ResourceTag и получаем актуальный список для такой манипуляции.
#info
{kind=link}
Расходы на прод против остальных
Интересные цифры: в AWS проектах обычно на prod-окружения уходит около 80% денег, на dev/stg/test/etc — 10-20%.
А как у вас? Сколько уходит на non-prod окружения? Примерно.
#опрос #расходы #статистика
Интересные цифры: в AWS проектах обычно на prod-окружения уходит около 80% денег, на dev/stg/test/etc — 10-20%.
А как у вас? Сколько уходит на non-prod окружения? Примерно.
#опрос #расходы #статистика
Для внутренних адресов можно выбрать несколько регионов, описанных в RFC1918:
Кроме того, Docker использует по умолчанию регион
Потому в общем случае не стоит мудрить и использовать для CIDR block подсети из 10.х.х.х (
#VPC #CIDR
10.0.0.0 - 10.255.255.255 (10.0.0.0/8 prefix)и RFC6598:
172.16.0.0 - 172.31.255.255 (172.16.0.0/12 prefix)
192.168.0.0 - 192.168.255.255 (192.168.0.0/16 prefix)
100.64.0.0 - 100.127.255.255 (100.64.0.0/10 prefix)
Из четырёх "удобными" являются лишь два - 10.0.0.0/8 и 192.168.0.0/16. Их подсети описываются очевидной схемой 10.х.х.х и 192.168.х.х, хорошо запоминаются и потому вероятность ошибиться минимальна, не путая локальные адреса с публичными.Кроме того, Docker использует по умолчанию регион
172.17.0.0/16 - пересечение с ним обеспечит незабываемые ощущения при отладке. Равно как и дефолтная подсеть VPC в Амазоне это 172.31.0.0/16, что сделает проблемным возможный пиринг при использовании такого же региона.Потому в общем случае не стоит мудрить и использовать для CIDR block подсети из 10.х.х.х (
10.0.0.0/8) — много адресов и обычно они банально короче (меньше кнопок жать).#VPC #CIDR
Disallow Actions as a Root User
Полгода назад я добавил тэг #paranoid к посту про защиту от работы из-под рута, а теперь это в официальной документации:
https://docs.aws.amazon.com/controltower/latest/userguide/strongly-recommended-guardrails.html#disallow-root-auser-actions
Полгода назад я добавил тэг #paranoid к посту про защиту от работы из-под рута, а теперь это в официальной документации:
https://docs.aws.amazon.com/controltower/latest/userguide/strongly-recommended-guardrails.html#disallow-root-auser-actions
{kind=link}
S3 history
Чтобы что-то понять глубоко - нужно знать историю если не появления, но точно развития. Особенно это важно, если вы относите себя к девопсам - нужно обладать знаниями многих областей. Запомнить беконечные массивы информации об апишках, фреймворках и прочих настройках невозможно да и не нужно.
Нужно - понимать. А чтобы как раз понимать - нужно знать как оно было и почему стало как сейчас.
Итак, отметим лишь точку отсчёта:
https://aws.amazon.com/blogs/aws/amazon_s3/
В общем - #S3 вместе с #SQS и #EC2 ведут свой отсчёт с 2006-го года.
Это время расцвета VPS-хостингов со всей болью, помноженной на стоимость и ненадёжность при существенных нагрузках. Айфон лишь рождался, а крупным потребителям вычислительных мощностей всё приходилось делать самим. Потому с появлением первого крупного игрока, обещавшего SLA 99,99%, огромное количество будущих крупных клиентов Амазона бросились изучать возможности и стабильность его сервисов, в первую очередь S3.
Цена в 15 центов за гигабайт на то время была вполне себе конкурентной, потому основными в тестах была надёжность и стабильность доступа на протяжении длительного времени. Одними из первых крупных интересантов выступили штатовские универы, которые хотели избавиться от расходов на железо и перекинуть всё своё хозяйство в Амазон.
Через годик, убедившись в достаточной надёжности, они стали активно переходить туда.
За сим завершу литературно- и околомаркетинговое словоблудие о причинах и результатах создания S3. В следующей части перейду к суровым будням протодевопсов (их тогда ещё предательски называли сисадминами).
#s3_history #history
Чтобы что-то понять глубоко - нужно знать историю если не появления, но точно развития. Особенно это важно, если вы относите себя к девопсам - нужно обладать знаниями многих областей. Запомнить беконечные массивы информации об апишках, фреймворках и прочих настройках невозможно да и не нужно.
Нужно - понимать. А чтобы как раз понимать - нужно знать как оно было и почему стало как сейчас.
Итак, отметим лишь точку отсчёта:
https://aws.amazon.com/blogs/aws/amazon_s3/
В общем - #S3 вместе с #SQS и #EC2 ведут свой отсчёт с 2006-го года.
Это время расцвета VPS-хостингов со всей болью, помноженной на стоимость и ненадёжность при существенных нагрузках. Айфон лишь рождался, а крупным потребителям вычислительных мощностей всё приходилось делать самим. Потому с появлением первого крупного игрока, обещавшего SLA 99,99%, огромное количество будущих крупных клиентов Амазона бросились изучать возможности и стабильность его сервисов, в первую очередь S3.
Цена в 15 центов за гигабайт на то время была вполне себе конкурентной, потому основными в тестах была надёжность и стабильность доступа на протяжении длительного времени. Одними из первых крупных интересантов выступили штатовские универы, которые хотели избавиться от расходов на железо и перекинуть всё своё хозяйство в Амазон.
Через годик, убедившись в достаточной надёжности, они стали активно переходить туда.
За сим завершу литературно- и околомаркетинговое словоблудие о причинах и результатах создания S3. В следующей части перейду к суровым будням протодевопсов (их тогда ещё предательски называли сисадминами).
#s3_history #history
Amazon
Amazon S3 | Amazon Web Services
Earlier today we rolled out Amazon S3, our reliable, highly scalable, low-latency data storage service. Using SOAP and REST interfaces, developers can easily store any number of blocks of data in S3. Each block can be up to 5 GB in length, and is associated…
S3 нулевых
Впервые столкнулся с AWS лет десять назад - нужно было посмотреть-оценить, как он подходит к одному проекту для виндового бэкапа. В то время "облачный бэкап" был модной темой, про Амазон уже все знали, нужно было попробовать в действии.
Забегая вперёд, скажу, что тема с Амазоном не выгорела, т.к. даже спустя четыре года с момента открытия он держал планку в 15 центов за гигабайт, что в 2010-м году уже не выглядело конкурентным ни разу и потому выбор пал на покупку своих
Но не об этом. Хотя ещё чуть-чуть о нём. Через два года стартапный бэкап так не взлетел и на Амазон таки мы переехали. Денег было потрачено столько, что навсегда хватит, чтобы понимать, насколько удобен Амазон для стартапов.
Как же работали с S3 десять лет назад? Консоль - это же очевидно? Вот и я так думал.
Зарегистрировался на AWS, скачал Access Key ID и Secret Access Key. Зашёл в AWS Management Console, однако там всё лишь для управления виртуалками, вкладки с S3 нет. Как быть?
Оказалось, что для управления S3 через веб нужно было ставить сторонние утилиты, одним из самых популярных (бесплатных) был плагин под Firefox с незамысловатым названием S3Fox (полное название The FireFox S3 Organizer). Его же рекомендовали и пользовались сами амазоновцы.
Это было удивительно. Я знал Амазон как главного лидера в облакостроении, а чтобы пользоваться его сервисом, даже спустя четыре года после старта #S3 — нужно было ставить чужие плагинчики или шпилить в неудобную командную строку из-под жавы.
Только много-долго после я понял и осознал всю мощу такого подхода. Когда другие пилят пока не допилят, Амазон уже не один год эксплуатирует и продаёт, доделывая по ходу.
Так, я отвлёкся. S3Fox просто настраивался, имел FTP-подобный интерфейс, действительно просто позволял работать с бакетами. Однако эта схожесть с обычным файлохранилищем, но при этом отсутствие хоть какой-то возможности разграничить доступ - особо разочаровывала.
Владелец AWS аккаунта (root-юзер по-нынешнему) автоматически имел доступ во все бакеты, мог удалить все виртуалки и прочие ресурсы. Хочешь разделить на окружения или проекты - заводи новый аккаунт, новая кредитка, почта и так далее для каждого проекта. С точки зрения минимального compliance это сильно напрягало и усложняло даже просто финансовое обслуживание.
Кто ещё не понял - да, тогда ещё не было #Bucket_polices и #IAM. Их завезли позже в 2010-м и это очень важно запомнить. Почему важно - станет ясно потом.
Итого запишем главный результат лирического отступления - первобытные девопсы амазонили на S3 без всяческих политик. Юзали всевозможные плагины, рубились в руби командной строкой и дотошно логировали все проблемы доступности S3, покрывая жалобами девелоперский форум.
#s3_history #history
Впервые столкнулся с AWS лет десять назад - нужно было посмотреть-оценить, как он подходит к одному проекту для виндового бэкапа. В то время "облачный бэкап" был модной темой, про Амазон уже все знали, нужно было попробовать в действии.
Забегая вперёд, скажу, что тема с Амазоном не выгорела, т.к. даже спустя четыре года с момента открытия он держал планку в 15 центов за гигабайт, что в 2010-м году уже не выглядело конкурентным ни разу и потому выбор пал на покупку своих
dedicated servers. Руководству сложно и в наше время понять, зачем это вот всё дорогущее и ненужное, когда вот они, свои железяки и специально обученные админы в комплекте. А что уж говорить про десять лет тому.Но не об этом. Хотя ещё чуть-чуть о нём. Через два года стартапный бэкап так не взлетел и на Амазон таки мы переехали. Денег было потрачено столько, что навсегда хватит, чтобы понимать, насколько удобен Амазон для стартапов.
Как же работали с S3 десять лет назад? Консоль - это же очевидно? Вот и я так думал.
Зарегистрировался на AWS, скачал Access Key ID и Secret Access Key. Зашёл в AWS Management Console, однако там всё лишь для управления виртуалками, вкладки с S3 нет. Как быть?
Оказалось, что для управления S3 через веб нужно было ставить сторонние утилиты, одним из самых популярных (бесплатных) был плагин под Firefox с незамысловатым названием S3Fox (полное название The FireFox S3 Organizer). Его же рекомендовали и пользовались сами амазоновцы.
Это было удивительно. Я знал Амазон как главного лидера в облакостроении, а чтобы пользоваться его сервисом, даже спустя четыре года после старта #S3 — нужно было ставить чужие плагинчики или шпилить в неудобную командную строку из-под жавы.
Только много-долго после я понял и осознал всю мощу такого подхода. Когда другие пилят пока не допилят, Амазон уже не один год эксплуатирует и продаёт, доделывая по ходу.
Так, я отвлёкся. S3Fox просто настраивался, имел FTP-подобный интерфейс, действительно просто позволял работать с бакетами. Однако эта схожесть с обычным файлохранилищем, но при этом отсутствие хоть какой-то возможности разграничить доступ - особо разочаровывала.
Владелец AWS аккаунта (root-юзер по-нынешнему) автоматически имел доступ во все бакеты, мог удалить все виртуалки и прочие ресурсы. Хочешь разделить на окружения или проекты - заводи новый аккаунт, новая кредитка, почта и так далее для каждого проекта. С точки зрения минимального compliance это сильно напрягало и усложняло даже просто финансовое обслуживание.
Кто ещё не понял - да, тогда ещё не было #Bucket_polices и #IAM. Их завезли позже в 2010-м и это очень важно запомнить. Почему важно - станет ясно потом.
Итого запишем главный результат лирического отступления - первобытные девопсы амазонили на S3 без всяческих политик. Юзали всевозможные плагины, рубились в руби командной строкой и дотошно логировали все проблемы доступности S3, покрывая жалобами девелоперский форум.
#s3_history #history
{kind=link}
S3 invention
Разбираясь с исторической точки зрения, нельзя не упомянуть про ещё один полезный подход, который очень эффективен для того, чтобы понять и разобраться, а не только запомнить. Это когда пытаешься сам изобрести, создать, придумать и настроить ту штуку, которая интересует. В данном случае - Amazon S3.
Итак, отбросим причины и прочую мишуру, оставим чисто техзадание, каким оно могло быть, зная, каким был результат.
1. Нужно иметь возможность закидывать файлы в будущее хранилище (а также, понятно, удалять и др. стандартные операции для файлов).
2. Нужна возможность делать эти файлы как приватными, так и доступными из интернета.
Вопросы доступности, устойчивости к нагрузками и прочие надёжности нас здесь не интересуют — нас интересует, как бы мы сделали, так сказать, "админку" или, по-правильному, какое API бы использовали для этого.
Имея представление о привычной файловой системе в линукс с её ACL расширением - логично использовать что-то типа, только с поправкой на будущее объектное хранилище.
Если кто не в курсе, что в линуксе кроме привычной схемы
---
Итак, у нас будут клиенты, они будут к нам логиниться в свои аккаунты и авторизоваться через апи - это будут типа юзеры из линукса.
У нас будут бакеты, которые создают юзеры и в которые они могут писать свои файлы - это будут типа папки из линукса.
Юзер всегда имеет полные права на свои бакеты и файлы в них. Он должен иметь возможность давать права писать в свои бакеты другим юзерам. Для этого у бакета добавим ACL, аналогичный ACL из линукса.
Аналогично для объектов, потому как и бакету, добавим каждому объекту свой ACL.
Объекты нужно иметь возможность делать публичными (доступными для других через интернет). Для этого добавим группу, принадлежа к которой, объект или бакет станет публичным - это будут типа группы из линукса.
===
Вроде всё. Просто, без замудренностей и должно работать - ведь работает в линуксе, верно?
Только что, в нескольких абзацах, мы заново изобрели #S3. Оно, действительно, работает. И, что важно, оно, дейстительно, работает так. Или точней и ещё более важней - так работало.
#s3_history #history
Разбираясь с исторической точки зрения, нельзя не упомянуть про ещё один полезный подход, который очень эффективен для того, чтобы понять и разобраться, а не только запомнить. Это когда пытаешься сам изобрести, создать, придумать и настроить ту штуку, которая интересует. В данном случае - Amazon S3.
Итак, отбросим причины и прочую мишуру, оставим чисто техзадание, каким оно могло быть, зная, каким был результат.
1. Нужно иметь возможность закидывать файлы в будущее хранилище (а также, понятно, удалять и др. стандартные операции для файлов).
2. Нужна возможность делать эти файлы как приватными, так и доступными из интернета.
Вопросы доступности, устойчивости к нагрузками и прочие надёжности нас здесь не интересуют — нас интересует, как бы мы сделали, так сказать, "админку" или, по-правильному, какое API бы использовали для этого.
Имея представление о привычной файловой системе в линукс с её ACL расширением - логично использовать что-то типа, только с поправкой на будущее объектное хранилище.
Если кто не в курсе, что в линуксе кроме привычной схемы
user:group можно использовать и ACL - погуглите по getfacl и setfacl.---
Итак, у нас будут клиенты, они будут к нам логиниться в свои аккаунты и авторизоваться через апи - это будут типа юзеры из линукса.
У нас будут бакеты, которые создают юзеры и в которые они могут писать свои файлы - это будут типа папки из линукса.
Юзер всегда имеет полные права на свои бакеты и файлы в них. Он должен иметь возможность давать права писать в свои бакеты другим юзерам. Для этого у бакета добавим ACL, аналогичный ACL из линукса.
Аналогично для объектов, потому как и бакету, добавим каждому объекту свой ACL.
Объекты нужно иметь возможность делать публичными (доступными для других через интернет). Для этого добавим группу, принадлежа к которой, объект или бакет станет публичным - это будут типа группы из линукса.
===
Вроде всё. Просто, без замудренностей и должно работать - ведь работает в линуксе, верно?
Только что, в нескольких абзацах, мы заново изобрели #S3. Оно, действительно, работает. И, что важно, оно, дейстительно, работает так. Или точней и ещё более важней - так работало.
#s3_history #history
{kind=link}
S3 bucket ACL cross-account access
С одной стороны, многим, если не большинству, кто ходил больше раза в амазоновскую консоль, знакома закладка Access Control List в разделе Permissions.
С другой стороны, многим, если не большинству, даже из тех, кто потыкался и попытался разобраться, так и осталось тайной, что она в реальности собой представляет и как там что-то работает. Потому что погуглив получение Canonical ID и попыташись с помощью него расшарить доступ в бакет из другого аккаунта - наверняка ничего не работало.
Понятной документации не так много, т.к. во всей новой не рекомендуется использовать ACL, а пользоваться для этого (кросс-аккаунта, да и всего прочего) Bucket Policy и IAM.
Но оно ж там ещё почему-то есть! Если бы не работало, убрали бы, наверное.
Ларчик открывается просто. Если у вас не заработало, значит вы честно выполняли рекомендации бестпрактиксов и делали это не из-под root-юзера, т.е. логинились в консоль как обычный IAM-юзер. А для того, чтобы эти артефакты работали и работали как надо - требуются руты и только руты.
Т.е. работать и логиниться в консоль для работы с ACL нужно из-под рута, шарить доступ в другой аккаунт и там тоже только рут (для консоли) и credentials рута (если программно). И никаких ролей.
Почему? Это было в предыдущих частях по #s3_history - мы же ведь ещё не придумали #bucket_policy и #IAM, у нас на дворе нулевые, а их завезли лишь в 2010-м. Поэтому только руты, только #ACL, только хардкор.
С одной стороны, многим, если не большинству, кто ходил больше раза в амазоновскую консоль, знакома закладка Access Control List в разделе Permissions.
С другой стороны, многим, если не большинству, даже из тех, кто потыкался и попытался разобраться, так и осталось тайной, что она в реальности собой представляет и как там что-то работает. Потому что погуглив получение Canonical ID и попыташись с помощью него расшарить доступ в бакет из другого аккаунта - наверняка ничего не работало.
Понятной документации не так много, т.к. во всей новой не рекомендуется использовать ACL, а пользоваться для этого (кросс-аккаунта, да и всего прочего) Bucket Policy и IAM.
Но оно ж там ещё почему-то есть! Если бы не работало, убрали бы, наверное.
Ларчик открывается просто. Если у вас не заработало, значит вы честно выполняли рекомендации бестпрактиксов и делали это не из-под root-юзера, т.е. логинились в консоль как обычный IAM-юзер. А для того, чтобы эти артефакты работали и работали как надо - требуются руты и только руты.
Т.е. работать и логиниться в консоль для работы с ACL нужно из-под рута, шарить доступ в другой аккаунт и там тоже только рут (для консоли) и credentials рута (если программно). И никаких ролей.
Почему? Это было в предыдущих частях по #s3_history - мы же ведь ещё не придумали #bucket_policy и #IAM, у нас на дворе нулевые, а их завезли лишь в 2010-м. Поэтому только руты, только #ACL, только хардкор.
Итак, чтобы попробовать, находим рутовые доступы к двум аккаунтам. Логинимся и в консоли жмём на своём имени My Security Credentials -> подтверждаем, что в своём уме и не хотим #IAM (Continue to Security Credentials) -> Access keys (access key ID and secret access key). Там создаём себе новые и прописываем в виртуалке.
В консоле одного из них создаём бакет. Закидываем файл. Проверяем из второго аккаунта - доступа, логично, нет. Попробуем расшарить.
Когда мы переизобретали #S3, то у нас клиенты - это были как юзеры в линукс. Клиенты логинятся через свою почту, но под капотом, понятно, у них должны быть однозначные айдишники. Это и есть Canonical ID - 64-байтный единый айдишник для всего AWS аккаунта (а не только S3). В случае же S3 именно этот айдишник выступает в качестве идентификатора owner-а для всех бакетов и файлов им созданных.
Поэтому, чтобы оперировать с доступом на S3 нужно иметь эти айдишники - амазоновское апи работает именно с ними, определяя доступ в структуре ACL. Получить их можно в консоли (из-под рута) My Security Credentials -> Account identifiers -> Canonical User ID или выполнив команду
Итак, в консоли в бакете на закладке Access Control List жмём Add account, вбиваем Canonical ID второго аккаунта и жмём галки Read и Write. Пробуем из другого аккаунта - в бакет файлы прекрасно входят и выходят. Что и требовалось доказать - оно работает. Так и было задумано - у бакета никаких полиси, а кросс-аккаунтный доступ есть. С поправкой, опять же, на руты, но других сущностей тогда и не было.
Вместо указания Canonical ID, Амазон, пытаясь как-то облегчить работу с апишкой, позволял указывать вместо него почту юзера (снова именно рута - т.е. на который регистрировался аккаунт). Это в частности, позволяла путём подбора, выяснить, зарегистрирован ли такой ящик на амазоне. Например, на картинке подставлен ящик создаля Амазона Jeff Barr и видно из ответа Амазона, что у него даже несколько аккаунтов.
Но в общем случае в ответе будет ошибка, что такого ящика нет. Даже если он у вашего аккаунта точно есть - это должен быть старый аккаунт, т.к. с 2014-го года эту фичу преобразования ящиков в Canonical ID (под капотом-то то именно он) отключили - ищите древней, а лучше просто указывайте айдишник.
Итого, чтобы пользоваться S3 bucket ACL - нужны руты и только руты. IAM не используется от слова совсем - руту плевать на любые наcтройки IAM, т.к. он просто никогда не заходит в эту апишку, ведь он более древняя сущность и потому работает напрямую с Амазоном. Однако он может взаимодействовать с Bucket Policy, но это уже другая история.
#bucket_acl
В консоле одного из них создаём бакет. Закидываем файл. Проверяем из второго аккаунта - доступа, логично, нет. Попробуем расшарить.
Когда мы переизобретали #S3, то у нас клиенты - это были как юзеры в линукс. Клиенты логинятся через свою почту, но под капотом, понятно, у них должны быть однозначные айдишники. Это и есть Canonical ID - 64-байтный единый айдишник для всего AWS аккаунта (а не только S3). В случае же S3 именно этот айдишник выступает в качестве идентификатора owner-а для всех бакетов и файлов им созданных.
Поэтому, чтобы оперировать с доступом на S3 нужно иметь эти айдишники - амазоновское апи работает именно с ними, определяя доступ в структуре ACL. Получить их можно в консоли (из-под рута) My Security Credentials -> Account identifiers -> Canonical User ID или выполнив команду
aws s3api list-buckets, которая в JSON отдаст в Owner.ID.Итак, в консоли в бакете на закладке Access Control List жмём Add account, вбиваем Canonical ID второго аккаунта и жмём галки Read и Write. Пробуем из другого аккаунта - в бакет файлы прекрасно входят и выходят. Что и требовалось доказать - оно работает. Так и было задумано - у бакета никаких полиси, а кросс-аккаунтный доступ есть. С поправкой, опять же, на руты, но других сущностей тогда и не было.
Вместо указания Canonical ID, Амазон, пытаясь как-то облегчить работу с апишкой, позволял указывать вместо него почту юзера (снова именно рута - т.е. на который регистрировался аккаунт). Это в частности, позволяла путём подбора, выяснить, зарегистрирован ли такой ящик на амазоне. Например, на картинке подставлен ящик создаля Амазона Jeff Barr и видно из ответа Амазона, что у него даже несколько аккаунтов.
Но в общем случае в ответе будет ошибка, что такого ящика нет. Даже если он у вашего аккаунта точно есть - это должен быть старый аккаунт, т.к. с 2014-го года эту фичу преобразования ящиков в Canonical ID (под капотом-то то именно он) отключили - ищите древней, а лучше просто указывайте айдишник.
Итого, чтобы пользоваться S3 bucket ACL - нужны руты и только руты. IAM не используется от слова совсем - руту плевать на любые наcтройки IAM, т.к. он просто никогда не заходит в эту апишку, ведь он более древняя сущность и потому работает напрямую с Амазоном. Однако он может взаимодействовать с Bucket Policy, но это уже другая история.
#bucket_acl
{kind=link}
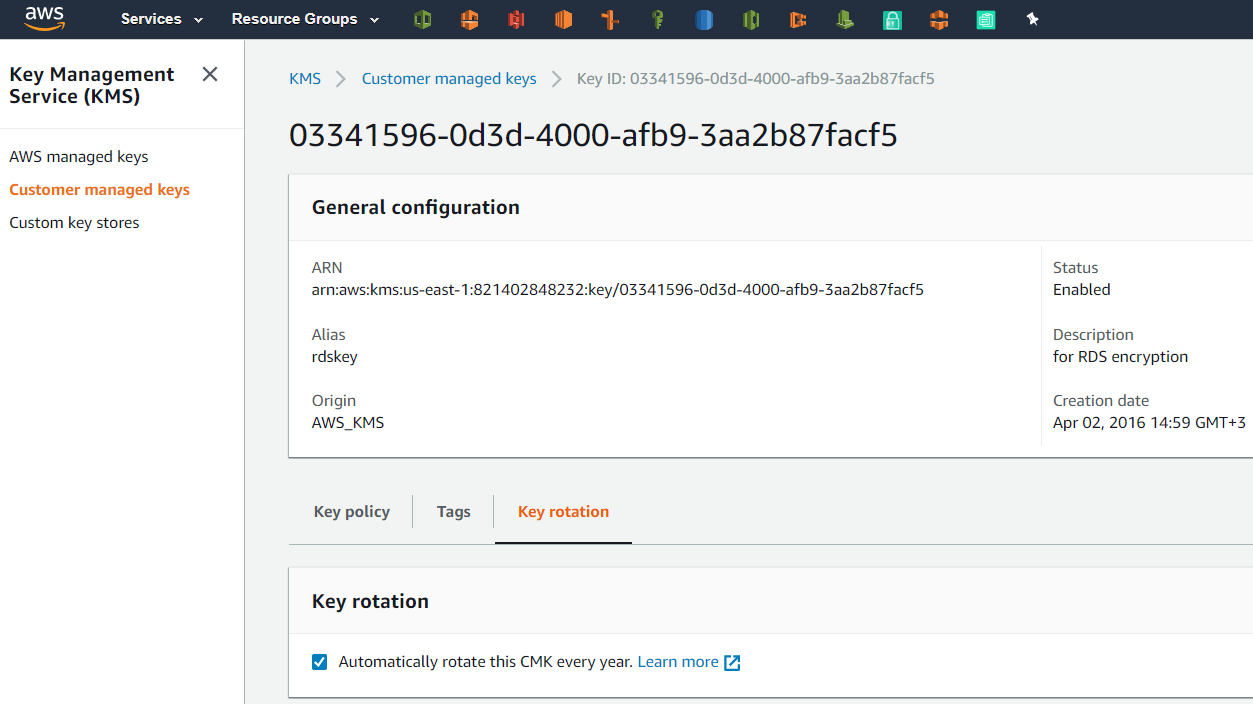
[](https://telegra.ph/file/290e2643259353e214332.png)KMS pricing for CMK
Обычно все знают, что стоимость одного KMS ключа - 1 доллар в месяц. Также те, кто следуют рекомендациям лучших ключеводов, включают ротацию CMK (Custom Managed Keys) ключей каждый год. И потом, для старых проектов, они могут обнаружить занимательную математику в биллинге за #KMS.
А всё потому, что мелкий текст обычно не читается:
For a CMK with key material generated by KMS, if you opt-in to have the CMK automatically rotated each year, each newly rotated version will raise the cost of the CMK by $1/month.
А это значит, что через год это будет 2, потом 3, 4 и т.д. долларов в месяц за каждый ключ.
Это потому, что все предыдущие ротируемые ключи сохраняются для возможности расшифровать старое по этому алиасу (т.е. старое не "перешифровывается", а просто всё новое шифруется уже новым ключём). И за них нужно платить.
Бэушное по цене нового, короче.
#стоимость #price #pricing
Обычно все знают, что стоимость одного KMS ключа - 1 доллар в месяц. Также те, кто следуют рекомендациям лучших ключеводов, включают ротацию CMK (Custom Managed Keys) ключей каждый год. И потом, для старых проектов, они могут обнаружить занимательную математику в биллинге за #KMS.
А всё потому, что мелкий текст обычно не читается:
For a CMK with key material generated by KMS, if you opt-in to have the CMK automatically rotated each year, each newly rotated version will raise the cost of the CMK by $1/month.
А это значит, что через год это будет 2, потом 3, 4 и т.д. долларов в месяц за каждый ключ.
Это потому, что все предыдущие ротируемые ключи сохраняются для возможности расшифровать старое по этому алиасу (т.е. старое не "перешифровывается", а просто всё новое шифруется уже новым ключём). И за них нужно платить.
Бэушное по цене нового, короче.
#стоимость #price #pricing
{kind=link}
Forwarded from AWS History
AWS history
Чтобы не смешивать мягкое с тёплым, скопировал сюда свои "исторические" посты из aws_notes и впредь буду писать на темы древнеамазонской эры здесь (aws_history).
Кому интересно узнать, как что-то работало на Амазоне, когда что-то добавили, что за странные сервисы и как это может работать сейчас - присоединяйтесь.
Ещё раз скажу, что я не был участником самого древнего периода AWS - впервые столкнулся где-то в середине протерозоя 2009-2010 гг., а реально начал работать с ним лишь в начале палеозоя 2012-го года. Однако мне, как и археологам, не заставших динозавров, всё равно интересно производить раскопки, выясняя чем там они питались и какой набор фич был у тогдашних утилит.
В общем, если вам интересно наблюдать за работой человека, с удовольствием копающегося в закоменелых экскрементах и деприкейтнутных апишках - милости прошу, я вас предупредил.
Чтобы не смешивать мягкое с тёплым, скопировал сюда свои "исторические" посты из aws_notes и впредь буду писать на темы древнеамазонской эры здесь (aws_history).
Кому интересно узнать, как что-то работало на Амазоне, когда что-то добавили, что за странные сервисы и как это может работать сейчас - присоединяйтесь.
Ещё раз скажу, что я не был участником самого древнего периода AWS - впервые столкнулся где-то в середине протерозоя 2009-2010 гг., а реально начал работать с ним лишь в начале палеозоя 2012-го года. Однако мне, как и археологам, не заставших динозавров, всё равно интересно производить раскопки, выясняя чем там они питались и какой набор фич был у тогдашних утилит.
В общем, если вам интересно наблюдать за работой человека, с удовольствием копающегося в закоменелых экскрементах и деприкейтнутных апишках - милости прошу, я вас предупредил.
{kind=link}
С одной стороны развлекаловка и тест на логическую непригодность дизайнеров иконок, с другой — полезная возможность узнать про сервисы Амазона, о которых даже не слышали:
https://quiz.cloudar.be
https://quiz.cloudar.be
quiz.cloudar.be
Cloudar AWS Logo Quiz
Test your AWS services icon knowledge!
Тарификация AZ или снова мелкий текст в договоре
Намедни появилась быстро ставшей популярная статья на популярном блоге Corey Quinn, где срываются покровы особенностей национального тарифообразования трафика в Амазоне:
https://www.lastweekinaws.com/blog/aws-cross-az-data-transfer-costs-more-than-aws-says/
Стоит (за)помнить, что если у вас там планируются или работают какие-то более-менее серьёзные мощности или вы просто занимаетесь бесчеловечным кост-менеджментом (и правильно делаете), то вчитывайтесь в детали и особенно подробно изучайте мелкий шрифт, чтобы не было никаких неясностей. Амазон - не благотворительная, а коммерческая организация и нужно всегда трезво оценивать его ценовую политику.
В частности, в случае мульти-AZ трафика между инстансами, в том числе, когда они соединены через VPC peering, то упоминаютые в основном прайсе 0.1 за гигабайт будут:
• за запрос исходящий из одной зоны
• плюс этот же запрос как входящий для другой зоны
Такая ситуация возникает, когда требуется сделать HA (High Availability) кластер для какой-нибудь собственной базы данных, для чего (т.е. отказоустойичовати) требуется задеплоить ноды в разных подзонах. Данные между нодами будут постоянно синхронизироваться и вы попадаете на бабки.
Ситуация не возникает для трафика балансеров (ELB/ALB/NLB), т.к. они имеют в каждой подзоне свой ENI (сетевую карту) и потому трафик получается внутри-зонный, т.е. бесплатный. Однако если балансировка происходит через VPC peering (да, так тоже можно), то включаются мульти-AZ издежрки.
п.с. Картинка по стоимости трафика, которая как-то была тут раньше.
#multi_az #pricing
Намедни появилась быстро ставшей популярная статья на популярном блоге Corey Quinn, где срываются покровы особенностей национального тарифообразования трафика в Амазоне:
https://www.lastweekinaws.com/blog/aws-cross-az-data-transfer-costs-more-than-aws-says/
Стоит (за)помнить, что если у вас там планируются или работают какие-то более-менее серьёзные мощности или вы просто занимаетесь бесчеловечным кост-менеджментом (и правильно делаете), то вчитывайтесь в детали и особенно подробно изучайте мелкий шрифт, чтобы не было никаких неясностей. Амазон - не благотворительная, а коммерческая организация и нужно всегда трезво оценивать его ценовую политику.
В частности, в случае мульти-AZ трафика между инстансами, в том числе, когда они соединены через VPC peering, то упоминаютые в основном прайсе 0.1 за гигабайт будут:
• за запрос исходящий из одной зоны
• плюс этот же запрос как входящий для другой зоны
Такая ситуация возникает, когда требуется сделать HA (High Availability) кластер для какой-нибудь собственной базы данных, для чего (т.е. отказоустойичовати) требуется задеплоить ноды в разных подзонах. Данные между нодами будут постоянно синхронизироваться и вы попадаете на бабки.
Ситуация не возникает для трафика балансеров (ELB/ALB/NLB), т.к. они имеют в каждой подзоне свой ENI (сетевую карту) и потому трафик получается внутри-зонный, т.е. бесплатный. Однако если балансировка происходит через VPC peering (да, так тоже можно), то включаются мульти-AZ издежрки.
п.с. Картинка по стоимости трафика, которая как-то была тут раньше.
#multi_az #pricing
{kind=link}
GitHub status
https://www.githubstatus.com
Стоит проверять, если вдруг в логах каких-то вещей Амазона, завязанных на гитхаб, что-то не то. Например, вчера вечером это могло кому-то очень пригодиться.
Чтобы не видеть такие ошибки задним числом, стоит прикрутить оповещение в свой рабочий мессенджер. Например, я использую Slack в работе, для которого есть простой способ интегрировать такую вещь - выполнить команду в своём рабочем канале:
#github #info #slack
https://www.githubstatus.com
Стоит проверять, если вдруг в логах каких-то вещей Амазона, завязанных на гитхаб, что-то не то. Например, вчера вечером это могло кому-то очень пригодиться.
Чтобы не видеть такие ошибки задним числом, стоит прикрутить оповещение в свой рабочий мессенджер. Например, я использую Slack в работе, для которого есть простой способ интегрировать такую вещь - выполнить команду в своём рабочем канале:
/feed subscribe https://www.githubstatus.com/history.atom#github #info #slack
{kind=link}
👍1
Route53 под DDoS атакой
Вчерашние проблемы с разрешением DNS для различных сервисов - S3-бакетов, RDS-эндпоинтов и прочие - продолжились (продолжаются?) и сегодня.
Проблемы многовероятны при создании и обновлении окружений. Особенно это касается S3-бакетов вида
Это недавно как раз описывалось здесь как рекомендация к использованию третьего типа написания бакета, которая могла быть спасительной для тех, кто ею воспользовался. Кто ещё нет - срочно переделайте свои бакеты к "правильному" виду
У кого не получается присоединиться к базе - попробуйте переключиться на гугловые днсы
В общем, если у вас есть возможность отложить обновление и создание критических ресурсов на пару дней - лучше обождать. Если же нет - нужно быть готовым к самым непредсказуемым ситуациям, создание CloudFormation стэков может давать ошибку, системные пакеты не обновляться, базы данных создаваться полчаса и больше, давая таймауты других операций - всего не перечесть. И это ведь ещё не пятница...
#route53 #ddos #s3 #rds
Вчерашние проблемы с разрешением DNS для различных сервисов - S3-бакетов, RDS-эндпоинтов и прочие - продолжились (продолжаются?) и сегодня.
Проблемы многовероятны при создании и обновлении окружений. Особенно это касается S3-бакетов вида
my-bucket.s3.amazonaws.com вне N.Virginia региона, т.к. для разрешения конечного имени делается ещё один DNS запрос.Это недавно как раз описывалось здесь как рекомендация к использованию третьего типа написания бакета, которая могла быть спасительной для тех, кто ею воспользовался. Кто ещё нет - срочно переделайте свои бакеты к "правильному" виду
my-bucket.s3.some-region.amazonaws.com и проблемы (связанные с DNS бакета) уйдут.У кого не получается присоединиться к базе - попробуйте переключиться на гугловые днсы
8.8.8.8 или от CloudFlare 1.1.1.1.В общем, если у вас есть возможность отложить обновление и создание критических ресурсов на пару дней - лучше обождать. Если же нет - нужно быть готовым к самым непредсказуемым ситуациям, создание CloudFormation стэков может давать ошибку, системные пакеты не обновляться, базы данных создаваться полчаса и больше, давая таймауты других операций - всего не перечесть. И это ведь ещё не пятница...
#route53 #ddos #s3 #rds
Исправлена ссылка "здесь" выше на пост по форматам написания бакетов.
Telegram
aws_notes
CloudFront и формат написания S3 бакета
1. В уже совсем древние времена все бакеты адресовались как:
s3.amazonaws.com/my-bucket
2. Потом формат мигрировал в "поддоменный" вариант:
my-bucket.s3.amazonaws.com
3. После активного размножения регионов добавился…
1. В уже совсем древние времена все бакеты адресовались как:
s3.amazonaws.com/my-bucket
2. Потом формат мигрировал в "поддоменный" вариант:
my-bucket.s3.amazonaws.com
3. После активного размножения регионов добавился…
Amazon Route 53[RESOLVED]
5:44 PM PDT On October 22, 2019, we detected and then mitigated a DDoS (Distributed Denial of Service) attack against Route 53. Due to the way that DNS queries are processed, this attack was first experienced by many other DNS server operators as the queries made their way through DNS resolvers on the internet to Route 53. The attack targeted specific DNS names and paths, notably those used to access the global names for S3 buckets. Because this attack was widely distributed, a small number of ISPs operating affected DNS resolvers implemented mitigation strategies of their own in an attempt to control the traffic. This is causing DNS lookups through these resolvers for a small number of AWS names to fail. We are doing our best to identify and contact these operators, as quickly as possible, and working with them to enhance their mitigations so that they do not cause impact to valid requests. If you are experiencing issues, please contact us so we can work with your operator to help resolve.
https://status.aws.amazon.com
#route53
5:44 PM PDT On October 22, 2019, we detected and then mitigated a DDoS (Distributed Denial of Service) attack against Route 53. Due to the way that DNS queries are processed, this attack was first experienced by many other DNS server operators as the queries made their way through DNS resolvers on the internet to Route 53. The attack targeted specific DNS names and paths, notably those used to access the global names for S3 buckets. Because this attack was widely distributed, a small number of ISPs operating affected DNS resolvers implemented mitigation strategies of their own in an attempt to control the traffic. This is causing DNS lookups through these resolvers for a small number of AWS names to fail. We are doing our best to identify and contact these operators, as quickly as possible, and working with them to enhance their mitigations so that they do not cause impact to valid requests. If you are experiencing issues, please contact us so we can work with your operator to help resolve.
https://status.aws.amazon.com
#route53
Let's Encrypt +
В ноябре местами ожидаются сайтопады со шквалистой сертификатной недостаточностью:
https://community.letsencrypt.org/t/blocking-old-cert-manager-versions/98753
Всё потому, что старые версии
Из-за серьёзных проблем у
Полезные ссылки:
• официальная страница обновления
• релизы
• helm-чарт для последнего (0.11)
#EKS
cert-manager - November 1В ноябре местами ожидаются сайтопады со шквалистой сертификатной недостаточностью:
https://community.letsencrypt.org/t/blocking-old-cert-manager-versions/98753
Всё потому, что старые версии
cert-manager, который используется по дефолту в #kubernetes для получения бесплатных сертификатов Let's Encrypt, перестанет получать сертификаты.Из-за серьёзных проблем у
cert-manager до 0.8.0 версии, когда он из-за ошибок сильно грузит сервера Let's Encrypt, поддержка старых версий cert-manager в ноябре будет прекращена. Потому, если у вас поднят свой или EKS-кластер, стоит озаботиться обновлением всего, использующего cert-manager, в этом месяце.Полезные ссылки:
• официальная страница обновления
cert-manager - https://docs.cert-manager.io/en/latest/tasks/upgrading/index.html• релизы
cert-manager - https://github.com/jetstack/cert-manager/releases• helm-чарт для последнего (0.11)
cert-manager - https://hub.helm.sh/charts/jetstack/cert-manager#EKS
Let's Encrypt Community Support
Blocking old cert-manager versions
We’ve been working with Jetstack, the authors of cert-manager, on a series of fixes to the client. Cert-manager sometimes falls into a traffic pattern where it sends excessive traffic to Let’s Encrypt’s servers, continuously. To mitigate this, we plan to…