
Джона Мюллера спросили о том, учитывает ли Google контент безанкорных ссылок типа «щелкните здесь», а также ссылочное окружение (контекст).
Джон сказал, что реально сильным мог быть якорный текст (который отсутствует в данном случае), а затем мелочи по бокам, «которые действительно нам немного помогают»
Фактически, Джон Мюллер подтвердил, что анкор ссылки - первичный сильный сигнал, а ссылочное окружение - менее важный, но всё же вторичный сигнал, по которому Google понимает тематику (контекст) ссылки.
Понятно, что всё это известные вещи. Пугает вот что. То ли Джон Мюллер впервые сказал что-то реальное, то ли Google перестал учитывать околоссылочный текст и анкоры 😮
🔗 https://www.seroundtable.com/google-context-around-links-30173.html
Варианты такие:
- Послушать Мюллера и сделать наоборот,
- Джон нашёл свои таблетки и ему стало лучше...
Джон сказал, что реально сильным мог быть якорный текст (который отсутствует в данном случае), а затем мелочи по бокам, «которые действительно нам немного помогают»
Фактически, Джон Мюллер подтвердил, что анкор ссылки - первичный сильный сигнал, а ссылочное окружение - менее важный, но всё же вторичный сигнал, по которому Google понимает тематику (контекст) ссылки.
Понятно, что всё это известные вещи. Пугает вот что. То ли Джон Мюллер впервые сказал что-то реальное, то ли Google перестал учитывать околоссылочный текст и анкоры 😮
🔗 https://www.seroundtable.com/google-context-around-links-30173.html
Варианты такие:
- Послушать Мюллера и сделать наоборот,
- Джон нашёл свои таблетки и ему стало лучше...
seroundtable.com
Google: The Context Around Links Is Secondary But Anchor Text Is Primary
You know that many uses of anchor text on links around the web do not say much about where it is linking to. There are tons of
Помните зелёную галку за 50 долларов в месяц? Я писал про нее еще в июне.
Google запускает в бета-тест эту программу (Реклама Местных Услуг - LSA) с другим форматом ценообразования — аукционом.
По словам Google, эта модель поможет привлечь больше клиентов к этой надежной группе рекламодателей.
Если прочитать между строк, то выходит так: «50 долларов — слишком мало за такую крутоту! Кто хочет зеленую галку — предлагайте свою цену. Мы — капиталисты!»
Google запускает в бета-тест эту программу (Реклама Местных Услуг - LSA) с другим форматом ценообразования — аукционом.
По словам Google, эта модель поможет привлечь больше клиентов к этой надежной группе рекламодателей.
Если прочитать между строк, то выходит так: «50 долларов — слишком мало за такую крутоту! Кто хочет зеленую галку — предлагайте свою цену. Мы — капиталисты!»
{kind=link}
Cloudflare анонсировал свой инструмент веб-аналитики. Судя по анонсу — это должен быть бесплатный инструмент с упором на конфиденциальность.
Cloudflare принципиально отстраивается от модели других систем аналитики, которые отслеживают поведение пользователей на сайте и используют эти данные для продажи рекламы. Cloudflare считает, что не нужно жертвовать конфиденциальностью посетителей, чтобы получить важные и точные показатели.
Cloudflare Web Analytics не будет собирать никаких данных на стороне пользователя (cookies, LocalStorage и прочее). При этом планируется отслеживать поведение конечного пользователя практически в реальном времени – в течение нескольких секунд после запроса сервера.
Новый сервис будет бесплатным и доступным даже не для клиентов Cloudflare. Открыта запись в лист ожидания нового инструмента. Тестим?
🔗 https://www.cloudflare.com/web-analytics/
При поддержке биржи Kwork.ru – фриланс без проблем!
Cloudflare принципиально отстраивается от модели других систем аналитики, которые отслеживают поведение пользователей на сайте и используют эти данные для продажи рекламы. Cloudflare считает, что не нужно жертвовать конфиденциальностью посетителей, чтобы получить важные и точные показатели.
Cloudflare Web Analytics не будет собирать никаких данных на стороне пользователя (cookies, LocalStorage и прочее). При этом планируется отслеживать поведение конечного пользователя практически в реальном времени – в течение нескольких секунд после запроса сервера.
Новый сервис будет бесплатным и доступным даже не для клиентов Cloudflare. Открыта запись в лист ожидания нового инструмента. Тестим?
🔗 https://www.cloudflare.com/web-analytics/
При поддержке биржи Kwork.ru – фриланс без проблем!
{kind=link}
Загрузка расходов и кликов из Google Ads в Метрику. Теперь в интерфейсе Метрики можно за пару кликов привязать кабинет Google Ads, чтобы статистика по этой рекламной системе появилась в отчёте по расходам и ROI.
В Метрике появятся данные о расходах и кликах в разбивке по дням из Google Ads. То, насколько подробными будут данные, зависит от того, как настроен ваш шаблон отслеживания в Google Ads. Обновляться данные будут ежедневно, а отключить их передачу можно в любой момент.
Обязательно нужно, чтобы реклама в Google Ads была размечена UTM-метками. Если разметка есть, нужно просто настроить подключение в интерфейсе Метрики:
1. В настройках счётчика откройте вкладку «Загрузка данных», прокрутите страницу до раздела «Загрузка расходов» и кликните на логотип Google Ads.
2. Дальше останется только войти в ваш аккаунт Google и выбрать нужный рекламный кабинет — система подскажет все нужные шаги.
Подробнее о подключении рекламного кабинета Google Ads можно прочитать в Справке.
🔗 https://yandex.ru/blog/metrika/google-ads-cost-import
В Метрике появятся данные о расходах и кликах в разбивке по дням из Google Ads. То, насколько подробными будут данные, зависит от того, как настроен ваш шаблон отслеживания в Google Ads. Обновляться данные будут ежедневно, а отключить их передачу можно в любой момент.
Обязательно нужно, чтобы реклама в Google Ads была размечена UTM-метками. Если разметка есть, нужно просто настроить подключение в интерфейсе Метрики:
1. В настройках счётчика откройте вкладку «Загрузка данных», прокрутите страницу до раздела «Загрузка расходов» и кликните на логотип Google Ads.
2. Дальше останется только войти в ваш аккаунт Google и выбрать нужный рекламный кабинет — система подскажет все нужные шаги.
Подробнее о подключении рекламного кабинета Google Ads можно прочитать в Справке.
🔗 https://yandex.ru/blog/metrika/google-ads-cost-import
{kind=link}
Похоже, что Google вывел в бета-тест для Google Мой Бизнес функцию Preview Call History – историю звонков клиентов из поиска и карт.
Согласно справке по этой функции, работать история звонков будет так. После нажатия клиентом кнопки «Позвонить» в профиле компании, информация о вызове попадает на вкладку «Звонки» в Google Мой бизнес. На этой вкладке представители компании смогут найти недавние вызовы, пропущенные вызовы и многое другое.
Важно, что при включенной истории звонков, клиенты будут связываться с компанией через номер для переадресации, а не через номер, указанный в профиле. В начале разговора будет звучать автоматическое сообщение «Звонок из Google».
Функцию истории звонков в Google My Business тестируют пока только в США на ограниченной группе компаний. В SEO-Твиттере уже попадаются скриншоты от участников теста — можно увидеть, как это будет выглядеть внутри кабинета Google My Business.
🔗 Ссылка на справку по новой функции https://support.google.com/business/answer/9688285
Кворк – магазин услуг фрилансеров от 500 р. для вашего бизнеса
Согласно справке по этой функции, работать история звонков будет так. После нажатия клиентом кнопки «Позвонить» в профиле компании, информация о вызове попадает на вкладку «Звонки» в Google Мой бизнес. На этой вкладке представители компании смогут найти недавние вызовы, пропущенные вызовы и многое другое.
Важно, что при включенной истории звонков, клиенты будут связываться с компанией через номер для переадресации, а не через номер, указанный в профиле. В начале разговора будет звучать автоматическое сообщение «Звонок из Google».
Функцию истории звонков в Google My Business тестируют пока только в США на ограниченной группе компаний. В SEO-Твиттере уже попадаются скриншоты от участников теста — можно увидеть, как это будет выглядеть внутри кабинета Google My Business.
🔗 Ссылка на справку по новой функции https://support.google.com/business/answer/9688285
Кворк – магазин услуг фрилансеров от 500 р. для вашего бизнеса
{kind=link}
Search Engine Journal сделал подборку свежих патентов Google. В статье собраны более 100 патентов, выданных за первую половину 2020 года. По этим документам можно представить, как будет развиваться поиск Google в ближайшем будущем.
Большая часть патентов касается виртуального помощника Google Assistant и голосового поиска. Google продолжает активно работать над обучением нейронных сетей и пониманием естественного языка (Natural language processing) не только в текстовом виде.
Еще одна значительная часть списка патентов касается работы с видео и изображениями. В этой категории — патенты по определению зон интереса в видео, распознаванию человека в видеопотоке, отображению ссылок в видео, возможности поиска по телевидению и многие другие.
Судя по нескольким отдельным патентам, предполагаем, что Google не забывает и про EAT, не ограничиваясь при этом только лишь сайтами. Так, например, в списке есть патенты по идентификации авторов контента и определению качества контента в социальных сетях.
Что касается поиска и ранжирования, тут Google ничего революционного пока не планирует. Компания продолжает развивать и совершенствовать ранее намеченные приоритеты: понимание контекста запроса и прогнозирование потребностей, улучшение механизмов рекомендаций, дополнения запросов и генерации расширенных результатов, улучшение локального поиска, выявление в контенте спама и оскорбительных слов, классификация контента по тональности и другое.
Яндекс, твой выход! 😎
🔗 https://www.searchenginejournal.com/google-patents-first-half-2020/383047/
Большая часть патентов касается виртуального помощника Google Assistant и голосового поиска. Google продолжает активно работать над обучением нейронных сетей и пониманием естественного языка (Natural language processing) не только в текстовом виде.
Еще одна значительная часть списка патентов касается работы с видео и изображениями. В этой категории — патенты по определению зон интереса в видео, распознаванию человека в видеопотоке, отображению ссылок в видео, возможности поиска по телевидению и многие другие.
Судя по нескольким отдельным патентам, предполагаем, что Google не забывает и про EAT, не ограничиваясь при этом только лишь сайтами. Так, например, в списке есть патенты по идентификации авторов контента и определению качества контента в социальных сетях.
Что касается поиска и ранжирования, тут Google ничего революционного пока не планирует. Компания продолжает развивать и совершенствовать ранее намеченные приоритеты: понимание контекста запроса и прогнозирование потребностей, улучшение механизмов рекомендаций, дополнения запросов и генерации расширенных результатов, улучшение локального поиска, выявление в контенте спама и оскорбительных слов, классификация контента по тональности и другое.
Яндекс, твой выход! 😎
🔗 https://www.searchenginejournal.com/google-patents-first-half-2020/383047/
Search Engine Journal
A Rundown of Google Patents from the First Half of 2020
Learn the latest info on Google patents. Here's a compilation of all the Google Search Patents of interest for the first six months of 2020.
Капиталисты из Яндекса продолжают безбожно топить за свои Турбо-страницы.
Вчера представили большое обновление Турбо-страниц для интернет-магазинов (дизайн с фокусом на смартфоны).
Говорят, изменения появились в результате положительных отзывов от пользователей на UX-тестированиях. При этом Яндекс продолжает строить догадки на счет того, что ИМ должен приносить заказы его владельцу, а не только деньги за рекламу в Яндекс (но это пока не точно, это по-прежнему лишь гипотеза). И чтобы гипотезу проверить, они пригласили партнёров поучаствовать в закрытом эксперименте. В среднем что-то выросло… не известно у кого, не известно почему. Главное, что выросло. Хотя по нашей практике после внедрения Турбо у клиентских сайтов все как-то грустно падает.
Если без шуток, то и правда много что обновили.
🔗 https://webmaster.yandex.ru/blog/bolshoe-obnovlenie-turbo-stranits-dlya-internet-magazinov-dizayn-s-fokusom-na-smartfony
Сегодня вдогонку Яндекс решил пригласить всех желающих на вебинар «Технология Турбо для интернет-магазинов», который состоится 22 октября в 12:00 (по московскому времени).
Обещают рассказать о планах по развитию технологии и последних обновлениях.
Участие бесплатное, необходима регистрация.
🔗 https://webmaster.yandex.ru/blog/priglashaem-na-vebinar-tekhnologiya-turbo-dlya-internet-magazinov
Те, кто пользуется Турбо, будут довольны, остальные, как и мы, проходят мимо.
—
Кворк – магазин услуг фрилансеров от 500 р. для вашего бизнеса
Вчера представили большое обновление Турбо-страниц для интернет-магазинов (дизайн с фокусом на смартфоны).
Говорят, изменения появились в результате положительных отзывов от пользователей на UX-тестированиях. При этом Яндекс продолжает строить догадки на счет того, что ИМ должен приносить заказы его владельцу, а не только деньги за рекламу в Яндекс (но это пока не точно, это по-прежнему лишь гипотеза). И чтобы гипотезу проверить, они пригласили партнёров поучаствовать в закрытом эксперименте. В среднем что-то выросло… не известно у кого, не известно почему. Главное, что выросло. Хотя по нашей практике после внедрения Турбо у клиентских сайтов все как-то грустно падает.
Если без шуток, то и правда много что обновили.
🔗 https://webmaster.yandex.ru/blog/bolshoe-obnovlenie-turbo-stranits-dlya-internet-magazinov-dizayn-s-fokusom-na-smartfony
Сегодня вдогонку Яндекс решил пригласить всех желающих на вебинар «Технология Турбо для интернет-магазинов», который состоится 22 октября в 12:00 (по московскому времени).
Обещают рассказать о планах по развитию технологии и последних обновлениях.
Участие бесплатное, необходима регистрация.
🔗 https://webmaster.yandex.ru/blog/priglashaem-na-vebinar-tekhnologiya-turbo-dlya-internet-magazinov
Те, кто пользуется Турбо, будут довольны, остальные, как и мы, проходят мимо.
—
Кворк – магазин услуг фрилансеров от 500 р. для вашего бизнеса
webmaster.yandex.ru
Большое обновление Турбо-страниц для интернет-магазинов: дизайн с фокусом на смартфоны — Блог Яндекса для вебмастеров
Каждая третья онлайн-покупка приходится на мобильные устройства, по данным опроса Яндекс.Маркета и GfK. Пользователи мобильных привыкли к быстрой работе приложений, их элементам, дизайну, и ожидают такого же комфорта от интернет-магазина на смартфоне. Чтобы…
Сегодня состоялся релиз Google Analytics 4 – обновленной версии платформы веб-аналитики.
Google называет новую версию «более интеллектуальной». В ее основе лежит машинное обучение, которое «позволяет автоматически получать полезные сведения и дает вам полное представление о ваших клиентах на разных устройствах и платформах».
В релизе Google пишет, что машинное обучение будет использоваться для прогнозирования результатов, таких как уровень оттока клиентов, изменение спроса на продукты из-за новых потребностей клиентов, потенциальный доход, который бизнес может получить от определенного сегмента клиентов.
Инструменты прогнозного анализа должны помочь маркетологам сосредоточиться на более ценной для бизнеса аудитории, эффективно управлять бюджетом и инвестициями в удержание клиентов.
🔗 Подробнее об обновленной Аналитике в блоге: https://blog.google/products/marketingplatform/analytics/new_google_analytics
Те, кто пользуется GA, должны кайфануть, наверное!
Google называет новую версию «более интеллектуальной». В ее основе лежит машинное обучение, которое «позволяет автоматически получать полезные сведения и дает вам полное представление о ваших клиентах на разных устройствах и платформах».
В релизе Google пишет, что машинное обучение будет использоваться для прогнозирования результатов, таких как уровень оттока клиентов, изменение спроса на продукты из-за новых потребностей клиентов, потенциальный доход, который бизнес может получить от определенного сегмента клиентов.
Инструменты прогнозного анализа должны помочь маркетологам сосредоточиться на более ценной для бизнеса аудитории, эффективно управлять бюджетом и инвестициями в удержание клиентов.
🔗 Подробнее об обновленной Аналитике в блоге: https://blog.google/products/marketingplatform/analytics/new_google_analytics
Те, кто пользуется GA, должны кайфануть, наверное!
Google
Introducing the new Google Analytics
The new Google Analytics will give you the essential insights you need to be ready for what’s next.
Google отключает функцию «Запросить индексирование» в инструменте проверки URL в Google Search Console. Ориентировочно на несколько недель, чтобы «внести изменения в инфраструктуру»:
🔗 https://twitter.com/googlewmc/status/1316463867296395268
Пока инструмент будет отключен Google призывать пользоваться другими привычными инструментами, описанными в справке:
🔗 https://developers.google.com/search/docs/guides/intro-indexing
PS Проверил, у нас пока что в панели GSC инструмент не отключен – см. скрин – я попробовал отправить несколько запросов, везде получилось: «Отправлен запрос на индексирование. URL добавлен в приоритетную очередь сканирования.»
PPS А Джон Мюллер сказал, что отключение функции «не влияет на нормальное сканирование и индексирование. В общем, сайтам никогда не нужно использовать эту функцию и большинство из них никогда ее не использовали».
Ох, плохое предчувствие, может они вообще отключат запрос на индексирование навсегда? 😭
🔗 https://twitter.com/googlewmc/status/1316463867296395268
Пока инструмент будет отключен Google призывать пользоваться другими привычными инструментами, описанными в справке:
🔗 https://developers.google.com/search/docs/guides/intro-indexing
PS Проверил, у нас пока что в панели GSC инструмент не отключен – см. скрин – я попробовал отправить несколько запросов, везде получилось: «Отправлен запрос на индексирование. URL добавлен в приоритетную очередь сканирования.»
PPS А Джон Мюллер сказал, что отключение функции «не влияет на нормальное сканирование и индексирование. В общем, сайтам никогда не нужно использовать эту функцию и большинство из них никогда ее не использовали».
Ох, плохое предчувствие, может они вообще отключат запрос на индексирование навсегда? 😭
{kind=link}
Аларма, аларма! 😈
Никто еще не знает, но Гугл сегодня ночью обновил руководство для асессоров!
Вчера смотрел дату документа (ссылка постоянная – Google ссылается на эту pdf-ку из справки) – дата была 2019 год. Сегодня перепроверил – дата стоит 14.10.2020.
https://static.googleusercontent.com/media/guidelines.raterhub.com/ru//searchqualityevaluatorguidelines.pdf
В конце документа есть ченджлог. Мало что понятно, надо переводить и сравнивать. Переводить мы его, конечно же, не будем 🤣 Держите в оригинале:
– Added note to clarify that ratings do not directly impact order of search results
– Emphasized ' The Role of Examples in these Guidelines ' as an independent section in the introduction
– Added clarification that Special Content Result Blocks may have links to landing pages; added illustrative example
– Updated guidance on how to rate pages with malware warnings and when to assign the Did Not Load flag; added illustrative examples
– Changed the order of Rating Flags section and Relationship between Page Quality and Needs Met section for clarity
– Added ' Rating Dictionary and Encyclopedia Results for Different Queries ': Emphasizes the importance of understanding the user intent and query for Needs Met rating; added illustrative examples
– Minor changes throughout (updated examples and explanations for consistency; simplified language regarding raters representing people in their locale; fixed typos; etc.)
PS День обновления руководства совпал с началом периода ретроградного Меркурия. Совпадение? 🤨
Никто еще не знает, но Гугл сегодня ночью обновил руководство для асессоров!
Вчера смотрел дату документа (ссылка постоянная – Google ссылается на эту pdf-ку из справки) – дата была 2019 год. Сегодня перепроверил – дата стоит 14.10.2020.
https://static.googleusercontent.com/media/guidelines.raterhub.com/ru//searchqualityevaluatorguidelines.pdf
В конце документа есть ченджлог. Мало что понятно, надо переводить и сравнивать. Переводить мы его, конечно же, не будем 🤣 Держите в оригинале:
– Added note to clarify that ratings do not directly impact order of search results
– Emphasized ' The Role of Examples in these Guidelines ' as an independent section in the introduction
– Added clarification that Special Content Result Blocks may have links to landing pages; added illustrative example
– Updated guidance on how to rate pages with malware warnings and when to assign the Did Not Load flag; added illustrative examples
– Changed the order of Rating Flags section and Relationship between Page Quality and Needs Met section for clarity
– Added ' Rating Dictionary and Encyclopedia Results for Different Queries ': Emphasizes the importance of understanding the user intent and query for Needs Met rating; added illustrative examples
– Minor changes throughout (updated examples and explanations for consistency; simplified language regarding raters representing people in their locale; fixed typos; etc.)
PS День обновления руководства совпал с началом периода ретроградного Меркурия. Совпадение? 🤨
{kind=link}
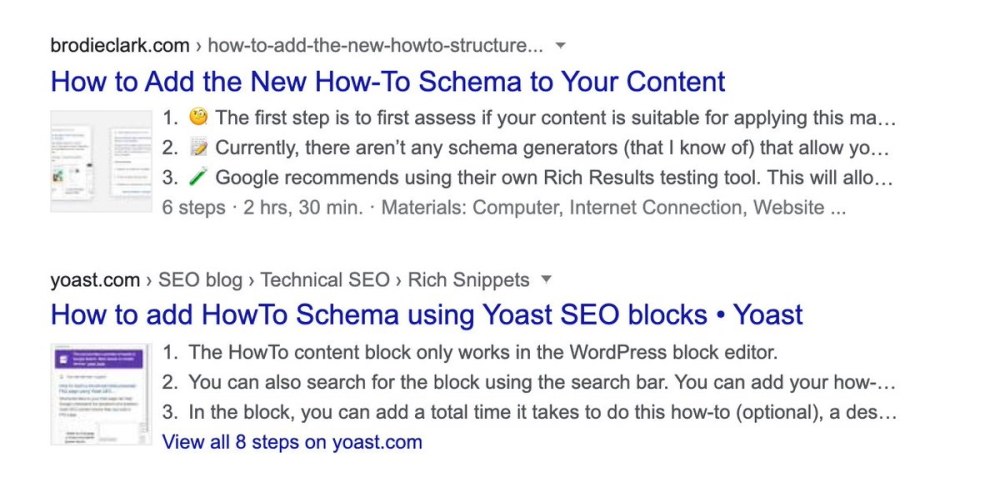
Похоже, что Google развертывает поддержку расширенных результатов для инструкций (HowTo Schema) в десктопной выдаче. Микроразметка HowTo – схема структурированных данных для пошаговых инструкций. Идеально подходит для описания последовательности действий, позволяющих выполнить определенную задачу.
Схема структурированных данных HowTo не новая. В 2019 году Google уже начал поддерживать ее в выдаче на мобильных устройствах. С мая 2020-го началось тестирование для десктопной выдачи и сейчас все больше вебмастеров замечают расширенные сниппеты инструкций. Причем, в выдаче на десктопах находятся примеры разных вариантов сниппетов (с миниатюрой изображения или дополнительной ссылкой для шагов инструкции).
Похоже, Google окончательно не выбрал финальный вариант и завершает тестирование. В официальной справке информации про поддержку разметки в десктоп выдаче тоже пока нет.
Расширенные сниппеты HowTo попадаются все чаще, а значит, запуск поддержки для десктопа — вопрос времени. Можно уже сейчас присматриваться к контенту на наших сайтах, в котором есть или уместно добавить пошаговую последовательность действий.
🔗 Подробнее о разметке:
Официальная справка Google - https://developers.google.com/search/docs/data-types/how-to
Полный список параметров разметки HowTo - https://schema.org/HowTo
Схема структурированных данных HowTo не новая. В 2019 году Google уже начал поддерживать ее в выдаче на мобильных устройствах. С мая 2020-го началось тестирование для десктопной выдачи и сейчас все больше вебмастеров замечают расширенные сниппеты инструкций. Причем, в выдаче на десктопах находятся примеры разных вариантов сниппетов (с миниатюрой изображения или дополнительной ссылкой для шагов инструкции).
Похоже, Google окончательно не выбрал финальный вариант и завершает тестирование. В официальной справке информации про поддержку разметки в десктоп выдаче тоже пока нет.
Расширенные сниппеты HowTo попадаются все чаще, а значит, запуск поддержки для десктопа — вопрос времени. Можно уже сейчас присматриваться к контенту на наших сайтах, в котором есть или уместно добавить пошаговую последовательность действий.
🔗 Подробнее о разметке:
Официальная справка Google - https://developers.google.com/search/docs/data-types/how-to
Полный список параметров разметки HowTo - https://schema.org/HowTo
{kind=link}
Forwarded from Devaka Talk
Google в ближайшее время обновит алгоритм ранжирования, чтобы уметь находить не только полностью релевантные запросу страницы, но и страницы, где есть релевантные запросу предложения/пассажи. Своего рода продолжение алгоритма поиска ответов на вопросы... но уже в более глобальном масштабе.
Проанонсировано это в Твиттере, изменения на выдачу еще не выкатили:
https://twitter.com/searchliaison/status/1318609604029263872
Как сейчас происходит ранжирование? Ищутся релевантные страницы. При этом, большие страницы, освещающие разные вопросы, могут остаться без трафика. В новом подходе такие страницы не останутся без внимания. Поисковик будет "выискивать" с помощью своей новой технологии релевантные предложения, которые могут быть полезным ответом на вопрос пользователя.
В общем, предложения становятся, по словам Google, "дополнительным фактором ранжирования"... Как обычно, поисковик от вас просит лишь делать качественные сайты, и дальше обо всем позаботится сам :) Но ждите серьезной тряски выдачи. Скорей всего по инфо-запросам.
Изменение коснется 7% поисковых запросов по всему миру.
Проанонсировано это в Твиттере, изменения на выдачу еще не выкатили:
https://twitter.com/searchliaison/status/1318609604029263872
Как сейчас происходит ранжирование? Ищутся релевантные страницы. При этом, большие страницы, освещающие разные вопросы, могут остаться без трафика. В новом подходе такие страницы не останутся без внимания. Поисковик будет "выискивать" с помощью своей новой технологии релевантные предложения, которые могут быть полезным ответом на вопрос пользователя.
В общем, предложения становятся, по словам Google, "дополнительным фактором ранжирования"... Как обычно, поисковик от вас просит лишь делать качественные сайты, и дальше обо всем позаботится сам :) Но ждите серьезной тряски выдачи. Скорей всего по инфо-запросам.
Изменение коснется 7% поисковых запросов по всему миру.
Twitter
Google SearchLiaison
Last week, we shared about how we will soon identify individual passages of a web page to better understand how relevant a page is to a search. This will be a global change improving 7% of queries: blog.google/products/searc… In this thread, more about how…
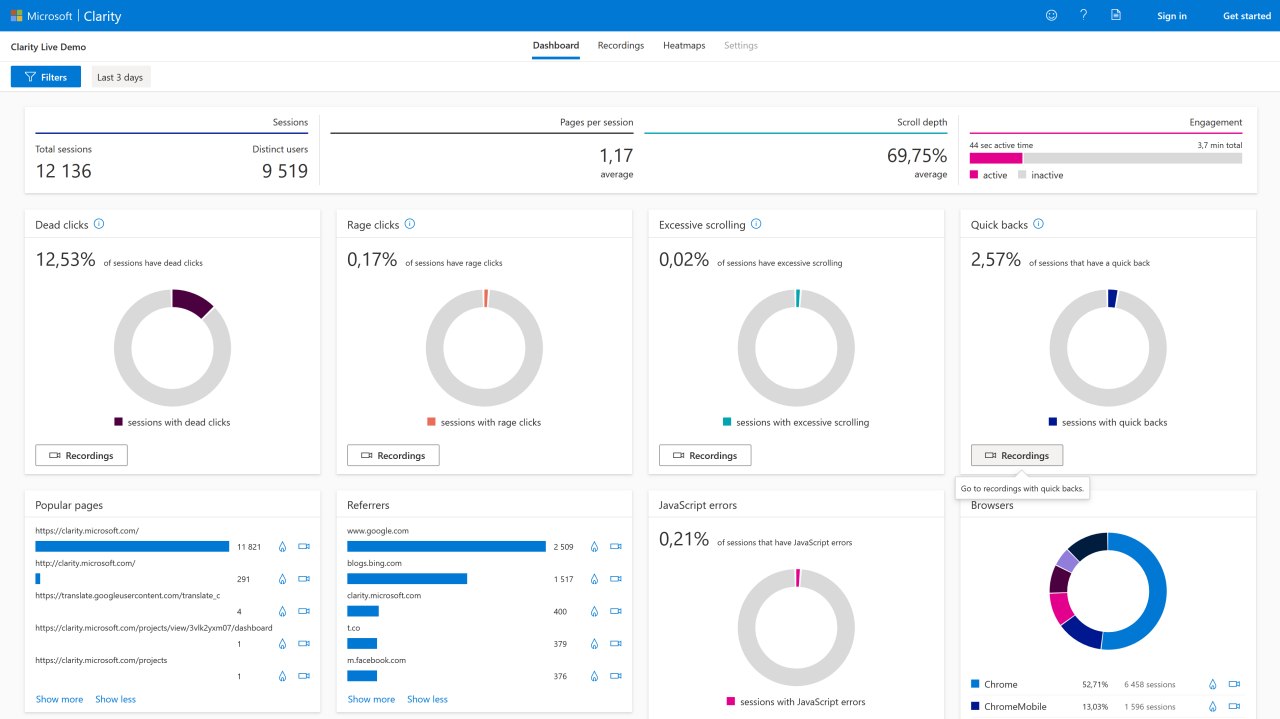
Microsoft запустил бесплатный инструмент для аналитики сайтов — Microsoft Clarity. В релизе говорится, что сервис интуитивно понятен и прост в использовании (не зря же он называется «Clarity» по-русски «Ясность»).
Microsoft Clarity уважает конфиденциальность и безопасность данных пользователей (такой сейчас тренд), оказывает минимальное влияние на время загрузки страницы (это мы еще посмотрим).
Основные возможности Microsoft Clarity можно условно разделить на три инструмента:
- воспроизведение сеанса;
- тепловые карты;
- панель аналитики.
Среди вполне знакомых функций попадаются и довольно оригинальные инструменты. Например, в Clarity есть отчет «Гневные клики», который показывает паттерн поведения пользователя, когда тот несколько раз нажимает на какую-либо часть страницы, ожидая перехода по ссылке.
🔗 Тестить новый сервис аналитики можно тут: https://clarity.microsoft.com/
—
Кворк – магазин услуг фрилансеров от 500 р. для вашего бизнеса
Microsoft Clarity уважает конфиденциальность и безопасность данных пользователей (такой сейчас тренд), оказывает минимальное влияние на время загрузки страницы (это мы еще посмотрим).
Основные возможности Microsoft Clarity можно условно разделить на три инструмента:
- воспроизведение сеанса;
- тепловые карты;
- панель аналитики.
Среди вполне знакомых функций попадаются и довольно оригинальные инструменты. Например, в Clarity есть отчет «Гневные клики», который показывает паттерн поведения пользователя, когда тот несколько раз нажимает на какую-либо часть страницы, ожидая перехода по ссылке.
🔗 Тестить новый сервис аналитики можно тут: https://clarity.microsoft.com/
—
Кворк – магазин услуг фрилансеров от 500 р. для вашего бизнеса
{kind=link}
Совсем недавно в Google появилась новость о том, что он способен анализировать отдельные куски текста: https://youtu.be/ZL5x3ovujiM?t=1042 – Google Presents: Search On 2020 – они тут на английском рассказывают, что к чему и почему, и это довольно интересно, поэтому рекомендую включить перевод на русские субтитры и посмотреть.
Короче, новость в том, что эта тема уже работает на практике!
По некоторым нашим проектам начали проскакивать целевые страницы в Google такого вида (смотрите на URL внизу скрина):
https://prnt.sc/v9vjj4
https://prnt.sc/v9vjrc
https://prnt.sc/v9vk4z
Ссылки имеют вид:
Первая мысль – закрыть от индексации в robots.txt 😨 но это невозможно, так как этих адресов или ссылок просто нет в коде сайта.
Оказалось, что ссылки такого вида соответствуют следующему синтаксису:
Такая подстановка в URL позволяет выделять цветом в поддерживаемых браузерах части текста, в которых textStart - начальная фраза, затем разделитель "," и конечная фраза - textEnd.
Это выглядят следующим образом: https://prnt.sc/v9vrmr
Google якорем направляет пользователя именно на ту часть текста, которая максимально соответствует запросу, и подсвечивает эту область.
Пример в результатах поиска: https://prnt.sc/v9wdcd (смотрим на url).
Замечали у себя такое?
Короче, новость в том, что эта тема уже работает на практике!
По некоторым нашим проектам начали проскакивать целевые страницы в Google такого вида (смотрите на URL внизу скрина):
https://prnt.sc/v9vjj4
https://prnt.sc/v9vjrc
https://prnt.sc/v9vk4z
Ссылки имеют вид:
#:~:text=Гальванический%20метод%20используют%20для%20придания,а%20также%20сохранения%20постоянного%20сопротивления.Первая мысль – закрыть от индексации в robots.txt 😨 но это невозможно, так как этих адресов или ссылок просто нет в коде сайта.
Оказалось, что ссылки такого вида соответствуют следующему синтаксису:
#:~:text=textStart,textEnd.Такая подстановка в URL позволяет выделять цветом в поддерживаемых браузерах части текста, в которых textStart - начальная фраза, затем разделитель "," и конечная фраза - textEnd.
Это выглядят следующим образом: https://prnt.sc/v9vrmr
Google якорем направляет пользователя именно на ту часть текста, которая максимально соответствует запросу, и подсвечивает эту область.
Пример в результатах поиска: https://prnt.sc/v9wdcd (смотрим на url).
Замечали у себя такое?
{kind=link}
Чуть не пропустили… 🎬 2 недели назад Google выпустил часовой документальный фильм «Триллионы вопросов, нет простых ответов: (домашний) фильм о том, как работает Google Поиск».
Судя по комментариям из сети, в фильме есть интересные моменты и комментарии от первых лиц Google (а не от Джона Мюллера, как обычно). Западное SEO-сообщество отдельно хвалит блок о YMYL-сайтах.
🔗 Кому интересен Google, посмотрите на досуге https://www.youtube.com/watch?v=tFq6Q_muwG0
PS К сожалению, на русском языке нет, да и вряд ли кто-то будет переводить. В оригинале присутствуют только английские субтитры, но есть встроенный перевод на любой язык, в том числе и русский (вполне сносно переводит).
А вообще фильм рассчитан на тех, кто работает в бурже, а те, кто работают в бурже, не имеют проблем с английским. Так что все норм!
Судя по комментариям из сети, в фильме есть интересные моменты и комментарии от первых лиц Google (а не от Джона Мюллера, как обычно). Западное SEO-сообщество отдельно хвалит блок о YMYL-сайтах.
🔗 Кому интересен Google, посмотрите на досуге https://www.youtube.com/watch?v=tFq6Q_muwG0
PS К сожалению, на русском языке нет, да и вряд ли кто-то будет переводить. В оригинале присутствуют только английские субтитры, но есть встроенный перевод на любой язык, в том числе и русский (вполне сносно переводит).
А вообще фильм рассчитан на тех, кто работает в бурже, а те, кто работают в бурже, не имеют проблем с английским. Так что все норм!
{kind=link}
Топвизирь пишет:
Анализ конкурентов вышел в паблик в формате открытой альфа-версии.
Доступны отчеты по доменам: поисковые фразы, конкуренты, структура сайта. Ждём бету, чтобы начать тестировать отчеты по ключевой фразе, подбор семантики, просчет лидеров по тематикам.
🔗 https://topvisor.com/competitors/
PS По-моему, посоны опоздали на пару лет с этой фичей... Как считаете?
Анализ конкурентов вышел в паблик в формате открытой альфа-версии.
Доступны отчеты по доменам: поисковые фразы, конкуренты, структура сайта. Ждём бету, чтобы начать тестировать отчеты по ключевой фразе, подбор семантики, просчет лидеров по тематикам.
🔗 https://topvisor.com/competitors/
PS По-моему, посоны опоздали на пару лет с этой фичей... Как считаете?
{kind=link}
В подкасте Search Off the Record от 4 ноября Мартин Сплитт довольно подробно рассказал, как Google обрабатывает канонизацию - определяет дубли страниц и выбирает каноничную. Ниже немного адаптированный перевод высказываний Мартина по теме:
“Сначала нужно обнаружить дубликаты, сгруппировать их вместе и отметить, что эти страницы дублируют друг друга. Затем для всех них нужно найти страницу лидера.
И то, как мы это делаем, возможно, так делают большинство людей и другие поисковые системы - сводят контент к хэшу или контрольной сумме, а затем сравнивают контрольные суммы. Это намного проще, чем сравнивать, например, три тысячи слов.
Итак, мы сокращаем содержание до контрольной суммы, потому что не хотим сканировать весь текст и потому что это просто не имеет смысла - это требует больше ресурсов, а результат будет примерно таким же. Мы вычисляем несколько видов контрольных сумм для текстового содержимого страницы, а затем сравниваем их.”
На вопрос обнаруживает ли такой метод только точные дубли или частичные тоже? Мартин ответил:
“У нас есть несколько алгоритмов, которые пытаются обнаружить и не учитывать шаблонную часть страниц. Так, например, мы исключаем навигацию из расчета контрольной суммы, убираем нижний колонтитул. Тогда у нас остается то, что мы называем центральным элементом, то есть центральное содержимое страницы, что-то вроде самой сути страницы.
После вычисления и сравнения контрольных сумм, те, которые похожи между собой (сильно или частично) мы объединяем в дублирующий кластер.”
Далее по словам Мартина, необходимо выбрать один документ из кластера, который и будет показываться в результатах поиска:
“Но вычислить какая из них будет ведущей в кластере не так просто. Есть случаи, когда даже людям будет сложно определить, какая именно страница должна отображаться в результатах поиска. Мы используем более двадцати сигналов, чтобы решить, какую страницу выбрать как каноническую из дублирующего кластера. Большинство из вас, вероятно, может догадаться, какие это сигналы.
Очевидно, что один из них - это содержание страницы. Но это могут быть и другие сигналы: у какой страницы более высокий PageRank, на каком протоколе страницы (http или https), включена ли страница в карту сайта, перенаправляется ли на другую страницу, проставлен ли атрибут rel=canonical… Каждый из этих сигналов имеет свой вес, а для подсчета весовых коэффициентов мы используем машинное обучение.
После сравнения всех сигналов для всех пар страниц, мы приближаемся к фактическому определению канонической.”
🔗 Полная стенограмма прошедшего подкаста: https://goo.gle/sotr009-transcription
“Сначала нужно обнаружить дубликаты, сгруппировать их вместе и отметить, что эти страницы дублируют друг друга. Затем для всех них нужно найти страницу лидера.
И то, как мы это делаем, возможно, так делают большинство людей и другие поисковые системы - сводят контент к хэшу или контрольной сумме, а затем сравнивают контрольные суммы. Это намного проще, чем сравнивать, например, три тысячи слов.
Итак, мы сокращаем содержание до контрольной суммы, потому что не хотим сканировать весь текст и потому что это просто не имеет смысла - это требует больше ресурсов, а результат будет примерно таким же. Мы вычисляем несколько видов контрольных сумм для текстового содержимого страницы, а затем сравниваем их.”
На вопрос обнаруживает ли такой метод только точные дубли или частичные тоже? Мартин ответил:
“У нас есть несколько алгоритмов, которые пытаются обнаружить и не учитывать шаблонную часть страниц. Так, например, мы исключаем навигацию из расчета контрольной суммы, убираем нижний колонтитул. Тогда у нас остается то, что мы называем центральным элементом, то есть центральное содержимое страницы, что-то вроде самой сути страницы.
После вычисления и сравнения контрольных сумм, те, которые похожи между собой (сильно или частично) мы объединяем в дублирующий кластер.”
Далее по словам Мартина, необходимо выбрать один документ из кластера, который и будет показываться в результатах поиска:
“Но вычислить какая из них будет ведущей в кластере не так просто. Есть случаи, когда даже людям будет сложно определить, какая именно страница должна отображаться в результатах поиска. Мы используем более двадцати сигналов, чтобы решить, какую страницу выбрать как каноническую из дублирующего кластера. Большинство из вас, вероятно, может догадаться, какие это сигналы.
Очевидно, что один из них - это содержание страницы. Но это могут быть и другие сигналы: у какой страницы более высокий PageRank, на каком протоколе страницы (http или https), включена ли страница в карту сайта, перенаправляется ли на другую страницу, проставлен ли атрибут rel=canonical… Каждый из этих сигналов имеет свой вес, а для подсчета весовых коэффициентов мы используем машинное обучение.
После сравнения всех сигналов для всех пар страниц, мы приближаемся к фактическому определению канонической.”
🔗 Полная стенограмма прошедшего подкаста: https://goo.gle/sotr009-transcription
{kind=link}
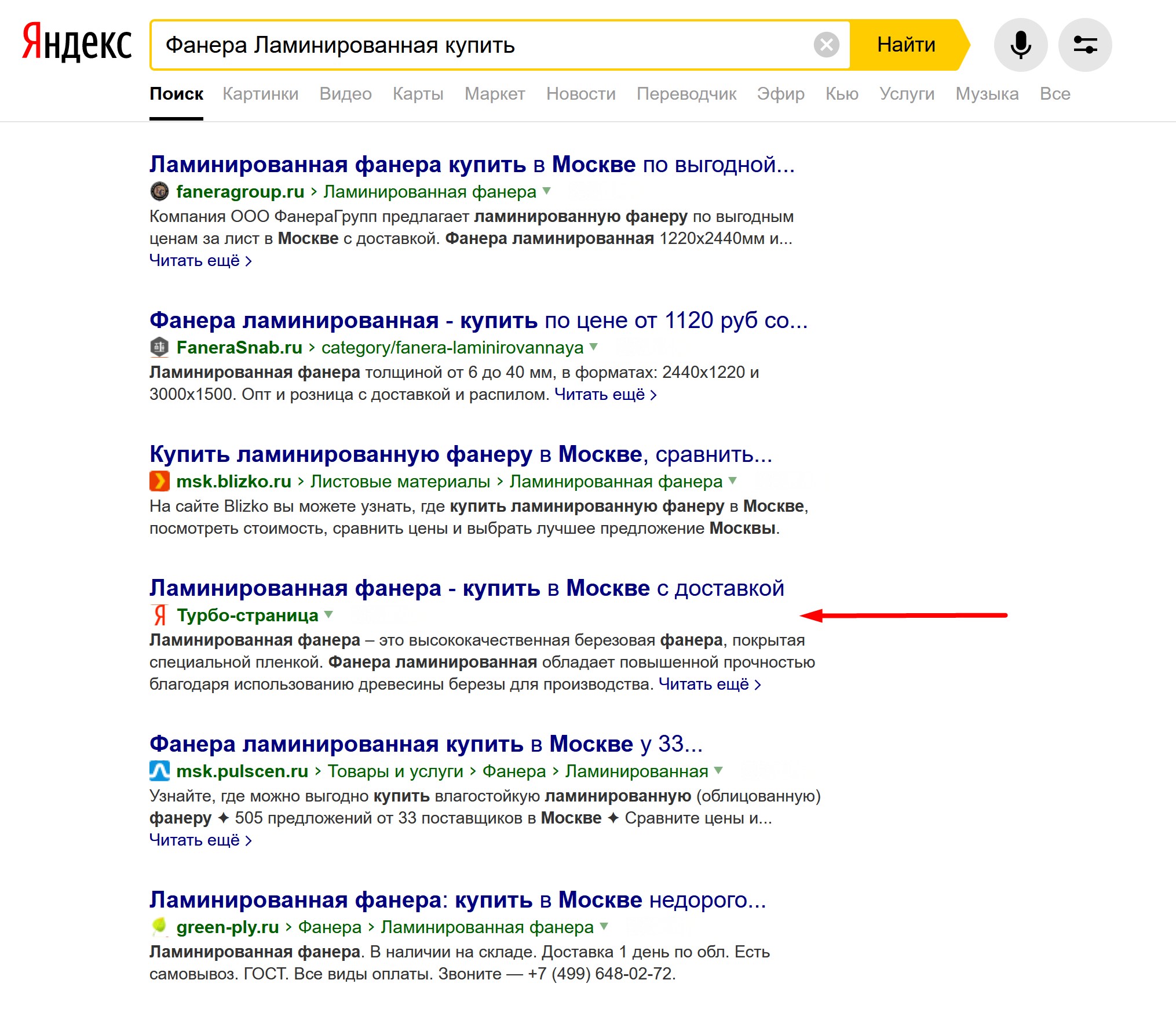
Вы уже встречали Турбо-страницы на выдаче?
Не сайт с турбо-страницами, а отдельная самостоятельная турбо-страница в органической выдаче.
Так, чтобы ранжировалась по конкурентному запросу.
В десктопной выдаче! Что странно, учитывая, что выглядит она явно не по-десктопному https://prnt.sc/vfwoqs
Там есть кнопка «Пожаловаться», и я подумал, что там должна быть возможность сообщить, что это нерелевантный контент.
Но нет… Яндекс считает, что турбо релевантны априори.
Но там есть другой подходящий пункт - https://prnt.sc/vfwqku - «Содержимое Турбо-страницы оскорбляет меня» и это так – выдача этой страницы в топе оскорбляет меня как SEO-специалиста!
PS И если вам показалось, что это просто пост для пожаловаться на тяжелую участь, то нет… Самый внимательный заметил бы, что турбо принадлежит одному из сайтов, который уже и так занимает место в топе, а с этой страницей он занимает теперь два места в десятке, в конкурентной нише!
Не сайт с турбо-страницами, а отдельная самостоятельная турбо-страница в органической выдаче.
Так, чтобы ранжировалась по конкурентному запросу.
В десктопной выдаче! Что странно, учитывая, что выглядит она явно не по-десктопному https://prnt.sc/vfwoqs
Там есть кнопка «Пожаловаться», и я подумал, что там должна быть возможность сообщить, что это нерелевантный контент.
Но нет… Яндекс считает, что турбо релевантны априори.
Но там есть другой подходящий пункт - https://prnt.sc/vfwqku - «Содержимое Турбо-страницы оскорбляет меня» и это так – выдача этой страницы в топе оскорбляет меня как SEO-специалиста!
PS И если вам показалось, что это просто пост для пожаловаться на тяжелую участь, то нет… Самый внимательный заметил бы, что турбо принадлежит одному из сайтов, который уже и так занимает место в топе, а с этой страницей он занимает теперь два места в десятке, в конкурентной нише!
{kind=link}
Google выделяет избранные результаты в расширенных сниппетах. Что это? Самый релевантный ответ?
Исторически выделение жирным шрифтом Google использовал для подсветки ключевых слов в сниппетах. Однако, недавно западные seo-специалисты (в частности Броди Кларк) заметили подобное выделение некоторых отдельных результатов в расширенных сниппетах https://prnt.sc/vgiics
Вот еще пример - https://prnt.sc/vgika4
Что этим хочет сказать нам Google? Что Apple Airpods – лучшие bluetooth наушники, а Samsung S20 и Note 20 Ultra – лучшие android телефоны? Ранее Google не говорил настолько прямо, что один продукт является лучшей альтернативой другому. Или это всего лишь намек на максимальную релевантность?
Кстати, это не единственный вариант выделения. Вот пример, где жирным выделены 3 различных результата - https://prnt.sc/vgiq2w
Хоть ранее подобное выделение было замечено для англоязычных запросов, можно найти примеры и для русскоязычных https://prnt.sc/vgii0x
Это, безусловно, интересная функция. Но как Google приходит к выводу какой результат выделять? Понятно, что у поиска достаточно данных и ресурсов, чтобы взвешенно принимать подобные решения. Однако, результат выделения конкретных результатов может идти вразрез с общепринятым мнением и стать предметом жарких споров.
Cледим за ситуацией. Не переключайтесь.
—
Кворк – маркетплейс услуг фрилансеров от 500 р. для вашего бизнеса
Исторически выделение жирным шрифтом Google использовал для подсветки ключевых слов в сниппетах. Однако, недавно западные seo-специалисты (в частности Броди Кларк) заметили подобное выделение некоторых отдельных результатов в расширенных сниппетах https://prnt.sc/vgiics
Вот еще пример - https://prnt.sc/vgika4
Что этим хочет сказать нам Google? Что Apple Airpods – лучшие bluetooth наушники, а Samsung S20 и Note 20 Ultra – лучшие android телефоны? Ранее Google не говорил настолько прямо, что один продукт является лучшей альтернативой другому. Или это всего лишь намек на максимальную релевантность?
Кстати, это не единственный вариант выделения. Вот пример, где жирным выделены 3 различных результата - https://prnt.sc/vgiq2w
Хоть ранее подобное выделение было замечено для англоязычных запросов, можно найти примеры и для русскоязычных https://prnt.sc/vgii0x
Это, безусловно, интересная функция. Но как Google приходит к выводу какой результат выделять? Понятно, что у поиска достаточно данных и ресурсов, чтобы взвешенно принимать подобные решения. Однако, результат выделения конкретных результатов может идти вразрез с общепринятым мнением и стать предметом жарких споров.
Cледим за ситуацией. Не переключайтесь.
—
Кворк – маркетплейс услуг фрилансеров от 500 р. для вашего бизнеса
{kind=link}
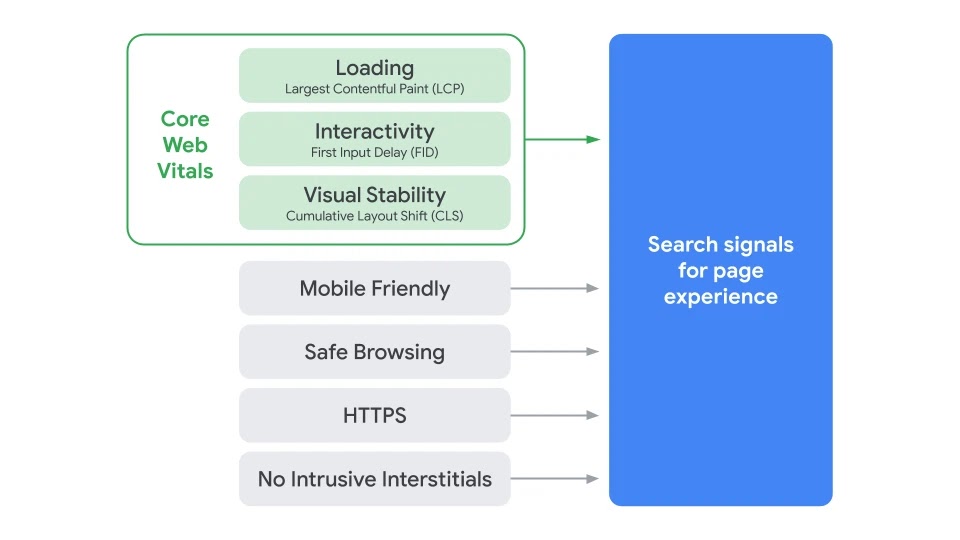
Google официально объявил, что в мае 2021 года начнет учитывать в ранжировании сигналы восприятия страницы пользователями (page experience), о которых объявили в мае этого года.
Напомню, речь идет о таких сигналах, как скорость загрузки страниц, удобство для мобильных устройств, наличие безопасного протокола https, отсутствие злонамеренного контента и навязчивой рекламы, а также о новых метриках Core Web Vitals: производительность загрузки, интерактивность, визуальная стабильность.
Google продолжает учитывать всё новые и новые критерии. С появлением Core Web Vitals поисковик не просто хочет получать полную картину удобства взаимодействия пользователя с каждой страницей, но и мотивировать вебмастеров значительно больше уделять внимания качеству своих сайтов.
Итак, в следующем году мы получим новые факторы ранжирования - показатели удобства страницы будут приниматься во внимание наряду с сотнями других сигналов. Однако, Google в последнем анонсе подчеркивает, что по-прежнему основополагающим фактором ранжирования остается информационная ценность страницы.
🔗 Больше материалов по теме:
Анонс о сроках запуска новых факторов ранжирования:
https://webmasters.googleblog.com/2020/11/timing-for-page-experience.html
Справка Google по page experience:
https://developers.google.com/search/docs/guides/page-experience
Справка Google по Core Web Vitals:
https://web.dev/vitals/
Инструменты Google для работы по улучшению восприятия страниц:
https://web.dev/vitals-tools/
Напомню, речь идет о таких сигналах, как скорость загрузки страниц, удобство для мобильных устройств, наличие безопасного протокола https, отсутствие злонамеренного контента и навязчивой рекламы, а также о новых метриках Core Web Vitals: производительность загрузки, интерактивность, визуальная стабильность.
Google продолжает учитывать всё новые и новые критерии. С появлением Core Web Vitals поисковик не просто хочет получать полную картину удобства взаимодействия пользователя с каждой страницей, но и мотивировать вебмастеров значительно больше уделять внимания качеству своих сайтов.
Итак, в следующем году мы получим новые факторы ранжирования - показатели удобства страницы будут приниматься во внимание наряду с сотнями других сигналов. Однако, Google в последнем анонсе подчеркивает, что по-прежнему основополагающим фактором ранжирования остается информационная ценность страницы.
🔗 Больше материалов по теме:
Анонс о сроках запуска новых факторов ранжирования:
https://webmasters.googleblog.com/2020/11/timing-for-page-experience.html
Справка Google по page experience:
https://developers.google.com/search/docs/guides/page-experience
Справка Google по Core Web Vitals:
https://web.dev/vitals/
Инструменты Google для работы по улучшению восприятия страниц:
https://web.dev/vitals-tools/
{kind=link}
Привет, друзья. В сентябре я не делился с вами итогами, потому что сказать было нечего. Просто все хорошо.
В любом случае делиться надо, ведь я обещал и даже хештег #итогимесяца специально завел, чтобы проще было искать посты.
По клиентам глобальных изменений нет, плюс-минус одинаково, сколько пришло-ушло я перестал считать.
По деньгам – без изменений. Август был хороший месяц, и я думал, что сентябрь будет хуже, но он оказался на уровне августа. Потом я думал, что октябрь будет лучше сентября, но мы снова оказались на том же уровне. Ощущения редко совпадают с математикой 🤔
Как говорят британцы – no news is good news (отсутствие новостей – это хорошая новость).
Какое-то затишье, как в делах студии, так и в отрасли в целом (я даже в канал пишу редко, потому что не о чем писать).
Понемногу обновляем CheckTrust, продолжаем пилить нашу CRM, разрабатываем новый сервис (расскажу о нем, когда уже можно будет пользоваться).
И пока я это писал даже заскучал.
А потом как вспомнил…
Проект, который меня порадовал в октябре! Мы ведь запустили интернет-магазин цветов в Москве и Краснодаре (два тестовые региона, где у нас есть партнеры - букеты готовят они, а мы генерим заказы).
Сам проект начали делать еще в начале года, пока разработка, наполнение, оптимизация и т.д. Короче, МСК запустили в индекс 5 месяцев назад, а Краснодар – 2 месяца.
Забавно, что мы сперва запустили проект, а потом решили искать партнеров (что оказалось задачей совершенно сложной), и непонятно откуда прилетевшие заказы на старте мы слили. Потом стали умнее.
На данный момент мы выполнили менее 10 заказов. Для MVP – это норм.
Мы примерно поняли, что к чему, надо только наращивать количество лидов, а потом искать партнеров в других городах и…а потом попячить Флорист и Рус-Букет. Пфф! Делов-то – раз плюнуть 🤣
Я верю в этот проект, и он мне интересен, потому что никогда ранее ничего подобного не доводилось запускать!
А какие у вас #итогимесяца? Как вообще дела?
В любом случае делиться надо, ведь я обещал и даже хештег #итогимесяца специально завел, чтобы проще было искать посты.
По клиентам глобальных изменений нет, плюс-минус одинаково, сколько пришло-ушло я перестал считать.
По деньгам – без изменений. Август был хороший месяц, и я думал, что сентябрь будет хуже, но он оказался на уровне августа. Потом я думал, что октябрь будет лучше сентября, но мы снова оказались на том же уровне. Ощущения редко совпадают с математикой 🤔
Как говорят британцы – no news is good news (отсутствие новостей – это хорошая новость).
Какое-то затишье, как в делах студии, так и в отрасли в целом (я даже в канал пишу редко, потому что не о чем писать).
Понемногу обновляем CheckTrust, продолжаем пилить нашу CRM, разрабатываем новый сервис (расскажу о нем, когда уже можно будет пользоваться).
И пока я это писал даже заскучал.
А потом как вспомнил…
Проект, который меня порадовал в октябре! Мы ведь запустили интернет-магазин цветов в Москве и Краснодаре (два тестовые региона, где у нас есть партнеры - букеты готовят они, а мы генерим заказы).
Сам проект начали делать еще в начале года, пока разработка, наполнение, оптимизация и т.д. Короче, МСК запустили в индекс 5 месяцев назад, а Краснодар – 2 месяца.
Забавно, что мы сперва запустили проект, а потом решили искать партнеров (что оказалось задачей совершенно сложной), и непонятно откуда прилетевшие заказы на старте мы слили. Потом стали умнее.
На данный момент мы выполнили менее 10 заказов. Для MVP – это норм.
Мы примерно поняли, что к чему, надо только наращивать количество лидов, а потом искать партнеров в других городах и…а потом попячить Флорист и Рус-Букет. Пфф! Делов-то – раз плюнуть 🤣
Я верю в этот проект, и он мне интересен, потому что никогда ранее ничего подобного не доводилось запускать!
А какие у вас #итогимесяца? Как вообще дела?