{kind=link}

Привет, друзья!
Вот и последний пост на канале в этом году. И он будет не про SEO!
🎄 Я надеюсь, что в этот день вы будете со своими родными, близкими и друзьями встречать новый 2023 год с хорошим настроением и позитивными мыслями!
🥳 И пусть у нас с вами все складывается удачно в следующем году, чтобы мы могли его вспомнить добрыми словами!
🥂 От себя и нашей команды хочу поздравить всех вас с наступающими праздниками!
🤣 А у меня был вчера интересный опыт – корпоратив по скайпу… Никогда такого не было и, надеюсь, однажды не придется сказать «и вот опять».
🧑🏼💻 Это хоть и необычно, но не так весело, а я бы предпочел оказаться по ту сторону экрана. Неужели так и проходят корпоративы большинства удалёнщиков?!
🤟🏻 До связи в следующем году, дорогие друзья! Буду рад, если вы оставите свои поздравления и пожелания в комментариях.
PS Памятная фотография прилагается!
Вот и последний пост на канале в этом году. И он будет не про SEO!
🎄 Я надеюсь, что в этот день вы будете со своими родными, близкими и друзьями встречать новый 2023 год с хорошим настроением и позитивными мыслями!
🥳 И пусть у нас с вами все складывается удачно в следующем году, чтобы мы могли его вспомнить добрыми словами!
🥂 От себя и нашей команды хочу поздравить всех вас с наступающими праздниками!
🤣 А у меня был вчера интересный опыт – корпоратив по скайпу… Никогда такого не было и, надеюсь, однажды не придется сказать «и вот опять».
🧑🏼💻 Это хоть и необычно, но не так весело, а я бы предпочел оказаться по ту сторону экрана. Неужели так и проходят корпоративы большинства удалёнщиков?!
🤟🏻 До связи в следующем году, дорогие друзья! Буду рад, если вы оставите свои поздравления и пожелания в комментариях.
PS Памятная фотография прилагается!
{kind=link}
С наступившим Новым Годом, ребята!
Как там ваш отдых проходит? У меня в работе! Вот за выходные начал писать сразу несколько новых постов. Один из которых сегодня закончил.
Если помните, я недавно купил MacBook PRO 14, сделал на него обзор и убрал на полку со словами: «я понял, что MacBook и MacOS – это не моё!»
Но потом решил провести эксперимент – месяц поработать на Маке.
Не знаю, каких результатов я ожидал в итоге, но как факт – теперь меня все устраивает, и я привык. Наверное, слово «привык» и является результатом.
Решил описать свои впечатления и ощущения, а также поделиться софтом, который помог мне освоиться.
Спасибо вам за советы, которые вы оставили в комментариях к прошлому посту. Теперь моя очередь делиться рекомендациями 😎
🔗 https://alaev.info/blog/post/9414
Если среди вас есть маководы и в прошлый раз вы ничего не писали, прошу вас поделиться своим джентльменским набором программ. Я буду вам очень благодарен!
PS А еще 31 декабря мы закончили обновление расширения Alaev SEO Tools – оно будет самым крупным за все время, уверен, вам понравится. Релиз на следующей неделе.
Как там ваш отдых проходит? У меня в работе! Вот за выходные начал писать сразу несколько новых постов. Один из которых сегодня закончил.
Если помните, я недавно купил MacBook PRO 14, сделал на него обзор и убрал на полку со словами: «я понял, что MacBook и MacOS – это не моё!»
Но потом решил провести эксперимент – месяц поработать на Маке.
Не знаю, каких результатов я ожидал в итоге, но как факт – теперь меня все устраивает, и я привык. Наверное, слово «привык» и является результатом.
Решил описать свои впечатления и ощущения, а также поделиться софтом, который помог мне освоиться.
Спасибо вам за советы, которые вы оставили в комментариях к прошлому посту. Теперь моя очередь делиться рекомендациями 😎
🔗 https://alaev.info/blog/post/9414
Если среди вас есть маководы и в прошлый раз вы ничего не писали, прошу вас поделиться своим джентльменским набором программ. Я буду вам очень благодарен!
PS А еще 31 декабря мы закончили обновление расширения Alaev SEO Tools – оно будет самым крупным за все время, уверен, вам понравится. Релиз на следующей неделе.
{kind=link}
Привет, друзья. Планировал сегодня представить вам самое крупное обновление нашего расширения Alaev SEO Tools.
Однако модерация прошла слишком быстро, и обновление вышло вчера. Зато многие из вас уже могли оценить нововведения!
🔗 Расширение, как и раньше, доступно в Chrome Web Store.
Те, у кого расширение обновилось само, уже видели ченджлог, а я хочу отдельно рассказать о самом интересном в версии 1.0.3:
- Новый стиль и возможности панели для Вордстат: ее можно сворачивать, закрывать, перемещать по странице, выбирать сразу несколько регионов.
- Добавили нумерацию результатов в выдаче Яндекса и Google, которая не бросается в глаза и не раздражает.
- Многие просили выводить структуру заголовков H1-H6, как на странице. Согласен – сделали!
- Стали собирать lang и hreflang – вдруг кому-то пригодится.
- Сделали много визуальных улучшений, пересмотрели содержимое каждой вкладки и кое-что поменяли местами.
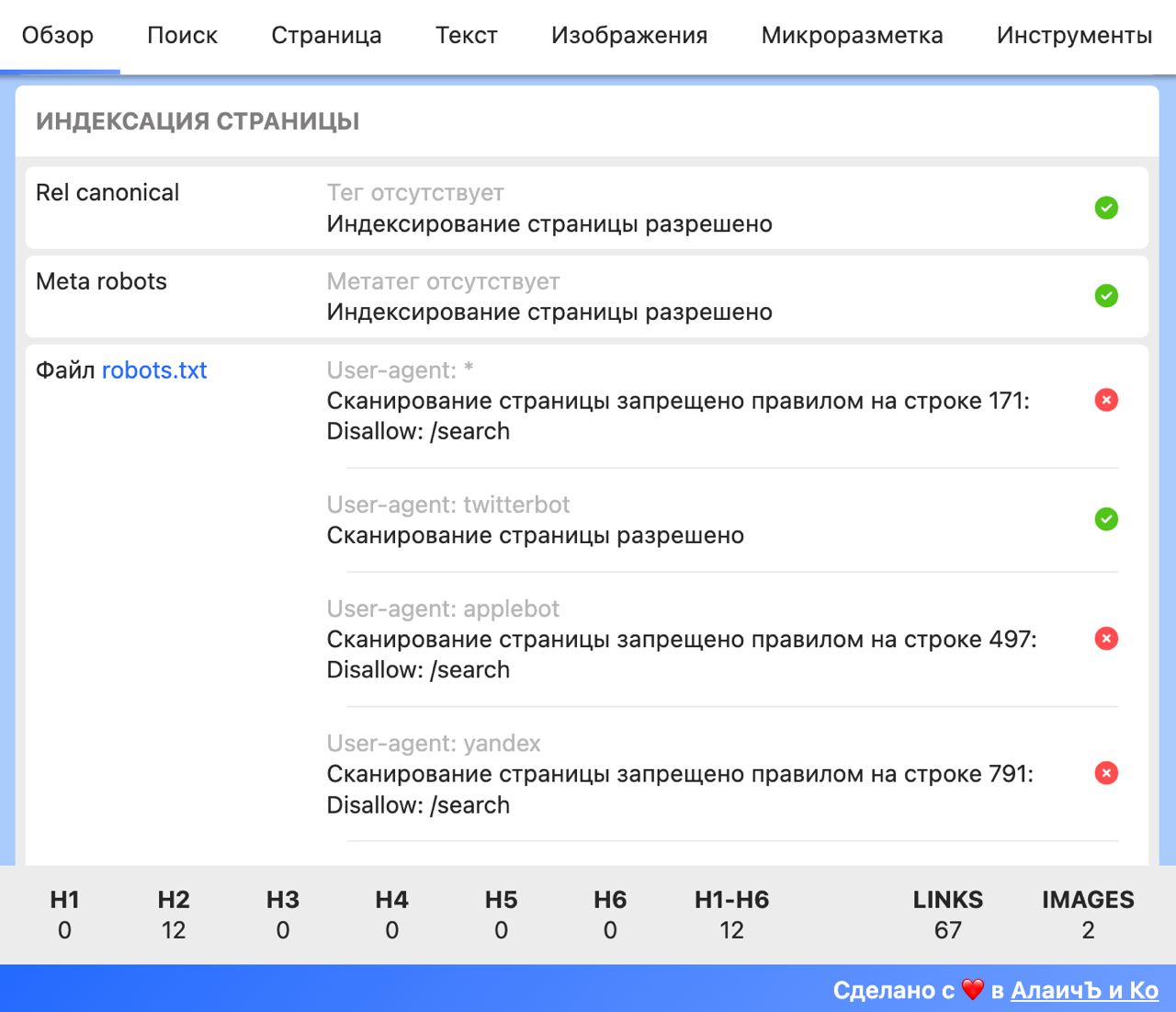
Главная и самая крутая фича обновления – проверка индексации страницы!
В отличие от других похожих расширений, мы не просто парсим и выводим содержимое rel canonical, meta robots.
Мы анализируем корректность заполнения тегов, сообщаем о найденных ошибках и выводим статус индексации страницы.
А также анализируем файл robots.txt, все юзер-агенты, и, если страница закрыта от сканирования, сообщаем, каким именно правилом и на какой строке.
Короче, там под капотом начал зарождаться большой аналитический модуль, который мы будем развивать в следующих версиях. Вам понравится!
Как всегда, с ❤️ от команды @alaevseo
⭐️ Буду вам признателен, если оставите нам оценку и отзыв в Chrome Web Store.
📍 А сейчас открываем пункт приема пожеланий и предложений в комментариях!
Однако модерация прошла слишком быстро, и обновление вышло вчера. Зато многие из вас уже могли оценить нововведения!
🔗 Расширение, как и раньше, доступно в Chrome Web Store.
Те, у кого расширение обновилось само, уже видели ченджлог, а я хочу отдельно рассказать о самом интересном в версии 1.0.3:
- Новый стиль и возможности панели для Вордстат: ее можно сворачивать, закрывать, перемещать по странице, выбирать сразу несколько регионов.
- Добавили нумерацию результатов в выдаче Яндекса и Google, которая не бросается в глаза и не раздражает.
- Многие просили выводить структуру заголовков H1-H6, как на странице. Согласен – сделали!
- Стали собирать lang и hreflang – вдруг кому-то пригодится.
- Сделали много визуальных улучшений, пересмотрели содержимое каждой вкладки и кое-что поменяли местами.
Главная и самая крутая фича обновления – проверка индексации страницы!
В отличие от других похожих расширений, мы не просто парсим и выводим содержимое rel canonical, meta robots.
Мы анализируем корректность заполнения тегов, сообщаем о найденных ошибках и выводим статус индексации страницы.
А также анализируем файл robots.txt, все юзер-агенты, и, если страница закрыта от сканирования, сообщаем, каким именно правилом и на какой строке.
Короче, там под капотом начал зарождаться большой аналитический модуль, который мы будем развивать в следующих версиях. Вам понравится!
Как всегда, с ❤️ от команды @alaevseo
⭐️ Буду вам признателен, если оставите нам оценку и отзыв в Chrome Web Store.
📍 А сейчас открываем пункт приема пожеланий и предложений в комментариях!
{kind=link}
Apple запускает Business Connect в качестве конкурента Google Мой Бизнес. По крайней мере, они так считают.
Apple Business Connect позиционируется как совершенно новый продукт, который позволяет управлять своей компанией на Apple Maps. Но на самом деле это перезапуск Apple Maps Connect, запущенного десять лет назад.
Там появилось множество новых функций: изображения и фотографии, информация о компании и даже настраиваемые call-to-action кнопки: заказ еды, бронирование гостиниц, покупка билетов, меню ресторана, расписание киносеансов и т. п.
Появился и раздел со статистикой, чтобы понимать, как пользователи взаимодействуют с карточкой компании: когда и как часто люди ее находили, чем интересовались, прежде чем попасть на карточку и т. д.
Короче, чуваки решили изобрести Google Business Profile, но для Apple Maps 😎
Не знаю, будет ли это поддерживаться и работать в РФ, но у меня даже нет айфона, чтобы это проверить.
Если кто-то из вас проверит, дайте знать!
Apple Business Connect позиционируется как совершенно новый продукт, который позволяет управлять своей компанией на Apple Maps. Но на самом деле это перезапуск Apple Maps Connect, запущенного десять лет назад.
Там появилось множество новых функций: изображения и фотографии, информация о компании и даже настраиваемые call-to-action кнопки: заказ еды, бронирование гостиниц, покупка билетов, меню ресторана, расписание киносеансов и т. п.
Появился и раздел со статистикой, чтобы понимать, как пользователи взаимодействуют с карточкой компании: когда и как часто люди ее находили, чем интересовались, прежде чем попасть на карточку и т. д.
Короче, чуваки решили изобрести Google Business Profile, но для Apple Maps 😎
Не знаю, будет ли это поддерживаться и работать в РФ, но у меня даже нет айфона, чтобы это проверить.
Если кто-то из вас проверит, дайте знать!
{kind=link}
Привет, друзья.
Полгода назад я писал, что Google добавил возможность скрыть адрес в профиле компании.
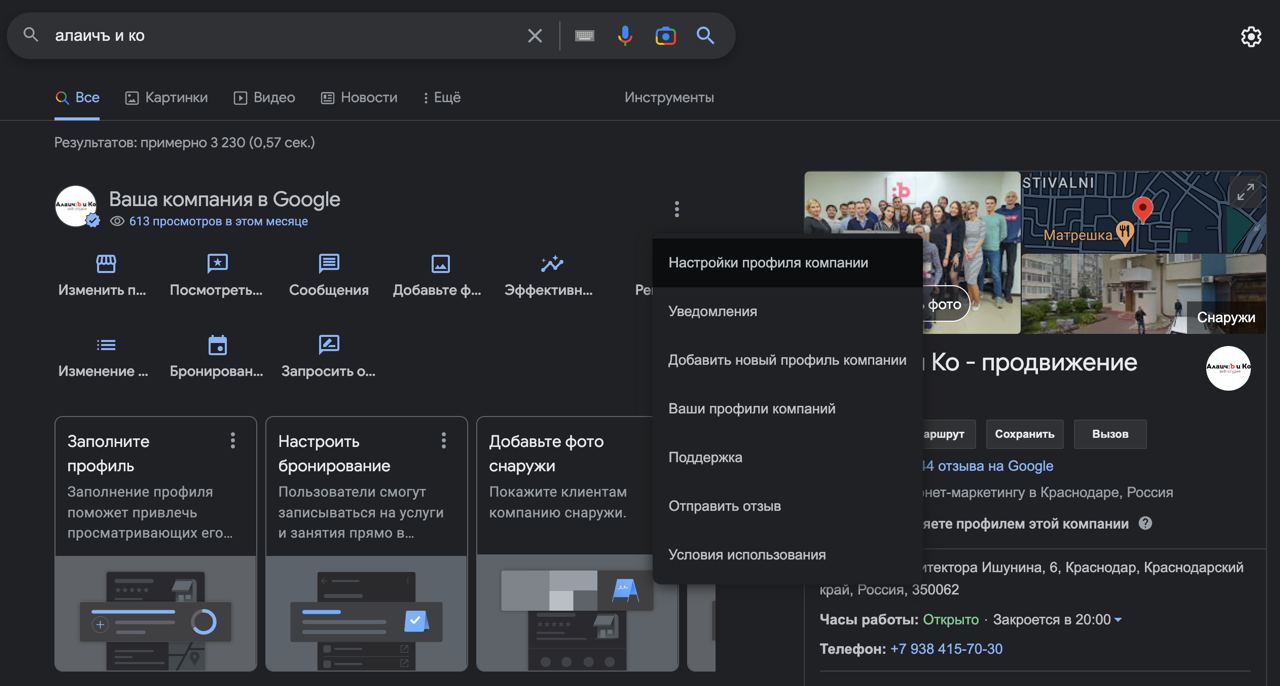
Вдруг вы не знали, но недавно появилась новая настройка, позволяющая скрыть и номер телефона у карточки своей компании в Google My Business (GMB).
Чтобы это сделать, авторизуйтесь в Гугле с тем аккаунтом, где подтверждена компания, вбейте в поиск название компании и увидите карточку и заголовок «Ваша компания в Google».
В меню (три точки) справа от заголовка выбирайте «Настройки профиля компании» – «Расширенные настройки», там увидите «Номер телефона» и переключатель «Не показывать».
И еще важная штука. Даже если вы решили, что не хотите указывать номер телефона, Google по-прежнему будет предлагать пользователям добавить его с помощью «Предложить изменение». Однако, при попытке добавить номер телефона, Google выдаст ошибку и фактически не добавит его.
Сначала адрес, теперь телефон убираем – какую еще информацию об организации будем скрывать? 😂 Такими темпами будем скрывать скоро названия!
Полгода назад я писал, что Google добавил возможность скрыть адрес в профиле компании.
Вдруг вы не знали, но недавно появилась новая настройка, позволяющая скрыть и номер телефона у карточки своей компании в Google My Business (GMB).
Чтобы это сделать, авторизуйтесь в Гугле с тем аккаунтом, где подтверждена компания, вбейте в поиск название компании и увидите карточку и заголовок «Ваша компания в Google».
В меню (три точки) справа от заголовка выбирайте «Настройки профиля компании» – «Расширенные настройки», там увидите «Номер телефона» и переключатель «Не показывать».
И еще важная штука. Даже если вы решили, что не хотите указывать номер телефона, Google по-прежнему будет предлагать пользователям добавить его с помощью «Предложить изменение». Однако, при попытке добавить номер телефона, Google выдаст ошибку и фактически не добавит его.
Сначала адрес, теперь телефон убираем – какую еще информацию об организации будем скрывать? 😂 Такими темпами будем скрывать скоро названия!
{kind=link}
Google придумал ачивки для Вебмастеров :)
Зачем? Не понятно! Говорят: «Мы хотим, чтобы вам было удобно оценивать эффективность своего сайта.»
Можете посмотреть, чего достигли ваши сайты по ссылке:
https://search.google.com/search-console/insights/
Наверху страницы будет новый блок «Достижения» и сообщение «Отлично! У вашего сайта новое достижение». Нажимайте.
Есть там и парочка советов, типа:
- Как найти подходящую тему
- Создавайте качественный контент
- Помогите пользователям находить ваш контент
- Создавайте современный и привлекательный контент
Думают, как привлечь в SEO молодёжь, выросшую на играх? 😎
Зачем? Не понятно! Говорят: «Мы хотим, чтобы вам было удобно оценивать эффективность своего сайта.»
Можете посмотреть, чего достигли ваши сайты по ссылке:
https://search.google.com/search-console/insights/
Наверху страницы будет новый блок «Достижения» и сообщение «Отлично! У вашего сайта новое достижение». Нажимайте.
Есть там и парочка советов, типа:
- Как найти подходящую тему
- Создавайте качественный контент
- Помогите пользователям находить ваш контент
- Создавайте современный и привлекательный контент
Думают, как привлечь в SEO молодёжь, выросшую на играх? 😎
{kind=link}
Что задумал Yahoo!?
В Twitter появился пост в аккаунте Yahoo Search:
«Просто заглянули, чтобы напомнить всем, что мы занимались поиском до того, как это стало крутым».
🔗 https://twitter.com/yahoosearch/status/1616469629559259136
Интересно, что эти чуваки замыслили? Просто шутка или они и правда что-то хотят представить?
PS Напомню, что сейчас поиск в Яху работает на технологиях Bing (как поиск Mailru работает на базе Яндекса).
В Twitter появился пост в аккаунте Yahoo Search:
«Просто заглянули, чтобы напомнить всем, что мы занимались поиском до того, как это стало крутым».
🔗 https://twitter.com/yahoosearch/status/1616469629559259136
Интересно, что эти чуваки замыслили? Просто шутка или они и правда что-то хотят представить?
PS Напомню, что сейчас поиск в Яху работает на технологиях Bing (как поиск Mailru работает на базе Яндекса).
{kind=link}
В последнее время очень активно обсуждается ChatGPT.
Даже SEO-специалисты вовсю оценивают перспективы ИИ: сможет ли он писать тексты, выполнять какую-то примитивную работу (составлять метатеги, собирать запросы и т.д.).
Когда в прошлом году мне предлагали порассуждать о будущем SEO, я отказывался, потому что не видел ничего нового. Но с января прямо прорвало, и я думаю, что в 2023 году в SEO что-то случится, как раз связанное с ИИ.
Как обычно, варианта два: либо произойдет какой-то прорыв, и появятся новые крутые инструменты на базе ИИ, либо все обосрется, а мы пройдем мимо и забудем, типа «ну, было и было, обычный хайп, не более».
Я же склоняюсь к варианту, что действительно появятся новые инструменты и сервисы, но кардинальных перемен ждать не стоит. Сеошники внезапно не лишатся работы.
Но речь не только про SEO, потому что область применения новых технологий намного шире.
Я недавно прочитать статью (на англ.) - https://www.searchenginejournal.com/openai-gpt-4/476759/
Она называется: «Грядет GPT-4: взгляд в будущее ИИ». Это краткий пересказ интервью с гендиректором OpenAI Сэмом Альтманом. Но я расскажу еще короче.
Основное, чего стоит ожидать в будущем – мультимодальность, то есть возможность работы в нескольких режимах, таких как текст, изображения и звуки.
Сейчас GPT не самообучается и не становится лучше сам по себе. «Думаю, мы это изменим». (Но не обязательно в GPT-4.)
Выпуск GPT-4 ожидается в первом квартале 2023 года. Возможно, вместе с этим ChatGPT научится общаться не только текстом, но и с помощью изображений.
Что касается видео, то есть очень много вопросов относительно безопасности такого контента. И пока не будет полной уверенности, что это не приведет к серьезным негативным последствиям, такая возможность не появится. Именно поэтому новые технологии появляются не так быстро, как многие этого бы хотели.
А вы уже успели попробовать все эти новомодные штуки в работе или просто побаловаться? Делитесь!
Даже SEO-специалисты вовсю оценивают перспективы ИИ: сможет ли он писать тексты, выполнять какую-то примитивную работу (составлять метатеги, собирать запросы и т.д.).
Когда в прошлом году мне предлагали порассуждать о будущем SEO, я отказывался, потому что не видел ничего нового. Но с января прямо прорвало, и я думаю, что в 2023 году в SEO что-то случится, как раз связанное с ИИ.
Как обычно, варианта два: либо произойдет какой-то прорыв, и появятся новые крутые инструменты на базе ИИ, либо все обосрется, а мы пройдем мимо и забудем, типа «ну, было и было, обычный хайп, не более».
Я же склоняюсь к варианту, что действительно появятся новые инструменты и сервисы, но кардинальных перемен ждать не стоит. Сеошники внезапно не лишатся работы.
Но речь не только про SEO, потому что область применения новых технологий намного шире.
Я недавно прочитать статью (на англ.) - https://www.searchenginejournal.com/openai-gpt-4/476759/
Она называется: «Грядет GPT-4: взгляд в будущее ИИ». Это краткий пересказ интервью с гендиректором OpenAI Сэмом Альтманом. Но я расскажу еще короче.
Основное, чего стоит ожидать в будущем – мультимодальность, то есть возможность работы в нескольких режимах, таких как текст, изображения и звуки.
Сейчас GPT не самообучается и не становится лучше сам по себе. «Думаю, мы это изменим». (Но не обязательно в GPT-4.)
Выпуск GPT-4 ожидается в первом квартале 2023 года. Возможно, вместе с этим ChatGPT научится общаться не только текстом, но и с помощью изображений.
Что касается видео, то есть очень много вопросов относительно безопасности такого контента. И пока не будет полной уверенности, что это не приведет к серьезным негативным последствиям, такая возможность не появится. Именно поэтому новые технологии появляются не так быстро, как многие этого бы хотели.
А вы уже успели попробовать все эти новомодные штуки в работе или просто побаловаться? Делитесь!
{kind=link}
Вчера на своем блоге всем-известный-сеошник-из-тулы Сергей Людкевич поделился способом определения геопривязки сайта к определенному региону.
Способ старый, и я совсем о нем забыл. Просто потому что и нужды такой не было. А вам это может пригодиться. Либо просто в копилку недокументированных возможностей Яндекс поиска 😎
Сходу узнать региональную привязку сайта в Яндекс Вебмастере и Яндекс Бизнесе не получится. Но можно узнать, привязан ли сайт к определенному региону.
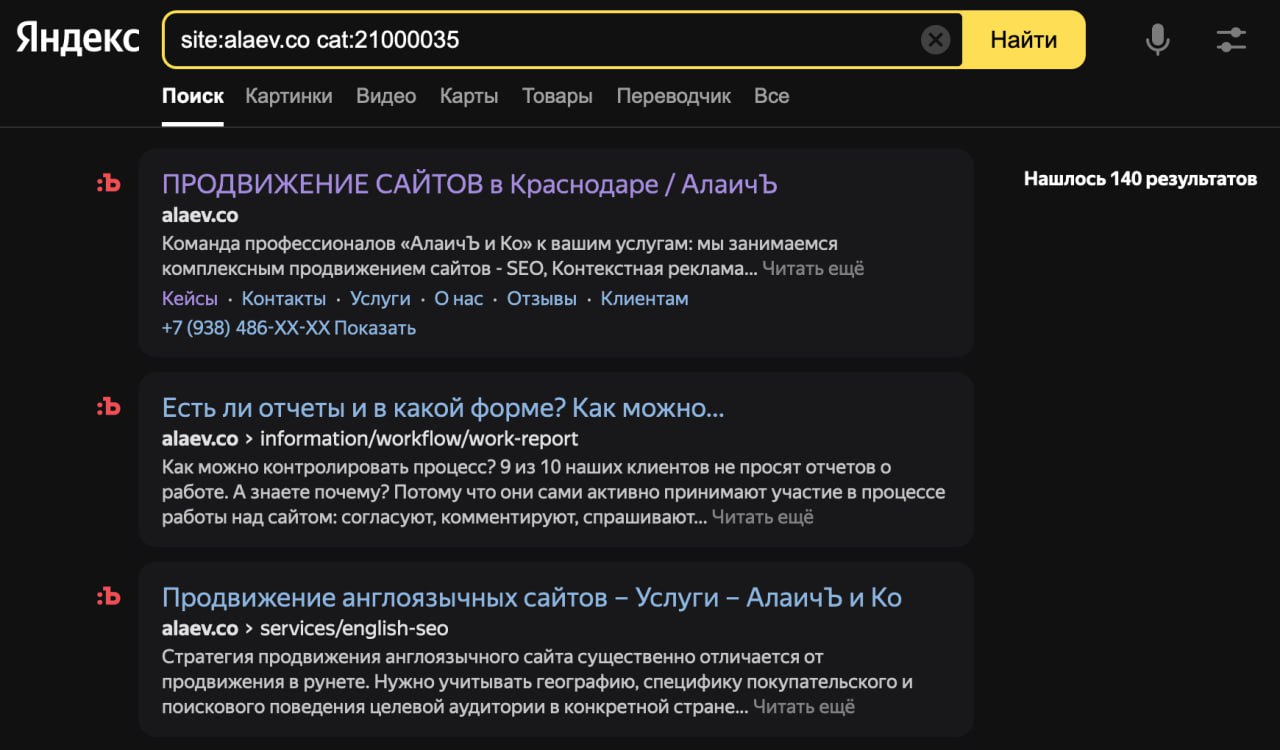
Это можно сделать с помощью документированного оператора site: и бывшего некогда документированным оператора cat:, в качестве аргумента для которого используются определенные идентификаторы, называемые смещениями.
Для проверки региональной привязки, сделанной через Яндекс Вебмастер, надо использовать смещение 21000000, а через Яндекс Бизнес - 81000000.
К смещению надо прибавить номер региона (значение get-параметра lr в URL страницы поисковой выдачи), для которого Вы хотите осуществить проверку. Например, для Москвы это 213.
Примеры запросов:
site:yandex.ru cat:21000213
site:yandex.ru cat:81000213
Если выдача непустая, значит соответствующая региональная привязка есть.
Способ старый, и я совсем о нем забыл. Просто потому что и нужды такой не было. А вам это может пригодиться. Либо просто в копилку недокументированных возможностей Яндекс поиска 😎
Сходу узнать региональную привязку сайта в Яндекс Вебмастере и Яндекс Бизнесе не получится. Но можно узнать, привязан ли сайт к определенному региону.
Это можно сделать с помощью документированного оператора site: и бывшего некогда документированным оператора cat:, в качестве аргумента для которого используются определенные идентификаторы, называемые смещениями.
Для проверки региональной привязки, сделанной через Яндекс Вебмастер, надо использовать смещение 21000000, а через Яндекс Бизнес - 81000000.
К смещению надо прибавить номер региона (значение get-параметра lr в URL страницы поисковой выдачи), для которого Вы хотите осуществить проверку. Например, для Москвы это 213.
Примеры запросов:
site:yandex.ru cat:21000213
site:yandex.ru cat:81000213
Если выдача непустая, значит соответствующая региональная привязка есть.
{kind=link}
В каждом канале про SEO (и не только) обсуждают главное событие последних дней – слив базы из Яндекса.
Сеошникам, понятное дело, интересны факторы ранжирования на поиске. Уже есть подборки ссылочных, текстовых, поведенческих, хостовых и других факторов.
Всего в оригинальном документе обозначено 1922 фактора: из них 244 с пометкой неиспользуемые (unused), а 988 – отмененные (deprecated).
Таким образом 64% факторов из документа либо не используются, либо были заменены (отменены), так что это больше похоже на 690 потенциальных факторов ранжирования.
Многие описания являются очень краткими и не всегда понятными, а некоторые ссылаются на внутреннюю (недоступную нам) wiki.
Тем не менее, изучить это интересно и полезно для общего развития, и чтобы понять, насколько изощренными могут быть разработчики алгоритмов.
Когда я читал исходный txt файл, сразу подумал, что неплохо было бы иметь какой-то классификатор. Всякие таблички и гугл-доки – это неплохо, но неудобно.
И на одном из зарубежных сайтов (да, там тоже сеошники обсуждают эту новость, но не так активно), я нашел ссылку https://yandex-explorer.herokuapp.com/.
На этом сайте есть полнотекстовый поиск (например, можете ввести «title» и увидеть все факторы, где в заголовке или описании упоминается title) и группировка по тегам.
Решил, что в дополнение к уже имеющейся у вас информации, этот ресурс будет не лишним 😎
Кто скачивал архив полностью, подскажите, что интересного в архиве wmconsole.tar.bz2?
Сеошникам, понятное дело, интересны факторы ранжирования на поиске. Уже есть подборки ссылочных, текстовых, поведенческих, хостовых и других факторов.
Всего в оригинальном документе обозначено 1922 фактора: из них 244 с пометкой неиспользуемые (unused), а 988 – отмененные (deprecated).
Таким образом 64% факторов из документа либо не используются, либо были заменены (отменены), так что это больше похоже на 690 потенциальных факторов ранжирования.
Многие описания являются очень краткими и не всегда понятными, а некоторые ссылаются на внутреннюю (недоступную нам) wiki.
Тем не менее, изучить это интересно и полезно для общего развития, и чтобы понять, насколько изощренными могут быть разработчики алгоритмов.
Когда я читал исходный txt файл, сразу подумал, что неплохо было бы иметь какой-то классификатор. Всякие таблички и гугл-доки – это неплохо, но неудобно.
И на одном из зарубежных сайтов (да, там тоже сеошники обсуждают эту новость, но не так активно), я нашел ссылку https://yandex-explorer.herokuapp.com/.
На этом сайте есть полнотекстовый поиск (например, можете ввести «title» и увидеть все факторы, где в заголовке или описании упоминается title) и группировка по тегам.
Решил, что в дополнение к уже имеющейся у вас информации, этот ресурс будет не лишним 😎
Кто скачивал архив полностью, подскажите, что интересного в архиве wmconsole.tar.bz2?
Яндекс прокомментировал недавнюю утечку данных в официальном пресс-релизе на сайте компании!
Рекомендую прочитать. И вот вам несколько интересных цитат:
«Мы продолжаем внутреннее расследование инцидента и считаем важным поделиться первыми результатами.»
«Опубликованные фрагменты действительно взяты из нашего внутреннего репозитория»
«Сложившаяся ситуация — повод провести масштабный аудит всего содержимого репозитория.»
«Зафиксированы случаи, когда логику работы сервисов корректировали не алгоритмическим способом, а “костылями”. Через такие «костыли» исправляли отдельные ошибки системы рекомендаций, которая отвечает за дополнительные элементы поисковой выдачи.»
«Некоторые части кода содержали слова, которые никак не влияли на работу сервисов, но сами по себе оскорбительны для людей разных рас и национальностей.»
«Сейчас нам очень стыдно, и мы приносим извинения нашим пользователям и партнёрам. Считаем необходимым рассказать, почему такое происходило, и что в связи с этим мы намерены предпринимать.»
«Большинство выявленных проблем связано с попытками вручную внести в сервис улучшение или устранить ошибку.»
«Сегодня Яндекс возобновляет работу по формированию стандартов и принципов техноэтики.»
«При этом мы считаем важным сохранить внутри Яндекса открытую среду разработки, в частности – единый репозиторий.»
🔗 https://yandex.ru/company/press_releases/2023/30-01-2023
Рекомендую прочитать. И вот вам несколько интересных цитат:
«Мы продолжаем внутреннее расследование инцидента и считаем важным поделиться первыми результатами.»
«Опубликованные фрагменты действительно взяты из нашего внутреннего репозитория»
«Сложившаяся ситуация — повод провести масштабный аудит всего содержимого репозитория.»
«Зафиксированы случаи, когда логику работы сервисов корректировали не алгоритмическим способом, а “костылями”. Через такие «костыли» исправляли отдельные ошибки системы рекомендаций, которая отвечает за дополнительные элементы поисковой выдачи.»
«Некоторые части кода содержали слова, которые никак не влияли на работу сервисов, но сами по себе оскорбительны для людей разных рас и национальностей.»
«Сейчас нам очень стыдно, и мы приносим извинения нашим пользователям и партнёрам. Считаем необходимым рассказать, почему такое происходило, и что в связи с этим мы намерены предпринимать.»
«Большинство выявленных проблем связано с попытками вручную внести в сервис улучшение или устранить ошибку.»
«Сегодня Яндекс возобновляет работу по формированию стандартов и принципов техноэтики.»
«При этом мы считаем важным сохранить внутри Яндекса открытую среду разработки, в частности – единый репозиторий.»
🔗 https://yandex.ru/company/press_releases/2023/30-01-2023
Компания Яндекс
Публикация кода: Яндекс раскрывает первые результаты расследования
На прошлой неделе в открытом доступе были обнаружены фрагменты программного кода некоторых сервисов Яндекса. Мы продолжаем внутреннее расследование инцидента и считаем важным поделиться первыми результатами.
А еще Яндекс поделился новостью, что больше нельзя «кастомизировать» адрес сайта на выдаче – а именно менять регистр.
«В Поиске Яндекса меняются требования к оформлению регистра имени сайта. По умолчанию название сайта обычно отображается в результатах выдачи строчными буквами — то есть по нижнему регистру. Теперь этот формат становится официальным стандартом для всех сайтов. Если в названии вашего сайта используются заглавные буквы, они будут переведены в строчные автоматически. Изменение регистра на верхний больше не допускается.
Обновления нужны для приведения выдачи к единому стилю и для повышения удобочитаемости домена. На ранжирование в результатах поиска формат написания регистра сайта не влияет.»
🔗 https://webmaster.yandex.ru/blog/obnovlenie-v-snippete-sayta
В вебмастере также пропала страница, где раньше это можно было настроить.
🤬 Лучше бы «Внешние ссылки» починили – сколько ждать-то можно?
PS А пока можно насладиться остатками было роскоши. Все же не так и плохо выглядел домен сайта, состоящий из нескольких слов…
«В Поиске Яндекса меняются требования к оформлению регистра имени сайта. По умолчанию название сайта обычно отображается в результатах выдачи строчными буквами — то есть по нижнему регистру. Теперь этот формат становится официальным стандартом для всех сайтов. Если в названии вашего сайта используются заглавные буквы, они будут переведены в строчные автоматически. Изменение регистра на верхний больше не допускается.
Обновления нужны для приведения выдачи к единому стилю и для повышения удобочитаемости домена. На ранжирование в результатах поиска формат написания регистра сайта не влияет.»
🔗 https://webmaster.yandex.ru/blog/obnovlenie-v-snippete-sayta
В вебмастере также пропала страница, где раньше это можно было настроить.
🤬 Лучше бы «Внешние ссылки» починили – сколько ждать-то можно?
PS А пока можно насладиться остатками было роскоши. Все же не так и плохо выглядел домен сайта, состоящий из нескольких слов…
{kind=link}
Вот, что я вам скажу.
Невероятно, но факт – зарубежные коллеги гораздо более качественно подошли к вопросу изучения слитых данных Яндекса. Да-да, это уже набило оскомину всем seo-специалистам, но еще пару недель это будет основной темой для обсуждений, а вспоминать это событие мы будем еще много лет!
Я пока не встретил ни одной серьезной публикации, где бы вдумчиво кто-то разобрался с информацией. Сам я этого делать не хочу, потому что надо бросить всю работу и пару дней только этим и заниматься. Поэтому пока в ру-сообществе только хи-хи да ха-ха, типа: «количество слешей в урле что-то значит», «а наличие яндекс директ на странице дает минус», «но домен в зоне ком – это хорошо» и т.д.
Так вот. Зарубежные статьи на удивление хороши. Может быть, потому что Яндекс им не интересен, как источник трафика или объект, под который надо оптимизировать сайт…не знаю. Как бы там ни было, они смотрят глубже, дальше и, возможно, более объективно и непредвзято.
Очень рекомендую вам прочитать первую статью (а если понравится, то и вторую):
🔗 Yandex scrapes Google and other SEO learnings from the source code leak на Search Engine Land
🔗 Yandex Search Ranking Factors Leak: Insights на Search Engine Journal
Обе статьи, разумеется, на английском. Но Гугл Транслейт вам в помощь (вполне сносно переводит, но лучше в оригинале, так как много специфических терминов).
Поверьте, это намного информативнее всего того, что вы встречали ранее.
Также в первой публикации автор говорит про 18 681 факторов, которые «доступны по ссылке». Но там все через регистрацию, которая еще и не принимает обычную почту. Короче, табличку я для вас скачал и выложу в первом комментарии к этому посту.
Невероятно, но факт – зарубежные коллеги гораздо более качественно подошли к вопросу изучения слитых данных Яндекса. Да-да, это уже набило оскомину всем seo-специалистам, но еще пару недель это будет основной темой для обсуждений, а вспоминать это событие мы будем еще много лет!
Я пока не встретил ни одной серьезной публикации, где бы вдумчиво кто-то разобрался с информацией. Сам я этого делать не хочу, потому что надо бросить всю работу и пару дней только этим и заниматься. Поэтому пока в ру-сообществе только хи-хи да ха-ха, типа: «количество слешей в урле что-то значит», «а наличие яндекс директ на странице дает минус», «но домен в зоне ком – это хорошо» и т.д.
Так вот. Зарубежные статьи на удивление хороши. Может быть, потому что Яндекс им не интересен, как источник трафика или объект, под который надо оптимизировать сайт…не знаю. Как бы там ни было, они смотрят глубже, дальше и, возможно, более объективно и непредвзято.
Очень рекомендую вам прочитать первую статью (а если понравится, то и вторую):
🔗 Yandex scrapes Google and other SEO learnings from the source code leak на Search Engine Land
🔗 Yandex Search Ranking Factors Leak: Insights на Search Engine Journal
Обе статьи, разумеется, на английском. Но Гугл Транслейт вам в помощь (вполне сносно переводит, но лучше в оригинале, так как много специфических терминов).
Поверьте, это намного информативнее всего того, что вы встречали ранее.
Также в первой публикации автор говорит про 18 681 факторов, которые «доступны по ссылке». Но там все через регистрацию, которая еще и не принимает обычную почту. Короче, табличку я для вас скачал и выложу в первом комментарии к этому посту.
{kind=link}
В свете максимального интереса к ChatGPT, зарубежные веб-мастера переживают и не хотят, чтобы контент их сайтов использовался для обучения.
Для обучения GPT-3 (и GPT-3.5) используются определенные наборы данных, среди которых есть краулинг (сканирование сайтов).
Я знаю, что вам не интересно, что к чему и почему, поэтому сразу к сути:
- Есть бот, которого зовут Common Crawl (CCBot).
- CCBot, как и все порядочные боты, следует правилам из robots.txt.
- Так что вы можете заблокировать сканирование своего сайта.
- Для этого надо добавить в файл robots.txt две строки:
- Или можно использовать meta robots на страницах:
Надо иметь в виду, что это рекомендации из не официальных источников, так что все может однажды измениться.
А если сайт уже был просканирован, собранные данные никак нельзя удалить.
Проклятые капиталисты 👊🏻
Для обучения GPT-3 (и GPT-3.5) используются определенные наборы данных, среди которых есть краулинг (сканирование сайтов).
Я знаю, что вам не интересно, что к чему и почему, поэтому сразу к сути:
- Есть бот, которого зовут Common Crawl (CCBot).
- CCBot, как и все порядочные боты, следует правилам из robots.txt.
- Так что вы можете заблокировать сканирование своего сайта.
- Для этого надо добавить в файл robots.txt две строки:
User-agent: CCBotDisallow: /- Или можно использовать meta robots на страницах:
<meta name="CCBot" content="noindex nofollow">Надо иметь в виду, что это рекомендации из не официальных источников, так что все может однажды измениться.
А если сайт уже был просканирован, собранные данные никак нельзя удалить.
Проклятые капиталисты 👊🏻
{kind=link}
Google первыми рассказали о своем отношении к сгенерированному искусственным интеллектом контенту. Еще бы…на фоне такого массового сумасшествия.
Итак, изменится ли политика оценки качества контента?
Google будет одинаково оценивать и ранжировать контент, каким бы способом он ни создавался. Факторы оценки EEAT никуда не делись.
Другими словами, совершенно неважно, кто, как и почему создает контент, и, если он качественный, полезный и нравится пользователям – контент будет хорошо ранжироваться. Такова главная задача Google.
Использование автоматизации с целью спама – конечно, является нарушением. При этом не все виды автоматизации (с использованием ИИ) являются спамом. Ведь поисковики и сами в ближайшее время будут эксплуатировать эту возможность по полной.
Так что «правильное» использование ИИ или автоматизации не противоречит правилам поиска Google. При этом (в рамках следования EEAT) указывать ИИ в качестве автора публикации – плохая идея (по крайней мере пока) 😅
🔗 https://developers.google.com/search/blog/2023/02/google-search-and-ai-content
Итак, изменится ли политика оценки качества контента?
Google будет одинаково оценивать и ранжировать контент, каким бы способом он ни создавался. Факторы оценки EEAT никуда не делись.
Другими словами, совершенно неважно, кто, как и почему создает контент, и, если он качественный, полезный и нравится пользователям – контент будет хорошо ранжироваться. Такова главная задача Google.
Использование автоматизации с целью спама – конечно, является нарушением. При этом не все виды автоматизации (с использованием ИИ) являются спамом. Ведь поисковики и сами в ближайшее время будут эксплуатировать эту возможность по полной.
Так что «правильное» использование ИИ или автоматизации не противоречит правилам поиска Google. При этом (в рамках следования EEAT) указывать ИИ в качестве автора публикации – плохая идея (по крайней мере пока) 😅
🔗 https://developers.google.com/search/blog/2023/02/google-search-and-ai-content
Привет, друзья.
Хотел порадовать вас обновлением расширения Alaev SEO Tools в честь небольшого юбилея – 5000 активных пользователей – но пока туда-сюда…в общем, нас уже почти 6 тысяч, а обновление и правда крутое!
Самое главное новшество – раздел со ссылками (см. скриншот). Теперь вы увидите максимально подробную информацию о ссылках на странице, а также сможете их фильтровать (внешние/внутренние, follow/nofollow и т.д.).
Чтобы получить информацию по статус кодам необходимо запустить проверку (можно указать задержку между запросами).
И, конечно, список ссылок можно экспортировать в csv. При этом экспорт происходит согласно фильтрации, так что вы сможете сразу выгрузить только то, что вам нужно.
Кроме этого добавили:
- копирование структуры заголовков H1-H6;
- отображение микроразметки Open Graph и Twitter;
- контекстное меню (правый клик мыши на странице) для подсчета количества символов в выделенном тексте.
На счет последнего пункта: подсчет символов в выделенном тексте был и ранее, но приходилось долго добираться до этого инструмента, что сводило на нет его преимущества. Теперь достаточно выделить текст на странице, кликнуть правой кнопкой и выбрать пункт из меню.
Если у вас уже установлено расширение, обновление прилетит само. Остальные смогут установить расширение по ссылке:
🔗 https://chrome.google.com/webstore/detail/alaev-seo-tools-free-audi/fgojlclhaecajjkchbcpelngbkdjeekg
(буду вам признателен за отзывы и оценки в chrome webstore)
Я наконец-то подготовил небольшой лендинг, где описал все возможности, выложил историю обновлений, а также информацию для тех, кто переживает насчет безопасности (объяснил для чего требуется каждое запрашиваемое разрешение).
🔗 https://seotools.alaev.info/features/
Следующее крупное обновление будет не скоро. Например, когда наберем 20к пользователей. А раз времени достаточно, прошу вас делиться идеями, предложениями и пожеланиями на будущее!
PS На волне хайпа подумалось, а не встроить ли нам какой-то ИИ помощник, например, на базе ChatGPT или подобного? Но эта штука платная, а на больших объемах, я бы сказал, дорогая. Бесплатных аналогов я не нашел (если вы знаете, подскажите). Так что пока с этим повремени.
Хотел порадовать вас обновлением расширения Alaev SEO Tools в честь небольшого юбилея – 5000 активных пользователей – но пока туда-сюда…в общем, нас уже почти 6 тысяч, а обновление и правда крутое!
Самое главное новшество – раздел со ссылками (см. скриншот). Теперь вы увидите максимально подробную информацию о ссылках на странице, а также сможете их фильтровать (внешние/внутренние, follow/nofollow и т.д.).
Чтобы получить информацию по статус кодам необходимо запустить проверку (можно указать задержку между запросами).
И, конечно, список ссылок можно экспортировать в csv. При этом экспорт происходит согласно фильтрации, так что вы сможете сразу выгрузить только то, что вам нужно.
Кроме этого добавили:
- копирование структуры заголовков H1-H6;
- отображение микроразметки Open Graph и Twitter;
- контекстное меню (правый клик мыши на странице) для подсчета количества символов в выделенном тексте.
На счет последнего пункта: подсчет символов в выделенном тексте был и ранее, но приходилось долго добираться до этого инструмента, что сводило на нет его преимущества. Теперь достаточно выделить текст на странице, кликнуть правой кнопкой и выбрать пункт из меню.
Если у вас уже установлено расширение, обновление прилетит само. Остальные смогут установить расширение по ссылке:
🔗 https://chrome.google.com/webstore/detail/alaev-seo-tools-free-audi/fgojlclhaecajjkchbcpelngbkdjeekg
(буду вам признателен за отзывы и оценки в chrome webstore)
Я наконец-то подготовил небольшой лендинг, где описал все возможности, выложил историю обновлений, а также информацию для тех, кто переживает насчет безопасности (объяснил для чего требуется каждое запрашиваемое разрешение).
🔗 https://seotools.alaev.info/features/
Следующее крупное обновление будет не скоро. Например, когда наберем 20к пользователей. А раз времени достаточно, прошу вас делиться идеями, предложениями и пожеланиями на будущее!
PS На волне хайпа подумалось, а не встроить ли нам какой-то ИИ помощник, например, на базе ChatGPT или подобного? Но эта штука платная, а на больших объемах, я бы сказал, дорогая. Бесплатных аналогов я не нашел (если вы знаете, подскажите). Так что пока с этим повремени.
{kind=link}
«Отключение поддержки rel="canonical" при переезде с https на http» - Яндекс так сказал!
Но не переживайте, если коротко – все норм.
Что меня смущает. Вот цитаты из новости:
«Выбор главного зеркала между http://site.ru и https://site.ru
Атрибут rel=”canonical” больше не поддерживается в случае адресов такого формата.»
«Выбор главного зеркала между https://www.site.ru и https://site.ru
В этом случае можно использовать как редирект 301/302, так и атрибут rel=”canonical”.»
А что реально есть люди, которые переезжали на другое зеркало с помощью rel canonical?
Яндекс и так обычно сам выбирает какое-то зеркало на свое усмотрение (если не заданы редиректы) и индексирует только его. Поменять потом можно в панели Вебмастера.
Вероятно, ранее canonical мог как-то повлиять на этот самый выбор, но я не уверен.
Второе, что меня смутило:
«Вместо него необходимо использовать редирект 301/302 на главный сайт».
А что реально при переезде кто-то использовал 302-редирект? Я имею в виду осознанно, а не по ошибке? Опять же, допускаю, что мог быть сценарий, когда абсолютно все страница сайта делают 302-редирект, и Яндекс это отождествлял с 301-редиректом (либо намерением использовать именно его). Кто знает…
В общем, новость из разряда: делайте так, как нужно, а как не нужно – не делайте.
🤔
🔗 https://webmaster.yandex.ru/blog/otklyuchenie-podderzhki-rel-canonical-pri-pereezde-s-https-na-http
Но не переживайте, если коротко – все норм.
Что меня смущает. Вот цитаты из новости:
«Выбор главного зеркала между http://site.ru и https://site.ru
Атрибут rel=”canonical” больше не поддерживается в случае адресов такого формата.»
«Выбор главного зеркала между https://www.site.ru и https://site.ru
В этом случае можно использовать как редирект 301/302, так и атрибут rel=”canonical”.»
А что реально есть люди, которые переезжали на другое зеркало с помощью rel canonical?
Яндекс и так обычно сам выбирает какое-то зеркало на свое усмотрение (если не заданы редиректы) и индексирует только его. Поменять потом можно в панели Вебмастера.
Вероятно, ранее canonical мог как-то повлиять на этот самый выбор, но я не уверен.
Второе, что меня смутило:
«Вместо него необходимо использовать редирект 301/302 на главный сайт».
А что реально при переезде кто-то использовал 302-редирект? Я имею в виду осознанно, а не по ошибке? Опять же, допускаю, что мог быть сценарий, когда абсолютно все страница сайта делают 302-редирект, и Яндекс это отождествлял с 301-редиректом (либо намерением использовать именно его). Кто знает…
В общем, новость из разряда: делайте так, как нужно, а как не нужно – не делайте.
🤔
🔗 https://webmaster.yandex.ru/blog/otklyuchenie-podderzhki-rel-canonical-pri-pereezde-s-https-na-http
Блог Яндекса
Отключение поддержки rel="canonical" при переезде с https на http
Как известно, сайты с одинаковым контентом, но разными адресами — например, https://www.site.ru, www.site.ru, http://site.ru — называются зеркалами. Рассказываем об изменениях в работе с такими сайтами.
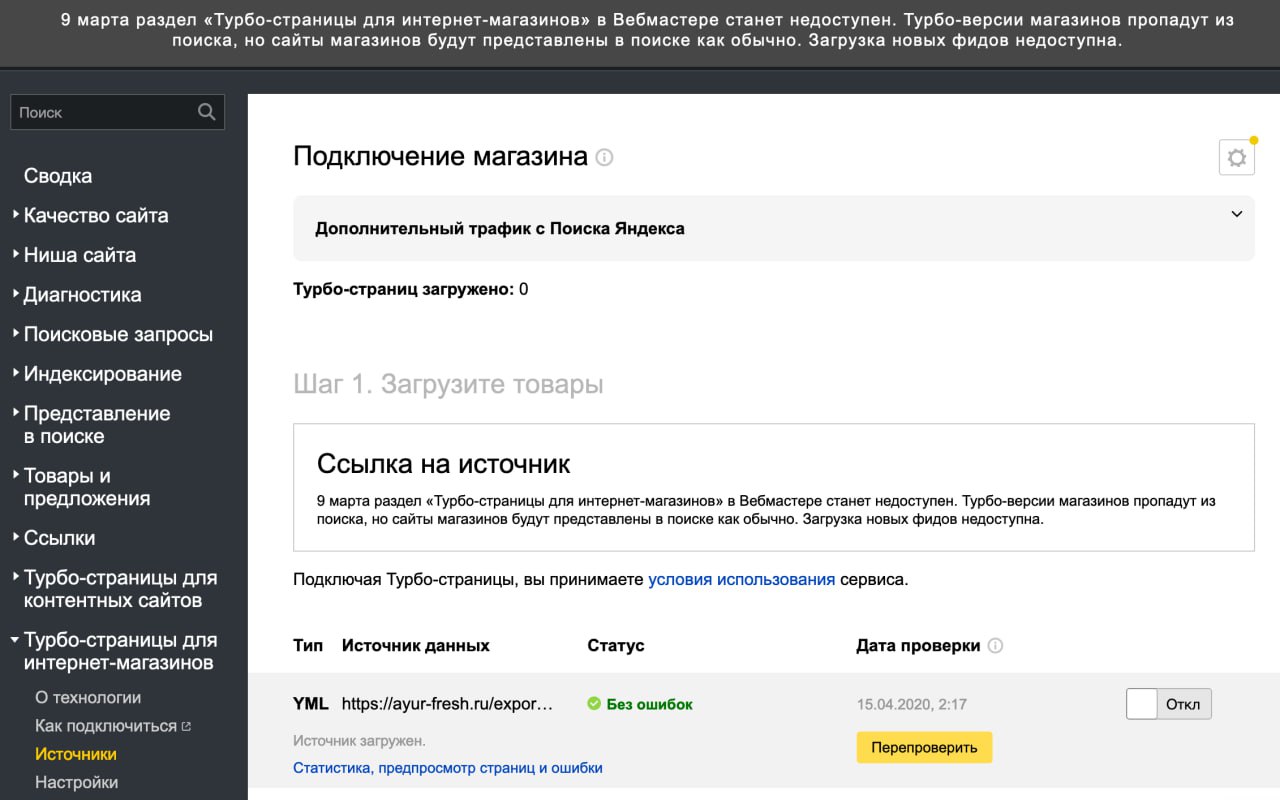
После нескольких лет капиталисты наконец-то прекращают обманывать людей и признают, что их турбо-страницы для ИМ – это турбо-шляпа! 👊🏻
«9 марта раздел «Турбо-страницы для интернет-магазинов» в Вебмастере станет недоступен. Турбо-версии магазинов пропадут из поиска, но сайты магазинов будут представлены в поиске как обычно. Загрузка новых фидов недоступна.»
Такое вот сообщение теперь красуется в панели Вебмастера Яндекса для всех сайтов, у которых когда-либо были загружены фиды для турбо-страниц для интернет-магазинов.
В мае 2020 года я шутил на этот счёт, мол, пришла рассылка от Яндекса, где они предлагают удалить свои турбо-страницы. Но слегка опередил время, и рассылка задержалась и пришла только сейчас (2 часа назад).
Оказалось, что не показалось, и турбо для ИМ реально ухудшали результаты продаж. Мы тестили на многих совершенно разных клиентских сайтах, и нигде не получили профита, но получили существенный негативный эффект.
Выходит, что кто-то всё это время пиздюнькал… 🤬
Технология «оказалась не настолько востребована, как мы ожидали» - просто люди туповатые, и за три года до них так и не дошло, что технология слишком хороша!
Яндекс писал в 2020 году, что:
«В среднем мы увидели: рост общего объёма товарного оборота на 20%, увеличение заказов на 4,5%, рост добавлений в корзину на 11%.»
За такой рост показателей любой владелец магазина готов на многое…
…а тут бесплатно, да? Да не, по-любому разводняк, даже пробовать не буду!
Типа так что ли? Хорошая технология и не востребованной оказалась?
Проклятые капиталисты нас опять переиграли, расходимся!
И это. Не забудьте «Удалить турбо».
PS У меня не пригорело, просто захотел немного поиздеваться над Яндексом. А то уж думал, что только у клиентов нашей студии все показатели из-за турбо падали, а мы – криворукие уроды – не могли с этим справиться.
«9 марта раздел «Турбо-страницы для интернет-магазинов» в Вебмастере станет недоступен. Турбо-версии магазинов пропадут из поиска, но сайты магазинов будут представлены в поиске как обычно. Загрузка новых фидов недоступна.»
Такое вот сообщение теперь красуется в панели Вебмастера Яндекса для всех сайтов, у которых когда-либо были загружены фиды для турбо-страниц для интернет-магазинов.
В мае 2020 года я шутил на этот счёт, мол, пришла рассылка от Яндекса, где они предлагают удалить свои турбо-страницы. Но слегка опередил время, и рассылка задержалась и пришла только сейчас (2 часа назад).
Оказалось, что не показалось, и турбо для ИМ реально ухудшали результаты продаж. Мы тестили на многих совершенно разных клиентских сайтах, и нигде не получили профита, но получили существенный негативный эффект.
Выходит, что кто-то всё это время пиздюнькал… 🤬
Технология «оказалась не настолько востребована, как мы ожидали» - просто люди туповатые, и за три года до них так и не дошло, что технология слишком хороша!
Яндекс писал в 2020 году, что:
«В среднем мы увидели: рост общего объёма товарного оборота на 20%, увеличение заказов на 4,5%, рост добавлений в корзину на 11%.»
За такой рост показателей любой владелец магазина готов на многое…
…а тут бесплатно, да? Да не, по-любому разводняк, даже пробовать не буду!
Типа так что ли? Хорошая технология и не востребованной оказалась?
Проклятые капиталисты нас опять переиграли, расходимся!
И это. Не забудьте «Удалить турбо».
PS У меня не пригорело, просто захотел немного поиздеваться над Яндексом. А то уж думал, что только у клиентов нашей студии все показатели из-за турбо падали, а мы – криворукие уроды – не могли с этим справиться.
{kind=link}
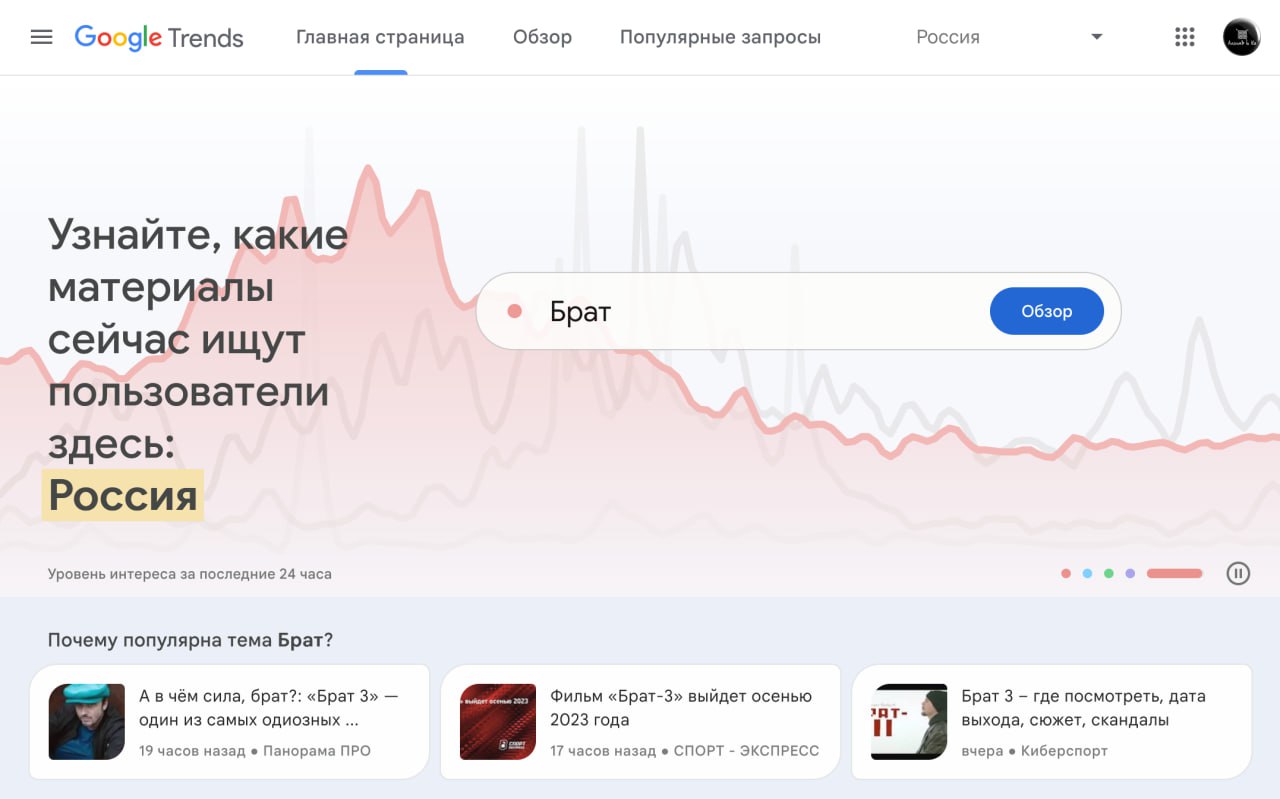
Google выкатил обновленный Google Trends. Говорят, в рамках весенней уборки решили прибраться и в инструменте 🧹
Теперь на главной странице показываются тренды в реальном времени. Они обновляются каждый час и сопровождаются ссылками на соответствующие новости.
И, как это принято, тренды показываются с некоторой долей персонализации – согласно стране или региону.
🔗 https://trends.google.com/home
PS Извините, что давно ничего для вас не писал, приболел сильно, но уже иду на поправку! Пока валялся в кровати, весна наступила, с чем вас и поздравляю :)
Теперь на главной странице показываются тренды в реальном времени. Они обновляются каждый час и сопровождаются ссылками на соответствующие новости.
И, как это принято, тренды показываются с некоторой долей персонализации – согласно стране или региону.
🔗 https://trends.google.com/home
PS Извините, что давно ничего для вас не писал, приболел сильно, но уже иду на поправку! Пока валялся в кровати, весна наступила, с чем вас и поздравляю :)
{kind=link}