
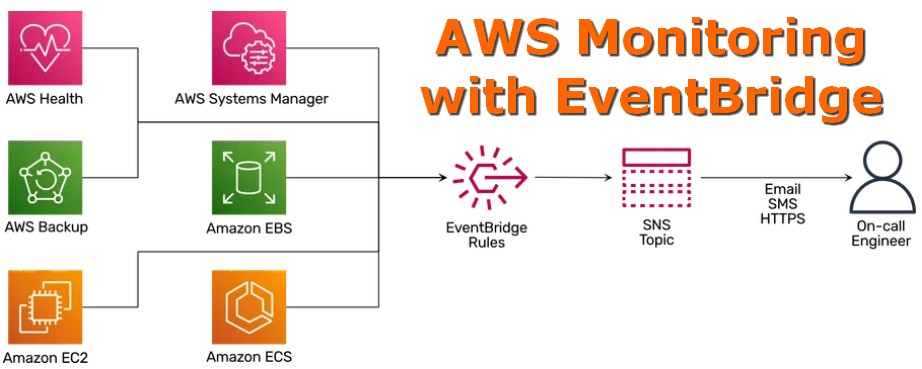
AWS Monitoring with EventBridge
https://cloudonaut.io/aws-monitoring-with-eventbridge/
Monitoring:
▪️ AWS account root user login
▪️ AWS Health announcements
▪️ EC2 Auto Scaling
▪️ EBS Snapshots
▪️ SSM Automation
▪️ ECS Tasks
▪️ ECR Image Scan
▪️ ACM
▪️ AWS Backup
▪️ Elastic Beanstalk
#EvenBridge #monitoring
https://cloudonaut.io/aws-monitoring-with-eventbridge/
Monitoring:
▪️ AWS account root user login
▪️ AWS Health announcements
▪️ EC2 Auto Scaling
▪️ EBS Snapshots
▪️ SSM Automation
▪️ ECS Tasks
▪️ ECR Image Scan
▪️ ACM
▪️ AWS Backup
▪️ Elastic Beanstalk
#EvenBridge #monitoring
{kind=link}
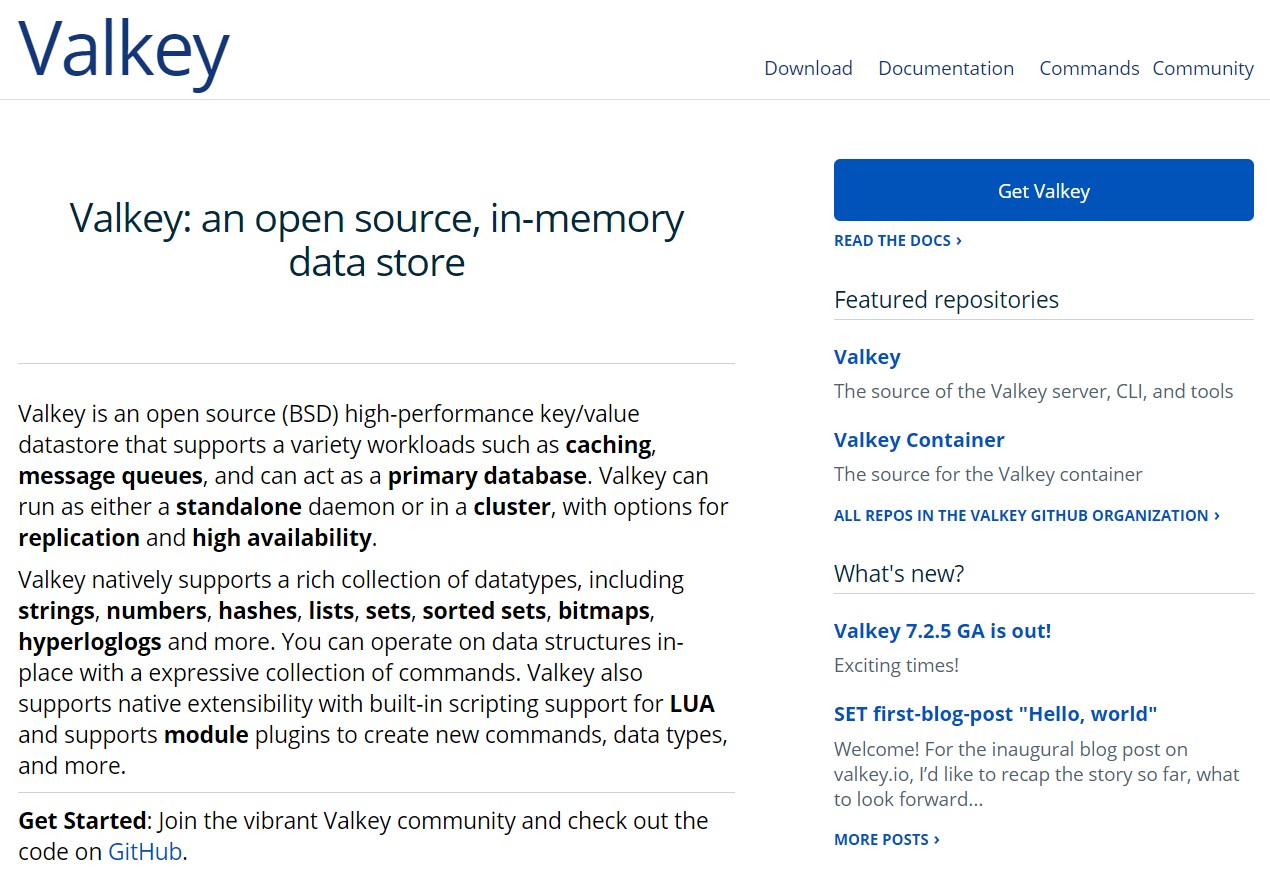
First release from Valkey (open source Redis) - version 7.2.5
https://valkey.io
❌ Redis is no longer licensed as Open Source.
🤝 Valkey is supported by major cloud giants including AWS, Google, Oracle.
#redis #valkey
https://valkey.io
❌ Redis is no longer licensed as Open Source.
🤝 Valkey is supported by major cloud giants including AWS, Google, Oracle.
#redis #valkey
{kind=link}
It is not a bug, it is by design.
https://medium.com/@maciej.pocwierz/how-an-empty-s3-bucket-can-make-your-aws-bill-explode-934a383cb8b1
Краткое изложение — автор статьи в результате экспериментов получил счёт на 1000+ долларов за пустой (!) приватный (!) S3 бакет.
Прочитав документацию, он обнаружил, что всё верно, так может быть. Мало того, техподдержка подтвердила: да, это предполагаемое поведение — владелец бакета платит за обращения к нему, включая те, что дают ошибку аутентификации. То есть в том числе от анонимных пользователей (читай "через интернет").
И это только сейчас заметили?!?
Нет, на моей памяти раз в несколько лет эта тема поднимается. Например, вот свежее обсуждение на Reddit (2024):
https://www.reddit.com/r/aws/comments/1cg7ce8/how_an_empty_private_s3_bucket_can_make_your_bill/
А вот она же трёхлетней давности (2021):
https://www.reddit.com/r/aws/comments/mwpuys/exploitable_hole_in_s3_requester_pays_bucket_to/
Вот обобщение в виде Denial-of-Wallet attacks (2020):
https://portswigger.net/daily-swig/denial-of-wallet-attacks-how-to-protect-against-costly-exploits-targeting-serverless-setups
S3 Requester Pays
Кто сдавал на сертификацию :) знают про существование такого режима и даже предполагают, что его недавно сделали как раз для борьбы с подобными проблемами.
Нет, это древняя фича (2008):
https://aws.amazon.com/blogs/aws/bits-for-sale-amazon-s3-requester-payment-model/
Но главное, она не защитит от подобной проблемы, так как:
Bucket owner is charged for the request under the following conditions:
• Request authentication fails (HTTP code 403).
• The request is anonymous (HTTP code 403).
Как же защититься от этого?!?
Ответ читайте в нашей популярной книжке "Никак".
◾ Можно генерировать длинные имена S3 бакетов из случайных символов (бесплатно)
◾ Использовать AWS Shield Advanced (3k$/month)
◾ Написать
◾ Разрешить доступ только из своей VPC (см. предыдущий пункт)
◾ Добавить в Readme "Я тебя найду по айпи!!" (недорого)
В общем, рекомендация почитать книжку оказывается наиболее актуальной.
But why?!?
S3 — очень старый сервис, некоторые даже думают, первый (в реальности первый SQS). Когда его придумывали, не было проблемы с приватностью (этого добра всегда есть и будет в on-premise варианте), была обратная проблема — сделать публичным. По дизайну сервис S3 и, главное, S3 API — публичные. Это нужно зафиксировать.
Все объекты в бакете можно сделать публичными с помощью S3 ACL. Да, именно того, что лишь год назад был по дефолту выключен.
Концепция VPC , а после и понятие "приватные бакеты", появились существенно позже, в 2011-м году. То есть важно отметить, это больше "маркетинговое" название, ибо by design сами бакеты публичные или могут таким стать, а также уникальные (всегда можно определить наличие такого, просто попытавшись создать и получив ошибку, что имя "занято").
Короче, невозможно полностью и бесплатно защититься от Denial-of-Wallet attacks по определению.
И что, реально так всё плохо?
Нет. Стоит помнить — проблема была всегда. У AWS есть способы её детекта и разрешения, в том числе с помощью техподдержки. Случайно сгенерировать существенный биллинг непросто, т.к. это должны быть не миллионы. а миллиарды запросов. Плюс, конечно же, у вас обязательно должен быть настроен алерт на бюджет. :)
А как у других?
В Google:
Generally, you are not charged for operations that return 307, 4xx, or 5xx responses. The exception is 404 responses returned by buckets with Website Configuration enabled and the NotFoundPage property set to a public object in that bucket.
Итого, AWS есть, что улучшать. И публичное обсуждение старой архитектурной проблемы — отличный стимул.
#S3
https://medium.com/@maciej.pocwierz/how-an-empty-s3-bucket-can-make-your-aws-bill-explode-934a383cb8b1
Краткое изложение — автор статьи в результате экспериментов получил счёт на 1000+ долларов за пустой (!) приватный (!) S3 бакет.
Прочитав документацию, он обнаружил, что всё верно, так может быть. Мало того, техподдержка подтвердила: да, это предполагаемое поведение — владелец бакета платит за обращения к нему, включая те, что дают ошибку аутентификации. То есть в том числе от анонимных пользователей (читай "через интернет").
И это только сейчас заметили?!?
Нет, на моей памяти раз в несколько лет эта тема поднимается. Например, вот свежее обсуждение на Reddit (2024):
https://www.reddit.com/r/aws/comments/1cg7ce8/how_an_empty_private_s3_bucket_can_make_your_bill/
А вот она же трёхлетней давности (2021):
https://www.reddit.com/r/aws/comments/mwpuys/exploitable_hole_in_s3_requester_pays_bucket_to/
Вот обобщение в виде Denial-of-Wallet attacks (2020):
https://portswigger.net/daily-swig/denial-of-wallet-attacks-how-to-protect-against-costly-exploits-targeting-serverless-setups
S3 Requester Pays
Кто сдавал на сертификацию :) знают про существование такого режима и даже предполагают, что его недавно сделали как раз для борьбы с подобными проблемами.
Нет, это древняя фича (2008):
https://aws.amazon.com/blogs/aws/bits-for-sale-amazon-s3-requester-payment-model/
Но главное, она не защитит от подобной проблемы, так как:
Bucket owner is charged for the request under the following conditions:
• Request authentication fails (HTTP code 403).
• The request is anonymous (HTTP code 403).
Как же защититься от этого?!?
◾ Можно генерировать длинные имена S3 бакетов из случайных символов (бесплатно)
◾ Использовать AWS Shield Advanced (3k$/month)
◾ Написать
<что угодно> в S3 bucket policy — не поможет (см. Request authentication fails)◾ Разрешить доступ только из своей VPC (см. предыдущий пункт)
◾ Добавить в Readme "Я тебя найду по айпи!!" (недорого)
В общем, рекомендация почитать книжку оказывается наиболее актуальной.
But why?!?
It is not a bug, it is by design.S3 — очень старый сервис, некоторые даже думают, первый (в реальности первый SQS). Когда его придумывали, не было проблемы с приватностью (этого добра всегда есть и будет в on-premise варианте), была обратная проблема — сделать публичным. По дизайну сервис S3 и, главное, S3 API — публичные. Это нужно зафиксировать.
Все объекты в бакете можно сделать публичными с помощью S3 ACL. Да, именно того, что лишь год назад был по дефолту выключен.
Концепция VPC , а после и понятие "приватные бакеты", появились существенно позже, в 2011-м году. То есть важно отметить, это больше "маркетинговое" название, ибо by design сами бакеты публичные или могут таким стать, а также уникальные (всегда можно определить наличие такого, просто попытавшись создать и получив ошибку, что имя "занято").
Короче, невозможно полностью и бесплатно защититься от Denial-of-Wallet attacks по определению.
И что, реально так всё плохо?
Нет. Стоит помнить — проблема была всегда. У AWS есть способы её детекта и разрешения, в том числе с помощью техподдержки. Случайно сгенерировать существенный биллинг непросто, т.к. это должны быть не миллионы. а миллиарды запросов. Плюс, конечно же, у вас обязательно должен быть настроен алерт на бюджет. :)
А как у других?
В Google:
Generally, you are not charged for operations that return 307, 4xx, or 5xx responses. The exception is 404 responses returned by buckets with Website Configuration enabled and the NotFoundPage property set to a public object in that bucket.
Итого, AWS есть, что улучшать. И публичное обсуждение старой архитектурной проблемы — отличный стимул.
#S3
Medium
How an empty S3 bucket can make your AWS bill explode
Imagine you create an empty, private AWS S3 bucket in a region of your preference. What will your AWS bill be the next morning?
Amazon Q Developer
https://aws.amazon.com/blogs/aws/amazon-q-developer-now-generally-available-includes-new-capabilities-to-reimagine-developer-experience/
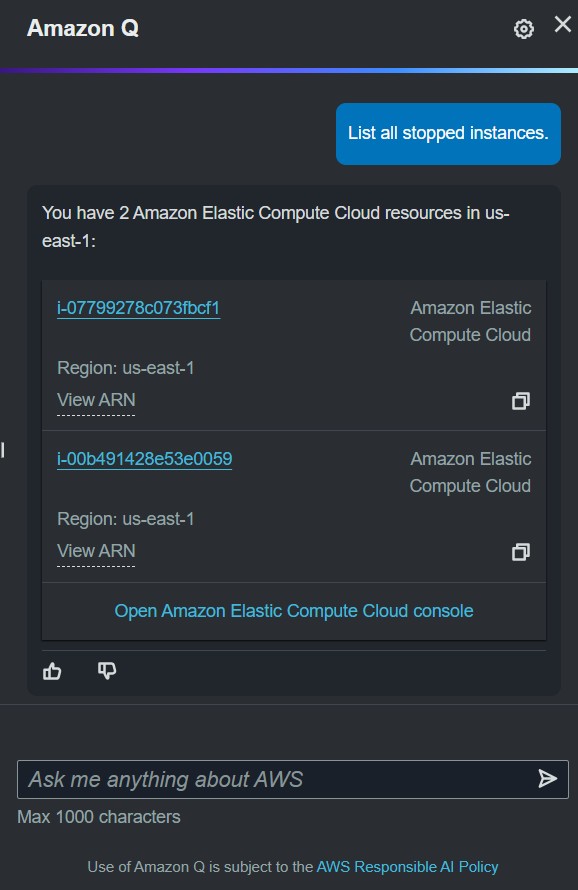
Если вы игнорировали Q до этого момента, то теперь он реально полезен для рутинных дел, потому что подтягивает все ресурсы аккаунта (видимо из AWS Config и даже, если он не включён? 😀).
Например, можно посмотреть, где стопнутые инстансы во всём аккаунте по регионам (см. картинку).
Мало того,для неграмотных тех, кому лень читать AWC CLI документацию, теперь Q напишет нужную команду по запросу... Хм, все мои попытки со своей командой провалились, значит придётся поверить на слово (потом допилят, альфа версия, все дела) - см. в статье.
В общем, польза есть, пользуемся.
#Q
https://aws.amazon.com/blogs/aws/amazon-q-developer-now-generally-available-includes-new-capabilities-to-reimagine-developer-experience/
Если вы игнорировали Q до этого момента, то теперь он реально полезен для рутинных дел, потому что подтягивает все ресурсы аккаунта (видимо из AWS Config и даже, если он не включён? 😀).
Например, можно посмотреть, где стопнутые инстансы во всём аккаунте по регионам (см. картинку).
Мало того,
В общем, польза есть, пользуемся.
#Q
{kind=link}
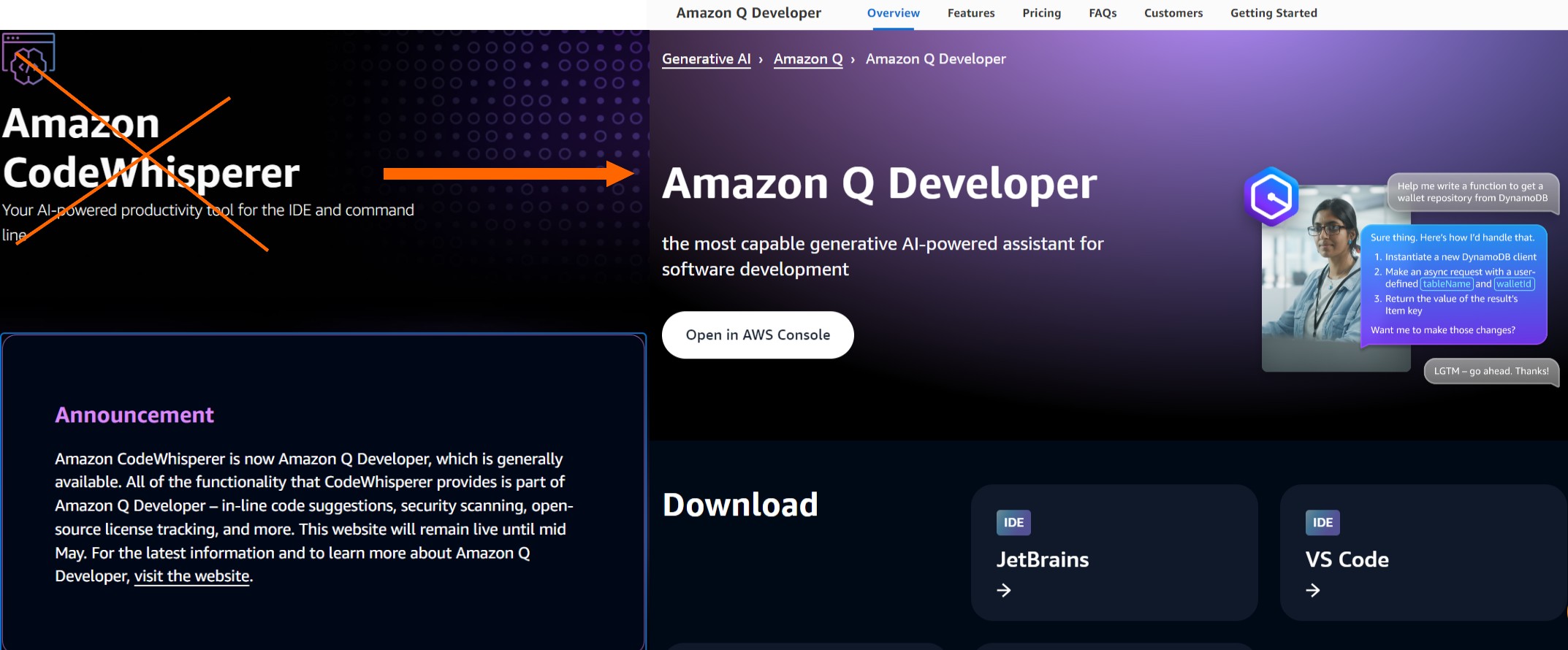
Amazon CodeWhisper is now Amazon Q Developer
✅ All of the functionality that CodeWhisperer provides is part of Amazon Q Developer.
https://aws.amazon.com/q/developer/
⏳ The old CodeWhisperer website will remain live until mid May.
https://aws.amazon.com/codewhisperer/
#CodeWhisperer #Qdev
✅ All of the functionality that CodeWhisperer provides is part of Amazon Q Developer.
https://aws.amazon.com/q/developer/
⏳ The old CodeWhisperer website will remain live until mid May.
https://aws.amazon.com/codewhisperer/
#CodeWhisperer #Qdev
{kind=link}
⚡️ Dropbox has been hacked - change your password and revoke your tokens.
📅 Date of Breach: April 24, 2024
What’s At Risk?
◘Emails & Usernames
◘Phone Numbers
◘Hashed Passwords
◘API Keys
◘OAuth Tokens
◘Multi-Factor Authentication Details
https://www.sec.gov/Archives/edgar/data/1467623/000146762324000024/dbx-20240429.htm
Immediate actions recommended:
1️⃣ Change your password NOW
2️⃣ Revoke and renew API keys and OAuth tokens
3️⃣ Review and strengthen MFA settings
📅 Date of Breach: April 24, 2024
What’s At Risk?
◘Emails & Usernames
◘Phone Numbers
◘Hashed Passwords
◘API Keys
◘OAuth Tokens
◘Multi-Factor Authentication Details
https://www.sec.gov/Archives/edgar/data/1467623/000146762324000024/dbx-20240429.htm
Immediate actions recommended:
1️⃣ Change your password NOW
2️⃣ Revoke and renew API keys and OAuth tokens
3️⃣ Review and strengthen MFA settings
Karpenter at Slack
https://aws.amazon.com/blogs/containers/how-slack-adopted-karpenter-to-increase-operational-and-cost-efficiency/
🔹 Efficiency boosted - Optimal instance selection for improved cluster utilization.
🔹 Cost reduction - Achieved a 12% savings on EKS compute costs.
🔹 Rapid scaling - Faster node provisioning directly via Amazon EC2 API.
🔹 Simplified management - Fewer Autoscaling Groups and streamlined operations.
🔹 Enhanced upgrades - Quicker, more efficient system upgrades.
🔹 Flexibility - Custom NodePool and EC2NodeClass across 200+ clusters.
#Karpenter #EKS
https://aws.amazon.com/blogs/containers/how-slack-adopted-karpenter-to-increase-operational-and-cost-efficiency/
🔹 Efficiency boosted - Optimal instance selection for improved cluster utilization.
🔹 Cost reduction - Achieved a 12% savings on EKS compute costs.
🔹 Rapid scaling - Faster node provisioning directly via Amazon EC2 API.
🔹 Simplified management - Fewer Autoscaling Groups and streamlined operations.
🔹 Enhanced upgrades - Quicker, more efficient system upgrades.
🔹 Flexibility - Custom NodePool and EC2NodeClass across 200+ clusters.
#Karpenter #EKS
Amazon
How Slack adopted Karpenter to increase Operational and Cost Efficiency | Amazon Web Services
Bedrock – Slack’s internal Kubernetes platform Slack is the AI-powered platform for work that connects people, conversations, apps, and systems together in one place. Slack adopted Amazon Elastic Kubernetes Service (Amazon ) to build “Bedrock,” the codename…
6️⃣ CloudWatch Agent можно установить в виртуалку прямо из AWS Console. Но это не точно.
Коллеги, подскажите, у кого-то работает сие чудо?
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/install-and-configure-cloudwatch-agent-using-ec2-console.html#install-and-configure-cw-agent-procedure
Всю жизнь мечтал. Вопрос каждого первого начинающего работать с AWS — а где нагрузка по процессам и свободное место на диске? Неужели свершилось?
Кто пропустил, краткая история предыдущих серий CloudWatch Agent.
1️⃣ Ничего не было,выживали мониторили, как могли.
2️⃣ Скрипт на Perl, ура, спасибо, что не Fortran! Установка ручками через SSH.
3️⃣ Везде Docker. Вдеревне Гадюкино CloudWatch Agent — скрипт на Perl, установка через SSH.
4️⃣ Везде Kubernetes и Serverless, в CloudWatch Agent — скрипт на Perl, установка через CloudFormation.
5️⃣ CloudWatch Agent переписали на Go, установка через SSM.
#CloudWatch
Коллеги, подскажите, у кого-то работает сие чудо?
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/install-and-configure-cloudwatch-agent-using-ec2-console.html#install-and-configure-cw-agent-procedure
Всю жизнь мечтал. Вопрос каждого первого начинающего работать с AWS — а где нагрузка по процессам и свободное место на диске? Неужели свершилось?
Кто пропустил, краткая история предыдущих серий CloudWatch Agent.
1️⃣ Ничего не было,
2️⃣ Скрипт на Perl, ура, спасибо, что не Fortran! Установка ручками через SSH.
3️⃣ Везде Docker. В
4️⃣ Везде Kubernetes и Serverless, в CloudWatch Agent — скрипт на Perl, установка через CloudFormation.
5️⃣ CloudWatch Agent переписали на Go, установка через SSM.
#CloudWatch
Amazon
Install and configure the CloudWatch agent using the Amazon EC2 console to add additional metrics - Amazon Elastic Compute Cloud
By default, Amazon CloudWatch provides basic metrics, such as CPUUtilization and NetworkIn , for monitoring your Amazon EC2 instances. To collect additional metrics, you can install the CloudWatch agent on your EC2 instances, and then configure the agent…
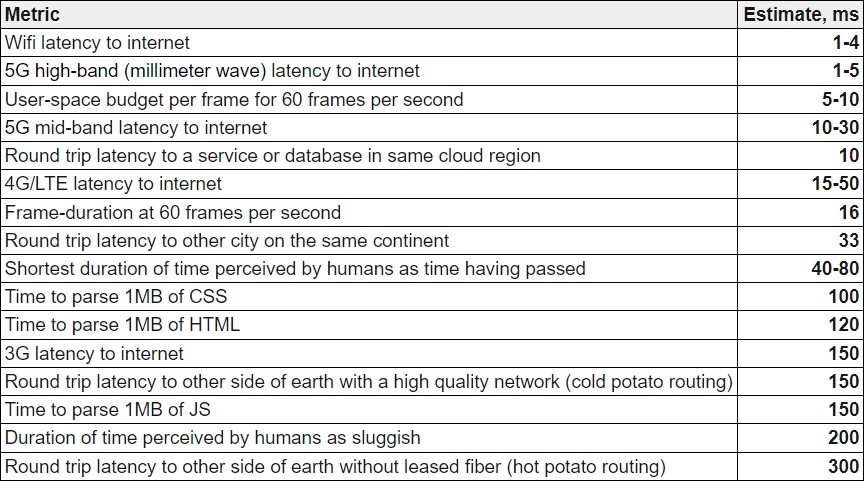
Latency numbers every frontend developer should know
https://vercel.com/blog/latency-numbers-every-web-developer-should-know
В списке определённо не хватает:
▪️ Загрузить все шрифты сразу, включая "нужно посмотреть как будет", "этот тоже прикольный" и "пусть будет на всякий" —
▪️ Выкачать пол-интернета, чтобы подгрузить библиотеку для отрисовки обычной формы —
▪️ Добавить падающие бесящие снежинки на главный экран "ну, ведь зима же" —
▪️ "Не знаю, у меня локально всё работает" —
#latency #frontend
https://vercel.com/blog/latency-numbers-every-web-developer-should-know
В списке определённо не хватает:
▪️ Загрузить все шрифты сразу, включая "нужно посмотреть как будет", "этот тоже прикольный" и "пусть будет на всякий" —
800 ms.▪️ Выкачать пол-интернета, чтобы подгрузить библиотеку для отрисовки обычной формы —
2400 ms.▪️ Добавить падающие бесящие снежинки на главный экран "ну, ведь зима же" —
3600 ms.▪️ "Не знаю, у меня локально всё работает" —
Access has been blocked by CORS policy.#latency #frontend
{kind=link}
HTTP GET /comfort-zone?exist=vote
Anonymous Poll
7%
Error 301: Moved Permanently.
3%
Error 401: Unauthorized.
10%
Error 402: Payment Required.
9%
Error 404: Comfort Zone Not Found.
6%
Error 410: Gone.
6%
Error 429: Too Many Requests.
5%
Error 451: Unavailable For Legal Reasons.
4%
Error 500: Internal Comfort Error.
7%
Error 503: Service Unavailable.
44%
👀 See results.
☒ Beating the CAP Theorem Checklist
Your blog/presentation/post/comment advocates a way to beat the CAP theorem. Your idea will not work.
Here is why it won't work:
✖ you are assuming that software/network/hardware failures will not happen
✖ you pushed the actual problem to another layer of the system
✖ your solution is equivalent to an existing one that doesn't beat CAP
✖ you're actually building an AP system
✖ you're actually building a CP system
✖ you are not, in fact, designing a distributed system
Specifically, your plan fails to account for:
❌ latency is a thing that exists
❌ high latency is indistinguishable from splits or unavailability
❌ network topology changes over time
❌ there might be more than 1 partition at the same time
❌ split nodes can vanish forever
❌ a split node cannot be differentiated from a crashed one by its peers
❌ clients are also part of the distributed system
❌ stable storage may become corrupt
❌ network failures will actually happen
❌ hardware failures will actually happen
❌ operator errors will actually happen
❌ deleted items will come back after synchronization with other nodes
❌ clocks drift across multiple parts of the system, forward and backwards in time
❌ things can happen at the same time on different machines
❌ side effects cannot be rolled back the way transactions can
❌ failures can occur while in a critical part of your algorithm
❌ designing distributed systems is actually hard
❌ implementing them is harder still
And the following technical objections may apply:
Furthermore, this is what I think about you:
❎ nice try, but blatantly false advertising
❎ you are badly reinventing existing concepts and should do some research
❎ in particular, you should read the definition of the word 'theorem'
❎ also you should read the definition of 'distributed system'
❎ you have no idea what you are doing
❎ do you even know what a logical clock is?
❎ you shouldn't be in charge of people's data
Source: https://ferd.ca/beating-the-cap-theorem-checklist.html
#architecture #distributed_system
Your blog/presentation/post/comment advocates a way to beat the CAP theorem. Your idea will not work.
Here is why it won't work:
✖ you are assuming that software/network/hardware failures will not happen
✖ you pushed the actual problem to another layer of the system
✖ your solution is equivalent to an existing one that doesn't beat CAP
✖ you're actually building an AP system
✖ you're actually building a CP system
✖ you are not, in fact, designing a distributed system
Specifically, your plan fails to account for:
❌ latency is a thing that exists
❌ high latency is indistinguishable from splits or unavailability
❌ network topology changes over time
❌ there might be more than 1 partition at the same time
❌ split nodes can vanish forever
❌ a split node cannot be differentiated from a crashed one by its peers
❌ clients are also part of the distributed system
❌ stable storage may become corrupt
❌ network failures will actually happen
❌ hardware failures will actually happen
❌ operator errors will actually happen
❌ deleted items will come back after synchronization with other nodes
❌ clocks drift across multiple parts of the system, forward and backwards in time
❌ things can happen at the same time on different machines
❌ side effects cannot be rolled back the way transactions can
❌ failures can occur while in a critical part of your algorithm
❌ designing distributed systems is actually hard
❌ implementing them is harder still
And the following technical objections may apply:
✕ your solution requires a central authority that cannot be unavailable✕ read-only mode is still unavailability for writes✕ your quorum size cannot be changed over time✕ your cluster size cannot be changed over time✕ using 'infinite timeouts' is not an acceptable solution to lost messages✕ your system accumulates data forever and assumes infinite storage✕ re-synchronizing data will require more bandwidth than everything else put together✕ acknowledging reception is not the same as confirming consumption of messages✕ you don't even wait for messages to be written to disk✕ you assume short periods of unavailability are insignificant✕ you are basing yourself on a paper or theory that has not yet been provenFurthermore, this is what I think about you:
❎ nice try, but blatantly false advertising
❎ you are badly reinventing existing concepts and should do some research
❎ in particular, you should read the definition of the word 'theorem'
❎ also you should read the definition of 'distributed system'
❎ you have no idea what you are doing
❎ do you even know what a logical clock is?
❎ you shouldn't be in charge of people's data
Source: https://ferd.ca/beating-the-cap-theorem-checklist.html
#architecture #distributed_system
Amplify Gen 2
https://aws.amazon.com/blogs/mobile/amplify-gen2-ga/
With Amplify Gen 2, every part of your app’s cloud backend is defined in TypeScript. Need an Auth backend? TypeScript. Data backend? TypeScript. Storage backend? TypeScript. Everything is defined in TypeScript. What’s not changing? Amplify is built by and on AWS, giving you the ability to add any of the 200+ AWS services when you need to. Including generative AI services such as Amazon Bedrock? You guessed it: TypeScript.
#Amplify
https://aws.amazon.com/blogs/mobile/amplify-gen2-ga/
With Amplify Gen 2, every part of your app’s cloud backend is defined in TypeScript. Need an Auth backend? TypeScript. Data backend? TypeScript. Storage backend? TypeScript. Everything is defined in TypeScript. What’s not changing? Amplify is built by and on AWS, giving you the ability to add any of the 200+ AWS services when you need to. Including generative AI services such as Amazon Bedrock? You guessed it: TypeScript.
#Amplify
Amazon
Fullstack TypeScript: Reintroducing AWS Amplify | Amazon Web Services
We are thrilled to announce the general availability of AWS Amplify Gen 2, a fullstack TypeScript experience for building cloud-connected apps. AWS Amplify helps you accomplish two jobs: Host your web app Build and connect to a cloud backend With Amplify…
Forwarded from Rinat Uzbekov
Календарь AWS Hands-on Workshops на ближайшее время
https://aws-experience.com/emea/smb/events/series/aws-cloudboost
https://aws-experience.com/emea/smb/events/series/aws-cloudboost
AWS Connected Community
AWS CloudBoost
Gain hands-on AWS cloud experience through our exciting series of webinars and workshops. From foundational to specialist topics, put theory into practice as you build your cloud skills.
Forwarded from Viktor Vedmich (AWS)
Вот и вышло наше новое видео! Совместно с архитектором Anton Kovalenko мы рассматриваем Amazon CodeCatalyst. Подробно разбираемся в его возможностях и функционале. https://youtu.be/WEK7lTsL7ek
В этом видео вы узнаете:
- Зачем нужен CodeCatalyst и почему он появился
- Как авторизоваться и начать работу
- Создание нового проекта с нуля
- Обзор основных возможностей и функционала
- Работа с Dev Environment
- Создание собственных Workflows
- Настройка Production окружений
- Использование секретов (Secrets)
- Демонстрация полного цикла разработки - от изменения кода до деплоя
- Интеграция с Amazon Q - ассистент теперь может решать задачи сам
В этом видео вы узнаете:
- Зачем нужен CodeCatalyst и почему он появился
- Как авторизоваться и начать работу
- Создание нового проекта с нуля
- Обзор основных возможностей и функционала
- Работа с Dev Environment
- Создание собственных Workflows
- Настройка Production окружений
- Использование секретов (Secrets)
- Демонстрация полного цикла разработки - от изменения кода до деплоя
- Интеграция с Amazon Q - ассистент теперь может решать задачи сам
YouTube
Разбираем Amazon CodeCatalyst за 50 минут
В этом видео мы вместе с архитектором Антоном Коваленко подробно разбираем новый облачный сервис Amazon CodeCatalyst:
• Зачем нужен CodeCatalyst и почему он появился
• Как авторизоваться и начать работу
• Создание нового проекта с нуля
• Обзор основных…
• Зачем нужен CodeCatalyst и почему он появился
• Как авторизоваться и начать работу
• Создание нового проекта с нуля
• Обзор основных…